05 ਅਕਤੂ 2025·8 ਮਿੰਟ
ਤੁਹਾਡੇ ਐਪਲੀਕੇਸ਼ਨਾਂ ਲਈ RabbitMQ: ਪੈਟਰਨ, ਸੈਟਅਪ, ਅਤੇ ਓਪਸ
ਸਿੱਖੋ ਕਿ ਆਪਣੇ ਐਪਲੀਕੇਸ਼ਨਾਂ ਵਿੱਚ RabbitMQ ਕਿਵੇਂ ਵਰਤਣਾ ਹੈ: ਮੁੱਖ ਧਾਰਣਾਵਾਂ, ਆਮ ਪੈਟਰਨ, ਭਰੋਸੇਯੋਗਤਾ ਟਿਪਸ, ਸਕੇਲਿੰਗ, ਸੁਰੱਖਿਆ ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਲਈ ਮਾਨੀਟਰਿੰਗ।
ਸਿੱਖੋ ਕਿ ਆਪਣੇ ਐਪਲੀਕੇਸ਼ਨਾਂ ਵਿੱਚ RabbitMQ ਕਿਵੇਂ ਵਰਤਣਾ ਹੈ: ਮੁੱਖ ਧਾਰਣਾਵਾਂ, ਆਮ ਪੈਟਰਨ, ਭਰੋਸੇਯੋਗਤਾ ਟਿਪਸ, ਸਕੇਲਿੰਗ, ਸੁਰੱਖਿਆ ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਲਈ ਮਾਨੀਟਰਿੰਗ।
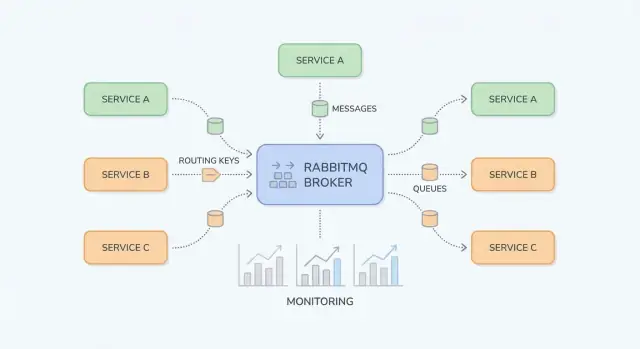
RabbitMQ ਇੱਕ message broker ਹੈ: ਇਹ ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੇ ਹਿੱਸਿਆਂ ਦੇ ਵਿਚਕਾਰ ਬੈਠਦਾ ਹੈ ਅਤੇ ਉਤਪਾਦਕਾਂ (producers) ਤੋਂ ਖਪਤਕਾਰਾਂ (consumers) ਵੱਲ "ਕੰਮ" (ਸੁਨੇਹੇ) ਨਿਰਭਰ ਯੋਗ ਢੰਗ ਨਾਲ ਭੇਜਦਾ ਹੈ। ਐਪਲੀਕੇਸ਼ਨ ਟੀਮਾਂ ਅਕਸਰ ਇਸ ਨੂੰ ਇਸ ਵੇਲੇ ਲਿਆਉਂਦੀਆਂ ਹਨ ਜਦੋਂ ਸਿੱਧੇ, synchronous ਕਾਲਾਂ (service-to-service HTTP, ਸਾਂਝਾ ਡੈਟਾਬੇਸ, cronjobs) ਨਾਜ਼ੁਕ dependencies, ਅਸਮਾਨ ਲੋਡ ਅਤੇ ਡਿਬੱਗ ਕਰਨ ਵਿੱਚ ਮੁਸ਼ਕਲ ਫੇਲ ਹੋ ਰਹੀਆਂ ਹੋਣ।
ਟ੍ਰੈਫਿਕ ਸਪੀਕਸ ਅਤੇ ਅਨਸਮਤ ਕੰਮਭਾਰ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਛੋਟੇ ਸਮੇਂ ਵਿੱਚ 10× ਜ਼ਿਆਦਾ ਸਿਗਨਅਪ ਜਾਂ ਆਰਡਰ ਮਿਲ ਜਾਣ, ਤਾਂ ਸਭ ਕੁਝ ਤੁਰੰਤ ਪ੍ਰੋਸੈਸ ਕਰਨਾ ਡਾਉਨਸਟਰੀਮ ਸੇਵਾਵਾਂ ਨੂੰ ਓਵਰਹੈਲਮ ਕਰ ਸਕਦਾ ਹੈ। RabbitMQ ਨਾਲ, producers ਤੇਜ਼ੀ ਨਾਲ ਕੰਮ enqueue ਕਰ ਸਕਦੇ ਹਨ ਅਤੇ consumers ਉਹਨਾਂ ਨੂੰ ਨਿਯੰਤਰਤ ਰਫ਼ਤਾਰ ਨਾਲ ਹਲ ਕਰਦੇ ਹਨ।
ਸੇਵਾਵਾਂ ਵਿਚਕਾਰ ਟਾਈਟ coupling। ਜਦੋਂ Service A ਨੂੰ Service B ਨੂੰ ਕਾਲ ਕਰਨੀ ਪੈਂਦੀ ਹੈ ਅਤੇ ਉੱਤਰ ਦੀ ਉਡੀਕ ਕਰਨੀ ਪੈਂਦੀ ਹੈ, ਤਾਂ failures ਅਤੇ ਲੈਟेंसी ਫੈਲਦੀਆਂ ਹਨ। ਮੈਸੇਜਿੰਗ ਉਹਨਾਂ ਨੂੰ ਡੀਕੈਪਲ ਕਰਦੀ ਹੈ: A ਇੱਕ ਸੁਨੇਹਾ publish ਕਰਦਾ ਹੈ ਅਤੇ ਅੱਗੇ ਵਧ ਜਾਂਦਾ ਹੈ; B ਜਦੋਂ ਤਿਆਰ ਹੋਵੇ ਤਾਂ ਇਸ ਨੂੰ ਪ੍ਰੋਸੈਸ ਕਰਦਾ ਹੈ।
ਸੁਰੱਖਿਅਤ ਫੇਲ੍ਹ ਸੰਭਾਲ। ਹਰ ਫੇਲ੍ਹ ਨੂੰ ਯੂਜ਼ਰ ਨੂੰ ਦਿਖਾਏ ਜਾਣ ਵਾਲੇ error ਵਿੱਚ ਤਬਦੀਲ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ। RabbitMQ ਤੁਹਾਡੇ ਨੂੰ ਬੈਕਗ੍ਰਾਊਂਡ ਵਿੱਚ retries ਕਰਨ, “poison” ਸੁਨੇਹਿਆਂ ਨੂੰ ਅਲੱਗ ਕਰਨ ਅਤੇ ਅਸਥਾਈ ਬੰਦਸ਼ਾਂ ਦੌਰਾਨ ਕੰਮ ਨਾ ਗੁਆਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ।
ਟੀਮਾਂ ਆਮ ਤੌਰ ਤੇ ਸਮਤਲ ਕੰਮਭਾਰ (buffering peaks), ਡੀਕੈਪਲਡ ਸੇਵਾਵਾਂ (ਘੱਟ runtime dependencies) ਅਤੇ ਨਿਯੰਤਰਿਤ retries ਪ੍ਰਾਪਤ ਕਰਦੀਆਂ ਹਨ। ਇੱਕੋ ਜਿੰਨਾ ਮਹੱਤਵਪੂਰਨ, ਇਹ ਪਤਾ ਕਰਨਾ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ ਕਿ ਕੰਮ ਕਿੱਥੇ ਫਸਿਆ ਹੈ—producer ਦੇ ਕਿਨਾਰੇ, queue ਵਿੱਚ ਜਾਂ consumer ਵਿੱਚ।
ਇਹ ਗਾਈਡ ਐਪਲੀਕੇਸ਼ਨ ਟੀਮਾਂ ਲਈ ਵਿਆਵਹਾਰਿਕ RabbitMQ 'ਤੇ ਧਿਆਨ ਕੇਂਦ੍ਰਿਤ ਕਰਦੀ ਹੈ: ਮੁੱਖ ਧਾਰਣਾਵਾਂ, ਆਮ ਪੈਟਰਨ (pub/sub, work queues, retries ਅਤੇ dead-letter queues), ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਚਿੰਤਾਵਾਂ (ਸੁਰੱਖਿਆ, ਸਕੇਲਿੰਗ, ਨਿਰੀਖਣਯੋਗਤਾ, ਟ੍ਰਬਲਸ਼ੂਟਿੰਗ)।
ਇਹ AMQP ਦੀ ਪੂਰੀ ਵਿਸਥਾਰਤ ਵਿਵਰਣੀ ਜਾਂ ਹਰ RabbitMQ plugin ਵਿੱਚ ਡੂੰਘਾਈ ਨਾਲ ਜਾਣ ਦਾ ਹੱਦਫ ਨਹੀਂ ਰੱਖਦੀ। ਲਕੜੀ ਦਾ ਮਕਸਦ ਤੁਹਾਨੂੰ ਐਸੇ message flows ਡਿਜ਼ਾਈਨ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨਾ ਹੈ ਜੋ ਅਸਲ ਸਿਸਟਮਾਂ ਵਿੱਚ ਬਣੇ ਰਹਿਣ।
RabbitMQ ਇੱਕ message broker ਹੈ ਜੋ ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੇ ਹਿੱਸਿਆਂ ਦੇ ਵਿਚਕਾਰ ਸੁਨੇਹੇ ਰੂਟ ਕਰਦਾ ਹੈ, ਤਾਂ ਜੋ producers ਕੰਮ ਸੌਂਪ ਸਕਣ ਅਤੇ consumers ਜਦੋਂ ਤਿਆਰ ਹੋਣ ਤਾਂ ਉਹਨਾਂ ਨੂੰ ਪ੍ਰੋਸੈਸ ਕਰ ਸਕਣ।
ਸਿੱਧੇ HTTP ਕਾਲ ਨਾਲ, Service A Service B ਨੂੰ ਇੱਕ ਨਿਰੋਧ ਭੇਜਦਾ ਹੈ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਉਡੀਕ ਕਰਦਾ ਹੈ। ਜੇ Service B ਹੌਲੀ ਜਾਂ ਡਾਊਨ ਹੈ, ਤਾਂ Service A ਫੇਲ ਜਾਂ ਰੁਕ ਸਕਦਾ ਹੈ, ਅਤੇ ਹਰ caller ਵਿੱਚ timeouts, retries ਅਤੇ backpressure ਸੰਭਾਲਣੀ ਪੈਂਦੀ ਹੈ।
RabbitMQ (ਆਮ ਤੌਰ 'ਤੇ AMQP ਰਾਹੀਂ) ਨਾਲ, Service A broker ਨੂੰ ਸੁਨੇਹਾ publish ਕਰਦਾ ਹੈ। RabbitMQ ਇਸ ਨੂੰ ਸੰਭਾਲਦਾ ਅਤੇ ਰੂਟ ਕਰਦਾ ਹੈ ਸਹੀ queue(ਆਂ) ਵੱਲ, ਅਤੇ Service B asynchronous ਤਰੀਕੇ ਨਾਲ ਇਸ ਨੂੰ ਖਪਾਉਂਦਾ ਹੈ। ਮੁੱਖ ਪਰਿਵਰਤਨ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਇੱਕ ਟਿਕਾਊ ਮਿਡਲ-ਲੇਅਰ ਰਾਹੀਂ ਗੱਲਬਾਤ ਕਰ ਰਹੇ ਹੋ ਜੋ spikes ਨੂੰ ਬਫਰ ਕਰਦਾ ਅਤੇ ਅਨਸਮਤ ਕੰਮਭਾਰ ਨੂੰ ਸਮਤਲ ਕਰਦਾ ਹੈ।
Messaging ਉਸ ਵੇਲੇ ਫ਼ਾਇਦੇਮੰਦ ਹੈ ਜਦੋਂ ਤੁਸੀਂ:
Messaging ਓਸ ਵੇਲੇ ਠੀਕ ਨਹੀਂ ਹੁੰਦਾ ਜਦੋਂ ਤੁਸੀਂ:
Synchronous (HTTP):
ਇੱਕ checkout service invoicing service ਨੂੰ HTTP ਅਪਡੇਟ ਕਰਦੀ ਹੈ: "ਇਨਵੌਇਸ ਬਣਾਓ।" ਯੂਜ਼ਰ invoicing ਦੇ ਦੌਰਾਨ ਉਡੀਕ ਕਰਦਾ ਹੈ। ਜੇ invoicing ਸਲੋ ਹੈ ਤਾਂ checkout latency ਵਧਦੀ ਹੈ; ਜੇ ਡਾਊਨ ਹੈ ਤਾਂ checkout ਫੇਲ ਹੋ ਜਾਂਦਾ ਹੈ।
Asynchronous (RabbitMQ):
Checkout invoice.requested publish ਕਰਦਾ ਹੈ order id ਨਾਲ। ਯੂਜ਼ਰ ਨੂੰ ਤੁਰੰਤ ਪੁਸ਼ਟੀ ਮਿਲਦੀ ਹੈ ਕਿ ਆਰਡਰ ਪ੍ਰਾਪਤ ਹੋ ਗਿਆ। Invoicing ਸੁਨੇਹਾ consume ਕਰਦਾ ਹੈ, ਇਨਵੌਇਸ ਬਣਾਉਂਦਾ ਹੈ, ਫਿਰ invoice.created publish ਕਰਦਾ ਹੈ ਤਾਂ ਕਿ email/notifications ਉਸਨੂੰ ਲੈ ਸਕਣ। ਹਰ ਕਦਮ ਅਲੱਗ-ਅਲੱਗ retry ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਅਸਥਾਈ ਬੰਦਸ਼ਾਂ ਸਾਰੇ ਫਲੋ ਨੂੰ ਤੁਰੰਤ ਤੌਰ 'ਤੇ ਬਰਬਾਦ ਨਹੀਂ ਕਰਦੀਆਂ।
RabbitMQ ਨੂੰ ਸਮਝਣਾ ਸੌਖਾ ਹੁੰਦਾ ਹੈ ਜੇ ਤੁਸੀਂ "ਕਿੱਥੇ ਸੁਨੇਹੇ publish ਹੁੰਦੇ ਹਨ" ਨੂੰ "ਕਿੱਥੇ ਸੁਨੇਹੇ ਸਟੋਰ ਹੁੰਦੇ ਹਨ" ਤੋਂ ਵੱਖ ਕਰ ਦਿਓ। Producers exchanges ਨੂੰ publish ਕਰਦੇ ਹਨ; exchanges ਸੁਨੇਹਿਆਂ ਨੂੰ queues ਵੱਲ ਰੂਟ ਕਰਦੇ ਹਨ; consumers queues ਤੋਂ ਪੜ੍ਹਦੇ ਹਨ।
ਇੱਕ exchange ਸੁਨੇਹੇ ਸਟੋਰ ਨਹੀਂ ਕਰਦੀ। ਇਹ ਨਿਯਮਾਂ ਦਾ ਮੁਲਾਂਕਣ ਕਰਦੀ ਹੈ ਅਤੇ ਸੁਨੇਹਿਆਂ ਨੂੰ ਇੱਕ ਜਾਂ ਹੋਰ queues ਨੂੰ ਅੱਗੇ ਭੇਜਦੀ ਹੈ।
billing ਜਾਂ email) ਚਾਹੁੰਦੇ ਹੋ ਤਦ ਵਰਤੋ।region=eu AND tier=premium) 'ਤੇ ਨਿਰਭਰ ਹੋਵੇ ਤਾਂ ਇਸਨੂੰ ਵਿਸ਼ੇਸ਼ ਕੇਸਾਂ ਲਈ ਰੱਖੋ, ਕਿਉਂਕਿ ਇਹ ਸੋਚਣ ਵਿੱਚ ਔਖਾ ਹੋ ਸਕਦਾ ਹੈ।ਇੱਕ queue ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਸੁਨੇਹੇ ਹੋਏ ਬੈਠੇ ਰਹਿੰਦੇ ਹਨ ਜਦ ਤੱਕ consumer ਉਹਨਾਂ ਨੂੰ ਪ੍ਰੋਸੈਸ ਨਹੀਂ ਕਰ ਲੈਂਦਾ। ਇੱਕ queue ਦਾ ਇੱਕ ਹੀ consumer ਹੋ ਸਕਦਾ ਹੈ ਜਾਂ ਬਹੁਤ ਸਾਰੇ (competing consumers), ਅਤੇ ਸੁਨੇਹੇ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਵੇਲੇ ਇੱਕ consumer ਨੂੰ ਦਿੱਤੇ ਜਾਂਦੇ ਹਨ।
ਇੱਕ binding exchange ਨੂੰ queue ਨਾਲ ਜੋੜਦੀ ਹੈ ਅਤੇ routing ਨਿਯਮ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦੀ ਹੈ। ਇਸਨੂੰ ਇੰਝ ਸੋਚੋ: "ਜਦੋਂ ਸੂਨੇਹਾ exchange X ਨਾਲ routing key Y ਦੇ ਨਾਲ ਆਵੇ, ਤਾਂ ਇਸ ਨੂੰ queue Q ਨੂੰ ਭੇਜੋ।" ਤੁਸੀਂ ਇੱਕ exchange ਨਾਲ ਕਈ queues ਨੂੰ bind ਕਰ ਸਕਦੇ ਹੋ (pub/sub) ਜਾਂ ਇੱਕ queue ਨੂੰ ਵੱਖ-ਵੱਖ routing keys ਲਈ bind ਕਰ ਸਕਦੇ ਹੋ।
Direct exchanges ਲਈ routing ਇਕਸਾਠ ਹੁੰਦੀ ਹੈ। Topic exchanges ਵਿੱਚ routing keys ਡੌਟ-ਵੱਖ-ਵੱਖ ਸ਼ਬਦਾਂ ਵਾਲੀਆਂ ਹੁੰਦੀਆਂ ਹਨ, ਜਿਵੇਂ:
orders.createdorders.eu.refundedBindings wildcards ਸ਼ਾਮਲ ਕਰ ਸਕਦੀਆਂ ਹਨ:
* ਇੱਕ ਸ਼ਬਦ ਨਾਲ ਮਿਲਦਾ ਹੈ (ਉਦਾਹਰਨ, orders.* orders.created ਨੂੰ ਮੇਚ ਕਰਦਾ ਹੈ)# ਜ਼ੀਰੋ ਜਾਂ ਵੱਧ ਸ਼ਬਦਾਂ ਨਾਲ ਮਿਲਦਾ ਹੈ (ਉਦਾਹਰਨ, orders.# orders.created ਅਤੇ orders.eu.refunded ਨੂੰ ਮੇਚ ਕਰਦਾ ਹੈ)ਇਸ ਨਾਲ ਤੁਹਾਨੂੰ ਨਵਾਂ consumer ਜੁੜਨ 'ਤੇ producers ਨੂੰ ਬਦਲਣ ਦੀ ਜ਼ਰੂਰਤ ਨਹੀਂ ਪੈਂਦੀ—ਨਵਾਂ queue ਬਣਾਓ ਅਤੇ ਤੁਹਾਨੂੰ ਚਾਹੀਦਾ pattern ਨਾਲ bind ਕਰੋ۔
RabbitMQ message ਡਿਲਿਵਰ ਕਰਨ ਤੋਂ ਬਾਅਦ, consumer ਨਤੀਜਾ ਦੱਸਦਾ ਹੈ:
Requeue ਦੇ ਨਾਲ ਸਾਵਧਾਨ ਰਹੋ: ਜੋ ਸੁਨੇਹਾ ਹਮੇਸ਼ਾਂ ਫੇਲ੍ਹ ਹੁੰਦਾ ਹੈ ਉਹ ਸਦੀਵੀ ਤੌਰ 'ਤੇ ਲੂਪ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ queue ਨੂੰ ਬਲੌਕ ਕਰ ਦੇ ਸਕਦਾ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ nack ਨੂੰ retry ਰਣਨੀਤੀ ਅਤੇ ਇੱਕ dead-letter queue ਨਾਲ ਜੋੜਦੀਆਂ ਹਨ (ਹੇਠਾਂ ਢੰਗ ਨਾਲ ਕਵਰ ਕੀਤਾ ਗਿਆ) ਤਾਂ ਕਿ ਫੇਲ੍ਹ predictable ਤਰੀਕੇ ਨਾਲ ਸੰਭਾਲੇ ਜਾਣ।
RabbitMQ ਉਹ ਵੇਲੇ ਚਮਕਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਆਪਣੇ ਸਿਸਟਮ ਦੇ ਹਿੱਸਿਆਂ ਵਿੱਚ ਕੰਮ ਜਾਂ ਨੋਟੀਫਿਕੇਸ਼ਨ ਭੇਜਣੇ ਹੁੰਦੇ ਹਨ ਬਿਨਾਂ ਸਰਬ-ਸੇਵਾ ਨੂੰ ਇੱਕ धीਮਾ ਕਦਮ ਬਣਾਉਣ ਦੇ। ਹੇਠਾਂ ਪ੍ਰੈਕਟਿਕਲ ਪੈਟਰਨ ਦਿੱਤੇ ਗਏ ਹਨ ਜੋ ਰੋਜ਼ਾਨਾ ਉਤਪਾਦਾਂ ਵਿੱਚ ਆਉਂਦੇ ਹਨ।
ਜਦੋਂ ਕਈ consumers ਨੂੰ ਇੱਕੋ ਹੀ ਇਵੈਂਟ 'ਤੇ ਪ੍ਰਤੀਕ੍ਰਿਆ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ—ਬਿਨਾਂ publisher ਜਾਣਨ ਦੇ ਕਿ ਉਹ ਕੌਣ ਹਨ—ਤਾਂ publish/subscribe ਇੱਕ ਸਾਫ਼ ਫਿੱਟ ਹੁੰਦਾ ਹੈ।
ਉਦਾਹਰਨ: ਜਦੋਂ ਇੱਕ ਯੂਜ਼ਰ ਆਪਣਾ ਪ੍ਰੋਫ਼ਾਈਲ ਅੱਪਡੇਟ ਕਰਦਾ ਹੈ, ਤੁਸੀਂ search indexing, analytics, ਅਤੇ CRM sync ਨੂੰ ਸਮਾਂ-ਸੰਨੁਕਤ ਤੌਰ 'ਤੇ ਸੂਚਿਤ ਕਰ ਸਕਦੇ ਹੋ। Fanout exchange ਨਾਲ ਤੁਸੀਂ bound queues ਨੂੰ broadcast ਕਰ ਸਕਦੇ ਹੋ; topic exchange ਨਾਲ ਤੁਸੀਂ ਨਿਰਦਿਸ਼ਟ ਰੂਪ ਵਿੱਚ ਰੂਟ ਕਰ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਣ user.updated, user.deleted)। ਇਹ ਸੇਵਾਵਾਂ ਨੂੰ ਟਾਈਟਲੀ ਕਨੈਕਟ ਹੋਣ ਤੋਂ ਬਚਾਉਂਦਾ ਅਤੇ ਟੀਮਾਂ ਨੂੰ producer ਬਦਲੇ ਬਿਨਾਂ ਨਵੀਆਂ subscribers ਜੋੜਨ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦਾ ਹੈ।
ਜੇ ਕੋਈ ਟਾਸਕ ਸਮਾਂ ਲੈਂਦਾ ਹੈ, ਤਾਂ ਇਸਨੂੰ queue 'ਤੇ ਧੱਕੋ ਅਤੇ workers ਨੂੰ asynchronously ਪ੍ਰੋਸੈਸ ਕਰਨ ਦਿਓ:
ਇਸ ਨਾਲ web requests ਤੇਜ਼ ਰਹਿਣਗੇ ਅਤੇ ਤੁਸੀਂ workers ਨੂੰ ਅਲੱਗ ਤੌਰ 'ਤੇ ਸਕੇਲ ਕਰ ਸਕਦੇ ਹੋ। ਇਹ concurrency ਨਿਯੰਤਰਣ ਕਰਨ ਦਾ ਕੁਦਰਤੀ ਤਰੀਕਾ ਵੀ ਹੈ: queue ਤੁਹਾਡੀ “to-do list” ਬਣ ਜਾਂਦੀ ਹੈ, ਅਤੇ worker ਗਿਣਤੀ ਤੁਹਾਡੀ throughput ਨਿਯੰਤਰਣ ਕਰਦੀ ਹੈ।
ਬਹੁਤ ਸਾਰੇ ਵਰਕਫਲੋ ਸੇਵਾ ਸਰਹੱਦਾਂ ਦੇ ਪਾਰ ਹੁੰਦੇ ਹਨ: order → billing → shipping ਇੱਕ ਕਲਾਸਿਕ ਉਦਾਹਰਨ ਹੈ। ਇੱਕ ਸੇਵਾ ਨੂੰ ਦੂਜੀ ਨੂੰ ਕਾਲ ਕਰਨ ਅਤੇ ਰੁਕਣ ਦੀ ਥਾਂ, ਹਰ ਸੇਵਾ ਇੱਕ ਇਵੈਂਟ publish ਕਰ ਸਕਦੀ ਹੈ ਜਦੋਂ ਉਹ ਆਪਣੇ ਕਦਮ ਨੂੰ ਖਤਮ ਕਰ ਲੈਂਦੀ ਹੈ। ਡਾਊਨਸਟਰੀਮ ਸੇਵਾਵਾਂ ਇਵੈਂਟ consume ਕਰਦੀਆਂ ਹਨ ਅਤੇ ਵਰਕਫਲੋ ਅੱਗੇ ਵਧਦੀ ਹੈ।
ਇਸ ਨਾਲ resilience ਵਧਦੀ ਹੈ (shipping ਵਿੱਚ ਅਸਥਾਈ ਬੰਦਸ਼ checkout ਨੂੰ ਬਰਬਾਦ ਨਹੀਂ ਕਰਦੀ) ਅਤੇ ਮੈਨੇਜਮੈਂਟ ਸਾਫ਼ ਹੋ ਜਾਂਦਾ ਹੈ: ਹਰ ਸੇਵਾ ਉਹਨਾਂ ਇਵੈਂਟਾਂ 'ਤੇ ਪ੍ਰਭਾਵਿਤ ਹੁੰਦੀ ਹੈ ਜੋ ਉਸਨੂੰ ਚਿੰਤਾ ਕਰਦੇ ਹਨ।
RabbitMQ ਤੁਹਾਡੇ ਐਪ ਅਤੇ ਉਹ dependencies (ਤੀਜੀ-ਪੱਖ APIs, legacy systems, batch databases) ਦੇ ਵਿਚਕਾਰ ਵੀ ਇੱਕ ਬਫਰ ਦੇ ਤੌਰ 'ਤੇ ਕੰਮ ਕਰਦਾ ਹੈ। ਤੁਸੀਂ ਬੇਹਤ ਤੇਜ਼ੀ ਨਾਲ requests enqueue ਕਰ ਸਕਦੇ ਹੋ, ਫਿਰ controlled retries ਨਾਲ ਉਨ੍ਹਾਂ ਨੂੰ ਪ੍ਰੋਸੈਸ ਕਰੋ। ਜੇ dependency ਡਾਊਨ ਹੈ, ਕੰਮ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਜਮ੍ਹਾ ਹੋ ਜਾਂਦਾ ਹੈ ਅਤੇ ਬਾਅਦ ਵਿੱਚ drain ਹੁੰਦਾ ਹੈ—ਇਸ ਦੀ ਥਾਂ ਕਿ ਸਾਰੇ ਐਪਲਿਕੇਸ਼ਨ ਟਾਈਮਆਉਟ ਹੋਣ।
ਜੇ ਤੁਸੀਂ ਕਦਮ ਬੜਾ ਕੇ queues ਲੈ ਕੇ ਜਾਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਛੋਟੀ "async outbox" ਜਾਂ ਇੱਕ single background-job queue ਆਮ ਤੌਰ 'ਤੇ ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਚੰਗਾ ਪਹਿਲਾ ਕਦਮ ਹੁੰਦਾ ਹੈ (ਦੇਖੋ /blog/next-steps-rollout-plan)।
ਇੱਕ RabbitMQ ਸੈਟਅਪ ਅਚਛਾ ਕੰਮ ਕਰਦਾ ਰਹਿੰਦਾ ਹੈ ਜਦੋਂ routes ਅੰਦਾਜ਼ਾ ਲਗਾਉਣ ਵਿੱਚ ਆਸਾਨ, ਨਾਂਮ ਲਗਾਤਾਰ ਅਤੇ payloads ਬਦਲਣ ਤੇ ਪੁਰਾਣੇ consumers ਨੂੰ ਤੋੜਦੇ ਨਹੀਂ। ਹੋਰ queue ਜੋੜਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਸੁਨੇਹੇ ਦੀ "ਕਹਾਣੀ" ਸਪਸ਼ਟ ਹੈ: ਇਹ ਕਿਥੋਂ ਆਉਂਦੀ ਹੈ, ਕਿਵੇਂ routed ਹੁੰਦੀ ਹੈ, ਅਤੇ ਇਕ ਟੀਮੀ ਮੇਬਰ ਇਹ end-to-end ਕਿਸ ਤਰ੍ਹਾਂ ਡਿਬੱਗ ਕਰੇਗਾ।
ਸਹੀ exchange ਚੁਣਨਾ ਅੱਗੇ ਨਾ-ਚਾਹੀਦਾ bindings ਅਤੇ ਹੈਰਾਨੀ ਭਰੇ fan-outs ਘਟਾਉਂਦਾ ਹੈ:
billing.invoice.created)।billing.*.created, *.invoice.*)। ਇਹ event-style routing ਲਈ ਆਮ ਚੋਣ ਹੈ।ਇੱਕ ਚੰਗਾ ਕੋਆਲ: ਜੇ ਤੁਸੀਂ ਕੋਡ ਵਿੱਚ ਕੁਝ ਜਟਿਲ routing logic "ਅਵਿਸ਼ਕਾਰ" ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਇਹ ਸ਼ਾਇਦ topic exchange ਪੈਟਰਨ ਵਿੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
Message bodies ਨੂੰ public APIs ਵਾਂਗੋਂ ਸਲਾਹ-ਮੰਨੋ। ਖੁਲ੍ਹੇ ਤੌਰ 'ਤੇ versioning (ਉਦਾਹਰਨ, top-level field schema_version: 2) ਅਤੇ backward compatibility ਉਦੇਸ਼ ਰੱਖੋ:
ਇਸ ਨਾਲ ਪੁਰਾਣੇ consumers ਆਪਣੇ ਸਮੇਂ 'ਤੇ ਨਵੇਂ schema ਉਪਣ ਕਰਨਗੇ ਅਤੇ ਕੰਮ ਜਾਰੀ ਰਹੇਗਾ।
ਤਕਨੀਕੀ ਸਮੱਸਿਆਵਾਂ ਸਸਤੀ ਬਣਾਉਣ ਲਈ metadata ਨੂੰ ਸਟੈਂਡਰਡ ਕਰੋ:
correlation_id: ਉਹ commands/events ਜੋ ਇੱਕੋ ਕਾਰੋਬਾਰੀ ਕਾਰਵਾਈ ਨਾਲ ਸਬੰਧਤ ਹਨ ਉਹਨਾਂ ਨੂੰ ਜੋੜਦਾ ਹੈ।trace_id (ਜਾਂ W3C traceparent): messages ਨੂੰ HTTP ਅਤੇ async flows ਵਿੱਚ distributed tracing ਨਾਲ ਜੋੜਦਾ ਹੈ।ਜਦੋਂ ਹਰ publisher ਇਹਨਾਂ ਨੂੰ ਲਗਾਤਾਰ ਸੈਟ ਕਰਦਾ ਹੈ, ਤੁਸੀਂ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਕਈ ਸੇਵਾਵਾਂ ਵਿੱਚ ਆਸਾਨੀ ਨਾਲ ਫਾਲੋ ਕਰ ਸਕਦੇ ਹੋ।
ਤੁਹਾਡੇ ਨਾਂ predictable ਅਤੇ searchable ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ। ਇੱਕ ਆਮ ਪੈਟਰਨ:
<domain>.<type> (ਉਦਾਹਰਨ, billing.events)<domain>.<entity>.<verb> (ਉਦਾਹਰਨ, billing.invoice.created)<service>.<purpose> (ਉਦਾਹਰਨ, reporting.invoice_created.worker)Consistency cleverness ਨਾਲ ਵਧੀਆ ਹੈ: ਭਵਿੱਤ ਦਾ ਤੁਸੀਂ (ਅਤੇ on-call ਰੋਟੇਸ਼ਨ) ਤੁਹਾਡਾ ਤਹਿ-ਦਿਲੋਂ ਧੰਨਵਾਦ ਕਰੇਗਾ।
ਭਰੋਸੇਯੋਗ messaging ਆਮ ਤੌਰ 'ਤੇ ਫ਼ੇਲ੍ਹ ਲਈ ਯੋਜਨਾ ਬਣਾਉਣ ਬਾਰੇ ਹੁੰਦੀ ਹੈ: consumers crash ਹੋ ਸਕਦੇ ਹਨ, downstream APIs timeout ਹੋ ਸਕਦੇ ਹਨ, ਅਤੇ ਕੁਝ events ਸਿਰਫ਼ ਖਰਾਬ schema ਜਾਂ ਘਟੇ ਅੰਸ਼ਾਂ ਹੋ ਸਕਦੇ ਹਨ। RabbitMQ ਤੁਹਾਨੂੰ ਟੂਲ ਦਿੰਦਾ ਹੈ, ਪਰ ਤੁਹਾਡੇ ਐਪ ਕੋਡ ਨੂੰ ਸਹਿਯੋਗ ਕਰਨਾ ਪੈਂਦਾ ਹੈ।
ਇੱਕ ਆਮ ਸੈਟਅਪ at-least-once delivery ਹੈ: ਇੱਕ ਸੁਨੇਹਾ ਇੱਕ ਤੋਂ ਵੱਧ ਵਾਰ ਡਿਲਿਵਰ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਉਨ੍ਹਾਂ ਨੂੰ ਚੁਪਚਾਪ ਗੁਆਉਣਾ ਨਹੀਂ ਚਾਹੀਦਾ। ਇਹ ਅਕਸਰ ਉਸ ਵੇਲੇ ਹੁੰਦਾ ਹੈ ਜਦੋਂ consumer ਸੁਨੇਹਾ ਲੈਂਦਾ ਹੈ, ਕੰਮ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ, ਅਤੇ ਫਿਰ ਅਕਾਂਕਸ਼ਾਂ ਤੋਂ ਪਹਿਲਾਂ ਫੇਲ੍ਹ ਹੋ ਜਾਂਦਾ ਹੈ—RabbitMQ ਸੁਨੇਹਾ ਮੁੜ queue ਕਰੇਗਾ ਅਤੇ redeliver ਕਰੇਗਾ।
ਵਿਆਵਹਾਰਿਕ ਨਤੀਜਾ: duplicates ਆਮ ਹਨ, ਇਸ ਲਈ ਤੁਹਾਡਾ handler ਬਾਰ-ਬਾਰ ਚਲਣ ਲਈ ਸੁਰੱਖਿਅਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
Idempotency ਦਾ ਮਤਲਬ ਹੈ "ਇੱਕੋ ਸੁਨੇਹੇ ਨੂੰ ਦੋ ਵਾਰੀ ਪ੍ਰੋਸੈਸ ਕਰਨ ਨਾਲ ਇੱਕੋ ਹੀ ਨਤੀਜਾ ਆਵੇ ਜਿਵੇਂ ਇੱਕ ਵਾਰੀ ਕਰਕੇ ਹੋਵੇ।" ਕੁਝ ਲਾਭਕਾਰੀ ਤਰੀਕੇ:
message_id (ਜਾਂ ਕਾਰੋਬਾਰੀ ਕੀ, ਜਿਵੇਂ order_id + event_type + version) ਸ਼ਾਮਲ ਕਰੋ ਅਤੇ ਇਸਨੂੰ TTL ਨਾਲ “processed” ਟੇਬਲ/ਕੈਸ਼ ਵਿੱਚ ਸਟੋਰ ਕਰੋ।PENDING ਹੋਣ 'ਤੇ ਹੀ update) ਜਾਂ ਡੇਟਾਬੇਸ uniqueness constraints ਨਾਲ double-creates ਰੋਕੋ।Retries ਨੂੰ ਬੈਦਾਰੀ ਤੌਰ 'ਤੇ ਇੱਕ ਵੱਖਰੀ flow ਵਜੋਂ ਦੇਖੋ, ਨਾ ਕਿ consumer ਵਿੱਚ ਤੰਗ ਲੂਪ ਵਜੋਂ।
ਆਮ ਪੈਟਰਨ:
ਇਸ ਨਾਲ backoff ਬਣ ਜਾਂਦਾ ਹੈ ਬਿਨਾਂ messages ਨੂੰ "unacked" ਰੱਖਣ ਦੇ।
ਕੁਝ ਸੁਨੇਹੇ ਕਦੇ ਵੀ ਸਫਲ ਨਹੀਂ ਹੋਣਗੇ (ਖਰਾਬ schema, ਗੁੰਮ ਹੋਈ referenced data, ਕੋਡ ਬੱਗ)। ਉਹਨਾਂ ਦੀ ਪਛਾਣ:
ਇਹਨਾਂ ਨੂੰ DLQ ਵਿੱਚ quarantine ਭੇਜੋ। DLQ ਨੂੰ ਇੱਕ operational inbox ਵਜੋਂ ਵੇਖੋ: payloads ਦੀ ਜਾਂਚ ਕਰੋ, ਮੂਢਲੀ ਸਮੱਸਿਆ ਠੀਕ ਕਰੋ, ਫਿਰ ਚੋਣੀ ਗਈ ਸੁਨੇਹਿਆਂ ਨੂੰ ਮੈਨੁਅਲ ਤੌਰ 'ਤੇ replay ਕਰੋ (ਵਧੀਆ ਤੌਰ 'ਤੇ ਇੱਕ ਨਿਯੰਤਰਿਤ ਟੂਲ/ਸਕ੍ਰਿਪਟ ਦੇ ਜ਼ਰੀਏ) ਨਾ ਕਿ ਸਾਰਿਆਂ ਨੂੰ ਮੁੜ ਮੁੱਖ queue ਵਿੱਚ dump ਕਰੋ।
RabbitMQ ਦਾ ਪ੍ਰਦਰਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਕੁਝ ਪ੍ਰਯੋਗਕਾਰੀ ਕਾਰਕਾਂ ਨਾਲ ਸੀਮਤ ਹੁੰਦਾ ਹੈ: ਤੁਸੀਂ connections ਨੂੰ ਕਿਵੇਂ ਮੈਨੇਜ ਕਰਦੇ ਹੋ, consumers ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਕੰਮ ਕਰ ਸਕਦੇ ਹਨ, ਅਤੇ ਕੀ queues ਨੂੰ "ਸਟੋਰੇਜ" ਵਜੋਂ ਵਰਤਿਆ ਜਾ ਰਿਹਾ ਹੈ। ਮਕਸਦ ਸਥਿਰ throughput ਹੈ ਬਿਨਾਂ ਵੱਧ ਰਿਹਾ backlog ਬਣਾਏ।
ਆਮ ਗਲਤੀ ਹਰ publisher ਜਾਂ consumer ਲਈ ਨਵਾਂ TCP connection ਖੋਲ੍ਹਣਾ ਹੈ। Connections ਸੋਚਣ ਤੋਂ ਵੱਧ ਭਾਰੀ ਹੁੰਦੇ ਹਨ (handshakes, heartbeats, TLS), ਇਸ ਲਈ ਉਹਨਾਂ ਨੂੰ ਲੰਬੇ ਸਮੇਂ ਲਈ ਜੀਵੰਤ ਰੱਖੋ ਅਤੇ reuse ਕਰੋ।
C******************************************************************************** (truncated for brevity in preview—full content preserved in final output)*
ਜੇ consumers ਇੱਕ ਵਾਰੀ ਵਿੱਚ ਬਹੁਤ ਸਾਰੇ ਸੁਨੇਹੇ ਖਿੱਚਦੇ ਹਨ, ਤਾਂ ਤੁਹਾਨੂੰ memory spikes, ਲੰਮੇ processing ਸਮੇਂ, ਅਤੇ ਅਸਮਤ latency ਵੇਖਣ ਨੂੰ ਮਿਲੇਗਾ। ਹਰ consumer ਲਈ prefetch ਸੈਟ ਕਰੋ ਤਾਂ ਜੋ ਉਹ ਨਿਯੰਤਰਿਤ ਗਿਣਤੀ ਵਾਲੇ unacked ਸੁਨੇਹੇ ਹੀ ਰੱਖੇ।
ਵਿਆਵਹਾਰਿਕ ਮਾਰਗਦਰਸ਼ਨ:
ਵੱਡੇ ਸੁਨੇਹੇ throughput ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ memory 'ਤੇ ਦਬਾਅ ਵਧਾਉਂਦੇ ਹਨ (publishers, broker, consumers ਤੇ)। ਜੇ ਤੁਹਾਡਾ ਪੇਲੋਡ ਵੱਡਾ ਹੈ (ਦਸਤਾਵੇਜ਼, ਚਿੱਤਰ, ਵੱਡਾ JSON), ਤਾਂ ਉਸਨੂੰ ਬਾਹਰ ਕਿਸੇ object storage ਜਾਂ ਡੇਟਾਬੇਸ ਵਿੱਚ ਰੱਖੋ ਅਤੇ ਸਿਰਫ਼ RabbitMQ ਰਾਹੀਂ ID + metadata ਭੇਜੋ।
ਇੱਕ ਚੰਗੀ ਸੂਚਨਾ: ਸੁਨੇਹੇ KB ਰੇਂਜ ਵਿੱਚ ਰੱਖੋ, MB ਨਹੀਂ।
Queue ਵਾਧਾ ਇੱਕ ਲੱਛਣ ਹੈ, रणनीਤੀ ਨਹੀਂ। producers ਨੂੰ ਧੀਮਾ ਕਰਨ ਲਈ backpressure ਸ਼ਾਮਲ ਕਰੋ:
ਸੰਦੇਹ ਹੋਵੇ ਤਾਂ ਇੱਕ-ਇੱਕ ਨੋਬ ਬਦਲੋ ਅਤੇ ਮਾਪੋ: publish rate, ack rate, queue length, ਅਤੇ end-to-end latency।
RabbitMQ ਦੀ ਸੁਰੱਖਿਆ ਆਮ ਤੌਰ 'ਤੇ "ਕਿਨਾਰਿਆਂ" ਨੂੰ ਕੱਸਣਾ ਹੁੰਦੀ ਹੈ: clients ਕਿਵੇਂ connect ਕਰਦੇ ਹਨ, ਕੌਣ ਕੀ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ credentials ਕਿਵੇਂ ਸੁਰੱਖਿਅਤ ਰੱਖੇ ਜਾਂਦੇ ਹਨ। ਇਹ ਚੈਕਲਿਸਟ ਇੱਕ ਬੇਸਲਾਈਨ ਵਜੋਂ ਵਰਤੋ ਅਤੇ ਫਿਰ ਆਪਣੇ compliance ਲੋੜਾਂ ਅਨੁਸਾਰ ਅਨੁਕੂਲ ਕਰੋ।
RabbitMQ permissions ਬੜੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਲਗਾਤਾਰ ਵਰਤਦੇ ਹੋ:
Operational hardening (ports, firewalls, auditing) ਲਈ ਇੱਕ ਛੋਟਾ internal runbook ਰੱਖੋ ਅਤੇ ਜਿਸਨੂੰ /docs/security ਵਿੱਚ ਲਿੰਕ ਕਰੋ ਤਾਂ ਕਿ ਟੀਮ ਇੱਕเดียว ਨਿਯਮ ਪ徂ੇ।
ਜਦੋਂ RabbitMQ ਠੀਕ ਤਰ੍ਹਾਂ ਕੰਮ ਨਹੀਂ ਕਰ ਰਿਹਾ, ਤਕਲੀਫ਼ਾਂ ਤੁਹਾਡੇ ਐਪਲੀਕੇਸ਼ਨ 'ਤੇ ਪਹਿਲਾਂ ਨਜ਼ਰ ਆਉਂਦੀਆਂ ਹਨ: slow endpoints, timeouts, missing updates, ਜਾਂ jobs ਜੋ "ਕਦੇ ਮੁੱਕਦੀਆਂ ਨਹੀਂ"। ਚੰਗੀ observability ਤੁਹਾਨੂੰ ਪੁਸ਼ਟੀ ਕਰਨ ਦਿੰਦੀ ਹੈ ਕਿ broker ਕਾਰਨ ਹੈ ਜਾਂ ਨਹੀਂ, bottleneck ਕਿੱਥੇ ਹੈ (publisher, broker, ਜਾਂ consumer), ਅਤੇ ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ ਨੋਟਿਸ ਹੋਣ ਤੋਂ ਪਹਿਲਾਂ ਕਾਰਵਾਈ ਕਰਨ ਲਈ ਸਮਰੱਥਾ ਦਿੰਦੀ ਹੈ।
ਪਹਿਲਾਂ ਉਹਨਾਂ ਨਿSIGNALਜ਼ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਦੱਸਦੀਆਂ ਹਨ ਕਿ ਸੁਨੇਹੇ ਬਹਿ ਰਹੇ ਹਨ:
ਪੁਲੀਨ thresholds ਦੀ ਥਾਂ ਰੁਝਾਨ 'ਤੇ alert ਕਰੋ:
depth > X ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਕਾਰਜਯੋਗ ਹੈ।Broker logs ਤੁਹਾਨੂੰ ਵੱਖ-ਵੱਖ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ: "RabbitMQ ਡਾਊਨ ਹੈ" ਜਾਂ "clients ਗਲਤ ਵਰਤ ਰਹੇ ਹਨ"। authentication failures, blocked connections (resource alarms), ਅਤੇ ਬਾਰ-ਬਾਰ channel errors ਦੀ ਖੋਜ ਕਰੋ। ਐਪਲੀਕੇਸ਼ਨ ਪਾਸੇ, ਹਰ processing ਕੋਸ਼ਿਸ਼ ਇੱਕ correlation ID, queue name, ਅਤੇ outcome (acked, rejected, retried) ਲਾਗ ਕਰੋ।
ਜੇ ਤੁਸੀਂ distributed tracing ਵਰਤਦੇ ਹੋ, ਤਾਂ trace headers ਨੂੰ message properties ਰਾਹੀਂ propagate ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ "API request → published message → consumer work" ਨੂੰ ਜੋੜ ਸਕੋ।
ਹਰ ਮਹੱਤਵਪੂਰਨ flow ਲਈ ਇੱਕ ਡੈਸ਼ਬੋਰਡ ਬਣਾਓ: publish rate, ack rate, depth, unacked, requeues, ਅਤੇ consumer count। ਡੈਸ਼ਬੋਰਡ 'ਤੇ ਸਿਧਾ internal runbook ਲਈ ਲਿੰਕ ਜੋੜੋ (ਜਿਵੇਂ /docs/monitoring) ਅਤੇ on-call responders ਲਈ "ਪਹਿਲਾਂ ਕੀ ਜਾਂਚਣਾ ਹੈ" ਦੀ ਚੈੱਕਲਿਸਟ ਸ਼ਾਮਲ ਕਰੋ।
ਜਦੋਂ ਕੁਝ "ਸਿਰਫ਼ ਹਿਲਣਾ ਬੰਦ" ਹੋ ਜਾਂਦਾ ਹੈ RabbitMQ ਵਿੱਚ, ਪਹਿਲਾਂ restart ਕਰਨ ਦਾ ਮਨ ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ। ਜ਼ਿਆਦਾਤਰ ਸਮੱਸਿਆਵਾਂ ਸਪਸ਼ਟ ਹੋ ਜਾਂਦੀਆਂ ਹਨ ਜਦੋਂ ਤੁਸੀਂ (1) bindings ਅਤੇ routing, (2) consumer health, ਅਤੇ (3) resource alarms ਦੇਖਦੇ ਹੋ।
ਜੇ publishers "ਸਫਲਤਾਪੂਰਵਕ ਭੇਜਿਆ" ਰਿਪੋਰਟ ਕਰ ਰਹੇ ਹਨ ਪਰ queues ਖਾਲੀ ਰਹਿੰਦੀ ਹੈ (ਜਾਂ ਗਲਤ queue ਭਰਦੀ ਹੈ), ਤਾਂ routing ਦੀ ਜਾਂਚ ਕਰੋ code ਤੋਂ ਪਹਿਲਾਂ।
Management UI ਵਿੱਚ ਸ਼ੁਰੂਆਤ ਕਰੋ:
topic exchanges ਵਿੱਚ)।ਜੇ queue ਵਿੱਚ messages ਹਨ ਪਰ ਕੁਝ consume ਨਹੀਂ ਕਰ ਰਿਹਾ, ਤਾਂ ਪੁਸ਼ਟੀ ਕਰੋ:
Duplicates ਆਮ ਤੌਰ 'ਤੇ retries (consumer crash ਇੱਕ ਵਾਰ ਕੰਮ ਕਰਨ ਤੋਂ ਬਾਅਦ ਪਰ ack ਤੋਂ ਪਹਿਲਾਂ), network interruptions, ਜਾਂ manual requeueing ਤੋਂ ਆਉਂਦੇ ਹਨ। ਇਸਦੀ ਨਿਵਾਰਨ ਲਈ handlers idempotent ਬਣਾਓ (ਉਦਾਹਰਨ: database ਵਿੱਚ message ID ਨਾਲ dedupe)।
Out-of-order delivery ਉਮੀਦ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਬਹੁਤ ਸਾਰੇ consumers ਹਨ ਜਾਂ requeues ਹੋ ਰਹੀਆਂ ਹਨ। ਜੇ order ਮਹੱਤਵਪੂਰਨ ਹੈ, ਤਾਂ ਉਸ queue ਲਈ ਇਕੱਲਾ consumer ਵਰਤੋਂ ਜਾਂ key ਅਨੁਸਾਰ partition ਕਰਕੇ ਬਹੁਤ ਸਾਰੀਆਂ queues ਬਣਾਓ।
Alarms RabbitMQ ਨੂੰ ਆਪਣੇ ਆਪ ਨੂੰ ਰੋਕਣ ਲਈ ਦਿੰਦੇ ਹਨ।
ਰੀਪਲੇ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਮੂਲ ਕਾਰਨ ਨੂੰ ਠੀਕ ਕਰੋ ਅਤੇ "poison message" ਲੂਪ ਨੂੰ ਰੋਕੋ। ਛੋਟੇ ਬੈਚਾਂ ਵਿੱਚ requeue ਕਰੋ, retry cap ਸ਼ਾਮਲ ਕਰੋ, ਅਤੇ failures metadata (attempt count, last error) ਨਾਲ stamp ਕਰੋ। ਸੋਚੋ ਕਿ replay ਕੀਤੇ ਸੁਨੇਹਿਆਂ ਨੂੰ ਇੱਕ ਤੁੱਲਨਾਤਮਕ queue ਵਿੱਚ ਭੇਜੋ ਪਹਿਲਾਂ, ਤਾਂ ਜੋ ਜੇ ਵਾਪਸ ਉਹੀ error ਆਉਂਦਾ ਹੈ ਤਾਂ ਤੁਸੀਂ ਫੌਰන් ਰੋਕ ਸਕੋ।
Messaging tool ਚੁਣਨਾ "ਸਭ ਤੋਂ ਵਧੀਆ" ਬਾਰੇ ਨਹੀਂ, ਬਲਕਿ ਤੁਹਾਡੇ ਟ੍ਰੈਫਿਕ ਪੈਟਰਨ, ਫੇਲ੍ਹ ਸਹਿਣਸ਼ੀਲਤਾ, ਅਤੇ operational ਆਰਾਮ ਦੇ ਨਾਲ ਮੇਲ ਖਾਣ ਉੱਤੇ ਨਿਰਭਰ ਹੈ।
RabbitMQ ਉਹ ਵੇਲੇ ਚਮਕਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਭਰੋਸੇਯੋਗ ਸੁਨੇਹੇ ਡਿਲਿਵਰੀ ਅਤੇ ਲਚਕੀਲਾ routing ਚਾਹੀਦਾ ਹੈ। ਇਹ classic async workflows—commands, background jobs, fan-out notifications, ਅਤੇ request/response patterns—ਲਈ ਮਜ਼ਬੂਤ ਚੋਣ ਹੈ, ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਤੁਸੀਂ:
ਜੇ ਤੁਹਾਡੀਆਂ ਐਪਲੀਕੇਸ਼ਨਾਂ event-driven ਹਨ ਪਰ ਮੁੱਖ ਲਕੜੀ ਕੰਮ ਨੂੰ "ਚਲਾਉਣਾ" ਹੈ ਨਾ ਕਿ ਲੰਮੀ ਇਵੈਂਟ ਇਤਿਹਾਸ ਨੂੰ ਰੱਖਣਾ, ਤਾਂ RabbitMQ ਅਕਸਰ ਇੱਕ ਆਰਾਮਦಾಯಕ ਡਿਫਾਲਟ ਹੁੰਦਾ ਹੈ।
Kafka ਅਤੇ ਸਮਾਨ ਪਲੇਟਫਾਰਮ ਉੱਚ-থਰਪੁੱਟ streaming ਅਤੇ ਲੰਬੀ ਮੁਦੱਤ event logs ਲਈ ਬਣਾਏ ਗਏ ਹਨ। Kafka-ਜਿਹੇ ਸਿਸਟਮ ਨੂੰ ਚੁਣੋ ਜਦੋਂ ਤੁਹਾਨੂੰ:
ਬਦਲਾ: Kafka-ਸਟਾਈਲ ਸਿਸਟਮ higher operational overhead ਲਿਆ ਸਕਦੇ ਹਨ ਅਤੇ ਤੁਹਾਨੂੰ throughput-oriented ਡਿਜ਼ਾਈਨ ਵੱਲ ਧਕਾਅ ਸਕਦੇ ਹਨ (batching, partition strategy)। RabbitMQ ਆਮ ਤੌਰ 'ਤੇ low-to-moderate throughput ਲਈ ਅਤੇ ਘੱਟ end-to-end latency ਅਤੇ ਜਟਿਲ routing ਲਈ ਆਸਾਨ ਰਹਿੰਦਾ ਹੈ।
ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਐਪ ਹੈ ਜੋ jobs ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਇੱਕ worker pool consumes ਕਰਦਾ ਹੈ—ਅਤੇ ਤੁਸੀਂ simpler semantics ਨਾਲ ਠੀਕ ਹੋ—ਤਾਂ Redis-based queue (ਜਾਂ managed task service) ਕਾਫ਼ੀ ਹੋ ਸਕਦੀ ਹੈ। ਟੀਮਾਂ ਅਕਸਰ ਇਸਨੂੰ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ ਜਦੋਂ ਉਹ stronger delivery guarantees, dead-lettering, ਬਹੁਤ ਸਾਰੇ routing patterns ਜਾਂ producers/consumers ਵਿੱਚ ਸਾਫ਼ ਵੱਖਰਾ-ਪਨ੍ਹਨਾ ਚਾਹੁੰਦੇ ਹਨ।
ਆਪਣੇ message contracts ਨੂੰ ਇੰਝ ਡਿਜ਼ਾਈਨ ਕਰੋ ਜਿਵੇਂ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ move ਕਰ ਸਕਦੇ ਹੋ:
ਜੇ ਤੁਹਾਨੂੰ ਬਾਅਦ ਵਿੱਚ replayable streams ਦੀ ਲੋੜ ਹੋਵੇ, ਤਾਂ ਤੁਸੀਂ ਅਕਸਰ RabbitMQ events ਨੂੰ ਇੱਕ log-based ਸਿਸਟਮ ਵਿੱਚ bridge ਕਰ ਸਕਦੇ ਹੋ ਜਦੋਂ ਤਕ RabbitMQ operational workflows ਲਈ ਰਹਿੰਦਾ ਹੈ। ਪ੍ਰਯੋਗਕ ਰੋਲਆਉਟ ਯੋਜਨਾ ਲਈ, ਵੇਖੋ /blog/rabbitmq-rollout-plan-and-checklist।
RabbitMQ ਰੋਲਆਉਟ ਉਹ ਵੇਲੇ ਸਭ ਤੋਂ ਵਧੀਆ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇਸਨੂੰ ਇੱਕ product ਵਾਂਗ ਸੋਚੋ: ਛੋਟਾ ਸ਼ੁਰੂ ਕਰੋ, ਮਾਲਕੀ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਅਤੇ ਵਧਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਭਰੋਸੇਯੋਗਤਾ ਪ੍ਰਮਾਣਿਤ ਕਰੋ।
ਇੱਕ workflow ਚੁਣੋ ਜੋ async ਪ੍ਰੋਸੈਸਿੰਗ ਨਾਲ ਫਾਇਦਾ ਪਾਏ (ਉਦਾਹਰਨ: emails ਭੇਜਣਾ, reports ਬਣਾਉਣਾ, ਤੀਜੀ-ਪੱਖ API ਨਾਲ sync)।
ਜੇ ਤੁਹਾਨੂੰ naming, retry tiers, ਅਤੇ ਮੂਢਲੀ ਨੀਤੀਆਂ ਲਈ ਇੱਕ reference template ਦੀ ਲੋੜ ਹੋਵੇ, ਉਹ /docs ਵਿੱਚ centralized ਰੱਖੋ।
ਕਈ ਟੀਮਾਂ Koder.ai ਵਰਤਦੀਆਂ ਹਨ ਤਾਂ ਜੋ ਚੈਟ prompt ਤੋਂ ਇੱਕ ਛੋਟਾ producer/consumer ਸਕੈਲਟਨ ਜੈਨਰੇਟ ਕਰਨ (naming conventions, retry/DLQ wiring, trace/correlation headers ਨਾਲ), ਫਿਰ source ਕੋਡ export ਕਰਕੇ review ਅਤੇ planning mode ਵਿੱਚ iteration ਕਰਨ।
RabbitMQ ਉਸ ਵੇਲੇ ਕਾਮਯਾਬ ਹੁੰਦਾ ਹੈ ਜਦੋਂ "ਕਿਸੇ ਕੋਲ ਕਿਊ ਦੀ ਮਾਲਕੀ" ਹੋਵੇ। ਪ੍ਰੋਡਕਸ਼ਨ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਫੈਸਲਾ ਕਰੋ:
ਜੇ ਤੁਸੀਂ support ਜਾਂ managed hosting formalize ਕਰ ਰਹੇ ਹੋ, ਤਦ expectations ਪਹਿਲਾਂ ਹੀ ਮਿਲਾਓ (ਦੇਖੋ /pricing) ਅਤੇ incidents ਜਾਂ onboarding help ਲਈ contact route ਸੈਟ ਕਰੋ (/contact)।
ਛੋਟੇ, ਸਮਾਂ-ਬੱਧ exercises ਚਲਾਓ ਤਾਂ ਕਿ ਭਰੋਸਾ ਬਣੇ:
ਜਦੋਂ ਇੱਕ ਸੇਵਾ ਕੁਝ ਹਫ਼ਤਿਆਂ ਲਈ stable ਹੋ ਜਾਵੇ, ਉਹੇ ਪੈਟਰਨ ਦੁਹਰਾਓ—ਹਰ ਟੀਮ ਲਈ ਨਵਾਂ ਕੁਝ ਬਣਾਉਣ ਦੀ ਲੋੜ ਨਹੀਂ।
RabbitMQ ਨੂੰ ਉਹ ਸਮਾਂ ਵਰਤੋਂ ਜਦੋਂ ਤੁਸੀਂ ਸੇਵਾਵਾਂ ਨੂੰ ਡੀਕੈਪਲ ਕਰਨਾ, ਟ੍ਰੈਫਿਕ ਸਪੀਕਸ ਨਿਭਾਣੇ ਜਾਂ ਰਿਕਵੇਸਟ ਪਾਥ ਤੋਂ ਭਾਰੀ ਕੰਮ ਨੂੰ ਹਟਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ।
ਚੰਗੇ ਮਿਸਾਲਾਂ ਵਿੱਚ background jobs (ਈਮੇਲ, PDF), ਬਹੁਤ ਸਾਰਿਆਂ ਨੂੰ ਨੋਟੀਫਿਕੇਸ਼ਨ ਭੇਜਣਾ, ਅਤੇ ਉਹ ਵਰਕਫਲੋ ਜੋ ਅਸਥਾਈ ਤੌਰ ਤੇ ਨੀਚੇ ਵਾਲੀਆਂ ਸੇਵਾਵਾਂ ਨਾਲ ਰੁਕਣਾ ਨਹੀਂ ਚਾਹੁੰਦੇ ਸ਼ਾਮਿਲ ਹਨ।
ਇਸ ਨੂੰ ਉਸ ਵੇਲੇ ਨਾ ਵਰਤੋ ਜਦੋਂ ਤੁਹਾਨੂੰ ਤੁਰੰਤ ਉੱਤਰ ਦੀ ਲੋੜ ਹੋਵੇ (ਸਧਾਰਨ ਰੀਡ/ਵੈਰੀਫਿਕੇਸ਼ਨ) ਜਾਂ ਜਦੋਂ ਤੁਸੀਂ versioning, retries ਅਤੇ monitoring ਲਈ ਵਚਨਬੱਧ ਨਹੀਂ ਹੋ—ਇਹ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਵਿਕਲਪਿਕ ਨਹੀਂ ਹਨ।
ਇੱਕ exchange ਵਿੱਚ ਪਬਲਿਸ਼ ਕਰੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ queues ਵਿੱਚ ਰੂਟ ਕਰੋ:
orders.* ਜਾਂ orders.# ਵਰਗੀਆਂ ਲਚਕੀਲੀ ਪੈਟਰਨਾਂ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ topic exchange ਵਰਤੋ।ਅਧਿਕਤਰ ਟੀਮਾਂ topic exchanges ਨੂੰ event-style routing ਲਈ ਡਿਫੌਲਟ ਰੱਖਦੀਆਂ ਹਨ।
Queue messages ਨੂੰ ਸੰਭਾਲਦਾ ਹੈ ਜਦੋਂ ਤੱਕ consumer ਉਹਨਾਂ ਨੂੰ ਪ੍ਰੋਸੈਸ ਨਹੀਂ ਕਰ ਲੈਂਦਾ; binding ਉਹ ਨਿਯਮ ਹੈ ਜੋ exchange ਨੂੰ queue ਨਾਲ ਜੋੜਦਾ ਹੈ।
Routing ਸਮੱਸਿਆ ਨਿਵਾਰਣ ਲਈ:
ਇਹ ਤਿੰਨ ਜਾਂਚਾਂ ਜ਼ਿਆਦਾਤਰ "ਪਬਲਿਸ਼ ਹੋਇਆ ਪਰ ਨਹੀਂ ਖਪਿਆ" ਘਟਨਾਵਾਂ ਦੀ ਵਜ੍ਹਾ ਹੁੰਦੀਆਂ ਹਨ।
Work queue ਵਰਤੋਂ ਜਦੋਂ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਹਰ ਟਾਸਕ ਨੂੰ ਉਨ੍ਹਾਂ ਵਿੱਚੋਂ ਇੱਕ(worker) ਹੰਡਲ ਕਰੇ।
ਵਰਤੋਂਯੋਗ ਸੈਟਅਪ ਟਿਪਸ:
At-least-once delivery ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਇੱਕ ਸੁਨੇਹਾ ਵਾਰ-ਵਾਰ ਡਿਲਿਵਰ ਹੋ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਨ ਲਈ, ਜੇ consumer ਨੇ ਕੰਮ ਕੀਤਾ ਪਰ ack ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ crash ਹੋ ਗਿਆ)।
ਇਸ ਲਈ consumers ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਓ:
message_id (ਜਾਂ ਕਾਰੋਬਾਰੀ ਕੀ) ਵਰਤੋ ਅਤੇ processed IDs TTL ਨਾਲ ਰਿਕਾਰਡ ਕਰੋ।ਡਿਜ਼ਾਇਨ ਅਸੀਂਪੈਕਟ: duplicates ਆਮ ਹਨ—ਉਹਨਾਂ ਲਈ ਤਿਆਰ ਰਹੋ।
ਟਾਇਟ requeue loops ਤੋਂ ਬਚੋ। ਇੱਕ ਆਮ ਢਾਂਚਾ "retry queues" + DLQ ਹੈ:
DLQ ਤੋਂ replay ਸਿਰਫ ਮੂਲ ਕਾਰਨ ਠੀਕ ਕਰਨ ਤੋਂ ਬਾਅਦ ਕਰੋ ਅਤੇ ਛੋਟੇ ਬੈਚਾਂ ਵਿੱਚ ਕਰੋ।
Message contracts ਨੂੰ maintainable ਰੱਖਣ ਲਈ ਪ੍ਰਤੀਖਿਆ ਅਤੇ ਨਾਂਮਕਰਨਪੁਰਨ ਪ੍ਰੈਕਟਿਸ ਅਪਣਾਓ:
schema_version ਸ਼ਾਮਲ ਕਰੋ।ਟਿੱਪਣੀਆਂ metadata ਲਈ:
ਉਹ ਕੁਝ ਸਿਗਨਲਾਂ ਜੋ ਕੰਮ ਦੀ ਸਰਗਰਮੀ ਦਿਖਾਉਂਦੇ ਹਨ ਉਨ੍ਹਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ:
Alert trends 'ਤੇ ਕਰੋ (ਉਦਾਹਰਨ: backlog 10 ਮਿੰਟ ਲਈ ਵਧ ਰਿਹਾ ਹੈ) ਅਤੇ ਲਾਗਜ਼ ਵਿੱਚ queue name, correlation_id ਅਤੇ outcome (acked/retried/rejected) ਦੀ ਜਾਣਕਾਰੀ ਸ਼ਾਮਲ ਰੱਖੋ।
ਘਰਮੁਖ ਸੁਰੱਖਿਆ ਕਦਮ:
ਇਹਨਾਂ ਲਈ ਛੋਟਾ internal runbook ਰੱਖੋ ਤਾਂ ਟੀਮ ਇੱਕ ਸਟੈਂਡਰਡ ਫਾਲੋ ਕਰੇ।
Flow ਕਿੱਥੇ ਰੁਕ ਰਿਹਾ ਹੈ ਇਹ ਲੱਭਣ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ:
ਰਿਸਟਾਰਟ ਕਰਨਾ ਆਮ ਤੌਰ 'ਤੇ ਪਹਿਲਾ ਜਾਂ ਸਭ ਤੋਂ ਵਧੀਆ ਕਦਮ ਨਹੀਂ ਹੁੰਦਾ।
correlation_id ਤਾਂ ਜੋ ਇੱਕ ਕਾਰੋਬਾਰੀ ਕਾਰਵਾਈ ਨਾਲ ਸਬੰਧਤ ਇਵੈਂਟ/ਕਮਾਂਡ ਜੋੜੇ ਜਾ ਸਕਣ।trace_id (ਜਾਂ W3C traceparent) ਤਾਂ ਜੋ async ਅਤੇ HTTP ਫਲੋਜ਼ ਵਿੱਚ distributed tracing ਜੁੜੇ।ਇਹ onboarding ਅਤੇ incident response ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।