06 ਮਈ 2025·8 ਮਿੰਟ
ਕਿਵੇਂ ਪ੍ਰੰਪਟ ਸਪਸ਼ਟਤਾ ਆਰਕੀਟੈਕਚਰ, ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਮੈਂਟੇਨੇਬਿਲਿਟੀ ਨੂੰ ਰੂਪ ਦਿੰਦੀ ਹੈ
ਜਾਣੋ ਕਿ ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਕਿਸ ਤਰ੍ਹਾਂ ਬਿਹਤਰ ਆਰਕੀਟੈਕਚਰ, ਸਾਫ਼ ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਆਸਾਨ ਮੈਨਟੇਨੇਬਿਲਿਟੀ ਲੈ ਕੇ ਆਉਂਦਾ ਹੈ—ਅਤੇ ਪ੍ਰੈਕਟਿਕਲ ਤਕਨੀਕਾਂ, ਉਦਾਹਰਣਾਂ ਅਤੇ ਚੈੱਕਲਿਸਟ।
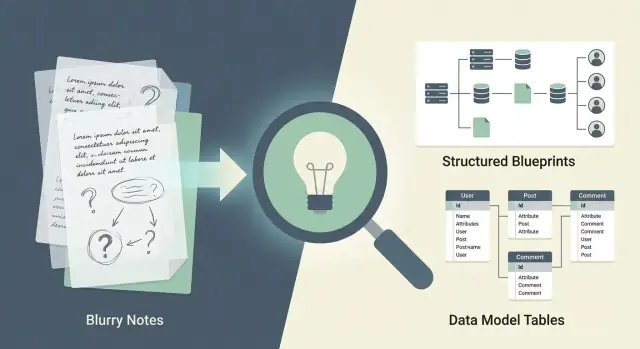
ਜਾਣੋ ਕਿ ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਕਿਸ ਤਰ੍ਹਾਂ ਬਿਹਤਰ ਆਰਕੀਟੈਕਚਰ, ਸਾਫ਼ ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਆਸਾਨ ਮੈਨਟੇਨੇਬਿਲਿਟੀ ਲੈ ਕੇ ਆਉਂਦਾ ਹੈ—ਅਤੇ ਪ੍ਰੈਕਟਿਕਲ ਤਕਨੀਕਾਂ, ਉਦਾਹਰਣਾਂ ਅਤੇ ਚੈੱਕਲਿਸਟ।
“Prompt clarity” ਦਾ ਮਤਲਬ ਹੈ ਆਪਣੀ ਮੰਗ ਇਸ ਤਰ੍ਹਾਂ ਦਰਸਾਉਣਾ ਕਿ ਵੱਖ-ਵੱਖ ਵਿਵਿਆਖਿਆਵਾਂ ਲਈ ਥੋੜ੍ਹੀ ਸਥਾਨ ਰਹਿ ਜਾਵੇ। ਪ੍ਰੋਡਕਟ ਅੰਸ਼ਾਂ ਵਿੱਚ ਇਹ ਸਾਫ਼ ਨਤੀਜੇ, ਯੂਜ਼ਰ, ਰੋਕਾਵਟਾਂ ਅਤੇ ਕਾਮਯਾਬੀ ਦੇ ਮਾਪਦੰਡ ਵਜੋਂ ਦਿੱਸਦਾ ਹੈ। ਇੰਜੀਨੀਅਰਿੰਗ ਦੀ ਭਾਸ਼ਾ ਵਿੱਚ, ਇਹ ਸਪਸ਼ਟ ਲੋੜਾਂ ਬਣ ਜਾਂਦੀਆਂ ਹਨ: ਇਨਪੁੱਟ, ਆਉਟਪੁੱਟ, ਡੇਟਾ ਨਿਯਮ, ਐਰਰ ਵਿਹੇਵਿਅਰ ਅਤੇ ਗੈਰ-ਫੰਕਸ਼ਨਲ ਉਮੀਦਾਂ (ਕਾਰਗੁਜ਼ਾਰੀ, ਸੁਰੱਖਿਆ, ਕੰਪਲਾਇੰਸ)।
ਪ੍ਰੰਪਟ ਸਿਰਫ ਉਹ ਲਫ਼ਜ਼ ਨਹੀਂ ਜੋ ਤੁਸੀਂ AI ਜਾਂ ਟੀਮਮੈਟ ਨੂੰ ਦਿੰਦੇ ਹੋ। ਇਹ ਸਾਰੇ ਨਿਰਮਾਣ ਦੀ ਬੀਜ ਹੁੰਦੀ ਹੈ:
ਜਦੋਂ ਪ੍ਰੰਪਟ ਸਪਸ਼ਟ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਨੀਚਲੇ ਪਦਾਰਥਾਂ ਵਿੱਚ ਸੰਗਤ ਰਹਿਣ ਦੇ ਮੌਕੇ ਵੱਧਦੇ ਹਨ: “ਅਸੀਂ ਕਿਸਦਾ ਮਤਲਬ ਲਿਆ?” ਉੱਤੇ ਘੱਟ ਵਿਚਾਰ-ਵਟਾਂਦਰੇ, ਆਖ਼ਰੀ ਸਮੇਂ ਵਿੱਚ ਘੱਟ ਬਦਲਾਵ ਅਤੇ ਕਿਨ੍ਹੇ ਵੀ ਐਜ ਕੇਸਾਂ ਵਿੱਚ ਘੱਟ ਹੈਰਾਨੀ।
ਅਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਲੋਕਾਂ (ਅਤੇ AI) ਨੂੰ ਅਨੁਮਾਨ ਭਰਨ ਲਈ ਮਜਬੂਰ ਕਰਦੇ ਹਨ—ਅਤੇ ਉਹ ਅਨੁਮਾਨ ਅਕਸਰ ਭੂਮਿਕਾ-ਸੁਤੰਤਰ ਨਹੀਂ ਹੁੰਦੇ। ਇੱਕ ਬੰਦਾ “ਤੇਜ਼” ਦਾ ਮਤਲਬ ਸਬ-ਸਕਿੰਟ ਸੱਦਾ ਸੋਚ ਸਕਦਾ ਹੈ; ਦੂਜਾ ਹਫ਼ਤਾਵਾਰ ਰਿਪੋਰਟ ਲਈ “ਕਾਫ਼ੀ ਤੇਜ਼” ਸੋਚ ਸਕਦਾ ਹੈ। ਇੱਕ ਲਈ “ਕਸਟਮਰ” ਵਿੱਚ ਟ੍ਰਾਇਲ ਯੂਜ਼ਰ ਸ਼ਾਮਲ ਹਨ; ਦੂਜੇ ਲਈ ਨਹੀਂ।
ਇਹ ਮਿਸਮੇਚ ਰੀਵਰਕ ਪੈਦਾ ਕਰਦਾ ਹੈ: ਡਿਜ਼ਾਈਨ ਲਾਗੂ ਹੋਣ ਤੋਂ ਬਾਅਦ ਬਦਲੇ ਜਾਂਦੇ ਹਨ, ਡੇਟਾ ਮਾਡਲ ਮਾਈਗ੍ਰੇਸ਼ਨ ਦੀ ਲੋੜ ਪੈਂਦੇ ਹਨ, APIs ਵਿੱਚ breaking changes ਆਉਂਦੇ ਹਨ, ਅਤੇ ਟੈਸਟ ਅਸਲ ਅਕਸੀਪਟੈਂਸ ਮਾਪਦੰਡਾਂ ਨੂੰ ਕੈਪਚਰ ਨਹੀਂ ਕਰਦੇ।
ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਆਰਕੀਟੈਕਚਰ, ਸਹੀ ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਮੈਂਟੇਨੇਬਲ ਕੋਡ ਦੇ ਸੰਭਾਵਨਾਂ ਨੂੰ ਬਹੁਤ ਬਿਹਤਰ ਬਣਾਉਂਦੇ ਹਨ—ਪਰ ਇਹਨਾਂ ਦੀ ਗਾਰੰਟੀ ਨਹੀਂ ਦਿੰਦੀਆਂ। ਤੁਹਾਨੂੰ ਫਿਰ ਵੀ ਸਮੀਖਿਆਵਾਂ, ਤਕਰੀਬ-ਤਾਰੇ ਅਤੇ ਇਟਰੇਸ਼ਨ ਦੀ ਲੋੜ ਹੈ। ਫਰਕ ਇਹ ਹੈ ਕਿ ਸਪਸ਼ਟਤਾ ਅੰਦੇਸ਼ਿਆਂ ਨੂੰ ਉਹ ਗੱਲਬਾਤਾਂ ਠੋਸ ਅਤੇ ਸਸਤੀ ਬਣਾਉਂਦੀ ਹੈ ਜੋ ਪਹਿਲਾਂ technical debt ਬਣ ਜਾਂਦੀਆਂ।
ਜਦੋਂ ਪ੍ਰੰਪਟ ਅਸਪਸ਼ਟ ਹੁੰਦਾ ਹੈ, ਟੀਮ (ਮਨੁੱਖ ਜਾਂ AI) ਖਾਲੀਆਂ ਥਾਵਾਂ ਅਨੁਮਾਨਾਂ ਨਾਲ ਭਰ ਦਿੰਦੀ ਹੈ। ਉਹ ਅਨੁਮਾਨ ਕਾਂਪੋਨੇਟ, ਸੇਵਾ ਬਾਉਂਡਰੀਆਂ ਅਤੇ ਡੇਟਾ ਫਲੋਜ਼ ਵਿੱਚ ਸਖ਼ਤ ਹੋ ਜਾਂਦੇ ਹਨ—ਅਕਸਰ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਕਿ ਕੋਈ ਇਸਦਾ ਅਹਿਸਾਸ ਕਰੇ ਕਿ ਕੋਈ ਫੈਸਲਾ ਕੀਤਾ ਗਿਆ।
ਜੇ ਪ੍ਰੰਪਟ "ਕੌਣ ਕਿਸਦਾ ਮਾਲਕ ਹੈ" ਨਹੀਂ ਦੱਸਦਾ, ਤਾਂ ਆਰਕੀਟੈਕਚਰ ਆਮ ਤੌਰ 'ਤੇ "ਜੋ ਹੁਣ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ" ਵੱਲ ਡ੍ਰਿਫਟ ਕਰਦਾ ਹੈ। ਤੁਸੀਂ ਦੇਖੋਗੇ ਕਿ ਐਡ-ਹਾਕ ਸੇਵਾਵਾਂ ਇਕ ਸਕ੍ਰੀਨ ਜਾਂ ਤੁਰੰਤ ਇੰਟੇਗ੍ਰੇਸ਼ਨ ਲਈ ਬਣਾਈਆਂ ਜਾਂਦੀਆਂ ਹਨ, ਬਿਨਾਂ ਕਿਸੇ ਸਥਿਰ ਜ਼ਿੰਮੇਵਾਰੀ ਮਾਡਲ ਦੇ।
ਉਦਾਹਰਣ ਲਈ, “add subscriptions” ਵਰਗਾ ਪ੍ਰੰਪਟ ਬਿਲਿੰਗ, ਐਂਟਾਈਟਲਮੈਂਟ ਅਤੇ ਕਸਟਮਰ ਸਟੇਟਸ ਨੂੰ ਇਕ ਝੂਠੇ ਮਾਡਿਊਲ ਵਿੱਚ ਮਿਲਾ ਸਕਦਾ ਹੈ। ਬਾਅਦ ਵਿੱਚ, ਹਰ ਨਵਾਂ ਫੀਚਰ ਇਸਨੂੰ ਛੂਹਦਾ ਹੈ ਅਤੇ ਬਾਉਂਡਰੀਆਂ ਅਸਲ ਡੋਮੇਨ ਨੂੰ ਦਰਸਾਉਂਣ ਬੰਦ ਕਰ ਦਿੰਦੀਆਂ ਹਨ।
ਆਰਕੀਟੈਕਚਰ ਰਾਹ-ਨਿਰਭਰ ਹੁੰਦੀ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਬਾਉਂਡਰੀਆਂ ਚੁਨ ਲੈਂਦੇ ਹੋ, ਤੁਸੀਂ ਇਹ ਵੀ ਚੁਨ ਲੈਂਦੇ ਹੋ:
ਜੇ ਮੂਲ ਪ੍ਰੰਪਟ ਨੇ ਰੋਕਾਵਟਾਂ ਨਹੀਂ ਸਪਸ਼ਟ ਕੀਤੀਆਂ (ਜਿਵੇਂ “refunds ਸਹਾਇਤ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ”, “ਹਰ ਖਾਤੇ ਲਈ ਕਈ ਯੋਜਨਾਵਾਂ”, “proration ਨਿਯਮ”), ਤਾਂ ਤੁਸੀਂ ਇੱਕ ਸਧਾਰਨ ਮਾਡਲ ਬਣਾ ਸਕਦੇ ਹੋ ਜੋ ਫੈਲ ਨਹੀਂ ਸਕਦਾ। ਬਾਅਦ ਵਿੱਚ ਠੀਕ ਕਰਨ ਲਈ ਅਕਸਰ ਮਾਈਗ੍ਰੇਸ਼ਨ, ਸੰਪੂਰਨ-ਬਦਲਾਅ, ਅਤੇ ਇੰਟੇਗ੍ਰੇਸ਼ਨ ਦੀ ਦੁਬਾਰਾ ਜਾਂਚ ਲਾਜ਼ਮੀ ਹੁੰਦੀ ਹੈ।
ਹਰ ਇੱਕ ਸਪਸ਼ਟੀਕਰਨ ਸੰਭਾਵਤ ਡਿਜ਼ਾਈਨਾਂ ਦੇ ਰੁੱਖ ਨੂੰ ਸੰਗੂੜਦਾ ਹੈ। ਇਹ ਚੰਗੀ ਗੱਲ ਹੈ: ਘੱਟ "ਸ਼ਾਇਦ" ਰਾਹਾਂ ਦਾ ਮਤਲਬ ਘੱਟ ਅਕਸੀਡੈਂਟਲ ਆਰਕੀਟੈਕਚਰ।
ਇੱਕ ਠੀਕ ਪ੍ਰੰਪਟ ਨਾ ਸਿਰਫ ਲਾਗੂ ਕਰਨ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ—ਇਹ ਫੈਸਲਿਆਂ ਨੂੰ ਵੀ ਦਿੱਖਾਉਂਦਾ ਹੈ। ਜਦੋਂ ਲੋੜਾਂ ਸਪਸ਼ਟ ਹੁੰਦੀਆਂ ਹਨ, ਟੀਮ ਮੰਜ਼ੂਰੀਆਂ ਇਰਾਦਾਪੂਰਕ ਤੌਰ 'ਤੇ ਚੁਣ ਸਕਦੀ ਹੈ (ਅਤੇ ਉਸਦਾ ਕਾਰਨ ਦਸਤਾਵੇਜ਼ ਕਰ ਸਕਦੀ ਹੈ), ਨਾ ਕਿ ਪਹਿਲੀ ਕਾਪੀ ਤੋਂ ਵਿਰਾਸਤ ਵਿੱਚ ਮਿਲਦੀਆਂ ਚੋਣਾਂ ਨੂੰ ਅਨੁਕੂਲ ਕਰਦੇ ਹੋਏ।
ਪ੍ਰੰਪਟ ਅਸਪਸ਼ਟਤਾ ਜਲਦੀ ਹੀ ਇਨ੍ਹਾਂ ਰੂਪਾਂ ਵਿੱਚ ਨਜ਼ਰ ਆਉਂਦੀ ਹੈ:
ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਆਰਕੀਟੈਕਚਰ ਦੀ ਗਾਰੰਟੀ ਨਹੀਂ ਦਿੰਦੇ, ਪਰ ਇਹ ਸੰਭਾਵਨਾ ਵਧਾਉਂਦੇ ਹਨ ਕਿ ਸਿਸਟਮ ਦੀ ਬਣਤਰ ਅਸਲ ਸਮੱਸਿਆ ਨਾਲ ਮੇਲ ਖਾਏ ਅਤੇ ਵਧਦੇ ਸਮੇਂ ਦੇ ਨਾਲ maintain ਰਹੇ।
ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਤੁਹਾਨੂੰ ਸਿਰਫ਼ “ਉਤਰ” ਪ੍ਰਾਪਤ ਕਰਨ ਵਿੱਚ ਮਦਦ ਨਹੀਂ ਕਰਦਾ—ਇਹ ਤੁਹਾਨੂੰ ਇਹ ਘੋਸ਼ਣਾ ਕਰਨ ਲਈ ਮਜਬੂਰ ਕਰਦਾ ਹੈ ਕਿ ਸਿਸਟਮ ਕਿਸਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ। ਇਹ ਸਾਫ਼ ਆਰਕੀਟੈਕਚਰ ਅਤੇ ਫੀਚਰਾਂ ਦੇ ਢੇਰ ਵਿੱਚ ਅੰਤਰ ਹੈ ਜੋ ਨਹੀਂ ਜਾਣਦੇ ਕਿ ਉਹ ਕਿੱਥੇ ਰਹਿਣ।
ਜੇ ਤੁਹਾਡਾ ਪ੍ਰੰਪਟ ਕਹਿੰਦਾ ਹੈ “ਯੂਜ਼ਰ 30 ਸਕਿੰਟ ਵਿੱਚ PDF ਵਜੋਂ ਇਨਵਾਇਸ ਨਿਰਯਾਤ ਕਰ ਸਕਦੇ ਹਨ,” ਤਾਂ ਇਹ ਤੁਰੰਤ ਕੁਝ ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਸੁਝਾਉਂਦਾ ਹੈ (PDF ਜਨਰੇਸ਼ਨ, ਜੌਬ ਟਰੈਕਿੰਗ, ਸਟੋਰੇਜ, ਨੋਟੀਫਿਕੇਸ਼ਨ)। ਇੱਕ ਨਾਨ-ਗੋਲ ਜਿਵੇਂ “v1 ਵਿੱਚ ਕੋਈ ਰੀਅਲ-ਟਾਈਮ ਕੋਲੈਬਰੇਸ਼ਨ ਨਹੀਂ” ਤੁਹਾਨੂੰ ਵੇਬਸਾਕੇਟਸ, ਸਾਂਝੇ ਲਾਕਸ ਅਤੇ ਸੰਘਰਸ਼ ਨਿਪਟਾਨ ਤੋਂ ਪਹਿਲਾਂ ਹੀ ਰੋਕਦਾ ਹੈ।
ਜਦੋਂ ਲਕਸ਼ ਮਾਪਯੋਗ ਹੁੰਦੇ ਹਨ ਅਤੇ ਨਾਨ-ਲਕਸ਼ ਸਪਸ਼ਟ, ਤਾਂ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਸਖ਼ਤ ਲਾਈਨਾਂ ਖਿੱਚ ਸਕਦੇ ਹੋ:
ਇੱਕ ਚੰਗਾ ਪ੍ਰੰਪਟ ਅਭਿਭਾਕਾਂ (actor) ਨੂੰ ਪਛਾਣਦਾ ਹੈ (customer, admin, support, automated scheduler) ਅਤੇ ਉਹ ਮੁੱਖ ਵਰਕਫ਼ਲੋਜ਼ ਜੋ ਉਹ ਟਰਿਗਰ ਕਰਦੇ ਹਨ। ਉਹ ਵਰਕਫ਼ਲੋਜ਼ ਸਾਫ਼-ਸਾਫ਼ ਕੰਪੋਨੇਟਾਂ ਨਾਲ ਮਿਲਦੀਆਂ ਹਨ:
ਕਈ ਵਾਰ ਪ੍ਰੰਪਟ ਉਹ “ਹਰ ਥਾਂ” ਦੀਆਂ ਲੋੜਾਂ ਨੂੰ ਛੱਡ ਦਿੰਦੇ ਹਨ ਜੋ ਆਰਕੀਟੈਕਚਰ ਨੂੰ ਘੇਰ ਲੈਂਦੀਆਂ ਹਨ: authentication/authorization, auditing, rate limits, idempotency, retries/timeouts, PII ਹੈਂਡਲਿੰਗ, ਅਤੇ observability (ਲੋਗ/ ਮੈਟਰਿਕ/ ਟ੍ਰੇਸ)। ਜੇ ਇਹ ਸਪਸ਼ਟ ਨਹੀਂ ਹੋਂਦੀਆਂ, ਉਹ ਅਸਮਰਥਤ ਤਰੀਕੇ ਨਾਲ ਲਾਗੂ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ।
ਡੇਟਾ ਮਾਡਲ ਅਕਸਰ SQL ਲਿਖਣ ਤੋਂ ਕਾਫ਼ੀ ਪਹਿਲਾਂ ਗਲਤ ਹੋ ਜਾਂਦਾ—ਜਦੋਂ ਪ੍ਰੰਪਟ ਅਸਪਸ਼ਟ ਨਾਮਾਂ ਦੀ ਵਰਤੋਂ ਕਰਦਾ ਹੈ ਜੋ “ਸਪਸ਼ਟ” ਲੱਗਦੇ ਹਨ। جیسے customer, account, ਅਤੇ user ਕਈ ਵੱਖ-ਵੱਖ ਅਸਲ-ਜੀਵਨ ਚੀਜ਼ਾਂ ਦਾ ਮਤਲਬ ਹੋ ਸਕਦੇ ਹਨ, ਅਤੇ ਹਰ ਵਿਆਖਿਆ ਇੱਕ ਵੱਖਰਾ ਸਕੀਮਾ ਬਣਾਉਂਦੀ ਹੈ।
ਜੇ ਪ੍ਰੰਪਟ ਕਹਿੰਦਾ ਹੈ “store customers and their accounts,” ਤਾਂ ਤੁਹਾਨੂੰ ਜਲਦੀ ਆਪੇ-ਆਪੇ ਸਵਾਲਾਂ ਦਾ ਸਾਹਮਣਾ ਕਰਨਾ ਪਏਗਾ ਜੋ ਪ੍ਰੰਪਟ ਨੇ ਨਹੀਂ ਜਵਾਬ ਦਿੱਤੇ:
ਬਿਨਾਂ ਪਰਿਭਾਸ਼ਾਵਾਂ ਦੇ, ਟੀਮ nullable ਕਾਲਮ, catch-all ਟੇਬਲਾਂ ਅਤੇ overloaded ਫੀਲਡਾਂ (type, notes, metadata) ਨਾਲ ਕੰਮ ਸਮਝਾਉਂਦੀ ਹੈ ਜੋ ਆਹਿਸਤੇ ਆਹਿਸਤੇ “ਜਿੱਥੇ ਅਸੀਂ ਹਰ ਚੀਜ਼ ਰੱਖਦੇ ਹਾਂ” ਬਣ ਜਾਂਦੇ ਹਨ।
ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਨਾਊਨ ਨੂੰ explicit ਐਂਟਿਟੀਜ਼ ਅਤੇ ਨਿਯਮਾਂ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ। ਉਦਾਹਰਣ ਲਈ: “A Customer is an organization. A User is a login that can belong to one organization. An Account is a billing account per organization.” ਹੁਣ ਤੁਸੀਂ ਯਕੀਨ ਨਾਲ ਡਿਜ਼ਾਈਨ ਕਰ ਸਕਦੇ ਹੋ:
customer_id vs. user_id ਬਦਲ-ਬਦਲੀਯੋਗ ਨਹੀਂਪ੍ਰੰਪਟ ਸਪਸ਼ਟਤਾ ਨੂੰ ਲਾਈਫਸਾਇਕਲ ਤੇ ਵੀ ਧਿਆਨ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ: ਕਿਵੇਂ ਰਿਕਾਰਡ ਬਣਾਏ ਜਾਂਦੇ ਹਨ, ਅਪਡੇਟ ਹੁੰਦੇ ਹਨ, ਨਿਸ਼ਕ੍ਰਿਆ ਕੀਤੇ ਜਾਂਦੇ ਹਨ, ਮਿਟਾਏ ਜਾਂਦੇ ਹਨ ਅਤੇ ਰਿਟੇਨ ਕਿਤਾ ਜਾਂਦਾ ਹੈ। “Delete customer” ਦਾ ਮਤਲਬ hard delete, soft delete, ਜਾਂ ਕਾਨੂੰਨੀ ਰਿਟੇਨਸ਼ਨ ਹੋ ਸਕਦਾ ਹੈ। ਪਹਿਲਾਂ ਇਹ ਜોર ਦੇਣ ਨਾਲ ਤੂਟੇ ਹੋਏ ਫੋਰਿਨ ਕਿਜ਼, ਅੌਰਫ਼ਨ ਹੋਏ ਡੇਟਾ ਅਤੇ ਗੈਰ-ਇਕਸ-ਪ੍ਰਤੀ-ਰਿਪੋਰਟਿੰਗ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਕੋ ਸੰਕਲਪ ਲਈ ਇਕੋ ਹੀ ਨਾਮ ਵਰਤੋਂ (ਉਦਾਹਰਣ ਲਈ ਹਮੇਸ਼ਾ customer_id, ਕਦੇ org_id ਨਾ)। overloaded ਕਾਲਮਾਂ ਦੀ ਥਾਂ ਵੱਖਰੇ ਸੰਕਲਪ ਮਾਡਲ ਕਰੋ—billing_status ਨੂੰ account_status ਤੋਂ ਅਲੱਗ ਰੱਖੋ, ਨਾ ਕਿ ਇੱਕ ਅੰਬਿਗਯੂਅਸ status ਜੋ ਪੰਜ ਵੱਖ-ਵੱਖ ਚੀਜ਼ਾਂ ਦਾ ਮਤਲਬ ਹੋਵੇ।
ਡੇਟਾ ਮਾਡਲ ਉਸ ਵੇਲੇ ਤੱਕ ਚੰਗਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਅੱਗੇ ਤੋਂ ਕਾਫ਼ੀ ਵੇਰਵੇ ਦਿੰਦੇ ਹੋ। ਜੇ ਪ੍ਰੰਪਟ ਕਹਿੰਦਾ ਹੈ “store customers and orders,” ਤਾਂ ਤੁਹਾਨੂੰ ਅਕਸਰ ਐਸਾ ਸਕੀਮਾ ਮਿਲਦਾ ਹੈ ਜੋ ਡੈਮੋ ਲਈ ਚੰਗਾ ਹੈ ਪਰ ਅਸਲ ਦੁਨੀਆ ਦੀਆਂ ਹਾਲਤਾਂ (ਡੁਪਲੀਕੇਟ, imports, partial records) ਅੰਦਰ ਫੇਲ ਹੁੰਦਾ ਹੈ।
ਐਂਟਿਟੀਜ਼ ਨੂੰ ਨਾਂ ਦੇਵੋ (ਜਿਵੇਂ Customer, Order, Payment) ਅਤੇ ਹਰ ਇੱਕ ਦੀ ਪਛਾਣ ਕਿਵੇਂ ਹੁੰਦੀ ਹੈ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ।
ਕਈ ਮਾਡਲ ਤਦ ਤੱਕ ਫੇਲ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਸਟੇਟ ਪਰਿਭਾਸ਼ਿਤ ਨਹੀਂ ਹੁੰਦੀ। ਸਪਸ਼ਟ ਕਰੋ:
ਉਹ ਦੱਸੋ ਜੋ ਲਾਜ਼ਮੀ ਹੈ ਅਤੇ ਜੋ ਗ਼ੈਰ-ਲਾਜ਼ਮੀ ਹੋ ਸਕਦਾ ਹੈ।
Examples:
ਇਹ ਪਹਿਲਾਂ ਨਿਰਧਾਰਿਤ ਕਰੋ ਤਾਂ ਕਿ ਛੁਪੇ ਹੋਏ ਸਥਿਰਤਾ-ਭੰਗੇ ਟਾਲੇ ਜਾ ਸਕਣ।
ਅਸਲ ਸਿਸਟਮ ਗੰਦੇ ਹਕੀਕਤਾਂ ਨੂੰ ਸਨਭਾਲਦੇ ਹਨ। ਇਹ ਦੱਸੋ ਕਿ ਕਿਵੇਂ ਸੰਭਾਲਣਾ ਹੈ:
API contracts ਉਹਨਾਂ ਮੈਂਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਹਨ ਜਿੱਥੇ ਪ੍ਰੰਪਟ ਸਪਸ਼ਟਤਾ ਦਾ ਫਾਇਦਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ: ਜਦੋਂ ਲੋੜਾਂ explicit ਹੁੰਦੀਆਂ ਹਨ, API ਗਲਤ ਵਰਤੋਂ ਲਈ ਮੁਸ਼ਕਲ ਹੁੰਦਾ ਹੈ, version ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ, ਅਤੇ breaking changes ਘੱਟ ਹੁੰਦੇ ਹਨ।
ਅਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਜਿਵੇਂ “add an endpoint to update orders” ਦੇ ਅਨੁਮੇਨਿਆਂ ਲਈ ਥਾਂ ਛੱਡ ਦਿੰਦੇ ਹਨ (partial vs. full updates, field names, default values, async vs. sync)। ਸਪਸ਼ਟ contract ਲੋੜਾਂ ਫੈਸਲੇ ਪਹਿਲਾਂ ਕਰਾਂਉਂਦੀਆਂ ਹਨ:
PUT (replace) ਹਨ ਜਾਂ PATCH (partial)“ਚੰਗੇ errors” ਕਿਵੇਂ ਦਿਖਣੇ ਚਾਹੀਦੇ ਹਨ, ਇਹ ਨਿਰਧਾਰਿਤ ਕਰੋ। ਘੱਟੋ-ਘੱਟ, ਇਹ ਦੱਸੋ:
ਇੱਥੇ ਅਸਪਸ਼ਟਤਾ client ਬੱਗ ਅਤੇ ਅਸਮਾਨ ਪ੍ਰਦਰਸ਼ਨ ਪੈਦਾ ਕਰਦੀ ਹੈ। ਨਿਯਮ ਦੱਸੋ:
Concrete request/response ਨਮੂਨੇ ਅਤੇ constraints (min/max lengths, allowed values, date formats) ਸ਼ਾਮਲ ਕਰੋ। ਕੁਝ ਉਦਾਹਰਣ ਲੰਬੇ ਪ੍ਰੋਜ਼ੇ ਦੇ ਇੱਕ panne ਦੇ ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਗੱਲਾਂ ਨੂੰ ਸਪਸ਼ਟ ਕਰਦੇ ਹਨ।
ਅਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਸਿਰਫ “ਗਲਤ ਉੱਤਰ” ਹੀ ਨਹੀਂ ਪੈਦਾ ਕਰਦੇ। ਉਹ ਛੁਪੇ ਹੋਏ ਅਨੁਮਾਨ ਬਣਾਉਂਦੇ ਹਨ—ਨਾਨਾ, undocumented ਫੈਸਲੇ ਜੋ ਕੋਡ ਪਾਥਾਂ, ਡੇਟਾ ਫੀਲਡਾਂ, ਅਤੇ API responses ਵਿੱਚ ਫੈਲ ਜਾਂਦੇ ਹਨ। ਨਤੀਜਾ ਇਹ ਹੁੰਦਾ ਹੈ ਕਿ ਸੌਫਟਵੇਅਰ ਸਿਰਫ਼ ਉਨ੍ਹਾਂ ਅਨੁਮਾਨਾਂ ਥੱਲੇ ਚੱਲਦਾ ਹੈ ਜੋ ਨਿਰਮਾਤਾ ਨੇ ਅਨੁਮਾਨ ਲਗਾ ਕੇ ਬਣਾਏ ਸਨ, ਅਤੇ ਜਦੋਂ ਅਸਲ ਵਰਤੋਂ ਇਹਨਾਂ ਤੋਂ ਵੱਖਰੀ ਹੋ ਜਾਂਦੀ ਹੈ ਤਾਂ ਸਿਸਟਮ ਟੁੱਟ ਜਾਂਦਾ ਹੈ।
ਜਦੋਂ ਪ੍ਰੰਪਟ ਅਸਪਸ਼ਟ ਹੁੰਦਾ ਹੈ (ਉਦਾਹਰਨ: “support refunds” ਬਿਨਾਂ ਨਿਯਮਾਂ), ਟੀਮ ਵੱਖ-ਵੱਖ ਥਾਵਾਂ ਇਸ ਖਾਲੀ ਥਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਢੰਗ ਨਾਲ ਭਰਦੀ ਹੈ: ਇੱਕ ਸੇਵਾ refund ਨੂੰ reversal ਮੰਨਦੀ ਹੈ, ਦੂਜੀ ਇਸਨੂੰ ਵੱਖਰਾ transaction ਮੰਨਦੀ ਹੈ, ਅਤੇ ਤੀਜੀ partial refunds ਨੂੰ ਬਿਨਾਂ ਸੀਮਾਵਾਂ ਦੇ ਮਨਜ਼ੂਰ ਕਰਦੀ ਹੈ।
ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ guesswork ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ invariants ਸਪਸ਼ਟ ਕਰਦੇ ਹਨ ("refunds 30 ਦਿਨ ਵਿੱਚ ਮਨਜ਼ੂਰ", "partial refunds ਦੀ ਆਗਿਆ ਹੈ", "digital goods ਲਈ inventory restock ਨਹੀਂ ਹੁੰਦਾ")। ਇਹ ਬਿਆਨ ਸਿਸਟਮ ਵਿੱਚ ਪਹਿਲਾਂ ਹੀ ਇਕਸਾਰ ਵਿਹਾਰ ਚਲਾਉਂਦੇ ਹਨ।
Maintainable systems ਸੋਚਣ ਵਿੱਚ ਆਸਾਨ ਹੁੰਦੇ ਹਨ। ਪ੍ਰੰਪਟ ਸਪਸ਼ਟਤਾ ਸਹਾਇਤਾ ਕਰਦੀ ਹੈ:
ਜੇ ਤੁਸੀਂ AI-ਸਹਾਇਤਾ ਵਿਕਾਸ ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ ਸਪਸ਼ਟ ਲੋੜਾਂ ਮਾਡਲ ਨੂੰ consistent implementations ਤਿਆਰ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ ਨਾ ਕਿ plausible-ਪਰ-mismatched ਟੁਕੜੇ।
Maintainability ਵਿੱਚ ਸਿਸਟਮ ਚਲਾਉਣਾ ਸ਼ਾਮਲ ਹੈ। ਪ੍ਰੰਪਟਸ ਨੂੰ observability ਉਮੀਦਾਂ ਨਿਰਧਾਰਿਤ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ: ਕੀ ਲਾਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ (ਅਤੇ ਕੀ ਨਹੀਂ), ਕਿਹੜੇ ਮੈਟ੍ਰਿਕਸ ਮਹੱਤਵਪੂਰਨ ਹਨ (error rates, latency, retries), ਅਤੇ ਫੇਲਿਅਰ ਕਿਵੇਂ surfaced ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ। ਬਿਨਾਂ ਇਸਦੇ, ਟੀਮਾਂ ਸਮੱਸਿਆਵਾਂ ਸਿਰਫ਼ ਗ੍ਰਾਹਕ ਦੇਖਣ ਤੋਂ ਬਾਅਦ ਹੀ ਖੋਜਦੀਆਂ ਹਨ।
ਅਸਪਸ਼ਟਤਾ ਅਕਸਰ low cohesion ਅਤੇ high coupling ਵਜੋਂ ਦਿਖਾਈ ਦਿੰਦੀ ਹੈ: ਅਣਸੰਬੰਧਿਤ ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਇਕਠੀਆਂ ਹੋ ਜਾਣੀਆਂ, “helper” ਮੋਡੀਊਲ ਜੋ ਸਭ ਕੁਝ ਛੁਹਦੇ ਹਨ, ਅਤੇ ਵਿਹਾਰ ਜੋ ਕਾਲਰ ਦੇ ਅਨੁਸਾਰ ਭਿੰਨ ਹੁੰਦਾ ਹੈ। ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ cohesive ਕੰਪੋਨੇਟ, ਤੰਗ ਇੰਟਰਫੇਸ ਅਤੇ ਭਵਿੱਖ-ਬਦਲਾਅ ਲਈ ਕੰਮ ਆਉਣ ਵਾਲੇ ਨਤੀਜੇ ਨੂੰ ਉਤਸ਼ਾਹਤ ਕਰਦੇ ਹਨ—ਜੋ ਅੱਗੇ ਤਬਦੀਲੀਆਂ ਨੂੰ ਸਸਤਾ ਬਣਾਉਂਦੇ ਹਨ। ਇੱਕ ਵਿਆਵਹਾਰਿਕ ਤਰੀਕਾ ਇਸਨੂੰ ਲਾਗੂ ਕਰਨ ਲਈ, ਦੇਖੋ /blog/review-workflow-catch-gaps-before-building.
ਅਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਨਾ ਸਿਰਫ ਅਸਪਸ਼ਟ ਪਾਠ ਬਣਾਉਂਦੇ ਹਨ—ਉਹ ਡਿਜ਼ਾਈਨ ਨੂੰ “generic CRUD” defaults ਵੱਲ ਧਕ ਦੇਂਦੇ ਹਨ। ਇੱਕ ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਫੈਸਲੇ ਜਲਦੀ ਕਰਵਾਉਂਦਾ ਹੈ: ਬਾਉਂਡਰੀਆਂ, ਡੇਟਾ ਮਾਲਕੀ, ਅਤੇ ਜੋ ਡੇਟਾਬੇਸ ਵਿੱਚ ਸੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
“Design a simple system to manage items. Users can create, update, and share items. It should be fast and scalable, with a clean API. Keep history of changes.”
ਜੋ ਨਿਰਮਾਤਾ (ਮਨੁੱਖ ਜਾਂ AI) ਭਰੋਸੇ ਨਾਲ ਨਹੀਂ ਨਿਰਧਾਰਿਤ ਕਰ ਸਕਦਾ:
“Design a REST API for managing generic items with these rules: items have
title(required, max 120),description(optional),status(draft|active|archived),tags(0–10). Each item belongs to exactly one owner (user). Sharing is per-item access for specific users with rolesviewer|editor; no public links. Every change must be auditable: store who changed what and when, and allow retrieving the last 50 changes per item. Non-functional: 95th percentile API latency < 200ms for reads; write throughput is low. Provide data model entities and endpoints; include error cases and permissions.”
ਹੁਣ ਆਰਕੀਟੈਕਚਰ ਅਤੇ ਸਕੀਮਾ ਚੋਣ ਤੁਰੰਤ ਬਦਲ ਜਾਂਦੀਆਂ ਹਨ:
items, item_shares (role ਨਾਲ many-to-many), ਅਤੇ item_audit_events (append-only)। status enum ਬਣ ਜਾਂਦਾ ਹੈ, ਅਤੇ tags ਨੂੰ 10-ਟੈਗ ਸੀਮਾ enforce ਕਰਨ ਲਈ join table ਵਿੱਚ ਰੱਖਣਾ ਹੋ ਸਕਦਾ ਹੈ।Ambiguous phrase → Clarified version
ਇੱਕ ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਲੰਬਾ ਹੋਣ ਦੀ ਲੋੜ ਨਹੀਂ—ਇਹ ਸੰਰਚਿਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਟੀਚਾ ਇਹ ਹੈ ਕਿ ਇੰਨਾ ਸੰਦਰਭ ਦਿਓ ਕਿ ਆਰਕੀਟੈਕਚਰ ਅਤੇ ਡੇਟਾ ਮਾਡਲਿੰਗ ਫੈਸਲੇ obvious ਹੋ ਜਾਣ, ਨਾ ਕਿ ਅਨੁਮਾਨ।
1) Goal
- What are we building, and why now?
- Success looks like: <measurable outcome>
2) Users & roles
- Primary users:
- Admin/support roles:
- Permissions/entitlements assumptions:
3) Key flows (happy path + edge cases)
- Flow A:
- Flow B:
- What can go wrong (timeouts, missing data, retries, cancellations)?
4) Data (source of truth)
- Core entities (with examples):
- Relationships (1:N, N:N):
- Data lifecycle (create/update/delete/audit):
- Integrations/data imports (if any):
5) Constraints & preferences
- Must use / cannot use:
- Budget/time constraints:
- Deployment environment:
6) Non-functional requirements (NFRs)
- Performance: target latency/throughput, peak load assumptions
- Uptime: SLA/SLO, maintenance windows
- Privacy/security: PII fields, retention, encryption, access logs
- Compliance: (if relevant)
7) Risks & open questions
- Known unknowns:
- Decisions needed from stakeholders:
8) Acceptance criteria + Definition of Done
- AC: Given/When/Then statements
- DoD: tests, monitoring, docs, migrations, rollout plan
9) References
- Link existing internal pages: /docs/<...>, /pricing, /blog/<...>
Sections 1–4 ਪਹਿਲਾਂ ਭਰੋ। ਜੇ ਤੁਸੀਂ core entities ਅਤੇ source of truth ਨਾਮ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਡਿਜ਼ਾਈਨ ਆਮ ਤੌਰ 'ਤੇ “API ਜੋ ਕਿ ਦੇਂਦਾ ਹੈ” ਵੱਲ ਡ੍ਰਿਫਟ ਕਰੇਗਾ, ਜਿਸ ਨਾਲ ਬਾਅਦ ਵਿੱਚ messy migrations ਅਤੇ ownership ambiguity ਆਵੇਗੀ।
NFRs ਲਈ, vague ਸ਼ਬਦਾਂ (“fast”, “secure”) ਤੋਂ ਬਚੋ। ਉਨ੍ਹਾਂ ਨੂੰ ਨੰਬਰਾਂ, ਥਰੈਸ਼ਹੋਲਡ ਅਤੇ explicit ਡੇਟਾ ਹੈਂਡਲਿੰਗ ਨਿਯਮਾਂ ਨਾਲ ਬਦਲੋ। ਇੱਕ ਅੰਦਾਜ਼ਾ ਵੀ (ਉਦਾਹਰਨ: “p95 < 300ms for reads at 200 RPS”) ਖਾਮੋਸ਼ੀ ਤੋਂ ਜ਼ਿਆਦਾ ਕਾਰਗਰ ਹੁੰਦਾ ਹੈ।
Acceptance criteria ਲਈ, ਘੱਟੋ-ਘੱਟ ਇੱਕ negative case (invalid input, permission denied) ਅਤੇ ਇੱਕ operational case (ਕਿਵੇਂ ਫੇਲਿਅਰ surface ਹੁੰਦੇ ਹਨ) ਸ਼ਾਮਲ ਕਰੋ। ਇਹ ਡਿਜ਼ਾਈਨ ਨੂੰ ਅਸਲ ਵਿਵਹਾਰ ਦੇ ਨਾਲ ਬੰਧੇ ਰੱਖਦਾ ਹੈ, ਨਾ ਕਿ ਸਿਰਫ਼ ਡਾਇਗਰਾਮਾਂ ਦੇ ਨਾਲ।
ਜਦੋਂ ਤੁਸੀਂ AI end-to-end ਨਾਲ ਬਣਾਉਂਦੇ ਹੋ—ਸਿਰਫ snippets ਹੀ ਨਹੀਂ—ਤਾਂ ਪ੍ਰੰਪਟ ਸਪਸ਼ਟਤਾ ਹੋਰ ਵੀ ਜ਼ਿਆਦਾ ਮੁਹੱਤਵਪੂਰਨ ਹੋ ਜਾਂਦੀ ਹੈ। ਇੱਕ vibe-coding workflow ਵਿੱਚ (ਜਿਥੇ ਪ੍ਰੰਪਟ ਲੋੜਾਂ, ਡਿਜ਼ਾਈਨ ਅਤੇ ਇੰਪਲੀਮੈਂਟੇਸ਼ਨ ਚਲਾਉਂਦੇ ਹਨ), ਛੋਟੀ ਅਸਪਸ਼ਟਤਾਵਾਂ schema ਚੋਣਾਂ, API contracts ਅਤੇ UI ਵਿਹਾਰ ਵਿੱਚ ਫੈਲ ਸਕਦੀਆਂ ਹਨ।
Koder.ai ਇਸ ਤਰ੍ਹਾਂ ਦੇ ਵਿਕਾਸ ਲਈ ਬਣਾਇਆ ਗਿਆ ਹੈ: ਤੁਸੀਂ ਚੈਟ ਵਿੱਚ ਇਕ ਸੰਰਚਿਤ ਪ੍ਰੰਪਟ 'ਤੇ ਦੁਹਰਾਈ ਕਰ ਸਕਦੇ ਹੋ, Planning Mode ਵਿਚ assumptions ਅਤੇ ਖੁਲੇ ਸਵਾਲ explicit ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਫਿਰ React ਵੈੱਬ, Go + PostgreSQL ਬੈਕਐਂਡ, Flutter ਮੋਬਾਈਲ ਵਰਗੇ ਸਟੈਕ ਲਈ ਕੰਮ ਕਰਨ ਵਾਲੀ ਐਪ ਸ਼ਿਪ ਕਰ ਸਕਦੇ ਹੋ। snapshots ਅਤੇ rollback ਵਰਗੀਆਂ ਵਿਵਹਾਰਿਕ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਤੁਹਾਨੂੰ ਜਦੋਂ ਲੋੜਾਂ ਬਦਲਦੀਆਂ ਹਨ ਤਦਿ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਅਜ਼ਮਾਇਸ਼ ਕਰਨ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦੀਆਂ ਹਨ, ਅਤੇ source code export ਨਾਲ ਟੀਮ ownership ਰੱਖ ਸਕਦੀ ਹੈ ਅਤੇ “black box” ਨਾ ਬਣੇ।
ਜੇ ਤੁਸੀਂ ਪ੍ਰੰਪਟਾਂ ਨੂੰ ਟੀਮਮੈਟਾਂ ਨਾਲ ਸਾਂਝਾ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਉਪਰ ਦਿੱਤੇ ਟੈਮਪਲੇਟ ਨੂੰ ਜੀਵੰਤ ਸਪੈਕ ਵਜੋਂ ਵਰਤਣਾ (ਅਤੇ ਐਪ ਨਾਲ version ਕਰਨਾ) ਆਮਤੌਰ 'ਤੇ ਸਾਫ਼ ਬਾਉਂਡਰੀਆਂ ਅਤੇ ਘੱਟ ਅਕਸੀਡੈਂਟਲ breaking changes ਲਿਆਉਂਦਾ ਹੈ।
ਇਕ ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਉਸ ਵੇਲੇ “ਪੂਰਾ” ਨਹੀਂ ਹੁੰਦਾ ਜਦੋਂ ਇਹ ਪਾਠਯੋਗ ਲੱਗੇ। ਇਹ ਉਸ ਵੇਲੇ ਪੂਰਾ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਦੋ ਵੱਖ-ਵੱਖ ਲੋਕ ਉਸ ਤੋਂ ਲਗਭਗ ਇਕੋ ਜਿਹਾ ਸਿਸਟਮ ਡਿਜ਼ਾਈਨ ਕਰਦੇ। ਇੱਕ ਹਲਕਾ-ਫੁਲਕਾ ਸਮੀਖਿਆ ਵਰਕਫਲੋ ਤੁਹਾਨੂੰ ਅਸਪਸ਼ਟਤਾ ਜਲਦੀ ਲੱਭਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ—ਜਦੋਂ ਉਹ ਆਰਕੀਟੈਕਚਰ ਚਰਨ, schema rewrites ਅਤੇ API breaking changes ਵਿੱਚ ਨਹੀਂ ਬਦਲਦੇ।
ਇੱਕ ਵਿਅਕਤੀ (PM, ਇੰਜੀਨੀਅਰ, ਜਾਂ AI) ਨੂੰ ਪ੍ਰੰਪਟ ਨੂੰ ਦੁਹਰਾਉਣ ਲਈ ਕਹੋ: goals, non-goals, inputs/outputs ਅਤੇ constraints। ਉਸ read-back ਦੀ ਤੁਲਨਾ ਤੁਹਾਡੇ ਇਰਾਦੇ ਨਾਲ ਕਰੋ। ਕੋਈ ਵੀ mismatch ਉਹ ਲੋੜ ਹੈ ਜੋ ਸਪਸ਼ਟ ਨਹੀਂ ਕੀਤੀ ਗਈ।
ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, “unknowns ਜੋ ਡਿਜ਼ਾਈਨ ਬਦਲ ਸਕਦੇ” ਉਨ੍ਹਾਂ ਨੂੰ ਲਿਖੋ। ਉਦਾਹਰਨ:
ਇਨ੍ਹਾਂ ਸਵਾਲਾਂ ਨੂੰ ਪ੍ਰੰਪਟ ਵਿੱਚ ਛੋਟੇ “Open questions” ਸੈਕਸ਼ਨ ਵਜੋਂ ਲਿਖੋ।
Assumptions ਠੀਕ ਹਨ, ਪਰ ਸਿਰਫ਼ ਜੇ ਉਹ ਨਜ਼ਰੀਅਤ ਵਿੱਚ ਹਨ। ਹਰ ਇੱਕ assumption ਲਈ ਇੱਕ ਚੋਣ ਕਰੋ:
ਇੱਕ ਮਹਾਂ-ਪ੍ਰੰਪਟ ਦੀ ਭਿੰਨਤਾ ਦੀ ਥਾਂ, 2–3 ਛੋਟੀਆਂ ਇਟਰੇਸ਼ਨ ਕਰੋ: ਪਹਿਲਾਂ ਬਾਉਂਡਰੀਆਂ ਸਪਸ਼ਟ ਕਰੋ, ਫਿਰ ਡੇਟਾ ਮਾਡਲ, ਫਿਰ API contract। ਹਰ ਪਾਸੇ ambiguity ਘਟਾਉਣਾ ਚਾਹੀਦਾ ਹੈ, scope ਨਹੀਂ ਵਧਾਉਣਾ।
ਸ਼ਕਤੀਸ਼ਾਲੀ ਟੀਮਾਂ ਵੀ ਛੋਟੀਆਂ, ਦੋਹਰਾਈ ਵਾਲੀਆਂ ਤਰ੍ਹਾਂ ਸਪਸ਼ਟਤਾ ਨੂੰ ਖੋ ਦਿੰਦੀਆਂ ਹਨ। ਚੰਗੀ ਗੱਲ ਇਹ ਹੈ ਕਿ ਜ਼ਿਆਦਾਤਰ ਸਮੱਸਿਆਵਾਂ ਅਸਾਨੀ ਨਾਲ ਸਪਾਟ ਕੀਤੀਆਂ ਜਾ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਕਿਸੇ ਕੋਡ ਨੂੰ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ ਠੀਕ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
Vague verbs ਡਿਜ਼ਾਈਨ ਫੈਸਲੇ ਛੁਪਾਉਂਦੇ ਹਨ। ਸ਼ਬਦ ਜਿਵੇਂ “support,” “handle,” “optimize,” ਜਾਂ “make it easy” ਤੁਸੀਂ ਕੀ ਕਾਮਯਾਬੀ ਸਮਝਦੇ ਹੋ, ਇਹ ਨਹੀਂ ਦੱਸਦੇ।
Undefined actors ਜ਼ਿੰਮੇਵਾਰੀ ਦਾ ਨਿਯਮ ਘਾਟ ਕਰਦੇ ਹਨ। “The system notifies the user” ਇਸ ਨੂੰ ਪੁਛਦਾ ਹੈ: ਕਿਹੜਾ ਸਿਸਟਮ ਕੰਪੋਨੈਂਟ, ਕਿਹੜਾ user type, ਅਤੇ ਕਿੜੇ channel ਤੋਂ?
Missing constraints ਐਕਸੀਡੈਂਟਲ ਆਰਕੀਟੈਕਚਰ ਬਣਾਉਂਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ scale, latency, privacy rules, audit needs, ਜਾਂ deployment boundaries ਨਹੀਂ ਦੱਸਦੇ, implementation ਅਨੁਮਾਨ ਕਰੇਗੀ—ਤੇ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਭੁਗਤੋਗੇ।
ਇੱਕ ਆਮ ਫੰਸੀ trap ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਟੂਲਜ਼ ਅਤੇ ਇੰਟਰਨਲ prescribe ਕਰ ਦਿਆਂ (“Use microservices,” “Store in MongoDB,” “Use event sourcing”) ਜਦੋਂ ਤੁਸੀਂ ਹਕੀਕਤ ਵਿੱਚ ਨਤੀਜਾ ਚਾਹੁੰਦੇ ਹੋ (“independent deployments,” “flexible schema,” “audit trail”)। ਕਾਰਨ ਦੱਸੋ ਕਿ ਤੁਸੀਂ ਇਹ ਚਾਹੁੰਦੇ ਕਿਉਂ ਹੋ, ਫਿਰ measurable requirements ਸ਼ਾਮਲ ਕਰੋ।
ਉਦਾਹਰਨ: “Use Kafka” ਦੀ ਥਾਂ ਲਿਖੋ “Events must be durable for 7 days and replayable to rebuild projections.”
Contradictions ਅਕਸਰ “must be real-time” ਨਾਲ “batch is fine” ਜਾਂ “no PII stored” ਨਾਲ “email users and show profiles” ਵਜੋਂ ਆਉਂਦੀਆਂ ਹਨ। ਪ੍ਰਧਾਨਤਾਵਾਂ (must/should/could) ਰੈਂਕ ਕਰਕੇ ਅਤੇ acceptance criteria ਜੋ ਦੋਹਾਂ ਨਹੀਂ ਹੋ ਸਕਦੇ, ਜੋੜ ਕੇ ਸੁਧਾਰ ਕਰੋ।
Anti-pattern: “Make onboarding simple.” Fix: “New users can complete onboarding in <3 minutes; max 6 fields; save-and-resume supported.”
Anti-pattern: “Admins can manage accounts.” Fix: Define actions (suspend, reset MFA, change plan), permissions, and audit logging.
Anti-pattern: “Ensure high performance.” Fix: “P95 API latency <300ms at 200 RPS; degrade gracefully when rate-limited.”
Anti-pattern: Mixed terms (“customer,” “user,” “account”). Fix: Add a small glossary and stick to it throughout.
ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਸਿਰਫ਼ ਇੱਕ ਸਹਾਇਕ ਨੂੰ “ਤਿਹਾਡਾ ਮਤਲਬ ਸਮਝਣ” ਵਿੱਚ ਮਦਦ ਨਹੀਂ ਕਰਦੇ। ਉਹ guesswork ਘਟਾਉਂਦੇ ਹਨ, ਜੋ ਤੁਰੰਤ ਸਾਫ਼ ਆਉਂਦਾ ਹੈ: ਸਾਫ਼ ਸਿਸਟਮ ਬਾਉਂਡਰੀਆਂ, ਘੱਟ ਡੇਟਾ-ਮਾਡਲ ਸਰਪ੍ਰਾਈਜ਼ ਅਤੇ ਅਸਾਨੀ ਨਾਲ ਵਿਕਸਿਤ ਹੋਣ ਵਾਲੇ APIs। ਅਸਪਸ਼ਟਤਾ ਉਸ ਤਰ੍ਹਾਂ ਦਾ ਰੀਵਰਕ ਬਣ ਜਾਂਦੀ ਹੈ: ਅਣ-ਤਿਆਰ ਮਾਈਗ੍ਰੇਸ਼ਨ, endpoints ਜੋ ਅਸਲ ਵਰਕਫ਼ਲੋਜ਼ ਨਾਲ ਮਿਲਦੇ ਨਹੀਂ, ਅਤੇ ਲਗਾਤਾਰ maintenance ਕੰਮ ਜੋ ਵਾਪਸ ਆਉਂਦੇ ਰਹਿੰਦੇ ਹਨ।
ਇਹ ਵਰਤੋਂ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਕਿ ਤੁਸੀਂ ਕੋਈ ਆਰਕੀਟੈਕਚਰ, ਸਕੀਮਾ, ਜਾਂ API ਡਿਜ਼ਾਈਨ ਮੰਗੋ:
ਜੇ ਤੁਸੀਂ ਵਧੇਰੇ ਵਰਤਭੁਗਤ ਪੈਟਰਨ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ /blog ਜਾਂ /docs 'ਚ ਮਦਦਗਾਰ ਗਾਈਡਾਂ ਵੇਖੋ।
Prompt clarity ਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਆਪਣੀ ਮੰਗ ਇਸ ਤਰ੍ਹਾਂ ਲਿਖੋ ਕਿ ਵੱਖ-ਵੱਖ ਵਿਆਖਿਆਵਾਂ ਲਈ ਥੋੜ੍ਹੀ ਜਗ੍ਹਾ ਰਹਿ ਜਾਵੇ। Amli ਵਿਚ, ਇਸਦਾ ਅਰਥ ਹੈ ਕਿ ਤੁਸੀਂ ਨਤੀਜੇ, ਯੂਜ਼ਰ, ਰੋਕਾਵਟਾਂ ਅਤੇ ਕਾਮਯਾਬੀ ਮਾਪਦੰਡ ਸਪਸ਼ਟ ਕਰੋ। ਇੰਜੀਨੀਅਰਿੰਗ ਦੀ ਭਾਸ਼ਾ ਵਿੱਚ, ਇਹ ਇਨਪੁੱਟ, ਆਉਟਪੁੱਟ, ਡੇਟਾ ਨਿਯਮ, ਐਰਰ ਵਿਹੇਵਿਅਰ ਅਤੇ ਗੈਰ-ਕਾਰਜਕ ਨਿਰਧਾਰਨ (ਪ੍ਰਦਰਸ਼ਨ, ਸੁਰੱਖਿਆ, ਕੰਪਲਾਇੰਸ) ਬਣ ਜਾਂਦੇ ਹਨ।
ਅਸਪଷਟਤਾ ਨਿਰਮਾਣਕਾਰਾਂ (ਲੋਕ ਜਾਂ AI) ਨੂੰ ਅਨੁਮਾਨ ਨਾਲ ਖਾਲੀ ਥਾਵਾਂ ਭਰਨ ਤੇ ਮਜਬੂਰ ਕਰਦੀ ਹੈ, ਅਤੇ ਵੱਖ-ਵੱਖ ਭੂਮਿਕਾਵਾਂ ਦੇ ਅਨੁਮਾਨ ਆਮ ਤੌਰ 'ਤੇ ਮਿਲਦੇ-ਜੁਲਦੇ ਨਹੀਂ ਹੁੰਦੇ। ਇਸ ਦੀ ਲਾਗਤ ਬਾਅਦ ਵਿੱਚ ਇਸ ਤਰ੍ਹਾਂ ਦਿੱਖਦੀ ਹੈ:
ਸਪਸ਼ਟਤਾ ਇਹ ਸਾਰੇ ਵਿਵਾਦ ਪਹਿਲਾਂ ਹੀ ਪ੍ਰਗਟ ਕਰ ਦਿੰਦੀ ਹੈ—ਜਦੋਂ ਠੀਕ ਕਰਨਾ ਸਸਤਾ ਹੁੰਦਾ ਹੈ।
ਆਰਕੀਟੈਕਚਰ ਫੈਸਲੇ ਰਾਹ-ਨਿਰਭਰ ਹੁੰਦੇ ਹਨ: ਪਹਿਲੇ ਅਨੁਵਾਦ ਸੇਵਾ ਸੀਮਾਵਾਂ, ਡੇਟਾ ਫਲੋ ਅਤੇ "ਕਿੱਥੇ ਨਿਯਮ ਰੱਖੇ ਜਾਣ" ਨੂੰ ਠੋਸ ਕਰ ਦਿੰਦੇ ਹਨ। ਜੇ ਪ੍ਰੰਪਟ ਜੁੰਮੇਵਾਰੀਆਂ (ਜਿਵੇਂ billing vs entitlements vs customer status) ਸਪਸ਼ਟ ਨਹੀਂ ਕਰਦਾ, ਤਾਂ ਟੀਮ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ catch-all ਮੋਡੀਊਲ ਬਣਾਉਂਦੀ ਹੈ ਜੋ ਬਾਅਦ ਵਿੱਚ ਬਦਲਣਾ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦਾ ਹੈ।
ਇੱਕ ਸਪਸ਼ਟ ਪ੍ਰੰਪਟ ਤੁਹਾਨੂੰ ਜ਼ਿੰਮੇਵਾਰੀ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਤੈਅ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਅਤੇ ਐਕਸੀਡੈਂਟਲ ਬਾਊਂਡਰੀਆਂ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਇਹ ਜੋੜੋ: ਲੱਖ-ਲੱਖ ਹੋ ਸਕਣ ਵਾਲੇ ਵਿਕਲਪ ਘਟਾਉਣ ਲਈ ਸਪਸ਼ਟ ਲਕਸ਼, ਨਾਨ-ਗੋਲ ਅਤੇ ਰੋਕਾਵਟਾਂ ਸ਼ਾਮਲ ਕਰੋ। ਉਦਾਹਰਣ:
ਹਰ ਇਕ ਕੌਂਕ੍ਰੀਟ ਬਿਆਨ ਕਈ “ਸ਼ਾਇਦ” ਆਰਕੀਟੈਕਚਰਾਂ ਨੂੰ ਹਟਾਉਂਦਾ ਹੈ ਅਤੇ ਫੈਸਲੇ ਇਰਾਦਾਪੂਰਕ ਬਣਾਉਂਦਾ ਹੈ।
ਹੇਠਾਂ ਦਿੱਤੇ cross-cutting ਲੋੜਾਂ ਨੂੰ ਹਮੇਸ਼ਾ ਪ੍ਰੰਪਟ ਵਿੱਚ ਨਾਮ ਦਿਓ, ਕਿਉਂਕਿ ਇਹ ਲਗਭਗ ਹਰ ਕੰਪੋਨੇਟ 'ਤੇ ਪ੍ਰਭਾਵ ਦਾਲਦੀਆਂ ਹਨ:
ਜੇ ਤੁਸੀਂ ਇਹ ਨਹੀਂ ਦੱਸਦੇ, ਤਾਂ ਇਹ ਬੇਨਿਯਮਤ ਤਰੀਕੇ ਨਾਲ ਇੰਪਲੀਮੈਂਟ ਹੁੰਦੇ ਹਨ (ਜਾਂ ਨਹੀਂ ਹੁੰਦੇ)।
customer, account, user ਵਰਗੇ ਸ਼ਬਦਾਂ ਨੂੰ ਸਪਸ਼ਟ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ। ਜਦੋਂ ਇਹ ਨਹੀਂ ਕੀਤਾ ਜਾਂਦਾ,/schema nullable ਕਾਲਮ ਅਤੇ overloaded fields (status, type, metadata) ਵਾਪਸ ਆਉਂਦੇ ਹਨ।
ਚੰਗਾ ਪ੍ਰੰਪਟ ਇਹ ਨਿਰਧਾਰਿਤ ਕਰਦਾ ਹੈ:
ਉਹ ਵੇਰਵੇ ਸ਼ਾਮਲ ਕਰੋ ਜੋ ਅਕਸਰ ਅਸਲ ਦੁਨੀਆ ਵਿੱਚ ਫੇਲ ਹੋਣ ਦਾ ਕਾਰਨ ਬਣਦੇ ਹਨ:
ਇਹ ਵੇਰਵੇ keys, constraints ਅਤੇ auditability ਨੂੰ ਡ੍ਰਾਈਵ ਕਰਦੇ ਹਨ ਨਾ ਕਿ ਅਨੁਮਾਨ ਨੂੰ।
API contracts ਤੇ ਸਪਸ਼ਟਤਾ ਦਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਨਤੀਜਾ ਮਿਲਦਾ ਹੈ: ਜਦੋਂ ਲੋੜਾਂ ਵਿਸ਼ੇਸ਼ ਹੁੰਦੀਆਂ ਹਨ, ਤਦ API ਦੀ ਗਲਤ ਵਰਤੋਂ ਘੱਟ ਹੁੰਦੀ ਹੈ, versioning ਆਸਾਨ ਹੁੰਦਾ ਹੈ ਅਤੇ breaking changes ਦੀ ਸੰਭਾਵਨਾ ਘੱਟ ਹੁੰਦੀ ਹੈ।
ਮਿਸਾਲ ਲਈ, update semantics (PUT vs PATCH), ਲਿਖਣ-ਯੋਗ/immutable fields, error handling standards, pagination/filters, ਅਤੇ idempotency ਜਿਹੇ ਫੈਸਲੇ ਪਹਿਲਾਂ ਕਰ ਲਓ।
ਚੌਣਾਂ ਸਪਸ਼ਟ ਹੋਣ ਨਾਲ ਕਲਾਇੰਟਾਂ ਲਈ ਅਣਚਾਹੇ ਤَوੜ-ਮੋੜ ਘੱਟ ਹੁੰਦੇ ਹਨ।
ਹਾਂ — ਜੇ Definition of Done ਵਿੱਚ ਇਹ ਸ਼ਾਮਲ ਹੈ ਤਾਂ। ਸਪਸ਼ਟ ਨਿਰਧਾਰਨ ਜੋਡੋ:
ਜੇ ਇਹ ਨਹੀਂ ਦੱਸਿਆ ਗਿਆ, ਤਾਂ observability ਅਕਸਰ ਅਸਮਰਥ ਹੁੰਦੀ ਹੈ ਅਤੇ production ਮੁੱਦਿਆਂ ਦੀ ਤਸ਼ਖੀਸ ਮਹਿੰਗੀ ਹੋ ਜਾਦੀ ਹੈ।
ਇੱਕ ਛੋਟੀ ਪੜਤਾਲ ਲੂਪ ਵਰਤੋ ਜੋ ਅਸਪਸ਼ਟਤਾਵਾਂ ਨੂੰ ਸਾਹਮਣਾ ਕਰਵਾਏ:
ਇਹ ਤਿੰਨ ਕਦਮ ਜ਼ਿਆਦਾਤਰ ਗੈਪਸ ਨੂੰ ਬਿਲਡ ਤੋਂ ਪਹਿਲਾਂ ਪਕੜ ਲੈਂਦੇ ਹਨ।
ਇਹ ਡੇਟਾ ਮਾਡਲ ਨੂੰ ਗਲਤ ਹੋਣ ਤੋਂ ਰੋਕਦਾ ਹੈ।