23 ਦਸੰ 2025·8 ਮਿੰਟ
SaaS API ਰੇਟ ਲਿਮਿਟਿੰਗ: ਪਰ-ਯੂਜ਼ਰ, ਪਰ-ਸੰਗਠਨ, ਅਤੇ IP ਪੈਟਰਨ
پر-یوزر، پر-آرگ، اور پر-IP کے لیے SaaS API ریکویسٹ حدود، واضح ہیڈرز، 429 جوابات، اور رول آؤٹ ٹِپس تاکہ گاہک سمجھ سکیں۔
پر-یوزر، پر-آرگ، اور پر-IP کے لیے SaaS API ریکویسٹ حدود، واضح ہیڈرز، 429 جوابات، اور رول آؤٹ ٹِپس تاکہ گاہک سمجھ سکیں۔
ਰੇਟ ਲਿਮਿਟ ਅਤੇ ਕੋਟਾ ਇੱਕੋ ਜਿਹੇ ਲੱਗਦੇ ਹਨ, ਇਸ ਲਈ ਲੋਕ ਅਕਸਰ ਦੋਹਾਂ ਨੂੰ ਇਕੋ ਸਮਝਦੇ ਹਨ। ਰੇਟ ਲਿਮਿਟ ਇਹ ਦਸਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਐਪੀ ਨੂੰ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਕਾਲ ਕਰ ਸਕਦੇ ਹੋ (ਰਿਕਵੈਸਟ/ਸੈਕਿੰਡ ਜਾਂ ਪ੍ਰਤੀ ਮਿੰਟ)। ਕੋਟਾ ਇਹ ਦਸਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਲੰਮੇ ਸਮੇਂ ਵਿੱਚ ਕਿੰਨਾ ਵਰਤੋਂ ਕਰ ਸਕਦੇ ਹੋ (ਰੋਜ਼ਾਨਾ, ਮਹੀਨਾਵਾਰ ਜਾਂ ਬਿੱਲਿੰਗ ਚੱਕਰ)। ਦੋਹਾਂ ਆਮ ਹਨ, ਪਰ ਜਦੋਂ ਨਿਯਮ ਵੇਖਣ ਯੋਗ ਨਹੀਂ ਹੁੰਦੇ ਤਾਂ ਉਹ ਰੈਂਡਮ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ।
ਕਲਾਸਿਕ ਸ਼ਿਕਾਇਤ ਹੁੰਦੀ ਹੈ: “ਇਹ ਕੱਲ੍ਹ ਕੰਮ ਕਰ ਰਿਹਾ ਸੀ।” ਵਰਤੋਂ ਅਕਸਰ ਸਥਿਰ ਨਹੀਂ ਰਹਿੰਦੀ। ਇੱਕ ਛੋਟਾ ਸਪਾਇਕ ਕਿਸੇ ਨੂੰ ਲਾਈਨ ਪਾਰ ਕਰ ਸਕਦਾ ਹੈ ਭਾਵੇਂ ਉਹਨਾਂ ਦਾ ਦੈਨੀਕ ਟੋਟਲ ਠੀਕ ਲੱਗਦਾ ਹੋਵੇ। ਸੋਚੋ ਇੱਕ ਗਾਹਕ ਜੋ ਰੋਜ਼ ਇੱਕ ਰਿਪੋਰਟ ਚਲਾਂਦਾ ਹੈ, ਪਰ ਅੱਜ ਜੌਬ ਇੱਕ timeout ਤੋਂ ਬਾਅਦ retry ਕਰਦਾ ਹੈ ਅਤੇ 2 ਮਿੰਟ ਵਿੱਚ 10x ਹੋਰ ਕਾਲਾਂ ਕਰ ਲੈਂਦਾ ਹੈ। API ਉਨ੍ਹਾਂ ਨੂੰ ਬਲਾਕ ਕਰ ਦਿੰਦੀ ਹੈ, ਅਤੇ ਉਹ ਸਿਰਫ਼ ਇਕ ਅਚਾਨਕ ਫੇਲਅਰ ਵੇਖਦੇ ਹਨ।
ਗੁੰਝਲਦਾਰੀ ਹੋਰ ਵੱਧਦੀ ਹੈ ਜਦੋਂ errors ਧੁੰਦਲੇ ਹੁੰਦੇ ਹਨ। ਜੇ API 500 ਜਾਂ generic ਸੁਨੇਹਾ ਦੇਂਦਾ ਹੈ ਤਾਂ ਗ੍ਰਾਹਕ ਸਮਝਦੇ ਹਨ ਕਿ ਤੁਹਾਡੀ ਸੇਵਾ ਡਾਊਨ ਹੈ, ਨਾ ਕਿ ਉਹਨਾਂ ਨੇ ਸੀਮਾ ਲੰਘਾਈ। ਉਹ ਤਾਜ਼ਗੀ ਟਿਕਟ ਖੋਲ੍ਹਦੇ ਹਨ, ਵਰਕਅਰਾਊਂਡ ਬਣਾਉਂਦੇ ਹਨ ਜਾਂ ਪ੍ਰੋਵਾਇਡਰ ਬਦਲ ਲੈਂਦੇ ਹਨ। ਇੱਥੇ ਤੱਕ ਕਿ 429 Too Many Requests ਵੀ ਔਰਤਾਂ ਨੂੰ ਨਿਰਾਸ਼ ਕਰ ਸਕਦਾ ਹੈ ਜੇ ਇਹ ਨਹੀਂ ਦੱਸਿਆ ਕਿ ਅਗਲਾ ਕਦਮ ਕੀ ਹੈ।
ਜ਼ਿਆਦਾਤਰ SaaS APIs ਦੋ ਵੱਖ-ਵੱਖ ਕਾਰਨਾਂ ਲਈ ਟ੍ਰੈਫਿਕ ਸੀਮਤ ਕਰਦੇ ਹਨ:
ਇਨਾਂ مقصدਾਂ ਨੂੰ ਮਿਲਾ ਕੇ ਬਦ ਡਿਜ਼ਾਈਨ ਹੁੰਦੇ ਹਨ। ਐਬਿਊਜ਼ ਕੰਟਰੋਲ ਆਮ ਤੌਰ 'ਤੇ per-IP ਜਾਂ per-token ਹੁੰਦੇ ਹਨ ਅਤੇ ਕਾਫ਼ੀ ਸਖਤ ਹੋ ਸਕਦੇ ਹਨ। ਸਧਾਰਨ ਵਰਤੋਂ ਦੀ ਸ਼ੇਪਿੰਗ ਆਮ ਤੌਰ 'ਤੇ per-user ਜਾਂ per-organization ਹੁੰਦੀ ਹੈ ਅਤੇ ਇਸਨੂੰ ਸਾਫ਼ ਮਾਰਗਦਰਸ਼ਨ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ: ਕਿਹੜੀ ਸੀਮਾ ਲੱਗੀ, ਕਦੋਂ ਇਹ ਰੀਸੈੱਟ ਹੋਏਗੀ, ਅਤੇ ਇਸਨੂੰ ਦੁਬਾਰਾ ਲੰਘਣ ਤੋਂ ਕਿਵੇਂ ਬਚਣਾ ਹੈ।
ਜਦੋਂ ਗ੍ਰਾਹਕ ਸੀਮਾਵਾਂ ਦੀ ਭਵਿੱਖਬਾਣੀ ਕਰ ਸਕਦੇ ਹਨ, ਉਹ ਉਸ ਅਨੁਸਾਰ ਯੋਜਨਾ ਬਣਾਉਂਦੇ ਹਨ। ਜਦੋਂ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਹਰ ਸਪਾਇਕ ਇੱਕ ਟੁੱਟਿਆ ਹੋਇਆ API ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ।
ਰੇਟ ਲਿਮਿਟ ਸਿਰਫ਼ ਧੱਕਾ ਨਹੀਂ — ਇਹ ਇੱਕ ਸੁਰੱਖਿਆ ਪ੍ਰਣਾਲੀ ਹੈ। ਨੰਬਰਾਂ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਤੁਸੀਂ ਕੀ ਬਚਾ ਰਹੇ ਹੋ, ਕਿਉਂਕਿ ਹਰ ਲਕ਼ਸ਼ ਵੱਖਰੇ ਲਿਮਿਟਾਂ ਅਤੇ ਉਮੀਦਾਂ ਵੱਲ ਲੈ ਜਾਂਦਾ ਹੈ।
Availability ਆਮ ਤੌਰ 'ਤੇ ਪਹਿਲਾਂ ਆਉਂਦੀ ਹੈ। ਜੇ ਕੁਝ ਕਲਾਇੰਟ ਟ੍ਰੈਫਿਕ spike ਕਰਕੇ ਤੁਹਾਡੇ API ਨੂੰ timeout ਵਿੱਚ ਧकेਲ ਸਕਦੇ ਹਨ, ਤਾਂ ਹਰ ਕੋਈ ਪ੍ਰਭਾਵਿਤ ਹੋਵੇਗਾ। ਇੱਥੇ ਲਿਮਿਟਸ ਸਰਵਰਾਂ ਨੂੰ bursts ਦੌਰਾਨ ਜਵਾਬਦੇਹ ਰੱਖਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ ਅਤੇ requests ਨੂੰ ਪਾਇਲਅਪ ਹੋਣ ਦੇ ਬਦਲੇ fail-fast ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ।
ਲਾਗਤ ਕਈ APIs ਦੇ ਪਿੱਛੇ ਇੱਕ ਚੁਪ ਚਾਲਕ ਹੁੰਦੀ ਹੈ। ਕੁਝ ਬੇਨਤੀਆਂ ਸਸਤੀ ਹੁੰਦੀਆਂ ਹਨ, ਹੋਰ ਮਹਿੰਗੀਆਂ (LLM calls, ਫਾਇਲ ਪ੍ਰੋਸੈਸਿੰਗ, storage writes, paid third-party lookups)। ਉਦਾਹਰਨ ਲਈ, Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ 'ਤੇ ਇੱਕ ਵੱਖਰੀ ਯੂਜ਼ਰ chat-based app generation ਰਾਹੀਂ ਬਹੁਤ ਸਾਰੇ ਮਾਡਲ ਕਾਲ ਟ੍ਰਿਗਰ ਕਰ ਸਕਦਾ ਹੈ। ਮਹਿੰਗੀਆਂ ਕਾਰਵਾਈਆਂ ਨੂੰ ਟਰੈਕ ਕਰਨ ਵਾਲੀਆਂ ਸੀਮਾਵਾਂ ਅਚਾਨਕ ਬਿੱਲਾਂ ਤੋਂ ਬਚਾ ਸਕਦੀਆਂ ਹਨ।
ਐਬਿਊਜ਼ ਵੱਖਰਾ ਦਿਸਦਾ ਹੈ — credential stuffing, token guessing ਅਤੇ scraping ਅਕਸਰ ਇੱਕ ਹੀ IPs ਜਾਂ ਅਕਾਊਂਟਾਂ ਤੋਂ ਬਹੁਤ ਸਾਰੀਆਂ ਛੋਟੀ-ਛੋਟੀ ਬੇਨਤੀਆਂ ਵਜੋਂ ਆਉਂਦੇ ਹਨ। ਇੱਥੇ ਤੁਹਾਨੂੰ ਸਖਤ ਸੀਮਾਵਾਂ ਅਤੇ ਤੇਜ਼ ਬਲਾਕਿੰਗ ਚਾਹੀਦੀ ਹੈ।
ਬਹੁ-ਟੇਨੈਂਟ ਸਿਸਟਮਾਂ ਵਿੱਚ ਨਿਆਂ ਵੀ ਮਹੱਤਵਪੂਰਣ ਹੈ। ਇੱਕ ਸ਼ੋਰ ਵਾਲਾ ਗਾਹਕ ਸਭ ਨੂੰ ਨੁਕਸਾਨ ਨਹੀਂ ਪੁੰਛਾਣਾ ਚਾਹੀਦਾ। ਅਮਲ ਵਿੱਚ, ਇਹ ਅਕਸਰ ਲੇਅਰਡ ਕੰਟਰੋਲ ਮੰਗਦਾ ਹੈ: ਇਕ burst guard ਜੋ API ਨੂੰ ਮਿੰਟ-ਬਾਇ-ਮਿੰਟ ਸਿਹਤਮੰਦ ਰੱਖੇ, ਇੱਕ cost guard ਮਹਿੰਗੇ ਐਂਡਪੌਇੰਟਾਂ ਲਈ, ਇੱਕ abuse guard auth ਅਤੇ ਸੰਦੇਹਜਨਕ ਪੈਟਰਨਾਂ 'ਤੇ ਧਿਆਨ ਦੇ ਕੇ, ਅਤੇ ਇੱਕ fairness guard ਤਾਂ ਜੋ ਇੱਕ org ਹੋਰਾਂ ਨੂੰ ਘੇਰ ਨਾ ਸਕੇ।
ਇੱਕ ਸਧਾਰਨ ਟੈਸਟ ਮਦਦ ਕਰਦਾ ਹੈ: ਇੱਕ ਐਂਡਪੌਇੰਟ ਚੁਣੋ ਅਤੇ ਪੁੱਛੋ, “ਜੇ ਇਹ ਬੇਨਤੀ 10x ਵੱਧ ਜਾਵੇ ਤਾਂ ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਕੀ ਟੁੱਟੇਗਾ?” ਜਵਾਬ ਦੱਸੇਗਾ ਕਿ ਕਿਹੜਾ ਰੱਖਿਆ ਲਕਸ਼ ਪ੍ਰਾਥਮਿਕਤਾ ਹੋਵੇ ਅਤੇ ਕਿਹੜੀ ਡਾਇਮੇਨਸ਼ਨ (user, org, IP) ਨੂੰ ਸੀਮਾ ਦੇਣੀ ਚਾਹੀਦੀ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇੱਕ ਸੀਮਾ ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਪਤਾ ਲੱਗਦਾ ਹੈ ਕਿ ਇਹ ਗਲਤ ਲੋਕਾਂ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾ ਰਹੀ ਹੈ। ਲਕਸ਼ ਇਹ ਹੈ ਕਿ ਉਹ ਡਾਇਮੇਨਸ਼ਨ ਚੁਣੋ ਜੋ ਅਸਲੀ ਵਰਤੋਂ ਨਾਲ ਮੇਲ ਖਾਂਦੇ ਹਨ: ਕੌਣ ਕਾਲ ਕਰ ਰਿਹਾ ਹੈ, ਕੌਣ ਭੁਗਤਾਨ ਕਰ ਰਿਹਾ ਹੈ, ਅਤੇ ਕੀ ਐਬਿਊਜ਼ ਵਰਗਾ ਦਿੱਖਦਾ ਹੈ।
SaaS ਵਿੱਚ ਆਮ ਡਾਇਮੇਨਸ਼ਨ ਇਹ ਹਨ:
ਪਰ-ਯੂਜ਼ਰ ਸੀਮਾਵਾਂ ਟੇਨੈਂਟ ਦੇ ਅੰਦਰ ਨਿਆਂ ਲਈ ਹਨ — ਜੇ ਇੱਕ ਵਿਅਕਤੀ ਵੱਡਾ export ਚਲਾਉਂਦਾ ਹੈ ਤਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਬਾਕੀ ਟੀਮ ਨਾਲੋਂ ਵੱਧ slow ਹੋਣਾ ਮਹਿਸੂਦ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਪਰ-ਓਰਗ ਸੀਮਾਵਾਂ ਬਜਟ ਅਤੇ ਸਮਰੱਥਾ ਲਈ ਹਨ। ਭਾਵੇਂ ਦਸ ਯੂਜ਼ਰ ਇਕੱਠੇ jobs ਚਲਾਉਣ, ਓਰਗ ਨੇ ਐਸਾ spike ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ ਜੋ ਸੇਵਾ ਜਾਂ ਤੁਹਾਡੇ ਪ੍ਰਾਈਸਿੰਗ ਅਨੁਮਾਨਾਂ ਨੂੰ ਤਬਾਹ ਕਰੇ।
ਪਰ-IP ਸੀਮਾਵਾਂ ਨੂੰ safety net ਵਜੋਂ ਹੀ ਰੱਖੋ, billing ਦਾ ਟੂਲ ਨਹੀਂ। IPs ਸਾਂਝੇ ਹੋ ਸਕਦੇ ਹਨ (ਆਫਿਸ NAT, ਮੋਬਾਈਲ ਕੇਰੀਅਰ), ਇਸ ਲਈ ਇਨ੍ਹਾਂ ਸੀਮਾਵਾਂ ਨੂੰ ਉਦਾਰ ਰੱਖੋ ਅਤੇ ਮੁੱਖ ਤੌਰ 'ਤੇ obvious abuse ਨੂੰ ਰੋਕਣ ਲਈ ਭਰੋਸਾ ਕਰੋ।
ਜਦੋਂ ਤੁਸੀਂ ਡਾਇਮੇਨਸ਼ਨਾਂ ਨੂੰ ਮਿਲਾਉਂਦੇ ਹੋ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਜਦੋਂ ਕਈ ਲਿਮਿਟ ਲਾਗੂ ਹੋ ਰਹੇ ਹੋ ਤਾਂ ਕਿਹੜਾ “ਜਿੱਤੇਗਾ”。 ਇਕ ਪ੍ਰਾਇਕਟੀਕਲ ਨਿਯਮ: ਜੇ ਕੋਈ ਵੀ ਸਬੰਧਿਤ ਸੀਮਾ ਲੰਘੀ ਹੋਵੇ ਤਾਂ ਰਿਕਵੈਸਟ ਨੂੰ reject ਕਰੋ, ਅਤੇ ਸਭ ਤੋਂ actionable ਕਾਰਨ ਵਾਪਸ ਕਰੋ। ਜੇ ਵਰਕਸਪੇਸ ਆਪਣੀ org quota ਪਾਰ ਕਰ ਗਿਆ ਹੈ ਤਾਂ ਯੂਜ਼ਰ ਜਾਂ IP ਨੂੰ ਦੋਸ਼ ਨਾ ਦਿਓ।
ਉਦਾਹਰਨ: ਇੱਕ Koder.ai ਵਰਕਸਪੇਸ Pro ਪਲਾਨ 'ਤੇ ਇੱਕ steady build requests ਪ੍ਰਤੀ-ਓਰਗ ਦੀ ਆਗਿਆ ਦੇ ਸਕਦਾ ਹੈ, ਜਦ ਕਿ ਇੱਕ ਯੂਜ਼ਰ ਨੂੰ ਇੱਕ ਮਿੰਟ ਵਿੱਚ ਸੈਂਕੜੇ ਰਿਕਵੈਸਟ ਫਾਇਰ ਕਰਨ ਤੋਂ ਰੋਕਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਇੱਕ ਭਾਗੀਦਾਰ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਇਕ ਸਾਂਝਾ ਟੋਕਨ ਵਰਤ ਰਿਹਾ ਹੈ, ਇੱਕ ਪਰ-ਟੋਕਨ ਲਿਮਿਟ ਇਸਨੂੰ interactive ਯੂਜ਼ਰਾਂ ਨੂੰ ਘੇਰਨ ਤੋਂ ਰੋਕ ਸਕਦੀ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਰੇਟ ਲਿਮਿਟਿੰਗ ਸਮੱਸਿਆਵਾਂ ਗਣਿਤ ਬਾਰੇ ਨਹੀਂ ਹੁੰਦੀਆਂ। ਉਹ ਇਸ ਬਾਰੇ ਹੁੰਦੀਆਂ ਹਨ ਕਿ ਕਿਹੜਾ ਵਿਵਹਾਰ ਗ੍ਰਾਹਕਾਂ ਦੇ ਐਪੀ ਕਾਲ ਕਰਨ ਦੇ ਢੰਗ ਨਾਲ ਮਿਲਦਾ ਹੈ, ਫਿਰ ਲੋਡ ਹੇਠਾਂ ਇਸਨੂੰ ਪ੍ਰਿਡਿਕਟੇਬਲ ਰੱਖਣਾ।
ਟੋਕਨ ਬੱਕੇਟ ਆਮ ਡਿਫੌਲਟ ਹੈ ਕਿਉਂਕਿ ਇਹ ਛੋਟੇ ਬਰਸਟਾਂ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ ਪਰ ਲੰਬੇ ਸਮੇਂ ਦਾ ਔਸਤ ਲਾਗੂ ਕਰਦਾ ਹੈ। ਇੱਕ ਯੂਜ਼ਰ ਜੋ ਡੈਸ਼ਬੋਰਡ ਰੀਫ੍ਰੈਸ਼ ਕਰਦਾ ਹੈ ਉਹ 10 ਤੇਜ਼ ਰਿਕਵੈਸਟ ਟ੍ਰਿਗਰ ਕਰ ਸਕਦਾ ਹੈ। ਟੋਕਨ ਬੱਕੇਟ ਜੇਕਰ ਉਹਨਾਂ ਕੋਲ ਟੋਕਨ ਬਚੇ ਹੋਣ ਤਾਂ ਇਹ ਹੋਣ ਦਿੰਦਾ ਹੈ, ਫਿਰ ਉਹਨਾਂ ਨੂੰ ਹੌਲੀ ਕਰਦਾ ਹੈ।
ਲੀਕੀ ਬੱਕੇਟ ਜ਼ਿਆਦਾ ਸਖਤ ਹੈ — ਇਹ ਟ੍ਰੈਫਿਕ ਨੂੰ ਇੱਕ ਲਗਾਤਾਰ ਪ੍ਰਭਾਹ ਵਿੱਚ ਸਿਮੇਟਦਾ ਹੈ, ਜੋ ਉਸ ਸਮੇਂ ਮਦਦਗਾਰ ਹੈ ਜਦੋਂ ਤੁਹਾਡਾ ਬੈਕਐਂਡ spikes ਬਰਦਾਸ਼ਤ ਨਹੀਂ ਕਰ ਸਕਦਾ (ਜਿਵੇਂ ਮਹਿੰਗੀ report generation)। ਇਸ ਦਾ ਟਰੇਡਆਫ ਇਹ ਹੈ ਕਿ ਗਾਹਕ ਪਹਿਲਾਂ ਹੀ ਇਸਨੂੰ ਮਹਿਸੂਸ ਕਰਨਗੇ, ਕਿਉਂਕਿ ਬਰਸਟ ਕਿਊਇੰਗ ਜਾਂ ਰੀਜੇਕਸ਼ਨ ਵਿੱਚ ਬਦਲ ਜਾਂਦੇ ਹਨ।
ਵਿੰਡੋ-ਆਧਾਰਿਤ ਕਾਊਂਟਰ ਸਧਾਰਨ ਹਨ, ਪਰ ਡੀਟੇਲ ਮਹੱਤਵਪੂਰਨ ਹਨ। ਫਿਕਸਡ ਵਿਂਡੋ boundary 'ਤੇ ਤੇਜ਼ ਧੱਕੇ ਬਣਾਉਂਦੀ ਹੈ (ਉਸੇ ਸੈਕਿੰਡ ਦੇ ਅਖੀਰ ਵਿੱਚ ਅਤੇ ਅਗਲੇ ਸੈਕਿੰਡ ਦੀ ਸ਼ੁਰੂਆਤ ਤੇ burst), ਜਦ ਕਿ sliding windows ਜ਼ਿਆਦਾ ਨਿਆਂਸੰਗਤ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ ਪਰ ਹੋਰ ਸਟੇਟ ਜਾਂ ਬੇਤਰ ਡੇਟਾ ਸਟਰਕਚਰਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਇੱਕ ਵੱਖਰੀ ਕਿਸਮ concurrency (in-flight requests) ਹੈ। ਇਹ ਤੁਹਾਨੂੰ slow client connections ਅਤੇ ਲੰਬੇ-ਚੱਲਦੇ ਐਂਡਪੌਇੰਟਾਂ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ। ਇੱਕ ਗਾਹਕ 60 requests/minute ਦੇ ਅੰਦਰ ਰਹਿ ਸਕਦਾ ਹੈ ਪਰ ਫਿਰ ਵੀ 200 open requests ਰੱਖ ਕੇ ਤੁਹਾਨੂੰ ਓਵਰਲੋਡ ਕਰ ਸਕਦਾ ਹੈ।
ਅਸਲੀ ਸਿਸਟਮਾਂ ਵਿੱਚ ਟੀਮਾਂ ਅਕਸਰ ਕੁਝ ਕੰਟਰੋਲ ਮਿਲਾ ਕੇ ਵਰਤਦੀਆਂ ਹਨ: ਜਨਰਲ ਰਿਕਵੈਸਟ ਰੇਟ ਲਈ ਟੋਕਨ ਬੱਕੇਟ, slow/heavy ਐਂਡਪੌਇੰਟਾਂ ਲਈ concurrency cap, ਅਤੇ ਐਂਡਪੌਇੰਟ ਗਰੁੱਪਾਂ ਲਈ ਵੱਖਰੇ ਬਜਟ (ਸਸਤੇ reads ਵਿਰੁੱਧ ਮਹਿੰਗੇ exports)। ਜੇ ਤੁਸੀਂ ਸਿਰਫ਼ ਰਿਕਵੈਸਟ ਕਾਊਂਟ ਨਾਲ ਸੀਮਤ ਕਰੋਗੇ ਤਾਂ ਇਕ ਮਹਿੰਗਾ ਐਂਡਪੌਇੰਟ ਸਭ ਕੁਝ crowd out ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ API randomly broken ਮਹਿਸੂਸ ਹੋਵੇਗੀ।
ਚੰਗੇ ਕੋਟੇ ਨਿਆਂਸੰਗਤ ਅਤੇ ਅਨੁਮਾਨਯੋਗ ਮਹਿਸੂਸ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ। ਗ੍ਰਾਹਕਾਂ ਨੂੰ ਨਿਯਮ ਸਿਰਫ਼ ਬਲਾਕ ਹੋਣ ਤੋਂ ਬਾਅਦ ਨਹੀਂ ਪਤਾ ਲੱਗਣੇ ਚਾਹੀਦੇ।
ਵੱਖਰਾ ਰੱਖੋ:
ਕਈ SaaS ਟੀਮਾਂ ਦੋਹਾਂ ਵਰਤਦੀਆਂ ਹਨ: ਇੱਕ ਛੋਟੀ ਰੇਟ ਲਿਮਿਟ bursts ਰੋਕਣ ਲਈ ਅਤੇ ਮਹੀਨਾਵਾਰ ਕੋਟਾ ਜੋ ਪ੍ਰਾਈਸਿੰਗ ਨਾਲ ਜੁੜਿਆ ਹੋਵੇ।
ਹਾਰਡ vs ਸਾਫਟ ਲਿਮਿਟ ਜ਼ਿਆਦਾਤਰ ਤੌਰ 'ਤੇ ਸਪੋਰਟ ਚੋਣ ਹੈ। ਹਾਰਡ ਲਿਮਿਟ turant block ਕਰਦਾ ਹੈ। ਸਾਫਟ ਪਹਿਲਾਂ ਚੇਤਾਵਨੀ ਦਿੰਦਾ ਹੈ, ਫਿਰ ਬਲਾਕ ਕਰਦਾ ਹੈ। ਸਾਫਟ ਲਿਮਿਟ ਗੁੱਸੇ ਵਾਲੀਆਂ ਟਿਕਟਾਂ ਘਟਾਉਂਦੇ ਹਨ ਕਿਉਂਕਿ ਲੋਕਾਂ ਕੋਲ ਬੱਗ ਠੀਕ ਕਰਨ ਜਾਂ ਅਪਗ੍ਰੇਡ ਕਰਨ ਲਈ ਸਮਾਂ ਹੁੰਦਾ ਹੈ।
ਜਦੋਂ ਕੋਈ ਲੰਘ ਜਾਵੇ, ਵਿਵਹਾਰ ਉਸ ਸੁਰੱਖਿਆ ਲਕਸ਼ ਨਾਲ ਮੇਲ ਖਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ overuse ਹੋਣ ਨਾਲ ਹੋਰ ਟੇਨੈਂਟ ਨੁਕਸਾਨ ਵਿੱਚ ਆ ਸਕਦੇ ਹਨ ਜਾਂ ਖਰਚ ਵਧ ਸਕਦੇ ਹਨ ਤਾਂ blocking ਠੀਕ ਹੈ। Degrading (ਹੌਲੀ ਪ੍ਰੋਸੈਸਿੰਗ ਜਾਂ ਘੱਟ ਪ੍ਰਾਇਰਟੀ) ਠੀਕ ਹੈ ਜਦ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਚੀਜ਼ें ਹਿਲਦੀਆਂ-ਡੁੱਲਦੀਆਂ ਚੱਲਦੀਆਂ ਰਹਿਣ। “ਬਿੱਲ ਬਾਅਦ” ਵੀ ਠੀਕ ਹੋ ਸਕਦਾ ਹੈ ਜਦ ਵਰਤੋਂ ਅਨੁਮਾਨਯੋਗ ਹੋਵੇ ਅਤੇ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਬਿਲਿੰਗ ਫਲੋ ਹੋਵੇ।
ਟੀਅਰ-ਅਧਾਰਿਤ ਸੀਮਾਵਾਂ ਸਭ ਤੋਂ ਵਧੀਆ ਤਾਂ ਵਰਤਦੀਆਂ ਹਨ ਜਦ ਹਰ ਟੀਅਰ ਦਾ “ਉਮੀਦ ਕੀਤੀ ਵਰਤੋਂ” ਸਪਸ਼ਟ ਹੋਵੇ। Free ਟੀਅਰ ਛੋਟੀ ਮਹੀਨਾਵਾਰ ਕੋਟਾ ਅਤੇ ਘੱਟ ਬਰਸਟ ਰੇਟ ਦੇ ਸਕਦਾ ਹੈ; business ਅਤੇ enterprise ਟੀਅਰ ਬੜੇ ਕੋਟੇ ਅਤੇ ਉੱਚ ਬਰਸਟ ਲਿਮਿਟ ਦੇ ਸਕਦੇ ਹਨ ਤਾਂ ਕਿ background jobs ਤੇਜ਼ੀ ਨਾਲ ਖ਼ਤਮ ਹੋ ਸਕਣ। ਇਹ ਕਿਵੇਂ Koder.ai ਦੇ_Free, Pro, Business, Enterprise_ ਟੀਅਰਾਂ ਨੇ ਵੱਖਰੀਆ ਉਮੀਦਾਂ ਸੈਟ ਕੀਤੀਆਂ ਹਨ ਦੇ ਸਮਾਨ ਹੈ।
Enterprise ਲਈ ਸ਼ੁਰੂਆਤੀ ਰੂਪ ਵਿੱਚ custom limits ਸਹਿਯੋਗ ਕਰਨਾ ਲਾਇਕੀ ਹੁੰਦਾ ਹੈ। ਇੱਕ ਸਾਫ਼ ਰਵੱਈਆ "defaults by plan, overrides by customer" ਹੈ। Org-ਸਤ੍ਹਰ ਤੇ admin-set override ਸਟੋਰ ਕਰੋ (ਕਦੀ-ਕਦੀ per-endpoint ਵੀ) ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਇਹ plan changes 'ਤੇ ਟਿਕੇ ਰਹਿੰਦੇ ਹਨ। ਇਹ ਵੀ ਨਿਰਧਾਰਿਤ ਕਰੋ ਕਿ ਕੌਣ ਬਦਲਾਅ ਮੰਗ ਸਕਦਾ ਹੈ ਅਤੇ ਉਹ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰਭਾਵੀ ਹੋਣਗੇ।
ਉਦਾਹਰਨ: ਇੱਕ ਗਾਹਕ ਮਹਿਲੇ ਮਹੀਨੇ ਦੇ ਆਖਰੀ ਦਿਨ 50,000 records import ਕਰਦਾ ਹੈ। ਜੇ ਉਹਨਾਂ ਦਾ ਮਹੀਨਾਵਾਰ ਕੋਟਾ ਲਗਭਗ ਖਤਮ ਹੋ ਰਿਹਾ ਹੈ, ਤਾਂ 80–90% 'ਤੇ ਇੱਕ soft warning ਉਨ੍ਹਾਂ ਨੂੰ ਰੋਕਣ ਦਾ ਸਮਾਂ ਦੇਂਦਾ ਹੈ। ਇੱਕ ਛੋਟੀ per-second rate limit import ਨੂੰ API ਨਾਲ flood ਕਰਨ ਤੋਂ ਰੋਕਦੀ ਹੈ। ਮਨਜ਼ੂਰ ਕੀਤਾ ਗਿਆ org override (ਅਸਥਾਈ ਜਾਂ ਸਥਾਈ) ਕਾਰੋਬਾਰ ਨੂੰ ਚਾਲੂ ਰੱਖ ਸਕਦਾ ਹੈ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਲਿਖੋ ਕਿ ਤੁਸੀਂ ਕੀ ਗਿਣ ਰਹੇ ਹੋ ਅਤੇ ਇਹ ਕਿਸਦਾ ਹੈ। ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਤਿੰਨ identities ਨਾਲ ਆਖ਼ਰ ਕਰਦੀਆਂ ਹਨ: ਸਾਈਨ-ਇਨ ਯੂਜ਼ਰ, ਗ੍ਰਾਹਕ ਓਰਗ (ਵਰਕਸਪੇਸ), ਅਤੇ ਕਲਾਇੰਟ IP।
ਇੱਕ ਪ੍ਰਾਇਕਟੀਕਲ ਪਲਾਨ:
ਜਦੋਂ ਤੁਸੀਂ limits ਸੈਟ ਕਰੋ, ਤੀਅਰ ਅਤੇ ਐਂਡਪੌਇੰਟ ਗਰੁੱਪਾਂ ਵਿਚ ਸੋਚੋ, ਇੱਕ ਗਲੋਬਲ ਨੰਬਰ ਵਿੱਚ ਨਹੀਂ। ਇੱਕ ਆਮ ਫ਼ੇਲ੍ਹ ਇਹ ਹੈ ਕਿ in-memory counters ਬਹੁਤ ਸਾਰੇ app servers 'ਤੇ ਭਰੋਸਾ ਕੀਤਾ ਜਾਵੇ — counters disagree ਕਰਦੇ ਹਨ ਅਤੇ ਯੂਜ਼ਰਾਂ ਨੂੰ random 429s ਦਿੱਸਦੇ ਹਨ। Redis ਵਰਗਾ shared store ਇੰਸਟੈਂਸਾਂ 'ਚ limits ਸਥਿਰ ਰੱਖਦਾ ਹੈ, ਅਤੇ TTLs ਡੇਟਾ ਛੋਟਾ ਰੱਖਦੇ ਹਨ।
ਰੋਲਆਉਟ ਮਹੱਤਵਪੂਰਨ ਹੈ। ਪਹਿਲਾਂ “report only” ਮੋਡ (ਕੀ ਬਲਾਕ ਕੀਤਾ ਜਾਂਦਾ ਦੇਖੋ), ਫਿਰ ਇੱਕ ਐਂਡਪੌਇੰਟ ਗਰੁੱਪ 'ਤੇ enforce, ਫਿਰ ਫੈਲਾਓ — ਇਹ ਇਸ ਤਰ੍ਹਾਂ ਹੈ ਕਿ ਤੁਸੀਂ ਸਵੇਰੇ support tickets ਦੀ ਇੱਕ ਭਾਰੀ ਲਹਿਰ ਨਾਲ ਜੱਗਦੇ ਨਹੀਂ।
ਜਦੋਂ ਗ੍ਰਾਹਕ ਸੀਮਾ 'ਤੇ ਪਹੁੰਚਦੇ ਹਨ, ਸਭ ਤੋਂ ਮਾੜਾ ਨਤੀਜਾ ਗੁੰਝਲਦਾਰੀ ਹੈ: “ਕੀ ਤੁਹਾਡੀ API ਡਾਊਨ ਹੈ, ਜਾਂ ਮੈਂ ਕੁਝ ਗਲਤ ਕੀਤਾ?” ਸਾਫ਼, consistent responses support tickets ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਲੋਕਾਂ ਨੂੰ ਕਲਾਈੰਟ ਵਿਹਾਰ ਸੁਧਾਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
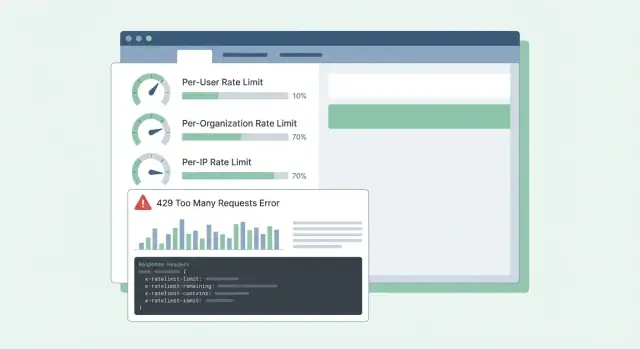
ਜਦੋਂ ਤੁਸੀਂ active blocking ਕਰ ਰਹੇ ਹੋ ਤਾਂ HTTP 429 Too Many Requests ਵਰਤੋ। ਰਿਸਪਾਂਸ ਬਾਡੀ ਪੇਸ਼ਗੋਈਯੋਗ ਰੱਖੋ ਤਾਂ SDKs ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਇਸਨੂੰ ਪੜ੍ਹ ਸਕਣ।
ਇੱਥੇ ਇੱਕ ਸਧਾਰਨ JSON ਆਕਾਰ ਹੈ ਜੋ per-user, per-org ਅਤੇ per-IP ਲਿਮਿਟਸ 'ਤੇ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ:
{
"error": {
"code": "rate_limit_exceeded",
"message": "Rate limit exceeded for org. Try again later.",
"limit_scope": "org",
"reset_at": "2026-01-17T12:34:56Z",
"request_id": "req_01H..."
}
}
ਹੈਡਰਾਂ ਨੂੰ ਮੌਜੂਦਾ ਵਿੰਡੋ ਅਤੇ ਅਗਲਾ ਕਦਮ ਸਮਝਾਉਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਸਿਰਫ਼ ਕੁਝ ਜੋੜ ਰਹੇ ਹੋ ਤਾਂ ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਇਹ: RateLimit-Limit, RateLimit-Remaining, RateLimit-Reset, Retry-After, ਅਤੇ X-Request-Id.
ਉਦਾਹਰਨ: ਇੱਕ ਗਾਹਕ ਦਾ cron job ਹਰ ਮਿੰਟ ਦੌੜਦਾ ਹੈ ਅਤੇ ਅਚਾਨਕ ਫੇਲ ਹੋਣਾ ਸ਼ੁਰੂ ਹੋ ਜਾਂਦਾ ਹੈ। 429 ਨਾਲ RateLimit-Remaining: 0 ਅਤੇ Retry-After: 20 ਹੋਣ ਤੇ ਉਹ ਤੁਰੰਤ ਜਾਣ ਲੈਂਦਾ ਹੈ ਕਿ ਇਹ ਸੀਮਾ ਹੈ, ਨਾ ਕਿ outage, ਅਤੇ ਉਹ 20 ਸਕਿੰਟ ਬਾਅਦ retries ਨੂੰ ਦੇਰ ਕਰ ਸਕਦਾ ਹੈ। ਜੇ ਉਹ X-Request-Id ਸਹਾਇਤਾ ਨਾਲ ਸਾਂਝਾ ਕਰਦੇ ਹਨ ਤਾਂ ਤੁਸੀਂ ਘਟਨਾ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਲੱਭ ਸਕਦੇ ਹੋ।
ਅੰਮਾ ਇਕ ਹੋਰ ਬਿੰਦੂ: ਸਫਲ ਰਿਕਵੈਸਟਾਂ 'ਤੇ ਵੀ ਉਹੇ ਹੈਡਰ ਵਾਪਸ ਕਰੋ। ਗ੍ਰਾਹਕ ਝੱਲਣ ਤੋਂ ਪਹਿਲਾਂ ਦੇਖ ਸਕਣ ਕਿ ਉਹ ਕਿੰਨੇ ਨੇੜੇ ਹਨ।
ਚੰਗੇ ਕਲਾਇੰਟ ਸੀਮਾਵਾਂ ਨੂੰ ਨਿਆਂਸੰਗਤ ਮਹਿਸੂਸ ਕਰਾਉਂਦੇ ਹਨ। ਮਾੜੇ ਕਲਾਇੰਟ ਇਕ ਅਸਥਾਈ ਸੀਮਾ ਨੂੰ outage ਬਣਾਉਂਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ ਹੋਰ ਜ਼ੋਰ ਨਾਲ hammer ਕਰਦੇ ਹਨ।
ਜਦੋਂ ਤੁਹਾਨੂੰ 429 ਮਿਲੇ, ਇਸਨੂੰ ਹੌਲੀਆਂ ਕਰਨ ਦਾ ਸੰਗੇਤ ਸਮਝੋ। ਜੇ ਰਿਸਪਾਂਸ ਦੱਸਦਾ ਹੈ ਕਿ ਕਦੋਂ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਕਰਨੀ ਹੈ (ਉਦਾਹਰਨ: Retry-After), ਤਾਂ ਘੱਟੋ-ਘੱਟ ਉਸ ਸਮੇਂ ਤੱਕ ਉਡੀਕ ਕਰੋ। ਜੇ ਨਹੀਂ ਦੱਸਿਆ, ਤਾਂ exponential backoff ਅਤੇ jitter ਵਰਤੋ ਤਾਂ ਕਿ ਹਜ਼ਾਰਾਂ ਕਲਾਇੰਟ ਇਕੱਠੇ ਸਮੇਂ ਰੀਟ੍ਰਾਈ ਨਾ ਕਰਨ।
ਰੀਟ੍ਰਾਈ bounded ਰੱਖੋ: ਕੋਸ਼ਿਸ਼ਾਂ ਵਿਚਕਾਰ ਦੇਰੇ ਨੂੰ cap ਕਰੋ (ਉਦਾਹਰਨ: 30–60 ਸਕਿੰਟ) ਅਤੇ ਕੁੱਲ retry ਸਮਾਂ ਵੀ cap ਕਰੋ (ਉਦਾਹਰਨ: 2 ਮਿੰਟ ਅਤੇ ਫੇਲ ਹੋ ਕੇ error surface ਕਰੋ)। ਇਸ ਘਟਨਾ ਨੂੰ limit details ਨਾਲ ਲੌਗ ਕਰੋ ਤਾਂ ਡੈਵਲਪਰ ਬਾਅਦ ਵਿੱਚ ਟਿਊਨ ਕਰ ਸਕਣ।
ਹਰ ਚੀਜ਼ ਨੂੰ ਰੀਟ੍ਰਾਈ ਨਾ ਕਰੋ। ਬਹੁਤ ਸਾਰੀਆਂ ਗਲਤੀਆਂ ਬਿਨਾਂ ਬਦਲਾਅ ਦੇ ਸਫਲ ਨਹੀਂ ਹੋਣਗੀਆਂ: 400 validation errors, 401/403 auth errors, 404 not found, ਅਤੇ 409 conflicts ਜੋ ਅਸਲੀ ਬਿਜ਼ਨਸ ਰੂਲ ਦਰਸਾਉਂਦੇ ਹਨ।
ਲਿਖਤੀਆਂ 'ਤੇ retry ਕਰਨਾ ਖਤਰਨਾਕ ਹੋ ਸਕਦਾ ਹੈ (create, charge, send email). ਜੇ timeout ਹੋਏ ਅਤੇ client retry ਕਰਦਾ ਹੈ ਤਾਂ duplicate ਬਣ ਸਕਦੇ ਹਨ। Idempotency keys ਵਰਤੋਂ: client ਹਰ ਲਾਜ਼ਮੀ ਕਾਰਵਾਈ ਲਈ ਇਕ ਵਿਲੱਖਣ key ਭੇਜਦਾ ਹੈ, ਅਤੇ ਸਰਵਰ ਉਸ key ਦੀ ਦੁਹਰਾਈ ਲਈ ਇਕੋ ਨਤੀਜਾ ਵਾਪਸ ਕਰਦਾ ਹੈ।
ਚੰਗੇ SDKs ਇਹ ਸੌਖਾ ਬਣਾਉਂਦੇ ਹਨ: status (429), ਕਿੰਨਾ ਦੇਰ ਰੁਕਣਾ ਹੈ, request safe to retry ਹੈ ਕਿ ਨਹੀਂ, ਅਤੇ ਇਕ ਸੁਨੇਹਾ ਜਿਵੇਂ “Rate limit exceeded for org. Retry after 8s or reduce concurrency.”
ਜ਼ਿਆਦਾਤਰ support tickets ਸੀਮਾਵਾਂ ਬਾਰੇ ਨਹੀਂ ਹੁੰਦੀਆਂ — ਉਹ ਹੈਰਾਨੀ ਤੇ ਹੁੰਦੀਆਂ ਹਨ। ਜੇ ਉਪਭੋਗੀ ਅਗਲਾ ਕਦਮ ਨਹੀਂ ਜਾਣਦੇ, ਉਹ assume ਕਰਦੇ ਹਨ ਕਿ API ਟੁੱਟੀ ਹੋਈ ਹੈ ਜਾਂ ਇਸਦਾ ਇਨਸਾਫ਼ ਨਹੀਂ।
ਕੇਵਲ IP-ਅਧਾਰਿਤ limits ਵਰਤਣਾ ਇੱਕ ਆਮ ਗਲਤੀ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਇਕ ਪਬਲਿਕ IP ਪਿੱਛੇ ਬੈਠਦੀਆਂ ਹਨ (ਆਫਿਸ Wi‑Fi, ਮੋਬਾਈਲ ਕੇਰੀਅਰ, ਕਲਾਊਡ NAT). ਜੇ ਤੁਸੀਂ IP ਤੇ ਕੈਪ ਲਾ ਦਿਓ, ਇੱਕ ਵੱਡਾ ਗਾਹਕ ਬਾਕੀ ਸਭ ਨੂੰ ਬਲਾਕ ਕਰ ਸਕਦਾ ਹੈ। ਪਰ-ਯੂਜ਼ਰ ਅਤੇ ਪਰ-ਓਰਗ ਨੂੰ ਤਰਜੀਹ ਦਿਓ, ਅਤੇ per-IP ਨੂੰ mainly abuse safety net ਰੱਖੋ।
ਦੂਜੀ ਸਮੱਸਿਆ ਸਾਰੇ ਐਂਡਪੌਇੰਟ ਨੂੰ ਇੱਕੋ ਸਮਾਨ ਮੰਨਣਾ ਹੈ। ਇੱਕ ਸਸਤਾ GET ਅਤੇ ਇੱਕ ਭਾਰੀ export job ਨੂੰ ਇਕੋ ਬਜਟ ਵਿੱਚ ਰੱਖਣ ਨਾਲ ਗਾਹਕ ਆਪਣੀ ਆਮ browsing ਕਰਕੇ allowance ਖਤਮ ਕਰ ਲੈਂਦੇ ਹਨ, ਫਿਰ ਜਦੋਂ ਉਹ ਅਸਲ ਕੰਮ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ ਤਾਂ ਬਲਾਕ ਹੋ ਜਾਂਦੇ ਹਨ। ਐਂਡਪੌਇੰਟ ਗਰੁੱਪ ਦੁਆਰਾ ਵੱਖਰੇ ਬਕੈਟ ਰੱਖੋ ਜਾਂ requests ਨੂੰ cost ਅਨੁਸਾਰ weight ਕਰੋ।
ਰੀਸੈੱਟ ਟਾਈਮਿੰਗ ਵੀ explicit ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। “Resets daily” ਕਾਫੀ ਨਹੀਂ। ਕਿਹੜਾ time zone? rolling window ਜਾਂ midnight reset? ਜੇ ਤੁਸੀਂ calendar resets ਕਰਦੇ ਹੋ ਤਾਂ time zone ਦੱਸੋ। ਜੇ rolling windows ਹਨ ਤਾਂ window length ਦੱਸੋ।
ਅੰਤ ਵਿੱਚ vague errors ਹੰਗਾਮਾ ਪੈਦਾ ਕਰਦੇ ਹਨ। 500 ਜਾਂ generic JSON ਵਾਪਸ ਕਰਨ ਨਾਲ ਲੋਕ ਜ਼ੋਰ ਨਾਲ retries ਕਰਨਗੇ। 429 ਵਰਤੋ ਅਤੇ RateLimit ਹੈਡਰ ਸ਼ਾਮਲ ਕਰੋ ਤਾਂ clients ਸਮਝ ਕੇ back off ਕਰ ਸਕਣ।
ਉਦਾਹਰਨ: ਜੇ ਇੱਕ ਟੀਮ Koder.ai ਇੰਟਿਗ੍ਰੇਸ਼ਨ shared corporate network ਤੋਂ ਬਣਾਉਂਦੀ ਹੈ, IP-only cap ਉਹਨਾਂ ਦੀ ਪੂਰੀ ਸੰਸਥਾ ਨੂੰ ਬਲਾਕ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਇਹ random outages ਵਾਂਗ ਲੱਗੇਗਾ। ਸਪਸ਼ਟ ਡਾਇਮੇਨਸ਼ਨ ਅਤੇ ਸਪਸ਼ਟ 429 responses ਇਹ ਰੋਕਦੇ ਹਨ।
Limits ਸਾਰਿਆਂ ਲਈ ਚਾਲੂ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, predictability 'ਤੇ ਧਿਆਨ ਦਿਨ ਅਤੇ ਇੱਕ ਅੰਤਿਮ ਪਾਸ ਕਰੋ:
ਇੱਕ ਗੁੱਟ-ਚੈੱਕ: ਜੇ ਤੁਹਾਡੇ ਉਤਪਾਦ ਦੇ ਟੀਅਰ Free, Pro, Business, Enterprise ਹਨ (ਜਿਵੇਂ Koder.ai), ਤਾਂ ਤੁਸੀਂ ਸਪਸ਼ਟ ਬੋਲਚਾਲ ਵਿੱਚ ਦੱਸ ਸਕੋ ਕਿ ਇੱਕ ਆਮ ਗ੍ਰਾਹਕ ਪ੍ਰਤੀ ਮਿੰਟ ਅਤੇ ਪ੍ਰਤੀ ਦਿਨ ਕੀ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ ਕਿਹੜੇ ਐਂਡਪੌਇੰਟ ਵੱਖਰੇ ਇਲਾਜ ਹਾਸਿਲ ਕਰਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਇੱਕ 429 ਨੂੰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਸਮਝਾ ਨਹੀਂ ਸਕਦੇ, ਤਾਂ ਗ੍ਰਾਹਕ ਮੰਨਣਗੇ ਕਿ API ਬ੍ਰੋਕਨ ਹੈ, ਨਾ ਕਿ ਸੇਵਾ ਦੀ ਰੱਖਿਆ ਹੋ ਰਹੀ ਹੈ।
ਇੱਕ B2B SaaS ਦਾ ਕਲਪਨਾ ਕਰੋ ਜਿਥੇ ਲੋਕ ਵਰਕਸਪੇਸ (org) ਦੇ ਅੰਦਰ ਕੰਮ ਕਰਦੇ ਹਨ। ਕੁਝ power users ਭਾਰੀ exports ਚਲਾਉਂਦੇ ਹਨ, ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਕਰਮਚਾਰੀ ਇਕ ਸਾਂਝੇ office IP 'ਤੇ ਬੈਠੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਸਿਰਫ IP ਨਾਲ ਸੀਮਾ ਲਗਾਉਂਦੇ ਹੋ ਤਾਂ ਤੁਸੀਂ ਪੂਰੀ ਕੰਪਨੀ ਨੂੰ ਬਲਾਕ ਕਰ ਸਕਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ ਸਿਰਫ user ਨਾਲ ਸੀਮਾ ਲਗਾਉਂਦੇ ਹੋ ਤਾਂ ਇੱਕ ਸਕ੍ਰਿਪਟ ਫਿਰ ਵੀ ਪੂਰੇ ਵਰਕਸਪੇਸ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾ ਸਕਦੀ ਹੈ।
ਇੱਕ ਪ੍ਰਾਇਕਟੀਕਲ ਮਿਕਸ ਇਹ ਹੈ:
ਜਦੋਂ ਕੋਈ ਸੀਮਾ ਲੱਗੇ, ਤੁਹਾਡਾ ਸੁਨੇਹਾ ਉਨ੍ਹਾਂ ਨੂੰ ਦੱਸੇ ਕਿ ਕੀ ਹੋਇਆ, ਅਗਲਾ ਕਦਮ ਕੀ ਹੈ, ਅਤੇ ਕਦੋਂ retry ਕਰਨਾ ਹੈ। Support ਨੂੰ ਇਹ ਸ਼ਬਦ ਪਿੱਠੇ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ:
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
ਏਸ ਸੁਨੇਹੇ ਨੂੰ Retry-After ਅਤੇ consistent RateLimit ਹੈਡਰਾਂ ਨਾਲ ਜੋੜੋ ਤਾਂ ਗ੍ਰਾਹਕਾਂ ਨੂੰ ਅਟਕਣਾ ਨਾ ਪਵੇ।
ਰੋਲਆਉਟ ਜੋ surprises ਤੋਂ ਬਚਾਏ: observe-only ਪਹਿਲਾਂ, ਫਿਰ warn (ਹੈਡਰ ਅਤੇ soft warnings), ਫਿਰ enforce (429s ਸਾਫ retry timing ਨਾਲ), ਫਿਰ thresholds ਨੂੰ ਟਿਊਨ ਕਰੋ ਪ੍ਰਤੀ ਟੀਅਰ, ਅਤੇ ਵੱਡੇ ਲਾਂਚਾਂ ਅਤੇ onboarding ਤੋਂ ਬਾਅਦ ਸਮੀਖਿਆ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਇਹ ਵਿਚਾਰ ਤੇਜ਼ੀ ਨਾਲ actionable ਕੋਡ ਵਿੱਚ ਬਦਲਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਇੱਕ vibe-coding platform ਜਿਵੇਂ Koder.ai (koder.ai) ਤੁਹਾਨੂੰ ਇੱਕ ਛੋਟਾ ਰੇਟ ਲਿਮਿਟ ਸਪੈਕ ਡ੍ਰਾਫਟ ਕਰਨ ਅਤੇ Go middleware ਜਨਰੇਟ ਕਰਨ 'ਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਸੇਵਾਵਾਂ 'ਤੇ ਨਾਲ-ਨਾਲ ਲਾਗੂ ਕੀਤਾ ਜਾ ਸਕੇ।
ਰੇਟ ਲਿਮਿਟ ਇਸ ਗੱਲ ਨੂੰ ਸੀਮਤ ਕਰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਬੇਨਤੀਆਂ ਕਰ ਸਕਦੇ ਹੋ — ਉਦਾਹਰਨ ਲਈ ਪ੍ਰਤੀ ਸਕਿੰਟ ਜਾਂ ਪ੍ਰਤੀ ਮਿੰਟ ਬੇਨਤੀਆਂ। ਕੋਟਾ ਉਸ ਗੱਲ ਨੂੰ ਸੀਮਤ ਕਰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਲੰਮੇ ਸਮੇਂ ਦੀ ਅਵਧੀ ਵਿੱਚ ਕਿੰਨਾ ਵਰਤੋਂ ਕਰ ਸਕਦੇ ਹੋ — ਜਿਵੇਂ ਪ੍ਰਤੀ ਦਿਨ, ਪ੍ਰਤੀ ਮਹੀਨਾ ਜਾਂ ਬਿੱਲਿੰਗ ਚੱਕਰ ਮੁਤਾਬਕ।
ਜੇ ਤੁਸੀਂ "ਇਹ ਕੱਲ੍ਹ ਕੰਮ ਕਰ ਰਿਹਾ ਸੀ" ਵਾਲੀਆਂ ਹੈਰਾਨੀ ਘਟਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਦੋਹਾਂ ਨੂੰ ਸਪਸ਼ਟ ਰੂਪ ਵਿੱਚ ਦਿਖਾਓ ਅਤੇ ਰੀਸੈੱਟ ਟਾਈਮਿੰਗ ਨੂੰ ਵਿਆਖਿਆਤ ਕਰੋ ਤਾਂ ਕਿ ਗ੍ਰਾਹਕ ਵਿਵਹਾਰ ਦੀ ਭਵਿੱਖਬਾਣੀ ਕਰ ਸਕਣ।
ਉਸ ਨੁਕਸਾਨ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ ਰੋਕ ਰਹੇ ਹੋ। ਜੇ ਬਰਸਟ ਕਾਰਨ ਟਾਈਮਆਊਟ ਹੋ ਰਹੇ ਹੋ, ਤਾਂ ਤੁਹਾਨੂੰ ਛੋਟੀ ਮਿਆਦ ਵਾਲੀ ਬਰਸਟ ਕੰਟਰੋਲ ਦੀ ਲੋੜ ਹੈ; ਜੇ ਕੁਝ ਐਂਡਪੌਇੰਟ ਖਰਚ ਵਧਾ ਰਹੇ ਹਨ ਤਾਂ ਤੁਹਾਨੂੰ ਲਾਗਤ-ਅਧਾਰਿਤ ਬਜਟ ਦੀ ਲੋੜ ਹੈ; ਜੇ ਤੁਸੀਂ ਬ੍ਰੂਟ ਫੋਰਸ ਜਾਂ ਸਕ੍ਰੈਪਿੰਗ ਵੇਖ ਰਹੇ ਹੋ ਤਾਂ ਸਖਤ ਐਬਿਊਜ਼ ਕੰਟਰੋਲ ਚਾਹੀਦੇ ਹਨ।
ਫੈਸਲਾ ਕਰਨ ਦਾ ਇੱਕ ਤੇਜ਼ ਤਰੀਕਾ: ਪੁੱਛੋ — "ਜੇ ਇਹ ਇੱਕ ਐਂਡਪੌਇੰਟ ਦੀ ਟ੍ਰੈਫਿਕ 10× ਹੋ ਜਾਵੇ, ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਕੀ ਟੁੱਟੇਗਾ: ਲੈਟੈਂਸੀ, ਲਾਗਤ ਜਾਂ ਸੁਰੱਖਿਆ?" ਫਿਰ ਉਸ ਮੁੱਖ ਦਫ਼ਾ ਲਈ ਸੀਮਾ ਡਿਜ਼ਾਈਨ ਕਰੋ।
ਪਰ-ਯੂਜ਼ਰ ਸੀਮਾਵਾਂ ਇੱਕ ਵਿਅਕਤੀ ਨੂੰ ਆਪਣੀ ਟੀਮ ਨੂੰ ਧੱਕਾ ਦੇਣ ਤੋਂ ਰੋਕਦੀਆਂ ਹਨ, ਅਤੇ ਪਰ-ਓਰਗ ਸੀਮਾਵਾਂ ਇੱਕ ਵਰکسਪੇਸ ਨੂੰ ਇੱਕ ਹੋਣਯੋਗ ਛੱਤ ਦੇਂਦੀਆਂ ਹਨ ਜੋ ਪ੍ਰਾਈਸਿੰਗ ਅਤੇ ਸਮਰੱਥਾ ਨਾਲ ਮਿਲਦੀ ਹੈ। ਜਦੋਂ ਕੋਈ ਸ਼ੇਅਰ ਕੀ ਜਾਂ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਅਧਾਰਿਤ ਹੈ ਤਾਂ ਪਰ-ਟੋਕਨ ਸੀਮਾਵਾਂ ਜੋੜੋ ਤਾਂ ਜੋ ਇੱਕ ਸ਼ੇਅਰ ਕੀ ਡਾਈਨਾਮਿਕ ਉਪਯੋਗਤਾਵਾਂ ਨੂੰ ਦਬਾ ਨਾ ਦੇਵੇ।
IP-ਅਧਾਰਿਤ ਸੀਮਾਵਾਂ ਨੂੰ ਸਿਰਫ਼ ਸਧਾਰਨ ਐਬਿਊਜ਼ ਲਈ ਸੁਰੱਖਿਆ ਜਾਲ ਵਜੋਂ ਲਵੋ, ਕਿਉਂਕਿ ਸਾਂਝੇ ਨੈੱਟਵਰਕ IP ਨਿਰਾਸ਼ਾਵਾਂ ਨੂੰ ਨਿਰਪੱਖ ਉਪਭੋਗਤਾਵਾਂ 'ਤੇ ਲਾ ਸਕਦੇ ਹਨ।
ਟੋਕਨ ਬੱਕੇਟ ਇੱਕ ਚੰਗਾ ਡਿਫੌਲਟ ਹੈ ਜਿਹੜਾ ਛੋਟੇ ਬਰਸਟਾਂ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ ਪਰ ਲੰਬੇ ਸਮੇਂ ਦਾ ਇਕ ਔਸਤ ਬਰਕਰਾਰ ਰੱਖਦਾ ਹੈ। ਇਹ ਡੈਸ਼ਬੋਰਡ ਜਿਹੜੇ ਕਈ ਤੇਜ਼ ਬੇਨਤੀਆਂ ਭੇਜਦੇ ਹਨ ਲਈ ਵਧੀਆ ਹੈ।
ਜੇ ਤੁਹਾਡਾ ਬੈਕਐਂਡ ਬਿਲਕੁਲ ਬਰਸਟ ਸਹ忍 ਨਹੀਂ ਕਰ ਸਕਦਾ, ਤਾਂ ਲੀਕੀ ਬੱਕੇਟ ਜਾਂ ਕਨਸਟੈਂਟ ਆਉਟਫਲ ਜਿਆਦਾ ਸਖਤ ਪਰ ਨਿਰੰਤਰ ਵਿਹਾਰ ਦਿਵਾਉਂਦੇ ਹਨ। ਖਿੜਕੀ-ਆਧਾਰਿਤ ਕਾਊਂਟਰ ਸਧਾਰਨ ਹਨ ਪਰ ਫਿਕਸਡ ਵਿਂਡੋ ਬਾਉਂਡਰੀ 'ਤੇ ਧੱਕਾ ਪੈਦਾ ਕਰ ਸਕਦੀ ਹੈ; ਸਲਾਈਡਿੰਗ ਵਿਂਡੋ ਜ਼ਿਆਦਾ ਨਿਆਂਸੰਗਤ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ ਪਰ ਹੋਰ ਸਟੇਟ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ।
ਇੱਥੇ ਇੱਕ ਹੋਰ ਪ੍ਰਕਾਰ concurrency (in-flight) ਹੈ — ਜੇ ਨੁਕਸਾਨ ਖੁੱਲ੍ਹੇ ਰਿਸਪਾਂਸਾਂ ਤੋਂ ਆ ਰਿਹਾ ਹੈ ਤਾਂ ਇਹ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ। ਅਸਲੀ ਸਿਸਟਮਾਂ ਵਿੱਚ ਅਕਸਰ ਟੋਕਨ ਬੱਕੇਟ + concurrency cap + ਐਂਡਪੌਇੰਟ-ਗਰੁੱਪ ਬਜਟ ਮਿਲਾ ਕੇ ਵਰਤੇ ਜਾਂਦੇ ਹਨ।
ਚੰਗੇ ਕੋਟੇ ਨਿਆਂਸੰਗਤ ਅਤੇ ਅਨੁਮਾਨਯੋਗ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ। ਗ੍ਰਾਹਕਾਂ ਨੂੰ ਨਿਯਮ ਬਲਾਕ ਹੋਣ ਤੋਂ ਬਾਅਦ ਹੀ ਨਹੀਂ ਮਿਲਣੇ ਚਾਹੀਦੇ।
ਛੋਟੀ ਅਵਧੀ ਦੀਆਂ ਰੇਟ ਲਿਮਿਟਸ (ਜਿਵੇਂ 10 ਰਿਕਵੈਸਟ/ਸੈਕਿੰਡ) ਸੇਵਾ ਨੂੰ ਬਰਸਟ ਤੋਂ ਰੋਕਦੀਆਂ ਹਨ। ਲੰਮੇ ਸਮੇਂ ਵਾਲੀਆਂ ਕੋਟਾਵਾਂ (ਰੋਜ਼ਾਨਾ/ਮਹੀਨਾਵਾਰ) ਲਾਗਤ ਦੀ ਰੱਖਿਆ ਲਈ ਹਨ ਅਤੇ ਪ੍ਰਾਈਸ ਟੀਅਰਾਂ ਨੂੰ ਤੁਲਨਯੋਗ ਰੱਖਦੀਆਂ ਹਨ।
ਹਾਰਡ vs ਸਾਫਟ ਲਿਮਿਟ: ਸਾਫਟ ਚੇਤਾਵਨੀ ਦੇ ਕੇ ਫਿਰ ਬਲਾਕ ਕਰਨਾ ਪਸੰਦੀਦਾ ਹੁੰਦਾ ਹੈ ਤਾਂ ਗ੍ਰਾਹਕਾਂ ਕੋਲ ਸੁਧਾਰ ਕਰਨ ਦਾ ਸਮਾਂ ਹੋਵੇ। ਜਦੋਂ ਬਲਾਕ ਹੋਵੇ ਤਾਂ ਹਰ ਵਿਹਾਰ ਉਸ ਸੁਰੱਖਿਆ ਲਕਸ਼ ਦੀ ਸੁਝਾਅ ਦੇਵੇ — ਕੁਝ ਹਾਲਤਾਂ ਵਿੱਚ ਰੋਕਣਾ ਠੀਕ ਹੈ, ਹੋਰਾਂ ਵਿੱਚ degraded ਸੇਵਾ ਜਾਂ ਬਿੱਲ-ਬਾਅਦ ਦਾ ਢੰਗ ਚੰਗਾ ਹੋ ਸਕਦਾ ਹੈ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਤੈਅ ਕਰੋ ਕਿ ਤੁਸੀਂ ਕੀ ਗਿਣ ਰਹੇ ਹੋ ਅਤੇ ਇਹ ਕਿਸਦਾ ਹੈ: ਸਾਈਨ-ਇਨ ਯੂਜ਼ਰ, ਗ੍ਰਾਹਕ ਓਰਗ (ਵਰਕਸਪੇਸ) ਅਤੇ ਕਲਾਇੰਟ IP. ਇੱਕ ਅਮਲਯੋਜਨਾ:
ਜਦੋਂ ਗ੍ਰਾਹਕ ਲਿਮਿਟ ਦੇ ਸਮੇਤ ਕਿਸੇ ਸੀਮਤ ਨਾਲ ਟਕਰਾਉ ਪੈਂਦੇ ਹਨ ਤਾਂ ਸਭ ਤੋਂ ਵੱਡੀ ਸਮੱਸਿਆ ਹੈ 혼ਭ੍ਰਮ: "ਕੀ ਤੁਹਾਡੀ API ਡਾਊਨ ਹੈ ਜਾਂ ਮੈਂ ਗਲਤ ਕਰ ਰਿਹਾ ਹਾਂ?" ਸਾਫ਼, ਇੱਕਸਾਰ ਰਿਸਪਾਂਸ ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ।
ਜਦੋਂ ਤੁਸੀਂ ਬਲਾਕ ਕਰ ਰਹੇ ਹੋ ਤਾਂ HTTP 429 Too Many Requests ਵਰਤੋ। ਰਿਸਪਾਂਸ ਬਾਡੀ ਉਹੀ ਰੂਪ ਰੱਖੋ ਤਾਂ ਜੋ SDKs ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਇਸਨੂੰ ਪੜ੍ਹ ਸਕਣ।
ਸਧਾਰਨ JSON ਸ਼ੇਪ ਜੋ ਪਰ-ਯੂਜ਼ਰ, ਪਰ-ਓਰਗ ਅਤੇ ਪਰ-IP ਲਿਮਿਟਸ 'ਤੇ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ, ਕੋਡ ਬਲਾਕ ਵਿੱਚ ਦਿੱਤਾ ਹੈ — ਕੰਮ ਕਰਨ ਵਾਲੀ ਜਾਣਕਾਰੀ: limit_scope, reset_at ਅਤੇ request_id।
ਹੈਡਰਾਂ ਨੂੰ ਮੁਹਈਆ ਕਰੋ: RateLimit-Limit, RateLimit-Remaining, RateLimit-Reset, Retry-After, ਅਤੇ X-Request-Id. ਸਫਲ ਰਿਕਵੈਸਟਾਂ 'ਤੇ ਵੀ ਇੱਕੋ ਵਰਗੇ ਹੈਡਰ ਜਾਰੀ ਕਰੋ ਤਾਂ ਗ੍ਰਾਹਕ ਪਤਾ ਲਗਾ ਸਕਣ ਕਿ ਉਹ ਕਿੰਨੇ ਨੇੜੇ ਹਨ।
ਚੰਗੇ ਕਲਾਇੰਟ ਸੀਮਾਵਾਂ ਨੂੰ ਨਿਆਂਸੰਗਤ ਮਹਿਸੂਸ ਕਰਾਉਂਦੇ ਹਨ। ਮਾੜੇ ਕਲਾਇੰਟ ਇਕ ਅਸਥਾਈ ਸੀਮਾ ਨੂੰ outage ਬਣਾਉਂਦੇ ਹਨ।
429 ਮਿਲਣ 'ਤੇ ਇਸਨੂੰ ਧੀਮਾ ਹੋਣ ਦਾ ਸਿੰਘਕ ਸਮਝੋ। ਜੇ ਰਿਸਪਾਂਸ ਵਿੱਚ Retry-After ਦਿੱਤਾ ਹੈ ਤਾਂ ਘੱਟੋ-ਘੱਟ ਉਸ ਸਮੇਂ ਤੱਕ ਰੁਕੋ। ਨਹੀਂ ਤਾਂ exponential backoff ਅਤੇ jitter ਵਰਤੋ ਤਾਂ ਜੋ ਹਜ਼ਾਰਾਂ ਕਲਾਇੰਟ ਇਕੱਠੇ ਰੀਟ੍ਰਾਈ ਨਾ ਕਰਨ।
ਰੀਟ੍ਰਾਈਜ਼ ਸੀਮਤ ਰੱਖੋ — ਪ੍ਰਤੀ ਕੋਸ਼ਿਸ਼ ਵਿਚਲੇ ਦੇਰੇ ਨੂੰ capped ਰੱਖੋ (ਉਦਾਹਰਨ: 30–60 ਸਕਿੰਟ) ਅਤੇ ਕੁੱਲ ਰੀਟ੍ਰਾਈ ਸਮਾਂ ਵੀ (ਉਦਾਹਰਨ: 2 ਮਿੰਟ) ਸੀਮਤ ਕਰੋ। ਹਰ ਤਰ੍ਹਾਂ ਦੀ ਗਲਤੀ ਨੂੰ ਰੀਟ੍ਰਾਈ ਨਾ ਕਰੋ — 400/401/403/404/409 ਆਮ ਤੌਰ ਤੇ ਗਲਤੀਆਂ ਹਨ ਜੋ ਬਿਨਾਂ ਬਦਲਾਅ ਦੇ ਬਰਾਮਦ ਨਹੀਂ ਹੋਣਗੀਆਂ।
ਲਿਖਤੀਆਂ 'ਤੇ ਰੀਟ੍ਰਾਈ ਖਤਰਨਾਕ ਹੁੰਦੇ ਹਨ — idempotency keys ਵਰਤੋਂ ਤਾਂ ਜੋ ਦੁਹਰਾਵਾਂ ਇੱਕੋ ਨਤੀਜੇ ਦਿਣ। ਚੰਗੇ SDKs 429 ਸਥਿਤੀ, ਕਿੰਨਾ ਦੇਰ ਰੁਕਣਾ ਹੈ, ਕਿ ਕੀ ਰਿਕਵੈਸਟ ਸੇਫ਼ ਹੈ ਰੀਟ੍ਰਾਈ ਕਰਨ ਲਈ, ਅਤੇ ਸਲਾਹ ਜਿਵੇਂ "Org ਲਈ ਰੇਟ ਲਿਮਿਟ ਲੰਘ ਗਿਆ। 8s ਬਾਅਦ ਰੀਟ੍ਰਾਈ ਕਰੋ ਜਾਂ concurrency ਘਟਾਓ।" ਦਿਖਾਉਂਦੇ ਹਨ।
ਜਿਆਦਾਤਰ ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਸੀਮਾਵਾਂ ਬਾਰੇ ਨਹੀਂ ਹੁੰਦੀਆਂ — ਉਹ ਝਟਕੇ ਤੇ ਹੁੰਦੀਆਂ ਹਨ। ਅਨੁਮਾਨਯੋਗਤਾ ਦੀ ਘਾਟ ਸਭ ਤੋਂ ਵੱਡੀ ਸਮੱਸਿਆ ਹੈ।
ਕੇਵਲ IP-ਅਧਾਰਿਤ ਸੀਮਾਵਾਂ ਵਰਤਣਾ ਇੱਕ ਆਮ ਭੁੱਲ ਹੈ — ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਇਕ ਪਬਲਿਕ IP ਪਿੱਛੇ ਬੈਠਦੀਆਂ ਹਨ (ਆਫਿਸ Wi‑Fi, ਮੋਬਾਈਲ ਕੇਰੀਅਰ, ਕਲਾਊਡ NAT). IP-ਕੈਪ ਨੇ ਇਕ ਗ੍ਰਾਹਕ ਪੂਰੇ ਨੈੱਟਵਰਕ ਨੂੰ ਬਲਾਕ ਕਰ ਸਕਦਾ ਹੈ। ਇਸ ਲਈ ਪਰ-ਯੂਜ਼ਰ ਅਤੇ ਪਰ-ਓਰਗ ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਅਤੇ per-IP ਨੂੰ ਸਿਰਫ਼ ਬੈਕਸਟਾਪ ਰੱਖੋ।
ਸਾਰੇ ਐਂਡਪੌਇੰਟ ਨੂੰ ਇਕੋ ਰੂਪ ਵਿੱਚ ਵਰਤਣਾ ਵੀ ਗਲਤ ਹੈ — ਇੱਕ ਸਸਤਾ GET ਅਤੇ ਇੱਕ ਭਾਰੀ export ਨੂੰ ਇੱਕੋ ਬਕੈਟ ਨਾਲ ਨਾ ਜੋੜੋ। ਵਿੰਡੋ ਰੀਸੈੱਟ ਟਾਈਮ ਵਰਗੀ ਚੀਜ਼ਾਂ ਸਪਸ਼ਟ ਰੱਖੋ — ਕਿਹੜਾ ਟਾਈਮਜ਼ੋਨ ਹੈ ਜਾਂ rolling window ਹੈ। vague errors (500 ਆਦਿ) ਲੋਕਾਂ ਨੂੰ ਅਣਜਾਣੀ ਰੀਟ੍ਰਾਈ ਤੇ ਧੱਕਦੇ ਹਨ।
ਉਦਾਹਰਨ: ਜੇ ਇੱਕ टीम Koder.ai ਇੰਟਿਗ੍ਰੇਸ਼ਨ එක ਤੋਂ shared corporate network 'ਤੇ ਬਣਾਈ ਹੈ, ਇੱਕ IP-only ਕੈਪ ਉਹਨਾਂ ਦੀ ਪੂਰੀ সংগਠਨ ਨੂੰ ਬਲਾਕ ਕਰ ਸਕਦੀ ਹੈ ਅਤੇ ਰੈੰਡਮ outage ਵਾਂਗ ਲੱਗ ਸਕਦੀ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ limits ਸਭ ਨੂੰ ਚਾਲੂ ਕਰਦੇ ਹੋ, ਤਦੋਂ predictability ਤੇ ਧਿਆਨ ਦੇ ਕੇ ਇੱਕ ਆਖਰੀ ਪਾਸ ਕਰੋ:
ਇੱਕ ਆਮ ਮਿਕਸ ਪ੍ਰਾਇਕਟਿਕ ਹੈ:
ਜਦੋਂ ਕੋਈ ਸੀਮਾ ਲੱਗੇ, ਤੁਹਾਡਾ ਸੁਨੇਹਾ ਉਹ ਦੱਸੇ ਕਿ ਕੀ ਹੋਇਆ, ਅਗਲਾ ਕਦਮ ਕੀ ਹੈ, ਅਤੇ ਕਦੋਂ ਰੀਟ੍ਰਾਈ ਕਰਨਾ ਹੈ। ਸਹਾਇਤਾ ਏਸੇ ਸ਼ਬਦਾਂ ਨੂੰ ਸਹਾਰਾ ਦੇ ਸਕੇ:
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
ਇਸ ਸੁਨੇਹੇ ਨੂੰ ਅਤੇ consistent RateLimit ਹੈਡਰਾਂ ਨਾਲ ਜੋੜੋ ਤਾਂ ਕਿ ਗ੍ਰਾਹਕਾਂ ਨੂੰ ਅਨੁਮਾਨ ਨਾ ਲਗੇ।
ਰੋਲਆਉਟ ਮਹੱਤਵਪੂਰਨ ਹੈ: ਪਹਿਲਾਂ report-only, ਫਿਰ ਇੱਕ ਐਂਡਪੌਇੰਟ ਗਰੁੱਪ 'ਤੇ ਐਨਫੋਰਸ, ਫਿਰ ਫੈਲਾਓ — ਇਸ ਨਾਲ support ਟਿਕਟਾਂ ਦਾ ਭਾਰ ਘਟੇਗਾ।
ਇੱਕ ਨਿਰਣਾਇਕ ਟੈਸਟ: ਜੇ ਤੁਹਾਡੇ ਉਤਪਾਦ ਦੇ ਟੀਅਰ Free, Pro, Business, Enterprise ਹਨ (ਜਿਵੇਂ Koder.ai), ਤਾਂ ਤੁਸੀਂ ਸਪਸ਼ਟ ਬੋਲਚਾਲ ਵਿੱਚ ਦੱਸ ਸਕੋ ਕਿ ਇੱਕ ਆਮ ਗ੍ਰਾਹਕ ਪ੍ਰਤੀ ਮਿੰਟ ਅਤੇ ਪ੍ਰਤੀ ਦਿਨ ਕੀ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਕਿਹੜੇ ਐਂਡਪੌਇੰਟ ਵੱਖਰੇ ਇਲਾਜ ਹੁੰਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਇੱਕ 429 ਨੂੰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਵਿਆਖਿਆ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਗ੍ਰਾਹਕ ਮਨ ਲੈਂਦੇ ਨੇ ਕਿ API ਟੁੱਟੀ ਹੋਈ ਹੈ, ਨਾ ਕਿ ਸੇਵਾ ਦੀ ਰੱਖਿਆ ਹੋ ਰਹੀ ਹੈ।
Retry-Afterਰੋਲਆਉਟ: observe-only -> warn (ਹੈਡਰ + soft warnings) -> enforce (429 with clear timing) -> thresholds ਟੀਅਰ ਅਨੁਸਾਰੀ ਟਿਊਨ -> ਬੱਡ ਲਾਂਚਾਂ ਅਤੇ onboarding ਤੋਂ ਬਾਅਦ ਰੀਵਿਊ।