01 ਨਵੰ 2025·8 ਮਿੰਟ
ਕਿਉਂ ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਸਟਾਰਟਅਪਾਂ ਲਈ ਲਾਗਤ ਦੇ ਮਾਡਲ ਬਦਲਦੇ ਹਨ
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਸਟਾਰਟਅਪਾਂ ਨੂੰ ਫਿਕਸਡ capacity ਵਾਲੇ ਖਰਚਾਂ ਤੋਂ ਇਸਤੇਮਾਲ-ਅਧਾਰਿਤ ਬਿੱਲਿੰਗ ਵੱਲ ਲੈ ਜਾਂਦੇ ਹਨ। ਪ੍ਰਾਇਸਿੰਗ ਕਿਵੇਂ ਕੰਮ ਕਰਦੀ ਹੈ, ਲੁਕਿਆ ਹੋਇਆ ਖਰਚ ਕਿੱਥੇ ਹੁੰਦੇ ਹਨ, ਅਤੇ ਖਰਚ ਦਾ ਅੰਦਾਜ਼ਾ ਕਿਵੇਂ ਲਗਾਇਆ ਜਾਵੇ — ਇਹ ਸਭ ਸਿੱਖੋ।
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਨਾਲ ਕੀ ਬਦਲਦਾ ਹੈ
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਪਹਿਲੇ ਸਵਾਲ ਨੂੰ ਹੀ ਬਦਲ ਦੇਂਦੇ ਹਨ: ਪੂਰਵ-ਨਿਰਧਾਰਿਤ “ਸਾਨੂੰ ਕਿੰਨੀ ਡੇਟਾਬੇਸ capacity ਖ਼ਰੀਦਣੀ ਚਾਹੀਦੀ ਹੈ?” ਦੇ ਬਜਾਏ ਤੁਸੀਂ ਪੁੱਛਦੇ ਹੋ “ਅਸੀਂ ਕਿੰਨੀ ਡੇਟਾਬੇਸ ਵਰਤੋਂਗੇ?” ਇਹ ਸੁਧਾਰਕ ਲੱਗਦਾ ਹੈ, ਪਰ ਇਹ ਬਜਟਿੰਗ, ਫੋਰਕਾਸਟਿੰਗ ਅਤੇ ਇੱਥੋਂ ਤੱਕ ਕਿ ਪ੍ਰੋਡਕਟ ਫੈਸਲਿਆਂ ਨੂੰ ਵੀ ਮੁੜ-ਬਣਾਉਂਦਾ ਹੈ।
ਪ੍ਰੋਵੀਜ਼ਨਿੰਗ ਤੋਂ pay-per-use ਵੱਲ
ਇੱਕ ਪਰੰਪਰਿਕ ਡੇਟਾਬੇਸ ਨਾਲ, ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਸਾਈਜ਼ (CPU/RAM/storage) ਚੁਣਦੇ ਹੋ, ਉਸ ਨੂੰ ਰਿਜ਼ਰਵ ਕਰਦੇ ਹੋ ਅਤੇ ਉਸਦਾ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ, ਚਾਹੇ ਟਰੈਫਿਕ ਜ਼ਿਆਦਾ ਹੋਵੇ ਜਾਂ ਘੱਟ। ਭਾਵੇਂ ਤੁਸੀਂ autoscale ਵਰਤੋ, ਫਿਰ ਵੀ ਤੁਸੀਂ ਇੰਸਟੈਂਸ ਅਤੇ peak capacity ਦੇ ਸੰਦਰਭ ਵਿੱਚ ਸੋਚਦੇ ਹੋ।
ਸਰਵਰਲੈਸ ਵਿੱਚ, ਬਿੱਲ ਆਮ ਤੌਰ 'ਤੇ ਉਪਭੋਗ ਦੀਆਂ ਯੂਨਿਟਾਂ ਨਾਲ ਟ੍ਰੈਕ ਹੁੰਦਾ ਹੈ—ਉਦਾਹਰਨ ਲਈ requests, compute time, read/write operations, storage ਜਾਂ data transfer. ਡੇਟਾਬੇਸ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ scale ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇਸ ਦਾ ਨੁਕਸ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਆਪਣੇ ਐਪ ਦੇ ਅੰਦਰ ਹੋਣ ਵਾਲੀ ਹਰ ਚੀਜ਼ ਲਈ ਸਿੱਧਾ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ: ਹਰ spike, background job ਅਤੇ ਅਣਉਪਯੋਗੀ ਕੁਐਰੀ ਖਰਚ 'ਤੇ ਦਰਜ ਹੋ ਸਕਦੀ ਹੈ।
ਸ਼ੁਰੂਆਤੀ ਦੌਰ ਵਿੱਚ ਲਾਗਤ ਮਾਡਲ ਬਦਲਣਾ ਕਿਉਂ ਮਹੱਤਵਪੂਰਨ ਹੈ
ਆਰੰਭਕ ਦੌਰ ਵਿੱਚ, performance ਆਮ ਤੌਰ 'ਤੇ “ਪਰਯਾਪਤ” ਹੁੰਦੀ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ ਸਪਸ਼ਟ ਯੂਜ਼ਰ ਪੇਨ ਨੂੰ ਨਹੀਂ ਛੁਹ ਦੇਂਦੇ। ਲਾਗਤ, ਦੂਜੇ ਪਾਸੇ, ਤੁਹਾਡੇ runway ਨੂੰ ਤੁਰੰਤ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ।
ਸਰਵਰਲੈਸ ਇਕ ਵੱਡੀ ਫਾਇਦਾ ਦੇ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ idle capacity ਲਈ ਭੁਗਤਾਨ ਨਹੀਂ ਕਰਦੇ, ਖਾਸ ਕਰਕੇ pre-product-market fit ਦੌਰਾਨ ਜਦੋਂ ਟਰੈਫਿਕ ਅਣਪਛਾਤਾ ਹੁੰਦਾ ਹੈ। ਪਰ ਇਸਦਾ ਮਤਲਬ ਇਹ ਵੀ ਹੈ:
- ਤੁਹਾਡੀ ਲਾਗਤ ਚਲਣਯੋਗ ਹੋ ਜਾਂਦੀ ਹੈ, ਨਾ ਕਿ ਜ਼ਿਆਦਾਤਰ ਫਿਕਸਡ।
- ਖਰਚ headcount ਨਾਲੋਂ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲ ਸਕਦੀ ਹੈ, ਇਸ ਲਈ ਅਕਸਰ ਇਨਵੌਇਸ ਆਉਣ ਤੱਕ ਸੂਝ ਨਹੀਂ ਹੁੰਦੀ।
- ਇੰਜੀਨੀਅਰਿੰਗ ਚੋਇਸਾਂ (ਕੁਐਰੀ ਪੈਟਰਨ, caching, batching) ਯੂਨਿਟ ਇਕਾਨੋਮਿਕਸ 'ਤੇ ਜਲਦੀ ਅਸਰ ਪਾਂਦੀਆਂ ਹਨ।
ਇਸ ਲਈ ਫਾਉਂਡਰਾਂ ਨੂੰ ਇਹ ਬਦਲਾਅ ਪਹਿਲਾਂ ਵਿੱਤੀ ਸਮੱਸਿਆ ਵਜੋਂ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ, ਨਾ ਕਿ ਸਕੇਲਿੰਗ ਦੀ ਸਮੱਸਿਆ ਵਜੋਂ।
ਇਸ ਗਾਈਡ ਤੋਂ ਕੀ ਉਮੀਦ ਰੱਖਣੀ ਚਾਹੀਦੀ ਹੈ
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਓਪਰੇਸ਼ਨ ਨੂੰ ਸਧਾਰਨ ਕਰ ਸਕਦੇ ਹਨ ਅਤੇ ਅੱਗੇ ਦੇ ਬੰਧਨ ਹਟਾ ਸਕਦੇ ਹਨ, ਪਰ ਇਹ ਨਵੇਂ ਟਰੇਡ-ਆਫ ਲਿਆਉਂਦੇ ਹਨ: ਕੀਮਤ ਦੀ ਜਟਿਲਤਾ, spikes ਦੌਰਾਨ ਆਕਸਮਿਕ ਖਰਚੇ, ਅਤੇ ਨਵੇਂ ਪ੍ਰਦਰਸ਼ਨ ਵੇਹਵਾਰ (ਜਿਵੇਂ cold starts ਜਾਂ throttling, ਪ੍ਰੋਵਾਈਡਰ ਦੇ ਅਨੁਸਾਰ)।
ਅਗਲੇ ਸੇਕਸ਼ਨਾਂ ਵਿੱਚ ਅਸੀਂ ਵੇਖਾਂਗੇ ਕਿ ਸਰਵਰਲੈਸ ਪ੍ਰਾਇਸਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਕਿਵੇਂ ਕੰਮ ਕਰਦੀ ਹੈ, ਲੁਕਿਆ ਹੋਇਆ ਖਰਚ ਕਿਥੇ ਮਿਲ ਸਕਦਾ ਹੈ, ਅਤੇ ਕਦੋਂ-ਕਿਵੇਂ ਖਰਚ ਦਾ ਫੋਰਕਾਸਟ ਅਤੇ ਨਿਯੰਤਰਣ ਕਰਨਾ ਹੈ—ਚਾਹੇ ਤੁਹਾਡੇ ਕੋਲ ਪੂਰਾ ਡੇਟਾ ਹੋਵੇ ਜਾਂ ਨਾ।
ਸਟਾਰਟਅਪਾਂ ਲਈ ਪਰੰਪਰਿਕ ਡੇਟਾਬੇਸ ਲਾਗਤ ਮਾਡਲ
ਸਰਵਰਲੈਸ ਤੋਂ ਪਹਿਲਾਂ, ਜ਼ਿਆਦਾਤਰ ਸਟਾਰਟਅਪ ਡੇਟਾਬੇਸ ਇਸੇ ਤਰੀਕੇ ਨਾਲ ਖਰੀਦਦੇ ਸਨ ਜਿਵੇਂ ਦਫ਼ਤਰ ਦੀ ਜਗ੍ਹਾ: ਤੁਸੀਂ ਇਕ ਸਾਈਜ਼ ਚੁਣਦੇ ਹੋ, ਪਲਾਨ 'ਤੇ ਸਾਇਨ-ਅਪ ਕਰਦੇ ਹੋ, ਅਤੇ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ ਚਾਹੇ ਤੁਸੀਂ ਉੱਸਦੀ ਪੂਰੀ ਵਰਤੋਂ ਕਰੋ ਜਾਂ ਨਾ ਕਰੋ।
ਫਿਕਸਡ ਲਾਗਤਾਂ: ਪ੍ਰੋਵੀਜ਼ਨਡ capacity ਲਈ ਭੁਗਤਾਨ
ਕਲਾਸਿਕ ਕਲਾਉਡ ਡੇਟਾਬੇਸ ਬਿੱਲ ਆਮ ਤੌਰ 'ਤੇ ਪ੍ਰੋਵੀਜ਼ਨਡ ਇੰਸਟੈਂਸ ਨਾਲ ਡੋਮਿਨੇਟ ਹੁੰਦੀ ਹੈ—ਇਕ ਨਿਸ਼ਚਿਤ ਮਸ਼ੀਨ ਸਾਈਜ਼ (ਜਾਂ ਕਲਸਟਰ ਸਾਈਜ਼) ਜੋ ਤੁਸੀਂ 24/7 ਚਲਾਉਂਦੇ ਹੋ। ਚਾਹੇ ਰਾਤ ਨੂੰ ਟਰੈਫਿਕ ਘੱਟ ਹੋਵੇ, ਮੀਟਰ ਚੱਲਦਾ ਰਹਿੰਦਾ ਹੈ ਕਿਉਂਕਿ ਡੇਟਾਬੇਸ ਅਜੇ ਵੀ “ਚਾਲੂ” ਹੈ।
ਜ਼ਰੂਰਤ ਘਟਾਉਣ ਲਈ, ਟੀਮਾਂ ਅਕਸਰ reserved capacity ਜੋੜਦੀਆਂ ਹਨ (ਇਕ ਜਾਂ ਤਿੰਨ ਸਾਲ ਦੀ ਕਮੇਟਮੈਂਟ ਲਈ ਛੂਟ)। ਇਹ ਪ੍ਰਤੀ-ਘੰਟੇ ਦਰ ਘਟਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਤੁਹਾਨੂੰ ਇੱਕ ਬੇਸਲਾਈਨ ਖਰਚ 'ਤੇ ਲਾਕ ਕਰ ਦਿੰਦਾ ਹੈ ਜੋ ਪ੍ਰੋਡਕਟ pivot, ਵਿਕਾਸ ਰੋਕਣਾ, ਜਾਂ ਆਰਕੀਟੈਕਚਰ ਬਦਲਣ 'ਤੇ ਫਿੱਟ ਨਹੀਂ ਬੈਠ ਸਕਦਾ।
ਫਿਰ ਆਉਂਦਾ ਹੈ overprovisioning: ਅਜਿਹਾ ਇੰਸਟੈਂਸ ਚੁਣਨਾ ਜੋ ਤੁਸੀਂ ਹੁਣੀਂ ਲੋੜ ਨਹੀਂ ਰੱਖਦੇ “ਕਿਸੇ ਇਮਰਜੰਸੀ ਲਈ।” ਇਹ ਇਕ ਬੁੱਧੀਮਾਨ ਚੋਣ ਹੈ ਜਦੋਂ ਤੁਸੀਂ outages ਤੋਂ ਡਰਦੇ ਹੋ, ਪਰ ਇਹ ਤੁਹਾਨੂੰ ਆਰੰਭ 'ਚ ਹੀ ਉੱਚ ਫਿਕਸਡ ਲਾਗਤ ਵੱਲ ਧੱਕ ਦਿੰਦਾ ਹੈ।
ਆਮ ਸਟਾਰਟਅਪ ਪੈਟਰਨ: ਪੀਕ ਲਈ ਖਰੀਦੋ, idle ਲਈ ਭੁਗਤਾਨ ਕਰੋ
ਸਟਾਰਟਅਪਾਂ ਕੋਲ ਮੁਲਾਇਮ, ਪੇਸ਼ਗੀ ਟਰੈਫਿਕ ਕਮ ਹੀ ਹੁੰਦੀ ਹੈ। ਤੁਸੀਂ ਇੱਕ ਪੱਤਰਿਕਾ spike, ਪਲੇਟਫਾਰਮ ਲਾਂਚ, ਜਾਂ ਮਹੀਨੇ ਦੇ ਅਖੀਰ ਦੇ ਰਿਪੋਰਟਿੰਗ ਟਰੈਫਿਕ ਦਾ ਸਾਹਮਣਾ ਕਰ ਸਕਦੇ ਹੋ। ਪਰੰਪਰਿਕ ਡੇਟਾਬੇਸ ਦੇ ਨਾਲ, ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਖ਼ਰਾਬ ਹਫ਼ਤੇ ਲਈ ਸਾਈਜ਼ ਕਰਦੇ ਹੋ, ਕਿਉਂਕਿ ਬਾਅਦ ਵਿੱਚ resize ਕਰਨਾ ਜੋਖ਼ਿਮ ਭਰਿਆ ਹੋ ਸਕਦਾ ਹੈ।
ਨਤੀਜਾ ਇੱਕ ਮਿਸ਼ਮੈਚ ਹੁੰਦਾ ਹੈ: ਤੁਸੀਂ ਪੀਕ capacity ਲਈ ਸਾਰਾ ਮਹੀਨਾ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ, ਜਦਕਿ ਤੁਸੀਂ ਵਾਸਤੇ ਬਹੁਤ ਘੱਟ ਵਰਤੋਂ ਕਰ ਰਹੇ ਹੋ। ਉਹ “idle spend” ਇਨਵੌਇਸ 'ਤੇ ਆਮ ਦਿੱਸਦਾ ਹੈ, ਪਰ ਇਹ ਚੁੱਪਚਾਪ ਇੱਕ ਵੱਡਾ ਰਿਕਰਿੰਗ ਇਨਫਰਾਸਟਰੱਕਚਰ ਖਰਚ ਬਣ ਸਕਦਾ ਹੈ।
ਓਪਰੇਸ਼ਨਲ ਓਵਰਹੈੱਡ ਵੀ ਇੱਕ ਲਾਗਤ ਹੈ
ਪਰੰਪਰਿਕ ਡੇਟਾਬੇਸਾਂ ਨਾਲ ਸਮਾਂ-ਲਾਗਤ ਵੀ ਹੁੰਦੀ ਹੈ ਜੋ ਛੋਟੀ ਟੀਮਾਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ:
- ਰੋਜ਼ਾਨਾ ਰਖ-ਰਖਾਵ (patching, upgrades, backups, tuning)
- ਸਕੇਲਿੰਗ ਕੰਮ (capacity planning, load testing, resizing)
- ਇਨਸਿਡੈਂਟ ਰਿਸਪਾਂਸ ਜਦੋਂ ਅਚਾਨਕ ਲੋਡ ਹੇਠ ਪ੍ਰਦਰਸ਼ਨ ਘਟਦਾ ਹੈ
ਭਾਵੇਂ ਤੁਸੀਂ managed services ਵਰਤ ਰਹੇ ਹੋ, ਫਿਰ ਵੀ ਕਿਸੇ ਨੂੰ ਇਹ ਕਾਰਜ ਸੰਭਾਲਣੇ ਪੈਦੇ ਹਨ। ਇੱਕ ਸਟਾਰਟਅਪ ਲਈ ਇਹ ਲਗਭਗ ਮਹਿੰਗਾ ਇੰਜੀਨੀਅਰਿੰਗ ਸਮਾਂ ਬਣ ਜਾਂਦਾ ਹੈ ਜੋ ਪ੍ਰੋਡਕਟ ਕੰਮ 'ਚ ਲੱਗ ਸਕਦਾ ਸੀ—ਇੱਕ ਗੁਪਤ ਲਾਗਤ ਜੋ ਇਕ ਇਕੱਲੇ ਲਾਈਨ ਆਈਟਮ ਵਿੱਚ ਨਹੀਂ ਦਿਖਦੀ, ਪਰ runway 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਂਦੀ ਹੈ।
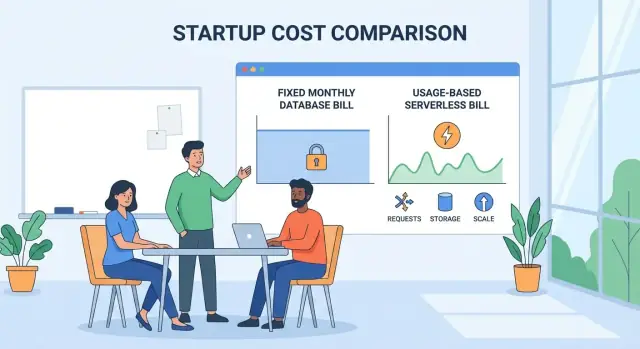
ਸਰਵਰਲੈਸ ਪ੍ਰਾਇਸਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਕਿਵੇਂ ਕੰਮ ਕਰਦੀ ਹੈ
“ਸਰਵਰਲੈਸ” ਡੇਟਾਬੇਸ ਅਕਸਰ managed ਡੇਟਾਬੇਸ ਹੁੰਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਦੀ elastic capacity ਹੁੰਦੀ ਹੈ। ਤੁਸੀਂ ਡੇਟਾਬੇਸ ਸਰਵਰ ਚਲਾਉਂਦੇ, patch ਨਹੀਂ ਕੀਤਾ ਜਾਂਦਾ, ਅਤੇ ਪਹਿਲਾਂ ਤੋਂ instance size ਨਹੀਂ ਚੁਣਦੇ। ਇਸ ਦੀ ਬਜਾਇ, ਪ੍ਰੋਵਾਈਡਰ capacity ਨੂੰ ਉੱਪਰ-ਥੱਲੇ ਕਰਦਾ ਹੈ ਅਤੇ ਵਰਤੋਂ ਦੇ ਸੰਕੇਤਾਂ ਦੇ ਅਧਾਰ 'ਤੇ ਤੁਹਾਨੂੰ ਬਿੱਲ ਕਰਦਾ ਹੈ।
ਮੁੱਖ meters ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਸੀਂ ਬਿੱਲ ਕੀਤੇ ਜਾਂਦੇ ਹੋ
ਜਿਆਦਾਤਰ ਪ੍ਰੋਵਾਈਡਰ ਕੁਝ ਬਿੱਲਿੰਗ ਮੀਟਰ ਮਿਲਾ ਦੇਂਦੇ ਹਨ (ਨਾਵਾਂ ਵੱਖ-ਵੱਖ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਵਿਚਾਰ ਇਕੋ ਹਨ):
- Compute: ਡੇਟਾਬੇਸ ਜੋ queries ਪ੍ਰੋਸੈਸ ਕਰਨ ਲਈ ਕਰਦਾ ਹੈ (ਅਕਸਰ “capacity units” ਪ੍ਰਤੀ ਸਕਿੰਟ/ਮਿੰਟ ਮਾਪੇ ਜਾਂਦੇ ਹਨ)।
- Storage: ਤੁਸੀਂ ਕਿੰਨਾ ਡੇਟਾ ਰੱਖਦੇ ਹੋ, ਕਈ ਵਾਰੀ ਡੇਟਾ ਅਤੇ ਇੰਡੈਕਸ ਵੱਖਰਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
- Reads/Writes (I/O): ਤੁਸੀਂ ਕਿੰਨੀ read ਅਤੇ write operations ਕਰਦੇ ਹੋ, ਜਾਂ ਕਿੰਨਾ ਡੇਟਾ ਸਕੈਨ ਹੁੰਦਾ ਹੈ।
- Requests/Queries: API calls ਜਾਂ SQL requests, ਕਈ ਵਾਰੀ “ਸਧਾਰਣ” ਅਤੇ “ਜਟਿਲ” ਲਈ ਵੱਖਰੇ ਟੀਅਰ ਹੁੰਦੇ ਹਨ।
- Connections: ਸਰਗਰਮ ਕਨੈਕਸ਼ਨ ਜਾਂ ਕਨੈਕਸ਼ਨ ਸਮਾਂ (ਘੱਟ ਆਮ, ਪਰ ਜਰੂਰੀ ਜਦੋਂ ਹੋਵੇ)।
ਕੁਝ ਵੇਂਡਰ backups, replication, data transfer, ਜਾਂ ਖਾਸ ਫੀਚਰਾਂ (encryption keys, point-in-time restore, analytics replicas) ਲਈ ਵੱਖਰਾ ਚਾਰਜ ਕਰਦੇ ਹਨ।
Autoscaling: ਕਿਉਂ ਤੁਹਾਡਾ ਬਿੱਲ ਮੰਗ ਨਾਲ ਹਿਲਦਾ ਹੈ
Autoscaling ਮੁੱਖ ਵਿਵਹਾਰਕ ਬਦਲਾਵ ਹੈ: ਜਦੋਂ ਟਰੈਫਿਕ spike ਕਰਦੀ ਹੈ, ਡੇਟਾਬੇਸ ਪ੍ਰਦਰਸ਼ਨ ਬਣਾਈ ਰੱਖਣ ਲਈ capacity ਵਧਾਉਂਦਾ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਉਸ ਸਮੇਂ ਜ਼ਿਆਦਾ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ। ਜਦੋਂ ਮੰਗ ਘੱਟ ਹੁੰਦੀ ਹੈ, capacity ਘਟਦੀ ਹੈ ਅਤੇ ਲਾਗਤ ਘਟ ਸਕਦੀ ਹੈ—ਕਈ ਵਾਰ spiky ਵਰਕਲੋਡ ਲਈ ਨਾਭੇਤਕੀ ਤੌਰ 'ਤੇ ਨਾਫ਼ਾ ਹੋ ਸਕਦਾ ਹੈ।
ਉਹ ਲਚਕੀਲਾਪਨ ਖਿੱਚਾਉਣ ਵਾਲਾ ਹੈ, ਪਰ ਇਸਦਾ ਨਤੀਜਾ ਇਹ ਵੀ ਹੈ ਕਿ ਤੁਹਾਡਾ ਖਰਚ ਫਿਕਸਡ “instance size” ਨਾਲ ਨਹੀਂ ਜੁੜਦਾ। ਤੁਹਾਡੀ ਲਾਗਤ ਪ੍ਰੋਡਕਟ ਦੀ ਵਰਤੋਂ ਦੇ ਨਮੂਨੇ ਦੀ ਪਿੱਛੇ-ਪਿੱਛੇ ਚੱਲਦੀ ਹੈ: ਇੱਕ ਮਾਰਕੀਟਿੰਗ ਮੁਹਿੰਮ, ਇੱਕ ਬੈਚ ਜੌਬ, ਜਾਂ ਇੱਕ ਅਣਉਪਯੋਗੀ ਕੁਐਰੀ ਤੁਹਾਡੇ ਮਹੀਨਾਵਾਰ ਬਿੱਲ ਨੂੰ ਬਦਲ ਸਕਦੀ ਹੈ।
“ਸਰਵਰਲੈਸ” ਦਾ ਮਤਲਬ “ਸਸਤਾ” ਨਹੀਂ
ਸਰਵਰਲੈਸ ਨੂੰ ਸਰਲਤਾ ਅਤੇ ਉਪਯੋਗਤਾ-ਅਧਾਰਿਤ ਭੁਗਤਾਨ ਦੇ ਤੌਰ 'ਤੇ ਪੜ੍ਹੋ, ਨਾ ਕਿ ਸਦਾ ਲਈ ਛੂਟ। ਮਾਡਲ ਉਤਾਰ-ਚੜ੍ਹਾਅ ਵਾਲੇ ਵਰਕਲੋਡ ਅਤੇ ਤੇਜ਼ iteration ਨੂੰ ਇਨਾਮ ਦਿੰਦਾ ਹੈ, ਪਰ ਜੇ ਵਰਕਲੋਡ ਲਗਾਤਾਰ ਉੱਚ ਹੈ ਜਾਂ ਕੁਐਰੀਆਂ ਅਣਉਪਯੋਗ ਹਨ, ਤਾਂ ਇਹ ਸਜ਼ਾ ਵੀ ਦੇ ਸਕਦਾ ਹੈ।
ਇੰਫ੍ਰਾਸਟਰੱਕਚਰ ਲਾਗਤ ਤੋਂ ਯੂਨਿਟ ਇਕਾਨੋਮੀਕਸ ਤੱਕ
ਪਰੰਪਰਿਕ ਡੇਟਾਬੇਸਾਂ ਨਾਲ, ਸ਼ੁਰੂਆਤੀ ਖਰਚ ਆਕਸਰ “ਕਿਰਾਇਆ” ਵਾਂਗ ਲੱਗਦੇ ਹਨ: ਤੁਸੀਂ ਇੱਕ ਸਰਵਰ ਸਾਈਜ਼ ਲਈ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ (ਨੂੰ replicas, backups ਅਤੇ ops ਸਮੇਂ ਦੇ ਨਾਲ), ਚਾਹੇ ਗਾਹਕ ਆਉਂਦੇ ਹਨ ਜਾਂ ਨਹੀਂ। ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਤੁਹਾਨੂੰ “cost of goods sold” ਸੋਚ ਵੱਲ ਧੱਕਦੇ ਹਨ—ਲਾਗਤ ਤੁਹਾਡੇ ਪ੍ਰੋਡਕਟ ਦੀਆਂ ਸੱਚੀਆਂ ਕਾਰਵਾਈਆਂ ਨਾਲ ਟ੍ਰੈਕ ਹੁੰਦੀ ਹੈ।
ਪ੍ਰੋਡਕਟ ਗਤੀਵਿਧੀ ਨੂੰ ਬਿੱਲਯੋਗ ਯੂਨਿਟਾਂ ਨਾਲ ਮੇਪ ਕਰੋ
ਇਸ ਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਨਿਯੰਤਰਿਤ ਕਰਨ ਲਈ, ਪ੍ਰੋਡਕਟ ਵਿਹਾਰ ਨੂੰ ਡੇਟਾਬੇਸ ਦੇ ਬਿੱਲਯੋਗ ਯੂਨਿਟਾਂ ਨਾਲ ਤਬਦੀਲ ਕਰੋ। ਕਈ ਟੀਮਾਂ ਲਈ ਸਭ ਤੋਂ ਪ੍ਰਯੋਗਸ਼ੀਲ ਮੈਪਿੰਗ ਇਹ ਵਰਗੀ ਦਿਖਦੀ ਹੈ:
- Signups → user records ਬਣਾਏ ਜਾਣ, profile writes, verification lookups
- Sessions → home feeds, cached views, personalization queries ਲਈ reads
- API calls → query executions, transactions, ਜਾਂ request units
- Orders/events → write bursts, inventory checks, audit logs
ਜਦੋਂ ਤੁਸੀਂ ਕਿਸੇ ਫੀਚਰ ਨੂੰ ਇਕ ਮਾਪਯੋਗ ਯੂਨਿਟ ਨਾਲ ਜੋੜ ਸਕਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹੋ: “ਜੇ ਗਤੀਵਿਧੀ ਦੋਗੁਣੀ ਹੋ ਜਾਵੇ, ਤਾਂ ਬਿੱਲ 'ਚ ਕੀ ਦੋਗੁਣੀ ਹੋਵੇਗਾ?”
ਸਧਾਰਨ ਯੂਨਿਟ ਇਕਾਨੋਮਿਕਸ ਮੈਟਰਿਕਸ ਲਾਗੂ ਕਰੋ
ਸਿਰਫ਼ ਕੁੱਲ ਕਲਾਉਡ ਖ਼ਰਚ ਟਰੈਕ ਕਰਨ ਦੀ ਬਜਾਏ, ਕੁਝ “ਲਾਗਤ ਪ੍ਰਤੀ” ਮੈਟ੍ਰਿਕਸ ਲਿਆਓ ਜੋ ਤੁਹਾਡੇ ਕਾਰੋਬਾਰੀ ਮਾਡਲ ਨਾਲ ਮਿਲਦੇ ਹਨ:
- ਲਾਗਤ ਪ੍ਰਤੀ ਯੂਜ਼ਰ (MAU)
- ਲਾਗਤ ਪ੍ਰਤੀ 1,000 ਰਿਕਵੇਸਟਸ (ਜਾਂ ਪ੍ਰਤੀ 1,000 reads/writes)
- ਲਾਗਤ ਪ੍ਰਤੀ ਆਰਡਰ (ਜਾਂ ਪ੍ਰਤੀ workflow completion)
ਇਹ ਨੰਬਰ ਤੁਹਾਨੂੰ ਮਦਦ ਕਰਦੇ ਹਨ ਦੇਖਣ ਵਿੱਚ ਕਿ ਵਾਧਾ ਸਿਹਤਮੰਦ ਹੈ ਜਾਂ ਨਹੀਂ। ਇੱਕ ਪ੍ਰੋਡਕਟ “ਸਕੇਲ” ਹੋ ਰਿਹਾ ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਮਾਰਜਿਨ ਖਾਮੋਸ਼ੀ ਨਾਲ ਬਿਗੜ ਰਹੇ ਹਨ ਜੇ ਡੇਟਾਬੇਸ ਵਰਤੋਂ ਰੇਵੇਨਿਊ ਨਾਲੋਂ ਤੇਜ਼ੀ ਨਾਲ ਵਧਦੀ ਹੈ।
ਕੀਮਤ ਫਰੀਮੀਅਮ ਅਤੇ ਟਰਾਇਲ ਡਿਜ਼ਾਈਨ ਨੂੰ ਕਿਵੇਂ ਅਕਾਰ ਦਿੰਦੀ ਹੈ
ਇਸਤਮਾਲ-ਅਧਾਰਿਤ ਕੀਮਤ ਸਿੱਧੇ ਤੌਰ 'ਤੇ ਇਸ ਗੱਲ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ ਕਿ ਤੁਸੀਂ free tiers ਅਤੇ trials ਨੂੰ ਕਿਵੇਂ ਬਣਾਉਂਦੇ ਹੋ। ਜੇ ਹਰ ਮੁਫ਼ਤ ਯੂਜ਼ਰ ਮਹੱਤਵਪੂਰਨ ਕੁਐਰੀ ਵਾਲੀ ਉਪਜ ਕਰਦਾ ਹੈ, ਤਾਂ ਤੁਹਾਡੇ “ਮੁਫ਼ਤ” ਅਧਿਕਾਰਤ ਚੈਨਲ ਲਈ ਵੈਰੀਏਬਲ ਲਾਗਤ ਹੋ ਸਕਦੀ ਹੈ।
ਪ੍ਰਾਇਕਟਿਕ ਸਧਾਰਨ ਬਦਲਾਅ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ ਮਹਿੰਗੀਆਂ ਕਾਰਵਾਈਆਂ ਨੂੰ ਸੀਮਿਤ ਕਰਨਾ (ਜਿਵੇਂ ਭਾਰੀ search, exports, ਲੰਬੀ history), free plans ਵਿੱਚ retention ਘਟਾਉਣਾ, ਜਾਂ ਉਹ ਫੀਚਰ ਗੇਟ ਕਰਨਾ ਜੋ ਬਰਸਟੀ ਵਰਕਲੋਡ ਨੂੰ ਚਲਾਉਂਦੇ ਹਨ। ਉਦੇਸ਼ ਪ੍ਰੋਡਕਟ ਨੂੰ ਖ਼ਤਮ ਕਰਨਾ ਨਹੀਂ—ਉਦੇਸ਼ ਇਹ ਯਕੀਨੀ ਬਣਾਉਣਾ ਹੈ ਕਿ ਮੁਫ਼ਤ ਅਨੁਭਵ ਇੱਕ ਟਿਕਾਊ cost per activated customer ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ।
ਕਿਉਂ ਸਟਾਰਟਅਪ ਪਹਿਲਾਂ ਪ੍ਰਭਾਵ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ
Ship with safe rollbacks
Snapshots ਅਤੇ rollback ਵਰਤੇ ਤਾਂ ਕਿ ਡੇਟਾਬੇਸ ਬਦਲਾਵਾਂ ਦੀ ਜਾਂਚ recovery ਚਕ੍ਰਾਂ ਦੇ ਬਗੈਰ ਹੋ ਸਕੇ।
ਸਟਾਰਟਅਪ ਆਮ ਤੌਰ 'ਤੇ “ਅੱਜ ਤੁਹਾਨੂੰ ਜੋ ਚਾਹੀਦਾ ਹੈ” ਅਤੇ “ਅਗਲੇ ਮਹੀਨੇ ਤੁਹਾਨੂੰ ਜੋ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ” ਦੇ ਦਰਮਿਆਨ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਅੰਤਰ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ। ਇਹੀ ਥਾਂ ਹੈ ਜਿੱਥੇ ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਲਾਗਤ ਦੀ ਗੱਲ-ਬਾਤ ਬਦਲ ਦਿੰਦੇ ਹਨ: ਉਹ capacity planning (ਅਦਬੁੱਧ ਅੰਦਾਜ਼ਾ) ਨੂੰ ਇੱਕ ਐਸੇ ਬਿੱਲ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ ਜੋ ਅਸਲ ਉਪਯੋਗ ਦੇ ਨਾਲ ਘੁੰਮਦਾ ਹੈ।
ਪਰਪੱਕਚ ਹੋਈ ਕੰਪਨੀਆਂ ਜਿਨ੍ਹਾਂ ਕੋਲ steady baselines ਅਤੇ ਵੱਖ-ਵੱਖ ops ਟੀਮ ਹਨ, ਉਨ੍ਹਾਂ ਨਾਲੋਂ ਜਲਦੀ ਟੀਮਾਂ runway, ਤੇਜ਼ ਪ੍ਰੋਡਕਟ iteration, ਅਤੇ ਅਣਪਛਾਤੀ ਮੰਗ ਨੂੰ ਸੰਭਾਲ ਰਹੀਆਂ ਹੁੰਦੀਆਂ ਹਨ। ਛੋਟਾ ਬਦਲਾਅ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਖ਼ਰਚ ਨੂੰ “ਗੋਲ-ਗੋਲੰਦਾ” ਤੋਂ ਇਕ ਮੁੱਖ ਲਾਈਨ ਆਈਟਮ ਤੱਕ ਲੈ ਜਾ ਸਕਦਾ ਹੈ, ਅਤੇ feedback loop ਤੁਰੰਤ ਹੁੰਦੀ ਹੈ।
ਸਪਾਈਕੀ ਟਰੈਫਿਕ ਆਮ ਹੈ, ਕਿਤੇ ਐੱਜ ਕੇਸ ਨਹੀਂ
ਸ਼ੁਰੂਆਤੀ ਵਾਧਾ ਸਮਤਲ ਅੰਦਾਜ਼ 'ਚ ਨਹੀਂ ਆਉਂਦਾ। ਇਹ ਬਰਸਟਾਂ ਵਿੱਚ ਆਉਂਦਾ ਹੈ:
- ਲਾਂਚ ਦਿਨ ਅਤੇ Product Hunt spikes
- ਮੁਹਿੰਮਾਂ, influencer mentions, ਪਤ੍ਰਕਾਰਤਾ, ਅਤੇ partnership referrals
- ਸੀਜ਼ਨਲ ਪੀਕ (ਛੁੱਟੀਆਂ, ਸਾਲਾਨਾ renewals, ਮਹੀਨੇ ਦੇ ਅਖੀਰ ਦੀ ਵਰਤੋਂ)
ਪਰੰਪਰਿਕ ਡੇਟਾਬੇਸ ਸੈਟਅਪ ਨਾਲ, ਤੁਸੀਂ ਅਕਸਰ ਮਹੀਨੇ ਭਰ ਲਈ ਪੀਕ capacity ਦਾ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ ਤਾਂ ਜੋ ਕੁਝ ਘੰਟਿਆਂ ਦੇ ਪੀਕ ਨੂੰ ਸੰਭਾਲ ਸਕੋ। ਸਰਵਰਲੈਸ ਨਾਲ, elasticity ਕੁਝ ਹੱਦ ਤੱਕ ਵਰਸਟੇਜ ਨੂੰ ਘਟਾ ਸਕਦੀ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਮਹਿੰਗੀ idle headroom ਰੱਖਣ ਦੀ ਲੋੜ ਘੱਟ ਰੱਖਦੇ ਹੋ।
ਸ਼ੁਰੂਆਤੀ ਅਣਿਸ਼ਚਿਤਤਾ fixed sizing ਨੂੰ ਦਰਦਨਾਕ ਬਣਾਉਂਦੀ ਹੈ
ਸਟਾਰਟਅਪ ਅਕਸਰ ਆਸਾਨੀ ਨਾਲ ਦਿਸ਼ਾ ਬਦਲਦੇ ਹਨ: ਨਵੇਂ ਫੀਚਰ, ਨਵੀਆਂ onboarding flows, ਨਵੇਂ pricing tiers, ਨਵੇਂ ਬਾਜ਼ਾਰ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਹਾਡਾ growth curve ਅਣਜਾਣ ਹੈ—ਅਤੇ ਤੁਹਾਡੀ ਡੇਟਾਬੇਸ ਵਰਕਲੋਡ ਅਚਾਨਕ ਬਿਨਾਂ ਚੇਤਾਵਨੀ ਦੇ ਬਦਲ ਸਕਦੀ ਹੈ (ਵਧੇਰੇ reads, ਭਾਰੀ analytics, ਵੱਡੇ documents, ਲੰਬੇ sessions)।
ਜੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਤੋਂ ਪ੍ਰੋਵੀਜ਼ਨ ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਦੋ ਮਹਿੰਗੀਆਂ ਤਰ੍ਹਾਂ ਦੀਆਂ ਗਲਤੀਆਂ ਕਰ ਸਕਦੇ ਹੋ:
- Over-sizing: ਉਹ capacity ਭੁਗਤਾਨ ਕਰਨਾ ਜੋ ਤੁਸੀਂ ਵਰਤ ਨਹੀਂ ਰਹੇ
- Under-sizing: performance ceilings ਨੂੰ ਛੂਹ ਜਾਣਾ, ਜੋ slow pages, failed checkouts, ਜਾਂ degraded user experience ਨੂੰ ਲੈ ਕੇ ਆ ਸਕਦਾ ਹੈ
ਸਰਵਰਲੈਸ ਅੰਡਰ-sizing ਦੇ ਕਾਰਨ outages ਦਾ ਜੋਖ਼ਮ ਘਟਾ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਮੰਗ ਨਾਲ scale ਕਰ ਸਕਦਾ ਹੈ ਨਾ ਕਿ ਕਿਸੇ ਮੈਨੂਅਲ resize ਦਾ ਇੰਤਜ਼ਾਰ ਕਰੇ।
ਪ੍ਰਭਾਵ ਵਿੱਤੀ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਦੋਹਾਂ ਹੈ
ਫਾਉਂਡਰਾਂ ਲਈ ਸਭ ਤੋਂ ਵੱਡੀ ਜਿੱਤ ਸਿਰਫ ਘੱਟ ਔਸਤ ਖ਼ਰਚ ਨਹੀਂ—ਇਹ ਪ੍ਰਤੀਬੱਧਤਾ ਘਟਾਉਣਾ ਵੀ ਹੈ। ਇਸਤੇਮਾਲ-ਅਧਾਰਿਤ ਕੀਮਤ ਤੁਹਾਨੂੰ traction ਨਾਲ ਲਾਗਤ ਨੂੰ ਮੇਲ ਕਰਨ ਦਿੰਦੀ ہے ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਸਿੱਖਣ ਨੂੰ ਸਹਾਇਕ ਹੁੰਦੀ ਹੈ: ਤੁਸੀਂ experiments ਚਲਾ ਸਕਦੇ ਹੋ, ਇੱਕ ਅਚਾਨਕ spike ਨੂੰ ਸਹਿਣ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਫਿਰ ਫੈਸਲਾ ਕਰ ਸਕਦੇ ਹੋ ਕਿ optimize ਕਰਨਾ ਹੈ, capacity reserve ਕਰਨੀ ਹੈ, ਜਾਂ ਵਿਕਲਪ ਵੇਖਣੇ ਹਨ।
ਟਰੇਡ-ਆਫ ਇਹ ਹੈ ਕਿ ਲਾਗਤ ਵੱਧ ਚਲਣਯੋਗ ਹੋ ਸਕਦੀ ਹੈ, ਇਸ ਲਈ ਸਟਾਰਟਅਪਾਂ ਨੂੰ ਜਲਦੀ ਕੁਝ ਹਲਕੇ guardrails (ਬਜਟ, ਅਲਰਟ, ਮੁਢਲੀ usage attribution) ਲਾਉਣੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ ਕਿ ਚੰਨਾ ਸਿਹਂਕਿਆਰ ਹੋਏ ਬਿਨਾਂ elasticity ਦਾ ਫਾਇਦਾ ਲੈ ਸਕਣ।
ਲੁਕਿਆ ਹੋਇਆ ਲਾਗਤ ਚਲਾਉਣ ਵਾਲੇ ਤੱਤ ਜਿਨ੍ਹਾਂ ਨੂੰ ਨਜ਼ਰ ਰੱਖਣੀ ਚਾਹੀਦੀ ਹੈ
ਸਰਵਰਲੈਸ ਬਿਲਿੰਗ activity ਨਾਲ ਖਰਚ ਨੂੰ ਮੈਚ ਕਰਨ ਵਿੱਚ ਮਹਾਨ ਹੈ—ਜਦ ਤਕ “activity” ਵਿੱਚ ਉਹ ਸਾਰਾ ਕੰਮ ਸ਼ਾਮਲ ਨਾ ਹੋ ਜੇ ਜੋ ਤੁਹਾਨੂੰ ਪਤਾ ਹੀ ਨਹੀਂ ਸੀ ਕਿ ਤੁਸੀਂ ਕਰਵਾ ਰਹੇ ਹੋ। ਸਭ ਤੋਂ ਵੱਡੀਆਂ ਹੈਰਾਨੀਆਂ ਛੋਟੀ, ਮੁੜ-ਮੁੜ ਹੋਣ ਵਾਲੀਆਂ ਬਿਹੇਵਿਯਰਾਂ ਤੋਂ ਆਉਂਦੀਆਂ ਹਨ ਜੋ ਸਮੇਂ ਨਾਲ ਗੁਣਾ ਖਾਂਦੀਆਂ ਹਨ।
Storage ਵਾਧਾ ਅਤੇ retention
Storage ਅਕਸਰ ਸਥਿਰ ਨਹੀਂ ਰਹਿੰਦੀ। event tables, audit logs, ਅਤੇ product analytics ਤੁਹਾਡੇ ਕੋਰ ਯੂਜ਼ਰ ਡੇਟਾ ਨਾਲੋਂ ਤੇਜ਼ੀ ਨਾਲ ਵਧ ਸਕਦੇ ਹਨ।
Backups ਅਤੇ point-in-time recovery ਵੀ ਅਲੱਗ ਚਾਰਜ ਹੋ ਸਕਦੇ ਹਨ (ਜਾਂ ਪ੍ਰਭਾਵਤ ਤੌਰ 'ਤੇ storage ਨੂੰ ਦੁਹਰਾਉਂਦੇ ਹਨ)। ਇੱਕ ਸਧਾਰਨ guardrail retention ਨੀਤੀਆਂ ਨਿਰਧਾਰਤ ਕਰਨਾ ਹੈ ਲਈ:
- application logs ਅਤੇ events
- historical snapshots ਅਤੇ exports
- test environments ਜੋ ਅਕਸਰ production-ਜੇਹੇ ਡੇਟਾਸੈਟ ਰੱਖ ਲੈਂਦੇ ਹਨ
ਨੈੱਟਵਰਕ ਅਤੇ ਡੇਟਾ ਟਰਾਂਸਫਰ ਚਾਰਜ
ਕਈ ਟੀਮ ਸੋਚਦੀਆਂ ਹਨ ਕਿ “ਡੇਟਾਬੇਸ ਲਾਗਤ” ਸਿਰਫ reads/writes ਅਤੇ storage ਹੈ। ਪਰ ਨੈੱਟਵਰਕ ਚੁਪਚਾਪ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੋ ਸਕਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ:
- app servers ਇਕ ਰੀਜਨ ਵਿੱਚ ਚਲਾਉਂਦੇ ਹੋ ਅਤੇ ਡੇਟਾਬੇਸ ਦੂਜੇ ਰੀਜਨ ਵਿੱਚ
- ਰੀਪਲੇਕੇਸ਼ਨ cross-region ਕਰਦੇ ਹੋ
- ਵੱਡੇ result sets ਕਲਾਇੰਟ ਜਾਂ analytics ਟੂਲਾਂ ਨੂੰ ਭੇਜਦੇ ਹੋ
ਭਾਵੇਂ ਪ੍ਰੋਵਾਈਡਰ ਘੱਟ ਪ੍ਰਤੀ-ਰਿਕਵੈਸਟ ਕੀਮਤ ਦਿਖਾਵੇ, inter-region ਟਰੈਫਿਕ ਅਤੇ egress ਇੱਕ ਠੋਸ ਲਾਈਨ ਆਈਟਮ ਬਣ ਸਕਦੇ ਹਨ।
ਅਣਉਪਯੋਗੀ ਕੁਐਰੀਆਂ ਜੋ ਵਰਤੋਂ ਨੂੰ ਗੁਣਾ ਕਰਦੀਆਂ ਹਨ
ਇਸਤਮਾਲ-ਅਧਾਰਿਤ ਕੀਮਤ ਖ਼ਰਾਬ ਕੁਐਰੀ ਪੈਟਰਨਾਂ ਨੂੰ ਵਧਾ ਦੇਂਦੀ ਹੈ। N+1 ਕੁਐਰੀਆਂ, missing indexes, ਅਤੇ ਅਣਬਾਊਂਡ ਸਕੈਨ ਇੱਕ ਯੂਜ਼ਰ ਕਾਰਵਾਈ ਨੂੰ ਦਰਜਨ (ਜਾਂ ਸੈਂਕੜੇ) ਬਿੱਲ ਕੀਤੇ ਜਾਂਦੇ ਓਪਰੈਸ਼ਨਾਂ ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹਨ।
ਜਿੱਥੇ latency dataset ਸਾਈਜ਼ ਨਾਲ ਵੱਧਦੀ ਹੋਵੇ, ਉੱਥੇ ਆਮ ਤੌਰ 'ਤੇ ਲਾਗਤ ਗੈਰ-ਰੇਖੀ ਹੁੰਦੀ ਹੈ।
ਕਨੈਕਸ਼ਨ ਸਟਾਰਮ ਅਤੇ concurrency ਹੱਦਾਂ
ਸਰਵਰਲੈਸ ਐਪ ਤੇਜ਼ੀ ਨਾਲ scale ਕਰ ਸਕਦੇ ਹਨ, ਜਿਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਕਨੈਕਸ਼ਨ ਗਿਣਤੀ ਵੀ ਤੁਰੰਤ spike ਕਰ ਸਕਦੀ ਹੈ। cold starts, autoscaling events, ਅਤੇ “thundering herd” retries ਐਸੇ ਬਰਸਟ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜੋ:
- billed compute/request units ਵਧਾਉਂਦੀਆਂ ਹਨ
- throttling-trigger ਹੋਕੇ ਹੋਰ retries ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ (ਅਤੇ ਹੋਰ ਵਰਤੋਂ)
ਜੇ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਪ੍ਰਤੀ-ਕਨੈਕਸ਼ਨ ਜਾਂ ਪ੍ਰਤੀ-concurrency billing ਕਰਦਾ ਹੈ, ਤਾਂ deploys ਜਾਂ incidents ਦੌਰਾਨ ਇਹ ਖ਼ਾਸ ਤੌਰ 'ਤੇ ਮਹਿੰਗਾ ਪੈ ਸਕਦਾ ਹੈ।
ਬੈਕਗ੍ਰਾਉਂਡ ਜੌਬ ਅਤੇ analytics ਵਰਕਲੋਡ
Backfills, re-indexing, recommendation jobs, ਅਤੇ dashboard refreshes “ਪ੍ਰੋਡਕਟ ਵਰਤੋਂ” ਜਿਹਾ محسوس ਨਹੀਂ ਹੁੰਦੇ, ਪਰ ਅਕਸਰ ਇਹ ਸਭ ਤੋਂ ਵੱਡੀਆਂ ਕੁਐਰੀਆਂ ਅਤੇ ਲੰਬੇ-ਲੰਬੇ reads ਚਲਾਉਂਦੇ ਹਨ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਨਿਯਮ: analytics ਅਤੇ batch processing ਨੂੰ ਵੱਖਰੇ ਵਰਕਲੋਡ ਵਜੋਂ ਟ੍ਰੀਟ ਕਰੋ, ਉਹਨਾਂ ਲਈ ਵੱਖਰਾ ਬਜਟ ਅਤੇ ਸ਼ਡਿਊਲ ਬਣਾਓ, ਤਾਂ ਜੋ ਉਹ ਚੁਪਚਾਪ ਉਪਭੋਗਤਾ ਸਰਵਿਸ ਲਈ ਰੱਖੇ ਬਜਟ ਨੂੰ ਖ਼ਤਮ ਨਾ ਕਰ ਦਿਓ।
ਲਾਗਤ-ਵਿਰੁੱਧ-ਪ੍ਰਦਰਸ਼ਨ ਟਰੇਡਆਫ
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਸਿਰਫ ਇਹ ਨਹੀਂ ਬਦਲਦੇ ਕਿ ਤੁਸੀਂ ਕਿੰਨਾ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ—ਉਹ ਇਹ ਵੀ ਬਦਲਦੇ ਹਨ ਕਿ ਤੁਸੀਂ ਕਿਸ ਲਈ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ। ਮੁੱਖ ਟਰੇਡਆਫ ਸਧਾਰਨ ਹੈ: ਤੁਸੀਂ scale-to-zero ਨਾਲ idle ਖ਼ਰਚ ਘਟਾ ਸਕਦੇ ਹੋ, ਪਰ ਤੁਸੀਂ latency ਅਤੇ ਵਿਵਿਧਤਾ ਲਿਆ ਸਕਦੇ ਹੋ ਜੋ ਯੂਜ਼ਰਾਂ ਨੂੰ ਪਤਾ ਲੱਗ ਸਕਦੀ ਹੈ।
Cold starts ਅਤੇ scale-to-zero: ਕਦੋਂ ਫਾਇਦਾ ਅਤੇ ਕਦੋਂ ਨੁਕਸਾਨ
Scale-to-zero spiky ਵਰਕਲੋਡ ਲਈ ਬਹੁਤ ਵਧੀਆ ਹੈ: admin dashboards, internal tools, early MVP ਟਰੈਫਿਕ, ਜਾਂ ਹਫ਼ਤਾਵਾਰੀ batch jobs. ਤੁਸੀਂ ਉਹ capacity ਲਈ ਭੁਗਤਾਨ ਰੋਕ ਦਿੰਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਵਰਤ ਨਹੀਂ ਰਹੇ।
ਨੁਕਸਾਨ cold starts ਹੈ। ਜੇ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ (ਜਾਂ ਉਸ ਦੀ compute layer) idle ਹੋ ਜਾਵੇ, ਤਾਂ ਅਗਲੀ ਰਿਕਵੈਸਟ 'ਤੇ ਇੱਕ “wake-up” penalty ਲੱਗ ਸਕਦੀ ਹੈ—ਕਈ ਵਾਰੀ ਕੁਝ ਸੌ ਮਿਲੀਸੈਕੰਡ, ਕਈ ਵਾਰੀ ਸੈਕੰਡ—ਸੇਵਾ ਅਤੇ ਕੁਐਰੀ ਪੈਟਰਨ ਦੇ ਅਨੁਸਾਰ। ਇਹ ਪਿਛੇ ਰਹਿਣ ਵਾਲੀਆਂ ਕਾਰਵਾਈਆਂ ਲਈ ਠੀਕ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਦਰਜਨਾਂ ਲਈ ਦਿਲਚਸਪ ਹੋ ਸਕਦਾ ਹੈ:
- Checkout ਅਤੇ login flows
- ਯੂਜ਼ਰ-ਲੰਬੀ search ਜਾਂ feeds
- APIs ਜਿੰਨ੍ਹਾਂ ਨੂੰ ਸਖ਼ਤ p95/p99 latency ਟੀਚੇ ਚਾਹੀਦੇ ਹਨ
ਅਕਸਰ ਸਟਾਰਟਅਪ ਦਾ ਗਲਤ ਪਸੇ: ਮਹੀਨਾਵਾਰ ਬਿੱਲ ਘੱਟ ਕਰਨ ਲਈ optimize ਕਰਨਾ, ਪਰ ਨਾ ਜਾਣਦੇ ਹੋਏ performance “ਬਜਟ” ਖਰਚ ਕਰਨਾ ਜੋ conversion ਜਾਂ retention ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦਾ ਹੈ।
caching ਅਤੇ warm-up ਰਣਨੀਤੀਆਂ ਜੋ ਲਾਗਤ ਅਤੇ latency ਨੂੰ ਸੰਤੁਲਿਤ ਕਰਦੀਆਂ ਹਨ
ਤੁਸੀਂ cold-start ਪ੍ਰਭਾਵ ਨੂੰ ਘਟਾ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਲਾਗਤ-ਬਚਤ ਤਿਆਗੇ:
- ਗਰਮ ਰੀਡ ਨੂੰ edge cache ਜਾਂ managed Redis ਵਿੱਚ cache ਕਰੋ ਤਾਂ ਕਿ ਦੁਹਰਾਉਂਦੀਆਂ ਕੁਐਰੀਆਂ ਘਟ ਜਾਣ
- ਮਹਿੰਗੇ ਨਤੀਜੇ ਪਹਿਲਾਂ ਹੀ ਪ੍ਰੀਕੰਪਿਊਟ ਕਰੋ (counts, rollups, recommendations) ਤਾਂ ਕਿ ਰਿਕਵੇਸਟਾਂ ਨੂੰ ਘੱਟ ਕੰਮ ਕਰਨਾ ਪਏ
- Warm-up schedules (ਹਲਕੀ ping ਹਰ ਕੁਝ ਮਿੰਟਾਂ 'ਤੇ) ਕਾਰੋਬਾਰੀ ਘੰਟਿਆਂ ਦੌਰਾਨ ਸਿਸਟਮ ਨੂੰ ਜੋਗਿਆਂ ਬਣਾਈ ਰੱਖਣਗੀਆਂ, ਜਦਕਿ ਰਾਤ ਨੂੰ ਫਿਰ scale-down ਹੋ ਸਕਦਾ ਹੈ
ਧਿਆਨ: ਹਰ ਮਿਟੀਗੇਸ਼ਨ ਖਰਚ ਨੂੰ ਇਕ ਹੋਰ ਲਾਈਨ ਆਈਟਮ (cache, functions, scheduled jobs) 'ਤੇ ਸਥਾਨਕ ਕਰਦਾ ਹੈ। ਇਹ ਅਕਸਰ ਹਮੇਸ਼ਾ-ਚਾਲੂ capacity ਨਾਲੋਂ ਸਸਤਾ ਹੁੰਦਾ ਹੈ, ਪਰ ਜਦੋਂ ਟਰੈਫਿਕ ਸਥਿਰ ਹੋਵੇ ਤਾਂ ਮੈਪ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਰੀਅਲ-ਟਾਈਮ ਸਰਵਿੰਗ, ਬੈਚ, ਅਤੇ ਹਾਈਬ੍ਰਿਡ ਪਹੁੰਚਾਂ ਵਿਚੋਂ ਚੋਣ
ਵਰਕਲੋਡ ਦੀ ਸਰੂਪਤਾ ਸਭ ਤੋਂ ਵਧੀਆ ਲਾਗਤ/ਪ੍ਰਦਰਸ਼ਨ ਸੰਤੁਲਨ ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ:
- ਰੀਅਲ-ਟਾਈਮ ਸਰਵਿੰਗ (ਘੱਟ latency, ਉੱਚ ਉਪਲਬਧਤਾ): ਘੱਟੋ-ਘੱਟ provisioned capacity ਜਾਂ ਸੇਵਾਵਾਂ ਨੂੰ warm ਰੱਖਣ 'ਤੇ ਧਿਆਨ ਦਿਓ
- ਬੈਚ (ETL, ਰਿਪੋਰਟ): ਸਰਵਰਲੈਸ ਚਮਕਦਾਰ ਹੈ—tezz chalao, finish fast, ਸਿਰਫ਼ ਜੌਬ ਲਈ ਭੁਗਤਾਨ ਕਰੋ
- ਹਾਈਬ੍ਰਿਡ: ਪ੍ਰੀਕੰਪਿਊਟ ਕੀਤੀਆਂ ਟੇਬਲਾਂ ਜਾਂ caches ਤੋਂ ਰੀਅਲ-ਟਾਈਮ ਸਰਵ ਕਰੋ, ਅਤੇ ਭਾਰੀ joins/aggregations ਨੂੰ ਬੈਚ ਵਿੱਚ ਚਲਾਓ
ਫਾਉਂਡਰਾਂ ਲਈ ਪ੍ਰਾਇਕਟਿਕ ਸਵਾਲ: ਕਿਹੜੀਆਂ ਯੂਜ਼ਰ ਕਾਰਵਾਈਆਂ ਨੂੰ ਲਗਾਤਾਰ ਤੇਜ਼ੀ ਦੀ ਲੋੜ ਹੈ, ਅਤੇ ਕਿਹੜੀਆਂ ਨੂੰ ਦੇਰੀ ਸਹਿ ਸਕਦੀ ਹੈ? ਡੇਟਾਬੇਸ ਮੋਡ ਨੂੰ ਉਸ ਜਵਾਬ ਨਾਲ ਮੇਲ ਖਾਣ ਦੇ ਲਈ ਅਲਾਇਨ ਕਰੋ, ਸਿਰਫ਼ ਬਿੱਲ ਦੇ ਨਾਲ ਨਹੀਂ।
ਬਿਨਾਂ ਪੂਰੇ ਡੇਟਾ ਦੇ ਲਾਗਤ ਦਾ ਫੋਰਕਾਸਟ ਕਰਨਾ
Prototype your unit economics
ਬਿਲਡ ਕਰਦੇ ਸਮੇਂ ਉਪਭੋਗਤਾ ਕਿਰਿਆਵਾਂ ਨੂੰ ਮਾਪਯੋਗ ਰੀਡ ਅਤੇ ਰਾਈਟ ਵਿੱਚ ਤਬਦੀਲ ਕਰੋ।
ਸ਼ੁਰੂਆਤ ਵਿੱਚ, ਤੁਸੀਂ ਅਕਸਰ ਆਪਣੇ ਕੁਐਰੀ ਮਿਕਸ, ਪੀਕ ਟਰੈਫਿਕ, ਜਾਂ ਫੀਚਰਾਂ ਦੀ ਦਹਨ-ਗ੍ਰਹਣਸ਼ੀਲਤਾ ਨਹੀਂ ਜਾਣਦੇ। ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸਾਂ ਦੇ ਨਾਲ, ਉਹ ਅਣਿਸ਼ਚਿਤਤਾ ਅਹਿਮ ਹੋ ਜਾਂਦੀ ਹੈ ਕਿਉਂਕਿ ਬਿੱਲ ਵਰਤੋਂ ਨੂੰ ਨਜ਼ਦੀਕੀ ਤੋਂ ਟ੍ਰੈਕ ਕਰਦਾ ਹੈ। ਲਕੜੀ ਦਾ ਮੰਤਵ ਸੁੱਧ ਨਹੀਂ—ਇੱਕ “ਠੀਕ ਕਾਫੀ” ਰੇਂਜ ਪ੍ਰਾਪਤ ਕਰਨਾ ਹੈ ਜੋ ਝਟਕੇ ਵਾਲੇ ਬਿੱਲ ਤੋਂ ਬਚਾਏ ਅਤੇ ਕੀਮਤ ਫੈਸਲਿਆਂ ਦਾ ਸਮਰਥਨ ਕਰੇ।
ਇੱਕ ਸਧਾਰਾ ਫੋਰਕਾਸਟਿੰਗ ਤਰੀਕਾ: baseline + growth + peak multiplier
ਇੱਕ ਪ੍ਰਤੀਨਿਧੀ ਹਫਤੇ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ ਜੋ “ਨਿਆਦਾ” ਵਰਤੋਂ ਦਰਸਾਉਂਦਾ ਹੋਵੇ (ਅਜੇ ਚਾਹੇ staging ਜਾਂ ਛੋਟੇ beta ਤੋਂ)। ਪ੍ਰੋਵਾਈਡਰ ਜੋ ਮੀਟਰ ਕਰਦਾ ਹੈ ਉਹਨਾਂ ਦੀਆਂ ਕੁਝ usage ਮੈਟ੍ਰਿਕਸ ਨੂੰ ਮਾਪੋ (ਆਮ: reads/writes, compute time, storage, egress)।
ਫਿਰ ਤਿੰਨ ਕਦਮਾਂ ਵਿੱਚ ਫੋਰਕਾਸਟ ਕਰੋ:
- Baseline: ਅੱਜ ਦੀ ਔਸਤ ਦੈਨਿਕ ਵਰਤੋਂ ਅਤੇ ਲਾਗਤ।
- Growth: ਇੱਕ ਹਫਤਾਵਾਰ/ਮਹੀਨਾਵਾਰ ਵਾਧਾ ਦਰ ਜੋ ਇੱਕ ਪ੍ਰੋਡਕਟ ਮੈਟਰਿਕ ਨਾਲ ਜੁੜੀ ਹੋਈ ਹੈ (signups, WAU, orders)।
- Peak multiplier: launches, marketing spikes, ਅਤੇ batch jobs ਲਈ baseline ਨੂੰ ਇੱਕ ਗੁਣਾ (ਅਕਸਰ 2× ਤੋਂ 5×)
ਇਹ ਤੁਹਾਨੂੰ ਇੱਕ ਬੈਂਡ ਦਿੰਦਾ ਹੈ: ਉਮੀਦ ਕੀਤੀ ਲਾਗਤ (baseline + growth) ਅਤੇ “stress spend” (peak multiplier)। cash flow ਦਾ ਯੋਜਨਾ stress ਨੰਬਰ ਦੇ अनुसार ਕਰੋ, ਨਾ ਕਿ ਸਿਰਫ ਔਸਤ।
ਕੁੰਜੀ ਮੀਲ ਦੀਆਂ ਹੱਦਾਂ 'ਤੇ ਲੋਡ ਟੈਸਟਾਂ ਨਾਲ ਲਾਗਤ ਅੰਦਾਜ਼ਾ
1k, 10k, ਅਤੇ 100k users ਵਰਗੀਆਂ milestones ਲਈ representative endpoints 'ਤੇ ਹਲਕੇ load tests ਚਲਾਓ ਤਾਂ ਕਿ ਖਰਚ ਦਾ ਅੰਦਾਜ਼ਾ ਲਗ ਸਕੇ। ਉਦਦੇਸ਼ ਬਿਲਕੁਲ ਸਹੀ ਨਹੀਂ—ਉਦੇਸ਼ ਇਹ ਪਤਾ ਲਾਉਣਾ ਹੈ ਕਿ ਕਦੋਂ ਖਰਚੀ ਕ੍ਰਿਵ ਬੈਂਡ ਹੁੰਦੀ ਹੈ (ਉਦਾਹਰਨ: ਜਦ ਇੱਕ chat ਫੀਚਰ writes ਦੁੱਗਣੇ ਕਰ ਦੇਂਦਾ, ਜਾਂ analytics ਕੁਐਰੀ ਭਾਰੀ scans ਟ੍ਰਿਗਰ ਕਰਦੀ)।
ਨਤੀਜੇ ਨਾਲ assumptions ਲਿਖੋ: average requests per user, read/write ਅਨੁਪਾਤ, ਅਤੇ peak concurrency।
ਹੈਰਾਨੀਆਂ ਹੋਣ ਤੋਂ ਪਹਿਲਾਂ guardrails ਰੱਖੋ
ਮਹੀਨਾਵਾਰ ਬਜਟ ਰੱਖੋ, ਫਿਰ alerts thresholds (ਉਦਾਹਰਨ 50%, 80%, 100%) ਅਤੇ ਦੈਨੀਕ ਖਰਚ 'ਤੇ “abnormal spike” alert। alerts ਨੂੰ ਇੱਕ playbook ਨਾਲ ਜੋੜੋ: ਗੈਰ-ਜ਼ਰੂਰੀ jobs ਨੂੰ ਬੰਦ ਕਰੋ, logging/analytics ਕੁਐਰੀਆਂ ਘਟਾਓ, ਜਾਂ ਮਹਿੰਗੇ endpoints 'ਤੇ rate-limit ਲਗਾਓ।
ਅੰਤੀਮ ਤੌਰ 'ਤੇ, ਪ੍ਰੋਵਾਈਡਰਾਂ ਜਾਂ ਟੀਅਰਾਂ ਦੀ ਤੁਲਨਾ ਕਰਦਿਆਂ, ਉਹੀ usage assumptions ਵਰਤੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ /pricing 'ਤੇ sanity-check ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਅੰਕ-ਬਜੁਦਾ ਮਿਲਾ-ਤੁਲਨਾ ਕਰ ਰਹੇ ਹੋ।
ਪ੍ਰਯੋਗਤਮਕ ਲਾਗਤ ਨਿਯੰਤਰਣ ਅਤੇ guardrails
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਕਾਰਗੁਜ਼ਾਰੀ ਦੀ ਇਨਾਮ ਦਿੰਦੇ ਹਨ, ਪਰ ਉਹ ਚੱਕਰਬੱਧਾ ਨੂੰ ਸਜ਼ਾ ਵੀ ਦੇ ਸਕਦੇ ਹਨ। ਉਦੇਸ਼ ਇਹ ਨਹੀਂ ਕਿ “ਸਬਰਦਾਰੀ ਹਰ ਚੀਜ਼ ਦਾ ਅਪਟਿਮਾਈਜ਼ ਕਰੋ”—ਉਦੇਸ਼ runaway spend ਨੂੰ ਰੋਕਣਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਹਾਲੇ ਵੀ ਆਪਣੇ ਟਰੈਫਿਕ ਪੈਟਰਨ ਸਿੱਖ ਰਹੇ ਹੋ।
environment ਅਨੁਸਾਰ ਬਜਟ ਸੈਟ ਕਰੋ
dev, staging, ਅਤੇ prod ਨੂੰ ਵੱਖ-ਵੱਖ ਉਤਪਾਦ ਵਜੋਂ ਲਓ ਅਤੇ ਵੱਖ-ਵੱਖ ਸੀਮਾਵਾਂ ਰੱਖੋ। ਆਮ ਗਲਤੀ ਇਹ ਹੈ ਕਿ experimental workloads ਨੂੰ customer traffic ਦੇ billing pool ਨਾਲ ਸਾਂਝਾ ਹੋਣ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ।
ਹਰ environment ਲਈ ਮਹੀਨਾਵਾਰ ਬਜਟ ਰੱਖੋ ਅਤੇ alerts thresholds ਲਾਉ। Dev ਨੂੰ ਜਾਣਬੂਝ ਕੇ ਤੰਗ ਰੱਖੋ: ਜੇ migration test ਅਸਲ ਪੈਸਾ ਬਰਬਾਦ ਕਰ ਸਕਦੀ ਹੈ, ਤਾਂ ਇਹ ਜ਼ੋਰ ਨਾਲ fail ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਇਟਰੈਟ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਉਹ tooling ਵਰਤੋਂ ਜੋ “safe change + fast rollback” ਰੁਟੀਨ ਬਣਾ ਦੇਵੇ। ਉਦਾਹਰਨ ਲਈ, Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ snapshots ਅਤੇ rollback ਨੂੰ ਜ਼ੋਰ ਦੇਂਦੇ ਹਨ ਤਾਂ ਕਿ ਤੁਸੀਂ experiments ship ਕਰ ਸਕੋ ਅਤੇ ਲਾਗਤ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ regressions 'ਤੇ ਕਾਬੂ ਰੱਖ ਸਕੋ।
ਲਾਗਤ ਨੂੰ ਟੈਗਿੰਗ ਅਤੇ allocation ਨਾਲ ਵਿਜ਼ੀਬਲ ਬਣਾਓ
ਜੇ ਤੁਸੀਂ ਲਾਗਤ ਨੂੰ atributable ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਤੁਸੀਂ ਉਸਨੂੰ manage ਨਹੀਂ ਕਰ ਸਕਦੇ। ਪਹਿਲੇ ਦਿਨ ਤੋਂ tags/labels standardize ਕਰੋ ਤਾਂ ਕਿ ਹਰ ਡੇਟਾਬੇਸ, ਪ੍ਰੋਜੈਕਟ, ਜਾਂ usage meter ਇੱਕ ਸਰਵਿਸ, ਟੀਮ, ਅਤੇ (ਸਭ ਤੋਂ ਵਧੀਆ) ਇੱਕ ਫੀਚਰ ਨਾਲ ਜੋੜੀ ਜਾ ਸਕੇ।
ਇੱਕ ਸਧਾਰਾ ਯੋਜਨਾ ਲਗਾਓ ਅਤੇ reviews ਵਿੱਚ enforcement ਕਰੋ:
- service: api, worker, analytics
- team: growth, core, data
- feature: search, onboarding, recommendations
ਇਸ ਨਾਲ “ਡੇਟਾਬੇਸ ਬਿੱਲ ਵਧ ਗਿਆ” ਸਥਾਨਕ ਤੌਰ 'ਤੇ “release X ਤੋਂ ਬਾਅਦ search reads ਦੁੱਗਣੇ ਹੋ ਗਏ” ਵਿੱਚ ਤਬਦੀਲ ਹੋ ਜਾਂਦਾ ਹੈ।
runaway ਬਿੱਲ ਰੋਕਣ ਲਈ ਸੋਝੀਆਂ defaults
ਜ਼ਿਆਦਾਤਰ spike ਖਰਚ ਇਕ ਛੋਟੇ ਨੰਬਰ ਖਰਾਬ ਪੈਟਰਨਾਂ ਤੋਂ ਆਉਂਦੇ ਹਨ: tight polling loops, missing pagination, unbounded queries, ਅਤੇ accidental fan-out.
ਹਲਕੀ guardrails ਸ਼ਾਮਲ ਕਰੋ:
- ਕਿਸੇ ਵੀ ਬਦਲਾਅ ਲਈ query review ਜੋ hot paths ਨੂੰ ਛੂਹਦਾ ਹੈ (ਖਾਸ ਕਰਕੇ ਨਵੇਂ indexes, joins, ਜਾਂ full scans)
- ਪ੍ਰਤੀ endpoint ਅਤੇ ਪ੍ਰਤੀ ਗਾਹਕ rate limits ਤਾਂ ਜੋ ਇੱਕ tenant ਸਾਰਾ ਖਰਚ ਨਾ ਖਾ ਲਏ
- Safe defaults: pagination required, max page size, timeouts, ਅਤੇ maximum result limits
caps, quotas, ਅਤੇ circuit breakers
ਜਦ downside of downtime open-ended bill ਤੋਂ ਘੱਟ ਹੋ, ਤਾਂ hard limits ਵਰਤੋਂ:
- Caps/quotas: dev/staging ਅਤੇ internal tools ਲਈ ਵਧੀਆ; prod ਵਿੱਚ per-tenant quotas 'ਤੇ ਵਿਚਾਰ ਕਰੋ
- Circuit breakers: ਜੇ spend ਜਾਂ QPS ਇੱਕ ਹੱਦ ਤੋਂ ਉੱਪਰ ਜਾਵੇ, ਤਾਂ graceful degrade (cache ਕੀਤੇ ਡੇਟਾ serve ਕਰੋ, ਭਾਰੀ ਫੀਚਰ disable ਕਰੋ, ਜਾਂ “ਕਿਰਪਾ ਕਰਕੇ ਬਾਅਦ ਵਿੱਚ ਕੋਸ਼ਿਸ਼ ਕਰੋ” ਵਾਪਸ ਦਿਓ)
ਜੇ ਤੁਸੀਂ ਹੁਣ ਇਹ ਨਿਯੰਤਰਣ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਬਾਅਦ ਵਿੱਚ FinOps ਅਤੇ ਗੰਭੀਰ ਕਲਾਉਡ ਖ਼ਰਚ ਪ੍ਰਬੰਧਨ 'ਤੇ ਜਦੋਂ ਤੁਸੀਂ ਅਸੀਂ ਸ਼ੁਰੂ ਕਰੋਗੇ ਤਾਂ ਤੁਹਾਨੂੰ ਇਹ ਯਾਦ ਆਵੇਗਾ।
ਜਦੋਂ ਸਰਵਰਲੈਸ ਸਭ ਤੋਂ ਸਸਤਾ ਚੋਣ ਨਹੀਂ ਹੁੰਦਾ
Export the source anytime
ਤੁਸੀਂ ਜਦੋਂ ਆਪਣਾ pipeline ਚਲਾਉਣ ਲਈ ਤਿਆਰ ਹੋ, ਕੋਡ ਨਿਰਯਾਤ ਕਰਕੇ ਕੰਟਰੋਲ ਆਪਣੇ ਕੋਲ ਰੱਖੋ।
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਉਹਨਾਂ ਵੇਲੇ ਚਮਕਦੇ ਹਨ ਜਦੋਂ ਵਰਕਲੋਡ spiky ਅਤੇ ਅਣਿਸ਼ਚਿਤ ਹੋ। ਪਰ ਜਦੋਂ ਤੁਹਾਡਾ ਵਰਕਲੋਡ ਸਥਿਰ ਅਤੇ ਭਾਰੀ ਹੋ ਜਾਵੇ, ਤਾਂ "pay-for-what-you-use" ਦੀ ਗਣਿਤ ਉਲਟ ਸਕਦੀ ਹੈ—ਕਈ ਵਾਰ ਕਾਫੀ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤੌਰ 'ਤੇ।
ਸਥਿਰ ਉੱਚ ਲੋਡ: provisioned ਜਿੱਤ ਸਕਦਾ ਹੈ
ਜੇ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਜ਼ਿਆਦਾਤਰ ਘੰਟਿਆਂ ਦੌਰਾਨ ਨਿਰੰਤਰ ਵਿਅਸਤ ਹੁੰਦਾ ਹੈ, ਤਾਂ usage-based ਕੀਮਤ ਇੱਕ provisioned instance (ਜਾਂ reserved capacity) ਨਾਲੋਂ ਵੱਧ ਪੈ ਸਕਦੀ ਹੈ ਜੋ ਤੁਸੀਂ ਚਾਹੇ ਵਰਤੋਂ ਜਾਂ ਨਾ ਕਰੋ ਉਸਦਾ ਭੁਗਤਾਨ ਹੁੰਦਾ ਹੈ।
ਇੱਕ ਆਮ ਪੈਟਰਨ ਹੈ ਇੱਕ ਪੱਕਾ B2B ਪ੍ਰੋਡਕਟ ਜਿਸਦੀ traffic ਬਿਜ਼ਨਸ ਘੰਟਿਆਂ ਦੌਰਾਨ ਲਗਾਤਾਰ ਹੁੰਦੀ ਹੈ, ਨਾਲੇ ਰਾਤ ਵਿੱਚ background jobs ਚਲਦੇ ਹਨ। ਇਸ ਸਥਿਤੀ ਵਿੱਚ, fixed-size cluster ਅਤੇ reserved pricing ਇੱਕ ਘਟੀਆ ਪ੍ਰਭਾਵੀ ਲਾਗਤ ਪ੍ਰਤੀ ਰਿਕਵੈਸਟ ਦੇ ਸਕਦੇ ਹਨ—ਖਾਸ ਤੌਰ 'ਤੇ ਜੇ ਤੁਸੀਂ utilization ਉੱਚ ਰੱਖ ਸਕਦੇ ਹੋ।
ਵਰਕਲੋਡ ਫਿੱਟ ਮਹੱਤਵਪੂਰਨ ਹੈ
ਸਰਵਰਲੈਸ ਹਮੇਸ਼ਾ-friendly ਨਹੀਂ ਹੁੰਦਾ:
- Predictable traffic ਜਿੱਥੇ ਤੁਸੀਂ fixed deployment ਨੂੰ right-size ਕਰ ਸਕਦੇ ਹੋ
- Heavy analytics (ਵੱਡੇ scans, ਵੱਡੇ joins) ਜੋ ਬਹੁਤ ਸਾਰੇ read/compute units ਖਾਂਦੇ ਹਨ
- Long-running queries ਜੋ resources ਨੂੰ ਮਿੰਟਾਂ ਤੱਕ ਰੋਕਦੀਆਂ ਹਨ
ਇਨ੍ਹਾਂ ਵਰਕਲੋਡਾਂ ਨਾਲ ਤੁਹਾਨੂੰ ਦੋਹਾਂ ਮਾਰੇ ਜਾ ਸਕਦੇ ਹਨ: ਵੱਧ ਮੀਟਰਡ ਵਰਤੋਂ ਅਤੇ ਕਦੇ-ਕਦੇ slowdown ਜਦ scaling limits ਜਾਂ concurrency caps ਪਹੁੰਚ ਜਾਂਦੇ ਹਨ।
ਵੇਂਡਰ ਤੁਲਨਾ ਚेकਲਿਸਟ (ਕਮੇਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ)
Pricing pages ਮਿਲਦੇ-ਜੁਲਦੇ ਲੱਗ ਸਕਦੇ ਹਨ ਪਰ meters ਵੱਖ-ਵੱਖ ਹੋ ਸਕਦੇ ਹਨ। ਪ੍ਰੋਵਾਈਡਰਾਂ ਦੀ ਤੁਲਨਾ ਕਰਦਿਆਂ ਪੁਸ਼ਟੀ ਕਰੋ:
- ਕੀ ਮੀਟਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ (compute, reads/writes, storage, I/O, backups, egress)
- Free tier ਦੇ ਵੇਰਵੇ ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਉਸ ਨੂੰ ਪਾਰ ਕਰਦੇ ਹੋ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ
- Scaling ਵਿਵਹਾਰ (ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ scale ਹੁੰਦਾ ਹੈ, minimum billing increments, scale-to-zero ਨਿਯਮ)
- Limits (max concurrency, max connections, rate limits, query timeouts)
“ਸਵਿੱਚ” ਫੈਸਲਾ ਕਰਨ ਵਾਲਾ ਮੁਕਾਮ
ਜਦੋਂ ਤੁਸੀਂ ਹੇਠਾਂ ਦਿੱਤੇ ਰੁਝਾਨ ਨੋਟ ਕਰੋ ਤਾਂ ਦੁਬਾਰਾ ਮਲਾਹਿਜ਼ਾ ਕਰੋ:
- ਤੁਹਾਡੀ baseline usage fluktuation ਬੰਦ ਹੋ ਕੇ ਇੱਕ ਸਿੱਧੀ ਰੇਖਾ ਵਰਗੀ ਲੱਗਣ ਲਗੇ
- ਤੁਹਾਡਾ ਯੂਨਿਟ ਲਾਗਤ ਪ੍ਰਤੀ ਗਾਹਕ ਵਧ ਰਿਹਾ ਹੈ (ਵਧਣ ਵਕਤ margins ਲਈ ਚੇਤਾਵਨੀ)
ਉਸ ਵੇਲੇ, ਇੱਕ side-by-side ਲਾਗਤ ਮਾਡਲ ਚਲਾਓ: ਮੌਜੂਦਾ ਸਰਵਰਲੈਸ ਬਿੱਲ vs ਇੱਕ right-sized provisioned ਸੈਟਅਪ (ਸੰਭਵਤ: reserved pricing) ਅਤੇ ਉਨ੍ਹਾਂ operational overhead ਨੂੰ ਸ਼ਾਮਲ ਕਰੋ ਜੋ ਤੁਸੀਂ ਸਵੈ-ਚਲਾਉਂਦੇ ਹੋਏ ਲੈ ਰਹੇ ਹੋਵੋਗੇ। ਜੇ ਮਾਡਲ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਚਾਹੀਦੀ ਹੋਵੇ ਤਾਂ /blog/cost-forecasting-basics ਨੂੰ ਦੇਖੋ।
ਫਾਉਂਡਰਾਂ ਲਈ ਤੇਜ਼ ਫੈਸਲਾ ਚੈਕਲਿਸਟ
ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਉਨ੍ਹਾਂ ਲਈ ਵਧੀਆ ਹੋ ਸਕਦੇ ਹਨ ਜੇ ਤੁਹਾਡੀ ਟਰੈਫਿਕ ਅਸਮਾਨ ਅਤੇ ਤੁਸੀਂ ਤੇਜ਼ iteration ਕੀਮਤ ਕਰਦੇ ਹੋ। ਪਰ ਜਦੋਂ “meters” ਤੁਹਾਡੇ ਪ੍ਰੋਡਕਟ ਦੇ ਵਿਹਾਰ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ, ਤਾਂ ਉਹ ਤੁਹਾਨੂੰ ਹੈਰਾਨ ਕਰ ਸਕਦੇ ਹਨ। ਇਸ ਚੈਕਲਿਸਟ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਫੈਸਲਾ ਕਰਨ ਲਈ ਵਰਤੋਂ, ਅਤੇ ਇਸ ਗੱਲ ਤੋਂ ਬਚਣ ਲਈ ਕਿ ਤੁਸੀਂ ਅਜਿਹੇ ਦਸਤਖਤ ਕਰ ਲਵੋ ਜਿੱਥੇ ਤੁਸੀਂ ਆਪਣੀ ਟੀਮ (ਜਾਂ ਨਿਵੇਸ਼ਕਾਂ) ਨੂੰ ਸਮਝਾ ਨਾ ਸਕੋ।
1) ਤੇਜ਼ ਚੈਕਲਿਸਟ: ਕੀ ਤੁਸੀਂ ਆਪਣੀ ਵਰਕਲੋਡ ਨੂੰ ਮਾਡਲ ਕਰ ਸਕਦੇ ਹੋ?
- ਵਰਕਲੋਡ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: ਕੋਰ ਪਾਥ ਕੀ ਹੈ—logins, feeds, checkouts, analytics? ਕਿਹੜੀਆਂ ਕਾਰਵਾਈਆਂ “ਹਮੇਸ਼ਾ ਚੱਲਦੀਆਂ” ਹਨ vs bursty?
- ਮੀਟਰਾਂ ਦਾ ਅੰਦਾਜ਼ਾ ਲਗਾਓ: Reads/writes, storage growth, compute time, request count, data transfer, backups, ਅਤੇ ਕੋਈ per-feature charges (indexes, vector search, change streams)
- ਬਜਟ ਅਤੇ alerts ਸੈਟ ਕਰੋ: ਇੱਕ ਮਹੀਨਾਵਾਰ ਬਜਟ ਅਤੇ “panic threshold” (ਉਦਾਹਰਨ: 2× ਆਮ ਹਫ਼ਤਾ)
- ਪੀਕ ਟੈਸਟ ਕਰੋ: worst hour/day ਲਈ load test ਚਲਾਓ ਜਾਂ production traffic replay ਕਰੋ। Pricing ਅਕਸਰ extremes 'ਤੇ ਬਦਲਦਾ ਹੈ।
2) ਪ੍ਰੋਵਾਈਡਰਾਂ ਨੂੰ ਪੁੱਛਣ ਵਾਲੇ ਪ੍ਰਸ਼ਨ (ਕਮੇਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ)
- ਇੱਕਜ਼ੈਕਟਲੀ ਕੀ ਬਿੱਲਯੋਗ ਹੈ, ਅਤੇ ਕਿਸ granularly? (per request, per second, per GB, per region)
- ਕਿਹੜੀਆਂ default settings ਖਰਚ ਵਧਾਉਂਦੀਆਂ ਹਨ? (retention, backups, replicas, autoscaling minimums)
- ਤੁਸੀਂ spikes ਨੂੰ ਕਿਵੇਂ price ਕਰਦੇ ਹੋ? ਕੀ throttling, smoothing, ਜਾਂ surge pricing ਹੁੰਦੀ ਹੈ?
- ਕੀ free tiers, credits, ਜਾਂ committed-use discounts ਹਨ—ਅਤੇ ਜਦੋਂ ਉਹ ਖਤਮ ਹੋ ਜਾਂਦੇ ਹਨ ਕੀ ਹੁੰਦਾ ਹੈ?
- Escape hatches ਕੀ ਹਨ? Data export speed/cost, lock-in risks, ਅਤੇ migration paths
- ਤੁਸੀਂ multi-tenant vs dedicated isolation ਨੂੰ ਕਿਵੇਂ ਸੰਭਾਲਦੇ ਹੋ? (noisy neighbors, performance variance)
ਮੁੱਖ ਨਤੀਜਾ
ਕੀਮਤ ਮਾਡਲ ਨੂੰ ਆਪਣੀ growth uncertainty ਨਾਲ ਮਿਲਾਓ: ਜੇ ਤੁਹਾਡੀ ਟਰੈਫਿਕ, ਕੁਐਰੀਜ਼, ਜਾਂ ਡੇਟਾ ਅਕਾਰ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲ ਸਕਦੇ ਹਨ, ਤਾਂ ਉਹ ਮਾਡਲ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਕੋਲ ਕੁਝ ਡਰਾਇਵਰਾਂ ਨਾਲ ਫੋਰਕਾਸਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਅਗਲਾ ਕਦਮ
ਇੱਕ ਛੋਟਾ ਪਾਇਲਟ ਇੱਕ ਅਸਲ ਫੀਚਰ ਲਈ ਚਲਾਓ, ਇੱਕ ਮਹੀਨੇ ਲਈ ਹਫਤਾਵਾਰ ਲਾਗਤ ਦੀ ਸਮੀਖਿਆ ਕਰੋ, ਅਤੇ ਨੋਟ ਲਵੋ ਕਿ ਕਿਸ ਮੀਟਰ ਨੇ ਹਰ ਛਾਲ ਨੂੰ ਚਲਾਇਆ। ਜੇ ਤੁਸੀਂ ਇਕ ਪੈਰਾਗ੍ਰਾਫ ਵਿੱਚ ਬਿੱਲ ਦੀ ਵਿਆਖਿਆ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਇਸ ਨੂੰ ਅਜੇ scale ਨਾ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਉਹ ਪਾਇਲਟ ਸ਼ੁਰੂ ਤੋਂ ਬਣਾਉਣ ਜਾ ਰਹੇ ਹੋ, ਤਾਂ ਸੋਚੋ ਕਿ ਤੁਸੀਂ instrumentation ਅਤੇ guardrails ਤੇ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਇਟਰੈਟ ਕਰ ਸਕਦੇ ਹੋ। ਉਦਾਹਰਨ ਲਈ, Koder.ai ਟੀਮਾਂ ਨੂੰ React + Go + PostgreSQL ਐਪ ਦਤਰਸ੍ਹੀ ਤੌਰ 'ਤੇ spin up ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੀ ਹੈ, ਜਦੋਂ ਲੋੜ ਹੋਵੇ ਤਾਂ ਸਰੋਤ ਕੋਡ ਨਿਰਯਾਤ ਕਰਨ ਦੀ ਸਹੂਲਤ ਦਿੰਦੀ ਹੈ, ਅਤੇ planning mode ਅਤੇ snapshots ਨਾਲ تجرباتی ਕੰਮ ਸੁਰੱਖਿਅਤ ਰੱਖਣ 'ਚ ਮਦਦ ਕਰਦੀ ਹੈ—ਇਹ ਉਪਯੋਗੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਅਜੇ ਸਿੱਖ ਰਹੇ ਹੋ ਕਿ ਕਿਹੜੀਆਂ ਕੁਐਰੀਆਂ ਅਤੇ ਵਰਕਫਲੋ ਤੁਹਾਡੀ ਯੂਨਿਟ ਇਕਾਨੋਮਿਕਸ ਨੂੰ ਚਲਾਉਣਗੀਆਂ।
ਅਕਸਰ ਪੁੱਛੇ ਜਾਣ ਵਾਲੇ ਸਵਾਲ
What’s the biggest cost-model difference between serverless and traditional databases?
ਇੱਕ ਪਾਰੰਪਰਿਕ ਡੇਟਾਬੇਸ ਤੁਹਾਨੂੰ capacity (ਇੰਸਟੈਂਸ ਸਾਈਜ਼, ਰਿਪਲਿਕਾ, reserved commitments) ਅੱਗੇ ਤਕਾਰਣਦੀ ਹੈ—ਚਾਹੇ ਤੁਸੀਂ ਉਸਦਾ ਇਸਤੇਮਾਲ ਕਰੋ ਜਾਂ ਨਾ ਕਰੋ। ਇਕ ਸਰਵਰਲੈਸ ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਖਪਤ ਦੇ ਆਧਾਰ 'ਤੇ ਬਿੱਲ ਕਰਦਾ ਹੈ (compute time, requests, reads/writes, storage, ਅਤੇ ਕਈ ਵਾਰੀ data transfer), ਇਸਲਈ ਤੁਹਾਡੇ ਖਰਚੇ ਹਰ ਰੋਜ਼ ਤੁਹਾਡੇ ਪ੍ਰੋਡਕਟ ਦੀ ਕਿਰਿਆ ਨੂੰ ਟ੍ਰੈਕ ਕਰਦੇ ਹਨ।
Why do startups feel the impact of serverless pricing sooner than larger companies?
ਕਿਉਂਕਿ ਖਰਚ ਵੈਰੀਏਬਲ ਹੋ ਜਾਂਦਾ ਹੈ ਅਤੇ ਇਹ headcount ਜਾਂ ਹੋਰ ਖਰਚਾਂ ਨਾਲੋਂ ਤੇਜ਼ ਬਦਲ ਸਕਦਾ ਹੈ। ਛੋਟੀ ਟ੍ਰੈਫਿਕ ਵਾਧਾ, ਨਵਾਂ background job, ਜਾਂ ਇਕ ਅਣਛੁਟੀ ਕੁਐਰੀ ਤੁਹਾਡੇ ਇਨਵੌਇਸ ਨੂੰ ਗੰਭੀਰ ਤੌਰ 'ਤੇ ਬਦਲ ਸਕਦੀ ਹੈ—ਇਸ ਲਈ ਲਾਗਤ ਪ੍ਰਬੰਧਨ runway ਦਾ ਮਸਲਾ ਬਣ ਜਾਂਦਾ ਹੈ।
What are the most common things serverless databases charge for?
ਆਮ meters ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
- Compute ਜਾਂ “capacity units” (ਪ੍ਰਤੀ ਸਕਿੰਟ/ਮਿੰਟ)
- Storage (ਡੇਟਾ ਅਤੇ ਕਈ ਵਾਰੀ ਇੰਡੈਕਸ)
- Reads/writes ਜਾਂ I/O ਵਾਲੀਮ
- Requests/queries
- ਜ਼ਿਆਦਾ ਚੀਜ਼ਾਂ ਜਿਵੇਂ backups, replication, data transfer/egress, ਅਤੇ ਖਾਸ ਫੀਚਰ (ਉਦਾਹਰਨ: PITR, encryption keys)
ਹਮੇਸ਼ਾ ਪ੍ਰੋਵਾਈਡਰ ਦੀ /pricing ਜਾਣਕਾਰੀ ਵਿੱਚ ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਕੀ ਸ਼ਾਮਲ ਹੈ ਅਤੇ ਕੀ ਅਲੱਗਮੀਟਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
How do I connect product usage to my serverless database bill?
ਉਸਤੇ ਕੋਸ਼ਿਸ਼ ਕਰੋ ਕਿ ਉਪਭੋਗਤਾ ਕਿਰਿਆਵਾਂ ਨੂੰ ਬਿੱਲਯੋਗ ਯੂਨਿਟਾਂ ਨਾਲ ਮੈਪ ਕਰੋ। ਉਦਾਹਰਨ ਵਜੋਂ:
- Signups → record writes + verification lookups
- Sessions → feeds/profiles ਲਈ ਬਾਰ-ਬਾਰ reads
- Orders/events → write bursts + consistency checks
ਫਿਰ ਕੁਝ ਆਸਾਨ ਅਨੁਪਾਤ ਟਰੈਕ ਕਰੋ ਜਿਵੇਂ cost per MAU, cost per 1,000 requests, ਜਾਂ cost per order ਤਾਂ ਜੋ ਤੁਸੀਂ ਦੇਖ ਸਕੋ ਕਿ ਵਾਧਾ ਸਿਹਤਮੰਦ ਹੈ ਜਾਂ ਨਹੀਂ।
What hidden cost drivers cause surprise bills with serverless databases?
ਅਕਸਰ ਚੇਤੇ ਰਹਿਣ ਵਾਲੇ ਮੁੱਖ ਕਾਰਨ ਹਨ:
- Unbounded queries ਜਾਂ missing pagination (ਵੱਡੀਆਂ scans)
- N+1 ਕੁਐਰੀ ਪੈਟਰਨ ਜੋ reads ਨੂੰ ਗੁਣਾ ਕਰਦੇ ਹਨ
- ਲੰਬੀ retention ਨਾਲ storage ਵਾਧਾ (ਲਾਗ/ਇਵੈਂਟਸ)
- Backups/PITR ਜੋ ਅਕਸਰ storage ਨੂੰ ਦੁਹਰਾਉਂਦੇ ਹਨ
- Cross-region ਟਰੈਫਿਕ ਅਤੇ analytics ਟੂਲਾਂ ਲਈ egress
- Background jobs (backfills, reindexing, dashboards) ਜੋ ਭਾਰੀ ਕੁਐਰੀ ਚਲਾਉਂਦੇ ਹਨ
ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਪ੍ਰਤੀ ਰਿਕਵੈਸਟ ਛੋਟੇ ਤੋਂ ਲੱਗਦੇ ਹਨ ਪਰ ਮਹੀਨਾਵਾਰ ਖਰਚ ਵੱਡਾ ਕਰ ਸਕਦੇ ਹਨ।
What are cold starts, and when do they matter for cost and performance?
Scale-to-zero idle ਖਰਚ ਘਟਾਉਂਦਾ ਹੈ, ਪਰ ਇਹ cold starts ਲਿਆ ਸਕਦਾ ਹੈ: idle ਤੋਂ ਬਾਅਦ ਪਹਿਲੀ ਰਿਕਵੈਸਟ ਨੂੰ ਵਾਧੂ latency ਦਾ ਸਾਹਮਣਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ (ਕਈ ਵਾਰੀ ਸੈਂਕੜੇ ਮਿਲੀਸੈਕੰਡ ਜਾਂ ਕੋੱਝ ਸੈਕੰਡ)। ਇਹ ਅਕਸਰ internal tools ਜਾਂ batch jobs ਲਈ ਠੀਕ ਹੁੰਦਾ ਹੈ, ਪਰ login, checkout, search ਜਿਹੜੀਆਂ flows ਹਨ ਜਿਨ੍ਹਾਂ ਦੇ ਕਠੋਰ p95/p99 latency ਟੀਚੇ ਹੁੰਦੇ ਹਨ, ਉਨ੍ਹਾਂ ਲਈ ਖਤਰਨਾਕ ਹੋ ਸਕਦਾ ਹੈ।
How can I reduce serverless database costs without hurting user experience?
ਟਾਰਗੇਟਡ ਰਾਹਤਾਂ ਦੀ ਵਰਤੋਂ ਕਰੋ:
- ਗਰਮ reads (profiles, flags) ਨੂੰ cache ਕਰੋ ਤਾਂ ਕਿ ਦੁਹਰਾਉਂਦੀਆਂ ਕੁਐਰੀਆਂ ਘਟ ਜਾਣ
- ਮਹਿੰਗੇ aggregates (counts, rollups) ਨੂੰ precompute ਕਰੋ
- writes ਨੂੰ batch ਕਰੋ ਅਤੇ chatty patterns ਤੋਂ ਬਚੋ
- ਕਾਰੋਬਾਰੀ ਘੰਟਿਆਂ ਦੌਰਾਨ services ਨੂੰ ਹਲਕੀ scheduled pings ਨਾਲ warm ਰੱਖੋ (ਜਿੱਥੇ موزੂਨ ਹੋ)
ਨਤੀਜਾ ਮਾਪੋ—ਕਿਉਂਕਿ ਇਨ ਉਪਾਇਆں ਨਾਲ ਖਰਚ ਹੋਰ ਸਰਵਿਸਾਂ (cache, functions, schedulers) 'ਤੇ ਵੱਧ ਸਕਦਾ ਹੈ।
How can I forecast spend when I don’t have much production data yet?
ਇਕ ਸਰਲ ਪਦਤੀ ਹੈ: baseline + growth + peak multiplier:
- ਇੱਕ ਪ੍ਰਤੀਨਿਧੀ ਹਫ਼ਤੇ ਦੀ ਨਾਪ ਲਓ (ਚਾਹੇ staging ਜਾਂ ਛੋਟੇ ਬੇਟਾ ਤੋਂ)
- ਉਹ usage ਮੈਟ੍ਰਿਕਸ ਮਾਪੋ ਜੋ ਪ੍ਰੋਵਾਈਡਰ ਚਾਰਜ ਕਰਦਾ ਹੈ (reads/writes, compute time, storage, egress)
What guardrails should we implement to avoid runaway serverless bills?
ਛੋਟੇ ਹਲਕੀਆਂ guardrails ਲਗਾਓ:
- ਮਹੀਨਾਵਾਰ ਬਜਟ ਅਤੇ ਅਲਰਟ (ਉਦਾਹਰਨ: 50%, 80%, 100%)
- ਮਨ-ਮੁਤਾਬਕ dev/staging/prod ਵੱਖ-ਵੱਖ ਬਜਟ ਰੱਖੋ
- consistent tags/labels ਨਾਲ ਲਾਗਤ attribution (service, team, feature)
- rate limits, pagination obligations, query timeouts ਅਤੇ max result sizes
- spend/QPS ਅੱਤਿ ਹੋਣ 'ਤੇ circuit breakers ਜੋ गैर-ਜ਼ਰੂਰੀ ਫੀਚਰਾਂ ਨੂੰ degrade ਕਰ ਦੇਂ
ਮਕਸਦ runaway ਬਿੱਲ ਤੋਂ ਬਚਣਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਆਪਣੀ ਵਰਕਲੋਡ ਪੈਟਰਨ ਸਿੱਖ ਰਹੇ ਹੋ।
When is serverless likely not the cheapest database option?
ਸਰਵਰਲੈਸ ਘੱਟ/ਅਣਜਾਣ ਟਰੈਫਿਕ ਲਈ ਬਹੁਤ ਚੰਗਾ ਹੈ। ਪਰ ਜਦੋਂ ਵਰਕਲੋਡ ਸਥਿਰ ਅਤੇ ਭਾਰੀ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ “pay-for-what-you-use” ਦਾ ਹਿਸਾਬ ਉਲਟ ਸਕਦਾ ਹੈ।
ਅਕਸਰ ਸਥਿਰ ਉੱਚ ਲੋਡ ਵਾਲੀਆਂ ਸਥਿਤੀਆਂ ਵਿੱਚ provisioned ਰਹਿਣਾ ਸਸਤਾ ਪੈਂਦਾ ਹੈ—ਇਹ ਉਹ ਸਥਿਤੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਨਿਰੀਖਿਤ cluster + reserved pricing ਨਾਲ ਉੱਚ utilization ਰੱਖ ਸਕਦੇ ਹੋ।
ਕੁਝ ਵਰਕਲੋਡ ਜੋ ਸਰਵਰਲੈਸ ਨੂੰ ਮਹਿੰਗਾ ਬਣਾ ਸਕਦੇ ਹਨ:
- Predictable traffic ਜਿੱਥੇ fixed deployment ਨੂੰ right-size ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ
- Heavy analytics (ਵੱਡੇ scans/joins)
- Long-running queries ਜੋ resources ਨੂੰ ਮਿੰਟਾਂ ਤੱਕ ਰੋਕਦੇ ਹਨ
ਇਸ ਲਈ ਤੁਹਾਨੂੰ ਆਪਣੀ ਮੌਜੂਦਾ ਬਿੱਲ ਨੂੰ ਇੱਕ right-sized provisioned ਵਿਵਸਥਾ ਨਾਲ side-by-side ਮਾਡਲ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ, ਜਿਸ ਵਿੱਚ operational overhead ਨੂੰ ਵੀ ਸ਼ਾਮਲ ਕੀਤਾ ਜਾਵੇ।