09 ਅਗ 2025·8 ਮਿੰਟ
ਸਿਸਟਮ ਵੱਧਣ ਤੇ ਫਰੇਮਵਰਕ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਕਿਵੇਂ ਲੀਕ ਹੁੰਦੀਆਂ ਹਨ
ਜਾਣੋ ਕਿ ਉੱਚ‑ਸਤਹ ਫਰੇਮਵਰਕ ਸਕੇਲ 'ਤੇ ਕਿਉਂ ਲੀਕ ਕਰਦੇ ਹਨ, ਸਭ ਤੋਂ ਆਮ ਲੀਕ ਪੈਟਰਨ, ਦੇਖਣ ਯੋਗ ਲੱਛਣ, ਅਤੇ ਪ੍ਰਾਇਕਟਿਕ ਡਿਜ਼ਾਈਨ ਅਤੇ ਓਪਸ ਫਿਕਸ।
ਜਾਣੋ ਕਿ ਉੱਚ‑ਸਤਹ ਫਰੇਮਵਰਕ ਸਕੇਲ 'ਤੇ ਕਿਉਂ ਲੀਕ ਕਰਦੇ ਹਨ, ਸਭ ਤੋਂ ਆਮ ਲੀਕ ਪੈਟਰਨ, ਦੇਖਣ ਯੋਗ ਲੱਛਣ, ਅਤੇ ਪ੍ਰਾਇਕਟਿਕ ਡਿਜ਼ਾਈਨ ਅਤੇ ਓਪਸ ਫਿਕਸ।
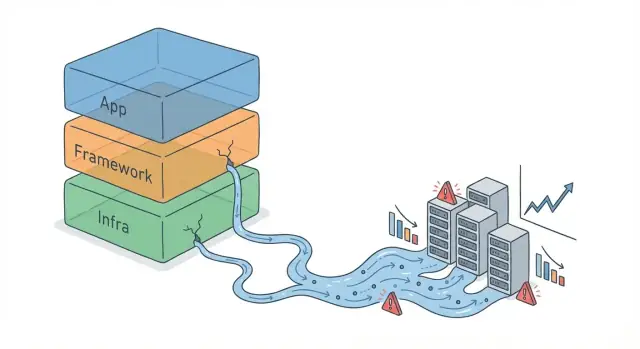
ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਇਕ ਸਧਾਰਣ ਪਰਤ ਹੁੰਦੀ ਹੈ: ਇੱਕ ਫਰੇਮਵਰਕ API, ORM, ਮੈਸੇਜ ਕਿਊ ਕਲਾਇੰਟ ਜਾਂ ਇਕ‑ਪੰਗਤੀ ਕੈਸ਼ ਹੈਲਪਰ। ਇਹ ਤੁਹਾਨੂੰ ਉੱਚ‑ਸਤਹ ਦੇ ਸੰਕਲਪਾਂ ("ਇਸ ਆਬਜੈਕਟ ਨੂੰ ਸੇਵ ਕਰੋ", "ਇਹ ਘਟਨਾ ਭੇਜੋ") 'ਤੇ ਸੋਚਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦੀ ਹੈ ਬਿਨਾਂ ਹਮੇਸ਼ਾ ਨੀਵੇਂ ਦਰਜੇ ਦੀਆਂ ਯੰਤ੍ਰਣਾਵਾਂ ਨੂੰ ਹੇਠਾਂ ਲਿਆਉਣ ਦੇ।
ਇੱਕ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਲੀਕ ਉਸ ਵੇਲੇ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਉਹ ਛੁਪੀਆਂ ਹੋਈਆਂ ਡੀਟੇਲਸ ਅਸਲ ਨਤੀਜਿਆਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਨ ਲੱਗਣ—ਇਸ ਲਈ ਤੁਹਾਨੂੰ ਉਹ ਸਮਝਣ ਅਤੇ ਮੈਨੇਜ ਕਰਨ ਲਈ ਮਜਬੂਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਜੋ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਛੁਪਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਹੀ ਸੀ। ਕੋਡ ਅਜੇ ਵੀ “ਚੱਲਦਾ” ਹੈ, ਪਰ ਸਧਾਰਨ ਮਾਡਲ ਅਸਲ ਵਿਹਾਰ ਦੀ ਭਵਿੱਖਵਾਣੀ ਨਹੀਂ ਕਰਦਾ।
ਸ਼ੁਰੂਆਤੀ ਵਾਧਾ ਮਾਫ਼ੀਵਾਂ ਹੁੰਦਾ ਹੈ। ਘੱਟ ਟ੍ਰੈਫਿਕ ਅਤੇ ਛੋਟੀ ਡਾਟਾਸੇਟਸ ਨਾਲ, ਅਣਕੁਸ਼ਲਤਾਵਾਂ ਖਾਲੀ CPU, ਗਰਮ ਕੈਸ਼ ਅਤੇ ਤੇਜ਼ ਕਵੇਰੀਜ਼ ਦੇ ਪਿੱਛੇ ਛਿੱਪ ਜਾਂਦੀਆਂ ਹਨ। ਲੇਟੈਂਸੀ ਦੀਆਂ spike ਕਮ ਹੁੰਦੀਆਂ ਹਨ, retries ਇਕੱਤਰ ਨਹੀਂ ਹੁੰਦੇ, ਅਤੇ ਇਕ ਘੱਟ‑ਜ਼ਿਆਦਾ ਲਾਗ ਲਾਈਨ ਨੂੰ ਕੋਈ ਫਰਕ ਨਹੀਂ ਪੈਂਦਾ।
ਜਿਵੇਂ ਖਪਤ ਵਧਦੀ ਹੈ, ਉਹੇ shortcut ਵਧ ਰਹੇ ਹਨ:
ਲੀਕੀ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਖੇਤਰਾਂ ਵਿੱਚ ਦਿਖਾਈ ਦਿੰਦੀਆਂ ਹਨ:
ਅੱਗੇ ਅਸੀਂ ਪ੍ਰਾਇਕਟਿਕ ਸਿੰਗਲਾਂ ਤੇ ਧਿਆਨ ਦੇਵਾਂਗੇ ਜੋ ਦੱਸਦੀਆਂ ਹਨ ਕਿ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਲੀਕ ਕਰ ਰਹੀ ਹੈ, ਅਸਲ ਕਾਰਨ ਦੀ ਜਾਂਚ ਕਿਵੇਂ ਕਰੋ (ਸਿਰਫ ਲੱਛਣਾਂ ਨਹੀਂ), ਅਤੇ ਰਾਹ‑ਨੁਮਾਈ—ਕਨਫ਼ਿਗਰੇਸ਼ਨ ਠੀਕ ਕਰਨ ਤੋਂ ਲੈ ਕੇ ਜਦੋਂ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਹੁਣ ਤੁਹਾਡੇ ਸਕੇਲ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀ ਤਾਂ ਨੀਵੇਂ ਪੱਧਰ 'ਤੇ ਜਾਓ।
ਬਹੁਤ ਸਾਰਾ ਸੌਫਟਵੇਅਰ ਇੱਕੋ ਜਿਹਾ ਰਾਹ ਪਿੱਛਾ ਕਰਦਾ ਹੈ: ਇਕ ਪ੍ਰੋਟੋਟਾਈਪ ਵਿਚਾਰ ਸਾਬਤ ਕਰਦਾ ਹੈ, ਉਤਪਾਦ ਨੂੰ ਰਿਲੀਜ਼ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਫਿਰ ਵਰਤੋਂ ਉਸ ਆਰਕੀਟੈਕਚਰ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਵਧਦੀ ਹੈ। ਸ਼ੁਰੂ ਵਿੱਚ, ਫਰੇਮਵਰਕ ਜਾਦੂਈ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਉਨ੍ਹਾਂ ਦੇ ਡਿਫ਼ੌਲਟ ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਅੱਗੇ ਵਧਣ ਦਿੰਦੇ ਹਨ—ਰਾਊਟਿੰਗ, ਡੇਟਾਬੇਸ ਐਕਸੈਸ, ਲੌਗਿੰਗ, ਰੀਟ੍ਰਾਈ ਅਤੇ ਪਿਛੋਕੜ ਨੌਕਰੀਆਂ “ਮੁਫ਼ਤ” ਮਿਲਦੀਆਂ ਹਨ।
ਸਕੇਲ 'ਤੇ, ਤੁਸੀਂ ਫਿਰ ਵੀ ਇਹ ਫਾਇਦੇ ਚਾਹੁੰਦੇ ਹੋ—ਪਰ ਡਿਫ਼ੌਲਟ ਅਤੇ ਸੁਖਾਵਾਂ ਅਕਸਰ ਅਨੁਮਾਨ ਬਣ ਜਾਂਦੀਆਂ ਹਨ।
ਫਰੇਮਵਰਕ ਡਿਫ਼ੌਲਟ ਆਮ ਤੌਰ ਤੇ ਇਹ ਮੰਨਦੇ ਹਨ:
ਉਹ ਅਨੁਮਾਨ ਸ਼ੁਰੂ ਵਿੱਚ ਠੀਕ ਰਹਿੰਦੇ ਹਨ, ਇਸ ਲਈ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਸੁੱਡਾ ਲੱਗਦਾ ਹੈ। ਪਰ ਸਕੇਲ "ਨਾਰਮਲ" ਦਾ ਅਰਥ ਬਦਲ ਦਿੰਦਾ ਹੈ। 10,000 ਵਿਕਤਾਂ 'ਤੇ ਠੀਕ ਰਹਿਣ ਵਾਲੀ ਕਵੇਰੀ 100 ਮਿਲੀਅਨ 'ਤੇ ਧੀਮੀ ਹੋ ਸਕਦੀ ਹੈ। ਇਕ synchronous ਹੈਂਡਲਰ ਜੋ ਸਧਾਰਨ ਲੱਗਦਾ ਸੀ, traffic spike 'ਤੇ timeout ਹੋ ਸਕਦਾ ਹੈ। ਇੱਕ retry ਨੀਤੀ ਜੋ ਕਦੇ‑ਕਦੇ ਫੇਲ ਨੂੰ ਸਮਤੋਲ ਕਰਦੀ ਸੀ, ਹਜ਼ਾਰਾਂ clients retry ਕਰਦੇ ਸਮੇਂ outage ਨੂੰ ਵਧਾ ਸਕਦੀ ਹੈ।
ਸਕੇਲ ਸਿਰਫ਼ "ਵੱਧ users" ਨਹੀਂ ਹੁੰਦਾ। ਇਹ ਵਧੇ ਡੇਟਾ ਵਾਲੀਅਮ, ਬਰਸਟੀ ਟ੍ਰੈਫਿਕ, ਅਤੇ ਵੱਧ ਇਕੱਠੇ ਕੰਮ ਹੁੰਦਾ ਹੈ। ਇਹ ਉਹ ਹਿੱਸੇ ਦੱਬਦੇ ਹਨ ਜੋ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਛੁਪਾਉਂਦੇ ਹਨ: connection pools, thread scheduling, queue depth, memory pressure, I/O ਸੀਮਾਵਾਂ, ਅਤੇ dependencies ਤੋਂ rate limits.
ਫਰੇਮਵਰਕ ਅਕਸਰ ਸੁਰੱਖਿਅਤ, ਜਨਰਿਕ ਸੈਟਿੰਗਾਂ (pool sizes, timeouts, batching) ਚੁਣਦੇ ਹਨ। ਲੋਡ ਹੇਠਾਂ, ਉਹ ਸੈਟਿੰਗਜ਼ contention, long‑tail latency, ਅਤੇ cascading failures ਵਿੱਚ ਬਦਲ ਸਕਦੀਆਂ ਹਨ—ਉਹ ਸਮੱਸਿਆਵਾਂ ਜੋ ਵਿਸਥਿਤ ਹੱਦਾਂ ਵਿੱਚ ਸਭ ਕੁਝ ਠੀਕ ਹੋਣ ਦੇ ਦੌਰਾਨ ਵੇਖੀਆਂ ਨਹੀਂ ਜਾਂਦੀਆਂ।
ਸਟੇਜਿੰਗ ਵਾਤਾਵਰਨ ਅਕਸਰ ਪ੍ਰੋਡਕਸ਼ਨ ਦੀਆਂ ਸਥਿਤੀਆਂ ਨਹੀਂ ਦਰਸਾਉਂਦੇ: ਛੋਟੀਆਂ ਡਾਟਾਸੇਟਸ, ਘੱਟ ਸਰਵਿਸਜ਼, ਵੱਖਰਾ ਕੈਸ਼ਿੰਗ ਵਿਹਾਰ, ਅਤੇ ਘੱਟ “ਅਵਿਵਸਥਤ” ਯੂਜ਼ਰ ਗਤੀਵਿਧੀ। ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਤੁਹਾਡੇ ਕੋਲ ਅਸਲ ਨੈਟਵਰਕ ਵੈਰੀਏਬਿਲਿਟੀ, noisy neighbors, rolling deploys, ਅਤੇ ਅੰਸ਼ਿਕ ਫੇਲਯਰ ਹੁੰਦੇ ਹਨ। ਇਹੀ ਕਾਰਨ ਹੈ ਕਿ ਟੈਸਟਾਂ ਵਿੱਚ ਜੋ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਟਾਈਟ ਲੱਗਦੇ ਸਨ ਉਹ ਅਸਲ‑ਦਿਨ ਦੀ ਦਬਾਅ ਦੀ ਹਾਲਤਾਂ ਹੇਠਾਂ ਲੀਕ ਕਰ ਸਕਦੇ ਹਨ।
ਜਦੋਂ ਇੱਕ ਫਰੇਮਵਰਕ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਲੀਕ ਕਰਦੀ ਹੈ, ਲੱਛਣ ਅਕਸਰ ਸਾਫ਼ error message ਵਜੋਂ ਨਹੀਂ ਦਿਖਦੇ। ਇਸ ਦੀ ਥਾਂ ਤੁਸੀਂ ਪੈਟਰਨ ਵੇਖਦੇ ਹੋ: ਘੱਟ ਟ੍ਰੈਫਿਕ 'ਤੇ ਠੀਕ ਰਹਿਣ ਵਾਲਾ ਵਿਹਾਰ ਵੱਧ ਵਾਲੀਉਮ 'ਤੇ ਅਣਪੇਸ਼ਗੀ ਜਾਂ ਮਹਿੰਗਾ ਹੋ ਜਾਂਦਾ ਹੈ।
ਲੀਕੀ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਯੂਜ਼ਰ-ਦਿਖਾਈ ਦੇਣ ਵਾਲੀ ਲੇਟੈਂਸੀ ਰਾਹੀਂ ਖੁਦ ਨੂੰ ਦੱਸਦੀ ਹੈ:
ਇਹ ਕਲਾਸਿਕ ਲੱਛਣ ਹਨ ਕਿ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਇਕ ਬੋਤਲਨੈਕ ਛੁਪਾ ਰਹੀ ਹੈ ਜਿਸਨੂੰ ਤੁਸੀਂ ਪਲਟuée ਕੇ ਬਿਨਾਂ ਨੀਵੇਂ ਪੱਧਰ ਦੇ ਵੇਖੇ ਨਹੀਂ ਹਟਾ ਸਕਦੇ (ਜਿਵੇਂ ਅਸਲ ਕਵੇਰੀਜ਼, connection ਵਰਤੋਂ ਜਾਂ I/O ਵਰਤੋਂ ਦੀ ਜਾਂਚ)।
ਕੁਝ ਲੀਕ ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਇਨਵੌਇਸਾਂ ਵਿੱਚ ਦਿਖਾਈ ਦਿੰਦੀਆਂ ਹਨ ਨਾ ਕਿ ਡੈਸ਼ਬੋਰਡ ਵਿੱਚ:
ਜੇ ਇੰਫ੍ਰਾਸਟਰੱਕਚਰ ਵਧਾਉਣ ਨਾਲ ਪ੍ਰਦਰਸ਼ਨ ਪ੍ਰਮਾਣੂਪੂਰਕ ਤੌਰ 'ਤੇ ਪੁਨਰਸਥਾਪਿਤ ਨਹੀਂ ਹੁੰਦਾ, ਤਾਂ ਅਕਸਰ ਇਹ ਰੌਹ ਨਹੀਂ ਕਿ ਕ_capacity ਦੀ ਘਾਟ ਹੈ—ਇਹ ਉਹ overhead ਹੈ ਜਿਸਦਾ ਤੁਸੀਂ ਖਰਚਾ ਨਹੀਂ ਜਾਣਦੇ।
ਲੀਕ ਭਰੋਸਯੋਗਤਾ ਦੀ ਸਮੱਸਿਆ ਬਣ ਜਾਂਦੀ ਹੈ ਜਦੋਂ ਇਹ retries ਅਤੇ ਡਿਪੈਂਡੇਸੀ ਚੇਨ ਨਾਲ ਇੰਟਰੈਕਟ ਕਰਦੀ ਹੈ:
ਸੈਂਜੀ ਹੋਣ ਤੋਂ ਪਹਿਲਾਂ ਇਸ ਨੂੰ sanity‑check ਕਰਨ ਲਈ ਵਰਤੋ:
ਜੇ ਲੱਛਣ ਇੱਕ dependency (DB, cache, network) ਵਿੱਚ ਕੇਂਦਰਿਤ ਹਨ ਅਤੇ "ਹੋਰ ਸਰਵਰ" ਨਾਲ predictable ਤਰੀਕੇ ਨਾਲ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤੌਰ 'ਤੇ ਜਵਾਬ ਨਹੀਂ ਦਿੰਦੇ, ਤਾਂ ਇਹ ਮਜ਼ਬੂਤ ਸੰਕੇਤ ਹੈ ਕਿ ਤੁਹਾਨੂੰ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਦੇ ਹੇਠਾਂ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ।
ORMs ਬੋਰਡਰ ਕਾਰਜਾਂ ਨੂੰ ਹਟਾਉਣ ਵਿੱਚ ਸ਼ਾਨਦਾਰ ਹਨ, ਪਰ ਉਹ ਇਹ ਭੁੱਲਣਾ ਵੀ ਆਸਾਨ ਬਣਾ ਦਿੰਦੇ ਹਨ ਕਿ ਹਰ ਆਬਜੈਕਟ ਆਖ਼ਿਰਕਾਰ SQL ਬਣਦਾ ਹੈ। ਛੋਟੇ ਸਕੇਲ 'ਤੇ, ਇਹ ਤਬਦੀਲੀ ਅਦ੍ਰਸ਼ ਰਹਿੰਦੀ ਹੈ। ਵੱਧ ਵਾਲੀਉਮ 'ਤੇ, ਡੇਟਾਬੇਸ ਅਕਸਰ ਪਹਿਲੀ ਥਾਂ ਹੁੰਦੀ ਹੈ ਜਿੱਥੇ "ਸਾਫ਼" ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਭੁੱਗਤਾਨ ਲੈਣਾ ਸ਼ੁਰੂ ਕਰਦੀ ਹੈ।
N+1 ਉਸ ਵੇਲੇ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਮਾਪੇ records ਦੀ ਲਿਸਟ ਲੋਡ ਕਰਦੇ ਹੋ (1 ਕਵੇਰੀ) ਅਤੇ ਫਿਰ ਲੂਪ ਵਿੱਚ ਹਰ ਮਾਪੇ ਲਈ ਸੰਬੰਧਤ records ਲੋਡ ਕਰਦੇ ਹੋ (ਹਰ ਇੱਕ ਲਈ N ਹੋਰ ਕਵੇਰੀਆਂ)। lokaal ਟੈਸਟਿੰਗ ਵਿੱਚ ਇਹ ਠੀਕ ਲੱਗਦਾ ਹੈ—ਸੁਭਾਵਿਕ ਤੌਰ 'ਤੇ N 20 ਹੈ। ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ, N 2,000 ਬਣ ਸਕਦਾ ਹੈ, ਅਤੇ ਤੁਹਾਡੀ ਐਪ ਇੱਕ ਰੀਕਵੈਸਟ ਨੂੰ ਹਜ਼ਾਰਾਂ ਰਾਊਂਡ‑ਟਰਿੱਪ ਵਿੱਚ ਬਦਲ ਦੇਂਦੀ ਹੈ।
ਮੁਸ਼ਕਲ ਗੱਲ ਇਹ ਹੈ ਕਿ ਕੁਝ ਤੁਰੰਤ "ਟੁੱਟਦਾ" ਨਹੀਂ; ਲੇਟੈਂਸੀ ਹੌਲੀ‑ਹੌਲੀ ਵਧਦੀ ਹੈ, connection pools ਭਰ ਜਾਂਦੇ ਹਨ, ਅਤੇ retries ਲੋਡ ਗੁਣਾ ਕਰ ਦਿੰਦੇ ਹਨ।
ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਡਿਫ਼ੌਲਟ ਵੇਲੇ ਪੂਰੇ objects ਫੈਚ ਕਰਨ ਨੂੰ ਉਤਸ਼ਾਹਿਤ ਕਰਦੀਆਂ ਹਨ, ਭਾਵੇਂ ਤੁਸੀਂ ਸਿਰਫ਼ ਦੋ ਫੀਲਡਾਂ ਦੀ ਲੋੜ ਹੋ। ਇਹ I/O, ਮੈਮੋਰੀ ਅਤੇ ਨੈਟਵਰਕ ਟ੍ਰਾਂਸਫਰ ਵਧਾਉਂਦਾ ਹੈ।
ਇਸੇ ਵੇਲੇ, ORMs ਐਸੀ ਕਵੇਰੀਜ਼ ਬਣਾਉਂ ਸਕਦੀਆਂ ਹਨ ਜੋ ਉਹ ਇੰਡੈਕਸਾਂ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ ਜਿਨ੍ਹਾਂ ਦੀ ਤੁਸੀਂ ਉਮੀਦ ਕੀਤੀ ਸੀ (ਜਾਂ ਜੋ ਕਦੇ ਬਣੀਆਂ ਹੀ ਨਹੀਂ ਸਨ)। ਇੱਕ ਗੁੰਮ ਹੋਇਆ ਇੰਡੈਕਸ ਇੱਕ selective lookup ਨੂੰ table scan ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ।
Joins ਵੀ ਇਕ ਛੁਪਿਆ ਖ਼ਰਚ ਹਨ: "ਸਿਰਫ਼ relation ਸ਼ਾਮਲ ਕਰੋ" ਵਖਰਾ ਵੱਡੇ interim ਨਤੀਜਿਆਂ ਵਾਲੀ multi‑join ਕਵੇਰੀ ਬਣਾ ਸਕਦਾ ਹੈ।
ਲੋਡ ਹੇਠਾਂ, ਡੇਟਾਬੇਸ ਕਨੈਕਸ਼ਨਾਂ ਸਮਾਨਤੀ ਰਿਸੋਰਸ ਹੁੰਦੀਆਂ ਹਨ। ਜੇ ਹਰ ਬੇਨਤੀ ਕਈ ਕਵੇਰੀ ਵਿੱਚ ਫੈਨ‑ਆਉਟ ਕਰਦੀ ਹੈ, ਤਾਂ ਪੂਲ ਆਪਣੀ ਸੀਮਾ ਤੇ ਜਲਦੀ ਪੁੱਜ ਜਾਂਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੀ ਐਪ ਕਤਾਰ ਬਣਾਉਣ ਲੱਗਦੀ ਹੈ।
ਲੰਬੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ (ਕਈ ਵਾਰ ਅਕਸਮਾਤ) ਵੀ contention ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ—ਲਾਕ ਲੰਮੇ ਚੱਲਦੇ ਹਨ, ਅਤੇ concurrency ਡਿੱਗਦੀ ਹੈ।
Concurrency ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਵਿਕਾਸ ਵਿੱਚ “ਸੁਰੱਖਿਅਤ” ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ ਅਤੇ ਫਿਰ ਲੋਡ ਹੇਠਾਂ ਜ਼ੋਰ ਨਾਲ਼ ਫੇਲ ਹੋ ਜਾਂਦੀ ਹੈ। ਇੱਕ ਫਰੇਮਵਰਕ ਦਾ ਡਿਫ਼ੌਲਟ ਮਾਡਲ ਅਕਸਰ ਅਸਲ ਸੀਮਿਤੀ ਨੂੰ ਛੁਪਾਉਂਦਾ ਹੈ: ਤੁਸੀਂ ਸਿਰਫ਼ ਬੇਨਤੀਆਂ ਸਰਵ ਕਰ ਰਹੇ ਨਹੀਂ ਹੋ—ਤੁਸੀਂ CPU, ਥਰੇਡ, ਸਾਕਟ ਅਤੇ ਡਾਊਨਸਟਰੀਮ ਸਮਰੱਥਾ ਲਈ contention ਵੀ ਮੈਨੇਜ ਕਰ ਰਹੇ ਹੋ।
Thread‑per‑request (ਰਵਾਇਤੀ ਵੈੱਬ ਸਟੈਕ ਵਿੱਚ ਆਮ) ਸਧਾਰਨ ਹੈ: ਹਰ ਬੇਨਤੀ ਨੂੰ ਇੱਕ ਵਰਕਰ ਥਰੇਡ ਮਿਲਦਾ ਹੈ। ਇਹ ਤਦ ਫੇਲ ਹੁੰਦਾ ਹੈ ਜਦੋਂ slow I/O (DB, API calls) ਥਰੇਡਾਂ ਨੂੰ ਜਮ੍ਹਾਂ ਕਰ ਦਿੰਦਾ ਹੈ। ਜਦੋਂ ਥਰੇਡ ਪੂਲ ਖਤਮ ਹੋ ਜਾਂਦਾ, ਨਵੀਆਂ ਬੇਨਤੀਆਂ ਕਤਾਰ ਵਿੱਚ ਪੈਂਦੀਆਂ ਹਨ, ਲੇਟੈਂਸੀ spike ਹੁੰਦੀ ਹੈ, ਅਤੇ ਆਖ਼ਿਰਕਾਰ timeouts ਹੋ ਜਾਂਦੇ ਹਨ—ਜਦੋਂ ਸਰਵਰ ਅਸਲ ਵਿੱਚ ਸਿਰਫ਼ ਉਡੀਕ ਕਰ ਰਿਹਾ ਹੁੰਦਾ ਹੈ।
Async/event‑loop ਮਾਡਲ ਬਹੁਤ ਸਾਰੀਆਂ in‑flight ਬੇਨਤੀਆਂ ਘੱਟ ਥਰੇਡਾਂ ਨਾਲ ਸੰਭਾਲਦਾ ਹੈ, ਇਸ ਲਈ ਇਹ ਉੱਚ concurrency 'ਤੇ ਚੰਗਾ ਹੈ। ਉਹ ਵੱਖਰੇ ਤਰੀਕੇ ਨਾਲ ਫੇਲ ਹੁੰਦੇ ਹਨ: ਇੱਕ blocking call (sync ਲਾਇਬਰਾਰੀ, ਧੀਮਾ JSON parsing, ਭਾਰੀ ਲੌਗਿੰਗ) event loop ਨੂੰ ਰੋਕ ਸਕਦਾ ਹੈ, ਜਿਸ ਨਾਲ "ਇੱਕ ਧੀਮਾ ਬੇਨਤੀ" ਸਾਰਿਆਂ ਲਈ ਧੀਮੀ ਹੋ ਜਾਂਦੀ ਹੈ। Async ਨਾਲ ਇਹ ਵੀ ਆਸਾਨ ਹੈ ਕਿ ਤੁਸੀਂ ਬਹੁਤ ਜ਼ਿਆਦਾ concurrency ਬਣਾਵੋ, ਜਿਸ ਨਾਲ dependency ਉਤੇ ਥਰੇਡ ਲਿਮਟ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਦਬਾਅ ਪੈਂਦਾ ਹੈ।
Backpressure ਉਹ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਸਿਸਟਮ ਕਾਲਰ ਨੂੰ ਕਹਿੰਦਾ ਹੈ, “ਮੈਂ ਹੋਰ ਨਹੀਂ ਲੈ ਸਕਦਾ।” ਬਿਨਾਂ ਇਸਦੇ, ਧੀਮਾ ਡਿਪੈਂਡੇਸੀ ਸਿਰਫ਼ ਰਿਸਪਾਂਸ ਨੂੰ ਧੀਮਾ ਨਹੀਂ ਕਰਦੀ—ਇਹ in‑flight ਕੰਮ, ਮੈਮੋਰੀ ਯੂਜ਼ ਅਤੇ ਕਤਾਰ ਦੀ ਲੰਬਾਈ ਵਧਾ ਦਿੰਦੀ ਹੈ। ਇਹ ਵਾਧਾ ਡਿਪੈਂਡੇਸੀ ਨੂੰ ਹੋਰ ਧੀਮਾ ਕਰਦਾ ਅਤੇ ਫੀਡਬੈਕ ਲੂਪ ਬਣ ਜਾਂਦਾ।
ਟਾਈਮਆਉਟ explicit ਅਤੇ ਲੇਅਰਡ হওਣੇ ਚਾਹੀਦੇ ਹਨ: client, service, ਅਤੇ dependency। ਜੇ ਟਾਈਮਆਉਟ ਬਹੁਤ ਲੰਬੇ ਹਨ ਤਾਂ ਕਤਾਰਾਂ ਵਧਦੀਆਂ ਹਨ ਅਤੇ ਰਿਕਵਰੀ ਦੇ ਸਮੇਂ ਨੂੰ ਲੰਮਾ ਕਰ ਦਿੰਦੀਆਂ ਹਨ। ਜੇ retries automatic ਅਤੇ aggressive ਹਨ, ਤਾਂ ਤੁਸੀਂ retry storm ਟ੍ਰਿਗਰ ਕਰ ਸਕਦੇ ਹੋ: dependency ਧੀਮੀ ਹੁੰਦਾ ਹੈ, calls timeout ਹੋਦੇ ਹਨ, callers retry ਕਰਦੇ ਹਨ, ਲੋਡ ਗੁਣਾ ਹੁੰਦਾ ਹੈ, ਅਤੇ dependency ਢਹਿ ਜਾਂਦੀ ਹੈ।
ਫਰੇਮਵਰਕ ਨੈਟਵਰਕਿੰਗ ਨੂੰ “ਸਿਰਫ਼ ਇਕ ਐਂਡਪੌਇੰਟ ਨੂੰ ਕਾਲ ਕਰਨਾ” ਵਾਲੀ ਭਾਵਨਾ ਦਿੰਦੇ ਹਨ। ਲੋਡ ਹੇਠਾਂ, ਇਹ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਅਕਸਰ ਮਿੱਡਲਵੇਅਰ ਸਟੈਕ, ਸਿਰਿਆਲਾਈਜ਼ੇਸ਼ਨ, ਅਤੇ payload handling ਦੁਆਰਾ ਲੀਕ ਹੁੰਦੀ ਹੈ।
ਹਰ ਪਰਤ—API gateway, auth middleware, rate limiting, request validation, observability hooks, retries—ਥੋੜ੍ਹਾ ਜਿਹਾ ਸਮਾਂ ਜੋੜਦੀ ਹੈ। ਇਕ ਵਧੇਰੇ ਮਿਲੀਸਕਿੰਟ ਵਿਕਾਸਕਾਲ ਵਿੱਚ ਕਦੇ ਮਹੱਤਵਪੂਰਨ ਨਹੀਂ ਲੱਗਦਾ; ਸਕੇਲ 'ਤੇ, ਕੁਝ ਮਿੱਡਲਵੇਅਰ hops ਇਕ 20 ms ਦੀ ਬੇਨਤੀ ਨੂੰ 60–100 ms ਤੱਕ ਬਦਾ ਸਕਦੇ ਹਨ, ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਕਤਾਰ ਬਣ ਜਾਂਦੀ ਹੈ।
ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਲੇਟੈਂਸੀ ਸਿਰਫ਼ ਜੋੜ੍ਹਦੀ ਨਹੀਂ—ਇਹ ਗੁਣਾ ਕਰਦੀ ਹੈ। ਛੋਟੇ ਦੇਰੀਆ ਇਸਟਿਤੀ ਵਿੱਚ ਵੱਧ concurrency ਪੈਦਾ ਕਰਦੇ ਹਨ (ਵੱਧ in‑flight requests), ਜਿਸ ਨਾਲ contention ਵੱਧਦਾ ਹੈ (ਥਰੇਡ/ਕਨੈਕਸ਼ਨ ਪੂਲ), ਜੋ ਫਿਰ ਫਿਰ ਦੇਰੀਆਂ ਵਧਾਉਂਦਾ ਹੈ।
JSON ਸੁਵਿਧਾਜਨਕ ਹੈ, ਪਰ ਵੱਡੇ payloads ਨੂੰ encode/decode ਕਰਨਾ CPU 'ਤੇ ਹਕਮਤ ਰਖਦਾ ਹੈ। ਲੀਕ ਉਹਨਾਂ ਚੀਜ਼ਾਂ ਵਿੱਚ ਦਿਖਦੀ ਹੈ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ "ਨੈਟਵਰਕ" ਮੰਨਦੇ ਹੋ ਪਰ ਅਸਲ ਵਿੱਚ ਐਪ CPU ਸਮਾਂ ਹੈ, ਨਾਲ‑ਨਾਲ ਬਫਰਾਂ ਤੋਂ memory churn ਵੀ।
ਵੱਡੇ payload ਸਾਰੇ ਚੀਜ਼ਾਂ ਨੂੰ ਧੀਮਾ ਕਰਦੇ ਹਨ:
Headers ਬੇਨਤੀ ਨੂੰ ਚੁੱਪਕੇ ਬੜਾ ਕਰ ਸਕਦੇ ਹਨ (cookies, auth tokens, tracing headers). ਇਹ ਵਧਾ ਹਰ ਕਾਲ ਅਤੇ ਹਰ ਹੋਪ 'ਤੇ ਗੁਣਾ ਹੋ ਜਾਂਦਾ ਹੈ।
ਕੰਪ੍ਰੈਸ਼ਨ ਇਕ ਹੋਰ ਟਰੇਡ‑ਅਫ਼ ਹੈ। ਇਹ bandwidth ਬਚਾ ਸਕਦੀ ਹੈ, ਪਰ CPU ਲਾਗਤ ਕਰਦੀ ਹੈ ਅਤੇ latency ਜੋੜ ਸਕਦੀ ਹੈ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਤੁਸੀਂ ਛੋਟੇ payload ਨੂੰ compress ਕਰਦੇ ਹੋ ਜਾਂ proxies ਰਾਹੀਂ ਕਈ ਵਾਰੀ compress ਹੁੰਦਾ ਹੈ।
ਅੰਤ ਵਿੱਚ, streaming vs buffering ਮਹੱਤਵਪੂਰਨ ਹੈ। ਬਹੁਤ ਸਾਰੇ ਫਰੇਮਵਰਕ ਡਿਫੋਲਟ ਰੂਪ ਵਿੱਚ ਪੂਰੇ request/response ਬਾਡੀ ਨੂੰ ਬਫਰ ਕਰਦੇ ਹਨ (retry, logging, ਜਾਂ content‑length ਗਿਣਤੀ ਲਈ)। ਇਹ ਸੁਵਿਧਾਜਨਕ ਹੈ, ਪਰ ਉੱਚ ਵਾਲੀਉਮ 'ਤੇ ਇਹ ਮੈਮੋਰੀ ਯੂਜ਼ਰੇਸ਼ਨ ਵਧਾਉਂਦਾ ਅਤੇ head‑of‑line blocking ਪੈਦਾ ਕਰਦਾ ਹੈ। Streaming ਮੈਮੋਰੀ ਨੂੰ ਪੂਰਾ‑ਪੇਸ਼ਗੀ ਰੱਖਣ ਅਤੇ time‑to‑first‑byte ਘਟਾਉਂਦਾ ਹੈ, ਪਰ ਇਸਨੂੰ ਹੋਰ ਸੰਭਾਲ ਅਤੇ error handling ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
payload ਆਕਾਰ ਅਤੇ middleware depth ਨੂੰ ਬਜਟ ਵਜੋਂ ਸTreat ਕਰੋ, ਬਾਅਦ ਵਿੱਚ नहीं:
ਜਦੋਂ ਸਕੇਲ ਨੈਟਵਰਕ ਓਵਰਹੈੱਡ ਨੂੰ ਪ੍ਰਗਟ ਕਰਦਾ ਹੈ, ਠੀਕ ਕਰਨਾ ਅਕਸਰ "ਨੈਟਵਰਕ ਨੂੰ optimize ਕਰੋ" ਨਹੀਂ ਹੁੰਦਾ, ਬਲਕਿ "ਹਰ ਬੇਨਤੀ 'ਤੇ ਲੁਕਿਆ ਕੰਮ ਰੋਕੋ" ਹੁੰਦਾ ਹੈ।
ਕੈਸ਼ਿੰਗ ਅਕਸਰ ਇੱਕ ਸਧਾਰਣ ਸਵਿੱਚ ਵਾਂਗ ਸਮਝੀ ਜਾਂਦੀ ਹੈ: Redis (ਜਾਂ CDN) ਜੋੜੋ, ਲੇਟੈਂਸੀ ਘਟਦੀ ਦੇਖੋ, ਅਤੇ ਅੱਗੇ ਵੱਧੋ। ਅਸਲ ਲੋਡ ਹੇਠਾਂ, ਕੈਸ਼ ਇੱਕ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਹੈ ਜੋ ਬुरी ਤਰ੍ਹਾਂ ਲੀਕ ਕਰ ਸਕਦੀ ਹੈ—ਕਿਉਂਕਿ ਇਹ ਇਹ ਬਦਲ ਦਿੰਦਾ ਹੈ ਕਿ ਕੰਮ ਕਿੱਥੇ ਹੁੰਦਾ ਹੈ, ਕਦੋਂ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਫੇਲਯਰ ਕਿਵੇਂ ਫੈਲਦੇ ਹਨ।
ਇੱਕ ਕੈਸ਼ ਹੋਰ ਨੈਟਵਰਕ ਹੋਪਸ, ਸਿਰਿਆਲਾਈਜ਼ੇਸ਼ਨ, ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਜਟਿਲਤਾ ਜੋੜਦਾ ਹੈ। ਇਸ ਨਾਲ ਇੱਕ ਦੂਜੀ "ਸੋਰਸ ਆਫ਼ ਟਰੂਥ" ਬਣ ਜਾਂਦੀ ਹੈ ਜੋ stale, ਕੁਝ ਭਰਪੂਰ ਨਹੀਂ ਜਾਂ ਉਪਲਬਧ ਨਹੀਂ ਹੋ ਸਕਦੀ। ਜਦੋਂ ਚੀਜ਼ਾਂ ਗਲਤ ਹੁੰਦੀਆਂ ਹਨ, ਸਿਸਟਮ ਸਿਰਫ਼ ਧੀਮਾ ਨਹੀਂ ਹੁੰਦਾ—ਇਹ ਵੱਖਰਾ ਵਿਹਾਰ ਕਰ ਸਕਦਾ ਹੈ (ਪੁਰਾਣਾ ਡਾਟਾ ਸੇਵਾ ਕਰਨਾ, retries ਨੂੰ amplify ਕਰਨਾ, ਜਾਂ ਡੇਟਾਬੇਸ ਨੂੰ overload ਕਰਨਾ)।
Cache stampedes ਉਸ ਵੇਲੇ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਬਹੁਤ ਸਾਰੀਆਂ ਬੇਨਤੀਆਂ ਇਕੱਠੇ cache miss ਕਰਦੀਆਂ (ਅਕਸਰ expiry ਤੋਂ ਬਾਅਦ) ਅਤੇ ਸਾਰੇ ਇੱਕੋ ਹੀ value ਨੂੰ rebuild ਕਰਨ ਲਈ ਦੌੜ ਪੈਂਦੇ ਹਨ। ਸਕੇਲ 'ਤੇ, ਇਹ ਛੋਟਾ miss rate ਡੇਟਾਬੇਸ spike ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ।
ਗਲਤ key ਡਿਜ਼ਾਈਨ ਇਕ ਹੋਰ ਮੂਹਾਂਬਾ ਸਮੱਸਿਆ ਹੈ। ਜੇ keys ਬਹੁਤ ਵਿਸ਼ਾਲ ਹਨ (ਜਿਵੇਂ user:feed ਬਿਨਾਂ parameters) ਤਾਂ ਤੁਸੀਂ ਗਲਤ ਡਾਟਾ ਸੇਵਾ ਕਰ ਸਕਦੇ ਹੋ। ਜੇ keys ਬਹੁਤ ਵਿਸ਼ੇਸ਼ ਹਨ (timestamps, random IDs, ਜਾਂ unordered query params ਸ਼ਾਮਿਲ ਕਰਦੇ ਹੋ), ਤਾਂ hit rate ਨੇੜੇ‑ਜ਼ੀਰੋ ਹੋ ਸਕਦੀ ਹੈ ਅਤੇ ਤੁਸੀਂ ਖ਼ਰਚ ਬਿਨਾਂ ਫਾਇਦੇ ਦੇ ਭਰਦੇ ਹੋ।
Invalidation ਕਲਾਸਿਕ ਜਾਲ ਹੈ: ਡੇਟਾਬੇਸ ਅਪਡੇਟ ਕਰਨਾ ਆਸਾਨ ਹੈ; ਇਹ ਯਕੀਨੀ ਬਣਾਉਣਾ ਕਿ ਹਰੇਕ ਸੰਬੰਧਤ cached view refreshed ਹੋ ਗਿਆ, ਨਹੀਂ। ਅੰਸ਼ਿਕ invalidation confusing “ਮੇਰੇ ਲਈ ਠੀਕ ਹੈ” ਵਾਲੀਆਂ ਬੱਗਾਂ ਅਤੇ ਅਸੰਗਤ ਰੀਡਸ ਪੈਦਾ ਕਰਦੀ ਹੈ।
ਅਸਲ ਟ੍ਰੈਫਿਕ ਇੱਕੋ ਤਰ੍ਹਾਂ ਵੰਡਿਆ ਨਹੀਂ ਹੁੰਦਾ। ਇਕ ਸੈਲੇਬ੍ਰਿਟੀ ਪ੍ਰੋਫਾਈਲ, ਲੋਕਪ੍ਰਿਯ ਉਤਪਾਦ, ਜਾਂ ਸਾਂਝਾ config endpoint ਇਕ hot key ਬਣ ਸਕਦਾ ਹੈ, ਜੋ ਲੋਡ ਨੂੰ ਇਕੇ entry ਅਤੇ ਉਸਦੇ backing store 'ਤੇ ਕੇਂਦਰਿਤ ਕਰਦਾ ਹੈ। ਜਦੋਂ ਕਿ ਔਸਤ ਪ੍ਰਦਰਸ਼ਨ ਠੀਕ ਲੱਗ ਸਕਦਾ ਹੈ, tail latency ਅਤੇ node‑ਸਤਹ ਦਬਾਅ ਫਟਾਕੇ ਵਧ ਸਕਦੇ ਹਨ।
ਫਰੇਮਵਰਕ ਅਕਸਰ ਮੈਮੋਰੀ ਨੂੰ "ਮੈਨੇਜਡ" ਮਹਿਸੂਸ ਕਰਵਾਉਂਦੇ ਹਨ, ਜੋ ਸਹਿਜ ਹੈ—ਪਰ ਜਦੋਂ ਟ੍ਰੈਫਿਕ ਚੜ੍ਹਦਾ ਹੈ ਅਤੇ ਲੇਟੈਂਸੀ CPU ਗ੍ਰਾਫਾਂ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀ, ਤਾਂ ਇਹ ਅਸੁਖਾਵੀ ਹੋ ਸਕਦਾ ਹੈ। ਬਹੁਤ ਸਾਰੇ ਡਿਫੌਲਟ ਡਿਵੈਲਪਰ ਸੁਵਿਧਾ ਲਈ ਟਿਊਨ ਕੀਤੇ ਜਾਂਦੇ ਹਨ, ਨਾ ਕਿ ਲੰਬੇ ਦੌਰ ਦੇ ਪੈਕੇਜਾਂ ਲਈ ਜੋ ਲੰਮੇ ਸਮੇਂ ਤੱਕ ਚੱਲਦੇ ਹਨ।
ਉੱਚ‑ਸਤਹ ਫਰੇਮਵਰਕ ਹਰ ਬੇਨਤੀ ਲਈ ਛੋਟੇ‑ਜੀਵੇਂ objects allocate ਕਰਦੇ ਹਨ: request/response wrappers, middleware context objects, JSON ਟ੍ਰੀ, regex matchers, ਅਤੇ ਅਸਥਾਈ strings। ਵਿਅਕਤੀਗਤ ਤੌਰ 'ਤੇ ਇਹ ਛੋਟੇ ਹਨ। ਸਕੇਲ 'ਤੇ, ਇਹ ਲਗਾਤਾਰ allocation ਦਬਾਅ ਬਣਾ ਦਿੰਦੇ ਹਨ, runtime ਨੂੰ ਜ਼ਿਆਦਾ GC ਚਲਾਉਣ ਲਈ ਧਕਾ ਦੇਂਦੇ ਹਨ।
GC pauses ਛੋਟੇ ਪਰ ਅਕਸਰ ਲੇਟੈਂਸੀ spikes ਵਜੋਂ ਦਿਸ ਸਕਦੇ ਹਨ। ਜਿਵੇਂ heap ਵੱਧਦਾ ਹੈ, pauses ਲੰਬੇ ਹੋ ਸਕਦੇ ਹਨ—ਜ਼ਰੂਰੀ ਨਹੀਂ ਕਿ ਤੁਸੀਂ ਲੀਕ ਕਰ ਰਹੇ ਹੋ, ਪਰ runtime ਨੂੰ ਮੈਮੋਰੀ ਸਪੈਨ ਨੂੰ ਸਕੈਨ ਅਤੇ compact ਕਰਨ ਲਈ ਹੋਰ ਸਮਾਂ ਚਾਹੀਦਾ ਹੈ।
ਲੋਡ ਹੇਠਾਂ, ਇੱਕ ਸਰਵਿਸ objects ਨੂੰ ਓਲਡਰ generations (ਜਾਂ ਸਮਾਨ ਲੰਬੀ ਉਮਰ ਵਾਲੇ ਖੇਤਰ) ਵਿੱਚ promote ਕਰ ਸਕਦੀ ਹੈ ਸਿਰਫ਼ ਇਸ ਲਈ ਕਿ ਉਹ ਕੁਝ GC cycles ਬਚ ਗਏ ਜਦੋਂ ਉਹ queues, buffers, connection pools, ਜਾਂ in‑flight requests ਵਿੱਚ ਰੁਕੇ ਰਹੀ। ਇਹ heap ਨੂੰ ਫੁਲਾਉ ਸਕਦਾ ਹੈ ਭਾਵੇਂ ਐਪ "ਠੀਕ" ਹੋਵੇ।
fragmentation ਇਕ ਹੋਰ ਛੁਪਿਆ ਖ਼ਰਚ ਹੈ: ਮੈਮੋਰੀ ਫਰੀ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਤੁਹਾਡੇ ਲੋੜ ਦੇ ਆਕਾਰ ਲਈ ਦੁਬਾਰਾ ਵਰਤੀ ਨਹੀਂ ਜਾ ਸਕਦੀ, ਇਸ ਲਈ process OS ਤੋਂ ਹੋਰ ਮੰਗ ਕਰਦਾ ਰਹਿੰਦਾ ਹੈ।
ਅਸਲੀ ਲੀਕ ਉਹ ਹੈ ਜੋ ਸਮੇਂ ਦੇ ਨਾਲ ਬੇਹਦ ਵਾਧਾ ਦਿਖਾਉਂਦੀ ਹੈ: ਮੈਮੋਰੀ ਚੜ੍ਹਦੀ ਰਹਿੰਦੀ ਹੈ, ਵਾਪਿਸ ਨਹੀਂ ਆਉਂਦੀ, ਅਤੇ ਆਖ਼ਰਕਾਰ OOM kills ਜਾਂ ਹੈਰਾਨਕ GC thrash ਪੈਦਾ ਕਰਦੀ ਹੈ। ਉੱਚ‑ਪਰ ਠੀਕ ਯੂਜ਼ੇਜ ਵੱਖਰਾ ਹੈ: ਮੈਮੋਰੀ ਗਰਮੀ ਦੇ ਬਾਅਦ ਇੱਕ ਪਲੇਟੋ 'ਤੇ ਚੜ੍ਹਦੀ ਹੈ, ਫਿਰ ਲਗਭਗ ਸਮਾਂ ਰਹਿੰਦੀ ਹੈ।
ਹੈਪ snapshot, allocation flame graphs ਵਰਗੇ profiling ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਤਾਂ ਕਿ hot allocation paths ਅਤੇ retained objects ਮਿਲ ਸਕਣ।
ਪੂਲਿੰਗ ਨਾਲ ਸਾਵਧਾਨ ਰਹੋ: ਇਹ allocations ਘਟਾ ਸਕਦੀ ਹੈ, ਪਰ ਇਕ ਗਲਤ ਸਾਈਜ਼ ਦੀ ਪੂਲ ਮੈਮੋਰੀ pinned ਕਰ ਸਕਦੀ ਹੈ ਅਤੇ fragmentation ਨੂੰ ਖ਼ਰਾਬ ਕਰ ਸਕਦੀ ਹੈ। ਪਹਿਲਾਂ allocations ਘਟਾਉਣ 'ਤੇ ਧਿਆਨ ਦਿਓ (buffering ਦੀ ਥਾਂ streaming, ਜ਼ਰੂਰੀ ਨਾਂਹ999 ਚੀਜ਼ਾਂ ਬਣਾਉਣ ਤੋਂ ਬਚੋ, ਪ੍ਰਤੀ‑ਰੀਕਵੈਸਟ caching ਸੀਮਿਤ ਕਰੋ), ਫਿਰ ਮਾਪਨ ਦੇ ਆਧਾਰ 'ਤੇ ਹੀ pooling ਸ਼ਾਮਿਲ ਕਰੋ।
Observability ਟੂਲ ਅਕਸਰ "ਮੁਫ਼ਤ" ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਫਰੇਮਵਰਕ ਤੁਹਾਨੂੰ ਸੁਵਿਧਾਜਨਕ ਡਿਫ਼ੌਲਟ ਦਿੰਦੇ ਹਨ: request logs, auto‑instrumented metrics, ਅਤੇ ਇੱਕ‑ਪੰਗਤੀ tracing। ਅਸਲ ਟ੍ਰੈਫਿਕ 'ਤੇ, ਉਹ ਡਿਫ਼ੌਲਟ ਤੁਹਾਡੇ ਲੋਡ ਦਾ ਇੱਕ ਹਿੱਸਾ ਬਣ ਸਕਦੇ ਹਨ।
Per‑request logging ਕਲਾਸਿਕ ਉਦਾਹਰਣ ਹੈ। ਹਰ ਬੇਨਤੀ ਲਈ ਇੱਕ ਲਾਈਨ ਪੈਰ ਸੋਝੀ ਲੱਗਦੀ ਹੈ—ਜਦ ਤੱਕ ਤੁਸੀਂ ਹਜਾਰਾਂ ਬੇਨਤੀਆਂ ਪ੍ਰਤੀ ਸੈਕੰਡ ਤੱਕ ਨਹੀਂ ਪਹੁੰਚਦੇ। ਫਿਰ ਤੁਸੀਂ string formatting, JSON encoding, disk ਜਾਂ network writes, ਅਤੇ downstream ingestion ਦਾ ਭੁਗਤਾਨ ਕਰ ਰਹੇ ਹੋ। ਲੀਕ ਹਟ ਕੇ tail latency, CPU spikes, log pipeline ਦੇ ਪਿੱਛੇ ਰਹਿਣ ਅਤੇ ਕਈ ਵਾਰੀ synchronous log flushing ਕਾਰਨ request timeouts ਵਜੋਂ ਦਿਖਦੀ ਹੈ।
Metrics ਸੂਖਮ ਤਰੀਕੇ ਨਾਲ ਸਿਸਟਮ ਨੂੰ ਓਵਰਲੋਡ ਕਰ ਸਕਦੇ ਹਨ। Counters ਅਤੇ histograms ਛੋਟੇ time series ਦੀ ਗਿਣਤੀ ਨਾਲ ਸਸਤੇ ਹਨ। ਪਰ ਫਰੇਮਵਰਕ ਅਕਸਰ user_id, email, path, ਜਾਂ order_id ਵਰਗੇ tags/labels ਜੋੜਨ ਦੀ ਸਹੂਲਤ ਦਿੰਦੇ ਹਨ। ਇਸ ਨਾਲ cardinality explosion ਹੁੰਦੀ ਹੈ: ਇੱਕ ਮੈਟ੍ਰਿਕ ਲਈ ਨਹੀਂ, ਪਰ ਮਿਲੀਅਨਜ਼ ਯੂਨੀਕ ਸੀਰੀਜ਼ ਬਣ ਜਾਂਦੀਆਂ ਹਨ। ਨਤੀਜਾ ਹੈ backend ਵਿੱਚ ਭਾਰੀ memory ਵਰਤੋਂ, ਡੈਸ਼ਬੋਰਡਾਂ ਵਿੱਚ slow queries, samples ਦੀ ਡਰਾਪਿੰਗ, ਅਤੇ ਆਸ਼ਚਰਯਜਨਕ ਖਰਚੇ।
Distributed tracing ਸਟੋਰੇਜ ਅਤੇ compute ਓਵਰਹੈੱਡ ਜੋ ਟ੍ਰੈਫਿਕ ਅਤੇ ਪ੍ਰਤੀ‑ਰੀਕਵੈਸਟ ਸਪੈਨ ਗਿਣਤੀ ਨਾਲ ਵਧਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਡਿਫ਼ੌਲਟ ਤੌਰ 'ਤੇ ਹਰ ਚੀਜ਼ ਨੂੰ trace ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਦੋ ਵਾਰੀ ਖਰਚ ਭਰ ਸਕਦੇ ਹੋ: ਇਕ ਵਾਰੀ ਐਪ ਓਵਰਹੈੱਡ (span ਬਣਾਉਣਾ, context propagate ਕਰਨਾ) ਅਤੇ ਦੂਜੀ ਵਾਰੀ tracing backend (ingestion, indexing, retention)।
Sampling ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਟੀਮਾਂ ਵਾਪਸ ਨਿਯੰਤਰਣ ਪਾਉਂਦੀਆਂ ਹਨ—ਪਰ ਇਹ ਗਲਤ ਤਰੀਕੇ ਨਾਲ ਕਰਨਾ ਆਸਾਨ ਹੈ। ਬਹੁਤ ਜ਼ਿਆਦਾ sampling ਖRare failures ਨੂੰ ਛੁਪਾ ਦੇਵੇਗਾ; ਬਹੁਤ ਘੱਟ sampling tracing ਨੂੰ ਮਹਿੰਗਾ ਕਰ ਦੇਵੇਗਾ। ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਢੰਗ ਹੈ ਕਿ errors ਅਤੇ high‑latency requests ਲਈ ਵੱਧ sample ਅਤੇ ਤੇਜ਼ paths ਲਈ ਘੱਟ।
ਜੇ ਤੁਸੀਂ ਜਾਣਨਾ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਕੀ ਕੁਝ collect ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ (ਅਤੇ ਕੀ ਨਹੀਂ), ਤਾਂ ਵੇਖੋ /blog/observability-basics.
Observability ਨੂੰ production ਟ੍ਰੈਫਿਕ ਵਾਂਗ treat ਕਰੋ: budgets (log volume, metric series count, trace ingestion) ਸੈਟ ਕਰੋ, ਟੈਗਜ਼ ਦੀ cardinality risk ਦੀ ਸਮੀਖਿਆ ਕਰੋ, ਅਤੇ instrumentation enable ਹੋ ਕੇ ਲੋਡ‑ਟੈਸਟ ਕਰੋ। ਮਕਸਦ "ਘੱਟ ਨਿਰੀਖਣਯੋਗਤਾ" ਨਹੀਂ—ਮਕਸਦ ਉਹ ਨਿਰੀਖਣਯੋਗਤਾ ਹੈ ਜੋ ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੇ ਦਬਾਅ ਹੇਠਾਂ ਵੀ ਕੰਮ ਕਰਦੀ ਰਹੇ।
ਫਰੇਮਵਰਕ ਅਕਸਰ ਇਕ ਹੋਰ ਸਰਵਿਸ ਨੂੰ ਕਾਲ ਕਰਨਾ ਇੱਕ ਲੋਕਲ ਫੰਕਸ਼ਨ ਵਾਂਗ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦੇ ਹਨ: userService.getUser(id) ਤੁਰੰਤ ਵਾਪਸ ਕਰਦਾ ਹੈ, errors "ਸਿਰਫ਼ exceptions" ਲੱਗਦੇ ਹਨ, ਅਤੇ retries ਨਰਮ ਲੱਗਦੇ ਹਨ। ਛੋਟੇ ਸਕੇਲ 'ਤੇ ਇਹ ਭਰਮ ਟਿਕਦੀ ਹੈ। ਵੱਡੇ ਸਕੇਲ 'ਤੇ, ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਲੀਕ ਹੋ ਜਾਦੀ ਹੈ ਕਿਉਂਕਿ ਹਰ "ਸਰਲ" ਕਾਲ ਲੁਕਿਆ coupling ਲਿਆਉਂਦੀ ਹੈ: ਲੇਟੈਂਸੀ, ਸਮਰੱਥਾ ਸੀਮਾਵਾਂ, ਅੰਸ਼ਿਕ ਫੇਲਯਰ ਅਤੇ ਵਰਜ਼ਨ mismatch।
ਇੱਕ ਰਿਮੋਟ ਕਾਲ ਦੋ ਟੀਮਾਂ ਦੀ ਰਿਲੀਜ਼ ਸਾਈਕਲ, ਡੇਟਾ ਮਾਡਲ ਅਤੇ uptime ਨੂੰ ਜੋੜਦਾ ਹੈ। ਜੇ Service A ਮੰਨਦਾ ਹੈ ਕਿ Service B ਹਮੇਸ਼ਾਂ ਉਪਲਬਧ ਅਤੇ ਤੇਜ਼ ਹੈ, ਤਾਂ A ਦਾ ਵਿਹਾਰ ਹੁਣ ਆਪਣੇ ਕੋਡ ਦੁਆਰਾ ਨਹੀਂ ਨਿਰਧਾਰਿਤ ਹੁੰਦਾ—ਇਹ B ਦੇ ਸਭ ਤੋਂ ਖਰਾਬ ਦਿਨ ਦੁਆਰਾ ਨਿਰਧਾਰਿਤ ਹੋ ਜਾਂਦਾ ਹੈ। ਇਸ ਤਰ੍ਹਾਂ ਕੋਡ ਮੋਡੀਊਲਰ ਲੱਗਣ ਦੇ ਬਾਵਜੂਦ ਸਿਸਟਮ ਕੜੀਵਾਰ ਬਣ ਜਾਂਦੇ ਹਨ।
ਵੰਡੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਇੱਕ ਆਮ ਜਾਲ ਹਨ: ਜੋ ਕੁਝ "save user, then charge card" ਵਾਂਗ ਸਧਾਰਨ ਲੱਗਦਾ ਸੀ ਉਹਨਾਂ ਵਿੱਚ ਡੇਟਾਬੇਸਾਂ ਅਤੇ ਸਰਵਿਸਜ਼ ਦੇ ਵਿਚਕਾਰ ਕਈ ਕਦਮ ਵਾਲਾ workflow ਬਣ ਜਾਂਦਾ ਹੈ। two‑phase commit ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਰੁਕਾਵਟਾਂ ਨਾਲ ਅਸਾਨ ਰਹਿੰਦਾ ਨਹੀਂ, ਇਸ ਲਈ ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮ eventual consistency ਤੇ ਸਵਿੱਚ ਕਰ ਲੈਂਦੇ ਹਨ (ਜਿਵੇਂ "payment ਜਲਦੀ ਪੁਸ਼ਟ ਹੋ ਜਾਵੇਗੀ")। ਇਹ ਤਬਦੀਲੀ ਤੁਹਾਨੂੰ retries, duplicates, ਅਤੇ out‑of‑order events ਲਈ ਡਿਜ਼ਾਈਨ ਕਰਨ ਉਤੇ ਮਜਬੂਰ ਕਰਦੀ ਹੈ।
Idempotency ਬਹੁਤ ਜ਼ਰੂਰੀ ਹੋ ਜਾਂਦੀ ਹੈ: ਜੇ ਕਿਸੇ timeout ਕਰਕੇ ਬੇਨਤੀ ਦੁਹਰਾਈ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਉਸਨੇ ਦੂਜੀ charge ਜਾਂ shipment ਨਹੀਂ ਬਣਾਉਣੀ ਚਾਹੀਦੀ। ਫਰੇਮਵਰਕ‑ਕੰਨੂੰ retry helpers ਸਮੱਸਿਆਵਾਂ ਨੂੰ amplify ਕਰ ਸਕਦੇ ਹਨ ਜਦੋਂ ਤੱਕ ਤੁਹਾਡੇ endpoints ਸਪਸ਼ਟ ਤੌਰ ਤੇ ਦੁਹਰਾਓਣਾ ਸੁਰੱਖਿਅਤ ਨਾ ਹੋਣ।
ਇੱਕ ਧੀਮੀ ਡਿਪੈਂਡੇਸੀ ਥਰੇਡ ਪੂਲ, ਕਨੈਕਸ਼ਨ ਪੂਲ, ਜਾਂ 큐ਜ਼ ਨੂੰ ਖਤਮ ਕਰ ਸਕਦੀ ਹੈ, ripple effect ਬਣਦੀ ਹੈ: timeouts retries ਨੂੰ ਟ੍ਰਿਗਰ ਕਰਦੇ ਹਨ, retries load ਵਧਾਉਂਦੀਆਂ ਹਨ, ਅਤੇ ਜਲਦੀ ਹੀ ਅਣਜੁੜੇ endpoints degrade ਹੋ ਜਾਂਦੇ ਹਨ। "ਸਿਰਫ਼ ਹੋਰ ਇੰਸ੍ਟੈਂਸ ਜੋੜੋ" ਬਹੁਤ ਵਾਰੀ ਤੂਫਾਨ ਨੂੰ ਹੋਰ ਖ਼ਰਾਬ ਕਰ ਸਕਦਾ ਹੈ ਜੇ ਹਰ ਕੋਈ ਇਕੱਠੇ retry ਕਰੇ।
ਸਪਸ਼ਟ contracts (schemas, error codes, ਅਤੇ versioning)Define ਕਰੋ, ਹਰ call ਲਈ timeouts ਅਤੇ budgets ਸੈਟ ਕਰੋ, ਅਤੇ ਜਿੱਥੇ ਮੁਕਾਬਲਤਯੋਗ ਹੋਵੇ fallback (cached reads, degraded responses) ਲਗਾਓ।
ਅੰਤ ਵਿੱਚ, ਹਰ dependency ਲਈ SLOs ਸੈੱਟ ਕਰੋ ਅਤੇ enforce ਕਰੋ: ਜੇ Service B ਆਪਣਾ SLO ਪੂਰਾ ਨਹੀਂ ਕਰ ਸਕਦਾ, ਤਾਂ Service A ਨੂੰ fail fast ਜਾਂ graceful degrade ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਬਜਾਏ ਚੁੱਪਚਾਪ ਸਾਰੇ ਸਿਸਟਮ ਨੂੰ ਥੱਲੇ ਲਿਆਉਣ ਦੇ।
ਜਦੋਂ ਇੱਕ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਸਕੇਲ 'ਤੇ ਲੀਕ ਕਰਦੀ ਹੈ, ਇਹ ਅਕਸਰ ਇੱਕ vague ਲੱਛਣ (timeouts, CPU spikes, slow queries) ਵਜੋਂ ਪ੍ਰਗਟ ਹੁੰਦਾ ਹੈ ਜੋ ਟੀਮਾਂ ਨੂੰ ਨਜਿੱਠੇ ਮੁੜ‑ਰਚਣ ਦੀ ਉਤੇਜਨਾ ਦਿੰਦਾ। ਇਕ ਵਧੀਆ ਅਦ ਦੀਰੀ ਤਰੀਕ ਇਹ ਹੈ ਕਿ ਹੱਫ਼ਤੇ ਨੂੰ ਸਬੂਤ ਵਿੱਚ ਬਦਲਿਆ ਜਾਵੇ।
1) Reproduce (ਇਸਨੂੰ ਡਿਮਾਂਡ 'ਤੇ ਫੇਲ ਕਰਵਾਓ).
ਉਹ ਸਭ ਤੋਂ ਛੋਟਾ ਸਕੈਰੀਓ ਕੈਪਚਰ ਕਰੋ ਜੋ ਅਜੇ ਵੀ ਸਮੱਸਿਆ ਟ੍ਰਿਗਰ ਕਰਦਾ ਹੈ: ਐਂਡਪੌਇੰਟ, ਬੈਕਗ੍ਰਾਊਂਡ ਜੀਬ, ਜਾਂ ਯੂਜ਼ਰ ਫਲੋ। ਇਸਨੂੰ ਲੋਕਲ ਜਾਂ ਸਟੇਜਿੰਗ ਵਿੱਚ ਦੁਹਰਾਓ ਜਿੱਥੇ production‑ਜਿਹੇ config (feature flags, timeouts, connection pools) ਹੋਣ।
2) Measure (ਦੋ ਜਾਂ ਤਿੰਨ ਸਿਗਨਲ ਚੁਣੋ).
ਉਹ ਕੁਝ ਮੈਟ੍ਰਿਕਸ ਚੁਣੋ ਜੋ ਦੱਸਦੀਆਂ ਹਨ ਕਿ ਸਮਾਂ ਅਤੇ ਰਿਸੋਰਸ ਕਿੱਥੇ ਜਾ ਰਹੇ ਹਨ: p95/p99 latency, error rate, CPU, memory, GC time, DB query time, queue depth। ਇੰਸਿਡੈਂਟ ਦੌਰਾਨ ਦਰਮਿਆਨੇ ਵਿੱਚ ਹੋਰ ਗ੍ਰਾਫ ਨਾ ਜੋੜੋ।
3) Isolate (ਸੰਦੇਹ ਨੂੰ ਵੇਖੋ).
ਟੂਲਿੰਗ ਦਿਆਂ ਨਾਲ "framework overhead" ਨੂੰ "ਤੁਹਾਡੇ ਕੋਡ" ਤੋਂ ਅਲੱਗ ਕਰੋ:
4) Confirm (cause ਅਤੇ effect ਸਾਬਤ ਕਰੋ).
ਇੱਕ ਵਾਰੀ ਵਿੱਚ ਇਕ ਵੈਰੀਏਬਲ ਬਦਲੋ: ਇੱਕ query ਲਈ ORM ਬਾਈਪਾਸ ਕਰੋ, ਇੱਕ middleware disable ਕਰੋ, ਲਾਗ ਵੋਲਿਊਮ ਘਟਾਓ, concurrency cap ਕਰੋ, ਜਾਂ pool sizes ਬਦਲੋ। ਜੇ ਲੱਛਣ Predictably ਸਥਾਨਾਂਤਰਤ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਲੀਕ ਲੱਭ ਲਈ ਏਹ ਸਾਬਤ ਕਰ ਲਈ ਹੈ।
ਵਾਸਤਵਿਕ ਡੇਟਾ ਆਕਾਰ (row counts, payload sizes) ਅਤੇ ਅਸਲੀ concurrency (bursts, long tails, slow clients) ਵਰਤੋ। ਬਹੁਤ ਸਾਰੀਆਂ ਲੀਕਾਂ ਸਿਰਫ਼ caches cold ਹੋਣ, ਟੇਬਲ ਵੱਡੀਆਂ ਹੋਣ, ਜਾਂ retries amplify ਕਰਨ 'ਤੇ ਦਿਖਾਈ ਦਿੰਦੀਆਂ ਹਨ।
ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਲੀਕ ਫਰੇਮਵਰਕ ਦੀ ਨਿੰਦਾ ਨਹੀਂ ਹਨ—ਉਹ ਇਕ ਸਿੰਗਲ ਹੈ ਕਿ ਤੁਹਾਡੀ ਸਿਸਟਮ ਦੀਆਂ ਲੋੜਾਂ "ਡਿਫ਼ੌਲਟ ਪਾਥ" ਤੋਂ ਵੱਧ ਗਈਆਂ ਹਨ। ਮਕਸਦ ਫਰੇਮਵਰਕ ਛੱਡਣਾ ਨਹੀਂ, ਪਰ ਜੇਕਰ ਉਸਨੂੰ tune ਕਰਨ ਦੀ ਜ਼ਰੂਰਤ ਹੈ ਜਾਂ bypass ਕਰਨ ਦੀ ਲੋੜ ਹੈ ਤਾਂ ਸੋਚ ਸਮਝ ਕੇ ਕਰਨਾ।
ਜਦੋਂ ਸਮੱਸਿਆ configuration ਜਾਂ ਵਰਤੋਂ ਨਾਲ ਸੰਬੰਧਤ ਹੋਵੇ ਨਾ ਕਿ ਮੂਲ ਅਣਪਾਸ, ਤਾਂ ਫਰੇਮਵਰਕ ਦੇ ਅੰਦਰ ਹੀ ਰਹੋ। ਚੰਗੇ ਉਮੀਦਵਾਰ:
ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਸੈਟਿੰਗਾਂ ਨੂੰ ਬੰਦ ਕਰਕੇ ਅਤੇ guardrails ਜੋੜ ਕੇ ਠੀਕ ਕਰ ਸਕਦੇ ਹੋ, ਤਾਂ upgrades ਆਸਾਨ ਰਹਿੰਦੀਆਂ ਹਨ ਅਤੇ "ਖਾਸ ਕੇਸ" ਘੱਟ ਬਣਦੇ ਹਨ।
ਅਧਿਕ ਤਰੱਕੀ ਉਹ ਹੈ ਕਿ ਬਹੁਤ ਸਾਰੇ ਮਚੂਰੇ ਫਰੇਮਵਰਕ ਤੁਹਾਨੂੰ abstraction ਤੋਂ ਬਾਹਰ ਕਦਮ ਰੱਖਣ ਦੇ ਤਰੀਕੇ ਦਿੰਦੇ ਹਨ ਬਿਨਾਂ ਸਾਰੇ ਕੁਝ ਮੁੜ ਲਿਖਨ ਦੇ। ਆਮ ਪੈਟਰਨ:
ਇਹ ਫਰੇਮਵਰਕ ਨੂੰ ਇੱਕ ਟੂਲ ਬਨਾਕੇ ਰੱਖਦਾ ਹੈ, ਨਾ ਕਿ ਇੱਕ ਨਿਰਣਾਇਕ dependency ਜੋ ਆਰਕੀਟੈਕਚਰ ਨਿਰਧਾਰਤ ਕਰੇ।
ਮਿਟੀਗੇਸ਼ਨ ਕੋਡ ਦੀ ਤਰ੍ਹਾਂ ਨਾਹੀਂ ਸਿਰਫ਼, ਪਰ ਚਾਲੂ ਕਰਨ ਵਾਲਾ ਕੰਮ ਵੀ ਹੈ:
ਸੰਬੰਧਤ rollout ਅਭਿਆਸਾਂ ਲਈ ਵੇਖੋ /blog/canary-releases.
ਜਦੋਂ (1) ਮੁੱਦਾ critical path ਨੂੰ ਛੇੜਦਾ ਹੈ, (2) ਤੁਸੀਂ ਜਿੱਤ ਮਾਪ ਸਕਦੇ ਹੋ, ਅਤੇ (3) ਬਦਲਾਅ ਲੰਬੇ ਸਮੇਂ ਦਾ maintenance ਟੈਕਸ ਨਹੀਂ ਬਣਾਉਂਦਾ—ਤਦ ਨੀਵੇਂ ਪੱਧਰ 'ਤੇ ਜਾਓ। ਜੇ ਕੇਵਲ ਇਕ ਵਿਅਕਤੀ ਨੂੰ bypass ਸਮਝ ਆਉਂਦਾ ਹੈ, ਤਾਂ ਇਹ "ਠੀਕ" ਨਹੀਂ—ਇਹ ਨਾਜ਼ੁਕ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ ਲੀਕ ਲੱਭ ਰਹੇ ਹੋ, ਗਤੀ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦੀ ਹੈ—ਪਰ ਉਨ੍ਹਾਂ ਤਬਦੀਲੀਆਂ ਨੂੰ ਵਾਪਸ ਕਰਨਯੋਗ ਰੱਖਣਾ ਵੀ। ਟੀਮਾਂ ਅਕਸਰ Koder.ai ਵਰਤਦੀਆਂ ਹਨ ਛੋਟੀ, ਇਕਲਛਿੱਤੀ reproduction ਬਣਾਉਣ ਲਈ (ਇੱਕ ਨਿਊਨਤਮ React UI, ਇਕ Go ਸਰਵਿਸ, ਇੱਕ PostgreSQL ਸਕੀਮਾ, ਅਤੇ ਇੱਕ load‑test harness) ਬਿਨਾਂ ਦਿਨਾਂ ਦਾ scaffolding ਬਣਾਉਣ ਦੇ।
ਇਸ ਦੀ planning mode ਤੁਹਾਡੇ ਬਦਲਾਅ ਅਤੇ ਕਾਰਨਾਂ ਨੂੰ ਦਸਤਾਵੇਜ਼ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ, ਜਦਕਿ snapshots ਅਤੇ rollback "ਨਿੱਕਾ ਹੱਥੋਂ ਥੱਲੇ" experiments (ਜਿਵੇਂ ਇੱਕ ORM query ਲਈ raw SQL swap) ਕਰਨ ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਨਾਉਂਦੇ ਹਨ ਅਤੇ ਫਿਰ ਡਾਟਾ ਸਹੀ ਨਹੀਂ ਹੋਣ ਤੇ ਆਸਾਨੀ ਨਾਲ revert ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਹ ਕੰਮ ਵੱਖ‑ਵੱਖ environment ਵਿੱਚ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ Koder.ai ਦੀ built‑in deployment/hosting ਅਤੇ exportable source code ਵੀ diagnosis artifacts (benchmarks, repro apps, internal dashboards) ਨੂੰ ਅਸਲੀ ਸੌਫਟਵੇਅਰ ਵਜੋਂ—versioned, shareable, ਅਤੇ ਕਿਸੇ ਦੀ local ਫੋਲਡਰ ਵਿੱਚ ਪੜੀਆਂ ਨਾ ਰਹਿ ਜਾਂ—ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ।
ਇੱਕ ਲੀਕੀ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਉਹ ਪਰਤ ਹੈ ਜੋ ਜਟਿਲਤਾ ਨੂੰ ਛੁਪਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੀ ਹੈ (ORMs, ਰੀਟ੍ਰਾਈ ਹੈਲਪਰ, ਕੈਸ਼ਿੰਗ ਰੈਪਰ, ਮਿੱਡਲਵੇਅਰ), ਪਰ ਲੋਡ ਵਧਣ 'ਤੇ ਛੁਪੀਆਂ ਹੋਈਆਂ ਡੀਟੇਲز ਨਤੀਜਿਆਂ ਨੂੰ ਬਦਲਣ ਲੱਗਦੀਆਂ ਹਨ.
ਵਿਆਹਿਕ ਤੌਰ 'ਤੇ, ਇਹ ਉਹਦੋਂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡਾ “ਸਰਲ ਮਾਨਸਿਕ ਮਾਡਲ” ਅਸਲ ਵਿਹਾਰ ਦੀ ਭਵਿੱਖਵਾਣੀ ਨਹੀਂ ਕਰਦਾ, ਅਤੇ ਤੁਹਾਨੂੰ query plans, connection pools, queue depth, GC, timeouts ਅਤੇ retries ਵਰਗੀਆਂ ਚੀਜ਼ਾਂ ਸਮਝਣੀਆਂ ਪੈਂਦੀਆਂ ਹਨ।
ਇੱਕ ਸ਼ੁਰੂਆਤੀ ਸਿਸਟਮ ਕੋਲ ਖ਼ਾਲੀ ਸਮਰੱਥਾ ਹੁੰਦੀ ਹੈ: ਛੋਟੀ ਟੇਬਲਾਂ, ਘੱਟ ਇਕੱਠ, گرم ਕੈਸ਼, ਅਤੇ ਘੱਟ ਫੇਲਯਰ ਇੰਟਰੈਕਸ਼ਨ।
ਜਿਵੇਂ ਹੀ ਵੋਲਿਊਮ ਵਧਦਾ ਹੈ, ਛੋਟੇ ਓਹਦੇ ਲਗਾਤਾਰ ਰੁਕਾਵਟਾਂ ਬਣ ਜਾਂਦੇ ਹਨ ਅਤੇ ਉਹ ਦਰਅਸਲ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਦੀਆਂ ਖ਼ੁਫ਼ੀਆ ਲਾਗਤਾਂ ਅਤੇ ਸੀਮਾਵਾਂ ਨੂੰ ਪ੍ਰਦਰਸ਼ਿਤ ਕਰਦੇ ਹਨ।
ਉਹ ਪੈਟਰਨ ਵੇਖੋ ਜੋ ਸਰੋਤ ਜੋੜਨ 'ਤੇ ਵੀ ਸੁਚੱਜੇ ਤਰੀਕੇ ਨਾਲ ਸੁਧਰਦੇ ਨਹੀਂ:
ਅੰਡਰਪ੍ਰੋਵਿਜ਼ਨਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਲਗਾਤਾਰ ਲੈਣ ਦੀ ਰੀਸਪਾਂਸ ਨਾਲ ਸੁਧਰਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਸਾਂਝ ਸ਼੍ਰੋਤ ਜੋੜਦੇ ਹੋ।
ਇੱਕ ਲੀਕ ਆਮ ਤੌਰ 'ਤੇ ਇਸ ਤਰ੍ਹਾਂ ਦਰਸਦੀ ਹੈ:
ਪੋਸਟ ਵਿੱਚ ਦਿੱਤੇ ਚੈੱਕਲਿਸਟ ਨੂੰ ਵਰਤੋ: ਜੇ ਡਬਲ ਕਰਨ ਨਾਲ ਸਮੱਸਿਆ ਲਗਾਤਾਰ ਸੁਧਰਦੀ ਨਹੀਂ ਤਾਂ ਸੰਭਾਵਨਾ ਹੈ ਕਿ ਲੀਕ ਹੈ।
ORMs ਇਸ ਗੱਲ ਨੂੰ ਛੁਪਾ ਸਕਦੇ ਹਨ ਕਿ ਹਰ object ऑपਰੇਸ਼ਨ ਆਖ਼ਿਰਕਾਰ SQL ਬਣ ਜਾਂਦਾ ਹੈ। ਆਮ ਲੀਕਾਂ:
ਪਹਿਲਾਂ ਕੀ ਕਰਨਾ:
ਕਨੈਕਸ਼ਨ ਪੂਲ ਇਕ concurrency ਕੈਪ ਲਗਾਉਂਦਾ ਹੈ ਤਾਂ ਕਿ DB ਨੂੰ ਰੋਕਿਆ ਜਾ ਸਕੇ, ਪਰ ਲੁਕਵੀਂ query proliferation ਪੂਲ ਨੂੰ ਖਤਮ ਕਰ ਸਕਦੀ ਹੈ.
ਜਦ ਪੂਲ ਭਰ ਜਾਂਦਾ ਹੈ ਤਾਂ ਐਪ ਵਿੱਚ ਰੀਕਵੈਸਟ ਕਤਾਰ ਵਿੱਚ ਲਗਦੇ ਹਨ, ਲੇਟੈਂਸੀ ਵਧਦੀ ਹੈ ਅਤੇ ਰਿਸੋਰਸ ਲੰਬੇ ਸਮੇਂ ਲਈ ਬੰਦ ਹੋ ਜਾਂਦੇ ਹਨ। ਲੰਬੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਇਸ ਨੂੰ ਖ਼ਰਾਬ ਕਰਦੇ ਹਨ ਕਿਉਂਕਿ ਲੌਕ ਵਧਦੇ ਹਨ ਅਤੇ ਕੁਨਕਰੇਂਸੀ ਘਟਦੀ ਹੈ।
ਵੱਧਦਾ ਰਸਤਾ:
Thread-per-request ਥੇਲੇ ਜਾਂਦਾ ਹੈ ਜਦੋਂ I/O ਧੀਮਾ ਹੋਵੇ ਅਤੇ ਥਰੇਡ ਕੋਲੈਕਸ਼ਨ ਭਰ ਜਾਂਦੇ ਹਨ; ਨਵੀਆਂ ਬੇਨਤੀ ਕਤਾਰ ਵਿੱਚ ਲੱਗਦੀਆਂ ਹਨ ਅਤੇ timeouts spike ਹੁੰਦੇ ਹਨ.
Async/event-loop ਮਾਡਲ ਉਹ ਵੱਖਰਾ ਤਰੀਕਾ ਹੈ: ਇਕ blocking ਕਾਲ ਲੂਪ ਨੂੰ ਰੋਕ ਸਕਦੀ ਹੈ, ਜਾਂ ਬਹੁਤ ਜ਼ਿਆਦਾ concurrency ਬਣਾਉਣਾ dependencies ਨੂੰ ਥੋੜ੍ਹੇ ਸਮੇਂ ਵਿੱਚ overwhelm ਕਰ ਸਕਦਾ ਹੈ.
ਦੋਹਾਂ ਕੇਸਾਂ ਵਿੱਚ, “ਫਰੇਮਵਰਕ concurrency ਸੰਭਾਲਦਾ ਹੈ” ਵਾਲੀ ਅਬਸਟ੍ਰੈਕਸ਼ਨ ਲੀਕ ਕਰਕੇ ਤੁਹਾਨੂੰ explicit limits, timeouts ਅਤੇ backpressure ਲਗਾਉਣੇ ਪੈਂਦੇ ਹਨ।
Backpressure ਉਹ ਸਿਸਟਮ ਹੈ ਜੋ ਕਾਲਰਾਂ ਨੂੰ ਦੱਸਦਾ ਹੈ, “ਧੀਮੇ ਹੋ ਜਾਓ; ਮੈਂ ਹੋਰ ਕੰਮ ਸੁਰੱਖਿਅਤ ਤੌਰ ਤੇ ਨਹੀਂ ਲੈ ਸਕਦਾ।”
ਬਿਨਾਂ ਇਸਦੇ, ਇੱਕ ਧੀਮਾ ਡਿਪੈਂਡੇਸੀ ਰੀਕਵੈਸਟਾਂ, ਮੈਮੋਰੀ ਵਰਤੋਂ ਅਤੇ ਕਤਾਰ ਦੀ ਲੰਬਾਈ ਵਧਾ ਦਿੰਦੀ—ਜੋ ਉਸ ਡਿਪੈਂਡੇਸੀ ਨੂੰ ਹੋਰ ਧੀਮਾ ਕਰ ਦਿੰਦਾ (ਇੱਕ ਫੀਡਬੈਕ ਲੂਪ)।
ਆਮ ਟੂਲਜ਼:
ਆਟੋਮੈਟਿਕ retries slowdown ਨੂੰ outage ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹਨ:
ਕਿਵੇਂ ਰੋਕਣਾ:
ਇੰਸਟ੍ਰੂਮੈਂਟੇਸ਼ਨ ਉੱਚ ਟ੍ਰੈਫਿਕ 'ਤੇ ਅਸਲ ਕੰਮ ਕਰਦੀ ਹੈ:
user_id, email, order_id) time series ਦੀ ਗਿਣਤੀ ਬਹੁਤ ਵਧਾ ਦਿੰਦੇ ਹਨਵ੍ਯਵਹਾਰਕ ਨਿਯੰਤਰਣ:
EXPLAIN ਨਾਲ ਵੈਲੀਡੇਟ ਕਰੋ ਅਤੇ ਇੰਡੈਕਸ ਨੂੰ ਐਪ ਡਿਜ਼ਾਈਨ ਦਾ ਹਿੱਸਾ ਬਣਾਓ