23 ਦਸੰ 2025·7 ਮਿੰਟ
ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਵਾਂ: ਸੈਗਮੈਂਟੇਸ਼ਨ ਅਤੇ ਕੋਹੋਰਟ ਵਿਸ਼ਲੇਸ਼ਣ
ਗਾਹਕ ਸੈਗਮੈਂਟੇਸ਼ਨ ਅਤੇ ਕੋਹੋਰਟ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਵੈੱਬ ਐਪ ਬਣਾਉਣ ਦਾ ਇੱਕ ਕਾਰਗਰ, ਕਦਮ-ਦਰ-ਕਦਮ ਗਾਈਡ: ਡਾਟਾ ਮਾਡਲ, ਪਾਈਪਲਾਈਨ, UI, ਮੈਟ੍ਰਿਕਸ, ਅਤੇ ਡਿਪਲੋਇਮੈਂਟ।
ਗਾਹਕ ਸੈਗਮੈਂਟੇਸ਼ਨ ਅਤੇ ਕੋਹੋਰਟ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਵੈੱਬ ਐਪ ਬਣਾਉਣ ਦਾ ਇੱਕ ਕਾਰਗਰ, ਕਦਮ-ਦਰ-ਕਦਮ ਗਾਈਡ: ਡਾਟਾ ਮਾਡਲ, ਪਾਈਪਲਾਈਨ, UI, ਮੈਟ੍ਰਿਕਸ, ਅਤੇ ਡਿਪਲੋਇਮੈਂਟ।
ਟੇਬਲ ਡਿਜ਼ਾਇਨ ਕਰਨ ਜਾਂ ਟੂਲ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਐਪ ਨੂੰ ਕਿਹੜੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇਣੇ ਹਨ। “ਸੈਗਮੈਂਟੇਸ਼ਨ ਅਤੇ ਕੋਹੋਰਟ” ਕਈ ਮਤਲਬ ਰੱਖ ਸਕਦੇ ਹਨ; ਸਪਸ਼ਟ ਯੂਜ਼ ਕੇਸ ਇਸ ਗੱਲ ਤੋਂ ਬਚਾਉਂਦੇ ਹਨ ਕਿ ਤੁਸੀਂ ਇੱਕ ਫੀਚਰ-ਸਮੀਤ ਉਤਪਾਦ ਬਣਾਉ ਜਿੱਥੇ ਫੈਸਲੇ ਲੈਣ ਵਿੱਚ ਮਦਦ ਨਾ ਹੋਵੇ।
ਉਹ ਫੈਸਲੇ ਲਿਖੋ ਜੋ ਲੋਕ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹਨ ਅਤੇ ਉਹ ਨੰਬਰ ਜੋ ਉਹ ਭਰੋਸਾ ਕਰਕੇ ਫੈਸਲਾ ਲੈਂਦੇ ਹਨ। ਆਮ ਸਵਾਲਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਹਰ ਸਵਾਲ ਲਈ ਸਮੇਂ ਦੀ ਖਿੜਕੀ (ਦੈਨੀਕ/ਹਫਤਾਵਾਰ/ਮਾਸਿਕ) ਅਤੇ ਗਰੈਨੁਲਰਟੀ (ਯੂਜ਼ਰ, ਖਾਤਾ, ਸਬਸਕ੍ਰਿਪਸ਼ਨ) ਨੋਟ ਕਰੋ। ਇਹ ਬਾਕੀ ਬਿਲਡ ਨੂੰ ਸੰਗਠਿਤ ਰੱਖਦਾ ਹੈ।
ਮੁੱਖ ਯੂਜ਼ਰਾਂ ਅਤੇ ਉਨ੍ਹਾਂ ਦੇ ਵਰਕਫਲੋਜ਼ ਪਛਾਣੋ:
ਅਮਲਦਾਰ ਲੋੜਾਂ ਵੀ ਕੈਪਚਰ ਕਰੋ: ਉਹ ਕਿੰਨੀ ਵਾਰੀ ਡੈਸ਼ਬੋਰਡ ਜਾਂਚਦੇ ਹਨ, ਉਹਨਾਂ ਲਈ “ਇੱਕ ਕਲਿਕ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ, ਅਤੇ ਉਹ ਕਿਸ ਡਾਟਾ ਨੂੰ ਅਧਿਕਾਰਤ ਮੰਨਦੇ ਹਨ।
ਇੱਕ ਨਿਊਨਤਮ ਯੋਗ ਵਰਜ਼ਨ ਨਿਰਧਾਰਤ ਕਰੋ ਜੋ ਉਪਰੋਕਤ 2–3 ਸવાલਾਂ ਦੇ ਭਰੋਸੇਯੋਗ ਜਵਾਬ ਦੇਵੇ। ਆਮ MVP ਸਕੋਪ: ਮੁੱਖ ਸੈਗਮੈਂਟ, ਕੁੱਝ ਕੋਹੋਰਟ ਵਿਊ (ਰਿਟੇਨਸ਼ਨ, ਰੈਵੇਨਿਊ) ਅਤੇ ਸ਼ੇਅਰੇਬਲ ਡੈਸ਼ਬੋਰਡ।
“ਅੱਛਾ ਹੋਵੇ” ਵਾਲੀਆਂ ਚੀਜ਼ਾਂ ਬਾਅਦ ਲਈ ਰੱਖੋ, ਜਿਵੇਂ ਸ਼ਡਿਊਲਡ ਐਕਸਪੋਰਟ, ਅਲਰਟਸ, ਆਟੋਮੇਸ਼ਨ ਜਾਂ ਜਟਿਲ ਅਤੇ ਕਈ-ਕਦਮ ਵਾਲੀ ਸੈਗਮੈਂਟ ਲਾਜਿਕ।
ਜੇ ਪਹਿਲੀ ਵਰਜ਼ਨ ਤੱਕ ਤੇਜ਼ੀ ਸਾਹਮਣੇ ਲੈ ਕੇ ਆਉਣੀ ਜ਼ਰੂਰੀ ਹੈ, ਤਾਂ MVP ਨੂੰ ਇੱਕ vibe-coding ਪਲੇਟਫਾਰਮ ਜਿਵੇਂ Koder.ai ਨਾਲ ਸਕੈਫੋਲਡ ਕਰਨ 'ਤੇ ਵਿਚਾਰ ਕਰੋ। ਤੁਸੀਂ ਚੈਟ ਵਿੱਚ ਸੈਗਮੈਂਟ ਬਿਲਡਰ, ਕੋਹੋਰਟ ਹੀਟਮੇਪ ਅਤੇ ਬੁਨਿਆਦੀ ETL ਲੋੜਾਂ ਦਾ ਵਰਣਨ ਕਰਕੇ ਇੱਕ ਕਾਰਜਕਾਰੀ React ਫਰੰਟਐਂਡ ਅਤੇ Go + PostgreSQL ਬੈਕਐਂਡ ਜਨਰੇਟ ਕਰਵਾ ਸਕਦے ਹੋ—ਫਿਰ stakeholders ਪਰਿਭਾਸ਼ਾਵਾਂ ਨੂੰ ਸ਼ੁੱਧ ਕਰਨ ਸਮੇਂ planning mode, snapshots ਅਤੇ rollback ਨਾਲ ਇਤਰਾਫ਼ ਕਰੋ।
ਸਫਲਤਾ ਨੂੰ ਮਾਪਯੋਗ ਬਣਾਉ। ਉਦਾਹਰਣ:
ਜਦੋਂ ਤਰਜੀحات ਆਉਂਦੀਆਂ ਹਨ, ਇਹ ਮੈਟ੍ਰਿਕ ਤੁਹਾਡੇ ਨਾਰਥ ਸਟਾਰ ਬਣਦੇ ਹਨ।
ਸਕ੍ਰੀਨ ਡਿਜ਼ਾਇਨ ਜਾਂ ETL ਜੌਬ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ, ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਸਿਸਟਮ ਵਿੱਚ “ਇੱਕ ਗਾਹਕ” ਅਤੇ “ਇੱਕ ਕਾਰਵਾਈ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ। ਕੋਹੋਰਟ ਅਤੇ ਸੈਗਮੈਂਟ ਨਤੀਜੇ ਉਨ੍ਹਾਂ ਪਰਿਭਾਸ਼ਾਵਾਂ ਤੇ ਹੀ ਭਰੋਸੇਯੋਗ ਹੁੰਦੇ ਹਨ।
ਇੱਕ ਪ੍ਰਧਾਨ ਪਹਿਚਾਨਕ ਚੁਣੋ ਅਤੇ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਕਿ ਸਭ ਕੁਝ ਇਸਦੇ ਨਾਲ ਕਿਵੇਂ ਜੋੜਿਆ ਜਾਂਦਾ ਹੈ:
user_id: ਵਿਆਕਤੀ ਸਭੰਧੀ ਵਰਤੋਂ ਅਤੇ ਰਿਟੇਨਸ਼ਨ ਲਈ ਸਭ ਤੋਂ ਚੰਗਾ।account_id: B2B ਲਈ ਬਿਹਤਰ, ਜਿੱਥੇ ਕਈ ਯੂਜ਼ਰ ਇੱਕ ਪੇਅਿੰਗ ਇਕਾਈ 'ਤੇ ਰੋਲਅਪ ਹੁੰਦੇ ਹਨ।anonymous_id: ਸਾਈਨਅਪ ਤੋਂ ਪਹਿਲਾਂ ਦੇ ਵਿਹਾਰ ਲਈ ਲੋੜੀਦਾ; ਇਸਨੂੰ ਬਾਅਦ ਵਿੱਚ ਜਾਣੇ-ਪਛਾਣੇ ਯੂਜ਼ਰ ਨਾਲ ਮਿਲਾਉਣ ਦੇ ਨਿਯਮ ਬਣਾਉਣਾ ਹੋਵੇਗਾ।Identity stitching ਬਾਰੇ ਵਾਜ਼ਹ ਹੋਵੋ: anonymous ਅਤੇ ਜਾਣੇ-ਪਛਾਣੇ ਪ੍ਰੋਫਾਈਲ ਕਦੋਂ ਜੋੜੇ ਜਾਣਗੇ, ਅਤੇ ਜੇ ਇੱਕ ਯੂਜ਼ਰ ਕਈ ਖਾਤਿਆਂ ਦਾ ਹਿੱਸਾ ਹੋਵੇ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ।
ਉਹ ਸਰੋਤ ਪਹਿਲਾਂ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਤੁਹਾਡੇ ਯੂਜ਼ ਕੇਸਾਂ ਦਾ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹਨ, ਫਿਰ ਜ਼ਰੂਰਤ ਮੁਤਾਬਕ ਹੋਰ ਜੋੜੋ:
ਹਰ ਸਰੋਤ ਲਈ ਸਿਸਟਮ-ਓਫ-ਰਿਕਾਰਡ ਅਤੇ ਰਿਫ੍ਰੈਸ਼ ਕੈਡੈਂਸ (ਰੇਅਲ-ਟਾਈਮ, ਘੰਟਾ, ਰੋਜ਼ਾਨਾ) ਨੋਟ ਕਰੋ। ਇਹ ਬਾਅਦ ਵਿੱਚ “ਕਿਉਂ ਨੰਬਰ ਮੈਚ ਨਹੀਂ ਕਰਦੇ?” ਦੇ ਬਹਿਸ ਰਾਹਤਦਾ ਹੈ।
ਰਿਪੋਰਟਿੰਗ ਲਈ ਇੱਕ ਇੱਕੋ ਟਾਈਮ ਜ਼ੋਨ ਨਿਰਧਾਰਤ ਕਰੋ (ਅਕਸਰ ਕਾਰੋਬਾਰੀ ਟਾਈਮਜ਼ੋਨ ਜਾਂ UTC) ਅਤੇ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਕਿ “ਦਿਨ”, “ਹਫਤਾ” ਅਤੇ “ਮਹੀਨਾ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ (ISO ਹਫ਼ਤੇ ਜਾਂ ਐਤਵਾਰ-ਸ਼ੁਰੂ ਹਫ਼ਤੇ)। ਜੇ ਤੁਸੀਂ ਰੈਵੇਨਿਊ ਸੰਭਾਲਦੇ ਹੋ, ਤਾਂ ਮੁਦਰਾ ਨਿਯਮ ਚੁਣੋ: ਸਟੋਰ ਕੀਤੀ ਮੁਦਰਾ, ਰਿਪੋਰਟਿੰਗ ਮੁਦਰਾ, ਅਤੇ ਐਕਸਚੇਂਜ ਰੇਟ ਸਮੇਂ ਨਿਰਧਾਰਨ।
ਸਧੀ ਭਾਸ਼ਾ ਵਿੱਚ definitions ਲਿਖੋ ਅਤੇ ਹਰ ਥਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਦੁਬਾਰਾ ਵਰਤੋ:
ਇਸ ਸ਼ਬਦਾਵਲੀ ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਦੀ ਲੋੜ ਸਮਝੋ: ਇਹ UI ਵਿੱਚ ਦਿਖਾਈ ਦੇਣੀ ਚਾਹੀਦੀ ਹੈ ਅਤੇ ਰਿਪੋਰਟਾਂ ਵਿੱਚ ਹਵਾਲਾ ਦਿੱਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ।
ਇੱਕ ਸੈਗਮੈਂਟੇਸ਼ਨ ਐਪ ਆਪਣੀ ਡਾਟਾ ਮਾਡਲ ਨਾਲ ਹੀ ਜੀਉਂਦਾ ਜਾਂ ਮਰਦਾ ਹੈ। ਜੇ ਵਿਸ਼ਲੇਸ਼ਕ ਆਮ ਸਵਾਲਾਂ ਦਾ ਸਿੱਧਾ ਸਵਾਲ ਨਾਲ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦੇ, ਹਰ ਨਵਾਂ ਸੈਗਮੈਂਟ ਇੱਕ ਇੰਜੀਨੀਅਰਿੰਗ ਟਾਸਕ ਬਣ جائےਗਾ।
ਹਰ ਉਹ ਚੀਜ਼ ਜੋ ਤੁਸੀਂ ਟਰੈਕ ਕਰਦੇ ਹੋ ਲਈ ਇੱਕ ਲਗਾਤਾਰ ਇਵੈਂਟ ਸਟ੍ਰਕਚਰ ਵਰਤੋ। ਇੱਕ ਪ੍ਰਭਾਵਸ਼ালী ਬੇਸਲਾਈਨ ਹੈ:
event_name (ਉਦਾਹਰਨ: signup, trial_started, invoice_paid)timestamp (UTC ਵਿੱਚ ਸਟੋਰ ਕਰੋ)user_id (ਕਿਰਿਆ ਕਰਨ ਵਾਲਾ)properties (JSON ਫਿਲਡ: utm_source, device, feature_name ਵਰਗੀਆਂ ਲਚਕੀਲੀਆਂ ਵੇਰਵਾ ਲਈ)event_name ਨੂੰ ਕੰਟਰੋਲ ਰੱਖੋ (ਇੱਕ ਪਰਿਭਾਸ਼ਤ ਸੂਚੀ) ਅਤੇ properties ਨੂੰ ਲਚਕੀਲੇ ਰੱਖੋ—ਪਰ ਉਮੀਦ ਕੀਤੀਆਂ ਕੁੰਜੀਆਂ ਦਸਤਾਵੇਜ਼ ਕਰੋ। ਇਹ ਤੁਹਾਨੂੰ ਰਿਪੋਰਟਿੰਗ ਲਈ ਇੱਕਸਾਰਤਾ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਪ੍ਰੋਡਕਟ ਬਦਲਾਵਾਂ ਨੂੰ ਰੋਕਣ ਦੇ।
ਸੈਗਮੈਂਟੇਸ਼ਨ ਜ਼ਿਆਦਾਤਰ “ਗੁਣਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਯੂਜ਼ਰ/ਖਾਤਿਆਂ ਨੂੰ ਫਿਲਟਰ ਕਰਨ” ਹੁੰਦੀ ਹੈ। ਉਹ ਗੁਣ dedicated ਟੇਬਲਾਂ ਵਿੱਚ ਰੱਖੋ ਨਾ ਕਿ ਸਿਰਫ਼ ਇਵੈਂਟ ਪ੍ਰੌਪਰਟੀਜ਼ ਵਿੱਚ।
ਆਮ ਗੁਣਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਇਸ ਨਾਲ ਗੈਰ-ਮਾਹਿਰ ਲੋਕ ਵੀ ਸਪਸ਼ਟ ਸੈਗਮੈਂਟ ਬਣਾ ਸਕਣਗੇ, ਉਦਾਹਰਨ: “SMB ਯੂਜ਼ਰ EU ਵਿੱਚ Pro ਤੇ partner ਰਾਹੀਂ ਆਏ” ਬਿਨਾਂ raw events ਵਿੱਚ ਖੋਜ ਕਰਨ ਦੇ।
ਕਈ ਗੁਣ ਸਾਲਾਂ ਵਿੱਚ ਬਦਲਦੇ ਹਨ—ਖ਼ਾਸ ਕਰਕੇ ਪਲੈਨ। ਜੇ ਤੁਸੀਂ صرف ਵਰਤਮਾਨ ਪਲੈਨ user/account ਰਿਕਾਰਡ 'ਤੇ ਸਟੋਰ ਕਰਦੇ ਹੋ, ਤਾ historical cohort ਨਤੀਜੇ drift ਹੋ ਜਾਣਗੇ।
ਦੋ ਆਮ ਪੈਟਰਨ ਹਨ:
account_plan_history(account_id, plan, valid_from, valid_to).ਕਵੈਰੀ ਸਪੀਡ ਬਨਾਮ ਸਟੋਰੇਜ਼/ਜਟਿਲਤਾ ਦੇ ਅਧਾਰ 'ਤੇ ਇੱਕ ਨਿਰਧਾਰ ਕਰਨ।
ਇੱਕ ਸਾਦਾ, query-friendly ਕੋਰ ਮਾਡਲ ਇਹ ਹੈ:
user_id, account_id, event_name, timestamp, properties)user_id, created_at, region, ਆਦਿ)account_id, plan, industry, ਆਦਿ)ਇਹ ਸੰਚਨਾ ਦੋਹਾਂ—ਗਾਹਕ ਸੈਗਮੈਂਟੇਸ਼ਨ ਅਤੇ ਕੋਹੋਰਟ/ਰਿਟੇਨਸ਼ਨ ਵਿਸ਼ਲੇਸ਼ਣ—ਨਾਲ ਸਾਫ਼ ਮੈਪ ਕਰਦੀ ਹੈ ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਹੋਰ ਪ੍ਰੋਡਕਟ, ਟੀਮਾਂ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਲਿਆਉਂਦੇ ਹੋ ਤਾਂ ਇਹ ਸਕੇਲ ਕਰਦੀ ਹੈ।
ਕੋਹੋਰਟ ਵਿਸ਼ਲੇਸ਼ਣ ਸਿਰਫ਼ ਆਪਣੇ ਨਿਯਮਾਂ ਦੀ ਹੀ ਭਰੋਸੇਯੋਗ ਹੈ। UI ਬਣਾਉਣ ਜਾਂ ਕਵੇਰੀਜ਼ optimize ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਅਪਣੇ ਐਪ ਦੀਆਂ ਠੀਕ ਪਰਿਭਾਸ਼ਾਵਾਂ ਲਿਖੋ ਤਾਂ ਕਿ ਹਰ ਚਾਰਟ ਅਤੇ ਐਕਸਪੋਰਟ stakeholders ਦੀ ਉਮੀਦਾਂ ਨਾਲ ਮਿਲੇ।
ਪਹਿਲਾਂ ਉਹ ਕੋਹੋਰਟ ਕਿਸਮਾਂ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਉਤਪਾਦ ਨੂੰ ਚਾਹੀਦੀਆਂ ਹਨ। ਆਮ ਵਿਕਲਪ ਹਨ:
ਹਰ ਕਿਸਮ ਨੂੰ ਇੱਕ ਸਪਸ਼ਟ anchor event (ਅਤੇ ਕਈ ਵਾਰੀ ਇੱਕ property) ਨਾਲ ਮੈਪ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ, ਕਿਉਂਕਿ ਉਹੀ anchor cohort ਮੈਂਬਰਸ਼ਿਪ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ। ਫੈਸਲਾ ਕਰੋ ਕਿ cohort ਮੈਂਬਰਸ਼ਿਪ immutable ਹੈ (ਇੱਕ ਵਾਰੀ ਜੁੜੇ ਤਾਂ ਕਦੇ ਨਹੀਂ ਬਦਲਦੀ) ਜਾਂ historical ਡਾਟਾ ਸਹੀ ਹੋਣ 'ਤੇ ਬਦਲ ਸਕਦੀ ਹੈ।
ਅਗਲੇ, ਕੋਹੋਰਟ ਇੰਡੈਕਸ ਕਿਵੇਂ ਗਣਨਾ ਕਰਦੇ ਹੋ (ਜਿਵੇਂ ਕਾਲਮ week 0, week 1…) ਇਹ ਨਿਰਧਾਰਤ ਕਰੋ:
ਇੱਥੇ ਛੋਟੇ-ਛੋਟੇ ਚੋਣਾਂ ਨੰਬਰਾਂ ਨੂੰ ਇਸ ਕ਼ਦਰ ਬਦਲ ਸਕਦੀਆਂ ਹਨ ਕਿ “ਇਹ ਮੇਲ ਨਹੀਂ ਖਾਂਦਾ” ਦੀ ਸ਼ਿਕਾਇਤ ਹੋ ਸਕਦੀ ਹੈ।
ਫੈਸਲੇ ਕਰੋ ਕਿ ਹਰ ਕੋਹੋਰਟ ਟੇਬਲ ਸੈੱਲ ਦਾ ਕੀ ਮਤਲਬ ਹੈ। ਆਮ ਮੈਟ੍ਰਿਕਸ ਸ਼ਾਮਲ ਹਨ:
ਦਰ ਮੈਟ੍ਰਿਕਸ ਲਈ ਡੀਨੋਮੇਨੇਟਰ ਵੀ ਨਿਰਧਾਰਤ ਕਰੋ (ਉਦਾਹਰਨ: retention rate = ਹਫ਼ਤਾ N ਵਿੱਚ ਸਰਗਰਮ ਯੂਜ਼ਰ ÷ ਕੋਹੋਰਟ ਆਕਾਰ week 0)।
ਕੋਹੋਰਟ ਦੇ ਕਿਨਾਰੇ ਟਰਿੱਕੀ ਹੋ ਜਾਂਦੇ ਹਨ। ਨਿਯਮ ਨਿਰਧਾਰਤ ਕਰੋ:
ਇਹ ਫੈਸਲੇ ਸਾਫ਼ ਭਾਸ਼ਾ ਵਿੱਚ ਦਸਤਾਵੇਜ਼ ਕਰੋ; ਤੁਹਾਡਾ ਭਵਿੱਖ ਦਾ ਆਪ ਅਤੇ ਤੁਹਾਡੇ ਯੂਜ਼ਰ ਇਸਦੇ ਲਈ ਧੰਨਵਾਦੀ ਹੋਣਗੇ।
ਤੁਹਾਡੀ ਸੈਗਮੈਂਟੇਸ਼ਨ ਅਤੇ ਕੋਹੋਰਟ ਵਿਸ਼ਲੇਸ਼ਣ ਉਸ ਡਾਟਾ ਦੀ ਭਰੋਸੇਯੋਗਤਾ 'ਤੇ ਨਿਰਭਰ ਹੈ ਜੋ ਆ ਰਹੀ ਹੈ। ਇੱਕ ਚੰਗੀ ਪਾਈਪਲਾਈਨ ਡਾਟਾ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੀ ਹੈ: ਹਰ ਰੋਜ਼ ਇੱਕੋ ਮਾਇਨੇ, ਇੱਕੋ ਸ਼ਕਲ, ਅਤੇ ਠੀਕ ਵਿਸਥਾਰ ਲੈ ਕੇ ਆਉਂਦੀ ਹੈ।
ਅਧਿਕਤਰ ਪ੍ਰੋਡਕਟ ਇੱਕ ਮਿਕਸ ਵਰਤਦੇ ਹਨ ਤਾਂ ਟੀਮਾਂ ਇੱਕ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਪਾਥ ਨਾਲ ਬੰਦ ਨਾ ਹੋਣ:
ਇੱਕ ਆਮ ਅਦਾਇਗੀ ਨਿਯਮ: ਉਹਨਾਂ “ਮਸਟ-ਹੈਵ” ਇਵੈਂਟਸ ਦੀ ਛੋਟੀ ਸੈੱਟ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਜੋ ਕੋਰ ਕੋਹੋਰਟ ਚਲਾਉਂਦੇ ਹਨ (ਉਦਾਹਰਨ: signup, first value action, purchase), ਫਿਰ ਵਧਾਓ।
ਇੰਨੇਸ਼ਨ ਦੇ ਨੇੜੇ ਵੈਲੇਡੀਸ਼ਨ ਸ਼ਾਮਲ ਕਰੋ ਤਾਂ ਕਿ ਖ਼ਰਾਬ ਡਾਟਾ ਫੈਲ ਕੇ ਨੁਕਸਾਨ ਨਾ ਕਰੇ।
ਧਿਆਨ ਰੱਖੋ:
ਜਦੋਂ ਤੁਸੀਂ ਰਿਕਾਰਡ ਰਿਜੈਕਟ ਜਾਂ ਫਿਕਸ ਕਰੋ, ਫੈਸਲਾ ਇੱਕ audit log ਵਿੱਚ ਲਿਖੋ ਤਾਂ ਕਿ “ਕਿਉਂ ਨੰਬਰ ਬਦਲੇ?” ਦੀ ਵਿਆਖਿਆ ਕੀਤੀ ਜਾ ਸਕੇ।
ਰਾਅ ਡਾਟਾ ਅਸੰਗਤ ਹੁੰਦਾ ਹੈ। ਇਸਨੂੰ ਸਾਫ਼, ਇਕਸਾਰ analytics ਟੇਬਲਾਂ ਬਣਾਓ:
user_id ਨੂੰ account_id/organization_id ਨਾਲ ਜੋੜੋ B2B ਸੈਗਮੈਂਟੇਸ਼ਨ ਲਈ।ਜੌਬ ਸੈਡਿਊਲ (ਜਾਂ streaming) 'ਤੇ ਚਲਾਓ ਅਤੇ ਸਾਫ਼ ਓਪਰੇਸ਼ਨਲ ਗਾਰਡਰੇਲ ਰੱਖੋ:
ਪਾਈਪਲਾਈਨ ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਵਾਂਗ ਸਮਝੋ: ਇਸ ਨੂੰ instrument ਕਰੋ, ਵੇਖੋ, ਅਤੇ ਬੋਰਿੰਗ ਤਰੀਕੇ ਨਾਲ ਭਰੋਸੇਯੋਗ ਰੱਖੋ।
ਕਿੱਥੇ ਤੁਸੀਂ analytics ਡਾਟਾ ਸਟੋਰ ਕਰਦੇ ਹੋ ਇਹ ਤੈਅ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡਾ ਕੋਹੋਰਟ ਡੈਸ਼ਬੋਰਡ ਤੁਰੰਤ ਮਹਿਸੂਸ ਹੋਵੇਗਾ ਜਾਂ ਬਹੁਤ ਹੌਲੀ। ਸਹੀ ਚੋਣ ਡਾਟਾ ਵਾਲੀਅਮ, ਕਵੇਰੀ ਪੈਟਰਨ, ਅਤੇ ਤੁਹਾਨੂੰ ਨਤੀਜੇ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਚਾਹੀਦੇ ਹਨ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ।
ਕਈ ਸ਼ੁਰੂਆਤੀ ਉਤਪਾਦਾਂ ਲਈ, PostgreSQL ਕਾਫ਼ੀ ਹੁੰਦਾ ਹੈ: ਇਹ ਜਾਣਿਆ-ਪਛਾਣਿਆ, ਸਸਤਾ ਚਲਾਉਣਾ, ਅਤੇ SQL ਨੂੰ ਭਲਕੇ ਸਹਿਯੋਗ ਦਿੰਦਾ ਹੈ। ਜਦੋਂ ਤੁਹਾਡਾ ਇਵੈਂਟ ਵਾਲੀਅਮ ਦਰਮਿਆਨਾ ਹੋ ਅਤੇ ਤੁਸੀਂ ਇੰਡੈਕਸਿੰਗ ਅਤੇ partitioning ਧਿਆਨ ਨਾਲ ਕਰਦੇ ਹੋ ਤਾਂ ਇਹ ਵਧੀਆ ਕੰਮ ਕਰਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਬਹੁਤ ਵੱਡੇ ਇਵੈਂਟ ਸਟ੍ਰੀਮ (ਸੈਂਕੜੇ ਮਿਲੀਅਨ ਤੋਂ ਬਿਲੀਅਨ ਰੋਜ਼) ਜਾਂ ਕਈ concurrent ਡੈਸ਼ਬੋਰਡ ਯੂਜ਼ਰਾਂ ਦੀ ਉਮੀਦ ਰੱਖਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਡੇਟਾ ਵੇਅਰਹਾਊਸ (ਉਦਾਹਰਨ: BigQuery, Snowflake, Redshift) ਜਾਂ OLAP ਸਟੋਰ (ਉਦਾਹਰਨ: ClickHouse, Druid) ਤੇ ਵਿਚਾਰ ਕਰੋ।
ਇੱਕ ਪ੍ਰੈਕਟੀਕਲ ਨਿਯਮ: ਜੇ ਤੁਹਾਡਾ “ਹਫ਼ਤਾ ਅਨੁਸਾਰ retention, ਸੈਗਮੈਂਟ ਨਾਲ ਫਿਲਟਰ” ਕਵੇਰੀ Postgres ਵਿੱਚ ਟਿਊਨਿੰਗ ਦੇ ਬਾਵਜੂਦ ਸਕਿੰਟ ਲੈਂਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਵੇਅਰਹਾਊਸ/OLAP ਖੇਤਰ ਦੇ ਨੇੜੇ ਹੋ।
ਰਾਅ events ਰੱਖੋ, ਪਰ ਕੁਝ analytics-friendly ਢਾਂਚੇ ਜੋੜੋ:
ਇਹ ਵੱਖਰਾ-ਵੱਖਰਾ ਕਰਨਾ ਤੁਹਾਨੂੰ cohorts/segments ਮੁੜ-ਗਣਨਾ ਕਰਨ ਦੇ ਸਮੇਂ events table ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਕੋਹੋਰਟ ਕਵੇਰੀਜ਼ ਸਮੇਂ, ਇਕਾਈ ਅਤੇ ਇਵੈਂਟ ਟਾਈਪ ਨਾਲ ਫਿਲਟਰ ਕਰਦੀਆਂ ਹਨ। ਪ੍ਰਾਥਮਿਕਤਾ ਦਿਓ:
(event_name, event_time))ਡੈਸ਼ਬੋਰਡ ਉਹੀ aggregation ਦੋਹਰਾਉਂਦਾ ਹੈ: retention by cohort, week ਅਨੁਸਾਰ counts, conversions by segment। ਇਨ੍ਹਾਂ ਨੂੰ schedule (ਘੰਟਾਵਾਰ/ਰੋਜ਼ਾਨਾ) ਤੇ precompute ਕਰਕੇ summary tables ਵਿੱਚ ਰੱਖੋ ਤਾਂ ਕਿ UI ਕੁਝ ਹਜ਼ਾਰ ਰੋਜ਼ਾਂ ਪੜ੍ਹੇ—ਨਹੀਂ ਕਿ ਕ੍ਰੋੜਾਂ।
ਡ੍ਰਿਲ-ਡਾਊਨ ਲਈ raw data ਰੱਖੋ, ਪਰ ਡਿਫਾਲਟ ਅਨੁਭਵ ਤੇਜ਼ summaries 'ਤੇ ਨਿਰਭਰ ਹੋਵੇ। ਇਹ “ਖੋਲ ਕੇ ਪੜ੍ਹੋ” ਅਤੇ “ਲੋਡ ਹੋਣ ਲਈ ਉਡੀਕ ਕਰੋ” ਵਿੱਚ ਫਰਕ ਹੈ।
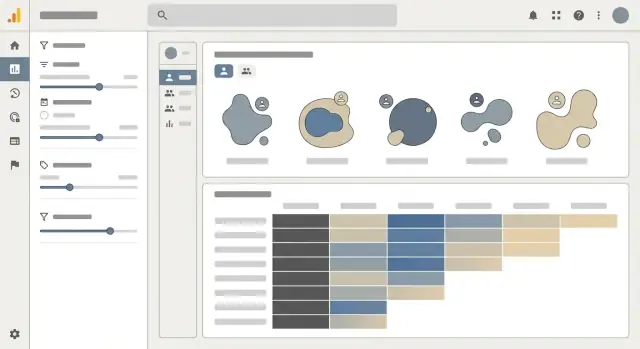
ਸੈਗਮੈਂਟ ਬਿਲਡਰ ਹੀ ਹੈ ਜਿੱਥੇ ਸੈਗਮੈਂਟੇਸ਼ਨ ਸਫਲ ਹੋ ਜਾਂਦੀ ਹੈ ਜਾਂ ਨਾਕਾਮ। ਜੇ ਇਹ SQL ਲਿਖਣ ਵਰਗਾ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦਾ ਹੈ ਤਾਂ ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇਸਨੂੰ ਵਰਤਣਗੀਆਂ ਨਹੀਂ। ਤੁਹਾਡਾ ਲਕੜੀ ਇਹ ਹੈ ਕਿ ਇੱਕ “ਸਵਾਲ ਬਿਲਡਰ” ਹੋਵੇ ਜੋ ਕਿਸੇ ਨੂੰ ਇਹ ਵੇਰਵਾ ਕਰਨ ਦੇਵੇ ਕਿ ਉਹ ਕੌਣ ਮੰਨਦੇ ਹਨ, ਬਿਨਾਂ ਇਹ ਜਾਣਨ ਦੀ ਲੋੜ ਕਿ ਡਾਟਾ ਕਿਵੇਂ ਸੰਭਾਲਿਆ ਗਿਆ ਹੈ।
ਛੋਟੇ rule types ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਅਸਲ ਸਵਾਲਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦੇ ਹਨ:
Country = United States, Plan is Pro, Acquisition channel = AdsTenure is 0–30 days, Revenue last 30 days > $100Used Feature X at least 3 times in the last 14 days, Completed onboarding, Invited a teammateਹਰ rule ਨੂੰ ਇੱਕ ਵਾਕ ਵਜੋਂ ਰੇਂਡਰ ਕਰੋ ਜਿਸ ਵਿੱਚ dropdowns ਅਤੇ ਦੋਸਤਾਨਾ ਫੀਲਡ ਨਾਂ ਹੋਣ (ਆਪਣੇ ਅੰਦਰੂਨੀ column ਨਾਂ ਛੁਪਾਓ)। ਜਿੱਥੇ ਸੰਭਵ ਹੋਵੇ ਉਦਾਹਰਨ ਦਿਖਾਓ (ਉਦਾਹਰਨ: “Tenure = days since first sign-in”).
ਗੈਰ-ਮਾਹਿਰ ਲੋਕ ਗਰੁੱਪ ਵਿੱਚ ਸੋਚਦੇ ਹਨ: “US ਅਤੇ Pro ਅਤੇ Feature X ਵਰਤਿਆ” ਅਤੇ ਬਿਨਾਂ ਅਪਵਰਚਾਂ ਜਿਵੇਂ “(US ਜਾਂ Canada) ਅਤੇ not churned”। ਇਸਨੂੰ ਆਸਾਨ ਰੱਖੋ:
ਯੂਜ਼ਰਾਂ ਨੂੰ ਸੇਵ ਕਰਨ ਦਿਓ: ਇੱਕ ਨਾਮ, ਵਰਣਨ, ਅਤੇ ਵਿਕਲਪਕ ਮਾਲਕ/ਟੀਮ। ਸੇਵਡ ਸੈਗਮੈਂਟ ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਕੋਹੋਰਟ ਵਿਊਜ਼ ਵਿੱਚ ਦੁਬਾਰਾ ਵਰਤੇ ਜਾ ਸਕਦੇ ਹਨ, ਅਤੇ ਵਰਜ਼ਨਡ ਹੋਣ ਚਾਹੀਦੇ ਹਨ ਤਾਂ ਕਿ ਬਦਲਾਅ ਪੁਰਾਣੀਆਂ ਰਿਪੋਰਟਾਂ ਨੂੰ ਚੁੱਪ ਕੀਤੇ ਬਿਨਾਂ ਨਾ ਬਦਲੇਂ।
ਜਦੋਂ rule ਬਦਲਦੇ ਹਨ ਤਾਂ ਅਨੁਮਾਨਿਤ ਜਾਂ ਸਹੀ segment size ਬਿਲਡਰ ਵਿੱਚ ਤੁਰੰਤ ਦਿਖਾਓ। ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਲਈ ਸੈਂਪਲਿੰਗ ਵਰਤਦੇ ਹੋ, ਤਾਂ ਖੁਲ੍ਹਕੇ ਦੱਸੋ:
ਸ਼ੁਰੂਆਤ 2–3 ਨਿਰਧਾਰਤ ਫੈਸਲਿਆਂ ਨਾਲ ਕਰੋ ਜੋ ਐਪ ਨੂੰ ਸਹਿਯੋਗ ਦੇਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ (ਜਿਵੇਂ ਕਿ ਚੈਨਲ ਅਨੁਸਾਰ ਹਫਤਾ-1 ਰਿਟੇਨਸ਼ਨ, ਯੋਜਨਾ ਅਨੁਸਾਰ ਚਰਨ ਰਿਸਕ), ਫਿਰ ਨਿਰਧਾਰ ਕਰੋ:
ਇਨ੍ਹਾਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਜਵਾਬ ਦੇਣ ਲਈ MVP ਤਿਆਰ ਕਰੋ, ਫਿਰ alerts, automations ਜਾਂ ਜਟਿਲ ਲਾਜਿਕ ਜੋੜੋ।
ਸਾਧੀ ਭਾਸ਼ਾ ਵਿੱਚ ਪਰਿਭਾਸ਼ਾਵਾਂ ਲਿਖੋ ਅਤੇ ਹਰ ਥਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਦੁਹਰਾਓ (UI ਟੂਲਟਿਪਸ, ਐਕਸਪੋਰਟ, ਡੌਕਸ)। ਘੱਟੋ-ਘੱਟ ਪਰਿਭਾਸ਼ਾ ਕਰੋ:
ਫਿਰ , , ਅਤੇ ਸਟੈਂਡਰਡ ਕਰੋ ਤਾਂ ਕਿ ਚਾਰਟ ਅਤੇ CSV ਮਿਲਦੇ-ਝੁਲਦੇ ਹੋਣ।
ਇੱਕ ਮੁੱਖ ਪਹਿਚਾਣਕ ਚੁਣੋ ਅਤੇ ਵਾਜ਼ਹ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਕਿ ਹੋਰ ਕਿਵੇਂ ਇਸ ਨਾਲ ਜੋੜਦੇ ਹਨ:
user_id ਵਿਅਕਤੀ-ਸਤ੍ਹਰ ਭਰੋ ਇਸਤੇਮਾਲ ਲਈaccount_id B2B rollups ਅਤੇ subscription ਮੈਟਰਿਕ ਲਈanonymous_id pre-signup ਵਿਹਾਰ ਲਈਨਿਰਧਾਰਤ ਕਰੋ ਕਿ identity stitching ਕਦੋਂ ਹੁੰਦੀ ਹੈ (ਉਦਾਹਰਨ: login ਤੇ), ਅਤੇ ਕਿਨ੍ਹਾਂ ਐਡਜ ਕੇਸਾਂ ਨਾਲ ਕਿਵੇਂ ਨਿਪਟਿਆ ਜਾਵੇ (ਇੱਕ ਯੂਜ਼ਰ ਕਈ ਖਾਤਿਆਂ ਵਿੱਚ ਹੋਣ ਤੇ, ਮਰਜਜ਼, ਡੁਪਲੀਕੇਟ)।
ਇੱਕ ਪ੍ਰਯੋਗੀ ਬੇਸਲਾਈਨ ਹੈ events + users + accounts ਮਾਡਲ:
event_name, timestamp (UTC), , , (JSON)ਜੇ(plan ਜਾਂ lifecycle ਸਟੇਟਸ ਵਰਗੀਆਂ) ਗੁਣ ਸਮੇਂ ਨਾਲ ਬਦਲਦੇ ਨੇ, ਸਿਰਫ਼ “ਮੌਜੂਦਾ” ਮੁੱਲ ਰੱਖਣਾ historical cohorts ਨੂੰ ਧੁੰਦਲਾ ਕਰ ਦੇਵੇਗਾ।
ਆਮ ਤਰੀਕੇ:
plan_history(account_id, plan, valid_from, valid_to)ਤੁਸੀਂ query speed ਜਾਂ storage/ETL ਸਾਦਗੀ ਵਿੱਚੋਂ ਕਿਸ ਨੂੰ ਤਰਜੀਹ ਦੇ ਰਹੇ ਹੋ, ਉਸ ਅਨੁਸਾਰ ਚੁਣੋ।
ਕੋਹੋਰਟ ਕਿਸੇ ਇੱਕ anchor event ਨਾਲ ਮੈਪ ਹੋਣ ਵਾਲੀ ਕਿਸਮ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ (signup, ਪਹਿਲੀ ਖਰੀਦ, ਮੁੱਖ ਫੀਚਰ ਦੀ ਪਹਿਲੀ ਵਰਤੋਂ)। ਫਿਰ ਨਿਰਧਾਰਤ ਕਰੋ:
ਇਸ ਦੇ ਨਾਲ ਇਹ ਵੀ ਫੈਸਲਾ ਕਰੋ ਕਿ cohort membership ਅਟੱਲ ਹੈ ਜਾਂ late/corrected ਡਾਟਾ ਨਾਲ ਬਦਲ ਸਕਦੀ ਹੈ।
ਆਮ ਤੌਰ 'ਤੇ ਨੁਕਸਾਂ ਜੋ metrics ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੀਆਂ ਹਨ:
ਇਨ੍ਹਾਂ ਨਿਯਮਾਂ ਨੂੰ ਟੂਲਟਿਪਸ ਅਤੇ ਐਕਸਪੋਰਟ ਮੈਟਾ ਡਾਟਾ ਵਿੱਚ ਦਿਓ ਤਾਂ ਕਿ ਹਿੱਸੇਦਾਰ ਨਤੀਜਿਆਂ ਨੂੰ ਇੱਕਸਾਰ ਤਰੀਕੇ ਨਾਲ ਸਮਝ ਸਕਣ।
ਇੰਜੇਸ਼ਨ ਰਾਹਾਂ ਉਹਨਾਂ ਸਰੋਤਾਂ ਦੇ ਅਨੁਸਾਰ ਬਨਾਓ ਜੋ ਸੱਚਮੁਚ ਸਰੋਤ-of-truth ਹਨ:
ਸਿੰਪਲ ਵੈਲਿਡੇਸ਼ਨ ਜ਼ਰੂਰੀ ਫੀਲਡਾਂ (event name, timestamp, user_id/anonymous_id) ਅਤੇ dedupe ਲਾਜ਼ਮੀ ਰੱਖੋ ਅਤੇ rejects/fixes ਦਾ audit ਲੌਗ ਰੱਖੋ ਤਾਂ ਕਿ ਨੰਬਰਾਂ ਵਿੱਚ ਬਦਲਾਅ ਦੀ ਵਿਆਖਿਆ ਕੀਤੀ ਜਾ ਸਕੇ।
ਮਿਆਨਰੀ ਤੇ moderate ਵਾਲੀ ਵਾਲਿਊਮ ਲਈ PostgreSQL ਕਾਫ਼ੀ ਹੁੰਦਾ ਹੈ ਜੇ ਤੁਸੀਂ indexing ਅਤੇ partitioning ਨੂੰ ਧਿਆਨ ਨਾਲ ਕਰਦੇ ਹੋ। ਬਹੁਤ ਵੱਡੇ events stream ਜਾਂ concurrency ਲਈ warehouse (BigQuery/Snowflake/Redshift) ਜਾਂ OLAP store (ClickHouse/Druid) ਤੇ ਵਿਚਾਰ ਕਰੋ।
ਡੈਸ਼ਬੋਰਡ ਤੇਜ਼ ਰੱਖਣ ਲਈ ਕੁਝ ਚੀਜ਼ਾਂ precompute ਕਰੋ:
segment_membership (ਜੇ membership ਬਦਲਦੀ ਹੈ ਤਾਂ validity windows ਦੇ ਨਾਲ)ਸਰਵਰ-ਪਾਸੇ RBAC ਲਾਗੂ ਕਰੋ ਅਤੇ ਇਹ ਨਿਯਮ ਸਪਸ਼ਟ ਰੱਖੋ:
Multi-tenant ਐਪ ਲਈ ਹਰ ਟੇਬਲ ਵਿੱਚ workspace_id ਸ਼ਾਮਲ ਕਰੋ ਅਤੇ RLS ਜਾਂ ਸਮਾਨ ਫਿਲਟਰ ਲਗਾਓ। PII ਘੱਟ ਕਰੋ, UI ਵਿੱਚ ਮਾਸਕਿੰਗ ਦਿਓ, ਅਤੇ હਾਰਡ ਡਿਲੀਸ਼ਨ/ਰੇਟੇਂਸ਼ਨ ਵਰਕਫਲੋ ਅਤੇ audit ਲੌਗ ਰੱਖੋ।
user_idaccount_idpropertiesevent_name ਨੂੰ ਨਿਯੰਤਰਿਤ ਰੱਖੋ (ਮਾਲੂਮ ਸੂਚੀ) ਅਤੇ properties ਲਚਕੀਲੇ ਪਰ ਦਸਤਾਵੇਜ਼ ਕੀਤੇ ਹੋਣ। ਇਹ ਜੋੜ cohort ਗਣਿਤ ਅਤੇ ਗੈਰ-ਮਾਹਿਰ ਸੈਗਮੈਂਟੇਸ਼ਨ ਦੋਹਾਂ ਨੂੰ ਸਮਰਥਨ ਦਿੰਦੇ ਹਨ।
ਡ੍ਰਿਲ-ਡਾਊਨ ਲਈ raw events ਰੱਖੋ, ਪਰ ਡਿਫਾਲਟ UI ਤੇਜ਼ summaries ਤੋਂ ਪੜ੍ਹੇ।