02 ਸਤੰ 2025·8 ਮਿੰਟ
APIs ਲਈ Protobuf ਬਨਾਮ JSON: ਗਤੀ, ਆਕਾਰ ਅਤੇ ਅਨੁਕੂਲਤਾ
APIs ਲਈ Protobuf ਅਤੇ JSON ਦੀ ਤੁਲਨਾ: ਪੇਲੋਡ ਆਕਾਰ, ਗਤੀ, ਪੜ੍ਹਨਯੋਗਤਾ, ਟੂਲਿੰਗ, ਵਰਜਨਿੰਗ ਅਤੇ ਅਸਲ ਉਤਪਾਦਾਂ ਵਿੱਚ ਦੋਨਾਂ ਵਿੱਚੋਂ ਕਦੋਂ ਕਿਹੜਾ ਫਾਰਮੈਟ ਵਧੀਆ ਹੈ।
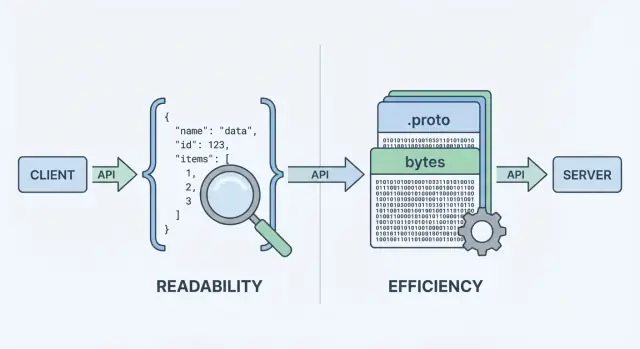
APIs ਲਈ Protobuf ਅਤੇ JSON ਦੀ ਤੁਲਨਾ: ਪੇਲੋਡ ਆਕਾਰ, ਗਤੀ, ਪੜ੍ਹਨਯੋਗਤਾ, ਟੂਲਿੰਗ, ਵਰਜਨਿੰਗ ਅਤੇ ਅਸਲ ਉਤਪਾਦਾਂ ਵਿੱਚ ਦੋਨਾਂ ਵਿੱਚੋਂ ਕਦੋਂ ਕਿਹੜਾ ਫਾਰਮੈਟ ਵਧੀਆ ਹੈ।
ਜਦੋਂ ਤੁਹਾਡੀ API ਡੇਟਾ ਭੇਜਦੀ ਜਾਂ ਪ੍ਰਾਪਤ ਕਰਦੀ ਹੈ, ਤਾਂ ਉਸਨੂੰ ਇੱਕ ਡੇਟਾ ਫਾਰਮੈਟ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ — ਇੱਕ ਮਿਆਰੀ ਤਰੀਕਾ ਜੋ ਰਿਕਵੇਸਟ ਅਤੇ ਰਿਸਪਾਂਸ ਬਾਡੀਜ਼ ਵਿੱਚ ਜਾਣਕਾਰੀ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ। ਉਹ ਫਾਰਮੈਟ ਫਿਰ ਸਿਰਿਆਲਾਈਜ਼ (ਬਾਈਟਾਂ ਵਿੱਚ ਤਬਦੀਲ ਕਰਨਾ) ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਨੈੱਟਵਰਕ 'ਤੇ ਭੇਜਣ ਲਈ, ਅਤੇ ਕਲਾਇੰਟ ਤੇ ਸਰਵਰ ਉੱਪਰ ਵਾਪਸ ਡਿਸਿਰਿਆਲਾਈਜ਼ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਦੋ ਆਮ ਚੋਣਾਂ ਹਨ JSON ਅਤੇ Protocol Buffers (Protobuf)। ਇਹ ਦੋਵੇਂ ਇਕੋ ਜਿਹੇ ਬਿਜ਼ਨਸ ਡੇਟਾ (ਉਪਭੋਗਤਾ, ਆਰਡਰ, ਟਾਈਮਸਟੈਂਪ, ਆਈਟਮਸ ਦੀ ਸੂਚੀ) ਦਰਸਾ ਸਕਦੇ ਹਨ, ਪਰ ਪ੍ਰਦਰਸ਼ਨ, ਪੇਲੋਡ ਆਕਾਰ ਅਤੇ ਵਿਕਾਸਕਾਰੀ ਵਰਕਫਲੋ ਦੇ ਮਾਮਲੇ ਵਿੱਚ ਵੱਖਰੇ ਤਜਰਬੇ ਪੇਸ਼ ਕਰਦੇ ਹਨ।
JSON (JavaScript Object Notation) ਇੱਕ ਟੈਕਸਟ-ਆਧਾਰਤ ਫਾਰਮੈਟ ਹੈ ਜਿਸ ਵਿੱਚ ਆਬਜੈਕਟ ਅਤੇ ਐਰੇ ਵਰਗੇ ਸਧਾਰਣ ਢਾਂਚੇ ਬਣਦੇ ਹਨ। ਇਹ REST APIs ਲਈ ਲੋਕਪ੍ਰਿਯ ਹੈ ਕਿਉਂਕਿ ਇਹ ਪੜ੍ਹਨ ਵਿੱਚ ਆਸਾਨ ਹੈ, ਲੌਗ ਕਰਨ ਵਿੱਚ ਸੌਖਾ ਹੈ, ਅਤੇ curl ਜਾਂ ਬ੍ਰਾਊਜ਼ਰ DevTools ਵਰਗੇ ਟੂਲਾਂ ਨਾਲ ਇਨਸਪੈਕਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਕ ਵੱਡਾ ਕਾਰਨ ਜਿਸ ਕਰਕੇ JSON ਹਰ ਜਗ੍ਹਾ ਵਰਤੀ ਜਾਂਦੀ ਹੈ: ਜਿਆਦਾਤਰ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਇਹਦਾ ਭਲੀਆਂ ਸਹਾਇਤਾ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਜਵਾਬ ਨੂੰ ਵਿਜੁਅਲ ਤੌਰ 'ਤੇ ਵੇਖ ਕੇ ਫੌਰਤ ਸਮਝ ਸਕਦੇ ਹੋ।
Protobuf ਗੂਗਲ ਵੱਲੋਂ ਬਣਾਇਆ ਗਇਆ ਇੱਕ ਬਾਈਨਰੀ ਸੀਰੀਅਲਾਈਜ਼ੇਸ਼ਨ ਫਾਰਮੈਟ ਹੈ। ਟੈਕਸਟ ਭੇਜਣ ਦੀ ਥਾਂ, ਇਹ ਇੱਕ ਸਕੀਮਾ (.proto ਫਾਈਲ) ਨਾਲ ਪਰਿਭਾਸ਼ਿਤ ਸੰਕੁਚਿਤ ਬਾਈਨਰੀ ਰਿਪ੍ਰਜ਼ੈਂਟੇਸ਼ਨ ਭੇਜਦਾ ਹੈ। ਸਕੀਮਾ ਫੀਲਡਾਂ, ਉਹਨਾਂ ਦੇ ਟਾਈਪਾਂ ਅਤੇ ਨੰਬਰਾਤਮਕ ਟੈਗਾਂ ਦਾ ਵਰਣਨ ਕਰਦਾ ਹੈ।
ਕਿਉਂਕਿ ਇਹ ਬਾਈਨਰੀ ਅਤੇ ਸਕੀਮਾ-ਚਾਲਿਤ ਹੈ, Protobuf ਆਮ ਤੌਰ 'ਤੇ ਛੋਟੇ ਪੇਲੋਡ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਪਾਰਸ ਕਰਨ ਵਿੱਚ ਤੇਜ਼ ਹੋ ਸਕਦਾ ਹੈ — ਇਹ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਵਧੀਆ ਹੁੰਦਾ ਹੈ ਜਿੱਥੇ ਬਹੁਤ ਵੱਧ ਰਿਕਵੇਸਟਾਂ, ਮੋਬਾਈਲ ਨੈਟਵਰਕ ਜਾਂ ਲੇਟੈਂਸੀ-ਸੰਵੇਦਨਸ਼ੀਲ ਸੇਵਾਵਾਂ ਹਨ (ਆਮ ਤੌਰ 'ਤੇ gRPC ਸੈਟਅੱਪ ਵਿੱਚ, ਪਰ ਸਿਰਫ gRPC ਲਈ ਹੀ ਸੀਮਿਤ ਨਹੀਂ)।
ਇਹ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿ ਤੁਸੀਂ ਜੋ ਭੇਜ ਰਹੇ ਹੋ (ਕੀ) ਨੂੰ ਇਸ ਗੱਲ ਤੋਂ ਅਲੱਗ ਰੱਖੋ ਕਿ ਕਿਸ ਤਰ੍ਹਾਂ ਉਹ ਐਨਕੋਡ ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੈ (ਕਿਵੇਂ)। ਇੱਕ “user” ਜਿਸਦਾ id, name ਅਤੇ email ਹੈ, ਉਦੋਂ ਦੋਹਾਂ JSON ਅਤੇ Protobuf ਵਿੱਚ ਮਾਡਲ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਫਰਕ ਉਹ ਖ਼ਰਚ ਹੈ ਜੋ ਤੁਸੀਂ ਭੁਗਤਦੇ ਹੋ:
ਇੱਕ-ਸਾਈਜ਼-ਫਿੱਟਸ-ਸਭ ਕੋਈ ਉਤਰ ਨਹੀਂ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਪਬਲਿਕ APIs ਲਈ JSON ਹੀ ਡਿਫੌਲਟ ਰਹਿੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਐਕਸੈਸਿਬਲ ਅਤੇ ਲਚਕੀਲਾ ਹੈ। ਅੰਦਰੂਨੀ ਸੇਵਾ-ਟੁ-ਸੇਵਾ ਕਮੇਨਿਕੇਸ਼ਨ, ਪ੍ਰਦਰਸ਼ਨ-ਸੰਵੇਦਨਸ਼ੀਲ ਪ੍ਰਣਾਲੀਆਂ ਜਾਂ ਕਠੋਰ ਕਾਂਟ੍ਰੈਕਟਾਂ ਲਈ Protobuf ਵਧੀਆ ਫਿੱਟ ਹੋ ਸਕਦਾ ਹੈ। ਇਸ ਗਾਈਡ ਦਾ ਮਕਸਦ ਤੁਹਾਨੂੰ ਰੋਕ-ਟੋਕ ਤੋਂ ਬਿਨਾਂ ਤੁਸੀਂ ਆਪਣੇ ਬੰਧਨਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਚੋਣ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨਾ ਹੈ।
ਜਦੋਂ ਇੱਕ API ਡੇਟਾ ਵਾਪਸ ਕਰਦਾ ਹੈ, ਉਹ ਸਿੱਧਾ “ਆਬਜੈਕਟ” ਨੈੱਟਵਰਕ 'ਤੇ ਭੇਜ ਨਹੀਂ ਸਕਦਾ। ਪਹਿਲਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਬਾਈਟਾਂ ਦੇ ਸ੍ਰੋਤ ਵਿੱਚ ਬਦਲਣਾ ਪੈਂਦਾ ਹੈ। ਇਹ ਰੂਪਾਂਤਰਨ ਸਿਰਿਆਲਾਈਜ਼ੇਸ਼ਨ ਹੈ — ਇਸਨੂੰ ਇੱਕ ਪੈਕ ਕਰਨ ਯੋਗ ਫਾਰਮ ਬਣਾਉਣ ਵਜੋਂ ਸੋਚੋ। ਦੂਜੇ ਪਾਸੇ, ਕਲਾਇੰਟ ਇਸਨੂੰ ਵਾਪਸ ਖੋਲ੍ਹਦਾ ਹੈ (ਡਿਸਿਰਿਆਲਾਈਜ਼ੇਸ਼ਨ), ਬਾਈਟਸ ਨੂੰ ਫਿਰ ਵਰਤਣ ਯੋਗ ਡੇਟਾ ਸੰਰਚਨਾ ਵਿੱਚ ਬਦਲ ਕੇ।
ਇਕ ਆਮ ਰਿਕਵੇਸਟ/ਰਿਸਪਾਂਸ ਫਲੋ ਇਹੋ ਜਿਹਾ ਹੁੰਦਾ ਹੈ:
ਇਹ “ਐਨਕੋਡਿੰਗ ਕਦਮ” ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਫਾਰਮੈਟ ਚੋਣ ਮਹੱਤਵਪੂਰਨ ਹੋ ਜਾਂਦੀ ਹੈ। JSON ਐਨਕੋਡਿੰਗ ਪੜ੍ਹਨਯੋਗ ਟੈਕਸਟ ਬਣਾਉਂਦੀ ਹੈ ਜਿਵੇਂ {\"id\":123,\"name\":\"Ava\"}। Protobuf ਐਨਕੋਡਿੰਗ ਸੰਕੁਚਿਤ ਬਾਈਨਰੀ ਬਾਈਟਸ ਬਣਾਉਂਦੀ ਹੈ ਜੋ ਟੂਲਿੰਗ ਤੋਂ ਬਿਨਾਂ ਮਨੁੱਖ ਲਈ ਸ਼ਬਦੀਕ ਨਹੀਂ ਹੁੰਦੇ।
ਕਿਉਂਕਿ ਹਰ ਰਿਸਪਾਂਸ ਨੂੰ ਪੈਕੇਟ ਕੀਤਾ ਅਤੇ ਖੋਲ੍ਹਿਆ ਜਾਣਾ ਲਾਜ਼ਮੀ ਹੈ, ਫਾਰਮੈਟ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ:
ਤੁਹਾਡੀ API ਸਟਾਈਲ ਅਕਸਰ ਫੈਸਲੇ ਨੂੰ ਨੁਡ ਕਰਦੀ ਹੈ:
curl ਨਾਲ ਆਸਾਨ ਟੈਸਟ ਅਤੇ ਲਾਗ/ਇਨਸਪੈਕਸ਼ਨ ਲਈ ਸਧਾਰਨ ਹੈ।ਤੁਸੀਂ gRPC ਵਿੱਚ JSON ਵਰਤ ਸਕਦੇ ਹੋ (transcoding ਰਾਹੀਂ) ਜਾਂ ਸਾਧਾਰਣ HTTP 'ਤੇ Protobuf ਵਰਤ ਸਕਦੇ ਹੋ, ਪਰ ਤੁਹਾਡੇ ਸਟੈਕ ਦੀ ਡਿਫੌਲਟ ਅਰਗੋਨੋਮਿਕਸ—ਫਰੇਮਵਰਕ, ਗੇਟਵੇ, ਕਲਾਇੰਟ ਲਾਇਬ੍ਰੇਰੀਆਂ ਅਤੇ ਡੀਬੱਗਿੰਗ ਅਭਿਆਸ—ਅਕਸਰ ਦਿਨ-ਪਰ-ਦਿਨ ਕੀ ਚਲਾਉਣਾ ਆਸਾਨ ਲੱਗਦਾ ਹੈ ਉਹ ਨਿਰਧਾਰਤ ਕਰ ਦਿੰਦੇ ਹਨ।
ਜਦੋਂ ਲੋਕ protobuf vs json ਤੋਲਦੇ ਹਨ, ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਦੋ ਮੈਟ੍ਰਿਕਸ ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੇ ਹਨ: ਪੇਲੋਡ ਕਿੰਨਾ ਵੱਡਾ ਹੈ ਅਤੇ ਐਨਕੋਡ/ਡਿਕੋਡ ਕਰਨ ਵਿੱਚ ਕਿੰਨਾ ਸਮਾਂ ਲੱਗਦਾ ਹੈ। ਸਾਰਾ ਸੰਦੇਸ਼ ਸਧਾਰਨ ਹੈ: JSON ਟੈਕਸਟ ਹੈ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ verbose ਹੁੰਦਾ ਹੈ; Protobuf ਬਾਈਨਰੀ ਹੈ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਸੰਕੁਚਿਤ ਹੁੰਦਾ ਹੈ।
JSON ਫੀਲਡ ਨਾਂ ਦੁਹਰਾਉਂਦਾ ਹੈ ਅਤੇ ਨੰਬਰ, ਬੂਲੀਆਨ ਅਤੇ ਸਟ੍ਰਕਚਰ ਲਈ ਟੈਕਸਟ ਪ੍ਰਤੀਨਿਧੀ ਵਰਤਦਾ ਹੈ, ਇਸ ਲਈ ਇਹ ਅਕਸਰ ਵਾਇਰ 'ਤੇ ਵੱਧ ਬਾਈਟਸ ਭੇਜਦਾ ਹੈ। Protobuf ਫੀਲਡ ਨਾਂ ਨੂੰ ਨੰਬਰਾਤਮਕ ਟੈਗਾਂ ਨਾਲ ਬਦਲਦਾ ਹੈ ਅਤੇ ਮੁੱਲਾਂ ਨੂੰ ਕੁਸ਼ਲਤਾਪੂਰਕ ਪੈਕ ਕਰਦਾ ਹੈ, ਜੋ ਖਾਸ ਕਰਕੇ ਵੱਡੇ ਆਬਜੈਕਟਾਂ, ਦੁਹਰਾਈਆਂ ਫੀਲਡਾਂ ਅਤੇ ਡੀਪਲੀ ਨੈਸਟਡ ਡੇਟਾ ਲਈ ਨੋਟੇਬਲ ਤੌਰ 'ਤੇ ਛੋਟਾ ਨਤੀਜਾ ਦਿੰਦਾ ਹੈ।
ਫਿਰ ਵੀ, ਕੰਪ੍ਰੈਸ਼ਨ ਗੈਪ ਘਟਾ ਸਕਦੀ ਹੈ। gzip ਜਾਂ brotli ਨਾਲ, JSON ਦੇ ਦੁਹਰਾਏ ਕੁੰਜੀਆਂ ਚੰਗੀ ਤਰ੍ਹਾਂ ਕੰਪ੍ਰੈੱਸ ਹੁੰਦੀਆਂ ਹਨ, ਇਸ ਲਈ "JSON ਵਿਰੁੱਧ Protobuf ਆਕਾਰ" ਫਰਕ ਹਕੀਕਤੀ ਤੌਰ 'ਤੇ ਘਟ ਸਕਦਾ ਹੈ। Protobuf ਵੀ ਕੰਪ੍ਰੈੱਸ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਪਰ ਰਿਸ਼ਤਦਾਰ ਫਾਇਦਾ ਜ਼ਿਆਦਾ ਨਾਜ਼ੁਕ ਹੁੰਦਾ ਹੈ।
JSON ਪਾਰਸਰਾਂ ਨੂੰ ਟੋਕਨਾਈਜ਼ ਕਰਨਾ ਪੈਂਦਾ ਹੈ, ਟੈਕਸਟ ਨੂੰ ਵੈਰਿਫਾਈ ਕਰਨਾ ਹੁੰਦਾ ਹੈ, ਸਤਰਾਂ ਨੂੰ ਨੰਬਰਾਂ ਵਿੱਚ ਬਦਲਣਾ ਪੈਂਦਾ ਹੈ ਅਤੇ ਐਸਕੇਪ/ਯੂਨੀਕੋਡ ਕੈਸਾਂ ਸੰਭਾਲਣੇ ਪੈਂਦੇ ਹਨ। Protobuf ਡਿਕੋਡਿੰਗ ਜ਼ਿਆਦਾ ਡਾਇਰੈਕਟ ਹੁੰਦੀ ਹੈ: ਟੈਗ ਪੜ੍ਹੋ → ਟਾਈਪ ਕੀਤੀ ਕੀਮਤ ਪੜ੍ਹੋ। ਬਹੁਤ ਸਾਰੀਆਂ ਸੇਵਾਵਾਂ ਵਿੱਚ, Protobuf CPU ਸਮਾਂ ਅਤੇ ਗਾਰਬੇਜ਼ ਬਣਤ ਘਟਾ ਦਿੰਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਲੋਡ ਹੇਠਾਂ ਰਹਿੰਦੇ ਹੋਏ ਟੇਲ ਲੇਟੈਂਸੀ ਸੁਧਰ ਸਕਦੀ ਹੈ।
ਮੋਬਾਈਲ ਨੈੱਟਵਰਕ ਜਾਂ ਉੱਚ-ਲੇਟੈਂਸੀ ਲਿੰਕਾਂ 'ਤੇ, ਘੱਟ ਬਾਈਟਸ ਆਮ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਟਰਾਂਸਫਰ ਅਤੇ ਘੱਟ ਰੇਡੀਓ ਸਮਾਂ ਦਾ ਮਤਲਬ ਹੁੰਦੇ ਹਨ (ਜੋ ਬੈਟਰੀ 'ਤੇ ਵੀ ਅਸਰ ਪਾਂਦਾ ਹੈ)। ਪਰ ਜੇ ਤੁਹਾਡੇ ਰਿਸਪਾਂਸ ਪਹਿਲਾਂ ਹੀ ਛੋਟੇ ਹਨ ਤਾਂ ਹੈਂਡਸ਼ੇਕ ਓਵਰਹੈਡ, TLS ਅਤੇ ਸਰਵਰ ਪ੍ਰੋਸੈਸਿੰਗ ਵੱਧ ਪ੍ਰਭਾਵਸ਼ালী ਹੋ ਸਕਦੇ ਹਨ — ਜਿਨ੍ਹਾਂ ਹਾਲਤਾਂ ਵਿੱਚ ਫਾਰਮੈਟ ਚੋਣ ਘੱਟ ਦਿੱਖ ਰਹੇਗੀ।
ਆਪਣੇ ਅਸਲ ਪੇਲੋਡਾਂ ਨਾਲ ਮਾਪੋ:
ਇਸ ਨਾਲ “API ਸੀਰੀਅਲਾਈਜ਼ੇਸ਼ਨ” ਵਾਲਾ ਵਿਵਾਦ ਉਹ ਡਾਟਾ ਦਿੰਦਾ ਹੈ ਜਿਸ 'ਤੇ ਤੁਸੀਂ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹੋ—ਤੁਹਾਡੇ ਖਾਸ API ਲਈ।
ਡਿਵੈਲਪਰ ਅਨੁਭਵ ਵਿੱਚ ਆਮ ਤੌਰ 'ਤੇ JSON ਪਹਿਲੇ ਹੀ ਆਸਾਨੀ ਨਾਲ ਜਿੱਤਦਾ ਹੈ। ਤੁਸੀਂ JSON ਰਿਕਵੇਸਟ ਜਾਂ ਰਿਸਪਾਂਸ ਨੂੰ ਕਿਤੇ ਵੀ ਇਨਸਪੈਕਟ ਕਰ ਸਕਦੇ ਹੋ: ਬ੍ਰਾਊਜ਼ਰ DevTools, curl ਆਉਟਪੁੱਟ, Postman, ਰਿਵਰਸ ਪ੍ਰਾਕਸੀਜ਼, ਅਤੇ ਸਧਾਰਣ ਟੈਕਸਟ ਲਾਗਜ਼। ਜਦੋਂ ਕੁਝ ਟੁੱਟਦਾ ਹੈ, "ਅਸੀਂ ਅਸਲ ਵਿੱਚ ਕੀ ਭੇਜਿਆ ਸੀ?" ਅਕਸਰ ਇੱਕ ਕਾਨੂੰਨੀ ਕਾਪੀ/ਪੇਸਟ ਦੂਰ ਹੁੰਦੀ ਹੈ।
Protobuf ਵੱਖਰਾ ਹੈ: ਇਹ ਸੰਕੁਚਿਤ ਅਤੇ ਸਖ਼ਤ ਹੈ, ਪਰ ਮਨੁੱਖ-ਪੜ੍ਹਨਯੋਗ ਨਹੀਂ। ਜੇ ਤੁਸੀਂ ਕੱਚੇ Protobuf ਬਾਈਟ ਲਾਗ ਕਰੋਗੇ ਤਾਂ ਤੁਹਾਨੂੰ base64 ਬਲੌਬ ਜਾਂ ਅਣਪੜਿਆ ਬਾਈਨਰੀ ਦੇਖਣ ਨੂੰ ਮਿਲੇਗਾ।payload ਨੂੰ ਸਮਝਣ ਲਈ ਤੁਹਾਨੂੰ ਸਹੀ .proto ਸਕੀਮਾ ਅਤੇ ਡਿਕੋਡਰ ਦੀ ਲੋੜ ਪਵੇਗੀ (ਜਿਵੇਂ protoc, ਭਾਸ਼ਾ-ਨਿਰਧਾਰਿਤ ਟੂਲਿੰਗ, ਜਾਂ ਤੁਹਾਡੇ ਸਰਵਿਸ ਦੇ ਜਨਰੇਟ ਕੀਤੇ ਟਾਈਪਜ਼)।
JSON ਨਾਲ, ਮੁੱਦੇ ਨੂੰ ਦੁਹਰਾਉਣਾ ਸੌਖਾ ਹੈ: ਇੱਕ ਲਾਗ ਕੀਤੀ ਪੇਲੋਡ ਲਵੋ, ਰਾਜ ਸੁਰੱਖਿਆ ਹਟਾਓ, curl ਨਾਲ ਰੀਪਲੇ ਕਰੋ, ਅਤੇ ਤੁਸੀਂ ਇੱਕ ਘੱਟੋ-ਘੱਟ ਟੈਸਟ ਕੇਸ ਦੇ ਨੇੜੇ ਹੋ।
Protobuf ਨਾਲ, ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਇੰਝ ਡੀਬੱਗ ਕਰੋਗੇ:
ਇਹ ਇਕ ਹੋਰ ਕਦਮ ਹੈ — ਪਰ ਜੇ ਟੀਮ ਕੋਲ ਦੁਹਰਾਊ ਵਰਕਫਲੋ ਹੋਵੇ ਤਾਂ ਇਹ ਸੰਭਾਲਯੋਗ ਹੈ।
ਸੰਰਚਿਤ ਲਾਗਿੰਗ ਦੋਹਾਂ ਫਾਰਮੈਟਾਂ ਲਈ ਮਦਦਗਾਰ ਹੈ। ਬਿਮੁਰਤੀ-ਪੂਰਵਕ ਲਾਗ ਕਰੋ: ਰਿਕਵੇਸਟ ਆਈਡੀ, ਮੈਥਡ ਨਾਂ, ਯੂਜ਼ਰ/ਅਕਾਊਂਟ ਆਈਡੀ, ਅਤੇ ਮੁੱਖ ਫੀਲਡਾਂ—ਬਹੁਤ ਸਾਰਾ ਬਾਡੀ ਨਹੀਂ।
Protobuf ਲਈ ਖਾਸ:
.proto ਵਰਤ ਰਹੇ ਸੀ?" ਦਾ ਸੰਦੇਹ ਨਾ ਰਹੇ।JSON ਲਈ, ਕੈਨੋਨਿਕਲਾਈਜ਼ਡ JSON (ਸਟੇਬਲ ਕੀ ਅਨੁਕ੍ਰਮ) ਲਾਗ ਕਰਨ 'ਤੇ ਵਿਚਾਰ ਕਰੋ ਤਾਂ ਕਿ ਡਿਫ ਅਤੇ ਘਟਨਾਕ੍ਰਮ ਪੜ੍ਹਨ ਵਿੱਚ ਆਸਾਨ ਹੋਵੇ।
APIs ਸਿਰਫ ਡੇਟਾ ਨਹੀਂ ਮੂਹਾਂ-ਬਦਲਦੇ—ਉਹ ਅਰਥ ਵੀ ਭੇਜਦੇ ਹਨ। JSON ਅਤੇ Protobuf ਵਿੱਚ ਸਭ ਤੋਂ ਵੱਡਾ ਫਰਕ ਇਹ ਹੈ ਕਿ ਉਹ ਅਰਥ ਕਿੰਨੇ ਸਪਸ਼ਟ ਅਤੇ ਲਾਗੂ ਕੀਤੇ ਗਏ ਹਨ।
JSON ਮੂਲ ਰੂਪ ਵਿੱਚ "ਸਕੀਮਾ-ਰਹਿਤ" ਹੈ: ਤੁਸੀਂ ਕਿਸੇ ਵੀ ਫੀਲਡ ਨਾਲ ਆਬਜੈਕਟ ਭੇਜ ਸਕਦੇ ਹੋ, ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਕਲਾਇੰਟ ਇਸਨੂੰ ਸਵੀਕਾਰ ਕਰ ਲੈਂਦੇ ਹਨ ਜੇ ਇਹ "ਠੀਕ-ਠਾਹਰ" ਦਿੱਸਦਾ ਹੈ।
ਇਹ ਸ਼ੁਰੂ ਵਿੱਚ ਸੁਵਿਧਾਜਨਕ ਹੈ, ਪਰ ਇਹ ਗਲਤੀਆਂ ਨੂੰ ਲੁਕਾ ਸਕਦਾ ਹੈ। ਆਮ ਫਲੈਨ:
userId, ਦੂਜੀ ਜਗ੍ਹਾ user_id, ਜਾਂ ਕੁਝ ਕੋਡ-ਪਾਥਾਂ 'ਤੇ ਫੀਲਡ ਗਾਇਬ।"42", "true", "2025-12-23" — ਜੋ ਬਣਾਉਣਾ ਆਸਾਨ ਹੈ ਪਰ ਪੜ੍ਹਨ ਵਿੱਚ ਔਖਾ ਹੋ ਸਕਦਾ ਹੈ।null ਦਾ ਮਤਲਬ "ਅਣਜਾਣ", "ਸੈੱਟ ਨਹੀਂ" ਜਾਂ "ਇਰਾਦੇ ਨਾਲ ਖਾਲੀ" ਹੋ ਸਕਦਾ ਹੈ, ਅਤੇ ਵੱਖ-ਵੱਖ ਕਲਾਇੰਟ ਇਹਨੂੰ ਵੱਖਰੇ ਢੰਗ ਨਾਲ ਲੈਂਦੇ ਹਨ।ਤੁਸੀਂ JSON Schema ਜਾਂ OpenAPI ਲਗਾ ਸਕਦੇ ਹੋ, ਪਰ JSON ਖੁਦ ਇਸਦੀ ਮੰਗ ਨਹੀਂ ਕਰਦਾ।
.proto ਰਾਹੀਂ ਸਪਸ਼ਟ ਕਾਂਟ੍ਰੈਕਟProtobuf ਇੱਕ ਸਕੀਮਾ ਮੰਗਦਾ ਹੈ ਜੋ .proto ਫਾਈਲ ਵਿੱਚ ਲਿਖਿਆ ਜਾਂਦਾ ਹੈ। ਇੱਕ ਸਕੀਮਾ ਇੱਕ ਸਾਂਝਾ ਕਾਂਟ੍ਰੈਕਟ ਹੈ ਜੋ ਦੱਸਦਾ ਹੈ:
ਇਹ ਕਾਂਟ੍ਰੈਕਟ ਅਚਾਨਕ ਬਦਲਾਅ ਰੋਕਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ — ਜਿਵੇਂ ਕਿ ਇਕ ਇੰਟੀਜਰ ਨੂੰ ਸਟਰਿੰਗ ਬਣਾਉਣਾ — ਕਿਉਂਕਿ ਜਨਰੇਟ ਕੀਤਾ ਕੋਡ ਖਾਸ ਟਾਈਪਾਂ ਦੀ ਉਮੀਦ ਰੱਖਦਾ ਹੈ।
Protobuf ਨਾਲ, ਨੰਬਰ ਨੰਬਰ ਰਹਿੰਦੇ ਹਨ, enums ਮਾਲੂਮ ਮੁੱਲਾਂ ਤੱਕ ਸੀਮਿਤ ਰਹਿੰਦੇ ਹਨ, ਅਤੇ timestamps ਆਮ ਤੌਰ 'ਤੇ well-known types ਨਾਲ ਮਾਡਲ ਕੀਤੇ ਜਾਂਦੇ ਹਨ (ਬਜਾਏ ਅਡ-ਹੋਕ ਸਟਰਿੰਗ ਫਾਰਮੈਟਾਂ)। proto3 ਵਿੱਚ, optional ਫੀਲਡਾਂ ਜਾਂ wrapper ਟਾਈਪਾਂ ਵਰਤ ਕੇ "ਨਾਥ ਪੈਣ" ਨੂੰ ਵੱਧ ਸਪਸ਼ਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਜੇ ਤੁਹਾਡੀ API ਨੂੰ ਸਖ਼ਤ ਟਾਈਪਾਂ ਅਤੇ ਭਰੋਸੇਯੋਗ ਪਾਰਸਿੰਗ ਦੀ ਲੋੜ ਹੈ ਤਾਂ Protobuf ਉਹ ਗਾਰਡਰੇਲ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ ਜੋ ਆਮ ਤੌਰ 'ਤੇ JSON ਵਿੱਚ ਰਵਾਇਤਾਂ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ ਹਨ।
APIs ਵਿਕਸਿਤ ਹੁੰਦੀਆਂ ਹਨ: ਤੁਸੀਂ ਫੀਲਡ ਜੋੜਦੇ ਹੋ, ਵਿਹਾਰ ਥੋੜ-ਬਹੁਤ ਬਦਲਦੇ ਹੋ, ਅਤੇ ਪੁਰਾਣੇ ਹਿੱਸਿਆਂ ਨੂੰ ਰਿਟਾਇਰ ਕਰਦੇ ਹੋ। ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਕਾਂਟ੍ਰੈਕਟ ਬਦਲਿਆ ਜਾਵੇ ਬਿਨਾਂ ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ ਹੈਰਾਨ ਕੀਤੇ।
ਵਧੀਆਂ ਵਿਕਾਸ ਰਣਨੀਤੀ ਦੋਹਾਂ ਲਈ ਯਤਨ ਕਰਦੀ ਹੈ, ਪਰ ਅਕਸਰ ਬੈਕਵਰਡ ਕਮਪੈਟਬਿਲਿਟੀ ਘੱਟੋ-ਘੱਟ ਮਾਪਦੰਡ ਹੁੰਦੀ ਹੈ।
Protobuf ਵਿੱਚ ਹਰ ਫੀਲਡ ਦਾ ਇੱਕ ਨੰਬਰ ਹੁੰਦਾ ਹੈ। ਇਹ ਨੰਬਰ — ਨਾ ਕਿ ਨਾਮ — ਵਾਇਰ 'ਤੇ ਜਾਂਦਾ ਹੈ। ਨਾਮ ਮੁੱਖ ਤੌਰ 'ਤੇ ਮਨੁੱਖਾਂ ਅਤੇ ਜਨਰੇਟ ਹੋਏ ਕੋਡ ਲਈ ਹੈ।
ਇਸ ਕਾਰਨ:
ਸਰੋਤ: reserved ਵਰਤੋ ਅਤੇ ਇੱਕ ਚੇਨਲੌਗ ਰੱਖੋ।
JSON ਵਿੱਚ ਇਮਰਜੈਂਟ ਤੌਰ 'ਤੇ ਕੋਈ ਇੰਬਿਲਟ ਸਕੀਮਾ ਨਹੀਂ ਹੁੰਦੀ, ਇਸ ਲਈ ਅਨੁਕੂਲਤਾ ਤੁਹਾਡੇ ਪੈਟਰਨਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ:
ਡਿਪ੍ਰੀਕੇਸ਼ਨਾਂ ਨੂੰ ਜਲਦੀ ਦਸਤਾਵੇਜ਼ ਕਰੋ: ਕਦੋਂ ਇੱਕ ਫੀਲਡ ਡਿਪ੍ਰੀਕੇਟ ਹੈ, ਕਿੰਨੇ ਸਮੇਂ ਤੱਕ ਸਮਰਥਿਤ ਰਹੇਗੀ, ਅਤੇ ਇਸਦੀ ਜਗ੍ਹਾ ਕੀ ਹੈ। ਇੱਕ ਸਧਾਰਨ ਵਰਜਨਿੰਗ ਨੀਤੀ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ (ਉਦਾਹਰਣ: "ਐਡੀਟਿਵ ਬਦਲਾਅ ਨਾਨ-ਬ੍ਰੇਕਿੰਗ ਹਨ; ਹਟਾਉਣਾਂ ਲਈ ਨਵਾਂ ਮੇਜਰ ਵਰਜ਼ਨ ਲੋੜੀਂਦਾ") ਅਤੇ ਇਸਦਾ ਪਾਲਣ ਕਰੋ।
JSON ਅਤੇ Protobuf ਦੇ ਵਿਚਕਾਰ ਚੋਣ ਅਕਸਰ ਇਸ ਗੱਲ ਤੇ ਆਧਾਰਤ ਹੁੰਦੀ ਹੈ ਕਿ ਤੁਹਾਡੀ API ਕਿੱਥੇ ਚੱਲੇਗੀ — ਅਤੇ ਟੀਮ ਕੀ ਰੱਖਣਾ ਚਾਹੁੰਦੀ ਹੈ।
JSON ਲਗਭਗ ਹਰ ਜਗ੍ਹਾ ਹੈ: ਹਰ ਬ੍ਰਾਊਜ਼ਰ ਅਤੇ ਬੈਕਐਂਡ ਰਨਟਾਈਮ ਇਸ ਨੂੰ ਬਿਨਾਂ ਵਾਧੂ ਡੀਪੈਂਡੈਂਸੀ ਦੇ ਪਾਰਸ ਕਰ ਸਕਦਾ ਹੈ। ਵੈਬ ਐਪ ਵਿੱਚ, fetch() + JSON.parse() ਖੁਸ਼ੀ ਦਾ ਰਸਤਾ ਹੈ, ਅਤੇ ਪ੍ਰਾਕਸੀਜ਼, API ਗੇਟਵੇ ਅਤੇ ਅਬਜ਼ਰਵੇਬਿਲਿਟੀ ਟੂਲ ਆਮ ਤੌਰ 'ਤੇ JSON ਨੂੰ ਆਊਟ-ਆਫ-ਬਾਕਸ ਸਮਝਦੇ ਹਨ।
Protobuf ਬ੍ਰਾਊਜ਼ਰ ਵਿਚ ਵੀ ਚੱਲ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਮੁਫ਼ਤ ਨਹੀਂ। ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ Protobuf ਲਾਇਬ੍ਰੇਰੀ (ਜਾਂ ਜੈਨਰੇਟਡ JS/TS ਕੋਡ) ਜੋੜੋਗੇ, ਬੰਡਲਿੰਗ ਆਕਾਰ ਦੀ ਪਰਬੰਧਨਾ ਕਰੋਗੇ, ਅਤੇ ਇਹ ਫੈਸਲਾ ਕਰੋਗੇ ਕਿ آیا ਤੁਸੀਂ plain HTTP 'ਤੇ Protobuf ਭੇਜ ਰਹੇ ਹੋ ਜਿਸ ਨੂੰ ਬ੍ਰਾਊਜ਼ਰ ਟੂਲ ਆਸਾਨੀ ਨਾਲ ਦਿਖਾ ਸਕਦੇ ਹਨ।
iOS/Android ਅਤੇ ਬੈਕਐਂਡ ਭਾਸ਼ਾਵਾਂ (Go, Java, Kotlin, C#, Python ਆਦਿ) ਵਿੱਚ Protobuf ਸਹਾਇਤਾ ਪੱਕੀ ਹੈ। Protobuf ਇਹ ਮੰਨਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਹਰ ਪਲੇਟਫਾਰਮ ਲਈ ਲਾਇਬ੍ਰੇਰੀਆਂ ਵਰਤੋਗੇ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ .proto ਫਾਈਲਾਂ ਤੋਂ ਕੋਡ ਜਨਰੇਟ ਕਰੋਗੇ।
ਕੋਡ ਜਨਰੇਸ਼ਨ ਨਾਲ ਹਕੀਕਤੀ ਫਾਇਦੇ ਆਉਂਦੇ ਹਨ:
ਇਸਦਾ ਖ਼ਰਚ ਵੀ ਹੈ:
.proto ਪੈਕੇਜ ਦਾ ਪ੍ਰਕਾਸ਼ਨ, ਵਰਜਨ ਪਿਨਿੰਗ)Protobuf ਆਮ ਤੌਰ 'ਤੇ gRPC ਨਾਲ ਜੁੜਿਆ ਹੈ, ਜੋ ਤੁਹਾਨੂੰ ਇੱਕ ਪੂਰਾ ਟੂਲਿੰਗ ਕਥਾ ਦਿੰਦਾ ਹੈ: ਸਰਵਿਸ ਡਿਫਿਨਿਸ਼ਨ, ਕਲਾਇੰਟ ਸਟਬ, ਸਟਰੀਮਿੰਗ, ਅਤੇ ਇੰਟਰਸੈਪਟਰ। ਜੇ ਤੁਸੀਂ gRPC 'ਤੇ ਨਜ਼ਰ ਮਾਰ ਰਹੇ ਹੋ ਤਾਂ Protobuf ਕੁਦਰਤੀ ਫਿੱਟ ਹੈ।
ਜੇ ਤੁਸੀਂ ਪਰੰਪਰਿਕ JSON REST API ਬਣਾ ਰਹੇ ਹੋ ਤਾਂ JSON ਦੀ ਟੂਲਿੰਗ ਇਕੋ-ਤਰੀਕੇ ਨਾਲ ਸਧਾਰਨ ਰਹਿੰਦੀ ਹੈ — ਖਾਸ ਤੌਰ 'ਤੇ ਪਬਲਿਕ APIs ਅਤੇ ਤੇਜ਼ ਇੰਟੇਗ੍ਰੇਸ਼ਨਾਂ ਲਈ।
ਜੇ ਤੁਸੀਂ API ਸਰਫੇਸ 'ਤੇ ਹਾਲੇ ਵੀ ਖੋਜ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਦੋਹਾਂ ਢੰਗਾਂ ਵਿੱਚ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰੋਟੋਟਾਈਪ ਬਣਾਉਣਾ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ। ਉਦਾਹਰਣ ਲਈ, ਟੀਮਾਂ ਅਕਸਰ ਇੱਕ JSON REST API ਜਲਦੀ ਨਾਲ ਉਤਾਰਦੀਆਂ ਹਨ ਅਤੇ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ gRPC/Protobuf ਸਰਵਿਸ ਵੇਖਦੀਆਂ ਹਨ, ਫਿਰ ਅਸਲ ਪੇਲੋਡਾਂ 'ਤੇ ਬੈਂਚਮਾਰਕ ਕਰਕੇ ਨਿਰਧਾਰਿਤ ਕਰਦੀਆਂ ਹਨ ਕਿ ਕੀ ਡਿਫੌਲਟ ਹੋਵੇ। Koder.ai ਵਰਗੇ ਟੂਲ ਇਸ ਪ੍ਰਕਿਰਿਆ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ ਪੂਰਾ-ਸਟੈਕ ਐਪ ਜਨਰੇਟ ਕਰਦੇ ਹਨ ਅਤੇ ਸਕੀਮਾ ਤੇ ਇਟਰੇਸ਼ਨ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ।
JSON ਅਤੇ Protobuf 'ਚੋਂ ਇਕ ਚੁਣਨਾ ਸਿਰਫ ਪੇਲੋਡ ਆਕਾਰ ਜਾਂ ਗਤੀ ਬਾਰੇ ਨਹੀਂ ਹੁੰਦਾ। ਇਹ ਇਸ ਗੱਲ ਨੂੰ ਵੀ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡੀ API ਕਿਵੇਂ ਕੈਸ਼ਿੰਗ ਲੇਅਰਾਂ, ਗੇਟਵੇਜ਼ ਅਤੇ ਉਪਲਬਧ ਟੂਲਜ਼ ਨਾਲ ਫਿੱਟ ਹੁੰਦੀ ਹੈ।
ਜ਼ਿਆਦਾਤਰ HTTP ਕੈਸ਼ਿੰਗ ਇੰਫਰਾਸਟ੍ਰਕਚਰ (ਬ੍ਰਾਊਜ਼ਰ ਕੈਚ, ਰਿਵਰਸ ਪ੍ਰਾਕਸ, CDN) HTTP semantics ਲਈ optimized ਹੁੰਦੇ ਹਨ, ਕਿਸੇ ਵਿਸ਼ੇਸ਼ ਬਾਡੀ ਫਾਰਮੈਟ ਲਈ ਨਹੀਂ। CDN ਕਿਸੇ ਵੀ ਬਾਈਟਸ ਨੂੰ ਕੈਸ਼ ਕਰ ਸਕਦੀ ਹੈ ਜੇਕਰ ਰਿਸਪਾਂਸ ਕੈਸ਼ੇਬਲ ਹੋਵੇ।
ਫਿਰ ਵੀ, ਕਈ ਟੀਮਾਂ ਕਿਨਾਰਿਆਂ 'ਤੇ HTTP/JSON ਦੀ ਉਮੀਦ ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ ਇਨਸਪੈਕਟ ਅਤੇ ਟ੍ਰਬਲਸ਼ੂਟ ਕਰਨਾ ਆਸਾਨ ਹੈ। Protobuf ਨਾਲ ਕੈਸ਼ਿੰਗ ਕੰਮ ਕਰਦੀ ਹੈ, ਪਰ ਤੁਹਾਨੂੰ ਸੋਚ-ਵਿਚਾਰ ਨਾਲ:
Vary) ਸੰਭਾਲਣੇ ਪੈਣਗੇCache-Control, ETag, Last-Modified) ਰੱਖੋContent-Type ਅਤੇ Accept)ਜੇ ਤੁਸੀਂ ਦੋਹਾਂ JSON ਅਤੇ Protobuf ਸਪੋਰਟ ਕਰਦੇ ਹੋ ਤਾਂ ਕੰਟੈਂਟ ਨੈਗੋਸ਼ੀਏਸ਼ਨ ਵਰਤੋਂ:
Accept: application/json ਜਾਂ Accept: application/x-protobuf ਭੇਜੇContent-Type ਦੇ ਨਾਲ ਮਿਲਦਾ ਜਵਾਬ ਦੇਕੈਸ਼ਸ ਨੂੰ ਸਮਝਾਉਣ ਲਈ Vary: Accept ਯਕੀਨੀ ਬਣਾਓ ਨਹੀਂ ਤਾਂ ਇੱਕ ਕੈਸ਼ JSON ਜਵਾਬ ਸਟੋਰ ਕਰਕੇ Protobuf ਕਲਾਇੰਟ ਨੂੰ ਦੇ ਸਕਦਾ ਹੈ (ਜਾਂ ਉਲਟ)।
API ਗੇਟਵੇਜ਼, WAFs, ਰਿਕਵੇਸਟ/ਰਿਸਪਾਂਸ ਟ੍ਰਾਂਸਫਾਰਮਰ ਅਤੇ ਅਬਜ਼ਰਵੇਬਿਲਿਟੀ ਟੂਲ ਆਮ ਤੌਰ 'ਤੇ JSON ਬਾਡੀਜ਼ ਨੂੰ ਮਨਜ਼ੂਰ ਕਰਦੇ ਹਨ ਜਿਵੇਂ:
ਬਾਈਨਰੀ Protobuf ਉਹ ਫੀਚਰ ਘਟਾ ਦੇ ਸਕਦੀ ਹੈ ਜਦ ਤੱਕ ਤੁਹਾਡੀ ਟੂਲਿੰਗ Protobuf-ਸਜਗ ਨਾ ਹੋਵੇ (ਜਾਂ ਤੁਸੀਂ ਡਿਕੋਡਿੰਗ ਕਦਮ ਜੋੜੋ)।
ਆਮ ਪੈਟਰਨ ਹੈ ਕਿਨਾਰੇ 'ਤੇ JSON, ਅੰਦਰ Protobuf:
ਇਸ ਨਾਲ ਬਾਹਰੀ ਇੰਟਗਰੇਸ਼ਨਾਂ ਨੂੰ ਸਾਦਾ ਰੱਖਦੇ ਹੋਏ ਅੰਦਰੂਨੀ ਜਗ੍ਹਾ 'ਤੇ Protobuf ਦੇ ਫਾਇਦੇ ਲੈ ਸਕਦੇ ਹੋ।
JSON ਜਾਂ Protobuf ਚੁਣਨ ਨਾਲ ਇਹ ਨਹੀਂ ਬਦਲਦਾ ਕਿ ਡੇਟਾ ਕਿਵੇਂ ਸ਼ਾਮਲ ਅਤੇ ਪਾਰਸ ਕੀਤਾ ਜਾਂਦਾ — ਪਰ ਇਹ ਇਹ ਨਿਰਧਾਰਤ ਕਰ ਸਕਦਾ ਹੈ ਕਿ ਤੁਹਾਡਾ ਢਾਂਚਾ ਕਿੰਨ੍ਹਾਂ ਹੱਦ ਤਕ ਮਦਦਗਾਰ ਹੋਵੇਗਾ। ਤੇਜ਼ ਸੀਰੀਅਲਾਈਜ਼ਰ ਇੱਕ API ਨੂੰ ਸੇਫ ਨਹੀਂ ਬਣਾਂਦਾ ਜੇਕਰ ਉਹ ਅਣ-ਭਰੋਸੇਮੰਦ ਇਨਪੁੱਟ ਲੈ ਰਿਹਾ ਹੋਵੇ।
ਇਹ ਲੁਭਾਵਣਾ ਹੋ ਸਕਦਾ ਹੈ ਕਿ Protobuf ਨੂੰ "ਜਿਆਦਾ ਸੇਫ" ਸਮਝ ਲਿਆ ਜਾਵੇ ਕਿਉਂਕਿ ਇਹ ਬਾਈਨਰੀ ਅਤੇ ਘੱਟ ਪੜ੍ਹਨਯੋਗ ਹੈ। ਇਹ ਕੋਈ ਸੁਰੱਖਿਆ ਰਣਨੀਤੀ ਨਹੀਂ। ਹਮਲਾਕਾਰਾਂ ਨੂੰ ਤੁਹਾਡੇ ਪੇਲੋਡ ਮਨੁੱਖ-ਪੜ੍ਹਨਯੋਗ ਹੋਣ ਦੀ ਲੋੜ ਨਹੀਂ — ਉਹ ਸਿਰਫ ਤੁਹਾਡੇ ਐਂਡਪੌਇੰਟ ਦੀ ਲੋੜ ਰੱਖਦੇ ਹਨ। ਜੇ API ਸेंसਿਟਿਵ ਫੀਲਡ ਲੀਕ ਕਰਦਾ ਹੈ, ਅਥਵਾ ਕਮਜ਼ੋਰ ਐਥੰਟੀਕੇਸ਼ਨ ਹੈ, ਤਾਂ ਫਾਰਮੈਟ ਬਦਲਣ ਨਾਲ ਇਹ ਦਿੱਕਤ ਸਹੀ ਨਹੀਂ ਹੋਵੇਗੀ।
ਟ੍ਰਾਂਸਪੋਰਟ ਨੂੰ ਇਨਕ੍ਰਿਪਟ ਕਰੋ (TLS), authz ਚੈੱਕ ਲਗਾਓ, ਇਨਪੁੱਟ ਵੈਲੀਡੇਸ਼ਨ ਕਰੋ ਅਤੇ ਲਾਗਿੰਗ ਸੁਰੱਖਿਅਤ ਰੱਖੋ ਭਾਵੇਂ ਤੁਸੀਂ JSON REST API ਜਾਂ gRPC Protobuf ਵਰਤੋ।
ਦੋਵੇਂ ਫਾਰਮੈਟ ਇੱਕੋ ਜਿਹੇ ਖਤਰੇ ਸਾਂਝੇ ਕਰਦੇ ਹਨ:
API ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਣ ਲਈ ਇਹਨਾਂ ਨਿਯਮਾਂ ਨੂੰ ਦੋਹਾਂ ਫਾਰਮੈਟਾਂ 'ਤੇ ਲਗਾਓ:
ਨਤੀਜਾ: "ਬਾਈਨਰੀ ਵਿਰੁੱਧ ਟੈਕਸਟ ਫਾਰਮੈਟ" ਮੁੱਖ ਤੌਰ 'ਤੇ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਵਰਕਫਲੋ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ। ਸੁਰੱਖਿਆ ਅਤੇ ਭਰੋਸੇਯੋਗਤਾ ਲਗਾਤਾਰ ਸੀਮਾਵਾਂ, ਅੱਪਡੇਟ ਕੀਤੀਆਂ ਨਿਰਭਰਤਾਵਾਂ ਅਤੇ ਸਪਸ਼ਟ ਵੈਲਿਡੇਸ਼ਨ ਤੋਂ ਆਉਂਦੀ ਹੈ।
JSON ਅਤੇ Protobuf ਵਿਚੋਂ ਚੋਣ ਕਰਨ ਦਾ ਮਾਮਲਾ ਇਹ ਨਹੀਂ ਹੈ ਕਿ ਕਿਹੜਾ "ਵਧੀਆ" ਹੈ, ਬਲਕਿ ਇਹ ਹੈ ਕਿ ਤੁਹਾਡੀ API ਨੂੰ ਕਿਸ ਗੱਲ ਲਈ ਓਪਟਿਮਾਈਜ਼ ਕਰਨ ਦੀ ਲੋੜ ਹੈ: ਮਨੁੱਖ-ਮਿਤ੍ਰਤਾ ਅਤੇ ਪਹੁੰਚ ਜਾਂ ਕੁਸ਼ਲਤਾ ਅਤੇ ਸਖ਼ਤ ਕਾਂਟ੍ਰੈਕਟ।
JSON ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਡਿਫੌਲਟ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਵਿਆਪਕ ਅਨੁਕੂਲਤਾ ਅਤੇ ਤੇਜ਼ ਡੀਬੱਗ ਕਰਨ ਦੀ ਲੋੜ ਹੋਵੇ।
ਟਿੱਪਣੀਯੋਗ ਸਥਿਤੀਆਂ:
Protobuf ਉਹ ਜਿੱਥੇ ਜਿੱਤਦਾ ਹੈ ਜਿੱਥੇ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਇੱਕਸਾਰਤਾ ਮਨੁੱਖੀ ਪੜ੍ਹਨਯੋਗਤਾ ਤੋਂ ਵੱਧ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦੀ ਹੈ।
ਟਿੱਪਣੀਯੋਗ ਸਥਿਤੀਆਂ:
ਇਹ ਸਵਾਲ ਤੇਜ਼ੀ ਨਾਲ ਚੋਣ ਨੂੰ ਘਟਾ ਦੇਣਗੇ:
ਇਸਨੂੰ ਆਪਣੇ ਡੌਕਸ ਵਿੱਚ ਟੇਬਲ ਵਜੋਂ ਖੋਲ੍ਹ ਸਕਦੇ ਹੋ:
ਜੇ ਤੁਸੀਂ ਫਿਰ ਵੀ ਫ਼ੈਸਲਾ ਨਹੀਂ ਕਰ ਪਾ ਰਹੇ, ਤਾਂ "ਕਿਨਾਰੇ ਤੇ JSON, ਅੰਦਰ Protobuf" ਇੱਕ ਯਥਾਰਥਪੂਰਕ ਸਮਝੌਤਾ ਹੋ ਸਕਦਾ ਹੈ।
ਫਾਰਮੈਟ ਮਾਈਗ੍ਰੇਸ਼ਨ ਸਭ ਕੁਝ ਦੁਬਾਰਾ ਲਿਖਣਾ ਨਹੀਂ ਹੁੰਦਾ — ਇਹ ਜੋਖਮ ਘਟਾਉਣ ਅਤੇ ਉਪਭੋਗਤਿਆਂ ਲਈ ਉਪਯੋਗਤਾ ਬਣਾਈ ਰੱਖਣ ਦਾ ਪ੍ਰਕਿਰਿਆ ਹੈ। ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਕਦਮ ਉਹ ਹਨ ਜੋ ਟ੍ਰੈਫਿਕ ਦੌਰਾਨ API ਵਰਤੋਗਿਆਂ ਨੂੰ ਵਰਤਣਯੋਗ ਬਣਾਈ ਰੱਖਦੇ ਹਨ ਅਤੇ ਰੋਲਬੈਕ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ।
ਘੱਟ-ਖਤਰੇ ਆਊਟਪੁੱਟ ਚੁਣੋ—ਅਕਸਰ ਇੱਕ ਅੰਦਰੂਨੀ ਸੇਵਾ-ਟੁ-ਸੇਵਾ ਕਾਲ ਜਾਂ ਇੱਕ ਪੜ੍ਹਨ-ਕੇਵਲ ਏਂਡਪੋਇੰਟ। ਇਸ ਨਾਲ ਤੁਹਾਨੂੰ Protobuf ਸਕੀਮਾ, ਜਨਰੇਟ ਕੀਤੇ ਕਲਾਇੰਟ, ਅਤੇ ਅਬਜ਼ਰਵੇਬਿਲਿਟੀ ਬਦਲਾਅ ਦੀ ਜਾਂਚ ਕਰਨ ਵਿੱਚ ਸਹੂਲਤ ਮਿਲਦੀ ਹੈ ਬਿਨਾਂ ਪੂਰੇ API ਨੂੰ "ਬਿਗ ਬੈਂਗ" ਪ੍ਰੋਜੈਕਟ ਬਣਾਏ।
ਪ੍ਰਾਯੋਗਿਕ ਪਹਿਲਾ ਕਦਮ ਇੱਕ ਮੌਜੂਦਾ ਰਿਸੋਰਸ ਲਈ Protobuf ਪ੍ਰਤੀਨਿਧੀ ਜੋੜਨਾ ਹੈ ਜਦੋਂ ਕਿ JSON ਰੂਪ ਅਣ-ਬਦਲਿਆ ਰਹੇ — ਇਸ ਨਾਲ ਤੁਸੀਂ ਜਲਦੀ ਦੇਖ ਸਕੋਗੇ ਕਿ ਤੁਹਾਡਾ ਡੇਟਾ ਮਾਡਲ ਕਿੱਥੇ ਅਸਪਸ਼ਟ ਹੈ (null vs missing, ਨੰਬਰ vs ਸਟਰਿੰਗ, ਤਾਰੀਖ ਫਾਰਮੈਟ) ਅਤੇ ਸਕੀਮਾ ਵਿੱਚ ਉਹਨਾਂ ਨੂੰ ਠੀਕ ਕਰ ਸਕਦੇ ਹੋ।
ਬਾਹਰੀ APIs ਲਈ, ਡੁਅਲ ਸਪੋਰਟ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਮੁਸ਼ਕਿਲ-ਰਹਿਤ ਰਾਹ ਹੈ:
Content-Type ਅਤੇ Accept ਹੈਡਰ ਵਰਤੋ।/v2/...)।ਇਸ ਦੌਰਾਨ, ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਦੋਹਾਂ ਫਾਰਮੈਟ ਇੱਕੋ ਸਰੋਤ-ਅਸਲ ਮਾਡਲ ਤੋਂ ਤਿਆਰ ਕੀਤੇ ਜਾ ਰਹੇ ਹਨ ਤਾਂ ਕਿ ਛੋਟਾ-ਜਿਹਾ ਡ੍ਰਿਫਟ ਨਾ ਪੈਦਾ ਹੋਵੇ।
ਯੋਜਨਾ ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰੋ:
.proto ਫਾਈਲਾਂ, ਫੀਲਡ ਟਿੱਪਣੀਆਂ ਅਤੇ Concrete request/response ਉਦਾਹਰਣ (JSON ਅਤੇ Protobuf ਦੋਹਾਂ) ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ ਤਾਂ ਕਿ ਉਪਭੋਗਤਾ ਯਕੀਨੀ ਬਣਾਉਣ ਸਕਣ ਕਿ ਉਹ ਡੇਟਾ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਸਮਝ ਰਹੇ ਹਨ। ਇੱਕ ਛੋਟਾ "ਮਾਈਗ੍ਰੇਸ਼ਨ ਗਾਈਡ" ਅਤੇ ਚੇਂਲੌਗ ਸਹਾਇਤਾ ਲੋਡ ਘਟਾਉਂਦਾ ਹੈ ਅਤੇ ਅਪਣਾਉਣ ਦਾ ਸਮਾਂ ਘਟਾਉਂਦਾ ਹੈ।
JSON ਅਤੇ Protobuf ਵਿਚੋਂ ਚੁਣਨ ਪਹਿਲਾਂ ਹੀ ਤੁਸੀਂ ਆਪਣੇ ਟ੍ਰੈਫਿਕ, ਕਲਾਇੰਟ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਸੀਮਾਵਾਂ ਨੂੰ ਨਾਪ ਲਵੋ। ਸਭ ਤੋਂ ਭਰੋਸੇਯੋਗ ਰਸਤਾ ਹੈ ਮਾਪੋ, ਫੈਸਲੇ ਦੀ ਦਸਤਾਵੇਜ਼ੀ ਕਰੋ, ਅਤੇ API ਬਦਲਾਅ ਨਿਰਾਕਾਰਕ ਬਣਾਓ।
ਇੱਕ ਛੋਟਾ ਪ੍ਰਯੋਗ ਚਲਾਓ ਪ੍ਰਤਿਨਿਧੀ ਏਂਡਪੋਇੰਟਾਂ 'ਤੇ।
ਟ੍ਰੈਕ ਕਰੋ:
ਇਹ staging ਵਿੱਚ production-ਸ਼ੈਲੀ ਡੇਟਾ ਨਾਲ ਕਰੋ, ਫਿਰ production ਵਿੱਚ ਛੋਟੇ ਟ੍ਰੈਫਿਕ ਸਲਾਈਸ 'ਤੇ ਵੈਰੀਫਾਈ ਕਰੋ।
ਚਾਹੇ ਤੁਸੀਂ JSON Schema/OpenAPI ਜਾਂ .proto ਫਾਈਲਾਂ ਵਰਤੋ:
ਭਾਵੇਂ ਤੁਸੀਂ ਪ੍ਰਦਰਸ਼ਨ ਲਈ Protobuf ਚੁਣੋ, ਆਪਣੇ ਡੌਕਸ ਨੂੰ ਦੋਸਤਾਨਾ ਰੱਖੋ:
ਜੇ ਤੁਸੀਂ ਡੌਕਸ ਜਾਂ SDK ਗਾਈਡ ਰੱਖਦੇ ਹੋ ਤਾਂ ਉਹਨਾਂ ਨੂੰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਦਰਸਾਓ (ਉਦਾਹਰਣ: /docs ਅਤੇ /blog)। ਜੇ ਕੀਮਤ ਜਾਂ ਉਪਯੋਗਤਾ ਸੀਮਾਵਾਂ ਫਾਰਮੈਟ ਚੋਣ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀਆਂ ਹਨ, ਤਾਂ ਉਹ ਵੀ ਦਰਸਾਓ (/pricing)।
JSON ਇੱਕ ਟੈਕਸਟ-ਆਧਾਰਤ ਫਾਰਮੈਟ ਹੈ ਜੋ ਆਸਾਨੀ ਨਾਲ ਪੜ੍ਹਿਆ, ਲੌਗ ਕੀਤਾ ਅਤੇ ਆਮ ਟੂਲਾਂ ਨਾਲ ਟੈਸਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। Protobuf ਇੱਕ ਕੁੰਪੈਕਟ ਬਾਈਨਰੀ ਫਾਰਮੈਟ ਹੈ ਜੋ .proto ਸਕੀਮਾ ਨਾਲ ਪਰਿਭਾਸ਼ਿਤ ਹੁੰਦਾ ਹੈ ਅਤੇ ਅਕਸਰ ਛੋਟੇ ਪੇਲੋਡ ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਪਾਰਸ ਕਰਨ ਦੇ ਨਤੀਜੇ ਦੇਂਦਾ ਹੈ।
ਚੁਣੋ ਤੁਹਾਡੇ ਬੰਧਨਾਂ ਤੇ ਆਧਾਰਿਤ: ਪਹੁੰਚ ਅਤੇ ਡੀਬੱਗਬਿਲਿਟੀ (JSON) ਵਿਰੁੱਧ ਕੁਸ਼ਲਤਾ ਅਤੇ ਕੜੇ ਕਾਂਟ੍ਰੈਕਟ (Protobuf).
APIs ਬਾਈਟਸ ਭੇਜਦੇ ਹਨ, ਇਨ-ਮੇਮੋਰੀ ਆਬਜੈਕਟ ਨਹੀਂ। ਸਿਰਿਆਲਾਈਜ਼ੇਸ਼ਨ ਤੁਹਾਡੇ ਸਰਵਰ ਆਬਜੈਕਟਾਂ ਨੂੰ ਟ੍ਰਾਂਸਪੋਰਟ ਲਈ ਪੇਲੋਡ (JSON ਟੈਕਸਟ ਜਾਂ Protobuf ਬਾਈਨਰੀ) ਵਿੱਚ ਐਨਕੋਡ ਕਰਦਾ ਹੈ; ਡੀਸਿਰਿਆਲਾਈਜ਼ੇਸ਼ਨ ਉਹ ਬਾਈਟਸ ਵਾਪਸ ਕਲਾਇੰਟ/ਸਰਵਰ ਆਬਜੈਕਟਾਂ ਵਿੱਚ ਡਿਕੋਡ ਕਰਦਾ ਹੈ।
ਤੁਹਾਡਾ ਫਾਰਮੈਟ ਚੋਣ ਬੈਂਡਵਿਡਥ, ਲੇਟੈਂਸੀ ਅਤੇ ਐਨਕੋਡ/ਡਿਕੋਡ ਕਰਨ ਵਿੱਚ ਲੱਗਣ ਵਾਲੇ CPU ਸਮੇਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ।
ਅਕਸਰ ਹਾਂ, ਖਾਸ ਕਰਕੇ ਵੱਡੇ ਜਾਂ ਨੈਸਟਡ ਆਬਜੈਕਟਾਂ ਅਤੇ ਰੀਪੀਟ ਕੀਤੀਆਂ ਫੀਲਡਾਂ ਲਈ, ਕਿਉਂਕਿ Protobuf ਨੰਬਰਾਤਮਕ ਟੈਗ ਅਤੇ ਕੁਸ਼ਲ ਬਾਈਨਰੀ ਐਨਕੋਡਿੰਗ ਵਰਤਦਾ ਹੈ।
ਪਰ ਜੇ ਤੁਸੀਂ gzip ਜਾਂ brotli ਜਿਵੇਂ ਕੰਪ੍ਰੈਸ਼ਨ ਚਲਾਓਗੇ ਤਾਂ JSON ਦੀਆਂ ਦੁਹਰਾਈਆਂ ਕੁੰਜੀਆਂ ਵਧੀਆ ਤਰ੍ਹਾਂ ਕੰਪ੍ਰੈੱਸ ਹੁੰਦੀਆਂ ਹਨ, ਇਸ ਲਈ ਅਸਲ-ਦੁਨੀਆਂ ਦੇ ਆਕਾਰ ਦਾ ਫ਼ਰਕ ਘੱਟ ਹੋ ਸਕਦਾ ਹੈ। ਕੱਢ ਕੇ ਕੱਚੇ ਅਤੇ ਕੰਪ੍ਰੈੱਸ ਕੀਤੇ ਆਕਾਰ ਦੋਹਾਂ ਮਾਪੋ।
ਇਹ ਹੋ ਸਕਦਾ ਹੈ। JSON ਪਾਰਸਰਾਂ ਨੂੰ ਟੈਕਸਟ ਟੋਕਨਾਈਜ਼, ਐਸਕੇਪਿੰਗ/ਯੂਨੀਕੋਡ ਹੈਂਡਲਿੰਗ ਅਤੇ ਸਤਰਾਂ ਨੂੰ ਨੰਬਰਾਂ ਵਿੱਚ ਬਦਲਣ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। Protobuf ਡਿਕੋਡਿੰਗ ਜ਼ਿਆਦਾ ਸਿੱਧਾ ਹੁੰਦੀ ਹੈ (ਟੈਗ → ਟਾਈਪ ਕੀਤੀ ਕੀਮਤ), ਜਿਸ ਨਾਲ ਅਕਸਰ CPU ਸਮਾਂ ਅਤੇ ਬਣ ਰਹੀ ਗਾਰਬੇਜ਼ ਘਟਦੀ ਹੈ।
ਫਿਰ ਵੀ, ਜੇ ਪੇਲੋਡ ਬਹੁਤ ਛੋਟੇ ਹਨ ਤਾਂ ਲੇਟੈਂਸੀ 'ਤੇ TLS, ਨੈੱਟਵਰਕ RTT ਅਤੇ ਐਪਲੀਕੇਸ਼ਨ ਕੰਮ ਜ਼ਿਆਦਾ ਪ੍ਰਭਾਵਿਤ ਕਰ ਸਕਦੇ ਹਨ।
ਇਹ ਮੂਲ ਤੌਰ 'ਤੇ ਕਿੱਤੇ ਉਤੇ ਮੁਸ਼ਕਲ ਹੈ। JSON ਮਨੁੱਖ-ਪੜ੍ਹਨਯੋਗ ਹੈ ਅਤੇ DevTools, ਲਾਗਜ਼, curl ਅਤੇ Postman ਵਿੱਚ ਆਸਾਨੀ ਨਾਲ ਵੇਖਿਆ ਜਾ ਸਕਦਾ ਹੈ। Protobuf ਡਿਫੌਲਟ ਤੌਰ 'ਤੇ ਬਾਈਨਰੀ ਹੁੰਦਾ ਹੈ, ਇਸ ਲਈ ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਮੇਲ ਖਾਣ ਵਾਲੀ .proto ਸਕੀਮਾ ਅਤੇ ਡਿਕੋਡਿੰਗ ਟੂਲ ਦੀ ਲੋੜ ਹੋਵੇਗੀ।
ਇੱਕ ਸੁਧਾਰਿਤ ਵਰਕਫਲੋ ਹੈ ਕਿ ਜਦੋਂ ਸੰਭਵ ਹੋਵੇ ਤਾਂ ਬਾਈਨਰੀ ਪੇਲੋਡ ਦੇ ਨਾਲ-ਨਾਲ ਇੱਕ ਡੀਕੋਡ ਕੀਤੀ ਹੋਈ, ਰੀਡੈਕਟ ਕੀਤੀ “ਡਿਬੱਗ ਵੀਵ” (ਅਕਸਰ JSON) ਲਾਗ ਕਰੋ।
JSON ਮੂਲ ਰੂਪ ਵਿੱਚ “ਸਕੀਮਾ-ਰਹਿਤ” ਹੈ: ਤੁਸੀਂ ਕਿਸੇ ਵੀ ਢਾਂਚੇ ਨੂੰ ਭੇਜ ਸਕਦੇ ਹੋ ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਕਲਾਇੰਟ ਇਸਨੂੰ ਠੀਕ ਸਮਝ ਲੈਂਦੇ ਹਨ। ਇਹ ਲਚਕੀਲਾਪਨ ਸ਼ੁਰੂਆਤ ਵਿੱਚ ਅਸਾਨ ਹੁੰਦਾ ਹੈ, ਪਰ ਗਲਤੀਆਂ ਲੁਕਾ ਸਕਦਾ ਹੈ (ਇਨਕਾਂਸਿਸਟੈਂਟ ਫੀਲਡਾਂ, stringly-typed ਡੇਟਾ, ਅਸਪਸ਼ਟ null ਵਰਤਾਰੇ)।
Protobuf .proto ਫਾਈਲ ਵਿੱਚ ਇੱਕ ਸਪਸ਼ਟ ਕਾਂਟ੍ਰੈਕਟ ਮੰਗਦਾ ਹੈ ਜੋ ਫੀਲਡਾਂ, ਟਾਇਪਾਂ ਅਤੇ ਵਾਇਰ 'ਤੇ ਹਰ ਫੀਲਡ ਦਾ ਨੰਬਰ ਦਰਸਾਂਦਾ ਹੈ। ਇਹ ਗਲਤੀਆਂ ਰੋਕਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ—ਜਿਵੇਂ ਕਿ ਨੰਬਰ ਸਦਾ ਨੰਬਰ ਰਹਿੰਦਾ ਹੈ, enums ਬਾਊਂਡ ਕੀਤੇ ਹਨ, ਅਤੇ timestamps ਲਈ ਅਕਸਰ ਆਮ ਟਾਈਪ ਵਰਤੇ ਜਾਂਦੇ ਹਨ।
Protobuf ਵਿੱਚ ਹਰ ਫੀਲਡ ਦੀ ਇੱਕ ਨੰਬਰਾਤਮਕ ਟੈਗ ਹੁੰਦੀ ਹੈ (ਜਿਵੇਂ email = 3)—ਉਹ ਨੰਬਰ ਵਾਇਰ 'ਤੇ ਜੇੜਾ ਆ ਰਹਾ ਹੈ। ਨਾਮ ਮਨੁੱਖਾਂ ਅਤੇ ਜਨਰੇਟ ਕੀਤੇ ਕੋਡ ਲਈ ਹਨ।
ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ ਬਦਲਾਅ: ਨਵੀਆਂ optional ਫੀਲਡਾਂ ਜੋੜੋ (ਨਵੇਂ ਨੰਬਰ), enums ਵਿੱਚ ਨਵੇਂ ਮੁੱਲ ਜੋੜੋ (ਉਪਯੋਗਤਾ ਅਨੁਸਾਰ), ਅਤੇ ਹਟਾਏ ਹੋਏ ਨੰਬਰ/ਨਾਂਵ ਨੂੰ reserved ਕਰੋ।
ਟੁਟੇ ਹੋਏ ਬਦਲਾਅ: ਇੱਕ ਹੀ ਨੰਬਰ ਨੂੰ ਵੱਖਰੇ ਅਰਥ/ਟਾਈਪ ਲਈ ਦੁਬਾਰਾ ਵਰਤਣਾ, ਅਸੰਗਤ ਟਾਈਪ ਬਦਲਣਾ (ਜਿਵੇਂ string → int), ਜਾਂ ਫੀਲਡ ਹਟਾ ਦੇਣਾ ਬਿਨਾਂ ਨੰਬਰ ਰਿਜ਼ਰਵ ਕੀਤੇ।
ਹਾਂ। ਸਮੱਗਰੀ ਨੈਗੋਸ਼ੀਏਸ਼ਨ ਵਰਤੋਂ:
Accept: application/json ਜਾਂ Accept: application/x-protobuf ਭੇਜੇ।Content-Type ਨਾਲ ਜਵਾਬ ਦੇਵੇ।Vary: Accept ਜੋੜੋ ਤਾਂ ਕਿ ਇੱਕ JSON ਜਵਾਬ ਪ੍ਰੋਟੋਬਫ ਕਲਾਇੰਟ ਨੂੰ ਨਾ ਚਲਿਆ ਜਾਵੇ।ਜੇ ਸਾਧਨਿਆਂ ਨਾਲ ਨੈਗੋਸ਼ੀਏਸ਼ਨ ਮੁਸ਼ਕਲ ਹੋਵੇ ਤਾਂ ਅਲੱਗ endpoint (ਉਦਾਹਰਣ ਵੱਜੋਂ ) ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਵਰਤੀ ਜਾ ਸਕਦੀ ਹੈ।
ਇਹ ਤੁਹਾਡੇ ਵਾਤਾਵਰਨ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ:
Protobuf ਚੁਣਦਿਆਂ shared ਪੈਕੇਜਾਂ ਦੀ ਰੱਖ-ਰਖਾਵ ਅਤੇ ਵਰਜਨ ਪਿਨਿੰਗ ਦੇ ਖ਼ਰਚੇ ਨੂੰ ਵੀ ਧਿਆਨ ਵਿੱਚ ਰੱਖੋ।
ਦੋਨੋਂ ਨੂੰ ਅਣ-ਭਰੋਸੇਮੰਦ ਇਨਪੁੱਟ ਵਜੋਂ ਹੀ ਰੱਖੋ। ਫਾਰਮੈਟ ਬਦਲਣ ਨਾਲ ਸੁਰੱਖਿਆ ਖੁਦ-ਬ-ਖੁਦ ਨਹੀਂ ਆਉਂਦੀ।
ਦੋਹਾਂ ਲਈ ਅਮਲਯੋਗ ਸੁਰੱਖਿਆ ਨਿਯਮ:
ਫੋਰਮੈਟ-ਵਿਸ਼ੇਸ਼ ਦੇਖਭਾਲ ਨਹੀਂ—ਸੁਰੱਖਿਆ ਉਸਤੋਂ ਆਉਂਦੀ ਹੈ ਕਿ ਤੁਸੀਂ ਸੀਮਾਵਾਂ, ਅੱਪਡੇਟ ਕੀਤੀਆਂ ਲਾਇਬ੍ਰੇਰੀਆਂ ਅਤੇ ਸਪਸ਼ਟ ਵੈਲਿਡੇਸ਼ਨ ਲਗਾਉਂਦੇ ਹੋ ਕਿ ਨਹੀਂ।
/v2/....proto