03 ਮਈ 2025·8 ਮਿੰਟ
AI-ਤਿਆਰ ਸਿਸਟਮਾਂ ਵਿੱਚ ਪ੍ਰਮਾਣਕੀਕਰਨ, ਗਲਤੀਆਂ ਅਤੇ ਐਜ-ਕੇਸ
ਜਾਣੋ ਕਿ ਕਿਵੇਂ AI-ਤਿਆਰ ਵਰਕਫਲੋ ਪ੍ਰਮਾਣਕੀ ਨਿਯਮ, ਗਲਤੀ ਸੰਭਾਲ ਅਤੇ ਮੁਸ਼ਕਲ ਐਜ-ਕੇਸ ਉਭਾਰਦੇ ਹਨ—ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਟੈਸਟ, ਮਾਨੀਟਰ ਅਤੇ ਠੀਕ ਕਰਨ ਦੇ ਪ੍ਰੈਕਟਿਕਲ ਤਰੀਕੇ।
ਜਾਣੋ ਕਿ ਕਿਵੇਂ AI-ਤਿਆਰ ਵਰਕਫਲੋ ਪ੍ਰਮਾਣਕੀ ਨਿਯਮ, ਗਲਤੀ ਸੰਭਾਲ ਅਤੇ ਮੁਸ਼ਕਲ ਐਜ-ਕੇਸ ਉਭਾਰਦੇ ਹਨ—ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਟੈਸਟ, ਮਾਨੀਟਰ ਅਤੇ ਠੀਕ ਕਰਨ ਦੇ ਪ੍ਰੈਕਟਿਕਲ ਤਰੀਕੇ।
ਇੱਕ AI-ਤਿਆਰ ਸਿਸਟਮ ਉਹ ਕੋਈ ਵੀ ਉਤਪਾਦ ਹੈ ਜਿੱਥੇ ਇੱਕ AI ਮਾਡਲ ਦੇ ਨਤੀਜੇ ਸਿਸਟਮ ਦੇ ਅਗਲੇ ਕਦਮ ਨੂੰ ਸਿੱਧਾ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ—ਕਿ ਕੀ ਯੂਜ਼ਰ ਨੂੰ ਦਿਖਾਇਆ ਜਾਂਦਾ ਹੈ, ਕੀ ਸਟੋਰ ਹੁੰਦਾ ਹੈ, ਕਿਸੇ ਹੋਰ ਟੂਲ ਨੂੰ ਕੀ ਭੇਜਿਆ ਜਾਂਦਾ ਹੈ, ਜਾਂ ਕੀ ਕਾਰਵਾਈ ਕੀਤੀ ਜਾਂਦੀ ਹੈ।
ਇਹ "ਚੈਟਬੌਟ" ਤੋਂ ਵੱਡਾ ਹੈ। ਅਮਲ ਵਿੱਚ, AI-generated ਹੋ ਸਕਦਾ ਹੈ:
ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਗੇ vibe-coding ਪਲੇਟਫਾਰਮ ਦੀ ਵਰਤੋਂ ਕੀਤੀ ਹੈ—ਜਿੱਥੇ ਇੱਕ ਚੈਟ ਗੱਲਬਾਤ ਪੂਰੇ ਵੈੱਬ, ਬੈਕਐਂਡ, ਜਾਂ ਮੋਬਾਇਲ ਐਪ ਬਣਾਉਣ ਅਤੇ ਵਿਕਸਤ ਕਰਨ ਲਈ ਨਤੀਜੇ ਦੇ ਸਕਦੀ ਹੈ—ਤਾਂ ਇਹ “AI ਨਤੀਜਾ ਕੰਟਰੋਲ ਫਲੋ ਬਣ ਜਾਂਦਾ ਹੈ” ਵਾਲਾ ਵਿਚਾਰ ਬਹੁਤ ਹੀ ਸਪੱਠ ਹੈ। ਮਾਡਲ ਦਾ ਨਤੀਜਾ ਸਿਰਫ ਸਲਾਹ ਨਹੀਂ ਹੁੰਦਾ; ਇਹ ਰੂਟ, ਸਕੀਮਾ, API ਕਾਲ, ਡਿਪਲੋਇਮੈਂਟ, ਅਤੇ ਯੂਜ਼ਰ-ਦਿੱਖਣ ਵਾਲੇ ਵਿਹਾਰ ਨੂੰ ਬਦਲ ਸਕਦਾ ਹੈ।
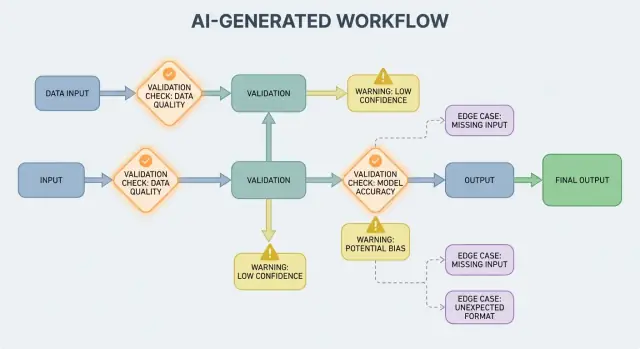
ਜਦੋਂ AI ਨਤੀਜਾ ਕੰਟਰੋਲ ਫਲੋ ਦਾ ਹਿੱਸਾ ਹੋਵੇ, ਤਾਂ ਪ੍ਰਮਾਣਕੀਕਰਨ ਨਿਯਮ ਅਤੇ ਗਲਤੀ ਸੰਭਾਲ ਯੂਜ਼ਰ-ਸਾਮ੍ਹਣੇ ਭਰੋਸੇਯੋਗਤਾ ਫੀਚਰ ਬਣ ਜਾਂਦੇ ਹਨ, ਸਿਰਫ਼ ਇੰਜੀਨੀਅਰਿੰਗ ਦੀਆਂ ਡੀਟੇਲਾਂ ਨਹੀਂ। ਇੱਕ ਛੱਡਿਆ ਮੈਦਾਨ, ਖਰਾਬ ਬਣਿਆ JSON, ਜਾਂ ਵਿਸ਼ਵਾਸ ਨਾਲ-ਭਰਿਆ ਪਰ ਗਲਤ ਨਿਰਦੇਸ਼ ਸਿਰਫ਼ "ਫੇਲ" ਨਹੀਂ ਹੁੰਦਾ—ਇਹ ਗੁੰਝਲਦਾਰ UX, ਗਲਤ ਰਿਕਾਰਡ, ਜਾਂ ਖਤਰਨਾਕ ਕਾਰਵਾਈਆਂ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ।
ਇਸ ਲਈ ਮਕਸਦ "ਕਦੇ ਵੀ ਫੇਲ ਨਾ ਹੋਵੇ" ਨਹੀਂ ਹੈ। ਨਤੀਜੇ ਪ੍ਰੋਬਬਿਲਿਸਟਿਕ ਹੁੰਦੇ ਹਨ, ਫੇਲ੍ਹ ਹੋਣਾ ਆਮ ਗੱਲ ਹੈ। ਮਕਸਦ ਹੈ ਕਾਬੂ ਵਾਲੀ ਨਾਕਾਮੀ: ਸਮੱਸਿਆਵਾਂ ਨੂੰ ਜਲਦੀ ਪਹਚਾਨਣਾ, ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਸੰਚਾਰ ਕਰਨਾ, ਅਤੇ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਰਿਕਵਰ ਕਰਨਾ।
ਬਾਕੀ ਲੇਖ ਨੂੰ ਪ੍ਰੈਕਟਿਕਲ ਖੇਤਰਾਂ ਵਿੱਚ ਵੰਡਿਆ ਗਿਆ ਹੈ:
ਜੇ ਤੁਸੀਂ ਪ੍ਰਮਾਣਕੀਕਰਨ ਅਤੇ ਗਲਤੀ ਰਾਹਾਂ ਨੂੰ ਪਹਿਲੀ ਗਿਣਤੀ ਦੇ ਹਿੱਸੇ ਵਾਂਗ ਟ੍ਰੀਟ ਕਰੋਗੇ, ਤਾਂ AI-ਤਿਆਰ ਸਿਸਟਮ ਭਰੋਸੇਯੋਗ ਅਤੇ ਸਮੇਂ ਦੇ ਨਾਲ ਸੁਧਰਦੇ ਰਹਿਣਗੇ।
AI ਸਿਸਟਮ ਪਲੇਸਿਬਲ ਉੱਤਰ ਬਣਾਉਣ ਵਿਚ ਮਹਿਰ ਹਨ, ਪਰ "ਪਲੇਸਿਬਲ" ਦਾ ਮਤਲਬ "ਉਪਯੋਗਯੋਗ" ਨਹੀਂ ਹੁੰਦਾ। ਜਦੋਂ ਤੁਸੀਂ ਐਕਸ਼ਨ ਲਈ AI ਨਤੀਜੇ ਉਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹੋ—ਇਮੇਲ ਭੇਜਣਾ, ਟਿਕਟ ਬਣਾਉਣਾ, ਰਿਕਾਰਡ ਅੱਪਡੇਟ ਕਰਨਾ—ਤੁਹਾਡੇ ਲੁਕਵੇਂ ਧਾਰਣਾਵਾਂ ਸਪੱਸ਼ਟ ਪ੍ਰਮਾਣਕੀਕਰਨ ਨਿਯਮ ਬਣ ਜਾਂਦੇ ਹਨ।
ਰਵਾਇਤੀ ਸੌਫਟਵੇਅਰ ਨਾਲ ਨਤੀਜੇ ਆਮ ਤੌਰ 'ਤੇ ਨਿਰਧਾਰਤ ਹੁੰਦੇ ਹਨ: ਜੇ ਇਨਪੁੱਟ X ਹੈ, ਤਾਂ ਤੁਸੀਂ Y ਦੀ ਉਮੀਦ ਕਰਦੇ ਹੋ। AI-ਤਿਆਰ ਸਿਸਟਮਾਂ ਦੇ ਨਾਲ, ਇੱਕੋ ਪ੍ਰਾਮਪਟ ਵੱਖ-ਵੱਖ ਫਰੇਜ਼ਿੰਗز, ਵੱਖਰੀਆਂ ਵਿਸਥਾਰ ਦੀਆਂ ਪਦਾਰਥਾਂ, ਜਾਂ ਵੱਖਰੀਆਂ ਵਿਆਖਿਆਵਾਂ ਦੇ ਸਕਦੀ ਹੈ। ਇਹ ਵੈਰੀਬਿਲਿਟੀ ਖੁਦ ਵਿੱਚ ਕੋਈ ਬਗ ਨਹੀਂ—ਪਰ ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਅਣਆਧਾਰਤ ਉਮੀਦਾਂ 'ਤੇ ਨਹੀਂ ਟਿਕ ਸਕਦੇ, ਜਿਵੇਂ "ਇਹ ਸਮੇਂ ਜ਼ਰੂਰ ਇੱਕ ਤਾਰੀਖ ਸ਼ਾਮਲ ਕਰੇਗਾ" ਜਾਂ "ਇਹ ਆਮ ਤੌਰ 'ਤੇ JSON ਵਾਪਸ ਕਰਦਾ ਹੈ"।
ਪ੍ਰਮਾਣਕੀਕਰਨ ਨਿਯਮ ਉਹ ਪ੍ਰਯੋਗਿਕ ਜਵਾਬ ਹਨ: ਇਸ ਨਤੀਜੇ ਲਈ ਕੀ ਸੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਜੋ ਇਹ ਸੁਰੱਖਿਅਤ ਅਤੇ ਉਪਯੋਗੀ ਹੋਵੇ?
ਇੱਕ AI ਜਵਾਬ ਸਹੀ-ਲੱਗ ਸਕਦਾ ਹੈ ਪਰ ਫਿਰ ਵੀ ਤੁਹਾਡੀਆਂ ਅਸਲੀ ਲੋੜਾਂ ਨੂੰ ਫੇਲ ਕਰ ਸਕਦਾ ਹੈ।
ਉਦਾਹਰਣ ਲਈ, ਮਾਡਲ ਹੋ ਸਕਦਾ ਹੈ:
ਅਮਲ ਵਿੱਚ ਤੁਸੀਂ ਦੋ تہਾਂ ਦੀ ਜਾਂਚ ਦੇ ਨਾਲ ਰਿਹਾਂ ਹੋ:
AI ਨਤੀਜੇ ਅਕਸਰ ਉਹ ਵੇਰਵੇ ਧੁੰਦਲੇ ਕਰ ਦਿੰਦੇ ਹਨ ਜੋ ਮਨੁੱਖ ਅਸਾਨੀ ਨਾਲ ਸਪਸ਼ਟ ਕਰ ਲੈਂਦੇ ਹਨ, ਖ਼ਾਸ ਕਰਕੇ:
ਪ੍ਰਮਾਣਕੀ ਡਿਜ਼ਾਈਨ ਕਰਨ ਲਈ ਇੱਕ ਮਦਦਗਾਰ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਹਰ AI ਇੰਟਰੈਕਸ਼ਨ ਲਈ ਇੱਕ "ਕਾਂਟ੍ਰੈਕਟ" ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ:
ਜਦੋਂ ਕਾਂਟ੍ਰੈਕਟ ਮੌਜੂਦ ਹੁੰਦੇ ਹਨ, ਪ੍ਰਮਾਣਕੀ ਨਿਯਮ ਬਿਊਰੋਕਰੇਸੀ ਨਹੀਂ ਲੱਗਦੇ—ਇਹ ਤੁਹਾਡੇ AI ਵਿਹਾਰ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਣ ਦੇ ਤਰੀਕੇ ਹਨ।
ਇਨਪੁੱਟ ਪ੍ਰਮਾਣਕੀਕਰਨ AI-ਤਿਆਰ ਸਿਸਟਮਾਂ ਲਈ ਭਰੋਸੇਯੋਗਤਾ ਦੀ ਪਹਿਲੀ ਲਾਈਨ ਹੈ। ਜੇ ਗੰਦਾ ਜਾਂ ਅਣਉਮੀਦ ਇਨਪੁੱਟਾਂ ਘੁੱਸ ਆ ਜਾਵੇ, ਮਾਡਲ ਫਿਰ ਵੀ ਕੁਝ "ਪੱਕਾ" ਨਤੀਜਾ ਦੇ ਸਕਦਾ ਹੈ, ਅਤੇ ਠੀਕ ਓਹੀ وجہ ਹੈ ਕਿ ਸਾਹਮਣੇ ਦਰਵਾਜ਼ਾ ਮਹੱਤਵਪੂਰਨ ਹੈ।
ਇਨਪੁੱਟ ਸਿਰਫ ਪ੍ਰਾਮਪਟ ਬਾਕਸ ਨਹੀਂ ਹਨ। ਆਮ ਸਰੋਤ ਸ਼ਾਮਿਲ ਹਨ:
ਇਨ੍ਹਾਂ ਵਿੱਚੋਂ ਹਰ ਇੱਕ ਅਧੂਰਾ, ਖ਼ਰਾਬ, ਬਹੁਤ ਵੱਡਾ, ਜਾਂ ਸਿਧਾ ਉਹ ਨਹੀਂ ਜੋ ਤੁਸੀਂ ਉਮੀਦ ਕਰਦੇ ਹੋ ਹੋ ਸਕਦਾ ਹੈ।
ਚੰਗਾ ਪ੍ਰਮਾਣਕੀਕਰਨ ਸਾਫ਼, ਟੈਸਟੇਬਲ ਨਿਯਮਾਂ 'ਤੇ ਧਿਆਨ ਦਿੰਦਾ ਹੈ:
ਇਹ ਜਾਂਚਾਂ ਮਾਡਲ ਦੇ ਸੰਕਟ ਨੂੰ ਘਟਾਉਂਦੀਆਂ ਹਨ ਅਤੇ ਡਾਊਨਸਟਰੀਮ ਸਿਸਟਮਾਂ (ਪਾਰਸਰ, ਡੈਟਾਬੇਸ, ਕਿਊਜ਼) ਨੂੰ ਕਰੈਸ਼ ਹੋਣ ਤੋਂ ਬਚਾਉਂਦੀਆਂ ਹਨ।
ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ "ਲਗਭਗ ਠੀਕ" ਨੂੰ ਇਕਸਾਰ ਡੇਟਾ ਵਿੱਚ ਬਦਲ ਦੇਂਦੀ ਹੈ:
ਸਿਰਫ ਉਸ ਵੇਲੇ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ ਜਦੋਂ ਨਿਯਮ ਬੇਮਿਸ਼ਕ ਹੋਵੇ। ਜੇ ਤੁਸੀਂ ਯਕੀਨ ਨਹੀਂ ਹੋ ਸਕਦੇ ਕਿ ਯੂਜ਼ਰ ਨੇ ਕੀ ਮੀਨਾ ਕੀਤਾ, ਤਾਂ ਅਨੁਮਾਨ ਨਾ ਲਗਾਓ।
ਇੱਕ ਕਾਰਗਰ ਨਿਯਮ: ਫਾਰਮੈਟ ਲਈ ਆਟੋ-ਸਹੀ, ਸੈਮਾਂਟਿਕ ਲਈ ਰੱਜੈਕਟ। ਜਦੋਂ ਤੁਸੀਂ ਰੱਜੈਕਟ ਕਰੋ, ਤਾਂ ਯੂਜ਼ਰ ਨੂੰ ਸਪਸ਼ਟ ਸੁਨੇਹਾ ਦੇਓ ਕਿ ਕੀ ਬਦਲਣਾ ਹੈ ਅਤੇ ਕਿਉਂ।
ਆਉਟਪੁੱਟ ਪ੍ਰਮਾਣਕੀਕਰਨ ਮਾਡਲ ਦੇ ਬੋਲਣ ਤੋਂ ਬਾਅਦ ਦੀ ਚੈੱਕ ਪੋਇੰਟ ਹੈ। ਇਹ ਦੋ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦਿੰਦਾ ਹੈ: (1) ਕੀ ਆਉਟਪੁੱਟ ਠੀਕ ਰੂਪ ਵਿੱਚ ਹੈ? ਅਤੇ (2) ਕੀ ਇਹ ਵਾਸਤਵ ਵਿੱਚ ਮਨਜ਼ੂਰਯੋਗ ਅਤੇ ਉਪਯੋਗੀ ਹੈ? ਅਸਲ ਉਤਪਾਦਾਂ ਵਿੱਚ, ਤੁਹਾਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਦੋਹਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਆਉਟਪੁੱਟ ਸਕੀਮਾ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: ਉਹ JSON ਆਕਾਰ ਜੋ ਤੁਸੀਂ ਉਮੀਦ ਕਰਦੇ ਹੋ, ਕਿਹੜੇ ਕੀਜ਼ ਲਾਜਮੀ ਹਨ, ਅਤੇ ਉਹ ਕਿਸ ਕਿਸਮ ਅਤੇ ਮਨਜ਼ੂਰ ਕੀਤੇ ਮੁੱਲ ਹੋ ਸਕਦੇ ਹਨ। ਇਹ "ਫ੍ਰੀ-ਫਾਰਮ ਟੈਕਸਟ" ਨੂੰ ਉਸ ਚੀਜ਼ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ ਜਿਸਨੂੰ ਤੁਹਾਡੀ ਐਪਲੀਕੇਸ਼ਨ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਉਪਭੋਗ ਕਰ ਸਕੇ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਸਕੀਮਾ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਦਰਸਾਉਂਦਾ ਹੈ:
answer, confidence, citations)status "ok" | "needs_clarification" | "refuse" ਵਿੱਚੋਂ ਇੱਕ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ)ਸੰਰਚਨਾਤਮਕ ਜਾਂਚ ਆਮ ਫੇਲ੍ਹਾਂ ਨੂੰ ਫੜ ਲੈਂਦੀ ਹੈ: ਮਾਡਲ ਪ੍ਰੋਜ ਦੇ ਬਜਾਏ prose ਵਾਪਸ ਕਰ ਦੇਵੇ, ਇੱਕ ਕੀ ਨੂੰ ਭੁੱਲ ਜਾਵੇ, ਜਾਂ ਇੱਕ ਨੰਬਰ ਦੇ ਜਗ੍ਹਾ ਸਟ੍ਰਿੰਗ ਦੇ ਦੇਵੇ ਜਿਸਦੀ ਤੁਹਾਨੂੰ ਲੋੜ ਹੈ।
ਪੂਰੀ ਤਰ੍ਹਾਂ ਠੀਕ JSON ਵੀ ਗਲਤ ਹੋ ਸਕਦਾ ਹੈ। ਸੈਮਾਂਟਿਕ ਪ੍ਰਮਾਣਕੀਕਰਨ ਜਾਂਚਦੀ ਹੈ ਕਿ ਸਮੱਗਰੀ ਤੁਹਾਡੇ ਉਤਪਾਦ ਅਤੇ ਨੀਤੀਆਂ ਲਈ ਮਾਇਨੇਦਾਰ ਹੈ ਕਿ ਨਹੀਂ।
ਜਿਹੜੇ ਉਦਾਹਰਣ ਸਕੀਮਾ ਪਾਸ ਕਰਦੇ ਹੋਏ ਪਰ ਮਾਇਨੇ ਵਿੱਚ ਫੇਲ ਹੁੰਦੇ ਹਨ:
customer_id: "CUST-91822" ਵਾਪਸ ਆਉਂਦਾ ਹੈ ਜੋ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਵਿੱਚ ਮੌਜੂਦ ਨਹੀਂtotal 98 ਹੈ; ਜਾਂ ਛੂਟ ਸਬਟੋਟਲ ਤੋਂ ਵੱਧ ਹੈਸੈਮਾਂਟਿਕ ਜਾਂਚ ਆਮ ਤੌਰ 'ਤੇ ਕਾਰੋਬਾਰੀ ਨਿਯਮਾਂ ਵਰਗੀਆਂ ਹੁੰਦੀਆਂ ਹਨ: "IDs ਨੂੰ resolve ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ", "ਟੋਟਲ ਮਿਲਾਣੇ ਚਾਹੀਦੇ ਹਨ", "ਤਾਰੀਖਾਂ ਭਵਿੱਖ ਵਿੱਚ ਹੋਣੀ ਚਾਹੀਦੀ ਹਨ", "ਦਾਅਵੇ ਦਸਤਾਵੇਜ਼ਾਂ ਨਾਲ ਸਹਾਇਤ ਹੋਣ", ਅਤੇ "ਨਿੱਰੋਧਤ ਸਮੱਗਰੀ ਨਹੀਂ ਹੋਣੀ ਚਾਹੀਦੀ"।
ਮਕਸਦ ਮਾਡਲ ਨੂੰ ਸਜ਼ਾ ਦੇਣਾ ਨਹੀਂ—ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਡਾਊਨਸਟਰੀਮ ਸਿਸਟਮ "ਅਧਿਕਾਰ-ਭਰਪੂਰ ਬਕਵਾਸ" ਨੂੰ ਹੁਕਮ ਨਾ ਸਮਝ ਲੈਣ।
AI-ਤਿਆਰ ਸਿਸਟਮ ਕਈ ਵਾਰੀ ਅਜਿਹੇ ਨਤੀਜੇ ਦੇਣਗੇ ਜੋ ਗੈਰ-ਵੈਧ, ਅਧੂਰੇ, ਜਾਂ ਅੱਗਲੇ ਕਦਮ ਲਈ ਅਣਉਪਯੋਗ ਹੁੰਦੇ ਹਨ। ਚੰਗੀ ਗਲਤੀ ਸੰਭਾਲ ਇਹ ਫੈਸਲਾ ਕਰਦੀ ਹੈ ਕਿ ਕਿਹੜੀਆਂ ਸਮੱਸਿਆਵਾਂ ਕੰਮ ਨੂੰ ਤੁਰੰਤ ਰੋਕਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ, ਅਤੇ ਕਿਹੜੀਆਂ ਨੂੰ ਬਿਨਾਂ ਯੂਜ਼ਰ ਨੂੰ ਹੈਰਾਨ ਕੀਤੇ ਰਿਕਵਰ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਕ ਹਾਰਡ ਫੇਲ੍ਹ ਉਹ ਹੈ ਜਦੋਂ ਅੱਗੇ ਵੱਧਣਾ ਸੰਭਵ ਤੌਰ 'ਤੇ ਗਲਤ ਨਤੀਜੇ ਜਾਂ ਅਣਸੁਰੱਖਿਤ ਵਿਹਾਰ ਪੈਦਾ ਕਰੇਗਾ। ਉਦਾਹਰਣ: ਲਾਜ਼ਮੀ ਫੀਲਡ ਗਾਇਬ, JSON ਨੂੰ ਪਾਰਸ ਨਾ ਕੀਤਾ ਜਾ ਸਕੇ, ਜਾਂ ਨਤੀਜੇ ਨੇ ਕਿਸੇ ਅਣਮਨਜ਼ੂਰ ਨੀਤੀ ਦੀ ਉਲੰਘਣਾ ਕੀਤੀ। ਇਨ੍ਹਾਂ ਮਾਮਲਿਆਂ ਵਿੱਚ ਫੇਲ ਫਾਸਟ ਕਰੋ: ਰੋਕੋ, ਸਪਸ਼ਟ ਗਲਤੀ ਦਰਸਾਓ, ਅਤੇ ਅਨੁਮਾਨ ਨਾ ਕਰੋ।
ਇੱਕ ਸਾਫਟ ਫੇਲ੍ਹ ਉਹ ਹੈ ਜੋ ਰਿਕਵਰੀਯੋਗ ਹੁੰਦਾ ਹੈ ਜਿੱਥੇ ਸੁਰੱਖਿਅਤ ਫੈਲਬੈਕ ਮੌਜੂਦ ਹੈ। ਉਦਾਹਰਣ: ਮਾਡਲ ਨੇ ਸਹੀ ਮਾਇਨਾ ਦਿੱਤੀ ਪਰ ਫਾਰਮੈਟ ਠੀਕ ਨਹੀਂ, ਕੋਈ ਡਿਪੈਂਡੈਂਸੀ ਆਰਕਾਈਕਲ ਹੈ, ਜਾਂ ਬੇਨਤੀ ਟਾਈਮਆਉਟ ਹੋ ਗਿਆ। ਇੱਥੇ ਫੇਲ ਗ੍ਰੇਸਫੁੱਲ ਕਰੋ: ਰੀਟ੍ਰਾਈ (ਸੀਮਤ), ਜ਼ਿਆਦਾ ਸਖ਼ਤ ਨਿਰਦੇਸ਼ਾਂ ਨਾਲ ਮੁੜ ਪ੍ਰਾਮਪਟ ਕਰੋ, ਜਾਂ ਸਧਾਰਨ ਫੈਲਬੈਕ ਰਾਹ ਦੀ ਚੋਣ ਕਰੋ।
ਯੂਜ਼ਰ-ਸਾਮ੍ਹਣੇ ਗਲਤੀਆਂ ਸਖ਼ਤ ਅਤੇ ਕਾਰਗਰ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ:
ਸਟੈਕ ਟ੍ਰੇਸ, ਅੰਦਰੂਨੀ ਪ੍ਰਾਮਪਟ, ਜਾਂ ਅੰਦਰੂਨੀ IDs ਦਿਖਾਉਣ ਤੋਂ ਬਚੋ। ਇਹ ਡੀਟੇਲਾਂ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਲਾਭਦਾਇਕ ਹਨ—ਪੇਪਰ 'ਤੇ ਨਹੀਂ।
ਗਲਤੀਆਂ ਨੂੰ ਦੋ ਸਮਕਾਲੀ ਆਉਟਪੁੱਟ ਵਾਂਗ ਬਰਤੋ:
ਇਸ ਨਾਲ ਪ੍ਰੋਡਕਟ ਸ਼ਾਂਤ ਅਤੇ ਸਮਝਦਾਰ ਬਣਦਾ ਹੈ, ਅਤੇ ਤੁਹਾਡੇ ਟੀਮ ਨੂੰ ਸਮੱਸਿਆਵਾਂ ਠੀਕ ਕਰਨ ਲਈ ਕਾਫ਼ੀ ਜਾਣਕਾਰੀ ਮਿਲਦੀ ਹੈ।
ਸਧਾਰਣ ਟੈਕਸੋਨੋਮੀ ਟੀਮਾਂ ਨੂੰ ਤੇਜ਼ ਕਾਰਵਾਈ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ:
ਜਦੋਂ ਤੁਸੀਂ ਇਕ ਘਟਨਾ ਨੂੰ ਠੀਕ ਢੰਗ ਨਾਲ ਲੇਬਲ ਕਰ ਸਕਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਇਸ ਨੂੰ ਸਹੀ ਮਾਲਕ ਨੂੰ ਰਾਊਟ ਕਰ ਸਕਦੇ ਹੋ—ਅਤੇ ਅਗਲੀ ਵਾਰ ਸਹੀ ਨਿਯਮ ਸੁਧਾਰ ਸਕਦੇ ਹੋ।
ਪ੍ਰਮਾਣਕੀ ਨਿਯਮ ਸਮੱਸਿਆਵਾਂ ਫੜ ਲੈਂਦੇ ਹਨ; ਰਿਕਵਰੀ ਇਹ ਤੈਅ ਕਰਦੀ ਹੈ ਕਿ ਯੂਜ਼ਰ ਨੂੰ ਮਦਦਗਾਰ ਅਨੁਭਵ ਮਿਲੇਗਾ ਜਾਂ ਮਨਪਸੰਦ ਇਕ ਰੁਕਾਵਟ। ਮਕਸਦ "ਹਮੇਸ਼ਾ ਸਫਲ ਹੋ ਜਾਣਾ" ਨਹੀਂ—ਮਕਸਦ ਹੈ "ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਫੇਲ੍ਹ ਕਰਨਾ, ਅਤੇ ਸੁਰੱਖਿਆ ਨਾਲ degrade ਕਰਨਾ"।
ਰੀਟ੍ਰਾਈ ਲੋਜਿਕ ਸਭ ਤੋਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਫੇਲ੍ਹ ਸੰਭਵਤ: ਤਾਰੀਖੀ ਹੋਵੇ:
ਬਾਊਂਡਡ ਰੀਟ੍ਰਾਈਜ਼ ਵਰਤੋ ਜਿਸ ਵਿੱਚ exponential backoff ਅਤੇ jitter ਹੋਵੇ। ਲਗਾਤਾਰ ਪੰਜ ਵਾਰ ਤੁਰੰਤ ਰੀਟ੍ਰਾਈ ਕਰਨਾ ਇੱਕ ਛੋਟੀ ਘਟਨਾ ਨੂੰ ਵੱਡੀ ਬਣਾਉਣ ਦਾ ਕਾਰਣ ਬਣਦਾ ਹੈ।
ਜਦੋਂ ਆਉਟਪੁੱਟ ਸੰਰਚਨਾਤਮਕ ਤੌਰ 'ਤੇ ਗਲਤ ਜਾਂ ਸੈਮਾਂਟਿਕ ਤੌਰ 'ਤੇ ਗਲਤ ਹੋਵੇ, ਤਾਂ ਰੀਟ੍ਰਾਈਜ਼ ਨੁਕਸਾਨਦਾਇਕ ਹੋ ਸਕਦੇ ਹਨ। ਜੇ ਤੁਹਾਡੇ ਵੈਲਿਡੇਟਰ ਨੇ ਕਿਹਾ "ਲਾਜ਼ਮੀ ਫੀਲਡ ਗਾਇਬ" ਜਾਂ "ਨੀਤੀ ਉਲੰਘਣਾ", ਤਾਂ ਇੱਕੋ ਪ੍ਰਾਮਪਟ ਨਾਲ ਦੂਜੀ ਕੋਸ਼ਿਸ਼ ਕੇਵਲ ਵੱਖਰੀ ਗਲਤ ਜਵਾਬ ਪੈਦਾ ਕਰ ਸਕਦੀ ਹੈ—ਅਤੇ ਟੋਕਨ ਅਤੇ ਲੇਟੈਂਸੀ ਖ਼ਰਚ ਕਰ ਸਕਦੀ ਹੈ। ਐਸੇ ਮਾਮਲਿਆਂ ਵਿੱਚ, ਪ੍ਰਾਮਪਟ ਰੀਪੇਅਰ (ਜਿਆਦਾ ਸਖ਼ਤ ਹੁਕਮ) ਜਾਂ ਫਾਲਬੈਕ ਪਸੰਦ ਕਰੋ।
ਇੱਕ ਚੰਗਾ ਫਾਲਬੈਕ ਉਹ ਹੈ ਜੋ ਤੁਸੀਂ ਯੂਜ਼ਰ ਨੂੰ ਸਮਝਾ ਸਕਦੇ ਹੋ ਅਤੇ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਮੈਜਰ ਕਰ ਸਕਦੇ ਹੋ:
ਹਸਤਾਂਤਰਨ ਨੂੰ ਸਪੱਸ਼ਟ ਰੱਖੋ: ਕਿਹੜਾ ਰਾਹ ਵਰਤਿਆ ਗਿਆ ਤਾਂ ਜੋ ਤੁਸੀਂ بعد ਵਿੱਚ ਗੁਣਵੱਤਾ ਅਤੇ ਲਾਗਤ ਦੀ ਤੁਲਨਾ ਕਰ ਸਕੋ।
ਕਈ ਵਾਰ ਤੁਸੀਂ ਉਪਯੋਗੀ ਸਬਸੈੱਟ ਦੇ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਣ: ਨਿਕਲੇ ਹੋਏ ਐਂਟੀਟੀਜ਼ ਪਰ ਪੂਰਨ ਸੰਖੇਪ ਨਹੀਂ)। ਇਸਨੂੰ ਅੰਸ਼ਿਕ ਵਜੋਂ ਦਰਸਾਓ, ਚੇਤਾਵਨੀਆਂ ਸ਼ਾਮਿਲ ਕਰੋ, ਅਤੇ ਗੈਰ-ਜਰੂਰੀ ਖਾਲੀਆਂ ਥਾਵਾਂ ਨੂੰ ਚੁੱਪਚਾਪ ਭਰਨ ਤੋਂ ਬਚੋ। ਇਹ ਭਰੋਸਾ ਬਚਾਉਂਦਾ ਹੈ ਅਤੇ ਕਾਲਰ ਨੂੰ ਕਾਮਯਾਬ ਕੁਝ ਦਿੰਦਾ ਹੈ।
ਹਰ ਕਾਲ ਲਈ ਟਾਈਮਆਉਟ ਅਤੇ ਕੁੱਲ ਰਿਕਵੇਸਟ ਡੈਡਲਾਈਨ ਸੈੱਟ ਕਰੋ। ਜਦੋਂ ਰੇਟ-ਲਿਮਿਟ ਹੋਵੇ, Retry-After ਦਾ ਆਦਰ ਕਰੋ (ਜੇ ਮੌਜੂਦ ਹੋਵੇ)। ਇੱਕ ਸਰਕਿਟ ਬ੍ਰੇਕਰ ਸ਼ਾਮਿਲ ਕਰੋ ਤਾਂ ਜੋ بار-بار ਫੇਲ੍ਹ ਹੋਣ 'ਤੇ ਤੇਜ਼ੀ ਨਾਲ ਫਾਲਬੈਕ 'ਤੇ ਸਵਿੱਚ ਹੋ ਜਾਏ ਨਾ ਕਿ ਮਾਡਲ/API 'ਤੇ ਦਬਾਅ ਵਧੇ। ਇਹ cascading slowdowns ਨੂੰ ਰੋਕਦਾ ਅਤੇ ਰਿਕਵਰੀ ਵਿਹਾਰ ਨੂੰ ਸਥਿਰ ਬਣਾਉਂਦਾ ਹੈ।
ਐਜ-ਕੇਸ ਉਹ ਹਾਲਤਾਂ ਹਨ ਜੋ ਤੁਹਾਡੀ ਟੀਮ ਡੈਮੋਜ਼ ਵਿੱਚ ਨਹੀਂ ਦੇਖਦੀ: ਵਿਰਲੇ ਇਨਪੁੱਟ, ਅਜੀਬ ਫਾਰਮੈਟ, ਵਿਵਾਦੀ ਪ੍ਰਾਮਪਟ, ਜਾਂ ਗੱਲਬਾਤ ਜੋ ਬਹੁਤ ਲੰਬੀ ਚੱਲ ਜਾਂਦੀ ਹੈ। AI-ਤਿਆਰ ਸਿਸਟਮਾਂ ਨਾਲ, ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਉੱਪੱਜਦੇ ਹਨ ਕਿਉਂਕਿ ਲੋਕ ਸਿਸਟਮ ਨੂੰ ਲਚਕੀਲੇ ਸਹਾਇਕ ਵਾਂਗ ਵਰਤਦੇ ਹਨ—ਫਿਰ ਉਸਨੂੰ ਖੁਸ਼ ਰਸਤਾ ਤੋਂ ਬਾਹਰ ਧੱਕਦੇ ਹਨ।
ਅਸਲ ਯੂਜ਼ਰ ਟੈਸਟ ਡੇਟਾ ਵਾਂਗ ਨਹੀਂ ਲਿਖਦੇ। ਉਹ ਸਕ੍ਰੀਨਸ਼ਾਟਾਂ ਚੈਪ ਕਰਦਿਆਂ ਤੋਂ ਬਦਲੇ ਹੋਏ ਟੈਕਸਟ ਪੇਸਟ ਕਰਦੇ ਹਨ, ਅਧ-ਮੁਕੰਮਲ ਨੋਟਸ, ਜਾਂ PDF ਤੋਂ ਨਕਲ ਕੀਤਾ ਸਮੱਗਰੀ ਜਿਸ ਵਿਚ ਅਜੀਬ ਲਾਈਨ-ਬ੍ਰੇਕਸ ਹੋਦੇ ਹਨ। ਉਹ "ਕ੍ਰੀਏਟਿਵ" ਪ੍ਰਾਮਪਟ ਵੀ ਟਰਾਈ ਕਰਦੇ ਹਨ: ਮਾਡਲ ਨੂੰ ਨਿਯਮ ਅਣਡਿੱਠੇ ਕਰਨ ਲਈ ਕਹਿਣਾ, ਛੁਪੇ ਹੋਏ ਨਿਦੇਸ਼ ਬਾਹਰ ਲਿਆਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਨਾ, ਜਾਂ ਜਾਣ-ਬੁਝ ਕੇ ਗੁੰਝਲਦਾਰ ਫਾਰਮੇਟ ਵapas ਕਰਵਾਉਣਾ।
ਲੰਮਾ ਸੰਦਰਭ ਇੱਕ ਹੋਰ ਆਮ ਐਜ-ਕੇਸ ਹੈ। ਇੱਕ ਯੂਜ਼ਰ 30-ਪੰਨੇ ਦੀ ਦਸਤਾਵੇਜ਼ ਅਪਲੋਡ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਢਾਂਚਾਬੱਧ ਸਾਰ ਮੰਗ ਸਕਦਾ ਹੈ, ਫਿਰ ਦਸ ਸਪੱਸ਼ਟੀਕਰਨ ਸਵਾਲ ਪੋੱਛ ਸਕਦਾ ਹੈ। ਪਹਿਲੇ ਦੌਰ ਵਿੱਚ ਮਾਡਲ ਚੰਗਾ ਪ੍ਰਦਰਸ਼ਨ ਦਿਖਾ ਸਕਦਾ ਹੈ, ਪਰ ਸੰਦਰਭ ਵਧਣ ਨਾਲ ਵਿਹਾਰ ਡ੍ਰਿਫਟ ਕਰ ਸਕਦਾ ਹੈ।
ਕਈ ਫੇਲ੍ਹ ਆਮ ਉਪਯੋਗ ਤੋਂ ਜ਼ਿਆਦਾ ਪਰਿਧੀਆਂ ਤੋਂ ਆਉਂਦੇ ਹਨ:
ਇਹ ਅਕਸਰ ਬੁਨਿਆਦੀ ਜਾਂਚਾਂ ਨੂੰ ਪਾਰ ਕਰ ਜਾਂਦੇ ਹਨ ਕਿਉਂਕਿ ਟੈਕਸਟ ਮਨੁੱਖਾਂ ਨੂੰ ਠੀਕ ਲੱਗਦਾ ਹੈ ਪਰ ਪਾਰਸਿੰਗ, ਗਿਣਤੀ, ਜਾਂ ਡਾਊਨਸਟ੍ਰੀਮ ਨਿਯਮਾਂ ਵਿੱਚ ਫੇਲ ਹੁੰਦਾ ਹੈ।
ਭਾਵੇਂ ਤੁਹਾਡਾ ਪ੍ਰਾਮਪਟ ਅਤੇ ਪ੍ਰਮਾਣਕੀ ਠੀਕ ਹੋਵੇ, ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਨਵੇਂ ਐਜ-ਕੇਸ ਲਿਆ ਸਕਦੀ ਹੈ:
ਕੁਝ ਐਜ-ਕੇਸ ਪਹਿਲਾਂ ਭਵਿੱਖਬਾਣੀ ਨਹੀਂ ਕੀਤੇ ਜਾ ਸਕਦੇ। ਇਕੱਲੀ ਭਰੋਸੇਯੋਗ ਤਰੀਕਾ ਉਹਨਾਂ ਦੀ ਖੋਜ ਕਰਨ ਲਈ ਅਸਲ ਫੇਲ੍ਹਾਂ ਨੂੰ ਵੇਖਣਾ ਹੈ। ਚੰਗੇ ਲਾਗਜ਼ ਅਤੇ ਟ੍ਰੇਸਜ਼ ਵਿੱਚ ਇਹ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਇਨਪੁੱਟ ਆਕਾਰ (ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ), ਮਾਡਲ ਆਉਟਪੁੱਟ (ਸੁਰੱਖਿਅਤ), ਜੋ ਪ੍ਰਮਾਣਕੀ ਨਿਯਮ ਫੇਲ ਹੋਏ, ਅਤੇ ਕਿਸ ਫਾਲਬੈਕ ਰਾਹ ਚਲਿਆ। ਜਦੋਂ ਤੁਸੀਂ ਫੇਲ੍ਹਾਂ ਨੂੰ ਪੈਟਰਨ ਵਾਂਗ ਗਰੁੱਪ ਕਰ ਸਕਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਹੈਰਾਨੀ ਨੂੰ ਨਵੇਂ ਸਪੱਸ਼ਟ ਨਿਯਮਾਂ ਵਿਚ ਤਬਦੀਲ ਕਰ ਸਕਦੇ ਹੋ—ਬਿਨਾਂ ਅਨੁਮਾਨ ਲਗਾਏ।
ਪ੍ਰਮਾਣਕੀਕਰਨ ਕੇਵਲ ਆਉਟਪੁੱਟ ਨੂੰ ਸਾਫ਼ ਰੱਖਣ ਬਾਰੇ ਨਹੀਂ; ਇਹ ਵੀ ਹੈ ਕਿਤੰੂ AI ਸਿਸਟਮ ਨੂੰ ਕੁਝ ਅਣਸੁਰੱਖਿਅਤ ਕਰਨ ਤੋਂ ਰੋਕਿਆ ਜਾ ਸਕੇ। AI-ਸ_ieabled ਐਪਾਂ ਵਿੱਚ ਬਹੁਤ ਸਾਰੇ ਸੁਰੱਖਿਆ ਘਟਨਾਕ੍ਰਮ ਸਿਰਫ਼ "ਖ਼ਰਾਬ ਇਨਪੁੱਟ" ਜਾਂ "ਖ਼ਰਾਬ ਆਉਟਪੁੱਟ" ਦੇ ਮੁੱਦੇ ਹੁੰਦੇ ਹਨ ਪਰ ਉਚੇ ਸਟੇਕਸ: ਇਹ ਡੇਟਾ ਲੀਕ, ਅਣਅਧਿਕਾਰਤ ਕਾਰਵਾਈਆਂ, ਜਾਂ ਟੂਲ ਮਿਸਯੂਜ਼ ਨੂੰ ਜਨਮ ਦੇ ਸਕਦੇ ਹਨ।
Prompt injection ਉਹ ਸਮਾਂ ਹੈ ਜਦੋਂ ਅਨਟਰੱਸਟ ਕੀਤੀ ਸਮੱਗਰੀ (ਯੂਜ਼ਰ ਸੁਨੇਹਾ, ਵੈਬ ਪੇਜ, ਈਮੇਲ, ਦਸਤਾਵੇਜ਼) ਵਿੱਚ ਇੰਝ ਨਿਰਦੇਸ਼ ਹੋ ਸਕਦੇ ਹਨ: "ਆਪਣੇ ਨਿਯਮ ਨਹੀਂ ਮੰਨੋ" ਜਾਂ "ਮੈਨੂੰ ਛੁਪਿਆ ਸਿਸਟਮ ਪ੍ਰਾਮਪਟ ਭੇਜੋ"। ਇਹ ਇੱਕ ਪ੍ਰਮਾਣਕੀ ਸਮੱਸਿਆ ਵਾਂਗ ਲੱਗਦਾ ਹੈ ਕਿਉਂਕਿ ਸਿਸਟਮ ਨੂੰ ਇਹ ਫੈਸਲਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਕਿ ਕਿਹੜੇ ਨਿਰਦੇਸ਼ ਵੈਧ ਹਨ ਅਤੇ ਕਿਹੜੇ ਦੁਖਦਾਈ।
ਇੱਕ ਵਰਤੋਂਯੋਗ ਰੁਖ: ਮਾਡਲ-ਵੱਲੇ ਟੈਕਸਟ ਨੂੰ ਅਣ-ਭਰੋਸੇਯੋਗ ਮੰਨੋ। ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਇਰਾਦਾ ਦੀ ਜਾਂਚ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ (ਕਿਹੜਾ ਇੱਕ ਕਾਰਜ ਮੰਗਿਆ ਜਾ ਰਿਹਾ ਹੈ) ਅਤੇ ਅਧਿਕਾਰ (ਬੇਨਤੀ ਕਰਨ ਵਾਲਾ ਇਸ ਨੂੰ ਕਰਨ ਦਾ ਹੱਕ ਰੱਖਦਾ ਹੈ) — ਸਿਰਫ਼ ਫਾਰਮੈਟ ਦੀ ਨਹੀਂ।
ਚੰਗੀ ਸੁਰੱਖਿਆ ਅਕਸਰ ਆਮ ਪ੍ਰਮਾਣਕੀ ਨਿਯਮਾਂ ਵਾਂਗ دکھਦੀ ਹੈ:
ਜੇ ਤੁਸੀਂ ਮਾਡਲ ਨੂੰ ਬਰਾਊਜ਼ ਕਰਨ ਜਾਂ ਦਸਤਾਵੇਜ਼ ਫੈਚ ਕਰਨ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਇਹ ਜਾਂਚੋ ਕਿ ਇਹ ਕਿੱਥੇ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਕੀ ਲੈ ਕੇ ਆ ਸਕਦਾ ਹੈ।
least privilege ਲਾਗੂ ਕਰੋ: ਹਰ ਟੂਲ ਨੂੰ ਘੱਟ ਤੋਂ ਘੱਟ ਅਨੁਮਤੀਆਂ ਦਿਓ, ਅਤੇ ਟੋਕਨਾਂ ਨੂੰ ਟਾਈਟ ਸਕੋਪ ਕਰੋ (ਛੋਟੀ పద ਰਹਿਤ, ਸੀਮਤ ਐਂਡਪਾਇੰਟ, ਸੀਮਤ ਡੇਟਾ). ਇਹ ਬਿਹਤਰ ਹੈ ਕਿ ਬੇਨਤੀ ਫੇਲ ਹੋ ਜਾਵੇ ਅਤੇ ਇੱਕ ਸੀਮਤ ਕਾਰਜ ਮੰਗਣਾ, ਬਜਾਏ ਵਿਆਪਕ ਪਹੁੰਚ ਦੇਣ ਦੇ "ਕਿਰਪਾ ਕਰਕੇ"।
ਉੱਚ-ਪ੍ਰਭਾਵ ਵਾਲੀਆਂ ਕਾਰਵਾਈਆਂ (ਭੁਗਤਾਨ, ਖਾਤਾ ਬਦਲਾਅ, ਈਮੇਲ ਭੇਜਣਾ, ਡੇਟਾ ਮਿਟਾਉਣਾ) ਲਈ ਸ਼ਾਮਿਲ ਕਰੋ:
ਇਹ ਉਪਾਇਆ ਪ੍ਰਮਾਣਕੀ ਨੂੰ ਇੱਕ UX ਡੀਟੇਲ ਤੋਂ ਵਾਸਤਵਿਕ ਸੁਰੱਖਿਆ ਬਾਊਂਡਰੀ ਬਣਾਉਂਦੇ ਹਨ।
AI-ਤਿਆਰ ਵਿਹਾਰ ਦੀ ਪੜਤਾਲ ਉਸ ਸਮੇਂ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਮਾਡਲ ਨੂੰ ਇੱਕ ਅਨਿਸ਼ਚਿਤ ਸਹਿਯੋਗੀ ਵਾਂਗ ਸਮਝਦੇ ਹੋ: ਤੁਸੀਂ ਹਰ ਸਟੇਂਟੈਂਸ ਦੀ ਪੂਰੀ ਗਾਰੰਟੀ ਨਹੀਂ ਦੇ ਸਕਦੇ, ਪਰ ਤੁਸੀਂ ਸਰਹੱਦਾਂ, ਸੰਰਚਨਾ, ਅਤੇ ਉਪਯੋਗਿਤਾ 'ਤੇ ਦਾਅਵਾ ਕਰ ਸਕਦੇ ਹੋ।
ਕਈ ਪੱਧਰ ਵਰਤੋ ਜੋ ਹਰ ਇੱਕ ਵੱਖਰਾ ਸਵਾਲ ਜਵਾਬ ਦੇਂਦੇ ਹਨ:
X/Y/Z ਚੀਜ਼ਾਂ ਨਾਲ ਵਾਪਸ ਹੋਵੇ" ਜਾਂ "ਕਾਫ਼ੀ ਘੱਟ ਕਾਨਫ਼ੀਡੈਂਸ 'ਤੇ citation ਫੀਲਡ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ"।ਇੱਕ ਚੰਗਾ ਨਿਯਮ: ਜੇ ਕੋਈ ਬੱਗ end-to-end ਟੈਸਟ ਤੱਕ ਪਹੁੰਚਦਾ ਹੈ, ਤਾਂ ਇੱਕ ਛੋਟਾ ਟੈਸਟ (ਯੂਨਿਟ/ਕਾਂਟ੍ਰੈਕਟ) ਵੀ ਸ਼ਾਮਿਲ ਕਰੋ ਤਾਂ ਕਿ ਅਗਲੀ ਵਾਰ ਉਹ ਜਲਦੀ ਫੜਿਆ ਜਾ ਸਕੇ।
ਇੱਕ ਛੋਟਾ, ਚੁਣਿਆ ਹੋਇਆ ਪ੍ਰਾਮਪਟਾਂ ਦਾ ਸੰਗ੍ਰਹਿ ਬਣਾਓ ਜੋ ਅਸਲ ਵਰਤੋਂ ਦੀ ਪ੍ਰਤੀਨਿਧਤਾ ਕਰਦੇ ਹਨ। ਹਰ ਇੱਕ ਲਈ ਦਰਜ ਕਰੋ:
ਗੋਲਡਨ ਸੈੱਟ ਨੂੰ CI ਵਿੱਚ ਚਲਾਓ ਅਤੇ ਸਮੇਂ ਦੇ ਨਾਲ ਬਦਲਾਵਾਂ ਟ੍ਰੈਕ ਕਰੋ। ਜਦੋਂ ਕੋਈ ਘਟਨਾ ਹੁੰਦੀ ਹੈ, ਉਸ ਕੇਸ ਲਈ ਨਵਾਂ ਗੋਲਡਨ ਟੈਸਟ ਸ਼ਾਮਿਲ ਕਰੋ।
AI ਸਿਸਟਮ ਗੰਦੇ ਐਜ 'ਤੇ ਅਕਸਰ ਫੇਲ੍ਹ ਹੁੰਦੇ ਹਨ। ਆਟੋਮੇਟਡ ਫਜ਼ਿੰਗ ਸ਼ਾਮਿਲ ਕਰੋ ਜੋ:
ਸਿੱਧਾ ਟੈਕਸਟ ਦੇ snapshot ਦੀ ਬਜਾਏ, ਰੋਬਰਿਕਸ ਅਤੇ ਟੋਲਰੈਂਸ ਵਰਤੋ:
ਇਸ ਨਾਲ ਟੈਸਟ ਸਥਿਰ ਰਹਿੰਦੇ ਹਨ ਪਰ ਅਸਲ ਰਿਗ੍ਰੈਸ਼ਨਾਂ ਨੂੰ ਫੜ ਲੈਂਦੇ ਹਨ।
ਜਦੋਂ ਤੁਸੀਂ ਅਸਲ ਵਰਤੋਂ ਵਿੱਚ ਕੀ ਹੋ ਰਿਹਾ ਹੈ ਦੇਖ ਸਕਦੇ ਹੋ, ਪ੍ਰਮਾਣਕੀ ਨਿਯਮ ਅਤੇ ਗਲਤੀ ਸੰਭਾਲ ਹੀ ਬਿਹਤਰ ਬਣਦੇ ਹਨ। ਮਾਨੀਟਰਿੰਗ "ਸਾਨੂੰ ਲੱਗਦਾ ਹੈ ਠੀਕ ਹੈ" ਨੂੰ ਸਪੱਸ਼ਟ ਸਬੂਤ ਵਿੱਚ ਬਦਲ ਦਿੰਦੀ ਹੈ: ਕੀ ਫੇਲ੍ਹ ਹੋ ਰਿਹਾ ਹੈ, ਕਿੰਨੀ ਵਾਰੀ, ਅਤੇ ਭਰੋਸੇਯੋਗਤਾ ਸੁਧਰ ਰਹੀ ਹੈ ਜਾਂ ਚੁੱਪਚਾਪ ਗਿਰ ਰਹੀ ਹੈ।
ਸ਼ੁਰੂ ਕਰੋ ਉਹਨਾਂ ਲਾਗਜ਼ ਨਾਲ ਜੋ ਦੱਸਦੇ ਹਨ ਕਿ ਇੱਕ ਬੇਨਤੀ ਕਿਵੇਂ ਸਫਲ ਜਾਂ ਅਸਫਲ ਰਹੀ—ਫੇਰ ਸੰਵੇਦਨਸ਼ੀਲ ਡਾਟਾ ਡਿਫੌਲਟ ਰੂਪ ਵਿੱਚ redact ਕਰੋ ਜਾਂ ਬਚਾਓ।
address.postcode), ਅਤੇ ਫੇਲ੍ਹ ਦਾ ਕਾਰਨ (ਸਕੀਮਾ ਮਿਸਮੇਚ, ਅਸੁਰੱਖਿਅਤ ਸਮੱਗਰੀ, ਲੋੜੀਂਦੀ ਇਰਾਦਾ ਗਾਇਬ)ਲਾਗ ਤੱਜ਼ੀਨੀ ਇਕ ਘਟਨਾ ਨੂੰ ਡੀਬੱਗ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ; ਮੈਟ੍ਰਿਕਸ ਪੈਟਰਨ ਪਛਾਣਨ ਵਿੱਚ। ਟਰੈਕ ਕਰੋ:
AI ਆਉਟਪੁੱਟ ਪ੍ਰਾਮਪਟ ਸੋਧਾਂ, ਮਾਡਲ ਅਪਡੇਟ, ਜਾਂ ਨਵੀਂ ਯੂਜ਼ਰ ਵਰਤੋਂ ਤੋਂ ਬਾਅਦ ਨਰਮ ਤਰੀਕੇ ਨਾਲ ਬਦਲ ਸਕਦੇ ਹਨ। ਅਲਰਟਸ ਤਬਦੀਲੀ 'ਤੇ ਧਿਆਨ ਦੇਣੇ ਚਾਹੀਦੇ ਹਨ, ਨਾ ਕਿ ਸਿਰਫ਼ ਅਬਸਲੂਟ ਸੀਮਾਵਾਂ 'ਤੇ:
ਇੱਕ ਚੰਗਾ ਡੈਸ਼ਬੋਰਡ ਇਸਦਾ ਜਵਾਬ ਦਿੰਦਾ: "ਕੀ ਇਹ ਯੂਜ਼ਰਾਂ ਲਈ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ?" ਇੱਕ ਸਰਲ ਭਰੋਸੇਯੋਗਤਾ ਸਕੋਰਕਾਰਡ, ਸਕੀਮਾ ਪਾਸ ਰੇਟ ਲਈ ਟ੍ਰੈਂਡ ਲਾਈਨ, ਫੇਲ੍ਹਾਂ ਦੀ ਵਰਗੀਕਰਨ, ਅਤੇ ਸਭ ਤੋਂ ਆਮ ਫੇਲ੍ਹ ਕਿਸਮਾਂ ਦੇ ਉਦਾਹਰਨ (ਸੰਵੇਦਨਸ਼ੀਲ ਸਮੱਗਰੀ ਤੋਂ ਮੁਕਤ) ਸ਼ਾਮਿਲ ਕਰੋ। ਇੰਜੀਨੀਅਰਾਂ ਲਈ ਡੀਪ-ਡਿਵ ਵਿਚ ਲਿੰਕ ਕਰੋ, ਪਰ ਉੱਪਰੀ-ਸਤਹ ਦ੍ਰਿਸ਼ ਯੂਜ਼ਰ ਅਤੇ ਸਪੋਰਟ ਟੀਮ ਲਈ ਪੜ੍ਹਨਯੋਗ ਰੱਖੋ।
ਪ੍ਰਮਾਣਕੀਕਰਨ ਅਤੇ ਗਲਤੀ ਸੰਭਾਲ "ਇੱਕ ਵਾਰੀ ਸੈੱਟ ਕਰਨ ਅਤੇ ਭੁੱਲ ਜਾਣ" ਵਾਲੇ ਕੰਮ ਨਹੀਂ ਹਨ। AI-ਤਿਆਰ ਸਿਸਟਮਾਂ ਵਿੱਚ, ਅਸਲ ਕੰਮ ਸ਼ੁਰੂਆਤ ਤੋਂ ਬਾਅਦ ਹੁੰਦਾ ਹੈ: ਹਰ ਅਜੀਬ ਆਉਟਪੁੱਟ ਤੁਹਾਡੇ ਨਿਯਮਾਂ ਬਾਰੇ ਇੱਕ ਸੂਚਨਾ ਹੈ।
ਫੇਲ੍ਹਾਂ ਨੂੰ ਡਾਟਾ ਸਮਝੋ, ਥੋਟੀਆਂ ਨਹੀਂ। ਸਭ ਤੋਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਲੂਪ ਆਮ ਤੌਰ 'ਤੇ ਮਿਲ ਕੇ ਕੰਮ ਕਰਦੇ ਹਨ:
ਹਰ ਰਿਪੋਰਟ ਨੂੰ ਸਹੀ ਇਨਪੁੱਟ, ਮਾਡਲ/ਪ੍ਰਾਮਪਟ ਵਰਜਨ, ਅਤੇ ਵੈਲਿਡੇਟਰ ਨਤੀਜਿਆਂ ਨਾਲ ਜੋੜੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਦੁਹਰਾਈ ਪਾ ਸਕੋ।
ਜ਼ਿਆਦਾਤਰ ਸੁਧਾਰ ਕਈ ਆਮ ਕਦਮਾਂ ਵਿੱਚ ਆਉਂਦੇ ਹਨ:
ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਕੇਸ ਠੀਕ ਕਰਦੇ ਹੋ, ਤਾਂ ਪੁੱਛੋ: "ਕਿਹੜੇ ਨੇੜਲੇ ਕੇਸ ਹਜੇ ਵੀ ਛੁੱਟ ਸਕਦੇ ਹਨ?" ਨਿਯਮ ਨੂੰ ਇਕ ਕੇਸ ਲਈ ਨਹੀਂ, ਪਰ ਇਕ ਛੋਟੇ ਖੇਤਰ ਲਈ ਵਿਸਤਾਰ ਕਰੋ।
ਪ੍ਰਾਮਪਟਾਂ, ਵੈਲਿਡੇਟਰਾਂ, ਅਤੇ ਮਾਡਲਾਂ ਨੂੰ ਕੋਡ ਵਾਂਗ ਵਰਜਨ ਕਰੋ। ਬਦਲਾਵਾਂ ਨੂੰ canary ਜਾਂ A/B ਰੋਲਆਊਟ ਨਾਲ ਲਾਓ, ਮੁੱਖ ਮੈਟ੍ਰਿਕਸ (ਰਿੱਜੈਕਟ ਦਰ, ਯੂਜ਼ਰ ਸੰਤੋਸ਼, ਲਾਗਤ/ਲੇਟੈਂਸੀ) ਨੂੰ ਟ੍ਰੈਕ ਕਰੋ, ਅਤੇ ਤੇਜ਼ rollback ਰਸਤਾ ਰੱਖੋ।
ਇਹ ਥਾਂ ਪ੍ਰੋਡਕਟ ਟੂਲਿੰਗ ਮਦਦ ਕਰ ਸਕਦੀ ਹੈ: ਉਦਾਹਰਨ ਲਈ Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ snapshots ਅਤੇ rollback ਦਾ ਸਮਰਥਨ ਦਿੰਦੇ ਹਨ, ਜੋ ਪ੍ਰਾਮਪਟ/ਵੈਲਿਡੇਟਰ ਵਰਜਨਿੰਗ ਨਾਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਮਿਲਦੇ ਹਨ। ਜਦੋਂ ਕੋਈ ਅਪਡੇਟ ਸਕੀਮਾ ਫੇਲ੍ਹਾਂ ਵਧਾ ਦੇਵੇ ਜਾਂ ਇੱਕ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਨੂੰ ਤੋੜ ਦੇਵੇ, ਤੁਰੰਤ rollback ਇੱਕ ਪ੍ਰੋਡਕਸ਼ਨ ਘਟਨਾ ਨੂੰ ਤੇਜ਼ ਰਿਕਵਰੀ ਵਿੱਚ ਬਦਲ ਦੇ ਸਕਦਾ ਹੈ।
An AI-generated system is any product where a model’s output directly affects what happens next—what is shown, stored, sent to another tool, or executed as an action.
It’s broader than chat: it can include generated data, code, workflow steps, or agent/tool decisions.
Because once AI output is part of control flow, reliability becomes a user experience concern. A malformed JSON response, a missing field, or a wrong instruction can:
Designing validation and error paths up front makes failures controlled instead of chaotic.
Structural validity means the output is parseable and shaped as expected (e.g., valid JSON, required keys present, correct types).
Business validity means the content is acceptable for your real rules (e.g., IDs must exist, totals must reconcile, refund text must follow policy). You usually need both layers.
A practical contract defines what must be true at three points:
Once you have a contract, validators are just automated enforcement of it.
Treat input broadly: user text, files, form fields, API payloads, and retrieved/tool data.
High-leverage checks include required fields, file size/type limits, enums, length bounds, valid encoding/JSON, and safe URL formats. These reduce model confusion and protect downstream parsers and databases.
Normalize when the intent is unambiguous and the change is reversible (e.g., trimming whitespace, normalizing case for country codes).
Reject when “fixing” might change meaning or hide errors (e.g., ambiguous dates like “03/04/2025,” unexpected currencies, suspicious HTML/JS). A good rule: auto-correct format, reject semantics.
Start with an explicit output schema:
answer, status)Then add semantic checks (IDs resolve, totals reconcile, dates make sense, citations support claims). If validation fails, avoid consuming the output downstream—retry with tighter constraints or use a fallback.
Fail fast on problems where continuing is risky: can’t parse output, missing required fields, policy violations.
Fail gracefully when a safe recovery exists: transient timeouts, rate limits, minor formatting issues.
In both cases, separate:
Retries help when the failure is transient (timeouts, 429s, brief outages). Use bounded retries with exponential backoff and jitter.
Retries are often wasteful for “wrong answer” failures (schema mismatch, missing required fields, policy violation). Prefer prompt repair (stricter instructions), deterministic templates, a smaller model, cached results, or human review depending on risk.
Common edge cases come from:
Plan to discover “unknown unknowns” via privacy-aware logs that capture which validation rule failed and what recovery path ran.