09 ਸਤੰ 2025·8 ਮਿੰਟ
SaaS ਸਥਿਤੀ ਪੰਨਾ ਕਿਵੇਂ ਬਣਾਇਆ ਜਾਵੇ — ਘਟਨਾ ਇਤਿਹਾਸ ਸਮੇਤ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ SaaS ਸਥਿਤੀ ਪੰਨਾ ਯੋਜਨਾ ਬਣਾਉਣ, ਬਣਾਉਣ, ਅਤੇ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਨ ਲਈ—ਜਿਸ ਵਿੱਚ ਘਟਨਾ ਇਤਿਹਾਸ, ਸਪਸ਼ਟ ਸੁਨੇਹਾ ਅਤੇ ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਸ਼ਾਮਲ ਹੋਣ ਤਾਂ ਜੋ ਗਾਹਕ ਆਊਟੇਜ ਦੌਰਾਨ ਜਾਣੂ ਰਹਿਣ।
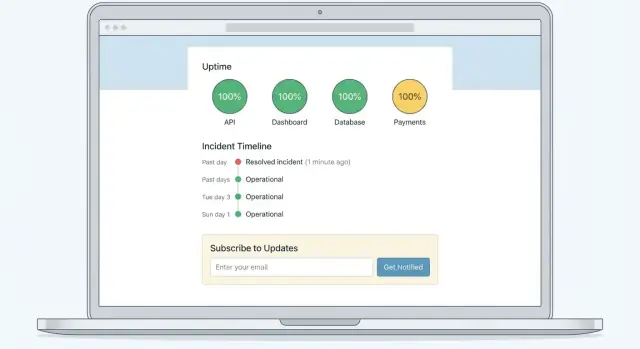
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ SaaS ਸਥਿਤੀ ਪੰਨਾ ਯੋਜਨਾ ਬਣਾਉਣ, ਬਣਾਉਣ, ਅਤੇ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਨ ਲਈ—ਜਿਸ ਵਿੱਚ ਘਟਨਾ ਇਤਿਹਾਸ, ਸਪਸ਼ਟ ਸੁਨੇਹਾ ਅਤੇ ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਸ਼ਾਮਲ ਹੋਣ ਤਾਂ ਜੋ ਗਾਹਕ ਆਊਟੇਜ ਦੌਰਾਨ ਜਾਣੂ ਰਹਿਣ।
SaaS ਸਥਿਤੀ ਪੰਨਾ ਇੱਕ ਪਬਲਿਕ (ਜਾਂ ਗਾਹਕ-ਕੇਵਲ) ਵੈਬਸਾਈਟ ਹੁੰਦਾ ਹੈ ਜੋ ਦਿਖਾਉਂਦਾ ਹੈ ਕਿ ਤੁਹਾਡਾ ਉਤਪਾਦ ਅਜੇ ਸਹੀ ਤਰ੍ਹਾਂ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ ਨਹੀਂ—ਅਤੇ ਜੇ ਨਹੀਂ, ਤਾਂ ਤੁਸੀਂ ਕੀ ਕਰ ਰਹੇ ਹੋ। ਇਹ ਘਟਨਾਵਾਂ ਦੌਰਾਨ ਇੱਕ ਸਿੰਗਲ ਸੋਰਸ ਆਫ਼ ਟਰੁਥ ਬਣ ਜਾਂਦਾ ਹੈ, ਜੋ ਸੋਸ਼ਲ ਮੀਡੀਆ, ਸਪੋਰਟ ਟਿਕਟ ਅਤੇ ਅਫਵਾਹੋਂ ਤੋਂ ਵੱਖਰਾ ਹੁੰਦਾ ਹੈ।
ਇਹ ਉਮੀਦ ਤੋਂ ਵੱਧ ਲੋਕਾਂ ਦੀ ਮਦਦ ਕਰਦਾ ਹੈ:
ਚੰਗੀ ਸੇਵਾ ਸਥਿਤੀ ਵੈਬਸਾਈਟ ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਸੰਬੰਧਤ (ਪਰ ਵੱਖਰੇ) ਪਰਤਾਂ ਰੱਖਦੀ ਹੈ:
ਮਕਸਦ ਸਪਸ਼ਟਤਾ ਹੈ: ਰੀਅਲ-ਟਾਈਮ ਸਥਿਤੀ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦੀ ਹੈ “ਕੀ ਮੈਂ ਉਤਪਾਦ ਵਰਤ ਸਕਦਾ/ਸਕਦੀ ਹਾਂ?” ਜਦਕਿ ਇਤਿਹਾਸ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦਾ ਹੈ “ਇਹ ਕਿੰਨੀ ਵਾਰੀ ਹੁੰਦਾ ਹੈ?” ਅਤੇ ਪੋਸਟਮਾਰਟਮ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦੇ ਹਨ “ਇਹ ਕਿਉਂ ਹੋਇਆ ਅਤੇ ਕੀ ਬਦਲਿਆ?”
ਇੱਕ ਸਥਿਤੀ ਪੰਨਾ ਤਦੋਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੁੰਦਾ ਹੈ ਜਦ ਅੱਪਡੇਟ ਤੇਜ਼, ਸਧੀ ਭਾਸ਼ਾ ਵਿੱਚ, ਅਤੇ ਪ੍ਰਭਾਵ ਬਾਰੇ ਇਮਾਨਦਾਰ ਹੁੰਦੇ ਹਨ। ਤੁਹਾਨੂੰ ਸਹੀ ਨਿਧਾਨ ਦੀ ਲੋੜ ਨਹੀਂ—ਪਰ ਤੁਹਾਨੂੰ ਟਾਈਮਸਟੈਂਪ, ਸਕੋਪ (ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਹੈ), ਅਤੇ ਅਗਲੇ ਅੱਪਡੇਟ ਦਾ ਸਮਾਂ ਲਾਜ਼ਮੀ ਚਾਹੀਦਾ ਹੈ।
ਤੁਸੀਂ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰੋਗੇ ਜਦ ਆਊਟੇਜ, ਘਟਿਆ ਪਰਫਾਰਮੈਂਸ (ਹੌਲੀ ਲੌਗਿਨ, ਦੇਰੀ ਵਾਲੇ webhook), ਅਤੇ ਨਿਯਤ ਰਖ-ਰਖਾਅ ਦੌਰਾਨ ਜੋ ਛੋਟੀ ਖਲਲ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ।
ਜਦ ਤੁਸੀਂ ਸਥਿਤੀ ਪੰਨੇ ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਸਤਹ ਵਾਂਗ ਸਮਝਦੇ ਹੋ (ਇੱਕ ਇਕ-ਵਾਰ ਦਾ ops ਪੰਨਾ ਨਹੀਂ), ਤਾਂ ਬਾਕੀ ਸੈਟਅੱਪ ਬਹੁਤ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ: ਤੁਸੀਂ ਮਾਲਿਕ ਨਿਧਾਰਤ ਕਰ ਸਕਦੇ ਹੋ, ਟੈਮਪਲੇਟ ਬਣਾਉਣਗੇ, ਅਤੇ ਮਾਨੀਟਰਿੰਗ ਨੂੰ ਜੋੜ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਹਰ ਘਟਨਾ 'ਚ ਪ੍ਰਕਿਰਿਆ ਨੂੰ ਦੁਬਾਰਾ ਆਵਿਸ਼ਕਾਰ ਕਰਨ ਤੋਂ।
ਟੂਲ ਚੁਣਣ ਜਾਂ ਲੇਆਉਟ ਡਿਜ਼ਾਈਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਤੁਹਾਡਾ ਸਥਿਤੀ ਪੰਨਾ ਕੀ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ। ਇੱਕ ਸਪਸ਼ਟ ਉਦੇਸ਼ ਅਤੇ ਸਪਸ਼ਟ ਮਾਲਕ ਹੀ ਘਟਨਾ ਦੌਰਾਨ ਸਥਿਤੀ ਪੰਨਿਆਂ ਨੂੰ ਲਾਭਕਾਰੀ ਰੱਖਦੇ ਹਨ—ਜਦ ਹਰ ਕੋਈ ਵਿਚ ਰੁਝਿਆ ਹੋਇਆ ਹੁੰਦਾ ਹੈ ਅਤੇ ਜਾਣਕਾਰੀ ੜਗੜਬੜ ਹੁੰਦੀ ਹੈ।
ਜ਼ਿਆਦਾਤਰ SaaS ਟੀਮਾਂ ਤਿੰਨ ਪ੍ਰੈਕਟਿਕਲ ਨਤੀਜਿਆਂ ਲਈ ਸਥਿਤੀ ਪੰਨਾ ਬਣਾਉਂਦੀਆਂ ਹਨ:
ਲਾਂਚ ਤੋਂ ਬਾਅਦ ਟ੍ਰੈਕ ਕਰਨ ਲਈ 2–3 ਮਾਪੇ ਜਾਣਯੋਗ ਸੰਕੇਤ ਲਿਖੋ: ਘਟਨਾ ਦੌਰਾਨ ਘੱਟ ਨਕਲ ਟਿਕਟ, ਪਹਿਲੀ ਅੱਪਡੇਟ ਲਈ ਤੇਜ਼ ਸਮਾਂ, ਜਾਂ ਵੱਧ ਗਾਹਕ ਸਬਸਕ੍ਰਾਈਬ ਕਰ ਰਹੇ ਹਨ।
ਤੁਹਾਡਾ ਮੁੱਖ ਪਾਠਕ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਗੈਰ-ਟੈਕਨੀਕਲ ਗਾਹਕ ਹੁੰਦਾ ਹੈ ਜੋ ਜਾਣਨਾ ਚਾਹੁੰਦਾ ਹੈ:
ਇਸ ਲਈ ਜਾਰਗਨ ਨੂੰ ਘਟਾਓ। “ਕੁਝ ਗਾਹਕ ਲੌਗਿਨ ਨਹੀਂ ਕਰ ਪਾ ਰਹੇ” ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਬਜਾਏ “auth ਉੱਤੇ ਵੱਧ 5xx ਦਰਾਂ।” ਜੇ ਤੁਹਾਨੂੰ ਤਕਨੀਕੀ ਵਿਵਰਣ ਦੇਣੀ ਲੋੜ ਹੋਵੇ, ਤਾਂ ਉਸਨੂੰ ਛੋਟੀ ਦੂਜੀ ਸੱਤਰ ਵਜੋਂ ਰੱਖੋ।
ਇੱਕ ਟੋਨ ਚੁਣੋ ਜੋ ਤੁਸੀਂ ਦਬਾਅ ਹੇਠ ਵੀ ਬਰਕਰਾਰ ਰੱਖ ਸਕਦੇ ਹੋ: ਸ਼ਾਂਤ, ਤਥ-ਅਧਾਰਿਤ, ਅਤੇ ਪਾਰਦਰਸ਼ੀ। ਪਹਿਲਾਂ ਤੈਅ ਕਰੋ:
ਮਾਲਕੀ ਸਪਸ਼ਟ ਰੱਖੋ: ਸਥਿਤੀ ਪੰਨਾ “ਹਰੇਕ ਦਾ ਕੰਮ” ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ—ਨਹੀਂ ਤਾਂ ਇਹ ਕਿਸੇ ਦਾ ਨਹੀਂ ਰਹਿੰਦਾ।
ਆਪਣੇ ਕੋਲ ਦੋ ਆਮ ਵਿਕਲਪ ਹਨ:
ਜੇ ਤੁਹਾਡੀ ਮੁੱਖ ਐਪ ਡਾਊਨ ਹੋ ਸਕਦੀ ਹੈ, ਤਾਂ standalone status site ਆਮ ਤੌਰ 'ਤੇ ਸੁਰੱਖਿਅਤ ਹੁੰਦੀ ਹੈ। ਤੁਸੀਂ ਇਸਨੂੰ ਆਪਣੇ ਐਪ ਅਤੇ help center (ਉਦਾਹਰਨ: /help) ਤੋਂ ਪ੍ਰਮੁੱਖ ਤਰੀਕੇ ਨਾਲ ਲਿੰਕ ਕਰ ਸਕਦੇ ਹੋ।
ਇੱਕ ਸਥਿਤੀ ਪੰਨਾ ਉਤਨਾ ਹੀ ਲਾਭਕਾਰੀ ਹੈ ਜਿੰਨਾ ਪਿੱਛੇ ਵਾਲਾ “ਨਕਸ਼ਾ” ਸਹੀ ਹੈ। ਰੰਗ ਜਾਂ ਨਕਸ਼ੇ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਕਿਸ ਦੀ ਰਿਪੋਰਟਿੰਗ ਕਰ ਰਹੇ ਹੋ। ਹਦਫ ਗਾਹਕਾਂ ਦੇ ਤਜਰਬੇ ਨੂੰ ਦਰਸਾਉਣਾ ਹੈ—ਨਾ ਕਿ ਤੁਹਾਡੀ ਆਰਗ ਚਾਰਟ ਨੂੰ।
ਉਹ ਟੁਕੜੇ ਲਿਸਟ ਕਰੋ ਜਿਨ੍ਹਾਂ ਨੂੰ ਗਾਹਕ ਉਹਨਾਂ ਦੇ “ਟੁੱਟ ਗਿਆ” ਕਹਿਣ 'ਤੇ ਵਰਣਨ ਕਰ ਸਕਦੇ ਹਨ। ਬਹੁਤ SaaS ਉਤਪਾਦਾਂ ਲਈ, ਇੱਕ ਵਰਤਣਯੋਗ ਸ਼ੁਰੂਆਤੀ ਸੈੱਟ ਇਸ ਤਰ੍ਹਾਂ ਹੈ:
ਜੇ ਤੁਸੀਂ ਕਈ ਖੇਤਰ ਜਾਂ ਟੀਅਰ ਪੇਸ਼ ਕਰਦੇ ਹੋ, ਉਹ ਵੀ ਦਰਜ ਕਰੋ (ਉਦਾਹਰਨ: “API – US” ਅਤੇ “API – EU”)। ਨਾਂ ਗਾਹਕ-ਮੁਖੀ ਰੱਖੋ: “Login” “IdP Gateway” ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਸਪਸ਼ਟ ਹੈ।
ਇੱਕ ਗਰੁੱਪਿੰਗ ਚੁਣੋ ਜੋ ਗਾਹਕਾਂ ਦੇ ਸੋਚਣ ਦੇ ਢੰਗ ਨਾਲ ਮਿਲਦੀ ਹੋਵੇ:
ਇੱਕ ਬੇਅੰਤ ਸੂਚੀ ਤੋਂ ਬਚੋ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਦਰਜਨਾਂ ਇੰਟਿਗ੍ਰੇਸ਼ਨਾਂ ਹਨ, ਤਾਂ ਇੱਕ ਪੇਰੈਂਟ ਕੰਪੋਨੈਂਟ (“Integrations”) ਅਤੇ ਕੁਝ ਉੱਚ ਪ੍ਰਭਾਵ ਵਾਲੇ ਚਿਲਡਰਨ (ਜਿਵੇਂ “Salesforce”, “Webhooks”) ਵਰਗਾ ਜ਼ਿਆਦਾ ਲੋੜੀਂਦਾ ਰਹੇਗਾ।
سادਾ, ਸਥਿਰ ਮਾਡਲ ਉਲਝਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ। ਆਮ ਲੇਵਲ ਹਨ:
ਹਰ ਲੇਵਲ ਲਈ ਅੰਦਰੂਨੀ ਮਾਪਦੰਡ ਲਿਖੋ (ਚਾਹੇ ਤੁਸੀਂ ਉਸਨੂੰ ਜਨਤਕ ਨ ਜਾਰੀ ਕਰੋ)। ਉਦਾਹਰਨ ਲਈ, “Partial Outage = ਇੱਕ ਖੇਤਰ ਡਾਊਨ” ਜਾਂ “Degraded = p95 latency X ਤੋਂ ਉੱਪਰ Y ਮਿੰਟਾਂ ਲਈ।” ਇਕਸਾਰਤਾ ਭਰੋਸਾ ਬਣਾਉਂਦੀ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਆਊਟੇਜ ਤੀਸਰੇ ਪੱਖੀਆਂ ਨਾਲ ਸੰਬੰਧਤ ਹੁੰਦੇ ਹਨ: ਕਲਾਉਡ ਹੋਸਟਿੰਗ, ਈਮੇਲ ਡਿਲਿਵਰੀ, ਭੁਗਤਾਨ ਪ੍ਰੋਸੈਸਰ, ਜਾਂ identity providers। ਇਨ੍ਹਾਂ ਡਿਪੈਂਡੈਂਸੀਜ਼ ਨੂੰ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਤਾਂ ਜੋ ਤੁਹਾਡੇ ਘਟਨਾ ਅੱਪਡੇਟ ਸਹੀ ਹੋ ਸਕਣ।
ਇਨ੍ਹਾਂ ਨੂੰ ਜਨਤਕ ਰੂਪ ਵਿੱਚ ਦਿਖਾਉਣਾ ਤੁਹਾਡੇ ਦਰਸ਼ਕ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ। ਜੇ ਗਾਹਕ ਸਿੱਧੇ ਪ੍ਰਭਾਵਿਤ ਹੋ ਸਕਦੇ ਹਨ (ਉਦਾਹਰਨ: payments), ਤਾਂ ਡਿਪੈਂਡੈਂਸੀ ਕੰਪੋਨੈਂਟ ਦਿਖਾਉਣਾ ਫਾਇਦੇਮੰਦ ਹੋ ਸਕਦਾ ਹੈ। ਜੇ ਇਹ ਸ਼ੋਰ ਵਧਾਉਂਦਾ ਹੈ ਜਾਂ ਦੋਸ਼-ਗੇਮਾਂ ਨੂੰ ਪ੍ਰੇਰਿਤ ਕਰਦਾ ਹੈ, ਤਾਂ ਡਿਪੈਂਡੈਂਸੀਜ਼ ਅੰਦਰੂਨੀ ਰੱਖੋ ਪਰ ਜਦ ਲੋੜ ਹੋਵੇ ਅਪਡੇਟ ਵਿੱਚ ਉਹਨਾਂ ਦਾ ਜਿਕਰ ਕਰੋ (ਉਦਾਹਰਨ: “ਅਸੀਂ ਆਪਣੇ payment provider ਉੱਤੇ ਵੱਧ ਗਲਤੀਆਂ ਜਾਂਚ ਰਹੇ ਹਾਂ”)।
ਇੱਕ ਵਾਰ ਤੁਹਾਡੇ ਕੋਲ ਇਹ ਕੰਪੋਨੈਂਟ ਮਾਡਲ ਹੋਵੇ, ਬਾਕੀ ਸਥਿਤੀ ਪੰਨਾ ਸੇਟਅੱਪ ਜ਼ਿਆਦਾ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ: ਹਰ ਘਟਨਾ ਨੂੰ ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਇੱਕ ਸਪਸ਼ਟ “ਕਿੱਥੇ” (ਕੰਪੋਨੈਂਟ) ਅਤੇ “ਕਿੰਨਾ ਬੁਰਾ” (ਸਥਿਤੀ) ਮਿਲ ਜਾਂਦਾ ਹੈ।
ਇੱਕ ਸਥਿਤੀ ਪੰਨਾ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਉਪਯੋਗੀ ਹੁੰਦਾ ਹੈ ਜਦ ਇਹ ਗਾਹਕ ਦੇ ਸਵਾਲਾਂ ਨੂੰ ਸੈਕੰਡਾਂ ਵਿੱਚ ਜਵਾਬ ਦੇ ਦਿੰਦਾ ਹੈ। ਲੋਕ ਆਮ ਤੌਰ 'ਤੇ ਤਣਾਅ ਵਿੱਚ ਆਉਂਦੇ ਹਨ ਅਤੇ ਸਪਸ਼ਟਤਾ ਚਾਹੁੰਦੇ ਹਨ—ਜ਼ਿਆਦਾ ਨੈਵੀਗੇਸ਼ਨ ਨਹੀਂ।
ਸਭ ਤੋਂ ਮੁੱਖ ਚੀਜ਼ਾਂ ਨੂੰ ਸਿਖਰ ਤੇ ਤਰਜੀਹ ਦਿਓ:
ਸਧੀ ਭਾਸ਼ਾ ਵਰਤੋ। “API ਬੇਨਤੀ 'ਤੇ ਵੱਧ error rates” ਨੂੰ “ਅਪਰਪਕ upstream dependency ਵਿਚ partial outage” ਨਾਲੋਂ ਹੋਰ ਸਪਸ਼ਟ ਸਮਝਿਆ ਜਾਂਦਾ ਹੈ। ਜੇ ਤਕਨੀਕੀ ਸ਼ਬਦ ਵਰਤਣੇ ਲਾਜ਼ਮੀ ਹੋਣ, ਤਾਂ ਇੱਕ ਛੋਟੀ ਤਰਤੀਬੀ ਵਾਕ ਮਿਲਾਓ (“ਕੁਝ ਬੇਨਤੀਆਂ ਫੇਲ ਹੋ ਸਕਦੀਆਂ ਹਨ ਜਾਂ timeout ਹੋ ਸਕਦੀਆਂ ਹਨ”)।
ਇੱਕ ਭਰੋਸੇਮੰਦ ਪੈਟਰਨ ਹੈ:
ਕੰਪੋਨੈਂਟ ਸੂਚੀ ਲਈ ਲੇਬਲ ਗਾਹਕ-ਮਿਤ੍ਰ ਰੱਖੋ। ਜੇ ਅੰਦਰੂਨੀ ਸੇਵਾ “k8s-cluster-2” ਹੈ, ਤਾਂ ਗਾਹਕਾਂ ਲਈ “API” ਜਾਂ “Background Jobs” ਜ਼ਿਆਦਾ ਸਪਸ਼ਟ ਹੈ।
ਪੰਨਾ ਦਬਾਅ ਹੇਠ ਵੀ ਪੜ੍ਹਨ ਯੋਗ ਬਣਾਓ:
ਸਿਖਰ (header ਜਾਂ ਬੈਨਰ ਦੇ ਥੱਲੇ) 'ਤੇ ਛੋਟੀ ਲਿੰਕਾਂ ਰੱਖੋ:
ਲਕੜੀ ਦਾ ਲਕੜਾ ਇਹ ਹੈ ਕਿ ਗਾਹਕ ਤੁਰੰਤ ਸਮਝ ਜਾਣ ਕਿ ਕੀ ਹੋ ਰਿਹਾ ਹੈ, ਇਸਦਾ ਕੀ ਪ੍ਰਭਾਵ ਹੈ, ਅਤੇ ਉਹ ਅੱਗੇ ਕਦੋਂ ਸੁਣਨਗੇ।
ਜਦ ਘਟਨਾ ਹੋਵੇ, ਤੁਹਾਡੀ ਟੀਮ ਨਿਧਾਨ, ਰੋਕਥਾਮ, ਅਤੇ ਗਾਹਕ ਸਵਾਲਾਂ ਦਾ ਇਕੱਠਾ ਸੰਭਾਲ ਰਹੀ ਹੁੰਦੀ ਹੈ। ਟੈਮਪਲੇਟ ਗੱਲ-ਬਾਤ ਨੂੰ ਘੱਟ ਕਰਦੇ ਹਨ ਤਾਂ ਜੋ ਅੱਪਡੇਟ ਇਕਸਾਰ, ਸਪਸ਼ਟ, ਅਤੇ ਤੇਜ਼ ਰਹਿਣ—ਖਾਸ ਕਰਕੇ ਜਦ ਵੱਖ-ਵੱਖ ਲੋਕ ਪੋਸਟ ਕਰ ਰਹੇ ਹੋਣ।
ਇੱਕ ਚੰਗਾ ਅੱਪਡੇਟ ਹਮੇਸ਼ਾ ਇਕੋ ਮੁੱਖ ਤੱਥਾਂ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ। ਘੱਟੋ-ਘੱਟ, ਇਹ ਖੇਤਰ ਸਧਾਰਨ ਰੱਖੋ:
ਜੇ ਤੁਸੀਂ ਘਟਨਾ ਇਤਿਹਾਸ ਪੰਨਾ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦੇ ਹੋ, ਤਾਂ ਇਹ ਖੇਤਰ ਲਗਾਤਾਰ ਰੱਖਣ ਨਾਲ ਪਿਛਲੀਆਂ ਘਟਨਾਵਾਂ ਨੂੰ ਆਸਾਨੀ ਨਾਲ ਸਕੈਨ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਤੁਲਨਾ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ।
ਛੋਟੇ ਅੱਪਡੇਟਾਂ ਲਈ ਹਮੇਸ਼ਾ ਉਹੀ ਪ੍ਰਸ਼ਨਾਂ ਦੇ ਜਵਾਬ ਦਿਓ। ਇਹ ਇੱਕ ਪ੍ਰਯੋਗਯੋਗ ਟੈਮਪਲੇਟ ਹੈ ਜੋ ਤੁਸੀਂ ਆਪਣੇ ਸਥਿਤੀ ਪੰਨਾ ਟੂਲ ਵਿੱਚ ਨਕਲ ਕਰ ਸਕਦੇ ਹੋ:
Title: ਸੰਖੇਪ, ਨਿਰਧਾਰਤ ਸਰਾਂਸ਼ (ਉਦਾਹਰਨ: “API errors for EU region”)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: ਯੂਜ਼ਰ ਕੀ ਵੇਖ ਰਹੇ ਹਨ (errors, timeouts, degraded performance) ਅਤੇ ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਹੈ
What we know: ਇੱਕ ਵਾਕ ਵਿੱਚ ਕਾਰਨ ਜੇ ਪੁਸ਼ਟੀ ਹੋਇਆ ਹੋਵੇ (ਕਰੂਸ-ਅਨੁਮਾਨ ਤੋਂ ਬਚੋ)
What we’re doing: ਨਿਰਧਾਰਤ ਕਾਰਵਾਈਆਂ (rollback, scaling, vendor escalation)
Next update: ਜਦ ਤੁਸੀਂ ਦੁਬਾਰਾ ਪੋਸਟ ਕਰੋਗੇ
Updates:
ਗਾਹਕ ਸਿਰਫ ਜਾਣਕਾਰੀ ਨਹੀਂ ਚਾਹੁੰਦੇ—ਉਹ ਪੇਸ਼ਗੀਭਾਵੀਤਾ ਚਾਹੁੰਦੇ ਹਨ।
ਯੋਜਿਤ ਰਖ-ਰਖਾਅ ਸ਼ਾਂਤ ਅਤੇ ਸੰਰਚਿਤ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। ਰਖ-ਰਖਾਅ ਪੋਸਟਾਂ ਨੂੰ ਨਿਰਧਾਰਤ ਕਰੋ:
ਰਖ-ਰਖਾਅ ਭਾਸ਼ਾ ਵਿਸ਼ੇਸ਼ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ (ਕੀ ਬਦਲ ਰਹਿਆ ਹੈ, ਗਾਹਕਾਂ ਨੂੰ ਕੀ ਮਹਿਸੂਸ ਹੋ ਸਕਦਾ ਹੈ), ਅਤੇ ਵਾਅਦਾ ਘੱਟ ਕਰੋ—ਗਾਹਕ ਸਚਾਈ ਨੂੰ ਇੰਜੈਕਟ ਕਰਦੇ ਹਨ।
ਘਟਨਾ ਇਤਿਹਾਸ ਸਿਰਫ਼ ਇੱਕ ਲੌਗ ਨਹੀਂ—ਇਹ ਇਕ ਤਰੀਕਾ ਹੈ ਜੋ ਗਾਹਕਾਂ (ਅਤੇ ਤੁਹਾਡੀ ਟੀਮ) ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਸਮਝਣ ਦਿੰਦਾ ਹੈ ਕਿ ਮੁੱਦੇ ਕਿੰਨੇ ਵਾਰੀ ਹੁੰਦੇ ਹਨ, ਕਿਹੜੀਆਂ ਤਰ੍ਹਾਂ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਦੁਹਰਾਈਆਂ ਜਾ ਰਹੀਆਂ ਹਨ, ਅਤੇ ਤੁਸੀਂ ਕਿਵੇਂ ਜਵਾਬ ਦੇ ਰਹੇ ਹੋ।
ਇੱਕ ਸਪਸ਼ਟ ਇਤਿਹਾਸ ਪਾਰਦਰਸ਼ੀਤਾ ਰਾਹੀਂ ਭਰੋਸਾ ਬਣਾਉਂਦਾ ਹੈ। ਇਹ ਰੁਝਾਨ ਵੀ ਦਿਖਾਉਂਦਾ ਹੈ: ਜੇ ਤੁਸੀਂ ਹਫਤੇ ਦੋ ਵਾਰੀ “API latency” ਦੇ ਘਟਨਾ ਵੇਖਦੇ ਹੋ, ਤਾਂ ਇਹ ਪ੍ਰਦਰਸ਼ਨ ਕੰਮ ਵਿੱਚ ਨਿਵੇਸ਼ ਕਰਨ ਦੀ ਸੰਕੇਤ ਹੈ। ਸਮੇਂ ਦੇ ਨਾਲ ਲਗਾਤਾਰ ਰਿਪੋਰਟਿੰਗ ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਘਟਾ ਸਕਦੀ ਹੈ ਕਿਉਂਕਿ ਗਾਹਕ ਆਪਣੇ ਆਪ ਜਵਾਬ ਲੱਭ ਸਕਦੇ ਹਨ।
ਇੱਕ ਰਿਟੇਨਸ਼ਨ ਵਿੰਡੋ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਗਾਹਕ ਦੀਆਂ ਉਮੀਦਾਂ ਅਤੇ ਉਤਪਾਦ ਦੀ ਪ੍ਰਗਟਤਾ ਨਾਲ ਮੇਚ ਕਰਦੀ ਹੋਵੇ।
ਜੋ ਵੀ ਤਿਆਰ ਕਰੋ, ਇਸਨੂੰ ਸਪਸ਼ਟ ਰੱਖੋ (ਉਦਾਹਰਨ: “Incident history is retained for 12 months”).
ਲਗਾਤਾਰਤਾ ਸਕੈਨਿੰਗ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੀ ਹੈ। ਇਕ ਅਣੁਕੂਲ ਨਾਂਗ ਫਾਰਮੈਟ ਵਰਤੋ:
YYYY-MM-DD — Short summary (ਉਦਾਹਰਨ: “2025-10-14 — Delayed email delivery”)
ਹਰ ਘਟਨਾ ਲਈ ਘੱਟੋ-ਘੱਟ ਦਿਖਾਓ:
ਜੇ ਤੁਸੀਂ postmortems ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦੇ ਹੋ, ਤਾਂ ਘਟਨਾ ਵਿਵਰਣ ਪੰਨੇ ਤੋਂ ਲਿਖਾਈ ਨੂੰ ਲਿੰਕ ਕਰੋ (ਉਦਾਹਰਨ: “Read the postmortem” linking to /blog/postmortems/2025-10-14-email-delays). ਇਹ ਟਾਈਮਲਾਈਨ ਨੂੰ ਸਾਫ਼ ਰੱਖਦਾ ਹੈ ਪਰ ਵੇਰਵਾ ਲੈਣਾ ਚਾਹੁੰਦੇ ਗਾਹਕਾਂ ਲਈ ਡੀਪ-ਲਿੰਕ ਮੁਹੱਈਆ ਕਰਦਾ ਹੈ।
ਲੋਕ ਜਦ ਪੰਨਾ ਦੇਖਣ ਦੀ ਸੋਚਦੇ ਹਨ ਤਾਂ ਹੀ ਇਹ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ। ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਇਸਨੂੰ ਉਲਟ ਕਰ ਦਿੰਦਾ ਹੈ: ਗਾਹਕ ਅਪਡੇਟ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਪ੍ਰਾਪਤ ਕਰ ਲੈਂਦੇ ਹਨ, ਬਿਨਾਂ ਪੇਜ ਰੀਫਰੇਸ਼ ਜਾਂ ਸਪੋਰਟ ਨੂੰ ਈਮੇਲ ਕਰਨ ਦੇ।
ਅਕਸਰ ਟੀਮ ਘੱਟੋ-ਘੱਟ ਕੁਝ ਵਿਕਲਪ ਉਮੀਦ ਕਰਦੀਆਂ ਹਨ:
ਜੇ ਤੁਸੀਂ ਕਈ ਚੈਨਲ ਸਹਾਇਤਾ ਕਰਦੇ ਹੋ, ਤਾਂ ਸੈਟਅੱਪ ਫਲੋ ਸुसੰਗਤ ਰੱਖੋ ਤਾਂ ਕਿ ਗਾਹਕਾਂ ਨੂੰ ਲੱਗੇ ਨਾ ਕਿ ਉਹ ਚਾਰ ਵੱਖ-ਵੱਖ ਢੰਗ ਨਾਲ ਸਾਈਨ-ਅਪ ਕਰ ਰਹੇ ਹਨ।
ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਹਮੇਸ਼ਾ opt-in ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ। ਖ਼ਾਸ ਕਰਕੇ SMS ਲਈ, ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਲੋਕ ਕੀ ਪ੍ਰਾਪਤ ਕਰਨਗੇ।
ਸਬਸਕ੍ਰਾਈਬਰਾਂ ਨੂੰ ਇਨ੍ਹਾਂ ਉੱਤੇ ਨਿਯੰਤਰਣ ਦਿਓ:
ਇਨ੍ਹਾਂ ਪਸੰਦਾਂ ਨਾਲ alert fatigue ਘਟਦੀ ਹੈ ਅਤੇ ਤੁਹਾਡੀਆਂ ਨੋਟੀਫਿਕੇਸ਼ਨ ਭਰੋਸੇਯੋਗ ਬਣਦੀਆਂ ਹਨ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲੇ ਪੱਧਰ ਤੇ ਕੰਪੋਨੈਂਟ-ਲੈਵਲ ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਨਹੀਂ ਹਨ, ਤਾਂ “All updates” ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਫਿਲਟਰਿੰਗ ਸ਼ਾਮਲ ਕਰੋ।
ਘਟਨਾ ਦੌਰਾਨ, ਸੁਨੇਹਾ ਮਾਤਰਾ ਵਧ ਜਾਂਦੀ ਹੈ ਅਤੇ ਤੀਸਰੇ-ਪੱਖ ਪ੍ਰੋवਾਇਡਰ ਟ੍ਰਾਫਿਕ ਨੂੰ throttle ਕਰ ਸਕਦੇ ਹਨ। ਇਹ ਚੈੱਕ ਕਰੋ:
ਤੁਹਾਡੇ ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਕੰਮ ਕਰਨ ਦੀ ਨਿਯਮਤ ਜਾਂਚ (ਕੁਆਰਟਰਲੀ) ਕਰਨ ਯੋਗ ਹੈ।
ਸਟੇਟਸ ਹੋਮਪੇਜ ਤੇ ਇੱਕ ਸਪਸ਼ਟ ਕਾਲਆ-ਟੂ-ਐਕਸ਼ਨ ਸ਼ਾਮਲ ਕਰੋ—ਜਿੰਨੀ ਹੋ ਸਕੇ ਉੱਪਰ ਫੋਲਡ 'ਤੇ—ਤਾਂ ਜੋ ਗਾਹਕ ਅਗਲੀ ਘਟਨਾ ਤੋਂ ਪਹਿਲਾਂ ਹੀ ਸਬਸਕ੍ਰਾਈਬ ਕਰ ਸਕਣ। ਮੋਬਾਇਲ 'ਤੇ ਵੀ ਇਹ ਵਿਸ਼ੇਸ਼ਤੌਰ 'ਤੇ ਦਿਖਾਈ ਦੇਵੇ, ਅਤੇ support portal ਜਾਂ /help center ਵਰਗੀਆਂ ਥਾਵਾਂ 'ਤੇ ਵੀ ਇਸਨੂੰ ਰੱਖੋ।
ਤੁਹਾਡਾ ਬਿਲਡ ਚੋਣ ਇਸ ਗੱਲ 'ਤੇ ਅਧਾਰਿਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕਿਸ ਚੀਜ਼ ਨੂੰ optimize ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ: ਲਾਂਚ ਦੀ ਰਫ਼ਤਾਰ, ਘਟਨਾ ਦੌਰਾਨ ਭਰੋਸੇਯੋਗਤਾ, ਅਤੇ ਹੋਰ ਰਖ-ਰਖਾਵ ਦੀ ਕੋਸ਼ਿਸ਼।
Hosted ਟੂਲ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਤੇਜ਼ ਰਸਤਾ ਹੁੰਦੇ ਹਨ। ਤੁਸੀਂ ਤਿਆਰ-ਮੁਹੱਈਆ status page, ਸਬਸਕ੍ਰਿਪਸ਼ਨ, ਘਟਨਾ ਟਾਈਮਲਾਈਨ, ਅਤੇ ਆਮ ਮਾਨੀਟਰਿੰਗ ਸਿਸਟਮਾਂ ਨਾਲ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਪ੍ਰਾਪਤ ਕਰ ਲੈਂਦੇ ਹੋ।
Hosted ਟੂਲ ਵਿੱਚ ਦੇਖਣ ਯੋਗ ਗੱਲਾਂ:
DIY ਚੰਗਾ ਵਿਕਲਪ ਹੋ ਸਕਦਾ ਹੈ ਜੇ ਤੁਸੀਂ ਡਿਜ਼ਾਈਨ, ਡੇਟਾ ਰਿਟੇਨਸ਼ਨ, ਅਤੇ ਘਟਨਾ ਇਤਿਹਾਸ ਪੇਸ਼ਕਸ਼ 'ਤੇ ਪੂਰਾ ਕੰਟਰੋਲ ਚਾਹੁੰਦੇ ਹੋ। ਟਰੇਡ-ਆਫ਼ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਭਰੋਸੇਯੋਗਤਾ ਅਤੇ ਆਪਰੇਸ਼ਨ ਦੀ ਜਿੰਮੇਵਾਰੀ ਸਵੀਕਾਰ ਕਰਦੇ ਹੋ।
ਇੱਕ ਵਰਤਣਯੋਗ DIY ਆਰਕੀਟੈਕਚਰ:
ਜੇ ਤੁਸੀਂ self-host ਕਰਦੇ ਹੋ, ਤਾਂ ਫੇਲਿਅਰ ਮੋਡਾਂ ਦੀ ਯੋਜਨਾ ਬਣਾਓ: ਜੇ ਮੁੱਖ ਡੇਟਾਬੇਸ ਉਪਲਬਧ ਨਹੀਂ ਹੈ ਜਾਂ deploy pipeline ਡਾਊਨ ਹੈ ਤਾਂ ਕੀ ਹੋਵੇਗਾ? ਬਹੁਤ ਟੀਮਾਂ ਸਥਿਤੀ ਪੰਨੇ ਨੂੰ ਮੁੱਖ ਉਤਪਾਦ ਤੋਂ ਅਲੱਗ ਇੰਫਰਾਸਟਰਕਚਰ 'ਤੇ ਰੱਖਦੀਆਂ ਹਨ।
ਜੇ ਤੁਸੀਂ DIY ਦਾ ਨਿਯੰਤਰਣ ਚਾਹੁੰਦੇ ਹੋ ਪਰ ਸਭ ਕੁਝ ਮੁੜ-ਬਨਾਉਣਾ ਨਹੀਂ ਚਾਹੁੰਦੇ, ਤਾਂ Koder.ai ਵਰਗਾ ਪਲੇਟਫਾਰਮ ਤੁਹਾਡੇ ਲਈ ਤੇਜ਼ੀ ਨਾਲ custom status site (web UI + incident API) ਖੜਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਉਨ੍ਹਾਂ ਟੀਮਾਂ ਲਈ ਵਿਸ਼ੇਸ਼ ਤੌਰ 'ਤੇ ਲਾਭਕਾਰੀ ਹੈ ਜੋ tailored component models, custom incident history UX, ਜਾਂ ਅੰਦਰੂਨੀ admin workflows ਚਾਹੁੰਦੇ ਹਨ—ਫਿਰ ਵੀ source code export ਅਤੇ ਤੇਜ਼ iteration ਦੀ ਆਜ਼ਾਦੀ ਦੇਂਦਾ ਹੈ।
Hosted ਟੂਲਾਂ ਦੀ ਮਹੀਨਾਵਾਰ ਕੀਮਤ ਆਮ ਤੌਰ 'ਤੇ ਅਨੁਮਾਨਯੋਗ ਹੁੰਦੀ ਹੈ; DIY ਵਿੱਚ ਇੰਜੀਨियरਿੰਗ ਸਮਾਂ, ਹੋਸਟਿੰਗ/CDN ਲਾਗਤ, ਅਤੇ ਚਾਲੂ ਰਖ-ਰਖਾਵ ਦੀ ਲਾਗਤ ਆਉਂਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਵਿਕਲਪਾਂ ਦੀ ਤੁਲਨਾ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਉਮੀਦ ਕੀਤੀ ਮਹੀਨਾਵਾਰ ਖਰਚ ਅਤੇ ਆਵශ්ਯਕ اندرੂਨੀ ਸਮਾਂ ਲਿਖੋ—ਫਿਰ ਇਸਨੂੰ ਆਪਣੇ ਬਜਟ ਨਾਲ ਤੁਲਨਾ ਕਰੋ (ਦੇਖੋ /pricing)।
ਸਥਿਤੀ ਪੰਨਾ ਤਦੋਂ ਹੀ ਲਾਭਕਾਰੀ ਹੈ ਜਦੋਂ ਇਹ ਜ਼ਲਦੀ ਹਕੀਕਤ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ। ਸਭ ਤੋਂ ਆਸਾਨ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਉਹ ਸਿਸਟਮ ਜੋ ਸਮੱਸਿਆ ਪਛਾਣਦੇ ਹਨ (monitoring) ਨੂੰ ਉਹਨਾਂ ਸਿਸਟਮਾਂ ਨਾਲ ਜੋੜੋ ਜੋ ਤੁਹਾਡੀ ਪ੍ਰਤੀਕ੍ਰਿਆ ਕੋਆਰਡੀਨੇਟ ਕਰਦੇ ਹਨ (incident workflow), ਤਾਂ ਜੋ ਅੱਪਡੇਟ ਲਗਾਤਾਰ ਅਤੇ ਸਮੇਂ-ਸਾਰ ਹੋਣ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮ ਤਿੰਨ ਡੇਟਾ ਸਰੋਤ ਮਿਲਾਉਂਦੀਆਂ ਹਨ:
ਇੱਕ ਪ੍ਰਯੋਗਯੋਗ ਨਿਯਮ: monitoring detect ਕਰਦਾ ਹੈ; incident workflow coordinate ਕਰਦਾ ਹੈ; status page communicate ਕਰਦਾ ਹੈ।
ਆਟੋਮੇਸ਼ਨ ਸਮਾਂ ਬਚਾ ਸਕਦੀ ਹੈ ਬਿਨਾਂ ਵਾਅਦਾ ਕਰਨ:
ਪਹਿਲਾ ਜਨਤਕ ਸੁਨੇਹਾ ਸੰਭਲਿਆ ਹੋਇਆ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। “Investigating elevated errors” ਜ਼ਿਆਦਾ ਸੁਰੱਖਿਅਤ ਹੈ ਬਜਾਏ “Outage confirmed” ਦੇ ਜਦ ਤੁਸੀਂ ਹਾਲੇ ਤੱਕ ਵੈਰੀਫਾਈ ਕਰ ਰਹੇ ਹੋ।
ਪੂਰੀ ਤਰ੍ਹਾਂ ਆਟੋਮੇਟਿਕ ਸੰਚਾਰ ਖ਼ਰਾਬ ਨਤੀਜੇ ਦੇ ਸਕਦਾ ਹੈ:
ਆਟੋਮੇਸ਼ਨ ਨੂੰ ਡਰਾਫਟ ਅਤੇ ਸੁਝਾਅ ਦੇਣ ਲਈ ਵਰਤੋ, ਪਰ ਗਾਹਕ-ਸਮੁਖ ਭਾਸ਼ਣ ਲਈ ਮਨੁੱਖੀ ਮਨਜ਼ੂਰੀ ਲਾਜ਼ਮੀ ਰੱਖੋ—ਖਾਸ ਕਰਕੇ Identified, Mitigated, ਅਤੇ Resolved ਸਟੇਟਸ ਲਈ।
ਸਥਿਤੀ পੰਨਾ ਨੂੰ ਗਾਹਕ-ਸਮੁਖ ਲੌਗਬੁੱਕ ਵਾਂਗ ਦੇਖੋ। ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਤੁਸੀਂ ਜਵਾਬ ਦੇ ਸਕੋ:
ਇਹ ਆਡੀਟ ਟਰੇਲ post-incident review ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ, ਹੇੰਡਾਫਸ ਦੌਰਾਨ ਉਲਝਣ ਘਟਾਉਂਦਾ ਹੈ, ਅਤੇ ਜਦ ਗਾਹਕ ਵਿਆਖਿਆ ਚਾਹੁੰਦੇ ਹਨ ਤਾਂ ਭਰੋਸਾ ਬਣਾਉਂਦਾ ਹੈ।
ਸਥਿਤੀ ਪੰਨਾ ਤਦੋਂ ਹੀ ਮਦਦਗਾਰ ਹੈ ਜਦ ਇਹ ਉਪਲਬਧ ਹੋ ਜਦ ਤੁਹਾਡਾ ਉਤਪਾਦ ਨਹੀਂ। ਸਭ ਤੋਂ ਆਮ ਫੇਲ ਮੋਡ ਉਹ ਹੈ ਜਦ ਤੁਸੀਂ ਸਥਿਤੀ ਸਾਈਟ ਨੂੰ ਉਸੇ ਇੰਫਰਾਸਟਰਕਚਰ 'ਤੇ ਬਣਾਉਂਦੇ ਹੋ ਜਿੱਥੇ অ্যੈਪ ਹੈ—ਇਸ ਲਈ ਜਦ ਐਪ ਡਾਊਨ ਹੋਵੇ, ਸਥਿਤੀ ਪੰਨਾ ਵੀ ਗਾਇਬ ਹੋ ਜਾਂਦਾ ਹੈ।
ਸੰਭਵ ਹੋਵੇ ਤਾਂ status page ਨੂੰ produção app ਤੋਂ ਵੱਖਰੇ provider ਤੇ host ਕਰੋ (ਜਾਂ ਘੱਟੋ-ਘੱਟ ਵੱਖਰਾ region/account)। ਮਕਸਦ blast-radius separation ਹੈ: ਤੁਹਾਡੀ app platform ਦੇ outage ਨਾਲ ਤੁਹਾਡੀ incident communications ਵੀ ਡਾਊਨ ਨਾ ਹੋਵੇ।
DNS ਵੀ ਅਲੱਗ ਰੱਖਣ 'ਤੇ ਵਿਚਾਰ ਕਰੋ। ਜੇ ਤੁਹਾਡੇ ਮੁੱਖ ਡੋਮੇਨ ਦਾ DNS ਉਹੀ ਜਗ੍ਹਾ 'ਤੇ ਹੈ ਜਿੱਥੇ ਤੁਹਾਡਾ app edge/CDN ਹੈ, ਤਾਂ DNS ਜਾਂ certificate ਮੁੱਦੇ ਦੋਹਾਂ ਨੂੰ ਬੰਨ੍ਹ ਸਕਦੇ ਹਨ। ਬਹੁਤ ਟੀਮਾਂ dedicated subdomain ਵਰਤਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ: status.yourcompany.com) ਜਿਸਦਾ DNS ਅਜ਼ਾਦ ਤੌਰ 'ਤੇ ਹੋਸਟ ਕੀਤਾ ਗਿਆ ਹੋਵੇ।
ਐਸੈਟ ਹਲਕੇ ਰੱਖੋ: ਘੱਟ ਜਾਵਾਸਕ੍ਰਿਪਟ, compressed CSS, ਅਤੇ ਕੋਈ dependency ਨਾ ਹੋਵੇ ਜੋ ਤੁਹਾਡੇ ਐਪ ਦੇ APIs ਦੀ ਲੋੜ ਰੱਖਦੀ ਹੋਏ। ਸਥਿਤੀ ਪੰਨੇ ਸਾਹਮਣੇ CDN ਪਾਓ ਅਤੇ static resources ਲਈ caching enable ਕਰੋ ਤਾਂ ਜੋ ਇਹ ਭਾਰ ਵਧਣ ਦੌਰਾਨ ਵੀ ਲੋਡ ਹੋਵੇ।
ਇੱਕ ਕਾਰਗਰ ਸੁਰੱਖਿਆ ਜਾਲ fallback static mode ਹੈ:
ਗਾਹਕਾਂ ਨੂੰ ਸੇਵਾ ਸਿਹਤ ਵੇਖਣ ਲਈ ਲੌਗਇਨ ਦੀ ਲੋੜ ਨਹੀਂ ਹੋਣੀ ਚਾਹੀਦੀ। ਸਥਿਤੀ ਪੰਨਾ ਪਬਲਿਕ ਰੱਖੋ, ਪਰ admin/editor ਟੂਲ authentication (SSO ਜੇ ਹੈ) ਦੇ ਪਿੱਛੇ ਰੱਖੋ, ਮਜ਼ਬੂਤ access controls ਅਤੇ audit logs ਨਾਲ।
ਅੰਤ ਵਿੱਚ, failure scenarios ਦੀ ਟੈਸਟਿੰਗ ਕਰੋ: ਆਪਣੇ staging ਵਾਤਾਵਰਨ ਵਿੱਚ ਅਸਲੀ app origin ਨੂੰ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਰੋਕੋ ਅਤੇ ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ status page ਅਜੇ ਵੀ resolve, ਤੇਜ਼ੀ ਨਾਲ ਲੋਡ, ਅਤੇ ਜਦ ਲੋੜ ਹੋਵੇ ਤਦ ਅਪਡੇਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਕ ਸਥਿਤੀ ਪੰਨਾ ਭਰੋਸਾ ਤਦੋਂ ਹੀ ਬਣਾਉਂਦਾ ਹੈ ਜਦ ਇਹ ਅਸਲੀ ਘਟਨਾਵਾਂ ਦੌਰਾਨ ਲਗਾਤਾਰ ਅੱਪਡੇਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਇਹ ਲਗਾਤਾਰਤਾ ਠੀਕ ਮਾਲਕ, ਸਧਾਰਨ ਨਿਯਮ, ਅਤੇ ਪੇਸ਼ਗੀ-ਨਿਰਧਾਰਤ ਕੈਡੈਂਸ ਦੇ ਬਿਨਾ ਨਹੀਂ ਹੁੰਦੀ।
ਮੁੱਖ ਟੀਮ ਨੂੰ ਛੋਟਾ ਅਤੇ ਸਪਸ਼ਟ ਰੱਖੋ:
ਜੇ ਤੁਸੀਂ ਛੋਟੀ ਟੀਮ ਹੋ, ਇੱਕ ਵਿਅਕਤੀ ਦੋ ਰੋਲ ਰੱਖ ਸਕਦਾ ਹੈ—ਪਰ ਪਹਿਲਾਂ ਤੋਂ ਨਿਰਧਾਰਤ ਕਰੋ। ਰੋਲ ਹੇਡਾਫਸ ਅਤੇ ਐਸਕਲੇਸ਼ਨ ਪਾਥਾਂ ਨੂੰ ਆਪਣੇ on-call handbook ਵਿੱਚ ਦਰਜ ਕਰੋ (ਦੇਖੋ /docs/on-call)।
ਜਦ ਕੋਈ alert ਗਾਹਕ-ਪ੍ਰਭਾਵੀ ਘਟਨਾ ਬਣਦੀ ਹੈ, ਇਕ ਦੋਹਰਾਏ ਜਾਣ ਵਾਲੇ ਫਲੋ ਨੂੰ ਫਾਲੋ ਕਰੋ:
ਅਮਲਯੋਗ ਨਿਯਮ: ਪਹਿਲਾ ਅੱਪਡੇਟ 10–15 ਮਿੰਟ ਦੇ ਅੰਦਰ ਪੋਸਟ ਕਰੋ, ਫਿਰ ਜਦ ਪ੍ਰਭਾਵ ਜਾਰੀ ਹੋਵੇ ਹਰ 30–60 ਮਿੰਟ ਵਿੱਚ—ਭਾਵੇਂ ਸੁਨੇਹਾ “ਕੋਈ ਤਬਦੀਲੀ ਨਹੀਂ, ਅਸੀਂ ਅਜੇ ਵੀ ਜਾਂਚ ਕਰ ਰਹੇ ਹਾਂ” ਹੀ ਕਿਉਂ ਨਾ ਹੋਵੇ।
1–3 ਕਾਰੋਬਾਰੀ ਦਿਨਾਂ ਵਿੱਚ ਇੱਕ ਹਲਕਾ post-incident review ਚਲਾਓ:
ਫਿਰ incident ਐਂਟਰੀ ਨੂੰ ਅੰਤਿਮ ਸੰਖੇਪ ਨਾਲ ਅੱਪਡੇਟ ਕਰੋ ਤਾਂ ਜੋ ਤੁਹਾਡਾ ਘਟਨਾ ਇਤਿਹਾਸ ਉਪਯੋਗੀ ਰਹੇ—ਸਿਰਫ਼ “resolved” ਸੁਨੇਹਿਆਂ ਦੀ ਲਿਸਟ ਨਹੀਂ।
ਇੱਕ ਸਥਿਤੀ ਪੰਨਾ ਤਦੋਂ ਹੀ ਲਾਭਕਾਰੀ ਹੁੰਦਾ ਹੈ ਜਦ ਇਹ ਆਸਾਨੀ ਨਾਲ ਮਿਲ ਜਾਂਦਾ, ਭਰੋਸੇਯੋਗ ਹੁੰਦਾ, ਅਤੇ ਲਗਾਤਾਰ ਅੱਪਡੇਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਐਲਾਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਤੇਜ਼ “production-ready” ਪਾਸ ਕਰੋ—ਫਿਰ ਸਮੇਂ-ਸਮੇਂ ਤੇ ਸੁਧਾਰ ਕਰਨ ਲਈ ਹਲਕਾ ਕੈਡੈਂਸ ਸੈੱਟ ਕਰੋ।
Copy ਅਤੇ structure
Branding ਅਤੇ trust
Access ਅਤੇ permissions
ਪੂਰੀ ਵਰਕਫਲੋ ਦਾ ਟੈਸਟ ਕਰੋ
ਐਲਾਨ
ਜੇ ਤੁਸੀਂ ਆਪਣਾ status site ਬਣਾਉ ਰਹੇ ਹੋ, ਤਾਂ ਪਹਿਲਾਂ staging ਜਗ੍ਹਾ 'ਤੇ ਇਹ ਸਾਰੇ ਚੈਕਲਿਸਟ ਚਲਾਓ। Koder.ai ਵਰਗੇ ਟੂਲ iteration ਨੂੰ ਤੇਜ਼ ਕਰਦੇ ਹਨ—UI, admin screens, ਅਤੇ backend endpoints ਇਕ spec ਤੋਂ ਬਣਾਓ, ਫਿਰ ਕੋਡ export ਅਤੇ deploy ਕਰੋ।
ਕੁਝ ਸਧਾਰਨ ਨਤੀਜੇ ਟ੍ਰੈਕ ਕਰੋ ਅਤੇ ਮਹੀਨੇਵਾਰ ਸਮੀਖਿਆ ਕਰੋ:
ਇਤਿਹਾਸ ਨੂੰ ਕਾਰਗਰ ਬਣਾਉਣ ਲਈ ਇੱਕ ਮੂਲ ਵਰਗੀਕਰਨ ਰੱਖੋ:
ਸਮਾਂ ਦੇ ਨਾਲ, ਛੋਟੇ ਸੁਧਾਰ—ਸਪਸ਼ਟ ਭਾਸ਼ਾ, ਤੇਜ਼ ਅੱਪਡੇਟ, ਬਿਹਤਰ ਵਰਗੀਕਰਨ—ਘੱਟ ਰੁਕਾਵਟਾਂ, ਘੱਟ ਟਿਕਟਾਂ, ਅਤੇ ਵੱਧ ਗਾਹਕ ਭਰੋਸੇ ਵਿੱਚ ਬਦਲ ਜਾਂਦੇ ਹਨ।
ਇੱਕ SaaS ਸਥਿਤੀ ਪੰਨਾ ਇੱਕ ਸਮਰਪਿਤ ਪੰਨਾ ਹੁੰਦਾ ਹੈ ਜੋ ਇੱਕ ਹੀ ਸਥਾਨ 'ਤੇ ਮੌਜੂਦਾ ਸੇਵਾ ਸਿਹਤ ਅਤੇ ਘਟਨਾ ਅੱਪਡੇਟ ਦਿਖਾਉਂਦਾ ਹੈ। ਇਹ ਇਸ ਲਈ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਇਹ “ਕੀ ਇਹ ਡਾਊਨ ਹੈ?” ਵਾਲੇ ਸਹਾਇਤਾ ਲੋਡ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ, ਬੇਲ-ਵਕਤ ਸਮੇਂ ਦੌਰਾਨ ਉਮੀਦਾਂ ਸੈੱਟ ਕਰਦਾ ਹੈ, ਅਤੇ ਸਪਸ਼ਟ, ਸਮੇਂ-ਟਿੱਪਣੀਵਾਲੀ ਸੰਚਾਰ ਨਾਲ ਭਰੋਸਾ ਬਣਾਉਂਦਾ ਹੈ।
ਰੇਅਲ-ਟਾਈਮ ਸਥਿਤੀ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦੀ ਹੈ “ਕੀ ਮੈਂ ਅਜੇ ਪ੍ਰੋਡਕਟ ਵਰਤ ਸਕਦਾ/ਸਕਦੀ ਹਾਂ?” — ਇਹ ਕੰਪੋਨੈਂਟ-ਲੈਵਲ ਦਰਜਿਆਂ ਨਾਲ ਹੁੰਦੀ ਹੈ।
ਘਟਨਾ ਇਤਿਹਾਸ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦਾ ਹੈ “ਇਹ ਕਿੰਨੀ ਵਾਰੀ ਹੁੰਦਾ ਹੈ?” — ਪਿਛਲੀਆਂ ਘਟਿਹਾਂ ਅਤੇ ਰਖ-ਰਖਾਅ ਦੀ ਟਾਈਮਲਾਈਨ ਨਾਲ।
ਪੋਸਟਮਾਰਟਮ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦੇ ਹਨ “ਇਹ ਕਿਉਂ ਹੋਇਆ ਅਤੇ ਕੀ ਬਦਲਿਆ?” — ਰੂਟ ਕਾਰਨ ਅਤੇ ਰੋਕਥਾਮ ਕਦਮਾਂ ਦੇ ਨਾਲ (ਅਕਸਰ ਘਟਨਾ ਐਂਟਰੀ ਤੋਂ ਲਿੰਕ ਕੀਤਾ ਜਾਂਦਾ ਹੈ)।
2–3 ਪਰਿਮਾਣਤ ਨਤੀਜਿਆਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਇਹ ਲੱਖੋ ਅਤੇ ਮਹੀਨੇਵਾਰ ਸਮੀਖਿਆ ਕਰੋ ਤਾਂ ਜੋ ਪੰਨਾ ਬੇਕਾਰ ਨਾ ਹੋ ਜਾਵੇ।
ਇੱਕ ਸਪਸ਼ਟ ਮਾਲਕ ਅਤੇ ਬੈਕਅੱਪ ਨਿਰਧਾਰਤ ਕਰੋ (ਅਕਸਰ on-call rotation). ਬਹੁਤ ਟੀਮਾਂ ਇਹ ਰੋਲ ਵਰਤਦੀਆਂ ਹਨ:
ਅੱਗੇ ਦੇ ਨਿਯਮ ਪਹਿਲਾਂ ਤੋਂ ਨਿਰਧਾਰਤ ਕਰੋ: ਕਿਸ ਨੂੰ ਪੋਸਟ ਕਰਨ ਦੀ ਆਗਿਆ ਹੈ, ਕੀ ਮਨਜ਼ੂਰੀ ਲੋੜੀਂਦੀ ਹੈ, ਅਤੇ ਘਟਨਾ ਦੌਰਾਨ ਘੱਟੋ-ਘੱਟ ਅੱਪਡੇਟ ਅੰਤਰਾਲ (ਉਦਾਹਰਨ: ਹਰ 30–60 ਮਿੰਟ)।
ਗਾਹਕਾਂ ਦੇ ਤਰੀਕੇ ਨਾਲ ਸਮੱਸਿਆ ਨੂੰ ਵਰਣਨ ਕਰਨ ਦੇ ਆਧਾਰ 'ਤੇ ਕੰਪੋਨੈਂਟਾਂ ਚੁਣੋ, ਨਾ ਕਿ ਅੰਦਰੂਨੀ ਸੇਵਾ ਨਾਂ। ਆਮ ਕੰਪੋਨੈਂਟਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਜੇ ਵਿਸ਼ਵਸਨੀਯਤਾ ਖੇਤਰਾਂ ਅਨੁਸਾਰ ਵੱਖਰੀ ਹੋਵੇ, ਤਾਂ ਖੇਤਰਾਂ ਅਨੁਸਾਰ ਵੰਡ ਕਰੋ (ਜਿਵੇਂ “API – US” ਅਤੇ “API – EU”)।
ਛੋਟਾ, ਸਥਿਰ ਦਰਜਿਆਂ ਦਾ ਸੈੱਟ ਵਰਤੋ ਅਤੇ ਹਰ ਇੱਕ ਲਈ ਅੰਦਰੂਨੀ ਮਾਪਦੰਡ ਲਿਖੋ:
ਮਹੱਤਵਪੂਰਨ ਗੱਲ ਹੈ ਲਗਾਤਾਰਤਾ — ਗਾਹਕ ਹਰ ਦਰਜੇ ਦੇ ਮਤਲਬ ਨੂੰ ਦੋਹਰਾਵਾਂ ਤੋਂ ਸਿੱਖਦੇ ਹਨ।
ਇੱਕ ਕਾਰਗਰ ਅੱਪਡੇਟ ਵਿਚ ਹਮੇਸ਼ਾ ਸ਼ਾਮਲ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
ਭਾਵੇਂ ਰੂਟ ਕਾਰਨ ਪਤਾ ਨਾ ਹੋਵੇ, ਤੁਸੀਂ ਸਕੋਪ, ਪ੍ਰਭਾਵ ਅਤੇ ਅਗਲੇ ਕਦਮ ਸੰਚਾਰ ਕਰ ਸਕਦੇ ਹੋ।
ਪਹਿਲਾ “Investigating” ਅੱਪਡੇਟ ਤੇਜ਼ੀ ਨਾਲ ਪੋਸਟ ਕਰੋ (ਅਕਸਰ 10–15 ਮਿੰਟ ਦੇ ਅੰਦਰ). ਫਿਰ:
ਜੇ ਤੁਸੀਂ ਆਪਣਾ ਕੈਡੈਂਸ ਨਿਭਾ ਨਹੀਂ ਸਕਦੇ, ਤਾਂ ਚੁੱਪ ਨਹੀਂ ਰਿਹਾ—ਇੱਕ ਛੋਟੀ ਨੋਟ ਪੋਸਟ ਕਰੋ ਅਤੇ ਉਮੀਦਾਂ ਰੀਸੈੱਟ ਕਰੋ।
Hosted ਟੂਲ ਤੇਜ਼ੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਵਧੀਆ ਹੁੰਦੇ ਹਨ। ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਤਿਆਰ-ਮੁਹੱਈਆ ਸਥਿਤੀ ਪੰਨਾ, ਸਬਸਕ੍ਰਿਪਸ਼ਨ, ਘਟਨਾ ਟਾਈਮਲਾਈਨ, ਅਤੇ ਨਿਗਰਾਨੀ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਦੇਂਦੇ ਹਨ.
DIY ਪੂਰੀ ਕਾਬੂ ਦੇ ਲਈ ਚੰਗਾ ਹੈ ਪਰ ਤੁਸੀਂ ਭਰੋਸੇਯੋਗਤਾ ਅਤੇ ਆਪਰੇਸ਼ਨ ਦੀ ਜਿੰਮੇਵਾਰੀ ਲੈਂਦੇ ਹੋ:
ਚੋਣ ਤੁਹਾਡੇ ਲਕੜੇ ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ: ਲਾਂਚ ਦੀ ਰਫ਼ਤਾਰ, ਭਰੋਸੇਯੋਗਤਾ ਅਤੇ ਰਖ-ਰਖਾਵ ਦੀ ਲਾਗਤ।
ਆਮ ਤੌਰ 'ਤੇ ਲਗਭਗ ਸਾਰੇ ਗਾਹਕਾਂ ਲਈ ਥੋੜੇ ਵਿਕਲਪ ਦਿਓ:
ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਹਮੇਸ਼ਾ opt-in ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ। ਲੋਕਾਂ ਨੂੰ ਇਨ੍ਹਾਂ ਦੇ ਪਸੰਦ-ਨਿਰਧਾਰਨ ਦੇ ਉੱਤੇ ਕੰਟਰੋਲ ਦਿਓ (ਸਕੋਪ, ਕਿਸਮ, ਅਤੇ ਗੰਭੀਰਤਾ ਦੁਆਰਾ ਫਿਲਟਰਿੰਗ) ਤਾਂ ਕਿ ਅਲਰਟ ਫੈਟੀਗ ਨਾ ਹੋਵੇ।
ਅਟੋਮੇਸ਼ਨ ਮਿੰਟਾਂ ਬਚਾ ਸਕਦਾ ਹੈ ਪਰ ਇਹ ਜ਼ਰੂਰੀ ਹੈ ਕਿ ਪਹਿਲਾ ਜਨਤਾ-ਸੁਨੇਹਾ ਸੰਭਲਿਆ ਹੋਵੈ। ਕੁਝ ਪੁਰਕਲਪਿਤ ਆਟੋਮੇਸ਼ਨ:
ਪਰ ਪੂਰੇ ਤੌਰ 'ਤੇ ਆਟੋ-ਪੋਸਟ ਕਰਨ ਦੀ ਥਾਂ ਮਨੁੱਖੀ ਸਮੀਖਿਆ ਰੱਖੋ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਤੁਸੀਂ “Identified”, “Mitigated” ਜਾਂ “Resolved” ਦਰਜਾ ਦਿਉਂਦੇ ਹੋ।
ਸਥਿਤੀ ਪੰਨਾ ਤਦੋਂ ਹੀ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ ਜਦ ਇਹ ਉਸ ਸਮੇਂ ਪਹੁੰਚਯੋਗ ਹੋਵੇ ਜਦ ਤੁਹਾਡਾ ਪ੍ਰੋਡਕਟ ਨਾਹ ਹੋਵੇ। ਆਮ ਤੌਰ 'ਤੇ:
ਅਤੇ ਇੱਕ fallback static ਮੋਡ ਰੱਖੋ—ਆਖਰੀ ਜਾਣਿਆ ਸਥਿਤੀ ਪ੍ਰੀ-ਰੈਂਡਰ ਕੀਤਾ ਹੋਇਆ ਅਤੇ object storage ਤੋਂ ਸੇਵਾ ਕੀਤਾ ਹੋਵੇ—ਤਾਂ ਜੋ ਭਾਰ ਵਧਣ 'ਤੇ ਵੀ ਪੰਨਾ ਲੋਡ ਹੋਵੇ।
ਛੋਟੇ ਅਤੇ ਸਪੱਸ਼ਟ ਰੋਜ਼ਾਨਾ ਨਿਯਮ ਬਣਾਓ:
ਛੋਟੀ ਟੀਮ ਵਿੱਚ ਇੱਕ ਵਿਅਕਤੀ ਦੋ ਰੋਲ ਸੰਭਾਲ ਸਕਦਾ ਹੈ—ਪਰ ਪਹਿਲਾਂ ਤੋਂ ਰੋਲ ਅਤੇ ਐਸਕਲੇਸ਼ਨ ਰਾਹ ਨਿਰਧਾਰਤ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ।
ਲਾਂਚ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਚੈਕਲਿਸਟ ਪੂਰਾ ਕਰੋ:
Copy ਅਤੇ structure:
Branding ਅਤੇ trust:
Access ਅਤੇ permissions:
ਕੁਝ ਸਧਾਰਨ ਨਤੀਜੇ ਮਾਣੋ ਅਤੇ ਮਹੀਨੇਵਾਰ ਸਮੀਖਿਆ ਕਰੋ:
ਇਨ੍ਹਾਂ ਮੈਟਰਿਕਸ ਨਾਲ ਤੁਹਾਨੂੰ ਦਿਸੇਗਾ ਕਿ ਤੁਹਾਡਾ ਸਥਿਤੀ ਪੰਨਾ ਕਿੰਨਾ ਪ੍ਰਭਾਵਸ਼ালী ਹੈ।
ਪੂਰੀ ਵਰਕਫਲੋ ਦੀ ਟੈਸਟਿੰਗ ਕਰੋ (ਟੈਸਟ ਘਟਨਾ) ਅਤੇ ਸਬਸਕ੍ਰਿਬਸ਼ਨ ਟੈਸਟ ਰਨ ਕਰੋ।