23 ਨਵੰ 2025·8 ਮਿੰਟ
ਫੀਡਬੈਕ ਇਕੱਤਰ ਕਰਨ ਅਤੇ ਸਰਵੇ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
UX, ਡੇਟਾ ਮਾਡਲ, ਐਨਾਲਿਟਿਕਸ ਅਤੇ ਪ੍ਰਾਈਵੇਸੀ ਤੱਕ—ਸਿੱਖੋ ਕਿ ਫੀਡਬੈਕ ਇਕੱਠਾ ਕਰਨ ਅਤੇ ਯੂਜ਼ਰ ਸਰਵੇ ਚਲਾਉਣ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਯੋਜਨਾ ਬਣਾਈਏ, ਬਣਾਈਏ ਅਤੇ ਲਾਂਚ ਕਰੀਏ।
UX, ਡੇਟਾ ਮਾਡਲ, ਐਨਾਲਿਟਿਕਸ ਅਤੇ ਪ੍ਰਾਈਵੇਸੀ ਤੱਕ—ਸਿੱਖੋ ਕਿ ਫੀਡਬੈਕ ਇਕੱਠਾ ਕਰਨ ਅਤੇ ਯੂਜ਼ਰ ਸਰਵੇ ਚਲਾਉਣ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਯੋਜਨਾ ਬਣਾਈਏ, ਬਣਾਈਏ ਅਤੇ ਲਾਂਚ ਕਰੀਏ।
ਕੋਡ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਕੀ ਬਣਾ ਰਹੇ ਹੋ। “ਫੀਡਬੈਕ” ਦਾ ਅਰਥ ਇੱਕ ਸਧਾਰਨ ਕਮੈਂਟ ਇਨਬਾਕਸ, ਇੱਕ ਸੰਰਚਿਤ ਸਰਵੇ ਟੂਲ, ਜਾਂ ਦੋਹਾਂ ਦਾ ਮਿਕਸ ਹੋ ਸਕਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਪਹਿਲੇ ਦਿਨ ਹੀ ਹਰ ਵਰਤੋਂ-ਮਾਮਲੇ ਨੂੰ ਕਵਰ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋਗੇ, ਤਾਂ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਜਟਿਲ ਉਤਪਾਦ ਆਏਗਾ ਜੋ ਸ਼ਿਪ ਕਰਨਾ ਔਖਾ ਹੋਵੇਗਾ—ਅਤੇ ਲੋਕਾਂ ਲਈ ਅਪਣਾਉਣਾ ਹੋਰ ਵੀ ਮੁਸ਼ਕਿਲ।
ਆਪਣੇ ਐਪ ਦਾ ਕੋਰ ਕੰਮ ਚੁਣੋ ਜੋ ਪਹਿਲੀ ਵਰਜ਼ਨ ਵਿੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
“ਦੋਹਾਂ” ਲਈ ਇੱਕ ਵਰਤਣਯੋਗ MVP ਹੈ: ਇੱਕ ਸਦਾ-ਉਪਲਬਧ ਫੀਡਬੈਕ ਫਾਰਮ + ਇੱਕ ਮੂਲ ਸਰਵੇ ਟੈਂਪਲੇਟ (NPS ਜਾਂ CSAT), ਦੋਹਾਂ ਨੂੰ ਇੱਕੋ ਜਵਾਬ ਲਿਸਟ ਵਿੱਚ ਫੀਡ ਕਰਦੇ ਹੋਏ।
ਸਫਲਤਾ ਹਫ਼ਤਿਆਂ ਵਿੱਚ ਦੇਖਣਯੋਗ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ, ਨਾ ਕਿ ਕਵਾਰਟਰਾਂ ਵਿੱਚ। ਇੱਕ ਛੋਟਾ ਸੈੱਟ ਮੈਟ੍ਰਿਕਸ ਚੁਣੋ ਅਤੇ ਬੇਸਲਾਈਨ ਟਾਰਗਟ ਸੈੱਟ ਕਰੋ:
ਜੇ ਤੁਸੀਂ ਹਰ ਮੈਟ੍ਰਿਕ ਲਈ ਕਿਵੇਂ ਗਣਨਾ ਕਰੋਗੇ ਸਮਝਾ ਨਹੀਂ ਸਕਦੇ, ਤਾਂ ਇਹ ਮੈਟ੍ਰਿਕ ਅਜੇ ਲਾਇਕ ਨਹੀਂ।
ਸਪੱਸ਼ਟ ਹੋਵੋ ਕਿ ਕੌਣ ਐਪ ਵਰਤੇਗਾ ਅਤੇ ਕਿਉਂ:
ਵੱਖ-ਵੱਖ ਦਰਸ਼ਕਾਂ ਨੂੰ ਵੱਖਰੇ ਟੋਨ, ਗੁਪਤਤਾ ਦੀ ਉਮੀਦ, ਅਤੇ follow-up ਵਰਕਫਲੋਜ਼ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਉਹ ਚੀਜ਼ਾਂ ਲਿਖੋ ਜੋ ਬਦਲੀ ਨਹੀਂ ਹੋ ਸਕਦੀਆਂ:
ਇਹ ਸਮੱਸਿਆ/MVP ਪਰਿਭਾਸ਼ਾ ਤੁਹਾਡਾ “ਸਕੋਪ ਕੰਟਰੈਕਟ” ਬਣ ਜਾਵੇਗੀ—ਅਤੇ ਇਹ ਤੁਹਾਨੂੰ ਬਾਅਦ ਵਿੱਚ ਦੁਬਾਰਾ ਬਣਾਉਣ ਤੋਂ ਬਚਾਏਗੀ।
ਸਕ੍ਰੀਨਾਂ ਡਿਜ਼ਾਈਨ ਕਰਨ ਜਾਂ ਫੀਚਰ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਐਪ ਕਿਸ ਲਈ ਹੈ ਅਤੇ ਹਰ ਵਿਅਕਤੀ ਲਈ “ਸਫਲਤਾ” ਕਿਵੇਂ ਲੱਗਦੀ ਹੈ। ਫੀਡਬੈਕ ਉਤਪਾਦ ਆਮ ਤੌਰ ਤੇ ਟੈਕਨੀਕਲ ਘਾਟਾਂ ਤੋਂ ਵੱਡੇ ਮਾਪ ਤੇ ਅਸਫਲ ਹੁੰਦੇ ਹਨ: ਹਰ ਕੋਈ ਸਰਵੇ ਬਣਾਉਂਦਾ ਹੈ, ਕੋਈ ਉਨ੍ਹਾਂ ਨੂੰ maintain ਨਹੀਂ ਕਰਦਾ, ਅਤੇ ਨਤੀਜੇ ਅਮਲ ਵਿੱਚ ਨਹੀਂ ਆਉਂਦੇ।
Admin workspace ਦਾ ਮਾਲਿਕ: billing, security, branding, user access, ਅਤੇ ਡੀਫੌਲਟ ਸੈਟਿੰਗਜ਼ (ਡੇਟਾ ਰੀਟੇਨਸ਼ਨ, domains allowed, consent text). ਉਹ ਨਿਯੰਤਰਣ ਅਤੇ consistency ਦੀ ਪਰਵਾਹ ਕਰਦਾ/ਕਰਦੀ ਹੈ।
Analyst (ਜਾਂ Product Manager) ਫੀਡਬੈਕ ਪ੍ਰੋਗਰਾਮ ਚਲਾਉਂਦਾ ਹੈ: ਸਰਵੇ ਬਣਾਉਂਦਾ, ਦਰਸ਼ਕ ਨਿਸ਼ਾਨਾ ਬਣਾਉਂਦਾ, response rate ਵੇਖਦਾ, ਅਤੇ ਨਤੀਜਿਆਂ ਨੂੰ ਫੈਸਲਿਆਂ ਵਿੱਚ ਬਦਲਦਾ ਹੈ। ਉਹ ਤੇਜ਼ੀ ਅਤੇ ਸਪਸ਼ਟਤਾ ਦੀ ਪਰਵਾਹ ਕਰਦਾ/ਕਰਦੀ ਹੈ।
End user / respondent ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦਿੰਦਾ ਹੈ। ਉਹ ਭਰੋਸਾ (ਮੈਨੂੰ ਕਿਉਂ ਪੁੱਛਿਆ ਜਾ ਰਿਹਾ ਹੈ?), ਕੋਸ਼ਿਸ਼ (ਇਹ ਕਿੰਨੀ ਲੰਬੀ ਹੈ?), ਅਤੇ ਨਿੱਜੀਅਤ ਦੀ ਪਰਵਾਹ ਕਰਦਾ/ਕਰਦੀ ਹੈ।
“ਹੈਪੀ ਪਾਥ” ਨੂੰ ਅੰਤ-ਤੱਕ ਨਕਸ਼ਾ ਕਰੋ:
ਭਾਵੇਂ ਤੁਸੀਂ “ਅਮਲ” ਫੀਚਰਾਂ ਨੂੰ ਪੋਸਟਪੋਨ ਕਰੋ, ਟੀਮਾਂ ਇਹ ਕਿਵੇਂ ਕਰਨਗੀਆਂ (ਜਿਵੇਂ CSV ਐਕਸਪੋਰਟ ਜਾਂ ਬਾਅਦ ਵਿੱਚ ਹੋਰ ਟੂਲ ਨੂੰ ਪੁਸ਼) ਦਸਤਾਵੇਜ਼ਿਤ ਕਰੋ। ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਇੱਕ ਸਿਸਟਮ ਨਾ ਭੇਜੋ ਜੋ ਸਿਰਫ ਡੇਟਾ ਇਕੱਠਾ ਕਰਦਾ ਹੈ ਪਰ ਫਾਲੋ-ਥਰੂ ਚਲਾਉਣ ਯੋਗ ਨਹੀਂ।
ਤੁਹਾਨੂੰ ਬਹੁਤ ਸਾਰੇ ਪੰਨੇ ਦੀ ਲੋੜ ਨਹੀਂ, ਪਰ ਹਰ ਇੱਕ ਨੂੰ ਇੱਕ ਸਪਸ਼ਟ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ:
ਇਹ ਯਾਤਰਾਵਾਂ ਸਪੱਸ਼ਟ ਹੋਣ ਤੋਂ ਬਾਅਦ ਫੀਚਰ ਫੈਸਲੇ ਆਸਾਨ ਹੋ ਜਾਂਦੇ ਹਨ—ਅਤੇ ਤੁਸੀਂ ਉਤਪਾਦ ਨੂੰ ਕੇਂਦ੍ਰਿਤ ਰੱਖ ਸਕਦੇ ਹੋ।
ਫੀਡਬੈਕ ਸੰਗ੍ਰਹਿ ਵੈੱਬ ਐਪ ਅਤੇ ਯੂਜ਼ਰ ਸਰਵੇ ਐਪਲੀਕੇਸ਼ਨ ਨੂੰ ਸਫਲ ਕਰਨ ਲਈ ਇੱਕ ਵਿਸਥਾਰ ਵਾਲੀ ਆਰਕੀਟੈਕਚਰ ਦੀ ਲੋੜ ਨਹੀਂ। ਤੁਹਾਡਾ ਪਹਿਲਾ ਲਕੜੀ ਇੱਕ ਭਰੋਸੇਯੋਗ ਸਰਵੇ ਬਿਲਡਰ ਸ਼ਿਪ ਕਰਨਾ, ਰਿਸਪਾਂਸ ਕੈਪਚਰ ਕਰਨਾ, ਅਤੇ ਨਤੀਜੇ ਆਸਾਨੀ ਨਾਲ ਰਿਵਿਊ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਣਾ ਹੈ—ਬਿਨਾਂ ਸੰਭਾਲ ਬੋਝ ਵਧਾਉਣ ਦੇ।
ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਲਈ, ਇੱਕ ਮੋਡੀਊਲਰ ਮੋਨੋਲਿਥ ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਸਭ ਤੋਂ ਸਧਾਰਨ ਥਾਂ ਹੈ: ਇੱਕ ਬੈਕਐਂਡ ਐਪ, ਇੱਕ ਡੇਟਾਬੇਸ, ਅਤੇ ਸਾਫ਼ ਅੰਦਰੂਨੀ ਮੋਡੀਊਲ (auth, surveys, responses, reporting)। ਤੁਸੀਂ ਹਾਲੇ ਵੀ ਹੱਦਾਂ ਸਾਫ਼ ਰੱਖ ਸਕਦੇ ਹੋ ਤਾਂ ਕਿ ਬਾਅਦ ਵਿੱਚ ਹਿੱਸਿਆਂ ਨੂੰ ਕੱਢਿਆ ਜਾ ਸਕੇ।
ਸਿਰਫ਼ ਜੇ ਕੋਈ ਮਜ਼ਬੂਤ ਕਾਰਨ ਹੋ—ਜਿਵੇਂ ਉੱਚ-ਮਾਤਰਾ ਵਾਲੀ ਈਮੇਲ ਭੇਜਣ, ਭਾਰੀ ਐਨਾਲਿਟਿਕਸ ਲੋਡ, ਜਾਂ ਸਖ਼ਤ ਵੱਖ-ਵੱਖ ਕਰਨ ਦੀ ਲੋੜ—ਤਦ ਹੀ ਸਧਾਰਨ ਸੇਵਾਵਾਂ ਚੁਣੋ। ਨਹੀਂ ਤਾਂ, ਮਾਈਕ੍ਰੋਸਰਵਿਸਜ਼ ਡੁਪਲੀਕੇਟ ਕੋਡ, ਜਟਿਲ ਡਿਪਲੋਇਮੈਂਟ, ਅਤੇ ਮੁਸ਼ਕਿਲ ਡਿਬੱਗਿੰਗ ਨਾਲ ਤੁਸੀਂ ਢੀਲੇ ਹੋ ਸਕਦੇ ਹੋ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਸਮਝੌਤਾ: ਮੋਨੋਲਿਥ + ਕੁਝ managed add-ons, ਜਿਵੇਂ background jobs ਲਈ queue ਅਤੇ ਐਕਸਪੋਰਟ ਲਈ object store।
ਫਰੰਟਏਂਡ 'ਤੇ, React ਅਤੇ Vue ਦੋਹਾਂ ਸਰਵੇ ਬਿਲਡਰ ਲਈ ਵਧੀਆ ਹਨ ਕਿਉਂਕਿ ਇਹ ਡਾਇਆਨਾਮਿਕ ਫਾਰਮਾਂ ਨੂੰ ਚੰਗਾ ਸੰਭਾਲਦੇ ਹਨ।
ਬੈਕਐਂਡ 'ਤੇ, ਉਹ ਚੁਣੋ ਜਿਸ ਵਿੱਚ ਤੁਹਾਡੀ ਟੀਮ ਤੇਜ਼ੀ ਨਾਲ ਹਿਲ ਸਕੇ:
ਜੋ ਵੀ ਚੁਣੋ, APIs ਨੂੰ ਪੇਸ਼ਗੋਈਯੋਗ ਰੱਖੋ। ਤੁਹਾਡੇ ਸਰਵੇ ਬਿਲਡਰ ਅਤੇ ਰਿਸਪਾਂਸ UI ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਵਿਕਸਤ ਹੋਣ ਵਿੱਚ endpoints ਦਾ ਲਗਾਤਾਰ ਅਤੇ ਸਿੱਧਾ ਹੋਣਾ ਮਦਦਗਾਰ ਹੋਵੇਗਾ।
ਜੇ ਤੁਸੀਂ “ਪਹਿਲਾ ਵਰਕਿੰਗ ਵਰਜ਼ਨ” ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰਾਪਤ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ ਬਿਨਾਂ ਮਹੀਨਿਆਂ ਦਾ scaffolding ਕਰਨ ਦੇ, ਤਾਂ Koder.ai ਵਰਗਾ vibe-coding ਪਲੇਟਫਾਰਮ ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਸ਼ੁਰੂਆਤ ਹੋ ਸਕਦਾ ਹੈ: ਤੁਸੀਂ ਚੈਟ ਰਾਹੀਂ React ਫਰੰਟਏਂਡ ਨਾਲ Go ਬੈਕਐਂਡ ਅਤੇ PostgreSQL ਨੂੰ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹੋ, ਫਿਰ ਜਦੋਂ ਤਿਆਰ ਹੋਵੋ ਤਾੰ ਸਰੋਤ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰ ਲਵੋ।
ਸਰਵੇਜ਼ "ਡਾਕਯੂਮੈਂਟ-ਨੁਮਾ" ਲੱਗਦੇ ਹਨ, ਪਰ ਜਿਆਦਾਤਰ ਉਤਪਾਦ ਫੀਡਬੈਕ ਵਰਕਫਲੋ ਦੀਆਂ ਲੋੜਾਂ ਰਿਲੇਸ਼ਨਲ ਹੁੰਦੀਆਂ ਹਨ:
ਇੱਕ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਜਿਵੇਂ PostgreSQL ਅਕਸਰ ਫੀਡਬੈਕ ਡੇਟਾਬੇਸ ਲਈ ਸਹੀ ਚੋਣ ਹੈ ਕਿਉਂਕਿ ਇਹ constraints, joins, reporting queries, ਅਤੇ ਭਵਿਖੀ ਐਨਾਲਿਟਿਕਸ ਬਿਨਾਂ ਵਿੱਤ-ਵਰਕਾਰ ਦੇ ਸਹਾਇਕ ਹੈ।
ਸੰਭਵ ਹੋਵੇ ਤਾਂ ਸ਼ੁਰੂ ਵਿੱਚ ਇੱਕ managed platform ਵਰਤੋ (ਉਦਾਹਰਨ ਲਈ, ਐਪ ਲਈ PaaS ਅਤੇ managed Postgres)। ਇਸ ਨਾਲ ops ਬੋਝ ਘਟਦਾ ਹੈ ਅਤੇ ਟੀਮ ਫੀਚਰਾਂ 'ਤੇ ਧਿਆਨ ਰੱਖ ਸਕਦੀ ਹੈ।
ਆਮ ਖਰਚੇ ਤੈ ਕਰਨ ਵਾਲੇ ਅੰਗ:
ਜਦੋਂ ਤੁਸੀਂ ਵਧਦੇ ਹੋ, ਤੁਸੀਂ ਪੀਸਿਆਂ ਨੂੰ ਬਦਲ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਸਭ ਕੁਝ ਦੁਬਾਰਾ ਲਿਖੇ—ਜੇ ਤੁਸੀਂ ਸ਼ੁਰੂ ਤੋਂ ਆਰਕੀਟੈਕਚਰ ਸਧਾਰਨ ਅਤੇ ਮੋਡੀਊਲਰ ਰੱਖਦੇ ਹੋ।
ਅੱਛਾ ਡੇਟਾ ਮਾਡਲ ਹੋਰ ਸਾਰੀਆਂ ਚੀਜ਼ਾਂ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ: ਸਰਵੇ ਬਿਲਡਰ ਬਣਾਉਣਾ, ਨਤੀਜਿਆਂ ਨੂੰ ਸਮਰਥਿਤ ਰੱਖਣਾ, ਅਤੇ ਭਰੋਸੇਯੋਗ ਐਨਾਲਿਟਿਕਸ ਤਿਆਰ ਕਰਨਾ। ਇੱਕ ਐਸਾ ਢਾਂਚਾ ਲਕੜੀ-ਸਪੱਸ਼ਟ ਰੱਖੋ ਜੋ ਕੁਇਰੀ ਕਰਨ ਲਈ ਸੌਖਾ ਅਤੇ ਅਕਸਮਾਤ ਤੌਰ 'ਤੇ ਖਰਾਬ ਕਰਨਾ ਮੁਸ਼ਕਿਲ ਹੋਵੇ।
ਜ਼ਿਆਦਾਤਰ ਫੀਡਬੈਕ ਸੰਗ੍ਰਹਿ ਵੈੱਬ ਐਪ ਇਸ ਛੇ ਕੁੰਜੀ ਇਕਾਈਆਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰ ਸਕਦਾ ਹੈ:
ਇਹ ਢਾਂਚਾ ਉਤਪਾਦ ਫੀਡਬੈਕ ਵਰਕਫਲੋ ਨਾਲ ਸਾਫ਼ ਨਕਸ਼ਾ ਬਣਾਉਂਦਾ ਹੈ: ਟੀਮਾਂ ਸਰਵੇ ਬਣਾਉਂਦੀਆਂ ਹਨ, ਰਿਸਪਾਂਸ ਇਕੱਠੇ ਕਰਦੀਆਂ ਹਨ, ਫਿਰ Answers ਦੀ ਵਿਸ਼ਲੇਸ਼ਣਾ ਕਰਦੀਆਂ ਹਨ।
ਸਰਵੇ ਵਿਕਸਤ ਹੁੰਦੇ ਹਨ। ਕੋਈ ਵਾਕ-ਸੰਸ਼ੋਧਨ ਕਰੇਗਾ, ਪ੍ਰਸ਼ਨ ਜੋੜੇ ਜਾਣਗੇ, ਜਾਂ ਵਿਕਲਪ ਬਦਲੇ ਜਾਣਗੇ। ਜੇ ਤੁਸੀਂ ਪ੍ਰਸ਼ਨਾਂ ਨੂੰ ਥਾਂ 'ਤੇ ਓਵਰਰਾਇਟ ਕਰ ਦਿਓਗੇ, ਤਾਂ ਪੁਰਾਣੇ ਜਵਾਬ ਗੁੰਝਲਦਾਰ ਜਾਂ ਅਣਪੜੇ ਹੋ ਸਕਦੇ ਹਨ।
ਵਰਜ਼ਨਿੰਗ ਵਰਤੋ:
ਇਸ ਤਰ੍ਹਾਂ, ਸਰਵੇ ਸੰਪਾਦਨ ਇੱਕ ਨਵੀਂ ਵਰਜ਼ਨ ਬਣਾਉਂਦਾ ਹੈ ਜਦੋਂ ਕਿ ਪੁਰਾਣੇ ਨਤੀਜੇ ਅਖੰਡ ਰਹਿੰਦੇ ਹਨ।
ਪ੍ਰਸ਼ਨ ਟਾਈਪ ਆਮ ਤੌਰ 'ਤੇ ਟੈਕਸਟ, ਸਕੇਲ/ਰੇਟਿੰਗ, ਅਤੇ ਮਲਟੀਪਲ ਚੌਇਸ ਸ਼ਾਮਿਲ ਹੁੰਦੇ ਹਨ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਪਹੁੰਚ:
type, title, required, position ਸਟੋਰ ਕਰਦਾ ਹੈquestion_id ਅਤੇ ਇੱਕ ਲਚਕੀਲਾ value ਸਟੋਰ ਕਰਦਾ ਹੈ (ਜੈਸੇ text_value, number_value, ਨਾਲ option_id ਚੋਣਾਂ ਲਈ)ਇਸ ਨਾਲ ਰਿਪੋਰਟਿੰਗ ਸਿੱਧੀ ਰਹਿੰਦੀ ਹੈ (ਜਿਵੇਂ scales ਦੀਆਂ averages, options ਪ੍ਰਤੀ counts)।
ਜਲਦੀ ਹੀ ਪਹਚਾਨ ਯੋਜਨਾ ਬਣਾਓ:
created_at, published_at, submitted_at, ਅਤੇ archived_at ਵਰਗੇ timestamps ਸ਼ਾਮਿਲ ਕਰੋ।channel (in-app/email/link), locale, ਅਤੇ ਵਿਕਲਪਤ external_user_id (ਜੇ ਤੁਸੀਂ ਰਿਸਪਾਂਸ ਨੂੰ ਆਪਣੇ ਉਤਪਾਦ ਯੂਜ਼ਰ ਨਾਲ ਜੋੜਨਾ ਚਾਹੁੰਦੇ ਹੋ)।ਇਹ ਬੁਨਿਆਦੀ ਚੀਜ਼ਾਂ ਤੁਹਾਡੀ ਸਰਵੇ ਐਨਾਲਿਟਿਕਸ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੀਆਂ ਹਨ ਅਤੇ ਆਡੀਟਸ ਨੂੰ ਆਸਾਨ ਕਰਦੀਆਂ ਹਨ।
ਇਕ ਫੀਡਬੈਕ ਸੰਗ੍ਰਹਿ ਵੈੱਬ ਐਪ ਆਪਣੀ UI 'ਤੇ ਟਿਕਦਾ ਜਾਂ ਡਿੱਠਾ ਹੁੰਦਾ ਹੈ: ਐਡਮਿਨਜ਼ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਸਰਵੇ ਬਣਾਉਣੇ ਚਾਹੀਦੇ ਹਨ, ਅਤੇ respondents ਨੂੰ ਇੱਕਦਾ, ਬਿਨਾ ਵਿਘਨ ਵਾਲਾ ਫਲੋ ਚਾਹੀਦਾ ਹੈ। ਇਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਤੁਹਾਡਾ ਯੂਜ਼ਰ ਸਰਵੇ ਐਪ “ਅਸਲ” ਮਹਿਸੂਸ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ।
ਇੱਕ ਸਧਾਰਨ ਸਰਵੇ ਬਿਲਡਰ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਪ੍ਰਸ਼ਨ ਸੂਚੀ ਦਾ ਸਮਰਥਨ ਕਰੇ:
ਜੇ ਤੁਸੀਂ branching ਜੋੜਦੇ ਹੋ, ਤਾਂ ਇਸਨੂੰ ਵਿਕਲਪਿਕ ਅਤੇ ਘੱਟ ਰੱਖੋ: “ਜੇ ਜਵਾਬ X → ਪ੍ਰਸ਼ਨ Y ਤੇ ਜਾਓ” ਦੀ ਆਗਿਆ ਦਿਓ। ਇਸਨੂੰ ਆਪਣੇ ਫੀਡਬੈਕ ਡੇਟਾਬੇਸ ਵਿੱਚ ਪ੍ਰਸ਼ਨ ਵਿਕਲਪ ਨਾਲ ਜੁੜੀ ਇੱਕ ਨਿਯਮ ਵਜੋਂ ਸਟੋਰ ਕਰੋ। ਜੇ branching v1 ਲਈ ਜੋਖ਼ਮਦਾਰ ਲੱਗੇ ਤਾਂ ਉਹ ਬਿਨਾਂ ਸ਼ਿਪ ਕਰੋ ਅਤੇ ਡੇਟਾ ਮਾਡਲ ਤਿਆਰ ਰੱਖੋ।
ਰਿਸਪਾਂਸ UI ਨੂੰ ਤੇਜ਼ ਲੋਡ ਅਤੇ ਫੋਨ 'ਤੇ ਚੰਗਾ ਮਹਿਸੂਸ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ:
ਭਾਰੀ client-side ਲੌਜਿਕ ਤੋਂ ਬਚੋ। ਸਰਲ ਫਾਰਮ ਰੈਂਡਰ ਕਰੋ, required answers ਨੂੰ validate ਕਰੋ, ਅਤੇ ਛੋਟੇ payloads ਵਿੱਚ responses submit ਕਰੋ।
ਆਪਣੀ in-app feedback widget ਅਤੇ ਸਰਵੇ ਪੰਨਾਂ ਨੂੰ ਸਭ ਲਈ ਵਰਤਣਯੋਗ ਬਣਾਓ:
ਪਬਲਿਕ ਲਿੰਕ ਅਤੇ ਈਮੇਲ ਨਿ�ਮੰਤਰਨ ਸਪੈਮ ਆਕਰਸ਼ਿਤ ਕਰਦੇ ਹਨ। ਹਲਕੇ-ਫੁਲਕੇ ਸੁਰੱਖਿਆ ਉਪਾਅ ਜੋੜੋ:
ਇਹ ਕੰਬੀਨੇਸ਼ਨ ਸਰਵੇ ਐਨਾਲਿਟਿਕਸ ਸਾਫ਼ ਰੱਖਦੀ ਹੈ ਬਿਨਾਂ ਵਾਸਤਵੀ respondents ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਣ ਦੇ।
ਚੈਨਲ ਉਹ ਢੰਗ ਹਨ ਜਿਸ ਨਾਲ ਤੁਹਾਡਾ ਸਰਵੇ ਲੋਕਾਂ ਤੱਕ ਪਹੁੰਚਦਾ ਹੈ। ਸਭ ਤੋਂ ਵਧੀਆ ਐਪ ਘੱਟੋ-ਘੱਟ ਤਿੰਨ ਦਾ ਸਮਰਥਨ ਕਰਦੇ ਹਨ: in-app ਵਿਜਟ ਐਕਟਿਵ ਯੂਜ਼ਰਾਂ ਲਈ, ਨਿਯਤ ਲੋਕਾਂ ਲਈ ਈਮੇਲ ਨਿਮੰਤਰਨ, ਅਤੇ ਵਿਆਪਕ ਵੰਡ ਲਈ ਸ਼ੇਅਰ ਕਰਨ ਲਾਇਕ ਲਿੰਕ। ਹਰ ਚੈਨਲ ਦੇ ਵੱਖਰੇ ਟਰੇਡ-ਆਫ़ ਹਨ response rate, ਡੇਟਾ ਗੁਣਵੱਤਾ, ਅਤੇ ਦੁਰੁਪਯੋਗ ਦੇ ਜੋਖ਼ਮ ਵਿੱਚ।
ਵਿਜਟ ਨੂੰ ਲੱਭਣਾ ਆਸਾਨ ਪਰ ਪਰੇਸ਼ਾਨ ਨਾ ਕਰਨ ਵਾਲਾ ਰੱਖੋ। ਆਮ ਥਾਂ ਬੋਤਮ ਕੋਨੇ 'ਚ ਛੋਟਾ ਬਟਨ, ਪਾਸੇ ਇਕ ਟੈਬ, ਜਾਂ ਕਿਸੇ ਨਿਰਦਿਸ਼ਟ ਕ੍ਰਿਆ ਤੋਂ ਬਾਅਦ ਉੱਠਦਾ modal ਹੁੰਦਾ ਹੈ।
Triggers ਨਿਯਮ-ਆਧਾਰਿਤ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ ਤਾਂ ਕਿ ਤੁਸੀਂ ਸਿਰਫ਼ ਉਹਨਾਂ ਵੇਲੇ ਪ੍ਰਦੱਖਸ਼ੀ ਕਰੋ ਜਦੋਂ ਮਤਲਬੀ ਹੋਵੇ:
ਫ੍ਰਿਕਵੈਂਸੀ ਸੀਮਾਵਾਂ ਜੋੜੋ (ਜਿਵੇਂ “ਇੱਕ ਹਫ਼ਤੇ ਵਿੱਚ ਵੱਧ ਤੋਂ ਵੱਧ ਇੱਕ ਵਾਰ ਪ੍ਰਦਰਸ਼ਿਤ”) ਅਤੇ ਇੱਕ ਸਪਸ਼ਟ “ਫਿਰ ਨਾ ਦਿਖਾਓ” ਵਿਕਲਪ।
ਈਮੇਲ ਟਰਾਂਜ਼ੈਕਸ਼ਨਲ ਪਲਾਹ ਵਿਚਕਾਰ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦੀ ਹੈ (ਟ੍ਰਾਇਲ ਖਤਮ ਹੋਣ ਤੋਂ ਬਾਅਦ) ਜਾਂ ਨਮੂਨਾ ਲੈਣ ਲਈ (ਹਰ ਹਫ਼ਤੇ N ਯੂਜ਼ਰ)। ਸਾਂਝੇ ਲਿੰਕ ਤੋਂ ਬਚਣ ਲਈ single-use tokens ਬਣਾਓ ਜੋ ਪ੍ਰਾਪਤ ਕਰਨ ਵਾਲੇ ਅਤੇ ਸਰਵੇ ਨਾਲ ਜੋੜੇ ਹੁੰਦੇ ਹਨ।
ਸਿਫਾਰਿਸ਼ ਕੀਤੇ ਨਿਯਮ:
ਪਬਲਿਕ ਲਿੰਕ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਲਈ ਵਰਤੋ ਜਿੱਥੇ ਤੁਸੀਂ ਪਹੁੰਚ ਚਾਹੁੰਦੇ ਹੋ: marketing NPS, event feedback, ਜਾਂ community surveys। spam ਨਿਯੰਤਰਣ ਦੀ ਯੋਜਨਾ ਬਣਾਓ (rate limiting, CAPTCHA, ਵਿਕਲਪਿਕ email verification)।
Authenticated surveys ਉਹਨਾਂ ਵੇਖੋ ਜਿੱਥੇ ਜਵਾਬਾਂ ਨੂੰ ਇੱਕ ਅਕਾਉਂਟ ਜਾਂ ਭੂਮਿਕਾ ਨਾਲ ਜੋੜਨਾ ਲਾਜ਼ਮੀ ਹੁੰਦਾ ਹੈ: customer support CSAT, ਅੰਦਰੂਨੀ ਕਰਮਚਾਰੀ ਫੀਡਬੈਕ, ਜਾਂ ਵਰਕਸਪੇਸ-ਸਤ੍ਹਰ ਉਤਪਾਦ ਫੀਡਬੈਕ ਵਰਕਫਲੋ।
Reminders responses ਵਧਾ ਸਕਦੇ ਹਨ, ਪਰ ਸਿਰਫ਼ guardrails ਨਾਲ:
ਇਹ ਬੁਨਿਆਦੀ ਨਿਯਮ ਤੁਹਾਡੇ ਫੀਡਬੈਕ ਸੰਗ੍ਰਹਿ ਵੈੱਬ ਐਪ ਨੂੰ ਸੋਚ-ਵਿਚਾਰ ਵਾਲਾ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦੇ ਹਨ ਅਤੇ ਤੁਹਾਡੇ ਡੇਟਾ ਨੂੰ ਭਰੋਸੇਯੋਗ ਰੱਖਦੇ ਹਨ।
Authentication ਅਤੇ authorization ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਫੀਡਬੈਕ ਸੰਗ੍ਰਹਿ ਵੈੱਬ ਐਪ ਆਹਿਸਤਾਂ-ਆਹਿਸਤਾਂ ਗਲਤ ਹੋ ਸਕਦਾ ਹੈ: ਉਤਪਾਦ ਕੰਮ ਕਰਦਾ ਹੈ, ਪਰ ਗਲਤ ਵਿਅਕਤੀ ਗਲਤ ਸਰਵੇ ਨਤੀਜੇ ਵੇਖ ਲੈਂਦਾ ਹੈ। identity ਅਤੇ tenant boundaries ਨੂੰ ਮੂਲ ਫੀਚਰ ਸਮਝੋ, ਨਾ ਕਿ ਐਡ-ਆਨ।
MVP ਲਈ email/password ਆਮ ਤੌਰ 'ਤੇ کافی ਹੁੰਦਾ ਹੈ—ਇਲਾਜ ਕਰਨ ਵਿੱਚ ਤੇਜ਼ ਅਤੇ ਸਹਿਜ।
ਜੇ ਤੁਸੀਂ ਬਿਨਾ enterprise complexity ਦੇ smoother sign-in ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ magic links (passwordless) ਬਾਰੇ ਸੋਚੋ। ਇਹ ਭੁੱਲੇ-ਪਾਸਵਰਡ ਟਿਕਟਾਂ ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ, ਪਰ ਚੰਗੀ email deliverability ਅਤੇ link-expiry ਸੰਭਾਲ ਲੋੜੀਂਦੀ ਹੈ।
SSO (SAML/OIDC) ਨੂੰ ਬਾਅਦ ਦੀ ਅਪਗਰੇਡ ਵਜੋਂ ਯੋਜਨਾ ਬਣਾਓ। ਮੁੱਖ ਗੱਲ ਤੁਹਾਡੇ ਯੂਜ਼ਰ ਮਾਡਲ ਨੂੰ ਇਉਂ ਡਿਜ਼ਾਈਨ ਕਰਨਾ ਹੈ ਤਾੰ ਜੋ SSO ਜੋੜਨ ਨਾਲ ਰੀਰਾਈਟ ਦੀ ਲੋੜ ਨਾ ਪਵੇ (ਜਿਵੇਂ, ਇੱਕ ਯੂਜ਼ਰ ਲਈ ਕਈ “identities” ਦਾ ਸਮਰਥਨ)।
ਸਰਵੇ ਬਿਲਡਰ ਲਈ ਸਪਸ਼ਟ, ਪੇਸ਼ਗੋਈਯੋਗ ਐਕਸੈਸ ਦੀ ਲੋੜ:
ਪਰਮਿਸ਼ਨਾਂ ਨੂੰ UI ਵਿੱਚ ਨਹੀਂ ਕੇਵਲ, ਬਲਕਿ ਕੋਡ ਵਿੱਚ (ਹਰ read/write ਦੇ ਆਲੇ-ਦੁਆਲੇ policy checks) explicit ਰੱਖੋ।
Workspaces ਏਜੰਸੀ, ਟੀਮਾਂ, ਜਾਂ ਉਤਪਾਦਾਂ ਨੂੰ ਇੱਕੋ ਪਲੇਟਫਾਰਮ ਤੇ ਸਾਂਝਾ ਕਰਨ ਦਿੰਦੀਆਂ ਹਨ ਪਰ ਡੇਟਾ ਨੂੰ ਅਲੱਗ ਰੱਖਦੀਆਂ ਹਨ। ਹਰ ਸਰਵੇ, ਰਿਸਪਾਂਸ, ਅਤੇ integration ਰਿਕਾਰਡ workspace_id ਧਾਰਨ ਕਰੇ—ਤੇ ਹਰ query ਇਸ ਨਾਲ scope ਹੋਵੇ।
ਅਸਲ ਤੋਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ users ਨੂੰ ਕਈ workspaces ਦਾ ਸਮਰਥਨ ਦਿਆਂਗੇ ਕਿ ਨਹੀਂ, ਅਤੇ switching ਕਿਵੇਂ ਕੰਮ ਕਰੇਗਾ।
ਜੇ ਤੁਸੀਂ API keys (in-app ਵਿਜਟ embed ਕਰਨ, feedback ਡੇਟਾਬੇਸ ਨਾਲ sync ਕਰਨ ਆਦਿ ਲਈ) ਪ੍ਰਦਾਨ ਕਰਦੇ ਹੋ, ਤਾਂ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ:
Webhooks ਲਈ, request sign ਕਰੋ, ਸੁਰੱਖਿਅਤ retry ਲਾਗੂ ਕਰੋ, ਅਤੇ ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ secrets disable ਜਾਂ regenerate ਕਰਨ ਲਈ ਸਧਾਰਨ settings ਸਕਰੀਨ ਦਿਓ।
ਐਨਾਲਿਟਿਕਸ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਇੱਕ ਫੀਡਬੈਕ ਐਪ ਫੈਸਲਾ-ਲੈਣ ਲਾਇਕ ਬਣਦਾ ਹੈ, ਨਾ ਕਿ ਸਿੱਫ਼ ਡੇਟਾ ਸਟੋਰੇਜ। ਪਹਿਲਾਂ ਇੱਕ ਛੋਟਾ, ਭਰੋਸੇਯੋਗ ਮੈਟ੍ਰਿਕਸ ਸੈੱਟ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਫਿਰ ਉਹ ਵਿਉਜ਼ ਬਣਾਓ ਜੋ ਰੋਜ਼ਾਨਾ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਤੇਜ਼ੀ ਨਾਲ ਦੇਨ।
ਹਰ ਸਰਵੇ ਲਈ ਮੁੱਖ ਘਟਨਾਵਾਂ Instrument ਕਰੋ:
ਇਨ੍ਹਾਂ ਤੋਂ ਤੁਸੀਂ start rate (starts/views) ਅਤੇ completion rate (completions/starts) ਦੀ गणਨਾ ਕਰ ਸਕਦੇ ਹੋ। ਨਾਲ ਹੀ drop-off points ਲਾਗ ਕਰੋ—ਉਦਾਹਰਨ ਲਈ ਆਖਰੀ ਪ੍ਰਸ਼ਨ ਜੋ ਵੇਖਿਆ ਗਿਆ ਜਾਂ ਉਹ ਕਦਮ ਜਿੱਥੇ ਯੂਜ਼ਰ ਫਿਰਦਾ ਹੈ। ਇਹ ਤੁਹਾਨੂੰ ਉਹ ਸਰਵੇਜ਼ ਪਛਾਣਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਜੋ ਬਹੁਤ ਲੰਬੇ, ਉਲਝਣਭਰੇ, ਜਾਂ ਗਲਤ ਨਿਸ਼ਾਨੇ ਵਾਲੇ ਹਨ।
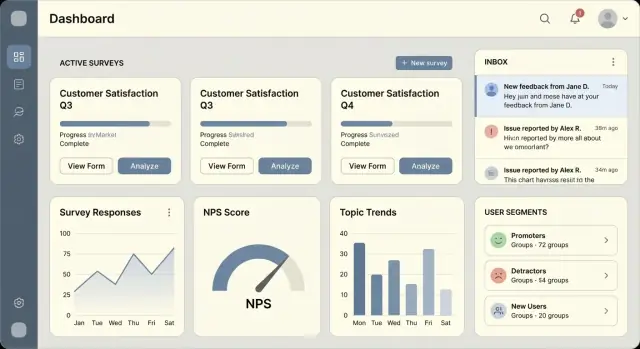
ਉੱਚ-ਸੰਕੇਤ ਵਾਲੇ ਕੁਝ widgets ਨਾਲ ਇੱਕ ਸਧਾਰਨ ਰਿਪੋਰਟਿੰਗ ਖੇਤਰ ਜਲਦੀ ਸ਼ਿਪ ਕਰੋ:
ਚਾਰਟ ਸਧਾਰੇ ਅਤੇ ਤੇਜ਼ ਰੱਖੋ। ਜ਼ਿਆਦਾਤਰ ਯੂਜ਼ਰਾਂ ਨੂੰ ਸਿਰਫ ਇਹ ਪੁਸ਼ਟੀ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, “ਕੀ ਇਹ ਬਦਲਾਅ ਰਵਾਇਆ ਸੁਧਾਰਿਆ?” ਜਾਂ “ਕੀ ਇਹ ਸਰਵੇ traction ਲੈ ਰਿਹਾ ਹੈ?”
ਸ਼ੁਰੂ ਵਿੱਚ ਫਿਲਟਰ ਜੋੜੋ ਤਾਂ ਕਿ ਨਤੀਜੇ ਭਰੋਸੇਯੋਗ ਅਤੇ ਕਾਰਗਰ ਹੋਣ:
ਚੈਨਲ ਮੁਤਾਬਕ ਸੈਗਮੈਂਟ ਕਰਨਾ ਖਾਸ ਤੌਰ 'ਤੇ ਮਹੱਤਵਪੂਰਨ ਹੈ: email invites ਅਤੇ in-product prompts ਆਮ ਤੌਰ ਤੇ ਵੱਖ-ਵੱਖ ਤਰੀਕੇ ਨਾਲ ਪੂਰੇ ਹੁੰਦੇ ਹਨ।
ਸਰਵੇ ਸੰਖੇਪ ਅਤੇ ਰਾ responses ਲਈ CSV export ਦਿਓ। timestamps, channel, user attributes (ਜਿੱਥੇ ਅਨੁਮਤ ਹੈ), ਅਤੇ question IDs/text ਲਈ ਕਾਲਮ ਸ਼ਾਮਿਲ ਕਰੋ। ਇਸ ਨਾਲ ਟੀਮਾਂ ਨੂੰ ਸਪ੍ਰੈਡਸ਼ੀਟਾਂ ਵਿੱਚ ਤੁਰੰਤ ਲਚੀਲਤਾ ਮਿਲਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਧੀਰੇ-ਧੀਰੇ ਹੋਰ ਰਿਪੋਰਟ ਬਣਾਉਂਦੇ ਹੋ।
ਫੀਡਬੈਕ ਅਤੇ ਸਰਵੇ ਐਪ ਅਕਸਰ ਵਿਅਕਤਿਗਤ ਡੇਟਾ ਇਕੱਠਾ ਕਰ ਲੈਂਦੇ ਹਨ ਬਿਨਾਂ ਮਨ ਤੋਂ: ਨਿਮੰਤਰਣਾਂ ਵਿੱਚ ਈਮੇਲ, ਖੁੱਲ੍ਹੇ-ਅੰਤ ਦੇ ਜਵਾਬਾਂ ਵਿੱਚ ਨਾਮ, ਲਾਗਾਂ ਵਿੱਚ IP addresses, ਜਾਂ in-app ਵਿਜਟ ਵਿੱਚ ਡਿਵਾਈਸ IDs। ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਤਰੀਕਾ “ਘੱਟ ਤੋਂ ਘੱਟ ਲੋੜੀਂਦਾ ਡੇਟਾ” ਦੇ ਸਿਧਾਂਤ ਤੇ ਡਿਜ਼ਾਈਨ ਕਰਨਾ ਹੈ।
ਆਪਣੀ ਫੀਡਬੈਕ ਸੰਗ੍ਰਹਿ ਵੈੱਬ ਐਪ ਲਈ ਇੱਕ ਸਧਾਰਣ ਡੇਟਾ ਡਿਕਸ਼ਨਰੀ ਬਣਾਓ ਜਿਸ ਵਿੱਚ ਹਰ ਫੀਲਡ, ਉਸਦਾ ਕਾਰਨ, UI ਵਿੱਚ ਕਿੱਥੇ ਦਿਖਦਾ ਹੈ, ਅਤੇ ਕੌਣ ਪਹੁੰਚ ਸਕਦਾ ਹੈ, ਦਰਜ ਹੋਵੇ। ਇਸ ਨਾਲ ਸਰਵੇ ਬਿਲਡਰ ਈਮਾਨਦਾਰ ਰਹਿੰਦਾ ਅਤੇ “ਸਿਰਫ਼ ਜਰੂਰਤ ਲਈ” ਫੀਲਡਾਂ ਤੋਂ ਬਚਣ ਵਿੱਚ ਮਦਦ ਮਿਲਦੀ ਹੈ।
ਉਦਾਹਰਣ:
ਜੇ ਤੁਸੀਂ anonymous surveys ਦਿੰਦੇ ਹੋ, ਤਾਂ “anonymous” ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਵਾਅਦਾ ਮੰਨੋ: identifiers hidden fields ਵਿੱਚ ਨਾ ਰੱਖੋ, ਅਤੇ response ਡੇਟਾ ਨੂੰ authentication ਡੇਟਾ ਨਾਲ ਮਿਸ਼ਰਤ ਕਰਨ ਤੋਂ ਬਚੋ।
ਜਦੋਂ ਲੋੜ ਹੋਵੇ ਤਾਂ consent ਸਪਸ਼ਟ ਬਣਾਓ (ਉਦਾਹਰਨ ਲਈ marketing follow-ups)। collection ਸਮੇਂ ਸਪਸ਼ਟ ਸ਼ਬਦ ਸ਼ਾਮਿਲ ਕਰੋ, ਨਾ ਕਿ settings ਵਿੱਚ ਛੁਪਾ ਕੇ। GDPR-ਅਨੁਕੂਲ ਸਰਵੇਜ਼ ਲਈ ਆਪਰੇਸ਼ਨਲ ਫਲੋ ਯੋਜਨਾ ਬਣਾਓ:
ਹਰ ਜਗ੍ਹਾ HTTPS ਵਰਤੋ (ਟ੍ਰਾਂਜ਼ਿਟ ਵਿੱਚ ਇੰਕ੍ਰਿਪਸ਼ਨ)। secrets managed secrets store ਵਿੱਚ ਰੱਖੋ (ਡੌਕਯੂਮੈਂਟਸ ਜਾਂ ਟਿਕਟਾਂ ਵਿੱਚ environment variables ਨਾਂ ਕਾਪੀ ਕਰੋ)। ਜਿੱਥੇ ਯੋਗ ਹੋਵੇ ਸੰਵੇਦਨਸ਼ੀਲ ਕਾਲਮ ਨੂੰ ਰੈਸਟ 'ਤੇ ਇੰਕ੍ਰਿਪਟ ਕਰੋ, ਅਤੇ ਬੈਕਅਪਸ ਇੰਕ੍ਰਿਪਟ ਅਤੇ restore drills ਨਾਲ ਟੈਸਟ ਕੀਤੇ ਜਾਣ।
ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਰਤੋ: ਡੇਟਾ ਕੌਣ ਇਕੱਠਾ ਕਰ ਰਿਹਾ ਹੈ, ਕਿਉਂ, ਕਿੰਨੀ ਦੇਰ ਲਈ ਰੱਖਿਆ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਸੰਪਰਕ ਕਿਵੇਂ ਕਰੋ। ਜੇ ਤੁਸੀਂ subprocessors ਵਰਤਦੇ ਹੋ (ਈਮੇਲ ਡਿਲਿਵਰੀ, ਐਨਾਲਿਟਿਕਸ), ਉਨ੍ਹਾਂ ਦੀ ਸੂਚੀ ਦਿਓ ਅਤੇ data processing agreement ਸਾਇਨ ਕਰਨ ਦਾ ਤਰੀਕਾ ਦਿਓ। ਆਪਣੀ privacy page ਨੂੰ survey response UI ਅਤੇ in-app ਵਿਜਟ ਤੋਂ ਆਸਾਨੀ ਨਾਲ ਮਿਲਣਯੋਗ ਰੱਖੋ।
ਸਰਵੇਜ਼ ਲਈ ਟਰੈਫਿਕ ਪੈਟਰਨ spike-prone ਹੁੰਦੇ ਹਨ: ਇੱਕ ਨਵਾਂ ਈਮੇਲ ਕੈਂਪੇਨ "ਚੁੱਪ" ਨੂੰ ਮਿੰਟਾਂ ਵਿੱਚ ਹਜ਼ਾਰਾਂ submissions ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ। ਪਹਿਲਾਂ ਹੀ ਭਰੋਸੇਯੋਗਤਾ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰਨ ਨਾਲ ਖ਼ਰਾਬ ਡੇਟਾ, ਡੁਪਲੀਕੇਟ ਜਵਾਬ, ਅਤੇ ਸੁਸਤ ਡੈਸ਼ਬੋਰਡ ਰੋਕੇ ਜਾ ਸਕਦੇ ਹਨ।
ਲੋਕ ਫਾਰਮ ਛੱਡ ਜਾਂਦੇ ਹਨ, ਕਨੈਕਸ਼ਨ ਹਾਰ ਜਾਂਦੀ ਹੈ, ਜਾਂ ਮੱਧ-ਸਰਵੇ ਡਿਵਾਈਸ ਬਦਲ ਦਿੰਦੇ ਹਨ। ਸਰਵਰ-ਪਾਸੇ validation ਕਰੋ, ਪਰ ਇਹ ਸੋਚ-ਸਮਝ ਕੇ ਕਰੋ ਕਿ ਕੀ ਲਾਜ਼ਮੀ ਹੈ।
ਲੰਮੇ ਸਰਵੇਜ਼ ਲਈ progress ਨੂੰ ਇੱਕ draft ਵਜੋਂ ਸੰਭਾਲਣ ਬਾਰੇ ਸੋਚੋ: partial answers in_progress ਸਟੇਟ ਨਾਲ ਸਟੋਰ ਕਰੋ, ਅਤੇ ਸਿਰਫ਼ ਜਦੋਂ ਸਾਰੇ required questions validation ਪਾਸ ਕਰ ਲੈਂ ਤਾਂ response ਨੂੰ submitted ਮਾਰਕ ਕਰੋ। UI ਲਈ ਖੇਤਰ-ਸਤ੍ਹਰ ਦੀਆਂ ਗਲਤੀਆਂ ਵਾਪਸ ਕਰੋ ਤਾਂ ਜੋ ਅਸੀਂ ਖਾਸ ਤੌਰ 'ਤੇ ਦਿਖਾ ਸਕੀਏ ਕਿ ਕਿਹੜਾ ਫੀਲਡ ਠੀਕ ਕਰਨ ਦੀ ਲੋੜ ਹੈ।
Double-clicks, back-button resubmits, ਅਤੇ ਨਿਰਭਰ ਨਾ ਹੋਣ ਵਾਲੇ ਮੋਬਾਈਲ ਨੈਟਵਰਕ ਆਸਾਨੀ ਨਾਲ ਡੁਪਲੀਕੇਟ ਰਿਕਾਰਡ ਬਣਾਉਂਦੇ ਹਨ।
ਤੁਹਾਡੇ submission endpoint ਨੂੰ idempotent ਬਣਾਉ: client ਵੱਲੋਂ ਇੱਕ idempotency key ਲਵੋ (ਉਹ response ਲਈ ਇੱਕ ਯੂਨੀਕ ਟੋਕਨ)। ਸਰਵਰ 'ਤੇ, key ਨੂੰ response ਨਾਲ ਸਟੋਰ ਕਰੋ ਅਤੇ uniqueness constraint ਲਗਾਓ। ਜੇ ਇੱਕੋ key ਫਿਰ ਭੇਜੀ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਅਸਲ ਨਤੀਜੇ ਨੂੰ ਵਾਪਸ ਕਰੋ ਬਜਾਏ ਨਵਾਂ row ਦਰਜ ਕਰਨ ਦੇ।
ਇਹ ਖਾਸ ਤੌਰ 'ਤੇ ਮਹੱਤਵਪੂਰਨ ਹੈ:
“submit response” ਰਿਕਵੈਸਟ ਨੂੰ ਤੇਜ਼ ਰੱਖੋ। ਕਦੇ-ਕਦੇ ਬਿਜੀ ਕੰਮ queue/worker 'ਚ ਭੇਜੋ:
retries ਨਾਲ backoff, repeated failures ਲਈ dead-letter queues, ਅਤੇ ਜਿੱਥੇ ਲਾਗੂ ਹੋ ਸਕੇ job deduplication ਲਗਾਓ।
ਜਿਵੇਂ responses ਵਧਦੇ ਹਨ analytics ਪੰਨੇ ਸਭ ਤੋਂ ਸੁਸਤ ਹੋ ਸਕਦੇ ਹਨ।
survey_id, created_at, workspace_id, ਅਤੇ ਕਿਸੇ “status” ਫੀਲਡ 'ਤੇ indexes ਸ਼ਾਮਿਲ ਕਰੋ।ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਨਿਯਮ: raw events ਸੰਭਾਲੋ, ਪਰ ਜਦੋਂ queries ਦਰਦ ਪੈਦਾ ਕਰਨ ਲੱਗੀਆਂ ਹਨ ਤਾਂ ਡੈਸ਼ਬੋਰਡ pre-aggregated tables ਤੋਂ ਸੇਵਾ ਦਿਓ।
ਸਰਵੇ ਐਪ ਨੂੰ ਸ਼ਿਪ ਕਰਨਾ "ਮੁੱਕਣ" ਬਾਰੇ ਨਹੀਂ, ਬਲਕਿ ਜਿਹੜੇ ਤੁਸੀਂ ਪ੍ਰਸ਼ਨ ਟਾਈਪ, ਚੈਨਲ, ਅਤੇ ਪਰਮਿਸ਼ਨ ਜੋੜਦੇ ਹੋ, ਉਨ੍ਹਾਂ ਨਾਲ regressions ਰੋਕਣ ਬਾਰੇ ਹੈ। ਇੱਕ ਛੋਟੀ, ਸਥਿਰ ਟੈਸਟ ਸੂਟ ਅਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲਾ QA ਰੁਟੀਨ ਟੁੱਟੇ ਲਿੰਕ, ਗੁੰਮ responses, ਅਤੇ ਗਲਤ ਐਨਾਲਿਟਿਕਸ ਤੋਂ ਬਚਾਉਂਦੇ ਹਨ।
ਉਹ ਲਾਜ਼ਮੀ flows ਤੇ focus ਕਰੋ ਜੋ ਮੈਨਯੂਅਲ ਤਰੀਕੇ ਨਾਲ ਪਾਉਣ ਵਿੱਚ ਮੁਸ਼ਕਿਲ ਹਨ:
ਫਿਕ্সਚਰ ਨਿੱਕੇ ਅਤੇ explicit ਰੱਖੋ। ਜੇ ਤੁਸੀਂ survey schemas ਵਰਜ਼ਨ ਕਰਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਟੈਸਟ ਸ਼ਾਮਿਲ ਕਰੋ ਜੋ "ਪੁਰਾਣੇ" ਸਰਵੇ definitions ਲੋਡ ਕਰਦਾ ਹੈ ਤਾਂ ਕਿ ਤੁਸੀਂ ਪੁਰਾਣੇ responses ਨੂੰ ਪੜ੍ਹ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰ ਸਕੋ।
ਹਰ ਰਿਲੀਜ਼ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਛੋਟਾ ਚੈੱਕਲਿਸਟ ਚਲਾਉ ਜੋ ਅਸਲ ਉਪਯੋਗ ਨੂੰ ਦਰਸਾਉਂਦਾ:
ਇਕ staging environment ਜੋ production settings (auth, email provider, storage) ਨੂੰ mirror ਕਰਦਾ ਹੋ ਰੱਖੋ। ਕੁਝ example workspaces, surveys (NPS, CSAT, multi-step), ਅਤੇ sample responses ਲਈ seed data ਸ਼ਾਮਿਲ ਕਰੋ। ਇਸ ਨਾਲ regression testing ਅਤੇ demos ਦੁਹਰਾਏ ਜਾ ਸਕਦੇ ਹਨ ਅਤੇ “ਮੇਰੇ ਖਾਤੇ 'ਤੇ ਠੀਕ ਕੰਮ ਕਰਦਾ ਹੈ” ਦੇ ਚੱਕਰ ਤੋਂ ਬਚਾ ਜਾ ਸਕਦਾ ਹੈ।
ਸਰਵੇ ਖਾਮੋਸ਼ੀ ਨਾਲ ਫੇਲ ਹੁੰਦੇ ਹਨ ਜਦ ਤੱਕ ਤੁਸੀਂ ਸਹੀ ਸੰਕੇਤਾਂ ਨੂੰ ਨਜ਼ਰ ਵਿੱਚ ਨਾ ਰੱਖੋ:
ਇੱਕ ਸਧਾਰਨ ਨਿਯਮ: ਜੇ ਇੱਕ customer 15 ਮਿੰਟ ਲਈ responses ਇਕੱਤਰ ਨਹੀਂ ਕਰ ਸਕਦਾ, ਤਾਂ ਤੁਹਾਨੂੰ ਉਹਨਾਂ ਤੋਂ ਪਹਿਲਾਂ ਪਤਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਫੀਡਬੈਕ ਸੰਗ੍ਰਹਿ ਵੈੱਬ ਐਪ ਨੂੰ ਸ਼ਿਪ ਕਰਨਾ ਇੱਕ ਇਕੱਲਾ “go-live” ਮੋਮੈਂਟ ਨਹੀਂ ਹੈ। ਲਾਂਚ ਨੂੰ ਇੱਕ ਨਿਯੰਤਰਿਤ ਲਰਨਿੰਗ ਸਾਈਕਲ ਵਜੋਂ ਸਾਂਭੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਅਸਲ ਟੀਮਾਂ ਨਾਲ ਆਪਣੇ ਯੂਜ਼ਰ ਸਰਵੇ ਐਪ ਨੂੰ ਵਰਫਾਈ ਕਰ ਸਕੋ ਅਤੇ ਸਹਾਇਤਾ manageable ਰੱਖ ਸਕੋ।
ਸ਼ੁਰੂ ਵਿੱਚ ਇੱਕ private beta (5–20 ਭਰੋਸੇਯੋਗ ਗਾਹਕ) ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜਿੱਥੇ ਤੁਸੀਂ ਦੇਖ ਸਕਦੇ ਹੋ ਕਿ ਲੋਕ ਅਸਲ ਵਿੱਚ ਸਰਵੇ ਕਿਵੇਂ ਬਣਾਉਂਦੇ, ਲਿੰਕ ਸਾਂਝੇ ਕਰਦੇ, ਅਤੇ ਨਤੀਜੇ ਕਿਵੇਂ ਵਿਆਖਿਆ ਕਰਦੇ ਹਨ। ਫਿਰ limited rollout (waitlist ਜਾਂ ਕਿਸੇ ਖਾਸ ਸੈਗਮੈਂਟ ਲਈ) ਅਤੇ ਅੰਤ ਵਿੱਚ full release ਜਦੋਂ ਮੁੱਖ flows ਸਥਿਰ ਹੋ ਜਾਣ ਅਤੇ ਤੁਹਾਡੀ ਸਪੋਰਟ ਲੋਡ ਪੇਸ਼ਗੀ ਤੌਰ 'ਤੇ ਅਨੁਮਾਨਯੋਗ ਹੋਵੇ।
ਹਰ ਪੜਾਅ ਲਈ ਸਫਲਤਾ ਮੈਟ੍ਰਿਕ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: activation rate (ਪਹਿਲਾ ਸਰਵੇ ਬਣਾਇਆ), response rate, ਅਤੇ time-to-first-insight (ਐਨਾਲਿਟਿਕਸ ਵੇਖੇ ਜਾਂ results export ਕੀਤੇ)। ਇਹ ਸਿੱਧੇ signup ਤੋਂ ਜ਼ਿਆਦਾ ਉਪਯੋਗੀ ਹਨ।
onboarding ਨੂੰ ਰਾਏ-ਤਯਾਰ ਰੱਖੋ:
onboarding ਨੂੰ ਦਸਤਾਵੇਜ਼ਾਂ ਵਿੱਚ নয়, ਉਤਪਾਦ ਦੇ ਅੰਦਰ ਰੱਖੋ।
ਫੀਡਬੈਕ ਤਦ ਹੀ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਸ 'ਤੇ ਕਾਰਵਾਈ ਹੋਵੇ। ਇੱਕ ਸਧਾਰਨ ਵਰਕਫਲੋ ਜੋੜੋ: owners ਨਿਯੁਕਤ ਕਰੋ, ਟੈਗ ਥੀਮਾਂ, ਇੱਕ status ਸੈੱਟ ਕਰੋ (ਨਵਾਂ → ਜਾਰੀ → ਹੱਲ), ਅਤੇ respondents ਨੂੰ ਨੋਟੀਫਾਈ ਕਰਕੇ ਜਦੋਂ ਮੁੱਦਾ ਹੱਲ ਕੀਤਾ ਜਾਵੇ loop ਬੰਦ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰੋ।
ਪਹਿਲਾਂ integrations (Slack, Jira, Zendesk, HubSpot) ਨੂੰ ਤਰਜੀਹ ਦਿਓ, ਹੋਰ NPS/CSAT ਟੈਂਪਲੇਟ ਸ਼ਾਮਿਲ ਕਰੋ, ਅਤੇ ਪੈਕੇਜਿੰਗ ਸੁਧਾਰੋ। ਜਦੋਂ ਤੁਸੀਂ ਮੋਨਟਾਈਜ਼ ਕਰਨ ਲਈ ਤਿਆਰ ਹੋ, users ਨੂੰ /pricing 'ਤੇ ਆਪਣੇ ਯੋਜਨਾਂ ਵੱਲ ਰੁਸ਼ਾਨ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਇਟਰੇਟ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਸੋਚੋ ਕਿ ਬਦਲਾਅ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਕਿਵੇਂ ਪ੍ਰਬੰਧਿਤ ਕਰੋ (rollbacks, staging, ਅਤੇ quick redeploys)। Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ snapshots ਅਤੇ rollback ਨਾਲ ਇਸ ਵਿੱਚ ਸਹਾਇਕ ਹਨ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਤੁਸੀਂ ਸਰਵੇ ਟੈਂਪਲੇਟ, ਵਰਕਫਲੋਜ਼, ਅਤੇ ਐਨਾਲਿਟਿਕਸ ਨਾਲ ਪ੍ਰਯੋਗ ਕਰ ਰਹੇ ਹੋ ਬਿਨਾਂ ਸ਼ੁਰੂਆਤ ਵਿੱਚ infrastructure babysit ਕੀਤੇ।
ਪਹਿਲਾਂ ਇੱਕ ਮੁੱਖ ਲਕੜੀ ਚੁਣੋ:
ਪਹਿਲੀ ਰਿਲੀਜ਼ ਨੂੰ 2–6 ਹਫ਼ਤੇ ਵਿੱਚ ਸ਼ਿਪ ਕਰਨ ਯੋਗ ਰੱਖੋ ਅਤੇ ਨਤੀਜੇ ਤੇਜ਼ੀ ਨਾਲ ਮਾਪੋ।
ਉਹ ਮੈਟ੍ਰਿਕਸ ਚੁਣੋ ਜੋ ਤੁਸੀਂ ਹਫ਼ਤਿਆਂ ਵਿੱਚ ਗਿਣ ਸਕੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ। ਆਮ ਚੋਣਾਂ:
ਜੇ ਤੁਸੀਂ ਦੱਸ ਨਹੀਂ ਸਕਦੇ ਕਿ numerator/denominator ਤੁਹਾਡੇ ਡੇਟਾ ਮਾਡਲ ਵਿੱਚ ਕਿਵੇਂ ਨਿਰਧਾਰਤ ਹੋ ਰਹੇ ਹਨ, ਤਾਂ ਮੈਟ੍ਰਿਕ ਤਿਆਰ ਨਹੀਂ ਹੈ।
ਰੋਲਾਂ ਸਧਾਰਣ ਅਤੇ ਅਸਲ ਕੰਮ ਦੇ ਅਨੁਕੂਲ ਰੱਖੋ:
ਜ਼ਿਆਦਾ ਕੇਸਾਂ ਵਿੱਚ ਅਰੰਭਕ ਪ੍ਰੋਡਕਟ ਫੇਲਿਅਰ ਅਸਪੱਸ਼ਟ permissions ਅਤੇ “ਹਰ ਕੋਈ ਪਬਲਿਸ਼ ਕਰ ਸਕਦਾ ਹੈ, ਕੋਈ ਰਖਿਆ ਨਹੀਂ ਕਰਦਾ” ਤੋਂ ਹੁੰਦੇ ਹਨ।
ਇੱਕ ਘਟੋ-ਘਟਾ, ਉੱਚ-ਪ੍ਰਭਾਵ ਵਾਲਾ ਸੈੱਟ:
ਜੇ ਕੋਈ ਸਕ੍ਰੀਨ ਕਿਸੇ ਸਪੱਸ਼ਟ ਸਵਾਲ ਦਾ ਜਵਾਬ ਨਹੀਂ ਦਿੰਦੀ, ਤਾਂ ਉਸਨੂੰ v1 ਤੋਂ ਕੱਟ ਦਿਓ।
ਅਕਸਰ ਟੀਮਾਂ ਲਈ ਇੱਕ ਮੋਡੀਊਲਰ ਮੋਨੋਲਿਥ ਸ਼ੁਰੂਆਤ ਲਈ ਸਭ ਤੋਂ ਸਧਾਰਨ ਹੈ: ਇੱਕ ਬੈਕਐਂਡ ਐਪ, ਇੱਕ ਡੇਟਾਬੇਸ, ਅਤੇ ਸਾਫ਼ ਮੋਡੀਊਲ ਹੱਦਾਂ (auth, surveys, responses, reporting). ਜੋ managed ਕੰਪੋਨੈਂਟ ਚਾਹੀਦੇ ਹੋਣ ਉਹਨਾਂ ਨੂੰ ਜੋੜੋ, ਉਦਾਹਰਨ ਲਈ:
ਮਾਈਕ੍ਰੋਸਰਵਿਸਜ਼ ਅਕਸਰ ਤੁਰੰਤ ਸ਼ਿਪਿੰਗ ਨੂੰ ਸੁਸਤ ਕਰ ਦਿੰਦੇ ਹਨ ਕਿਉਂਕਿ ਡਿਪਲੋਇਮੈਂਟ ਅਤੇ ਡਿਬੱਗਿੰਗ ਔਬਰ ਹੈ।
ਰਿਲੇਸ਼ਨਲ ਕੋਰ (ਅਕਸਰ PostgreSQL) ਵਰਤੋ ਅਤੇ ਇਹ ਏਨਟਿਟੀਆਂ ਰੱਖੋ:
ਵਰਜ਼ਨਿੰਗ ਮਹੱਤਵਪੂਰਨ ਹੈ: ਸਰਵੇ ਨੂੰ ਸੋਧਣ ਤੇ ਨਵੀਂ SurveyVersion ਬਣਾਓ ਤਾਂ ਕਿ ਪੁਰਾਣੇ ਜਵਾਬ ਸਮਝਣਯੋਗ ਰਹਿਣ।
ਬਿਲਡਰ ਨੂੰ ਛੋਟਾ ਪਰ ਲਚਕੀਲਾ ਰੱਖੋ:
ਜੇ branching ਜੋੜ ਰਹੇ ਹੋ ਤਾਂ ਉਹ ਨਿੱਘਾ ਅਤੇ ਸੀਮਿਤ ਰੱਖੋ (ਜਿਵੇਂ “ਜੇ option X → ਪ੍ਰਸ਼ਨ Y ਲਈ ਜਾਓ”) ਅਤੇ ਇਸਨੂੰ options ਨਾਲ ਜੁੜੇ ਨਿਯਮ ਵਜੋਂ ਮਾਡਲ ਕਰੋ।
ਇੱਕ ਪ੍ਰਾਕਟਿਕਲ ਘੱਟੋ-ਘੱਟ ਤਿੰਨ ਚੈਨਲ:
ਹਰ ਚੈਨਲ ਲਈ channel ਮੈਟਾਡੇਟਾ ਰਿਕਾਰਡ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਨਤੀਜੇ ਸਗਮੈਂਟ ਕਰ ਸਕੋ।
ਉਸਨੂੰ ਇੱਕ ਉਤਪਾਦ ਵਾਅਦਾ ਸਮਝੋ ਅਤੇ ਡੇਟਾ ਕਲੈਕਸ਼ਨ ਵਿੱਚ ਯਹ ਪ੍ਰਭਾਵਿਤ ਕਰੋ:
ਇੱਕ ਸਧਾਰਣ ਡੇਟਾ ਡਿਕਸ਼ਨਰੀ ਬਣਾਓ ਤਾਂ ਕਿ ਤੁਸੀਂ ਹਰ ਫੀਲਡ ਲਈ ਕਾਰਨ ਦਰਜ ਕਰ ਸਕੋ।
ਖਰਾਬ ਡੇਟਾ ਬਣਾਉਣ ਵਾਲੇ ਫੇਲ ਹੋਣ ਵਾਲੇ ਮੋਡਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ:
submitted ਮਾਰਕ ਕਰੋworkspace_id, survey_id, created_at), ਅਤੇ cached aggregates ਰੱਖੋਇਨ੍ਹਾਂ ਨਾਲ ਡੁਪਲੀਕੇਟਸ ਘਟਦੇ ਹਨ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਭਰੋਸੇਯੋਗ ਬਣਦਾ ਹੈ।