23 ਜੂਨ 2025·8 ਮਿੰਟ
Snowflake ਦਾ ਸਟੋਰੇਜ/ਕੰਪਿਊਟ ਵੰਡ: ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਇਕੋਸਿਸਟਮ
ਜਾਣੋ ਕਿ Snowflake ਨੇ ਸਟੋਰੇਜ ਅਤੇ ਕੰਪਿਊਟ ਨੂੰ ਵੱਖਰਾ ਕਰਕੇ ਕਿਵੇਂ ਲੋਕਪ੍ਰਿਯ ਕੀਤਾ, ਇਹ ਸਕੇਲਿੰਗ ਅਤੇ ਖਰਚ ਦੇ trade-offs ਨੂੰ ਕਿਵੇਂ ਬਦਲਦਾ ਹੈ, ਅਤੇ ਕਿਉਂ ਇਕੋਸਿਸਟਮ ਤੇਜ਼ੀ ਦੇ ਬਰਾਬਰ ਮਹੱਤਵਪੂਰਨ ਹੈ।
ਜਾਣੋ ਕਿ Snowflake ਨੇ ਸਟੋਰੇਜ ਅਤੇ ਕੰਪਿਊਟ ਨੂੰ ਵੱਖਰਾ ਕਰਕੇ ਕਿਵੇਂ ਲੋਕਪ੍ਰਿਯ ਕੀਤਾ, ਇਹ ਸਕੇਲਿੰਗ ਅਤੇ ਖਰਚ ਦੇ trade-offs ਨੂੰ ਕਿਵੇਂ ਬਦਲਦਾ ਹੈ, ਅਤੇ ਕਿਉਂ ਇਕੋਸਿਸਟਮ ਤੇਜ਼ੀ ਦੇ ਬਰਾਬਰ ਮਹੱਤਵਪੂਰਨ ਹੈ।
Snowflake ਨੇ ਕਲਾਉਡ ਡੇਟਾ ਵੇਅਰਹਾਊਸਿੰਗ ਵਿੱਚ ਇੱਕ ਸਧਾਰਣ ਪਰ ਫਰਕ ਪੈਦਾ ਕਰਨ ਵਾਲੀ ਸੋਚ ਨੂੰ ਲੋਕਪ੍ਰਿਯ ਕੀਤਾ: ਡੇਟਾ ਸਟੋਰੇਜ ਅਤੇ ਕਵੈਰੀ ਕੰਪਿਊਟ ਨੂੰ ਵੱਖਰਾ ਰੱਖੋ। ਇਹ ਵੰਡ ਦੋ ਰੋਜ਼ਾਨਾ ਮੁੱਦਿਆਂ—ਕਿਵੇਂ ਵੇਅਰਹਾਊਸ ਸਕੇਲ ਹੁੰਦੇ ਹਨ ਅਤੇ ਤੁਸੀਂ ਉਹਨਾਂ ਲਈ ਕਿਵੇਂ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ—ਨੂੰ ਬਦਲ ਦਿੰਦੀ ਹੈ।
ਇੱਕ ਇੱਕੋ “ਬਾਕਸ” ਵਾਂਗੋਂ ਵੇਅਰਹਾਊਸ ਦੇਖਣ ਦੀ ਥਾਂ (ਜਿੱਥੇ ਵੱਧ ਯੂਜ਼ਰ, ਵੱਧ ਡੇਟਾ ਜਾਂ ਜ਼ਿਆਦਾ ਜਟਿਲ ਕਵੈਰੀਆਂ ਸਭ ਇੱਕੋ ਹੀ ਸਰੋਤਾਂ ਲਈ ਮੁਕਾਬਲਾ ਕਰਦੀਆਂ ਹਨ), Snowflake ਦਾ ਮਾਡਲ ਤੁਹਾਨੂੰ ਡੇਟਾ ਇਕ ਵਾਰ ਸੰਭਾਲ ਕੇ ਰੱਖਣ ਅਤੇ ਲੋੜ ਮੁਤਾਬਕ ਢੰਗ ਦਾ compute ਚਲਾਉਣ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦਾ ਹੈ। ਨਤੀਜਾ ਆਮ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਸਵਾਲ-ਦੇਣ ਦਾ ਸਮਾਂ, ਪੀਕ ਦੌਰਾਨ ਘੱਟ ਬੋਤਲਨੀਕ ਅਤੇ ਇਸ ਗੱਲ 'ਤੇ ਵਧੀਆ ਨਿਯੰਤਰਣ ਹੁੰਦਾ ਹੈ ਕਿ ਕਦੋਂ ਖਰਚ ਆਉਂਦਾ ਹੈ (ਅਤੇ ਕਦੋਂ)।
ਇਹ ਪੋਸਟ ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ ਵਿਆਖਿਆ ਕਰਦੀ ਹੈ ਕਿ ਸਟੋਰੇਜ ਅਤੇ ਕੰਪਿਊਟ ਵੱਖੇ ਕਰਨ ਦਾ ਅਸਲ ਮਤਲਬ ਕੀ ਹੈ—ਅਤੇ ਇਹ ਕੀ ਪ੍ਰਭਾਵ ਪਾਉਂਦਾ ਹੈ:
ਅਸੀਂ ਇਹ ਵੀ ਦੱਸਾਂਗੇ ਕਿ ਇਹ ਮਾਡਲ ਸਭ ਕੁਝ ਜਾਦੂਈ ਤਰੀਕੇ ਨਾਲ ਹੱਲ ਨਹੀਂ ਕਰਦਾ—ਕਈ ਵਾਰ ਲਾਗਤ ਅਤੇ ਕਾਰਗੁਜ਼ਾਰੀ ਦੇ ਅਚਾਨਕ ਨਤੀਜੇ ਵਰਕਲੋਡ ਡਿਜ਼ਾਈਨ ਤੋਂ ਆਉਂਦੇ ਹਨ, ਨਾ ਕਿ ਪਲੇਟਫਾਰਮ ਤੋਂ ਹੀ।
ਤੀਜ਼ ਪਲੇਟਫਾਰਮ ਸਭ ਕੁਝ ਨਹੀਂ। ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਲਈ, ਮੁੱਲ ਮਿਲਣ ਦਾ ਸਮਾਂ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ ਕੀ ਤੁਸੀਂ ਆਸਾਨੀ ਨਾਲ ਵਾਰਹਾਊਸ ਨੂੰ ਉਹਨਾਂ ਟੂਲਾਂ ਨਾਲ ਜੋੜ ਸਕਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ ਤੋਂ ਵਰਤਦੇ ਹੋ—ETL/ELT ਪਾਈਪਲਾਈਨ, BI ਡੈਸ਼ਬੋਰਡ, ਕੈਟਾਲੌਗ/ਗਵਰਨੈਂਸ ਟੂਲ, ਸੁਰੱਖਿਆ ਨਿਯੰਤਰਣ ਅਤੇ ਭਾਗੀਦਾਰ ਡੇਟਾ ਸੋース।
Snowflake ਦਾ ਇਕੋਸਿਸਟਮ (ਜਿਸ ਵਿੱਚ ਡੇਟਾ ਸ਼ੇਅਰਿੰਗ ਪੈਟਰਨ ਅਤੇ ਮਾਰਕੀਟਪਲੇਸ-ਸਟਾਈਲ ਵੰਡ ਸ਼ਾਮਲ ਹਨ) ਇੰਪਲੀਮੇਂਟੇਸ਼ਨ ਸਮੇਂ ਨੂੰ ਛੋਟਾ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਕਸਟਮ ਇੰਜੀਨੀਅਰਿੰਗ ਘਟਾ ਸਕਦਾ ਹੈ। ਇਹ ਪੋਸਟ ਦਰਸਾਉਂਦੀ ਹੈ ਕਿ "ਇਕੋਸਿਸਟਮ ਦੀ ਗਹਿਰਾਈ" ਅਮਲੀ ਤੌਰ 'ਤੇ ਕੀ ਦਿਖਦੀ ਹੈ ਅਤੇ ਆਪਣੇ ਸੰਗਠਨ ਲਈ ਇਸ ਦੀ ਮੁਲਾਂਕਣ ਕਿਵੇਂ ਕਰੋ।
ਇਹ ਗਾਈਡ ਡੇਟਾ ਲੀਡਰਾਂ, ਵਿਸ਼ਲੇਸ਼ਕਾਂ, ਅਤੇ ਗੈਰ-ਖਾਸ ਤਰਾਂ ਦੇ ਫੈਸਲਾ ਕਰਨ ਵਾਲਿਆਂ ਲਈ ਲਿਖੀ ਗਈ ਹੈ—ਜੋ ਕੋਈ ਵੀ Snowflake ਆਰਕੀਟੈਕਚਰ, ਸਕੇਲਿੰਗ, ਲਾਗਤ ਅਤੇ ਇੰਟਿਗਰੇਸ਼ਨ ਚੋਣਾਂ ਦੀਆਂ trade-offs ਨੂੰ ਸਾਦੀ ਭਾਸ਼ਾ ਵਿੱਚ ਸਮਝਣਾ ਚਾਹੁੰਦੇ ਹਨ ਬਿਨਾਂ ਵੈਂਡਰ ਜਾਰਗਨ ਵਿੱਚ ਡੁੱਬੇ।
ਪਰੰਪਰਾਗਤ ਡੇਟਾ ਵੇਅਰਹਾਊਸ ਇਸ ਸੌਧਾਰ ਤੇ ਬਣੇ ਸਨ: ਤੁਸੀਂ ਇੱਕ ਨਿਸ਼ਚਿਤ ਹਾਰਡਵੇਅਰ ਦੀ ਰਕਮ ਖਰੀਦਦੇ/ਕਿਰਾਏ 'ਤੇ ਲੈਂਦੇ, ਅਤੇ ਸਭ ਕੁਝ ਉਸੇ ਬਾਕਸ ਜਾਂ ਕਲੱਸਟਰ 'ਤੇ ਚਲਾਉਂਦੇ। ਜਦ ਕਿ ਲੋੜਾਂ ਪੇਸ਼ਗੀ ਹੁੰਦੀਆਂ ਹਨ ਤੇ ਵਾਧਾ ਨਰਮ ਹੁੰਦਾ, ਇਹ ਠੀਕ ਕੰਮ ਕਰਦਾ ਸੀ—ਪਰ ਜਦ ਡੇਟਾ ਅਤੇ ਯੂਜ਼ਰ ਗਿਣਤੀ ਤੇਜ਼ੀ ਨਾਲ ਵਧਗੀ ਤਾਂ ਇਹ ਰਚਨਾਤਮਕ ਸੀਮਾਵਾਂ ਬਣ ਗਈਆਂ।
On-prem ਸਿਸਟਮ ਅਤੇ ਸ਼ੁਰੂਆਤੀ cloud "lift-and-shift" ਨਿਯਮਾਂ ਅਕਸਰ ਇਹੋ ਜਿਹਾ ਦਿਖਦੇ ਸਨ:
ਜਦੋਂ ਵੀ ਵੇਂਡਰ "ਨੋਡਜ਼" ਦਿੱਤੇ, ਮੂਲ ਪੈਟਰਨ ਇੱਕੋ ਰਹਿੰਦਾ ਸੀ: ਸਕੇਲ ਆਮ ਤੌਰ 'ਤੇ ਵੱਡੇ ਜਾਂ ਵੱਧ ਨੋਡਜ਼ ਸ਼ਾਮਲ ਕਰਨ ਵਾਲਾ ਹੁੰਦਾ ਸੀ ਜੋ ਇੱਕ SaaShared environment ਨੂੰ ਵਧਾਉਂਦਾ।
ਇਸ ਡਿਜ਼ਾਈਨ ਨਾਲ ਕੁਝ ਆਮ ਸਮੱਸਿਆਵਾਂ ਪੈਦਾ ਹੁੰਦੀਆਂ:
ਕਿਉਂਕਿ ਇਹ ਵੇਅਰਹਾਊਸ ਆਪਣੀਆਂ ਵਾਤਾਵਰਣਾਂ ਨਾਲ ਕਠੋਰ ਤੌਰ 'ਤੇ ਜੁੜੇ ਹੁੰਦੇ ਸਨ, ਇੰਟੇਗ੍ਰੇਸ਼ਨਾਂ ਅਕਸਰ ਜੈਵਿਕ ਤਰੀਕੇ ਨਾਲ ਵਧਦੀਆਂ: ਕਸਟਮ ETL ਸਕ੍ਰਿਪਟ, ਹੱਥ ਨਾਲ ਬਣੇ ਕਨੈਕਟਰ, ਅਤੇ ਇੱਕ-ਵਾਰੀ ਪਾਈਪਲਾਈਨ। ਉਹ ਕੰਮ ਕਰਦੇ—ਜਦ ਤੱਕ ਇੱਕ ਸਕੀਮਾ ਬਦਲਿਆ, ਉੱਪਸਟ੍ਰੀਮ ਸਿਸਟਮ ਖਿਸਕ ਗਿਆ, ਜਾਂ ਕੋਈ ਨਵਾਂ ਟੂਲ ਆਇਆ। ਸਭ ਕੁਝ ਚਲਦੀ ਰੱਖਣਾ ਇਕ ਲਗਾਤਾਰ ਮਰੰਮਤ ਵਰਗਾ ਲੱਗ ਸਕਦਾ ਸੀ।
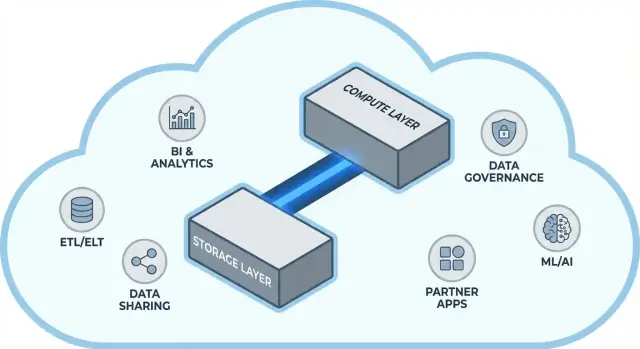
ਪਰੰਪਰਾਗਤ ਡੇਟਾ ਵੇਅਰਹਾਊਸ ਅਕਸਰ ਦੋ ਬਹੁਤ ਵੱਖ-ਵੱਖ ਕੰਮਾਂ ਨੂੰ ਜੋੜ ਦਿੰਦੇ ਹਨ: ਸਟੋਰੇਜ (ਜਿੱਥੇ ਤੁਹਾਡਾ ਡੇਟਾ ਰਹਿੰਦਾ ਹੈ) ਅਤੇ ਕੰਪਿਊਟ (ਹੋਰਸਪਾਵਰ ਜੋ ਉਹ ਡੇਟਾ ਪੜ੍ਹਦਾ, ਜੋੜਦਾ, ਗਣਨਾ ਕਰਦਾ ਅਤੇ ਲਿਖਦਾ ਹੈ)।
ਸਟੋਰੇਜ ਇਕ ਲੰਮੇ ਸਮੇਂ ਦੀ ਪੈਂਟਰੀ ਵਾਂਗ ਹੈ: ਟੇਬਲਾਂ, ਫਾਇਲਾਂ ਅਤੇ ਮੈਟਾਡੇਟਾ ਸਸਤੇ, ਭਰੋਸੇਯੋਗ ਅਤੇ ਹਮੇਸ਼ਾਂ ਉਪਲਬਧ ਰੱਖੇ ਜਾਂਦੇ ਹਨ।
ਕੰਪਿਊਟ ਰਸੋਈ ਕਰਮਚਾਰੀ ਵਾਂਗ ਹੈ: CPU ਅਤੇ ਮੈਮੋਰੀ ਜੋ ਤੁਹਾਡੀਆਂ ਕਵੈਰੀਆਂ ਨੂੰ "ਪਕਾਉਂਦੇ" ਹਨ—SQL ਚਲਾਉਣਾ, ਸਾਰਟ, ਸਕੈਨ, ਨਤੀਜੇ ਬਣਾਉਣਾ ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਯੂਜ਼ਰਾਂ ਨੂੰ ਹੈਂਡਲ ਕਰਨਾ।
Snowflake ਇਹ ਦੋਹਾਂ ਨੂੰ ਅਲੱਗ ਕਰਦਾ ਹੈ ਤਾਂ ਜੋ ਤੁਸੀਂ ਹਰੇਕ ਨੂੰ ਬਿਨਾਂ ਦੂਜੇ ਨੂੰ ਬਦਲੇ ਐਡਜਸਟ ਕਰ ਸਕੋ।
ਅਮਲੀ ਤੌਰ 'ਤੇ, ਇਹ ਦਿਨ-ਬ-ਦਿਨ ਓਪਰੇਸ਼ਨ ਨੂੰ ਬਦਲ ਦਿੰਦਾ ਹੈ: ਤੁਸੀਂ ਸਟੋਰੇਜ ਵਧਣ ਕਰਕੇ compute ਨੂੰ "ਓਵਰਬਾਇ" ਨਹੀਂ ਕਰਨਾ ਚਾਹੁੰਦੇ, ਅਤੇ ਤੁਸੀਂ ਵਰਕਲੋਡ ਨੂੰ ਆਈਸੋਲੇਟ ਕਰ ਸਕਦੇ ਹੋ ਤਾਂ ਕਿ ਉਹ ਇਕ-ਦੂਜੇ ਨੂੰ ਸੁਸਤ ਨਾ ਕਰਣ।
ਇਹ ਵੰਡ ਸ਼ਕਤੀਸ਼ਾਲੀ ਹੈ, ਪਰ ਜਾਦੂ ਨਹੀਂ:
ਮੁੱਲ ਨਿਯੰਤਰਣ ਵਿੱਚ ਹੈ: ਸਟੋਰੇਜ ਅਤੇ compute ਲਈ ਅਲੱਗ-ਅਲੱਗ ਭੁਗਤਾਨ ਅਤੇ ਹਰ ਇੱਕ ਨੂੰ ਤੁਹਾਡੀ ਟੀਮਾਂ ਦੀ ਲੋੜ ਮੁਤਾਬਕ ਮੈਚ ਕਰਨਾ।
Snowflake ਨੂੰ ਤਿੰਨ ਪਰਤਾਂ ਵਜੋਂ ਸਮਝਣਾ ਸਭ ਤੋਂ ਆਸਾਨ ਹੈ ਜੋ ਇਕੱਠੇ ਕੰਮ ਕਰਦੀਆਂ ਹਨ ਪਰ ਅਲੱਗ-ਅਲੱਗ ਸਕੇਲ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਤੁਹਾਡੀਆਂ ਟੇਬਲਾਂ ਆਖ਼ਿਰਕਾਰ cloud provider ਦੇ object storage (ਜਿਵੇਂ S3, Azure Blob, ਜਾਂ GCS) ਵਿੱਚ ਡੇਟਾ ਫਾਇਲਾਂ ਵਜੋਂ ਰਹਿੰਦੀਆਂ ਹਨ। Snowflake ਤੁਹਾਡੇ ਲਈ ਫਾਇਲ ਫਾਰਮੈਟ, ਕੰਪ੍ਰੈਸ਼ਨ ਅਤੇ ਸੰਗਠਨ ਦਾ ਪ੍ਰਬੰਧ ਕਰਦਾ ਹੈ। ਤੁਸੀਂ "ਡਿਸਕ ਜੁੜਨਾ" ਜਾਂ storage volumes ਸਾਈਜ਼ ਕਰਨਾ ਨਹੀਂ ਕਰਦੇ—storage ਡੇਟਾ ਵਧਣ ਨਾਲ ਵੱਧਦਾ ਹੈ।
ਕੰਪਿਊਟ ਨੂੰ virtual warehouses ਵਜੋਂ ਪੈਕੇਜ ਕੀਤਾ ਜਾਂਦਾ ਹੈ: CPU/ਮੈਮੋਰੀ ਦੇ ਅਲੱਗ ਕਲੱਸਟਰ ਜੋ ਕਵੈਰੀਜ਼ ਨੂੰ ਐਗਜ਼ੈਕਿਊਟ ਕਰਦੇ ਹਨ। ਤੁਸੀਂ ਇੱਕੋ ਵੇਲੇ ਇੱਕੋ ਡੇਟਾ 'ਤੇ ਕਈ warehouses ਚਲਾ ਸਕਦੇ ਹੋ। ਇਹ ਪੁਰਾਣੇ ਸਿਸਟਮਾਂ ਤੋਂ ਮੁੱਖ ਫਰਕ ਹੈ, ਜਿੱਥੇ ਭਾਰੀ ਵਰਕਲੋਡ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕੋ ਸਰੋਤ ਲਈ ਮੁਕਾਬਲਾ ਕਰਦੇ ਸਨ।
ਇੱਕ ਵੱਖਰੀ ਸਰਵਿਸ ਲੇਅਰ "ਸਿਸਟਮ ਦਾ ਦਿਮਾਗ" ਸੰਭਾਲਦੀ ਹੈ: authentication, query parsing ਅਤੇ optimization, transaction/metadata management, ਅਤੇ ਕੋਆਰਡੀਨੇਸ਼ਨ। ਇਹ ਲੇਅਰ ਫੈਸਲਾ ਕਰਦੀ ਹੈ ਕਿ ਕਿਵੇਂ ਇੱਕ ਕਵੈਰੀ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਢੰਗ ਨਾਲ ਚਲਾਇਆ ਜਾਵੇ ਪਹਿਲਾਂ ਕਿ compute ਡੇਟਾ ਨੂੰ ਛੂਹੇ।
ਜਦੋਂ ਤੁਸੀਂ SQL ਸਬਮਿਟ ਕਰਦੇ ਹੋ, Snowflake ਦੀ services ਲੇਅਰ ਉਸਨੂੰ parse ਕਰਦੀ, execution plan ਬਣਾਉਂਦੀ, ਅਤੇ ਫਿਰ ਉਹ ਪਲਾਨ ਕਿਸੇ ਚੁਣੀ ਹੋਈ virtual warehouse ਨੂੰ ਦੇ ਦਿੰਦੀ ਹੈ। warehouse ਜ਼ਰੂਰੀ ਡੇਟਾ ਫਾਇਲਾਂ ਨੂੰ object storage ਤੋਂ ਪੜ੍ਹਦਾ ਹੈ (ਅਤੇ ਜੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ caching ਦਾ ਫਾਇਦਾ ਲੈਂਦਾ ਹੈ), ਉਹਨਾਂ ਨੂੰ process ਕਰਦਾ, ਅਤੇ ਨਤੀਜੇ ਵਾਪਸ ਕਰਦਾ—ਬਿਨਾਂ ਤੁਹਾਡੇ ਮੁਲ ਡੇਟਾ ਨੂੰ ਸਥਾਈ ਤੌਰ 'ਤੇ warehouse ਵਿੱਚ ਹਿਲਾਏ।
ਜੇ ਬਹੁਤ ਸਾਰੇ ਲੋਕ ਇੱਕੋ ਸਮੇਂ ਕਵੈਰੀ ਚਲਾ ਰਹੇ ਹਨ, ਤੁਸੀਂ:
ਇਹ Snowflake ਦੀ ਕਾਰਗੁਜ਼ਾਰੀ ਅਤੇ “noisy neighbor” ਕੰਟਰੋਲ ਦੀ ਆਧਾਰਭੂਤ ਰਚਨਾ ਹੈ।
Snowflake ਦਾ ਵੱਡਾ ਅਮਲੀ ਬਦਲਾਅ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ compute ਨੂੰ ਡੇਟਾ ਤੋਂ ਅਲੱਗ ਸਕੇਲ ਕਰਦੇ ਹੋ। "ਵੇਅਰਹਾਊਸ ਵੱਡਾ ਹੋ ਰਿਹਾ ਹੈ" ਦੀ ਥਾਂ, ਤੁਹਾਨੂੰ ਹਰ ਵਰਕਲੋਡ ਲਈ ਸਰੋਤ ਉੱਪਰ-ਥੱਲੇ ਕਰਨ ਦੀ ਸਮਰਥਾ ਮਿਲਦੀ—ਬਿਨਾਂ ਟੇਬਲਾਂ ਦੀ ਨਕਲ, ਡਿਸਕ ਰੀਪਾਰਟੀਸ਼ਨ, ਜਾਂ ਡਾਉਨਟਾਈਮ ਸ਼ੈਡਿਊਲ ਕੀਤੇ।
Snowflake ਵਿਚ, ਇੱਕ virtual warehouse ਉਹ compute ਇੰਜਣ ਹੈ ਜੋ ਕਵੈਰੀਜ਼ ਚਲਾਉਂਦਾ ਹੈ। ਤੁਸੀਂ ਇਸਨੂੰ seconds ਵਿੱਚ resize ਕਰ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ Small ਤੋਂ Large), ਅਤੇ ਡੇਟਾ ਇੱਕੋ ਥਾਂ 'ਤੇ ਰਹਿੰਦਾ ਹੈ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਪ੍ਰਦਰਸ਼ਨ ਟਿਊਨਿੰਗ ਅਕਸਰ ਇੱਕ ਸਧਾਰਣ ਸਵਾਲ ਬਣ ਜਾਂਦੀ ਹੈ: "ਕੀ ਇਸ ਵਰਕਲੋਡ ਨੂੰ ਹੁਣ ਵੱਧ ਹਾਰਸਪਾਵਰ ਦੀ ਲੋੜ ਹੈ?"
ਇਸ ਨਾਲ ਅਸਥਾਈ ਬਰਸਟ ਵੀ ਸੰਭਵ ਹੁੰਦੀ ਹੈ: ਮਾਨੋ ਮਹੀਨੇ-ਅੰਤ ਲਈ ਸਕੇਲ-ਅੱਪ, ਫਿਰ spike ਖਤਮ ਹੋਣ 'ਤੇ ਘਟਾ ਦੇਵੋ।
ਪੁਰਾਣੇ ਸਿਸਟਮ ਅਕਸਰ ਵੱਖ-ਵੱਖ ਟੀਮਾਂ ਨੂੰ ਇੱਕੋ compute ਸਾਂਝਾ ਕਰਨ 'ਤੇ ਮਜਬੂਰ ਕਰਦੇ ਸਨ, ਜਿਸ ਨਾਲ ਜੀਭ-ਵੰਡ ਵਰਗਾ ਮਾਹੌਲ ਬਣ ਜਾਂਦਾ ਸੀ।
Snowflake ਤੁਹਾਨੂੰ ਹਰੇਕ ਟੀਮ ਜਾਂ ਵਰਕਲੋਡ ਲਈ ਵੱਖਰੇ warehouses ਚਲਾਉਣ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦਾ—ਉਦਾਹਰਣ ਵਜੋਂ ਇਕ ਨੂੰ analysts ਲਈ, ਇਕ ਨੂੰ dashboards ਲਈ, ਅਤੇ ਇਕ ਨੂੰ ETL ਲਈ। ਇਨ੍ਹਾਂ warehouses ਨੂੰ ਇੱਕੋ ਮੂਲ ਡੇਟਾ ਪੜ੍ਹਨ ਦਾ ਹੱਕ ਹੋਣ ਦੇ ਨਾਲ, ਤੁਸੀਂ "ਮੇਰਾ ਡੈਸ਼ਬੋਰਡ ਤੇਰਾ ਰਿਪੋਰਟ ਵੀ ਸੁਸਤ ਕਰਦਾ" ਵਾਲੀ ਸਮੱਸਿਆ ਘਟਾ ਦਿੰਦੇ ਹੋ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਜਿਆਦਾ ਭਵਿੱਖਬਾਣੀਯੋਗ ਬਣਾਉਂਦੇ ਹੋ।
Elastic compute ਆਪਣੀ ਆਪ ਵਿੱਚ ਸਫਲਤਾ ਨਹੀਂ ਲਿਆਉਂਦੀ। ਆਮ ਗਲਤੀਆਂ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹਨ:
ਨੈੱਟ ਬਦਲਾਅ ਇਹ ਹੈ ਕਿ ਸਕੇਲਿੰਗ ਅਤੇ concurrency ਇੰਫਰਾਸਟਰੱਕਚਰ ਪ੍ਰਾਜੈਕਟਾਂ ਤੋਂ ਦੈਨਿਕ ਓਪਰੇਟਿੰਗ ਫੈਸਲਿਆਂ ਵੱਲ ਬਦਲ ਜਾਂਦੇ ਹਨ।
Snowflake ਦਾ "ਜੋ ਤੁਸੀਂ ਵਰਤਦੇ ਉਸਦਾ ਭੁਗਤਾਨ" ਅਸਲ ਵਿੱਚ ਦੋ ਮੀਟਰ ਇਕੱਠੇ ਚਲ ਰਹੇ ਹਨ:
ਇਹ ਵੰਡ ਓਸ ਥਾਂ ਹੈ ਜਿੱਥੇ ਬਚਤ ਹੋ ਸਕਦੀ ਹੈ: ਤੁਸੀਂ ਬਹੁਤ ਸਾਰਾ ਡੇਟਾ ਮੁਕਾਬਲੇ ਵਿੱਚ ਸਸਤੇ ਢੰਗ ਨਾਲ ਰੱਖ ਸਕਦੇ ਹੋ ਅਤੇ compute ਸਿਰਫ ਜਦੋਂ ਲੋੜ ਹੋਵੇ ਚਲਾਉਂਦੇ ਹੋ।
ਜ਼ਿਆਦਾਤਰ "ਅਣਉਮੀਦ" ਖਰਚ compute ਦੇ ਵ੍ਯਵਹਾਰ ਤੋਂ ਆਉਂਦੇ ਹਨ ਨਾ ਕਿ ਸਿੱਧਾ storage ਤੋਂ। ਆਮ ਕਾਰਕ ਹਨ:
ਸਟੋਰੇਜ-ਕੰਪਿਊਟ ਵੱਖਰਾ ਹੋਣ ਨਾਲ ਕਵੈਰੀਆਂ ਖ਼ਰਚੀਲੇ ਬਣਦੀਆਂ ਨਹੀਂ ਹਨ—ਮਗਰ ਬੁਰੇ SQL ਫਿਰ ਵੀ credits ਤੇਜ਼ੀ ਨਾਲ ਖਾਧ ਸਕਦਾ ਹੈ।
ਤੁਹਾਨੂੰ ਫਾਇਨੈਂਸ ਵਿਭਾਗ ਦੀ ਲੋੜ ਨਹੀਂ—ਸਿਰਫ ਕੁਝ guardrails:
ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਵਰਤੋਂ 'ਚ, ਇਹ ਮਾਡਲ ਅਨੁਸ਼ਾਸਨ ਨੂੰ ਇਨਾਮ ਦਿੰਦਾ ਹੈ: ਛੋਟੇ-ਚਲਦੇ, ਠੀਕ-ਸਾਈਜ਼ਡ compute ਨਾਲ ਪ੍ਰਭਾਵਸ਼ਾਲੀ storage ਬਰਤੀ।
Snowflake ਸ਼ੇਅਰਿੰਗ ਨੂੰ ਐਸਾ ਕੁਝ ਸਮਝਦਾ ਹੈ ਜੋ ਪਲੇਟਫਾਰਮ ਵਿੱਚ ਹੀ ਡਿਜ਼ਾਇਨ ਕੀਤਾ ਗਿਆ—na ਕਿ export, file drops, ਅਤੇ ਇੱਕ-ਵਾਰੀ ETL 'ਤੇ ਬੋਲਟ ਕੀਤਾ ਗਿਆ।
ਫਾਇਲਾਂ ਭੇਜਣ ਦੀ ਥਾਂ, Snowflake ਕਿਸੇ ਹੋਰ account ਨੂੰ secure "share" ਰਾਹੀਂ ਉਹੀ ਅਧਾਰਭੂਤ ਡੇਟਾ query ਕਰਨ ਦੀ ਆਗਿਆ ਦੇ ਸਕਦਾ ਹੈ। ਕਈ ਦ੍ਰਿਸ਼ਾਂਤਾਂ ਵਿੱਚ, ਡੇਟਾ ਨੂੰ ਦੂਜੇ ਵੇਅਰਹਾਊਸ ਵਿੱਚ ਨਕਲ ਕਰਨ ਦੀ ਜ਼ਰੂਰਤ ਨਹੀਂ ਹੁੰਦੀ। ਗਾਹਕ ਉਹ ਸਾਂਝਿਆ ਡੇਟਾਬੇਸ/ਟੇਬਲ ਨੂੰ ਆਪਣੇ ਕੋਲ ਲੋਕਲ ਵਾਂਗ ਵੇਖਦੇ ਹਨ, ਜਦਕਿ ਪ੍ਰਦਾਤਾ ਨਿਰਧਾਰਿਤ ਕੀਤੇ ਚੀਜ਼ਾਂ 'ਤੇ ਨਿਯੰਤਰਣ ਰੱਖਦਾ ਹੈ।
ਇਹ "ਡੇਕਪਲਡ" ਤਰੀਕਾ ਡੇਟਾ ਫੈਲਾਉ ਘਟਾਉਂਦਾ, ਪਹੁੰਚ ਤੇਜ਼ ਕਰਦਾ, ਅਤੇ ਬਣਾਈਆਂ ਅਤੇ ਰੱਖ-ਰਖਾਅ ਵਾਲੀਆਂ ਪਾਈਪਲਾਈਨਾਂ ਦੀ ਗਿਣਤੀ ਘਟਾਉਂਦਾ।
ਭਾਗੀਦਾਰ ਅਤੇ ਗ੍ਰਾਹਕ ਸ਼ੇਅਰਿੰਗ: ਇੱਕ ਵੇਂਡਰ curated datasets ਗਾਹਕਾਂ ਨੂੰ ਪਬਲਿਸ਼ ਕਰ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਣ ਲਈ usage analytics ਜਾਂ reference data) ਸਾਫ਼ ਹੱਦਾਂ ਦੇ ਨਾਲ—ਕੇਵਲ ਮਨਜ਼ੂਰ ਕੀਤੇ schema, tables, ਜਾਂ views।
ਅੰਦਰੂਨੀ ਡੋਮੇਨ ਸ਼ੇਅਰਿੰਗ: ਕੇਂਦਰੀ ਟੀਮਾਂ ਪ੍ਰਮਾਣਿਤ datasets ਨੂੰ product, finance, ਅਤੇ operations ਨੂੰExpose ਕਰ ਸਕਦੀਆਂ ਹਨ ਬਿਨਾਂ ਹਰ ਟੀਮ ਨੂੰ ਆਪਣੀਆਂ ਨਕਲਾਂ ਬਣਾਉਣ ਦੇ। ਇਹ "ਇੱਕ ਹੀ ਨੰਬਰਾਂ ਦਾ ਸੈਟ" ਸੰਸਕਾਰ ਨੂੰ ਸਮਰਥਨ ਕਰਦਾ ਹੈ ਜਦਕਿ ਹਰੇਕ ਟੀਮ ਆਪਣਾ compute ਚਲਾ ਸਕਦੀ ਹੈ।
ਸ਼ਾਸਤਰੀ ਸਹਿਯੋਗ: ਸਾਂਝੇ ਪ੍ਰਾਜੈਕਟਾਂ (ਜਿਵੇਂ ਏਜੰਸੀ, ਸਪਲਾਇਰ, ਜਾਂ ਸਬਸిడਰੀ) ਲਈ ਸਾਂਝੇ dataset 'ਤੇ ਕੰਮ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈਜਿਸ ਦੌਰਾਨ ਸੰਵੇਦਨਸ਼ੀਲ ਕਾਲਮ-ਾਂ ਨੂੰ masked ਰੱਖਿਆ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਐਕਸੈਸ ਲੌਗ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
Sharing "ਇੱਕ ਵਾਰੀ ਕਰਕੇ ਭੁਲਾ ਦੇਣ" ਵਾਲੀ ਚੀਜ਼ ਨਹੀਂ ਹੈ। ਤੁਹਾਨੂੰ ਫਿਰ ਵੀ ਲੋੜ ਹੁੰਦੀ ਹੈ:
ਇੱਕ ਤੇਜ਼ ਵੇਅਰਹਾਊਸ ਕੀਮਤੀ ਹੈ, ਪਰ ਸਿਰਫ ਰਫ਼ਤਾਰ ਹੀ ਅਕਸਰ ਇਹ ਨਹੀਂ ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਕਿ ਪ੍ਰਾਜੈਕ्ट ਸਮੇਂ 'ਤੇ ਪਹੁੰਚੇਗਾ। ਜ਼ਿਆਦातर ਵਾਰ, ਫਰਕ ਬਣਾਉਂਦਾ ਹੈ ਪਲੇਟਫਾਰਮ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਦਾ ਇਕੋਸਿਸਟਮ: ਤਿਆਰ-ਬਣੇ ਕਨੈਕਟਰ, ਟੂਲ, ਅਤੇ ਗਿਆਨ ਜੋ ਕਸਟਮ ਕੰਮ ਘਟਾਉਂਦੇ ਹਨ।
ਅਮਲੀ ਤੌਰ 'ਤੇ, ਇੱਕ ਇਕੋਸਿਸਟਮ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹਨ:
Benchmarks ਨਿਯੰਤ੍ਰਿਤ ਹਾਲਤਾਂ 'ਚ ਰਫ਼ਤਾਰ ਦਾ ਇੱਕ ਸੰਕੁਚਿਤ ਹਿੱਸਾ ਮਾਪਦੇ ਹਨ। ਅਸਲ ਪ੍ਰਾਜੈਕਟ ਇਨ੍ਹਾਂ 'ਤੇ ਜ਼ਿਆਦਾ ਸਮਾਂ ਗੁਜ਼ਾਰਦੇ ਹਨ:
ਜੇ ਤੁਹਾਡੇ ਪਲੇਟਫਾਰਮ ਕੋਲ ਇਨ੍ਹਾਂ ਕਦਮਾਂ ਲਈ ਸਮੱਗਰੀ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਹਨ, ਤਾਂ ਤੁਸੀਂ glue code ਬਣਾਉਣ ਤੋਂ ਬਚ ਜਾਂਦੇ ਹੋ। ਇਸ ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਇਮਪਲੀਮੇਂਟੇਸ਼ਨ ਸਮਾਂ ਘਟਦਾ, ਭਰੋਸੇਯੋਗਤਾ ਬਢ਼ਦੀ, ਅਤੇ ਟੀਮਾਂ/ਵੇਂਡਰਾਂ ਨੂੰ ਬਦਲਣ 'ਤੇ ਦੁਬਾਰਾ ਸਭ ਕੁਝ ਲਿਖਣਾ ਘੱਟ ਹੁੰਦਾ ਹੈ।
ਜਦ ਤੁਸੀਂ ਇਕੋਸਿਸਟਮ ਦੀ ਮੁਲਾਂਕਣ ਕਰ ਰਹੇ ਹੋ, ਤੱਕੋ:
ਪ੍ਰਦਰਸ਼ਨ ਤੁਹਾਨੂੰ ਸਮਰੱਥਾ ਦਿੰਦਾ ਹੈ; ਇਕੋਸਿਸਟਮ ਅਕਸਰ ਨਿਰਣਯ ਕਰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਉਸ ਸਮਰੱਥਾ ਨੂੰ ਕਾਰੋਬਾਰੀ ਨਤੀਜਿਆਂ ਵਿੱਚ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲ ਸਕਦੇ ਹੋ।
Snowflake ਤੇਜ਼ ਕਵੈਰੀ ਚਲਾ ਸਕਦਾ ਹੈ, ਪਰ ਮੁੱਲ ਉਸ ਵੇਲੇ ਆਉਂਦਾ ਹੈ ਜਦ ਡੇਟਾ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਤੁਹਾਡੇ ਸਟੈਕ ਵਿੱਚ ਚਲਦਾ ਹੈ: ਸੋਰਸ ਤੋਂ Snowflake, ਅਤੇ ਫਿਰ ਉੱਥੋਂ ਉਹ ਟੂਲਾਂ ਵਿੱਚ ਜਿਥੇ ਲੋਕ ਰੋਜ਼ਾਨਾ ਵਰਤਦੇ ਹਨ। "ਆਖ਼ਰੀ ਮੀਲ" ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ ਕਿ ਇੱਕ ਪਲੇਟਫਾਰਮ ਸੁਖਦ ਜਾਂ ਲਗਾਤਾਰ ਕੰਮ ਕਰਦਾ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਨੂੰ ਮਿਕਸ ਦੀ ਜ਼ਰੂਰਤ ਪੈਂਦੀ ਹੈ:
ਹਰ "Snowflake-compatible" ਟੂਲ ਇਕੋ ਜਿਹਾ ਵਰਤੋਂ ਨਹੀਂ ਕਰਦਾ। ਮੁਲਾਂਕਣ ਦੌਰਾਨ ਪ੍ਰਾਇਕਟਿਕਲ ਵੇਰਵੇ 'ਤੇ ਧਿਆਨ ਦਿਓ:
ਇੰਟੀਗ੍ਰੇਸ਼ਨਾਂ ਨੂੰ day-2 readiness ਦੀ ਵੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: monitoring ਅਤੇ alerting, lineage/catalog hooks, ਅਤੇ incident response ਵਰਕਫ਼ਲੋਜ਼ (ਟਿਕਟਿੰਗ, on-call, runbooks). ਇਕ ਮਜ਼ਬੂਤ ਇਕੋਸਿਸਟਮ ਸਿਰਫ਼ ਹੋਰ ਲੋਗੋ ਨਹੀਂ ਹੁੰਦਾ—ਇਹ ਅਜਿਹੇ ਘਟਨਾਵਾਂ ਨੂੰ ਘੱਟ ਕਰਦਾ ਹੈ ਜਦ ਪਾਈਪਲਾਈਨ 2 ਵਜੇ ਸਵੇਰੇ fail ਹੋ ਜਾਂਦੀ ਹੈ।
ਜਦ ਟੀਮਾਂ ਵੱਧਦੀਆਂ ਹਨ, ਐਨਾਲਿਟਿਕਸ ਦਾ ਸਭ ਤੋਂ ਮੁਸ਼ਕਿਲ ਭਾਗ ਅਕਸਰ ਰਫ਼ਤਾਰ ਨਹੀਂ—ਇਹ ਯਕੀਨੀ ਬਣਾਉਣਾ ਹੈ ਕਿ ਸਹੀ ਲੋਕਾਂ ਕੋਲ ਸਹੀ ਡੇਟਾ ਹੈ, ਸਹੀ ਉਦੇਸ਼ ਲਈ, ਅਤੇ ਇਹ ਦਿਖਾ ਸਕਣਾ ਕਿ ਨਿਯੰਤਰਣ ਕੰਮ ਕਰ ਰਹੇ ਹਨ। Snowflake ਦੀਆਂ governance ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਇਸ ਹਕੀਕਤ ਲਈ ਡਿਜ਼ਾਇਨ ਕੀਤੀਆਂ ਗਈਆਂ ਹਨ: ਬਹੁਤ ਸਾਰੇ ਯੂਜ਼ਰ, ਬਹੁਤ ਸਾਰੇ ਡੇਟਾ ਪ੍ਰੋਡਕਟ, ਅਤੇ ਅਕਸਰ ਸ਼ੇਅਰਿੰਗ।
ਸਾਫ਼ roles ਅਤੇ least-privilege ਮਨੋਭਾਵ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਵਿਅਕਤੀਆਂ ਨੂੰ ਸਿੱਧਾ access ਦੇਣ ਦੀ ਥਾਂ, roles (ਉਦਾਹਰਣ ANALYST_FINANCE ਜਾਂ ETL_MARKETING) ਪਰिभਾਸ਼ਿਤ ਕਰੋ, ਫਿਰ ਉਹਨਾਂ roles ਨੂੰ ਖਾਸ databases, schemas, tables, ਅਤੇ ਜ਼ਰੂਰਤ ਪੈਣ 'ਤੇ views ਲਈ ਅਧਿਕਾਰ ਦਿਓ।
ਸੰਵੇਦਨਸ਼ੀਲ ਫੀਲਡਸ (PII, ਵਿੱਤੀ identifiers) ਲਈ masking policies ਵਰਤੋਂ ਤਾਂ ਕਿ ਲੋਕ datasets ਨੂੰ query ਕਰ ਸਕਣ ਬਿਨਾਂ raw values ਦੇਖਣ ਦੇ, ਜਦ ਤੱਕ ਉਹਨਾਂ ਦੀ role ਅਨੁਮਤੀ ਨਾ ਹੋਵੇ। ਇਸ ਨਾਲ auditing ਜੋੜੋ: 谁 ਨੇ ਕਿਸੇ ਚੀਜ਼ ਨੂੰ ਕਦੋਂ query ਕੀਤਾ, ਇਸਦਾ ਟ੍ਰੈਕ ਰੱਖੋ ਤਾਂ ਕਿ ਸੁਰੱਖਿਆ ਅਤੇ compliance ਟੀਮਾਂ ਬਿਨਾਂ ਅਨੁਮਾਨ ਦੇ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦੇ ਸਕਣ।
ਚੰਗੀ ਗਵਰਨੈਂਸ ਡੇਟਾ ਸ਼ੇਅਰਿੰਗ ਨੂੰ ਸੁਰੱਖਿਅਤ ਅਤੇ ਸਕੇਲਯੋਗ ਬਣਾਉਂਦੀ ਹੈ। ਜਦੋਂ ਤੁਹਾਡਾ sharing ਮਾਡਲ roles, policies, ਅਤੇ audited access 'ਤੇ ਅਧਾਰਿਤ ਹੁੰਦਾ ਹੈ, ਤੁਸੀਂ ਆਤਮ-ਸੇਵਾ (ਅਧਿਕਤਮ ਲੋਕ ਡੇਟਾ ਖੋਜ ਸਕਦੇ ਹਨ) ਨੂੰ ਆਸਾਨੀ ਨਾਲ ਸਸ਼ਕਤ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਅਣਜਾਣੀ ਰੁੱਜਾਨ ਵਾਲੇ ਖੁਲਾਸਿਆਂ ਨੂੰ ਜਨਮ ਦਿੱਤੇ।
ਇਸ ਨਾਲ compliance ਮੁਕੱਦਮਿਆਂ ਲਈ friction ਘਟਦਾ ਹੈ: ਨੀਤੀਆਂ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਨਿਯੰਤਰਣ ਬਣ ਜਾਂਦੀਆਂ ਹਨ ਨਾ ਕਿ ਇੱਕ-ਵਾਰੀ ਛੋਟ। ਇਹ ਮਹੱਤਵਪੂਰਣ ਹੈ ਜਦ datasets ਪ੍ਰੋਜੈਕਟਾਂ, ਵਿਭਾਗਾਂ, ਜਾਂ ਬਾਹਰੀ ਭਾਗੀਦਾਰਾਂ ਦੁਆਰਾ ਦੁਬਾਰਾ ਵਰਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ।
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X)। ਸੰਗਤਤਾ ਸਮੀਖਿਆ ਤੇ ਘਟਨਾ ਘਟਾਉਂਦੀ ਹੈ।ਵੱਡੇ ਪੱਧਰ 'ਤੇ ਭਰੋਸਾ ਇੱਕ "ਪ੍ਰਤੀਕਰ-perfect" ਨਿਯੰਤਰਣ ਬਾਰੇ ਨਹੀਂ ਹੈ, ਬਲਕਿ ਛੋਟੇ, ਭਰੋਸੇਯੋਗ ਆਦਤਾਂ ਦਾ ਇੱਕ ਸਿਸਟਮ ਹੈ ਜੋ ਐਕਸੈਸ ਨੂੰ ਇਰਾਦਤਨ ਅਤੇ ਸਮਝਣਯੋਗ ਰੱਖਦਾ ਹੈ।
ਜਦ ਬਹੁਤ ਸਾਰੇ ਲੋਕ ਅਤੇ ਟੂਲ ਇੱਕੋ ਡੇਟਾ ਨੂੰ ਵੱਖ-ਵੱਖ ਕਾਰਨਾਂ ਲਈ ਕਵੈਰੀ ਕਰਦੇ ਹਨ, Snowflake ਮੱਠਾ ਉੱਥੇ ਚਮਕਦਾ ਹੈ। ਕਿਉਂਕਿ compute independent warehouses ਵਿੱਚ ਪੈਕੇਜ ਕੀਤੀ ਜਾਂਦੀ ਹੈ, ਤੁਸੀਂ ਹਰ ਵਰਕਲੋਡ ਨੂੰ ਉਸਦੀ ਸੂਰਤ ਅਤੇ ਸਾਰਣੀ ਅਨੁਸਾਰ ਬਣਾਉ ਸਕਦੇ ਹੋ।
Analytics & dashboards: BI ਟੂਲਾਂ ਨੂੰ ਇੱਕ ਸਮਰਪਿਤ warehouse 'ਤੇ ਰੱਖੋ ਜੋ steady, predictable query volume ਲਈ sized ਹੋ। ਇਸ ਨਾਲ dashboard refreshes ad hoc exploration ਨਾਲ ਸਲੋ ਨਹੀਂ ਹੁੰਦੀਆਂ।
Ad hoc analysis: analysts ਨੂੰ ਵੱਖਰਾ warehouse ਦਿਓ (ਅਕਸਰ ਛੋਟਾ) ਜਿਸ 'ਤੇ auto-suspend ਚਾਲੂ ਹੋਵੇ। ਤੁਹਾਨੂੰ ਤੇਜ਼ iteration ਮਿਲਦੀ ਹੈ ਬਿਨਾਂ idle ਸਮੇਂ ਲਈ ਖਰਚ ਕਰਨ ਦੇ।
Data science & experimentation: ਇੱਕ warehouse ਵਰਤੋ ਜੋ ਭਾਰੀ scans ਅਤੇ ਕਦੇ-ਕਦੇ bursts ਲਈ sized ਹੋ। ਜੇ experiments spike ਕਰਦੇ ਹਨ, ਇਸ warehouse ਨੂੰ ਥੋੜ੍ਹੀ ਵਾਰ ਲਈ scale up ਕਰੋ ਬਿਨਾਂ BI ਯੂਜ਼ਰਾਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕੀਤੇ।
Data apps & embedded analytics: app traffic ਨੂੰ production service ਵਾਂਗ treat ਕਰੋ—ਵੱਖਰਾ warehouse, conservative timeouts, ਅਤੇ resource monitors ਤਾ ਕਿ ਅਚਾਨਕ ਖਰਚ ਨਾ ਵੱਧੇ।
ਜੇ ਤੁਸੀਂ ਹਲਕੇ-ਫੁਲਕੇ ਅੰਦਰੂਨੀ ਡੇਟਾ ਐਪਸ ਬਣਾ ਰਹੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ ਇੱਕ ops portal ਜੋ Snowflake ਨੂੰ query ਕਰਦਾ ਹੈ ਅਤੇ KPIs ਦਿਖਾਉਂਦਾ ਹੈ), ਇੱਕ ਤੇਜ਼ ਰਾਹ ਇਹ ਹੈ ਕਿ React + API scaffold ਬਣਾਇਆ ਜਾਵੇ ਅਤੇ stakeholder ਨਾਲ iterate ਕੀਤਾ ਜਾਵੇ। Koder.ai ਵਰਗੀਆਂ ਪਲੇਟਫਾਰਮਾਂ ਟੀਮਾਂ ਨੂੰ ਇਹ Snowflake-backed ਐਪਸ ਤੇਜ਼ੀ ਨਾਲ prototype ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਫਿਰ ਜਦ ਤਿਆਰ ਹੋਵੋ ਤਾਂ source code export ਕਰੋ।
ਇੱਕ ਸਧਾਰਣ ਨਿਯਮ: audience ਅਤੇ purpose ਅਨੁਸਾਰ warehouses ਨੂੰ ਵੱਖਰਾ ਕਰੋ (BI, ELT, ad hoc, ML, app). ਇਸਨੂੰ ਚੰਗੇ query ਆਦਤਾਂ ਨਾਲ ਮਿਲਾਓ—boolean SELECT * ਤੋਂ ਬਚੋ, ਜਲਦੀ ਫਿਲਟਰ ਕਰੋ, ਅਤੇ ਅਕਾਰਥ joins 'ਤੇ ਨਜ਼ਰ ਰੱਖੋ। ਮਾਡਲਿੰਗ ਪਾਸੇ, ਉਨ੍ਹਾਂ ਬਣਤਰਾਂ ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਜੋ ਲੋਕ ਕਿਵੇਂ query ਕਰਦੇ ਹਨ (ਅਕਸਰ ਇੱਕ ਸਾਫ਼ semantic layer ਜਾਂ ਵੱਧ-ਤੈਅਰ marts), na ਕਿ ਭੌਤਿਕ ਲੇਆਉਟ ਨੂੰ ਜ਼ਿਆਦਾ optimize ਕਰਨ ਦੇ।
Snowflake ਹਰ ਚੀਜ਼ ਲਈ ਰਿਪਲੇਸਮੈਂਟ ਨਹੀਂ ਹੈ। ਹਾਈ-ਥਰੂਪੁੱਟ, ਘੱਟ-ਲੇਟੈਂਸੀ transactional ਵਰਕਲੋਡ (ਆਮ OLTP) ਲਈ ਇਕ ਵਿਸ਼ੇਸ਼ ਡੇਟਾਬੇਸ ਜ਼ਿਆਦਾ ਉੱਚਿਤ ਹੁੰਦਾ ਹੈ, ਅਤੇ Snowflake ਆਮ ਤੌਰ 'ਤੇ analytics, reporting, sharing, ਅਤੇ downstream data products ਲਈ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ। ਹਾਈਬ੍ਰਿਡ ਸੈਟਅੱਪ ਆਮ ਹਨ—ਅਤੇ ਅਕਸਰ ਸਭ ਤੋਂ ਪ੍ਰਯੋਗਿਕ।
Snowflake ਮਾਈਗ੍ਰੇਸ਼ਨ ਅਕਸਰ "lift and shift" ਨਹੀਂ ਹੁੰਦੀ। storage/compute ਵੰਡ ਇਹ ਬਦਲ ਦਿੰਦੀ ہے ਕਿ ਤੁਸੀਂ ਵਰਕਲੋਡਾਂ ਨੂੰ ਕਿਵੇਂ size, tune, ਅਤੇ pay ਕਰਦੇ ਹੋ—ਇਸ ਲਈ ਅੱਗੇ ਯੋਜਨਾ ਬਣਾਉਣਾ ਬਾਅਦ ਦੇ ਅਚਾਨਕ ਨਤੀਜਿਆਂ ਤੋਂ ਬਚਾਂਦਾ ਹੈ।
ਇਕ ਇਨਵੈਂਟਰੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਕਿਹੜੇ data sources warehouse ਨੂੰ ਫੀਡ ਕਰਦੇ ਹਨ, ਕਿਹੜੀਆਂ pipelines ਉਹਨਾਂ ਨੂੰ transform ਕਰਦੀਆਂ ਹਨ, ਕਿਹੜੇ dashboards ਉਨ੍ਹਾਂ 'ਤੇ ਨਿਰਭਰ ਹਨ, ਅਤੇ ਹਰ ਹਿੱਸੇ ਦੀ ਮਲਕੀਅਤ ਕੌਣ ਕਰਦਾ ਹੈ। ਫਿਰ ਕਾਰੋਬਾਰੀ ਪ੍ਰਭਾਵ ਅਤੇ ਜਟਿਲਤਾ ਅਨੁਸਾਰ ਪ੍ਰਾਥਮਿਕਤਾ ਦਿਓ (ਉਦਾਹਰਣ ਲਈ critical finance reporting ਪਹਿਲਾਂ, experimental sandboxes ਬਾਅਦ)।
ਅਗلے ਪੜਾਅ 'ਚ SQL ਅਤੇ ETL ਲਾਜ਼ਿਕ ਨੂੰ ਬਦਲੋ। ਬਹੁਤ ਸਾਰਾ standard SQL ਗੁਜ਼ਰਦਾ ਹੈ, ਪਰ functions, date handling, procedural ਕੋਡ, ਅਤੇ temp-table ਪੈਟਰਨ ਆਮ ਤੌਰ 'ਤੇ ਦੁਬਾਰਾ ਲਿਖਣ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ। ਨਤੀਜਿਆਂ ਦੀ ਪਹਿਲਾਂ ਹੀ ਪੁਸ਼ਟੀ ਕਰੋ: parallel outputs ਚਲਾਓ, row counts ਅਤੇ aggregates ਤੁਲਨਾ ਕਰੋ, ਅਤੇ edge cases (nulls, time zones, dedup logic) ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ। ਆਖ਼ਰ ਵਿੱਚ cutover ਦੀ ਯੋਜਨਾ ਬਣਾਓ: ਇੱਕ freeze window, rollback ਰਾਹ, ਅਤੇ ਹਰ dataset ਅਤੇ report ਲਈ "definition of done"।
Hidden dependencies ਸਭ ਤੋਂ ਆਮ ਹਨ: spreadsheet extract, hard-coded connection string, ਇੱਕ downstream job ਜੋ ਕੋਈ ਯਾਦ ਨਹੀਂ ਰੱਖਦਾ। ਪ੍ਰਦਰਸ਼ਨ ਦੇ ਅਚਾਨਕ ਨਤੀਜੇ ਵੀ ਹੋ ਸਕਦੇ ਹਨ ਜਦ ਪੁਰਾਣੇ ਟਿਊਨਿੰਗ ਅਨੁਮਾਨ ਲਾਗੂ ਨਹੀਂ ਹੁੰਦੇ (ਉਦਾਹਰਣ: ਬਹੁਤ ਛੋਟੇ warehouses ਦੀ ਬੇਮਿਸਾਲ ਵਰਤੋਂ, ਜਾਂ concurrency ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਨ ਰੱਖ ਕੇ ਕਈ ਛੋਟੀ ਕਵੈਰੀਜ਼ ਚਲਾਉਣਾ)। ਕਿਸੇ-ਵੀ ਸਮੇਂ ਖਰਚ spikes ਆਮ ਤੌਰ 'ਤੇ warehouses ਛੱਡਣ, uncontrolled retries, ਜਾਂ duplicate dev/test workloads ਤੋਂ ਹੁੰਦੇ ਹਨ। permission gaps ਅੰਦਰ ਆਉਂਦੀਆਂ ਹਨ ਜਦ coarse roles ਤੋਂ ਜ਼ਿਆਦਾ granular governance 'ਤੇ migrate ਕੀਤਾ ਜਾਂਦਾ—ਟੈਸਟ ਵਿੱਚ least privilege user ਰੋਲਾਂ ਨੂੰ ਵੀ ਸ਼ਾਮਿਲ ਕਰੋ।
ਇਕ ownership ਮਾਡਲ ਸੈੱਟ ਕਰੋ (ਡੇਟਾ, pipelines, ਅਤੇ ਖਰਚ ਕਿਸ ਦਾ), analysts ਅਤੇ engineers ਲਈ role-based training ਦਿਓ, ਅਤੇ cutover ਤੋਂ ਪਹਿਲੀਆਂ ਹਫਤਿਆਂ ਲਈ ਸਮਰਥਨ ਯੋਜਨਾ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (on-call rotation, incident runbook, ਅਤੇ issues ਰਿਪੋਰਟ ਕਰਨ ਲਈ ਇੱਕ ਥਾਂ)।
ਆਧੁਨਿਕ ਡੇਟਾ ਪਲੇਟਫਾਰਮ ਚੁਣਨਾ ਸਿਰਫ peak benchmark speed ਬਾਰੇ ਨਹੀਂ। ਇਹ ਬਾਰੇ ਹੈ ਕਿ ਪਲੇਟਫਾਰਮ ਤੁਹਾਡੇ ਅਸਲ ਵਰਕਲੋਡ, ਤੁਹਾਡੇ ਟੀਮ ਦੇ ਕੰਮ ਕਰਨ ਦੇ ਢੰਗ, ਅਤੇ ਉਹ ਟੂਲ ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਨਿਰਭਰ ਹੋ—ਇਨ੍ਹਾਂ ਨਾਲ ਕਿਵੇਂ ਮਿਲਦਾ ਹੈ।
ਇਹ ਸਵਾਲ ਤੁਹਾਡੇ shortlist ਅਤੇ ਵੈਂਡਰ ਗੱਲ-ਬਾਤ ਨੂੰ ਮਾਰਗਦਰਸ਼ਿਤ ਕਰਨਗੇ:
2–3 ਪ੍ਰਤੀਨਿਧੀ datasets ਚੁਣੋ (ਕੋਈ toy sample ਨਹੀਂ): ਇੱਕ ਵੱਡੀ fact table, ਇੱਕ messy semi-structured source, ਅਤੇ ਇੱਕ ਬਿਜ਼ਨਸ-ਹੁੰਦਾ domain।
ਫਿਰ ਅਸਲੀ ਯੂਜ਼ਰ ਕਵੈਰੀਜ਼ ਚਲਾਓ: ਸਵੇਰੇ ਪੀਕ 'ਤੇ dashboards, analysts ਦੀ ਖੋਜ, scheduled loads, ਅਤੇ ਕੁਝ worst-case joins। ਟਰੈਕ ਕਰੋ: query ਸਮਾਂ, concurrency ਵਿਹਾਰ, ingest ਸਮਾਂ, ਓਪਰੇਸ਼ਨਲ ਕੋਸ਼ਿਸ਼, ਅਤੇ ਹਰ ਵਰਕਲੋਡ ਲਈ ਲਾਗਤ।
ਜੇ ਤੁਸੀਂ ਇਹ ਵੀ ਦੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਕਿ "ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਅਸੀਂ ਕੁਝ ਯੂਜ਼ਰਾਂ ਲਈ ਵਰਤੀਯੋਗ ਚੀਜ਼ ਸ਼ਿਪ ਕਰ ਸਕਦੇ ਹਾਂ", ਤਦ ਪਾਇਲਟ ਵਿੱਚ ਇੱਕ ਨਿਾਲਾ deliverable ਸ਼ਾਮਿਲ ਕਰੋ—ਜਿਵੇਂ ਇੱਕ ਅੰਦਰੂਨੀ metrics ਐਪ ਜਾਂ ਇੱਕ governed data-request workflow ਜੋ Snowflake ਨੂੰ query ਕਰਦਾ। ਇਹ ਉਹਨੇ ਚੀਜ਼ਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਬਤਲ ਦਿੰਦਾ ਜੋ ਸਿਰਫ benchmarks ਨਾਲ ਨਹੀਂ ਦਿਖਦੀਆਂ, ਅਤੇ Koder.ai ਵਰਗੇ ਟੂਲ prototype-to-production ਚਕ੍ਰ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ ਚੈਟ ਰਾਹੀਂ app structure ਬਣਾਉਂਦੇ ਅਤੇ code export ਦੀ ਆਸਾਨੀ ਦਿੰਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਖਰਚ ਦਾ ਅੰਦਾਜ਼ਾ ਲਓਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਪਹਿਲਾ ਕਦਮ ਪ੍ਰਾਈਸਿੰਗ ਹੋ ਸਕਦਾ ਹੈ।
ਮਾਈਗ੍ਰੇਸ਼ਨ ਅਤੇ ਗਵਰਨੈਂਸ ਲਈ ਸਬੰਧਿਤ ਲੇਖ ਬਲੌਗ ਵਿੱਚ ਵੇਖੋ।
Snowflake ਤੁਹਾਡਾ ਡੇਟਾ cloud object storage ਵਿਚ ਰੱਖਦਾ ਹੈ ਅਤੇ ਕਵੈਰੀਜ਼ ਨੂੰ ਚਲਾਉਣ ਲਈ ਅਲੱਗ compute ਕਲੱਸਟਰ (virtual warehouses) ਵਰਤਦਾ ਹੈ। ਕਿਉਂਕਿ storage ਅਤੇ compute ਅਲੱਗ ਹਨ, ਤੁਸੀਂ compute ਨੂੰ ਬਿਨਾਂ ਅੰਡਰਲਾਈੰਗ ਡੇਟਾ ਨੂੰ ਹਿਲਾਏ ਜਾਂ ਡੁਪਲੀਕੇਟ ਕੀਤੇ ਬਿਨਾਂ ਉੱਪਰ-ਥੱਲੇ ਕਰ ਸਕਦੇ ਹੋ।
ਇਹ ਸੰਸਾਧਨਾਂ ਦੀ ਟਕਰਾਰ ਘਟਾਉਂਦਾ ਹੈ। ਤੁਸੀਂ ਵੱਖ-ਵੱਖ ਵਰਕਲੋਡ ਨੂੰ ਵੱਖਰੇ virtual warehouses 'ਤੇ ਚਲਾ ਸਕਦੇ ਹੋ (ਜਿਵੇਂ BI ਵਿਰੁੱਧ ETL), ਜਾਂ spike ਦੌਰਾਨ compute ਵਧਾਉਣ ਲਈ multi-cluster warehouses ਵਰਤ ਸਕਦੇ ਹੋ। ਇਸ ਨਾਲ ਪਰੰਪਰਾਗਤ MPP ਸੈਟਅੱਪ ਦੇ “ਇਕ ਜੁੱਟ ਕਲੱਸਟਰ” ਦੀਆਂ ਕਤਾਰਾਂ ਵਰਗੀਆਂ ਸਮੱਸਿਆਵਾਂ ਘਟਦੀਆਂ ਹਨ।
ਆਪੋ-ਆਪ ਨਹੀਂ।Elastic compute ਤੁਹਾਨੂੰ ਨਿਯੰਤਰਣ ਦਿੰਦਾ ਹੈ, ਪਰ ਤੁਹਾਨੂੰ ਫਿਰ ਵੀ guardrails ਲਗਾਉਣੇ ਪੈਂਦੇ ਹਨ:
ਬੁਰੇ SQL, ਲਗਾਤਾਰ ਡੈਸ਼ਬੋਰਡ ਰੀਫਰੇਸ਼, ਜਾਂ ਹਮੇਸ਼ਾਂ ਚੱਲਦੇ ਰਹਿਣ ਵਾਲੇ warehouses ਫਿਰ ਵੀ ਵੱਧ ਖਰਚ ਕਰਵਾ ਸਕਦੇ ਹਨ।
ਬਿਲਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਦੋ ਮੁੱਖ ਹਿੱਸਿਆਂ ਵਿੱਚ ਵੰਡੀ ਹੁੰਦੀ ਹੈ:
ਇਸ ਨਾਲ ਇਹ ਸਪਸ਼ਟ ਹੁੰਦਾ ਹੈ ਕਿ ਹੁਣੇ-ਹੁਣੇ ਕੀ ਖਰਚ ਕਰ ਰਿਹਾ ਹੈ (compute) ਅਤੇ ਕੀ ਸਥਿਰ ਤੌਰ ਤੇ ਵੱਧ ਰਿਹਾ ਹੈ (storage)।
ਅਕਸਰ ਕਾਰਨ operação ਨਾਲ ਸਬੰਧਤ ਹੁੰਦੇ ਹਨ, ਨਾ ਕਿ ਸਿਰਫ ਡੇਟਾ ਦੇ ਆਕਾਰ ਨਾਲ:
ਕੁਝ practical ਨਿਯੰਤਰਣ (auto-suspend, monitors, scheduling) ਆਮ ਤੌਰ 'ਤੇ ਵੱਡੀ ਬਚਤ ਦਿੰਦੇ ਹਨ।
ਇਹ suspended warehouse ਦੇ ਫਿਰ start ਹੋਣ 'ਤੇ ਆਉਣ ਵਾਲੀ ਦੇਰੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਘੱਟ-ਆਵ੍ਰਿਤੀ ਵਾਲੇ ਵਰਕਲੋਡ ਰੱਖਦੇ ਹੋ ਤਾਂ auto-suspend ਪੈਸਾ ਬਚਾਂਦਾ ਹੈ ਪਰ ਪਹਿਲੀ ਕਵੈਰੀ 'ਤੇ ਛੋਟੀ ਲੇਟੈਂਸੀ ਮਿਲ ਸਕਦੀ ਹੈ। ਯੂਜ਼ਰ-ਫੇਸਿੰਗ ਡੈਸ਼ਬੋਰਡ ਲਈ, ਲਗਾਤਾਰ ਦੀ ਮੰਗ ਲਈ ਇੱਕ ਸਮਰਪਿਤ warehouse ਰੱਖਣਾ ਵਿਚਾਰਯੋਗ ਹੈ ਤਾਂ ਕਿ frequent suspend/resume ਨਾ ਹੋਵੇ।
ਇੱਕ virtual warehouse ਇੱਕ ਅਜ਼ਾਦ compute ਕਲੱਸਟਰ ਹੈ ਜੋ SQL ਚਲਾਉਂਦਾ ਹੈ। ਬਿਹਤਰ ਅਭਿਆਸ ਇਹ ਹੈ ਕਿ warehouses ਨੂੰ ਦਰਸ਼ਕਾਂ/ਉਦੇਸ਼ਾਂ ਅਨੁਸਾਰ ਮੈਪ ਕੀਤਾ ਜਾਵੇ, ਉਦਾਹਰਨ ਲਈ:
ਇਸ ਨਾਲ ਪ੍ਰਦਰਸ਼ਨ ਆਇਸੋਲੇਟ ਹੁੰਦਾ ਹੈ ਅਤੇ ਖਰਚ ਦੀ ਮਾਲਕੀ ਵਿਸ਼ੇਸ਼ ਹੋ ਜਾਂਦੀ ਹੈ।
ਅਕਸਰ, ਹਾਂ।Snowflake sharing ਇੱਕ ਹੋਰ account ਨੂੰ ਉਹੀ ਡੇਟਾ query ਕਰਨ ਦੀ ਆਗਿਆ ਦੇ ਸਕਦਾ ਹੈ ਜੋ ਤੁਸੀਂExpose ਕਰਦੇ ਹੋ (tables/views) ਬਿਨਾਂ ਫਾਇਲਾਂ export ਕੀਤੇ ਜਾਂ ਵਾਧੂ pipelines ਬਣਾਉਣ ਦੇ। ਪਰ ਤੋਹਾਨੂੰ ਫਿਰ ਵੀ ਮਜ਼ਬੂਤ governance ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ—ਸਾਫ਼ ਮਲਕੀਅਤ, access reviews, ਅਤੇ ਸੰਵੇਦਨਸ਼ੀਲ ਫੀਲਡਸ ਲਈ ਨੀਤੀਆਂ—ਤਾਕਿ sharing ਕੰਟਰੋਲਡ ਅਤੇ ਆਡੀਟੇਬਲ ਰਹੇ।
ਕਿਉਂਕਿ ਡਿਲਿਵਰੀ ਦਾ ਵੱਡਾ ਹਿੱਸਾ ਇੱਕੀਕਰਨ ਅਤੇ ਆਪਰੇਸ਼ਨਲ ਕੰਮ ਹੁੰਦਾ ਹੈ, ਨਿਰਲੇਖ ਗਤੀਵਿਧੀ (benchmarks) ਅਕਸਰ ਰੀਅਲ-ਵਰਕਲੋਡ ਦੀਆਂ ਲੋੜਾਂ ਨਹੀਂ ਦੱਸਦੇ। ਇੱਕ ਮਜ਼ਬੂਤ ecosystem ਹੁੰਦਾ ਹੈ:
ਇਹਨਾਂ ਨਾਲ custom engineering ਘੱਟ ਹੁੰਦੀ ਹੈ ਅਤੇ day-2 maintenance ਦਾ ਬੋਝ ਘਟਦਾ ਹੈ।
ਇੱਕ ਛੋਟਾ, ਹਕੀਕਤੀ ਪਾਇਲਟ (ਆਮ ਤੌਰ 'ਤੇ 2–4 ਹਫ਼ਤੇ):
ਜੇ ਤੁਹਾਨੂੰ ਖਰਚ ਦਾ ਅੰਦਾਜ਼ਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ "pricing" ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ, ਅਤੇ ਮਾਈਗ੍ਰੇਸ਼ਨ/ਗਵਰਨੈਂਸ ਮਦਦ ਲਈ ਬਲੌਗ ਦੇ ਸੰਬੰਧਿਤ ਲੇਖ ਵੇਖੋ।