12 ਜੂਨ 2025·8 ਮਿੰਟ
ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਤੋਂ ਡੇਟਾਬੇਸ ਸਕੀਮਾ: ਇੱਕ AI-ਮਾਰਗਦਰਸ਼ਿਤ ਵਿਧੀ
ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼, ਐਂਟਿਟੀਆਂ ਅਤੇ ਵਰਕਫਲੋਜ਼ ਨੂੰ ਸਾਫ਼ ਡੇਟਾਬੇਸ ਸਕੀਮਾ ਵਿੱਚ ਬਦਲਣ ਦਾ ਪ੍ਰਯੋਗਿਕ ਤਰੀਕਾ ਸਿਖੋ, ਅਤੇ ਕਿਵੇਂ AI ਵਿਚਾਰ-ਪ੍ਰਕਿਰਿਆ ਤੁਹਾਨੂੰ ਗੈਪ ਅਤੇ ਨਿਯਮ ਚੈੱਕ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ।
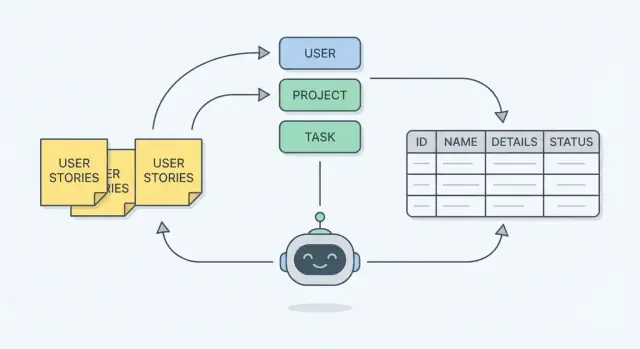
ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼, ਐਂਟਿਟੀਆਂ ਅਤੇ ਵਰਕਫਲੋਜ਼ ਨੂੰ ਸਾਫ਼ ਡੇਟਾਬੇਸ ਸਕੀਮਾ ਵਿੱਚ ਬਦਲਣ ਦਾ ਪ੍ਰਯੋਗਿਕ ਤਰੀਕਾ ਸਿਖੋ, ਅਤੇ ਕਿਵੇਂ AI ਵਿਚਾਰ-ਪ੍ਰਕਿਰਿਆ ਤੁਹਾਨੂੰ ਗੈਪ ਅਤੇ ਨਿਯਮ ਚੈੱਕ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ।
ਇੱਕ ਡੇਟਾਬੇਸ ਸਕੀਮਾ ਤੁਹਾਡੇ ਐਪ ਲਈ ਯਾਦ ਰੱਖਣ ਦਾ ਯੋਜਨਾ ਹੈ। ਵਿਹਾਰਕ ਤੌਰ 'ਤੇ, ਇਹ ਹੈ:
ਜਦੋਂ ਸਕੀਮਾ ਅਸਲੀ ਕੰਮ ਦੇ ਨਾਲ ਮਿਲਦਾ ਹੈ, ਇਹ ਉਹ ਦਿਖਾਉਂਦਾ ਹੈ ਜੋ ਲੋਕ ਅਸਲ ਵਿੱਚ ਕਰਦੇ ਹਨ—create, review, approve, schedule, assign, cancel—ਨ ਕਿ ਸਿਰਫ਼ ਬੋਰਡ 'ਤੇ ਸੁੰਦਰ ਦਿੱਸਣ ਵਾਲੀ ਚੀਜ਼।
ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਅਤੇ acceptance criteria ਸਧਾਰਣ ਭਾਸ਼ਾ ਵਿੱਚ ਅਸਲ ਲੋੜਾਂ ਦੱਸਦੇ ਹਨ: ਕੌਣ ਕਿਆ ਕਰਦਾ ਹੈ, ਅਤੇ “ਮੁਕੰਮਲ” ਦਾ ਮਤਲਬ ਕੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਇਹਨਾਂ ਨੂੰ ਸਰੋਤ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਸਕੀਮਾ ਮੁੱਖ ਤੱਥਾਂ ਨੂੰ ਛੱਡਣ ਦੀ ਸੰਭਾਵਨਾ ਘੱਟ ਹੁੰਦੀ ਹੈ (ਜਿਵੇਂ “ਸਾਨੂੰ ਇਹ ਟ੍ਰੈਕ ਕਰਨਾ ਲਾਜ਼ਮੀ ਹੈ ਕਿ ਕਿਸ ਨੇ ਰਿਫ਼ੰਡ ਮਨਜ਼ੂਰ ਕੀਤਾ” ਜਾਂ “ਇੱਕ booking ਕਈ ਵਾਰ reschedule ਹੋ ਸਕਦਾ ਹੈ”)।
ਸਟੋਰੀਜ਼ ਤੋਂ ਸ਼ੁਰੂ ਕਰਨ ਨਾਲ ਸਕੋਪ ਬਾਰੇ ਸੱਚਾਈ ਬਣੀ ਰਹਿੰਦੀ ਹੈ। ਜੇ ਇਹ ਕਹਾਣੀਆਂ (ਜਾਂ ਵਰਕਫਲੋ) ਵਿੱਚ ਨਹੀਂ ਹੈ, ਤਾਂ ਉਹਨਾਂ ਨੂੰ ਵਿਕਲਪਿਕ ਧਾਰੋ ਅਤੇ ਬਿਨਾਂ ਲੋੜ ਦੇ ਜਟਿਲ ਮਾਡਲ ਨਾ ਬਣਾਓ।
AI ਤੁਹਾਡੇ ਕੰਮ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ:
AI ਯਕੀਨੀ ਤੌਰ 'ਤੇ ਨਹੀਂ ਕਰ ਸਕਦਾ:
AI ਨੂੰ ਇੱਕ ਸ਼ਕਤੀਸ਼ালী ਸਹਾਇਕ ਸਮਝੋ, ਫੈਸਲਾ-ਕਰਨ ਵਾਲਾ ਨਹੀਂ।
ਜੇ ਤੁਸੀਂ ਉਸ ਸਹਾਇਕ ਨੂੰ ਗਤੀ ਵਿੱਚ ਬਦਲਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ vibe-coding ਪਲੇਟਫ਼ਾਰਮ ਜਿਵੇਂ Koder.ai ਤੁਹਾਡੀ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ ਤਾਂ ਕਿ ਤੁਸੀਂ ਸਕੀਮਾ ਦੇ ਫੈਸਲਿਆਂ ਤੋਂ ਇਕ ਕਾਰਯਕਾਰੀ React + Go + PostgreSQL ਐਪ ਤਕ ਤੇਜ਼ੀ ਨਾਲ পৌঁਚ ਸਕੋ—ਅਜੇ ਵੀ ਮਾਡਲ, ਪਾਬੰਦੀਆਂ ਅਤੇ migrations 'ਤੇ ਤੁਹਾਡਾ ਕਬੂਜ਼ਾ ਰੱਖਦੇ ਹੋਏ।
ਸਕੀਮਾ ਡਿਜ਼ਾਈਨ ਇੱਕ ਲੂਪ ਹੈ: draft → stories ਅਤੇ ਟੈਸਟ → ਗੁੰਮ ਡੇਟਾ ਲੱਭੋ → ਸੋਧ. 목표 ਇੱਕ ਪਹਿਲੀ ਕੋਸ਼ਿਸ਼ ਵਿੱਚ ਪੂਰਨ ਨਤੀਜਾ ਨਹੀਂ; ਲਕਸ਼ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਹਰ ਯੂਜ਼ਰ ਸਟੋਰੀ ਨਾਲ ਟ੍ਰੇਸ ਕਰ ਸਕੋ ਅਤੇ ਪੱਕਾ ਕਹਿ ਸਕੋ: “ਹਾਂ, ਅਸੀਂ ਇਸ ਵਰਕਫਲੋ ਦੀ ਹਰ ਲੋੜ ਸਟੋਰ ਕਰ ਸਕਦੇ ਹਾਂ—ਅਤੇ ਹਰ ਟੇਬਲ ਕਿਉਂ ਮੌਜੂਦ ਹੈ ਇਹ ਸਮਝਾ ਸਕਦੇ ਹਾਂ।”
ਟੇਬਲਾਂ ਵਿੱਚ ਲੋੜਾਂ ਬਦਲਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਤੁਸੀਂ ਕੀ ਮਾਡਲ ਕਰ ਰਹੇ ਹੋ। ਇੱਕ ਵਧੀਆ ਸਕੀਮਾ ਕਦਾਚਿਤ ਖਾਲੀ ਪੰਨੇ ਤੋਂ ਨਹੀਂ ਸ਼ੁਰੂ ਹੁੰਦਾ—ਇਹ ਉਹਨਾਂ ਅਸਲ ਕੰਮਾਂ ਤੋਂ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ ਜੋ ਲੋਕ ਕਰਦੇ ਹਨ ਅਤੇ ਉਸ ਪੂਰੇ ਸਬੂਤ (ਸਕਰੀਨ, ਆਉਟਪੁੱਟ, edge cases) ਤੋਂ ਜੋ ਤੁਹਾਨੂੰ ਬਾਅਦ ਵਿੱਚ ਚਾਹੀਦਾ ਹੋਵੇਗਾ।
User stories ਸਿਰਲੇਖ ਹਨ, ਪਰ ਉਹ ਇਕੱਲੇ ਕਾਫ਼ੀ ਨਹੀਂ। ਇਕੱਠਾ ਕਰੋ:
ਜੇ ਤੁਸੀਂ AI ਵਰਤ ਰਹੇ ਹੋ, ਇਨ੍ਹਾਂ ਇਨਪੁਟਸ ਨਾਲ ਮਾਡਲ ਗ੍ਰਾਊਂਡਡ ਰਹਿੰਦਾ ਹੈ। AI ਤੇਜ਼ੀ ਨਾਲ ਐਂਟਿਟੀਆਂ ਅਤੇ ਫੀਲਡ ਸੁਝਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਹਨਾਂ ਨੂੰ ਅਸਲ ਆਰਟੀਫੈਕਟਸ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਤਾਂ ਕਿ ਉਹ ਉਤਪੰਨ ਢਾਂਚਾ ਤੁਹਾਡੇ ਪ੍ਰੋਡਕਟ ਨਾਲ ਮੇਲ ਖਾਂਦੇ।
Acceptance criteria ਅਕਸਰ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਣ ਡੇਟਾਬੇਸ ਨਿਯਮ ਰਖਦੇ ਹਨ, ਭਾਵੇਂ ਉਹ ਸਿੱਧੇ ਤੌਰ 'ਤੇ ਡੇਟਾ ਦਾ ਜ਼ਿਕਰ ਨਾ ਕਰਨ। ਇਨ੍ਹਾਂ ਤਰ੍ਹਾਂ ਦੇ ਬਿਆਨਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ:
ਵੈਗ ਸਟੋਰੀਜ਼ (“As a user, I can manage projects”) ਕਈ ਐਂਟਿਟੀਆਂ ਅਤੇ ਵਰਕਫਲੋਜ਼ ਨੂੰ ਛੁਪਾਉਂਦੀਆਂ ਹਨ। ਹੋਰ ਇੱਕ ਆਮ ਗੈਪ ਕੈਂਸਲੈਸ਼ਨ, ਰੀਟ੍ਰਾਈ, ਭਾਗ-ਪੁਨਰ ਅਦਾਇਗੀ ਜਾਂ ਦੁਬਾਰਾ ਨਿਯੁਕਤੀ ਜਿਵੇਂ edge cases ਦਾ ਗੁੰਮ ਹੋਣਾ ਹੁੰਦਾ ਹੈ।
ਟੇਬਲਾਂ ਜਾਂ ਡਾਇਗ੍ਰਾਮ ਸੋਚਣ ਤੋਂ ਪਹਿਲਾਂ, ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਪੜ੍ਹੋ ਅਤੇ ਨਾਉਂਜ਼ ਨੂੰ ਹਾਈਲਾਈਟ ਕਰੋ। ਰਿਕਵਾਇਰਮੈਂਟ ਲਿਖਣ ਵਿੱਚ, ਨਾਉਂਜ਼ ਆਮ ਤੌਰ 'ਤੇ ਉਹ “ਚੀਜ਼ਾਂ” ਹੁੰਦੀਆਂ ਹਨ ਜੋ ਤੁਹਾਡੀ ਸਿਸਟਮ ਨੂੰ ਯਾਦ ਰੱਖਣੀਆਂ ਹੁੰਦੀਆਂ—ਇਹਨਾਂ ਨੂੰ ਅਕਸਰ ਤੁਹਾਡੇ ਸਕੀਮਾ ਵਿੱਚ ਐਂਟਿਟੀਜ਼ ਮਿਲਦੀਆਂ ਹਨ।
ਇੱਕ ਤੇਜ਼ ਮਨੋਵਿਗਿਆਨਿਕ ਨਿਯਮ: ਨਾਉਂਜ਼ ਐਂਟਿਟੀ ਬਣਦੇ ਹਨ, ਜਦਕਿ ਵਰਬ ਐਕਸ਼ਨ ਜਾਂ ਵਰਕਫਲੋਜ਼ ਬਣਦੇ ਹਨ। ਜੇ ਇੱਕ ਕਹਾਣੀ ਕਹਿੰਦੀ ਹੈ “A manager assigns a technician to a job,” ਤਾਂ ਸੰਭਾਵਿਤ ਐਂਟਿਟੀਆਂ ਹਨ manager, technician, ਅਤੇ job—ਅਤੇ “assigns” ਇੱਕ ਰਿਸ਼ਤੇ ਦੀ ਇਸ਼ਾਰਾ ਕਰਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਮਾਡਲ ਕਰੋਗੇ।
ਹਰ ਨਾਉਂ ਨੂੰ ਆਪਣੀ ਟੇਬਲ ਬਣਾਉਣ ਦੀ ਲੋੜ ਨਹੀਂ। ਇੱਕ ਨਾਉਂ ਵਧੀਆ ਉਮੀਦਦਾਰ ਹੈ ਜੇ ਇਹ:
ਜੇਕਰ ਕੋਈ ਨਾਉਂ ਸਿਰਫ਼ ਇਕ ਵਾਰੀ ਆਉਂਦਾ ਹੈ, ਜਾਂ ਕਿਸੇ ਹੋਰ ਚੀਜ਼ ਨੂੰ ਵਰਣਨ ਕਰਦਾ ਹੈ (“red button”, “Friday”), ਤਾਂ ਇਹ ਸ਼ਾਇਦ ਐਂਟਿਟੀ ਨਹੀਂ ਹੋਵੇਗਾ।
ਹਰ ਵੇਰਵੇ ਨੂੰ ਟੇਬਲ ਬਣਾਉਣਾ ਆਮ ਗਲਤੀ ਹੈ। ਇਹ ਨਿਯਮ ਵਰਤੋ:
ਦੋ ਕਲਾਸਿਕ ਉਦਾਹਰਣ:
AI ਕਹਾਣੀਆਂ ਸਕੈਨ ਕਰਕੇ ਥੀਮਾਂ ਅਨੁਸਾਰ ਕੈਂਡੀਡੇਟ ਨਾਉਂਜ਼ ਦੀ ਡਰਾਫਟ ਲਿਸਟ ਦੇ ਕੇ ਐਂਟਿਟੀ ਖੋਜ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ (ਲੋਕ, ਵਰਕ ਆਈਟਮ, ਦਸਤਾਵੇਜ਼, ਸਥਾਨ ਆਦਿ). ਇਕ ਉਪਯੋਗੀ ਪ੍ਰਾਂਪਟ ਹੋ ਸਕਦਾ ਹੈ: “ਉਹ ਨਾਉਂ ਕੱਢੋ ਜੋ ਡੇਟਾ ਸਟੋਰ ਕਰਨਾ ਲਾਜ਼ਮੀ ਹਨ, ਤੇ synonyms/duplicates ਨੂੰ ਗਰੁੱਪ ਕਰੋ।”
ਆਉਟਪੁੱਟ ਨੂੰ ਸ਼ੁਰੂਆਤੀ ਬਿੰਦੂ ਸਮਝੋ, ਅੰਤਿਮ ਜਵਾਬ ਨਹੀਂ। follow-ups ਪੁੱਛੋ ਜਿਵੇਂ:
ਕਦਮ 1 ਦਾ ਲਕਸ਼ ਇਹ ਹੈ ਕਿ ਇੱਕ ਛੋਟੀ, ਸਾਫ਼ ਲਿਸਟ ਬਣ ਜਾਵੇ ਜਿਸਨੂੰ ਤੁਸੀਂ ਅਸਲ ਕਹਾਣੀਆਂ ਨਾਲ ਜਸਟਿਫਾਈ ਕਰ ਸਕੋ।
ਜਦ ਤੁਸੀਂ ਐਂਟਿਟੀਆਂ ਦੇ ਨਾਮ ਰੱਖ ਲਏ (ਜਿਵੇਂ Order, Customer, Ticket), ਅਗਲਾ ਕੰਮ ਉਹ ਵੇਰਵੇ ਪਕੜਨਾ ਹੈ ਜੋ ਤੁਹਾਨੂੰ ਬਾਅਦ ਵਿੱਚ ਲੋੜ ਹੋਣਗੇ। ਡੇਟਾਬੇਸ ਵਿੱਚ, ਉਹ ਵੇਰਵੇ ਫੀਲਡ ਹੁੰਦੇ ਹਨ—ਉਹ ਯਾਦਾਂ ਜੋ ਤੁਹਾਡੀ ਸਿਸਟਮ ਭੁੱਲ ਨਹੀਂ ਸਕਦੀ।
ਯੂਜ਼ਰ ਸਟੋਰੀ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ, ਫਿਰ acceptance criteria ਨੂੰ ਇੱਕ ਚੈਕਲਿਸਟ ਵਜੋਂ ਪੜ੍ਹੋ।
ਜੇ ਇੱਕ ਲੋੜ ਕਹਿੰਦੀ ਹੈ “Users orders ਨੂੰ delivery date ਨਾਲ ਫਿਲਟਰ ਕਰ ਸਕਦੇ ਹਨ,” ਤਾਂ delivery_date ਵਿਕਲਪਿਕ ਨਹੀਂ—ਇਹ ਇੱਕ ਫੀਲਡ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ (ਜਾਂ ਹੋਰ ਸਟੋਰ ਕੀਤੇ ਡੇਟਾ ਤੋਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਨਿਕਲੀ ਹੋਵੇ)। ਜੇ ਲਿਖਿਆ ਹੈ “ਦਿਖਾਓ ਕਿ ਕਿਸ ਨੇ request approve ਕੀਤਾ ਅਤੇ ਕਦੋਂ,” ਤਾਂ ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ approved_by ਅਤੇ approved_at ਦੀ ਲੋੜ ਹੋਵੇਗੀ।
ਇੱਕ ਪ੍ਰਯੋਗਾਤਮਕ ਟੈਸਟ: ਕੀ ਕੋਈ ਇਸ ਨੂੰ ਡਿਸਪਲੇ, ਖੋਜ, ਛਾਂਟ, ਆਡਿਟ ਜਾਂ ਗਣਨਾ ਲਈ ਵਰਤਣਾ ਚਾਹੇਗਾ? ਜੇ ਹਾਂ, ਤਾਂ ਇਹ ਸ਼ਾਇਦ ਇੱਕ ਫੀਲਡ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
Customers ਵਿੱਚ ਇਕ ਵਾਰੀ ਸਟੋਰ ਕਰੋ ਅਤੇ ਰੇਫਰੈਂਸ ਰੱਖੋ।ਕਈ ਸਟੋਰੀਜ਼ ਵਿੱਚ “status,” “type,” ਜਾਂ “priority” ਵਰਗੇ ਸ਼ਬਦ ਆਉਂਦੇ ਹਨ। ਇਨ੍ਹਾਂ ਨੂੰ ਕੰਟਰੋਲਡ ਵੈਲ੍ਯੂਜ਼ ਸਮਝੋ—ਇੱਕ ਸੀਮਤ ਸਮੂਹ ਮਨਜ਼ੂਰ ਮੁੱਲ।
ਜੇ ਸਮੂਹ ਛੋਟਾ ਅਤੇ ਸਥਿਰ ਹੈ, ਤਾਂ ਸਧਾਰਨ enum-ਸਟਾਈਲ ਫੀਲਡ ਸਹੀ ਰਹੇਗਾ। ਜੇ ਇਹ ਵਧ ਸਕਦਾ ਹੈ, ਲੇਬਲ ਦੀ ਲੋੜ ਹੈ, ਜਾਂ permissions ਲੋੜੀਂਦੇ ਹਨ (ਜਿਵੇਂ admin-managed categories), ਤਾਂ ਅਲੱਗ lookup table (ਉਦਾਹਰਣ: status_codes) ਬਣਾਓ ਅਤੇ ਇੱਕ ਰੇਫਰੈਂਸ ਸਟੋਰ ਕਰੋ।
ਇਸ ਤਰ੍ਹਾਂ ਕਹਾਣੀਆਂ ਫੀਲਡਾਂ ਵਿੱਚ ਬਦਲਦੀਆਂ ਹਨ ਜੋ ਭਰੋਸੇਯੋਗ, searchable ਅਤੇ ਸਹੀ ਕਰਨ ਵਾਲੀਆਂ ਹੁੰਦੀਆਂ ਹਨ।
ਜਦ ਤੁਸੀਂ ਐਂਟਿਟੀਆਂ (User, Order, Invoice, Comment ਆਦਿ) ਦੀ ਸੂਚੀ ਬਣਾਲੈ ਅਤੇ ਉਹਨਾਂ ਦੇ ਫੀਲਡ ਤਿਆਰ ਕਰ ਲਏ, ਤਾਂ ਅਗਲਾ ਕਦਮ ਉਹਨਾਂ ਨੂੰ ਜੋੜਣਾ ਹੈ। ਰਿਸ਼ਤੇ ਉਹ ਪਰਤ ਹਨ ਜੋ ਕਹਾਣੀਆਂ ਦੁਆਰਾ ਦਰਸਾਏ ਗਏ “ਇਹਨਾਂ ਚੀਜ਼ਾਂ ਦਾ ਇਕੱਠੇ ਕਿਵੇਂ ਕੰਮ ਕਰਨਾ” ਹੈ।
One-to-one (1:1) ਦਾ ਮਤਲਬ ਹੈ “ਇੱਕ ਚੀਜ਼ ਦਾ ਸਿਰਫ ਇੱਕ ਹੋਰ ਚੀਜ਼ ਨਾਲ ਸਬੰਧ ਹੈ।”
User ↔ Profile (ਅਕਸਰ ਤੁਸੀਂ ਇਹਨਾਂ ਨੂੰ ਇੱਕ-ਇੱਕ ਕਰਕੇ ਜੋੜ ਸਕਦੇ ਹੋ ਜਦ ਤੱਕ ਵੱਖ-ਵੱਖ ਕਰਨ ਦਾ ਕੋਈ ਕਾਰਨ ਨਾ ਹੋਵੇ)।One-to-many (1:N) ਦਾ ਮਤਲਬ ਹੈ “ਇੱਕ ਚੀਜ਼ ਦੇ ਕਈ ਹੋ ਸਕਦੇ ਹਨ।” ਇਹ ਸਭ ਤੋਂ ਆਮ ਹੈ।
User → Order (Order ਤੇ user_id ਰੱਖੋ)।Many-to-many (M:N) ਦਾ ਮਤਲਬ ਹੈ “ਕਈ ਚੀਜ਼ਾਂ ਕਈ ਚੀਜ਼ਾਂ ਨਾਲ ਜੁੜ ਸਕਦੀਆਂ ਹਨ।” ਇਸ ਲਈ ਅਤਿਰਿਕਤ ਟੇਬਲ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਡੇਟਾਬੇਸ Order ਵਿੱਚ “product IDs ਦੀ ਇੱਕ ਸੂਚੀ” ਗੰਢਣਾ ਸਹੀ ਤਰੀਕਾ ਨਹੀਂ ਹੈ—ਇਸ ਨਾਲ ਬਾਅਦ ਵਿੱਚ ਖੋਜ, ਅਪਡੇਟ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦੀਆਂ ਹਨ। ਇਸਦਾ ਬਦਲਾ ਇੱਕ join table ਬਣਾਓ ਜੋ ਖੁਦ ਰਿਸ਼ਤੇ ਨੂੰ ਦਰਸਾਂਦਾ ਹੈ।
ਉਦਾਹਰਣ:
Order\n- Product\n- OrderItem (join table)OrderItem ਅਕਸਰ ਇਹ ਰੱਖਦਾ ਹੈ:
order_id\n- product_id\n- ਕਹਾਣੀ ਦੇ ਹੋਰ ਵੇਰਵੇ ਜਿਵੇਂ quantity, unit_price, discountਨੋਟ ਕਰੋ ਕਿ ਕਹਾਣੀ ਦੇ ਵੇਰਵੇ (“quantity”) ਅਕਸਰ ਰਿਸ਼ਤੇ 'ਤੇ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, ਨਾ ਕਿ ਕਿਸੇ ਇਕੱਲੇ ਐਂਟਿਟੀ 'ਤੇ।
ਕਹਾਣੀਆਂ ਦੱਸਦੀਆਂ ਹਨ ਕਿ ਕੌਣ-ਕਿਹੜਾ ਲਿੰਕ ਜਰੂਰੀ ਹੈ ਜਾਂ ਕਈ ਵਾਰੀ ਗੈਰ-ਮੌਜੂਦ ਹੋ ਸਕਦਾ ਹੈ।
Order ਨੂੰ user_id ਚਾਹੀਦਾ ਹੈ (ਖਾਲੀ ਨਾ ਰਹਿਣ ਦਿੱਤਾ ਜਾਵੇ)।\n- “ਇੱਕ user ਦਾ phone number ਹੋ ਸਕਦਾ ਹੈ” → phone ਖਾਲੀ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।\n- “ਇੱਕ order ਦਾ shipping address ਹੋ ਸਕਦਾ ਹੈ (ਜੇ physical goods ਹਨ)” → shipping_address_id ਡਿਜ਼ੀਟਲ ਆਈਟਮਾਂ ਲਈ ਖਾਲੀ ਹੋ ਸਕਦੀ ਹੈ।ਤੇਜ਼ ਚੈੱਕ: ਜੇ ਕਹਾਣੀ ਇੰਪਲਾਈ ਕਰਦੀ ਹੈ ਕਿ ਤੁਸੀਂ record ਬਣਾਉਣ ਤੋਂ ਬਿਨਾਂ ਲਿੰਕ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਉਸਨੂੰ required ਮਾਨੋ। ਜੇ ਕਹਾਣੀ ਕਹਿੰਦੀ ਹੈ “can”, “may”, ਜਾਂ exception ਦਿੰਦੀ ਹੈ, ਤਾਂ optional ਮਾਨੋ।
ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਕਹਾਣੀ ਪੜ੍ਹਦੇ ਹੋ, ਇਸਨੂੰ ਸਧਾਰਨ ਜੋੜਿਆਂ ਵਾਂਗ ਦੁਬਾਰਾ ਲਿਖੋ:
User 1:N Comment\n- “A comment belongs to one user” → Comment N:1 Userਹਰ ਇੰਟਰੈਕਸ਼ਨ ਲਈ ਇਹ ਕਰੋ। ਅੰਤ ਵਿੱਚ, ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਜੁੜਿਆ ਹੋਇਆ ਮਾਡਲ ਹੋਵੇਗਾ ਜੋ ਅਸਲ ਕੰਮ ਕਰਨ ਦੇ ਢੰਗ ਨਾਲ ਮਿਲਦਾ ਹੈ—ER ਡਾਇਗ੍ਰਾਮ ਟੂਲ ਖੋਲ੍ਹਣ ਤੋਂ ਪਹਿਲਾਂ।
ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਤੁਹਾਨੂੰ ਦੱਸਦੀਆਂ ਹਨ ਕਿ ਲੋਕ ਕੀ ਚਾਹੁੰਦੇ ਹਨ। ਵਰਕਫਲੋਜ਼ ਦਿਖਾਉਂਦੇ ਹਨ ਕਿ ਕੰਮ ਅਸਲ ਵਿੱਚ ਕਿਵੇਂ ਚਲਦਾ ਹੈ, ਇੱਕ-ਕਦਮ-ਦਰ-ਕਦਮ। ਵਰਕਫਲੋ ਨੂੰ ਡੇਟਾ ਵਿੱਚ ਅਨੁਵਾਦ ਕਰਨਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਤਰੀਕਿਆਂ ਵਿੱਚੋਂ ਇੱਕ ਹੈ ਜੋ “ਅਸੀਂ ਉਹ ਨਹੀਂ ਸਟੋਰ ਕਰ ਰਹੇ” ਸਮੱਸਿਆਵਾਂ ਨੂੰ ਬਿਲਡ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਪਕੜਦਾ ਹੈ।
ਵਰਕਫਲੋ ਨੂੰ ਕਾਰਵਾਈਆਂ ਅਤੇ ਸਟੇਟ ਚੇਨਜਾਂ ਦੀ ਲੜੀ ਵਜੋਂ ਲਿਖੋ। ਉਦਾਹਰਣ:
ਉਹ ਬੋਲਡ ਸ਼ਬਦ ਅਕਸਰ ਇੱਕ status ਫੀਲਡ ਬਣ ਜਾਂਦੇ ਹਨ (ਜਾਂ ਇੱਕ ਛੋਟੀ “state” ਟੇਬਲ), ਜਿਸ ਵਿੱਚ ਸਪਸ਼ਟ ਮਨਜ਼ੂਰ ਮੁੱਲ ਹੁੰਦੇ ਹਨ।
ਕਦਮ-ਬਦ-ਕਦਮ ਹੇਠਾਂ ਪੁੱਛੋ: “ਬਾਅਦ ਵਿੱਚ ਸਾਨੂੰ ਕੀ ਜਾਣਨਾ ਚਾਹੀਦਾ ਹੈ?” ਵਰਕਫਲੋਜ਼ ਆਮ ਤੌਰ 'ਤੇ ਇਹਨਾਂ ਫੀਲਡਾਂ ਨੂੰ ਬਾਹਰ ਲਿਆਉਂਦੇ ਹਨ:
submitted_at, approved_at, completed_at\n- ownership: created_by, assigned_to, approved_by\n- reason/context: rejection_reason, approval_note\n- ordering: sequence multi-step processes ਲਈਜੇ ਤੁਹਾਡੇ ਵਰਕਫਲੋ ਵਿੱਚ ਰੁਕਾਵਟ, ਐਸਕਲੇਸ਼ਨ, ਜਾਂ ਹੈਂਡਆਫ਼ ਹਨ, ਤਾਂ ਤੁਹਾਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਘੱਟੋ-ਘੱਟ ਇੱਕ timestamp ਅਤੇ ਇੱਕ “ਹੁਣ ਕਿਸਦੇ ਕੋਲ ਹੈ” ਫੀਲਡ ਦੀ ਲੋੜ ਹੋਵੇਗੀ।
ਕੁਝ ਵਰਕਫਲੋ ਕਦਮ ਸਿਰਫ਼ ਫੀਲਡ ਨਹੀਂ ਹੁੰਦੇ—ਉਹ ਵੱਖ-ਵੱਖ ਡੇਟਾ ਸਟ੍ਰਕਚਰ ਹਨ:
AI ਨੂੰ ਦੋਹਾਂ ਦੇਵੋ: (1) ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਅਤੇ acceptance criteria, ਅਤੇ (2) ਵਰਕਫਲੋ ਕਦਮ। ਪੁੱਛੋ ਕਿ ਇਹ ਹਰ ਕਦਮ ਦੀ ਸੂਚੀ ਬਣਾਵੇ ਅਤੇ ਹਰ ਕਦਮ ਲਈ ਲੋੜੀਂਦਾ ਡੇਟਾ (state, actor, timestamps, outputs) ਪੱਤਰ ਕਰੇ, ਫਿਰ ਉਨ੍ਹਾਂ ਲੋੜਾਂ ਵਿੱਚੋਂ ਉਹਨੂੰ ਹਾਈਲਾਈਟ ਕਰੇ ਜੋ ਮੌਜੂਦਾ ਫੀਲਡ/ਟੇਬਲ ਨਾਲ ਸਪੋਰਟ ਨਹੀਂ ਹੁੰਦੀਆਂ।
Koder.ai ਵਰਗੀਆਂ ਪਲੇਟਫਾਰਮਾਂ ਵਿੱਚ, ਇਹ “ਗੈਪ ਚੈੱਕ” ਖਾਸਾ ਪ੍ਰਯੋਗਸ਼ੀਲ ਬਣ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਇਤਰੈਟ ਕਰ ਸਕਦੇ ਹੋ: ਸਕੀਮਾ ਧਾਰਣਾਂ ਨੂੰ ਸੋਧੋ, scaffolding ਦੁਬਾਰਾ ਜਨਰੇਟ ਕਰੋ, ਅਤੇ ਲੰਬੇ ਮੈਨੂਅਲ ਬੋਇਲਰਪਲੇਟ ਨੂੰ ਛੱਡ ਕੇ ਅੱਗੇ ਵਧੋ।
ਜਦ ਤੁਸੀਂ ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਨੂੰ ਟੇਬਲਾਂ ਵਿੱਚ ਬਦਲਦੇ ਹੋ, ਤੁਸੀਂ ਸਿਰਫ਼ ਫੀਲਡਾਂ ਦੀ ਲਿਸਟ ਨਹੀਂ ਬਣਾ ਰਹੇ—ਤੁਸੀਂ ਇਹ ਵੀ ਫੈਸਲਾ ਕਰ ਰਹੇ ਹੋ ਕਿ ਡੇਟਾ ਸਮੇਂ ਦੇ ਨਾਲ ਕਿਵੇਂ ਪਛਾਣਯੋਗ ਅਤੇ ਇਕਸਾਰ ਰਹੇਗਾ।
ਇੱਕ primary key ਇੱਕ ਰਿਕਾਰਡ ਨੂੰ ਵਿਲੱਖਣ ਤਰੀਕੇ ਨਾਲ ਪਛਾਣਦੀ ਹੈ—ਇਸਨੂੰ ਸੋਚੋ ਜਿਵੇਂ ਰੋ ਦਾ ਸਥਾਈ ਪਹਿਚਾਨ ਪੱਤਰ।
ਹਰ ਰੋ ਨੂੰ ਇੱਕ ਐਸਾ ID ਚਾਹੀਦਾ ਹੈ ਕਿਉਂਕਿ ਕਹਾਣੀਆਂ ਅਪਡੇਟ, ਰੇਫਰੈਂਸ ਅਤੇ ਇਤਿਹਾਸ ਨੂੰ ਇਸ਼ਾਰਾ ਕਰਦੀਆਂ ਹਨ। ਅਮਲ ਵਿੱਚ, ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਅੰਦਰੂਨੀ id ਹੁੰਦਾ ਹੈ (ਆਮ ਤੌਰ 'ਤੇ ਨੰਬਰ ਜਾਂ UUID) ਜੋ ਕਦੇ ਨਹੀਂ ਬਦਲਦਾ।
ਇੱਕ foreign key ਇੱਕ ਟੇਬਲ ਨੂੰ ਦੂਜੇ ਨਾਲ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਜੋੜਦੀ ਹੈ। ਜੇ orders.customer_id customers.id ਨੂੰ refer ਕਰਦਾ ਹੈ, ਤਾਂ ਡੇਟਾਬੇਸ ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਹਰ ਆਰਡਰ ਇੱਕ ਅਸਲ ਗਾਹਕ ਨਾਲ ਜੁੜਿਆ ਹੋਇਆ ਹੈ।
ਇਹ ਉਹ ਕਹਾਣੀਆਂ ਮਿਲਦਾ-ਜੁਲਦਾ ਹੈ ਜਿਵੇਂ “As a user, I can see my invoices.” ਇਨਵੌਇਸ ਖਾਲੀ ਨਹੀਂ ਹੈ; ਇਹ ਕਿਸੇ customer (ਅਕਸਰ ਕਿਸੇ order ਜਾਂ subscription) ਨਾਲ ਜੁੜੀ ਹੁੰਦੀ ਹੈ।
ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਅਕਸਰ ਲੁਕੀਆਂ ਯੂਨੀਕਨੈਸ ਲੋੜਾਂ ਰੱਖਦੀਆਂ ਹਨ:
ਇਹ ਨਿਯਮ ਉਹ duplicates ਰੋਕਦੇ ਹਨ ਜੋ ਮਹੀਨਿਆਂ ਬਾਅਦ “ਡੇਟਾ ਬੱਗ” ਬਣ ਜਾਂਦੇ ਹਨ।
ਇੰਡੈਕਸ ਖੋਜਾਂ ਨੂੰ ਤੇਜ਼ ਕਰਦੇ ਹਨ ਜਿਵੇਂ “email ਦੁਆਰਾ customer ਲੱਭੋ” ਜਾਂ “customer ਦੇ orders ਸੂਚੀਬੱਧ ਕਰੋ”। ਸ਼ੁਰੂਆਤ ਉਸ ਇੰਡੈਕਸ ਨਾਲ ਕਰੋ ਜੋ ਤੁਹਾਡੀਆਂ ਸਭ ਤੋਂ ਆਮ ਕੁਏਰੀਆਂ ਅਤੇ ਯੂਨੀਕਨੈਸ ਰੂਲਾਂ ਦੇ ਨਾਲ ਲਾਈਨ ਕਰਦਾ ਹੋਵੇ।
ਦਰਅਸਲ ਕੀ ਛੱਡਣਾ ਹੈ: ਰੱਸੀ ਹੋਈ ਰਿਪੋਰਟਾਂ ਜਾਂ ਅਨੁਮਾਨੀ ਫਿਲਟਰਾਂ ਲਈ ਭਾਰੀ ਇੰਡੈਕਸਿੰਗ — ਪਹਿਲਾਂ ਸਕੀਮਾ ਪੱਕਾ ਕਰੋ, ਫਿਰ ਅਸਲ ਵਰਤੋਂ ਅਤੇ slow-query ਸਬੂਤ ਦੇ ਆਧਾਰ ਤੇ ਅਪਟਿਮਾਈਜ਼ ਕਰੋ।
ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਦਾ ਇੱਕ ਹੀ ਲਕਸ਼: ਟਕਰਾ-ਟਕਰੇ ਨਕਲਾਂ ਤੋਂ ਬਚਣਾ। ਜੇ ਇੱਕੇ ਤੱਥ ਨੂੰ ਦੋ ਥਾਵਾਂ 'ਤੇ ਸਟੋਰ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਤਾਂ ਦੋਨਾ ਇੱਕ ਦਿਨ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਹੋ ਜਾਣਗੇ। ਇੱਕ ਨਾਰਮਲਾਈਜ਼ਡ ਸਕੀਮਾ ਹਰ ਤੱਥ ਨੂੰ ਇੱਕ ਵਾਰੀ ਰੱਖਦਾ ਹੈ, ਫਿਰ ਹੋਰ ਥਾਵਾਂ ਤੋਂ ਉਸਨੂੰ ਰੇਫਰੈਂਸ ਕਰਦਾ ਹੈ।
1) ਦੁਹਰਾਏ ਗਰੁੱਪਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ
ਜੇ ਤੁਸੀਂ “Phone1, Phone2, Phone3” ਜਾਂ “ItemA, ItemB, ItemC” ਵਰਗੀਆਂ ਪੈਟਰਨਾਂ ਵੇਖਦੇ ਹੋ, ਤਾਂ ਇਹ ਇੱਕ(child) ਟੇਬਲ ਲਈ ਸੂਚਕ ਹੈ (ਉਦਾਹਰਣ: CustomerPhones, OrderItems). ਦੁਹਰਾਏ ਗਰੁੱਪ ਖੋਜ, ਵੈਧਤਾ ਅਤੇ ਸਕੇਲਿੰਗ ਨੂੰ ਮੁਸ਼ਕਲ ਬਣਾਉਂਦੇ ਹਨ।
2) ਇਕੋ ਨਾਮ/ਵੇਰਵਾ ਨਕਲ ਨਾ ਕਰੋ
ਜੇ CustomerName Orders, Invoices, ਅਤੇ Shipments ਵਿੱਚ ਦਿੱਤਾ ਗਿਆ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਇੱਕ ਤੋਂ ਵੱਧ ਸੱਚਾਈ ਦੇ ਸਰੋਤ ਬਣਾਦਿਤਾ ਹੈ। Customers ਵਿੱਚ ਗਾਹਕ ਵੇਰਵੇ ਰੱਖੋ, ਅਤੇ ਬਾਕੀਆਂ ਥਾਵਾਂ ਤੇ ਸਿਰਫ਼ customer_id ਰੱਖੋ।
3) ਇੱਕੋ ਵਸ্তু ਲਈ ਕਈ ਕਾਲਮ ਤੋਂ ਬਚੋ
billing_address, shipping_address, home_address ਨੂੰ ਅਲੱਗ-ਅਲੱਗ ਰੱਖਣਾ ਠੀਕ ਹੈ ਜੇ ਉਹ ਵਾਸਤਵ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਅੱਥਾਹਾਂ ਹਨ। ਪਰ ਜੇ ਤੁਸੀਂ “ਕਈ ਪਤੇ” ਮਾਡਲ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ Addresses ਟੇਬਲ ਬਣਾਓ ਜਿਸ ਵਿੱਚ type ਫੀਲਡ ਹੋਵੇ।
4) ਲੁੱਕਅਪਜ਼ ਨੂੰ ਫ੍ਰੀ-ਟੈਕਸਟ ਤੋਂ ਵੱਖ ਕਰੋ
ਜੇ ਯੂਜ਼ਰ ਕਿਸੇ ਜਾਣੇ-ਪਹਚਾਣੇ ਸੈੱਟ (status, category, role) ਵਿੱਚੋਂ ਚੁਣਦਾ ਹੈ, ਤਾਂ ਇਸਨੂੰ ਇਕਸਾਰ ਤਰੀਕੇ ਨਾਲ ਮਾਡਲ ਕਰੋ: ਜਾਂ ਤੰਗ enum ਜਾਂ lookup table। ਇਸ ਤੋਂ “Pending” vs “pending” vs “PENDING” ਵਰਗੀਆਂ ਗ਼ਲਤੀਆਂ ਰੋਕੀਆਂ ਜਾਣਗੀਆਂ।
5) ਹਰ non-ID ਫੀਲਡ ਕਿਵੇਂ ਸਬੰਧਤ ਹੈ ਇਹ ਚੈੱਕ ਕਰੋ
ਇੱਕ ਸਦਾਹਰਣ ਗਟ-ਚੈੱਕ: ਇੱਕ ਟੇਬਲ ਵਿੱਚ, ਜੇ ਇੱਕ ਕਾਲਮ ਉਸ ਟੇਬਲ ਦੇ ਮੁੱਖ ਐਂਟਿਟੀ ਤੋਂ ਇਲਾਵਾ ਕਿਸੇ ਹੋਰ ਚੀਜ਼ ਨੂੰ ਵਰਣਨ ਕਰਦਾ ਹੈ, ਤਾਂ ਉਹ ਅਕਸਰ ਹੋਰ ਜਗ੍ਹਾ ਦਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਉਦਾਹਰਣ: Orders ਨੂੰ product_price ਰੱਖਣ ਨਹੀਂ ਚਾਹੀਦਾ ਜੇ ਇਸਦਾ ਮਤਲਬ “order ਸਮੇਂ ਦੀ ਕੀਮਤ” ਨਹੀਂ; ਜੇ ਇਹ historical snapshot ਹੈ, ਤਾਂ ਇਸ ਨੂੰ ਸਪਸ਼ਟ ਰੱਖੋ।
ਕਈ ਵਾਰ ਤੁਸੀਂ ਜਾਣ-ਬੁਝ ਕੇ ਨਕਲ ਸਟੋਰ ਕਰਦੇ ਹੋ:
ਛੇਤੀ ਗੱਲ ਇਹ ਹੈ ਕਿ ਇਹ ਇਰਾਦਾ-ਪੂਰਕ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਇਹ ਦੱਸੋ ਕਿ ਕਿਹੜਾ ਫੀਲਡ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਹੈ ਅਤੇ ਕਾਪੀਆਂ ਕਿਵੇਂ ਅਪਡੇਟ ਹੁੰਦੀਆਂ ਹਨ।
AI ਸ਼ੱਕ ਲਾਉਂਦੀਆਂ ਨਕਲਾਂ (repeated columns, ਸਮਾਨ field names, inconsistent “status” fields) ਨੂੰ ਠੱਠਾ ਸਕਦਾ ਹੈ ਅਤੇ ਟੇਬਲਾਂ ਵਿੱਚ ਵੰਡਨ ਦੀ ਸੁਝਾਅ ਦੇ ਸਕਦਾ ਹੈ। ਮਨੁੱਖ ਫੈਸਲਾ ਕਰਦੇ ਹਨ ਕਿ ਸੌਖਪਣ, ਲਚਕੀਲਾਪਨ ਅਤੇ ਪਰਫਾਰਮੈਂਸ ਵਿੱਚ ਕਿਹੜਾ ਟਰੇਡ-ਆਫ਼ ਠੀਕ ਹੈ—ਇਹ ਨਿਰਭਰ ਹੈ ਕਿ ਉਤਪਾਦ ਅਸਲ ਵਿੱਚ ਕਿਵੇਂ ਵਰਤਿਆ ਜਾਵੇਗਾ।
ਇੱਕ ਉਪਯੋਗੀ ਨਿਯਮ: ਉਹ ਤੱਥ ਸਟੋਰ ਕਰੋ ਜੋ ਤੁਸੀਂ ਭਵਿੱਖ ਵਿੱਚ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਦੁਬਾਰਾ ਬਣਾਅ ਨਹੀਂ ਸਕਦੇ; ਹੋਰ ਸਾਰਾ ਗਣਤ ਕਰੋ।
ਸਟੋਰ ਕੀਤੀ ਡੇਟਾ ਅਸਲ ਸੱਚਾਈ ਹੁੰਦੀ ਹੈ: ਵਿਅਕਤੀਗਤ line items, timestamps, status changes, ਕਿਸ ਨੇ ਕੀ ਕੀਤਾ। ਗਣਤ (derived) ਡੇਟਾ ਉਹ ਹੁੰਦਾ ਹੈ ਜੋ ਉਹਨਾਂ ਤੱਥਾਂ ਤੋਂ ਨਿਕਲਦਾ ਹੈ: totals, counters, flags ਜਿਵੇਂ “is overdue”, ਅਤੇ rollups ਜਿਵੇਂ “current inventory”。
ਜੇ ਦੋ ਮੁੱਲਾਂ ਨੂੰ ਇੱਕੋ underlying facts ਤੋਂ ਗਣਤ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਤਾਂ facts ਸਟੋਰ ਕਰੋ ਅਤੇ ਹੋਰ ਨੂੰ ਕੈਲਕੁਲੇਟ ਕਰੋ—ਨਹੀਂ ਤਾਂ ਵਿਰੋਧ ਹੋ ਸਕਦਾ ਹੈ।
Derived values ਜਦੋਂ ਉਨ੍ਹਾਂ ਦੇ inputs ਬਦਲਦੇ ਹਨ ਤਾਂ ਬਦਲ ਜਾਂਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ inputs ਅਤੇ derived ਨਤੀਜੇ ਦੋਹਾਂ ਸਟੋਰ ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਹਾਨੂੰ ਹਰ workflow ਅਤੇ edge case (edits, refunds, partial shipments, backdated changes) ਤੇ ਉਹਨਾਂ ਨੂੰ sync ਰੱਖਣਾ ਪੈਂਦਾ ਹੈ। ਇੱਕ ਛੁੱਟੀ ਹੋਈ ਅਪਡੇਟ ਨਾਲ ਡੇਟਾਬੇਸ ਦੋ ਵੱਖ-ਵੱਖ ਕਹਾਣੀਆਂ ਦੱਸਣਾ ਸ਼ੁਰੂ ਕਰ ਦੇਵੇਗਾ।
ਉਦਾਹਰਣ: order_total ਨੂੰ ਸਟੋਰ ਕਰਨਾ ਅਤੇ order_items ਨੂੰ ਵੀ ਸਟੋਰ ਕਰਨਾ। ਜੇ ਕਿਸੇ ਨੇ quantity ਬਦਲ ਦਿੱਤੀ ਜਾਂ discount ਲਾਇਆ ਅਤੇ total ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਅਪਡੇਟ ਨਹੀਂ ਹੋਇਆ, ਤਾਂ finance ਨੂੰ ਇਕ ਨੰਬਰ ਅਤੇ cart ਨੂੰ ਦੂਜਾ ਨੰਬਰ ਦਿਖਾਈ ਦੇਵੇਗਾ।
ਵਰਕਫਲੋਜ਼ ਦੱਸਦੇ ਹਨ ਕਿ ਤੁਹਾਨੂੰ ਕਦੋਂ ਇਤਿਹਾਸਕ ਸੱਚਾਈ ਦੀ ਲੋੜ ਹੈ, ਨਾ ਕਿ ਸਿਰਫ਼ “ਮੌਜੂਦਾ ਸੱਚਾ”। ਜੇ ਯੂਜ਼ਰਾਂ ਨੂੰ ਇਹ ਜਾਣਨਾ ਲੋੜੀਂਦਾ ਹੈ ਕਿ ਕਿਸ ਵੇਲੇ ਕੀ ਮੁੱਲ ਸੀ, ਤਾਂ snapshot ਸਟੋਰ ਕਰੋ।
ਉਦਾਹਰਣ ਲਈ ਇੱਕ order, ਤੁਸੀਂ ਸਟੋਰ ਕਰ ਸਕਦੇ ਹੋ:
order_total (snapshot), ਕਿਉਂਕਿ taxes, discounts, ਅਤੇ pricing rules ਬਾਅਦ ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹਨਇਨਵੈਂਟਰੀ ਲਈ, “inventory level” ਆਮ ਤੌਰ 'ਤੇ movements (receipts, sales, adjustments) ਤੋਂ ਗਣਤ ਹੁੰਦਾ ਹੈ। ਪਰ ਜੇ ਤੁਸੀਂ audit trail ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ movements ਸਟੋਰ ਕਰੋ ਅਤੇ ਵਰੇਪੋਰਟਿੰਗ ਤੇਜ਼ ਕਰਨ ਲਈ ਸਮੇਂ-ਸਮੇਂ 'ਤੇ snapshots ਰੱਖੋ।
ਲੌਗਇਨ ਟ੍ਰੈਕਿੰਗ ਲਈ, last_login_at ਇਕ factual event timestamp ਵਜੋਂ ਸਟੋਰ ਕਰੋ। “ਕੀ ਪਿਛਲੇ 30 ਦਿਨਾਂ ਵਿੱਚ active ਹੈ?” ਨੂੰ ਕੈਲਕੁਲੇਟ ਰੱਖੋ।
ਆਓ ਇੱਕ ਅੰਜ਼ਾਨੋ support ticket ਐਪ ਲਏਂ। ਅਸੀਂ ਪੰਜ ਯੂਜ਼ਰ ਸਟੋਰੀਜ਼ ਤੋਂ ਇਕ ਸਧਾਰਨ ER ਮਾਡਲ (ਐਂਟਿਟੀਆਂ + ਫੀਲਡ + ਰਿਸ਼ਤੇ) ਬਣਾਵਾਂਗੇ, ਫਿਰ ਇੱਕ ਵਰਕਫਲੋ ਦੇ ਖਿਲਾਫ਼ ਇਸਨੂੰ ਚੈੱਕ ਕਰਾਂਗੇ।
ਇਨ੍ਹਾਂ ਨਾਉਂਜ਼ ਤੋਂ ਸਾਡੀਆਂ ਕੋਰ ਐਂਟਿਟੀਆਂ ਮਿਲਦੀਆਂ ਹਨ:
ਪਹਿਲਾਂ (ਆਮ ਗਲਤੀ): Ticket ਕੋਲ assignee_id ਹੈ, ਪਰ ਅਸੀਂ ਇਹ ਯਕੀਨੀ ਨਹੀਂ ਬਣਾਇਆ ਕਿ ਸਿਰਫ਼ agents ਹੀ assignee ਹੋ ਸਕਦੇ ਹਨ।
ਬਾਅਦ: AI ਇਸ ਨੂੰ ਫਲੈਗ ਕਰਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਇੱਕ عملي ਨਿਯਮ ਜੋੜਦੇ ਹੋ: assignee ਇੱਕ User ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਜਿਸ ਦੀ role = “agent” (ਇਸਨੂੰ application validation ਜਾਂ database constraint/policy ਨਾਲ ਲਾਗੂ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਤੁਹਾਡੇ stack 'ਤੇ ਨਿਰਭਰ ਕਰਕੇ)। ਇਹ ਰਿਪੋਰਟਾਂ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਟੁੱਟਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਇੱਕ ਸਕੀਮਾ "ਮੁਕੰਮਲ" ਤਦ ਹੀ ਹੁੰਦਾ ਹੈ ਜਦ ਹਰ ਯੂਜ਼ਰ ਸਟੋਰੀ ਦਾ ਜਵਾਬ ਉਹ ਡੇਟਾ ਦੇ ਕੇ ਦਿੱਤਾ ਜਾ ਸਕੇ ਜੋ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਸਟੋਰ ਕਰਦੇ ਹੋ ਅਤੇ ਕਵੇਰੀ ਕਰ ਸਕਦੇ ਹੋ। ਸਭ ਤੋਂ ਸਧਾਰਨ ਵੈਰੀਫਿਕੇਸ਼ਨ ਕਦਮ ਇਹ ਹੈ ਕਿ ਹਰ ਕਿੱਤੀ ਸਟੋਰੀ ਚੁੱਕੋ ਅਤੇ ਪੁੱਛੋ: "ਕੀ ਅਸੀਂ ਇਸ ਸਵਾਲ ਦਾ ਡੇਟਾਬੇਸ ਤੋਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਹਮੇਸ਼ਾ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹਾਂ?" ਜੇ ਜਵਾਬ “ਸ਼ਾਇਦ” ਹੈ, ਤਾਂ ਤੁਹਾਡਾ ਮਾਡਲ ਗੈਪ ਰੱਖਦਾ ਹੈ।
ਹਰ ਯੂਜ਼ਰ ਸਟੋਰੀ ਨੂੰ ਇੱਕ ਜਾਂ ਵੱਧ ਟੈਸਟ ਸਵਾਲਾਂ ਵਜੋਂ ਦੁਬਾਰਾ ਲਿਖੋ—ਉਹ ਸਵਾਲ ਜੋ ਤੁਸੀਂ ਉਮੀਦ ਕਰੋ ਕਿ ਰਿਪੋਰਟ, ਸਕਰੀਨ ਜਾਂ API ਪੁੱਛੇਗਾ। ਉਦਾਹਰਣ:
ਜੇ ਤੁਸੀਂ ਇੱਕ ਕਹਾਣੀ ਨੂੰ ਸਪਸ਼ਟ ਤਰੀਕੇ ਨਾਲ ਪ੍ਰਗਟ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਕਹਾਣੀ ਅਸਪਸ਼ਟ ਹੈ। ਜੇ ਤੁਸੀਂ ਪ੍ਰਗਟ ਕਰ ਸਕਦੇ ਹੋ—ਪਰ ਸਕੀਮਾ ਨਾਲ ਇਸਦਾ ਜਵਾਬ ਨਹੀਂ ਮਿਲਦਾ—ਤਾਂ ਤੁਸੀਂ ਇੱਕ ਫੀਲਡ, ਰਿਸ਼ਤਾ, status/event, ਜਾਂ constraint ਗੁਆ ਚੁੱਕੇ ਹੋ।
ਇੱਕ ਛੋਟਾ ਡੇਟਾ ਸੈੱਟ ਬਣਾਓ (ਮੁੱਖ ਟੇਬਲਾਂ ਲਈ 5–20 rows) ਜਿਸ ਵਿੱਚ ਆਮ ਕੇਸ ਅਤੇ ਅਜੀਬ ਕੇਸ ਜਿਵੇਂ duplicates, missing values, cancellations ਸ਼ਾਮਲ ਹੋਣ। ਫਿਰ ਉਹਨਾਂ ਨਾਲ ਕਹਾਣੀਆਂ ਨੂੰ “ਪਲੇ-ਥਰੂ” ਕਰੋ। ਤੁਸੀਂ ਟੁਰੰਤ ਸਮੱਸਿਆਵਾਂ ਦੇਖ ਲਵੋਗੇ ਜਿਵੇਂ “ਅਸੀਂ ਇਹ ਨਹੀਂ ਦੱਸ ਸਕਦੇ ਕਿ ਕਿਹੜਾ ਐਡਰੈੱਸ ਖਰੀਦ ਸਮੇਂ ਵਰਤਿਆ ਗਿਆ ਸੀ” ਜਾਂ “ਅਸੀਂ ਕਿਸਨੇ ਚੇਜ਼ ਨੂੰ ਮਨਜ਼ੂਰ ਕੀਤਾ ਉਹ ਥਾਂ ਨਹੀਂ ਹੈ।”
AI ਨੂੰ ਕਹੋ ਕਿ ਉਹ ਹਰ ਕਹਾਣੀ ਲਈ validation ਸਵਾਲ ਜਨਰੇਟ ਕਰੇ (edge cases ਅਤੇ delete scenarios ਸਮੇਤ), ਅਤੇ ਇਹ ਲਿਖੇ ਕਿ ਉਨ੍ਹਾਂ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਲਈ ਕਿਹੜਾ ਡੇਟਾ ਲੋੜੀਂਦਾ ਹੈ। ਇਸ ਲਿਸਟ ਦੀ ਤੁਲਨਾ ਆਪਣੇ ਸਕੀਮਾ ਨਾਲ ਕਰੋ: ਕੋਈ ਵੀ mismatch ਇੱਕ ਵਾਸਤਵਿਕ ਕਾਰਵਾਈ ਆਈਟਮ ਹੁੰਦਾ ਹੈ, ਨਾ ਕਿ ਇੱਕ vague ਭਾਵ “ਕੁਝ ਗਲਤ ਹੈ”।
AI ਡੇਟਾ ਮਾਡਲਿੰਗ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਸੰਵੇਦਨਸ਼ੀਲ ਜਾਣਕਾਰੀ ਲੀਕ ਕਰਨ ਜਾਂ ਗਲਤ ਧਾਰਣਾਵਾਂ ਨਿਰਧਾਰਤ ਕਰਨ ਦਾ ਖਤਰਾ ਵੀ ਵਧਾਉਂਦਾ ਹੈ। ਇਸਨੂੰ ਬਹੁਤ ਤੇਜ਼ ਸਹਾਇਕ ਸਮਝੋ: ਉਪਯੋਗੀ, ਪਰ guardrails ਦੀ ਲੋੜ ਹੈ।
ਵਹੀ ਇਨਪੁਟ ਸਾਂਝਾ ਕਰੋ ਜੋ ਮਾਡਲ ਕਰਨ ਲਈ ਯਥਾਰਥ ਹੈ, ਪਰ ਕਾਫ਼ੀ sanitize ਕੀਤਾ ਹੋਇਆ ਹੈ:
invoice_total: 129.50, status: "paid")\n- ਮੌਜੂਦਾ CSV headers / ਮੌਜੂਦਾ ਟੇਬਲਾਂ (ਸੰਰਚਨਾ ਆਮ ਤੌਰ 'ਤੇ ਸੁਰੱਖਿਅਤ ਹੁੰਦੀ ਹੈ; ਸਮੱਗਰੀ ਅਕਸਰ ਨਹੀਂ)ਇਹਨਾਂ ਨੂੰ ਨਾ ਸਾਂਝਾ ਕਰੋ ਜੋ ਕਿਸੇ ਦੀ ਪਹਿਚਾਣ ਕਰ ਸਕਦੀਆਂ ਹਨ ਜਾਂ ਗੁਪਤ ਕਾਰਵਾਈਆਂ ਖੋਲ੍ਹਦੀਆਂ ਹਨ:
ਜੇ ਤੁਹਾਨੂੰ ਵਾਸਤਵਿਕਤਾ ਦੀ ਲੋੜ ਹੈ, ਤਦ synthetic samples ਬਣਾਓ ਜੋ ਫਾਰਮੈਟ ਅਤੇ ਰੇਂਜ ਮਿਲਾਣ—ਕਦੇ ਪ੍ਰੋਡਕਸ਼ਨ ਸਤਰਾਂ ਨੂੰ ਸਿੱਧਾ ਨਕਲ ਨਾ ਕਰੋ।
ਸਕੀਮਾਜ਼ਿਆਦਾ ਅਕਸਰ "ਸਭ ਨੇ ਮੰਨਿਆ" ਗੱਲਾਂ ਕਰਕੇ fail ਹੁੰਦਾ ਹੈ। ਆਪਣੇ ER ਮਾਡਲ ਦੇ ਨੇੜੇ (ਜ਼ਿਆਦਾ ਵਧੀਆ ਰੇਪੋ ਵਿੱਚ) ਛੋਟੀ decision log ਰੱਖੋ:
ਤੁਹਾਡਾ ਸਕੀਮਾ ਨਵੇਂ ਕਹਾਣੀਆਂ ਨਾਲ ਵਿਕਸਤ ਹੋਵੇਗਾ। ਇਸਨੂੰ ਸੁਰੱਖਿਅਤ ਰੱਖਣ ਲਈ:
ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ snapshots ਅਤੇ rollback ਵਰਗੀਆਂ guardrails ਲਾਭ ਉਠਾਓ ਜਦ ਤੁਸੀਂ ਸਕੀਮਾ ਬਦਲ ਰਹੇ ਹੋ, ਅਤੇ ਜਦ ਲੋੜ ਹੋਵੇ ਤਾਂ ਸੋਰਸ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰੋ ਤਾ ਕਿ ਡੀਪ ਓਵਰਰਾਈਡ ਕੀਤੇ ਜਾ ਸਕਣ।
ਸ਼ੁਰੂਆਤ ਕਹਾਣੀਆਂ ਤੋਂ ਹੀ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਉਹਨਾਂ ਵਿੱਚੋਂ ਉਹ ਸ਼ਬਦ (ਨਾਉਂ) ਹਾਈਲਾਈਟ ਕਰੋ ਜੋ ਤੁਹਾਡੀ ਸਿਸਟਮ ਨੂੰ ਯਾਦ ਰੱਖਣੇ ਲਾਇਕ ਚੀਜ਼ਾਂ ਦਰਸਾਉਂਦੇ ਹਨ (ਜਿਵੇਂ Ticket, User, Category).
ਇੱਕ ਨਾਉਂ ਨੂੰ ਐਂਟਿਟੀ ਬਣਾਉ ਜਦੋਂ ਇਹ:
ਛੋਟਾ ਸੂਚੀ ਰੱਖੋ ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਵਿਸ਼ੇਸ਼ ਕਹਾਣੀ ਵਾਕਾਂਸ਼ ਨਾਲ ਸਹੀ ਢੰਗ ਨਾਲ ਜਸਟਿਫਾਈ ਕਰ ਸਕੋ।
“ਐਟਰੀਬਿਊਟ ਬਨਾਮ ਐਂਟਿਟੀ” ਟੈਸਟ ਵਰਤੋ:
customer.phone_number).ਇੱਕ ਛੋਟੀ ਨਿਸ਼ਾਨੀ: ਜੇ ਤੁਹਾਨੂੰ “ਇਹਨਾਂ ਵਿੱਚੋਂ ਕਈ” ਦੀ ਲੋੜ ਪੈ ਸਕਦੀ ਹੈ, ਤਾਂ ਹੋ ਸਕਦਾ ਹੈ ਤੁਹਾਨੂੰ ਹੋਰ ਟੇਬਲ ਦੀ ਲੋੜ ਹੋਵੇ।
ਐਕਸੈਪਟੈਂਸ ਕਰਾਈਟਰੀਆ ਨੂੰ ਇੱਕ ਸਟੋਰੇਜ ਚੈਕਲਿਸਟ ਵਜੋਂ ਲਓ। ਜੇ ਲੋੜ ਹੈ ਕਿ ਤੁਸੀਂ ਕਿਸੇ ਚੀਜ਼ ਨਾਲ ਫਿਲਟਰ/ਸੋਰਟ/ਡਿਸਪਲੇ/ਆਡਿਟ ਕਰ ਸਕੋ, ਤਾਂ ਇਸਨੂੰ ਸਟੋਰ ਕਰਨਾ ਲੋੜੀਂਦਾ ਹੈ (ਜਾਂ ਕਿਸੇ ਹੋਰ ਸਟੋਰ ਕੀਤੀ ਜਾਣ ਵਾਲੀ ਗੱਲ ਤੋਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਉਤਪੰਨ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ)।
ਉਦਾਹਰਨ:
approved_by, approved_atਕਹਾਣੀ ਵਾਕਾਂਸ਼ਾਂ ਨੂੰ ਸੰਬੰਧ ਵਾਕਾਂਸ਼ਾਂ ਵਿੱਚ ਦੁਹਰਾਓ:
orders ਉੱਤੇ customer_id ਰੱਖੋ)order_items ਜੋੜੋ)ਜੇ ਰਿਸ਼ਤਾ ਖ਼ੁਦ ਵਿੱਚ ਡੇਟਾ ਰੱਖਦਾ ਹੈ (quantity, price, role), ਤਾਂ ਉਹ ਡੇਟਾ join table 'ਤੇ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
M:N ਨੂੰ ਇੱਕ join table ਨਾਲ ਮਾਡਲ ਕਰੋ ਜੋ ਦੋਹਾਂ foreign keys ਦੇ ਨਾਲ ਰਿਸ਼ਤੇ-ਖਾਸ ਫੀਲਡ ਵੀ ਰੱਖਦਾ ਹੋਵੇ।
ਆਮ ਪੈਟਰਨ:
ordersਵਰਕਫਲੋ ਨੂੰ ਕਦਮ-ਬੰਦ ਧੰਗ ਨਾਲ ਚਲਾਓ ਅਤੇ ਪੁੱਛੋ: “ਭਵਿੱਖ ਵਿੱਚ ਇਸ ਘਟਨਾ ਨੂੰ ਸਾਬਤ ਕਰਨ ਲਈ ਸਾਨੂੰ ਕੀ ਜਾਣਨਾ ਲੋੜੀਂਦਾ ਹੈ?”
ਆਮ ਤੌਰ 'ਤੇ ਜੋੜੇ ਜਾਂਦੇ ਹਨ:
submitted_at, closed_atਸ਼ੁਰੂ ਕਰੋ:
id)orders.customer_id → customers.id)ਫਿਰ ਆਪਣੀਆਂ সবচਿਆੰਮ ਲੁੱਛਣ ਲਈ index ਜੋੜੋ (ਜਿਵੇਂ , , ). ਅਣਜਾਣੇ ਇੰਡੈਕਸਿੰਗ ਨੂੰ ਬਾਅਦ ਲਈ ਛੱਡੋ ਜਦ ਤੱਕ ਅਸੀਂ ਅਸਲੀ ਕਵੈਰੀ ਪੈਟਰਨ ਨਹੀਂ ਵੇਖਦੇ।
ਇੱਕ ਤੇਜ਼ consistency ਚੈਕ ਚਲਾਓ:
Phone1/Phone2 ਦਿਖਾਈ ਦੇ ਰਹੇ ਹਨ, ਉਸਨੂੰ ਚਾਈਲਡ ਟੇਬਲ ਵਿੱਚ ਲਿਜਾਓ।Denormalize ਕੇਵਲ ਸਪਸ਼ਟ ਕਾਰਨ (ਪਰਫਾਰਮੈਂਸ, ਰਿਪੋਰਟਿੰਗ, ਆਡਿਟ) ਨਾਲ ਬਾਅਦ ਵਿੱਚ ਕਰੋ ਅਤੇ ਦਸਤਾਵੇਜ਼ ਬਣਾਓ ਕਿ ਕੌਣ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਹੈ।
ਉਹ ਤੱਥ ਸਟੋਰ ਕਰੋ ਜੋ ਤੁਹਾਨੂੰ ਬਾਦ ਵਿੱਚ ਦੁਬਾਰਾ ਭਾਲ ਕੇ ਪ੍ਰਾਪਤ ਨਹੀਂ ਹੋ ਸਕਦਾ; ਬਾਕੀ ਗਣਨਾ ਕਰੋ।
ਚੰਗਾ ਸਟੋਰ ਕਰਨ ਵਾਲਾ:
ਚੰਗਾ ਗਣਿਤ ਕਰਨ ਵਾਲਾ:
ਜੇ ਤੁਸੀਂ derived values ਸਟੋਰ ਕਰਦੇ ਹੋ (ਜਿਵੇਂ ), ਫੈਸਲਾ ਕਰੋ ਕਿ ਇਹ ਕਿਵੇਂ sync ਰਹੇਗਾ ਅਤੇ ਕਿਨ੍ਹਾਂ edge cases (refunds, edits) ਨੂੰ ਟੈਸਟ ਕਰੋ।
AI ਨੂੰ ਡ੍ਰਾਫਟ ਲਈ ਵਰਤੋ, ਪਰ ਸਬੂਤਾਂ ਦੇ ਖਿਲਾਫ਼ ਪੱਕਾ ਕਰਕੇ ਮਾਨਵ ਵੈਰੀਫਿਕੇਸ਼ਨ ਕਰੋ।
ਪ੍ਰੈਕਟਿਕਲ ਪ੍ਰਾਂਪਟ:
ਗਾਰਡਰੇਲਸ:
delivery_dateemail 'ਤੇ ਯੂਨੀਕ ਕੰਸਟਰੈਂਟ/ਇੰਡੈਕਸproductsorder_items ਜਿਸ ਵਿੱਚ order_id, product_id, quantity, unit_price ਹੋਵੈਇੱਕ single column ਵਿੱਚ “IDs ਦੀ ਲਿਸਟ” ਸਟੋਰ ਕਰਨ ਤੋਂ ਬਚੋ—ਇਸ ਨਾਲ ਕਵੈਰੀ, ਅਪਡੇਟ ਅਤੇ ਇੰਟੈਗ੍ਰਿਟੀ ਦੀ ਵਰਤੋਂ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦੀ ਹੈ।
created_by, assigned_to, closed_byrejection_reasonਜੇ ਤੁਸੀਂ ਜਾਣਨਾ ਚਾਹੁੰਦੇ ਹੋ “ਕਿਸ ਨੇ ਕਦੋਂ ਕੀ ਬਦਲਾ”, ਤਾਂ ਇੱਕ event/audit ਟੇਬਲ ਜੋੜੋ ਬਦਲੇ ਇੱਕ ਫੀਲਡ ਨੂੰ ਓਵਰਰਾਈਟ ਕਰਨ ਦੇ।
emailcustomer_idstatus + created_atorder_total