08 ਅਗ 2025·8 ਮਿੰਟ
ਰੌਇ ਫੀਲਡਿੰਗ ਦਾ REST: ਆਧੁਨਿਕ ਵੈੱਬ API ਬਣਾਉਣ ਵਾਲੇ ਨਿਯਮ
ਰੌਇ ਫੀਲਡਿੰਗ ਦੇ REST ਨਿਯਮਾਂ ਨੂੰ ਸਮਝੋ ਅਤੇ ਦੇਖੋ ਕਿ ਇਹ client-server, stateless, cache, uniform interface, layers ਅਤੇ ਹੋਰ ਕਿਵੇਂ ਵਰਤਮਾਨ API ਅਤੇ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਇਨ ਨੂੰ ਆਕਾਰ ਦਿੰਦੇ ਹਨ।
ਰੌਇ ਫੀਲਡਿੰਗ ਦੇ REST ਨਿਯਮਾਂ ਨੂੰ ਸਮਝੋ ਅਤੇ ਦੇਖੋ ਕਿ ਇਹ client-server, stateless, cache, uniform interface, layers ਅਤੇ ਹੋਰ ਕਿਵੇਂ ਵਰਤਮਾਨ API ਅਤੇ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਇਨ ਨੂੰ ਆਕਾਰ ਦਿੰਦੇ ਹਨ।
ਰੌਇ ਫੀਲਡਿੰਗ ਸਿਰਫ਼ ਇੱਕ ਨਾਂ ਨਹੀਂ ਜੋ ਇੱਕ API ਬਜ਼ਵਰਡ ਨਾਲ ਜੁੜਿਆ ਹੋਇਆ ਹੈ। ਉਹ HTTP ਅਤੇ URI ਵਿਸ਼ੇਸ਼ਣਾਂ ਦੇ ਮੁੱਖ ਲੇਖਕਾਂ ਵਿੱਚੋਂ ਇੱਕ ਸਨ ਅਤੇ ਆਪਣੀ PhD ਡਿਸਰਟੇਸ਼ਨ ਵਿੱਚ ਉਹਨਾਂ ਨੇ REST (Representational State Transfer) ਨਾਮਕ ਇੱਕ ਆਰਕੀਟੈਕਚਰਲ ਸਟਾਈਲ ਵਰਣਨ ਕੀਤੀ, ਜੋ ਦੱਸਦੀ ਹੈ ਕਿ ਵੈੱਬ ਇੰਨੇ ਚੰਗੇ ਤਰੀਕੇ ਨਾਲ ਕਿਵੇਂ ਕੰਮ ਕਰਦੀ ਹੈ।
ਇਸ ਉਤਪੱਤੀ ਦੀ ਮਹੱਤਤਾ ਇਸ ਗੱਲ ਵਿੱਚ ਹੈ ਕਿ REST “ਸੁੰਦਰ ਐਂਡਪੋਇੰਟ” ਬਣਾਉਣ ਲਈ ਨਹੀਂ ਬਣਾਇਆ ਗਿਆ ਸੀ। ਇਹ ਉਹ ਨਿਯਮ ਦਰਸਾਉਂਦਾ ਹੈ ਜੋ ਇੱਕ ਗਲੋਬਲ, ਅਣਅਨੁਕੂਲ ਨੈੱਟਵਰਕ ਨੂੰ ਫਿਰ ਵੀ ਸਕੇਲ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ: ਬਹੁਤ ਸਾਰੇ ਕਲਾਇੰਟ, ਬਹੁਤ ਸਾਰੇ ਸਰਵਰ, ਇੰਟਰਮੀਡੀਏਰੀਜ਼, caching, ਆਧਾ-ਫੇਲੋ, ਅਤੇ ਲਗਾਤਾਰ ਬਦਲਾਅ।
ਜੇ ਤੁਸੀਂ ਕਦੇ ਸੋਚਿਆ ਹੈ ਕਿ ਦੋ “REST APIs” ਕਿਉਂ ਬਿਲਕੁਲ ਵੱਖਰੇ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ—ਜਾਂ ਇੱਕ ਛੋਟੀ ਡਿਜ਼ਾਈਨ ਚੋਇਸ ਕਿਵੇਂ ਬਾਅਦ ਵਿੱਚ pagination ਦੀ ਪੀੜ, caching ਦੀ ਗੜਬੜ, ਜਾਂ breaking changes ਵਿੱਚ ਬਦਲ ਸਕਦੀ ਹੈ—ਤਾਂ ਇਹ ਗਾਈਡ ਉਹਨਾਂ ਚੌਕਾਣਿਆਂ ਨੂੰ ਘਟਾਉਣ ਲਈ ਹੈ।
ਤੁਸੀਂ ਲੈ ਕੇ ਜਾਉਗੇ:
REST ਕੋਈ ਚੈੱਕਲਿਸਟ, ਪ੍ਰੋਟੋਕੋਲ ਜਾਂ ਸਰਟੀਫਿਕੇਸ਼ਨ ਨਹੀਂ ਹੈ। Fielding ਨੇ ਇਸਨੂੰ ਇੱਕ ਆਰਕੀਟੈਕਚਰਲ ਸਟਾਈਲ ਦੇ ਰੂਪ ਵਿੱਚ ਦਰਸਾਇਆ: ਨਿਯਮਾਂ ਦਾ ਸੰਕਲਪ ਜੋ ਇੱਕਠੇ ਲਾਗੂ ਕੀਤੇ ਜਾਣ 'ਤੇ ਉਹ ਸਿਸਟਮ ਬਣਾਉਂਦੇ ਹਨ ਜੋ ਵੈੱਬ ਵਾਂਗ ਸਕੇਲ ਕਰਦੇ ਹਨ—ਵਰਤੋਂ ਵਿੱਚ ਸਧਾਰਨ, ਸਮੇਂ ਦੇ ਨਾਲ ਵਿਕਸਿਤ ਹੋ ਸਕਣ ਅਤੇ ਇੰਟਰਮੀਡੀਏਰੀਜ਼ (proxies, caches, gateways) ਲਈ ਦੋਸਤਾਨਾ।
ਸ਼ੁਰੂਆਤੀ ਵੈੱਬ ਨੂੰ ਕਈ ਸੰਗਠਨਾਂ, ਸਰਵਰਾਂ, ਨੈੱਟਵਰਕਾਂ ਅਤੇ ਕਲਾਇੰਟ ਕਿਸਮਾਂ ਵਿੱਚ ਕੰਮ ਕਰਨਾ ਸੀ। ਇਸਨੂੰ ਕੇਂਦਰੀ ਨਿਯੰਤਰਣ ਬਿਨਾਂ ਵਧਣਾ, ਹਿੱਸੇਵਾਰ ਫੇਲਅਰਾਂ ਤੋਂ ਬਚਣਾ, ਅਤੇ ਨਵੀਆਂ ਖੂਬੀਆਂ ਆਉਣ 'ਤੇ ਪੁਰਾਣੀਆਂ ਨੂੰ ਟੁੱਟਣ ਤੋਂ ਬਿਨਾਂ ਸਹਾਇਕ ਬਣਾਉਣਾ ਸੀ। REST ਇਸ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਹੱਲ ਕਰਦਾ ਹੈ ਕਿ ਇਹ ਕੁਝ ਵਿਅਪਕ ਤੌਰ 'ਤੇ ਸਾਂਝੇ ਧਾਰਣਾਵਾਂ (ਜਿਵੇਂ identifiers, representations, ਅਤੇ standard operations) ਨੂੰ ਤਰਜੀਹ ਦਿੰਦਾ ਹੈ ਨ ਕਿ ਕਸਟਮ, ਕਠੋਰ ਤੌਰ 'ਤੇ ਜੋੜੇ ਹੋਏ contracts ਨੂੰ।
ਇੱਕ ਨਿਯਮ ਉਹ ਹੁੰਦਾ ਹੈ ਜੋ ਡਿਜ਼ਾਇਨ ਦੀ ਆਜ਼ਾਦੀ ਨੂੰ ਸੀਮਤ ਕਰਦਾ ਹੈ, ਬਦਲੇ ਵਿੱਚ ਕੁਝ ਫਾਇਦੇ ਦੇ ਕੇ। ਉਦਾਹਰਨ ਵਜੋਂ, ਤੁਸੀਂ ਸਰਵਰ-ਸਾਈਡ ਸੈਸ਼ਨ ਸਟੇਟ ਤਿਆਗ ਸਕਦੇ ਹੋ ਤਾਂ ਕਿ ਕਿਸੇ ਵੀ ਸਰਵਰ ਨੋਡ ਦੁਆਰਾ ਬੇਨਤੀਆਂ ਹੰਢਾਈਆਂ ਜਾ ਸਕਣ, ਜੋ ਭਰੋਸੇਯੋਗਤਾ ਅਤੇ ਸਕੇਲਿੰਗ ਨੂੰ ਸੁਧਾਰਦਾ ਹੈ। ਹਰ REST ਨਿਯਮ ਇੱਕੋ ਜਿਹੀ ਵਪਾਰ-ਅਲੋਪਦੀ ਕਰਦਾ ਹੈ: ਘੱਟ ਐਡ-ਹੌਕ ਲਚਕ, ਜ਼ਿਆਦਾ ਪੂਰਵਾਨੁਮਾਨਤਾ ਅਤੇ ਵਿਕਾਸਯੋਗਤਾ।
ਕਈ HTTP APIs REST ਵਿਚਾਰਾਂ ਨੂੰ ਲੈਂਦੇ ਹਨ (HTTP 'ਤੇ JSON, URL endpoints, ਸ਼ਾਇਦ status codes) ਪਰ ਪੂਰੇ ਨਿਯਮਾਂ ਨੂੰ ਲਾਗੂ ਨਹੀਂ ਕਰਦੇ। ਇਹ ਗਲਤ ਨਹੀਂ ਹੈ—ਅਕਸਰ ਇਹ ਉਤਪਾਦ ਡੈਡਲਾਈਨਾਂ ਜਾਂ ਅੰਦਰੂਨੀ ਲੋੜਾਂ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ। ਫਰਕ ਨੂੰ ਨਾਮ ਦੇਣਾ ਫਾਇਦੇਮੰਦ ਹੈ: ਇੱਕ API resource-oriented ਹੋ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਪੂਰੀ ਤਰ੍ਹਾਂ REST ਹੋਣ ਦੇ।
REST ਸਿਸਟਮ ਨੂੰ ਸੋਚੋ ਜਿਵੇਂ resources (ਉਹ ਚੀਜ਼ਾਂ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ URLs ਨਾਲ ਨਾਮ ਦੇ ਸਕਦੇ ਹੋ) ਜਿਨ੍ਹਾਂ ਨਾਲ ਕਲਾਇੰਟ representations (ਇਕ ਸਮੇਂ 'ਤੇ resource ਦਾ ਵਰਤਮਾਨ ਦ੍ਰਿਸ਼) ਰਾਹੀਂ ਅੰਤਰਕਿਰਿਆ ਕਰਦੇ ਹਨ, ਅਤੇ ਇਹ ਸਾਰੇ ਕਾਰਜ links ਨਾਲ ਦਿਖਾਏ ਜਾਂਦੇ ਹਨ (ਅਗਲੇ ਕਾਰਵਾਈਆਂ ਅਤੇ ਸਬੰਧਿਤ ਸਰੋਤ)। ਕਲਾਇੰਟ ਨੂੰ ਗੁਪਤ, ਆਉਟ-ਆਫ-ਬੈਂਡ ਨਿਯਮਾਂ ਦੀ ਲੋੜ ਨਹੀਂ—ਉਹ ਸਧਾਰਨ semantics ਨੂੰ ਫਾਲੋ ਕਰਦਾ ਹੈ ਅਤੇ ਲਿੰਕਾਂ ਰਾਹੀਂ ਨੈਵੀਗੇਟ ਕਰਦਾ ਹੈ, ਉਦੋਂ ਹੀ ਇਕ ਬਰਾਊਜ਼ਰ ਵੈੱਬ 'ਤੇ ਘੁੰਮਦਾ ਹੈ।
ਨਿਯਮਾਂ ਅਤੇ HTTP ਵਿਸਤਰ ਵਿੱਚ ਖੋ ਜਾਣ ਤੋਂ ਪਹਿਲਾਂ, REST ਇੱਕ ਸਧਾਰਣ ਸ਼ਬਦਾਵਲੀ ਬਦਲਾਅ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ: resources ਵਿੱਚ ਸੋਚੋ, ਨਾ ਕਿ actions ਵਿੱਚ।
ਇੱਕ resource ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੀ ਇੱਕ addressable "ਚੀਜ਼" ਹੈ: ਇੱਕ user, ਇੱਕ invoice, ਇੱਕ product category, ਇੱਕ shopping cart। ਅਹੰਕਾਰਪੂਰਵਕ ਗੱਲ ਇਹ ਹੈ ਕਿ ਇਹ ਇੱਕ ਨਾਉਂ ਹੈ ਜਿਸ ਦੀ ਇੱਕ ਪਛਾਣ ਹੈ।
ਇਸ ਲਈ /users/123 ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਪੜ੍ਹਦਾ ਹੈ: ਇਹ ਉਹ user ਜਿਸਦਾ ID 123 ਹੈ ਨੂੰ ਪਛਾਣਦਾ ਹੈ। ਇਸ ਦੀ ਤੁਲਨਾ action-ਆਕਾਰ URLs ਜਿਵੇਂ /getUser ਜਾਂ /updateUserPassword ਨਾਲ ਕਰੋ। ਇਹ ਵਰਬ ਦਰਸਾਉਂਦੇ ਹਨ—ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਸੀਂ ਓਪੀਰੇਸ਼ਨ ਕਰ ਰਹੇ ਹੋ—ਨ ਕਿ ਚੀਜ਼ ਨੂੰ ਜਿਸ 'ਤੇ ਇਹ ਓਪੀਰੇਸ਼ਨ ਹੋ ਰਹੇ ਹਨ।
REST ਇਹ ਨਹੀਂ ਕਹਿੰਦਾ ਕਿ ਤੁਸੀਂ ਕਾਰਵਾਈਆਂ ਨਹੀਂ ਕਰ ਸਕਦੇ। ਇਹ ਕਹਿੰਦਾ ਹੈ ਕਿ ਕਾਰਵਾਈਆਂ ਨੂੰ uniform interface ਰਾਹੀਂ ਪ੍ਰਗਟ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ (HTTP APIs ਲਈ, ਇਸਦਾ ਅਰਥ ਆਮ ਤੌਰ 'ਤੇ GET/POST/PUT/PATCH/DELETE ਵਰਗੀਆਂ ਮੈਥਡ ਹਨ) ਜੋ resource identifiers 'ਤੇ ਕਾਰਵਾਈ ਕਰਦੀਆਂ ਹਨ।
ਇੱਕ representation ਉਹ ਹੈ ਜੋ ਤੁਸੀਂ ਤਾਰ (wire) 'ਤੇ ਭੇਜਦੇ ਹੋ—resource ਦਾ ਇੱਕ snapshot ਜਾਂ ਨਜ਼ਾਰਾ। ਇੱਕੋ resource ਦੀਆਂ ਕਈ representations ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਉਦਾਹਰਨ ਵਜੋਂ, resource /users/123 JSON ਵਜੋਂ ਐਪ ਲਈ, ਜਾਂ HTML ਵਜੋਂ ਬਰਾਊਜ਼ਰ ਲਈ ਦਰਸਾਇਆ ਜਾ ਸਕਦਾ ਹੈ।
GET /users/123
Accept: application/json
ਮਿਲ ਸਕਦਾ ਹੈ:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
ਜਦਕਿ:
GET /users/123
Accept: text/html
ਇੱਕ HTML ਪੰਨਾ ਵਾਪਸ ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਓਹੀ ਯੂਜ਼ਰ ਵੇਰਵੇ ਰੇਂਡਰ ਕਰਦਾ ਹੈ।
ਮੁੱਖ ਵਿਚਾਰ: resource JSON ਨਹੀਂ ਹੈ ਅਤੇ ਨਾ ਹੀ ਇਹ HTML ਹੈ। ਇਹ ਉਹ ਫਾਰਮੈਟ ਹਨ ਜੋ ਇਸ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ।
ਜਦੋਂ ਤੁਸੀਂ ਆਪਣਾ API resources ਅਤੇ representations ਦੇ ਆਧਾਰ 'ਤੇ ਮਾਡਲ ਕਰਦੇ ਹੋ, ਤਾਂ ਕਈ ਅਮਲੀ ਫੈਸਲੇ ਆਸਾਨ ਹੋ ਜਾਂਦੇ ਹਨ:
/users/123 ਵਜੋਂ ਬਚਦਾ ਹੈ ਭਾਵੇਂ ਤੁਹਾਡੀ UI, ਵਰਕਫਲੋ ਜਾਂ ਡੇਟਾ ਮਾਡਲ ਬਦਲੇ।ਇਹ resource-first ਸੋਚ REST ਨਿਯਮਾਂ ਦਾ ਆਧਾਰ ਹੈ। ਇਸ ਦੇ ਬਿਨਾਂ, “REST” ਅਕਸਰ "HTTP ਉੱਤੇ JSON" ਤੱਕ ਹੀ ਸੀਮਿਤ ਰਹਿ ਜਾਂਦਾ ਹੈ।
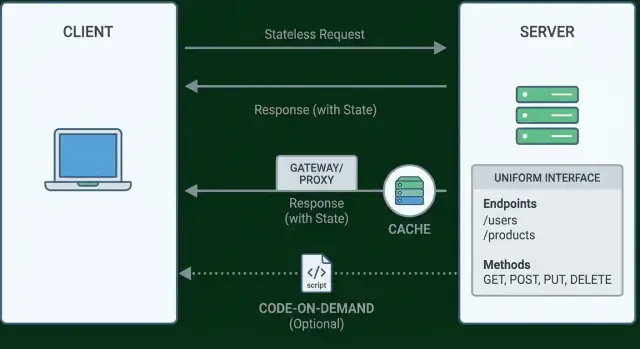
Client–server ਵੰਡ REST ਦਾ ਇੱਕ ਸਾਫ਼ ਜ਼ਿੰਮੇਵਾਰੀ ਭੇਦ लागू ਕਰਨ ਦਾ ਤਰੀਕਾ ਹੈ। ਕਲਾਇੰਟ ਯੂਜ਼ਰ ਅਨੁਭਵ ਤੇ ਧਿਆਨ ਰੱਖਦਾ ਹੈ (ਲੋਕ ਕੀ ਦੇਖਦੇ ਅਤੇ ਕੀ ਕਰਦੇ ਹਨ), ਜਦਕਿ ਸਰਵਰ ਡੇਟਾ, ਨਿਯਮ ਅਤੇ ਸਥਿਰਤਾ ਤੇ (ਕੀ ਸੱਚ ਹੈ ਅਤੇ ਕੀ ਮਨਜ਼ੂਰ) ਫੋਕਸ ਕਰਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਇਹ ਚਿੰਤਾਵਾਂ ਅਲੱਗ ਰੱਖਦੇ ਹੋ, ਹਰ ਪਾਸੇ ਬਦਲ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਦੂਜੇ ਪਾਸੇ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣ ਮਜਬੂਰ ਕੀਤੇ।
ਰੋਜ਼ਮਰਾ ਦੀਆਂ ਸ਼ਬਦਾਂ ਵਿੱਚ, ਕਲਾਇੰਟ "ਪ੍ਰੇਜ਼ੇੰਟੇਸ਼ਨ ਲੇਅਰ" ਹੈ: ਸਕ੍ਰੀਨ, ਨੈਵੀਗੇਸ਼ਨ, ਫਾਰਮ ਵੈਲਿਡੇਸ਼ਨ ਤੇ ਤੇਜ਼ ਫੀਡਬैक, ਅਤੇ optimistic UI ਵਰਤਣ ਦੇ ਭਾਵ (ਜਿਵੇਂ ਨਵਾਂ comment ਤੁਰੰਤ ਦਿਖਾਉਣਾ)। ਸਰਵਰ "ਸਰੋਤ-ਅਫ-ਸੱਚ" ਹੈ: authentication, authorization, business rules, data storage, auditing, ਅਤੇ ਜੋ ਕੁਝ ਵੀ ਡਿਵਾਇਸਾਂ 'ਤੇ ਸਾਂਝਾ ਸਥਿਰ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ।
ਇੱਕ ਪ੍ਰਾਯੋਗਿਕ ਨਿਯਮ: ਜੇ ਕੋਈ ਫੈਸਲਾ ਸੁਰੱਖਿਆ, ਪੈਸਾ, ਅਨੁਮਤੀਆਂ ਜਾਂ ਸਾਂਝੇ ਡੇਟਾ ਸਥਿਰਤਾ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ, ਤਾਂ ਇਹ ਸਰਵਰ 'ਤੇ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਫੈਸਲਾ ਸਿਰਫ਼ ਅਨੁਭਵ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ (ਲੇਆਉਟ, ਸਥਾਨਕ ਇਨਪੁਟ ਸੁਝਾਅ, loading states), ਤਾਂ ਇਹ ਕਲਾਇੰਟ 'ਤੇ ਰਹੇ।
ਹੁਣ ਦੇ ਸੈਟਅਪ ਨਾਲ ਇਹ ਨਿਯਮ ਸਿੱਧਾ ਮੇਲ ਖਾਂਦਾ ਹੈ:
Client–server ਵਿਭਾਜਨ ਹੀ "ਇੱਕ backend, ਬਹੁਤ frontends" ਨੂੰ ਹਕੀਕਤ ਬਣਾਉਂਦਾ ਹੈ।
ਅਕਸਰ ਗਲਤੀ ਇਹ ਹੁੰਦੀ ਹੈ ਕਿ UI workflow state (ਉਦਾਹਰਨ: "checkout ਦੀ ਕਿਸੇ ਕਦਮ 'ਤੇ ਯੂਜ਼ਰ ਹੈ") ਨੂੰ ਸਰਵਰ-ਸਾਈਡ ਸੈਸ਼ਨ ਵਿੱਚ ਸਟੋਰ ਕਰ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ। ਇਹ backend ਨੂੰ ਇੱਕ ਖਾਸ screen flow ਨਾਲ ਜੋੜਦਾ ਹੈ ਅਤੇ ਸਕੇਲਿੰਗ ਨੂੰ ਮੁਸ਼ਕਿਲ ਬਣਾ ਦਿੰਦਾ ਹੈ।
ਪਸੰਦ ਕਰੋ ਕਿ ਸਾਰਾ ਲੋੜੀਂਦਾ ਸੰਦਰਭ ਹਰ ਬੇਨਤੀ ਨਾਲ ਭੇਜਿਆ ਜਾਵੇ (ਜਾਂ ਸੰਭਾਲੇ ਗਏ resources ਤੋਂ ਨਿਰਧਾਰਿਤ ਕੀਤਾ ਜਾਵੇ), ਤਾਂ ਕਿ ਸਰਵਰ resources ਅਤੇ ਨਿਯਮਾਂ 'ਤੇ ਹੀ ਰਹੇ—ਕਿਸੇ ਖਾਸ UI ਦੀ ਯਾਦ ਨਹੀਂ ਰੱਖੇ।
Statelessness ਦਾ ਅਰਥ ਹੈ ਕਿ ਸਰਵਰ ਨੂੰ ਕਲਾਇੰਟ ਬਾਰੇ ਬੇਨਤੀਆਂ ਦੇ ਦਰਮਿਆਨ ਕੁਝ ਯਾਦ ਨਹੀਂ ਰੱਖਣਾ। ਹਰ ਬੇਨਤੀ ਆਪਣੀ ਪ੍ਰਕਿਰਿਆ ਲਈ ਲੋੜੀਂਦੀ ਸਾਰੀ ਜਾਣਕਾਰੀ ਲੈ ਕੇ ਆਉਂਦੀ ਹੈ—ਕੌਣ ਕਾਲ ਕਰ ਰਿਹਾ ਹੈ, ਉਹ ਕੀ ਚਾਹੁੰਦਾ ਹੈ, ਅਤੇ ਕੋਈ ਵੀ ਸੰਦਰਭ ਜੋ ਕੰਮ ਕਰਨ ਲਈ ਜ਼ਰੂਰੀ ਹੈ।
ਜਦੋਂ ਬੇਨਤੀਆਂ ਆਜ਼ਾਦ ਹੋਂਦੀਆਂ ਹਨ, ਤੁਸੀਂ ਲੋਡ ਬੈਲੈਂਸਰ ਦੇ ਪਿੱਛੇ ਸਰਵਰ ਜੋੜ/ਹਟਾ ਸਕਦੇ ਹੋ ਬਿਨਾਂ "ਕਿਹੜਾ ਸਰਵਰ ਮੇਰੀ session ਜਾਣਦਾ ਹੈ" ਦੀ ਚਿੰਤਾ ਕੀਤੇ। ਇਹ ਸਕੇਲਿੰਗ ਅਤੇ ਉਦਮੀਤਾ (resilience) ਨੂੰ ਬਹਾਲ ਕਰਦਾ ਹੈ: ਕੋਈ ਵੀ ਇੰਸਟੈਂਸ ਕਿਸੇ ਵੀ ਬੇਨਤੀ ਨੂੰ ਹੰਢਾ ਸਕਦਾ ਹੈ।
ਇਸ ਨਾਲ operations ਵੀ ਸਧਾਰਨ ਹੁੰਦੇ ਹਨ। ਡੀਬੱਗ ਕਰਨਾ ਅਕਸਰ ਆਸਾਨ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਪੂਰਾ ਸੰਦਰਭ ਬੇਨਤੀ (ਅਤੇ ਲੌਗ) 'ਚ ਦੇਖਿਆ ਜਾ ਸਕਦਾ ਹੈ, ਨਾ ਕਿ ਸਰਵਰ-ਸਾਈਡ ਸੈਸ਼ਨ ਮੈਮੋਰੀ ਵਿੱਚ ਲੁਕਿਆ।
Stateless APIs ਆਮ ਤੌਰ 'ਤੇ ਹਰ ਕਾਲ ਵਿੱਚ ਕੁਝ ਵਧੇਰੇ ਡਾਟਾ ਭੇਜਦੇ ਹਨ। ਸਰਵਰ-ਸਾਈਡ ਸੈਸ਼ਨ 'ਤੇ ਨਿਰਭਰ ਹੋਣ ਦੀ ਥਾਂ, ਕਲਾਇੰਟ ਹਰ ਵਾਰ credentials ਅਤੇ ਸੰਦਰਭ ਸ਼ਾਮਲ ਕਰਦੇ ਹਨ।
ਤੁਹਾਨੂੰ "stateful" ਯੂਜ਼ਰ ਫਲੋਜ਼ (ਜਿਵੇਂ pagination ਜਾਂ multi-step checkouts) ਬਾਰੇ ਖੁੱਲ ਕੇ ਸੋਚਣਾ ਪੈਂਦਾ ਹੈ। REST ਮਨਾਅ ਨਹੀਂ ਕਰਦਾ ਕਿ multi-step experiences ਨਹੀਂ ਹੋ ਸਕਦੇ—ਇਹ ਸਿਰਫ਼ ਸਟੇਟ ਨੂੰ ਕਲਾਇੰਟ ਜਾਂ ਪਛਾਣਯੋਗ ਸਰਵਰ resources 'ਤੇ ਰੱਖਣ ਨੂੰ ਤਰਜੀਹ ਦਿੰਦਾ ਹੈ।
Authorization: Bearer … ਹੈਡਰ ਸ਼ਾਮਲ ਕਰਦੀ ਹੈ ਤਾਂ ਕਿ ਕੋਈ ਵੀ ਸਰਵਰ ਇਸਨੂੰ authenticate ਕਰ ਸਕੇ।Idempotency-Key ਭੇਜਦੇ ਹਨ تاکہ retries ਨਾਲ duplicate ਕੰਮ ਨਾ ਬਣੇ।X-Correlation-Id ਵਰਗਾ ਹੈਡਰ ਇੱਕ ਯੂਜ਼ਰ ਕਾਰਵਾਈ ਨੂੰ ਸੇਵਾਵਾਂ ਅਤੇ ਲੌਗਜ਼ ਵਿੱਚ ਟਰੇਸ ਕਰਨ ਦੀ ਆਸਾਨੀ ਦਿੰਦਾ ਹੈ।Pagination ਲਈ, "server page 3 ਯਾਦ ਰੱਖਦਾ ਹੈ" ਤੋਂ ਬਚੋ। ਇਸਦੀ ਥਾਂ explicit parameters ਵਰਤੋ ਜਿਵੇਂ ?cursor=abc ਜਾਂ ਇੱਕ next link ਜੋ ਕਲਾਇੰਟ ਫਾਲੋ ਕਰ ਸਕੇ, ਅਤੇ ਨੈਵੀਗੇਸ਼ਨ ਸਟੇਟ ਨੂੰ responses ਵਿੱਚ ਰੱਖੋ ਨਾ ਕਿ ਸਰਵਰ ਮੈਮੋਰੀ ਵਿੱਚ।
Caching ਦਾ ਮਤਲਬ ਹੈ ਪਹਿਲਾਂ ਦਿੱਤੇ ਜਵਾਬ ਨੂੰ ਸੁਰੱਖਿਅਤ ਰੂਪ ਵਿੱਚ ਦੁਬਾਰਾ ਵਰਤਣਾ ਤਾਂ ਜੋ client (ਜਾਂ ਰਾਹ ਵਿੱਚ ਕੋਈ) ਤੁਹਾਡੇ ਸਰਵਰ ਨੂੰ ਇੱਕੋ ਕੰਮ ਲਈ ਮੁੜ ਨਾ ਪੁੱਛੇ। ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਕੀਤਾ ਜਾਵੇ ਤਾਂ ਇਹ ਯੂਜ਼ਰ ਲਈ latency ਘਟਾਉਂਦਾ ਅਤੇ ਤੁਹਾਡੇ ਲਈ ਲੋਡ ਘਟਾਉਂਦਾ—ਬਿਨਾਂ API ਦੇ ਅਰਥ ਨੂੰ ਬਦਲੇ।
ਇੱਕ ਜਵਾਬ cacheable ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਹ ਸੁਰੱਖਿਅਤ ਹੋ ਕਿ ਕਿਸੇ ਹੋਰ ਬੇਨਤੀ ਲਈ ਇੱਕ ਨਿਰਧਾਰਤ ਸਮੇਂ ਲਈ ਇਕੋ payload ਦਿੱਤਾ ਜਾ ਸਕੇ। HTTP ਵਿੱਚ ਤੁਸੀਂ caching headers ਨਾਲ ਇਹ ਇਰਾਦਾ ਦਰਸਾਉਂਦੇ ਹੋ:
Cache-Control: ਮੁੱਖ ਸਵਿੱਚਬੋਰਡ (ਕਿੰਨਾ ਸਮਾਂ ਰੱਖਣਾ, shared caches ਲਈ ਮਨਜ਼ੂਰ/ਪਾਬੰਦੀ ਆਦਿ)ETag ਅਤੇ Last-Modified: validators ਜੋ clients ਨੂੰ ਪੁੱਛਣ ਦੀ ਆਗਿਆ ਦਿੰਦੇ ਹਨ "ਕੀ ਇਹ ਬਦਲਿਆ ਹੈ?" ਅਤੇ ਸਸਤੇ 304 Not Modified ਜਵਾਬ ਮਿਲ ਸਕਦੇ ਹਨExpires: ਇੱਕ ਪੁਰਾਣਾ ਤਰੀਕਾ freshness ਦਰਸਾਉਣ ਲਈ, ਅਜੇ ਵੀ ਵਾਇਡ ਵਿੱਚ ਵੇਖਿਆ ਜਾਂਦਾ ਹੈਇਹ browser caching ਤੋਂ ਵੱਡਾ ਹੈ। proxies, CDNs, API gateways, ਅਤੇ ਬੰਦ-ਇਨ-ਮੋਬਾਈਲ ਐਪਸ ਵੀ responses ਦਾ ਦੁਬਾਰਾ ਉਪਯੋਗ ਕਰ ਸਕਦੇ ਹਨ ਜੇ ਨਿਯਮ ਸਪਸ਼ਟ ਹਨ।
ਚੰਗੇ ਉਮੀਦਵਾਰ:
ਆਮ ਤੌਰ 'ਤੇ ਓਹੁ cheeza:
private caching rules)ਮੁੱਖ ਵਿਚਾਰ: caching ਸੋਚ-ਵਿਚਾਰ ਦੇ ਬਾਅਦ ਦਾ ਕੰਮ ਨਹੀਂ—ਇਹ REST ਦਾ ਇੱਕ ਨਿਯਮ ਹੈ ਜੋ ਉਹ APIs ਇਨाम ਦਿੰਦਾ ਹੈ ਜੋ freshness ਅਤੇ validation ਨੂੰ ਸਪਸ਼ਟ ਤਰੀਕੇ ਨਾਲ ਕੰਮ ਵਿੱਚ ਲਿਆਉਂਦੇ ਹਨ।
uniform interface ਨੂੰ ਅਕਸਰ "ਪੜ੍ਹਨ ਲਈ GET ਅਤੇ ਬਣਾਉਣ ਲਈ POST ਵਰਤੋ" ਸਮਝ ਲਿਆ ਜਾਂਦਾ ਹੈ। ਇਹ ਸਿਰਫ਼ ਇੱਕ ਚੋਟਾ ਹਿੱਸਾ ਹੈ। Fielding ਦਾ ਵਿਚਾਰ ਵੱਡਾ ਹੈ: APIs ਇੰਨੇ ਇੱਕਸਾਰ ਮਹਿਸੂਸ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ ਕਿ ਕਲਾਇੰਟਾਂ ਨੂੰ ਹਰ ਇੱਕ ਐਂਡਪੋਇੰਟ ਲਈ ਵਿਸ਼ੇਸ਼ ਗਿਆਨ ਦੀ ਲੋੜ ਨਾ ਪਏ।
Resources ਦੀ ਪਛਾਣ: ਤੁਸੀਂ ਚੀਜ਼ਾਂ (resources) ਨੂੰ ਸਥਿਰ identifiers (ਅਕਸਰ URLs) ਨਾਲ ਨਾਮ ਦਿੰਦੇ ਹੋ, ਨਾ ਕਿ ਕਾਰਵਾਈਆਂ ਨਾਲ। /orders/123 ਸੋਚੋ, ਨਾ ਕਿ /createOrder।
Representations ਰਾਹੀਂ ਮੈਨਿਪੂਲੇਸ਼ਨ: ਕਲਾਇੰਟ resource ਨੂੰ ਇੱਕ representation ਭੇਜ ਕੇ ਬਦਲਦੇ ਹਨ (JSON, HTML ਆਦਿ)। ਸਰਵਰ resource 'ਤੇ ਨਿਯੰਤ੍ਰਣ ਰੱਖਦਾ ਹੈ; ਕਲਾਇੰਟ ਇਸਦੇ representations trade ਕਰਦਾ ਹੈ।
Self-descriptive messages: ਹਰ request/response ਵਿੱਚ ਇੰਨੀ ਜਾਣਕਾਰੀ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਕਿ ਉਹ ਕਿਸ ਤਰ੍ਹਾਂ ਪ੍ਰਕਿਰਿਆ ਹੋਵੇ—method, status code, headers, media type, ਅਤੇ ਸਾਫ਼ ਬਾਡੀ। ਜੇ ਅਰਥ docs ਵਿੱਚ ਲੁਕਿਆ ਹੋਵੇ ਤਾਂ ਕਲਾਇੰਟ tightly coupled ਹੋ ਜਾਂਦੇ ਹਨ।
Hypermedia (HATEOAS): responses ਵਿੱਚ links ਅਤੇ ਮਨਜ਼ੂਰ actions ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ ਤਾਂ ਕਿ ਕਲਾਇੰਟ workflow ਨੂੰ hard-code ਕੀਤੇ URLs ਦੇ ਬਿਨਾਂ follow ਕਰ ਸਕੇ।
ਇੱਕ ਲਗਾਤਾਰ ਇੰਟਰਫੇਸ ਕਲਾਇੰਟਾਂ ਨੂੰ ਅੰਦਰੂਨੀ ਸਰਵਰ ਵੇਰਵਿਆਂ 'ਤੇ ਘੱਟ ਨਿਰਭਰ ਬਣਾਉਂਦੀ ਹੈ। ਸਮੇਂ ਦੇ ਨਾਲ, ਇਸਦਾ ਮਤਲਬ ਘੱਟ breaking changes, ਘੱਟ "special cases", ਅਤੇ endpoints ਦੀ ਤਬਦੀਲ ਦੇ ਦੌਰਾਨ ਘੱਟ rework ਹੈ।
200 ਪੜ੍ਹਨਾਂ ਲਈ, 201 created ਲਈ (ਨਾਲ Location), 400 validation ਮੁੱਦਿਆਂ ਲਈ, 401/403 auth ਲਈ, 404 ਜਦੋਂ resource ਮੌਜੂਦ ਨਾ ਹੋਵੇ।code, message, details, requestId।Content-Type, caching headers), ਤਾਂ ਜੋ messages ਆਪਣੀ ਵਿਆਖਿਆ ਆਪਣੇ ਵਿੱਚ ਹੀ ਕਰਦੇ ਹੋਣ।Uniform interface ਦੀ ਲਕੜੀ ਹੈ predictability ਅਤੇ evolvability, ਸਿਰਫ਼ "sahi verbs" ਹੀ ਨਹੀਂ।
"Self-descriptive" message ਉਹ ਹੁੰਦੀ ਹੈ ਜੋ ਪ੍ਰਾਪਤਕਰਤਾ ਨੂੰ ਦੱਸਦੀ ਹੈ ਕਿ ਇਸਨੂੰ ਕਿਵੇਂ ਸਮਝਣਾ ਹੈ—ਬਿਨਾਂ ਬਾਹਰਲੀ tribal knowledge ਦੇ। ਜੇ ਇੱਕ ਕਲਾਇੰਟ (ਜਾਂ intermediary) ਇਕ response ਦਾ ਮਤਲਬ ਕੇਵਲ HTTP headers ਅਤੇ body ਦੇਖ ਕੇ ਸਮਝ ਨਹੀਂ سکتا, ਤਾਂ ਤੁਸੀਂ HTTP 'ਤੇ ਇੱਕ ਪ੍ਰਾਈਵੇਟ ਪ੍ਰੋਟੋਕੋਲ ਬਣਾ ਦਿੱਤਾ ਹੈ।
ਸਭ ਤੋਂ ਆਸਾਨ ਜਿੱਤ Content-Type (ਤੁਸੀਂ ਕੀ ਭੇਜ ਰਹੇ ਹੋ) ਅਤੇ ਅਕਸਰ Accept (ਤੁਸੀਂ ਕੀ ਵਾਪਸ ਚਾਹੁੰਦੇ ਹੋ) ਨਾਲ ਸਪਸ਼ਟ ਰਹਿਣਾ ਹੈ। Content-Type: application/json ਬੁਨਿਆਦੀ parsing ਨਿਯਮ ਦੱਸਦਾ ਹੈ, ਪਰ ਤੁਸੀਂ ਜਦੋਂ ਮਤਲਬ ਵੱਧ ਜਟਿਲ ਹੋਵੇ ਤਾਂ vendor ਜਾਂ profile-based media types ਨਾਲ ਅੱਗੇ ਵੀ ਜਾ ਸਕਦੇ ਹੋ।
ਪਹੁੰਚਾਂ:
application/json ਅਤੇ ਧਿਆਨ ਨਾਲ ਸੰਭਾਲਿਆ schema। ਜਿਆਦਾਤਰ ਟੀਮਾਂ ਲਈ ਸਭ ਤੋਂ ਆਸਾਨ।application/vnd.acme.invoice+json ਜੋ ਇੱਕ ਵਿਸ਼ੇਸ਼ representation ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ।application/json ਰੱਖੋ, ਇੱਕ profile ਪੈਰਾਮੀਟਰ ਜਾਂ ਲਿੰਕ ਜੋ semantics ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦਾ ਹੈ ਜੋੜੋ।Versioning ਮੌਜੂਦਾ ਕਲਾਇੰਟਾਂ ਦੀ ਰੱਖਿਆ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ। ਲੋਕਪ੍ਰਿਯ ਵਿਕਲਪ:
/v1/orders): ਸਪਸ਼ਟ, ਪਰ ਇਸ ਨਾਲ representations ਨੂੰ fork ਕਰਨ ਦਾ ਰੁਝਾਨ ਵੱਧ ਸਕਦਾ ਹੈ।Accept ਰਾਹੀਂ): URLs ਸਥਿਰ ਰੱਖਦਾ ਹੈ ਅਤੇ "ਇਸਦਾ ਕੀ ਮਤਲਬ ਹੈ" ਸੰਦਰਭ ਵਿੱਚ ਰੱਖਦਾ ਹੈ।ਜੋ ਵੀ ਚੁਣੋ, ਪਹਿਲਾਂ ਬੈਕਵਰਡ ਕੰਪੈਟਬਿਲਟੀ ਨੂੰ ਲੱਖੀਏ: ਫੀਲਡਾਂ ਦੇ ਨਾਮ casually ਨਾ ਬਦਲੋ, ਅਰਥ ਬਿਨਾਂ ਸੁਚੇਤ ਤੌਰ 'ਤੇ ਬਦਲਣਾ ਨਾ ਕਰੋ, ਅਤੇ ਰਿਮੂਵਲ ਨੂੰ breaking change ਮੰਨੋ।
ਜਿੱਥੇ errors ਹਰ ਥਾਂ ਇਕੋ ਜਿਹੇ ਹੁੰਦੇ ਹਨ, ਕਲਾਇੰਟ ਤੇਜ਼ੀ ਨਾਲ ਸਿੱਖਦੇ ਹਨ। ਇੱਕ error shape ਚੁਣੋ (ਉਦਾਹਰਨ: code, message, details, traceId) ਅਤੇ ਇਹ ਸਾਰੇ endpoints 'ਤੇ ਵਰਤੋ। ਸਾਫ਼, ਪੇਸ਼ਗੀ ਨਿਯਮਤ ਫੀਲਡ ਨਾੰ॥ (ਜਿਵੇਂ createdAt vs created_at) ਚੁਣੋ ਅਤੇ ਇੱਕ convention 'ਤੇ ਟਿਕੋ।
ਚੰਗੀ ਡੌਕਸ ਅਡਾਪਸ਼ਨ ਤੇਜ਼ ਕਰਦੀ ਹੈ, ਪਰ ਉਹ ਇੱਕੋ ਹੀ ਸਥਾਨ ਨਹੀਂ ਹੋ ਸਕਦੀ ਜਿੱਥੇ ਅਰਥ ਰਹਿੰਦਾ ਹੈ। ਜੇ ਇੱਕ ਕਲਾਇੰਟ ਨੂੰ ਦੇਖਣਾ ਪੈਂਦਾ ਹੈ ਕਿ status: 2 ਦਾ ਮਤਲਬ "paid" ਹੈ ਜਾਂ "pending", ਤਾਂ message self-descriptive ਨਹੀਂ। ਚੰਗੇ headers, media types, ਅਤੇ ਪੜ੍ਹਨਯੋਗ payloads tribal knowledge ਦੀ ਲੋੜ ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਸਿਸਟਮਾਂ ਨੂੰ ਵਿਕਸਿਤ ਕਰਨ ਵਿੱਚ ਆਸਾਨੀ ਦਿੰਦੇ ਹਨ।
Hypermedia (ਜਿਸਨੂੰ HATEOAS: Hypermedia As The Engine Of Application State ਕਿਹਾ ਜਾਂਦਾ ਹੈ) ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਇੱਕ ਕਲਾਇੰਟ ਨੂੰ API ਦੇ ਅਗਲੇ URLs ਪਹਿਲਾਂ ਤੋਂ "ਜਾਣਨ" ਦੀ ਲੋੜ ਨਹੀਂ। ਹਰ response discoverable ਅਗਲੇ ਕਦਮਾਂ ਨੂੰ link ਰਾਹੀਂ ਦਿੰਦਾ ਹੈ: ਕਿੱਥੇ ਜਾਂਣਾ ਹੈ, ਕਿਹੜੀਆਂ ਕਾਰਵਾਈਆਂ ਸੰਭਵ ਹਨ, ਅਤੇ ਕਈ ਵਾਰ ਕਿਹੜਾ HTTP method ਵਰਤਣਾ ਹੈ।
ਇਸ ਦੀ ਥਾਂ ਕਿ ਕਲਾਇੰਟ /orders/{id}/cancel ਵਰਗੀ paths ਨੂੰ hard-code ਕਰੇ, ਕਲਾਇੰਟ ਸਰਵਰ ਵੱਲੋਂ ਦਿੱਤੇ ਲਿੰਕਾਂ ਨੂੰ follow ਕਰਦਾ ਹੈ। ਸਰਵਰ ਅਸਲ ਵਿੱਚ ਕਹਿ ਰਿਹਾ ਹੈ: "ਇਸ ਰਿਸੋਰਸ ਦੀ ਮੌਜੂਦਾ ਸਥिति ਦੇ ਨੁਸਕਿਆਂ ਦੇ ਅਧਾਰ 'ਤੇ, ਇੱਥੇ ਮਨਜ਼ੂਰ moves ਹਨ।"
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
ਜੇ order paid ਹੋ ਜਾਂਦਾ ਹੈ, ਸਰਵਰ ਸ਼ਾਇਦ cancel ਲਿੰਕ ਹਟਾ ਦੇਵੇ ਅਤੇ refund ਜੋੜ ਦੇਵੇ—ਬਿਨਾਂ ਇੱਕ ਚੰਗੇ ਕੁਲਾਇੰਟ ਨੂੰ ਤੋੜੇ।
Hypermedia ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਚਮਕਦਾ ਹੈ ਜਦੋਂ flows ਵਿਕਸਿਤ ਹੁੰਦੇ ਹਨ: onboarding steps, checkout, approvals, subscriptions, ਜਾਂ ਕੋਈ ਵੀ ਪ੍ਰਕਿਰਿਆ ਜਿਸ ਵਿੱਚ "ਅੱਗੇ ਕੀ ਮਨਜ਼ੂਰ ਹੈ" ਸਥਿਤੀ, ਅਨੁਮਤੀ, ਜਾਂ ਕਾਰੋਬਾਰੀ ਨਿਯਮਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਬਦਲਦੀ ਹੈ।
ਇਹ hard-coded URLs ਅਤੇ ਨਾਜੁਕ ਕਲਾਇੰਟ ਅਨੁਮਾਨ ਘਟਾਉਂਦਾ ਹੈ। ਤੁਸੀਂ routes ਨੂੰ ਦੁਬਾਰਾ ਸੰਗਠਿਤ ਕਰ ਸਕਦੇ ਹੋ, ਨਵੀਆਂ ਕਾਰਵਾਈਆਂ ਜੁੜ ਸਕਦੀਆਂ ਹਨ, ਜਾਂ ਪੁਰਾਣੀਆਂ deprecated ਹੋ ਸਕਦੀਆਂ ਹਨ, ਜੇਕਰ ਤੁਸੀਂ link relations ਦਾ ਅਰਥ ਬਰਕਰਾਰ ਰੱਖੋ।
ਟੀਮਾਂ ਅਕਸਰ HATEOAS ਨੂੰ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ ਵਧੇਰੇ ਕੰਮ ਜਾਪਦਾ ਹੈ: link formats ਬਨਾਉਣੇ, relation names 'ਤੇ ਸਹਿਮਤ ਹੋਣਾ, ਅਤੇ ਕਲਾਇੰਟ ਡਿਵੈਲਪਰਾਂ ਨੂੰ links follow کرنا Sikhana.
ਜੋ ਤੁਸੀਂ ਗਵਾਂਦੇ ਹੋ ਉਹ ਹੈ ਇੱਕ ਮੁੱਖ REST ਲਾਭ: ਢੀਲਾ coupling। Hypermedia ਦੇ ਬਿਨਾਂ, ਬਹੁਤ ਸਾਰੇ APIs "RPC over HTTP" ਬਣ ਜਾਂਦੇ ਹਨ—ਉਹ HTTP ਵਰਤਦੇ ਹਨ, ਪਰ ਕਲਾਇੰਟ ਫਿਰ ਵੀ ਬਾਹਰੀ ਡੌਕਸ ਤੇ ਫਿਕਸਡ URL ਟੈਂਪਲੇਟਾਂ 'ਤੇ ਨਿਰਭਰ ਰਹਿੰਦੇ ਹਨ।
Layered system ਦਾ ਅਰਥ ਹੈ ਕਿ ਕਲਾਇੰਟ ਨੂੰ ਪਤਾ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ (ਅਤੇ ਅਕਸਰ ਨਹੀਂ ਹੁੰਦਾ) ਕਿ ਉਹ "ਅਸਲ" origin server ਨਾਲ ਗੱਲ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ ਰਾਹ ਵਿੱਚ intermediaries ਨੇ ਜਵਾਬ ਦਿੱਤਾ ਹੈ। ਉਹ levels ਇੱਕ API gateway, reverse proxies, CDNs, auth services, WAFs, service meshes, ਅਤੇ ਅੰਦਰੂਨੀ ਮਾਈਕਰੋਸਰਵਿਸ ਰੂਟਿੰਗ ਸਮੇਤ ਹੋ ਸਕਦੇ ਹਨ।
ਲੇਅਰਜ਼ ਸਾਫ਼ ਸਰਹੱਦ ਬਣਾਉਂਦੇ ਹਨ। ਸੁਰੱਖਿਆ ਟੀਮਾਂ TLS, rate limits, authentication, ਅਤੇ request validation edge ਤੇ ਲਾਗੂ ਕਰ ਸਕਦੀਆਂ ਹਨ ਬਿਨਾਂ ਹਰ backend ਸਰਵਿਸ ਨੂੰ ਬਦਲੇ। operations ਟੀਮਾਂ horizontal scale ਕਰ ਸਕਦੀਆਂ ਹਨ, CDN ਵਿੱਚ caching ਜੋੜ ਸਕਦੀਆਂ ਹਨ, ਜਾਂ incidents ਦੌਰਾਨ ਟ੍ਰੈਫਿਕ ਸਵਿੱਚ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਕਲਾਇੰਟ ਲਈ, ਇਹ ਸਧਾਰਨ ਕਰ ਸਕਦਾ ਹੈ: ਇੱਕ ਸਥਿਰ API endpoint, ਇਕਸਾਰ headers, ਅਤੇ predictable error formats.
Intermediaries hidden latency ਲਿਆ ਸਕਦੇ ਹਨ (ਅਤਿਰਿਕਤ hops, ਅਤਿਰਿਕਤ handshakes) ਅਤੇ ਡਿਬੱਗਿੰਗ ਮੁਸ਼ਕਿਲ ਹੋ ਸਕਦੀ ਹੈ: ਬੱਗ gateway rules, CDN cache ਜਾਂ origin code ਵਿੱਚ ਹੋ ਸਕਦੀ ਹੈ। caching ਵੀ ਗੁੰਝਲਦਾਰ ਹੋ ਸਕਦੀ ਹੈ ਜਦੋਂ ਵੱਖ-ਵੱਖ layers ਵੱਖ-ਵੱਖ ਤਰੀਕਿਆਂ ਨਾਲ cache ਕਰਦੀਆਂ ਹਨ, ਜਾਂ ਜਦੋਂ gateway headers rewrite ਕਰਦਾ ਹੈ ਜੋ cache keys ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ।
ਜੇ ਸਿਸਟਮ observable ਅਤੇ predictable ਰਹੇ ਤਾਂ ਲੇਅਰਜ਼ ਤਾਕਤਵਰ ਹੁੰਦੇ ਹਨ।
Code-on-demand ਇੱਕ REST ਨਿਯਮ ਹੈ ਜੋ ਖਾਸ ਤੌਰ 'ਤੇ ਵਿਕਲਪਿਕ ਹੈ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਸਰਵਰ client ਨੂੰ executable code ਭੇਜ ਕੇ ਉਸਦੀ ਸਮਰੱਥਾ ਵਧਾ ਸਕਦਾ ਹੈ। ਬਿਨਾਂ ਹਰ ਵਰਤੋਂਕਾਰ ਨੂੰ ਪਹਿਲਾਂ ਤੋਂ ਹਰ ਹਰ ਬਰਤਮਾਨ ਵਰਤੋਂਕਾਰ-ਸਾਈਡ ਕੋਡ ਭੇਜੇ, client ਜ਼ਰੂਰਤ ਮੁਤਾਬਿਕ ਨਵਾਂ logic ਡਾਊਨਲੋਡ ਕਰ ਸਕਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਕਦੇ ਕੋਈ webpage ਲੋਡ ਕੀਤਾ ਜਿਸ ਤੋਂ ਬਾਅਦ ਉਹ interactive ਬਣ ਗਿਆ—form validate ਕਰਨਾ, chart render ਕਰਨਾ, table filter ਕਰਨਾ—ਤਾਂ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ code-on-demand ਵਰਤ ਚੁੱਕੇ ਹੋ। ਸਰਵਰ HTML ਅਤੇ data ਦੇ ਨਾਲ JavaScript ਭੇਜਦਾ ਹੈ ਜੋ browser ਵਿੱਚ ਚੱਲ ਕੇ ਵਰਤੋਂਕਾਰ ਅਨੁਭਵ ਦਿੰਦਾ ਹੈ।
ਇਹ ਇੱਕ ਵੱਡਾ ਕਾਰਨ ਹੈ ਕਿ ਵੈੱਬ ਤੇਜ਼ੀ ਨਾਲ ਵਿਕਸਤ ਹੋ ਸਕਦਾ ਹੈ: browser ਇੱਕ general-purpose client ਰਹਿੰਦਾ ਹੈ, ਜਦ ਕਿ sites bina user-installed app ਦੇ ਨਵੀਆਂ functionality ਭੇਜ ਸਕਦੇ ਹਨ।
REST ਬਿਨਾ code-on-demand ਦੇ ਵੀ "ਕਾਮ" ਕਰ ਸਕਦੀ ਹੈ ਕਿਉਂਕਿ ਹੋਰ ਨਿਯਮ ਪਹਿਲਾਂ ਹੀ ਸਕੇਲਬਿਲਟੀ, ਸਾਦਗੀ, ਅਤੇ ਇੰਟਰੋਪਰਬਿਲਟੀ ਯਕੀਨੀ ਬਣਾਉਂਦੇ ਹਨ। ਇੱਕ API ਖ਼ਾਲੀ resource-oriented ਹੋ ਸਕਦੀ ਹੈ—JSON ਵਰਗੀਆਂ representations ਸੇਵਾ ਕਰਦੇ ਹੋਏ—ਜਦ ਕਿ ਕਲਾਇੰਟ ਆਪਣਾ ਆਚਰਨ ਅਪਣਾਉਂਦਾ ਹੈ।
ਅਸਲ ਵਿੱਚ, ਬਹੁਤ ਆਧੁਨਿਕ Web APIs ਇਰਾਦਾ ਨਾਲ executable code ਭੇਜਣਾ ਨਹੀਂ ਚਾਹੁੰਦੇ ਕਿਉਂਕਿ ਇਹ:
ਜੇ ਤੁਸੀਂ client environment 'ਤੇ ਕੰਟਰੋਲ ਰੱਖਦੇ ਹੋ ਅਤੇ UI ਬਿਹੇਵਿਓਰ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ rollout ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਜਾ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ patla client ਹੈ ਜੋ ਸਰਵਰ ਤੋਂ "plugins" ਜਾਂ rules ਡਾਊਨਲੋਡ ਕਰਦਾ ਹੈ, ਤਾਂ code-on-demand ਮਦਦਗਾਰ ਹੋ ਸਕਦੀ ਹੈ। ਪਰ ਇੱਕ ਟੂਲ ਵਜੋਂ ਇਸਨੂੰ ਵਰਤੋ, ਜ਼ਰੂਰੀ ਗੈਰ-ਜ਼ਰੂਰੀ ਲਾਜ਼ਮੀ ਨਹੀਂ।
ਮੁੱਖ ਨਤੀਜਾ: ਤੁਸੀਂ code-on-demand ਦੇ ਬਿਨਾਂ ਪੂਰੇ REST 'ਤੇ عمل ਕਰ ਸਕਦੇ ਹੋ—ਅਤੇ ਕਈ production APIs ਅਸਲ ਵਿੱਚ ਵੀ ਇਹ ਕਰਦੇ ਹਨ—ਕਿਉਂਕਿ ਇਹ ਨਿਯਮ ਇਕ ਵਿਕਲਪਿਕ ਵਾਧਾ ਹੈ, resource-based interaction ਦਾ ਨੀਵ ਹੈ ਨਹੀਂ।
ਆਧਿਕਤਮ ਟੀਮਾਂ REST ਨੂੰ ਸਿੱਧਾ ਰੱਦ ਨਹੀਂ ਕਰਦੀਆਂ—ਉਹ HTTP ਨੂੰ ਇੱਕ ਬਾਹੁ-ਉਪਯੋਗੀ ਅਧਾਰ ਵਜੋਂ ਵਰਤਦੀਆਂ ਹਨ ਪਰ ਕਈ ਨਿਯਮਾਂ ਨੂੰ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ। ਇਹ ਠੀਕ ਹੋ ਸਕਦਾ ਹੈ, ਜੇਕਰ ਇਹ ਇੱਕ ਸੋਚ-ਵਿਚਾਰ ਵਾਲਾ ਫੈਸਲਾ ਹੋਵੇ ਨ ਕਿ ਇਕ ਐਕਸਿਡੇਂਟ ਜੋ ਬਾਅਦ ਵਿੱਚ brittle clients ਅਤੇ ਮਹਿੰਗੀਆਂ ਰੀ-ਰਾਈਟਾਂ ਵਜੋਂ ਸਾਹਮਣਾ ਕਰਾਏ।
ਕੁਝ ਨਮੂਨੇ ਮੁੜ-ਮੁੜ ਮਿਲਦੇ ਹਨ:
/doThing, /runReport, /users/activate—ਨਾਮ ਰੱਖਣ ਵਿੱਚ ਆਸਾਨ, ਵਾਇਰ-ਅਪ ਵਿੱਚ ਆਸਾਨ।/createOrder, /updateProfile, /deleteItem—HTTP methods ਅਕਸਰ ਧਿਆਨ ਵਿੱਚ ਨਹੀਂ ਰਹਿੰਦੀਆਂ।ਇਹ ਚੋਣਾਂ ਸ਼ੁਰੂ ਵਿੱਚ ਉਤਪਾਦਕਤਾ ਵਧਾਉਂਦੀਆਂ ਮਹਿਸੂਸ ਹੋ ਸਕਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਹ ਅੰਦਰੂਨੀ ਫੰਕਸ਼ਨ ਨਾਂਆਂ ਅਤੇ ਕਾਰੋਬਾਰੀ ਓਪਰੇਸ਼ਨਾਂ ਦੀ ਨਕਲ ਕਰਦੀਆਂ ਹਨ।
ਇਸ ਨੂੰ ਇੱਕ "ਅਸੀਂ ਕਿੰਨੇ REST ਹਾਂ" ਸਮੀਖਿਆ ਦੇ ਤੌਰ 'ਤੇ ਵਰਤੋ:
/orders/{id} ਨੂੰ /createOrder ਉੱਤੇ ਤਰਜੀਹ ਦਿਓ।Cache-Control, ETag, ਅਤੇ Vary define ਕਰੋ।REST ਨਿਯਮ ਸਿਰਫ਼ ਸਿਧਾਂਤ ਨਹੀਂ—ਉਹ ਗਾਰਡਰੇਲ ਹਨ ਜੋ ਤੁਸੀਂ ਜਦੋਂ ship ਕਰ ਰਹੇ ਹੋ ਤਾਂ ਮਹਿਸੂਸ ਕਰਦੇ ਹੋ। ਜਦੋਂ ਤੁਸੀਂ ਤੁਰੰਤ API ਤਿਆਰ ਕਰ ਰਹੇ ਹੋ (ਉਦਾਹਰਨ: React frontend ਨੂੰ Go + PostgreSQL backend ਨਾਲ scaffolding), ਸਭ ਤੋਂ ਆਸਾਨ ਗਲਤੀ ਇਹ ਹੁੰਦੀ ਹੈ ਕਿ "ਜੋ ਵੀ ਜ਼ਿਆਦਾ ਤੇਜ਼ੀ ਨਾਲ ਜੋੜ ਜਾਏ" ਤੁਹਾਡੀ ਇੰਟਰਫੇਸ ਨਿਰਧਾਰਤ ਕਰੇ।
ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਗੇ vibe-coding ਪਲੈਟਫਾਰਮ ਦੀ ਵਰਤੋਂ ਕਰ ਰਹੇ ਹੋ ਜੋ chat ਤੋਂ ਇੱਕ ਵੈੱਬ ਐਪ ਬਣਾਉਂਦਾ ਹੈ, ਤਾਂ ਇਹ REST ਨਿਯਮਾਂ ਨੂੰ ਗੱਲ-ਬਾਤ 'ਚ ਸ਼ੁਰੂ ਤੋਂ ਲਿਆਉਣਾ ਫਾਇਦੇਵੰਦ ਹੈ—ਸਰੋਤ ਪਹਿਲਾਂ ਨਾਮ ਰੱਖਣਾ, stateless ਰਹਿਣਾ, ਇਕਸਾਰ error shapes.define ਕਰਨਾ, ਅਤੇ ਕਿੱਥੇ caching ਸੁਰੱਖਿਅਤ ਹੈ ਫੈਸਲਾ ਕਰਨਾ। ਇਸ ਤਰ੍ਹਾਂ, ਤੇਜ਼ iteration ਦੇ ਬਾਵਜੂਦ API ਉਹਨਾਂ clienਟਾਂ ਲਈ predictable ਅਤੇ evolve ਕਰਨ ਯੋਗ ਰਹਿੰਦੇ ਹਨ। (ਅਤੇ ਕਿਉਂਕਿ Koder.ai source code export support ਕਰਦਾ ਹੈ, ਤੁਸੀਂ API contract ਅਤੇ implementation ਨੂੰ ਜਿਵੇਂ-ਜਿਵੇਂ ਲੋੜ ਹੋਵੇ refine ਕਰ ਸਕਦੇ ਹੋ.)
ਪਹਿਲਾਂ ਆਪਣੇ ਮੁੱਖ resources define ਕਰੋ, ਫਿਰ ਨਿਯਮ ਸੋਚ-ਸਮਝ ਕੇ ਚੁਣੋ: ਜੇ ਤੁਸੀਂ caching ਜਾਂ hypermedia ਛੱਡ ਰਹੇ ਹੋ, ਤਾਂ ਇਸਦਾ ਕਾਰਨ ਅਤੇ ਜੋ ਵਿਆਪਕਤਾ ਤੁਸੀਂ ਵਰਤ ਰਹੇ ਹੋ ਉਸਨੂੰ ਦਰਸਾਓ। ਮਨੋਰਥ ਸੁਧਾਰ ਹੈ—ਸ਼ੁੱਧਤਾ ਨਹੀਂ: ਸਥਿਰ resource identifiers, predictable semantics, ਅਤੇ ਸਪਸ਼ਟ trade-offs ਜੋ ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੇ ਵਿਕਾਸ ਦੌਰਾਨ ਕਲਾਇੰਟਾਂ ਨੂੰ resilient ਰੱਖਣ।
REST (Representational State Transfer) ਇੱਕ ਆਰਕੀਟੈਕਚਰਲ ਸਟਾਈਲ ਹੈ ਜੋ ਰੌਇ ਫੀਲਡਿੰਗ ਨੇ ਦਰਸਾਇਆ ਕਿ ਵੈੱਬ ਕਿਵੇਂ ਸਕੇਲ ਕਰਦੀ ਹੈ।
ਇਹ ਕੋਈ ਪ੍ਰੋਟੋਕੋਲ ਜਾਂ ਸਰਟੀਫਿਕੇਸ਼ਨ ਨਹੀਂ—ਇਹ ਕੁਝ ਨਿਯਮਾਂ ਦਾ ਸੈੱਟ ਹੈ (client–server, statelessness, cacheability, uniform interface, layered system, ਵਿਕਲਪਿਕ code-on-demand) ਜੋ ਕੁਝ ਲਚਕ ਛੱਡ ਕੇ ਸਕੇਲਬਿਲਟੀ, ਵਿਕਾਸਯੋਗਤਾ ਅਤੇ ਇੰਟਰੋਪਰਬਿਲਟੀ ਦੇ ਫਾਇਦੇ ਦਿੰਦੇ ਹਨ।
ਕਈ APIs ਸਿਰਫ਼ REST ਦੇ ਕੁਝ ਵਿਚਾਰਾਂ ਨੂੰ ਲੈਂਦੇ ਹਨ (ਜਿਵੇਂ JSON ਉੱਤੇ HTTP ਅਤੇ ਚੰਗੀਆਂ URLs) ਪਰ ਹੋਰ ਨਿਯਮਾਂ (ਜਿਵੇਂ cacheability ਯਾ hypermedia) ਛੱਡ ਦਿੰਦੈ ਹਨ।
ਇਸ ਲਈ ਦੋ “REST APIs” ਬਿਲਕੁਲ ਵੱਖਰੇ ਮਹਿਸੂਸ ਹੋ ਸਕਦੇ ਹਨ, ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਕੇ ਕਿ ਉਹ:
ਇੱਕ resource ਇੱਕ ਨਾਊਨ ਹੈ ਜਿਸਨੂੰ ਤੁਸੀਂ ਪਛਾਣ ਸਕਦੇ ਹੋ (ਉദਾਹਰਨ: /users/123). ਇੱਕ action endpoint URL ਵਿੱਚ ਬਨਾ ਹੋਇਆ ਵਰਬ ਹੁੰਦਾ ਹੈ (ਉਦਾਹਰਨ: /getUser, /updatePassword).
Resource-oriented ਡਿਜ਼ਾਇਨ ਅਕਸਰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਉਮਰ ਲਾਂਦੀ ਹੈ ਕਿਉਂਕਿ identifiers ਸਥਿਰ ਰਹਿੰਦੇ ਹਨ ਜਦ ਕਿ workflow ਅਤੇ UI ਬਦਲ ਸਕਦੇ ਹਨ। Action-ਤਰ੍ਹਾਂ endpoints ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਉਹ ਆਮ ਤੌਰ 'ਤੇ HTTP methods ਅਤੇ representations ਰਾਹੀਂ ਦਰਸਾਏ ਜਾਂਦੇ ਹਨ ਨ ਕਿ verb-shaped paths ਰਾਹੀਂ।
ਇੱਕ resource ਸਮਝਾਇਆ ਜਾਂਦਾ ਹੈ (ਉਦਾਹਰਨ “user 123”)। ਇੱਕ representation ਉਹ snapshot ਹੈ ਜੋ ਤੁਸੀਂ ਟ੍ਰਾਂਸਫਰ ਕਰਦੇ ਹੋ (JSON, HTML ਆਦਿ)।
ਇਹ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਇੱਕ resource identifier ਬਿਨਾਂ ਬਦਲੇ ਵੱਖ-ਵੱਖ representations ਸ਼ਾਮਲ ਕਰ ਸਕਦੇ ਹੋ। ਕਲਾਇੰਟ ਨੂੰ resource ਦੇ ਮਤਲਬ 'ਤੇ ਨਿਰਭਰ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ, ਇੱਕ ਖਾਸ payload ਫਾਰਮੈਟ 'ਤੇ ਨਹੀਂ।
Client–server ਵਿਭਾਜਨ ਨਾਲ ਚਿੰਤਾਵਾਂ ਅਲੱਗ ਰਹਿੰਦੀਆਂ ਹਨ:
ਜੇ ਕੋਈ ਫੈਸਲਾ ਸੁਰੱਖਿਆ, ਪੈਸਾ, ਅਨੁਮਤੀਆਂ ਜਾਂ ਸਾਂਝੇ consistency ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ, ਉਹ ਸਰਵਰ 'ਤੇ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਸ ਵਿਭਾਜਨ ਨਾਲ “ਇੱਕ backend, ਬਹੁਤ frontends” ਸੰਭਵ ਹੋ ਜਾਂਦਾ ਹੈ।
Statelessness ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਸਰਵਰ ਨੂੰ ਇਕ-ਦੂਜੇ ਬੇਨਤੀਆਂ ਵਿੱਚੋਂ ਕਿਸੇ ਕਲਾਇੰਟ ਬਾਰੇ ਕੁਝ ਯਾਦ ਨਹੀਂ ਰੱਖਣਾ। ਹਰ ਬੇਨਤੀ ਆਪਣੇ ਆਪ ਵਿੱਚ ਸਮਝਣਯੋਗ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ—ਕੌਣ ਬੁਲਾਇਆ, ਕੀ ਚਾਹੀਦਾ, ਅਤੇ ਕਿਹੜਾ ਸੰਦਰਭ ਲੋੜੀਂਦਾ ਹੈ।
ਲਾਭ:
ਆਮ ਨਮੂਨੇ:
Cacheable responses ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਪਹਿਲਾਂ ਦਿੱਤੇ ਗਏ ਇਕ ਜਵਾਬ ਨੂੰ ਇੱਕ ਸਮੇਂ ਲਈ ਦੁਬਾਰਾ ਵਰਤਣਾ ਸੁਰੱਖਿਅਤ ਹੈ, ਤਾਂ ਜੋ client ਜਾਂ ਕੋਈ intermediary ਉਹੀ ਕੰਮ ਦੁਬਾਰਾ ਨਾ ਕਰੇ। ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਕਰਨ 'ਤੇ ਇਹ latency ਘਟਾਉਂਦਾ ਅਤੇ ਲੋਡ ਘਟਾਉਂਦਾ ਹੈ—ਬਿਨਾਂ API ਦੇ ਅਰਥ ਨੂੰ ਬਦਲੇ।
ਮੁਖ਼ੀ ਟੂਲ:
Uniform interface ਸਿਰਫ਼ "GET ਪੜ੍ਹਨ ਲਈ, POST ਬਣਾਉਣ ਲਈ" ਹੀ ਨਹੀਂ। ਇਹ ਵੱਡੀ ਗੱਲ ਹੈ: APIs ਇਸ ਤਰ੍ਹਾਂ ਸਹੀ ਅਤੇ ਇੱਕਸਾਰ ਮਹਿਸੂਸ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ ਕਿ ਕਲਾਇੰਟਾਂ ਨੂੰ ਹਰ ਐਂਡਪੋਇੰਟ ਲਈ ਅਲੱਗ ਜਾਣਕਾਰੀ ਦੀ ਲੋੜ ਨਾ ਪਏ।
ਅਮਲੀ ਧਿਆਨ:
Hypermedia ਦਾ ਮਤਲਬ ਹੈ ਕਿ responses ਵਿੱਚ links ਹੁੰਦੇ ਹਨ ਜੋ ਅਗਲੇ ਮੰਜ਼ਿਲਾਂ ਅਤੇ ਮਨਜ਼ੂਰ actions ਨੁੰ ਦਰਸਾਉਂਦੇ ਹਨ, ਤਾਂ ਕਿ ਕਲਾਇੰਟ ਪਹਿਲਾਂ ਤੋਂ URLs hard-code ਨਾ ਕਰਨ।
ਇਹ ਸਭ ਤੋਂ ਵਰਤੋਂਯੋਗ ਹੈ ਜਦੋਂ flows latency, ਅਨੁਮਤੀਆਂ ਜਾਂ ਰਾਜ (state) ਦੇ ਆਧਾਰ 'ਤੇ ਬਦਲਦੇ ਹਨ (onboarding, checkout, approvals)।
ਕਈ ਟੀਮ ਇਸਨੂੰ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ link ਫਾਰਮੈਟ ਬਣਾ ਕੇ ਅਤੇ relation names ਹਾਂਡੀ ਰੱਖ ਕੇ ਕਲਾਇੰਟ ਡਿਵੈਲਪਰਾਂ ਨੂੰ ਇਹ ਵਰਤਣਾ ਸਿੱਖਾਉਣਾ ਵੱਧ ਕੰਮ ਲੱਗਦਾ ਹੈ। ਪਰ ਇਸਦੀ ਕਮੀ ਨਾਲ ਤੁਸੀਂ loose coupling ਦਾ ਇੱਕ ਵਡੀ ਲਾਭ ਗਵਾ ਦਿੰਦੇ ਹੋ।
Layered system ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਕਲਾਇੰਟ ਨੂ ਪਤਾ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ (ਅਤੇ ਅਕਸਰ ਪਤਾ ਨਹੀਂ ਹੁੰਦਾ) ਕਿ ਉਹ ਸਰਵਰ ਨਾਲ ਸਿੱਧਾ ਗੱਲ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ ਰਾਹ ਵਿੱਚ ਦਿੱਤੇ ਗਏ intermediaries (CDN, gateway, proxy ਆਦਿ) ਨਾਲ।
ਭਲੇ-ਫਾਇਦੇ:
ਸਾਵਧਾਨੀ:
Authorization: Bearer …?cursor=... ਜਾਂ next link) — ਸਰਵਰ "page 3 ਯਾਦ ਰੱਖਦਾ ਹੈ" ਜਿਸ ਤਰ੍ਹਾਂ ਨਹੀਂCache-Control freshness ਅਤੇ scope ਲਈETag ਅਤੇ Last-Modified ਵੈਰੀਡੇਸ਼ਨ ਲਈ (304 Not Modified)Vary ਜਦੋਂ ਜਵਾਬ headers (ਜਿਵੇਂ Accept) ਦੇ ਆਧਾਰ 'ਤੇ ਬਦਲਦਾ ਹੋਵੇਨਿਯਮ: public, ਸਾਂਝਾ GET ਡਾਟਾ ਨੂੰ aggressively cache ਕਰੋ; user-specific ਡਾਟਾ ਨੂੰ ਧਿਆਨ ਨਾਲ ਹੇਠਾਂ ਰਖੋ (ਆਮ ਤੌਰ 'ਤੇ private ਜਾਂ ਨਾ cacheable)।
200, 201 + Location, 400, 401/403, 404)code, message, details, requestId)ਇਹ ਘੱਟ coupling ਅਤੇ ਵਧੀਕ ਐਵੋਲਵਬਿਲਟੀ ਦਿੰਦਾ ਹੈ।
500 ਨਾ ਬਣਾਓ)ਲੇਅਰਜ਼ ਤਬੀ ਯੂਜ਼ਫੁੱਲ ਹਨ ਜਦ систему observable ਅਤੇ predictable ਰਹਿੰਦੀ ਹੈ।