ਪ੍ਰੋਡਕਸ਼ਨ ਫੇਲਿਅਰਾਂ ਨੂੰ ਸ਼ੁਰੂ ਵਿੱਚ ਕਿਉਂ ਪਕੜਨਾ ਮੁਸ਼ਕਿਲ ਹੁੰਦਾ ਹੈ
ਪਰੋਡਕਸ਼ਨ ਅਕਸਰ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਪਲ 'ਤੇ “ਟੁੱਟਦਾ” ਨਹੀਂ। ਜ਼ਿਆਦਾਤਰ ਵਾਰ ਇਹ ਚੁੱਪਚਾਪ ਡਿਗਦਾ ਹੈ: ਕੁਝ ਰਿਕਵੇਸਟ ਲੰਮੇ ਹੋ ਜਾਂਦੇ ਹਨ, ਇੱਕ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਪਿੱਛੇ ਰਹਿ ਜਾਂਦਾ ਹੈ, CPU ਹੌਲੀ-ਹੌਲੀ ਵਧਦਾ ਹੈ, ਤੇ ਗਾਹਕ ਪਹਿਲਾਂ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ—ਕਿਉਂਕਿ ਤੁਹਾਡੇ ਮੋਨੀਟਰਿੰਗ ਪੈਨਲ ਅਜੇ ਵੀ “ਗ੍ਰੀਨ” ਦਿਖਾ ਰਿਹਾ ਹੁੰਦਾ ਹੈ।
ਫੇਲਿਅਰ ਲੱਛਣ ਵਜੋਂ ਆਉਂਦੇ ਹਨ, ਕਾਰਨ ਵਜੋਂ ਨਹੀਂ
ਯੂਜ਼ਰ ਦੀ ਰਿਪੋਰਟ ਆਮ ਤੌਰ 'ਤੇ ਥੋੜ੍ਹੀ ਅਸਪਸ਼ਟ ਹੁੰਦੀ ਹੈ: “ਇਹ ਧੀਮਾ ਲੱਗਦਾ ਹੈ।” ਇਹ ਕਈ ਵੱਖ-ਵੱਖ ਮੂਲ ਕਾਰਨਾਂ ਦਾ ਲੱਛਣ ਹੋ ਸਕਦਾ ਹੈ—ਡਾਟਾਬੇਸ ਲੌਕ ਕਨਟੈਂਸ਼ਨ, ਨਵਾਂ ਕੁਐਰੀ ਪਲੈਨ, ਮਿਸਿੰਗ ਇੰਡੈਕਸ, noisy neighbor, ਰੀਟ੍ਰਾਈ ਸਟੌਰਮ, ਜਾਂ ਬਾਹਰੀ ਡਿਪੈਂਡੇਸੀ ਜੋ ਬੇਬਾਕੀ ਨਾਲ ਫੇਲ ਹੋ ਰਹੀ ਹੋਵੇ।
ਚੰਗੀ ਵਿਜ਼ੀਬਿਲਟੀ ਨ ਹੋਣ 'ਤੇ ਟੀਮ ਅਟਕਦੇ ਹਨ:
- ਕੀ slowdown ਗਲੋਬਲ ਹੈ ਜਾਂ ਕੇਵਲ ਇੱਕ endpoint 'ਤੇ ਸੀ?\n- ਕੀ ਇਹ ਡਿਪਲੌਇ, ਸੈਟਿੰਗ ਬਦਲਾਅ, ਜਾਂ ਟ੍ਰੈਫਿਕ ਸਪਾਈਕ ਤੋਂ ਬਾਅਦ ਸ਼ੁਰੂ ਹੋਇਆ ਸੀ?\n- ਕੀ ਸਮੱਸਿਆ ਐਪਲੀਕੇਸ਼ਨ ਵਿੱਚ ਹੈ, ਡਾਟਾਬੇਸ ਵਿੱਚ, ਜਾਂ ਉਹਨਾਂ ਦੇ ਵਿਚਕਾਰ ਨੈਟਵਰਕ ਵਿੱਚ?
ਤੁਹਾਡੇ ਡੈਸ਼ਬੋਰਡ ਯੂਜ਼ਰਾਂ ਦੇ ਅਨੁਭਵ ਨੂੰ ਨਹੀਂ ਵੇਖ ਸਕਦੇ
ਕਈ ਟੀਮ ਸਿਰਫ਼ ਔਸਤਾਂ (average latency, average CPU) ਟਰੈਕ ਕਰਦੀਆਂ ਹਨ। ਔਸਤ ਦਰਦ ਨੂੰ ਛੁਪਾ ਦਿੰਦੇ ਹਨ। ਬਹੁਤ ਘੱਟ ਪ੍ਰਤੀਸ਼ਤ ਬਹੁਤ ਧੀਮੀ ਰਿਕਵੇਸਟਾਂ ਅਨੁਭਵ ਨੂੰ ਖ਼ਰਾਬ ਕਰ ਸਕਦੀਆਂ ਹਨ ਜਦਕਿ ਕੁੱਲ ਮੈਟਰਿਕ ਠੀਕ ਲੱਗਦੇ ਹਨ। ਅਤੇ ਜੇ ਤੁਸੀਂ ਸਿਰਫ਼ “up/down” ਮਾਨੀਟਰ ਕਰੋਗੇ ਤਾਂ ਤਕਨੀਕੀ ਤੌਰ 'ਤੇ ਸਿਸਟਮ ਚਾਲੂ ਹੋਣ ਵਾਲੀ ਲੰਮੀ ਮਿਆਦ ਨੂੰ ਮੁਸਲਸਲ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰ ਦਿਓਗੇ—ਜਦਕਿ ਉਹ ਵਰਤੋਂਯੋਗ ਨਹੀਂ ਰਹਿੰਦਾ।
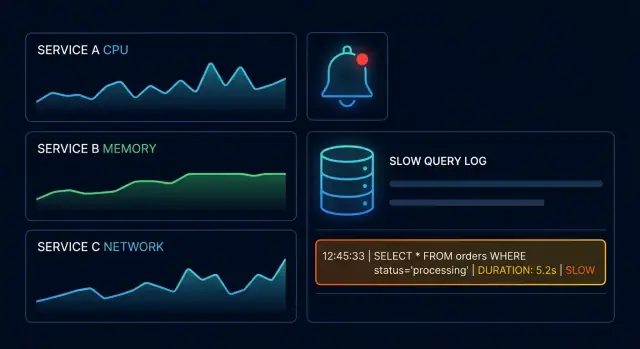
Observability + ਸਲੋ ਕੁਐਰੀ ਲੌਗ: ਪੂਰਨਤਾ ਵਾਲੇ ਸੰਕੇਤ
Observability ਤੁਹਾਡੀ ਮਦਦ ਕਰਦੀ ਹੈ ਇਸ ਗੱਲ ਦਾ ਪਤਾ ਲਗਾਉਣ ਵਿੱਚ ਕਿ ਸਿਸਟਮ ਕਿਥੇ ਡਿਗ ਰਿਹਾ ਹੈ (ਕਿਹੜੀ service, endpoint ਜਾਂ ਡਿਪੈਂਡੇਸੀ)। ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਤੁਹਾਨੂੰ ਦਿਖਾਉਂਦੇ ਹਨ ਕਿ ਡਾਟਾਬੇਸ ਕਿਸ ਕੰਮ ਵਿੱਚ ਲੱਗਾ ਸੀ ਜਦ ਰਿਕਵੇਸਟ ਰੁਕ ਗਈ (ਕਿਹੜੀ ਕੁਐਰੀ, ਕਿੰਨਾ ਸਮਾਂ ਲੱਗਿਆ, ਅਤੇ ਅਕਸਰ ਕਿਸ ਤਰ੍ਹਾਂ ਦੀ ਕੰਮਇੰਗ)।
ਇਹ ਗਾਈਡ ਕਾਰਗੁਜ਼ਾਰ ਹੈ: ਜਲਦੀ ਚੇਤਾਵਨੀ ਪਾਉਣ ਦੇ ਤਰੀਕੇ, ਯੂਜ਼ਰ-ਮੁਖੀ ਲੈਟੈਂਸੀ ਨੂੰ ਖਾਸ ਡਾਟਾਬੇਸ ਕੰਮ ਨਾਲ ਜੋੜਨਾ, ਅਤੇ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਸਮੱਸਿਆ ਹੱਲ ਕਰਨਾ—ਬਿਨਾਂ ਕਿਸੇ vendor-ਵਿਸ਼ੇਸ਼ ਵਾਅਦੇ 'ਤੇ ਨਿਰਭਰ ਹੋਏ।
Observability ਦੇ ਬੁਨਿਆਦੀ ਤੱਤ: ਮੈਟਰਿਕਸ, ਲੌਗ ਅਤੇ ਟ੍ਰੇਸ
Observability ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਹਾਡੇ ਸਿਸਟਮ ਤੋਂ ਨਿਕਲਣ ਵਾਲੇ ਸੰਕੇਤਾਂ ਨੂੰ ਦੇਖ ਕੇ ਸਮਝਣਾ—ਬਿਨਾਂ ਅਨੁਮਾਨ ਲਗਾਉਣ ਜਾਂ "ਲੋ컬 ਵਿੱਚ ਦੁਹਰਾਉਣ" ਦੀ ਲੋੜ ਦੇ। ਇਹ ਫਰਕ ਹੈ ਜਾਣਨ ਦਾ ਕਿ ਯੂਜ਼ਰ ਢੀਲਾਪਨ ਮਹਿਸੂਸ ਕਰ ਰਹੇ ਹਨ ਅਤੇ ਪੁષ્ટ ਕਰਨ ਦਾ ਕਿ ਢੀਲਾਪਨ ਕਿੱਥੇ ਹੋ ਰਿਹਾ ਹੈ ਅਤੇ ਕਿਉਂ ਇਹ ਸ਼ੁਰੂ ਹੋਇਆ।
ਤਿੰਨ ਸਤੰਭ (ਅਤੇ ਹਰ ਇੱਕ ਲਈ ਕੀ ਵਧੀਆ ਹੈ)
ਮੈਟਰਿਕਸ ਸਮੇਂ-ਸਿਰ ਨੰਬਰ ਹਨ (CPU %, request rate, error rate, database latency)। ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਪੁੱਛੇ ਜਾਂਦੇ ਹਨ ਅਤੇ ਰੁਝਾਨ ਅਤੇ ਅਚਾਨਕ spike ਵੇਖਣ ਲਈ ਉਤਮ ਹਨ।
ਲੌਗ ਉਹ ਇਵੈਂਟ ਰਿਕਾਰਡ ਹਨ ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਵਿਸਥਾਰ ਹੁੰਦਾ ਹੈ (ਇੱਕ error message, SQL ਟੈਕਸਟ, user ID, timeout)। ਇਹ ਮਨੁੱਖ-ਪੜਨ ਯੋਗ ਤਰੀਕੇ ਨਾਲ ਕੀ ਹੋਇਆ ਦੀ ਵਿਆਖਿਆ ਕਰਨ ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ ਹਨ।
ਟ੍ਰੇਸ ਇੱਕ ਹੀ ਰਿਕਵੇਸਟ ਨੂੰ ਸੇਵਾਵਾਂ ਅਤੇ ਡਿਪੈਂਡੇਸੀਆਂ ਵਿੱਚ ਫਰੰਮ ਕਰਦੇ ਹਨ (API → app → database → cache)। ਇਹ ਇਸ ਦਾ ਜਵਾਬ ਦੇਣ ਲਈ ਉਤਮ ਹਨ ਕਿ ਕਿੱਥੇ ਸਮਾਂ ਲੱਗਿਆ ਅਤੇ ਕਿਹੜਾ ਕਦਮ slowdown ਦਾ ਕਾਰਨ ਸੀ।
ਇੱਕ ਮਾਨਸਿਕ ਮਾਡਲ: ਮੈਟਰਿਕਸ ਦੱਸਦੇ ਹਨ ਕੁਝ ਗਲਤ ਹੈ, ਟ੍ਰੇਸ ਦਿਖਾਉਂਦੇ ਹਨ ਕਿੱਥੇ, ਅਤੇ ਲੌਗ ਦੱਸਦੇ ਹਨ ઠੀਕ-ਠਾਕ ਕੀ।
ਚੰਗੀ observability ਕਿਹੜੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇਣੀ ਚਾਹੀਦੀ ਹੈ
ਇੱਕ ਸਿਹਤਮੰਦ ਸੈੱਟਅੱਪ ਤੁਹਾਨੂੰ ਘਟਨਾ 'ਤੇ ਸਾੱਫ਼ ਜਵਾਬ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ:
- ਕੀ ਟੁੱਟਿਆ? (errors, timeouts, saturation)
- ਕਿੱਥੇ? (ਕਿਹੜਾ endpoint, service, dependency, ਜਾਂ ਕੁਐਰੀ)
- ਹੁਣ ਕਿਉਂ? (ਡਿਪਲੌਇ, ਟ੍ਰੈਫਿਕ ਬਦਲਾਅ, ਫੀਚਰ ਫਲੈਗ, ਡੇਟਾ ਵਾਧਾ)
ਮਾਨੀਟਰਿੰਗ ਵਸ, observability ਨਹੀਂ (ਅਕਸਰ ਗਲਤ ਫਹਿਮੀ)
ਮਾਨੀਟਰਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਪਹਿਲਾਂ ਤੋਂ ਪਰਿਭਾਸ਼ਿਤ ਚੈਕਸ ਅਤੇ ਅਲਰਟਾਂ ('CPU > 90%') ਬਾਰੇ ਹੁੰਦੀ ਹੈ। Observability ਅੱਗੇ ਵਧਦੀ ਹੈ: ਇਹ ਤੁਹਾਨੂੰ ਘਟਨਾ ਦੌਰਾਨ ਨਵੀਆਂ ਗੈਰ-ਉਮੀਦਵਾਰ ਫੇਲ ਮੋਡਾਂ ਨੂੰ ਪੁੱਛ ਕੇ ਜਾਂਚ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦੀ (ਉਦਾਹਰਣ ਲਈ, ਕੇਵਲ ਇੱਕ ਗਾਹਕ ਸੈਕਸ਼ਨ ਕਾ checkout ਸਲੋ ਹੋ ਰਿਹਾ ਹੈ ਜੋ ਇੱਕ ਖਾਸ ਡਾਟਾਬੇਸ ਕਾਲ ਨਾਲ ਜੁੜਿਆ ਹੈ)।
ਇਸ ਸਮਰੱਥਾ ਨਾਲ ਤੁਸੀਂ ਘਟਨਾ ਦੌਰਾਨ ਨਵੇਂ ਸਵਾਲ ਪੁੱਛ ਸਕਦੇ ਹੋ ਅਤੇ ਕੱਚੇ ਟੈਲੀਮੇਟਰੀ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਸ਼ਾਂਤ-ਰੂਪ ਸਥਿਤੀ ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹੋ।
ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਕੀ ਹੁੰਦੇ ਹਨ ਅਤੇ ਇਹ ਕੀ ਦਰਸਾਉਂਦੇ ਹਨ
ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਇੱਕ ਕੇਂਦਰਿਤ ਰਿਕਾਰਡ ਹੁੰਦਾ ਹੈ ਉਹਨਾਂ ਡਾਟਾਬੇਸ ਓਪਰੇਸ਼ਨਾਂ ਦਾ ਜੋ ਇੱਕ "ਸਲੋ" ਥ੍ਰੈਸ਼ਹੋਲਡ ਤੋਂ ਵੱਧ ਗਏ। ਆਮ ਕੁਐਰੀ ਲੌਗਿੰਗ ਦੇ ਬਜਾਏ (ਜੋ ਬਹੁਤ ਬਹੁਤ ਹੋ ਸਕਦਾ ਹੈ), ਇਹ ਉਹ ਬਿਆਨ ਉਭਾਰਦੇ ਹਨ ਜੋ ਯੂਜ਼ਰ-ਦਿੱਖੀ ਲੈਟੈਂਸੀ ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਘਟਨਾਵਾਂ ਦਾ ਕਾਰਨ ਬਣ ਸਕਦੇ ਹਨ।
ਆਮ ਤੌਰ 'ਤੇ ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਵਿੱਚ ਕੀ ਦਰਜ ਹੁੰਦਾ ਹੈ
ਜਿਆਦਾਤਰ ਡਾਟਾਬੇਸ ਇੱਕੋ ਜਿਹੇ ਕੋਰ ਫੀਲਡ ਕੈਪਚਰ ਕਰ ਸਕਦੇ ਹਨ:
- ਕੁਐਰੀ (ਅਕਸਰ ਨਾਰਮਲਾਈਜ਼ਡ SQL ਟੈਕਸਟ)
- ਦੌਰਾਨੀ (ਕੁੱਲ ਲਗਿਆ ਸਮਾਂ, ਕਈ ਵਾਰੀ ਵਿਭਾਜਨ ਸਮੇਤ)
- ਟਾਈਮਸਟੈਂਪ (ਕਦੋਂ ਸ਼ੁਰੂ ਹੋਇਆ ਅਤੇ ਕਦੋਂ ਖਤਮ)
- ਸੰਦਰਭ ਜਿਵੇਂ database/user, host, application name, rows examined/returned, ਅਤੇ ਕਈ ਵਾਰੀ ਕੁਐਰੀ ਪਲੈਨ ਜਾਂ ਪਲੈਨ ਹੈਸ਼
ਇਹ ਸੰਦਰਭ ਇਹ ਬਣਾਉਂਦਾ ਹੈ ਕਿ "ਇਹ ਕੁਐਰੀ ਸਲੋ ਸੀ" ਤੋਂ "ਇਹ ਕੁਐਰੀ ਇਸ ਸੇਵਾ ਲਈ, ਇਸ ਕਨੈਸ਼ਨ ਪੂਲ ਤੋਂ, ਇਸ ਬਿਲਕੁਲ ਸਮੇਂ 'ਤੇ ਸਲੋ ਸੀ" ਤੱਕ ਦਾ ਨਿਸ਼ਚੇਤ ਤੱਥ ਮਿਲ ਸਕੇ—ਜੋ ਬਹੁਤ ਜ਼ਰੂਰੀ ਹੁੰਦਾ ਹੈ ਜਦ ਕਈ ਐਪ ਇੱਕੋ ਹੀ ਡਾਟਾਬੇਸ ਸਾਂਝਾ ਕਰ ਰਹੇ ਹੋਣ।
ਸਲੋ ਕੁਐਰੀ ਆਮ ਤੌਰ 'ਤੇ ਕਿਉਂ ਆਉਂਦੇ ਹਨ
ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਹੁੰਦੇ ਹੀ ਆਮ ਤੌਰ 'ਤੇ "ਖ਼ਰਾਬ SQL" ਦੇ ਬਾਰੇ ਨਹੀਂ ਹੁੰਦੇ। ਇਹ ਸੰਕੇਤ ਹੁੰਦੇ ਹਨ ਕਿ ਡਾਟਾਬੇਸ ਨੂੰ ਵਧੇਰੇ ਕੰਮ ਕਰਨਾ ਪਿਆ ਜਾਂ ਉਹ ਕੁਝ ਦੇਣ ਦੀ ਉਡੀਕ ਕਰ ਰਿਹਾ ਸੀ। ਆਮ ਕਾਰਨ:
- ਮਿਸਿੰਗ ਜਾਂ ਅਕਰਾਮਕ ਇੰਡੈਕਸ, ਜੋ ਫੁੱਲ ਸਕੈਨ ਜਾਂ ਮਹਿੰਗੇ JOIN ਵਜੋਂ ਨਤੀਜਾ ਦਿੰਦੇ ਹਨ
- ਖ਼ਰਾਬ ਇਕਸਿਕਿਊਸ਼ਨ ਪਲੈਨ (ਅਕਸਰ ਪੈਰਾਮੀਟਰ ਮੁੱਲ, ਪੁਰਾਣੇ ਸਟੈਟਿਸਟਿਕਸ, ਜਾਂ ਪਲੈਨ ਕੈਸ਼ ਬਿਹੈਵਿਅਰ ਕਾਰਨ)
- ਲੌਕ ਵੇਟ ਅਤੇ ਕਨਟੈਂਸ਼ਨ, ਜਿੱਥੇ ਕੁਐਰੀ ਚਲਦੀ ਤੇਜ਼ ਹੁੰਦੀ ਹੈ ਪਰ ਵੈਟ ਕਰਦੀ ਹੈ
- ਲੋਡ ਸਪਾਈਕਸ, ਜਿੱਥੇ ਆਮ ਤੌਰ 'ਤੇ ਠੀਕ ਕੁਐਰੀ concurrency ਜਾਂ I/O ਦਬਾਅ ਹੇਠਾਂ ਸਲੋ ਹੋ ਜਾਂਦੀ ਹੈ
ਇਕ ਸਹਾਇਕ ਮਾਨਸਿਕ ਮਾਡਲ: ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਦੋਹਾਂ ਨੂੰ ਕੈਪਚਰ ਕਰਦੇ ਹਨ—ਕੰਮ (CPU/I/O ਭਾਰੀ ਕੁਐਰੀਆਂ) ਅਤੇ ਉਡੀਕ (ਲੌਕ, ਸੈਚੁਰੇਸ਼ਨ)।
“ਸਲੋ” ਦੀ ਪਰਿਭਾਸ਼ਾ: ਥ੍ਰੈਸ਼ਹੋਲਡ ਅਤੇ ਪर्सੈਂਟਾਈਲ
ਇੱਕ ਸਿੰਗਲ ਥ੍ਰੈਸ਼ਹੋਲਡ (ਉਦਾਹਰਨ ਲਈ, "500ms ਤੋਂ ਵੱਧ ਕੁਝ ਵੀ ਲੌਗ ਕਰੋ") ਸਧਾਰਨ ਹੈ, ਪਰ ਇਹ ਉਦਾਹਰਣ ਵਾਪਸ ਨਾ ਦੇਖੇ ਜਾ ਸਕਦੇ ਜਦ ਟਾਇਪਿਕਲ ਲੈਟੈਂਸੀ ਕਾਫ਼ੀ ਘੱਟ ਹੋਵੇ। ਵਿਚਾਰ ਕਰੋ:
- ਇੱਕ ਫਿਕਸਡ ਥ੍ਰੈਸ਼ਹੋਲਡ ਜੋ ਸੱਚਮੁਚ ਬੁਰੇ ਆਊਟਲਾਈਅਰਾਂ ਪਕੜਦਾ ਹੈ
- ਇੱਕ ਪ੍ਰਸੈਂਟਾਈਲ-ਅਧਾਰਿਤ ਦ੍ਰਿਸ਼ਟੀ (p95/p99) ਤਾਂ ਜੋ ਤੁਸੀਂ ਰੈਗਰੈਸ਼ਨ ਨੋਟਿਸ ਕਰ ਸਕੋ ਜਦ ਅਬਸੋਲੂਟ ਸਮਾਂ "ਠੀਕ" ਲੱਗੇ
ਇਸ ਨਾਲ ਸਲੋ ਕੁਐਰੀ ਲੌਗ actionable ਰਹਿੰਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੇ ਮੈਟਰਿਕ ਰੁਝਾਨਾਂ ਨੂੰ ਉਭਾਰਦਾ ਹੈ।
ਗੋਪਨੀਯਤਾ ਨੋਟ: ਸੰਵੇਦਨਸ਼ੀਲ ਮੁੱਲ ਲਾਉਣ ਤੋਂ ਬਚੋ
ਜੇ ਪੈਰਾਮੀਟਰ inline ਹੋਣ ਤਾਂ ਸਲੋ ਕੁਐਰੀ ਲੌਗਾਂ ਅਕਸਰ ਨਿੱਜੀ ਡੇਟਾ ਫੜ ਸਕਦੀਆਂ ਹਨ (ਈਮੇਲ, ਟੋਕਨ, IDs)। ਪੈਰਾਮੀਟਰਾਈਜ਼ਡ ਕੁਐਰੀਆਂ ਅਤੇ ਉਹ ਸੈਟਿੰਗਾਂ ਵਰਤੋ ਜੋ ਕੁਐਰੀ ਸ਼ੇਪ ਲੌਗ ਕਰਦੀਆਂ ਹਨ ਨਾ ਕਿ ਰੋ-ਵੈਲਿਊਜ਼। ਜੇ ਬਚਣਾ ਨਾਹੀੰ ਹੋਵੇ ਤਾਂ ਲੌਗ ਪਾਈਪਲਾਈਨ ਵਿੱਚ ਮਾਸਕਿੰਗ/ਰੈਡੈਕਸ਼ਨ ਜੋੜੋ ਪਹਿਲਾਂ ਕਿ ਲੰਬੇ ਸਮੇਂ ਲਈ ਸਟੋਰ ਕੀਤਾ ਜਾਵੇ ਜਾਂ ਘਟਨਾ-ਵਾਰ ਸਾਂਝਾ ਕੀਤਾ ਜਾਵੇ।
ਸਲੋ ਕੁਐਰੀਆਂ ਕਿਵੇਂ ਆਊਟੇਜ ਅਤੇ ਯੂਜ਼ਰ-ਦਿਖਾਈ ਦੇਣ ਵਾਲੀ ਲੈਟੈਂਸੀ ਵਿੱਚ ਬਦਲਦੀਆਂ ਹਨ
ਇਕ ਸਲੋ ਕੁਐਰੀ ਅਕਸਰ "ਕੇਵਲ ਸਲੋ" ਹੀ ਨਹੀਂ ਰਹਿੰਦੀ। ਆਮ ਚੇਨ ਇਸ ਤਰ੍ਹਾਂ ਹੁੰਦੀ ਹੈ: ਯੂਜ਼ਰ ਲੈਟੈਂਸੀ → API ਲੈਟੈਂਸੀ → ਡਾਟਾਬੇਸ ਦਬਾਅ → ਟਾਈਮਆਊਟ। ਯੂਜ਼ਰ ਪਹਿਲਾਂ ਇਸਨੂੰ ਮਹਿਸੂਸ ਕਰਦਾ ਹੈ—ਪੇਜ ਅਟਕ ਜਾਂ ਸਕ੍ਰੀਨ ਘੁੰਮਣ। ਫਿਰ API ਮੈਟਰਿਕਸ ਵਿੱਚ ਉੱਚੇ ਰਿਸਪਾਂਸ ਟਾਈਮ ਆਉਂਦੇ ਹਨ, ਹਾਲਾਂਕਿ ਐਪ ਕੋਡ ਵਿੱਚ ਕੁਝ ਨਹੀਂ ਬਦਲਿਆ।
ਕਿਉਂ ਡਾਟਾਬੇਸ ਦੀ ਤਕلیف ਐਪ ਦੀ ਸਮੱਸਿਆ ਵਾਂਗ ਲੱਗਦੀ ਹੈ
ਬਾਹਰੋਂ ਵੇਖਣ 'ਤੇ, ਇੱਕ ਸਲੋ ਡਾਟਾਬੇਸ ਅਕਸਰ “ਐਪ ਸਲੋ ਹੈ” ਵਾਂਗ ਲੱਗਦਾ ਹੈ ਕਿਉਂਕਿ API ਥ੍ਰੈਡ ਕੁਐਰੀ ਦੀ ਉਡੀਕ ਕਰ ਰਹੀ ਹੁੰਦੀ ਹੈ। ਐਪ ਸਰਵਰਾਂ ਉੱਤੇ CPU ਅਤੇ ਮੈਮੋਰੀ ਆਮ ਤੌਰ 'ਤੇ ਨਾਰਮਲ ਨਜ਼ਰ ਆ ਸਕਦੇ ਹਨ, ਫਿਰ ਵੀ p95 ਅਤੇ p99 ਲੈਟੈਂਸੀ ਵਧ ਸਕਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਸਿਰਫ਼ ਐਪ-ਲੈਵਲ ਮੈਟਰਿਕ ਦੇਖਦੇ ਹੋ ਤਾਂ ਤੁਸੀਂ ਗਲਤ ਇਨ੍ਹੇਰੈਂਟ ਸ਼ੱਕ ਦੀ ਪਿੱਛੇ ਲੱਗ ਸਕਦੇ ਹੋ—HTTP ਹੈਂਡਲਰ, cache, ਜਾਂ ਡਿਪਲੌਇ—ਜਦਕਿ ਅਸਲ ਬੋਤਲ-ਨੇਕ ਇੱਕ ਇਕੱਲਾ ਕੁਐਰੀ ਪਲੈਨ ਰਿਗਰੈਸ ਹੋ ਸਕਦਾ ਹੈ।
ਸਲੋ ਕੁਐਰੀਆਂ ਕਿਵੇਂ ਆਊਟੇਜ ਵਿੱਚ ਬਦਲਦੀਆਂ ਹਨ
ਜਿਵੇਂ ਹੀ ਇੱਕ ਕੁਐਰੀ ਧੀਮੀ ਹੋ ਜਾਂਦੀ ਹੈ, ਸਿਸਟਮ ਨਿਪਟਾਰਾ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ—ਅਤੇ ਉਹ coping mechanisms ਫੇਲ ਨੂੰ ਵਧਾ ਸਕਦੇ ਹਨ:
- ਕਲਾਇੰਟ ਜਾਂ ਅੰਦਰੂਨੀ ਸਰਵਿਸਾਂ ਤੋਂ ਰੀਟ੍ਰਾਈ ਟ੍ਰੈਫਿਕ ਨੂੰ ਗੁਣਾ ਕਰ ਦਿੰਦੇ ਹਨ, DB ਲੋਡ ਵਧ ਜਾਂਦਾ ਹੈ।
- ਕਨੈਕਸ਼ਨ ਪੂਲ ਖਪਤ ਹੁੰਦੀ ਹੈ ਜਦ ਰਿਕਵੇਸਟਾਂ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਜ਼ਿਆਦਾ ਸਮੇਂ ਲਈ ਰੋਕ ਲੈਂਦੀਆਂ ਹਨ, ਨਵੇਂ ਰਿਕਵੇਸਟਾਂ ਨੂੰ ਉਡੀਕ ਕਰਵਾਉਂਦੀਆਂ ਹਨ।
- ਕਿਊ ਬਿਲਡਅਪ ਜੌਬ ਵਰਕਰਾਂ ਅਤੇ 메시ਜ ਕਨਸਿਊਮਰਾਂ ਵਿੱਚ ਬਣ ਜਾਂਦੀ ਹੈ ਜਿਵੇਂ throughput ਘਟਦਾ ਹੈ।
- ਟਾਈਮਆਊਟ ਹੌਂਦੇ ਹਨ ਜੋ ਅੰਸ਼ਿਕ ਫੇਲਿਆਵਟ ਕਰਦੇ ਹਨ, ਜਿਸ ਨਾਲ ਹੋਰ ਰੀਟ੍ਰਾਈ ਅਤੇ ਨਕਲ ਕੰਮ ਹੋ ਜਾਂਦਾ ਹੈ।
ਇਕ ਸਧਾਰਨ ਦ੍ਰਿਸ਼
ਇੱਕ checkout endpoint ਕਲਪਨਾ ਕਰੋ ਜੋ SELECT ... FROM orders WHERE user_id = ? ORDER BY created_at DESC LIMIT 1 ਚਲਾਉਂਦਾ ਹੈ। ਡੇਟਾ ਵਾਧੇ ਤੋਂ ਬਾਅਦ ਇੰਡੈਕਸ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸਹਾਇਤਾ ਨਹੀਂ ਕਰ ਰਿਹਾ ਅਤੇ ਕੁਐਰੀ ਸਮਾਂ 20ms ਤੋਂ 800ms ਹੋ ਜਾਂਦਾ ਹੈ। ਆਮ ਟ੍ਰੈਫਿਕ ਹੇਠਾਂ ਇਹ ਨਿਰਾਸ਼ਜਨਕ ਹੋ ਸਕਦਾ ਹੈ। ਪੀਕ ਟ੍ਰੈਫਿਕ ਹੇਠਾਂ, API ਰਿਕਵੇਸਟ DB ਕਨੈਕਸ਼ਨਾਂ ਦੀ ਉਡੀਕ ਵਿੱਚ ਇਕਠੇ ਹੋ ਜਾਂਦੀਆਂ ਹਨ, 2 ਸੈਕੰਡ 'ਤੇ timeout ਹੋ ਜਾਂਦੀਆਂ ਹਨ, ਅਤੇ ਕਲਾਇੰਟ ਰੀਟ੍ਰਾਈ ਕਰਦੇ ਹਨ। ਕੁਝ ਮਿੰਟਾਂ ਵਿੱਚ, ਇੱਕ "ਛੋਟੀ" ਸਲੋ ਕੁਐਰੀ ਯੂਜ਼ਰ-ਦਿੱਖੀ errors ਅਤੇ ਪੂਰਾ ਪ੍ਰੋਡਕਸ਼ਨ ਘਟਨਾ ਬਣ ਸਕਦਾ ਹੈ।
ਉਨ੍ਹਾਂ ਮੈਟਰਿਕਸ ਜੋ ਡਾਟਾਬੇਸ ਦਰਦ ਤੇਜ਼ੀ ਨਾਲ ਦਰਸਾਉਂਦੇ ਹਨ
ਜਦੋਂ ਡਾਟਾਬੇਸ ਸੰਘਰਸ਼ ਕੀਤਾ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ, ਪਹਿਲੇ ਤਰ੍ਹਾਂ ਦੇ ਸੁਝਾਅ ਆਮ ਤੌਰ 'ਤੇ ਕੁਝ ਮੈਟਰਿਕਸ ਵਿੱਚ ਦਿਖਾਈ ਦਿੰਦੇ ਹਨ। ਲਕਸ਼ ਮੰਨੋ ਸਭ ਕੁਝ ਟਰੈਕ ਨਾ ਕਰਨਾ—ਉਦੇਸ਼ ਤੇਜ਼ੀ ਨਾਲ ਇੱਕ ਬਦਲਾਵ ਪਕੜਨਾ ਅਤੇ ਫਿਰ ਇਸਦਾ ਸਰੋਤ ਨਿਰਧਾਰਤ ਕਰਨਾ ਹੈ।
ਸੋਨੇ ਦੇ ਸੰਕੇਤਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਇਹ ਚਾਰ ਸੰਕੇਤ ਤੁਹਾਨੂੰ ਦੱਸਣਗੇ ਕਿ ਕੀ ਤੁਸੀਂ ਡਾਟਾਬੇਸ ਸਮੱਸਿਆ ਦੇਖ ਰਹੇ ਹੋ, ਐਪ ਸਮੱਸਿਆ, ਜਾਂ ਦੋਹਾਂ:
- ਲੈਟੈਂਸੀ: ਉੱਠ ਰਹੀ p95/p99 ਰਿਕਵੇਸਟ ਟਾਈਮ ਅਕਸਰ ਪਹਿਲਾ ਗਾਹਕ-ਨਜ਼ਰੀਆ ਲੱਛਣ ਹੁੰਦਾ ਹੈ।
- ਟ੍ਰੈਫਿਕ: ਟ੍ਰੈਫਿਕ ਸਪਾਈਕ ਕਾਰਨ ਹੋ ਸਕਦਾ ਹੈ (ਜ਼ਿਆਦਾ ਲੋਡ) ਜਾਂ ਨਤੀਜਾ (ਰੀਟ੍ਰਾਈ ਅਤੇ herds)।
- ਐਰਰ: ਟਾਈਮਆਊਟ, 5xx, ਅਤੇ ਡਾਟਾਬੇਸ ਐਰਰ ਕੋਡ ਵੇਖੋ।
- ਸੈਚੁਰੇਸ਼ਨ: ਇੱਕ DB "ਆਪ" ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਸੈਚੁਰੇਟਡ—CPU, I/O, ਕਨੈਕਸ਼ਨ ਸਲਾਟ, ਜਾਂ ਲੌਕ ਕਨਟੈਂਸ਼ਨ।
ਵੇਖਣ ਯੋਗ ਕੁਝ ਮੁੱਖ ਡੀ.ਬੀ. ਮੈਟਰਿਕਸ
ਕੁਝ DB-ਨਿਰਧਾਰਤ ਚਾਰਟ ਤੁਹਾਨੂੰ ਦੱਸ ਸਕਦੇ ਹਨ ਕਿ ਬੋਤਲ-ਨੈਕ execution, concurrency, ਜਾਂ storage ਨਾਲ ਸਬੰਧਤ ਹੈ:
- ਕੁਐਰੀ ਲੈਟੈਂਸੀ ਵੰਡ (ਸਿਰਫ਼ ਔਸਤ ਨਹੀਂ): ਤੇਜ਼ ਟੇਲ (p95/p99) ਅਤੇ ਵੈਰੀਅੰਸ 'ਤੇ ਧਿਆਨ ਦਿਓ।
- ਕਨੈਕਸ਼ਨ ਅਤੇ ਪੂਲ ਯੂਟਿਲਾਈਜ਼ੇਸ਼ਨ: ਵਧ ਰਹੇ "active" ਕਨੈਕਸ਼ਨ, ਪੂਲ ਵਿੱਚ ਕਤਾਰਬੰਦੀ, ਜਾਂ ਅਕਸਰ ਪੂਲ ਖਤਮ ਹੋਣਾ।
- ਲੌਕ ਅਤੇ ਉਡੀਕ ਸਮਾਂ: ਲੌਕ ਵੇਟ ਦੌਰਾਨੀ ਅਤੇ ਡੈਡਲਾਕ; ਇਹ ਅਕਸਰ ਅਚਾਨਕ ਲੈਟੈਂਸੀ ਛਾਲਾਂ ਨਾਲ ਸੰਬੰਧਿਤ ਹੁੰਦੇ ਹਨ।
- ਕੈਸ਼ ਹਿਟ ਰੇਟ / ਬਫਰ ਕੈਸ਼ ਦੀ ਪ੍ਰਭਾਵਸ਼ੀਲਤਾ: ਡ੍ਰੌਪ ਦਾ ਮਤਲਬ ਹੋ ਸਕਦਾ ਹੈ ਕਿ ਤੁਹਾਡਾ ਵਰਕਿੰਗ ਸੈੱਟ ਹੁਣ ਫਿੱਟ ਨਹੀਂ ਹੁੰਦਾ, ਜਿਸ ਨਾਲ ਡਿਸਕ ਰੀਡ ਵੱਧਦਾ ਹੈ।
ਸਰਵਿਸ-ਸਤ੍ਹਰੀ ਮੈਟਰਿਕਸ ਜੋ DB 'ਤੇ ਇਸ਼ਾਰਾ ਕਰਦੀਆਂ ਹਨ
DB ਮੈਟਰਿਕਸ ਨੂੰ ਸੇਵਾ ਦੇ ਅਨੁਭਵ ਨਾਲ ਜੋੜੋ:
- ਰਿਕਵੇਸਟ ਰੇਟ ਅਤੇ ਟਾਈਮਆਊਟ (ਉਪਸਟ੍ਰੀਮ ਟਾਈਮਆਊਟ ਸਮੇਤ)
- p95/p99 ਲੈਟੈਂਸੀ ਰੋਟ ਦੁਆਰਾ: ਇੱਕ ਹੀ endpoint ਦਾ ਡਿਗਣਾ ਇੱਕ ਖਾਸ ਕੁਐਰੀ ਪੈਟਰਨ ਦਾ ਇਸ਼ਾਰਾ ਕਰ ਸਕਦਾ ਹੈ।
- ਰੀਟ੍ਰਾਈ ਰੇਟ: ਰੀਟ੍ਰਾਈ ਲੋਡ ਨੂੰ ਵਧਾ ਸਕਦੇ ਹਨ ਅਤੇ ਮੂਲ ਟриггер ਨੂੰ ਛੁਪਾ ਸਕਦੇ ਹਨ।
ਡੈਸ਼ਬੋਰਡ ਜੋ ਸਹੀ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦਿੰਦੇ ਹਨ
ਡੈਸ਼ਬੋਰਡ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਤੇਜ਼ੀ ਨਾਲ ਇਹ ਪੁੱਛ ਸਕਣ:
- ਕੀ ਇਹ ਨਵਾਂ ਹੈ? ਪਿਛਲੇ ਦਿਨ/ਹਫਤੇ ਨਾਲ ਤੁਲਨਾ ਕਰੋ।
- ਕੀ ਇਹ ਅਲੱਗ ਹੈ? ਇੱਕ endpoint, ਇੱਕ tenant, ਇੱਕ ਨੋਡ, ਇੱਕ AZ?
- ਕੀ ਇਹ ਵਧ ਰਿਹਾ ਹੈ? ਕਿਆ saturation trending up ਹੈ ਅਤੇ ਕਿਊਜ਼ ਬਣ ਰਹੀਆਂ ਹਨ?
ਜਦ ਇਹ ਮੈਟਰਿਕਸ ਮਿਲਦੇ ਹਨ—ਟੇਲ ਲੈਟੈਂਸੀ ਵਧ ਰਹੀ, ਟਾਈਮਆਊਟ ਵੱਧ ਰਹੇ, ਸੈਚੁਰੇਸ਼ਨ ਚੜ੍ਹ ਰਿਹਾ—ਤੁਹਾਡੇ ਕੋਲ ਮਜ਼ਬੂਤ ਸੰਕੇਤ ਹੁੰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ slow query logs ਅਤੇ tracing ਵੱਲ ਮੋੜੋ ਅਤੇ ਅਸਲ ਓਪਰੇਸ਼ਨ ਦੀ ਪਛਾਣ ਕਰੋ।
ਅਣਸ਼ਾਂ 'ਤੇ ਠੀਕ ਸਲੋ ਓਪਰੇਸ਼ਨ ਨੂੰ ਟ੍ਰੇਸ ਕਰਨਾ
ਹੁਣੇ ਹੋਰਾਂ ਨੂੰ ਸ਼ਾਮਲ ਕਰੋ
ਟੀਮ-ਮੇਟ ਜਾਂ ਦੋਸਤਾਂ ਨੂੰ workflow ਵਿੱਚ ਲਿਆਂਓ ਅਤੇ ਜਦੋਂ ਉਹ Koder.ai 'ਤੇ ਬਿਲਡ ਸ਼ੁਰੂ ਕਰਨ ਤਾਂ ਕ੍ਰੈਡਿਟ ਪ੍ਰਾਪਤ ਕਰੋ।
ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਤੁਹਾਨੂੰ ਦੱਸਦੇ ਹਨ ਡਾਟਾਬੇਸ ਵਿੱਚ ਕੀ ਸਲੋ ਸੀ। ਡਿਸਟ੍ਰਿਬਿਊਟਡ ਟਰੇਸਿੰਗ ਦੱਸਦੀ ਹੈ ਕਿਸਨੇ ਇਸ ਨੂੰ ਮੰਗਿਆ, ਕਿੱਥੋਂ, ਅਤੇ ਕਿਉਂ ਇਹ ਮਹੱਤਵਪੂਰਨ ਸੀ।
ਹੰਝੇ ਤੇ ਅਟਕਣ ਦੇ ਬਜਾਏ ਰਿਕਵੇਸਟ ਨੂੰ ਫਾਲੋ ਕਰੋ
ਟ੍ਰੇਸਿੰਗ ਹੋਣ 'ਤੇ, "ਡਾਟਾਬੇਸ ਸਲੋ ਹੈ" ਦੀ alert ਇੱਕ ਸਪਸ਼ਟ ਕਹਾਣੀ ਬਣ ਜਾਂਦੀ ਹੈ: ਇੱਕ ਖਾਸ endpoint (ਜਾਂ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ) ਨੇ ਕਾਲ ਕੀਤੀ, ਜਿਸ ਵਿੱਚੋਂ ਇੱਕ ਡਾਟਾਬੇਸ ਓਪਰੇਸ਼ਨ ਨੇ ਜ਼ਿਆਦਾਤਰ ਸਮਾਂ ਲਿਆ।
ਆਪਣੀ APM UI ਵਿੱਚ, ਉੱਚ-ਲੈਟੈਂਸੀ trace ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਲੱਭੋ:
- ਉਹ route ਜਾਂ job ਨਾਮ ਜਿਹੜੇ ਨੇ ਬੇਨਤੀ ਸ਼ੁਰੂ ਕੀਤੀ (ਉਦਾਹਰਣ:
GET /checkout ਜਾਂ billing_reconcile_worker)।
- ਇੱਕ ਡਾਟਾਬੇਸ span ਜਿਸ ਦੀ ਦੌਰਾਨੀ ਜਾਂ time-to-first-row ਅਸਧਾਰਨ ਉੱਚੀ ਹੋਵੇ।
- ਕੀ ਇਹ ਸਲੋਪਨ ਇੱਕ ਹੀ ਰਿਕਵੇਸਟ ਟਾਈਪ ਤੱਕ ਸੀਮੇਤ ਹੈ ਜਾਂ ਬਹੁਤ ਸਾਰੀਆਂ ਵਿੱਚ ਫੈਲਿਆ ਹੋਇਆ ਹੈ।
ਸਪੈਨਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਟੈਗ ਕਰੋ (ਬਿਨਾਂ SQL ਲੀਕ ਕੀਤੇ)
ਟ੍ਰੇਸਾਂ ਵਿੱਚ ਪੂਰਾ SQL ਰਿਸ਼ਕ (PII, secrets, ਵੱਡਾ payload) ਹੋ ਸਕਦਾ ਹੈ। ਇਕ ਕਾਰਗੁਜ਼ਾਰ ਤਰੀਕਾ ਹੈ span ਨੂੰ ਕੁਐਰੀ ਨਾਮ/ਓਪਰੇਸ਼ਨ ਨਾਲ ਟੈਗ ਕਰਨਾ ਨਾ ਕਿ ਪੂਰੇ ਬਿਆਨ ਨਾਲ:
db.operation=SELECT ਅਤੇ db.table=ordersapp.query_name=orders_by_customer_v2feature_flag=checkout_upsell
ਇਸ ਨਾਲ ਟਰੇਸ ਖੋਜਯੋਗ ਅਤੇ ਸੁਰੱਖਿਅਤ ਰਹਿੰਦੇ ਹਨ ਅਤੇ ਫਿਰ ਵੀ ਤੁਹਾਨੂੰ ਕੋਡ ਪਾਥ ਵੱਲ ਇਸ਼ਾਰਾ ਮਿਲਦਾ ਹੈ।
ਸਭ ਕੁਝ IDs ਨਾਲ ਜੋੜੋ
"trace → app logs → slow query entry" ਨੂੰ ਜਲਦੀ ਜੋੜਨ ਦਾ ਤੇਜ਼ ਤਰੀਕਾ ਇੱਕ ਸਾਂਝਾ ਆਈਡੀ ਹੈ:
- trace ID ਨੂੰ ਐਪ ਲੌਗਾਂ ਵਿੱਚ propagate ਕਰੋ।
- ਜੇ ਸੰਭਵ ਹੋਵੇ, slow query ਲੌਗ ਸੰਦਰਭ ਵਿੱਚ trace ID (ਜਾਂ request ID) ਜੋੜੋ (ਜਾਂ ਜਦ ਸੁਰੱਖਿਅਤ ਹੋਵੇ ਤਾਂ ਕੁਐਰੀ ਵਿੱਚ comment ਨਾਂ ਆਰੋਪ ਕਰਕੇ)।
ਹੁਣ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਉੱਚ-ਮੁੱਲ ਦੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹੋ:
- ਕਿਹੜਾ route ਜਾਂ worker ਸਲੋ ਕਾਲ trigger ਕਰ ਰਿਹਾ ਸੀ?
- ਕੀ ਇਹ ਕਿਸੇ ਖਾਸ tenant/customer, ਖੇਤਰ, ਜਾਂ ਯੋਜਨਾ ਨਾਲ ਜੁੜਿਆ ਸੀ?
- ਕੀ ਇਹ ਕਿਸੇ release ਜਾਂ ਸੈਟਿੰਗ ਬਦਲਾਅ ਤੋਂ ਬਾਅਦ ਸ਼ੁਰੂ ਹੋਇਆ?
- ਕੀ ਇਹ ਇੱਕ ਮਹਿੰਗੀ ਕੁਐਰੀ ਹੈ ਜਾਂ ਕਈ ਛੋਟੀ ਕੁਐਰੀਆਂ ਦੀ ਬਰਸਾਤ (N+1)?
ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਸੈੱਟਅੱਪ ਕਰਨਾ ਬਿਨਾਂ ਡੇਟਾ ਵਿੱਚ ਡੁੱਬਣ ਦੇ
ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਉਪਯੋਗੀ ਉਹ ਹੁੰਦੇ ਹਨ ਜਦ ਉਹ ਪੜ੍ਹਨਯੋਗ ਅਤੇ actionable ਰਹਿੰਦੇ ਹਨ। ਟੀਚਾ ਇਹ ਨਹੀਂ ਕਿ "ਸਭ ਕੁਝ ਹਮੇਸ਼ਾਂ ਲਾਗ ਹੋਵੇ"—ਇਹ ਹੈ ਕਾਫੀ ਵਿਸਥਾਰ ਕੈਪਚਰ ਕਰਨਾ ਤਾਂ ਜੋ ਪਤਾ ਚੱਲੇ ਕਿਉਂ ਕੁਐਰੀਆਂ ਸਲੋ ਹਨ, ਬਿਨਾਂ ਮਹੱਤਵਪੂਰਨ ਓਵਰਹੈੱਡ ਜਾਂ ਖ਼ਰਚ ਵਿਧਾਨ ਬਣੇ।
ਆਪਣੀ ਐਪ ਦੇ ਅਨੁਭਵ ਨਾਲ ਮੇਲ ਖਾਂਦੀਆਂ thresholds ਚੁਣੋ
ਇੱਕ ਅਬਸੋਲੂਟ ਥ੍ਰੈਸ਼ਹੋਲਡ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਯੂਜ਼ਰ ਉਮੀਦਾਂ ਅਤੇ ਤੁਹਾਡੇ ਡਾਟਾਬੇਸ ਦੀ ਭੂਮਿਕਾ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੋਵੇ:
- ਉਦਾਹਰਣ: OLTP ਹੈਵੀ ਐਪ ਲਈ
>200ms, ਮਿਲੇ-ਜੁле ਵਰਕਲੋਡ ਲਈ >500ms
ਫਿਰ ਇੱਕ ਨਿਸ਼ਪੱਖ ਦ੍ਰਿਸ਼ ਜੋ ਤੁਸੀਂ ਸਿਸਟਮ ਜਦ੍ਹੋਂ ਹੌਲਾ ਹੋ ਜਾਵੇ ਤਾਂ ਵੀ ਰੈਗਰੈਸ਼ਨ ਦੇਖ ਸਕੋ:
- ਉਦਾਹਰਣ: “ਮਿੰਟ ਵਿੱਚ top 100 slowest” ਜਾਂ “ਸਭ ਤੋਂ ਤੇਜ਼ 1% statements”
ਦੋਹਾਂ ਵਰਤਣ ਨਾਲ ਅੰਧੇ ਧੱਫੇ ਰੋਕੇ ਜਾਂਦੇ ਹਨ: ਅਬਸੋਲੂਟ ਥ੍ਰੈਸ਼ਹੋਲਡ ਹਮੇਸ਼ਾਂ-ਗੰਭੀਰ ਕੁਐਰੀਆਂ ਨੂੰ ਪਕੜਦਾ ਹੈ, ਜਦਕਿ ਸਬੰਧਤ ਥ੍ਰੈਸ਼ਹੋਲਡ ਵੀੜ੍ਹੇ ਵੇਲੇ ਰੈਗਰੈਸ਼ਨ ਦਿਖਾਉਂਦਾ ਹੈ।
ਸੈਂਪਲਿੰਗ ਸਮਝਦਾਰੀ ਨਾਲ ਅਤੇ ਉਹ ਸੰਦਰਭ ਕੈਪਚਰ ਕਰੋ ਜੋ ਅਸਲ ਵਿੱਚ ਵਰਤੀ ਜਾਵੇਗੀ
ਚੋਟੀ ਦੇ ਟ੍ਰੈਫਿਕ 'ਤੇ ਹਰ ਸਲੋ ਬਿਆਨ ਲਾਗ ਕਰਨ ਨਾਲ ਕਾਰਗੁਜ਼ਾਰੀ 'ਤੇ ਅਸਰ ਪੈ ਸਕਦਾ ਹੈ ਅਤੇ ਸ਼ੋਰ ਬਣ ਸਕਦਾ ਹੈ। ਸੈਂਪਲਿੰਗ ਵਰਤੋ (ਉਦਾਹਰਨ ਲਈ, 10–20% slow events ਲਾਗ ਕਰੋ) ਅਤੇ ਅਨੁਸਥਿਤੀ ਦੌਰਾਨ ਜਾਂ ਘਟਨਾ 'ਤੇ ਐਕਟਿਵਲੀਟੀ ਵਧਾਓ।
ਹਰ ਇਵੈਂਟ ਵਿੱਚ ਉਹ ਸੰਦਰਭ ਹੋਵੇ ਜੋ ਤੁਸੀਂ ਕਰਨ ਅਨੁਕੂਲ ਕਾਰਵਾਈ ਲਈ ਵਰਤੋਗੇ: duration, rows examined/returned, database/user, application name, ਅਤੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ request ਜਾਂ trace ID।
ਕੁਐਰੀਆਂ ਨੂੰ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ ਤਾਂ ਕਿ pattern ਸਪਸ਼ਟ ਹੋਣ
ਕੱਚੇ SQL ਸਟ੍ਰਿੰਗਾਂ ਵਿੱਚ ਵਧੀਆ ਮੀਆਂ-ਮਸਲੇ ਹੁੰਦੇ ਹਨ: ਵੱਖ-ਵੱਖ IDs ਅਤੇ timestamps ਇਕੋ ਕੁਐਰੀ ਨੂੰ ਵੱਖਰਾ ਦਿਖਾਉਂਦੇ ਹਨ। ਕੁਐਰੀ ਫਿੰਗਰਪ੍ਰਿੰਟਿੰਗ ਵਰਤੋ ਤਾਂ ਜੋ ਇੱਕੋ ਜਿਹੀ ਸ਼ਕਲ ਗਰੁੱਪ ਹੋ ਜਾਵੇ, ਉਦਾਹਰਨ WHERE user_id = ?।
ਇਸ ਨਾਲ ਤੁਸੀਂ ਪੁੱਛ ਸਕਦੇ ਹੋ: "ਕਿਹੜੀ ਕੁਐਰੀ ਸ਼ੇਪ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਲੈਟੈਂਸੀ ਪੈਦਾ ਕਰਦੀ ਹੈ?" ਨਾਂ ਕਿ ਇੱਕ-ਇੱਕ ਉਦਾਹਰਣ ਦਾ ਪਿਛਾ ਕਰੋ।
ਘਟਨਾ-ਧਾਰਾ ਅਤੇ ਲਾਗ ਰਿਟੇਸ਼ਨ
ਘਟਨਾ ਦੌਰਾਨਾ ਤੁਲਨਾ ਕਰਨ ਲਈ ਕਾਫੀ ਸਮੇਂ ਲਈ ਵਿਸਥਾਰ ਰੱਖੋ—ਅਮੂਮਨ 7–30 ਦਿਨ ਇੱਕ ਕਾਰਗੁਜ਼ਾਰ ਸ਼ੁਰੂਆਤੀ ਦਾਇਰਾ ਹੈ।
ਜੇ ਸਟੋਰੇਜ਼ ਚਿੰਤਾ ਹੈ, ਤਾਂ ਪਰਾਣੇ ਡੇਟਾ ਨੂੰ ਡਾਊਨਸੈਂਪ ਕਰੋ (ਅਗਰੀਗੇਟ ਅਤੇ top fingerprints ਰੱਖੋ) ਅਤੇ ਨਵੀਨਤਮ ਵਿੰਡੋ ਲਈ ਪੂਰੀ fidelity ਲੌਗ ਰੱਖੋ।
ਅਲਰਟ ਜੋ ਗਾਹਕਾਂ ਤੋਂ ਪਹਿਲਾਂ slowdown ਪਕੜਦੇ ਹਨ
ਸਬਕਾਂ ਨੂੰ ਕ੍ਰੈਡਿਟ ਵਿੱਚ ਬਦਲੋ
Koder.ai 'ਤੇ ਬਿਲਡ ਕਰਨ ਦੌਰਾਨ ਜੋ ਸਿੱਖਿਆ ਉਹ ਸਾਂਝਾ ਕਰੋ ਅਤੇ ਸਮੱਗਰੀ ਲਈ ਕ੍ਰੈਡਿਟ ਹਾਸਲ ਕਰੋ।
ਅਲਰਟ ਉਹਨਾਂ ਚੀਜ਼ਾਂ 'ਤੇ ਚਾਹੀਦੇ ਹਨ ਜੋ ਦੱਸਣ ਕਿ "ਯੂਜ਼ਰ ਇਸਨੂੰ ਮਹਿਸੂਸ ਕਰਨ ਵਾਲਾ ਹੈ" ਅਤੇ ਤੁਹਾਨੂੰ ਪਹਿਲਾਂ ਕਿੱਥੇ ਦੇਖਣਾ ਹੈ। ਸੌਖਾ ਤਰੀਕਾ ਹੈ ਲੱਛਣ (ਗਾਹਕ ਪ੍ਰਭਾਵ) ਅਤੇ ਕਾਰਨ (ਜੋ ਇਹ ਚਲਾ ਰਿਹਾ) 'ਤੇ ਅਲਰਟ ਰੱਖਣਾ, ਨਾਲੇ noise ਕੰਟਰੋਲ ਤਾਂ ਕਿ on-call ਨੂੰ ਪੇਜ਼ ਨੂੰ ਅਣਦੇਖਾ ਕਰਨ ਦੀ ਆਦਤ ਨਾ ਪਏ।
ਲੱਛਣਾਂ (ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ) 'ਤੇ ਅਲਰਟ ਕਰੋ
ਛੋਟਾ ਸੈਟ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਗਾਹਕ ਦਰਦ ਨਾਲ ਮਿਲਦਾ ਹੈ:
- ਮਹੱਤਵਪੂਰਨ endpoints ਲਈ ਉੱਠ ਰਹੀ p95/p99 ਰਿਕਵੇਸਟ ਲੈਟੈਂਸੀ (ਸਿਰਫ਼ ਔਸਤ ਨਹੀਂ)
- ਟਾਈਮਆਊਟ ਦਰ (ਐਪ ਟਾਈਮਆਊਟ ਅਤੇ ਉਪਸਟ੍ਰੀਮ ਟਾਈਮਆਊਟ) ਅਤੇ ਰੀਟ੍ਰਾਈ ਦਰ
- ਕਿਊ ਡੈਪਥ / ਵਰਕਰ ਸੈਚੁਰੇਸ਼ਨ (ਥ੍ਰੈਡ ਪੂਲ, ਕਨੈਕਸ਼ਨ ਪੂਲ)
- ਡਾਟਾਬੇਸ ਲੌਕ ਵੇਟਸ ਅਤੇ ਬਲਾਕਡ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ
ਜੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ ਅਲਰਟਾਂ ਨੂੰ "ਸੋਨੇ ਦੇ ਰਸਤਿਆਂ" (checkout, login, search) 'ਤੇ ਸੀਮਿਤ ਕਰੋ ਤਾਂ ਕਿ ਘੱਟ-ਮਹੱਤਵਪੂਰਨ ਰੂਟਾਂ 'ਤੇ ਪੇਜ਼ ਨਾ ਆਵਣ।
ਕਾਰਨਾਂ (ਜਿਨ੍ਹਾਂ ਨੂੰ ਜਾਂਚਣਾ ਹੈ) 'ਤੇ ਅਲਰਟ ਕਰੋ
ਲੱਛਣ ਅਲਰਟਾਂ ਨੂੰ ਕਾਰਨ-ਕੇਂਦਰਤ ਅਲਰਟਾਂ ਨਾਲ ਜੋੜੋ ਤਾਂ ਜੋ ਪਛਾਣ ਤੇਜ਼ ਹੋਵੇ:
- ਸਿਖਰ ਦੀਆਂ ਸਲੋ ਕੁਐਰੀ ਫਿੰਗਰਪ੍ਰਿੰਟਾਂ ਜੋ ਥ੍ਰੈਸ਼ਹੋਲਡ ਨੂੰ ਭੰਨਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ: p95 ਦੌਰਾਨੀ ਜਾਂ ਕੁੱਲ ਲੱਗਣ ਵਾਲਾ ਸਮਾਂ)
- ਪਲੈਨ ਬਦਲਾਅ (ਅਚਾਨਕ rows examined ਵਿੱਚ ਬਦਲਾਅ, ਨਵਾਂ ਫੁੱਲ ਟੇਬਲ ਸਕੈਨ, ਇੰਡੈਕਸ ਨਾ ਵਰਤਿਆ ਜਾਣਾ)
- ਡਾਟਾਬੇਸ ਤਰੱਫੋਂ ਐਰਰ ਸਪਾਈਕਸ (ਡੈਡਲਾਕ, ਬਹੁਤ ਸਾਰੇ ਕਨੈਕਸ਼ਨ, ਕੁਐਰੀ ਕੈਂਸਲ)
ਇਹ ਕਾਰਨ ਅਲਰਟ ideal ਤੌਰ 'ਤੇ ਕਵਲ query fingerprint, sanitized example parameters, ਅਤੇ ਸਰਕਾਰੀ ਡੈਸ਼ਬੋਰਡ ਜਾਂ trace view ਵਿੱਚ ਜਾਣ ਦਾ ਸੰਦ ਮਦਦ ਨਾਲ ਆਉਣ।
ਅਵਾਜ਼ ਘਟਾਉਣ ਬਿਨਾਂ ਅਸਲ ਘਟਨਾਵਾਂ ਨੂੰ ਛੱਡਣ
ਵਰਤੋਂ ਕਰੋ:
- SLO burn-rate alerts (ਤੇਜ਼ ਪੇਜ਼ ਲਈ rapid regressions, ਹੌਲੀ ਪੇਜ਼ ਲਈ sustained degradation)
- ਮਲਟੀ-ਵਿੰਡੋ ਚੈੱਕਸ (ਉਦਾਹਰਣ: 5m ਅਤੇ 30m) ਤਾਂ ਕਿ ਫਲੈਪਿੰਗ ਨਾ ਹੋਵੇ
- ਡਿਡੂਪਿੰਗ ਅਤੇ ਗਰੂਪਿੰਗ (ਸੇਵਾ/DB + query fingerprint ਪ੍ਰਤੀ ਇੱਕ ਘਟਨਾ)
ਹਰ ਪੇਜ਼ 'ਤੇ "ਮੈਂ ਅਗਲੇ ਕੀ ਕਰਾਂ?" ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ—ਇੱਕ ਰਨਬੁੱਕ ਦੇ ਪਹਿਲੇ ਤਿੰਨ ਜਾਂਚ-ਕਦਮ (ਲੈਟੈਂਸੀ ਪੈਨਲ, ਸਲੋ ਕੁਐਰੀ ਸੂਚੀ, ਲੌਕ/ਕਨੈਕਸ਼ਨ ਗ੍ਰਾਫ) ਦਰਸਾਓ। (ਉਦਾਹਰਣ: incident runbook)
ਇਕ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਇੰਸੀਡੈਂਟ ਵਰਕਫਲੋ: spike ਤੋਂ root cause ਤੱਕ
ਜਦ ਲੈਟੈਂਸੀ spike ਹੁੰਦੀ ਹੈ, ਤੇਜ਼ੀ ਨਾਲ ਬਹੁਤ ਸੁਧਾਰ ਅਤੇ ਲੰਮਾ ਓਟੇਜ ਦੇ ਵਿਚਕਾਰ ਫ਼ਰਕ ਹੁੰਦਾ ਹੈ ਇੱਕ ਦੋਹਰਾਉਣਯੋਗ ਵਰਕਫਲੋ ਹੋਣਾ। ਉਦਦੇਸ਼ ਹੈ "ਕੁਝ ਸਲੋ ਹੈ" ਤੋਂ ਇੱਕ ਵਿਸ਼ੇਸ਼ ਕੁਐਰੀ, endpoint, ਅਤੇ ਬਦਲਾਅ ਤੱਕ ਜਾਣਾ ਜੋ ਇਸਨੂੰ ਸ਼ੁਰੂ ਕੀਤਾ।
1) ਪਤਾ ਲਗਾਓ → ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਇਹ ਅਸਲ ਹੈ
ਯੂਜ਼ਰ ਲੱਛਣ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਉੱਚੀ ਰਿਕਵੇਸਟ ਲੈਟੈਂਸੀ, ਟਾਈਮਆਊਟ, ਜਾਂ ਐਰਰ ਦਰ।
ਛੋਟੇ ਸੈੱਟ ਉੱਤੇ ਪੁਸ਼ਟੀ ਕਰੋ: p95/p99 ਲੈਟੈਂਸੀ, throughput, ਅਤੇ ਡਾਟਾਬੇਸ ਸਿਹਤ (CPU, connections, queue/wait time)। ਇੱਕ-ਹੋਸਟ ਅਨੋਮਲੀਜ਼ ਦਾ ਪਿਛਾ ਨਾ ਕਰੋ—ਸੇਵਾ ਪੱਧਰ 'ਤੇ ਪੈਟਰਨ ਤਲਾਸ਼ੋ।
2) ਸਕੋਪ → ਕੌਣ ਅਤੇ ਕੀ ਪ੍ਰਭਾਵਿਤ ਹੈ
ਬਲਾਸਟ ਰੇਡੀਅਸ ਘਟਾਓ:
- ਕਿਹੜੇ endpoints ਸਲੋ ਹਨ (p95 ਦੁਆਰਾ top routes)?
- ਕੀ ਇਹ ਸਾਰੇ ਗਾਹਕਾਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ ਉੱਥੇ ਕੋਈ ਉਪ-ਸੈੱਟ (tenant, ਖੇਤਰ, ਯੋਜਨਾ)?
- ਕੀ ਇਹ ਕਿਸੇ ਸਪੱਸ਼ਟ ਸਮਾਂ ਸਰਹੱਦ (ਡਿਪਲੌਇ, ਬੈਚ ਜੌਬ, ਟ੍ਰੈਫਿਕ ਬਦਲਾਅ) 'ਤੇ ਸ਼ੁਰੂ ਹੋਇਆ?
ਇਹ ਸਟੈਪ ਤੁਹਾਨੂੰ ਗਲਤ ਚੀਜ਼ ਤੇ optimize ਕਰਨ ਤੋਂ ਰੋਕਦੀ ਹੈ।
3) ਵਰਕਫਲੋ ਨੂੰ ਤਨਖਾਹ ਕਰੋ → ਟ੍ਰੇਸਾਂ ਨਾਲ ਸਲੋ ਓਪਰੇਸ਼ਨ ਲੱਭੋ
ਉੱਚ-ਲੈਟੈਂਸੀ trace ਖੋਲ੍ਹੋ ਅਤੇ ਸਭ ਤੋਂ ਲੰਬੀ ਦਰੂਟਿਨ ਨੂੰ ਛਾਂਟੋ।
ਉਹ span ਲੱਭੋ ਜੋ ਰਿਕਵੇਸਟ ਦਾ ਵੱਡਾ ਹਿੱਸਾ ਘੇਰ ਰਿਹਾ ਹੈ: ਇੱਕ ਡਾਟਾਬੇਸ ਕਾਲ, ਲੌਕ ਵੇਟ, ਜਾਂ ਦਹਰਾਈਆਂ ਕੁਐਰੀਆਂ (N+1)। trace ਦੇ context tags (release version, tenant ID, endpoint name) ਨਾਲ ਇਹ ਦੇਖੋ ਕਿ ਕੀ slowdown ਕਿਸ ਡਿਪਲੌਇ ਜਾਂ ਖਾਸ ਗਾਹਕ ਵਰਕਲੋਡ ਨਾਲ ਮਿਲਦਾ ਹੈ।
4) ਪੁਸ਼ਟੀ ਕਰੋ → ਟ੍ਰੇਸ ਨੂੰ ਸਲੋ ਕੁਐਰੀ ਲੌਗ ਨਾਲ ਜੋੜੋ
ਹੁਣ ਸੰਦੇਹੀ ਕੁਐਰੀ ਨੂੰ slow query logs ਵਿੱਚ ਵੈਰੀਫਾਈ ਕਰੋ।
"ਫਿੰਗਰਪ੍ਰਿੰਟ" (ਨਾਰਮਲਾਈਜ਼ਡ ਕੁਐਰੀਆਂ) 'ਤੇ ਧਿਆਨ ਦਿਓ ਤਾਂ ਜੋ ਕੁੱਲ ਸਮੇਂ ਅਤੇ ਗਿਣਤੀ ਦੇ ਆਧਾਰ 'ਤੇ ਸਭ ਤੋਂ ਵੱਡੇ offenders ਮਿਲ ਸਕਣ। ਫਿਰ ਪ੍ਰਭਾਵਿਤ ਟੇਬਲਾਂ ਅਤੇ ਪ੍ਰੇਡੀਕੇਟ (filters ਅਤੇ joins) ਨੋਟ ਕਰੋ। ਇੱਥੇ ਤੁਸੀਂ ਅਕਸਰ ਮਿਸਿੰਗ ਇੰਡੈਕਸ, ਨਵਾਂ JOIN, ਜਾਂ ਕੁਐਰੀ ਪਲੈਨ ਬਦਲਾਅ ਲੱਭਦੇ ਹੋ।
5) ਰਾਹਤ ਕਰੋ → ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ ਘੱਟ ਕਰੋ, ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ
ਸਭ ਤੋਂ ਘੱਟ ਖਤਰਨਾਕ mitigation ਪਹਿਲਾਂ ਚੁਣੋ: ਰੋਲਬੈਕ ਰਿਲੀਜ਼, ਫੀਚਰ ਫਲੈਗ disable, ਲੋਡ shed, ਜਾਂ connection pool ਸੀਮਾਵਾਂ ਵਧਾਓ ਸਿਰਫ਼ ਜਦ ਤੁਸੀਂ ਯਕੀਨ ਕਰੋ ਕਿ ਇਹ contention ਨੂ ਵਧਾਏਗਾ ਨਹੀਂ। ਜੇ ਤੁਸੀਂ ਕੁਐਰੀ ਬਦਲਣ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਛੋਟਾ ਅਤੇ ਮਾਪਯੋਗ ਬਦਲਾਅ ਕਰੋ।
ਇੱਕ ਕਾਰਗੁਜ਼ਾਰ ਸੁਝਾਅ: ਜੇ ਤੁਹਾਡੀ delivery pipeline ਇਸਨੂੰ ਸਹਾਇਤਾ ਕਰਦੀ ਹੈ ਤਾਂ "rollback" ਨੂੰ ਪਹਿਲ-ਸ਼੍ਰੇਣੀ ਬਟਨ ਸਮਝੋ, ਨਾ ਕਿ ਨਿਰਭਰਤਾ ਵਾਲਾ ਕਦਮ। ਪਲੇਟਫਾਰਮਾਂ ਜਿਵੇਂ Koder.ai ਇਹਨੂੰ snapshots ਅਤੇ rollback workflows ਨਾਲ ਸਹੁਲਤ ਦਿੰਦੀਆਂ ਹਨ, ਜੋ ਰਿਲੀਜ਼ ਦੇ ਕਾਰਨ ਆਏ slow query patterns ਮੌਕੇ ਤੇ mitigate ਕਰਨ ਦੇ ਸਮੇਂ ਨੂੰ ਘਟਾ ਸਕਦੇ ਹਨ।
6) ਦਸਤਾਵੇਜ਼ ਕਰੋ → ਅਗਲੇ ਘਟਨਾ ਨੂੰ ਛੋਟਾ ਬਣਾਓ
ਦਰਜ ਕਰੋ: ਕੀ ਬਦਲਿਆ, ਤੁਸੀਂ ਇਹ ਕਿਵੇਂ ਪਾਇਆ, ਠੀਕ ਕੀਤੀ ਗਈ ਫਿੰਗਰਪ੍ਰਿੰਟ, ਪ੍ਰਭਾਵਿਤ endpoints/tenants, ਅਤੇ ਕੀ ਇਸਨੂੰ ਠੀਕ ਕੀਤਾ। ਇਸਨੂੰ follow-up ਵਿੱਚ ਬਦਲੋ: ਇਕ ਅਲਰਟ ਜੋੜੋ, ਇੱਕ ਡੈਸ਼ਬੋਰਡ ਪੈਨਲ, ਅਤੇ ਇੱਕ ਪਰਫਾਰਮੈਂਸ ਗਾਰਡਰੇਲ (ਉਦਾਹਰਨ: "ਕੋਈ ਵੀ query fingerprint X ms ਤੋਂ ਵੱਧ p95 'ਤੇ ਨਹੀਂ ਹੋਵੇ").
ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਸਲੋ ਕੁਐਰੀਆਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਠੀਕ ਕਰਨਾ
ਜਦ ਇੱਕ ਸਲੋ ਕੁਐਰੀ ਯੂਜ਼ਰਾਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰ ਰਹੀ ਹੋਵੇ, ਟੀਚਾ ਪਹਿਲਾਂ ਪ੍ਰਭਾਵ ਘਟਾਉਣਾ ਅਤੇ ਫਿਰ ਪ੍ਰਦਰਸ਼ਨ ਸੁਧਾਰਨਾ—ਉਦੋ ਵੀ ਕਿ ਘਟਨਾ ਨੂੰ ਹੋਰ ਖਰਾਬ ਨਾ ਕੀਤਾ ਜਾਵੇ। Observability ਡੇਟਾ (ਸਲੋ ਕੁਐਰੀ ਨਮੂਨੇ, ਟ੍ਰੇਸ, ਅਤੇ ਮੁੱਖ DB ਮੈਟਰਿਕਸ) ਤੁਹਾਨੂੰ ਦੱਸਦਾ ਹੈ ਕਿ ਕਿਹੜਾ ਲਿਵਰ ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਖਿੱਚਣਾ ਹੈ।
1) ਨੀਵ-ਖਤਰਾ mitigation ਨਾਲ ਸਥਿਰਤਾ ਲਿਆਓ
ਉਸ ਤਰੀਕੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਡੇਟਾ ਵਿਹਵਾਰ ਨੂੰ ਬਦਲੇ ਬਿਨਾਂ ਲੋਡ ਘਟਾਉਂਦੇ ਹਨ:
- ਫੀਚਰ ਫਲੈਗ: ਮਹਿੰਗੇ endpoints, ਰਿਪੋਰਟ, search filters, ਜਾਂ "recent activity" ਪੈਨਲ ਨੂੰ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਬੰਦ ਕਰੋ।
- ਰੇਟ ਲਿਮਿਟ/ਕੁਆਟਾ: trace ਵਿੱਚ ਦਰਸਾਏ ਸਭ ਤੋਂ ਖਰਾਬ ਰੂਟ ਜਾਂ ਗਾਹਕ ਸੈਗਮੈਂਟ ਨੂੰ throttle ਕਰੋ।
- ਕੈਸ਼ਿੰਗ: ਪੜ੍ਹਨ-ਭਾਰੇ endpoints ਲਈ ਛੋਟੀ ਅਵਧੀ ਵਾਲਾ cache ਜੋੜੋ (30–120 ਸਕਿੰਟ ਵੀ DB ਲੋਡ ਘਟਾ ਸਕਦਾ ਹੈ)। ਪਹਿਲਾਂ application/request-ਸਤ੍ਹਰੀ caching ਨੂੰ ਤਰਜੀਹ ਦਿਓ DB ਸਤਰ ਦੇ ਮੋਡੀਫਿਕੇਸ਼ਨ ਦੇ मुकाबਲੇ।
- ਮਹਿੰਗੇ ਪਾਥ ਅਯੋਗ ਕਰੋ: ਵਿਕਲਪਿਕ JOINs, "order by relevance", ਜਾਂ ਡੀਪ pagination ਨੂੰ ਫਲੈਗ ਪਿੱਛੇ ਰੱਖੋ।
ਇਹ mitigations ਵਕਤ ਖਰੀਦਦੇ ਹਨ ਅਤੇ p95 ਲੈਟੈਂਸੀ ਅਤੇ DB CPU/IO ਮੈਟਰਿਕਸ ਵਿੱਚ ਤੁਰੰਤ ਸੁਧਾਰ ਦਿਖਾਉਣੇ ਚਾਹੀਦੇ ਹਨ।
2) ਡਾਟਾਬੇਸ ਫਿਕਸ: ਨਿਸ਼ਾਨਕ ਅਤੇ ਟੈਸਟ ਕਰਨ ਯੋਗ
ਜਦ ਸਥਿਰ ਹੋ ਜਾਵੇ, ਅਸਲ ਕੁਐਰੀ ਪੈਟਰਨ ਨੂੰ ਠੀਕ ਕਰੋ:
- ਇੰਡੈਕਸ ਜੋੜੋ ਜੋ ਕੁਐਰੀ ਦੇ filter + sort ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੋਵੇ।
EXPLAIN ਨਾਲ ਸੱਚਮੁਚ rows scanned ਘਟਨ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ।
- ਕੁਐਰੀ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖੋ ਤਾਂ ਜੋ ਸਕੈਨ ਕੀਤੀ ਡੇਟਾ ਘੱਟ ਹੋਵੇ (ਘੱਟ ਕਾਲਮ ਚੁਣੋ,
SELECT * ਤੋਂ ਬਚੋ, ਚੁਣਿੰਦ਼ਾ predicates ਜੋੜੋ, correlated subqueries ਨੂੰ ਤਬਦੀਲ ਕਰੋ)।
- N+1 ਪੈਟਰਨ ਘਟਾਓ IDs ਬੈਚ ਕਰਕੇ, prefetches ਜੋੜ ਕੇ, ਜਾਂ ਇਕ ਹੀ JOIN ਦੇ ਨਾਲ ਸੰਭਾਲਿਆ ਗਿਆ ਕੁਐਰੀ ਵਰਤੋ।
ਬਦਲਾਅ ਨੂੰ تدريجي ਤੌਰ 'ਤੇ ਲਗਾਓ ਅਤੇ ਉਹੀ trace/span ਅਤੇ slow query ਸਿਗਨੇਚਰ ਨਾਲ ਸੁਧਾਰ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ।
3) ਜਦ ਕੋਡ ਤੁਰੰਤ ਨਹੀਂ ਬਦਲ ਸਕਦੇ ਤਾਂ ਪ੍ਰਚਾਲਕੀ ਰਾਹਤਾਂ
- ਕੈਪੈਸਿਟੀ ਵਧਾਓ (read replicas, ਵੱਡੀ ਇੰਸਟੈਂਸ) ਤਾਂ ਜੋ bleeding ਰੁਕੇ।
- ਕਨੈਕਸ਼ਨ ਪੂਲ ਟਿਊਨ ਕਰੋ ਤਾਂ ਕਿ ਕਿਊਇੰਗ ਅਤੇ ਥ੍ਰੈਡ ਖ਼ਤਮ ਹੋਣ ਤੋਂ ਬਚਾਓ।
- ਟਾਈਮਆਊਟ ਸੈਟਿੰਗਸ ਘਟਾਓ ਤਾਂ ਕਿ ਸਿਸਟਮ ਤੇਜ਼ੀ ਨਾਲ ਫੇਲ ਹੋਵੇ ਨਾ ਕਿ ਇੱਕੱਠੇ ਰਿਕਵੇਸਟ ਰੁਕ ਕੇ ਚਲਦੀ ਜਾਵੇ।
ਰੋਲਬੈਕ: revert vs. hotfix
ਜਦ ਬਦਲਾਅ errors, ਲੌਕ ਕਨਟੈਂਸ਼ਨ, ਜਾਂ ਲੋਡ ਨੂੰ ਅਣਪੇਛਾਣੇ ਤਰੀਕੇ ਨਾਲ ਵਧਾਵੇ ਤਾਂ ਰੋਲਬੈਕ ਕਰੋ। ਜਦ ਤੁਸੀਂ ਇੱਕੋ ਕੁਐਰੀ ਜਾਂ ਇੱਕੋ endpoint ਨੂੰ ਅਲੱਗ ਕਰਕੇ ਨਿਰਧਾਰਿਤ ਕਰ ਲਓ ਅਤੇ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ/ਬਾਅਦ ਟੈਲੀਮੇਟਰੀ ਹੋਵੇ ਤਾਂ hotfix ਕਰੋ।
ਦੁਹਰਾਅ ਰੋਕਣਾ: SLOs ਅਤੇ ਪਰਫਾਰਮੈਂਸ ਗਾਰਡਰੇਲ
ਇੱਕ ਅਸਲ ਵਾਤਾਵਰਣ ਚਲਾਉ
ਆਪਣਾ ਐਪ ਡੈਪਲੋ ਅਤੇ ਹੋਸਟ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਜਲਦੀ ਅਸਲ ਟ੍ਰੈਫਿਕ ਪੈਟਰਨ ਵੇਖ ਸਕੋ।
ਜਦ ਤੁਸੀਂ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਸਲੋ ਕੁਐਰੀ ਠੀਕ ਕਰ ਲੈਂਦੇ ਹੋ, ਅਸਲ ਫਾਇਦਾ ਇਹ ਹੈ ਕਿ ਇਕੋ ਪੈਟਰਨ ਮੁੜ ਨਾ ਆਵੇ। ਸਪੱਸ਼ਟ SLOs ਅਤੇ ਕੁਝ ਲਘੂ ਗਾਰਡਰੇਲ ਇਕ ਘਟਨਾ ਨੂੰ ਲੰਬੀ ਮਿਆਦ ਦੀ ਭਰੋਸੇਮੰਦਤਾ ਵਿੱਚ ਬਦਲ ਦਿੰਦੀਆਂ ਹਨ।
SLOs ਨੂੰ ਯੂਜ਼ਰ ਅਨੁਭਵ ਨਾਲ ਜੋੜੋ
ਉਨ੍ਹਾਂ SLIs ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਸੀਧੇ ਗਾਹਕ ਅਨੁਭਵ ਨਾਲ ਮਿਲਦੇ ਹਨ:
- p95 (ਅਤੇ p99) endpoint latency, ਮਹੱਤਵਪੂਰਨ ਰੂਟਸ ਅਤੇ tenants ਦੁਆਰਾ ਵੰਡਿਆ ਹੋਇਆ
- ਐਰਰ ਰੇਟ (ਟਾਈਮਆਊਟ, 5xx, ਅਤੇ "ਸਾਫਟ ਐਰਰ" ਜਿਵੇਂ cancellations ਕਾਰਨ ਖਾਲੀ ਨਤੀਜੇ)
- ਸੈਚੁਰੇਸ਼ਨ ਸੰਕੇਤ ਜੋ slowdown ਨਾਲ ਸੰਬੰਧਿਤ ਹਨ (DB CPU, ਕਨੈਕਸ਼ਨ ਪੂਲ ਵੇਟ ਟਾਈਮ)
ਇੱਕ SLO ਐਸਾ ਰੱਖੋ ਜੋ ਮਨੁੱਖੀ ਢੰਗ 'ਤੇ ਅੰਗੀਕਾਰਯੋਗ ਹੋਵੇ, ਪੂਰਨ ਨਹੀਂ। ਉਦਾਹਰਣ: “p95 checkout ਲੈਟੈਂਸੀ 600ms ਤੋਂ ਘੱਟ 99.9% ਮਿੰਟਾਂ।” ਜਦ SLO ਖਤਰੇ ਵਿੱਚ ਹੋਵੇ, ਤੁਹਾਡੇ ਕੋਲ ਨਿਸ਼ਚਿਤ ਕਾਰਨ ਹੁੰਦਾ ਹੈ deploy ਰੋਕਣ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰਨ ਦਾ।
ਰਿਲੀਜ਼ ਦੁਆਰਾ regressions ਟ੍ਰੈਕ ਕਰੋ, vibes ਨਾਲ ਨਹੀਂ
ਜ਼ਿਆਦਾਤਰ ਦੁਹਰਾਉਂਦੀਆਂ ਘਟਨਾਵਾਂ regressions ਹੁੰਦੀਆਂ ਹਨ। ਉਨ੍ਹਾਂ ਨੂੰ ਅਸਾਨ ਬਣਾਓ:
- ਹਰ ਰਿਲੀਜ਼ ਲਈ ਪਹਿਲਾਂ/ਬਾਅਦ ਦੀ ਤੁਲਨਾ ਕਰੋ: ਇੱਕੋ endpoint ਲਈ traces ਵੇਖੋ ਅਤੇ ਇੱਕ ਨਵਾਂ span ਜੋ ਕੁੱਲ ਸਮਾਂ 'ਤੇ ਵਧਿਆ ਹੋ ਉਸ ਦੀ ਪਛਾਣ ਕਰੋ।
- ਸਲੋ ਕੁਐਰੀ ਫਿੰਗਰਪ੍ਰਿੰਟਸ ਦੀ ਤੁਲਨਾ ਕਰੋ ਤਾਂ ਜੋ ਨਵੀਂ ਕੁਐਰੀ ਸ਼ਕਲ, ਮਿਸਿੰਗ ਇੰਡੈਕਸ, ਜਾਂ rows scanned ਵਿੱਚ ਅਚਾਨਕ ਕੌਂਕਰ ਮਿਲੇ।
ਕੁੰਜੀ ਇਹ ਹੈ ਕਿ ਵਰਤੋਂ ਦਿਸ਼ਾ (p95/p99) 'ਚ ਬਦਲਾਅ ਵੇਖੋ, ਨਾ ਕਿ ਸਿਰਫ਼ ਔਸਤ।
ਮਹੱਤਵਪੂਰਨ ਰਸਤੇ ਲਈ ਪਰਫਾਰਮੈਂਸ ਟੈਸਟ ਜੋੜੋ
ਇੱਕ ਛੋਟਾ ਸੈਟ ਚੁਣੋ "ਜੋ ਦੇਰ ਨਾ ਹੋਣ" ਵਾਲੇ endpoints ਅਤੇ ਉਹਨਾਂ ਦੀਆਂ ਕੁੰਜੀ ਕੁਐਰੀਆਂ। CI ਵਿੱਚ performance checks ਸ਼ਾਮਲ ਕਰੋ ਜੋ latency ਜਾਂ query cost ਇੱਕ ਸੀਮਾ ਤੋਂ ਉੱਤੇ ਜਾਣ 'ਤੇ fail ਹੋ ਜਾਣ। ਇਹ N+1 ਬੱਗ, ਬੇ-ਹੱਦ ਫੁੱਲ ਟੇਬਲ ਸਕੈਨ, ਅਤੇ uncontrolled pagination ਨੂੰ ship ਹੋਣ ਤੋਂ ਪਹਿਲਾਂ ਪਕੜ ਲੈਂਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਸਰਵਿਸ ਬਣਾ ਰਹੇ ਹੋ (ਉਦਾਹਰਣ: Koder.ai ਵਰਗੀ chat-driven app builder ਜਿਸ ਨਾਲ React frontends, Go backends, ਅਤੇ PostgreSQL schemas ਤੇਜ਼ੀ ਨਾਲ ਬਣਦੇ ਹਨ), ਇਹ guardrails ਹੋਰ ਵੀ ਜ਼ਰੂਰੀ ਹੋ ਜਾਂਦੇ ਹਨ: ਰਫਤਾਰ ਇੱਕ ਫੀਚਰ ਹੈ, ਪਰ ਜੇ ਤੁਸੀਂ ਪਹਿਲੇ ਦਿਨ ਤੋਂ ਟੈਲੀਮੇਟਰੀ (trace IDs, query fingerprinting, ਅਤੇ ਸੁਰੱਖਿਅਤ ਲੌਗਿੰਗ) ਨਹੀਂ ਜੋੜਦੇ ਤਾਂ ਉਹ ਖਤਰਨਾਕ ਹੋ ਸਕਦਾ ਹੈ।
ਮਲਕੀਅਤ ਅਤੇ ਸਮੀਖਿਆ ਰੁਟੀਨ ਬਣਾਓ
slowdown-ਕੁਐਰੀ ਸਮੀਖਿਆ ਕਿਸੇ ਇਕ ਦਾ ਕੰਮ ਬਣਾਓ, ਨਾ ਕਿ ਬਾਅਦ ਦੇ ਖਿਆਲ:
- ਹਰ service/database ਲਈ ਇਕ ਮਾਲਕ ਨਿਰਧਾਰਤ ਕਰੋ।
- ਹਫਤਾਵਾਰ (ਅਕਸਰ کافی) slow query ਰਿਪੋਰਟ ਸਮੀਖਿਆ ਰੱਖੋ।
- ਇੱਕ ਛੋਟੀ ਬੈਕਲੌਗ ਰੱਖੋ: ਕੁਐਰੀ ਫਿੰਗਰਪ੍ਰਿੰਟ, ਸੰਦੇਹੀ ਕਾਰਨ, ਅਗਲਾ ਕਾਰਵਾਈ, ਅਤੇ ਉਮੀਦ ਕੀਤੇ ਪ੍ਰਭਾਵ ਨਾਲ।
SLOs "ਕੀ ਚੰਗਾ ਦਿੱਸਦਾ ਹੈ" ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰਕੇ ਅਤੇ guardrails drift ਨੂੰ ਫੜਕੇ, ਪਰਫਾਰਮੈਂਸ ਇੱਕ ਇਮਰਜੈਂਸੀ ਨਾ ਰਹਿ ਕੇ ਡਿਲਿਵਰੀ ਦਾ ਇੱਕ ਹਿੱਸਾ ਬਣ ਜਾਂਦਾ ਹੈ।
ਡਾਟਾਬੇਸ ਲਈ observability ਸੈੱਟਅੱਪ ਵਿੱਚ ਕੀ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ
ਇੱਕ ਡਾਟਾਬੇ스-ਕੇਂਦਰਤ observability ਸੈੱਟਅੱਪ ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਦੋ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦਿਨਾ ਚਾਹੀਦਾ ਹੈ: "ਕੀ ਡਾਟਾਬੇਸ ਬੋਤਲ-ਨੈਕ ਹੈ?" ਅਤੇ "ਕਿਹੜੀ ਕੁਐਰੀ (ਅਤੇ ਕਿਹੜਾ ਪੁਕਾਰਨਹਾਰ) ਇਸਦਾ ਕਾਰਨ ਹੈ?" ਸਭ ਤੋਂ ਵਧੀਆ ਸੈਟਅੱਪ ਇਹ ਸਪਸ਼ਟ ਬਣਾ ਦੇਂਦੇ ਹਨ ਬਿਨਾਂ ਇੰਜੀਨੀਅਰਾਂ ਨੂੰ ਇੱਕ ਘੰਟਾ ਰਾਹ ਖੋਜਣ ਲਈ ਕੱਚੇ ਲੌਗਾਂ ਵਿੱਚ grep ਕਰਨ ਲੈ।
ਇੱਕ ਪ੍ਰਯੋਗਕਰ ਚੈੱਕਲਿਸਟ
ਲਾਜ਼ਮੀ ਮੈਟਰਿਕਸ (ਉੱਤੇ ਕੋਠੇ, ਕਲਸਟਰ, ਅਤੇ role/replica ਦੁਆਰਾ ਟੁੱਟੇ ਹੋਏ ideally):
- ਕੁਐਰੀ ਲੈਟੈਂਸੀ (p50/p95/p99), throughput (QPS), ਅਤੇ error rate
- ਕਨੈਕਸ਼ਨ ਪੂਲ ਵਰਤੋਂ, active/idle connections, wait time
- ਲੌਕ: ਲੌਕ ਵੇਟ ਟਾਈਮ, ਡੈਡਲਾਕ, row lock contention
- ਸਰੋਤ ਸੰਕੇਤ: CPU, ਮੈਮੋਰੀ, ਡਿਸਕ I/O, cache hit ratio
- ਪ੍ਰਤਿਲਿਪੀ ਲੈਗ (ਜੇ ਲਾਗੂ ਹੋ)
ਸਲੋ ਕੁਐਰੀ ਲੌਗਾਂ ਲਈ ਲਾਜ਼ਮੀ ਲੌਗ ਫੀਲਡ:
- ਟਾਈਮਸਟੈਂਪ, ਦੌਰਾਨੀ, ਡਾਟਾਬੇਸ/ਸਕੀਮਾ, ਯੂਜ਼ਰ/ਰੋਲ, ਕਲਾਇੰਟ/ਐਪ ਪਛਾਣ
- ਨਾਰਮਲਾਈਜ਼ਡ ਕੁਐਰੀ ਜਾਂ ਫਿੰਗਰਪ੍ਰਿੰਟ, ਨਾਲ ਇੱਕ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਪੂਰਾ ਟੈਕਸਟ ਐਵੇਲੇਬਲ ਕਰਨਾ ਜੇ ਅਨੁਮਤ ਹੋ
- Rows examined/returned, query plan hash (ਜੇ ਉਪਲਬਧ)
ਟ੍ਰੇਸ ਟੈਗਸ ਜੋ ਬਿਨੈਤੀਆਂ ਨੂੰ ਕੁਐਰੀਆਂ ਨਾਲ ਜੋੜਦੇ ਹਨ:
- service.name, endpoint/route, environment, version
- db.system, db.name, db.statement fingerprint, db.operation
- request_id / trace_id ਜੋ ਲੌਗਾਂ ਵਿੱਚ surfaced ਹੋ
ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਅਲਰਟਸ ਜੋ ਤੁਸੀਂ ਉਮੀਦ ਕਰ ਸਕਦੇ ਹੋ:
- “DB pain” ਓਵਰਵਿਊ: p95 ਲੈਟੈਂਸੀ + QPS + connection waits + lock waits
- Top N query fingerprints by total time ਅਤੇ by p95
- Sustained p95/p99 ਵਾਧੇ 'ਤੇ ਅਲਰਟ, ਲੌਕ ਵੇਟ spike, ਅਤੇ ਪੂਲ ਸੈਚੁਰੇਸ਼ਨ (ਸਿਰਫ਼ CPU ਨਹੀਂ)
ਟੂਲ ਜਾਂ ਵੇਂਡਰ ਨੂੰ ਪੁੱਛਣ ਲਈ ਸਵਾਲ
ਕੀ ਇਹ endpoint latency spike ਨੂੰ ਇਕ ਨਿਰਧਾਰਿਤ query fingerprint ਅਤੇ release version ਨਾਲ correlate ਕਰ ਸਕਦਾ ਹੈ? ਇਹ ਸੈਂਪਲਿੰਗ ਨੂੰ ਕਿਵੇਂ ਹੈਂਡਲ ਕਰਦਾ ਹੈ ਤਾਂ ਕਿ ਤੁਸੀਂ rare, ਮਹਿੰਗੀਆਂ ਕੁਐਰੀਆਂ ਨੂੰ ਰੱਖ ਸਕੋ? ਕੀ ਇਹ noisy statements ਨੂੰ deduplicate (fingerprinting) ਕਰਦਾ ਹੈ ਅਤੇ ਸਮੇਂ ਦੇ ਨਾਲ regressions ਨੂੰ ਹਾਈਲਾਈਟ ਕਰਦਾ ਹੈ?
ਡੇਟਾ ਹੈਂਡਲਿੰਗ ਜਿੱਥੇ ਤੁਸੀਂ ਸਮਝੌਤਾ ਨਹੀਂ ਕਰਨਾ ਚਾਹੋਗੇ
Built-in redaction (PII ਅਤੇ literals), RBAC, ਅਤੇ ਸਪੱਸ਼ਟ retention limits ਲੱਭੋ। ਯਕੀਨੀ ਬਣਾਓ ਕਿ data warehouse/SIEM 'ਤੇ export ਇਸਨੂੰ ਬਾਈਪਾਸ ਨਾ ਕਰੇ।
ਜੇ ਤੁਹਾਡੀ ਟੀਮ ਵਿਕਲਪਾਂ ਮੁਲਾਂਕਣ ਕਰ ਰਹੀ ਹੈ, ਤਾਂ ਜਲਦੀ ਤੋਂ ਜਲਦੀ ਮੰਗਾਂ ਨੂੰ ਏਲਾਈਨ ਕਰੋ—ਅੰਦਰੂਨੀ ਤਾਲਿਕਾ ਸਾਂਝਾ ਕਰੋ, ਫਿਰ ਵੇਂਡਰਾਂ ਨੂੰ ਸ਼ਾਮਲ ਕਰੋ। ਜੇ ਤੁਸੀਂ ਚਾਹੋਗੇ ਤਾਂ ਇਕ ਛੋਟੀ ਤੁਲਨਾ ਜਾਂ ਰਹਿਨੁਮਾ ਲਈ ਸਹਾਇਤਾ ਕਰ ਸਕਦਾ ਹਾਂ—pricing ਜਾਂ contact ਨਾਲ ਸੰਪਰਕ ਕਰੋ।