ਉੱਲਮੈਨ ਕਿਉਂ ਆਧੁਨਿਕ ਡੇਟਾ ਨਾਲ ਮਹੱਤਵ ਰੱਖਦੇ ਹਨ
ਜਿਆਦਾਤਰ ਲੋਕ ਜੋ SQL ਲਿਖਦੇ ਹਨ, ਡੈਸ਼ਬੋਰਡ ਬਣਾਉਂਦੇ ਹਨ, ਜਾਂ ਕਿਸੇ ਧੀਮੀ ਕੁਇਰੀ ਨੂੰ ਟਿਊਨ ਕਰਦੇ ਹਨ, ਉਹ Jeffrey Ullman ਦੇ ਕੰਮ ਤੋਂ ਲਾਭਾਨਵੀਤ ਰਹੇ ਹਨ—ਚਾਹੇ ਉਹਨਾਂ ਨੇ ਉਸਦਾ ਨਾਮ ਸੁਣਿਆ ਵੀ ਨਾ ਹੋਵੇ। Ullman ਇੱਕ ਕੰਪਿਊਟਰ ਵਿਗਿਆਨੀ ਅਤੇ ਸਿੱਖਿਆਦਾਤਾ ਹਨ ਜਿਹਨਾਂ ਦੀਆਂ ਰਿਸਰਚ ਅਤੇ ਟੈਕਸਟਬੁੱਕ ਨੇ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ ਕਿ ਡੇਟਾਬੇਸ ਡੇਟਾ ਨੂੰ ਕਿਵੇਂ ਦਰਸਾਉਂਦੇ ਹਨ, ਕੁਇਰੀਆਂ ਬਾਰੇ ਕਿਵੇਂ ਤਰਕ ਕਰਦੇ ਹਨ, ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਕੁਸ਼ਲਤਾ ਨਾਲ ਕਿਵੇਂ ਚਲਾਇਆ ਜਾਂਦਾ ਹੈ।
ਹਰ ਰੋਜ਼ ਦੇ ਟੂਲ ਪਿੱਛੇ ਚੁਪ ਚਾਪ ਪ੍ਰਭਾਵ
ਜਦੋਂ ਕੋਈ ਡੇਟਾਬੇਸ ਇੰਜਨ ਤੁਹਾਡੇ SQL ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਬਦਲਦਾ ਹੈ ਕਿ ਉਹ ਤੇਜ਼ ਚੱਲ ਸਕੇ, ਤਾਂ ਉਹ ਅਜਿਹੀਆਂ ਵਿਚਾਰਧਾਰਾਵਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰ ਰਿਹਾ ਹੁੰਦਾ ਹੈ ਜੋ ਬਹੁਤ ਨਿਰਧਾਰਤ ਅਤੇ ਲਚਕੀਲੀਆਂ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ ਨੇ। Ullman ਨੇ ਕੁਇਰੀਆਂ ਦੇ ਅਰਥ ਨੂੰ ਫਾਰਮਲ ਕੀਤਾ (ਤਾਂ ਜੋ ਸਿਸਟਮ ਉਨ੍ਹਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਰੀਰਾਈਟ ਕਰ ਸਕੇ), ਅਤੇ ਉਸਨੇ ਡੇਟਾਬੇਸ ਸੋਚ ਨੂੰ ਕੰਪਾਇਲਰ ਸੋਚ ਨਾਲ ਜੋੜਿਆ (ਤਾਂ ਜੋ ਇੱਕ ਕੁਇਰੀ ਨੂੰ parse, optimize, ਅਤੇ executable ਕਦਮਾਂ ਵਿੱਚ ਤਬਦੀਲ ਕੀਤਾ ਜਾ ਸਕੇ)।
ਇਹ ਪ੍ਰਭਾਵ ਚੁਪ ਹੈ ਕਿਉਂਕਿ ਇਹ ਤੁਹਾਡੇ BI ਟੂਲ ਵਿੱਚ ਕੋਈ ਬਟਨ ਜਾਂ ਕਲਾਉਡ ਕਨਸੋਲ ਵਿੱਚ ਕੋਈ ਦਿੱਖ-ਯੋਗ ਫੀਚਰ ਵਜੋਂ ਨਹੀਂ ਆਉਂਦਾ। ਇਹ ਨਤੀਜੇ ਵਜੋਂ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ:
- ਐਸੀ ਕੁਇਰੀਆਂ ਜੋ ਤੇਜ਼ ਚਲਦੀਆਂ ਹਨ ਜੇ ਤੁਸੀਂ ਇੰਡੈਕਸ ਜੋੜਦੇ ਹੋ ਜਾਂ
JOIN ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਦੇ ਹੋ
- ਉਹ ਓਪਟੀਮਾਈਜ਼ਰ ਜੋ ਡੇਟਾ ਵੱਧਣ 'ਤੇ ਵੱਖ-ਵੱਖ ਯੋਜਨਾਵਾਂ ਚੁਣਦੇ ਹਨ
- ਸਿਸਟਮ ਜੋ ਰਿਜ਼ਲਟ ਬਦਲੇ ਬਗੈਰ ਸਕੇਲ ਹੋ ਸਕਦੇ ਹਨ
ਇਸ ਲੇਖ 'ਚ ਤੁਸੀਂ ਕੀ ਸਿੱਖੋਗੇ (ਬਿਨਾਂ ਭਾਰੀ ਗਣਿਤ ਦੇ)
ਇਹ ਪੋਸਟ Ullman ਦੇ ਮੁੱਖ ਵਿਚਾਰਾਂ ਨੂੰ ਵਰਤਦਿਆਂ ਉਹ ਡੇਟਾਬੇਸ ਅੰਦਰੂਨੀ ਗੱਲਾਂ ਦਾ ਦਰਸਨ ਕਰਵਾਉਂਦੀ ਹੈ ਜੋ ਅਮਲ ਵਿੱਚ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਮਹੱਤਵ ਰੱਖਦੀਆਂ ਹਨ: SQL ਦੇ ਨੀਵੇਂ ਰਿਹਾ ਰਿਲੇਸ਼ਨਲ ਬੀਜਗਣਿਤ ਕਿਵੇਂ ਬੈਠਦੀ ਹੈ, ਕੁਇਰੀ ਰੀਰਾਈਟਸ ਦਾ ਮਤਲਬ ਕਿਵੇਂ ਸੁਰੱਖਿਅਤ ਰਹਿੰਦਾ ਹੈ, ਕੋਸਟ-ਅਧਾਰਿਤ ਓਪਟੀਮਾਈਜ਼ਰ ਕਿਉਂ ਉਹ ਫੈਸਲੇ ਕਰਦੇ ਹਨ ਜੋ ਉਹ ਕਰਦੇ ਹਨ, ਅਤੇ ਜੋਇਨ ਅਲਗੋਰਿਦਮ ਅਕਸਰ ਇਹ ਤੈਅ ਕਰਦੇ ਹਨ ਕਿ ਇੱਕ ਕੰਮ ਸੈਕਿੰਡਾਂ ਵਿੱਚ ਖਤਮ ਹੋਵੇ ਜਾਂ ਘੰਟਿਆਂ ਵਿੱਚ।
ਅਸੀਂ ਕੁਝ ਕੰਪਾਇਲਰ-ਨੁਮਾ ਸੰਕਲਪ ਵੀ ਲਿਆਉਂਦੇ ਹੋਵਾਂਗੇ—parsing, rewriting, ਅਤੇ planning—ਕਿਉਂਕਿ ਡੇਟਾਬੇਸ ਇੰਜਨ ਬਹਿਸ਼ਕ ਕੰਪਾਇਲਰਾਂ ਦੇ ਬਹੁਤ ਹੀ ਉੱਨਤ ਵਰਜ਼ਨ ਵਾਂਗ ਵਰਤਦੇ ਹਨ।
ਇੱਕ ਛੋਟੀ ਵਾਅਦਾ: ਅਸੀਂ ਚਰਚਾ ਨੂੰ ਸਹੀ ਰੱਖਾਂਗੇ ਪਰ ਗਣਿਤੀ ਸਬੂਤਾਂ ਤੋਂ ਬਚਾਂਗੇ। ਲਕਸ਼ ਹੈ ਕਿ ਤੁਸੀਂ ਅਗਲੀ ਵਾਰੀ ਜਦੋਂ ਪ੍ਰਦਰਸ਼ਨ, ਸਕੇਲ, ਜਾਂ ਗੁੰਝਲਦਾਰ ਕੁਇਰੀ ਵਿਵਹਾਰ ਆਵੇ ਤਾਂ ਕਾਰਜ-ਯੋਗ ਮਾਨਸਿਕ ਮਾਡਲ ਲੈ ਕੇ ਜਾ ਸਕੋ।
ਉਹ ਡੇਟਾਬੇਸ ਮੁੱਲ-ਭੂਤ ਸਿਧਾਂਤ ਜੋ Ullman ਨੇ ਮਜ਼ਬੂਤ ਕੀਤੇ
ਜੇ ਤੁਸੀਂ ਕਦੇ SQL ਲਿਖੀ ਹੈ ਅਤੇ ਉਮੀਦ ਕੀਤੀ ਕਿ ਇਹ "ਸਿਰਫ ਇਕ ਹੀ ਮਤਲਬ ਰੱਖਦੀ ਹੈ," ਤਾਂ ਤੁਸੀਂ ਉਹਨਾਂ ਧਾਰਾਵਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰ ਰਹੇ ਹੋ ਜੋ Jeffrey Ullman ਨੇ ਲੋਕਪ੍ਰিয় ਅਤੇ ਫਾਰਮਲ ਕੀਤੀਆਂ: ਡੇਟਾ ਲਈ ਇੱਕ ਸਾਫ ਮਾਡਲ, ਅਤੇ ਉਹ ਤਰੀਕੇ ਜੋ ਕੁਇਰੀ ਕੀ ਮੰਗ ਨੂੰ ਨਿਰਧਾਰਤ ਕਰਦੇ ਹਨ।
ਸਧਾਰਨ ਸ਼ਬਦਾਂ ਵਿੱਚ ਰਿਲੇਸ਼ਨਲ ਮਾਡਲ
ਮੂਲ ਰੂਪ ਵਿੱਚ, ਰਿਲੇਸ਼ਨਲ ਮਾਡਲ ਡੇਟਾ ਨੂੰ ਟੇਬਲਾਂ (relations) ਵਜੋਂ ਮੰਨਦਾ ਹੈ। ਹਰ ਟੇਬਲ ਵਿੱਚ ਕਤਾਰਾਂ (tuples) ਅਤੇ ਕਾਲਮ (attributes) ਹੁੰਦੇ ਹਨ। ਹੁਣ ਇਹ ਆਮ ਗੱਲ ਲੱਗਦੀ ਹੈ, ਪਰ ਮਹੱਤਵਪੂਰਨ ਗੱਲ ਇਹ ਹੈ ਕਿ ਇਹ ਕਿਸ ਤਰ੍ਹਾਂ ਦਾ ਅਨੁਸ਼ਾਸਨ ਬਣਾਉਂਦਾ ਹੈ:
- ਕੀਜ਼ ਕਤਾਰਾਂ ਦੀ ਪਛਾਣ ਕਰਦੀਆਂ ਹਨ। ਇੱਕ primary key ਹਰ ਰਿਕਾਰਡ ਲਈ "ਨਾਮ-ਟੈਗ" ਵਾਂਗ ਹੁੰਦੀ ਹੈ।
- ਰਿਸ਼ਤੇ ਟੇਬਲਾਂ ਨੂੰ foreign keys ਰਾਹੀਂ ਜੋੜਦੇ ਹਨ, ਤਾਂ ਜੋ ਤੁਸੀਂ ਤੱਥ ਇੱਕ ਥਾਂ ਰੱਖ ਕੇ ਹੋਰ ਥਾਣੇ ਤੇ ਰੇਫਰ ਕਰ ਸਕੋ।
ਇਹ ਸੰਜੋਗ ਸਹੀਪਨ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਬਾਰੇ ਹੱਥ-ਹਵਾਲੇ ਤਰਕ ਕਰਨ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਜਾਣਦੇ ਹੋ ਕਿ ਇੱਕ ਟੇਬਲ ਕੀ ਦਰਸਾਂਦੀ ਹੈ ਅਤੇ ਕਿਵੇਂ ਕਤਾਰਾਂ ਦੀ ਪਛਾਣ ਹੁੰਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਅਣੂਮਾਨ ਲਗਾ ਸਕਦੇ ਹੋ ਕਿ joins ਕੀ ਕਰਨਗੇ, duplicates ਕਿਉਂ ਹਨ, ਅਤੇ ਕਿਉਂ ਕੁਝ ਫਿਲਟਰ ਨਤੀਜਿਆਂ ਨੂੰ ਬਦਲ ਦਿੰਦੇ ਹਨ।
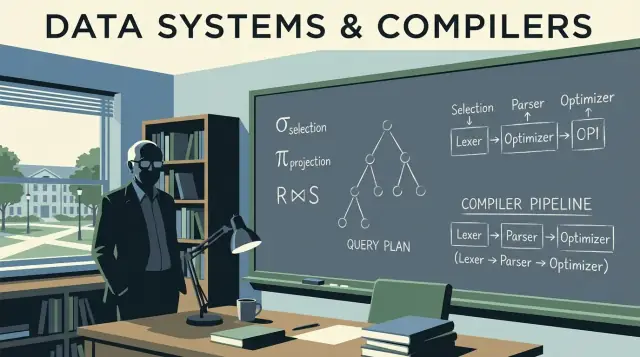
ਰਿਲੇਸ਼ਨਲ ਬੀਜਗਣਿਤ: ਕੁਇਰੀ ਲਈ ਇੱਕ ਕੈਲਕੁਲੇਟਰ
Ullman ਦੀ ਸਿੱਖਿਆ ਆਮ ਤੌਰ 'ਤੇ ਰਿਲੇਸ਼ਨਲ ਬੀਜਗਣਿਤ ਨੂੰ ਇੱਕ ਕਿਸਮ ਦਾ ਕੁਇਰੀ ਕੈਲਕੁਲੇਟਰ ਵਜੋਂ ਵਰਤਦੀ ਹੈ: ਇੱਕ ਛੋਟਾ ਸੈੱਟ ਓਪਰੇਸ਼ਨਾਂ (select, project, join, union, difference) ਜੋ ਤੁਸੀਂ ਮਿਲਾ ਕੇ ਆਪਣੀ ਮੰਗ ਨੂੰ ਵਿਆਖਿਆ ਕਰ ਸਕਦੇ ਹੋ।
ਕਾਮ ਦੀ ਗੱਲ ਇਹ ਹੈ ਕਿ ਡੇਟਾਬੇਸ SQL ਨੂੰ ਇੱਕ ਐਲਜਬ੍ਰਿਕ ਫਾਰਮ ਵਿੱਚ ਤਬਦੀਲ ਕਰਦੇ ਹਨ ਅਤੇ ਫਿਰ ਇਸ ਨੂੰ ਇਕ ਸਮਤੁਲ ਰੂਪ ਵਿੱਚ ਰੀਰਾਈਟ ਕਰਦੇ ਹਨ। ਦੋ ਕੁਇਰੀਆਂ ਜੋ ਵੱਖਰਾ ਦਿਖਦੀਆਂ ਹਨ ਉਹ algebraic ਤੌਰ 'ਤੇ ਇਕੋ ਹੀ ਹੋ ਸਕਦੀਆਂ ਹਨ—ਇਸੇ ਤਰ੍ਹਾਂ ਓਪਟੀਮਾਈਜ਼ਰ joins ਨੂੰ ਦੁਬਾਰਾ ਕ੍ਰਮਬੱਧ ਕਰ ਸਕਦੇ ਹਨ, ਫਿਲਟਰਾਂ ਨੂੰ ਅੱਗੇ ਧੱਕ ਸਕਦੇ ਹਨ, ਜਾਂ ਫੁਨਕਸ਼ਨਲ ਕੰਮ ਹਟਾ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਅਰਥ ਬਦਲੇ।
ਐਲਜਬ੍ਰਾ بمੁਕਾਬਲੇ ਕੈਲਕੁਲਸ (ਉੱਚ-ਸਤਰ)
- ਰਿਲੇਸ਼ਨਲ ਬੀਜਗਣਿਤ ਵਧੇਰੇ "ਕਿਵੇਂ": ਨਤੀਜਾ ਕੱਢਣ ਲਈ ਕਦਮ-ਦਰ-ਕਦਮ ਓਪਰੇਸ਼ਨ।
- ਰਿਲੇਸ਼ਨਲ ਕੈਲਕੁਲਸ ਵਧੇਰੇ "ਕੀ": ਤੁਸੀਂ ਕਿਸ ਨਤੀਜੇ ਦੀ ਇੱਛਾ ਰੱਖਦੇ ਹੋ, ਉਹ ਵਰਣਨ ਕਰਦਾ ਹੈ।
SQL ਜ਼ਿਆਦਾਤਰ "ਕੀ" ਦੀ ਭਾਸ਼ਾ ਹੈ, ਪਰ ਇੰਜਨ ਆਮ ਤੌਰ 'ਤੇ ਐਲਜਬ੍ਰਿਕ "ਕਿਵੇਂ" ਵਰਤ ਕੇ ਓਪਟੀਮਾਈਜ਼ ਕਰਦੇ ਹਨ।
ਫੰਡਾਮੈਂਟਲ ਦੀ ਸਮਝ ਕੋਇ ਡਾਇਲੈਕਟ ਯਾਦ ਕਰਨ ਤੋਂ ਵਧ ਕੇ ਹੈ
SQL ਡਾਇਲੈਕਟ ਵੱਖ-ਵੱਖ ਹੋ ਸਕਦੇ ਹਨ (Postgres ਵਿਰੁੱਧ Snowflake ਵਿਰੁੱਧ MySQL), ਪਰ ਮੂਲ ਗੱਲਾਂ ਨਹੀਂ ਬਦਲਦੀਆਂ। ਕੀ, ਰਿਸ਼ਤੇ ਅਤੇ ਐਲਜਬ੍ਰਿਕ ਸਮਤੁਲਤਾ ਦੀ ਸਮਝ ਤੁਹਾਨੂੰ ਦੱਸਦੀ ਹੈ ਕਿ ਜਦੋਂ ਇੱਕ ਕੁਇਰੀ ਤਾਰਕਿਕ ਤੌਰ 'ਤੇ ਗਲਤ ਹੈ, ਜਦੋਂ ਉਹ ਸਿਰਫ ਧੀਮੀ ਹੈ, ਅਤੇ ਕਿਹੜੇ ਬਦਲਾਅ ਮਤਲਬ ਨੂੰ ਕਾਇਮ ਰੱਖਦੇ ਹਨ।
ਰਿਲੇਸ਼ਨਲ ਬੀਜਗਣਿਤ: SQL ਦੇ ਹੇਠਾਂ ਦੀ ਛੁਪੀ ਭਾਸ਼ਾ
ਰਿਲੇਸ਼ਨਲ ਬੀਜਗਣਿਤ SQL ਦਾ "ਹੇਠਲਾ ਗਣਿਤ" ਹੈ: ਕੁਝ ਓਪਰੇਟਰਾਂ ਦਾ ਸੈੱਟ ਜੋ ਤੁਸੀਂ ਇਕੱਠੇ ਕਰਕੇ ਉਹ ਨਤੀਜਾ ਦਰਸਾ ਸਕਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ। Jeffrey Ullman ਦਾ ਕੰਮ ਇਸ ਓਪਰੇਟਰ-ਦੇਖ ਨੂੰ ਸਾਫ ਅਤੇ ਸਿਖਣਯੋਗ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦਗਾਰ ਰਿਹਾ—ਅਤੇ ਅਜੇ ਵੀ ਜ਼ਿਆਦਾਤਰ ਓਪਟੀਮਾਈਜ਼ਰਾਂ ਦੀ ਮਾਨਸਿਕ ਮਾਡਲ यही ਹੈ।
ਮੁੱਖ ਓਪਰੇਟਰ (ਅਤੇ ਉਹ ਕੀ ਮਤਲਬ ਰੱਖਦੇ ਹਨ)
ਇੱਕ ਡੇਟਾਬੇਸ ਕੁਇਰੀ ਕੁਝ ਇਕਾਈ ਨਿਰਮਾਣ-ਪੱਧਰਾਂ ਦੇ ਤੌਰ 'ਤੇ ਦਰਸਾਈ ਜਾ ਸਕਦੀ ਹੈ:
- Select (σ): ਕਤਾਰਾਂ ਨੂੰ ਫਿਲਟਰ ਕਰਨਾ (SQL
WHERE)
- Project (π): ਖਾਸ ਕਾਲਮ ਰੱਖਣਾ (SQL
SELECT col1, col2)
- Join (⋈): ਸ਼ਰਤ 'ਤੇ ਟੇਬਲਾਂ ਨੂੰ ਜੋੜਨਾ (
JOIN ... ON ...)
- Union (∪): ਇੱਕੋ ਜਿਹੇ ਆਕਾਰ ਵਾਲੇ ਨਤੀਜਿਆਂ ਨੂੰ ਉਪਰ-ਤੀਂ ਰੱਖਨਾ (
UNION)
- Difference (−): A ਵਿੱਚੋਂ ਉਹ ਕਤਾਰਾਂ ਜੋ B ਵਿੱਚ ਨਹੀਂ (ਕਈ SQL ਡਾਇਲੈਕਟਾਂ ਵਿੱਚ
EXCEPT ਵਰਗਿਆ)
ਇਸ ਛੋਟੀ ਸੈੱਟ ਕਾਰਨ, correctness ਬਾਰੇ ਤਰਕ ਕਰਨਾ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ: ਜੇ ਦੋ ਐਲਜਬ੍ਰਿਕ ਪ੍ਰਕਿਰਿਆਵਾਂ ਸਮਾਨ ਹਨ, ਉਹ ਕਿਸੇ ਵੀ ਵੈਧ ਡੇਟਾਬੇਸ ਸਥਿਤੀ ਲਈ ਇਕੋ-ਓਹੀ ਟੇਬਲ ਵਾਪਸ ਕਰਦੀਆਂ ਹਨ।
SQL ਕਿਵੇਂ ਐਲਜਬ੍ਰਾ ਨਾਲ ਨਕਸ਼ਾ ਹੁੰਦਾ ਹੈ (ਹੇਠਾਂ ਦੀ ਸੋਚ)
ਇੱਕ ਜਾਣ-ਪਛਾਣ ਵਾਲੀ ਕੁਇਰੀ ਲਓ:
SELECT c.name
FROM customers c
JOIN orders o ON o.customer_id = c.id
WHERE o.total > 100;
ਆਮ ਤੌਰ 'ਤੇ, ਇਹ ਹੈ:
-
ਇੱਕ join ਨਾਲ customers ਅਤੇ orders ਦੀ ਸ਼ੁਰੂਆਤ: customers ⋈ orders
-
ਸਿਰਫ਼ ਉਹ orders ਚੁਣੋ ਜਿਨ੍ਹਾਂ ਦੀ ਕੁੱਲ ਰਕਮ 100 ਤੋਂ ਵੱਧ ਹੈ: σ(o.total > 100)(...)
-
ਜੋ ਕਾਲਮ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਉਹ ਪ੍ਰੋਜੈਕਟ ਕਰੋ: π(c.name)(...)
ਇਹ ਹਰ ਇੰਜਨ ਦੇ ਅੰਦਰੂਨੀ ਨੋਟੇਸ਼ਨ ਦੇ bilkul exact ਨ ਹੋ ਸਕਦਾ ਪਰ ਆਈਡਿਆ ਸਹੀ ਹੈ: SQL ਇੱਕ ਓਪਰੇਟਰ ਟ੍ਰੀ ਬਣ ਜਾਂਦੀ ਹੈ।
ਸਮਤੁਲਤਾ: ਓਪਟਿਮਾਈਜ਼ੇਸ਼ਨ ਲਈ ਦਰਵਾਜ਼ਾ
ਬਹੁਤ ਸਾਰੀਆਂ ਵੱਖ-ਵੱਖ ਟ੍ਰੀਜ਼ ਇੱਕੋ ਨਤੀਜੇ ਨੂੰ ਦਰਸਾ ਸਕਦੀਆਂ ਹਨ। ਉਦਾਹਰਨ ਲਈ, ਫਿਲਟਰ ਆਮ ਤੌਰ 'ਤੇ ਪਹਿਲਾਂ ਲਾਇਆ ਜਾ ਸਕਦਾ ਹੈ (ਬੱਡੇ join ਤੋਂ ਪਹਿਲਾਂ σ ਲਗਾਉਣਾ), ਅਤੇ ਪ੍ਰੋਜੈਕਸ਼ਨ ਅਕਸਰ ਬਿਨਾਂ ਲੋੜ ਦੇ ਕਾਲਮ ਪਹਿਲਾਂ ਹੀ ਹਟਾ ਸਕਦੀ ਹੈ (ਪਹਿਲਾਂ π ਲਗਾਉਣਾ)।
ਇਹ ਸਮਤੁਲਤਾ ਨਿਯਮ ਡੇਟਾਬੇਸ ਨੂੰ ਤੁਹਾਡੀ ਕੁਇਰੀ ਨੂੰ ਇੱਕ ਸਸਤੀ ਯੋਜਨਾ ਵਿੱਚ ਰੀਰਾਈਟ ਕਰਨ ਦਿੰਦੇ ਹਨ ਬਿਨਾਂ ਅਰਥ ਬਦਲੇ। ਇੱਕ ਵਾਰੀ ਤੁਸੀਂ ਕੁਇਰੀਆਂ ਨੂੰ ਐਲਜਬ੍ਰਿਕ ਰੂਪ ਵਿੱਚ ਦੇਖਦੇ ਹੋ, ਤਾਂ "ਓਪਟੀਮਾਈਜ਼ੇਸ਼ਨ" ਜਾਦੂ ਨਹੀਂ ਰਹਿੰਦੀ—ਇਹ ਨਿਯਮਾਂ ਤੇ ਆਧਾਰਤ ਇਕ ਸੁਰੱਖਿਅਤ ਰੀਸ਼ੇਪਿੰਗ ਹੁੰਦੀ ਹੈ।
SQL ਤੋਂ ਕੁਇਰੀ ਯੋਜਨਾਵਾਂ ਤੱਕ: ਉਹ ਰੀਰਾਈਟਸ ਜੋ ਮਾਨਤਾ ਸੁਰੱਖਿਅਤ ਰੱਖਦੇ ਹਨ
ਜਦੋਂ ਤੁਸੀਂ SQL ਲਿਖਦੇ ਹੋ, ਡੇਟਾਬੇਸ ਉਹਨੂੰ "ਜਿਵੇਂ ਲਿਖਿਆ" ਨਹੀਂ ਚਲਾਉਂਦਾ। ਇਹ ਤੁਹਾਡੇ ਬਿਆਨ ਨੂੰ ਇੱਕ ਕੁਇਰੀ ਯੋਜਨਾ ਵਿੱਚ ਤਬਦੀਲ ਕਰਦਾ ਹੈ: ਕੰਮ ਦੀ ਇੱਕ ਸਰਚਿਤ ਪ੍ਰਤਿਨਿਧੀ।
ਇੱਕ ਚੰਗੀ ਮਾਨਸਿਕ ਤਸਵੀਰ ਇੱਕ ਓਪਰੇਟਰ ਟ੍ਰੀ ਦੀ ਹੈ। ਪੱਤਿਆਂ ਉੱਤੇ ਟੇਬਲ ਜਾਂ ਇੰਡੈਕਸ ਪੜ੍ਹਦੇ ਹਨ; ਅੰਦਰੂਨੀ ਨੋਡ ਕਤਾਰਾਂ ਨੂੰ ਤਬਦੀਲ ਅਤੇ ਮਿਲਾਉਂਦੇ ਹਨ। ਆਮ ਓਪਰੇਟਰਾਂ ਵਿੱਚ scan, filter (selection), project (columns ਚੁਣਨਾ), join, group/aggregate, ਅਤੇ sort ਸ਼ਾਮਲ ਹਨ।
ਲਾਜ਼ਮੀ ਯੋਜਨਾ ਵਿਰੁੱਧ ਭੌਤਿਕ ਯੋਜਨਾ (ਕੀ ਵਿਰੁੱਧ ਕਿਵੇਂ)
ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਯੋਜਨਾ ਨੂੰ ਦੋ ਪਰਤਾਂ ਵਿੱਚ ਵੰਡਦੇ ਹਨ:
- ਲਾਜਿਕਲ ਯੋਜਨਾ: ਕਿਸ ਨਤੀਜੇ ਨੂੰ ਕੱਢਣਾ ਹੈ, abstrct ਓਪਰੇਟਰਾਂ ਨਾਲ (filter, join, aggregate) ਅਤੇ ਉਨ੍ਹਾਂ ਦੇ ਰਿਸ਼ਤਿਆਂ ਨਾਲ।
- ਭੌਤਿਕ ਯੋਜਨਾ: ਇਸਨੂੰ ਅਸਲ ਸਟੋਰੇਜ ਅਤੇ ਹਾਰਡਵੇਅਰ 'ਤੇ ਕਿਵੇਂ ਚਲਾਉਣਾ ਹੈ (index scan vs full scan, hash join vs nested-loop join, ਪੈਰਲੇਲ vs ਸਿੰਗਲ-ਥ੍ਰੈਡ)।
Ullman ਦਾ ਪ੍ਰਭਾਵ "ਅਰਥ-ਰੱਖਣ ਵਾਲੀ ਬਦਲੀ" 'ਤੇ ਟਿਕਿਆ ਹੋਇਆ ਹੈ: ਲਾਜ਼ਮੀ ਯੋਜਨਾ ਨੂੰ ਬੇਅੰਤੀ ਗਿਣਤ ਤਰੀਕਿਆਂ ਨਾਲ ਦੁਬਾਰਾ ਵਿਵਸਥਿਤ ਕਰੋ ਬਿਨਾਂ ਜਵਾਬ ਬਦલે, ਫਿਰ ਇੱਕ ਪ੍ਰਭਾਵਸ਼ালী ਭੌਤਿਕ ਰਣਨੀਤੀ ਚੁਣੋ।
ਕੰਮ ਘਟਾਉਣ ਵਾਲੀਆਂ ਨਿਯਮ-ਆਧਾਰਿਤ ਰੀਰਾਈਟਸ
ਅੰਤਿਮ ਐਗਜ਼ਿਕਿਊਸ਼ਨ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ, ਓਪਟੀਮਾਈਜ਼ਰ ਐਲਜਬ੍ਰਿਕ "ਸਫਾਈ" ਨਿਯਮ ਲਗਾਉਂਦੇ ਹਨ। ਇਹ ਰੀਰਾਈਟਸ ਨਤੀਜੇ ਨਹੀਂ ਬਦਲਦੇ; ਪਰ ਇਹ ਬੇਲੋੜਾ ਕੰਮ ਘਟਾ ਦਿੰਦੇ ਹਨ।
ਆਮ ਉਦਾਹਰਣ:
- Selection pushdown: ਫਿਲਟਰਾਂ ਨੂੰ ਜਿੰਨਾ ਜਰੂਰੀ ਹੋ ਸਕੇ ਉਤਨਾ ਪਹਿਲਾਂ ਲਗਾਓ ਤਾਂ ਕਿ ਘੱਟ ਕਤਾਰਾਂ ਬਾਅਦ ਵਾਲੇ ਕਦਮਾਂ ਉੱਤੇ ਜਾਣ।
- Projection pruning: ਸਿਰਫ਼ ਲੋੜੀਂਦੇ ਕਾਲਮ ਰੱਖੋ, I/O ਅਤੇ ਮੈਮੋਰੀ ਘਟਾਉਣ ਲਈ।
- Join reordering: ਜਦੋਂ ਸੁਰੱਖਿਅਤ ਹੋਵੇ, ਛੋਟੇ/intermediate ਨਤੀਜਿਆਂ ਨੂੰ ਪਹਿਲਾਂ ਜੋੜੋ—SQL ਦੇ ਸਤਹ-ਕ੍ਰਮ ਨੂੰ ਫੋਲੋ ਨਾ ਕਰੋ।
ਇੱਕ ਸਧਾਰਨ ਰੀਰਾਈਟ ਉਦਾਹਰਣ
ਮਾਨ ਲਓ ਤੁਸੀਂ ਕਿਸੇ ਦੇਸ਼ ਦੇ ਉਪਭੋਗਤਿਆਂ ਦੇ ਆਰਡਰ ਚਾਹੁੰਦੇ ਹੋ:
SELECT o.order_id, o.total
FROM users u
JOIN orders o ON o.user_id = u.id
WHERE u.country = 'CA';
ਇੱਕ ਨਾਹੀਵ ਰੂਪ ਅਕਸਰ ਸਾਰੇ users ਨੂੰ ਸਾਰੀਆਂ orders ਨਾਲ ਜੋੜ ਕੇ ਫਿਰ Canada ਫਿਲਟਰ ਕਰੇਗਾ। ਇੱਕ ਅਰਥ-ਰੱਖਣ ਵਾਲਾ ਰੀਰਾਈਟ ਫਿਲਟਰ ਨੂੰ ਅੱਗੇ ਧੱਕਦਾ ਹੈ ਤਾਂ ਜੋ join ਘੱਟ ਕਤਾਰਾਂ 'ਤੇ ਲਾਗੂ ਹੋਵੇ:
- Users ਨੂੰ
country = 'CA' ਲਈ ਫਿਲਟਰ ਕਰੋ
- ਫਿਰ ਉਹਨਾਂ users ਨੂੰ orders ਨਾਲ join ਕਰੋ
- ਫਿਰ ਸਿਰਫ਼
order_id ਅਤੇ total ਪ੍ਰੋਜੈਕਟ ਕਰੋ
ਯੋਜਨਾ ਟਰਮੀਨਲੋਜੀ ਵਿੱਚ, ਓਪਟੀਮਾਈਜ਼ਰ ਇਸਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਬਦਲਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ:
Join(Users, Orders) → Filter(country='CA') → Project(order_id,total)
ਨੂੰ ਕੁਝ ਇਸ ਦੇ ਨੇੜੇ:
Filter(country='CA') on Users → Join(with Orders) → Project(order_id,total)
ਉਹੀ ਜਵਾਬ। ਘੱਟ ਕੰਮ।
ਇਹ ਰੀਰਾਈਟਸ ਆਸਾਨੀ ਨਾਲ ਨਜ਼ਰਅੰਦਾਜ਼ ਹੋ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ ਤੁਸੀਂ ਕਿਸੇ ਨੂੰ ਟਾਈਪ ਨਹੀਂ ਕਰਦੇ—ਫਿਰ ਵੀ ਇਹ ਇੱਕ ਵੱਡਾ ਕਾਰਣ ਹੈ ਕਿ ਇਕੋ ਹੀ SQL ਇੱਕ ਡੇਟਾਬੇਸ 'ਤੇ ਤੇਜ਼ ਅਤੇ ਦੂਜੇ 'ਤੇ ਧੀਮਾ ਚਲ ਸਕਦੀ ਹੈ।
ਕੋਸਟ-ਅਧਾਰਿਤ ਓਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਬਿਨਾਂ ਜਾਰਗਨ ਦੇ
ਜਦੋਂ ਤੁਸੀਂ SQL ਚਲਾਉਂਦੇ ਹੋ, ਡੇਟਾਬੇਸ ਇਕੋ ਨਤੀਜੇ ਦੇਣ ਵਾਲੀਆਂ ਕਈ ਵਿਵਿਧ ਯੋਜਨਾਵਾਂ 'ਤੇ ਵਿਚਾਰ ਕਰਦਾ ਹੈ ਅਤੇ ਫਿਰ ਉਹ ਚੁਣਦਾ ਹੈ ਜਿਸਦੀ ਲਾਗਤ ਉਸ ਨੂੰ ਸਭ ਤੋਂ ਸਸਤੀ ਲੱਗਦੀ ਹੈ। ਇਹ ਫੈਸਲਾ ਪ੍ਰਕਿਰਿਆ ਹੀ ਹੈ ਜਿਸਨੂੰ cost-based optimization ਕਹਿੰਦੇ ਹਨ—ਅਤੇ ਇਹ ਅਜਿਹੀ ਥਾਂ ਹੈ ਜਿੱਥੇ Ullman-ਸ਼ੈਲੀ ਦਾ ਸਿਧਾਂਤ ਰੋਜ਼ਮਰਾ ਦੀ ਕਾਰਗੁਜ਼ਾਰੀ 'ਚ ਦਰਸਦਾ ਹੈ।
"ਕੋਸਟ ਮਾਡਲ" ਅਸਲ ਵਿੱਚ ਕੀ ਹੈ
ਇਕ ਕੋਸਟ ਮਾਡਲ ਇੱਕ ਸਕੋਰਿੰਗ ਸسٽਮ ਹੈ ਜੋ ਓਪਟੀਮਾਈਜ਼ਰ ਵੱਖ-ਵੱਖ ਯੋਜਨਾਵਾਂ ਦੀ ਤੁਲਨਾ ਕਰਨ ਲਈ ਵਰਤਦਾ ਹੈ। ਜ਼ਿਆਦਾਤਰ ਇੰਜਨ ਕੁਝ ਮੁੱਖ ਸਰੋਤਾਂ ਦੀ ਆਧਾਰ 'ਤੇ ਲਾਗਤ ਅੰਦਾਜ਼ਾ ਲਗਾਉਂਦੇ ਹਨ:
- ਪ੍ਰੋਸੈਸ ਕੀਤੀਆਂ ਕਤਾਰਾਂ (ਕਾਮ ਆਮ ਤੌਰ 'ਤੇ ਇਸ ਉੱਤੇ ਆਧਾਰਿਤ ਹੁੰਦਾ ਹੈ ਕਿ ਹਰ ਕਦਮ ਵਿੱਚ ਕਿੰਨਾ ਡੇਟਾ ਗੁਜ਼ਰਦਾ ਹੈ)
- I/O (ਡਿਸਕ ਜਾਂ SSD ਤੋਂ ਪੰਨਿਆਂ ਨੂੰ ਪੜ੍ਹਨਾ, ਅਤੇ ਕੈਸ਼ ਪ੍ਰਭਾਵ)
- CPU (ਫਿਲਟਰਿੰਗ, hashing, sorting, aggregating)
- ਮੈਮੋਰੀ (ਕੀ ਇੱਕ ਆਪਰੇਸ਼ਨ RAM ਵਿੱਚ ਫਿੱਟ ਹੁੰਦਾ ਹੈ ਜਾਂ ਡਿਸਕ 'ਤੇ spill ਕਰਦਾ ਹੈ)
ਮਾਡਲ ਨੂੰ ਪਰਫੈਕਟ ਹੋਣ ਦੀ ਲੋੜ ਨਹੀਂ; ਉਸਨੂੰ ਅਕਸਰ ਕਿਦਰ ਸੁਝਾਅ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾ ਕਿ ਵਧੀਆ ਯੋਜ਼ਨਾ ਚੁਣੀ ਜਾ ਸਕੇ।
cardinality estimation, ਸਧਾਰਨ ਪਾਠ
ਯੋਜਨਾ ਨੂੰ ਅੰਕੜਾ ਲਗਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, optimizer ਹਰ ਕਦਮ 'ਤੇ ਪੁੱਛਦਾ ਹੈ: ਇਸ ਤੋਂ ਕਿੰਨੀ ਕਤਾਰਾਂ ਨਿਕਲਣਗੀਆਂ? ਇਹੇ cardinality estimation ਹੈ।
ਜੇ ਤੁਸੀਂ WHERE country = 'CA' ਫਿਲਟਰ ਲਗਾਉਂਦੇ ਹੋ, ਤਾਂ ਇੰਜਨ ਅੰਦਾਜ਼ਾ ਲਗਾਏਗਾ ਕਿ ਟੇਬਲ ਦਾ ਕਿੰਨਾ ਹਿਸਾ ਮਿਲੇਗਾ। ਜੇ ਤੁਸੀਂ customers ਨੂੰ orders ਨਾਲ join ਕਰਦੇ ਹੋ, ਤਾਂ ਉਹ ਅੰਦਾਜ਼ਾ ਲਗਾਏਗਾ ਕਿ ਕਿੰਨੇ ਜੋੜ-ਜੋੜੀ ਮਿਲਣਗੀਆਂ। ਇਹ ਰੋ-ਕਾਉਂਟ ਅੰਦਾਜ਼ੇ ਇਹ ਨਿਰਧਾਰਿਤ ਕਰਦੇ ਹਨ ਕਿ ਉਹ index scan ਨੂੰ full scan ਨਾਲ ਤਲਣਾ, hash join ਕਰਨਾ ਜਾਂ nested loop ਵਰਤਣਾ ਚਾਹੇ।
statistics ਦਾ ਮਹੱਤਵ (ਅਤੇ ਬਿਨਾਂ ਉਹਨਾਂ ਕੀ ਗਲਤ ਹੁੰਦਾ)
ਓਪਟੀਮਾਈਜ਼ਰ ਦੇ ਅੰਦਾਜ਼ੇ statistics 'ਤੇ ਆਧਾਰਿਤ ਹੁੰਦੇ ਹਨ: ਗਿਣਤੀਆਂ, ਮੁੱਲਾਂ ਦੀ ਵੰਡ, null ਦਰਾਂ, ਅਤੇ ਕਈ ਵਾਰ ਕਾਲਮਾਂ ਵਿਚਕਾਰ correlation ਵੀ।
ਜਦੋਂ stats stale ਜਾਂ ਗੈਰ-ਮੌਜੂਦ ਹੁੰਦੇ ਹਨ, ਤਾ ਐਂਜਨ ਕਤਾਰਾਂ ਦਾ ਅੰਦਾਜ਼ਾ ਕਈ ਗੁਣਾ ਗਲਤ ਕਰ ਸਕਦਾ ਹੈ। ਇੱਕ ਯੋਜਨਾ ਜੋ ਕਾਗਜ਼ 'ਤੇ ਸਸਤੀ ਲੱਗਦੀ ਸੀ, ਅਸਲियत ਵਿੱਚ ਮਹਿੰਗੀ ਸਾਬਤ ਹੋ ਸਕਦੀ ਹੈ—ਇਸ ਦੇ ਲੱਛਣਾਂ ਵਿੱਚ ਡੇਟਾ ਵਧਣ ਦੇ ਬਾਅਦ ਅਚਾਨਕ ਹੌਲੀ ਹੋਣਾ, "ਰੈਂਡਮ" ਯੋਜਨਾਬਦਲ, ਜਾਂ joins ਜੋ ਅਣਉਮੀਦ ਤੌਰ 'ਤੇ ਡਿਸਕ 'ਤੇ spill ਹੋ ਰਹੇ ਹਨ ਸ਼ਾਮਲ ਹਨ।
ਐਕ-ਆਉਣ ਵਾਲਾ ਟਰੇਡ-ਆਫ: ਸਹੀਅੱਤ বনਾਮ ਯੋਜਨਾ ਸਮਾਂ
ਚੰਗੇ ਅੰਦਾਜ਼ੇ ਅਕਸਰ ਵਧੇਰੇ ਕੰਮ ਮੰਗਦੇ ਹਨ: ਜ਼ਿਆਦਾ ਵੇਰਵਾ ਵਾਲੀ stats, ਨਮੂਨਾ ਲੈਣਾ, ਜਾਂ ਹੋਰ ਉਮੀਦਵਾਰ ਯੋਜਨਾਵਾਂ ਦੀ ਜਾਂਚ। ਪਰ ਯੋਜਨਾ ਬਣਾਉਣ ਖੁਦ ਵੀ ਸਮਾਂ ਲੈਂਦੀ ਹੈ, ਖ਼ਾਸ ਕਰਕੇ ਜਟਿਲ ਕੁਇਰੀਆਂ ਲਈ।
ਇਸ ਲਈ ਓਪਟੀਮਾਈਜ਼ਰ ਦੋ ਲਕੜਾਂ ਵਿੱਚ ਸੰਤੁਲਨ ਬਣਾਂਦੇ ਹਨ:
- ਇੰਟਰੈਕਟਿਵ ਵਰਕਲੋਡਾਂ ਲਈ ਯੋਜਨਾ ਕਾਫੀ ਤੇਜ਼ ਬਣਾਉਣਾ
- ਭਾਰੀ ਗਲਤੀ ਵਾਲੀਆਂ ਚੋਣਾਂ ਤੋਂ ਬਚਣ ਲਈ ਯੋਜਨਾ ਕਾਫੀ ਸਮਝਦਾਰ ਬਣਾਉਣਾ
EXPLAIN ਆਉਟਪੁੱਟ ਨੂੰ ਸਮਝਦੇ ਸਮੇਂ ਇਹ ਟਰੇਡ-ਆਫ ਯਾਦ ਰੱਖਣਾ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ: ਓਪਟੀਮਾਈਜ਼ਰ ਚਾਲਾਕੀ ਨਹੀਂ ਕਰ ਰਿਹਾ—ਉਹ ਸੀਮਤ ਜਾਣਕਾਰੀ ਹੇਠਾਂ ਪ੍ਰੀਡਿਕਟਬਲ ਤੌਰ 'ਤੇ ਸਹੀ ਹੋਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਿਹਾ ਹੈ।
ਜੋਇਨ ਅਲਗੋਰਿਦਮ ਅਤੇ ਕੁਇਰੀ ਪ੍ਰਦਰਸ਼ਨ ਦਾ ਦਿਲ
Ullman ਦਾ ਕੰਮ ਇੱਕ ਸਧਾਰਨ ਪਰ ਤਾਕਤਵਰ ਵਿਚਾਰ ਨੂੰ ਪ੍ਰਸਿੱਧ ਕਰਨ ਵਿੱਚ ਮਦਦਗਾਰ ਰਿਹਾ: SQL ਨੂੰ "ਚਲਾਇਆ" ਨਹੀਂ ਜਾਂਦਾ, ਬਲਕਿ ਇਹਨੂੰ ਇੱਕ ਐਗਜ਼ਿਕਿਊਸ਼ਨ ਯੋਜਨਾ ਵਿੱਚ ਅਨੁਵਾਦ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਇਹ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ joins 'ਚ ਸਪੱਸ਼ਟ ਹੁੰਦਾ ਹੈ। ਦੋ ਕੁਇਰੀਆਂ ਜੋ ਇਕੋ ਲਾਈਨਾਂ ਵਾਪਸ ਕਰਦੀਆਂ ਹਨ, ਉਹਨਾਂ ਦੀ ਰਨਟਾਈਮ ਭਰਪੂਰ ਤਰੀਕੇ ਨਾਲ ਵੱਖਰੀ ਹੋ ਸਕਦੀ ਹੈ, ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰ ਕੇ ਕਿ ਇੰਜਨ ਕਿਹੜਾ join algorithm ਚੁਣਦਾ ਹੈ—ਅਤੇ ਕਿਹੜੇ ਕ੍ਰਮ ਵਿੱਚ ਉਹ tables ਨੂੰ ਜੋੜਦਾ ਹੈ।
Nested loop, hash join, merge join—ਕਦੋਂ ਕਿਹੜਾ ਮਾੜ ਹੈ
Nested loop join ਸਿਧਾ ਹੈ: ਖੱਬੇ ਪਾਸੇ ਦੀ ਹਰ ਕਤਾਰ ਲਈ ਸੱਜੇ ਪਾਸੇ ਦੀਆਂ ਮੇਲ ਖੋਜੋ। ਜਦੋਂ ਖੱਬਾ ਛੋਟਾ ਹੋ ਅਤੇ ਸੱਜਾ ਇੰਡੈਕਸ ਨਾਲ ਤੇਜ਼ੀ ਨਾਲ ਚੈੱਕ ਹੋ ਸਕੇ ਤਾਂ ਇਹ ਤੇਜ਼ ਹੋ ਸਕਦਾ ਹੈ।
Hash join ਇੱਕ ਇਨਪੁੱਟ (ਅਕਸਰ ਛੋਟਾ) ਤੋਂ ਇੱਕ ਹੈਸ਼ ਟੇਬਲ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਦੂਜੇ ਤੋਂ probe ਕਰਦਾ ਹੈ। ਇਹ ਬੜੇ, ਅਸਰਗਤ ਇਨਪੁੱਟਾਂ ਲਈ ਚਮਕਦਾਰ ਹੁੰਦਾ ਹੈ ਜਦੋਂ شرط equality ਹੋਵੇ (ਜਿਵੇਂ A.id = B.id), ਪਰ ਇਹ ਮੈਮੋਰੀ ਮੰਗਦਾ ਹੈ; ਜੇ spill-to-disk ਹੁੰਦਾ ਹੈ ਤਾਂ ਫਾਇਦਾ ਖਤਮ ਹੋ ਸਕਦਾ ਹੈ।
Merge join ਦੋਵੇਂ ਇਨਪੁੱਟਾਂ ਨੂੰ sort ਕੀਤੇ ਹੋਏ ਕ੍ਰਮ ਵਿੱਚ ਚਲਾਉਂਦਾ ਹੈ। ਜਦੋਂ ਦੋਹਾਂ ਪਾਸੇ ਪਹਿਲਾਂ ਤੋਂ order ਹੋਵੇ (ਜਾਂ indexes ਤੋਂ join-key ਕ੍ਰਮ ਸਸਤੇ ਮਿਲਦੇ ਹੋਣ), ਇਹ ਬਹੁਤ ਵਧੀਆ ਫਿੱਟ ਹੁੰਦਾ ਹੈ।
ਕਿਉਂ join order ਪ੍ਰਦਰਸ਼ਨ 'ਤੇ ਰਾਜ ਕਰ ਸਕਦਾ ਹੈ
ਤਿੰਨ ਜਾਂ ਵੱਧ ਟੇਬਲਾਂ ਨਾਲ, ਸੰਭਵ join ਆਰਡਰਾਂ ਦੀ ਗਿਣਤੀ ਬਹੁਤ ਵਧ ਜਾਂਦੀ ਹੈ। ਪਹਿਲਾਂ ਦੋ ਵੱਡੀਆਂ ਟੇਬਲਾਂ ਜੋੜਨਾ ਇੱਕ ਵੱਡਾ intermediate ਨਤੀਜਾ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਬਾਕੀ ਕੰਮ ਨੂੰ ਧੀਮਾ ਕਰ ਦੇਵੇ। ਇੱਕ ਚੰਗਾ ਕ੍ਰਮ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਚੁਣਿੰਦਰ (selective) ਫਿਲਟਰ ਤੋਂ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ ਅਤੇ ਬਾਹਰ ਵੱਲ join ਕਰਦਾ ਹੈ, intermediates ਨੂੰ ਛੋਟਾ ਰੱਖਣ ਲਈ।
ਇੰਡੈਕਸ ਵਧੇਰੇ ਯੋਜਨਾਵਾਂ ਨੂੰ ਉਪਲੱਬਧ ਕਰਵਾਉਂਦੇ ਹਨ
ਇੰਡੈਕਸ ਸਿਰਫ lookup ਤੇ ਰਫਤਾਰ ਨਹੀਂ ਲਿਆਉਂਦੇ—ਉਹ ਕੁਝ join ਰਣਨੀਤੀਆਂ ਨੂੰ viable ਬਣਾਉਂਦੇ ਹਨ। join key 'ਤੇ ਇੰਡੈਕਸ ਇੱਕ ਮਹਿੰਗੇ nested loop ਨੂੰ ਇੱਕ ਤੇਜ਼ "seek per row" ਪੈਟਰਨ ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ। ਵਿਰੁੱਧ, ਗੈਰ-ਮੌਜੂਦ ਜਾਂ ਅਣਉਪਯੋਗ ਇੰਡੈਕਸ engine ਨੂੰ hash joins ਜਾਂ merge joins ਲਈ ਵੱਡੇ sorts ਵੱਲ dhakel ਸਕਦੇ ਹਨ।
ਪ੍ਰਾਇਕਟਿਕ ਚੈੱਕਲਿਸਟ: ਖਰਾਬ join ਯੋਜਨਾ ਦੇ ਲੱਛਣ
- ਕੁਝ ਡੇਟਾ ਵੱਧਣ 'ਤੇ ਰਨਟਾਈਮ ਨाटਕੀ ਤੌਰ 'ਤੇ ਵਧਦਾ ਹੈ (join order intermediate results ਨੂੰ amplify ਕਰ ਰਿਹਾ ਹੈ)।
- ਯੋਜਨਾ ਵਿੱਚ "rows estimated vs rows actual" ਵਿੱਚ ਵੱਡੇ ਫਰਕ dikhai ਦੇ ਰਹੇ ਹਨ (ਖਰਾਬ cardinality ਅੰਦਾਜ਼ੇ ਗਲਤ join ਚੋਣ ਨੂੰ ਲੈ ਆਉਂਦੇ ਹਨ)।
- ਤੁਸੀਂ ਵੱਡੇ sorts ਜਾਂ hash spills ਡਿਸਕ 'ਤੇ ਦੇਖਦੇ ਹੋ (ਮੈਮੋਰੀ ਦਬਾਅ ਜਾਂ ਸਹਾਇਕ ਇੰਡੈਕਸਾਂ ਦੀ ਕਮੀ)।
- ਇੱਕ ਛੋਟਾ filtered ਟੇਬਲ ਦੇਰੀ ਨਾਲ join ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੈ, ਨਾ ਕਿ ਜਲਦੀ (ਫਿਲਟਰ ਪਹਿਲਾਂ ਨਾ ਲਗ ਰਹੇ ਹੋਣ)।
- join predicate ਸਾਫ਼ equality ਨਹੀਂ ਹੈ ਜਾਂ ਕੰਪੈਟੀਬਲ types ਤੇ ਨਹੀਂ (ਜੋ efficient hash/merge ਵਿਹਾਰ ਨੂੰ ਰੋਕਦਾ ਹੈ)।
ਡੇਟਾਬੇਸ ਇੰਜਨਾਂ ਵਿੱਚ ਕੰਪਾਇਲਰ ਦੇ ਵਿਚਾਰ
ਡੇਟਾਬੇਸ ਸਿਰਫ SQL "ਚਲਾਉਂਦੇ" ਨਹੀਂ। ਉਹ ਇਸਨੂੰ ਕੰਪਾਈਲ ਕਰਦੇ ਹਨ। Ullman ਦਾ ਪ੍ਰਭਾਵ ਦੋਹਾਂ ਡੇਟਾਬੇਸ ਸਿਧਾਂਤ ਅਤੇ ਕੰਪਾਇਲਰ ਸੋਚ 'ਤੇ ਫੈਲਾ ਹੋਇਆ ਹੈ, ਅਤੇ ਇਹ ਜੋੜ ਇਹ ਸਮਝਾਉਂਦਾ ਹੈ ਕਿ query engines programming language toolchains ਵਰਗੇ ਕਿਉਂ ਵਰਤਦੇ ਹਨ: ਉਹ translate, rewrite, ਅਤੇ optimize ਕਰਦੇ ਹਨ ਹਰੇਕ ਅਮਲ ਤੋਂ ਪਹਿਲਾਂ।
Parsing ਅਤੇ syntax trees: SQL ਕਿਵੇਂ ਪੜ੍ਹਿਆ ਜਾਂਦਾ ਹੈ
ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਕੁਇਰੀ ਭੇਜਦੇ ਹੋ, ਪਹਿਲਾ ਕਦਮ ਕੰਪਾਇਲਰ ਦੇ front end ਵਾਂਗ ਹੁੰਦਾ ਹੈ। ਇੰਜਨ keywords ਅਤੇ identifiers ਨੂੰ tokenise ਕਰਦਾ ਹੈ, grammar ਚੈੱਕ ਕਰਦਾ ਹੈ, ਅਤੇ ਇੱਕ parse tree ਬਣਾਉਂਦਾ ਹੈ (ਅਕਸਰ ਸਰਲ ਰੂਪ ਵਿੱਚ abstract syntax tree)। ਇਹੀ ਥਾਂ ਹੈ ਜਿੱਥੇ ਬੁਨਿਆਦੀ ਗਲਤੀਆਂ ਫੜੀਆਂ ਜਾਂਦੀਆਂ ਹਨ: ਗੁੰਮ ਹੋਏ ਕੋਮਾ, ambiguous column names, ਗਲਤ grouping ਨਿਯਮ ਆਦਿ।
ਇੱਕ ਸਹਾਈ ਮਾਨਸਿਕ ਮਾਡਲ: SQL ਇੱਕ ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ ਹੈ ਜਿਸਦਾ "प्रੋਗ੍ਰਾਮ" ਡੇਟਾ ਸੰਬੰਧਾਂ ਨੂੰ ਵਰਣਨ ਕਰਦਾ ਹੈ ਨਾ ਕਿ ਲੂਪਾਂ ਨੂੰ।
parse tree ਤੋਂ logical operators ਤੱਕ
ਕੰਪਾਇਲਰ syntax ਨੂੰ ਇੱਕ intermediate representation (IR) ਵਿੱਚ ਬਦਲਦੇ ਹਨ। ਡੇਟਾਬੇਸ ਵੀ ਕੁਝ ਇਸੇ ਤਰ੍ਹਾਂ ਕਰਦੇ ਹਨ: ਉਹ SQL syntax ਨੂੰ logical operators ਵਿੱਚ ਤਬਦੀਲ ਕਰਦੇ ਹਨ ਜਿਵੇਂ:
- Selection (row filtering)
- Projection (columns ਚੁਣਨਾ)
- Join (ਟੇਬਲਾਂ ਨੂੰ ਜੋੜਨਾ)
- Aggregation (
GROUP BY)
ਉਹ ਲਾਜ਼ਮੀ ਰੂਪ SQL ਟੈਕਸਟ ਤੋਂ ਜ਼ਿਆਦਾ relational algebra ਦੇ ਨੇੜੇ ਹੁੰਦਾ ਹੈ, ਜੋ ਕਿ ਮਾਨਤਾ ਅਤੇ ਸਮਤੁਲਤਾ ਬਾਰੇ ਸੋਚਣਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਕਿਉਂ ਓਪਟੀਮਾਈਜ਼ਰ ਕੰਪਾਇਲਰ ਅਪਟੀਮਾਈਜੇਸ਼ਨਾਂ ਵਰਗੇ ਲੱਗਦੇ ਹਨ
ਕੰਪਾਇਲਰ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਪ੍ਰੋਗ੍ਰਾਮ ਦੇ ਨਤੀਜੇ ਨੂੰ ਅਗੇ ਹੀ ਬਦਲ ਦੇਣ ਬਿਨਾਂ ਚਲਾਉਟ ਨੂੰ ਸਸਤਾ ਬਣਾਉਂਦੀ ਹੈ। ਡੇਟਾਬੇਸ ਓਪਟੀਮਾਈਜ਼ਰ ਵੀ ਇਹੀ ਕਰਦੇ ਹਨ, ਨਿਯਮ ਪ੍ਰਣਾਲੀ ਵਰਤ ਕੇ ਜਿਵੇਂ:
- ਫਿਲਟਰਾਂ ਨੂੰ ਜਲਦੀ ਧੱਕੋ (ਕੰਮ ਘਟਾਉਣ ਲਈ)
- joins ਨੂੰ ਦੁਬਾਰਾ ਕ੍ਰਮਬੱਧ ਕਰੋ (ਉਹੀ ਨਤੀਜਾ, ਵੱਖਰਾ ਲਾਗਤ)
- Redundant computations ਹਟਾਓ
ਇਹ "dead code elimination" ਦਾ ਡੇਟਾਬੇਸ ਸੰਸਕਰਣ ਹੈ: ਇਕੋ ਫੈਲਸਫ਼ਾ—ਸੈਮਾਂਟਿਕਸ ਨੂੰ ਬਰਕਰਾਰ ਰੱਖਦੇ ਹੋਏ ਲਾਗਤ ਘਟਾਉਣਾ।
ਡਿਬੱਗਿੰਗ: compiled code ਵਾਂਗ ਯੋਜਨਾਵਾਂ ਨੂੰ ਪੜ੍ਹਨਾ
ਜੇ ਤੁਹਾਡੀ ਕੁਇਰੀ ਧੀਮੀ ਹੈ, ਤਾਂ ਸਿਰਫ SQL ਦੇਖੋ ਨਾ। query plan ਨੂੰ ਉਸ ਤਰ੍ਹਾਂ ਦੇਖੋ ਜਿਵੇਂ ਕਿ ਤੁਸੀਂ ਕੰਪਾਇਲਰ ਦੇ ਆਉਟਪੁੱਟ ਦੀ ਜਾਂਚ ਕਰ ਰਹੇ ਹੋ। ਇੱਕ ਯੋਜਨਾ ਦੱਸਦੀ ਹੈ ਕਿ ਇੰਜਨ ਨੇ ਅਸਲ ਵਿੱਚ ਕੀ ਚੁਣਿਆ: join order, index ਵਰਤੋਂ, ਅਤੇ ਕਿੱਥੇ ਸਮਾਂ ਲੱਗ ਰਿਹਾ ਹੈ।
ਪ੍ਰਾਇਕਟਿਕ ਨਤੀਜਾ: EXPLAIN ਆਉਟਪੁੱਟ ਨੂੰ ਪੜ੍ਹਨਾ ਇੱਕ ਪ੍ਰਦਰਸ਼ਨ “ਅਸੈਂਬਲੀ ਲਿਸਟਿੰਗ” ਵਾਂਗ ਸਿੱਖੋ। ਇਹ tuning ਨੂੰ ਅਨੁਮਾਨ-ਅਧਾਰਤ ਤੋਂ ਸਬੂਤ-ਆਧਾਰਿਤ ਡੀਬੱਗਿੰਗ ਬਣਾਉਂਦਾ।