10 ਅਕਤੂ 2025·8 ਮਿੰਟ
Redis ਤੁਹਾਡੀਆਂ ਐਪਲੀਕੇਸ਼ਨਾਂ ਲਈ: ਪੈਟਰਨ, ਪਿਟਫਾਲਸ ਅਤੇ ਸੁਝਾਵ
ਆਪਣੀਆਂ ਐਪਾਂ ਵਿੱਚ Redis ਦੀ ਵਰਤੋਂ ਦੇ ਪ੍ਰਯੋਗੀ ਤਰੀਕੇ ਸਿੱਖੋ: caching, sessions, queues, pub/sub, rate limiting—ਅਤੇ ਸਕੇਲਿੰਗ, persistence, ਮਾਨੀਟਰਿੰਗ ਅਤੇ ਸੰਭਾਵਿਤ ਔਖਿਆਂ ਬਾਰੇ ਸੁਝਾਵ।
ਆਪਣੀਆਂ ਐਪਾਂ ਵਿੱਚ Redis ਦੀ ਵਰਤੋਂ ਦੇ ਪ੍ਰਯੋਗੀ ਤਰੀਕੇ ਸਿੱਖੋ: caching, sessions, queues, pub/sub, rate limiting—ਅਤੇ ਸਕੇਲਿੰਗ, persistence, ਮਾਨੀਟਰਿੰਗ ਅਤੇ ਸੰਭਾਵਿਤ ਔਖਿਆਂ ਬਾਰੇ ਸੁਝਾਵ।
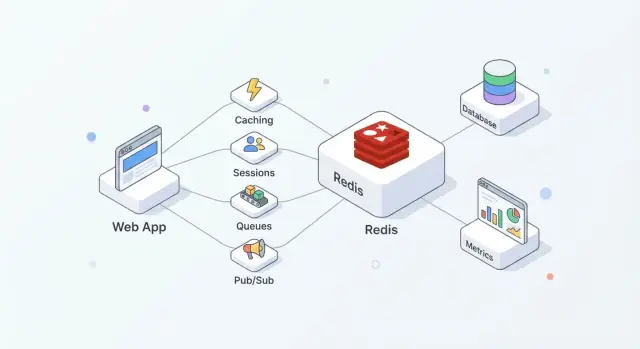
Redis ਇੱਕ in-memory ਡੇਟਾ ਸਟੋਰ ਹੈ ਜੋ ਅਕਸਰ ਐਪਲੀਕੇਸ਼ਨਾਂ ਲਈ ਸਾਂਝਾ “ਤੇਜ਼ ਲੇਅਰ” ਵਜੋਂ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ। ਟੀਮਾਂ ਇਸਨੂੰ ਪਸੰਦ ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ ਅਪਣਾਉਣ ਵਿੱਚ ਸਧਾਰਨ ਹੈ, ਆਮ ਓਪਰੇਸ਼ਨਾਂ ਲਈ ਬਹੁਤ ਤੇਜ਼ ਹੈ, ਅਤੇ ਇਹ ਇੱਕੋ ਸਮੇਂ ਕਈ ਕੰਮ (cache, sessions, counters, queues, pub/sub) ਸੰਭਾਲ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਹਰ ਇਕ ਲਈ ਨਵੀਂ ਸਿਸਟਮ ਜੋੜੇ।
ਅਮਲ ਵਿੱਚ, Redis ਉਸ ਵੇਲੇ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇਸਨੂੰ ਗਤੀ + ਕੋਆਰਡੀਨੇਸ਼ਨ ਵਜੋਂ ਵਰਤਦੇ ਹੋ, ਅਤੇ ਤੁਹਾਡਾ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਹੀ ਸਰੋਤ-ਏ-ਸਚਾਈ ਰਹਿੰਦਾ ਹੈ।
ਇੱਕ ਆਮ ਸੈਟਅਪ ਇਸ ਤਰ੍ਹਾਂ ਹੁੰਦਾ ਹੈ:
ਇਹ ਵਿਭਾਜਨ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਨੂੰ correctness ਅਤੇ durability 'ਤੇ ਧਿਆਨ ਦੇਣ ਦਿੰਦਾ ਹੈ, ਜਦکہ Redis ਉੱਚ-ਫ੍ਰਿਕਵੈਂਸੀ reads/writes ਨੂੰ ਸਹਿਣ ਕਰਦਾ ਹੈ ਜੋ ਨਹੀਂ ਤਾਂ latency ਜਾਂ ਲੋਡ ਵਧਾ ਸਕਦੇ।
ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਵਰਤਣ 'ਤੇ Redis ਕੁਝ ਪ੍ਰਯੋਗੀ ਨਤੀਜੇ ਦਿੰਦਾ ਹੈ:
Redis ਕਿਸੇ primary database ਦਾ ਬਦਲ ਨਹੀਂ। ਜੇ ਤੁਹਾਨੂੰ ਜਟਿਲ ਕਵੈਰੀਆਂ, ਲੰਬੇ ਸਮੇਂ ਦੀ ਸਟੋਰੇਜ਼ ਗਾਰੰਟੀਜ਼, ਜਾਂ analytics-ਸਟਾਇਲ ਰਿਪੋਰਟਿੰਗ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਹੀ ਠੀਕ ਘਰ ਹੈ।
ਅਤੇ, Redis ਨੂੰ "ਡਿਫਾਲਟ ਰੂਪ ਵਿੱਚ ਟਿਕਾਊ" ਸਮਝੋ ਨਾ। ਜੇ ਇੱਕ-ਦੋ ਸਕਿੰਟ ਦਾ ਡੇਟਾ ਖੋ ਜਾਣਾ ਅਸਵੀਕਾਰਯੋਗ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਧਿਆਨ ਨਾਲ persistence settings ਚਾਹੀਦੇ ਹੋਣਗੇ—ਜਾਂ ਕਿਸੇ ਹੋਰ ਸਿਸਟਮ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ—ਤੁਹਾਡੇ ਅਸਲ recovery ਲੋੜਾਂ ਦੇ ਆਧਾਰ 'ਤੇ।
Redis ਨੂੰ ਅਕਸਰ "key-value store" ਕਿਹਾ ਜਾਂਦਾ ਹੈ, ਪਰ ਇਸਨੂੰ ਇੱਕ ਬਹੁਤ ਤੇਜ਼ ਸਰਵਰ ਵਜੋਂ ਸੋਚੋ ਜੋ ਨਾਂ (key) ਦੁਆਰਾ ਛੋਟੇ ਟੁਕੜੇ ਡੇਟਾ ਨੂੰ ਰੱਖ ਅਤੇ ਹੈਂਡਲ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਮਾਡਲ predictable access patterns ਨੂੰ ਉਤਸ਼ਾਹਤ ਕਰਦਾ ਹੈ: ਤੁਹਾਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਪਤਾ ਹੁੰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕੀ ਚਾਹੁੰਦੇ ਹੋ (ਇੱਕ session, ਇੱਕ cached page, ਇੱਕ counter), ਅਤੇ Redis ਇੱਕ ਸਿੰਗਲ ਰਾਊਂਡ-ਟ੍ਰਿਪ ਵਿੱਚ ਇਹ ਨੂੰ ਫੈਚ ਜਾਂ ਅਪਡੇਟ ਕਰ ਸਕਦਾ ਹੈ।
Redis ਡੇਟਾ ਨੂੰ RAM ਵਿੱਚ ਰੱਖਦਾ ਹੈ, ਇਸੇ ਲਈ ਇਹ ਮਾਇਕ੍ਰੋਸੈਕੰਡ ਤੋਂ ਘੱਟ ਤੋਂ ਲੋ ਮੀਲਿਸੈਕੰਡ ਤੱਕ ਜਵਾਬ ਦੇ ਸਕਦਾ ਹੈ। ਟਰੇਡ-ਆਫ਼ ਇਹ ਹੈ ਕਿ RAM ਸੀਮਿਤ ਅਤੇ ਡਿਸਕ ਨਾਲੋਂ ਮਹਿੰਗਾ ਹੈ।
ਜਲਦੀ ਤੈਅ ਕਰੋ ਕਿ Redis:
Redis ਡੇਟਾ ਨੂੰ ਡਿਸਕ 'ਤੇ persist ਕਰ ਸਕਦਾ ਹੈ (RDB snapshots ਅਤੇ/ਜਾਂ AOF append-only logs), ਪਰ persistence ਲਿਖਤ ਓਵਰਹੈਡ ਜੋੜਦਾ ਹੈ ਅਤੇ durability ਚੋਣਾਂ ਮੰਗਦਾ ਹੈ (ਉਦਾਹਰਣ ਲਈ, "ਤੇਜ਼ ਪਰ ਇੱਕ ਸਕਿੰਟ ਖੋ ਸਕਦਾ ਹੈ" ਬਨਾਮ "ਧੀਮਾ ਪਰ ਸੁਰੱਖਿਅਤ")। Persistence ਨੂੰ ਇੱਕ ਡਾਇਲ ਸਮਝੋ ਜੋ ਤੁਸੀਂ ਬਿਜ਼ਨਸ ਪ੍ਰਭਾਵ ਦੇ ਆਧਾਰ 'ਤੇ ਸੈੱਟ ਕਰਦੇ ਹੋ, ਨਾ ਕਿ ਇੱਕ ਡਿਬਟ ਬਾਕਸ ਜਿਸ ਨੂੰ ਆਪੋ-ਆਪਣੇ ਚੇਕ ਕਰਨਾ ਹੈ।
Redis ਜ਼ਿਆਦਾਤਰ ਕਮਾਂਡਾਂ ਨੂੰ ਇੱਕ ਸੀੰਗਲ ਥਰੇਡ ਵਿੱਚ ਚਲਾਉਂਦਾ ਹੈ, ਜੋ ਸ਼ੁਰੂ ਵਿੱਚ ਸੀਮਤ ਲਗ ਸਕਦਾ ਹੈ, ਪਰ ਦੋ ਗੱਲਾਂ ਯਾਦ ਰੱਖੋ: ਓਪਰੇਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਛੋਟੇ ਹੁੰਦੇ ਹਨ, ਅਤੇ ਕਈ ਵਰਕਰ ਥਰੇਡਾਂ ਵਿਚਕਾਰ ਕੋਈ ਲਾਕਿੰਗ ਓਵਰਹੈਡ ਨਹੀਂ ਹੁੰਦਾ। ਜਦ ਤੱਕ ਤੁਸੀਂ ਮਹਿੰਗੀਆਂ ਕਮਾਂਡਾਂ ਅਤੇ ਵੱਡੇ payloads ਤੋਂ ਬਚਦੇ ਹੋ, ਇਹ ਮਾਡਲ ਉੱਚ concurrency ਹੇਠ ਬਹੁਤ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੋ ਸਕਦਾ ਹੈ।
ਤੁਹਾਡੀ ਐਪ Redis ਨਾਲ TCP ਰਾਹੀਂ client ਲਾਇਬ੍ਰੇਰੀਆਂ ਦੁਆਰਾ ਗੱਲ ਕਰਦੀ ਹੈ। connection pooling ਵਰਤੋ, ਬੇਨਤੀਆਂ ਨਿੱਕੀਆਂ ਰੱਖੋ, ਅਤੇ ਜਦੋਂ ਤੁਹਾਨੂੰ ਇਕ ਤੋਂ ਵਧੇਰੇ ਓਪਰੇਸ਼ਨ ਚਾਹੀਦੇ ਹੋ ਤਾਂ batching/pipelining ਨੂੰ ਤਰਜੀਹ ਦਿਓ।
Timeouts ਅਤੇ retries ਲਈ ਯੋਜਨਾ ਬਣਾਓ: Redis ਤੇਜ਼ ਹੈ, ਪਰ ਨੈੱਟਵਰਕ ਨਹੀਂ—ਤੁਹਾਡੀ ਐਪ ਨੂੰ graceful ਢੰਗ ਨਾਲ degrade ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਜਦੋਂ Redis ਬਿਜੀ ਜਾਂ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਅਣਉਪਲਬਧ ਹੋਵੇ।
ਜੇ ਤੁਸੀਂ ਨਵੀਂ ਸੇਵਾ ਬਣਾਉਂਦੇ ਹੋ ਅਤੇ ਇਹ ਬੁਨਿਆਦੀ ਗੱਲਾਂ ਤੁਰੰਤ ਸਥਾਪਤ ਕਰਨੀ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਪਲੇਟਫ਼ਾਰਮ ਜਿਵੇਂ Koder.ai ਤੁਹਾਨੂੰ React + Go + PostgreSQL ਐਪ ਸਕੈਫੋਲਡ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਫਿਰ Redis-ਬੈਕਡ ਫੀਚਰ (caching, sessions, rate limiting) ਜੋੜ ਸਕਦਾ ਹੈ—ਜਦੋਂ ਵੀ ਤੁਸੀਂ ਚਾਹੋ ਤਾਂ ਸੋਰਸ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰਨ ਦੀ ਆਜ਼ਾਦੀ ਦੇਂਦਾ ਹੈ।
Caching ਸਿਰਫ ਉਸ ਵੇਲੇ ਮਦਦਗਾਰ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਇਸਦੀ ਸਪੱਸ਼ਟ ਮਾਲਕੀ ਹੋਵੇ: ਕੌਣ ਭਰਦਾ ਹੈ, ਕੌਣ.invalidate ਕਰਦਾ ਹੈ, ਅਤੇ "ਕਿੰਨੀ ਤਾਜ਼ਗੀ" ਗੁਡ-ਇਨਫ સંપ੍ਰਤੀ ਦਾ ਕੀ ਮਤਲਬ ਹੈ।
Cache-aside ਦਾ ਮਤਲਬ ਹੈ ਕਿReads ਅਤੇ Writes ਨੂੰ ਤੁਹਾਡੀ ਐਪ ਕੰਟਰੋਲ ਕਰਦੀ ਹੈ—Redis ਨਹੀਂ।
ਆਮ ਫਲੋ:
Redis ਇੱਕ ਤੇਜ਼ key-value store ਹੈ; ਤੁਹਾਡੀ ਐਪ ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ ਕਿ entries ਨੂੰ ਕਿਵੇਂ serialize, version, ਅਤੇ expire ਕਰਣਾ ਹੈ।
TTL ਇੱਕ ਉਤਪਾਦ ਫੈਸਲਾ ਹੈ ਜਿੰਨਾ ਕਿ ਤਕਨੀਕੀ। ਛੋਟੇ TTL staleਨੈਸ ਘਟਾਉਂਦੇ ਹਨ ਪਰ ਡੇਟਾਬੇਸ ਲੋਡ ਵਧਾਉਂਦੇ ਹਨ; ਲੰਬੇ TTL ਕੰਮ ਬਚਾਉਂਦੇ ਹਨ ਪਰ outdated ਨਤੀਜੇ ਦਾ ਖ਼ਤਰਾ ਬਣਾਉਂਦੇ ਹਨ।
ਵਿਆਵਹਾਰਿਕ ਟਿਪਸ:
user:v3:123 ਵਰਗੇ versioned keys ਵਰਤੋ ਤਾਂ ਕਿ ਪੁਰਾਣੇ cached shapes ਨਵੇਂ ਕੋਡ ਨੂੰ ਤੋੜਨ।ਜਦੋਂ ਇੱਕ hot key expire ਹੁੰਦਾ ਹੈ, ਬਹੁਤ ਸਾਰੀਆਂ ਰਿਕਵੇਸਟਾਂ ਇੱਕੋ ਵਾਰ miss ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਆਮ ਰੋਕਥਾਮ:
ਚੰਗੇ ਉਮੀਦਵਾਰਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ API responses, ਮਹਿੰਗੇ query results, ਅਤੇ computed objects (recommendations, aggregations)। ਪੂਰੀ HTML pages ਨੂੰ cache ਕਰਨਾ ਕੰਮ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ personalization ਅਤੇ permissions ਨਾਲ ਸਾਬਧਾਨ ਰਹੋ—ਜਦੋਂ user-specific logic ਲਗਦੀ ਹੈ ਤਾਂ fragments cache ਕਰੋ।
Redis ਇੱਕ ਅਚਛੀ ਥਾਂ ਹੈ ਛੋਟੇ-ਅਵਧੀ ਵਾਲੇ ਲੌਗਿਨ ਸਟੇਟ ਰੱਖਣ ਲਈ: session IDs, refresh-token metadata, ਅਤੇ “remember this device” flags। ਮਕਸਦ authentication ਨੂੰ ਤੇਜ਼ ਬਣਾਉਣਾ ਹੈ ਜਦ ਕਿ session lifetime ਅਤੇ revocation ਉੱਤੇ ਕੜੀ ਨਿਗਰਾਨੀ ਰਹੇ।
ਇੱਕ ਆਮ ਪੈਟਰਨ ਇਹ ਹੈ: ਤੁਹਾਡੀ ਐਪ ਇਕ random session ID ਜਾਰੀ ਕਰਦੀ ਹੈ, Redis ਵਿੱਚ ਇੱਕ ਸੰਕੁੱਚਿਤ record ਰੱਖਦੀ ਹੈ, ਅਤੇ ID ਨੂੰ HTTP-only cookie ਵਜੋਂ ਬ੍ਰਾਉਜ਼ਰ ਨੂੰ ਵਾਪਸ ਕਰ ਦਿੰਦੀ ਹੈ। ਹਰ ਰੀਕਵੇਸਟ 'ਤੇ, ਤੁਸੀਂ session key ਨੂੰ ਲੱਭ ਕੇ user identity ਅਤੇ permissions ਰਿਕਵੇਸਟ context ਵਿੱਚ ਲਗਾ ਦਿੰਦੇ ਹੋ।
Redis ਇੱਥੇ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ ਕਿਉਂਕਿ session reads ਵਾਰ-ਵਾਰ ਹੁੰਦੇ ਹਨ, ਅਤੇ session expiration built-in ਹੈ।
Keys ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਉਹਨਾਂ ਨੂੰ ਸਕੈਨ ਅਤੇ revoke ਕਰਨਾ ਆਸਾਨ ਹੋਵੇ:
sess:{sessionId} → session payload (userId, issuedAt, deviceId)user:sessions:{userId} → active session IDs ਦੀ Set (ਇੱਕ ਵਿਕਲਪ, “log out everywhere” ਲਈ)sess:{sessionId} ਤੇ TTL ਵਰਤੋ ਜੋ ਤੁਹਾਡੇ session lifetime ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੋਵੇ। ਜੇ ਤੁਸੀਂ sessions ਰੋਟੇਟ ਕਰਦੇ ਹੋ (ਸੁਝਾਇਆ ਗਿਆ), ਤਾਂ ਨਵਾਂ session ID ਬਣਾਓ ਅਤੇ ਪੁਰਾਣਾ ਤੁਰੰਤ ਮਿਟਾ ਦਿਓ।
"sliding expiration" (ਹਰ ਰਿਕਵੇਸਟ 'ਤੇ TTL ਵਧਾਉਣਾ) ਨਾਲ ਧਿਆਨ ਰੱਖੋ: ਇਹ ਭਾਰੀ ਯੂਜ਼ਰਾਂ ਲਈ sessions ਨੂੰ ਅਨੰਤਕਾਲ ਤੱਕ ਜਿਊਂਦਾ ਰੱਖ ਸਕਦਾ ਹੈ। ਇੱਕ ਸੁਰੱਖਿਅਤ compromise ਇਹ ਹੈ ਕਿ TTL ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਵਧਾਇਆ ਜਾਵੇ ਜਦੋਂ ਇਹ ਨਜ਼ਦੀਕ ਸਮੇਂ 'ਤੇ expire ਹੋ ਰਿਹਾ ਹੋਵੇ।
ਇੱਕ device ਨੂੰ logout ਕਰਨ ਲਈ, sess:{sessionId} ਨੂੰ ਮਿਟਾ ਦਿਓ।
ਸਾਰੇ ਡਿਵਾਈਸਾਂ 'ਤੇ logout ਕਰਨ ਲਈ, ਜਾਂ ਤਾਂ:
user:sessions:{userId} ਵਿੱਚ ਮਿਲੇ ਸਾਰੇ session IDs ਨੂੰ ਮਿਟਾ ਦਿਓ, ਜਾਂuser:revoked_after:{userId} timestamp ਰੱਖੋ ਅਤੇ ਕਿਸੇ ਵੀ session ਨੂੰ ਜੋ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਜਾਰੀ ਹੋਇਆ ਹੈ ਅਵੈਧ ਮੰਨੋTimestamp ਸੁਸਥੀ large fan-out deletes ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ।
Redis ਵਿੱਚ ਜੋੜਨ ਲਈ ਜ਼ਰੂਰੀ ਘੱਟੋ-ਘੱਟ ਡੇਟਾ ਰੱਖੋ—IDs ਨੂੰ personal data 'ਤੇ ਤਰਜੀਹ ਦਿਓ। ਕਦੇ ਵੀ raw passwords ਜਾਂ ਲੰਬੇ-ਅਵਧੀ ਵਾਲੇ secrets ਨਾ ਰੱਖੋ। ਜੇ ਟੋਕਨ-ਸੰਬੰਧੀ ਡੇਟਾ ਰੱਖਣਾ ਲਾਜ਼ਮੀ ਹੈ, ਤਾਂ hashes ਰੱਖੋ ਅਤੇ ਕੜੀ TTLs ਵਰਤੋ।
ਕੌਣ Redis ਨਾਲ ਕਨੈਕਟ ਕਰ ਸਕਦਾ ਹੈ ਉੱਤੇ ਸੀਮਿਤ ਕਰੋ, authentication ਦੀ ਮੰਗ ਕਰੋ, ਅਤੇ session IDs ਨੂੰ high-entropy ਰੱਖੋ ਤਾਂ ਕਿ guessing attacks ਰੁਕੀ ਰਹਿਣ।
Rate limiting ਇਸੇ ਜਗ੍ਹਾ 'ਤੇ Redis ਨੂੰ ਚਮਕ ਮਿਲਦੀ ਹੈ: ਇਹ ਤੇਜ਼ ਹੈ, ਤੁਹਾਡੀ ਸਾਰੀ ਐਪ ਇੰਸਟਰੈਂਸਾਂ ਵਿਚ ਸਾਂਝਾ ਹੈ, ਅਤੇ atomic operations ਦਿੰਦੀ ਹੈ ਜੋ ਭਾਰੀ ਟ੍ਰੈਫਿਕ ਹੇਠ counters ਨੂੰ consistent ਰੱਖਦੀਆਂ ਹਨ। ਇਹ ਲੌਗਿਨ endpoints, ਮਹਿੰਗੀ searches, password reset flows, ਅਤੇ ਕਿਸੇ ਵੀ API ਲਈ ਉਪਯੋਗੀ ਹੈ ਜੋ scraped ਜਾਂ brute-forced ਹੋ ਸਕਦਾ ਹੈ।
Fixed window ਸਾਰਾ ਤੋਂ ਸਧਾਰਣ ਹੈ: "100 requests per minute." ਤੁਸੀਂ ਮੌਜੂਦਾ ਮਿੰਟ ਬੱਕੇਟ ਵਿੱਚ requests ਗਿਣਦੇ ਹੋ। ਇਹ ਸੌਖਾ ਹੈ, ਪਰ ਬਾਉਂਡਰੀ ਤੇ ਬਰਸ ਦੀ ਆਗਿਆ ਦੇ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਣ: 12:00:59 'ਤੇ 100 ਅਤੇ 12:01:00 'ਤੇ 100)।
Sliding window ਬਾਉਂਡਰੀ ਨੂੰ ਸਮਥਰ ਕਰਦਾ ਹੈ, ਪਿਛਲੇ N ਸਕਿੰਟ/ਮਿੰਟ ਦੇਖ ਕੇ। ਇਹ ਨਿਆਂਸੰਗਤ ਹੈ, ਪਰ ਆਮ ਤੌਰ 'ਤੇ ਵੱਧ ਲਾਗਤ ਵਾਲਾ ਹੁੰਦਾ ਹੈ (ਤੁਹਾਨੂੰ sorted sets ਜਾਂ ਹੋਰ ਬੁੱਕੀਪਿੰਗ ਦੀ ਜ਼ਰੂਰਤ ਪੈ ਸਕਦੀ ਹੈ)।
Token bucket burst ਵੀਹਾਰ ਲਈ ਵਧੀਆ ਹੈ। ਯੂਜ਼ਰ ਸਮੇਂ ਨਾਲ ਟੋਕਨ "ਕਮਾਉਂਦੇ" ਹਨ ਇੱਕ ਕੈਪ ਤੱਕ; ਹਰ ਰਿਕਵੇਸਟ ਇੱਕ ਟੋਕਨ ਖਰਚ ਕਰਦੀ ਹੈ। ਇਹ ਛੋਟੇ bursts ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ ਜਦੋਂ ਕਿ ਔਸਤ ਰੇਟ ਨੂੰ ਲਾਗੂ ਕਰਦਾ ਹੈ।
INCR/EXPIRE ਅਤੇ atomicityਇੱਕ ਆਮ fixed-window ਪੈਟਰਨ ਇਹ ਹੈ:
INCR key ਨਾਲ counter ਵਧਾਓEXPIRE key window_seconds ਨਾਲ TTL ਸੈੱਟ/ਰੀਸੈੱਟ ਕਰੋਚਾਲਾਕੀ ਇਹ ਹੈ ਕਿ ਇਹ ਸਭ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਕਰੋ। ਜੇ ਤੁਸੀਂ INCR ਅਤੇ EXPIRE ਨੂੰ ਅਲੱਗ ਕਾਲਾਂ ਵਜੋਂ ਚਲਾਉਂਦੇ ਹੋ, ਤਾਂ ਇੱਕ crash ਉਹਨਾਂ ਦੇ ਵਿਚਕਾਰ ਉਹ keys ਬਣਵਾ ਦੇ ਸਕਦਾ ਹੈ ਜੋ ਕਦੇ expire ਨਹੀਂ ਹੋਣ।
ਵਧੀਆ ਤਰੀਕੇ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
INCR ਕਰੇ ਅਤੇ expiry ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਸੈੱਟ ਕਰੇ ਜਦੋਂ counter ਪਹਿਲੀ ਵਾਰੀ ਬਣ ਰਿਹਾ ਹੋਵੇ।SET key 1 EX <ttl> NX initialization ਲਈ ਵਰਤੋ, ਫਿਰ INCR ਬਾਅਦ (ਅਕਸਰ ਫਿਰ ਵੀ race ਤੋਂ ਬਚਣ ਲਈ ਇੱਕ ਸਕ੍ਰਿਪਟ ਵਿੱਚ ਲਪੇਟਿਆ ਜਾਂਦਾ ਹੈ)।Atomic operations ਵਧੇਰੇ ਜ਼ਰੂਰੀ ਹਨ ਜਦੋਂ ਟ੍ਰੈਫਿਕ spike ਕਰੇ: ਬਿਨਾਂ ਉਹਨਾਂ ਦੇ, ਦੋ ਰਿਕਵੇਸਟ ਇੱਕੋ ਹੀ ਬਚੀ ਹੋਈ ਕੁਆਟਾ ਦੇਖ ਕੇ ਦੋਨੋ ਪਰਵਾਨਗੀ ਦੇ ਸਕਦੀਆਂ ਹਨ।
ਜ਼ਿਆਦਾਤਰ ਐਪਾਂ ਨੂੰ ਇਕ ਨਾਲ ਕਈ ਪੱਧਰਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ:
rl:user:{userId}:{route})ਬਰਸਟ-ਪਰੂ endpoints ਲਈ, token bucket (ਅਥਵਾ ਇੱਕ ਦਿਲਾਸਾ fixed window ਨਾਲ ਛੋਟੀ "burst" window) legitimate spikes ਜਿਵੇਂ page loads ਜਾਂ mobile reconnects ਨੂੰ ਸਜ਼ਾ ਨਹੀਂ ਦਿੰਦੇ।
ਪਹਿਲਾਂ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ "ਸੁਰੱਖਿਅਤ" ਦਾ ਕੀ ਮਤਲਬ ਹੈ:
ਆਮ ਸਮਝੌਤਾ ਇਹ ਹੈ ਕਿ low-risk routes ਲਈ fail-open ਅਤੇ ਸੰवेਦਨਸ਼ੀਲਾਂ (login, password reset, OTP) ਲਈ fail-closed ਰੱਖੋ, ਅਤੇ ਮਾਨਟਰਿੰਗ ਰੱਖੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਵੇਖ ਸਕੋ ਕਿ rate limiting ਕਦੋਂ ਰੁਕੀ ਹੋਈ ਹੈ।
Redis ਨੂੂੰ background jobs ਲਈ ਪਾਵਰ ਦੇ ਸਕਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ emails ਭੇਜਣ, images resize ਕਰਨ, ਡੇਟਾ sync ਕਰਨ, ਜਾਂ periodic tasks ਲਈ ਹਲਕੀ ਕਿਊ ਚਾਹੀਦੀ ਹੋਵੇ। ਕੁੰਜੀ ਇਹ ਹੈ ਕਿ ਸਹੀ data structure ਚੁਣੋ ਅਤੇ retries ਅਤੇ failure handling ਲਈ ਸਪਸ਼ਟ ਨਿਯਮ ਰੱਖੋ।
Lists ਸਭ ਤੋਂ ਸਧਾਰਣ queue ਹਨ: producers LPUSH, workers BRPOP। ਇਹ ਆਸਾਨ ਹਨ, ਪਰ ਤੁਹਾਨੂੰ "in-flight" jobs, retries, ਅਤੇ visibility timeouts ਲਈ ਵਾਧੂ logic ਬਣਾਉਣਾ ਪਏਗਾ।
Sorted sets scheduling ਦੇ ਵੇਲੇ ਚਮਕਦਾਰ ਹਨ। score ਨੂੰ timestamp (ਜਾਂ priority) ਵਜੋਂ ਵਰਤੋ, ਅਤੇ workers ਅਗਲਾ due job ਫੈਚ ਕਰਦੇ ਹਨ। ਇਹ delayed jobs ਅਤੇ priority queues ਲਈ ਠੀਕ ਹੈ।
Streams ਆਮ ਤੌਰ 'ਤੇ durable work distribution ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ ਡਿਫਾਲਟ ਹਨ। ਉਹ consumer groups ਨੂੰ ਸਹਿਯੋਗ ਦਿੰਦੇ ਹਨ, ਇਤਿਹਾਸ ਰੱਖਦੇ ਹਨ, ਅਤੇ ਕਈ workers ਨੂੰ coordination ਦੇਣਗੇ ਬਿਨਾਂ ਆਪਣਾ "processing list" ਬਣਾਉਣ ਦੇ।
Streams consumer groups ਨਾਲ, worker ਇੱਕ message ਪੜ੍ਹਦਾ ਹੈ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ACK ਕਰਦਾ ਹੈ। ਜੇ worker crash ਹੋ ਜਾਂਦਾ ਹੈ, message pending ਰਹਿੰਦਾ ਹੈ ਅਤੇ ਕਿਸੇ ਹੋਰ worker ਦੁਆਰਾ claim ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
Retries ਲਈ, attempt counts ਨੂੰ track ਕਰੋ (message payload ਵਿੱਚ ਜਾਂ ਸਾਈਡ ਕੁੰਜੀ ਵਿੱਚ) ਅਤੇ exponential backoff ਲਗਾਓ (ਅਕਸਰ ਇੱਕ sorted set "retry schedule" ਰਾਹੀਂ)। ਇੱਕ ਮੈਕਸ ਮਹਿਲਾ limit ਤੋਂ ਬਾਅਦ, job ਨੂੰ dead-letter queue (ਹੋਰ stream ਜਾਂ list) 'ਤੇ ਭੇਜੋ manual review ਲਈ।
ਮੰਨ ਲੌ ਕਿ jobs ਦੋ ਵਾਰੀ ਚੱਲ ਸਕਦੀਆਂ ਹਨ। handlers ਨੂੰ idempotent ਬਣਾਓ:
job:{id}:done) SET ... NX ਨਾਲ side effects ਤੋਂ ਪਹਿਲਾਂpayloads ਛੋਟੇ ਰੱਖੋ (ਵੱਡੇ ਡੇਟਾ ਨੂੰ ਹੋਰ ਜਗ੍ਹਾ ਸਟੋਰ ਕਰੋ ਅਤੇ references ਭੇਜੋ)। Backpressure ਜੋੜੋ queue ਲੰਬਾਈ ਸੀਮਤ ਕਰਕੇ, ਜਦੋਂ lag ਵਧੇ ਤਾਂ producers ਨੂੰ slow ਕਰੋ, ਅਤੇ pending depth ਅਤੇ processing time ਦੇ ਆਧਾਰ 'ਤੇ workers scale ਕਰੋ।
Redis Pub/Sub ਸਭ ਤੋਂ ਸਧਾਰਣ ਤਰੀਕੇ ਨਾਲ events ਨੂੰ broadcast ਕਰਦਾ ਹੈ: publishers ਇਕ channel 'ਤੇ message ਭੇਜਦੇ ਹਨ, ਅਤੇ ਹਰ connected subscriber ਨੂੰ ਇਹ ਤੁਰੰਤ ਮਿਲ ਜਾਂਦਾ ਹੈ। ਇੱਥੇ polling ਨਹੀਂ—ਸਿਰਫ਼ ਇੱਕ ਹਲਕੀ "push" ਜੋ real-time updates ਲਈ ਚੰਗੀ ਹੈ।
Pub/Sub ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਚਮਕਦਾਰ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ guaranteed delivery ਨਾਲੋਂ speed ਅਤੇ fan-out ਨੂੰ ਜ਼ਿਆਦਾ ਮਹੱਤਵ ਦਿੰਦੇ ਹੋ:
ਇੱਕ ਯੂਜ਼ਫੁਲ ਮਾਨਸਿਕ ਮਾਡਲ: Pub/Sub ਇੱਕ ਰੇਡੀਓ ਸਟੇਸ਼ਨ ਵਰਗਾ ਹੈ। ਜੋ ਵੀ tuned in ਹੈ ਉਹ broadcast ਸੁਣਦਾ ਹੈ, ਪਰ ਕਿਸੇ ਨੂੰ ਰਿਕਾਰਡਿੰਗ ਆਟੋਮੈਟਿਕ ਨਹੀਂ ਮਿਲਦੀ।
Pub/Sub ਦੇ ਮਹੱਤਵਪੂਰਨ ਟਰੇਡ-ਆਫ ਹਨ:
ਇਸ ਕਰਕੇ, Pub/Sub ਉਹਨਾਂ workflows ਲਈ ਮਾੜਾ ਹੈ ਜਿੱਥੇ ਹਰ event ਨੂੰ ਪ੍ਰਕਿਰੀਆ ਕਰਨਾ ਲਾਜ਼ਮੀ ਹੈ (exactly once—ਜਾਂ ਹੱਤੋਂ ਘੱਟ ਵੀ ਨਹੀਂ)।
ਜੇ ਤੁਹਾਨੂੰ durability, retries, consumer groups, ਜਾਂ backpressure handling ਚਾਹੀਦਾ ਹੈ, ਤਾਂ Redeis Streams ਆਮ ਤੌਰ 'ਤੇ ਚੰਗੀ ਚੋਣ ਹੁੰਦੇ ਹਨ। Streams ਤੁਹਾਨੂੰ events ਸਟੋਰ ਕਰਨ, acknowledgements ਨਾਲ ਪ੍ਰੋਸੈਸ ਕਰਨ, ਅਤੇ restarts ਤੋਂ ਬਾਅਦ recover ਕਰਨ ਦਿੰਦੇ ਹਨ—ਇੱਕ ਹਲਕੀ-ਫੁਲਕੀ message queue ਵਰਗੀ ਸਮਰੱਥਾ।
ਅਸਲੀ ਡਿਪਲਾਇਮੈਂਟ ਵਿੱਚ ਤੁਹਾਡੇ ਕੋਲ ਕਈ app instances subscribing ਹੋਣਗੇ। ਕੁਝ ਪ੍ਰਯੋਗੀ ਟਿਪਸ:
app:{env}:{domain}:{event} (ਉਦਾਹਰਣ: shop:prod:orders:created).notifications:global, ਅਤੇ users ਨੂੰ ਟਾਰਗਟ ਕਰਨਾ notifications:user:{id} ਵਰਗੀਆਂ ਚੈਨਲਾਂ ਨਾਲ ਕਰੋ।ਇਸ ਤਰ੍ਹਾਂ Pub/Sub ਤੇਜ਼ event "signal" ਬਣ ਜਾਂਦਾ ਹੈ, ਜਦਕਿ Streams (ਜਾਂ ਹੋਰ queue) ਉਹ events ਸੰਭਾਲਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਗੁਆ ਨਹੀਂ ਸਕਦੇ।
Redis data structure ਚੁਣਨਾ ਸਿਰਫ਼ "ਕੀ ਕੰਮ ਕਰਦਾ ਹੈ" ਦਾ ਮਸਲਾ ਨਹੀਂ—ਇਹ memory ਵਰਤੋਂ, query ਤੇਜ਼ੀ, ਅਤੇ ਕੋਡ ਦੀ ਸਾਦਗੀ 'ਤੇ ਅਸਰ ਪਾਂਦਾ ਹੈ। ਇੱਕ ਚੰਗਾ ਨੀਯਮ ਇਹ ਹੈ ਕਿ ਉਸ structure ਨੂੰ ਚੁਣੋ ਜੋ ਉਸ ਸਵਾਲ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਪੁੱਛੋਗੇ (read patterns), ਨਾ ਕਿ ਸਿਰਫ਼ ਅੱਜ ਤੁਸੀਂ ਡੇਟਾ ਕਿਵੇਂ ਸਟੋਰ ਕਰਦੇ ਹੋ।
INCR/DECR ਨਾਲ।SISMEMBER ਅਤੇ ਅਸਾਨ set operations।Redis operations ਕਮਾਂਡ-ਸਤਰ 'ਤੇ atomic ਹੁੰਦੀਆਂ ਹਨ, ਇਸ ਲਈ ਤੁਸੀਂ counters ਨੂੰ race conditions ਤੋਂ ਬਿਨਾਂ ਸੰਭਾਲ ਸਕਦੇ ਹੋ। Page views ਅਤੇ rate-limit counters ਆਮ ਤੌਰ 'ਤੇ strings ਨਾਲ INCR ਅਤੇ expiry ਵਰਤਦੇ ਹਨ।
Leaderboards ਵਿੱਚ sorted sets ਨੂੰ ਕੋਈ ਟੱਕਰ ਨਹੀਂ: ਤੁਸੀਂ scores ਅਪਡੇਟ ਕਰ ਸਕਦੇ ਹੋ (ZINCRBY) ਅਤੇ top players ਲੈ ਸਕਦੇ ਹੋ (ZREVRANGE) ਬਿਨਾਂ ਸਾਰੇ ਐਂਟ੍ਰੀਆਂ ਨੂੰ ਸਕੈਨ ਕੀਤੇ।
ਜੇ ਤੁਸੀਂ ਬਹੁਤ ਸਾਰੇ keys ਬਣਾਉਂਦੇ ਹੋ ਜਿਵੇਂ user:123:name, user:123:email, user:123:plan, ਤਾਂ ਤੁਸੀਂ per-key overhead ਕਾਰਨ ਯਾਦਾਸ਼ ਬਹੁਤ ਵੱਧ ਹੋ ਜਾਵੇਗੀ।
user:123 ਵਰਗਾ hash ਜਿਸ ਵਿੱਚ fields (name, email, plan) ਹਨ, ਸੰਬੰਧਿਤ ਡੇਟਾ ਨੂੰ ਇਕੱਠਾ ਰੱਖਦਾ ਹੈ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ key count ਘਟਾਉਂਦਾ ਹੈ। ਇਹ partial updates ਨੂੰ ਵੀ ਸੌਖਾ ਬਣਾਉਂਦਾ ਹੈ (ਇੱਕ field ਅਪਡੇਟ ਕਰੋ ਬਜਾਏ ਪੂਰੇ JSON string ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣ ਦੇ)।
ਸ਼ੱਕ ਹੋਵੇ ਤਾਂ ਇੱਕ ਛੋਟੀ sample ਮਾਡਲ ਕਰੋ ਅਤੇ memory ਵਰਤੋਂ ਨੂੰ ਮਾਪੋ ਪਹਿਲਾਂ ਕਿ ਤੁਸੀਂ ਕਿਸੇ high-volume ਡੇਟਾ ਲਈ structure ਨੂੰ ਫਾਈਨਲ ਕਰੋ।
Redis ਨੂੰ ਅਕਸਰ “in-memory” ਕਿਹਾ ਜਾਂਦਾ ਹੈ, ਪਰ ਤੁਹਾਡੇ ਕੋਲ ਫਿਰ ਵੀ ਚੋਣਾਂ ਹੁੰਦੀਆਂ ਹਨ ਕਿ node restart ਹੋਣ 'ਤੇ, disk ਭਰ ਜਾਣ 'ਤੇ, ਜਾਂ server ਗੁਆ ਹੋਣ 'ਤੇ ਕੀ ਹੋਵੇਗਾ। ਸਹੀ ਸੈਟਅਪ ਇਹਨਾਂ ਗੱਲਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕਿੰਨਾ ਡੇਟਾ ਗੁਆ ਸਕਦੇ ਹੋ ਅਤੇ ਕਿੰਨੀ ਜਲਦੀ recover ਕਰਨਾ ਹੈ।
RDB snapshots ਤੁਹਾਡੇ dataset ਦਾ point-in-time dump ਸੇਵ ਕਰਦੇ ਹਨ। ਇਹ compact ਅਤੇ startup 'ਤੇ ਤੁਰੰਤ ਲੋਡ ਹੋਣ ਵਾਲੇ ਹੁੰਦੇ ਹਨ, ਜਿਸ ਨਾਲ restarts ਤੇਜ਼ ਹੋ ਸਕਦੇ ਹਨ। ਟਰੇਡ-ਆਫ਼ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਆਖਰੀ snapshots ਤੋਂ ਬਾਅਦ ਦੇ ਲਿਖੇ ਕੁਝ ਰਿਕਾਰਡ ਗੁਆ ਸਕਦੇ ਹੋ।
AOF (append-only file) write operations ਨੂੰ ਜਿਵੇਂ ਹੀ ਹੁੰਦੇ ਹਨ ਲੌਗ ਕਰਦਾ ਹੈ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਸੰਭਾਵਿਤ ਡੇਟਾ-ਲਾਸ਼ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ ਕਿਉਂਕਿ ਪਰਿਵਰਤਨ ਲਗਾਤਾਰ ਰਿਕਾਰਡ ਹੁੰਦੇ ਹਨ। AOF ਫਾਈਲਾਂ ਵੱਡੀਆਂ ਹੋ ਸਕਦੀਆਂ ਹਨ, ਅਤੇ startup 'ਤੇ replays ਲੰਬੇ ਹੋ ਸਕਦੇ ਹਨ—ਹਾਲਾਂਕਿ Redis AOF ਨੂੰ rewrite/compact ਕਰ ਸਕਦਾ ਹੈ ਤਾਂ ਜੋ ਇਹ manageable ਰਹੇ।
ਕਈ ਟੀਮ ਦੋਹਾਂ ਚਲਾਉਂਦੀਆਂ ਹਨ: ਤੇਜ਼ restarts ਲਈ snapshots ਅਤੇ ਲਿਖਤ durability ਲਈ AOF।
Persistence ਮੁਫ਼ਤ ਨਹੀਂ। Disk writes, AOF fsync policies, ਅਤੇ background rewrite operations latency spikes ਜੋੜ ਸਕਦੇ ਹਨ ਜੇ ਤੁਹਾਡੀ storage slow ਜਾਂ saturated ਹੋਵੇ। ਦੂਜੇ ਪਾਸੇ, persistence restarts ਨੂੰ ਘੱਟ ਡਰਾਉਣਾ ਬਣਾਉਂਦਾ ਹੈ: bina persistence, ਇੱਕ ਅਣਯੋਜਿਤ restart ਦਾ ਮਤਲਬ ਖਾਲੀ Redis ਹੋ ਸਕਦਾ ਹੈ।
Replication ਇੱਕ primary ਤੋਂ replicas 'ਤੇ ਡੇਟਾ ਦੀ ਨਕਲ ਰੱਖਦਾ ਹੈ ਤਾਂ ਕਿ primary down ਹੋਣ 'ਤੇ fail over ਕੀਤਾ ਜਾ ਸਕੇ। ਲਕਸ਼ਯ ਆਮ ਤੌਰ 'ਤੇ availability ਪਹਿਲਾਂ ਹੁੰਦੀ ਹੈ, ਨਾ ਕਿ perfect consistency। failure ਦੇ ਸਮੇਂ replicas thode piche ਹੋ ਸਕਦੇ ਹਨ, ਅਤੇ failover ਕੁਝ acknowled gedwrites ਨੂੰ ਗੁਵਾ ਸਕਦਾ ਹੈ।
ਕਿਸੇ ਵੀ ਚੀਜ਼ ਨੂੰ ਟਿਊਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਦੋ ਨੰਬਰ ਲਿਖੋ:
ਇਹ ਟਾਰਗਟਾਂ ਵਰਤ ਕੇ RDB frequency, AOF settings, ਅਤੇ replicas (ਅਤੇ automated failover) ਦੀ ਲੋੜ ਦਾ ਫੈਸਲਾ ਕਰੋ—ਚਾਹੇ Redis cache, session store, queue, ਜਾਂ primary data store ਹੋਵੇ।
ਇੱਕ single Redis node ਤੁਹਾਨੂੰ ਆਸ਼ਚਰਜ ਅਜੇਹਾ ਤੱਕ ਲੈ ਜਾ ਸਕਦੀ ਹੈ: ਇਹ ਚਲਾਉਣ ਵਿੱਚ ਸਧਾਰਨ, ਸੋਚਣ ਵਿੱਚ ਆਸਾ��, ਅਤੇ ਕਈ caching, session, ਜਾਂ queue workloads ਲਈ ਅਕਸਰ ਕਾਫ਼ੀ ਤੇਜ਼ ਹੁੰਦੀ ਹੈ।
ਸਕੇਲਿੰਗ ਦੀ ਲੋੜ ਆਮ ਤੌਰ 'ਤੇ ਉਦੋਂ ਆਉਂਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਮਾੜੇ ਸੀਮਾਵਾਂ ਨੂੰ ਛੂਹ ਲੈਉ—ਅਕਸਰ memory ਸੀਲਿੰਗ, CPU ਸੰਤ੍ਰਪਤੀ, ਜਾਂ ਇਕ single node ਨੂੰ single point of failure ਮੰਨਣਾ।
ਹੇਠਾਂ ਦੀਆਂ ਸਥਿਤੀਆਂ ਵਿੱਚ nodes ਵਧਾਉਣ 'ਤੇ ਵਿਚਾਰ ਕਰੋ:
ਇੱਕ ਵਿਆਵਹਾਰਿਕ ਪਹਿਲਾ ਕਦਮ ਅਕਸਰ workloads ਨੂੰ ਵੱਖ-ਵੱਖ ਕਰਨਾ ਹੁੰਦਾ ਹੈ (ਦੋ ਅਲੱਗ Redis instances) ਪਹਿਲਾਂ ਕਿ cluster 'ਤੇ ਜਾਣ।
Sharding ਮਤਲਬ keys ਨੂੰ ਵੱਖ-ਵੱਖ Redis nodes ਵਿੱਚ ਵਾਂਡਣਾ ਹੈ ਤਾਂ ਕਿ ਹਰ node ਸਿਰਫ਼ ਡੇਟਾ ਦਾ ਇੱਕ ਹਿੱਸਾ ਰੱਖੇ। Redis Cluster Redis ਦਾ built-in ਤਰੀਕਾ ਹੈ ਜੋ ਇਹ ਆਟੋਮੈਟਿਕ ਤਰੀਕੇ ਨਾਲ ਕਰਦਾ ਹੈ: keyspace ਨੂੰ slots ਵਿੱਚ ਵੰਡਿਆ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਹਰ node ਕੁਝ slots ਦਾ ਮਾਲਕ ਹੁੰਦਾ ਹੈ।
ਫਾਇਦਾ ਕੁੱਲ ਮੈਮੋਰੀ ਅਤੇ ਕੁੱਲ throughput ਵੱਧਣਾ ਹੈ। ਟਰੇਡ-ਆਫ਼ ਜ਼ਿਆਦਾ complexity ਹੈ: multi-key operations constrained ਹੋ ਜਾਂਦੀਆਂ ਹਨ (keys ਨੂੰ ਇੱਕੋ shard 'ਤੇ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ), ਅਤੇ troubleshooting ਵਿੱਚ ਹੋਰ moving parts ਸ਼ਾਮਲ ਹੁੰਦੇ ਹਨ।
ਇੱਕੋ ਹੀ shard ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ਅਸਲੀ ਟ੍ਰੈਫਿਕ ਅਸਮਾਨ ਹੋ ਸਕਦੀ ਹੈ। ਇੱਕ ਪ੍ਰਸਿੱਧ key ("hot key") ਇੱਕ node ਨੂੰ ਓਵਰਲੋਡ ਕਰ ਸਕਦੀ ਹੈ ਜਦੋਂ ਕਿ ਹੋਰ idle ਰਹਿੰਦੇ ਹਨ।
ਮੁਕਾਬਲਾ ਕਰਨ ਲਈ TTLs ਵਿੱਚ jitter ਜੋੜੋ, value ਨੂੰ ਕਈ keys 'ਤੇ ਵੰਡੋ (key hashing), ਜਾਂ access patterns ਨੂੰ redesign ਕਰੋ ਤਾਂ ਕਿ reads ਵੰਡ ਜਾਣ।
Redis Cluster ਨੂੰ ਇੱਕ cluster-aware client ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਜੋ topology discover ਕਰ ਸਕੇ, requests ਨੂੰ ਸਹੀ node ਤੇ ਰੂਟ ਕਰ ਸਕੇ, ਅਤੇ ਜਦੋਂ slots move ਹੋਣ ਤਾਂ redirections ਫਾਲੋ ਕਰੇ।
ਮਾਈਗਰੇਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਪੁਸ਼ਟੀ ਕਰੋ:
ਸਕੇਲਿੰਗ ਸਭ ਤੋਂ ਵਧੀਆ ਹੈ ਜਦੋਂ ਇਹ ਯੋਜਨਾਬੱਧ ਉਤਾਰ-ਚੜ੍ਹਾਅ ਹੋਵੇ: load tests ਨਾਲ ਤਸਦੀਕ ਕਰੋ, key latency ਨੂੰ instrument ਕਰੋ, ਅਤੇ traffic ਨੂੰ gradual ਤਰੀਕੇ ਨਾਲ migrate ਕਰੋ ਨਾ ਕਿ ਸਭ ਕੁਝ ਇਕ ਵਾਰੀ ਬਦਲ ਦਿਓ।
Redis ਅਕਸਰ "ਅੰਦਰੂਨੀ ਪਲੰਬਿੰਗ" ਸਮਝਿਆ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਇਹੀ ਕਾਰਨ ਹੈ ਕਿ ਇਹ ਆਮ ਨਿਸ਼ਾਨ ਬਣ ਜਾਂਦਾ ਹੈ: ਇੱਕ ਖੁੱਲਾ ਪੋਰਟ ਪੂਰੇ ਡੇਟਾ ਲੀਕ ਜਾਂ attacker-controlled cache ਕਾਰਨ ਬਣ ਸਕਦਾ ਹੈ। Redis ਨੂੰ ਸੰਵੇਦਨਸ਼ੀਲ ਇੰਫਰਾਸ਼ਟਰੱਕਚਰ ਮੰਨੋ, ਭਾਵੇਂ ਤੁਸੀਂ ਕੇਵਲ "ਅਰਜ਼ੀ" ਡੇਟਾ ਹੀ ਰੱਖਦੇ ਹੋ।
ਸ਼ੁਰੂਆਤ authentication enable ਕਰਨ ਨਾਲ ਕਰੋ ਅਤੇ ACLs (Redis 6+) ਵਰਤੋ। ACLs ਤੁਹਾਨੂੰ ਇਹ ਕਰਨ ਦਿੰਦੇ ਹਨ:
ਹਰ ਕੰਪੋਨੈਂਟ ਲਈ ਇੱਕੋ password ਸਾਂਝਾ ਨਾ ਕਰੋ। ਉਸ ਦੀ ਬਜਾਏ per-service credentials ਜਾਰੀ ਕਰੋ ਅਤੇ permissions ਨੂੰ ਸੰਕੁਚਿਤ ਰੱਖੋ।
ਸਭ ਤੋਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਕੰਟਰੋਲ ਇਹ ਹੈ ਕਿ Redis ਕੰਞੀ ਨਹੀਂ ਹੋ। Redis ਨੂੰ private interface 'ਤੇ bind ਕਰੋ, private subnet 'ਤੇ ਰੱਖੋ, ਅਤੇ security groups/firewalls ਨਾਲ inbound traffic ਨੂੰ ਸਿਰਫ਼ ਜ਼ਰੂਰੀ ਸੇਵਾਵਾਂ ਤੱਕ ਸੀਮਿਤ ਕਰੋ।
Redis ਟ੍ਰੈਫਿਕ host ਹੱਦਾਂ ਤੋਂ ਪਾਰ ਜਾਂ ਜੇ ਤੁਸੀਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਕਬਜ਼ਾ ਨਹੀਂ ਰੱਖਦੇ (multi-AZ, shared networks, Kubernetes nodes, ਜਾਂ hybrid environments) ਤਾਂ TLS ਵਰਤੋ। TLS sniffing ਅਤੇ credential theft ਨੂੰ ਰੋਕਦਾ ਹੈ, ਅਤੇ sessions, tokens, ਜਾਂ ਕਿਸੇ ਵੀ user-related data ਲਈ ਥੋੜ੍ਹੇ overhead ਵਾਜਿਬ ਹਨ।
ਉਹ commands lock down ਕਰੋ ਜੋ ਗਲਤ ਹੱਥਾਂ ਵਿੱਚ ਵੱਡਾ ਨੁਕਸਾਨ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਆਮ ਉਦਾਹਰਣ ਹਨ: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG, ਅਤੇ EVAL (ਜਾਂ scripting ਨੂੰ ਘੱਟ ਆਜ਼ਾਦੀ ਦਿਓ)। rename-command ਨਾਲ ਸੁਰੱਖਿਆ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਧਿਆਨ ਰੱਖੋ—ACLs ਆਮ ਤੌਰ 'ਤੇ ਜ਼ਿਆਦਾ ਸਾਫ਼ ਅਤੇ audit-friendly ਹੁੰਦੇ ਹਨ।
Redis credentials ਨੂੰ ਆਪਣੇ secrets manager ਵਿੱਚ ਰੱਖੋ (ਕੋਡ ਜਾਂ container images ਵਿੱਚ ਨਹੀਂ), ਅਤੇ rotation ਦੀ ਯੋਜਨਾ ਬਣਾਓ। Rotation ਉਸ ਵੇਲੇ ਸਭ ਤੋਂ ਆਸਾਨ ਹੁੰਦੀ ਹੈ ਜਦੋਂ clients credentials reload ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ redeploy ਦੇ, ਜਾਂ ਜਦੋਂ ਤੁਸੀਂ transition window ਦੌਰਾਨ ਦੋ ਵੈਧ credentials ਨੂੰ ਸਹਿਯੋਗ ਦਿੰਦੇ ਹੋ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਪ੍ਰੈਟਿਕਲ ਚੈੱਕਲਿਸਟ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਨੂੰ ਆਪਣੇ runbooks ਵਿੱਚ ਰੱਖੋ ਨਾਲ ਹੀ /blog/monitoring-troubleshooting-redis ਨੋਟਸ।
Redis ਅਕਸਰ "ਠੀਕ ਮਹਿਸੂਸ" ਹੁੰਦਾ ਹੈ… ਜਦ ਤੱਕ ਟ੍ਰੈਫਿਕ ਬਦਲਦਾ ਨਹੀਂ, memory creep ਨਹੀਂ ਹੁੰਦੀ, ਜਾਂ ਇੱਕ slow command ਸਭ ਕੁਝ ਰੁਕਦਾ ਨਹੀਂ। ਇੱਕ ਹਲਕੀ ਮਾਨੀਟਰਿੰਗ routine ਅਤੇ ਸਾਫ incident checklist ਜ਼ਿਆਦਾਤਰ ਆਸ਼ਚਰਜਾਂ ਨੂੰ ਰੋਕਦੇ ਹਨ।
ਸੋਚ ਕੇ ਇੱਕ ਛੋਟਾ ਸੈੱਟ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਟੀਮ ਦੇ ਕਿਸੇ ਵੀ ਮੈਂਬਰ ਲਈ ਸਮਝਦਾਰ ਹੋਵੇ:
ਜਦੋਂ ਕੁਝ "ਧੀਮਾ" ਮਹਿਸੂਸ ਹੋਵੇ, Redis ਦੇ ਆਪਣੇ ਟੂਲ ਨਾਲ ਉਸਦੀ ਪੁਸ਼ਟੀ ਕਰੋ:
KEYS, SMEMBERS, ਜਾਂ ਵੱਡੇ LRANGE calls ਵਿੱਚ ਇੱਕ ਅਚਾਨਕ ਵਾਧਾ ਆਮ ਅਲਾਰਮ ਹੈ।ਜੇ latency spike ਆਏ ਅਤੇ CPU ਠੀਕ ਲੱਗੇ, ਤਾਂ ਨੈੱਟਵਰਕ saturation, oversized payloads, ਜਾਂ blocked clients ਨੂੰ ਵੀ ਸੋਚੋ।
ਵਿਕਾਸ ਲਈ ਯੋਜਨਾ ਬਣਾਉਣ ਵੇਲੇ headroom (ਆਮ ਤੌਰ 'ਤੇ 20–30% ਫ਼੍ਰੀ memory) ਰੱਖੋ ਅਤੇ launches ਜਾਂ feature flags ਤੋਂ ਬਾਅਦ ਅਨੁਮਾਨ ਮੁੜ ਦੇਖੋ। "steady evictions" ਨੂੰ ਇੱਕ ਚੇਤਾਵਨੀ ਨਹੀਂ, outage ਸਮਝੋ।
ਇੱਕ incident ਦੌਰਾਨ, (ਕ੍ਰਮ ਵਿੱਚ) ਜਾਂਚੋ: memory/evictions, latency, client connections, slowlog, replication lag, ਅਤੇ ਹਾਲੀਆ deploys। top recurring causes ਨੂੰ ਲਿਖੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਸਥਾਈ ਤੌਰ 'ਤੇ ਠੀਕ ਕਰੋ—ਸਿਰਫ alerts ਕਾਫ਼ੀ ਨਹੀਂ ਹੋਣਗੇ।
ਜੇ ਤੁਹਾਡੀ ਟੀਮ ਤੇਜ਼ੀ ਨਾਲ iterate ਕਰ ਰਹੀ ਹੈ, ਤਾਂ ਇਹ ਓਪਰੇਸ਼ਨਲ ਉਮੀਦਾਂ ਨੂੰ ਆਪਣੇ development workflow ਵਿੱਚ ਬੇਕ ਕਰਨਾ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ। ਉਦਾਹਰਣ ਵਜੋਂ, Koder.ai ਦੀ planning mode ਅਤੇ snapshots/rollback ਨਾਲ, ਤੁਸੀਂ Redis-ਬੈਕਡ ਫੀਚਰਾਂ (ਜਿਵੇਂ caching ਜਾਂ rate limiting) ਦਾ ਪ੍ਰੋਟੋਟਾਈਪ ਬਣਾ ਸਕਦੇ ਹੋ, ਉਨ੍ਹਾਂ ਨੂੰ load ਹੇਠ ਟੈਸਟ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਬਦਲਾਅ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਰੋਲਬੈਕ ਕਰ ਸਕਦੇ ਹੋ—ਇਹ ਸਭ ਇੰਪਲੇਮੈਂਟੇਸ਼ਨ ਤੁਹਾਡੇ ਕੋਡਬੇਸ ਵਿੱਚ source export ਰਾਹੀਂ ਬਣੇ ਰਹਿਣਗੇ।
Redis ਇੱਕ ਸਾਂਝਾ, in-memory “ਤੇਜ਼ ਲੇਅਰ” ਵਜੋਂ ਸਭ ਤੋਂ ਵਧੀਆ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਕਰ ਸਕਦੇ ਹੋ:
ਟਿਕਾਊ, ਪ੍ਰਧਾਨ ਅਤੇ ਜਟਿਲ ਕਵੈਰੀਆਂ ਲਈ ਆਪਣਾ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਵਰਤੋ। Redis ਨੂੰ ਤੇਜ਼ੀ ਅਤੇ ਕੋਆਰਡੀਨੇਸ਼ਨ ਲਈ ਵਰਤੋ, ਨਾ ਕਿ ਸਰੋਤ-ਏ-ਸਚਾਈ ਲਈ।
ਨਹੀਂ। Redis persist ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਉਹ "ਡਿਫੌਲਟ ਰੂਪ ਵਿੱਚ ਟਿਕਾਊ" ਨਹੀਂ ਮਨਿਆ ਜਾਣਾ ਚਾਹੀਦਾ। ਜੇ ਤੁਹਾਨੂੰ ਜਟਿਲ ਕਵੈਰੀਆਂ, ਮਜ਼ਬੂਤ durability ਜਾਂ analytics/reporting ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਉਹ ਡੇਟਾ ਤੁਹਾਡੇ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਵਿੱਚ ਹੀ ਰੱਖੋ。
ਜੇ ਕੁਝ ਸਕਿੰਟ ਦਾ ਡੇਟਾ ਖੋ ਜਾਣਾ ਬਰਦਾਸ਼ਤ ਨਹੀ ਕੀਤਾ ਜਾ ਸਕਦਾ, ਤਾਂ Redis ਦੀ persistence settings ਤੇ ਭਰੋਸਾ ਨਾ ਕਰੋ ਬਿਨਾਂ ਧਿਆਨ ਨਾਲ ਕੰਫਿਗਰ ਕੀਤੇ (ਜਾਂ ਕਿਸੇ ਹੋਰ ਸਿਸਟਮ ਬਾਰੇ ਸੋਚੋ)।
ਆਪਣੇ ਮਨਜ਼ੂਰਯੋਗ ਡੇਟਾ-ਹਾਰਣ ਅਤੇ ਰੀਸਟਾਰਟ ਬਿਹੇਵਿਅਰ ਦੇ ਆਧਾਰ ਤੇ ਫੈਸਲਾ ਕਰੋ:
ਪਹਿਲਾਂ RPO/RTO ਟਾਰਗਟ ਲਿਖੋ, ਫਿਰ persistence ਨੂੰ ਉਹਨਾਂ ਦੇ ਮੁਤਾਬਕ ਟਿਊਨ ਕਰੋ।
Cache-aside ਵਿੱਚ ਤੁਹਾਡੀ ਐਪ ਲੋਜਿਕ ਨੂੰ ਸੰਭਾਲਦੀ ਹੈ:
ਜਦੋਂ ਤੁਹਾਡੀ ਐਪ ਰੇਅਰ ਮਿਸਜ਼ ਸਹਿ ਸਕਦੀ ਹੈ ਅਤੇ ਤੁਸੀਂ expiration/invalidation ਲਈ ਸਾਫ਼ ਯੋਜਨਾ ਰੱਖਦੇ ਹੋ, ਇਹ ਅਕਸਰ ਚੰਗਾ ਵਿਕਲਪ ਹੁੰਦਾ ਹੈ।
TTL ਦਾ ਚੋਣ ਉਪਭੋਗੀ ਪ੍ਰਭਾਵ ਅਤੇ ਬੈਕਐਂਡ ਲੋਡ 'ਤੇ ਆਧਾਰਿਤ ਕਰੋ:
user:v3:123)।ਅਣਜਾਣ ਹੋਵੋ ਤਾਂ ਛੋਟੀ TTL ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਡਾਟਾਬੇਸ ਲੋਡ ਮਾਪੋ, ਫਿਰ ਢੁਲਖ਼ਤਾ ਰੱਖੋ।
ਇਨ੍ਹਾਂ ਵਿੱਚੋਂ ਇੱਕ ਜਾਂ ਵਧੇਰੇ ਵਰਤੋ:
ਇਹ patterns synchronized cache misses ਤੋਂ ਡੇਟਾਬੇਸ 'ਤੇ ਹੋਣ ਵਾਲੇ ਧੱਕੇ ਰੋਕਦੇ ਹਨ।
ਆਮ ਤੌਰ 'ਤੇ yaklaşım ਇਹ ਹੈ:
sess:{sessionId} ਹੇਠ session ਡੇਟਾ TTL ਨਾਲ ਸਟੋਰ ਕਰੋ ਜੋ session lifetime ਨੂੰ ਮੈਚ ਕਰਦਾ ਹੈ।user:sessions:{userId} ਨੂੰ active session IDs ਦੇ set ਵਜੋਂ ਰੱਖਣਾ ਇੱਕ ਵਿਕਲਪ ਹੈ ("log out everywhere" ਲਈ)।ਹਰ ਰੀਕਵੇਸਟ 'ਤੇ TTL ਵਧਾਉਣ ("sliding expiration") ਤੋਂ ਸਾਵਧਾਨ ਰਹੋ; ਇਹ ਤੇਜ਼ ਯੂਜ਼ਰਾਂ ਲਈ sessions ਨੂੰ ਅਨੰਤਕਾਲ ਤੱਕ ਜੀਵਿਤ ਰੱਖ ਸਕਦਾ ਹੈ—ਇੱਕ ਵਧੀਆ ਸਮਝੌਤਾ ਹੈ ਕਿ TTL ਸਿਰਫ਼ ਨਜ਼ਦੀਕੀ ਸਮੇਂ ਤੇ ਹੀ ਵਧਾਇਆ ਜਾਵੇ।
Atomic updates ਵਰਤੋ ਤਾਂ counters race ਨਾ ਕਰਨ:
INCR ਅਤੇ EXPIRE ਨੂੰ ਅਲੱਗ-ਅਲੱਗ, ਅਸੁਰੱਖਿਅਤ ਕਾਲਾਂ ਵਜੋਂ ਨਾ ਚਲਾਓ।INCR ਅਤੇ expiry ਸੈੱਟ ਕਰੇ।ਕੁੰਜੀਆਂ ਨੂੰ ਸੋਚ-ਸਮਝ ਕੇ scope ਕਰੋ (per-user, per-IP, per-route), ਅਤੇ ਪਹਿਲਾਂ ਹੀ ਫੈਸਲਾ ਕਰੋ ਕਿ Redis ਅਣਉਪਲਬਧ ਹੋਣ 'ਤੇ fail-open ਕਰਨਾ ਹੈ ਜਾਂ fail-closed—ਖਾਸ ਕਰਕੇ ਲੌਗਿਨ ਵਰਗੀਆਂ ਸੰਵੇਦਨਸ਼ੀਲ APIs ਲਈ।
ਚੁਣੋ ਜੋ ਤੁਹਾਡੀਆਂ durability ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਲੋੜਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ:
LPUSH/BRPOP): ਸਧਾਰਣ, ਪਰ retries, in-flight tracking, ਅਤੇ visibility timeouts ਤੁਹਾਨੂੰ ਆਪਣੀ طرفੋਂ ਬਣਾਉਣੇ ਪੈਣਗੇ।Use Pub/Sub ਜਦੋਂ ਤੁਸੀਂ ਤੇਜ਼ fan-out ਚਾਹੁੰਦੇ ਹੋ ਅਤੇ ਖੋ ਜਾਣਾ ਮਨਜ਼ੂਰ ਹੋ ਸਕਦਾ ਹੈ (presence, live dashboards). ਇਹ:
ਜੇ ਹਰ event ਨੂੰ ਸੰਪੂਰਨ ਰੂਪ ਵਿੱਚ ਪ੍ਰੋਸੈਸ ਕੀਤਾ ਜਾਣਾ ਲਾਜ਼ਮੀ ਹੈ, ਤਾਂ durability, consumer groups, retries, ਅਤੇ backpressure ਲਈ Redis Streams ਨੂੰ ਪਸੰਦ ਕਰੋ। ਆਪਰੇਸ਼ਨਲ ਹਾਈਜੀਨ ਲਈ Redis ਨੂੰ ACLs/network isolation ਨਾਲ ਲਾਕ ਡਾਊਨ ਕਰੋ ਅਤੇ latency/evictions ਟ੍ਰੈਕ ਕਰੋ; ਆਪਣਾ ਰਨਬੁੱਕ ਰੱਖੋ ਜਿਵੇਂ ।
ਕੋਸ਼ਿਸ਼ ਕਰੋ payloads ਛੋਟੇ ਰੱਖੋ; ਵੱਡੇ blobs ਹੋਰ ਥਾਂ ਸਟੋਰ ਕਰੋ ਅਤੇ ਸਿਰਫ refernces ਭੇਜੋ।
/blog/monitoring-troubleshooting-redis