10 ਜੁਲਾ 2025·4 ਮਿੰਟ
ਈਮੇਲ ਅਤੇ ਵੈੱਬਹੁੱਕ ਲਈ ਸਧਾਰਨ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਕਿਊ ਪੈਟਰਨ
ਵੀਖੋ ਕਿ ਕਿਵੇਂ ਸਧਾਰਨ ਡੇਟਾਬੇਸ-ਅਧਾਰਿਤ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਕਿਊ ਨਾਲ ਈਮੇਲ, ਰਿਪੋਰਟ, ਅਤੇ ਵੈੱਬਹੁੱਕ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਭੇਜਣੀਆਂ ਹਨ—ਰੀਟ੍ਰਾਈ, ਬੈਕਆਫ ਅਤੇ ਡੈਡ-ਲੈਟਰ ਦੇ ਨਾਲ—ਬਿਨਾਂ ਭਾਰੀ ਟੂਲਾਂ ਦੇ।
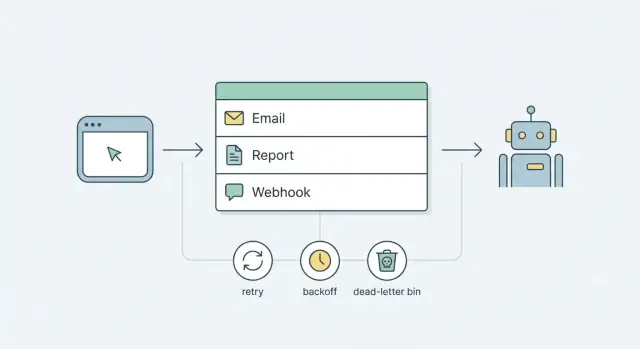
ਵੀਖੋ ਕਿ ਕਿਵੇਂ ਸਧਾਰਨ ਡੇਟਾਬੇਸ-ਅਧਾਰਿਤ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਕਿਊ ਨਾਲ ਈਮੇਲ, ਰਿਪੋਰਟ, ਅਤੇ ਵੈੱਬਹੁੱਕ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਭੇਜਣੀਆਂ ਹਨ—ਰੀਟ੍ਰਾਈ, ਬੈਕਆਫ ਅਤੇ ਡੈਡ-ਲੈਟਰ ਦੇ ਨਾਲ—ਬਿਨਾਂ ਭਾਰੀ ਟੂਲਾਂ ਦੇ।
ਕੋਈ ਵੀ ਕੰਮ ਜੋ ਇੱਕ ਜਾਂ ਦੋ ਸਕਿੰਟ ਤੋਂ ਵੱਧ ਲੈ ਸਕਦਾ ਹੈ, ਉਹ ਯੂਜ਼ਰ ਦੇ ਰਿਕਵੇਸਟ ਦੇ ਅੰਦਰ ਨਹੀਂ ਚਲਣਾ ਚਾਹੀਦਾ। ਈਮੇਲ ਭੇਜਣਾ, ਰਿਪੋਰਟ ਬਣਾਉਣਾ, ਅਤੇ ਵੈੱਬਹੁੱਕ ਡਿਲਿਵਰੀ ਨੈਟਵਰਕ, ਤੀਜੀ-ਪੱਖੀ ਸੇਵਾਵਾਂ ਜਾਂ ਹੌਲੀ ਕਊਰੀਜ਼ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ ਹਨ। ਕਦੇ-ਕਦੇ ਉਹ ਰੁਕ ਜਾਂਦੇ ਹਨ, ਫੇਲ ਹੋ ਜਾਂਦੇ ਹਨ, ਜਾਂ ਸੋਚ ਤੋਂ ਜ਼ਿਆਦਾ ਸਮਾਂ ਲੈਂਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਉਹ ਕੰਮ ਯੂਜ਼ਰ ਦੇ ਉਡੀਕ ਰਹਿੰਦੇ ਸਮੇਂ ਕਰਦੇ ਹੋ, ਤਾਂ ਲੋਕ ਤੁਰੰਤ ਮੈਸੂਸ ਕਰਦੇ ਹਨ। ਪੰਨੇ ਫ੍ਰੀਜ਼ ਹੋ ਜਾਂਦੇ ਹਨ, "Save" ਬਟਨ ਘੁੰਮਦਾ ਰਹਿੰਦਾ ਹੈ, ਅਤੇ ਰਿਕਵੇਸਟ ਟਾਈਮਆਉਟ ਹੋ ਜਾਂਦੇ ਹਨ। ਰੀਟ੍ਰਾਈਜ਼ ਵੀ ਗਲਤ ਜਗ੍ਹਾ 'ਤੇ ਹੋ ਸਕਦੇ ਹਨ: ਯੂਜ਼ਰ ਰੀਫ੍ਰੈਸ਼ ਕਰਦਾ ਹੈ, ਲੋਡ ਬੈਲੈਂਸਰ ਦੁਬਾਰਾ ਭੇਜ ਦਿੰਦਾ ਹੈ, ਜਾਂ ਫਰੰਟਐਂਡ ਦੁਬਾਰਾ ਸਬਮਿਟ ਕਰ ਦਿੰਦਾ ਹੈ, ਅਤੇ ਤੁਹਾਡੇ ਕੋਲ ਨਕਲਈ ਈਮੇਲ, ਨਕਲਈ ਵੈੱਬਹੁੱਕ ਕਾਲਾਂ, ਜਾਂ ਇੱਕੋ ਸਮੇਂ ਦੋ ਰਿਪੋਰਟ ਰਨ ਹੋ ਜਾਣਗੀਆਂ।
ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਇਸਨੂੰ ਠੀਕ ਕਰਦੇ ਹਨ: ਰਿਕਵੇਸਟ ਨੂੰ ਛੋਟਾ ਅਤੇ ਪੇਸ਼ਗੋਈਯੋਗ ਰਖੋ: ਐਕਸ਼ਨ ਸਵੀਕਾਰ ਕਰੋ, ਇੱਕ ਜੌਬ ਦਰਜ ਕਰੋ ਜੋ ਬਾਅਦ ਵਿੱਚ ਚਲਾਇਆ ਜਾਵੇ, ਤੇ ਤੁਰੰਤ ਜਵਾਬ ਦਿਓ। ਜੌਬ ਰਿਕਵੇਸਟ ਤੋਂ ਬਾਹਰ ਚਲਦਾ ਹੈ, ਅਤੇ ਨਿਯਮ ਤੁਸੀਂ ਨਿਰਧਾਰਿਤ ਕਰਦੇ ਹੋ।
ਮੁਸ਼ਕਲ ਹਿੱਸਾ ਭਰੋਸੇਯੋਗਤਾ ਹੈ। ਜਦ ਕੰਮ ਰਿਕਵੇਸਟ ਰਸਤੇ ਤੋਂ ਬਾਹਰ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਦ ਵੀ ਤੁਹਾਨੂੰ ਇਹ ਸਵਾਲ ਜਵਾਬ ਦੇਣੇ ਪੈਂਦੇ ਹਨ:
ਕਈ ਟੀਮਾਂ "ਭਾਰੀ ਇੰਫ੍ਰਾਸਟ੍ਰਕਚਰ" ਜੋੜਕੇ ਜਵਾਬ ਦਿੰਦੀਆਂ ਹਨ: ਮੇਸੇਜ ਬ੍ਰੋਕਰ, ਵੱਖਰੇ ਵਰਕਰ ਫਲੀਟ, ਡੈਸ਼ਬੋਰਡ, ਅਲਾਰਟਿੰਗ, ਅਤੇ ਪਲੇਅਬੁੱਕ। ਜਦ ਤੁਹਾਨੂੰ ਸੱਚਮੁੱਚ ਇਹਨਾਂ ਦੀ ਲੋੜ ਹੋਵੇ ਤਾਂ ਇਹ ਸਾਧਨ ਲਾਭਦਾਇਕ ਹੁੰਦੇ ਹਨ, ਪਰ ਇਹ ਨਵੇਂ ਮੁੱਦੇ ਅਤੇ ਫੇਲਯਾਰੀ ਮੋਡ ਵੀ ਲਿਆਉਂਦੇ ਹਨ।
ਇੱਕ ਬਿਹਤਰ ਸ਼ੁਰੂਆਤੀ ਲਕੜੀ ਸਧਾਰਨ ਹੈ: ਉਹ ਕੰਮ ਭਰੋਸੇਯੋਗ ਬਣਾਓ ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਵਰਤ ਰਹੇ ਹਿੱਸਿਆਂ ਨਾਲ ਕਰ ਸਕੋ। ਜ਼ਿਆਦਾਤਰ ਉਤਪਾਦਾਂ ਲਈ, ਇਹ ਮਤਲਬ ਹੈ ਕਿ ਡੇਟਾਬੇਸ-ਬੈਕਡ ਕਿਊ ਅਤੇ ਇੱਕ ਛੋਟਾ ਵਰਕਰ ਪ੍ਰੋਸੈਸ। ਇਕ ਸਾਫ਼ ਰੀਟ੍ਰਾਈ ਅਤੇ ਬੈਕਆਫ ਰਣਨੀਤੀ ਜੋੜੋ, ਅਤੇ ਜਿਨ੍ਹਾਂ ਜੌਬਾਂ ਨੇ ਲਗਾਤਾਰ ਫੇਲ ਕੀਤਾ ਉਨ੍ਹਾਂ ਲਈ ਡੈਡ-ਲੈਟਰ ਪੈਟਰਨ। ਤੁਹਾਨੂੰ ਜ਼ਿਆਦਾ ਜਟਿਲ ਪਲੇਟਫਾਰਮ 'ਤੇ ਦਿਨ ਪਹਿਲਾਂ ਫਸਣ ਦੀ ਲੋੜ ਨਹੀਂ ਪਵੇਗੀ।
ਭਾਵੇਂ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ Koder.ai ਵਰਗੇ ਚੈਟ-ਚਲਿਤ ਟੂਲ ਨਾਲ ਬਣਾਉਂਦੇ ਹੋ, ਇਹ ਵਿਭਾਜਨ ਫਿਰ ਵੀ ਮਹੱਤਵਪੂਰਨ ਹੈ। ਯੂਜ਼ਰ ਨੂੰ ਹੁਣ ਇੱਕ ਤੇਜ਼ ਜਵਾਬ ਮਿਲਣਾ ਚਾਹੀਦਾ ਹੈ, ਅਤੇ ਤੁਹਾਡੀ ਪ੍ਰਣਾਲੀ ਪਿਛੋਕੜ ਵਿਚ ਹੌਲੀ, ਗਲਤੀ-ਪ੍ਰਵਣ ਕੰਮ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਖਤਮ ਕਰ ਦੇਵੇ।
ਕਿਊ ਕੰਮ ਲਈ ਉਡੀਕ ਕਰਨ ਵਾਲੀ ਲਾਈਨ ਹੈ। ਥੱਲੇ ਦਿੱਤੇ ਕੰਮਾਂ ਨੂੰ ਯੂਜ਼ਰ ਰਿਕਵੇਸਟ ਦੌਰਾਨ ਕਰਨ ਦੀ ਬਜਾਏ (ਈਮੇਲ ਭੇਜਣਾ, ਰਿਪੋਰਟ ਬਣਾਉਣਾ, ਵੈੱਬਹੁੱਕ ਕਾਲ), ਤੁਸੀਂ ਇੱਕ ਛੋਟੀ ਰਿਕਾਰਡ ਕਿਊ ਵਿੱਚ ਪਾਉਂਦੇ ਹੋ ਅਤੇ ਤੁਰੰਤ ਵਾਪਸ ਕਰ ਦਿੰਦੇ ਹੋ। ਬਾਅਦ ਵਿੱਚ, ਇੱਕ ਵੱਖਰਾ ਪ੍ਰੋਸੈਸ ਉਹ ਰਿਕਾਰਡ ਲੈਂਦਾ ਹੈ ਅਤੇ ਕੰਮ ਕਰਦਾ ਹੈ।
ਕੁਝ ਮੁੱਖ ਸ਼ਬਦ:
ਸਭ ਤੋਂ ਸਾਦਾ ਫਲੋ ਇਸ ਤਰ੍ਹਾਂ ਹੁੰਦਾ ਹੈ:
Enqueue: ਤੁਹਾਡੀ ਐਪ ਜੌਬ ਰਿਕਾਰਡ (type, payload, run time) ਸੇਵ ਕਰਦੀ ਹੈ।
Claim: ਇੱਕ ਵਰਕਰ ਅਗਲਾ ਉਪਲਬਧ ਜੌਬ ਲੱਭਦਾ ਹੈ ਅਤੇ ਉਸਨੂੰ "ਲੌਕ" ਕਰਦਾ ਹੈ ਤਾਂ ਕਿ ਕੇਵਲ ਇੱਕ ਵਰਕਰ ਹੀ ਇਸਨੂੰ ਚਲਾਏ।
Run: ਵਰਕਰ ਕੰਮ ਕਰਦਾ ਹੈ (ਭੇਜੋ, ਤਿਆਰ ਕਰੋ, ਡਿਲਿਵਰ ਕਰੋ)।
Finish: ਦੋਨਾ ਮਾਰਕ ਕਰੋ, ਜਾਂ ਫੇਲ ਹੋਣ 'ਤੇ ਅਗਲੀ ਰਨ ਟਾਈਮ ਦਰਜ ਕਰੋ।
ਜੇ ਤੁਹਾਡੀ ਜੌਬ ਵॉलਿਊਮ ਮੋਡਸਟ ਹੈ ਅਤੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਇੱਕ ਡੇਟਾਬੇਸ ਰੱਖਦੇ ਹੋ, ਤਾਂ ਡੇਟਾਬੇਸ-ਬੈਕਡ ਕਿਊ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫ਼ੀ ਹੁੰਦੀ ਹੈ। ਇਹ ਸਮਝਣ ਵਿੱਚ ਆਸਾਨ, ਡੀਬੱਗ ਕਰਨ ਵਿੱਚ ਆਸਾਨ, ਅਤੇ ਆਮ ਜ਼ਰੂਰਤਾਂ ਲਈ ਫਿੱਟ ਹੁੰਦੀ ਹੈ ਜਿਵੇਂ ਕਿ ਈਮੇਲ ਜੌਬ ਪ੍ਰੋਸੈਸਿੰਗ ਅਤੇ ਵੈੱਬਹੁੱਕ ਡਿਲਿਵਰੀ ਭਰੋਸੇਯੋਗਤਾ।
ਸਟ੍ਰੀਮਿੰਗ ਪਲੇਟਫਾਰਮ ਤਦੋਂ ਮਾਣਯੋਗ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਤੁਹਾਨੂੰ ਬਹੁਤ ਉੱਚ throughput, ਬਹੁਤ ਸਾਰੇ ਅਜ਼ਾਦ ਖਪਤਕਾਰ, ਜਾਂ ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮਾਂ 'ਤੇ ਇਵੈਂਟ ਇਤਿਹਾਸ ਨੂੰ ਰੀਪਲੇ ਕਰਨ ਦੀ ਲੋੜ ਹੋਵੇ। ਜੇ ਤੁਸੀਂ ਘੰਟੇ ਵਿੱਚ ਮਿਲੀਅਨਜ਼ ਇਵੈਂਟ ਚਲਾ ਰਹੇ ਹੋ, ਤਾਂ Kafka ਵਰਗੇ ਟੂਲ ਮਦਦگار ਹੋ ਸਕਦੇ ਹਨ। ਉੱਥੋਂ ਤੱਕ, ਇੱਕ ਡੇਟਾਬੇਸ ਟੇਬਲ ਅਤੇ ਵਰਕਰ ਲੂਪ ਬਹੁਤ ਸਾਰੀਆਂ ਹਕੀਕਤੀਆਂ ਕਵਰ ਕਰਦਾ ਹੈ।
ਇੱਕ ਡੇਟਾਬੇਸ ਕਿਊ ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਸਹੀ ਹੈ ਜਦੋਂ ਹਰ ਜੌਬ ਰਿਕਾਰਡ ਤਿੰਨ ਸਵਾਲਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇ ਸਕੇ: ਕੀ ਕਰਨਾ ਹੈ, ਅਗਲੀ ਕੋਸ਼ਿਸ਼ ਕਦੋਂ ਕਰਨੀ ਹੈ, ਅਤੇ ਪਿਛਲੇ ਵਾਰੀ ਕੀ ਹੋਇਆ। ਇਹ ਠੀਕ ਕਰੋ ਅਤੇ ਓਪਰੇਸ਼ਨ ਨਿਰਾਸਤੀ (boring) ਹੋ ਜਾਉਣਗੇ (ਜੋ ਕਿ ਲਕੜੀ ਹੈ)।
ਜੋ ਕੁਝ ਵੀ ਵਰਕ ਕਰਨ ਲਈ ਸਭ ਤੋਂ ਛੋਟਾ ਇਨਪੁੱਟ ਲੋੜੀਂਦਾ ਹੈ, ਉਹ ਰੱਖੋ, ਨਾ ਕਿ ਪੂਰਾ ਰੇਂਡਰ ਕੀਤਾ ਆਉਟਪੁਟ। ਚੰਗੇ payloads ID ਅਤੇ ਕੁਝ ਪੈਰਾਮੀਟਰ ਹੁੰਦੇ ਹਨ, ਜਿਵੇਂ { "user_id": 42, "template": "welcome" }.
ਵੱਡੇ ਬਲੌਬ (ਪੂਰੇ HTML ਈਮੇਲ, ਵੱਡਾ ਰਿਪੋਰਟ ਡੇਟਾ, ਬਹੁਤ ਵੱਡੇ webhook ਬਾਡੀ) ਸਟੋਰ ਕਰਨ ਤੋਂ ਬਚੋ। ਇਹ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਵਧਾਉਂਦਾ ਹੈ ਅਤੇ ਡੀਬੱਗਿੰਗ ਕਰਨਾ ਮੁਸ਼ਕਲ ਬਣਾਉਂਦਾ ਹੈ। ਜੇ ਜੌਬ ਨੂੰ ਵੱਡੇ ਦਸਤਾਵੇਜ਼ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਉਸਦੀ ਥਾਂ ਇਕ ਸੰਦਰਭ ਰੱਖੋ: report_id, export_id, ਜਾਂ ਇੱਕ ਫਾਇਲ ਕੀ। ਵਰਕਰ ਚਲਾਉਂਦੇ ਸਮੇਂ ਪੂਰਾ ਡੇਟਾ ਫੈਚ ਕਰ ਸਕਦਾ ਹੈ।
ਘੱਟੋ-ਘੱਟ, ਇਹਨਾਂ ਲਈ ਸਥਾਨ ਰੱਖੋ:
job_type ਹੈਂਡਲਰ (send_email, generate_report, deliver_webhook) ਚੁਣਦਾ ਹੈ। payload ਛੋਟੇ ਇਨਪੁੱਟ ਰੱਖਦਾ ਹੈ ਜਿਵੇਂ IDs ਤੇ options।queued, running, succeeded, failed, dead).attempt_count ਅਤੇ max_attempts ਤਾਂ ਜੋ ਤੁਸੀਂ retry ਰੋਕ ਸਕੋ ਜਦੋਂ ਇਹ ਸਪਸ਼ਟ ਨਾ-ਚੱਲੇਵੇ।created_at ਅਤੇ next_run_at (ਜਦੋਂ ਇਹ eligible ਹੁੰਦਾ ਹੈ)। started_at ਅਤੇ finished_at ਜੋੜੋ ਜੇ ਤੁਸੀਂ ਹੌਲੇ ਜੌਬਾਂ ਦੀ ਵਧੀਕ ਦਿੱਖ ਚਾਹੁੰਦੇ ਹੋ।idempotency_key, ਅਤੇ last_error ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਿਨਾਂ ਲੋਗਾਂ ਦੇ ਖੋਜ ਕੀਤੇ ਜਾਣ ਦੇ ਕਾਰਨ ਦੇਖ ਸਕੋ।Idempotency ਸ਼ਬਦ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਲੱਗਦਾ ਹੈ, ਪਰ ਵਿਚਾਰ ਸਧਾਰਨ ਹੈ: ਜੇ ਇੱਕੋ ਜੌਬ ਦੋ ਵਾਰ ਚਲੇ, ਤਾਂ ਦੂਜੀ ਵਾਰੀ ਨੂੰ ਖਤਰਨਾਕ ਕੰਮ ਨਾ ਕਰਨ ਲਈ ਪਛਾਣ ਕਰੋ। ਉਦਾਹਰਨ ਲਈ, webhook delivery ਜੌਬ webhook:order:123:event:paid ਵਰਗਾ idempotency key ਵਰਤ ਸਕਦੀ ਹੈ ਤਾਂ ਕਿ ਤੁਸੀਂ ਇੱਕੋ ਇਵੈਂਟ ਨੂੰ ਦੁਬਾਰਾ ਨਾ ਭੇਜੋ ਜੇ retry ਟਾਈਮਆਉਟ ਨਾਲ ਓਵਰਲੈਪ ਹੋ ਜਾਵੇ।
ਕੁਝ ਬੁਨਿਆਦੀ ਨੰਬਰ ਵੀ ਅਰੰਭ ਵਿੱਚ ਕੈਪਚਰ ਕਰੋ। ਤੁਹਾਨੂੰ ਵੱਡਾ ਡੈਸ਼ਬੋਰਡ ਚਾਹੀਦਾ ਨਹੀਂ; ਸਿਰਫ ਕੁਝ ਕ੍ਵੇਰੀਆਂ ਜੋ ਦੱਸਦੀਆਂ ਹਨ: ਕਿੰਨੇ ਜੌਬ ਕਿਊ ਵਿੱਚ ਹਨ, ਕਿੰਨੇ ਫੇਲ ਹੋ ਰਹੇ ਹਨ, ਅਤੇ ਸਭ ਤੋਂ ਪੁਰਾਣੇ ਕਿਉ ਵਿੱਚ ਜੌਬ ਦੀ ਉਮਰ ਕਿੰਨੀ ਹੈ।
ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਡੇਟਾਬੇਸ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਨਵੀਂ ਇੰਫ੍ਰਾਸਟ੍ਰਕਚਰ ਜੋੜਨ ਦੀ ਬਜਾਏ ਬੈਕਗ੍ਰਾਊਂਡ ਕਿਊ ਸ਼ੁਰੂ ਕਰ ਸਕਦੇ ਹੋ। ਜੌਬਾਂ ਦੀਆਂ ਰੋਜ਼ਾਂ ਹੁੰਦੀਆਂ ਹਨ, ਅਤੇ ਇੱਕ ਵਰਕਰ ਇੱਕ ਪ੍ਰੋਸੈਸ ਹੁੰਦਾ ਜੋ ਮੁੜ ਕੇ_due rows` ਚੁਣਦਾ ਅਤੇ ਕੰਮ ਕਰਦਾ ਹੈ।
ਟੇਬਲ ਛੋਟੀ ਅਤੇ ਸਧਾਰਨ ਰੱਖੋ। ਤੁਹਾਨੂੰ ਇੰਨੇ ਫੀਲਡ ਚਾਹੀਦੇ ਹਨ ਕਿ ਜੌਬ ਚਲ ਸਕੇ, retry ਹੋ ਸਕੇ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਡੀਬੱਗ ਕੀਤਾ ਜਾ ਸਕੇ।
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
ਜੇ ਤੁਸੀਂ Postgres 'ਤੇ ਬਣਾ ਰਹੇ ਹੋ (Go ਬੈਕਐਂਡ ਨਾਲ ਆਮ), ਤਾਂ jsonb ਜੌਬ ਡੇਟਾ ਸਟੋਰ ਕਰਨ ਲਈ ਵਰਤੋਂਯੋਗ ਹੈ, ਉਦਾਹਰਨ { "user_id":123,"template":"welcome" }.
ਜਦੋਂ ਯੂਜ਼ਰ ਐਕਸ਼ਨ ਕਿਸੇ ਜੌਬ ਨੂੰ ਟ੍ਰਿਗਰ ਕਰਨਾ ਹੋਵੇ (ਈਮੇਲ ਭੇਜੋ, webhook ਫਾਇਰ ਕਰੋ), ਤਾਂ ਜੌਬ ਰੋਅ ਨੂੰ ਮੁੱਖ ਚੇਂਜ ਦੇ ਨਾਲ ਇਕੋ ਡੇਟਾਬੇਸ ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਲਿਖੋ ਜੇ ਸੰਭਵ ਹੋਵੇ। ਇਸ ਨਾਲ "ਯੂਜ਼ਰ ਬਣਿਆ ਪਰ ਜੌਬ ਗਾਇਬ" ਦੀ ਸਮੱਸਿਆ ਨ ਆਵੇ ਜੇ ਮੱਖ ਲਿਖਤ ਤੋਂ ਬਾਅਦ ਕ੍ਰੈਸ਼ ਹੋ ਜਾਵੇ।
ਉਦਾਹਰਨ: ਜਦ ਯੂਜ਼ਰ ਸਾਈਨ ਅੱਪ ਕਰਦਾ ਹੈ, user ਰੋਅ ਅਤੇ send_welcome_email ਜੌਬ ਨੂੰ ਇਕੋ ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਦਰਜ ਕਰੋ।
ਇੱਕ ਵਰਕਰ ਇੱਕੋ ਚੱਕਰ ਦੁਹਰਾਉਂਦਾ ਹੈ: ਇੱਕ ਦੇਯੂ ਜੌਬ ਲੱਭੋ, ਉਸਨੂੰ ਕਲੇਮ ਕਰੋ ਤਾਂ ਕਿ ਹੋਰ ਕੋਈ ਨਾ ਲਵੇ, ਪ੍ਰੋਸੈਸ ਕਰੋ, ਫਿਰ ਹੋਰ ਜਾਂ ਦੋਬਾਰਾ ਰਨ ਕਰਨ ਲਈ ਨਿਯਤ ਕਰੋ।
ਅਮਲੀ ਰੂਪ ਵਿੱਚ ਇਹ ਮਤਲਬ ਹੈ:
status='queued' ਅਤੇ next_run_at <= now() ਵਾਲੀ ਇੱਕ ਜੌਬ ਚੁਣੋ।SELECT ... FOR UPDATE SKIP LOCKED ਆਮ ਤਰੀਕਾ ਹੈ)।status='running', locked_at=now(), locked_by='worker-1' ਸੈੱਟ ਕਰੋ।done/succeeded) ਮਾਰਕ ਕਰੋ, ਜਾਂ last_error ਦਰਜ ਕਰੋ ਅਤੇ ਅਗਲੀ ਕੋਸ਼ਿਸ਼ ਸ਼ੈਡਿਊਲ ਕਰੋ।ਕਈ ਵਰਕਰ ਇੱਕੋ ਸਮੇਂ ਚੱਲ ਸਕਦੇ ਹਨ। ਕਲੇਮ ਕਦਮ ਹੀ ਦੂਜੇ-ਪਿਕਿੰਗ ਨੂੰ ਰੋਕਦਾ ਹੈ।
ਸ਼ਟਡਾਊਨ 'ਤੇ, ਨਵੇਂ ਜੌਬ ਨਾ ਲਓ, ਮੌਜੂਦਾ ਨਿਪਟਾਓ, ਫਿਰ ਬਾਹਰ ਨਿਕਲੋ। ਜੇ ਕੋਈ ਪ੍ਰੋਸੈਸ ਮਿਡ-ਜੌਬ ਮਰਨਦਾ ਹੈ, ਤਾਂ ਸਧਾਰਨ ਨਿਯਮ ਵਰਤੋ: running ਵਿੱਚ ਅਟਕੀ ਹੋਈ ਜੌਬਾਂ ਨੂੰ ਟਾਈਮਆਉਟ ਤੋਂ ਬਾਦ periodਿਕ "reaper" ਟਾਸਕ ਦੁਆਰਾ ਮੁੜ-ਕਿਊ ਯੋਗ ਕਰੋ।
ਜੇ ਤੁਸੀਂ Koder.ai 'ਤੇ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਇਹ ਡੇਟਾਬੇਸ-ਕਿਊ ਪੈਟਰਨ ਈਮੇਲ, ਰਿਪੋਰਟ, ਅਤੇ ਵੈੱਬਹੁੱਕ ਲਈ ਇੱਕ ਮਜ਼ਬੂਤ ਡਿਫਾਲਟ ਹੈ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਕਿ ਤੁਸੀਂ ਵਿਸ਼ੇਸ਼ queue ਸੇਵਾਵਾਂ ਜੋੜੋ।
ਰੀਟ੍ਰਾਈਜ਼ ਉਹ ਤਰੀਕਾ ਹੈ ਜੋ ਕਿਊ ਨੂੰ ਬਾਹਰੀ ਦੁਨੀਆ ਦੀ ਗੜਬੜੀ 'ਤੇ ਸ਼ਾਂਤ ਰੱਖਦਾ ਹੈ। ਬਿਨਾਂ ਸਾਫ਼ ਨਿਯਮਾਂ ਦੇ, ਰੀਟ੍ਰਾਈਜ਼ ਇੱਕ ਸ਼ੋਰ ਵਾਲੇ ਲੂਪ ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹਨ ਜੋ ਯੂਜ਼ਰਾਂ ਨੂੰ ਸਪੈਮ ਕਰਦਾ, APIs ਨੂੰ ਹਮੇਸ਼ਾ ਹੱਥੋਂ ਮਾਰਦਾ, ਅਤੇ ਅਸਲੀ ਬੱਗ ਨੂੰ ਛਪਾ ਦਿੰਦਾ।
ਸ਼ੁਰੂਆਤ ਕਰਨ ਲਈ ਸੋਚੋ ਕਿ ਕੀ retry ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਅਤੇ ਕੀ ਤੁਰੰਤ ਫੇਲ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਟੁਟਿ-ਫੁਟਿ ਸਮੱਸਿਆਵਾਂ retry ਕਰੋ: ਨੈਟਵਰਕ ਟਾਈਮਆਉਟ, 502/503, ਰੇਟ ਲਿਮਿਟ, ਜਾਂ ਡੇਟਾਬੇਸ ਕਨੈਕਸ਼ਨ ਬਲਿੱਬ।
ਜਦ ਜੌਬ ਕਦੇ ਨਹੀਂ ਚਲੇਗੀ: ਤੁਰੰਤ ਫੇਲ ਕਰੋ: ਗੁੰਮ ਈਮੇਲ ਐਡਰੈੱਸ, ਵੈੱਬਹੁੱਕ ਲਈ 400 ਕਿਉਂਕਿ ਪੇਲੋਡ ਗਲਤ ਹੈ, ਜਾਂ ਇੱਕ ਮਿਟਿਆ ਖਾਤਾ ਲਈ ਰਿਪੋਰਟ ਬੇਨਤੀ।
ਬੈਕਆਫ ਕੋਸ਼ਿਸ਼ਾਂ ਦੇ ਵਿਚਕਾਰ ਦਾ ਅੰਤਰ ਹੈ। ਲీనਿਅਰ ਬੈਕਆਫ (5s, 10s, 15s) ਸਧਾਰਨ ਹੈ, ਪਰ ਇਹ ਫਿਰ ਵੀ ਟ੍ਰੈਫਿਕ ਦੀ ਲਹਿਰ ਬਣਾਉ ਸਕਦਾ ਹੈ। ਐਕਸਪੋਨੇਸ਼ੀਅਲ ਬੈਕਆਫ (5s, 10s, 20s, 40s) ਭਾਰ ਵੰਡਦਾ ਹੈ ਅਤੇ ਵੈੱਬਹੁੱਕ ਅਤੇ ਤੀਜੀ-ਪੱਖੀ ਪ੍ਰੋਵਾਈਡਰਾਂ ਲਈ ਆਮ ਤੌਰ 'ਤੇ ਸੁਰੱਖਿਅਤ ਰਹਿੰਦਾ ਹੈ। ਥੋੜ੍ਹਾ jitter (ਇੱਕ ਛੋਟਾ ਰੈਂਡਮ ਦੇਰੀ) ਜੋੜੋ ਤਾਂ ਕਿ ਹਜ਼ਾਰਾਂ ਜੌਬ ਇਕੋ ਹੀ ਸੈਕੰਡ ਵਿੱਚ ਨਹੀਂ ਰੀਟ੍ਰਾਈ ਕਰਦੇ।
ਉਤਪਾਦਨ ਵਿੱਚ ਚੰਗਾ ਵਰਤਣ ਵਾਲੇ ਨਿਯਮ:
Max attempts ਨੁਕਸਾਨ ਸੀਮਤ ਕਰਨ ਲਈ ਹਨ। ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਲਈ 5 ਤੋਂ 8 ਕੋਸ਼ਿਸ਼ਾਂ ਕਾਫੀ ਹਨ। ਇਸ ਤੋਂ ਬਾਅਦ retry ਰੋਕੋ ਅਤੇ ਜੌਬ ਨੂੰ ਰੀਵਯੂ ਲਈ ਰੱਖੋ (dead-letter) ਬਜਾਏ ਅਨੰਤ ਲੂਪ ਦੇ।
ਟਾਈਮਆਉਟ "ਜ਼ੋੰਬੀ" ਜੌਬਾਂ ਨੂੰ ਰੋਕਦੇ ਹਨ। ਈਮੇਲਾਂ ਲਈ ਹਰ ਕੋਸ਼ਿਸ਼ 10–20 ਸਕਿੰਟ ਦਾ ਟਾਈਮਆਉਟ ਹੋ ਸਕਦਾ ਹੈ। ਵੈੱਬਹੁੱਕ ਲਈ ਛੋਟਾ ਸੀਮਾ (5–10 ਸਕਿੰਟ) ਵਧੀਆ ਹੁੰਦਾ ਹੈ, ਕਿਉਂਕਿ ਰਿਸੀਵਰ ਡਾਊਨ ਹੋ ਸਕਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਅੱਗੇ ਵੱਧਣਾ ਚਾਹੁੰਦੇ ਹੋ। ਰਿਪੋਰਟ ਬਣਾਉਣਾ ਮਿੰਟ ਲੈ ਸਕਦਾ ਹੈ, ਪਰ ਫਿਰ ਵੀ ਰੂੜੀ ਕਟਆਫ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਹ Koder.ai ਵਿੱਚ ਬਣਾ ਰਹੇ ਹੋ, ਤਾਂ should_retry, next_run_at, ਅਤੇ idempotency key ਨੂੰ ਪਹਿਲੀ ਪੜ੍ਹਾਈ ਦੇ ਫੀਲਡ ਸਮਝੋ। ਇਹ ਛੋਟੇ ਵੇਰਵੇ ਸਿਸਟਮ ਨੂੰ ਚੁੱਪ ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ ਜਦੋਂ ਕੁਝ ਗਲਤ ਹੋਵੇ।
ਡੈਡ-ਲੈਟਰ ਸਟੇਟ ਉਹ ਹੈ ਜਿੱਥੇ ਜੌਬ ਜਾਂਦੇ ਹਨ ਜਦੋਂ retries ਹੋਰ ਸੁਰੱਖਿਅਤ ਜਾਂ ਲਾਭਦਾਇਕ ਨਹੀਂ ਹੁੰਦੀਆਂ। ਇਹ ਖਾਮੋਸ਼ ਫੇਲਯਾਰੀ ਨੂੰ ਕੁਝ ਐਸਾ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਦੇਖ ਸਕੋ, ਖੋਜ ਸਕੋ, ਅਤੇ ਕਾਰਵਾਈ ਕਰ ਸਕੋ।
ਜੋ ਘੱਟੋ-ਘੱਟ ਜਾਣਕਾਰੀ ਲੋੜੀਦੀ ਹੈ ਉਹ ਰੱਖੋ ਤਾਂ ਕਿ ਕੀ ਹੋਇਆ ਸਮਝ ਆ ਸਕੇ ਅਤੇ ਜਰੂਰਤ ਪੈਂਦੀ ਤਾਂ ਜੌਬ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾਇਆ ਜਾ ਸਕੇ, ਪਰ ਸੀਕ੍ਰੇਟ्स ਬਾਰੇ ਧਿਆਨ ਰੱਖੋ।
ਰੱਖੋ:
ਜੇ payload ਵਿੱਚ ਟੋਕਨ ਜਾਂ ਨਿੱਜੀ ਡੇਟਾ ਹੈ, ਤਾਂ ਸਟੋਰ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ redact ਜਾਂ encrypt ਕਰੋ।
ਜਦੋਂ ਕੋਈ ਜੌਬ dead-letter 'ਤੇ ਪਹੁੰਚਦਾ ਹੈ, ਤੁਰੰਤ ਫੈਸਲਾ ਕਰੋ: retry, fix, ਜਾਂ ignore。
Retry ਬਾਹਰੀ outage ਅਤੇ ਟਾਈਮਆਉਟ ਲਈ ਹੈ। Fix ਖਰਾਬ ਡੇਟਾ (ਗੁੰਮ ਈਮੇਲ, ਗਲਤ URL) ਜਾਂ ਕੋਡ ਬੱਗ ਲਈ ਹੈ। Ignore ਕਮੀ ਮਾਮਲਿਆਂ ਵਿੱਚ ਠੀਕ ਹੈ, ਜਦ ਜੌਬ ਹੁਣ ਸੰਬੰਧਤ ਨਹੀਂ ਰਹਿੰਦਾ (ਉਦਾਹਰਨ: ਗਾਹਕ ਨੇ ਆਪਣਾ ਖਾਤਾ ਮਿਟਾ ਦਿੱਤਾ)। ਜੇ ਤੁਸੀਂ ignore ਕਰੋ, ਤਾਂ ਕਾਰਨ ਦਰਜ ਕਰੋ ਤਾਂ ਕਿ ਜੌਬ ਗੁਮ ਨਾ ਲੱਗੇ।
Manual requeue ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਹੈ ਜਦੋਂ ਇਹ ਇੱਕ ਨਵਾਂ ਜੌਬ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਪੁਰਾਣੇ ਜੌਬ ਨੂੰ ਅਪਾਰੀਟ ਬਣਾਈ ਰੱਖਦਾ ਹੈ। dead-letter ਜੌਬ ਨੂੰ ਦਰਜ ਕਰੋ ਕਿ ਕਿਸ ਨੇ, ਕਦੋਂ, ਅਤੇ ਕਿਉਂ requeue ਕੀਤਾ, ਫਿਰ ਨਵਾਂ ਰਿਕਾਰਡ enqueue ਕਰੋ ਜਿਸਦੀ ਨਵੀਂ ID ਹੋਵੇ।
ਅਲਾਰਟਿੰਗ ਲਈ, ਉਹ ਸੰਕੇਤ ਦੇਖੋ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਦਰਦ ਦਾ ਇਸ਼ਾਰਾ ਹੁੰਦੇ ਹਨ: dead-letter ਗਿਣਤੀ ਤੇਜ਼ੀ ਨਾਲ ਵੱਧ ਰਹੀ ਹੋਵੇ, ਇੱਕੋ ਹੀ error ਕਈ ਜੌਬਾਂ 'ਚ ਵਾਰ-ਵਾਰ ਆ ਰਿਹਾ ਹੋਵੇ, ਜਾਂ ਪੁਰਾਣੇ queued ਜੌਬ ਜੋ ਕਲੇਮ ਨਹੀਂ ਹੋ ਰਹੇ।
ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ snapshots ਅਤੇ rollback ਮਦਦ ਕਰਦੇ ਹਨ ਜਦੋਂ ਇੱਕ ਖ਼ਰਾਬ ਰਿਲੀਜ਼ ਅਚਾਨਕ failure spike ਕਰਦੇ ਹੋ, ਕਿਉਂਕਿ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਪਿੱਛੇ ਹਟ ਸਕਦੇ ਹੋ ਜਦੋਂ ਤੁਸੀਂ ਜਾਂਚ ਕਰ ਰਹੇ ਹੋ।
ਅਖੀਰ ਵਿੱਚ, vendor outages ਲਈ safety valves ਜੋੜੋ। ਹਰ provider ਲਈ sends ਨੂੰ rate-limit ਕਰੋ, ਅਤੇ ਇਕ circuit breaker ਵਰਤੋ: ਜੇ ਕਿਸੇ webhook endpoint ਤੇਜ਼ੀ ਨਾਲ ਫੇਲ ਕਰ ਰਿਹਾ ਹੈ, ਤਾਂ ਲਈ ਇਨ੍ਹਾਂ ਦੇ ਸਰਵਰਾਂ (ਅਤੇ ਤੁਹਾਡੇ) ਨੂੰ ਭਾਰ ਨਾਲ ਭਰਨਾ ਰੋਕਣ ਲਈ ਕਈ ਸਮੇਂ ਲਈ ਨਵੇਂ ਕੋਸ਼ਿਸ਼ਾਂ ਨੂੰ ਰੋਕ ਦਿਓ।
ਕਿਊ ਸਭ ਤੋਂ ਵਧੀਆ ਤਦੋਂ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦੋਂ ਹਰ ਜੌਬ ਕਿਸਮ ਦੀਆਂ ਸਾਫ਼ ਨਿਯਮ ਹੋਣ: ਕਾਮਯਾਬੀ ਕੀ ਗਿਣਤੀ ਹੁੰਦੀ ਹੈ, ਕੀ retry ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਅਤੇ ਕੀ ਕਦੇ ਵੀ ਦੋ ਵਾਰੀ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ।
ਈਮੇਲ. ਜ਼ਿਆਦਾਤਰ ਈਮੇਲ ਫੇਲਯਾਰੀਆਂ ਆਸਥਾਈ ਹੁੰਦੀਆਂ ਹਨ: ਪ੍ਰੋਵਾਈਡਰ ਟਾਈਮਆਉਟ, ਰੇਟ ਲਿਮਿਟ, ਜਾਂ ਛੋਟੇ outage। ਇਹਨਾਂ ਨੂੰ retryਯੋਗ ਮਨੋ, ਬੈਕਆਫ ਸਮੇਤ। ਵੱਡੀ ਖਤਰਾ duplicate sends ਹੈ, ਇਸ ਲਈ ਈਮੇਲ ਜੌਬ idempotent ਬਣਾਓ। ਇੱਕ stable dedupe key ਜਿਵੇਂ user_id + template + event_id ਸਟੋਰ ਕਰੋ ਅਤੇ ਜੇ ਉਹ key ਪਹਿਲਾਂ ਹੀ ਭੇਜਿਆ ਗਿਆ ਦਰਜ ਹੋਵੇ ਤਾਂ ਭੇਜਣਾ ਮਨਾਓ।
ਇਸਦੇ ਨਾਲ template ਨਾਮ ਅਤੇ ਵਰਜ਼ਨ (ਜਾਂ rendered subject/body ਦਾ hash) ਸਟੋਰ ਕਰਨ ਯੋਗ ਹੈ। ਜੇ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਜੌਬ ਦੁਬਾਰਾ ਚਲਾਉਣੀ ਪਏ, ਤਾਂ ਤੁਸੀਂ ਫੈਸਲਾ ਕਰ ਸਕਦੇ ਹੋ ਕਿ ਕੀ ਇੱਕੋ ਹੀ ਸਮੱਗਰੀ ਦੁਬਾਰਾ ਭੇਜਨੀ ਹੈ ਜਾਂ ਨਵੀਂ template ਤੋਂ ਦੁਬਾਰਾ ਰੇਂਡਰ ਕਰਨੀ ਹੈ। ਜੇ ਪ੍ਰੋਵਾਈਡਰ message ID ਵਾਪਸ ਕਰਦਾ ਹੈ, ਤਾਂ ਉਸਨੂੰ ਸੇਵ ਕਰੋ ਤਾਂ ਕਿ ਸਹਾਇਤਾ ਟਰੇਸ ਕਰ ਸਕੇ ਕਿ ਕੀ ਹੋਇਆ।
ਰਿਪੋਰਟ. ਰਿਪੋਰਟ ਵੱਖਰੇ ਤਰੀਕੇ ਨਾਲ ਫੇਲ ਹੁੰਦੀਆਂ ਹਨ। ਉਹ ਮਿੰਟਾਂ ਲਈ ਚੱਲ ਸਕਦੀਆਂ ਹਨ, pagination ਸੀਮਾਵਾਂ ਨੂੰ ਹਿੱਟ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਜਾਂ ਇੱਕ ਵਾਰੀ ਵਿੱਚ ਸਭ ਕੁਝ ਕਰਨ ਨਾਲ ਮੈਮੋਰੀ ਖਤਮ ਹੋ ਸਕਦੀ ਹੈ। ਕੰਮ ਨੂੰ ਛੋਟੇ ਟੁਕੜਿਆਂ ਵਿੱਚ ਵੰਡੋ। ਆਮ ਪੈਟਰਨ: ਇੱਕ "report request" ਜੌਬ ਕਈ "page" ਜਾਂ "chunk" ਜੌਬ ਬਣਾਉਂਦਾ ਹੈ, ਹਰ ਇੱਕ ਡੇਟਾ ਦਾ ਹਿੱਸਾ ਪ੍ਰੋਸੈਸ ਕਰਦਾ ਹੈ।
ਯੂਜ਼ਰ ਨੂੰ ਉਡੀਕਣ ਦੀ ਬਜਾਏ ਨਤੀਜੇ ਡਾਊਨਲੋਡ ਲਈ ਸਟੋਰ ਕਰੋ। ਇਹ ਡੇਟਾਬੇਸ ਟੇਬਲ report_run_id ਦੁਆਰਾ key ਕੀਤੀ ਹੋ ਸਕਦੀ ਹੈ, ਜਾਂ ਫਾਇਲ ਰੇਫਰੰਸ ਤੇ metadata (status, row count, created_at)। ਪ੍ਰਗਤੀ ਫੀਲਡ ਜੋੜੋ ਤਾਂ ਕਿ UI "processing" vs "ready" ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਦਿਖਾ ਸਕੇ।
ਵੈੱਬਹੁੱਕ. ਵੈੱਬਹੁੱਕ ਡਿਲਿਵਰੀ ਭਰੋਸੇਯੋਗਤਾ ਬਾਰੇ ਹਨ, ਤੇਜ਼ੀ ਬਾਰੇ ਨਹੀਂ। ਹਰ request ਨੂੰ sign ਕਰੋ (ਉਦਾਹਰਨ HMAC shared secret ਨਾਲ) ਅਤੇ replay ਰੋਕਣ ਲਈ timestamp ਸ਼ਾਮਿਲ ਕਰੋ। ਸਿਰਫ ਉਸ ਵੇਲੇ retry ਕਰੋ ਜਦੋਂ ਪ੍ਰਾਪਤਕਰਤਾ ਬਾਅਦ ਵਿੱਚ ਸਫਲ ਹੋ ਸਕਦਾ ਹੈ।
ਸਧਾਰਨ ਨਿਯਮ:
ਆਰਡਰਿੰਗ ਅਤੇ ਪ੍ਰਾਇਓਰਿਟੀ. ਬਹੁਤ ਸਾਰੀਆਂ ਜੌਬਾਂ ਨੂੰ ਸਖਤ ਆਰਡਰਿੰਗ ਦੀ ਲੋੜ ਨਹੀਂ ਹੁੰਦੀ। ਜਦੋਂ ਆਰਡਰ ਮਹੱਤਵਪੂਰਨ ਹੋ, ਅਕਸਰ ਇਹ per-key (per user, per invoice, per webhook endpoint) ਤੇ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦਾ ਹੈ। group_key ਜੋੜੋ ਅਤੇ ਇੱਕ ਕੀ ਦੇ ਲਈ ਇਕੋ ਸਮੇਂ ਇੱਕ ਹੀ in-flight ਜੌਬ ਰੱਖੋ।
ਪ੍ਰਾਇਓਰਿਟੀ ਲਈ, ਤੁਰੰਤ ਕੰਮ ਨੂੰ ਹੌਲੇ ਕੰਮ ਤੋਂ ਵੱਖ ਕਰੋ। ਇੱਕ ਵੱਡਾ ਰਿਪੋਰਟ backlog password reset emails ਨੂੰ ਦੇਰੀ ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ।
ਉਦਾਹਰਨ: ਖਰੀਦ ਤੋਂ ਬਾਅਦ, ਤੁਸੀਂ enqueue ਕਰੋ (1) ਆਰਡਰ ਪੁਸ਼ਟੀ ਈਮੇਲ, (2) ਪਾਰਟਨਰ webhook, ਅਤੇ (3) ਰਿਪੋਰਟ ਅਪਡੇਟ ਜੌਬ। ਈਮੇਲ ਤੇਜ਼ੀ ਨਾਲ retry ਕਰ ਸਕਦੀ ਹੈ, webhook ਵੱਧ ਬੈਕਆਫ ਨਾਲ retry ਕਰਦਾ ਹੈ, ਅਤੇ ਰਿਪੋਰਟ ਗ਼ੈਰ-ਅਹਿਮ ਤੌਰ 'ਤੇ ਬਾਅਦ ਵਿੱਚ ਚਲੇਗੀ।
ਇੱਕ ਯੂਜ਼ਰ ਤੁਹਾਡੀ ਐਪ ਲਈ ਸਾਈਨਅਪ ਕਰਦਾ ਹੈ। ਤਿੰਨ ਜ਼ਰੂਰੀ ਕੰਮ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, ਪਰ ਕੋਈ ਵੀ ਸਾਈਨਅਪ ਪੰਨੇ ਨੂੰ ਸست ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ: welcome email ਭੇਜੋ, CRM ਨੂੰ webhook ਨਾਲ ਸੂਚਿਤ ਕਰੋ, ਅਤੇ ਯੂਜ਼ਰ ਨੂੰ nightly activity report ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰੋ।
ਜਿਵੇਂ ਹੀ ਤੁਸੀਂ user ਰਿਕਾਰਡ ਬਣਾਉਂਦੇ ਹੋ, ਤਿੰਨ jobs ਰੋਜ਼ਾਂ ਨੂੰ ਆਪਣੇ ਡੇਟਾਬੇਸ ਕਿਊ ਵਿਚ ਲਿਖੋ। ਹਰ ਰੋਅ ਵਿੱਚ type, payload (ਜਿਵੇਂ user_id), status, attempt count, ਅਤੇ next_run_at timestamp ਹੁੰਦਾ ਹੈ।
ਟਾਈਪਿਕਲ ਲਾਈਫਸਾਇਕਲ ਇਸ ਤਰ੍ਹਾਂ ਹੁੰਦੀ ਹੈ:
queued: ਬਣਾਇਆ ਗਿਆ ਤੇ ਵਰਕਰ ਵਾਸਤੇ ਉਡੀਕ ਕਰ ਰਿਹਾ ਹੈrunning: ਇੱਕ ਵਰਕਰ ਨੇ ਇਸਨੂੰ ਕਲੇਮ ਕੀਤਾ ਹੈsucceeded: ਮੁਕੰਮਲfailed: ਫੇਲ ਹੋਇਆ, ਬਾਅਦ ਵਿੱਚ ਯਾਤਰਾ ਲਈ ਸ਼ੈਡਿਊਲ ਕੀਤਾ ਗਿਆ ਜਾਂ retries ਖਤਮdead: ਬਹੁਤ ਵਾਰੀ ਫੇਲ ਹੋ ਗਿਆ ਅਤੇ ਮਨੁੱਖੀ ਜਾਂਚ ਦੀ ਲੋੜ ਹੈWelcome email ਜੌਬ ਵਿੱਚ idempotency key ਸ਼ਾਮਿਲ ਹੁੰਦੀ ਹੈ ਜਿਵੇਂ welcome_email:user:123। ਭੇਜਣ ਤੋਂ ਪਹਿਲਾਂ, ਵਰਕਰ ਮੁਕੰਮਲ idempotency keys ਦੀ ਟੇਬਲ ਜਾਂ unique constraint ਚੈੱਕ ਕਰਦਾ ਹੈ। ਜੇ ਜੌਬ ਦੋ ਵਾਰੀ ਚੱਲ ਜਾਵੇ, ਦੂਜੀ ਵਾਰੀ key ਵੇਖ ਕੇ ਛੱਡ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ। ਕੋਈ ਦੋ ਵਾਰੀ welcome email ਨਹੀਂ ਜਾਵੇਗਾ।
ਹੁਣ CRM webhook ਐਂਡਪੌਇੰਟ ਡਾਊਨ ਹੈ। webhook ਜੌਬ ਟਾਈਮਆਉਟ ਨਾਲ ਫੇਲ ਹੋ ਜਾਂਦਾ ਹੈ। ਤੁਹਾਡਾ ਵਰਕਰ ਬੈਕਆਫ (ਉਦਾਹਰਨ: 1 ਮਿੰਟ, 5 ਮਿੰਟ, 30 ਮਿੰਟ, 2 ਘੰਟੇ) ਅਤੇ ਥੋੜ੍ਹਾ jitter ਜੋੜ ਕੇ retry ਸ਼ੈਡਿਊਲ ਕਰਦਾ ਹੈ ਤਾਂ ਕਿ ਕਈ ਜੌਬ ਇਕੋਵੇਲੇ retry ਨਾ ਕਰਨ।
Max attempts ਤੋਂ ਬਾਅਦ, ਜੌਬ dead ਬਣ ਜਾਂਦਾ ਹੈ। ਯੂਜ਼ਰ ਫਿਰ ਵੀ ਸਾਈਨਅਪ ਹੋਇਆ, welcome email ਮਿਲ ਗਿਆ, ਅਤੇ ਨਾਈਟਲੀ ਰਿਪੋਰਟ ਜੌਬ ਸਧਾਰਨ ਤਰੀਕੇ ਨਾਲ ਚਲ ਸਕਦੀ ਹੈ। ਸਿਰਫ CRM ਸੂਚਨਾ ਆਟਕੀ ਰਹਿੰਦੀ ਹੈ ਅਤੇ ਇਹ ਨਜ਼ਰ ਆਉਂਦੀ ਹੈ।
ਅਗਲੇ ਸਵੇਰੇ, support ਜਾਂ ਜਿੰਨਾ ਵੀ on-call ਹੈ, ਉਹ ਇਸਨੂੰ ਘੰਟਿਆਂ ਲੋਗ ਲੱਗਣ ਤੋਂ ਬਚਾਉਂਦੇ ਹੋਏ ਢੁਕਵਾਂ ਤਰੀਕੇ ਨਾਲ ਸੰਭਾਲ ਸਕਦੇ ਹਨ:
webhook.crm) ਨਾਲ ਫਿਲਟਰ ਕਰੋਜੇ ਤੁਸੀਂ Koder.ai 'ਤੇ ਐਪ ਬਣਾਂਉਂਦੇ ਹੋ, ਇਹੋ ਹੀ ਪੈਟਰਨ ਲਾਗੂ ਹੁੰਦੀ ਹੈ: ਯੂਜ਼ਰ ਫਲੋ ਨੂੰ ਤੇਜ਼ ਰੱਖੋ, ਸਾਈਡ-ਅਫੈਕਟਸ ਨੂੰ ਜੌਬਾਂ ਵਿੱਚ ਧੱਕੋ, ਅਤੇ ਫੇਲਯਾਰੀਆਂ ਨੂੰ ਆਸਾਨੀ ਨਾਲ ਦੇਖਣ ਅਤੇ ਦੁਬਾਰਾ ਚਲਾਉਣਯੋਗ ਬਣਾਓ।
ਸਭ ਤੋਂ ਤੇਜ਼ ਤਰੀਕਾ ਕਿਊ ਨੂੰ ਤੋੜਨ ਦਾ ਇਹ ਹੈ ਕਿ ਇਸਨੂੰ ਵਿਕਲਪਿਕ ਸਮਝੋ। ਟੀਮਾਂ ਅਕਸਰ "ਇਸ ਵੇਲੇ ਸਿਰਫ਼ ਇਸ ਵਾਰ ਰਿਕਵੇਸਟ ਵਿੱਚ ਈਮੇਲ ਭੇਜ ਦਿਓ" ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ ਸਧਾਰਨ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ। ਫਿਰ ਇਹ ਫੈਲਦਾ ਹੈ: password resets, receipts, webhooks, report exports. ਜਲਦੀ ਹੀ ਐਪ ਹੌਲੀ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ, ਟਾਈਮਆਉਟ ਵਧਦੇ ਹਨ, ਅਤੇ ਕੋਈ ਤੀਜੀ-ਪੱਖੀ ਖਾਮੀ ਤੁਹਾਡੀ outage ਬਣ ਜਾਂਦੀ ਹੈ।
ਹੋਰ ਇਕ ਆਮ ਫਸਾਉਣਾ idempotency ਛੱਡਣਾ ਹੈ। ਜੇ ਇੱਕ ਜੌਬ ਦੋ ਵਾਰੀ ਚੱਲ ਸਕਦਾ ਹੈ, ਤਾਂ ਇਸਨੂੰ ਦੋ ਨਤੀਜੇ ਬਣਾਉਣ ਲਈ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ। idempotency ਨਹੀਂ ਹੋਵੇ ਤਾਂ retries duplicate emails, repeated webhook events, ਜਾਂ ਹੋਰ ਖਤਰਨਾਕ ਗਲਤੀਆਂ ਕਰ ਸਕਦੇ ਹਨ।
ਤੀਜਾ ਮੁੱਦਾ ਨਜ਼ਰਅੰਦਾਜ਼ੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਕੇਵਲ support ਟਿਕਟਾਂ ਤੋਂ ਫੇਲਿਅਰਾਂ ਬਾਰੇ ਪਤਾ ਲਗਾਉਂਦੇ ਹੋ, ਤਾਂ ਕਿਊ ਪਹਿਲਾਂ ਹੀ ਯੂਜ਼ਰਾਂ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾ ਰਿਹਾ ਹੁੰਦਾ ਹੈ। ਇੱਕ ਬੁਨਿਆਦੀ ਅੰਦਰੂਨੀ ਦ੍ਰਿਸ਼-ਯੂਜ਼ਰ ਜੋ job counts by status ਅਤੇ searchable last_error ਦਿਖਾਉਂਦਾ ਹੈ, ਸਮਾਂ ਬਚਾਉਂਦਾ ਹੈ।
ਕੁਝ ਮੁੱਦੇ ਸ਼ੁਰੂ ਵਿੱਚ ਹੀ ਸਾਹਮਣੇ ਆਉਂਦੇ ਹਨ, ਜEven in simple queues:
ਬੈਕਆਫ ਆਪਣੇ ਆਪ ਬਣਾਉਂਦੇ ਹੋਏ outage ਰੋਕਦਾ ਹੈ। ਇੱਕ ਬੁਨਿਆਦੀ ਸ਼ੈਡਿਊਲ ਜਿਵੇਂ 1 ਮਿੰਟ, 5 ਮਿੰਟ, 30 ਮਿੰਟ, 2 ਘੰਟੇ failure ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦਾ ਹੈ। साथै max attempts limit ਸੈੱਟ ਕਰੋ ਤਾਂ ਕਿ ਟੁੱਟੇ ਹੋਏ ਜੌਬ ਨੂੰ ਰੋਕਿਆ ਜਾ ਸਕੇ ਅਤੇ ਉਹ ਦਿੱਖ ਵਿੱਚ ਆ ਜਾਵੇ।
ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਤ ਰਹੇ ਹੋ, ਇਹ ਬੇਸਿਕਜ਼ ਫੀਚਰ ਦੇ ਨਾਲ feature ਦੇ ਨਾਲ ਹੀ ਸ਼ਿਪ ਕਰਨ ਵਿੱਚ ਮਦਦਗਾਰ ਹੁੰਦੇ ਹਨ, ਨਾ ਕਿ ਹਫ਼ਤਿਆਂ ਬਾਅਦ ਸਾਜ-ਸੰਵਾਰ ਦੇ ਤੌਰ 'ਤੇ।
ਵਧੇਰੇ ਟੂਲ ਜੋੜਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਬੇਸਿਕਜ਼ ਠੀਕ ਹਨ। ਜਦੋਂ ਹਰ ਜੌਬ ਦਾਅਵਾ ਕਰਨ ਯੋਗ, retry ਕਰਨ ਯੋਗ, ਅਤੇ ਇਨਸਪੈਕਟ ਕਰਨ ਯੋਗ ਹੋ, ਡੇਟਾਬੇਸ-ਬੈਕਡ ਕਿਊ ਬਹੁਤ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ।
ਇੱਕ ਤੁਰੰਤ ਭਰੋਸੇਮੰਦੀ ਚੈਕਲਿਸਟ:
ਅਗਲਾ ਕਦਮ: ਆਪਣੇ ਪਹਿਲੇ ਤਿੰਨ job types ਚੁਣੋ ਅਤੇ ਉਹਨਾਂ ਦੇ ਨਿਯਮ ਲਿਖੋ। ਉਦਾਹਰਨ ਲਈ: password reset email (ਤੇਜ਼ retries, ਛੋਟਾ max), nightly report (ਘੱਟ retries, ਲੰਮੇ timeouts), webhook delivery (ਜ਼ਿਆਦਾ retries, ਲੰਮਾ ਬੈਕਆਫ, ਸਥਾਈ 4xx 'ਤੇ ਰੋਕ)।
ਜੇ ਤੁਸੀਂ ਇਹ ਨਿਰਣਾ ਨਹੀਂ ਕਰ ਰਹੇ ਕਿ ਕਦੋਂ ਡੇਟਾਬੇਸ ਕਿਊ ਕਾਫੀ ਨਹੀਂ ਰਹਿੰਦੀ, ਤਾਂ ਇਸ ਤਰ੍ਹਾਂ ਦੇ ਸੰਕੇਤਾਂ ਨੂੰ ਵੇਖੋ: ਬਹੁਤ ਸਾਰੇ ਵਰਕਰਾਂ ਤੋਂ row-level contention, ਬਹੁਤ ਸਕੰਦਾ ordering ਦੀ ਲੋੜ, ਇੱਕ event ਨਾਲ ਹਜ਼ਾਰਾਂ ਜੌਬ trigger ਹੋਣਾ, ਜਾਂ cross-service consumption ਜਿੱਥੇ ਵੱਖ-ਵੱਖ ਟੀਮਾਂ ਵੱਖਰੇ ਵਰਕਰ ਚਲਾਂਦੀਆਂ ਹਨ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਤੇਜ਼ ਪ੍ਰੋਟੋਟਾਈਪ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ Koder.ai (koder.ai) ਵਿੱਚ planning mode ਵਿੱਚ ਫਲੋ ਸਕੇਚ ਕਰ ਸਕਦੇ ਹੋ, ਜੌਬਸ ਟੇਬਲ ਅਤੇ ਵਰਕਰ ਲੂਪ generate ਕਰੋ, ਅਤੇ snapshots ਤੇ rollback ਨਾਲ ਦੋਹਰਾਓ।
If a task can take more than a second or two, or depends on a network call (email provider, webhook endpoint, slow query), move it to a background job.
Keep the user request focused on validating input, writing the main data change, enqueueing a job, and returning a fast response.
Start with a database-backed queue when:
Add a broker/streaming tool later when you need very high throughput, many independent consumers, or cross-service event replay.
Track the basics that answer: what to do, when to try next, and what happened last time.
A practical minimum:
Store inputs, not big outputs.
Good payloads:
user_id, template, report_id)Avoid:
The key is an atomic “claim” step so two workers can’t take the same job.
Common approach in Postgres:
FOR UPDATE SKIP LOCKED)running and set locked_at/locked_byThen your workers can scale horizontally without double-processing the same row.
Assume jobs will run twice sometimes (crashes, timeouts, retries). Make the side effect safe.
Simple patterns:
idempotency_key like welcome_email:user:123This is especially important for emails and webhooks to prevent duplicates.
Use a clear default policy and keep it boring:
Fail fast on permanent errors (like missing email address, invalid payload, most 4xx webhook responses).
Dead-letter means “stop retrying and make it visible.” Use it when:
max_attemptsStore enough context to act:
Handle “stuck running” jobs with two rules:
running jobs older than a threshold and re-queues them (or marks them failed)This lets the system recover from worker crashes without manual cleanup.
Use separation so slow work can’t block urgent work:
If ordering matters, it’s usually “per key” (per user, per webhook endpoint). Add a group_key and ensure only one in-flight job per key to preserve local ordering without forcing global ordering.
job_type, payloadstatus (queued, running, succeeded, failed, dead)attempts, max_attemptsnext_run_at, plus created_atlocked_at, locked_bylast_erroridempotency_key (or another dedupe mechanism)If the job needs big data, store a reference (like report_run_id or a file key) and fetch the real content when the worker runs.
last_error and last status code (for webhooks)When you replay, prefer creating a new job and keeping the dead one immutable.