29 ਅਪ੍ਰੈ 2025·8 ਮਿੰਟ
ਇੱਕ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ ਜੋ SLA ਅਨੁਕੂਲਤਾ ਨੂੰ ਸਹੀ ਢੰਗ ਨਾਲ ਟਰੈਕ ਕਰੇ
ਸਿੱਖੋ ਕਿ ਇਕ ਐਸਾ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਇਆ ਜਾਵੇ ਜੋ SLA ਅਨੁਕੂਲਤਾ ਟਰੈਕ ਕਰੇ: ਮੈਟਰਿਕ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਇਵੈਂਟ ਇਕੱਠੇ ਕਰੋ, ਨਤੀਜੇ ਗਣਨਾ ਕਰੋ, ਬ੍ਰੀਚਾਂ 'ਤੇ ਅਲਰਟ ਕਰੋ, ਅਤੇ ਸਹੀ ਰਿਪੋਰਟ ਦਿਓ।
ਸਿੱਖੋ ਕਿ ਇਕ ਐਸਾ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਇਆ ਜਾਵੇ ਜੋ SLA ਅਨੁਕੂਲਤਾ ਟਰੈਕ ਕਰੇ: ਮੈਟਰਿਕ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਇਵੈਂਟ ਇਕੱਠੇ ਕਰੋ, ਨਤੀਜੇ ਗਣਨਾ ਕਰੋ, ਬ੍ਰੀਚਾਂ 'ਤੇ ਅਲਰਟ ਕਰੋ, ਅਤੇ ਸਹੀ ਰਿਪੋਰਟ ਦਿਓ।
SLA ਅਨੁਕੂਲਤਾ ਦਾ ਮਤਲਬ ਹੈ ਉਹ ਮਾਪਣਯੋਗ ਵਾਅਦੇ ਜੋ ਇੱਕ Service Level Agreement (SLA) ਵਿੱਚ ਦਿੱਤੇ ਜਾਂਦੇ ਹਨ—ਇੱਕ ਪ੍ਰਦਾਤਾ ਅਤੇ ਗਾਹਕ ਦਰਮਿਆਨ ਦਾ ਠੇਕਾ। ਤੁਹਾਡੀ ਐਪ ਦਾ ਕੰਮ ਸਬੂਤ ਦੇ ਕੇ ਇੱਕ ਸਧਾਰਨ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦੇਣਾ ਹੈ: ਕੀ ਅਸੀਂ ਇਸ ਗਾਹਕ ਲਈ, ਇਸ ਸਮੇਂ ਦੀ ਮਿਆਦ ਵਿੱਚ, ਜੋ ਵਾਅਦਾ ਕੀਤਾ ਸੀ ਉਹ ਪੂਰਾ ਕੀਤਾ?
ਇਹ ਤਿੰਨ ਸਬੰਧਤ ਸ਼ਬਦਾਂ ਨੂੰ ਵੱਖ ਕਰਕੇ ਸੋਚਣਾ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ:
ਜ਼ਿਆਦਾਤਰ SLA ਟਰੈਕਿੰਗ ਵੈੱਬ ਐਪਾਂ ਇੱਕ ਛੋਟੀ ਸੈਟ ਤੋਂ ਸ਼ੁਰੂ ਹੁੰਦੀਆਂ ਹਨ ਜੋ ਵਾਸਤਵਿਕ ਓਪਰੇਸ਼ਨਲ ਡੇਟਾ ਨਾਲ ਮਿਲਦੀਆਂ ਹਨ:
ਵੱਖ-ਵੱਖ ਯੂਜ਼ਰ ਇਕੋ ਸੱਚਾਈ ਨੂੰ ਵੱਖ ਢੰਗ ਨਾਲ ਦੇਖਣਾ ਚਾਹੁੰਦੇ ਹਨ:
ਇਹ ਉਤਪਾਦ ਟ੍ਰੈਕ ਕਰਨ, ਸਬੂਤ ਜਮ੍ਹਾਂ ਕਰਨ, ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਬਾਰੇ ਹੈ: ਸਿਗਨਲ ਇਕੱਠੇ ਕਰਨਾ, ਸਹਿਮਤ ਨਿਯਮ ਲਗਾਉਣਾ, ਅਤੇ ਆਡਿਟ-ਯੋਗ ਨਤੀਜੇ ਬਣਾਉਣਾ। ਇਹ ਪ੍ਰਦਰਸ਼ਨ ਦੀ ਗਾਰੰਟੀ ਨਹੀਂ ਦਿੰਦਾ; ਇਹ ਉਸਨੂੰ ਮਾਪਦਾ ਹੈ—ਸਹੀ, ਲਗਾਤਾਰ, ਅਤੇ ਇਸ ਤਰ੍ਹਾਂ ਕਿ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਇਹ ਬਚਾਅ ਕਰ ਸਕੋ।
ਟੇਬਲਾਂ ਡਿਜ਼ਾਈਨ ਜਾਂ ਕੋਡ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ, ਤੁਹਾਡੇ ਲਈ यह ਬਹੁਤ ਜ਼ਰੂਰੀ ਹੈ ਕਿ ਤੁਸੀਂ ਬਿਲਕੁਲ ਸਪੱਸ਼ਟ ਹੋ ਜਾਓ ਕਿ "compliance" ਤੁਹਾਡੇ ਕਾਰੋਬਾਰ ਲਈ ਕੀ ਮਤਲਬ ਰੱਖਦੀ ਹੈ। ਜ਼ਿਆਦਾਤਰ SLA ਟਰੈਕਿੰਗ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਤਕਨੀਕੀ ਨਹੀਂ—ਇਹ requirements ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਹੁੰਦੀਆਂ ਹਨ।
ਅਰੰਭ ਵਿੱਚ ਸਚਾਈ ਦੇ ਸਰੋਤ ਇਕੱਠੇ ਕਰੋ:
ਇਨ੍ਹਾਂ ਨੂੰ ਸਪੱਸ਼ਟ ਨਿਯਮਾਂ ਵਜੋਂ ਲਿਖੋ। ਜੇ ਕੋਈ ਨਿਯਮ ਸਪੱਸ਼ਟ ਤੌਰ ਤੇ ਨਹੀਂ ਦੱਸਿਆ ਜਾ ਸਕਦਾ, ਤਾਂ ਉਹ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਗਣਨਾ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ।
ਹਕੀਕਤੀ "ਚੀਜ਼ਾਂ" ਦੀ ਸੂਚੀ ਬਣਾਓ ਜੋ SLA ਨੰਬਰ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾ ਸਕਦੀਆਂ ਹਨ:
ਇਸਦੇ ਨਾਲ ਹੀ ਪਛਾਨੋ ਕਿ ਕੌਣ-ਕੌਣ ਕੀ ਲੋੜ ਰੱਖਦਾ ਹੈ: support ਨੂੰ real-time breach risk ਚਾਹੀਦਾ ਹੈ, ਮੈਨੇਜਰਜ਼ ਨੂੰ weekly rollups, ਗਾਹਕਾਂ ਨੂੰ ਸਧਾਰਨ ਸੰਖੇਪ (ਅਕਸਰ status page ਲਈ)।
ਦਾਇਰਾ ਛੋਟਾ ਰੱਖੋ। ਘੱਟੋ-ਘੱਟ ਸੈੱਟ ਚੁਣੋ ਜੋ ਸਿਸਟਮ ਨੂੰ end-to-end ਸਾਬਤ ਕਰੇ, ਉਦਾਹਰਨ ਲਈ:
ਇੱਕ ਸਫੇ ਦੀ ਚੈੱਕਲਿਸਟ ਬਣਾਓ ਜੋ ਤੁਸੀਂ ਬਾਦ ਵਿੱਚ ਟੈਸਟ ਕਰ ਸਕੋ:
ਸਫਲਤਾ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਦੇਖੋ: ਦੋ ਲੋਕ ਇੱਕ ਨਮੂਨਾ ਮਹੀਨਾ ਹੱਥ ਨਾਲ ਗਣਨਾ ਕਰਨ ਅਤੇ ਤੁਹਾਡੀ ਐਪ ਉਸਨੂੰ ਬਿਲਕੁਲ ਮੇਲ ਖਾਂਦੀ ਹੋਵੇ।
ਇੱਕ ਸਹੀ SLA ਟਰੈਕਰ ਇੱਕ ਡੇਟਾ ਮਾਡਲ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ ਜੋ ਇਹ ਵਿਆਖਿਆ ਕਰ ਸਕੇ ਕਿ ਇੱਕ ਨੰਬਰ ਕਿਉਂ ਹੈ ਜੋ ਇਹ ਹੈ। ਜੇ ਤੁਸੀਂ ਮਹੀਨਾਵਾਰ availability ਆਂਕੜੇ ਨੂੰ ਉਸ ਦੇ ਬਿਲਕੁਲ ਸਪੱਸ਼ਟ events ਅਤੇ ਨਿਯਮਾਂ ਤੱਕ ਨਹੀਂ ਟ੍ਰੇਸ ਕਰ ਸਕਦੇ, ਤਾਂ ਗਾਹਕ ਵਿਵਾਦ ਅਤੇ ਅੰਦਰੂਨੀ ਅਣਿਸ਼ਚਿਤਤਾ ਨਾਲ ਜੂਝਣਾ ਪਵੇਗਾ।
ਘੱਟੋ-ਘੱਟ ਇਹਨਾਂ ਨੂੰ ਮਾਡਲ ਕਰੋ:
ਇੱਕ ਲਾਭਦਾਇਕ ਸੰਬੰਧ ਹੈ: customer → service → SLA policy (ਜੋ plan ਰਾਹੀਂ ਵੀ ਹੋ ਸਕਦਾ ਹੈ). Incidents ਅਤੇ events ਫਿਰ service ਅਤੇ customer ਨੂੰ reference ਕਰਦੇ ਹਨ।
ਟਾਈਮ ਬਗਸ ਸਭ ਤੋਂ ਵੱਧ ਗਲਤ SLA ਗਣਤੀ ਦੇ ਕਾਰਨ ਹਨ। ਸਟੋਰ ਕਰੋ:
occurred_at ਨੂੰ UTC ਵਜੋਂ (timestamp with timezone semantics)received_at (ਜਦ ਤੁਹਾਡਾ ਸਿਸਟਮ ਇਸਨੂੰ ਵੇਖਿਆ)source (monitor name, integration, manual)external_id (retry ਨੂੰ dedupe ਕਰਨ ਲਈ)payload (ਭਵਿੱਖੀ debugging ਲਈ raw JSON)ਗਾਹਕ ਦਾ customer.timezone (IANA string ਜਿਵੇਂ America/New_York) ਦਿਖਾਵੇ ਅਤੇ ਕਾਰੋਬਾਰੀ ਘੰਟਿਆਂ ਲਈ ਰੱਖੋ, ਪਰ ਇਵੈਂਟ ਸਮੇਂ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣ ਲਈ ਇਸਦੀ ਵਰਤੋਂ ਨਾ ਕਰੋ।
ਜੇ response-time SLA ਕਾਰੋਬਾਰੀ ਘੰਟਿਆਂ ਤੋਂ ਬਾਹਰ ਰੁਕ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਕੈਲੰਡਰਾਂ ਨੂੰ ਸਪੱਸ਼ਟ ਤੌਰ 'ਤੇ ਮਾਡਲ ਕਰੋ:
working_hours ਪ੍ਰਤੀ ਗਾਹਕ (ਜਾਂ ਪ੍ਰਤੀ ਖੇਤਰ/ਸੇਵਾ): ਹਫ਼ਤੇ ਦੇ ਦਿਨ + ਸ਼ੁਰੂ/ਅੰਤ ਸਮਾਂholiday_calendar ਖੇਤਰ ਜਾਂ ਗਾਹਕ ਨਾਲ ਜੁੜਿਆ, ਤਾਰੀਖ ਰੇਂਜ ਅਤੇ ਲੇਬਲਾਂ ਸਮੇਤਨਿਯਮ ਡੇਟਾ-ਡ੍ਰਿਵਨ ਰੱਖੋ ਤਾਂ ਕਿ ops ਇੱਕ holiday ਨੂੰ deploy ਬਿਨਾਂ ਅਪਡੇਟ ਕਰ ਸਕਣ।
Raw events ਨੂੰ append-only ਟੇਬਲ ਵਿੱਚ ਰੱਖੋ, ਅਤੇ calculated results ਨੂੰ ਅਲੱਗ ਸਟੋਰ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ sla_period_result). ਹਰ result row ਵਿੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਪੀਰੀਅਡ ਸੀਮਾਵਾਂ, inputs ਵਰਜ਼ਨ (policy version + engine version), ਅਤੇ ਉਹ event IDs ਜੋ ਵਰਤੇ ਗਏ। ਇਸ ਨਾਲ recomputation ਸੁਰੱਖਿਅਤ ਬਣਦੀ ਹੈ ਅਤੇ ਜਦ ਗਾਹਕ ਪੁੱਛੇ, “ਕਿਹੜੇ outage ਮਿੰਟ ਤੁਸੀ ਗਿਣੇ?” ਤਾਂ ਤੁਸੀਂ ਜਵਾਬ ਦੇ ਸਕੋਗੇ।
ਤੁਹਾਡੇ SLA ਨੰਬਰ ਉਨਾਂ events 'ਤੇ ਨਿਰਭਰ ਹਨ ਜੋ ਤੁਸੀਂ ਇਨਜੇਸਟ ਕਰਦੇ ਹੋ। ਲਕੜੀ ਦਾ ਲਕੜੀ-ਮੁੱਢਲਾ ਉਦਦੇਸ਼ ਸਿੱਧਾ ਹੈ: ਹਰ ਉਸ ਬਦਲਾਅ ਨੂੰ ਕੈਪਚਰ ਕਰੋ ਜੋ ਮਾਇਨੇ ਰੱਖਦਾ ਹੈ (ਇਕ outage ਸ਼ੁਰੂ ਹੋਇਆ, incident acknowledged ਹੋਇਆ, ਸੇਵਾ ਰੀਸਟੋਰ ਹੋਈ) ਸਥਿਰ timestamps ਅਤੇ ਕਾਫੀ ਸੰਦਰਭ ਦੇ ਨਾਲ ਤਾਂ ਜੋ ਬਾਅਦ ਵਿੱਚ compliance ਗਣਨਾ ਹੋ ਸਕੇ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਮਿਲੀ-ਜੁਲੀ ਸਿਸਟਮਾਂ ਤੋਂ ਖਿੱਚ ਲਾਉਂਦੀਆਂ ਹਨ:
Webhooks ਆਮ ਤੌਰ 'ਤੇ real-time ਸਹੀਤਾ ਅਤੇ ਘੱਟ ਲੋਡ ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ ਹੁੰਦੇ ਹਨ: source ਸਿਸਟਮ ਤੁਹਾਡੇ endpoint 'ਤੇ events push ਕਰਦਾ ਹੈ।
Polling ਉਹ fallback ਹੈ ਜਦ webhooks ਉਪਲਬਧ ਨਹੀਂ: ਤੁਹਾਡੀ ਐਪ ਸਮੇਂ-ਸਮੇਂ ਤੇ last cursor ਤੋਂ ਬਦਲਾਅ ਖਿੱਚਦੀ ਹੈ। ਤੁਹਾਨੂੰ rate-limit ਹੈਂਡਲਿੰਗ ਅਤੇ "since" ਲੋਜਿਕ ਦੀ ਧਿਆਨ ਰੱਖਣੀ ਪਏਗੀ।
CSV import backfills ਅਤੇ migrations ਲਈ ਮਦਦਗਾਰ ਹੈ। ਇਸਨੂੰ ਇੱਕ first-class ingestion path ਮੰਨੋ ਤਾਂ ਜੋ ਤੁਸੀਂ historical ਪੀਰੀਅਡਾਂ ਨੂੰ ਬਿਨਾਂ hacks ਦੇ reprocess ਕਰ ਸਕੋ।
ਪ upstream payload ਵੱਖ ਹੋਣ ਦੇ ਬਾਵਜੂਦ ਸਭ ਕੁਝ ਇੱਕ ਇਕਮੱਤ internal "event" ਸ਼ੇਪ ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ:
event_id (ਲਾਜ਼ਮੀ): ਇੱਕ ਵਿਲੱਖਣ ਅਤੇ ਸਥਿਰ ID retries ਦੌਰਾਨ. ਸਰੋਤ ਦਾ GUID ਵੀਰੀਅਸ ਕਰੋ ਜਾਂ deterministic hash ਬਣਾਓ।source (ਲਾਜ਼ਮੀ): ਉਦਾਹਰਨ datadog, servicenow, manual.event_type (ਲਾਜ਼ਮੀ): ਉਦਾਹਰਨ incident_opened, incident_acknowledged, service_down, service_up.occurred_at (ਲਾਜ਼ਮੀ): ਸਮਾਂ ਜਦ ਘਟਨਾ ਹੋਈ (ਜਦ ਤੁਹਾਨੂੰ ਮਿਲੀ ਨਹੀਂ), ਟਾਈਮਜ਼ੋਨ ਸਮੇਤ.received_at (ਸਿਸਟਮ): ਜਦ ਤੁਹਾਡੇ ਐਪ ਨੇ ਇਸਨੂੰ ਇਨਜੇਸਟ ਕੀਤਾ.service_id (ਲਾਜ਼ਮੀ): ਉਹ SLA-ਸਬੰਧਤ ਸਰਵਿਸ ਜਿਸ 'ਤੇ ਇਹ ਪ੍ਰਭਾਵੀ ਹੈ.incident_id (ਵੈਕਲਪਿਕ ਪਰ ਅਨੁਸ਼ਾਸਨਯੋਗ): ਕਈ events ਨੂੰ ਇੱਕ incident ਨਾਲ ਜੋੜਦਾ ਹੈ.attributes (ਵੈਕਲਪਿਕ): priority, region, customer segment ਆਦਿ.event_id 'ਤੇ unique constraint ਲਗਾਓ ਤਾਂ ਜੋ ingestion idempotent ਬਣ ਜਾਵੇ: retries duplicates ਨਹੀਂ ਪੈਦਾ ਕਰਨਗੇ।
ਉਹ events reject ਜਾਂ quarantine ਕਰੋ ਜੋ:
occurred_at ਭਵਿੱਖ ਵਿੱਚ ਬਹੁਤ ਅੱਗੇ ਹੋਵੇservice_id ਨਾਲ ਮੇਪ ਨਾ ਹੁੰਦੇ (ਜਾਂ explicit “unmapped” workflow ਦੀ ਲੋੜ ਹੋ)event_id ਨੂੰ duplicate ਕਰਦੇ ਹਨਇਹ ਆਗੇ ਹੀ ਡਿਸਿਪਲਿਨ ਤੁਹਾਨੂੰ SLA ਰਿਪੋਰਟਾਂ 'ਤੇ ਬਾਅਦ ਵਿੱਚ ਤਰਕ ਕਰਨ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ—ਕਿਉਂਕਿ ਤੁਸੀਂ ਸਾਫ਼, ਟ੍ਰੇਸਬਲ ਇਨਪੁੱਟਸ ਨੂੰ ਦਰਸਾ ਸਕੋਗੇ।
ਤੁਹਾਡਾ ਕੈਲਕੁਲੇਸ਼ਨ ਇੰਜਿਨ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ "ਐਰਾ ਰਾ events" SLA ਨਤੀਜਿਆਂ ਵਿੱਚ ਬਦਲਦੇ ਹਨ ਜੋ ਤੁਸੀਂ ਬਚਾ ਸਕਦੇ ਹੋ। ਸੰਖੇਪ ਇਹ ਹੈ: ਇਸਨੂੰ accounting ਵਾਂਗੋ ਜਿਓ—ਨਿਯਤ ਨਿਯਮ, ਸਪੱਸ਼ਟ ਇਨਪੁੱਟ, ਅਤੇ replayable trail.
ਸਭ ਕੁਝ ਇੱਕ Ordered stream ਵਿੱਚ ਰੂਪਾਂਤਰਿਤ ਕਰੋ ਪ੍ਰਤੀ incident (ਜਾਂ ਪ੍ਰਤੀ service-impact):
ਇਸ ਟਾਈਮਲਾਈਨ ਤੋਂ, ਅੰਤਰਾਲਾਂ ਨੂੰ ਜੋੜ ਕੇ ਗਣਨਾ ਕਰੋ, ਨਾ ਕਿ ਬੇਵਕੂਫੀ ਨਾਲ ਦੋ timestamps ਨੂੰ ਘਟਾ ਕੇ।
TTFR ਨੂੰ incident_start ਅਤੇ first_agent_response (ਜਾਂ acknowledged, SLA wording ਅਨੁਸਾਰ) ਦਰਮਿਆਨ ਦਾ chargeable ਸਮਾਂ ਮੰਨੋ। TTR ਨੂੰ incident_start ਅਤੇ resolved ਦਰਮਿਆਨ ਦਾ chargeable ਸਮਾਂ।
"Chargeable" ਦਾ ਮਤਲਬ ਉਹ ਅੰਤਰਾਲ ਹਟਾਉਣਾ ਹੈ ਜੋ ਗਿਣੇ ਨਹੀਂ ਜਾਣੇ:
Implementation detail: ਇੱਕ calendar function (business hours, holidays) ਅਤੇ rule function ਰੱਖੋ ਜੋ ਇੱਕ timeline ਲੈਂਦਾ ਅਤੇ billable intervals ਵਾਪਸ ਕਰਦਾ ਹੈ।
ਪਹਿਲਾਂ ਨਿਰਧਾਰਨ ਕਰੋ ਕਿ ਤੁਹਾਡੀ ਗਣਨਾ:
Partial outages ਵਿੱਚ, impact ਦੇ ਅਨੁਸਾਰ weight ਕਰੋ ਸਿਰਫ ਜੇ ਤੁਹਾਡਾ SLA contract ਇਸ ਦੀ ਮੰਗ ਕਰਦਾ ਹੈ; ਨਹੀਂ ਤਾਂ "degraded" ਨੂੰ ਇੱਕ ਵੱਖਰਾ breach ਸ਼੍ਰੇਣੀ ਵਜੋਂ ਸਮਝੋ।
ਹਰੇਕ ਕੈਲਕੁਲੇਸ਼ਨ ਨੂੰ ਦੁਹਰਾਉਣਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਸਨੂੰ persist ਕਰੋ:
ਜਦ ਨਿਯਮ ਬਦਲਦੇ ਹਨ, ਤੁਸੀਂ ਵਰਜਨ ਅਨੁਸਾਰ calculations ਦੁਬਾਰਾ ਚਲਾ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਇਤਿਹਾਸ ਨੂੰ ਲਿਖਤ ਕਰਨ—ਆਡਿਟ ਅਤੇ ਗਾਹਕ ਵਿਵਾਦਾਂ ਲਈ ਇਹ ਅਤਿ-ਰੋਜ਼ਮਰਾ ਹੈ।
ਰਿਪੋਰਟਿੰਗ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ SLA ਟਰੈਕਿੰਗ ਭਰੋਸਾ ਕਮਾਉਂਦੀ ਹੈ—ਜਾਂ ਸ਼ੱਕ ਦਾ ਵਿਸ਼ਾ ਬਣ ਜਾਂਦੀ ਹੈ। ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਸਾਫ਼ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਕਿਹੜੀ ਸਮੇਂ ਦੀ ਮਿਆਦ ਮਾਪੀ ਜਾ ਰਹੀ ਹੈ, ਕਿਹੜੇ ਮਿੰਟ ਗਿਣੇ ਜਾ ਰਹੇ ਹਨ, ਅਤੇ ਆਖਰੀ ਨੰਬਰ ਕਿਵੇਂ ਬਣਾਇਆ ਗਿਆ।
ਉਹ ਆਮ ਰਿਪੋਰਟਿੰਗ ਪੀਰੀਅਡਾਂ ਨੂੰ ਸਮਰਥਨ ਕਰੋ ਜੋ ਗਾਹਕ ਅਸਲ ਵਿੱਚ ਵਰਤਦੇ ਹਨ:
ਪੀਰੀਅਡਾਂ ਨੂੰ explicit start/end timestamps ਵਜੋਂ ਸਟੋਰ ਕਰੋ ("month = 3" ਨਹੀਂ) ਤਾਂ ਜੋ ਤੁਸੀਂ ਰੀਪਲੇ calculations ਬਾਅਦ ਵਿਚ ਕਰ ਸਕੋ ਅਤੇ ਨਤੀਜਿਆਂ ਦੀ ਵਿਆਖਿਆ ਦੇ ਸਕੋ।
ਹੁੱਕ ਹੀ ਇੱਕ ਗਲਤੀ ਇਹ ਹੈ ਕਿ denominator ਪੂਰੇ ਪੀਰੀਅਡ ਨੂੰ ਲਿਆ ਗਿਆ ਕਿ ਕੇਵਲ “eligible” ਸਮਾਂ।
ਹਰ ਪੀਰੀਅਡ ਲਈ ਦੋ ਮੁੱਲ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ:
ਫਿਰ ਕੈਲਕੁਲੇਟ ਕਰੋ:
availability_percent = 100 * (eligible_minutes - downtime_minutes) / eligible_minutes
ਜੇ eligible minutes ਸਿਫ਼ਰ ਹੋ ਸਕਦੇ ਹਨ (ਉਦਾਹਰਨ: ਇੱਕ ਸੇਵਾ ਜੋ ਸਿਰਫ ਕਾਰੋਬਾਰੀ ਘੰਟਿਆਂ ਵਿੱਚ ਮਾਨੀਟਰ ਕੀਤੀ ਜਾਂਦੀ ਹੈ ਅਤੇ ਪੀਰੀਅਡ ਵਿੱਚ ਕੋਈ ਘੰਟੇ ਨਹੀਂ), ਤਾਂ ਪਹਿਲਾਂ ਨੀਤੀ ਨਿਰਧਾਰਤ ਕਰੋ: ਜਾਂ “N/A” ਦਿਖਾਓ ਜਾਂ 100% ਮੰਨੋ—ਪਰ ਲਗਾਤਾਰ ਹੋਵੋ ਅਤੇ ਦਸਤਾਵੇਜ਼ ਕਰੋ।
ਜ਼ਿਆਦਾਤਰ SLAs ਨੂੰ ਪ੍ਰਤੀਸ਼ਤ ਅਤੇ ਬਾਈਨਰੀ ਨਤੀਜੇ ਦੋਹਾਂ ਚਾਹੀਦੇ ਹਨ।
ਡੈਸ਼ਬੋਰਡ ਲਈ “distance to breach” (ਬਚਿਆ downtime budget) ਵੀ ਰੱਖੋ ਤਾਂ ਕਿ ਚੇਤਾਵਨੀ ਦਿੱਤੀ ਜਾ ਸਕੇ ਪਹਿਲਾਂ ਹੀ ਸੀਮਾ ਭਰੋਣ ਤੋਂ ਪਹਿਲਾਂ।
customer ਦੀ), ਅਤੇ events ਨੂੰ ਲਗਾਤਾਰ ਤਰੀਕੇ ਨਾਲ ਕਨਵਰਟ ਕਰੋ।ਅੰਤ ਵਿੱਚ, raw inputs (include/exclude events ਅਤੇ adjustments) ਰੱਖੋ ਤਾਂ ਕਿ ਹਰ ਰਿਪੋਰਟ ਸਪੱਸ਼ਟ ਜਵਾਬ ਦੇ ਸਕੇ: “ਇਹ ਨੰਬਰ ਕਿਉਂ ਹੈ?” ਬਿਨਾਂ ਹੱਥ ਨਾਲ ਜਵਾਬ ਦਿੱਤੇ।
ਤੁਹਾਡਾ calculation engine ਭਲੀ-ਭਾਂਤੀ ਹੋ ਸਕਦਾ ਹੈ ਅਤੇ ਫਿਰ ਵੀ ਯੂਜ਼ਰ ਫੇਲ ਹੋ ਜਾ ਸਕਦਾ ਹੈ ਜੇ UI ਬੁਨਿਆਦੀ ਸਵਾਲ ਦਾ ਤੁਰੰਤ ਜਵਾਬ ਨਹੀਂ ਦਿੰਦੀ: “ਕੀ ਅਸੀਂ ਹੁਣ SLA ਪੂਰਾ ਕਰ ਰਹੇ ਹਾਂ, ਅਤੇ ਕਿਉਂ?” ਹਰ ਸਕਰੀਨ ਨੂੰ ਇਸ ਤਰੀਕੇ ਨਾਲ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਹਰ ਸਕਰੀਨ ਇੱਕ ਸਪੱਸ਼ਟ ਸਥਿਤੀ ਨਾਲ ਸ਼ੁਰੂ ਹੋਵੇ, ਫਿਰ ਲੋਕ ਨੰਬਰਾਂ ਅਤੇ ਉਹ ਰਾ events ਦੇਖ ਸਕਣ ਜੋ ਉਨ੍ਹਾਂ ਨੂੰ ਬਣਾਏ।
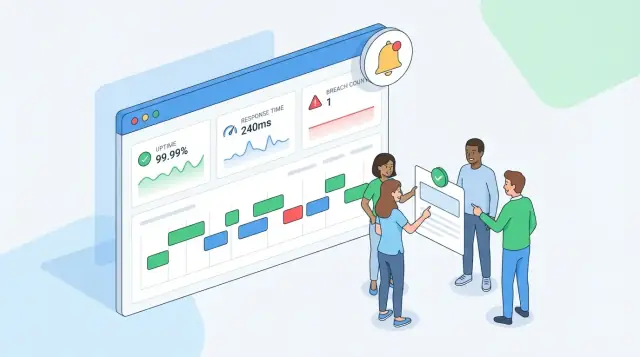
Overview dashboard (operators ਅਤੇ managers ਲਈ). ਛੋਟੇ ਟਾਇਲਾਂ ਨਾਲ ਅਗਵਾਈ ਕਰੋ: ਮੌਜੂਦਾ ਪੀਰੀਅਡ compliance, availability, response-time compliance, ਅਤੇ “ਬ੍ਰੀਚ ਤੋਂ ਬਚਿਆ ਸਮਾਂ” ਜਿੱਥੇ ਲਾਗੂ ਹੋਵੇ। ਲੇਬਲ ਸਪੱਸ਼ਟ ਰੱਖੋ (ਉਦਾਹਰਨ: “Availability (this month)” ਬਜਾਏ “Uptime”). ਜੇ ਤੁਸੀਂ ਇੱਕ ਗਾਹਕ ਲਈ ਕਈ SLA ਸਪੋਰਟ ਕਰਦੇ ਹੋ, ਸਭ ਤੋਂ ਖਰਾਬ ਸਥਿਤੀ ਪਹਿਲਾਂ ਦਿਖਾਓ ਅਤੇ ਵਿਸਥਾਰ ਲਈ ਖੋਲ੍ਹਣ ਦਿਓ।
Customer detail (account teams ਅਤੇ customer-facing reporting ਲਈ). ਗਾਹਕ ਪੇਜ ਸਾਰੀਆਂ ਸਰਵਿਸਜ਼ ਅਤੇ SLA ਟੀਅਰਾਂ ਦਾ ਸੰਖੇਪ ਦੇਵੇ, ਸਧਾਰਾ pass/warn/fail ਸਥਿਤੀ ਅਤੇ ਇੱਕ ਛੋਟਾ ਸ਼ਬਦੀ ਕਾਰਨ ("2 incidents counted; 18m downtime counted") ਨਾਲ। /status (ਜੇ ਤੁਸੀਂ customer-facing status page ਦਿੰਦੇ ਹੋ) ਅਤੇ report export ਲਈ ਲਿੰਕ ਜੋੜੋ।
Service detail (ਗਹਿਰਾਈ ਲਈ). ਇੱਥੇ ਤੁਸੀਂ ਠੀਕ SLA ਨਿਯਮ, ਕੈਲਕੁਲੇਸ਼ਨ ਖਿੜਕੀ, ਅਤੇ ਕਿਵੇਂ compliance ਨੰਬਰ ਬਣਾਏ ਗਏ ਦਾ ਵਿਭਾਜਨ ਦਿਖਾਓ। availability ਦਾ ਚਾਰਟ ਅਤੇ SLA ਵਿੱਚ ਗਿਣੇ گئے incidents ਦੀ ਲਿਸਟ ਸ਼ਾਮਲ ਕਰੋ।
Incident timeline (ਆਡਿਟ ਲਈ). ਇੱਕ incident view timeline ਦਿਖਾਏ (detected, acknowledged, mitigated, resolved) ਅਤੇ ਕਿਹੜੇ timestamps "response" ਅਤੇ "resolution" ਮੈਟ੍ਰਿਕਸ ਲਈ ਵਰਤੇ ਗਏ।
ਹਰ ਸਕਰੀਨ 'ਤੇ filters consistent ਰੱਖੋ: date range, customer, service, tier, ਅਤੇ severity। ਹਰ ਜਗ੍ਹਾ ਇੱਕੋ ਇਕਾਈ ਵਰਤੋ (minutes vs seconds; percentages ਇੱਕੋ decimals). ਜਦ ਯੂਜ਼ਰ date range ਬਦਲਦੇ ਹਨ, ਪੰਨੇ ਦੇ ਸਾਰੇ ਮੈਟ੍ਰਿਕ ਅਪਡੇਟ ਕਰੋ ਤਾਂ ਕਿ ਕੋਈ mismatch ਨਾ ਹੋਵੇ।
ਹਰ summary metric ਨੂੰ ਇੱਕ "Why?" ਰਾਹ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
ਟੂਲਟਿਪ्स ਕਾਬੂ ਨਾਲ ਵਰਤੋ term դիտਾਂ ਜਿਵੇਂ “Excluded downtime” ਜਾਂ “Business hours” ਨੂੰ define ਕਰਨ ਲਈ, ਅਤੇ ਸਰਵਿਸ ਪੇਜ 'ਤੇ ਨਿਯਮ ਦਾ exact ਪਾਠ ਦਿਖਾਓ ਤਾਂ ਕਿ ਲੋਕ ਅਨੁਮਾਨ ਨਾ ਲਗਾਉਣ।
ਸੰਕੁਚਿਤ ਭਾਸ਼ਾ ਨੂੰ ਤਰਜੀਹ ਦਿਓ ("Response time" ਬਜਾਏ "MTTA" ਜਦ ਤੱਕ ਤੁਹਾਡੀ audience ਇਹ ਦੀ ਉਮੀਦ ਨਹੀਂ ਕਰਦੀ). ਸਥਿਤੀ ਲਈ ਰੰਗ ਦੇ ਨਾਲ-ਨਾਲ text labels ਵੀ ਦਿਖਾਓ ("At risk: 92% of error budget used") ਤਾਂ ਕਿ ਅਸਪਸ਼ਟਤਾ ਨਾ ਰਹੇ। ਜੇ ਤੁਹਾਡੀ ਐਪ audit logs ਸਮਰਥਨ ਕਰਦੀ ਹੈ, SLA ਨਿਯਮਾਂ ਅਤੇ exclusions 'ਤੇ ਇੱਕ ਛੋਟੀ "Last changed" ਬਕਸਾ ਜੋੜੋ ਜਿਸ ਵਿੱਚ /audit ਲਈ ਰੇਫਰੈਂਸ ਹੋਵੇ ਤਾਂ ਯੂਜ਼ਰ ਵੇਰੀਫਾਈ ਕਰ ਸਕਣ ਕਿ ਨਿਯਮ ਕਦੋਂ ਬਦਲੇ।
ਅਲਰਟਿੰਗ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਤੁਹਾਡੀ SLA ਟਰੈਕਿੰਗ ਵੈੱਬ ਐਪ ਪੈਸੀਵ ਰਿਪੋਰਟ ਤੋਂ ਬਾਹਰ ਆ ਕੇ ਟੀਮਾਂ ਨੂੰ ਸਜ਼ਾ ਤੋਂ ਬਚਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ। ਸਭ ਤੋਂ ਵਧੀਆ ਅਲਰਟ ਤਤਕਾਲ, ਨਿਰਦੇਸ਼ਕ, ਅਤੇ ਕਾਰਵਾਈਯੋਗ ਹੁੰਦੇ ਹਨ—ਮਤਲਬ ਉਹ ਦੱਸਦੇ ਹਨ ਕਿ ਅਗਲਾ ਕਦਮ ਕੀ ਹੈ, ਨਾ ਕਿ ਕੇਵਲ "ਬੁਰੀ ਹਾਲਤ" ਹੈ।
ਤਿੰਨ ਟਰਿੱਗਰ ਪ੍ਰਕਾਰਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
Triggers ਨੂੰ per customer/service/SLA অনুসਾਰ ਕਨਫਿਗਰ ਕਰਨਯੋਗ ਰੱਖੋ, ਕਿਉਂਕਿ ਵੱਖ-ਵੱਖ contracts ਵੱਖ thresholds ਨੂੰ ਬਰਦਾਸ਼ਤ ਕਰਦੇ ਹਨ।
ਅਲਰਟ ਭੇਜੋ ਜਿੱਥੇ ਲੋਕ ਅਸਲ ਵਿੱਚ ਜਵਾਬ ਦਿੰਦੇ ਹਨ:
ਹਰੇਕ ਅਲਰਟ ਵਿੱਚ ਡੀਪ ਲਿੰਕਾਂ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ ਜਿਵੇਂ /alerts, /customers/{id}, /services/{id}, ਅਤੇ incident ਜਾਂ event detail page ਤਾਂ ਜੋ responders ਨੰਬਰਾਂ ਨੂੰ ਜਲਦੀ ਵੇਰੀਫਾਈ ਕਰ ਸਕਣ।
Deduplication ਲਾਗੂ ਕਰੋ by grouping alerts with the same key (customer + service + SLA + period) ਅਤੇ repeats ਨੂੰ cooldown window ਦੌਰਾਨ suppress ਕਰੋ।
Quiet hours (ਟੀਮ ਦੇ ਟਾਈਮਜ਼ੋਨ ਪ੍ਰਤੀ) ਜੋੜੋ ਤਾਂ ਕਿ non-critical “approaching breach” alerts ਕਾਰੋਬਾਰੀ ਘੰਟਿਆਂ ਤੱਕ ਰੁਕੇ ਰਹਿਣ, ਜਦਕਿ “breach occurred” ਉੱਚ ਗੰਭੀਰਤਾ ਹੋਣ 'ਤੇ quiet hours override ਕਰ ਸਕਦੀ ਹੈ।
ਅੰਤ ਵਿੱਚ, escalation rules ਸਮਰਥਨ ਕਰੋ (ਉਦਾਹਰਨ: 10 ਮਿੰਟ ਬਾਅਦ on-call notify ਕਰੋ, 30 ਮਿੰਟ ਬਾਅਦ manager ਤੱਕ escalate) ਤਾਂ ਕਿ alerts ਇੱਕ ਇਨਬੌਕਸ ਵਿੱਚ ਫਸ ਕੇ ਰੁਕ ਨਾ ਜਾਣ।
SLA ਡੇਟਾ ਸਵੇਤਨਸ਼ੀਲ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਅੰਦਰੂਨੀ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਗਾਹਕ-ਨਿਰਧਾਰਤ entitlements ਨੂੰ ਦਰਸਾ ਸਕਦਾ ਹੈ। ਐਕਸੇਸ ਕੰਟਰੋਲ ਨੂੰ SLA "ਮੈਥ" ਦਾ ਹਿੱਸਾ ਸਮਝੋ: ਇੱਕੋ incident ਵੱਖ-ਵੱਖ ਗਾਹਕਾਂ ਲਈ ਵੱਖ ਨਤੀਜੇ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ ਜੇ ਵੱਖ SLA ਲਾਗੂ ਕੀਤੇ ਜਾਣ।
ਰੋਲ ਸਧੇਰੇ ਰੱਖੋ, ਫਿਰ ਬਹੁਤ-ਨੁਕਤ ਦਰਜੇ ਦੀਆਂ ਅਨੁਮਤੀਆਂ ਤੇ ਫੈਲਾਓ:
RBAC + tenant scoping ਲਈ ਇੱਕ ਵਿਅਵਹਾਰਕ ਡੀਫੌਲਟ ਹੈ:
ਗਾਹਕ-ਖ਼ਾਸ ਡੇਟਾ ਬਾਰੇ explicit ਰਹੋ:
ਸ਼ੁਰੂਆਤ email/password ਨਾਲ ਕਰੋ ਅਤੇ internal roles ਲਈ MFA ਲਾਜ਼ਮੀ ਕਰੋ। ਬਾਅਦ ਵਿੱਚ SSO (SAML/OIDC) ਲਈ ਯੋਜਨਾ ਬਣਾਓ, identity (ਉਹ ਕੌਣ ਹੈ) ਨੂੰ authorization (ਉਹ ਕੀ ਕਰ ਸਕਦਾ ਹੈ) ਤੋਂ ਅਲੱਗ ਰੱਖ ਕੇ। ਇੰਟੀਗ੍ਰੇਸ਼ਨਾਂ ਲਈ, narrow-scoped API keys ਜਾਰੀ ਕਰੋ ਜਿਸ ਵਿੱਚ ਰੋਟੇਸ਼ਨ ਸਹਿਯੋਗ ਹੋਵੇ।
ਨਿਮਨਲਿਖਤ ਲਈ immutable audit entries ਸ਼ਾਮਲ ਕਰੋ:
Who, what changed (before/after), when, where (IP/user agent), ਅਤੇ correlation ID ਸਟੋਰ ਕਰੋ। ਆਡਿਟ ਲੌਗ searchable ਅਤੇ exportable ਬਣਾਓ (ਉਦਾਹਰਨ: /settings/audit-log)।
ਇੱਕ SLA ਟਰੈਕਿੰਗ ਐਪ ਅਕਸਰ ਇਕ ਇਕਾਂਤ ਵਿੱਚ ਨਹੀਂ ਹੁੰਦੀ। ਤੁਸੀਂ ਇੰਝ API ਚਾਹੁੰਦੇ ਹੋ ਜੋ ਮਾਨਟਰਿੰਗ ਟੂਲ, ਟਿਕਟਿੰਗ ਸਿਸਟਮ, ਅਤੇ ਅੰਦਰੂਨੀ ਵਰਕਫਲੋਜ਼ ਨੂੰ incidents ਬਣਾਉਣ, events push ਕਰਨ, ਅਤੇ ਰਿਪੋਰਟ ਆਕਸਿਸ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਏ।
ਵਰਜ਼ਨਯਾਦਾਰ base path ਵਰਤੋ (ਉਦਾਹਰਨ /api/v1/...) ਤਾਂ ਕਿ ਤੁਸੀਂ payloads ਨੂੰ ਬਿਨਾਂ existing integrations ਤੋੜੇ ਵਿਕਸਤ ਕਰ ਸਕੋ।
ਜ਼ਰੂਰੀ endpoints ਜੋ ਜ਼ਿਆਦਾਤਰ ਕੇਸ ਕਵਰ ਕਰਦੇ ਹਨ:
POST /api/v1/events state changes ਇਨਜੇਸਟ ਕਰਨ ਲਈ (up/down, latency samples, maintenance windows). GET /api/v1/events audits ਅਤੇ debugging ਲਈ।POST /api/v1/incidents, PATCH /api/v1/incidents/{id} (acknowledge, resolve, assign), GET /api/v1/incidents.GET /api/v1/slas, POST /api/v1/slas, PUT /api/v1/slas/{id} contracts ਅਤੇ thresholds manage ਕਰਨ ਲਈ।GET /api/v1/reports/sla?service_id=...&from=...&to=... compliance summaries ਲਈ।POST /api/v1/alerts/subscriptions webhook/email targets manage ਕਰਨ ਲਈ; GET /api/v1/alerts alert history ਲਈ।ਇਕ convention ਚੁਣੋ ਅਤੇ ਹਰ ਜਗ੍ਹਾ ਵਰਤੋ। ਉਦਾਹਰਨ ਲਈ: limit, cursor pagination, ਨਾਲ ਹੀ standard filters ਜਿਵੇਂ service_id, sla_id, status, from, ਅਤੇ to. sorting predictable ਰੱਖੋ (ਉਦਾਹਰਨ: sort=-created_at).
ਸੰਰਚਿਤ errors ਵਾਪਸ ਕਰੋ जिनमें stable fields ਹੋਣ:
{ "error": { "code": "VALIDATION_ERROR", "message": "service_id is required", "fields": { "service_id": "missing" } } }
ਸਾਫ਼ HTTP statuses ਵਰਤੋ (400 validation, 401/403 auth, 404 not found, 409 conflict, 429 rate limit). ਇਵੈਂਟ ingestion ਲਈ idempotency (Idempotency-Key) ਬਾਰੇ ਸੋਚੋ ਤਾਂ retries incidents ਨੂੰ duplicate ਨਾ ਕਰਨ।
ਹਰ token ਤੇ reasonable rate limits ਲਗਾਓ (ਅਤੇ ingestion endpoints ਲਈ ਸਖਤ limits), inputs sanitize ਕਰੋ, ਅਤੇ timestamps/time zones validate ਕਰੋ। scoped API tokens (read-only reporting vs. write access to incidents) ਤਰਜੀਹ ਦਿਓ, ਅਤੇ ਕਿਸ ਨੇ ਕਿਹੜਾ endpoint ਕਾਲ ਕੀਤਾ ਇਹ ਲੌਗ ਕਰੋ (ਜੋ ਤੁਸੀਂ audit log ਸੈਕਸ਼ਨ ਵਿੱਚ ਦੱਸਦੇ ਹੋ)।
SLA ਨੰਬਰ ਸਿਰਫ਼ ਲਾਭਕਾਰੀ ਹਨ ਜੇ ਲੋਕ ਉਨ੍ਹਾਂ 'ਤੇ ਭਰੋਸਾ ਕਰਨ। SLA ਟਰੈਕਿੰਗ ਐਪ ਲਈ ਟੈਸਟਿੰਗ ਦਾ ਧਿਆਨ "ਪੰਨਾ ਲੋਡ ਹੁੰਦਾ ਹੈ" ਤੋਂ ਘੱਟ ਅਤੇ "ਨਿਯਮਾਂ अनुसार time math ਸਹੀ ਹੈ" 'ਤੇ ਵੱਧ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਆਪਣੀ calculation rules ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਫੀਚਰ ਵਾਂਗ ਟੈਸਟ ਸੂਟ ਨਾਲ ਬTreat ਕਰੋ।
ਆਰੰਭ ਕਰੋ unit tests ਨਾਲ ਜੋ SLA calculation engine ਨੂੰ deterministic inputs ਦੇਕੇ ਚਲਾਉਂਦੇ ਹਨ: events ਦੀ ਇੱਕ timeline (incident opened, acknowledged, mitigated, resolved) ਅਤੇ ਇੱਕ ਸਪੱਸ਼ਟ SLA rule set।
ਅਪਣੇ tests ਨੂੰ "freeze time" ਨਾਲ ਚਲਾਓ ਤਾਂ ਕਿ tests ਘੜੀ 'ਤੇ ਨਿਰਭਰ ਨਾ ਕਰਨ। edge cases cover ਕਰੋ ਜੋ ਅਕਸਰ SLA ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਤੋੜਦੇ ਹਨ:
ਇੱਕ ਛੋਟਾ set end-to-end tests ਸ਼ਾਮਲ ਕਰੋ ਜੋ ਪੂਰੇ flow ਨੂੰ ਚਲਾਉਂਦੇ ਹਨ: ingest events → calculate compliance → generate report → render UI. ਇਹ ਉਸ ਤਰ੍ਹਾਂ ਦੇ mismatches ਪਕੜਦੇ ਹਨ ਜੋ "engine ਨੇ ਕੀ ਕਿਹਾ" ਅਤੇ "ਡੈਸ਼ਬੋਰਡ ਕੀ ਦਿਖਾ ਰਿਹਾ" ਵਿੱਚ ਹੋ ਸਕਦੇ ਹਨ। ਘਟ ਕੇਸਾਂ ਨੂੰ ਘੱਟ ਪਰ high-value scenarios ਰੱਖੋ, ਅਤੇ ਅੰਤੀਮ ਨੰਬਰਾਂ 'ਤੇ assert ਕਰੋ (availability %, breach yes/no, time-to-ack)।
business hours, holidays, ਅਤੇ time zones ਲਈ test fixtures ਬਣਾਓ। ਤੁਸੀਂ repeatable cases ਚਾਹੁੰਦੇ ਹੋ ਜਿਵੇਂ "incident Friday 17:55 local time" ਅਤੇ "holiday response time counting shifted"।
ਟੈਸਟ deploy 'ਤੇ ਹੀ ਨਹੀਂ ਰੁਕਦੇ। ਜਾਬ failures, queue/backlog size, recalculation duration, ਅਤੇ error rates ਲਈ ਮਾਨੀਟਰਿੰਗ ਜੋੜੋ। ਜੇ ingestion ਲੈਟ ਹੋ ਜਾਂ nightly job fail ਹੋਵੇ, ਤਾਂ ਤੁਹਾਡੀ SLA ਰਿਪੋਰਟ ਗਲਤ ਹੋ ਸਕਦੀ ਹੈ ਭਾਵੇਂ ਕੋਡ ਸਹੀ ਹੋਵੇ।
SLA ਟਰੈਕਿੰਗ ਐਪ ਨੂੰ ਸ਼ਿਪ ਕਰਨਾ ਸ਼ਾਨਦਾਰ ਇੰਫਰਾਸਟਰਕਚਰ ਦੇ ਬਾਰੇ ਘੱਟ ਹੈ ਅਤੇ ਭਰੋਸੇਯੋਗ ਓਪਰੇਸ਼ਨ ਬਾਰੇ ਜ਼ਿਆਦਾ: ਤੁਹਾਡੀਆਂ ਗਣਨਾਵਾਂ ਸਮੇਤ ਚੱਲਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ, ਡੇਟਾ ਸੁਰੱਖਿਅਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਅਤੇ ਰਿਪੋਰਟਾਂ ਦੁਹਰਾਉਣਯੋਗ ਹੋਣ।
ਮੈਨੇਜਡ ਸਰਵਿਸਜ਼ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ correctness 'ਤੇ ਧਿਆਨ ਦੇ ਸਕੋ:
Environments ਨੂੰ ਘੱਟ ਰੱਖੋ: dev → staging → prod, ਹਰ ਇੱਕ ਨਾਲ ਆਪਣਾ ਡੇਟਾਬੇਸ ਅਤੇ secrets।
SLA tracking purely request/response ਨਹੀਂ ਹੈ; ਇਹ scheduled ਕੰਮਾਂ 'ਤੇ ਨਿਰਭਰ ਹੈ।
Jobs ਨੂੰ worker process + queue ਦੁਆਰਾ ਚਲਾਓ, ਜਾਂ managed scheduler ਨਾਲ internal endpoints invoke ਕਰੋ। Jobs idempotent ਬਣਾਓ (retry-safe) ਅਤੇ ਹਰ ਇੱਕ run ਦਾ ਲੌਗ ਰੱਖੋ।
ਡੇਟਾ ਟਾਈਪ ਅਨੁਸਾਰ retention ਨਿਰਧਾਰਿਤ ਕਰੋ: derived compliance results ਨੂੰ raw event streams ਨਾਲੋਂ ਲੰਬਾ ਰੱਖੋ। exports ਲਈ ਪਹਿਲਾਂ CSV ਦਿਓ (ਤੇਜ਼, ਪਾਰਦਰਸ਼ੀ), ਫਿਰ PDF templates ਬਾਅਦ ਵਿੱਚ। ਸਪਸ਼ਟ ਰਹੋ: exports "best-effort formatting" ਹਨ, ਜਦੋਂ DB ਸੋਰਸ-ਆਫ-ਟ੍ਰੂਥ ਰਹੇਗਾ।
ਜੇ ਤੁਸੀਂ ਆਪਣਾ ਡੇਟਾ ਮਾਡਲ, ingestion flow, ਅਤੇ reporting UI ਜਲਦੀ validate ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗਾ vibe-coding ਪਲੇਟਫਾਰਮ ਤੁਹਾਨੂੰ end-to-end ਪ੍ਰੋਟੋਟਾਈਪ ਤੱਕ ਤੇਜ਼ੀ ਨਾਲ ਲੈ ਜਾ ਸਕਦਾ ਹੈ। Koder.ai ਚੈਟ ਰਾਹੀਂ ਪੂਰੇ ਐਪ (web UI ਨਾਲ-ਨਾਲ backend) ਜਨਰੇਟ ਕਰਦਾ ਹੈ, ਇਸ ਤਰ੍ਹਾਂ ਤੁਸੀਂ ਤੇਜ਼:
ਜਦ requirements ਅਤੇ calculations ਸਾਬਤ ਹੋ ਜਾਂਦੇ ਹਨ (ਹਾਰਡ ਹਿੱਸਾ), ਤੁਸੀਂ ਜਾਰੀ ਰੱਖ ਸਕਦੇ ਹੋ, source code export ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਇੱਕ ਆਮ build-and-operate workflow ਵਿੱਚ ਪਰਿਵਰਤਿਤ ਹੋ ਸਕਦੇ ਹੋ—ਤੇਜ਼ ਇਟਰੇਸ਼ਨ ਦੌਰਾਨ snapshots ਅਤੇ rollback ਵਰਗੀਆਂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਰਖਦਿਆਂ।
ਇੱਕ SLA ਟਰੈਕਰ ਇੱਕ ਸਵਾਲ ਦਾ ਸਬੂਤ-ਸਹਿਤ ਜਵਾਬ ਦਿੰਦਾ ਹੈ: ਕੀ ਤੁਸੀਂ ਕਿਸੇ ਖ਼ਾਸ ਗਾਹਕ ਅਤੇ ਸਮੇਂ ਦੀ ਮਿਆਦ ਲਈ ਠੇਕੇ ਵਿੱਚ ਦਿੱਤੇ ਗਏ ਵਾਅਦੇ ਪੂਰੇ ਕੀਤੇ?
ਅਮਲ ਵਿੱਚ ਇਹ ਮਤਲਬ ਹੈ ਕਿ ਰਾ ਸਿਗਨਲ (ਮਾਨਟਰਿੰਗ, ਟਿਕਟਸ, ਮੈਨੂਅਲ ਅਪਡੇਟ) ਗ੍ਰਹਿਣ ਕਰ ਕੇ, ਗਾਹਕ ਦੇ ਨਿਯਮ (ਕਾਰੋਬਾਰੀ ਘੰਟੇ, ਛੁਟੀਆਂ, ਹੋਰ ਬਿਜ਼ਨਸ-ਨਿਯਮ) ਲਾਗੂ ਕਰਕੇ, ਆਡਿਟ-ਯੋਗ ਪਾਸ/ਫੇਲ ਨਤੀਜਾ ਅਤੇ ਸਹਾਇਕ ਵੇਰਵਾ ਤਿਆਰ ਕਰਨਾ।
ਇਸ ਤਰ੍ਹਾਂ ਵਰਤੋ:
ਇਨ੍ਹਾ ਨੂੰ ਵੱਖ-ਵੱਖ ਮਾਡਲ ਕਰਨ ਨਾਲ ਤੁਸੀਂ ਸਥਿਰਤਾ ਹੁਣ ਕਰ ਸਕਦੇ ਹੋ (SLO) ਬਿਨਾਂ ਉਨ੍ਹਾਂ ਬਾਹਰੀ ਰਿਪੋਰਟਾਂ ਨੂੰ ਬਦਲੇ ਜੋ SLA ਦੇ ਤਹਿਤ ਹੋਣਗੇ।
ਮਜ਼ਬੂਤ MVP ਆਮ ਤੌਰ 'ਤੇ 1–3 ਮੈਟ੍ਰਿਕਸ end-to-end ਟਰੈਕ ਕਰਦਾ ਹੈ:
ਇਹ ਸਹੀ ਡੇਟਾ ਸੋਚਣ ਵਾਲੇ ਸਰੋਤਾਂ ਨਾਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਮਿਲਦੇ ਹਨ ਅਤੇ ਤੁਹਾਨੂੰ ਜ਼ਰੂਰੀ ਮੁਸ਼ਕਲਾਂ (ਪੀਰੀਅਡ, ਕੈਲੰਡਰ, ਖ਼ਾਸ ਛੁਟੀਆਂ) ਜਲਦੀ ਲਾਗੂ ਕਰਨ ਲਈ ਮਜਬੂਰ ਕਰਦੇ ਹਨ।
ਜਿਆਦਾਤਰ ਤਾਲਮੇਲ ਦੀਆਂ ਗਲਤੀਆਂ ਅਣਕਹੀਆਂ ਨਿਯਮਾਂ ਕਾਰਨ ਹੁੰਦੀਆਂ ਹਨ। ਇਕੱਠਾ ਕਰੋ ਅਤੇ ਲਿਖੋ:
ਜੇਕਰ ਕੋਈ ਨਿਯਮ ਸਪੱਸ਼ਟ ਤੌਰ ਤੇ ਨਹੀਂ ਲਿਖਿਆ ਜਾ ਸਕਦਾ, ਤਾਂ ਉਸਨੂੰ ਕੋਡ ਵਿੱਚ ਨਿਯਮ ਵਜੋਂ ਲਾਉਣਾ ਭਰੋਸੇਯੋਗ ਨਤੀਜੇ ਨਹੀਂ ਦੇਵੇਗਾ—ਸਪੱਸ਼ਟੀਕਰਨ ਲੈਓ।
ਸਧਾਰਨ, ਇੱਕ ਭਰੋਸੇਯੋਗ SLA ਟਰੈਕਰ ਲਈ ਨਿਮਨਲਿਖਤ ਏਂਟਿਟੀਆਂ ਲੋੜੀਂਦੀਆਂ ਹਨ:
ਮਕਸਦ traceability: ਹਰ ਰਿਪੋਰਟ ਕੀਤੇ ਨੰਬਰ ਨੂੰ ਵਿਸ਼ੇਸ਼ event IDs ਅਤੇ ਨੀਤੀ ਵਰਜਨ ਨਾਲ ਜੋੜ ਸਕਣਾ ਚਾਹੀਦਾ ਹੈ।
ਟਾਈਮ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਸਟੋਰ ਕਰੋ ਅਤੇ ਇੱਕ ਨਿਰਧਾਰਤ ਨੀਤੀ ਅਪਣਾਓ:
occurred_at ਨੂੰ UTC ਵਿੱਚ ਸਟੋਰ ਕਰੋreceived_at ਵੀ ਸਟੋਰ ਕਰੋ (ਤੁਹਾਡੇ ਸਿਸਟਮ ਨੇ ਕਦੋਂ ਲਿਆ)America/New_York ਵਰਗਾ) ਸਿਰਫ ਦਿਖਾਵੇ ਅਤੇ ਕਾਰੋਬਾਰੀ ਘੰਟਿਆਂ ਲਈ—ਇਵੈਂਟ ਸਮੇਂ ਨੂੰ ਦੁਬਾਰਾ ਨਹੀਂ ਲਿਖੋਫਿਰ ਪੀਰੀਅਡ explicit start/end timestamps ਰੱਖੋ ਤਾਂ ਜੋ ਤੁਹਾਡੀਆਂ ਰਿਪੋਰਟਾਂ ਦੁਬਾਰਾ ਚਲਾਈਆਂ ਜਾ ਸਕਣ—DST ਬਦਲਾਵ ਸਮੇਤ।
ਸਭ ਕੁਝ ਇੱਕ ਆੰਤਰਿਕ "event" ਸ਼ੇਪ ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ ਅਤੇ ਇੱਕ ਸਥਿਰ ਵਿਲੱਖਣ ID ਰੱਖੋ:
event_id (ਵਿਸ਼ਵਸਨੀਯ ਅਤੇ ਰੀਟ੍ਰਾਈਜ਼ ਦੇ ਦੌਰਾਨ ਸਥਿਰ)source, event_type, , ਟਾਈਮ-ਟੂ-ਫਰਸਟ-ਰਿਸਪਾਂਸ (TTFR) ਅਤੇ ਟਾਈਮ-ਟੂ-ਰਿਜ਼ੋਲਿਊਸ਼ਨ (TTR) ਨੂੰ chargeable ਅੰਤਰਾਲਾਂ ਦੇ ਜੋੜ ਕੇ ਕੈਲਕੁਲੇਟ ਕਰੋ—ਸਿਰਫ timestamps ਨੂੰ ਘਟਾ ਕੇ ਨਹੀਂ।
Chargeable ਵਿੱਚੋਂ ਹਟਾਓ:
Derived intervals ਅਤੇ ਕਾਰਨ ਕੋਡ ਸਟੋਰ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਿਆਨ ਕਰ ਸਕੋ ਕਿ ਕੀ ਗਿਣਿਆ ਗਿਆ ਅਤੇ ਕਿਉਂ।
ਦੋ ਅਲੱਗ ਗਿਨਤੀਆਂ ਰੱਖੋ:
ਫਿਰ ਗਣਨਾ ਕਰੋ:
availability_percent = 100 * (eligible_minutes - downtime_minutes) / eligible_minutes
ਜੇ eligible minutes ਸ਼ੂਨ્ય ਹੋ ਸਕਦੇ ਹਨ, ਤਦ ਨੀਤੀ ਪੂਰਬ ਨਿਰਧਾਰਤ ਕਰੋ: ਦਿਖਾਉਣਾ ਜਾਂ 100% ਮੰਨਣਾ—ਪਰ ਲਗਾਤਾਰ ਅਤੇ ਦਸਤਾਵੇਜ਼ੀ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
UI ਨੂੰ ਇੱਕ ਨਤਰ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ: “ਕੀ ਅਸੀਂ SLA ਮੌਜੂਦਾ ਸਮੇਂ ਵਿੱਚ ਪੂਰਾ ਕਰ ਰਹੇ ਹਾਂ, ਅਤੇ ਕਿਉਂ?”
occurred_atservice_idincident_id ਅਤੇ attributesevent_id 'ਤੇ unique constraint ਲਗਾਉ: ਇਸ ਨਾਲ idempotency ਮਿਲਦੀ ਹੈ। ਮੈਪ ਨਾ ਹੋ ਸਕਣ ਵਾਲੇ ਜਾਂ ਆਉਟ-ਆਫ-ਆਰਡਰ ਇਵੈਂਟਾਂ ਨੂੰ quarantine/flag ਕਰੋ—ਸਿਸਟਮ ਨੂੰ ਖੁਦ-ਬ-ਖੁਦ ਠੀਕ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਾ ਕਰੋ।