18 ਮਈ 2025·8 ਮਿੰਟ
ਸਕੀਮਾ ਡਿਜ਼ਾਈਨ ਪਹਿਲਾਂ: ਸ਼ੁਰੂਆਤੀ ਕੁਏਰੀ ਟਿਊਨਿੰਗ ਨਾਲੋਂ ਤੇਜ਼ ਐਪ
ਸ਼ੁਰੂਆਤੀ ਪ੍ਰਦਰਸ਼ਨ ਦੇ ਜਿੱਤ ਆਮ ਤੌਰ 'ਤੇ ਸਹੀ ਸਕੀਮਾ ਡਿਜ਼ਾਈਨ ਤੋਂ ਆਉਂਦੇ ਹਨ: ਠੀਕ ਟੇਬਲਾਂ, ਕੁੰਜੀਆਂ ਅਤੇ ਪਾਬੰਦੀਆਂ ਬਾਅਦ ਵਿੱਚ ਸਲੋ ਕੁਏਰੀਆਂ ਅਤੇ ਮਹਿੰਗੀਆਂ ਦੁਬਾਰਿਆਂ ਨੂੰ ਰੋਕਦੀਆਂ ਹਨ।
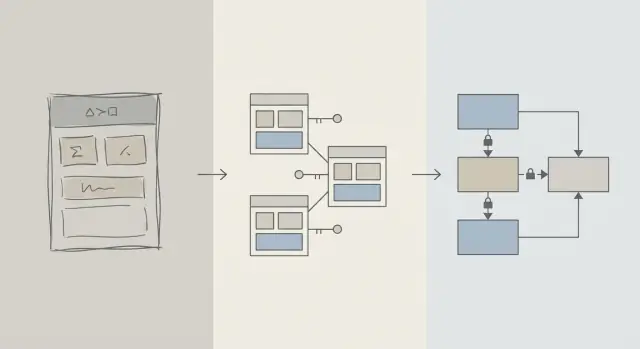
ਸਕੀਮਾ ਅਤੇ ਕੁਏਰੀ ਸੁਧਾਰ: ਅਰਥ ਕੀ ਹੈ
ਜਦੋਂ ਕੋਈ ਐਪ ਸਲੋ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ, ਤਾਂ ਪਹਿਲੀ ਪ੍ਰੇਰਣਾ ਅਕਸਰ 'SQL ਠੀਕ ਕਰੋ' ਹੋਂਦੀ ਹੈ। ਇਹ ਸਮਝਦਾਰ ਹੈ: ਇੱਕ ਕੁਏਰੀ ਦਿੱਖਣ ਯੋਗ, ਮਾਪਯੋਗ ਅਤੇ ਆਸਾਨ ਨੁਕਸ ਕਰਨ ਯੋਗ ਹੁੰਦੀ ਹੈ। ਤੁਸੀਂ EXPLAIN ਚਲਾ ਸਕਦੇ ਹੋ, ਇੱਕ ਇੰਡੈਕਸ ਜੋੜ ਸਕਦੇ ਹੋ, JOIN ਤਬਰ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਕਈ ਵਾਰੀ ਤੁਰੰਤ ਸੁਧਾਰ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ。
ਪਰ ਪ੍ਰਾਡਕਟ ਦੀ ਸ਼ੁਰੂਆਤੀ ਜ਼ਿੰਦਗੀ ਵਿੱਚ, ਸਪੀਡ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਖਾਸ ਕੁਏਰੀ ਪਾਠ ਤੋਂ ਬਹੁਤ ਜ਼ਿਆਦਾ ਡੇਟਾ ਦੀ ਬਣਤਰ ਤੋਂ ਆ ਸਕਦੀਆਂ ਹਨ। ਜੇ ਸਕੀਮਾ ਤੁਹਾਨੂੰ ਡੇਟਾਬੇਸ ਨਾਲ ਲੜਨ 'ਤੇ ਮਜ਼ਬੂਰ ਕਰਦਾ ਹੈ, ਤਾਂ ਕੁਏਰੀ ਟਿਊਨਿੰਗ ਇੱਕ ਹਮ-ਬੁਝਾਈ ਵਾਲੇ ਖੇਡ ਵਿੱਚ ਬਦਲ ਸਕਦੀ ਹੈ।
ਸਕੀਮਾ ਡਿਜ਼ਾਈਨ (ਸਧਾਰਨ ਭਾਸ਼ਾ)
ਸਕੀਮਾ ਡਿਜ਼ਾਈਨ ਤੁਹਾਡੇ ਡੇਟਾ ਨੂੰ ਕਿਵੇਂ ਸੰਗਠਿਤ ਕੀਤਾ ਗਿਆ ਹੈ—ਟੇਬਲਾਂ, ਕਾਲਮ, ਰਿਸ਼ਤੇ ਅਤੇ ਨਿਯਮ। ਇਸ ਵਿੱਚ ਅਸਲ ਫੈਸਲੇ ਸ਼ਾਮਲ ਹਨ ਜਿਵੇਂ:
- ਕਿਹੜੀਆਂ 'ਚੀਜ਼ਾਂ' ਵੱਖਰੀ ਟੇਬਲ ਦੀ ਹੱਕਦਾਰ ਹਨ (users, orders, events)
- ਟੇਬਲਾਂ ਕਿਵੇਂ ਜੁੜਦੀਆਂ ਹਨ (one-to-many, many-to-many)
- ਕੀ ਅਦੁਤੀ ਭਾਵ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਜਾਂ ਲਾਜ਼ਮੀ ਹੈ (constraints)
- ਰਾਜ ਅਤੇ ਇਤਿਹਾਸ ਨੂੰ ਕਿਵੇਂ ਦਰਸਾਇਆ ਜਾਵੇ (timestamps, status fields, audit records)
ਚੰਗੇ ਸਕੀਮਾ ਨਾਲ ਉਹ ਸਵਾਲ ਜੋ ਤੁਸੀਂ ਕੁਦਰਤੀ ਰੂਪ ਵਿੱਚ ਪੁੱਛਦੇ ਹੋ, ਉਹ ਹੀ ਤੇਜ਼ ਵੀ ਹੁੰਦੇ ਹਨ।
ਕੁਏਰੀ ਸੁਧਾਰ (ਸਧਾਰਨ ਭਾਸ਼ਾ)
ਕੁਏਰੀ ਸੁਧਾਰ ਦਾ ਮਤਲਬ ਹੈ ਡੇਟਾ ਲੈਣ ਜਾਂ ਅਪਡੇਟ ਕਰਨ ਦੇ ਤਰੀਕੇ ਨੂੰ ਬਿਹਤਰ ਕਰਨਾ: ਕੁਏਰੀਆਂ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣਾ, ਇੰਡੈਕਸ ਜੋੜਨਾ, ਫਾਲਤੂ ਕੰਮ ਘਟਾਉਣਾ, ਅਤੇ ਉਹ ਰੁਝਾਨਾਂ ਟਾਲਣਾ ਜੋ ਵੱਡੇ ਸਕੈਨ ਬਣਾਉਂਦੀਆਂ ਹਨ।
ਦੋਹਾਂ ਮਹੱਤਵਪੂਰਣ—ਪਰ ਸਮਾਂ ਜ਼ਿਆਦਾ ਮਹੱਤਵਪੂਰਣ ਹੈ
ਇਹ ਲੇਖ 'ਸਕੀਮਾ ਚੰਗਾ, ਕੁਏਰੀ ਮਾੜੀ' ਨਹੀਂ ਹੈ। ਇਹ ਕਾਰਜ-ਕ੍ਰਮ ਬਾਰੇ ਹੈ: ਪਹਿਲਾਂ ਡੇਟਾਬੇਸ ਸਕੀਮਾ ਦੇ ਬੁਨਿਆਦੀ ਹਿੱਸੇ ਠੀਕ ਕਰੋ, ਫਿਰ ਉਹ ਕੁਏਰੀਆਂ ਟਿਊਨ ਕਰੋ ਜਿਨ੍ਹਾਂ ਨੂੰ ਵਾਸਤਵ ਵਿੱਚ ਲੋੜ ਹੈ।
ਤੁਹਾਨੂੰ ਪਤਾ ਲੱਗੇਗਾ ਕਿ ਕਿਉਂ ਸ਼ੁਰੂਆਤੀ ਸਮੇਂ ਸਕੀਮਾ ਫੈਸਲੇ ਸਾਰੀਆਂ ਪ੍ਰਦਰਸ਼ਨ ਸਮੱਸਿਆਵਾਂ 'ਤੇ ਛਾਂਗ ਕਰਦੇ ਹਨ, ਕਿਵੇਂ ਪਛਾਣੀਦਾ ਹੈ ਕਿ ਸਕੀਮਾ ਅਸਲ ਬੋਤਲ-ਨੇਕ ਹੈ, ਅਤੇ ਕਿਵੇਂ ਇਸ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਬਦਲਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਇਹ ਲੇਖ ਪ੍ਰੋਡਕਟ ਟੀਮਾਂ, ਫਾਉਂਡਰਾਂ ਅਤੇ ਡਿਵੈਲਪਰਾਂ ਲਈ ਹੈ—ਡੇਟਾਬੇਸ ਵਿਸ਼ੇਸ਼ਜਿਆਂ ਲਈ ਨਹੀਂ।
ਕਿਉਂ ਸਕੀਮਾ ਡਿਜ਼ਾਈਨ ਸ਼ੁਰੂਆਤੀ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਚਲਾਉਂਦਾ ਹੈ
ਸ਼ੁਰੂਆਤੀ ਪ੍ਰਦਰਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਧੁਰੰਧਰ SQL ਬਾਰੇ ਨਹੀਂ ਹੁੰਦਾ—ਇਹ ਇਸ ਬਾਰੇ ਹੁੰਦਾ ਹੈ ਕਿ ਡੇਟਾਬੇਸ ਨੂੰ ਕਿੰਨਾ ਡੇਟਾ ਛੇਡਣਾ ਪੈਂਦਾ ਹੈ।
ਢਾਂਚਾ ਨਿਰਧਾਰਿਤ ਕਰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕਿੰਨਾ ਸਕੈਨ ਕਰੋਗੇ
ਇੱਕ ਕੁਏਰੀ ਉਸ ਮਾਡਲ ਹੀਨੀ ਹੋ ਸਕਦੀ ਹੈ ਜਿਸ ਤੱਕ ਡੇਟਾ ਮਾਡਲ ਦੀ ਸਖਤੀ ਪਰਮਿਟ ਕਰਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ 'status', 'type' ਜਾਂ 'owner' ਨੂੰ ਢਿੱਲੇ-ਧਰੇ ਫੀਲਡਾਂ ਵਿੱਚ ਰੱਖਦੇ ਹੋ ਜਾਂ ਅਨਿਸ਼ਚਿਤ ਟੇਬਲਾਂ ਵਿੱਚ ਫੈਲਾਉਂਦੇ ਹੋ, ਤਾਂ ਡੇਟਾਬੇਸ ਅਕਸਰ ਇਸ ਨੂੰ ਮਿਲਾਉਣ ਲਈ ਬਹੁਤ ਸਾਰੇ ਰੋਜ਼ ਸਕੈਨ ਕਰਨਾ ਪੈਂਦਾ ਹੈ।
ਚੰਗਾ ਸਕੀਮਾ ਖੁਦ-ਬ-ਖੁਦ ਖੋਜ ਦੀ ਜਗ੍ਹਾ ਘਟਾਉਂਦਾ ਹੈ: ਸਾਫ਼ ਕਾਲਮ, ਇੱਕਸਾਰ ਡੇਟਾ ਟਾਈਪ ਅਤੇ ਅੱਛੀ ਤਰ੍ਹਾਂ ਹੱਦਬੰਧ ਟੇਬਲਾਂ ਨਾਲ ਕੁਏਰੀਆਂ ਪਹਿਲਾਂ ਫਿਲਟਰ ਲਾ ਕੇ ਘੱਟ ਪੰਣੇ ਪੜ੍ਹਦੀਆਂ ਹਨ।
ਗੁੰਮ ਹੋਏ ਕੁੰਜੀਆਂ ਮਹਿੰਗਾ ਕੰਮ ਬਣਾਉਂਦੀਆਂ ਹਨ
ਜਦੋਂ ਪ੍ਰਾਈਮਰੀ ਕੀ ਅਤੇ ਫੋਰਿਨ ਕੀ ਗੈਰਮੌਜੂਦ ਹੁੰਦੀਆਂ ਹਨ ਜਾਂ ਲਾਗੂ ਨਹੀਂ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ, ਰਿਸ਼ਤੇ ਅਨੁਮਾਨ ਬਣ ਜਾਂਦੇ ਹਨ। ਇਹ ਕੰਮ ਨੂੰ ਕੁਏਰੀ ਪਰਤ ਵਿੱਚ ਧੱਕ ਦਿੰਦਾ ਹੈ:
- Joins ਵੱਡੇ ਹੋ ਜਾਂਦੇ ਹਨ ਕਿਉਂਕਿ ਕੋਈ ਭਰੋਸੇਮੰਦ, ਇੰਡੈਕਸਡ ਜੋਇਨ ਰਸਤਾ ਨਹੀਂ ਹੁੰਦਾ।
- Filters ਹੋਰ ਜਟਿਲ ਹੋ ਜਾਂਦੇ ਹਨ ਕਿਉਂਕਿ ਤੁਸੀਂ ਨਕਲਾਂ, nulls ਅਤੇ 'ਲਗਭਗ ਮੇਲ' ਵਾਲੇ ਮੁੱਲਾਂ ਲਈ ਭੁਗਤਾਨ ਕਰ ਰਹੇ ਹੋ।
ਬਿਨਾਂ constraints ਦੇ, ਖਰਾਬ ਡੇਟਾ ਜੁਟਦਾ ਹੈ—ਅਤੇ ਜਿਵੇਂ ਜਿਵੇਂ ਰੋਜ਼ ਵਧਦੇ ਹਨ, ਕੁਏਰੀਆਂ ਹੋਰ ਸਲੋ ਹੁੰਦੀਆਂ ਜਾਂਦੀਆਂ ਹਨ।
ਇੰਡੈਕਸ ਸਕੀਮਾ ਦੇ ਪਿੱਛੇ ਚੱਲਦੇ ਹਨ (ਅਤੇ ਸਭ ਕੁਝ ਠੀਕ ਨਹੀਂ ਕਰ ਸਕਦੇ)
ਇੰਡੈਕਸ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਤਦ ਹੀ ਲਾਭਦਾਇਕ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਉਹ ਪੇਸ਼ਗੀ ਪਹੁੰਚ ਰਾਹਾਂ ਨਾਲ ਮਿਲਦੇ ਹਨ: ਫੋਰਿਨ ਕੀ ਨਾਲ ਜੁੜਨਾ, ਵੱਖ-ਵੱਖ ਸਪਸ਼ਟ ਕਾਲਮਾਂ ਨਾਲ ਫਿਲਟਰ ਕਰਨਾ, ਆਮ ਫੀਲਡਾਂ ਨਾਲ ਸੋਰਟ ਕਰਨਾ। ਜੇ ਸਕੀਮਾ ਮਹੱਤਵਪੂਰਣ ਗੁਣਾਂ ਨੂੰ ਗਲਤ ਟੇਬਲ ਵਿੱਚ ਰੱਖਦਾ ਹੈ, ਇੱਕ ਕਾਲਮ ਵਿੱਚ ਅਰਥ ਮਿਲਾਉਂਦਾ ਹੈ ਜਾਂ ਟੈਕਸਟ ਪਾਰਸਿੰਗ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ, ਤਾਂ ਇੰਡੈਕਸ ਤੁਹਾਡੀ ਮਦਦ ਨਹੀਂ ਕਰ ਸਕਦੇ—ਤੁਸੀਂ ਫਿਰ ਵੀ ਬਹੁਤ ਸਕੈਨ ਅਤੇ ਤਬਦੀਲੀਆਂ ਕਰ ਰਹੇ ਹੋਵੋਗੇ।
ਡਿਫਾਲਟ ਰੂਪ ਵਿੱਚ ਤੇਜ਼
ਸਾਫ਼ ਰਿਸ਼ਤੇ, ਸਥਿਰ ਪਛਾਣਕ, ਅਤੇ ਸਮਝਦਾਰ ਟੇਬਲ ਹੱਦਬੰਧੀਆਂ ਦੇ ਨਾਲ, ਬਹੁਤ ਸਾਰੇ ਰੋਜ਼ਾਨਾ ਕੁਏਰੀਆਂ 'ਡਿਫਾਲਟ ਤੌਰ' ਤੇ ਤੇਜ਼ ਹੋ ਜਾਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਹ ਘੱਟ ਡੇਟਾ ਛੂਹਦੀਆਂ ਹਨ ਅਤੇ ਸਧਾਰਣ, ਇੰਡੈਕਸ-ਮਿੱਤਰ predicate ਵਰਤਦੀਆਂ ਹਨ। ਫਿਰ ਕੁਏਰੀ ਟਿਊਨਿੰਗ ਇਕ ਫਿਨਿਸ਼ਿੰਗ ਸਟੈਪ ਬਣ ਜਾਂਦੀ ਹੈ—ਹਰ ਵੇਲੇ ਦੀ ਜੰਗ ਨਹੀਂ।
ਸ਼ੁਰੂਆਤੀ ਦਰਜੇ ਦਾ ਹਕੀਕਤ: ਬਦਲਾਅ ਲਗਾਤਾਰ ਹੁੰਦੇ ਹਨ
ਸ਼ੁਰੂਆਤੀ ਉਤਪਾਦਾਂ ਕੋਲ 'ਸਥਿਰ ਰਿਕਵਾਇਰਮੈਂਟ' ਨਹੀਂ ਹੁੰਦੇ—ਉਹ ਪ੍ਰਯੋਗ ਹੋਂਦੇ ਹਨ। ਫੀਚਰ ਜਾਰੀ ਹੁੰਦੇ ਹਨ, ਦੁਬਾਰਾ ਲਿਖੇ ਜਾਂਦੇ ਹਨ ਜਾਂ ਗੁਜਰ ਜਾਂਦੇ ਹਨ। ਇਕ ਛੋਟੀ ਟੀਮ ਰੋਡਮੈਪ, ਸਹਾਇਤਾ ਅਤੇ ਇੰਫਰਾਸਟਰਕਚਰ ਨੂੰ ਸੰਭਾਲ ਰਹੀ ਹੁੰਦੀ ਹੈ ਜਿਸ ਕੋਲ ਪੁਰਾਣੇ ਫੈਸਲਿਆਂ ਨੂੰ ਫਿਰ ਤੋਂ ਦੇਖਣ ਲਈ ਸੀਮਤ ਸਮਾਂ ਹੁੰਦਾ ਹੈ।
ਸਭ ਤੋਂ ਵੱਧ ਕੀ ਬਦਲਦਾ ਹੈ
ਜ਼ਿਆਦਾਤਰ ਵਾਰੀ SQL ਪਾਠ ਪਹਿਲਾਂ ਨਹੀਂ ਬਦਲਦਾ। ਡੇਟਾ ਦਾ ਅਰਥ ਬਦਲਦਾ ਹੈ: ਨਵੇਂ ਸਟੇਟ, ਨਵੇਂ ਰਿਸ਼ਤੇ, ਨਵੇਂ 'ਸਾਨੂੰ ਵੀ ਟ੍ਰੈਕ ਕਰਨ ਦੀ ਲੋੜ ਹੈ' ਫੀਲਡ, ਅਤੇ ਪੂਰੇ ਵਰਕਫਲੋ ਜੋ ਲਾਂਚ 'ਤੇ ਸੋਚੇ ਹੀ ਨਹੀਂ ਗਏ ਸਨ। ਇਹ ਹਿੱਲ-ਚੱਲ ਨਾਰਮਲ ਹੈ—ਅਤੇ ਇਹੀ ਕਾਰਨ ਹੈ ਕਿ ਸ਼ੁਰੂਆਤੀ ਸਮੇਂ ਸਕੀਮਾ ਚੋਣਾਂ ਇਤਨੇ ਮਹੱਤਵਪੂਰਣ ਹਨ।
ਬਾਅਦ ਵਿੱਚ ਸਕੀਮਾ ਠੀਕ ਕਰਨਾ ਇੱਕ ਕੁਏਰੀ ਠੀਕ ਕਰਨ ਦੀ ਤੁਲਨਾ ਵਿੱਚ ਕਿਉਂ ਮੁਸ਼ਕਲ ਹੈ
ਕੁਏਰੀ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣਾ ਆਮ ਤੌਰ 'ਤੇ ਵਾਪਸੀਯੋਗ ਅਤੇ ਸਥਾਨਕ ਹੁੰਦਾ ਹੈ: ਤੁਸੀਂ ਸੁਧਾਰ ਜਾਰੀ ਕਰ ਸਕਦੇ ਹੋ, ਮਾਪ ਸਕਦੇ ਹੋ, ਅਤੇ ਲੋੜ ਪੈਣ 'ਤੇ ਰੋਲਬੈਕ ਕਰ ਸਕਦੇ ਹੋ।
ਸਕੀਮਾ ਦੁਬਾਰਾ ਲਿਖਣਾ ਵੱਖਰਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਅਸਲ ਗਾਹਕ ਡੇਟਾ ਸਟੋਰ ਕਰ ਚੁੱਕੇ ਹੋ, ਹਰ ਢਾਂਚাগত ਬਦਲਾਅ ਇੱਕ ਪ੍ਰੋਜੈਕਟ ਬਣ ਜਾਂਦਾ ਹੈ:
- ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਜੋ ਟੇਬਲਾਂ ਨੂੰ ਲੌਕ ਕਰਦੀਆਂ ਹਨ ਜਾਂ ਚੋਟੀ ਦੇ ਸਮੇਂ ਵਿੱਚ ਲਿਖਤਾਂ ਨੂੰ ਸੁਸਤ ਕਰਦੀਆਂ ਹਨ
- ਬੈਕਫਿਲਜ਼ ਨਵੇਂ ਕਾਲਮ ਭਰਨ ਜਾਂ ਡੇਰਿਵਡ ਡੇਟਾ ਨੂੰ ਦੁਬਾਰਾ ਬਣਾਉਣ ਲਈ
- ਡੁਅਲ-ਰਾਇਟ ਜਾਂ ਸ਼ੈਡੋ ਟੇਬਲਾਂ ਜਿੱਥੇ ਟ੍ਰਾਂਜ਼ਿਸ਼ਨ ਦੌਰਾਨ ਐਪ ਚੱਲਦੀ ਰਹੇ
- ਡਾਉਨਟਾਈਮ ਦਾ ਰਿਸਕ ਜੇ ਕੋਈ ਬਦਲਾਅ ਆਨਲਾਈਨ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ
ਚੰਗੇ ਟੂਲਿੰਗ ਦੇ ਨਾਲ ਵੀ, ਸਕੀਮਾ ਬਦਲਾਅ ਕੋਆਰਡੀਨੇਸ਼ਨ ਖਰਚ ਲਿਆਉਂਦੇ ਹਨ: ਐਪ ਕੋਡ ਅੱਪਡੇਟ, ਤੈਨਾਤੀ ਅਨੁਕ੍ਰਮ ਅਤੇ ਡੇਟਾ ਵੈਰੀਫਿਕੇਸ਼ਨ।
ਸ਼ੁਰੂਆਤੀ ਫੈਸਲੇ ਕਿਵੇਂ ਜਟਿਲ ਹੋ ਜਾਂਦੇ ਹਨ
ਜਦੋਂ ਡੇਟਾਬੇਸ ਛੋਟਾ ਹੁੰਦਾ ਹੈ, ਇੱਕ ਅਣਚੰਗਾ ਸਕੀਮਾ 'ਠੀਕ' ਲੱਗ ਸਕਦਾ ਹੈ। ਜਿਵੇਂ ਰੋਜ਼ ਹਜ਼ਾਰ ਤੋਂ ਮਿਲੀਅਨ ਬਣਦੇ ਹਨ, ਉਹੀ ਡਿਜ਼ਾਈਨ ਵੱਡੇ ਸਕੈਨ, ਭਾਰੀ ਇੰਡੈਕਸ ਅਤੇ ਮਹਿੰਗੇ joins ਬਣਾਉਂਦੀ ਹੈ—ਤੇ ਹਰ ਨਵਾਂ ਫੀਚਰ ਇਸ ਬੁਨਿਆਦ 'ਤੇ ਬਣਦਾ ਹੈ।
ਇਸ ਲਈ ਸ਼ੁਰੂਆਤੀ ਲਕੜੀ ਸੰਜੋਣ ਦਾ ਲਕਸ perfection ਨਹੀਂ ਹੈ। ਇਹ ਐਸਾ ਸਕੀਮਾ ਚੁਣਣਾ ਹੈ ਜੋ ਬਦਲਾਅ ਨੂੰ ਜ਼ਿਆਦਾ ਖਤਰਨਾਕ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ 'ਤੇ ਦਬਾਅ ਪਾਏ ਬਿਨਾਂ ਸ਼ੁਕਰਾਨਾ ਕਰ ਸਕੇ।
ਡਿਜ਼ਾਈਨ ਮੁਢਲੇ ਤੱਤ ਜੋ ਸਲੋ ਕੁਏਰੀਆਂ ਨੂੰ ਰੋਕਦੇ ਹਨ
ਸ਼ੁਰੂ 'ਚ ਜ਼ਿਆਦਾਤਰ 'ਸਲੋ ਕੁਏਰੀ' ਸਮੱਸਿਆਵਾਂ SQL ਯੁਕਤੀਬੱਧ ਨਹੀਂ—ਉਹ ਡੇਟਾ ਮਾਡਲ ਵਿੱਚ ਅਸਪਸ਼ਟਤਾ ਹੁੰਦੀਆਂ ਹਨ। ਜੇ ਸਕੀਮਾ ਇਹ ਅਸਪਸ਼ਟ ਬਣਾਂਦਾ ਹੈ ਕਿ ਇੱਕ ਰਿਕਾਰਡ ਕੀ ਦਰਸਾਉਂਦਾ ਹੈ ਜਾਂ ਰਿਕਾਰਡ ਕਿਵੇਂ ਜੁੜਦੇ ਹਨ, ਤਾਂ ਹਰ ਕੁਏਰੀ ਲਿਖਣ, ਚਲਾਉਣ ਅਤੇ ਬਣਾਏ ਰੱਖਣ ਲਈ ਮਹਿੰਗੀ ਹੋ ਜਾਂਦੀ ਹੈ।
ਕੁਝ ਕੋਰ ਇਕਾਈਆਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਉਸ ਛੋਟੀ ਚੀਜ਼ਾਂ ਨੂੰ ਨਾਮ ਦਿਓ ਜਿਨ੍ਹਾਂ ਦੇ ਬਿਨਾਂ ਤੁਹਾਡੀ ਪ੍ਰੋਡਕਟ ਕੰਮ ਨਹੀਂ ਕਰ ਸਕਦੀ: users, accounts, orders, subscriptions, events, invoices—ਜੋ ਵੀ ਸਚਮੁਚ ਕੇਂਦਰੀ ਹੈ। ਫਿਰ ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਸਪੱਸ਼ਟ ਤੌਰ ਤੇ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: one-to-many, many-to-many (ਆਮ ਤੌਰ 'ਤੇ join table ਨਾਲ), ਅਤੇ ਮਾਲਕੀ (ਕੋਣ ਕਿਸ ਨੂੰ 'ਰੱਖਦਾ' ਹੈ)।
ਇੱਕ ਪ੍ਰਯੋਗੀ ਜਾਂਚ: ਹਰ ਟੇਬਲ ਲਈ ਤੁਸੀਂ ਇਹ ਵਾਕ ਪੂਰਾ ਕਰ ਸਕੋ 'ਇਸ ਟੇਬਲ ਦੀ ਇੱਕ ਕਤਾਰ ਦਰਸਾਉਂਦੀ ਹੈ ___.' ਜੇ ਤੁਸੀਂ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਟੇਬਲ ਸੰਭਵਤ: ਧਾਰਾਵਾਹਿਕ ਸੰਕਲਪ ਮਿਲਾ ਰਿਹਾ ਹੈ, ਜੋ ਬਾਅਦ ਵਿੱਚ ਜਟਿਲ ਫਿਲਟਰ ਅਤੇ joins ਨੂੰ ਮਜ਼ਬੂਰ ਕਰਦਾ ਹੈ।
ਨਾਮਕਰਨ ਅਤੇ ਮਾਲਕੀ ਬਹੁਤ ਹੀ ਇਕਸਾਰ ਰੱਖੋ
ਇਕਸਾਰਤਾ ਅਚਾਨਕ joins ਅਤੇ ਗੁੰਝਲਦਾਰ API ਵਰਤੋਂ ਨੂੰ ਰੋਕਦੀ ਹੈ। ਰਿਵਾਜ ਚੁਣੋ (snake_case ਜਾਂ camelCase, *_id, created_at/updated_at) ਅਤੇ ਓਹਦੇ ਉੱਤੇ ਟਿਕੋ।
ਇਸ ਦੇ ਨਾਲ ਇਹ ਵੀ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਸ ਦਾ ਖੇਤਰ ਹੈ। ਉਦਾਹਰਣ ਲਈ, 'billing_address' ਇੱਕ order ਨਾਲ ਮਲੂਕ ਹੈ (ਖਰੀਦ ਸਮੇਂ ਦਾ ਸਨੇਪਸ਼ਾਟ) ਜਾਂ user ਨਾਲ (ਮੌਜੂਦਾ ਡਿਫ਼ੌਲਟ)? ਦੋਹਾਂ ਵੈਧ ਹੋ ਸਕਦੇ—ਪਰ ਬਿਨਾਂ ਸਾਫ਼ ਨੀਤੀ ਦੇ ਮਿਲਾਉਣਾ ਸੁਲਝਣ ਅਤੇ ਗਲਤੀਆਂ ਵਾਲੀਆਂ ਕੁਏਰੀਆਂ ਬਣਾਉਂਦਾ ਹੈ।
ਹਕੀਕਤ ਨਾਲ ਮਿਲਦੇ ਡੇਟਾ ਟਾਈਪ ਚੁਣੋ
ਉਹ ਟਾਈਪ ਵਰਤੋ ਜੋ ਰਨਟਾਈਮ ਰੂਪ ਵਿੱਚ ਬਦਲਾਅ ਤੋਂ ਬਚਾਉਂਦੇ ਹਨ:
- ਸਮਝਦਾਰ ਨਿਯਮਾਂ ਵਾਲੇ timestamps ਵਰਤੋ।
- ਪੈਸੇ ਲਈ decimals ਵਰਤੋ (floats ਨਹੀਂ)।
- ਪਛਾਣਯੋਗ ਸ਼੍ਰੇਣੀਆਂ ਲਈ enums/reference tables ਵਰਤੋ।
ਜਦੋਂ ਟਾਈਪ ਗਲਤ ਹੁੰਦੇ ਹਨ, ਡੇਟਾਬੇਸ ਪ੍ਰਭਾਵੀ ਤਰੀਕੇ ਨਾਲ ਤੁਲਨਾ ਨਹੀਂ ਕਰ ਸਕਦਾ, ਇੰਡੈਕਸ ਘੱਟ ਲਾਹੇਵੰਦ ਬਣ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਕੁਏਰੀਆਂ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ casting ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ।
ਯੋਜਨਾ ਦੇ ਬਿਨਾਂ ਤੱਥਾਂ ਦੀ ਨਕਲ ਨਾ ਕਰੋ
ਉਹੀ ਤੱਥ ਕਈ ਥਾਵਾਂ ਤੇ ਸਟੋਰ ਕਰਨਾ (ਜਿਵੇਂ order_total ਅਤੇ sum(line_items)) ਡ੍ਰਿਫਟ ਬਣਾਉਂਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਡੇਰਿਵਡ ਮੁੱਲ ਕੈਸ਼ ਕਰਦੇ ਹੋ, ਤਾਂ ਇਸਨੂੰ ਦਸਤਾਵੇਜ਼ ਕਰੋ, ਸਚਾਈ ਦਾ ਸਰੋਤ ਬਤਾਓ, ਅਤੇ ਅਪਡੇਟਾਂ ਨੂੰ ਨਿਰੰਤਰ ਰੱਖਣ ਦੀ ਯੋਜਨਾ ਬਣਾਓ (ਅਕਸਰ ਐਪਲੀਕੇਸ਼ਨ ਲਾਜਿਕ + constraints ਨਾਲ)।
ਕੁੰਜੀਆਂ ਅਤੇ ਪਾਬੰਦੀਆਂ: ਡੇਟਾ ਇੰਟੈਗ੍ਰਿਟੀ ਨਾਲ ਤੇਜ਼ੀ ਆਉਂਦੀ ਹੈ
ਇੱਕ ਤੇਜ਼ ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਭਵਿੱਖਬਾਣੀਯੋਗ ਡੇਟਾਬੇਸ ਹੁੰਦਾ ਹੈ। ਕੁੰਜੀਆਂ ਅਤੇ ਪਾਬੰਦੀਆਂ ਤੁਹਾਡੇ ਡੇਟਾ ਨੂੰ ਭਵਿੱਖਬਾਣੀਯੋਗ ਬਣਾਉਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਹ ਗਲਤ ਹਾਲਤਾਂ—ਗੁੰਮ ਰਿਸ਼ਤੇ, ਨਕਲ ਆਈਡੈਂਟਿਟੀ, ਜਾਂ ਉਹ ਮੁੱਲ ਜੋ ਐਪ ਸੋਚਦਾ ਹੈ ਉਸ ਤੋਂ ਵੱਖਰੇ—ਨੂੰ ਰੋਕਦੀਆਂ ਹਨ। ਇਹ ਸਫਾਈ ਸਿੱਧੀ ਤਰ੍ਹਾਂ ਪ੍ਰਦਰਸ਼ਨ ਤੇ ਪ੍ਰਭਾਵ ਪਾਉਂਦੀ ਹੈ ਕਿਉਂਕਿ ਡੇਟਾਬੇਸ ਕੁਏਰੀ ਯੋਜਨਾ ਬਣਾਉਣ ਵੇਲੇ ਵਧੀਆ ਅਨੁਮਾਨ ਲਾ ਸਕਦਾ ਹੈ।
ਪ੍ਰਾਈਮਰੀ ਕੁੰਜੀਆਂ: ਹਰ ਟੇਬਲ ਨੂੰ ਇੱਕ ਸਥਿਰ ਪਛਾਣਕ ਚਾਹੀਦਾ ਹੈ
ਹਰ ਟੇਬਲ ਨੂੰ ਇੱਕ ਪ੍ਰਾਈਮਰੀ ਕੀ (PK) ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ: ਇੱਕ ਕਾਲਮ ਜਾਂ ਛੋਟਾ ਸੈੱਟ ਜੋ ਇੱਕ ਕਤਾਰ ਨੂੰ ਯੂਨੀਕ ਤੌਰ ਤੇ ਪਛਾਣਦਾ ਹੈ ਅਤੇ ਕਦੇ ਨਹੀਂ ਬਦਲਦਾ। ਇਹ ਸਿਰਫ਼ ਡੇਟਾਬੇਸ ਨਿਯਮ ਨਹੀਂ—ਇਹ ਉਨ੍ਹਾਂ ਗੱਲਾਂ ਲਈ ਜਰੂਰੀ ਹੈ ਜੋ ਤੁਹਾਨੂੰ joins, cache ਅਤੇ ਰੇਫਰੈਂਸਾਂ ਵਿੱਚ ਆਸਾਨੀ ਦਿੰਦਾ ਹੈ।
ਇੱਕ ਸਥਿਰ PK ਮਹਿੰਗੇ ਵర్కਅਰਾਊਂਡ ਤੋਂ ਵੀ ਬਚਾਉਂਦੀ ਹੈ। ਜੇ ਇੱਕ ਟੇਬਲ ਕੋਲ ਸੱਚੀ ਪਛਾਣ ਨਹੀਂ, ਤਾਂ ਐਪਲੀਕੇਸ਼ਨ ਕਤਾਰਾਂ ਦੀ ਪਛਾਣ ਇਮੇਲ, ਨਾਮ, timestamp ਜਾਂ ਕਈ ਕਾਲਮਾਂ ਦੇ ਬੰਡਲ ਨਾਲ ਕਰਨ ਲੱਗਦੀ—ਜੋ ਵਾਇਡ ਇੰਡੈਕਸ, ਸਲੋ joins ਅਤੇ ਏਜ ਕੇਸ ਜਦੋਂ ਉਹ ਮੁੱਲ ਬਦਲਦੇ ਹਨ ਬਣਾਉਂਦਾ ਹੈ।
ਫੋਰਿਨ ਕੁੰਜੀਆਂ: optimizer ਲਈ ਇੰਟੈਗ੍ਰਿਟੀ ਜੋ ਮਦਦ ਕਰਦੀ ਹੈ
ਫੋਰਿਨ ਕੁੰਜੀਆਂ (FKs) ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਪ੍ਰਭਾਵੀ ਬਣਾਉਂਦੀਆਂ ਹਨ: ਉਦਾਹਰਣ ਲਈ orders.user_id ਨੂੰ ਮੌਜੂਦ users.id ਨਾਲ ਜੋੜਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। FKs ਦੇ ਬਗੈਰ, ਗ਼ਲਤ ਰਿਫਰੈਂਸ ਰੁਕੀ ਰਹਿੰਦੀ (ਮਿਟੇ ਹੋਏ ਯੂਜ਼ਰਾਂ ਲਈ orders, ਮਿਸਿੰਗ ਪੋਸਟਾਂ ਲਈ comments), ਅਤੇ ਫਿਰ ਹਰ ਕੁਏਰੀ ਨੂੰ ਸਾਵਧਾਨੀ ਨਾਲ ਫਿਲਟਰ, left-join ਅਤੇ nulls ਸੰਭਾਲਣੇ ਪੈਂਦੇ ਹਨ।
FKs ਦੇ ਨਾਲ, ਕੁਏਰੀ ਪਲੈਨਰ ਅਕਸਰ joins ਨੂੰ ਜਿਆਦਾ ਨਿਸ਼ਚਿਤ ਤਰੀਕੇ ਨਾਲ optimize ਕਰ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ ਰਿਸ਼ਤਾ ਸਪੱਸ਼ਟ ਅਤੇ ਗਾਰੰਟੀਸ਼ੁਦਾ ਹੁੰਦਾ ਹੈ। ਤੁਸੀਂ ਵੀ orphan rows ਜੋ ਟੇਬਲਾਂ ਅਤੇ ਇੰਡੈਕਸਾਂ ਨੂੰ ਬਲੋਟ ਕਰਦੇ ਹਨ, ਉਨ੍ਹਾਂ ਨੂੰ ਘੱਟ ਬਣਾਓਗੇ।
ਪਾਬੰਦੀਆਂ: ਸਾਫ਼, ਤੇਜ਼ ਡੇਟਾ ਲਈ ਗਾਰਡਰੇਲ
ਪਾਬੰਦੀਆਂ ਕੋਈ ਅਮਲਦਾਰੀ ਨਹੀਂ—ਉਹ ਗਾਰਡਰੇਲ ਹਨ:
- UNIQUE ਨਕਲਾਂ ਨੂੰ ਰੋਕਦਾ ਹੈ ਜੋ ਐਪ ਨੂੰ ਵਧੀਕ ਲੁਕਅਪ ਅਤੇ ਸਾਫਾਈ ਕਰਨ ਲਈ ਮਜ਼ਬੂਰ ਕਰਦੀਆਂ ਹਨ। ਉਦਾਹਰਨ: ਇੱਕ canonical
users.email। - NOT NULL ਤਲ-ਤੱਤ ਤਰਤੀਬ ਨਾਲ ਤਿੰਨ-ਸਥਿਤੀ ਲਾਜਿਕ ਅਤੇ ਅਚਾਨਕ null-ਹੈਂਡਲਿੰਗ ਬਰਾਂਚਾਂ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
- CHECK ਮੁੱਲਾਂ ਨੂੰ ਜਾਣੇ-ਪਛਾਣੇ ਸੈਟ ਵਿੱਚ ਰੱਖਦਾ ਹੈ (ਉਦਾਹਰਨ,
status IN ('pending','paid','canceled'))।
ਸਾਫ਼ ਡੇਟਾ ਮਤਲਬ ਸਧਾਰਣ ਕੁਏਰੀਆਂ, ਘੱਟ fallback ਸ਼ਰਤਾਂ, ਅਤੇ ਘੱਟ 'ਸਿਰਫ਼ ਸੰਭਾਲ ਲਈ' joins।
ਆਮ ਐਂਟੀ-ਪੈਟਰਨ ਜੋ ਤੁਹਾਨੂੰ ਦੇਰ ਨਾਲ ਭੁਗਤਣਾ ਪੈਂਦਾ ਹੈ
- ਕੋਈ ਫੋਰਿਨ ਕੁੰਜੀਆਂ ਨਹੀਂ: ਬਾਅਦ ਵਿੱਚ orphan ਸਾਫ਼ ਕਰਨ ਵਾਲੇ ਜੌਬ ਅਤੇ ਜਟਿਲ ਕੁਏਰੀ ਲਾਜਿਕ ਲਈ ਤੁਸੀਂ ਭੁਗਤੋਗੇ।
- ਇਮੇਲ ਫੀਲਡ ਦੀ ਨਕਲ (ਉਦਾਹਰਣ,
users.emailਅਤੇcustomers.email): ਤੁਸੀਂ conflicting identities ਅਤੇ ਨਕਲ ਇੰਡੈਕਸਾਂ ਨਾਲ ਮਿਲਦੇ ਹੋ। - ਮੁਫ਼ਤ-ਰੂਪ ਰੂਪ 'status' ਸਤਰੰਗ: 'Cancelled' vs 'canceled' ਵਰਗੀਆਂ ਟਾਈਪੋ ਛੁਪੇ ਹੋਏ ਸੈਗਮੈਂਟ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜੋ ਫਿਲਟਰਾਂ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਭੰਗ ਕਰ ਦਿੰਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਸ਼ੁਰੂ 'ਚ ਤੇਜ਼ੀ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਖਰਾਬ ਡੇਟਾ ਸਟੋਰ ਕਰਨਾ ਮੁਸ਼ਕਲ ਬਣਾ ਦਿਓ। ਡੇਟਾਬੇਸ ਤੁਹਾਨੂੰ ਸਧਾਰਨ ਯੋਜਨਾਵਾਂ, ਛੋਟੇ ਇੰਡੈਕਸ ਅਤੇ ਘੱਟ ਪ੍ਰਦਰਸ਼ਨ ਅਚਾਨਕੇ ਨਾਲ ਇਨਾਮ ਦੇਵੇਗਾ।
ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ vs ਡੀ-ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ: ਇਕ ਵਿਹਾਰਿਕ ਸੰਤੁਲਨ
ਕਿਸੇ ਵੀ ਵੇਲੇ ਆਪਣਾ ਸੋਰਸ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰੋ
ਜਦੋਂ ਤੁਹਾਡਾ ਸਕੀਮਾ ਅਤੇ ਫੀਚਰ ਬਦਲਦੇ ਹਨ ਤਾਂ ਸੋਰਸ ਕੋਡ ਨੂੰ ਕਿਸੇ ਵੀ ਵੇਲੇ ਐਕਸਪੋਰਟ ਕਰਕੇ ਨਿਯੰਤਰਣ ਰੱਖੋ।
ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਇੱਕ ਸਿੱਧੀ ਸੋਚ ਹੈ: ਹਰ 'ਤੱਥ' ਨੂੰ ਇੱਕ ਹੀ ਥਾਂ ਤੇ ਰੱਖੋ ਤਾਂ ਕਿ ਡੇਟਾ ਕਈ ਟੇਬਲਾਂ ਵਿੱਚ ਨਕਲ ਨਾ ਹੋਵੇ। ਜਦੋਂ ਇੱਕੋ ਮੁੱਲ ਕਈ ਟੇਬਲਾਂ ਵਾਲੀ ਨਕਲ ਹੋ ਜਾਂਦੀ ਹੈ, ਅਪਡੇਟ ਖਤਰਨਾਕ ਹੋ ਜਾਂਦੇ ਹਨ—ਇੱਕ ਨਕਲ ਬਦਲੀ, ਦੂਜੀ ਨਹੀਂ, ਅਤੇ ਤੁਹਾਡੀ ਐਪ ਵਿਰੋਧੀ ਨਤੀਜੇ ਦਿਖਾਉਂਦੀ ਹੈ।
ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ (ਡਿਫਾਲਟ): ਇੱਕ ਤੱਥ, ਇੱਕ ਘਰ
ਅਮਲ ਵਿੱਚ, ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਦਾ ਮਤਲਬ ਹੈ ਇਕਾਈਆਂ ਨੂੰ ਵੱਖ ਕਰਨਾ ਤਾਂ ਜੋ ਅਪਡੇਟ ਸਾਫ਼ ਅਤੇ ਪੇਸ਼ਗੀ ਹੋਵਣ। ਉਦਾਹਰਨ ਲਈ, ਇੱਕ ਪ੍ਰੋਡਕਟ ਦਾ ਨਾਮ ਅਤੇ ਕੀਮਤ products ਟੇਬਲ ਵਿੱਚ ਹੋਵੇ, ਨਾ ਕਿ ਹਰ ਆਰਡਰ ਰੋ ਵਿੱਚ ਦੁਹਰਾਇਆ ਜਾਵੇ। ਇੱਕ ਸ਼੍ਰੇਣੀ ਦਾ ਨਾਮ categories ਵਿੱਚ ਹੋਵੇ ਅਤੇ ID ਨਾਲ ਰੈਫਰੰਸ ਕੀਤਾ ਜਾਵੇ।
ਇਸ ਨਾਲ ਘੱਟ ਹੁੰਦਾ ਹੈ:
- ਡਾਟਾ ਦੀ ਨਕਲ (ਘੱਟ ਬਟਾਅ, ਘੱਟ ਅਸਮੰਨਤਾ)
- ਅਪਡੇਟ ਗਲਤੀਆਂ (ਇੱਕ ਵਾਰੀ ਬਦਲੋ, ਹਰ ਜਗ੍ਹਾ ਪ੍ਰਭਾਵ)
- ਗੁੰਝਲਦਾਰ 'ਕਿਹੜਾ ਮੁੱਲ ਸਹੀ ਹੈ?' ਬਗ
ਜਦੋਂ ਅਤਿ-ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੀ ਹੈ
ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਨੂੰ ਬਹੁਤ ਅੱਗੇ ਲੈ ਜਾ ਕੇ ਤੁਸੀਂ ਡੇਟਾ ਨੂੰ ਛੋਟੇ-ਛੋਟੇ ਟੇਬਲਾਂ ਵਿੱਚ ਵੰਡ ਦਿੰਦੇ ਹੋ ਜੋ ਹਰ ਰੋਜ਼ ਦੀਆਂ ਸਕ्रीनز ਲਈ ਲਾਜ਼ਮੀ joins ਬਣਾਉਂਦੀਆਂ ਹਨ। ਡੇਟਾਬੇਸ ਸਹੀ ਨਤੀਜੇ ਦੇ ਸਕਦਾ ਹੈ, ਪਰ ਆਮ ਰੀਡ ਫੀਚਰ ਸਲੋ ਅਤੇ ਜ਼ਿਆਦਾ ਜਟਿਲ ਹੋ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ ਹਰ ਬੇਨਤੀ ਨੂੰ ਕਈ joins ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਇੱਕ ਆਮ ਸ਼ੁਰੂਆਤੀ ਲੱਛਣ: ਇੱਕ 'ਸਧਾਰਣ' ਪੰਨਾ (ਜਿਵੇਂ order history list) 6–10 ਟੇਬਲਾਂ ਨੂੰ join ਕਰਨ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ, ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ cache ਗਰਮੀ ਤੇ ਨਿਭਰ ਕਰਦਾ ਹੈ।
ਵਿਹਾਰਿਕ ਦ੍ਰਿਸ਼ਟੀਕੋਣ: ਕੋਰ ਤੱਥ ਨਾਰਮਲ ਰੱਖੋ, ਹottest ਰੀਡ ਲਈ ਸੋਚ ਸਮੇਤ ਡੀ-ਨਾਰਮਲਾਈਜ਼ ਕਰੋ
ਇਕ ਬੇਹਦ ਸਮਝਦਾਰ ਸੰਤੁਲਨ:
- ਕੋਰ ਤੱਥ ਅਤੇ ਮਾਲਕੀ ਨੂੰ ਨਾਰਮਲ ਰੱਖੋ (source of truth)। ਉਤਪਾਦ ਲੱਛਣ
productsਵਿੱਚ, ਸ਼੍ਰੇਣੀ ਨਾਮcategoriesਵਿੱਚ, ਅਤੇ ਰਿਸ਼ਤੇ ਫੋਰਿਨ ਕੀ ਰਾਹੀਂ ਰੱਖੋ। - ਸਭ ਤੋਂ ਗਰਮ ਰੀਡ ਲਈ ਧਿਆਨ ਨਾਲ ਡੀ-ਨਾਰਮਲਾਈਜ਼ ਕਰੋ—ਪਰ ਸਿਰਫ ਜਦੋਂ ਤੁਸੀਂ ਲਾਭ ਸਪਸ਼ਟ ਕਰ ਸਕੋ ਅਤੇ ਇਸ ਨੂੰ ਸਹੀ ਰੱਖਣ ਦੀ ਯੋਜਨਾ ਹੋਵੇ।
ਡੀ-ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਦਾ ਮਤਲਬ ਲੜਾਈਵਾਰ ਥੋੜ੍ਹਾ ਡੇਟਾ ਨਕਲ ਕਰਕੇ ਅਕਸਰ ਕੁਏਰੀ ਨੂੰ ਸਸਤਾ ਬਣਾਉਣਾ ਹੈ (ਘੱਟ joins, ਤੇਜ਼ ਲਿਸਟਾਂ)। ਮੁੱਖ ਸ਼ਬਦ ਹੈ 'ਧਿਆਨ ਨਾਲ': ਹਰ duplicated ਫੀਲਡ ਲਈ ਇਸਨੂੰ ਅਪਡੇਟ ਵਿੱਚ ਰੱਖਣ ਦੀ ਯੋਜਨਾ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ।
ਉਦਾਹਰਨ: products, categories, ਅਤੇ order items
ਨਾਰਮਲਾਈਜ਼ਡ ਸੈੱਟਅਪ ਇੰਝ ਹੋ ਸਕਦਾ ਹੈ:
products(id, name, price, category_id)categories(id, name)orders(id, customer_id, created_at)order_items(id, order_id, product_id, quantity, unit_price_at_purchase)
ਇੱਕ ਸੁਬਟ ਜਿੱਤ: order_items unit_price_at_purchase ਰੱਖਦੀ ਹੈ (ਡੀ-ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਦਾ ਇੱਕ ਰੂਪ) ਕਿਉਂਕਿ ਤੁਹਾਨੂੰ ਇਤਿਹਾਸਕ ਸਹੀਤਾ ਚਾਹੀਦੀ ਹੈ ਭਾਵੇਂ product price ਬਾਅਦ ਵਿੱਚ ਬਦਲ ਜਾਵੇ। ਇਹ ਨਕਲ ਇਰਾਦਤ ਨਾਲ ਅਤੇ ਸਥਿਰ ਹੈ।
ਜੇ ਤੁਹਾਡੀ ਸਭ ਤੋਂ ਆਮ ਸਕ੍ਰੀਨ 'orders with item summaries' ਹੈ, ਤਾਂ ਤੁਸੀਂ product_name ਨੂੰ order_items ਵਿੱਚ ਵੀ ਵਾਲੀ ਕਰ ਸਕਦੇ ਹੋ ਤਾਂ ਜੋ ਹਰ ਲਿਸਟ ਲਈ products ਨੂੰ ਜੋਇਨ ਕਰਨ ਦੀ ਲੋੜ ਨਾ ਪਏ—ਪਰ ਸਿਰਫ ਜੇ ਤੁਸੀਂ ਉਸਨੂੰ ਸਿੰਕ ਰੱਖਣ ਜਾਂ ਖਰੀਦ ਸਮੇਂ ਦਾ ਸਨੇਪਸ਼ਾਟ ਮਨਜ਼ੂਰ ਕਰਨ ਲਈ ਤਿਆਰ ਹੋ।
ਇੰਡੈਕਸ ਰਣਨੀਤੀ ਸਕੀਮਾ ਦੀ ਪਾਲਣਾ ਕਰਦੀ ਹੈ, ਉਸ ਦੇ ਉਲਟ ਨਹੀਂ
ਇੰਡੈਕਸਾਂ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਇਕ ਜਾਦੂਈ 'ਤੇਜ਼ੀ ਬਟਨ' ਸਮਝਿਆ ਜਾਂਦਾ ਹੈ, ਪਰ ਉਹ ਤਦ ਹੀ ਚੰਗੇ ਕੰਮ ਕਰਦੇ ਹਨ ਜਦੋਂ ਅਧਾਰਭੂਤ ਟੇਬਲ ਦੀ ਰਚਨਾ ਸਮਝਦਾਰ ਹੋਵੇ। ਜੇ ਤੁਸੀਂ ਅਜੇ ਵੀ ਕਾਲਮਾਂ ਦੇ ਨਾਮ ਬਦਲ ਰਹੇ ਹੋ, ਟੇਬਲਾਂ ਨੂੰ ਵੰਡ ਰਹੇ ਹੋ, ਜਾਂ ਇਹ ਬਦਲ ਰਹੇ ਹੋ ਕਿ ਰਿਕਾਰਡ ਇੱਕ ਦੂਜੇ ਨਾਲ ਕਿਵੇਂ ਸਬੰਧਤ ਹਨ, ਤਾਂ ਤੁਹਾਡੇ ਇੰਡੈਕਸ ਵੀ ਬਦਲਦੇ ਰਹਿਣਗੇ। ਇੰਡੈਕਸ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦੇ ਹਨ ਜਦੋਂ ਕਾਲਮ (ਅਤੇ ਐਪ ਦੇ ਫਿਲਟਰ/ਸੋਰਟ ਕਰਣ ਦੇ ਤਰੀਕੇ) ਇੰਨੇ ਸਥਿਰ ਹੋਣ ਕਿ ਤੁਸੀਂ ਹਰ ਹਫ਼ਤੇ ਉਹਨਾਂ ਨੂੰ ਦੁਬਾਰਾ ਨਹੀਂ ਬਣਾਉਂਦੇ।
ਉਹ ਸਵਾਲ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਹਾਡੀ ਐਪ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਪੁੱਛਦੀ ਹੈ, ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਤੁਹਾਨੂੰ ਪਰਫੈਕਟ ਪੂਰਬਾਂਕਲ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ, ਪਰ ਤੁਹਾਨੂੰ ਉਹ ਕੁਝ ਕੁਏਰੀਆਂ ਦੀ ਛੋਟੀ ਸੂਚੀ ਚਾਹੀਦੀ ਹੈ ਜੋ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਣ ਹਨ:
- 'ਇਮੇਲ ਨਾਲ ਯੂਜ਼ਰ ਲੱਭੋ'
- 'ਕਸਟਮਰ ਲਈ ਹਾਲ ਹੀ ਵਿੱਚ ਆਏ ਆਰਡਰ ਦਿਖਾਓ'
- 'ਸਟੇਟਸ ਦੁਆਰਾ ਇਨਵੌਇਸ ਲਿਸਟ ਕਰੋ, ਨਵਾਂ ਤੋਂ ਪੁਰਾਣਾ'
ਇਹ ਬਿਆਨ ਸਿੱਧਾ ਦੱਸਦੇ ਹਨ ਕਿ ਕਿਹੜੇ ਕਾਲਮ ਇੰਡੈਕਸ ਦੇ ਲਾਇਕ ਹਨ। ਜੇ ਤੁਸੀਂ ਆਵਾਜ਼ ਵਿੱਚ ਇਹ ਨਹੀਂ ਕਹਿ ਸਕਦੇ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਇੱਕ ਸਕੀਮਾ ਸਪਸ਼ਟੀਕਰਨ ਸਮੱਸਿਆ ਹੈ—ਇੰਡੈਕਸਿੰਗ ਦੀ ਨਹੀਂ।
ਸਮੰਯੋਜੀ ਇੰਡੈਕਸ, ਸਧਾਰਨ ਸ਼ਬਦਾਂ ਵਿੱਚ
ਇੱਕ ਸਮੰਯੋਜੀ (composite) ਇੰਡੈਕਸ ਇੱਕ ਤੋਂ ਵੱਧ ਕਾਲਮ ਨੂੰ ਕਵਰ ਕਰਦਾ ਹੈ। ਕਾਲਮਾਂ ਦਾ ਕ੍ਰਮ ਮਹੱਤਵਪੂਰਕ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਡੇਟਾਬੇਸ ਇੰਡੈਕਸ ਨੂੰ ਖੱਬੇ-ਤੋ-ਸੱਜੇ ਤਰੀਕੇ ਨਾਲ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਰੂਪ ਵਿੱਚ ਵਰਤ ਸਕਦਾ ਹੈ।
ਉਦਾਹਰਨ ਵਜੋਂ, ਜੇ ਤੁਸੀਂ ਅਕਸਰ customer_id ਨਾਲ ਫਿਲਟਰ ਕਰਦੇ ਹੋ ਅਤੇ ਫਿਰ created_at ਨਾਲ ਸੋਰਟ ਕਰਦੇ ਹੋ, ਤਾਂ (customer_id, created_at) ਉੱਤੇ ਇੱਕ ਇੰਡੈਕਸ ਆਮ ਤੌਰ 'ਤੇ ਲਾਭਦਾਇਕ ਹੈ। ਉਲਟ (created_at, customer_id) ਉਹੇ ਕੁਏਰੀ ਨੂੰ ਉਤਨਾ ਫਾਇਦਾ ਨਹੀਂ ਦੇ ਸਕਦੀ।
ਹਰ ਚੀਜ਼ 'ਤੇ ਇੰਡੈਕਸ ਨਾ ਲਗਾਓ
ਹਰ ਇਕ ਵਾਧੂ ਇੰਡੈਕਸ ਦੀ ਇਕ ਲਾਗਤ ਹੁੰਦੀ ਹੈ:
- ਸਲੇਖਣਾਂ ਤੇ ਸਲੋ ਲਿਖਤਾਂ: inserts/updates ਹਰ ਇੰਡੈਕਸ ਨੂੰ ਵੀ ਅੱਪਡੇਟ ਕਰਦੇ ਹਨ।
- ਹੋਰ ਸਟੋਰੇਜ: ਇੰਡੈਕਸ DB ਨਾਪ ਦਾ ਵੱਡਾ ਹਿੱਸਾ ਬਣ ਸਕਦਾ ਹੈ।
- ਹੋਰ ਜਟਿਿਲਤਾ: ਵਾਧੂ ਇੰਡੈਕਸ ਨਰੰਭ-maintenance ਅਤੇ ਟਿਊਨਿੰਗ ਨੂੰ ਔਖਾ ਬਣਾ ਦਿੰਦੇ ਹਨ।
ਇੱਕ ਸਾਫ਼, ਇੱਕਸਾਰ ਸਕੀਮਾ 'ਸਹੀ' ਇੰਡੈਕਸਾਂ ਨੂੰ ਇੱਕ ਛੋਟੀ ਸੈੱਟ ਤੱਕ ਸੀਮਤ ਕਰ ਦਿੰਦਾ ਹੈ ਜੋ ਅਸਲੀ ਪਹੁੰਚ ਪੈਟਰਨ ਨਾਲ ਮਿਲਦੇ ਹਨ—ਬਿਨਾਂ ਲਿਖਤ ਅਤੇ ਸਟੋਰੇਜ ਟੈਕਸ ਦੇ।
ਲਿਖਣ ਦੀ ਪ੍ਰਦਰਸ਼ਨ: ਇਕ ਗਡ਼ਬੜ ਸਕੀਮਾ ਦੀ ਛੁਪੀ ਲਾਗਤ
ਸਿੱਖਦੇ ਸਮੇਂ ਕ੍ਰੈਡਿਟਸ ਘਟਾਓ
Koder.ai ਬਾਰੇ ਸਮੱਗਰੀ ਬਣਾਕੇ ਜਾਂ ਨਵੇਂ ਯੂਜ਼ਰਾਂ ਦਾ ਹਵਾਲਾ ਦੇ ਕੇ ਕ੍ਰੈਡਿਟਸ ਪ੍ਰਾਪਤ ਕਰੋ।
ਸਲੋ ਐਪ ਹਮੇਸ਼ਾ ਰੀਡ ਤੋਂ ਨਹੀਂ ਸੁਸਤ ਹੁੰਦੇ। ਕਈ ਸ਼ੁਰੂਆਤੀ ਪ੍ਰਦਰਸ਼ਨ ਸਮੱਸਿਆਵਾਂ ਇਨਸਰਟਾਂ ਅਤੇ ਅਪਡੇਟਾਂ ਦੌਰਾਨ ਉਭਰਦੀਆਂ ਹਨ—ਯੂਜ਼ਰ ਸਾਇਨਅੱਪ, ਚੈਕਆਊਟ ਫਲੋ, ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ—ਕਿਉਂਕਿ ਇਕ ਗਡ਼ਬੜ ਸਕੀਮਾ ਹਰ ਲਿਖਾਈ ਨੂੰ ਥੋੜ੍ਹਾ ਹੋਰ ਕੰਮ ਕਰਵਾ ਦਿੰਦਾ ਹੈ।
ਲਿਖਤਾਂ ਮਹਿੰਗੀਆਂ ਕਿਉਂ ਹੋ ਜਾਂਦੀਆਂ ਹਨ
ਕੁਝ ਸਕੀਮਾ ਚੋਣਾਂ ਪ੍ਰਤੀ ਇਕ ਬਦਲਾਅ ਦੇ ਖਰਚ ਨੂੰ ਗੁਣਾ ਕਰ ਦਿੰਦੀਆਂ ਹਨ:
- ਚੌੜੇ ਰੋਜ਼: ਦਹਾਂ ਜਾਂ ਸੈਂਕੜੇ ਕਾਲਮ ਇਕ ਟੇਬਲ ਵਿੱਚ ਭਰਨਾ ਅਕਸਰ ਵੱਡੀਆਂ ਰੋਜ਼, ਵੱਧ I/O ਅਤੇ cache churn ਦਾ ਕਾਰਨ ਬਣਦਾ ਹੈ—ਭਾਵੇਂ ਬਹੁਤ ਸਾਰੇ ਕਾਲਮ ਕਦੇ ਵਰਤੇ ਨਾ ਵੀ ਜਾਣ।
- ਬਹੁਤ ਸਾਰੇ ਇੰਡੈਕਸ: ਇੰਡੈਕਸ ਰੀਡ ਨੂੰ ਤੇਜ਼ ਕਰਦੇ ਹਨ, ਪਰ ਹਰ insert/update ਨੂੰ ਹਰ ਇੰਡੈਕਸ ਵੀ ਅੱਪਡੇਟ ਕਰਨਾ ਪੈਂਦਾ ਹੈ।
- Triggers ਅਤੇ cascades: triggers ਇੱਕ ਸਧਾਰਨ
INSERTਦੇ ਪਿੱਛੇ ਛੁਪਿਆ ਹੋਇਆ ਕੰਮ ਦਿਖਾ ਸਕਦੇ ਹਨ। Cascading foreign keys ਸਹੀ ਅਤੇ ਮਦਦਗਾਰ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਉਹ ਵੀ ਲਿਖਤ-ਵੇਲੇ ਕੰਮ ਜੋੜਦੇ ਹਨ ਜੋ ਸੰਬੰਧਿਤ ਡੇਟਾ ਨਾਲ ਵੱਧਦਾ ਹੈ।
ਰੀਡ-ਭਾਰੀ vs ਲਿਖਤ-ਭਾਰੀ: ਆਪਣਾ ਦਰਦ ਦਰੁਸਤ ਚੁਣੋ
ਜੇ ਤੁਹਾਡਾ ਵਰਕਲੋਡ ਰੀਡ-ਭਾਰੀ ਹੈ (ਫੀਡ, ਖੋਜ ਪੰਨੇ), ਤਾਂ ਤੁਸੀਂ ਹੋਰ ਇੰਡੈਕਸਿੰਗ ਅਤੇ ਚੁਣੀਦਾ ਡੀ-ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਸਹਿਣ ਕਰ ਸਕਦੇ ਹੋ। ਜੇ ਇਹ ਲਿਖਤ-ਭਾਰੀ ਹੈ (ਘਟਨਾਵਾਂ ਦੀ ਕਪਿਆਈ, ਟੈਲੀਮੈਟਰੀ, ਬਹੁਤ ਵੱਧ ਆਰਡਰ), ਤਾਂ ਉਹ ਸਕੀਮਾ ਪ੍ਰਾਥਮਿਕਤਾ ਦਿਓ ਜੋ ਲਿਖਤਾਂ ਨੂੰ ਸਧਾਰਨ ਅਤੇ ਪੌਰੇ ਤੌਰ ਤੇ ਰੱਖਦਾ ਹੈ, ਅਤੇ ਫਿਰ ਜ਼ਰੂਰਤ ਪੈਣ 'ਤੇ ਰੀਡ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਜੋੜੋ।
ਉਹ ਆਮ ਸ਼ੁਰੂਆਤੀ ਪੈਟਰਨ ਜੋ ਲਿਖਤਾਂ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੇ ਹਨ
- ਆਡਿਟ ਲੋਗਸ: ਅਨੁਕੂਲਤਾ ਲਈ ਵਧੀਆ, ਪਰ ਹਰ ਅਪਡੇਟ 'ਤੇ ਵਿਸ਼ਾਲ ਸਨੇਪਸ਼ਾਟ ਲਾਗੂ ਕਰਨ ਤੋਂ ਬਚੋ।
- ਈਵੈਂਟ ਟੇਬਲਾਂ: append-only ਟੇਬਲ ਵਧੀਆਂ ਸਕੇਲ ਕਰਦੀਆਂ ਹਨ, ਪਰ ਜੇ ਤੁਸੀਂ ਬੇਕਾਰ payloads ਸਟੋਰ ਕਰਦੇ ਹੋ ਤਾਂ ਉਹ ਭਾਰੀ ਹੋ ਸਕਦੀਆਂ ਹਨ।
- ਸੌਫਟ ਡੀਲੀਟਸ: ਸਹੂਲਤਕਾਰ, ਪਰ ਇਹ ਇੰਡੈਕਸ ਆਕਾਰ ਵਧਾਉਂਦੇ ਹਨ ਅਤੇ ਅਪਡੇਟ ਅਤੇ ਕੁਏਰੀਆਂ ਨੂੰ ਮੰਨ੍ਹਾ ਸਕਦੇ ਹਨ ਜੇ ਧਿਆਨ ਨਾਲ ਯੋਜਨਾ ਨਾ ਹੋਵੇ।
ਇਤਿਹਾਸ ਬਚਾਉਂਦੇ ਹੋਏ ਲਿਖਤਾਂ ਸਧਾਰਨ ਰੱਖੋ
ਇੱਕ ਵਿਹਾਰਿਕ ਤਰੀਕਾ:
- 'ਮੌਜੂਦਾ ਅਵਸਥਾ' ਇੱਕ ਟੇਬਲ ਵਿੱਚ ਰੱਖੋ, ਅਤੇ ਇਤਿਹਾਸ ਇੱਕ ਵੱਖਰੀ append-only ਟੇਬਲ ਵਿੱਚ।
- ਇਤਿਹਾਸੀ ਕਤਾਰਾਂ ਨੂੰ ਪਤਲਾ ਰੱਖੋ (ਸਿਰਫ਼ ਜੋ ਤੁਸੀਂ ਸੱਚਮੁਚ ਚਾਹੁੰਦੇ ਹੋ: ਕੌਣ/ਕਦੋਂ/ਕੀ ਬਦਲਾ)।
- ਇਤਿਹਾਸ ਲਈ ਇੰਡੈਕਸ ਉਹਨਾਂ ਅਸਲ ਪਹੁੰਚ ਪੈਟਰਨਾਂ 'ਤੇ ਜੋੜੋ (ਆਮ ਤੌਰ 'ਤੇ
entity_id,created_at)। - ਆਰੰਭ ਵਿੱਚ ਆਡਿਟਿੰਗ ਲਈ triggers ਤੋਂ ਬਚੋ; ਲੋਕੀਤ ਐਪਲਿਕੇਸ਼ਨ ਲਿਖਤਾਂ ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਤਾ ਕਿ ਲਾਗਤ ਦਿੱਖੀ ਜਾ ਸਕੇ ਅਤੇ ਟੈਸਟ ਕੀਤਾ ਜਾ ਸਕੇ।
ਸਾਫ਼ ਲਿਖਤ ਰਾਹ ਤੁਹਾਨੂੰ ਹੇਡਰੂਮ ਦਿੰਦੇ ਹਨ—ਅਤੇ ਉਹ ਬਾਅਦ ਵਿੱਚ ਕੁਏਰੀ ਟਿਊਨਿੰਗ ਨੂੰ ਕਾਫੀ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ।
ORMs ਅਤੇ APIs ਕਿਵੇਂ ਸਕੀਮਾ ਦੇ ਫੈਸਲਿਆਂ ਨੂੰ ਵਧਾਉਂਦੇ ਹਨ
ORMs ਡੇਟਾਬੇਸ ਕੰਮ ਨੂੰ ਬੇਝੜ ਬਣਾਉਂਦੇ ਹਨ: ਤੁਸੀਂ ਮਾਡਲ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦੇ ਹੋ, ਮੈਥਡ ਕਾਲ ਕਰਦੇ ਹੋ, ਅਤੇ ਡੇਟਾ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ। ਫੇਰ ਵੀ, ORM ਮਹਿੰਗੀ SQL ਛੁਪਾ ਸਕਦਾ ਹੈ ਜਦ ਤੱਕ ਇਹ ਦਰਦ ਕਰਨ ਲੱਗੇ।
ORMs: ਸਹੂਲਤ ਜੋ ਸਲੋ ਪੈਟਰਨਾਂ ਨੂੰ ਛੁਪਾ ਸਕਦੀ ਹੈ
ਦੋ ਆਮ ਜਾਲ:
- ਗੈਰ-ਕੁਸ਼ਲ joins: ਇੱਕ ਠੀਕ-ਲੱਗਣ ਵਾਲੀ
.include()ਜਾਂ nested serializer ਵੱਡੇ joins, ਨਕਲ ਰੋਜ਼, ਜਾਂ ਵੱਡੇ sorts ਬਣ ਸਕਦੇ ਹਨ—ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ ਰਿਸ਼ਤੇ ਸਪਸ਼ਟ ਤੌਰ ਤੇ ਪਰਿਭਾਸ਼ਿਤ ਨਹੀਂ ਹੁੰਦੇ। - N+1 ਕੁਏਰੀਆਂ: ਤੁਸੀਂ 50 ਰਿਕਾਰਡ ਫੇਚ ਕਰਦੇ ਹੋ, ਫਿਰ ORM ਚੁੱਪਚਾਪ 50 ਹੋਰ ਕੁਏਰੀਆਂ ਚਲਾਉਂਦਾ ਹੈ ਤਾਂ ਜੋ ਸੰਬੰਧਤ ਡੇਟਾ ਲੋਡ ਕੀਤਾ ਜਾ ਸਕੇ। ਇਹ ਵਿਕਾਸ ਵਿੱਚ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ ਪਰ ਅਸਲ ਟ੍ਰੈਫਿਕ ਹੇਠਾਂ ਟੁੱਟ ਜਾਂਦਾ ਹੈ।
ਚੰਗੇ ਤਰੀਕੇ ਨਾਲ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਗਿਆ ਸਕੀਮਾ ਇਹਨਾਂ ਪੈਟਰਨਾਂ ਦੇ ਉਭਾਰ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ ਅਤੇ ਜਦੋਂ ਉਹ ਆਉਂਦੇ ਹਨ ਤਦ ਉਨ੍ਹਾਂ ਦੀ ਪਛਾਣ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਸਪਸ਼ਟ ਰਿਸ਼ਤੇ ORM ਵਰਤੋਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦੇ ਹਨ
ਜਦੋਂ ਟੇਬਲਾਂ ਕੋਲ ਸਪਸ਼ਟ ਫੋਰਿਨ ਕੁੰਜੀਆਂ, ਯੂਨੀਕ ਪਾਬੰਦੀਆਂ, ਅਤੇ NOT NULL ਨਿਯਮ ਹੁੰਦੇ ਹਨ, ORM ਸੁਰੱਖਿਅਤ ਕੁਏਰੀਆਂ ਬਣਾਉਣ ਅਤੇ ਤੁਹਾਡਾ ਕੋਡ ਮੁਤਾਬਕ ਨਿਰੰਤਰ ਅਨੁਮਾਨਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਨ ਵਿੱਚ ਸਹਾਇਕ ਹੁੰਦਾ ਹੈ।
ਉਦਾਹਰਨ ਲਈ, orders.user_id ਦਾ ਹੋਣਾ (FK) ਅਤੇ users.email ਦਾ unique ਹੋਣਾ ਐ ਐਪ-ਪੱਧਰੀ edge-cases ਦੀਆਂ ਕਲਾਸਾਂ ਨੂੰ ਰੋਕਦਾ ਹੈ ਜੋ ਨਹੀਂ ਹੁੰਦੇ ਤਾਂ ਐਪ-ਲੈਵਲ ਚੈੱਕ ਅਤੇ ਵਧੇਰੇ ਕੁਏਰੀ ਕੰਮ ਬਣਨ ਲਗਦੇ।
APIs ਸਕੀਮਾ ਫੈਸਲਿਆਂ ਨੂੰ ਪ੍ਰੋਡਕਟ ਵਿਹਾਰ ਵਿੱਚ ਬਦਲ ਦੇਂਦੇ ਹਨ
ਤੁਹਾਡੇ API ਡਿਜ਼ਾਈਨ ਸਕੀਮਾ ਦਾ ਡਾਉਨਸਟਰੀਮ ਹੈ:
- ਸਥਿਰ IDs (ਅਤੇ ਇੱਕਸਾਰ key ਟਾਈਪ) URLs, cache ਅਤੇ client-side state ਨੂੰ ਸਧਾਰਨ ਬਣਾਉਂਦੇ ਹਨ।
- Pagination ਉਹਨਾਂ ਵਰਤੋਂ ਲਈ ਸਭ ਤੋਂ ਚੰਗਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਇੰਡੈਕਸਡ, ਮੋਨੋਟੋਨਿਕ ਕਾਲਮ (ਅਕਸਰ
created_at+id) ਨਾਲ order ਕਰ ਸਕਦੇ ਹੋ। - Filtering ਭਰੋਸੇਯੋਗ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਕਾਲਮ ਅਸਲ ਗੁਣ ਦਰਸਾਉਂਦੇ ਹਨ (ਨ ਕਿ ਓਵਰਲੋਡ ਕੀਤੇ strings ਜਾਂ JSON blobs) ਅਤੇ constraints ਮੁੱਲਾਂ ਨੂੰ ਸਾਫ਼ ਰੱਖਦੀਆਂ ਹਨ।
ਇਸਨੂੰ ਇੱਕ ਵਰਕਫਲੋ ਬਣਾਓ, ਬਚਾ rescue ਮਿਸ਼ਨ ਨਾ ਬਣਾਓ
ਸਕੀਮਾ ਫੈਸਲਿਆਂ ਨੂੰ ਪਹਿਲੀ-ਸ਼੍ਰੇਣੀ ਇੰਜੀਨੀਅਰਿੰਗ ਮੰਨੋ:
- ਹਰ ਬਦਲਾਅ ਲਈ migrations ਵਰਤੋ, ਜਿਸ ਤਰ੍ਹਾਂ ਨੂੰ ਕੋਡ ਵਰਗਾ ਰਿਵਿਊ ਕੀਤਾ ਜਾਵੇ।
- ਨਵੇਂ endpoints ਲਈ ਹਲਕੀ-ਫੁੱਲਕੀ 'ਸਕੀਮਾ ਰਿਵਿਊ' ਸ਼ਾਮਲ ਕਰੋ: ਕਿਹੜੇ ਟੇਬਲ, ਕਿਹੜੀਆਂ ਕੁੰਜੀਆਂ, ਕਿਹੜੀਆਂ ਪਾਬੰਦੀਆਂ, ਅਤੇ ਕਿਹੜੀ ਕੁਏਰੀ ਸ਼ੇਪ।
- ਸਟੇਜਿੰਗ ਵਿੱਚ ORM ਕੁਏਰੀਆਂ ਲੌਗ ਕਰੋ ਅਤੇ N+1 ਪੈਟਰਨਾਂ ਨੂੰ ਪ੍ਰੋਡਕਸ਼ਨ ਤੋਂ ਪਹਿਲਾਂ ਫਲੈਗ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਚੈਟ-ਚਲਿਤ ਵਿਕਾਸ ਨਾਲ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਂਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ, React ਐਪ ਅਤੇ Go/PostgreSQL ਬੈਕਐਂਡ ਨੂੰ Koder.ai ਵਿੱਚ ਪੈਦਾ ਕਰਨਾ), ਤਾਂ 'ਸਕੀਮਾ ਰਿਵਿਊ' ਨੂੰ ਮੁਲਾਕਾਤ ਦੀ ਸ਼ੁਰੂਆਤ ਵਿੱਚ ਸ਼ਾਮਲ ਕਰਨਾ ਫਾਇਦੀਮੰਦ ਹੁੰਦਾ ਹੈ। ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਇਟਰੇਟ ਕਰ ਸਕਦੇ ਹੋ, ਪਰ ਤੁਹਾਨੂੰ fir_constraints, keys, ਅਤੇ migration ਯੋਜਨਾ ਸਾਵਧਾਨੀ ਨਾਲ ਰੱਖਣੀ ਚਾਹੀਦੀ ਹੈ—ਖ਼ਾਸ ਕਰਕੇ ਟ੍ਰੈਫਿਕ ਆਉਣ ਤੋਂ ਪਹਿਲਾਂ।
ਸ਼ੁਰੂਆਤੀ ਚੇਤਾਵਨੀ ਲੱਛਣ ਕਿ ਤੁਹਾਡਾ ਸਕੀਮਾ ਬੋਤਲ-ਨੇਕ ਹੈ
ਕੁਝ ਪ੍ਰਦਰਸ਼ਨ ਸਮੱਸਿਆਵਾਂ 'ਖਰਾਬ SQL' ਤੋਂ ਵੱਧ 'ਤੁਹਾਡਾ ਡੇਟਾ ਆਕਾਰ ਦੇ ਨਾਲ ਲੜਦਾ' ਹੋ ਸਕਦੀਆਂ ਹਨ। ਜੇ ਤੁਸੀਂ ਕਈ endpoints ਅਤੇ ਰਿਪੋਰਟਾਂ 'ਤੇ ਇੱਕੋ ਜਿਹੇ ਮੁੱਦੇ ਵੇਖਦੇ ਹੋ, ਤਾਂ ਇਹ ਅਕਸਰ ਸਕੀਮਾ ਦਾ ਇਸ਼ਾਰਾ ਹੁੰਦਾ ਹੈ, ਨਾ ਕਿ ਇੱਕ ਕੁਏਰੀ-ਟਿਊਨਿੰਗ ਮੌਕਾ।
ਆਮ ਲੱਛਣ ਜਿਨ੍ਹਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ
ਸਲੋ ਫਿਲਟਰ ਇੱਕ ਕਲਾਸਿਕ ਸੰਕੇਤ ਹੈ। ਜੇ ਸਧਾਰਨ ਸ਼ਰਤਾਂ ਜਿਵੇਂ 'ਕਸਟਮਰ ਦੁਆਰਾ ਆਰਡਰ ਲੱਭੋ' ਜਾਂ 'created date ਨਾਲ ਫਿਲਟਰ' ਲਗਾਤਾਰ ਸੁਸਤ ਹੋ ਰਹੀਆਂ ਹਨ, ਤਾਂ ਸਮੱਸਿਆ ਗਾਇਰ-ਰਿਸ਼ਤੇ, ਟਾਈਪ ਦੇ ਮਿਸਮੇਚ, ਜਾਂ ਐਸੀ ਕਾਲਮਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ ਜਿਨ੍ਹਾਂ ਨੂੰ ਪ੍ਰਭਾਵੀ ਤੌਰ 'ਤੇ ਇੰਡੈਕਸ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ।
ਹੋਰ ਲਾਲ ਝੰਡਾ joins ਦੀ ਗਿੰਡ ਵਧ ਜਾਣਾ ਹੈ: ਇੱਕ ਕੁਏਰੀ ਜੋ 2–3 ਟੇਬਲ join ਕਰ ਕੇ ਹੱਲ ਹੋ ਜਾਣੀ ਚਾਹੀਦੀ ਸੀ, ਉਹ 6–10 ਟੇਬਲ ਚੇਂਨ ਕਰਨ ਲੱਗਦੀ ਹੈ (ਅਕਸਰ over-normalized lookups, polymorphic patterns, ਜਾਂ 'ਸਭ ਕੁਝ ਇੱਕ ਟੇਬਲ' ਡિઝ਼ਾਈਨ ਕਾਰਨ)।
ਇਸਦੇ ਨਾਲ ਕਾਲਮਾਂ ਵਿੱਚ ਅਸਮਰਥ ਮੁੱਲ (ਜੋ enums ਵਾਂਗ ਵਰਤਿਆ ਜਾਣਾ) ਦਾ ਹੋਣਾ ਵੀ ਤੰਗ ਕਰਦਾ ਹੈ—ਖ਼ਾਸ ਕਰਕੇ status fields ('active', 'ACTIVE', 'enabled', 'on')। ਅਸਮਰਥਤਾ defensive ਕੁਏਰੀਆਂ (LOWER(), COALESCE(), OR-chains) ਨੂੰ ਜਨਮ ਦਿੰਦੀ ਹੈ ਜੋ ਕਿੰਨੇ ਵੀ ਟਿੂਨ ਕੀਤੇ ਜਾਂ, ਹਮੇਸ਼ਾ ਸਲੋ ਰਹਿੰਦੇ ਹਨ।
ਸਕੀਮਾ ਚੈੱਕਲਿਸਟ (ਤੇਜ਼ ਜਾਂਚ ਲਈ)
- ਫੋਰਿਨ ਕੀ ਤੇ ਗੈਰਮੌਜੂਦ ਇੰਡੈਕਸ (joins ਵੱਡੇ ਸਕੈਨ ਬਣ ਜਾਂਦੇ ਹਨ ਜਿਵੇਂ ਟੇਬਲ ਵੱਧਦੇ ਹਨ)।
- ਗਲਤ ਡੇਟਾ ਟਾਈਪ (ਉਦਾਹਰਨ, IDs ਨੂੰ strings ਵਜੋਂ ਸਟੋਰ ਕਰਨਾ, dates ਨੂੰ text, ਪੈਸਾ ਨੂੰ floats)។
- EAV ਟੇਬਲਾਂ (Entity–Attribute–Value) ਨੂੰ ਕੋਰ ਡੇਟਾ ਲਈ ਵਰਤਣਾ: ਸ਼ੁਰੂ ਵਿੱਚ ਲਚਕੀਲਾ, ਪਰ ਫਿਲਟਰ/ਸੋਰਟ ਕਈ joins ਅਤੇ ਘੱਟ-ਇੰਡੈਕਸਯੋਗ predicates ਵਿੱਚ ਤਬਦੀਲ ਹੋ ਜਾਂਦੇ ਹਨ।
ਸਧਾਰਨ, ਟੂਲ-ਅਗਨੋਸਟਿਕ ਨਿਧਾਨ
ਸਮਝ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਹਰ ਟੇਬਲ ਲਈ row counts, ਅਤੇ ਮੁੱਖ ਕਾਲਮਾਂ ਲਈ cardinality (ਕਿੰਨੇ ਵਿਭਿੰਨ ਮੁੱਲ)। ਜੇ ਇੱਕ 'status' ਕਾਲਮ ਤੋਂ ਉਮੀਦ ਕੀਤੀ 4 ਮੁੱਲ ਹਨ ਪਰ ਤੁਹਾਨੂੰ 40 ਮਿਲਦੇ ਹਨ, ਤਾਂ ਸਕੀਮਾ ਪਹਿਲਾਂ ਹੀ ਜਟਿਲਤਾ ਲੀਕ ਕਰ ਰਿਹਾ ਹੈ।
ਫਿਰ ਆਪਣੇ ਸਲੋ endpoints ਲਈ ਕੁਏਰੀ ਪਲਾਨ ਵੇਖੋ। ਜੇ ਤੁਸੀਂ ਵਾਰ-ਵਾਰ join ਕਾਲਮਾਂ 'ਤੇ sequential scans ਜਾਂ ਵੱਡੇ ਵਿਚਕਾਰਲੀ ਨਤੀਜੇ ਵੇਖਦੇ ਹੋ, ਤਾਂ ਸਕੀਮਾ ਅਤੇ ਇੰਡੈਕਸਿੰਗ ਸੰਭਵਤ: ਮੁੱਖ ਕਾਰਨ ਹਨ।
ਅਖੀਰ 'ਚ, slow query logs ਨੂੰ ਯੋਗ ਕਰੋ ਅਤੇ ਸਮੀਖਿਆ ਕਰੋ। ਜਦੋਂ ਕਈ ਵੱਖ-ਵੱਖ ਕੁਏਰੀਆਂ ਇਕੋ ਤਰ੍ਹਾਂ ਸਲੋ ਹੁੰਦੀਆਂ ਹਨ (ਉਹੀ ਟੇਬਲਾਂ, ਉਹੇ predicates), ਤਾਂ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਢਾਂਚਾਗਤ ਮੁੱਦਾ ਹੁੰਦਾ ਹੈ ਜੋ ਮਾਡਲ ਪੱਧਰ 'ਤੇ ਠੀਕ ਕਰਨ ਯੋਗ ਹੈ।
ਵਧਣ ਦੇ ਨਾਲ਼ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਸਕੀਮਾ ਈਵੋਲਵ ਕਰੋ
ਚੈਟ ਵਿੱਚ ਆਪਣੇ ਸਕੀਮਾ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਜਦੋਂ ਤੁਸੀਂ ਬਣਾਉਂਦੇ ਹੋ ਤਾਂ ਇਕ PostgreSQL ਸਕੀਮਾ ਬਣਾਓ—ਇਕਾਈਆਂ, ਕੁੰਜੀਆਂ ਅਤੇ ਪਾਬੰਦੀਆਂ ਨੂੰ ਚੈਟ ਵਿੱਚ ਰੂਪ ਦਿਓ।
ਸ਼ੁਰੂਆਤੀ ਸਕੀਮਾ ਚੋਣਾਂ ਆਮ ਤੌਰ 'ਤੇ ਸੱਚੇ ਯੂਜ਼ਰਾਂ ਨਾਲ ਪਹਿਲੀ ਮੁਲਾਕਾਤ ਬਾਅਦ ਜੀਵਿਤ ਨਹੀਂ ਰਹਿੰਦੀਆਂ। ਲਕਸ਼ perfection ਨਹੀਂ—ਇਹ ਉਦੱਸ਼ ਹੈ ਪ੍ਰੋਡਕਸ਼ਨ ਨੂੰ ਤੋੜਣ, ਡੇਟਾ ਖੋਣ ਜਾਂ ਟੀਮ ਨੂੰ ਹਫ਼ਤੇ ਲਈ ਫ੍ਰੀਜ਼ ਕਰਨ ਬਿਨਾਂ ਬਦਲਾਉ ਕਰਨਾ।
ਇੱਕ ਹਲਕੀ, ਦੁਹਰਾਯੋਗ ਬਦਲਾਅ ਪ੍ਰਕਿਰਿਆ
ਇੱਕ ਵਿਹਾਰਿਕ ਵਰਕਫਲੋ ਜੋ ਇਕਲੌਤਾ-ਵਿਕਾਸ ਕਾਰਜ ਤੋਂ ਵੱਡੀ ਟੀਮ ਤੱਕ ਸਕੇਲ ਕਰਦਾ ਹੈ:
- Model: ਨਵੀਂ ਰੂਪ-ਰੇਖਾ ਲਿਖੋ (ਟੇਬਲ/ਕਾਲਮ, ਰਿਸ਼ਤੇ, ਅਤੇ ਸੱਚਾਈ ਦਾ ਸਰੋਤ)। ਉਦਾਹਰਣ ਰਿਕਾਰਡ ਅਤੇ edge-cases ਸ਼ਾਮਲ ਕਰੋ।
- Migrate: ਨਵੀਂ ਰਚਨਾ ਬੈਕਵਰਡ-ਕੰਪੈਟਿਬਲ ਤਰੀਕੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ (ਪਹਿਲਾਂ ਨਵੇਂ ਕਾਲਮ/ਟੇਬਲ ਜੋੜੋ; turਣੀ ਤੌਰ ਤੇ ਹਟਾਉਣਾ ਜਾਂ rename ਤੁਰੰਤ ਨਾ ਕਰੋ)।
- Backfill: ਮੌਜੂਦਾ ਡੇਟਾ ਤੋਂ ਨਵੇਂ ਫੀਲਡ ਭਰੋ, ਬੈਚਾਂ ਵਿੱਚ। ਪ੍ਰਗਟਿ ਨੂੰ ਟਰੈਕ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਫੇਰ ਰੀਜ਼ਿਊਮ ਕਰ ਸਕੋ।
- Validate: ਡੇਟਾ ਸਾਫ਼ ਹੋਣ ਤੋਂ ਬਾਅਦ ਹੀ constraints ਜੋੜੋ (ਉਦਾਹਰਨ, NOT NULL, foreign keys)। ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ ਆਉਟਪੁੱਟ ਦੀ ਤੁਲਨਾ ਕਰਨ ਵਾਲੇ ਚੈੱਕ ਚਲਾਓ।
ਫੀਚਰ ਫਲੈਗ ਅਤੇ ਡੁਅਲ-ਰਾਇਟ (ਸਾਵਧਾਨੀ ਨਾਲ ਵਰਤੋ)
ਜਿਆਦਾਤਰ ਸਕੀਮਾ ਬਦਲਾਅ ਨੂੰ ਜ਼ਰੂਰੀ ਨਹੀਂ ਕਿ복잡 ਰੋਲਆਉਟ ਪੈਟਰਨਾਂ ਦੀ ਲੋੜ ਹੋਵੇ। 'expand-and-contract' ਪਹੁੰਚ ਨੂੰ ਤਰਜੀਹ ਦਿਓ: ਐਸਾ ਕੋਡ ਲਿਖੋ ਜੋ ਦੋਹਾਂ ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ ਰੂਪ ਨੂੰ ਪੜ੍ਹ ਸਕੇ, ਫਿਰ ਜਦ ਤੱਕ ਤੁਸੀਂ ਨਿਰਭਰ ਨਹੀਂ ਹੋ, ਲਿਖਤਾਂ ਨੂੰ ਸਵਿੱਚ ਨਾ ਕਰੋ।
ਫੀਚਰ ਫਲੈਗ ਜਾਂ ਡੁਅਲ ਲਿਖਤ ਸਿਰਫ਼ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਵਰਤੋ ਜਦੋਂ ਤੁਹਾਨੂੰ ਅਸਲ ਵਿੱਚ ਗਰੈਜਵਾਲ ਰੋਲਆਉਟ ਦੀ ਲੋੜ ਹੋਵੇ (ਉੱਚ ਟ੍ਰੈਫਿਕ, ਲੰਮੇ ਬੈਕਫਿਲਜ਼, ਜਾਂ ਕਈ ਸੇਵਾ-ਕਾਰਜ)। ਜੇ ਤੁਸੀਂ ਡੁਅਲ-ਰਾਇਟ ਕਰਦੇ ਹੋ, ਤਾਂ ਡ੍ਰਿਫਟ ਨੂੰ ਪਛਾਣਣ ਲਈ ਮਾਨੀਟਰਨਿੰਗ ਜੋੜੋ ਅਤੇ ਟਕਰਾਅ ਵਿੱਚ ਕਿਹੜਾ ਪਾਸਾ ਜਿੱਤੇਗਾ ਇੱਕ ਨਿਯਮ ਬਣਾ ਕਰੋ।
ਰੋਲਬੈਕ ਅਤੇ ਮਾਈਗ੍ਰੇਸ਼ਨ ਟੈਸਟ ਜੋ ਹਕੀਕਤ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ
ਸੁਰੱਖਿਅਤ ਰੋਲਬੈਕ ਉਨ੍ਹਾਂ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੇ ਹਨ ਜੋ ਉਲਟ-ਯੋਗ ਹਨ। 'Undo' ਰਸਤਾ ਅਭਿਆਸ ਕਰੋ: ਇੱਕ ਨਵਾਂ ਕਾਲਮ ਡ੍ਰੌਪ ਕਰਨਾ ਆਸਾਨ ਹੈ; ਓਵਰਰਾਈਟ ਡੇਟਾ ਮੁੜ ਪ੍ਰਾਪਤ ਕਰਨਾ ਨਹੀਂ।
ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਨੂੰ ਹਕੀਕਤੀ ਡੇਟਾ ਅਮਾਊਂਟਾਂ 'ਤੇ ਟੈਸਟ ਕਰੋ। ਜੋ ਮਾਈਗ੍ਰੇਸ਼ਨ ਲੈਪਟਾਪ ਉੱਤੇ 2 ਸਕਿੰਟ ਵਿੱਚ ਖਤਮ ਹੁੰਦੀ ਹੈ, ਉਹ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਮਿੰਟਾਂ ਲਈ ਟੇਬਲਾਂ ਨੂੰ ਲੌਕ ਕਰ ਸਕਦੀ ਹੈ। ਪ੍ਰੋਡਕਸ਼ਨ-ਜੈਸਾ row counts ਅਤੇ ਇੰਡੈਕਸਾਂ ਨਾਲ ਟੈਸਟ ਕਰੋ ਅਤੇ ਰਨਟਾਈਮ ਦੀ ਮਾਪ ਕਰੋ।
ਇਹ ਉਹ ਐਸਾ ਸਥਾਨ ਹੈ ਜਿੱਥੇ ਪਲੇਟਫਾਰਮ ਟੂਲਿੰਗ ਖਤਰੇ ਘਟਾ ਸਕਦੀ ਹੈ: ਭਰੋਸੇਯੋਗ ਤੈਨਾਤੀ, ਸਨੈਪਸ਼ਾਟ/ਰੋਲਬੈਕ ਸਮਰੱਥਾ (ਅਤੇ ਲੋੜ ਪੈਣ 'ਤੇ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰਨ ਦੀ ਯੋਗਤਾ) ਹੋਣ ਨਾਲ ਸਕੀਮਾ ਅਤੇ ਐਪ ਲਾਜਿਕ ਨੂੰ ਇਕੱਠੇ ਇਟਰੇਟ ਕਰਨਾ ਸੁਰੱਖਿਅਤ ਬਣਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ ਜਦੋਂ ਤੁਸੀਂ ਅਜਿਹੀਆਂ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਲਿਆਉਣ ਵਾਲੇ ਹੋ ਜਿਨ੍ਹਾਂ ਨੂੰ ਧਿਆਨ ਨਾਲ ਲੜਨਾ ਪਵੇ, ਤਾਂ snapshots ਅਤੇ planning mode ਤੇ ਭਰੋਸਾ ਕਰੋ।
ਭਵਿੱਖ ਲਈ ਫੈਸਲਿਆਂ ਦਾ ਦਸਤਾਵੇਜ਼ ਰੱਖੋ (ਭਵਿੱਖ ਦਾ ਤੁਹਾਡਾ ਖੁਦ)
ਇੱਕ ਛੋਟਾ ਸਕੀਮਾ ਲੌਗ ਰੱਖੋ: ਕੀ ਬਦਲਿਆ, ਕਿਉਂ, ਅਤੇ ਕਿਹੜੇ ਸੌਦਿਆਂ ਨੂੰ ਮਨਜ਼ੂਰ ਕੀਤਾ ਗਿਆ। ਇਸ ਨੂੰ /docs ਜਾਂ ਆਪਣੇ ਰੇਪੋ README ਨਾਲ ਲਿੰਕ ਕਰੋ। ਐਸੀਆਂ ਨੋਟਾਂ ਸ਼ਾਮਲ ਕਰੋ ਜਿਵੇਂ 'ਇਹ ਕਾਲਮ ਇਰਾਦਤ ਨਾਲ ਡੀ-ਨਾਰਮਲਾਈਜ਼ ਕੀਤਾ ਗਿਆ ਹੈ' ਜਾਂ 'ਫੋਰਿਨ ਕੀ 2025-01-10 ਨੂੰ ਬੈਕਫਿਲ ਤੋਂ ਬਾਅਦ ਜੋੜੀ ਗਈ' ਤਾਂ ਕਿ ਭਵਿੱਖ ਦੇ ਬਦਲਾਅ ਉਹੀ ਸੋਚ ਦੁਹਰਾਉਣ ਨਾ ਕਰਨ।
ਕਦੋਂ ਕੁਏਰੀਆਂ ਨੂੰ optimize ਕਰੋ (ਅਤੇ ਤਰਤੀਬ)
ਕੁਏਰੀ ਸੁਧਾਰ ਮਹੱਤਵਪੂਰਣ ਹੈ—ਪਰ ਇਹ ਉਸ ਸਮੇਂ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡਾ ਸਕੀਮਾ ਤੁਹਾਡੇ ਨਾਲ ਲੜਾਈ ਨਾ ਕਰ ਰਿਹਾ ਹੋਵੇ। ਜੇ ਟੇਬਲਾਂ ਨੂੰ ਸਪਸ਼ਟ ਕੀਜ਼ ਨਹੀਂ ਮਿਲ ਰਹੀਆਂ, ਰਿਸ਼ਤੇ inconsistent ਹਨ, ਜਾਂ 'ਇੱਕ ਰੋ ਕਦਮ' ਨੀਤੀ ਲੰਘ ਰਹੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਘੰਟਿਆਂ ਕੁਏਰੀ ਟਿਊਨਿੰਗ 'ਤੇ ਖਰਚ ਕਰ ਸਕਦੇ ਹੋ ਜਿਸ ਨੂੰ ਅਗਲੇ ਹਫ਼ਤੇ ਮੁੜ ਲਿਖਨਾ ਪਵੇਗਾ।
ਇੱਕ ਵਿਹਾਰਿਕ ਤਰਜੀਹੀ ਕ੍ਰਮ
-
ਸਕੀਮਾ ਬਲਾਕਰਾਂ ਨੂੰ ਪਹਿਲਾਂ ਠੀਕ ਕਰੋ। ਉਹ ਸਾਰੇ ਚੀਜ਼ਾਂ ਫਿਕਸ ਕਰੋ ਜੋ ਸਹੀ ਕੁਏਰੀ ਨੂੰ ਮੁਸ਼ਕਲ ਬਣਾਉਂਦੀਆਂ ਹਨ: ਗੁੰਮ ਪ੍ਰਾਈਮਰੀ ਕੀਜ਼, inconsistent ਫੋਰਿਨ ਕੀਜ਼, ਕਾਲਮ ਜੋ ਕਈ ਅਰਥ ਮਿਲਾਉਂਦੇ ਹਨ, ਨਕਲ ਸਰੋਤ, ਜਾਂ ਟਾਈਪ ਜੋ ਹਕੀਕਤ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ (ਉਦਾਹਰਨ, dates strings ਵਜੋਂ)।
-
ਪਹੁੰਚ ਪੈਟਰਨ ਨੂੰ ਸਥਿਰ ਕਰੋ। ਜਦੋਂ ਡੇਟਾ ਮਾਡਲ ਐਪ ਦੇ ਵਰਤਾਰੇ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ (ਅਤੇ ਅਗਲੇ ਕੁਝ ਸਪ੍ਰਿੰਟਾਂ ਲਈ ਸੰਭਵਤ: ਐਸਾ ਹੀ ਰਹੇਗਾ), ਕੁਏਰੀ ਟਿਊਨਿੰਗ ਮਜ਼ਬੂਤ ਅਤੇ ਟਿਕਾਊ ਬਣਦੀ ਹੈ।
-
ਟੌਪ ਕੁਏਰੀਆਂ ਨੂੰ optimize ਕਰੋ—ਸਭ ਕੁਏਰੀਆਂ ਨੂੰ ਨਹੀਂ। logs/APM ਤੋਂ sabse slow ਅਤੇ frequency ਵਾਲੀਆਂ ਕੁਏਰੀਆਂ ਪਛਾਣੋ। ਦਿਨ ਵਿੱਚ 10,000 ਵਾਰ ਹੱਟ ਹੋਣ ਵਾਲਾ ਇੱਕ endpoint ਅਕਸਰ ਇੱਕ ਦਰਸ਼ਨੀ admin ਰਿਪੋਰਟ ਨਾਲ ਤੁਲਨਾ ਵਿੱਚ ਜ਼ਿਆਦਾ ਮਹੱਤਵਪੂਰਣ ਹੁੰਦਾ ਹੈ।
ਸ਼ੁਰੂਆਤੀ ਕੁਏਰੀ ਟਿਊਨਿੰਗ ਦਾ 80/20
ਸ਼ੁਰੂਆਤੀ ਜਿੱਤਾਂ ਅਕਸਰ ਥੋੜੀਆਂ ਚਲਾਂ ਤੋਂ ਆਉਂਦੀਆਂ ਹਨ:
- ਸਹੀ ਇੰਡੈਕਸ ਜੋੜੋ ਤੁਹਾਡੇ ਸਭ ਤੋਂ ਆਮ ਫਿਲਟਰ ਅਤੇ joins ਲਈ (ਤੇ ਜਾਂਚੋ ਕਿ ਇਹ ਅਸਲ ਵਿੱਚ ਵਰਤਿਆ ਜਾ ਰਿਹਾ ਹੈ)।
- ਘੱਟ ਕਾਲਮ ਵਾਪਸ ਕਰੋ (
SELECT *ਤੋਂ ਬਚੋ, ਖ਼ਾਸ ਕਰਕੇ ਵਾਇਡ ਟੇਬਲਾਂ 'ਤੇ)। - ਫਾਲਤੂ joins ਨੂੰ ਟਾਲੋ—ਕਈ ਵਾਰੀ ਇੱਕ join ਸਿਰਫ ਇਸ ਲਈ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਸਕੀਮਾ ਤੁਹਾਨੂੰ 'ਮੁਢਲੀ' ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਦੀ ਖੋਜ ਕਰਨ ਲਈ ਮਜ਼ਬੂਰ ਕਰਦਾ ਹੈ।
ਉਮੀਦ ਰੱਖੋ: ਇਹ ਲਗਾਤਾਰ ਕੰਮ ਹੈ, ਪਰ ਬੁਨਿਆਦ ਪਹਿਲਾਂ ਆਉਂਦੀ ਹੈ
ਪ੍ਰਦਰਸ਼ਨ ਕੰਮ ਕਦੇ ਖ਼ਤਮ ਨਹੀਂ ਹੁੰਦਾ, ਪਰ ਲਕਸ਼ਯ ਇਹ ਹੈ ਕਿ ਇਸਨੂੰ ਭਵਿੱਖਦ੍ਰਿਸ਼ਟੀਯੋਗ ਬਣਾਇਆ ਜਾਵੇ। ਇੱਕ ਸਾਫ਼ ਸਕੀਮਾ ਹੋਣ ਨਾਲ, ਹਰ ਨਵਾਂ ਫੀਚਰ ਸ਼ਾਮਿਲਤਾ ਬ੍ਹੜੀ ਬੋਝ ਨਾ ਬਣਾਉਂਦਾ; ਇੱਕ ਗਡ਼ਬੜ ਸਕੀਮਾ ਹੋਣ ਨਾਲ, ਹਰ ਫੀਚਰ ਇੱਕ ਜਟਿਲਤਾ ਵਿੱਚ ਦਬਦਾ ਚਲਾ ਜਾਂਦਾ ਹੈ।
ਇਸ ਹਫ਼ਤੇ ਲਈ ਚੈੱਕਲਿਸਟ
- ਸੂਚੀ ਬਣਾਓ ਟਾਪ 5 ਸਭ ਤੋਂ ਸਲੋ ਅਤੇ ਟਾਪ 5 ਸਭ ਤੋਂ ਅਕਸਰ ਚਲੀਆਂ ਕੁਏਰੀਆਂ ਦੀ।
- ਹਰ ਇੱਕ ਲਈ ਪੁਸ਼ਟੀ ਕਰੋ: primary key ਮੌਜੂਦ ਹੈ, joins key-to-key ਹਨ, ਅਤੇ ਟਾਈਪ ਸਹੀ ਹਨ।
- ਇੱਕ ਐਸਾ ਇੰਡੈਕਸ ਸ਼ਾਮਲ ਕਰੋ ਜੋ ਮੁੱਖ ਫਿਲਟਰ/ਆਰਡਰ ਨਾਲ ਮਿਲਦਾ ਹੋਵੇ।
- ਇੱਕ ਹਾਟ ਪਾਥ ਵਿੱਚ
SELECT *ਨੂੰ ਬਦਲੋ। - ਮੁੜ-ਮਾਪੋ ਅਤੇ ਅਗਲੇ ਸਪ੍ਰਿੰਟ ਲਈ ਇੱਕ ਸਧਾਰਨ 'ਪਹਿਲਾਂ/ਬਾਅਦ' ਨੋਟ ਰੱਖੋ।