26 ਨਵੰ 2025·8 ਮਿੰਟ
ਰੁਕਾਵਟਾਂ ਟ੍ਰੈਕ ਕਰਨ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਵਰਕਫਲੋ ਡੇਟਾ ਕੈਪਚਰ ਕਰਨ, ਰੁਕਾਵਟਾਂ ਪਛਾਣਨ ਅਤੇ ਟੀਮਾਂ ਨੂੰ ਦੇਰੀਆਂ ਠੀਕ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨ ਲਈ ਵੈੱਬ ਐਪ ਯੋਜਨਾ, ਡિઝ਼ਾਈਨ ਅਤੇ ਸ਼ਿਪ ਕਰਨ ਦੀ ਕਦਮ-ਦਰ-ਕਦਮ ਗਾਈਡ।
ਸਮੱਸਿਆ ਅਤੇ ਫੈਸਲੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਇੱਕ ਪ੍ਰਕਿਰਿਆ ਟਰੈਕਿੰਗ ਵੈੱਬ ਐਪ ਤਾਂ ਹੀ ਮਦਦ ਕਰਦੀ ਹੈ ਜਦੋਂ ਇਹ ਕਿਸੇ ਖਾਸ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦੇਵੇ: “ਅਸੀਂ ਕਿੱਥੇ ਫਸ ਰਹੇ ਹਾਂ, ਅਤੇ ਸਾਨੂੰ ਇਸ ਬਾਰੇ ਕੀ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ?” ਸਕਰੀਨਾਂ ਡਰਾਅ ਕਰਨ ਜਾਂ ਆਰਕੀਟੈਕਚਰ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਪਰਿਭਾਸ਼ਾ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਸੰਚਾਲਨ ਵਿੱਚ “ਰੁਕਾਵਟ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ।
ਰੁਕਾਵਟ ਨੂੰ ਕਿਸ ਤਰ੍ਹਾਂ ਗਿਣਿਆ ਜਾਏ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਇੱਕ ਰੁਕਾਵਟ ਕੋਈ ਕਦਮ (ਉਦਾਹਰਣ: “QA ਰਿਵਿਊ”), ਟੀਮ (ਉਦਾਹਰਣ: “ਫੁਲਫਿਲਮੈਂਟ”), ਸਿਸਟਮ (ਉਦਾਹਰਣ: “ਪੇਮੈਂਟ ਗੇਟਵੇ”) ਜਾਂ ਕਿੱਤੇਦਾਰ/ਵੈਂਡਰ (ਉਦਾਹਰਨ: “ਕੈਰੀਅਰ ਪਿਕਅਪ”) ਹੋ ਸਕਦੀ ਹੈ। ਉਹ ਪਰਿਭਾਸ਼ਾਵਾਂ ਚੁਣੋ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ ਵਾਸਤਵ ਵਿੱਚ ਮੈਨੇਜ ਕਰੋਗੇ। ਉਦਾਹਰਣ ਲਈ:
- ਜਦੋਂ ਕਿਸੇ ਕਦਮ ਦਾ ਔਸਤ ਕਤਾਰ ਸਮਾਂ 24 ਘੰਟੇ ਤੋਂ ਵੱਧ ਹੋਵੇ ਤਾਂ ਉਹ ਰੁਕਾਵਟ ਮੰਨੀ ਜਾਵੇਗੀ।
- ਜਦੋਂ ਕਿਸੇ ਟੀਮ ਵਿੱਚ ਵਰਕ-ਇਨ-ਪ੍ਰੋਗਰੈਸ ਤਿੰਨ ਦਿਨਾਂ ਤੋਂ ਵੱਧ ਇੱਕ ਨਿਰਧਾਰਤ ਸੀਮਾ ਤੋਂ ਉੱਪਰ ਰਿਹਾ, ਉਹ ਟੀਮ ਰੁਕਾਵਟ ਹੈ।
- ਜਦੋਂ ਕਿਸੇ ਸਿਸਟਮ ਦੇ ਇੰਸਿਡੈਂਟ ਕਾਰਨ ਚੱਕਰ ਸਮਾਂ ਮੰਨਿਆ ਗਿਆ ਰੇਂਜ ਤੋਂ ਬਹੁਤ ਵੱਧ ਜਾਂਦਾ ਹੈ, ਉਹ ਇੱਕ ਰੁਕਾਵਟ ਹੈ।
ਉਹ ਫੈਸਲੇ ਲਿਖੋ ਜੋ ਐਪ ਨੂੰ ਤੇਜ਼ ਬਣਾਉਣੇ ਚਾਹੀਦੇ ਹਨ
ਤੁਹਾਡਾ ਓਪਰੇਸ਼ਨ ਡੈਸ਼ਬੋਰਡ ਸਿਰਫ਼ ਰਿਪੋਰਟਿੰਗ ਲਈ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ — ਇਹ ਕਾਰਵਾਈ ਨੂੰ ਚਲਾਉਣਾ ਚਾਹੀਦਾ ਹੈ। ਉਹ ਫੈਸਲੇ ਲਿਖੋ ਜੋ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਅਤੇ ਜ਼ਿਆਦਾ ਭਰੋਸੇ ਨਾਲ ਲੈਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਉਦਾਹਰਣ:
- ਸਟਾਫਿੰਗ: “ਕੀ ਅਸੀਂ ਇਸ ਹਫਤੇ ਟੀਮ A ਤੋਂ ਟੀਮ B ਨੂੰ ਇੱਕ ਵਿਅਕਤੀ ਦੇਖਾ ਦੇਵਾਂ?”
- ਤਰਜੀਹ: “ਕਿਹੜੇ ਆਰਡਰ/ਟਿਕਟ SLA ਬਚਾਉਣ ਲਈ ਲਾਈਨ ਬਾਈਪਾਸ ਕਰਨੇ ਚਾਹੀਦੇ ਹਨ?”
- ਆਟੋਮੇਸ਼ਨ: “ਕਿਹੜਾ ਕਦਮ ਪਹਿਲਾਂ ਆਟੋਮੇਟ ਕਰਨ ਲਈ ਕਾਫੀ ਸਥਿਰ ਅਤੇ ਮਹਿੰਗਾ ਹੈ?”
ਮੁੱਖ ਯੂਜ਼ਰ ਅਤੇ ਉਹਨਾਂ ਦੀਆਂ ਲੋੜਾਂ ਪਛਾਣੋ
ਵੱਖ-ਵੱਖ ਯੂਜ਼ਰਾਂ ਨੂੰ ਵੱਖ ਰੂਪ ਦੀਆਂ ਵਿਊਜ਼ ਚਾਹੀਦੀਆਂ ਹੁੰਦੀਆਂ ਹਨ:
- Ops ਮੈਨੇਜ਼ਰ ਨੂੰ ਇੱਕ ਸਾਫ਼ “ਅੱਜ ਦਖਲ ਕਿੱਥੇ ਦੇਣਾ” ਵਿਊ ਚਾਹੀਦੀ ਹੈ।
- ਟੀਮ ਲੀਡ ਨੂੰ ਵਿਅਕਤੀਗਤ ਕਤਾਰਾਂ, ਰੁਕਾਵਟਾਂ ਅਤੇ ਹੈਂਡੌਫ਼ਾਂ ਵਿੱਚ ਡ੍ਰਿਲ-ਡਾਊਨ ਚਾਹੀਦਾ ਹੈ।
- ਐਨਾਲਿਸਟ ਨੂੰ ਵਰਕਫਲੋ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਸਥਿਰ ਪਰਿਭਾਸ਼ਾਵਾਂ ਅਤੇ ਐਕਸਪੋਰਟ ਚਾਹੀਦੇ ਹਨ।
ਐਪ ਲਈ ਸਫਲਤਾ ਮੈਟ੍ਰਿਕਸ ਨਿਰਧਾਰਿਤ ਕਰੋ
ਤੁਹਾਡੇ ਲਈ ਐਪ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ ਇਸਦਾ ਪਤਾ ਲਾਉਣ ਲਈ ਮਾਪ ਦਿਓ। ਚੰਗੇ ਮਾਪਣ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹਨ: ਅਡਾਪਸ਼ਨ (ਹਫਤਾਵਾਰ ਸਰਗਰਮ ਯੂਜ਼ਰ), ਰਿਪੋਰਟਿੰਗ 'ਤੇ ਸਮਾਂ ਬਚਨਾ, ਅਤੇ ਤੇਜ਼ ਹੱਲ (ਰੁਕਾਵਟਾਂ ਦੀ ਖੋਜ ਅਤੇ ਠੀਕ ਕਰਨ ਦਾ ਘਟਿਆ ਸਮਾਂ)। ਇਹ ਮੈਟ੍ਰਿਕਸ ਤੁਹਾਨੂੰ ਨਤੀਜਿਆਂ 'ਤੇ ਧਿਆਨ ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ, ਨਾ ਕਿ ਖਾਸ ਫੀਚਰਾਂ 'ਤੇ।
ਵਰਕਫਲੋ ਚੁਣੋ ਅਤੇ ਇੱਕ ਸਾਦਾ ਪ੍ਰਕਿਰਿਆ ਨਕਸ਼ਾ ਲਿਖੋ
ਟੇਬਲਾਂ, ਡੈਸ਼ਬੋਰਡਾਂ ਜਾਂ ਚੇਤਾਵਨੀਆਂ ਡਿਜ਼ਾਇਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਇੱਕ ਵਰਕਫਲੋ ਚੁਣੋ ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਇੱਕ ਵਾਕ ਵਿੱਚ ਵਰਣਨ ਕਰ ਸਕੋ। ਮਕਸਦ ਹੈ ਕਿੱਥੇ ਕੰਮ ਰੁਕਦਾ ਹੈ ਉਸਨੂੰ ਟ੍ਰੈਕ ਕਰਨਾ—ਇਸ ਲਈ ਛੋਟੇ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਇੱਕ ਜਾਂ ਦੋ ਪ੍ਰਕਿਰਿਆਵਾਂ ਚੁਣੋ ਜੋ ਮਹੱਤਵਪੂਰਣ ਹਨ ਅਤੇ ਲਗਾਤਾਰ ਆਮ ਆਯਾਤ ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ, ਜਿਵੇਂ ਆਰਡਰ ਫੁਲਫਿਲਮੈਂਟ, ਸਪੋਰਟ ਟਿਕਟਾਂ, ਜਾਂ ਕਰਮਚਾਰੀ ਔਨਬੋਰਡਿੰਗ।
ਸੰਕੁਚਿਤ ਸਕੋਪ "ਡਿਫ਼ਿਨੀਸ਼ਨ ਆਫ ਡਨ" ਨੂੰ ਸਾਫ਼ ਰੱਖਦਾ ਹੈ ਅਤੇ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਉਸ ਵੇਲੇ ਰੁਕਣ ਤੋਂ ਰੋਕਦਾ ਹੈ ਜਦੋਂ ਵੱਖ-ਵੱਖ ਟੀਮਾਂ ਇਹ ਤੇ ਨਹੀਂ ਹੁੰਦੀਆਂ ਕਿ ਪ੍ਰਕਿਰਿਆ ਕਿਵੇਂ ਕੰਮ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ।
1–2 ਉੱਚ-ਸਿਗਨਲ ਪ੍ਰਕਿਰਿਆਵਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਉਹ ਵਰਕਫਲੋ ਚੁਣੋ ਜੋ:
- ਅਕਸਰ ਹੁੰਦੇ ਹਨ (pattern ਦੇਖਣ ਲਈ ਕਾਫੀ ਡੇਟਾ)
- ਘੱਟੋ-ਘੱਟ ਇੱਕ ਹੈਂਡੌਫ਼ ਨੂੰ ਕ੍ਰਾਸ ਕਰਦੇ ਹਨ (ਜਿੱਥੇ ਕਤਾਰ ਬਣਦੀ ਹੈ)
- ਗਾਹਕ 'ਤੇ ਸਪੱਸ਼ਟ ਪ੍ਰਭਾਵ ਹੁੰਦਾ ਹੈ (ਸਮਾਂ, ਲਾਗਤ, ਸੰਤੁਸ਼ਟੀ)
ਉਦਾਹਰਣ ਲਈ, “ਸਪੋਰਟ ਟਿਕਟਾਂ” ਆਮ ਤੌਰ 'ਤੇ “ਕਸਟਮਰ ਸਫਲਤਾ” ਨਾਲੋਂ ਵਧੀਆ ਹੁੰਦੀ ਹੈ ਕਿਉਂਕਿ ਇਸ ਦੇ ਕੋਲ ਇਕ ਸਪੱਸ਼ਟ ਇਕਾਈ ਅਤੇ ਟਾਈਮਸਟੈਂਪ ਕੀਤੇ ਕਾਰਜ ਹੁੰਦੇ ਹਨ।
ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ ਕਦਮ ਅਤੇ ਹੈਂਡੌਫ਼ ਨਕਸ਼ਾ ਬਣਾਓ
ਵਰਕਫਲੋ ਨੂੰ ਇਕ ਸਧਾਰਨ ਸੂਚੀ ਵਜੋਂ ਲਿਖੋ ਜੋ ਟੀਮ ਪਹਿਲਾਂ ਹੀ ਵਰਤਦੀ ਹੈ। ਤੁਸੀਂ ਨੀਤੀ ਦਸਤਾਵੇਜ਼ ਨਹੀਂ ਬਣਾ ਰਹੇ—ਤੁਸੀਂ ਉਹ ਸਥਿਤੀਆਂ ਦਰਜ ਕਰ ਰਹੇ ਹੋ ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਵਰਕ ਆਈਟਮ ਵੱਧਦਾ ਜਾਂ ਘਟਦਾ ਹੈ।
ਇੱਕ ਹਲਕਾ-ਫੁਲਕਾ ਪ੍ਰਕਿਰਿਆ ਨਕਸ਼ਾ ਐਵੇਂ ਹੋ ਸਕਦਾ ਹੈ:
- Ticket created → triaged → assigned → agent working → waiting on customer → resolved
ਇਸ ਪੜਾਅ 'ਤੇ ਹੈਂਡੌਫ਼ਾਂ ਨੂੰ ਖਾਸ ਤੌਰ 'ਤੇ ਦਰਸਾਓ (triage → assigned, agent → specialist ਆਦਿ)। ਹੈਂਡੌਫ਼ਾਂ ਅਕਸਰ ਉਹ ਥਾਂ ਹਨ ਜਿੱਥੇ ਕਤਾਰ ਸਮਾਂ ਲੁਕਿਆ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਇਹ ਉਹ ਮੋਮੈਂਟ ਹਨ ਜੋ ਤੁਸੀਂ ਮਾਪਣਾ ਚਾਹੋਗੇ।
ਹਰ ਕਦਮ ਲਈ ਸ਼ੁਰੂ/ਅੰਤਈਵੈਂਟ ਅਤੇ “ਡਨ” ਪਰਿਭਾਸ਼ਾ ਕਰੋ
ਹਰ ਕਦਮ ਲਈ ਦੋ ਚੀਜ਼ਾਂ ਲਿਖੋ:
- ਸ਼ੁਰੂਈਵੈਂਟ (ਕੀ ਸਾਬਤ ਕਰਦਾ ਹੈ ਕਿ ਕਦਮ ਸ਼ੁਰੂ ਹੋਇਆ?)
- ਅੰਤਈਵੈਂਟ (ਕੀ ਸਾਬਤ ਕਰਦਾ ਹੈ ਕਿ ਕਦਮ ਮੁੱਕ ਗਿਆ?)
ਇਹ ਸਭ ਕੁਝ ਨਿਰੀਖਣਯੋਗ ਰੱਖੋ। “Agent starts investigating” ਵਿਕਲਪਿਕ ਹੈ; “status changed to In Progress” ਜਾਂ “first internal note added” ਟਰੈਕ ਕਰਨਯੋਗ ਹੈ।
ਇਸਦੇ ਨਾਲ ਇਹ ਵੀ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਕਿ “ਡਨ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ ਤਾਂ ਜੋ ਐਪ ਅਧੂਰੇ ਕੰਮ ਨੂੰ ਪੂਰਾ ਸਮਝ ਕੇ ਗਲਤ ਨਤੀਜਿਆਂ 'ਤੇ ਨਾ ਆ ਜਾਵੇ। ਉਦਾਹਰਨ ਲਈ, “resolved” ਦਾ ਮਤਲਬ ਹੋ ਸਕਦਾ ਹੈ “resolution message ਭੇਜਿਆ ਗਿਆ ਅਤੇ ticket ਨੂੰ Resolved ਮੰਨਿਆ ਗਿਆ,” ਨਾ ਕਿ ਸਿਰਫ ਅੰਦਰੂਨੀ ਕੰਮ ਪੂਰਾ ਹੋਣਾ।
ਆਮ ਸੁਵਿਧਾਵਾਂ (exceptions) ਨੋਟ ਕਰੋ ਜੋ ਤੁਸੀਂ ਬਾਦ ਵਿੱਚ ਟ੍ਰੈਕ ਕਰੋਗੇ
ਅਸਲ ਸੰਚਾਲਨ ਗੰਦੇ ਰਾਹਾਂ ਨਾਲ ਭਰਿਆ ਹੁੰਦਾ ਹੈ: ਰੀਵਰਕ, ਐਸਕਲੇਸ਼ਨ, ਗੁੰਮ ਜਾਣਕਾਰੀ, ਅਤੇ ਖੁੱਲੇ ਆਈਟਮ। ਪਹਿਲੇ ਦਿਨ ਸਭ ਕੁਝ ਮਾਡਲ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਾ ਕਰੋ—ਸਿਰਫ ਉਹ ਛੋਟੀ ਨੋਟ ਲਿਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਜਾਣ-ਬੂਝ ਕੇ ਉਹਨਾਂ ਨੂੰ ਸ਼ਾਮਿਲ ਕਰੋ।
ਇੱਕ ਸਧਾਰਨ ਨੋਟ ਜਿਵੇਂ “10–15% ਟਿਕਟ Tier 2 ਨੂੰ escalate ਹੁੰਦੇ ਹਨ” ਕਾਫੀ ਹੈ। ਇਹ ਨੋਟ ਤੁਹਾਨੂੰ ਇਹ ਫੈਸਲਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰੇਗੀ ਕਿ ਕਦੋਂ exceptions ਨੂੰ ਵੱਖ-ਵੱਖ ਕਦਮ, ਟੈਗ, ਜਾਂ ਵੱਖਰੇ ਫਲੋ ਵਜੋਂ ਰੱਖਣਾ ਹੈ।
ਉਹ ਮੈਟ੍ਰਿਕ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਜੋ ਵਾਸਤਵ 'ਚ ਰੁਕਾਵਟ ਦਰਸਾਉਂਦੇ ਹਨ
ਰੁਕਾਵਟ ਇਕ ਭਾਵਨਾ ਨਹੀਂ—ਇਹ ਕਿਸੇ ਖਾਸ ਕਦਮ 'ਤੇ ਮਾਪੀਆਂ ਜਾ ਸਕਣ ਵਾਲੀ ਧੀਮੀ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। ਚਾਰਟ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਤੈਅ ਕਰੋ ਕਿ ਕਿਹੜੇ ਅੰਕ ਇਹ ਸਾਬਤ ਕਰਨਗੇ ਕਿ ਕੰਮ ਕਿੱਥੇ ਪਈਆਂ ਦਿੱਤੀਆਂ ਹਨ ਅਤੇ ਕਿਉਂ।
ਕੁਝ ਮੁੱਖ ਮੈਟ੍ਰਿਕ ਚੁਣੋ
ਜ਼ਿਆਦਾਤਰ ਵਰਕਫਲੋ ਲਈ ਚਾਰ ਮੈਟਰਿਕ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
- Cycle time: ਕਿਸੇ ਆਈਟਮ ਨੂੰ ਸ਼ੁਰੂ ਤੋਂ ਡਨ ਤੱਕ ਲੱਗਣ ਵਾਲਾ ਸਮਾਂ।
- Wait/queue time: ਕਦਮਾਂ ਵਿਚਕਾਰ ਆਈਟਮ ਕਿੰਨਾ ਸਮਾਂ ਬੇਕਾਰ ਬੈਠਦੀ ਹੈ।
- Throughput: ਇੱਕ ਨਿਰਧਾਰਤ ਸਮੇਂ ਵਿੱਚ ਕਿੰਨੇ ਆਈਟਮ ਪੂਰੇ ਹੋਏ।
- WIP (work in progress): ਨਿਰਦੇਸ਼ਕ ਸਮੇਂ 'ਤੇ ਸਿਸਟਮ ਵਿੱਚ ਕਿੰਨੇ ਆਈਟਮ ਹਨ।
ਇਹ ਤੇਜ਼ੀ (cycle), ਨਿਸ਼ਕ੍ਰਿਆਤਾ (queue), ਨਿਕਾਸ (throughput), ਅਤੇ ਲੋਡ (WIP) ਕਵਰ ਕਰਦੇ ਹਨ। ਜ਼ਿਆਦਾਤਰ “ਰਹੱਸਮਈ ਦੇਰੀਆਂ” ਕਿਸੇ ਵਿਸ਼ੇਸ਼ ਕਦਮ 'ਤੇ ਵਧ ਰਹੀ ਕਤਾਰ ਸਮਾਂ ਅਤੇ WIP ਦੇ ਤੌਰ 'ਤੇ ਦਿਖਾਈ ਦਿੰਦੀਆਂ ਹਨ।
ਹਿਸਾਬ-ਕਿਤਾਬ (calculations) ਅਤੇ ਐਜ਼ ਕੇਸ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਉਹ ਪਰਿਭਾਸ਼ਾਵਾਂ ਲਿਖੋ ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਹਾਡੀ ਟੀਮ ਸਹਿਮਤ ਹੋ ਸਕੇ ਅਤੇ ਫਿਰ ਠੀਕ ਓਹੀ ਅਮਲ ਕਰੋ।
- Cycle time =
done_timestamp − start_timestamp.- ਐਜ ਕੇਸ: ਆਈਟਮ ਮੁੜ-ਖੁੱਲੇ (reopened) ਹੋਣ 'ਤੇ ਉਸਨੂੰ ਨਵਾਂ cycle ਮੰਨਣਾ ਜਾਂ ਮੂਲ ਨੂੰ ਵਧਾਉਣਾ; ਕਦੇ ਨ ਸ਼ੁਰੂ ਹੋਏ ਆਈਟਮ (cycle time ਤੋਂ ਬਾਹਰ ਰੱਖੋ ਪਰ WIP ਵਿੱਚ ਗਿਣੋ); ਗੁੰਮ ਟਾਈਮਸਟੈਂਪ (ਡੇਟਾ ਕੁਆਲਟੀ ਲਈ ਫਲੈਗ)।
- Queue time = ਉਹਨਾਂ ਕਦਮਾਂ ਵਿਚਕਾਰ ਖਾਲੀ ਸਮਿਆਂ ਦਾ ਜੋੜ ਜਿੱਥੇ ਸਥਿਤੀ “waiting” ਹੋਵੇ।
- ਐਜ ਕੇਸ: ਰਾਤਾਂ/ਹਫ਼ਤਿਆਂ ਦੇ ਛੁੱਟੀਆਂ (ਕੈਲੰਡਰ ਸਮਾਂ ਵਰਲੈਵੀਨ) ਅਤੇ ਬਲਾਕਡ ਸਥਿਤੀਆਂ (ਜਿਹਨਾਂ ਨੂੰ ਅਲੱਗ ਤੌਰ 'ਤੇ ਗਿਣਣਾ ਚਾਹੀਦਾ ਹੈ)।
- Throughput = ਉਸ ਖਿੜਕੀ ਵਿੱਚ
done_timestampਵਾਲੇ ਆਈਟਮਾਂ ਦੀ ਗਿਣਤੀ।- ਐਜ ਕੇਸ: ਕੈਂਸਲੇਸ਼ਨ (ਛੱਡ ਦਿਓ ਜਾਂ ਅਲੱਗ ਟਰੈਕ ਕਰੋ), ਅਧੂਰੇ ਪੂਰਣ।
- WIP = ਕਿਸੇ ਸਮੇਂ ਬਿੰਦੂ 'ਤੇ ਟਰਮੀਨਲ ਸਥਿਤੀ ਵਿੱਚ ਨਾ ਰਹਿਣ ਵਾਲੇ ਆਈਟਮਾਂ ਦੀ ਗਿਣਤੀ।
- ਐਜ ਕੇਸ: on-hold ਆਈਟਮ (ਅਜੇ ਵੀ WIP, ਪਰ ਤੁਸੀਂ ਇੱਕ ਅਲੱਗ “blocked WIP” ਰੱਖਣਾ ਚਾਹੋਗੇ)।
ਉਹ ਵੰਡ (breakdowns) ਚੁਣੋ ਜੋ ਫੈਸਲੇ ਚਲਾਉਂਦੇ ਹਨ
ਉਹ ਸਲਾਈਸ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਮੈਨੇਜਰ ਵਰਤਦੇ ਹਨ: ਟੀਮ, ਚੈਨਲ, ਪ੍ਰੋਡਕਟ ਲਾਈਨ, ਰਜੀਅਨ, ਅਤੇ ਪ੍ਰਾਇਰਟੀ। ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਇਸਦਾ ਜਵਾਬ ਮਿਲੇ: “ਕਿੱਥੇ ਧੀਮਗੀ ਹੈ, ਕਿਸ ਲਈ ਅਤੇ ਕਿਹੜੀਆਂ ਹਾਲਤਾਂ ਵਿੱਚ?”
ਸਮੇਂ ਦੀਆਂ ਖਿੜਕੀਆਂ ਅਤੇ ਟਾਰਗੇਟ ਸੈੱਟ ਕਰੋ
ਆਪਣਾ ਰਿਪੋਰਟਿੰਗ ਰਿਥਮ ਨਿਰਧਾਰਿਤ ਕਰੋ (ਰੋਜ਼ਾਨਾ ਅਤੇ ਹਫਤਾਵਾਰ ਆਮ ਹਨ) ਅਤੇ ਟਾਰਗੇਟ ਤੈਅ ਕਰੋ ਜਿਵੇਂ SLA/SLO ਸੀਮਾ (ਉਦਾਹਰਨ: “80% high-priority ਆਈਟਮ 2 ਦਿਨਾਂ ਵਿੱਚ ਪੂਰੇ ਹੋਣ”). ਟਾਰਗੇਟਾਂ ਡੈਸ਼ਬੋਰਡ ਨੂੰ ਸਿਰਫ਼ ਸੁੰਦਰ ਬਣਾਉਣ ਦੀ ਬਜਾਇਆ ਕਾਰਵਾਈਯੋਗ ਬਣਾਉਂਦੀਆਂ ਹਨ।
ਡੇਟਾ ਸਰੋਤ ਅਤੇ ਕੈਪਚਰ ਵਿਧੀ ਦੀ ਯੋਜਨਾ ਬਣਾਓ
ਰੁਕਾਵਟ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਨੂੰ ਅਡਾਣੇ 'ਤੇ ਰੋਕਣ ਦਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਤਰੀਕਾ ਇਹ ਸੋਚਣਾ ਹੈ ਕਿ ਡੇਟਾ “ਆਪਣੇ-ਆਪ ਨੇ ਉੱਠੇ ਹੋਵੇਗਾ”। ਟੇਬਲਾਂ ਜਾਂ ਚਾਰਟਾਂ ਡਿਜ਼ਾਇਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਲਿਖੋ ਕਿ ਹਰ ਘਟਨਾ ਅਤੇ ਟਾਈਮਸਟੈਂਪ ਕਿੱਥੋਂ ਆਏਗਾ—ਅਤੇ ਤੁਸੀਂ ਇਸਨੂੰ ਕਿਵੇਂ ਲਗਾਤਾਰ ਸਥਿਰ ਰੱਖੋਗੇ।
ਹੁਣ ਮੌਜੂਦ ਸਰੋਤਾਂ ਦੀ ਸੂਚੀ ਬਣਾਓ
ਜ਼ਿਆਦਾਤਰ ਓਪਰੇਸ਼ਨ ਟੀਮ ਪਹਿਲਾਂ ਹੀ ਕੁਝ ਥਾਵਾਂ 'ਤੇ ਕੰਮ ਟ੍ਰੈਕ ਕਰਦੀ ਹੈ। ਆਮ ਸ਼ੁਰੂਆਤੀ ਸਰੋਤ:
- ਹੈਂਡਓਫ਼ ਲਈ ਵਰਤੇ ਜਾਂਦੇ ਸਪਰੇਡਸ਼ੀਟ
- ERP/CRM ਸਿਸਟਮ (ਆਰਡਰ, ਗਾਹਕ, ਫੁਲਫਿਲਮੈਂਟ ਕਦਮ)
- ਟਿਕਟਿੰਗ ਟੂਲ (ਸਪੋਰਟ ਕਤਾਰਾਂ, ਚੇਨਜ ਰਿਕਵੇਸਟ)
- ਆੰਦਰੂਨੀ ਡੇਟਾਬੇਸ (ਵੇਅਰਹਾਊਸ ਸਕੈਨ, ਜੌਬ ਸ਼ੈਡਿਊਲਿੰਗ, ਨਿਰਮਾਣ ਇਕਸੀਕਿਊਸ਼ਨ ਡੇਟਾ)
ਹਰ ਸਰੋਤ ਲਈ ਨੋਟ ਕਰੋ ਕਿ ਉਹ ਕੀ ਪ੍ਰਦਾਨ ਕਰ ਸਕਦਾ ਹੈ: ਇੱਕ ਸਥਿਰ ਰਿਕਾਰਡ ID, ਸਥਿਤੀ ਇਤਿਹਾਸ (ਸਿਰਫ ਮੌਜੂਦਾ ਸਥਿਤੀ ਨਹੀਂ), ਅਤੇ ਘੱਟੋ-ਘੱਟ ਦੋ ਟਾਈਮਸਟੈਂਪ (ਐਂਟਰਿਡ/ਏਗਜ਼ਿਟ ਕਦਮ) — ਬਿਨਾਂ ਇਹਨਾਂ ਦੇ, ਕਤਾਰ ਸਮਾਂ ਅਤੇ ਸਾਇਕਲ ਟਾਈਮ ਟ੍ਰੈਕਿੰਗ ਅਨੁਮਾਨ ਹੋਵੇਗੀ।
ਸਰੋਤ ਦੇ ਮੁਤਾਬਕ ਕੈਪਚਰ ਵਿਧੀ ਚੁਣੋ
ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਡੇ ਕੋਲ ਤਿੰਨ ਵਿਕਲਪ ਹਨ, ਅਤੇ ਬਹੁਤ ਸਾਰੀਆਂ ਐਪਾਂ ਮਿਕਸ ਵਰਤਦੀਆਂ ਹਨ:
- API pull: ERP/CRM/ticketing ਟੂਲ ਤੋਂ ਸਮਾਂ-ਸਮਾਂ ਤੇ ਸਿੰਕ। ਸੋਝੀ-ਸਮਝੀ ਹੋ ਸਕਦੀ ਹੈ ਪਰ pagination, rate limits ਅਤੇ ਇੰਕ੍ਰਿਮੈੰਟਲ ਅਪਡੇਟਸ ਦਾ ਧਿਆਨ ਰੱਖੋ।
- Webhooks: ਕੰਮ ਬਦਲਣ ਤੇ ਪੁਸ਼ ਅਪਡੇਟ। ਨੇਅਰ-ਰੀਅਲ-ਟਾਈਮ ਚੇਤਾਵਨੀਆਂ ਲਈ ਵਧੀਆ, ਪਰ retries ਅਤੇ ਆਉਟ-ਆਫ-ਆਰਡਰ ਘਟਨਾਵਾਂ ਲਈ ਡਿਜ਼ਾਈਨ ਲੋੜੀਂਦਾ ਹੈ।
- Manual entry / CSV upload: ਸਪਰੇਡਸ਼ੀਟ ਤੋਂ ਸ਼ੁਰੂ ਕਰਨ ਵਾਲੀਆਂ ਟੀਮਾਂ ਲਈ ਉਪਯੋਗੀ। ਟੈਂਪਲੇਟ, ਵੈਲੀਡੇਸ਼ਨ ਅਤੇ ਸਪਸ਼ਟ ਐਰਰ ਸੁਨੇਹੇ ਨਾਲ ਇਹ ਸੁਰੱਖਿਅਤ ਬਣਾਓ।
ਡੇਟਾ ਕੁਆਲਟੀ ਦੀ ਯੋਜਨਾ ਬਣਾਓ (ਕਿਉਂਕਿ ਇਹ ਹੋਵੇਗੀ)
ਗੁਮ ਟਾਈਮਸਟੈਂਪ, ਡੁਪਲੀਕੇਟ ਅਤੇ ਅਸੰਗਤ ਸਥਿਤੀਆਂ ਦੀ ਉਮੀਦ ਰੱਖੋ ("In Progress" ਵਿਰੁੱਧ "Working")। ਪਹਿਲਾਂ ਹੀ ਨਿਯਮ ਬਣਾਓ:
- ਭੁਲਾਂ ਦੀ ਥਾਂ ਅਟੱਲ ਇਵੈਂਟ ਲੌਗ ਨੂੰ ਤਰਜੀਹ ਦਿਓ
- source ID + event time + status ਨਾਲ ਡੈਡੀਪਲੀਕੇਟ ਕਰੋ
- ਸਥਿਤੀਆਂ ਨੂੰ ਆਪਣੇ ਐਪ ਦੇ canonical steps ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ
- ਉਹ ਰਿਕਾਰਡ ਫਲੈਗ ਕਰੋ ਜੋ ਭਰੋਸੇਯੋਗ cycle time ਟ੍ਰੈਕ ਕਰਨ ਯੋਗ ਨਹੀਂ ਹਨ
ਰਿਫ੍ਰੈਸ਼ ਕੈਡੰਸ ਨਿਰਧਾਰਿਤ ਕਰੋ
ਹਰ ਪ੍ਰਕਿਰਿਆ ਨੂੰ ਰੀਅਲ-ਟਾਈਮ ਦੀ ਲੋੜ ਨਹੀਂ। ਫੈਸਲੇ ਦੀਆਂ ਜਰੂਰਤਾਂ ਮੁਤਾਬਕ ਚੁਣੋ:
- ਰੀਅਲ-ਟਾਈਮ: dispatching, support triage, SLA ਖਤਰਾ
- ਘੰਟਾਵਾਰ: ਵੇਅਰਹਾਊਸ throughput, ਕਤਾਰ ਸਮਾਂ ਮਾਨੀਟਰਿੰਗ
- ਦੈਨੀਕ: ਹਫਤਾਵਾਰ ਰਿਪੋਰਟਿੰਗ, ਨਿਰੰਤਰ ਸੁਧਾਰ ਸਮੀਖਿਆ
ਇਸਨੂੰ ਹੁਣ ਲਿਖੋ; ਇਹ ਤੁਹਾਡੇ ਸਿੰਕ ਰਣਨੀਤੀ, ਲਾਗਤਾਂ, ਅਤੇ ਉਮੀਦਾਂ 'ਤੇ ਅਸਰ ਪਾਏਗਾ।
ਸਮੇਂ-ਅਧਾਰਤ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਡੇਟਾ ਮਾਡਲ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਰੁਕਾਵਟ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਇਸ ਗੱਲ 'ਤੇ ਟਿਕਕੀ ਹੈ ਕਿ ਇਹ ਸਮੇਂ ਵਾਲੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਕਿੰਝ ਦੇ ਸਕਦਾ ਹੈ: “ਇਸ ਨੂੰ ਕਿੰਨਾ ਸਮਾਂ ਲੱਗਿਆ?”, “ਕਿੱਥੇ ਇਹ ਰੁਕਿਆ?”, ਅਤੇ “ਧੀਮਗੀ ਤੋਂ ਠੋਕੇ ਤੋਂ ਪਹਿਲਾਂ ਕੀ ਬਦਲਿਆ?” ਅਜਿਹੇ ਸਵਾਲਾਂ ਨੂੰ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਸਹਾਇਤਾ ਦੇਣ ਲਈ ਪਹਿਲੇ ਦਿਨ ਤੋਂ ਹੀ ਆਪਣੇ ਡੇਟਾ ਨੂੰ ਇਵੈਂਟਸ ਅਤੇ ਟਾਈਮਸਟੈਂਪਾਂ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਮਾਡਲ ਕਰੋ।
ਮੂਲ ਏਂਟੀਟੀਆਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਮਾਡਲ ਨੂੰ ਛੋਟਾ ਅਤੇ ਸਪਸ਼ਟ ਰੱਖੋ:
- Process: ਕੁੱਲ ਵਰਕਫਲੋ (ਉਦਾਹਰਣ: “Order Fulfillment”).
- Step: ਪ੍ਰਕਿਰਿਆ ਦੇ ਅੰਦਰ ਇਕ ਪੜਾਅ (ਜਿਵੇਂ “Pick”, “Pack”, “Ship”).
- Work item: ਉਹ ਇਕਾਈ ਜੋ ਕਦਮਾਂ ਵਿੱਚ ਹਿਲਦੀ ਹੈ (ਟਿਕਟ, ਆਰਡਰ, ਕਲੇਮ)।
- Event: ਸਥਿਤੀ ਵਿੱਚ ਹੋਇਆ ਰਿਕਾਰਡ ਚੇਨ (entered a step, assigned, blocked, completed).
- User/Team ਅਤੇ Assignment: ਕਿਸ ਨੇ ਕਿਸ ਸਮੇਂ ਕੰਮ ਦੀ ਦਾਇਤ ਲੀ।
ਇਹ ਸੰਰਚਨਾ ਤੁਹਾਨੂੰ ਚੱਕਰ ਸਮਾਂ ਪ੍ਰਤੀ ਕਦਮ ਮਾਪਣ, ਕਦਮਾਂ ਵਿਚਕਾਰ ਕਤਾਰ ਸਮਾਂ ਮਾਪਣ, ਅਤੇ ਕੁੱਲ ਵਰਕਫਲੋ ਲਈ throughput ਮਾਪਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦੀ ਹੈ ਬਿਨਾਂ ਵਿਸ਼ੇਸ਼ ਕੇਸ ਬਣਾਉਣ ਦੇ।
“ਕਰੰਟ ਸਥਿਤੀ” ਫੀਲਡਾਂ ਤੋਂ ਬਦਲੇ ਇਵੈਂਟ ਲੌਗ ਨੂੰ ਤਰਜੀਹ ਦਿਓ
ਹਰ ਸਥਿਤੀ ਬਦਲਣ ਨੂੰ ਇੱਕ ਅਟੱਲ ਇਵੈਂਟ ਰਿਕਾਰਡ ਸਮਝੋ। current_step ਨੂੰ overwrite ਕਰਨ ਦੀ ਬਜਾਏ ਇਹ ਇਵੈਂਟ append ਕਰੋ:
- work_item_id
- from_step → to_step (ਜਾਂ “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
ਤੁਸੀਂ ਤੇਜ਼ੀ ਲਈ “current state” ਸ્નੈਪਸ਼ੌਟ ਰੱਖ ਸਕਦੇ ਹੋ, ਪਰ ਤੁਹਾਡੀਆਂ analytics ਇਵੈਂਟ ਲੌਗ 'ਤੇ ਨਿਰਭਰ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ।
ਸਮੇਂ ਅਤੇ ਟ੍ਰੇਸਬਿਲਟੀ ਨੂੰ ਬੇ-ਚਰਚਾ ਰੱਖੋ
ਟਾਈਮਸਟੈਂਪ ਨੂੰ ਸਦਾ UTC ਵਿੱਚ ਸਟੋਰ ਕਰੋ। ਨਾਲ ਹੀ ਮੂਲ ਸਰੋਤ ਪਰਿਚੀਨ (ਜਿਵੇਂ Jira issue key, ERP order ID) work items ਅਤੇ events 'ਤੇ رکھੋ ਤਾਂ ਹਰ ਚਾਰਟ ਨੂੰ ਇੱਕ ਅਸਲੀ ਰਿਕਾਰਡ ਤੱਕ ਟਰੇਸ ਕੀਤਾ ਜਾ ਸਕੇ।
ਰੁਕਾਵਟਾਂ ਨੂੰ ਬਿਨਾਂ ਝੰਝਟ ਦੇ ਕੈਪਚਰ ਕਰੋ
ਉਨ੍ਹਾਂ ਘਟਨਾਵਾਂ ਲਈ ਹਲਕਾ-ਫੁਲਕਾ ਫੀਲਡ ਰਖੋ ਜੋ ਦੇਰੀਆਂ ਦੀ ਵਜ੍ਹਾ ਸਮਝਾਉਂਦੀਆਂ ਹਨ:
- reason_code (ਮਿਆਰੀ ਵਿਕਲਪ ਜਿਵੇਂ “Waiting on customer”)
- comment (ਵਿਕਲਪਿਕ ਟੈਕਸਟ)
- blocked_flag ਜਾਂ severity
ਇਨ੍ਹਾਂ ਨੂੰ ਵਿਕਲਪਿਕ ਅਤੇ ਆਸਾਨ ਭਰਨਯੋਗ ਰੱਖੋ, ਤਾਂ ਜੋ ਤੁਸੀਂ exceptions ਤੋਂ ਸਿੱਖੋ ਬਿਨਾਂ ਐਪ ਨੂੰ ਫਾਰਮ-ਭਰਨ ਦੀ مشਕਲ ਵਿੱਚ ਬਦਲਣ ਦੇ।
ਆਪਣੀ ਟੀਮ ਲਈ ਫਿਟ ਆਰਕੀਟੈਕਚਰ ਚੁਣੋ
ਸਾਦਾ ਪ੍ਰਕਿਰਿਆ ਨਕਸ਼ੇ ਤੋਂ ਬਣਾਓ
ਆਪਣੇ ਪ੍ਰਕਿਰਿਆ ਨਕਸ਼ੇ ਨੂੰ ਕਦਮ, ਘਟਨਾਵਾਂ ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਵਿੱਚ ਬਦਲੋ ਬਿਨਾਂ ਹਫ਼ਤਿਆਂ ਦੇ ਸੈਟਅਪ ਦੇ।
“ਸਭ ਤੋਂ ਵਧੀਆ” ਆਰਕੀਟੈਕਚਰ ਉਹ ਹੈ ਜੋ ਤੁਹਾਡੀ ਟੀਮ ਸਾਲਾਂ ਤੱਕ ਬਣਾਉ, ਸਮਝੇ ਅਤੇ ਚਲਾਂ ਸਕੇ। ਆਪਣੀ hiring ਪੂਲ ਅਤੇ ਮੌਜੂਦਾ ਹੁਨਰਾਂ ਦੇ ਅਨੁਕੂਲ ਸਟੈਕ ਚੁਣੋ— ਆਮ, ਬਹੁਤ ਸਹਾਇਤ ਕੀਤੇ ਜਾਂਦੇ ਚੋਣਾਂ ਜਿਵੇਂ React + Node.js, Django, ਜਾਂ Rails। ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਐਸਾ ਓਪਰੇਸ਼ਨ ਡੈਸ਼ਬੋਰਡ ਚਲਾਉਂਦੇ ਹੋ ਜਿਸ 'ਤੇ ਲੋਕ ਹਰ ਰੋਜ਼ ਨਿਰਭਰ ਕਰਦੇ ਹਨ ਤਾਂ consistency novelty ਤੋਂ ਵਧੀਅਾ ਹੈ।
ਪਰੇਸ਼ਾਨੀਆਂ ਨੂੰ ਵੱਖ ਕਰੋ ਤਾਂ ਕਿ ਸਿਸਟਮ ਸੋਧਮਣ ਰਹੇ
ਇਕ ਰੁਕਾਵਟ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਆਮ ਤੌਰ 'ਤੇ ਸਪਸ਼ਟ ਲੇਅਰਾਂ ਵਿੱਚ ਵੰਡਣ 'ਤੇ ਬਿਹਤਰ ਕੰਮ ਕਰਦੀ ਹੈ:
- Ingestion: ਇਵੈਂਟ ਪ੍ਰਾਪਤ ਕਰਨਾ (ਸਟੇਟਸ ਬਦਲਣ, ਟਾਈਮਸਟੈਂਪ, ਹੈਂਡਓਫ਼) ਫਾਰਮ, ਇੰਟੀਗਰੇਸ਼ਨ ਜਾਂ ਇੰਪੋਰਟ ਤੋਂ।
- Storage: ਭਰੋਸੇਯੋਗ ਲਿਖਾਈ ਅਤੇ ਆਡਿਟ ਇਤਿਹਾਸ ਲਈ ਟਰਾਂਜ਼ੈਕਸ਼ਨਲ ਡੇਟਾਬੇਸ।
- Analytics queries: Cycle time, queue time, throughput ਗਿਣਨ ਲਈ ਪੜ੍ਹਨ-ਅਨੁਕੂਲ views ਜਾਂ ਕੁਇਰੀਜ਼।
- UI/API: ਐਂਡਪੌਇੰਟ ਅਤੇ ਸਕਰੀਨਾਂ ਜਿਨ੍ਹਾਂ ਨਾਲ ਡੈਸ਼ਬੋਰਡ ਤੇਜ਼ ਅਤੇ ਪੇਸ਼ਗੋਇਆ ਬਣੇ।
ਇਸ ਵੰਡ ਨਾਲ ਤੁਸੀਂ ਇਕ ਹਿੱਸਾ ਬਦਲ ਸਕਦੇ ਹੋ (ਜਿਵੇਂ ਨਵਾਂ ਡੇਟਾ ਸਰੋਤ ਸ਼ਾਮਲ ਕਰਨਾ) ਬਿਨਾਂ ਸਾਰਾ ਸਿਸਟਮ ਦੁਬਾਰਾ ਲਿਖਣ ਦੇ।
ਕਿਹੜੀਆਂ ਗਣਨਾਵਾਂ ਕਿੱਥੇ ਰਹਿਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ ਫ਼ੈਸਲਾ ਕਰੋ
ਕੁਝ ਮੈਟ੍ਰਿਕਸ ਡੇਟਾਬੇਸ ਕੁਇਰੀਜ਼ ਵਿੱਚ ਸਿੱਧੇ ਹੀ ਹਿਸਾਬ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ (ਉਦਾਹਰਣ: “last 7 days ਵਿਚ ਸਰਗਰਮ ਔਸਤ queue time”), ਦੂਜੇ ਮਹਿੰਗੇ ਹਨ ਜਾਂ ਪ੍ਰੀ-ਪਰੋਸੈਸਿੰਗ ਲੋੜਦੇ ਹਨ (ਉਦਾਹਰਣ: percentile, anomaly detection, weekly cohorts)। ਵਿਹਾਰਕ ਨਿਯਮ:
- ਰੀਅਲ-ਟਾਈਮ ਫਿਲਟਰ ਅਤੇ ਬ੍ਰੇਕਡਾਊਨ ਡੇਟਾਬੇਸ ਵਿੱਚ ਕਰੋ।
- ਭਾਰੀ aggregates ਲਈ ਬੈਕਗਰਾਊਂਡ ਜੌਬ ਪੂਰਕ ਰੱਖੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਤੇਜ਼ ਡੈਸ਼ਬੋਰਡ ਲੋਡ ਲਈ ਸਟੋਰ ਕਰੋ।
- ਜੇ ਤੁਹਾਡੀ ਟੀਮ ਇਸਨੂੰ ਸੰਭਾਲ ਸਕਦੀ ਹੈ ਤਾਂ analytics layer ਸ਼ਾਮਲ ਕਰੋ।
ਪ੍ਰਦਰਸ਼ਨ (performance) ਲਈ ਪਹਿਲੇ ਹੀ ਯੋਜਨਾ ਬਣਾਓ
ਓਪਰੇਸ਼ਨ ਡੈਸ਼ਬੋਰਡ ਉਸ ਵੇਲੇ ਫੇਲ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਉਹ ਧੀਮਾ ਮਹਿਸੂਸ ਹੋਵੇ। ਟਾਈਮਸਟੈਂਪਸ, ਵਰਕਫਲੋ step IDs, ਅਤੇ tenant/team IDs 'ਤੇ ਇੰਡੈਕਸਿੰਗ ਵਰਤੋਂ। ਇਵੈਂਟ ਲੌਗ ਲਈ pagination ਜੋੜੋ। ਆਮ ਡੈਸ਼ਬੋਰਡ ਵੇਖਾਂ (ਜਿਵੇਂ “today” ਅਤੇ “last 7 days”) ਲਈ cache ਰੱਖੋ ਅਤੇ ਨਵੇਂ ਇਵੈਂਟ ਆਉਣ 'ਤੇ cache invalidate ਕਰੋ।
ਜੇ ਤੁਸੀਂ tradeoffs 'ਤੇ ਡੀਪਰ ਗੱਲ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਆਪਣੇ ਰੇਪੋ ਵਿੱਚ ਇੱਕ ਛੋਟੀ decision record ਰੱਖੋ ਤਾਂ ਭਵਿੱਖ ਵਿੱਚ ਬਦਲਾਅ drift ਨਾ ਹੋਵੇ।
ਤੇਜ਼ ਰਾਹ ਉਹ ਟੀਮਾਂ ਲਈ ਜੋ ਜਲਦੀ ਰਿਲੀਜ਼ ਕਰਨਾ ਚਾਹੁੰਦੀਆਂ ਹਨ
ਜੇ ਤੁਹਾਡਾ ਮਕਸਦ workflow analytics ਅਤੇ ਚੇਤਾਵਨੀ ਨੂੰ validate ਕਰਨਾ ਹੈ ਬਿਨਾਂ ਪੂਰੇ ਬਿਲਡ ਤੇ commitment ਕੀਤੇ, ਤਾਂ ਇੱਕ vibe-coding ప్లੈਟਫਾਰਮ ਜਿਵੇਂ Koder.ai ਤੁਹਾਨੂੰ ਪਹਿਲਾ ਵਰਜ਼ਨ ਤੇਜ਼ੀ ਨਾਲ ਖੜਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ: ਤੁਸੀਂ ਵਰਕਫਲੋ, ਏਂਟੀਟੀਜ਼, ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਚੈਟ ਵਿੱਚ ਵਰਣਨ ਕਰਦੇ ਹੋ, ਫਿਰ ਜਨਰేట్ ਹੋਈ React UI ਅਤੇ Go + PostgreSQL ਬੈਕਐਂਡ 'ਤੇ ਇਟਰੇਟ ਕਰੋ।
ਬੋਤਲਨੈਕ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਲਈ ਵਾਸਤਵਿਕ ਫਾਇਦਾ feedback ਤੱਕ ਤੇਜ਼ੀ ਨਾਲ ਪਹੁੰਚ ਹੈ: ਤੁਸੀਂ ingestion (API pulls, webhooks, ਜਾਂ CSV import) ਪਾਇਲਟ ਕਰ ਸਕਦੇ ਹੋ, ਡ੍ਰਿਲ-ਡਾਊਨ ਸਕਰੀਨਾਂ ਜੋੜ ਸਕਦੇ ਹੋ, ਅਤੇ KPI ਪਰਿਭਾਸ਼ਾਵਾਂ ਬਿਨਾਂ ਹਫਤਿਆਂ ਦੀ ਚੜ੍ਹਾਈ ਦੇ ਠੀਕ ਕਰ ਸਕਦੇ ਹੋ। ਜਦੋਂ ਤੁਸੀਂ ਤਿਆਰ ਹੋਵੋਗੇ, Koder.ai ਸਰੋਤ ਕੋਡ ਨਿਰਯਾਤ ਅਤੇ ਡਿਪਲੋਇਮੈਂਟ/ਹੋਸਟਿੰਗ ਵੀ ਸਮਰਥਨ ਕਰਦਾ ਹੈ, ਜੋ ਪ੍ਰੋਟੋਟਾਈਪ ਤੋਂ ਲੰਬੇ ਸਮੇਂ ਵਾਲੇ ਇੰਟਰਨਲ ਟੂਲ ਲਈ ਮੋਵ ਕਰਨ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
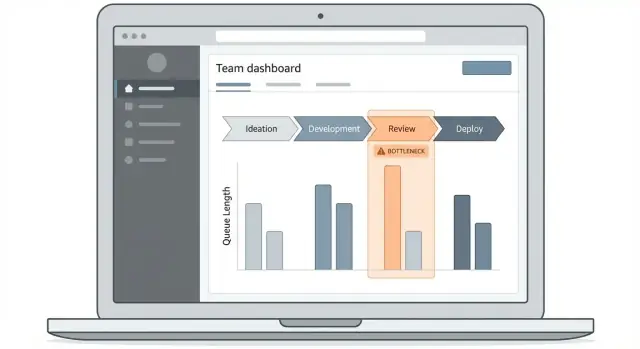
ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਡ੍ਰਿਲ-ਡਾਊਨ ਅਨੁਭਵ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਰੁਕਾਵਟ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਦੀ ਕਿਸਮਤ ਇਹਨਾਂ 'ਤੇ ਨਿਰਭਰ ਹੈ ਕਿ ਲੋਕ ਜੋੜ ਕੇ ਇੱਕ ਸਵਾਲ ਜਵਾਬ ਕਰ ਸਕਦੇ ਹਨ: “ਹੁਣ ਕਿੱਥੇ ਕੰਮ ਫਸ ਰਿਹਾ ਹੈ, ਅਤੇ ਕਿਹੜੇ ਆਈਟਮ ਇਸਦਾ ਕਾਰਨ ਹਨ?” ਤੁਹਾਡਾ ਡੈਸ਼ਬੋਰਡ ਉਹ ਰਸਤਾ ਸਪਸ਼ਟ ਬਣਾਏ, ਭਾਵੇਂ ਕੋਈ ਹਫਤੇ ਵਿਚ ਇਕ ਵਾਰੀ ਆਵੇ।
2–3 ਮੁੱਖ ਸਕ੍ਰੀਨਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਪਹਿਲੀ ਰਿਲੀਜ਼ ਨੂੰ ਟਾਈਟ ਰੱਖੋ:
- Overview dashboard: cycle time, queue time, ਅਤੇ top blocked steps ਲਈ "ਸਟੇਟਸ ਬੋਰਡ"।
- Work-item list: ਫਿਲਟਰ ਅਤੇ ਖੋਜਯੋਗ ਟੇਬਲ ਜਿਸ ਵਿੱਚ ਦੇਰੀਆਂ ਵਾਲੇ ਆਈਟਮ ਦਿਖਾਏ ਜਾਣ।
- Workflow detail: ਹਰੇਕ ਸਟੇਪ ਵਿੱਚ ਲੱਗੇ ਸਮੇਂ ਅਤੇ ਹੈਂਡੌਫ਼ ਬਿੰਦੂਆਂ ਦੇ ਨਾਲ ਕਦਮ-ਬਾਈ-ਕਦਮ ਵਿਊ।
ਇਹ ਸਕਰੀਨਾਂ ਨੇਚਰਲ ਡ੍ਰਿਲ-ਡਾਊਨ ਫਲੋ ਬਣਾਉਂਦੀਆਂ ਹਨ ਬਿਨਾਂ ਯੂਜ਼ਰਾਂ ਨੂੰ ਇੱਕ ਜਟਿਲ UI ਸਿੱਖਣ ਲਈ ਮਜਬੂਰ ਕਰਨ ਦੇ।
ਸਮਾਂ ਅਤੇ ਫਲੋ ਨੂੰ ਸਮਝਾਉਣ ਵਾਲੇ ਵਿਜ਼ੂਅਲ ਵਰਤੋ
ਉਹ ਚਾਰਟ ਕਿਸਮਾਂ ਚੁਣੋ ਜੋ ਓਪਰੇਸ਼ਨ ਸਵਾਲਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦੀਆਂ ਹਨ:
- Stage funnel: ਦਿਖਾਉਂਦਾ ਹੈ ਕਿ ਕਿੱਥੇ ਵਾਲਿਊਮ ਇਕੱਠਾ ਹੁੰਦੀ ਹੈ (ਕਤਾਰਾਂ ਨੂੰ ਪਛਾਣਨ ਲਈ ਚੰਗਾ)
- Time-in-stage bars: ਕਦਮਾਂ ਨੂੰ ਮੀਡੀਅਨ ਅਤੇ ਪਰਸੈਂਟਾਈਲ ਦੁਆਰਾ ਤੁਲਨਾ ਕਰਦਾ ਹੈ, ਸਿਰਫ ਔਸਤੋਂ ਨਹੀਂ।
- Trend lines: ਪੁੱਛਦੇ ਹਨ “ਕੀ ਇਹ ਹਫਤਿਆਂ ਵਿੱਚ ਬਿਹਤਰ ਜਾਂ ਖਰਾਬ ਹੋ ਰਿਹਾ ਹੈ?”
- Heatmaps: ਪੈਟਰਨ ਦਿਖਾਉਂਦੇ ਹਨ ਜਿਵੇਂ “ਸੋਮਵਾਰਾਂ ਵਿੱਚ Review” ਜਾਂ “ਨਾਈਟ ਸ਼ਿਫਟ ਹੈਂਡੌਫ਼”।
ਲੇਬਲ ਸਧਾਰਨ ਰੱਖੋ: “Time waiting” ਬਨਾਮ “Queue latency”।
ਫਿਲਟਰ consistent ਅਤੇ ਆਸਾਨੀ ਨਾਲ ਮਿਲਣ ਯੋਗ ਰੱਖੋ
ਸਕਰੀਨਾਂ 'ਤੇ ਇੱਕ ਸਾਂਝਾ ਫਿਲਟਰ ਬਾਰ ਵਰਤੋ (ਉਹੀ ਸਥਿਤੀ, ਉਹੀ ਡਿਫੌਲਟ): ਤਾਰੀਖ ਰੇਂਜ, ਟੀਮ, ਪ੍ਰਾਇਰਟੀ, ਅਤੇ ਸਟੇਪ। ਐਕਟਿਵ ਫਿਲਟਰ ਚਿਪਾਂ ਵਜੋਂ ਦਿਖਾਓ ਤਾਂ ਲੋਕ ਨੰਬਰਾਂ ਨੂੰ ਗਲਤ ਨਾ ਪੜ੍ਹਣ।
ਸਪਸ਼ਟ ਡ੍ਰਿਲ-ਡਾਊਨ ਰਸਤੇ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਹਰ KPI ਟਾਈਲ ਨੂੰ ਕਲਿਕਯੋਗ ਬਣਾਓ ਅਤੇ ਕਿਸੇ ਉਪਯੋਗੀ ਵਿਊ 'ਤੇ ਲੈ ਜਾਓ:
KPI → step → impacted item list
ਉਦਾਹਰਣ: “Longest queue time” 'ਤੇ ਕਲਿਕ ਕਰਨ 'ਤੇ step detail ਖੁਲਦਾ ਹੈ, ਫਿਰ ਇਕ ਕਲਿਕ ਨਾਲ ਤੁਹਾਨੂੰ ਠੀਕ ਆਈਟਮ ਦਿਖਾਈ ਦਿੰਦੇ ਹਨ—ਉਮਰ, ਪ੍ਰਾਇਰਟੀ, ਅਤੇ ਮਾਲਕ ਦੇ ਅਧਾਰ 'ਤੇ sorted। ਇਹ ਜਾਣ-ਪਛਾਣ ਨੂੰ ਇੱਕ ਸਪਸ਼ਟ ਕਾਰਜ ਸੂਚੀ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ, ਜੋ ਡੈਸ਼ਬੋਰਡ ਨੂੰ ਵਰਤਿਆ ਜਾਣ ਵਾਲਾ ਬਣਾਉਂਦਾ ਹੈ।
ਚੇਤਾਵਨੀਆਂ ਅਤੇ ਜਲਦੀ-ਚੇਤਾਵਨੀ ਸੰਕੇਤ ਜੋੜੋ
ਇਜਾਜ਼ਤ-ਸਹੀਤ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਵਿਊਅਰ, ਮੈਨੇਜਰ, ਅਤੇ ਐਡਮਿਨ ਐਕਸੈਸ ਸ਼ਾਮਲ ਕਰੋ ਅਤੇ ਆਡਿਟ-ਫ੍ਰੈਂਡਲੀ ਚੇਨਜ਼ ਟਰੈਕਿੰਗ ਰੱਖੋ।
ਡੈਸ਼ਬੋਰਡ ਸਮੀਖਿਆਆਂ ਲਈ ਵਧੀਆ ਹੁੰਦੇ ਹਨ, ਪਰ ਰੁਕਾਵਟ ਅਕਸਰ ਮੀਟਿੰਗਾਂ ਦੇ ਵਿਚਕਾਰ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਨੁਕਸਾਨ ਕਰਦੀਆਂ ਹਨ। ਚੇਤਾਵਨੀਆਂ ਤੁਹਾਡੇ ਐਪ ਨੂੰ ਅर्लੀ-ਵਾਰਨਿੰਗ ਸਿਸਟਮ ਬਣਾਉਂਦੀਆਂ ਹਨ: ਤੁਸੀਂ ਸਮੱਸਿਆਵਾਂ ਉਸ ਵੇਲੇ ਪਛਾਣ ਲੈਂਦੇ ਹੋ ਜਦੋਂ ਉਹ ਬਣ ਰਹੀਆਂ ਹੁੰਦੀਆਂ ਹਨ, ਨਾ ਕਿ ਹਫਤਾ ਗੁਜ਼ਰਨ ਤੋਂ ਬਾਅਦ।
ਸਪਸ਼ਟ, ਸਧਾਰਣ ਨਿਯਮਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਉਹ Alert ਕਿਸਮਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜਿਨ੍ਹਾਂ 'ਤੇ ਟੀਮ ਪਹਿਲਾਂ ਹੀ ਸਹਿਮਤ ਹੈ:
- Threshold breaches: cycle time ਜਾਂ queue time ਕਿਸੇ ਜਾਣੇ-ਮਾਨੇ ਸੀਮਾ ਤੋਂ ਉਪਰ (ਉਦਾਹਰਨ: “Review step > 24 hours”).
- Abnormal increases: ਅਜੇ ਦਾ ਮੀਡੀਅਨ cycle time ਪਿਛਲੇ ਹਫਤੇ ਨਾਲੋਂ 30% ਵੱਧ।
- Stuck items: N ਘੰਟਿਆਂ/ਦਿਨਾਂ ਲਈ ਕੋਈ ਸਥਿਤੀ ਬਦਲਾਅ ਨਹੀਂ, ਜਾਂ ਆਈਟਮ अधिक ਤੋਂ अधिक ਉਮਰ ਪਾਰ ਕਰ ਚੁੱਕੇ।
ਪਹਿਲੇ ਵਰਜਨ ਨੂੰ ਸਧਾਰਣ ਰੱਖੋ। ਕੁਝ ਨਿਯਮ ਜ਼ਿਆਦਾਤਰ ਮਸਲੇ ਫੜ ਲੈਂਦੇ ਹਨ ਅਤੇ ਜਟਿਲ ਮਾਡਲਾਂ ਨਾਲੋਂ ਵਧੇਰੇ ਭਰੋਸੇਯੋਗ ਹੁੰਦੇ ਹਨ।
ਹਲਕੇ-ਭਾਰ ਅਨੋਮਲੀ ਚੈੱਕ ਜੋੜੋ
ਜਦੋਂ thresholds ਸਥਿਰ ਹੋ ਜਾਣ, ਤਾਂ ਬੁਨਿਆਦੀ “ਇਹ ਅਜੀਬ ਹੈ?” ਸੰਕੇਤ ਜੋੜੋ:
- ਪਿਛਲੇ ਹਫਤੇ ਨਾਲ ਪ੍ਰਤिशत ਬਦਲਾਅ (ਉਹੇ ਵੀਕਡੇ ਨੂੰ ਤੁਲਨਾ ਕਰਨ ਨਾਲ false alarms ਘੱਟ ਹੁੰਦੇ ਹਨ)
- Moving average drift (ਉਦਾਹਰਨ: 7-ਦਿਨ ਦੀ ਔਸਤ ਲਗਾਤਾਰ ਵੱਧ ਰਹੀ)
- ਵਾਲਿਊਮ mismatch (ਇੱਕ ਕਦਮ 'ਤੇ ਆਉਟਪੁਟ ਤੋਂ ਤੇਜ਼ ਇਨਪੁੱਟ)
ਅਨੋਮਲੀਜ਼ ਨੂੰ “ਸੁਝਾਅ” ਵਜੋਂ ਪੇਸ਼ ਕਰੋ, ਨਾਲ ਤੋਂ ਨਹੀਂ: ਉਨ੍ਹਾਂ ਨੂੰ “Heads up” ਲੇਬਲ ਦਿਓ ਜਦ ਤੱਕ ਯੂਜ਼ਰ ਇਹਨਾਂ ਦੀ ਯੂਟਿਲਿਟੀ ਪੁਸ਼ਟੀ ਨਹੀਂ ਕਰਦੇ।
ਚੇਤਾਵਨੀਆਂ ਉਹਥੇ ਭੇਜੋ ਜਿੱਥੇ ਲੋਕ ਕੰਮ ਕਰਦੇ ਹਨ
ਕਈ ਚੈਨਲ ਸਹਿਯੋਗ ਕਰੋ ਤਾਂ ਟੀਮ ਉਹ ਚੋਣ ਸਕੇ ਜੋ ਉਨ੍ਹਾਂ ਲਈ ਠੀਕ ਹੋਵੇ:
- ਮੈਨੇਜਰਾਂ ਲਈ ਈਮੇਲ ਅਤੇ ਦੈਨੀਕ ਸੰਖੇਪ
- ਤੁਰੰਤ ਟ੍ਰਾਇਅਜ ਲਈ Slack/Microsoft Teams
- ਟੂਲ ਦੇ ਅੰਦਰ-ਅਪ ਨੋਟੀਫਿਕੇਸ਼ਨ ਮਾਲਕਾਂ ਲਈ
ਹਰ ਚੇਤਾਵਨੀ ਕਾਰਵਾਈਯੋਗ ਬਣਾਓ
ਇੱਕ ਚੇਤਾਵਨੀ ਨੂੰ “ਕੀ, ਕਿੱਥੇ, ਤੇ ਅੱਗੇ ਕੀ?” ਦਾ ਜਵਾਬ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ:
- ਕਿਹੜਾ ਸਟੇਪ ਪ੍ਰਭਾਵਿਤ ਹੈ ਅਤੇ ਕਿਹੜੀ ਸਮੇਂ ਵਿੰਡੋ
- ਟੌਪ ਡ੍ਰਾਈਵਰ (ਟੀਮ, category, ਪ੍ਰਾਇਰਟੀ)
- ਖੋਜ ਕਰਨ ਲਈ ਸਿੱਧਾ ਰਸਤਾ, ਉਦਾਹਰਨ:
/dashboard?step=review&range=7d&filter=stuck
ਜੇ ਚੇਤਾਵਨੀਆਂ ਕਿਸੇ ਨਿਸ਼ਚਿਤ ਅਗਲੇ ਕਦਮ ਤੱਕ ਨਹੀਂ ਲੈ ਜਾਂਦੀਆਂ, ਲੋਕ ਉਹਨਾਂ ਨੂੰ ਮਿਊਟ ਕਰ ਦੇਣਗੇ—ਇਸ ਲਈ ਚੇਤਾਵਨੀ ਗੁਣਵੱਤਾ ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਫੀਚਰ ਸਮਝੋ, ਨਾ ਕਿ ਇਕ ਜੋੜੇ।
ਪਰਮਿਸ਼ਨ, ਸੁਰੱਖਿਆ ਅਤੇ ਆਡਿਟੇਬਿਲਟੀ ਸੰਭਾਲੋ
ਇੱਕ ਬੋਤਲਨੈਕ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਜ਼ਲਦੀ ਹੀ “ਸੱਚਾਈ ਦਾ ਸਰੋਤ” ਬਣ ਜਾਂਦਾ ਹੈ। ਇਹ ਵਧੀਆ ਹੈ—ਜਦ ਤਕ ਗਲਤ ਵਿਅਕਤੀ ਕੋਈ ਪਰਿਭਾਸ਼ਾ ਸੋਧ ਨਾ ਦੇਵੇ, ਸੰਵੇਦਨਸ਼ੀਲ ਡੇਟਾ ਐਕਸਪੋਰਟ ਨਾ ਕਰ ਸਕੇ, ਜਾਂ ਡੈਸ਼ਬੋਰਡ ਕਿਸੇ ਹੋਰ ਟੀਮ ਨਾਲ ਬੇ-ਇਜਾਜ਼ਤ ਸਾਂਝਾ ਨਾ ਕਰੇ। ਪਰਮਿਸ਼ਨ ਅਤੇ ਆਡਿਟ ਟਰੇਲ ਲੋੜੀਂਦੇ ਹਨ; ਉਹ ਨੰਬਰਨਾਂ 'ਤੇ ਭਰੋਸਾ ਬਚਾਉਂਦੇ ਹਨ।
ਰੋਲ ਅਤੇ ਐਕਸੈਸ ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਛੋਟੀ, ਸਪਸ਼ਟ ਰੋਲ ਮਾਡਲ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਜਰੂਰਤ ਹੋਣ ਤੇ ਹੀ ਵਧਾਓ:
- Viewer: ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਰਿਪੋਰਟਾਂ ਲਈ ਸਿਰਫ਼ ਪੜ੍ਹਨ ਦੀ ਆਗਿਆ।
- Manager: ਟੀਮ ਦੁਆਰਾ ਫਿਲਟਰ ਕਰਨ, ਸੇਵਡ ਵਿਊ ਬਣਾਉਣ, ਚੇਤਾਵਨੀਆਂ acknowledge ਕਰਨ, ਅਤੇ ਨੋਟ ਜੋੜਣ ਦੇ ਯੋਗ (ਪਰ ਗਲੋਬਲ ਸੈਟਿੰਗਜ਼ ਨਾ ਬਦਲ ਸਕੇ)।
- Admin: ਪ੍ਰਕਿਰਿਆ ਪਰਿਭਾਸ਼ਾਵਾਂ, KPI ਫਾਰਮੂਲੇ, ਇੰਟੀਗਰੇਸ਼ਨ, ਅਤੇ ਯੂਜ਼ਰ ਐਕਸੇਸ ਮੈਨੇਜ ਕਰਨ ਵਾਲਾ।
ਹਰ ਰੋਲ ਲਈ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਉਹ ਕੀ ਕਰ ਸਕਦਾ ਹੈ: ਰਾ-ਇਵੈਂਟ ਵੇਖਣਾ ਬਨਾਮ.aggregate metrics, ਡੇਟਾ export, thresholds ਸੋਧਣਾ, ਅਤੇ ਇੰਟੀਗਰੇਸ਼ਨ ਮੈਨੇਜ ਕਰਨਾ।
ਡੇਟਾ ਟੀਮ ਜਾਂ ਬਿਜ਼ਨਸ ਯੂਨਿਟ ਅਨੁਸਾਰ ਵੱਖ ਕਰੋ
ਜੇ ਕਈ ਟੀਮਾਂ ਐਪ ਵਰਤ ਰਹੀਆਂ ਹਨ, ਤਾਂ ਡੇਟਾ ਲੇਅਰ 'ਤੇ ਵੱਖਰਾ ਕਰਨ ਨੂੰ ਲਾਗੂ ਕਰੋ—not ਸਿਰਫ UI 'ਚ। ਆਮ ਵਿਕਲਪ:
- Multi-tenant: ਹਰ ਰਿਕਾਰਡ ਵਿੱਚ
tenant_idਹੁੰਦਾ ਹੈ, ਅਤੇ ਹਰ ਕੁਇਰੀ ਉਸਦੀ ਸੀਮਾ ਵਿੱਚ ਚਲਦੀ ਹੈ। - Partitions/projects: ਹਰ ਬਿਜ਼ਨਸ ਯੂਨਿਟ ਲਈ ਵੱਖ “workspaces”, ਆਪਣੇ ਸੈਟਿੰਗਜ਼ ਅਤੇ ਡੈਸ਼ਬੋਰਡ।
ਸੁਰੂਆਤ ਵਿੱਚ ਨਿਰਧਾਰਿਤ ਕਰੋ ਕਿ ਮੈਨੇਜਰ ਹੋਰ ਟੀਮਾਂ ਦਾ ਡੇਟਾ ਦੇਖ ਸਕਦੇ ਹਨ ਜਾਂ ਨਹੀਂ। ਕ੍ਰਾਸ-ਟੀਮ ਵਿਜ਼ਿਬਿਲਟੀ ਨੂੰ ਡਿਫੌਲਟ ਨਾ ਬਨਾਓ—ਇਹ ਇੱਕ ਜਾਣ-ਬੂਝ ਕੇ ਦਿੱਤੀ ਇਜਾਜ਼ਤ ਬਣਾਓ।
ਸੁਰੱਖਿਅਤ authentication (SSO ਜਾਂ MFA-ready)
ਜੇ ਤੁਹਾਡੇ ਸੰਗਠਨ ਕੋਲ SSO (SAML/OIDC) ਹੈ ਤਾਂ ਇਸਦੀ ਵਰਤੋਂ ਕਰੋ ਤਾਂ ਕਿ offboarding ਅਤੇ ਐਕਸੇਸ ਕੰਟਰੋਲ ਕੇਂਦਰੀਕ੍ਰਿਤ ਹੋ ਜਾਵੇ। ਨਾ ਹੋਣ ਤੇ, ਐਸਾ ਲੌਗਿਨ ਸਿਸਟਮ ਬਣਾਓ ਜੋ MFA-ready ਹੋ (TOTP ਜਾਂ passkeys), ਸੁਰੱਖਿਅਤ password reset, ਅਤੇ session timeouts ਲੱਗੂ ਕਰਦਾ ਹੋਵੇ।
ਬਦਲਾਅ ਆਡਿਟ ਯੋਗ ਬਣਾਓ
ਉਹ ਕਾਰਵਾਈਆਂ ਲਾਗ ਕਰੋ ਜੋ ਨਤੀਜੇ ਬਦਲ ਸਕਦੀਆਂ ਹਨ ਜਾਂ ਡੇਟਾ ਖੋਲ ਸਕਦੀਆਂ ਹਨ: exports, threshold ਬਦਲਾਅ, workflow edits, permission updates, ਅਤੇ integration settings। ਕੈਪਚਰ ਕਰੋ ਕਿ ਕਿਸਨੇ, ਕਦੋਂ, ਕੀ ਬਦਲਿਆ (before/after), ਅਤੇ ਕਿੱਥੇ (workspace/tenant)। ਇੱਕ “Audit Log” ਵਿਊ ਦਿਓ ਤਾਂ ਤਜਰਬੇ ਦੀ ਜਾਂਚ ਤੇਜ਼ੀ ਨਾਲ ਕੀਤੀ ਜਾ ਸਕੇ।
ਨਜ਼ਰੀਆ ਨੂੰ ਕਾਰਵਾਈ ਅਤੇ ਪ੍ਰਕਿਰਿਆ ਸੁਧਾਰ ਵਿੱਚ ਬਦਲੋ
ਇਕ ਬੋਤਲਨੈਕ ਡੈਸ਼ਬੋਰਡ ਤਦ ਹੀ ਮਹੱਤਵਪੂਰਣ ਹੈ ਜਦੋਂ ਇਹ ਲੋਕਾਂ ਦੀਆਂ ਅਗਲੀ ਕਾਰਵਾਈਆਂ ਨੂੰ ਬਦਲੇ। ਇਸ ਭਾਗ ਦਾ ਲਕਸ਼ ਹੈ “ਰੁਚਿਕਾਰ ਚਾਰਟ” ਨੂੰ ਇੱਕ ਦੋਹਰਾਉਣਯੋਗ ਓਪਰੇਟਿੰਗ ਰਿਥਮ ਵਿੱਚ ਬਦਲਨਾ: ਫੈਸਲਾ ਕਰੋ, ਕਾਰਵਾਈ ਕਰੋ, ਮਾਪੋ, ਅਤੇ ਜੋ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ ਉਹ ਜਾਰੀ ਰੱਖੋ।
ਹਲਕਾ-ਫੁਲਕਾ ਬੋਤਲਨੈਕ ਸਮੀਖਿਆ ਬਣਾਓ
ਸਧਾਰਨ ਹਫਤਾਵਾਰ ਕੈਡੰਸ ਰੱਖੋ (30–45 ਮਿੰਟ) ਜਿਸ ਵਿੱਚ ਸਪਸ਼ਟ ਮਾਲਿਕ ਹੋਵੇ। ਸਿਖਲਾਈ ਕਿ ਸ਼ੁਰੂਆਤ top 1–3 ਬੋਤਲਨੈਕ ਪ੍ਰਭਾਵ ਦੇ ਆਧਾਰ 'ਤੇ (ਉਦਾਹਰਨ: ਸਭ ਤੋਂ ਵੱਡੀ queue time ਜਾਂ throughput ਵਿੱਚ ਸਭ ਤੋਂ ਵੱਡਾ ਘਟਾਅ) ਫਿਰ ਹਰ ਬੋਤਲਨੈਕ ਲਈ ਇਕ ਕਾਰਵਾਈ ਤੇ ਸਹਿਮਤੀ ਕਰੋ।
ਵਰਕਫਲੋ ਨੂੰ ਛੋਟਾ ਰੱਖੋ:
- Owner: ਹਰ ਕਾਰਵਾਈ ਲਈ ਇਕ ਜਿੰਮੇਵਾਰ ਵਿਅਕਤੀ
- Due date: ਅਗਲੇ ਸਮੀਖਿਆ ਤੱਕ ਮੂਲ ਤੌਰ 'ਤੇ
- Definition of done: ਇੱਕ ਮਾਪਯੋਗ ਬਦਲਾਅ ("ਹੋਰ ਜਾਂਚ" ਨਹੀਂ)
ਫੈਸਲੇ ਸਿੱਧੇ ਐਪ ਵਿੱਚ ਕੈਪਚਰ ਕਰੋ ਤਾਂ ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਕਾਰਵਾਈ ਲੌਗ ਜੁੜੇ ਰਹਿਣ।
ਸੁਧਾਰਾਂ ਨੂੰ ਪ੍ਰਯੋਗਾਂ ਵਾਂਗ ਟ੍ਰੈਕ ਕਰੋ
ਫਿਕਸਾਂ ਨੂੰ ਪ੍ਰਯੋਗ ਵਾਂਗੋਂ ਟ੍ਰੀਟ ਕਰੋ ਤਾਂ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਸਿੱਖੋ ਅਤੇ “ਯਾਦਗਾਰ ਕਾਰਵਾਈਆਂ” ਤੋਂ ਬਚੋ। ਹਰ ਬਦਲਾਅ ਲਈ ਦਰਜ ਕਰੋ:
- Hypothesis (ਕੀ ਚੀਜ਼ धीਮ੍ਹੀ ਕਰ ਰਹੀ ਹੈ ਅਤੇ ਕਿਉਂ)
- Change (ਤੁਸੀਂ ਕੀ ਕਰੋਗੇ)
- Expected impact (ਕਿਹੜਾ ਮੈਟ੍ਰਿਕ ਕਿਵੇਂ ਹਿਲਨਾ ਚਾਹੀਦਾ ਹੈ)
- Result (ਅਸਲ ਨਤੀਜਾ)
ਸਮੇਂ ਨਾਲ ਇਹ ਉਹ ਖੇਡ-ਪੁਸਤਕ ਬਣ ਜਾਵੇਗਾ ਜੋ ਦਰਸਾਏਗਾ ਕਿ ਕੀ ਚੀਜ਼ cycle time ਘਟਾਉਂਦੀ ਹੈ, ਕੀ ਰੀਵਰਕ ਘਟਾਉਂਦੀ ਹੈ, ਅਤੇ ਕੀ ਕਾਰਗਰ ਨਹੀਂ ਸੀ।
ਅਨੁਸੂਚਨਾਵਾਂ (annotations) ਨਾਲ ਸੰਦਰਭ ਜੋੜੋ
ਬਿਨਾਂ ਸੰਦਰਭ ਦੇ ਚਾਰਟ ਗੋਰਕ ਕਰ ਸਕਦੇ ਹਨ। ਟਾਈਮਲਾਈਨ ਉੱਤੇ ਸਧਾਰਨ ਅਨੋਟੇਸ਼ਨ (ਉਦਾਹਰਨ: ਨਵਾਂ ਹਾਇਰ ਆਇਆ, ਸਿਸਟਮ ਆਉਟੇਜ, ਨੀਤੀ ਅਪਡੇਟ) ਜੋੜੋ ਤਾਂ ਦਰਸ਼ਕ ਕਤਾਰ ਸਮੇਂ ਜਾਂ throughput ਵਿੱਚ ਹੋਏ ਬਦਲਾਅ ਨੂੰ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਸਮਝ ਸਕਣ।
ਸਾਂਝਾ ਕਰਨਾ ਆਸਾਨ ਬਣਾਓ
ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਲਈ export ਵਿਕਲਪ ਦਿਓ—CSV ਡਾਊਨਲੋਡ ਅਤੇ ਨਿਸ਼ਚਿਤ ਰਿਪੋਰਟ—ਤਾਂ ਕਿ ਟੀਮਾਂ ਆਪਣੀਆਂ ਨਤੀਜਿਆਂ ਨੂੰ ops ਅੱਪਡੇਟਾਂ ਅਤੇ ਲੀਡਰਸ਼ਿਪ ਸਮੀਖਿਆ ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰ ਸਕਣ। ਜੇ ਤੁਹਾਡੀ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਰਿਪੋਰਟਿੰਗ ਪੇਜ ਹੈ ਤਾਂ ਉਸਨੂੰ ਆਪਣੇ ਡੈਸ਼ਬੋਰਡ ਤੋਂ ਲਿੰਕ ਕਰੋ (ਉਦਾਹਰਨ: /reports).
ਡਿਪਲੋਇ, ਨਿਗਰਾਨੀ ਕਰੋ, ਅਤੇ ਡੇਟਾ ਤਾਜ਼ਾ ਰੱਖੋ
ਪੂਰਾ ਸਰੋਤ ਕੰਟਰੋਲ ਰੱਖੋ
ਜਦੋਂ ਤੁਸੀਂ ਲੰਬੇ ਸਮੇਂ ਦੀ ਮਾਲਕੀ ਲਈ ਤਿਆਰ ਹੋਵੋ ਤਾਂ ਬਣਾਇਆ ਗਿਆ ਸਰੋਤ ਕੋਡ ਆਪਣੇ ਨਾਲ ਲੈ ਜਾਓ।
ਇੱਕ ਬੋਤਲਨੈਕ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਤਦ ਹੀ ਲਾਭਕਾਰੀ ਹੈ ਜਦੋਂ ਇਹ ਲਗਾਤਾਰ ਉਪਲਬਧ ਹੋਵੇ ਅਤੇ ਨੰਬਰ ਭਰੋਸੇਯੋਗ ਰਹਿਣ। ਡਿਪਲੋਇਮੈਂਟ ਅਤੇ ਡੇਟਾ ਤਾਜ਼ਗੀ ਨੂੰ ਉਤਪਾਦ ਦਾ ਹਿੱਸਾ ਸਮਝੋ, ਨਾ ਕਿ ਬਾਅਦ ਦੀ ਸੋਚ।
ਵੱਖ-ਵੱਖ ਵਾਤਾਵਰਣ ਅਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਡਿਪਲੋਇਮੈਂਟ ਵਰਤੋ
ਸ਼ੁਰੂ ਵਿੱਚ dev / staging / prod ਸੈੱਟ ਕਰੋ। ਸਟੇਜਿੰਗ ਨੂੰ ਪ੍ਰੋਡਕਸ਼ਨ ਦੀ ਨਕਲ ਬਨਾਓ (ਉਹੀ ਡੇਟਾਬੇਸ ਇੰਜਣ, ਸਮਾਨ ਡੇਟਾ ਵਾਲੀਮੀਨ, ਉਹੀ ਬੈਕਗਰਾਊਂਡ ਜੌਬ) ਤਾਂ ਤੁਹਾਨੂੰ ਸੁਸਤ ਕੁਇਰੀਜ਼ ਅਤੇ ਟੁੱਟੀਆਂ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਨੂੰ ਯੂਜ਼ਰਾਂ ਤੋਂ ਪਹਿਲਾਂ ਫੜ ਸਕੋ।
ਡਿਪਲੋਇਮੈਂਟ automate ਕਰੋ: ਟੈਸਟ ਚਲਾਓ, migrations ਲਗਾਓ, deploy ਕਰੋ, ਫਿਰ ਤੇਜ਼ smoke check (ਲਾਗਇਨ, ਡੈਸ਼ਬੋਰਡ ਲੋਡ, ingestion ਚੱਲ ਰਹੀ ਹੈ ਜਾਂ ਨਹੀਂ) ਕਰੋ। deploy ਛੋਟੇ ਅਤੇ ਨਿਯਮਤ ਰੱਖੋ; ਇਹ ਜੋਖਮ ਘਟਾਉਂਦਾ ਅਤੇ rollback ਅਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਐਪ ਅਤੇ ਪਾਈਪਲਾਈਨ ਦੀ ਨਿਗਰਾਨੀ ਕਰੋ
ਤੁਸੀਂ ਦੋ ਅੱਗੇ-ਵੱਲ ਨਿਗਰਾਨੀ ਚਾਹੁੰਦੇ ਹੋ:
- App health: error rates, latency, slow endpoints, ਅਤੇ slow queries।
- Data health: ingestion failures, backlog size, ਅਤੇ “last event ਮਿਲਣ ਤੋਂ ਬਾਅਦ ਕਿੱਨਾ ਸਮਾਂ”।
ਉਨ੍ਹਾਂ ਅਲਾਰਮਾਂ ਤੇ ਚੇਤਾਵਨੀ ਕਰੋ ਜੋ ਯੂਜ਼ਰ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ (ਡੈਸ਼ਬੋਰਡ timeout) ਅਤੇ ਉਹ ਸਿਗਨਲ ਜਿਨ੍ਹਾਂ ਤੇ ਜਲਦੀ ਕਾਰਵਾਈ ਕਰਨ ਦੀ ਲੋੜ ਹੈ (30 ਮਿੰਟ ਲਈ ਕਿਸੇ ਕਤਾਰ ਦਾ ਵਧਣਾ)। ਨਾਲ ਹੀ metric computation failures ਨੂੰ ਭੀ ਟਰੈਕ ਕਰੋ—ਕਈ ਵਾਰ missing cycle times ਨੂੰ “ਸੁਧਾਰ” ਵਜੋਂ ਗਲਤ ਸਮਝਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਡੇਟਾ ਤਾਜ਼ਗੀ: late events, corrections, ਅਤੇ backfills ਸੰਭਾਲੋ
ਓਪਰੇਸ਼ਨ ਡੇਟਾ ਦੇਰ ਨਾਲ, ਆਉਟ-ਆਫ-ਆਰਡਰ ਜਾਂ ਸਹੀ ਕੀਤਾ ਹੋਇਆ ਆ ਸਕਦਾ ਹੈ। ਯੋਜਨਾ ਬਣਾਓ:
- Idempotent ingestion (ਇੱਕੋ ਹੀ ਇਵੈਂਟ ਨੂੰ ਦੁਬਾਰਾ ਪ੍ਰੋਸੈਸ ਕਰਨ ਨਾਲ double-count ਨਾ ਹੋਵੇ)
- Backfills ਉਹ ਵੇਲੇ ਜਦੋਂ ਕੋਈ ਸਰੋਤ ਡਾਊਨ ਸੀ
- Recomputes ਜਦੋਂ ਸੰਦਰਭ ਡੇਟਾ ਬਦਲਦਾ ਹੈ (ਉਦਾਹਰਨ: shift calendars ਅਪਡੇਟ)
“ਤਾਜ਼ਾ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (ਉਦਾਹਰਨ: 95% ਇਵੈਂਟ 5 ਮਿੰਟਾਂ ਵਿੱਚ ਆ ਜਾਣ)। UI ਵਿੱਚ freshness ਦਿਖਾਓ।
ਰਨਬੁੱਕ ਲਿਖੋ ਤਾਂ fixes ਅੰਦਾਜੇ 'ਤੇ ਨਹੀਂ ਹੋਣ
ਸਟੈਪ-ਬਾਈ-ਸਟੈਪ ਰਨਬੁੱਕ ਦਸਤਾਵੇਜ਼ ਕਰੋ: ਇੱਕ ਟੁੱਟੀ ਸਿੰਕ ਕਿਵੇਂ ਰੀਸਟਾਰਟ ਕਰਨੀ, ਕੱਲ ਦੇ KPIs ਕਿਵੇਂ validate ਕਰਨੇ, ਅਤੇ backfill ਨੇ ਇਤਿਹਾਸਕ ਨੰਬਰਾਂ ਨੂੰ ਅਪੇਖਿਤ ਤਰੀਕੇ ਨਾਲ ਨਹੀਂ ਬਦਲਿਆ ਇਹ ਕਿਵੇਂ confirm ਕਰਨਾ। ਪ੍ਰੋਜੈਕਟ ਨਾਲ ਉਨ੍ਹਾਂ ਨੂੰ ਸਟੋਰ ਕਰੋ ਅਤੇ /docs ਤੋਂ ਲਿੰਕ ਕਰੋ ਤਾਂ ਟੀਮ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇ ਸਕੇ।
ਯੂਜ਼ਰਾਂ ਨਾਲ ਇਟਰੈੱਟ ਕਰੋ ਅਤੇ ਕਵਰੇਜ ਵਧਾਓ
ਇੱਕ ਬੋਤਲਨੈਕ-ਟ੍ਰੈਕਿੰਗ ਐਪ ਉਸ ਸਮੇਂ ਕਾਮਯਾਬ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਲੋਕ ਇਸ 'ਤੇ ਭਰੋਸਾ ਕਰਨ ਅਤੇ ਵਾਕਈ ਇਸਨੂੰ ਵਰਤਦੇ ਹਨ। ਇਹ ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਅਸਲ ਯੂਜ਼ਰਾਂ ਨੂੰ ਦੇਖੋ ਕਿ ਉਹ ਸੱਚਮੁੱਚ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਕਿਵੇਂ ਲੱਭਦੇ ਹਨ (“ਇਸ ਹਫਤੇ approvals ਕਿਉਂ ਸੰਤੁਸ਼ਟ ਨਹੀਂ?”) ਅਤੇ ਫਿਰ ਉਤਪਾਦ ਨੂੰ ਉਹਨਾਂ ਵਰਕਫਲੋਜ਼ ਦੇ ਆਸ-ਪਾਸ ਤਿੱਖਾ ਕਰੋ।
ਇੱਕ ਪਾਈਲਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਸਿੱਖੋ ਕਿ ਕੀ ਟੁੱਟਦਾ ਹੈ
ਇੱਕ ਪਾਈਲਟ ਟੀਮ ਅਤੇ ਕੁਝ ਪ੍ਰਕਿਰਿਆਵਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਸਕੋਪ ਐਨਾ ਨਾਰੋ ਰੱਖੋ ਕਿ ਤੁਸੀਂ ਵਰਤੋਂ ਦੇਖ ਸਕੋ ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇ ਸਕੋ।
ਪਹਿਲੇ ਇੱਕ-ਦੋ ਹਫਤਿਆਂ ਵਿੱਚ ਫੋਕਸ ਕਰੋ:
- ਕਿਹੜੇ ਚਾਰਟ ਯੂਜ਼ਰ ਗਲਤ ਸਮਝਦੇ ਹਨ?
- ਡ੍ਰਿਲ-ਡਾਊਨ ਕਰਦਿਆਂ ਉਹ ਕਿੱਥੇ ਫਸਦੇ ਹਨ?
- ਉਹ ਕਿਹੜਾ ਡੇਟਾ ਉਮੀਦ ਕਰਦੇ ਹਨ ਪਰ ਨਹੀਂ ਲੱਭਦਾ?
- ਕਿਸ ਬੋਤਲਨੈਕ ਨੂੰ ਉਹ “ਸਪਸ਼ਟ” ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ ਪਰ ਐਪ ਨਹੀਂ ਦਿਖਾਂਦਾ?
ਫੀਡਬੈਕ ਸਿੱਧਾ ਟੂਲ ਵਿੱਚ capture ਕਰੋ (ਕੁੱਝ ਮੁੱਖ ਸਕ੍ਰੀਨਾਂ 'ਤੇ "ਕੀ ਇਹ ਉਪਯੋਗੀ ਸੀ?" ਪ੍ਰਾਂਪਟ ਵਰਗਾ)।
"ਡੈਸ਼ਬੋਰਡ ਦੀਆਂ ਜ਼ਗੜੀਆਂ" ਰੋਕਣ ਲਈ ਮੈਟ੍ਰਿਕਸ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ
ਵਧੇਰੇ ਟੀਮਾਂ ਤੱਕ ਵਧਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਉਹ ਪਰਿਭਾਸ਼ਾਵਾਂ ਲਾਕ ਕਰੋ ਜਿਨ੍ਹਾਂ ਲਈ ਲੋਗ ਜ਼ਿੰਮੇਵਾਰ ਹੋਣਗੇ। ਬਹੁਤ ਸਾਰੇ ਰੋਲਆਊਟ ਫੇਲ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਟੀਮਾਂ ਇਹ ਨਹੀਂ ਮੰਨਦੀਆਂ ਕਿ ਮੈਟ੍ਰਿਕ ਦਾ ਕੀ ਮਤਲਬ ਹੈ।
ਹਰ KPI (cycle time, queue time, rework rate, SLA breaches) ਲਈ ਦਸਤਾਵੇਜ਼ ਕਰੋ:
- ਨਿਰਧਾਰਤ ਸ਼ੁਰੂ ਅਤੇ ਅੰਤਈਵੈਂਟ
- pauses, weekend, ਅਤੇ missing timestamps ਦਾ ਹੱਲ
- exceptions (cancellations, escalations, reopens) ਨੂੰ ਕਿਵੇਂ ਗਿਣਿਆ ਜਾਂਦਾ ਹੈ
ਫਿਰ ਉਨ੍ਹਾਂ ਪਰਿਭਾਸ਼ਾਵਾਂ ਨੂੰ ਯੂਜ਼ਰਾਂ ਨਾਲ ਸਮੀਖਿਆ ਕਰੋ ਅਤੇ UI ਵਿੱਚ ਛੋਟੇ ਟੂਲਟਿਪ ਦਿਓ। ਜੇ ਤੁਸੀਂ ਕੋਈ ਪਰਿਭਾਸ਼ਾ ਬਦਲਦੇ ਹੋ, ਤਾਂ ਸਪਸ਼ਟ changelog ਦਿਖਾਓ ਤਾਂ ਲੋਕ ਸਮਝ ਸਕਣ ਕਿ ਨੰਬਰ ਕਿਉਂ ਹਿਲੇ।
ਐਪ ਨੂੰ ਬਿਨਾਂ ਗੜਬੜ ਤੋਂ ਵਿਸ਼ਾਲ ਕਰੋ
ਪਾਈਲਟ ਟੀਮ ਦੇ ਵਰਕਫਲੋ ਵਿਸ਼ਲੇਸ਼ਣ ਸਥਿਰ ਹੋਣ 'ਤੇ ਹੀ ਫੀਚਰ ਧੀਰੇ-ਧੀਰੇ ਜੋੜੋ। ਆਮ ਅਗਲੇ ਵਾਧੇ:
- ਕਸਟਮ ਸਟੈਪ (ਅਲੱਗ ਟੀਮਾਂ ਵੱਖ-ਵੱਖ ਸਟੇਜ ਨਾਂ ਰੱਖਦੀਆਂ ਹਨ)
- ਹੋਰ ਸਰੋਤ (ਟਿਕਟ + CRM + ਸਪਰੇਡਸ਼ੀਟ)
- ਉन्नਤ ਵਿਭਾਗੀकरण (ਪ੍ਰੋਡਕਟ ਲਾਈਨ, ਰਜੀਅਨ, ਪ੍ਰਾਇਰਟੀ, ਗਾਹਕ ਟੀਅਰ)
ਇੱਕ ਵਰਤੀ ਯੋਜ਼ਨਾ: ਹਰ ਵਾਰ ਇੱਕ ਨਵਾਂ dimension ਜੋੜੋ ਅਤੇ ਪਰਖੋ ਕਿ ਕੀ ਇਹ ਫੈਸਲੇ ਬੇਹਤਰ ਬਣਾਉਂਦਾ ਹੈ, ਸਿਰਫ਼ ਰਿਪੋਰਟਿੰਗ ਨਹੀਂ।
ਓਨਬੋਰਡਿੰਗ ਆਸਾਨ ਅਤੇ ਦੁਹਰਾਏ ਯੋਗ ਬਣਾਓ
ਜਿਵੇਂ ਤੁਸੀਂ ਹੋਰ ਟੀਮਾਂ ਨੂੰ ਰੋਲ ਆਉਟ ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਲਗਾਤਾਰਤਾ ਦੀ ਲੋੜ ਮਹਿਸੂਸ ਕਰੋਗੇ। ਇੱਕ ਛੋਟੀ onboarding guide ਬਣਾਓ: ਡੇਟਾ ਕਿਵੇਂ ਕਨੈਕਟ ਕਰਨਾ, ਓਪਰੇਸ਼ਨ ਡੈਸ਼ਬੋਰਡ ਕਿਵੇਂ ਪੜ੍ਹਨਾ, ਅਤੇ ਬੋਤਲਨੈਕ ਚੇਤਾਵਨੀਆਂ 'ਤੇ ਕਿਵੇਂ ਕਾਰਵਾਈ ਕਰਨੀ।
ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ ਉਤਪਾਦ ਅਤੇ ਸਮੱਗਰੀ ਦੇ ਲਿੰਕ ਦਿਓ, ਜਿਵੇਂ /pricing ਅਤੇ /blog, ਤਾਂ ਨਵੇਂ ਯੂਜ਼ਰ ਸਵੈ-ਸੇਵਾ ਕਰ ਸਕਣ ਬਿਨਾਂ ਟਰੇਨਿੰਗ ਦੇ ਇੰਤਜ਼ਾਰ ਕੀਤੇ।