30 ਅਕਤੂ 2025·8 ਮਿੰਟ
ਉਤਪਾਦਾਂ ਵਾਰ ਪ੍ਰਯੋਗ ਨਤੀਜੇ ਟਰੈਕ ਕਰਨ ਲਈ ਵੈਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈਬ ਐਪ ਬਣਾਈਏ ਜੋ ਉਤਪਾਦਾਂ ਵਿੱਚ experiments ਦੇ ਨਤੀਜੇ ਟਰੈਕ ਕਰੇ: ਡਾਟਾ ਮਾਡਲ, ਮੈਟਰਿਕਸ, ਅਨੁਮਤੀਆਂ, ਇੰਟੀਗ੍ਰੇਸ਼ਨ, ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਭਰੋਸੇਯੋਗ ਰਿਪੋਰਟਿੰਗ।
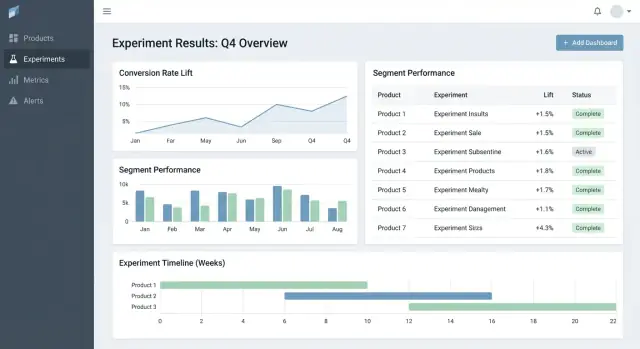
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈਬ ਐਪ ਬਣਾਈਏ ਜੋ ਉਤਪਾਦਾਂ ਵਿੱਚ experiments ਦੇ ਨਤੀਜੇ ਟਰੈਕ ਕਰੇ: ਡਾਟਾ ਮਾਡਲ, ਮੈਟਰਿਕਸ, ਅਨੁਮਤੀਆਂ, ਇੰਟੀਗ੍ਰੇਸ਼ਨ, ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਭਰੋਸੇਯੋਗ ਰਿਪੋਰਟਿੰਗ।
ਜ਼ਿਆਦਾ ਟੀਮਾਂ ਵਿਚ ਪਰਯੋਗਾਂ ਦੀ ਪ੍ਰਸਤੁਤੀ ਦੀ ਘਾਟ ਨਹੀਂ ਹੁੰਦੀ—ਨਤੀਜੇ ਵਿਖਰੇ ਹੋਏ ਹੋਂਦੇ ਹਨ। ਇਕ ਉਤਪਾਦ ਵਿਚ ਚਾਰਟਸ analytics ਟੂਲ ਵਿੱਚ, ਦੂਜੇ ਵਿਚ spreadsheet, ਤੇ ਤੀਜੇ ਵਿਚ slide deck ਨਾਲ ਸਕ੍ਰੀਨਸ਼ਾਟ। ਕਈ ਮਹੀਨੇ ਬਾਅਦ, ਕੋਈ ਆਸਾਨ ਸਵਾਲ ਜਿਵੇਂ “ਕੀ ਅਸੀਂ ਇਹ ਪਹਿਲਾਂ ਟੈਸਟ ਕੀਤਾ ਸੀ?” ਜਾਂ “ਕਿਹੜਾ ਵਰਜ਼ਨ ਜਿੱਤਿਆ, ਕਿਹੜੀ ਮੈਟਰਿਕ ਪਰਿਭਾਸ਼ਾ ਨਾਲ?” ਦਾ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦਾ।
ਇੱਕ experiment tracking ਵੈਬ ਐਪ ਨੂੰ ਕੇਂਦਰਿਤ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਕੀ ਟੈਸਟ ਕੀਤਾ ਗਿਆ, ਕਿਉਂ, ਕਿਵੇਂ ਮਾਪਿਆ ਗਿਆ, ਅਤੇ ਕੀ ਨਤੀਜ਼ਾ ਆਇਆ—ਕਈ ਉਤਪਾਦਾਂ ਅਤੇ ਟੀਮਾਂ ਵਿੱਚ। ਇਸ ਦੇ ਬਿਨਾਂ, ਟੀਮਾਂ ਰਿਪੋਰਟਾਂ ਦੁਬਾਰਾ ਬਣਾਉਂਦੀਆਂ ਹਨ, ਅੰਕਾਂ 'ਤੇ ਬਹਿਸ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਪੁਰਾਣੇ ਟੈਸਟ ਫਿਰ ਚਲਾਏ ਜਾਂਦੇ ਹਨ ਕਿਉਂਕਿ ਸਿੱਖਿਆ searchable ਨਹੀਂ ਹੁੰਦੀ।
ਇਹ ਸਿਰਫ਼ ਵਿਸ਼ਲੇਸ਼ਕਾਂ ਲਈ ਟੂਲ ਨਹੀਂ ਹੈ।
ਇੱਕ ਚੰਗਾ ਟਰੈਕਰ ਕਾਰੋਬਾਰੀ ਮੁੱਲ ਬਣਾਉਂਦਾ ਹੈ:
ਖੁਲਾਸਾ: ਇਹ ਐਪ ਮੁੱਖ ਤੌਰ 'ਤੇ ਪ੍ਰਯੋਗ ਨਤੀਜਿਆਂ ਦੀ ਟਰੈਕਿੰਗ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਲਈ ਹੈ—ਪੂਰੇ end-to-end ਪ੍ਰਯੋਗ ਚਲਾਉਣ ਲਈ ਨਹੀਂ। ਇਹ ਮੌਜੂਦਾ ਟੂਲਾਂ (feature flagging, analytics, data warehouse) ਨਾਲ link ਕਰ ਸਕਦਾ ਹੈ ਪਰ experiment ਅਤੇ ਉਸ ਦੀ ਅੰਤਿਮ, ਸਹਿਮਤ ਵਿਵਚਨਾ ਦਾ structured record ਆਪਣੇ ਅੰਦਰ ਰੱਖੇਗਾ।
ਇੱਕ MVP experiment tracker ਨੂੰ ਦੋ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ ਬਿਨਾਂ ਦਸਤਾਵੇਜ਼ਾਂ ਜਾਂ spreadsheets ਵਿੱਚ ਖੋਜ ਕੀਤੇ: ਅਸੀਂ ਕੀ ਟੈਸਟ ਕਰ ਰਹੇ ਹਾਂ ਅਤੇ ਅਸੀਂ ਕੀ ਸਿੱਖਿਆ। ਪਹਿਲਾਂ ਕੁਝ entities ਅਤੇ fields ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਹਰੇਕ ਉਤਪਾਦ ਲਈ ਕੰਮ ਕਰਨਗੇ, ਫਿਰ ਓਸੇ ਵੇਲੇ ਵਧਾਓ ਜਦੋਂ ਟੀਮਾਂ ਨੂੰ ਅਸਲੀ ਦਰਦ ਮਹਿਸੂਸ ਹੋਵੇ।
ਡਾਟਾ ਮਾਡਲ ਸਾਦਾ ਰੱਖੋ ਤਾਂ ਹਰ ਟੀਮ ਇਸਨੂੰ ਇੱਕੋ ਢੰਗ ਨਾਲ ਵਰਤੇ:
ਪ੍ਰਤੀ ਦਿਨ ਸਭ ਤੋਂ ਆਮ ਪੈਟਰਨ ਸਪੋਰਟ ਕਰੋ:
ਜੇ rollouts ਪਹਿਲਾਂ formal statistics ਨਹੀਂ ਵਰਤਦੇ, ਫਿਰ ਵੀ ਉਨ੍ਹਾਂ ਨੂੰ experiments ਨਾਲ track ਕਰਨ ਨਾਲ ਟੀਮਾਂ ਬਿਨਾਂ ਰਿਕਾਰਡ ਦੇ ਇਕੋ “ਟੈਸਟ” ਦੁਬਾਰਾ ਨਾ ਕਰਨ।
ਬਣਾਉਣ ਸਮੇਂ, ਸਿਰਫ਼ ਉਹੀ ਲੋੜੀਦਾ ਰੱਖੋ ਜੋ ਬਾਅਦ ਵਿੱਚ ਟੈਸਟ ਚਲਾਉਣ ਅਤੇ interpret ਕਰਨ ਲਈ ਜ਼ਰੂਰੀ ਹੋਵੇ:
ਫੈਸਲਿਆਂ ਨੂੰ ਤੁਲਨਯੋਗ ਬਣਾਉਣ ਲਈ ਢਾਂਚਾ ਲਾਵੋ:
ਜੇ ਤੁਸੀਂ ਸਿਰਫ ਇਹ ਬਣਾਉਂਦੇ ਹੋ, ਟੀਮਾਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ experiments ਲੱਭ ਸਕਦੀਆਂ, setup ਸਮਝ ਸਕਦੀਆਂ, ਅਤੇ outcomes ਰਿਕਾਰਡ ਕਰ ਸਕਦੀਆਂ—ਐਸੀ ਵੱਡੀ ਇੰਟਗ੍ਰੇਸ਼ਨ ਜਾਂ automation ਤੋਂ ਪਹਿਲਾਂ ਹੀ।
ਕ੍ਰਾਸ-ਪ੍ਰੋਡਕਟ experiment tracker ਆਪਣੀ ਡਾਟਾ ਮਾਡਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ। ਜੇ IDs ਟਕਰਾਉਂਦੀਆਂ ਹਨ, metrics drift ਹੁੰਦੇ ਹਨ, ਜਾਂ segments inconsistent ਹਨ, ਤਾਂ ਤੁਹਾਡਾ ਡੈਸ਼ਬੋਰਡ "ਠੀਕ" ਲੱਗ ਸਕਦਾ ਹੈ ਪਰ ਗਲਤ ਕਹਾਣੀ ਦੱਸਦਾ ਹੋਵੇਗਾ।
ਸਪਸ਼ਟ identifier ਰਣਨੀਤੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
checkout_free_shipping_banner) ਨਾਲ ਇੱਕ immutable experiment_idcontrol, treatment_aਇਸ ਨਾਲ ਤੁਸੀਂ ਉਤਪਾਦਾਂ ਦੇ ਵਿਚਕਾਰ ਨਤੀਜੇ ਤੁਲਨਾ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਇਹ ਅਨੁਮਾਨ ਲਗਾਏ ਕਿ “Web Checkout” ਅਤੇ “Checkout Web” ਇੱਕੋ ਹਨ।
ਕੋਰ entities ਨੂਂ ਛੋਟਾ ਅਤੇ explicit ਰੱਖੋ:
ਭਾਵੇਂ computation ਕਿਤੇ ਹੋਰ ਹੋਵੇ, outputs (results) ਸਟੋਰ ਕਰਨ ਨਾਲ ਤੇਜ਼ ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਭਰੋਸੇਯੋਗ history ਮਿਲਦੀ ਹੈ।
Metrics ਅਤੇ experiments ਸਥਿਰ ਨਹੀਂ ਹੁੰਦੇ। ਮਾਡਲ ਕਰੋ:
ਇਸ ਨਾਲ ਪਿਛਲੇ ਮਹੀਨੇ ਦੇ experiments ਤਬਦੀਲੀ ਦੇ ਕਾਰਨ ਬਦਲਦੇ ਨਹੀਂ।
ਉਤਪਾਦਾਂ ਵਿੱਚ consistent segments ਦੀ ਯੋਜਨਾ ਬਣਾਓ: country, device, plan tier, new vs returning.
ਅੰਤ ਵਿੱਚ, ਇੱਕ audit trail ਸ਼ਾਮਲ ਕਰੋ ਜੋ ਦੱਸੇ ਕਿ ਕਿਸਨੇ ਕੀ ਬਦਲਿਆ ਅਤੇ ਕਦੋਂ (status changes, traffic splits, metric definition updates)। ਇਹ trust, reviews, ਅਤੇ governance ਲਈ ਜ਼ਰੂਰੀ ਹੈ।
ਜੇ ਤੁਹਾਡਾ tracker metric ਗ਼ਲਤ ਮੈਥ ਕਰਦਾ ਹੈ (ਜਾਂ ਉਤਪਾਦਾਂ ਵਿੱਚ inconsistent), ਤਾਂ “ਨਤੀਜਾ” ਸਿਰਫ਼ ਇਕ ਰਾਇ ਹੋਵੇਗੀ ਇੱਕ ਚਾਰਟ ਨਾਲ। ਇਸ ਤੋਂ بچਣ ਲਈ ਤੇਜ਼ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ metrics ਨੂੰ shared product assets ਵਜੋਂ treatment ਕੀਤਾ ਜਾਵੇ—ਬਹੁਤ ਸਧਾਰਨ query snippets ਨਹੀਂ।
ਇੱਕ metric catalog ਬਣਾਓ ਜੋ definitions, calculation logic, ਅਤੇ ownership ਦਾ ਇਕੋ ਸੋਰਸ ਹੋਵੇ। ਹਰ metric entry ਵਿੱਚ ਇਹ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
ਕੈਟਾਲੌਗ ਨੂੰ ਉਹਥੇ ਰੱਖੋ ਜਿੱਥੇ ਲੋਕ ਕੰਮ ਕਰਦੇ ਹਨ (ਉਦਾਹরণ: experiment creation flow ਤੋਂ linked) ਅਤੇ version ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ historical results ਨੂੰ ਸਮਝਾ ਸਕੋ।
ਪਹਿਲਾਂ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਹਰ metric ਕਿਸ “unit of analysis” ਨੂੰ ਵਰਤਦਾ: per user, per session, per account, ਜਾਂ per order। conversion rate "per user" "per session" ਨਾਲ ਵੱਖ ਹੋ ਸਕਦੀ ਹੈ ਭਾਵੇਂ ਦੋਵੇਂ ਸਹੀ ਹੋਣ।
ਗੁੰਝਲ ਨੂੰ ਘਟਾਉਣ ਲਈ, metric definition ਨਾਲ aggregation choice ਸਟੋਰ ਕਰੋ, ਅਤੇ experiment setup ਵੇਲੇ ਇਸਨੂੰ ਲਾਜ਼ਮੀ ਕਰੋ। ਹਰ ਟੀਮ ਨੂੰ ad hoc unit ਚੁਣਨ ਨਾ ਦਿਓ।
ਕਈ ਉਤਪਾਦਾਂ ਕੋਲ conversion windows ਹੁੰਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ: signup ਅੱਜ, purchase 14 ਦਿਨਾਂ ਅੰਦਰ)। attribution rules consistent ਤਰੀਕੇ ਨਾਲ define ਕਰੋ:
ਇਹ ਨਿਯਮ ਡੈਸ਼ਬੋਰਡ 'ਤੇ ਦਿੱਖਾਓ ਤਾਂ ਕਿ ਪੜ੍ਹਨ ਵਾਲੇ ਜਾਣ ਸਕਣ ਕਿ ਉਹ ਕੀ ਦੇਖ ਰਹੇ ਹਨ।
ਤੇਜ਼ ਡੈਸ਼ਬੋਰਡ ਅਤੇ auditability ਲਈ, ਦੋਹਾਂ ਰੱਖੋ:
ਇਸ ਨਾਲ ਤੇਜ਼ rendering ਹੋਵੇਗਾ ਅਤੇ ਜਦੋਂ definitions ਬਦਲਣ, ਤੁਸੀਂ ਫਿਰ ਤੋਂ ਗਣਨਾ ਕਰ ਸਕੋਗੇ।
ਇੱਕ naming standard ਅਪਣਾਓ ਜੋ ਅਰਥ ਦਰਸਾਂਦਾ (ਉਦਾਹਰਨ: activation_rate_user_7d, revenue_per_account_30d)। unique IDs ਦੀ ਮੰਗ ਕਰੋ, aliases enforce ਕਰੋ, ਅਤੇ metric creation ਵੇਲੇ near-duplicates ਨੂੰ flag ਕਰੋ ਤਾਂ ਕਿ ਕੈਟਾਲੌਗ ਸਾਫ਼ ਰਹੇ।
ਤੁਹਾਡਾ experiment tracker ਉਸ ਡਾਟੇ ਤੇ ਹੀ ਭਰੋਸਾ ਕਰਦਾ ਹੈ ਜੋ ਇਹ ingest ਕਰਦਾ ਹੈ। ਲਕੜੀ ਦਾ ਮੁੱਖ ਉਦੇਸ਼ ਹੈ ਹਰ ਉਤਪਾਦ ਲਈ ਦੋ ਸਵਾਲਾਂ ਦਾ ਭਰੋਸੇਯੋਗ ਜਵਾਬ ਦੇਣਾ: ਕੌਣ ਕਿਸ variant ਨੂੰ expose ਹੋਇਆ, ਅਤੇ ਉਨ੍ਹਾਂ ਨੇ ਬਾਅਦ ਵਿੱਚ ਕੀ ਕੀਤਾ? ਸਭ ਕੁਝ—metrics, statistics, dashboards—ਉਹੀ ਇਸ ਬੁਨਿਆਦ 'ਤੇ ਨਿਰਭਰ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇਹਨਾਂ ਪੈਟਰਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਚੁਣਦੀਆਂ ਹਨ:
ਜੋ ਵੀ ਰਾਹ ਚੁਣੋ, ਹਰ ਉਤਪਾਦ 'ਤੇ ਘੱਟੋ ਘੱਟ event set standardize ਕਰੋ: exposure/assignment, ਮੁੱਖ conversion events, ਅਤੇ ਜੁੜਨ ਲਈ ਕਾਫ਼ੀ context (user ID/device ID, timestamp, experiment ID, variant)।
raw events ਤੋਂ metrics ਤਕ ਇੱਕ ਸਪਸ਼ਟ mapping define ਕਰੋ (ਉਦਾਹਰਨ: purchase_completed → Revenue, signup_completed → Activation)। ਹਰ ਉਤਪਾਦ ਲਈ ਇਹ mapping maintain ਕਰੋ, ਪਰ products ਵਿੱਚ naming consistent ਰੱਖੋ ਤਾਂ ਕਿ A/B test results dashboard like-with-like compare ਕਰ ਸਕੇ।
ਸ਼ੁਰੂ ਵਿੱਚ completeness validate ਕਰੋ:
ਹਰ ਲੋਡ 'ਤੇ ਚੱਲਣ ਵਾਲੇ checks ਬਣਾਓ ਅਤੇ ਜ਼ੋਰਦਾਰ ਤਰੀਕੇ ਨਾਲ fail ਕਰਨ:
ਇਹਨਾਂ ਨੂੰ experiment ਵਿੱਚ warnings ਵਜੋਂ ਦੇਖਾਓ, logs ਵਿੱਚ ਛੁਪਾ ਕੇ ਨਹੀਂ।
Pipeline ਬਦਲਦੇ ਹਨ। ਜਦੋਂ ਤੁਸੀਂ instrumentation ਬੱਗ ਜਾਂ dedupe logic ਠੀਕ ਕਰਦੇ ਹੋ, ਤੁਹਾਨੂੰ historical data reprocess ਕਰਨ ਦੀ ਲੋੜ ਪਵੇਗੀ ਤਾਂ ਕਿ metrics ਅਤੇ KPIs consistent ਰਹਿਣ।
ਯੋਜਨਾ ਬਣਾਓ:
Integrations ਨੂੰ product features ਵਾਂਗ treat ਕਰੋ: supported SDKs, event schemas, ਅਤੇ troubleshooting steps ਦਸਤਾਵੇਜ਼ ਕਰੋ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ docs ਖੇਤਰ ਹੈ, ਤਾਂ ਇਸਨੂੰ relative path ਵਜੋਂ link ਕਰੋ ਜਿਵੇਂ /docs/integrations।
ਜੇ ਲੋਕਨਾਂ ਨੂੰ ਅੰਕਾਂ 'ਤੇ ਭਰੋਸਾ ਨਹੀਂ, ਉਹ tracker ਵਰਤਣਗੇ ਨਹੀਂ। ਉਦੇਸ਼ math ਨਾਲ ਪ੍ਰਭਾਵਿਤ ਕਰਨਾ ਨਹੀਂ—ਉਦੇਸ਼ ਫੈਸਲੇ repeatable ਅਤੇ دفاعਯੋਗ ਬਣਾਉਣਾ ਹੈ across products।
ਪਹਿਲਾਂ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਤੁਸੀਂ ਆਪਣੀ ਐਪ ਵਿੱਚ frequentist ਨਤੀਜੇ (p-values, confidence intervals) ਦਿਖਾਉਗੇ ਜਾਂ Bayesian ਨਤੀਜੇ (probability of improvement, credible intervals)। ਦੋਹਾਂ ਚੰਗੇ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਉਨ੍ਹਾਂ ਨੂੰ products ਵਿੱਚ mix ਨਾ ਕਰੋ—ਇਸ ਨਾਲ ਪਰੇਸ਼ਾਨੀ ਆਉਂਦੀ ਹੈ।
ਵਿਆਵਹਾਰਕ ਨਿਯਮ: ਉਹ approach ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਸੰਸਥਾ ਪਹਿਲਾਂ ਹੀ ਸਮਝਦੀ ਹੈ, ਫਿਰ terminology, defaults, ਅਤੇ thresholds standardize ਕਰੋ।
ਘੱਟੋ-ਘੱਟ, results view ਨੂੰ ਇਹਨਾਂ ਚੀਜਾਂ ਨੂੰ ਅਸਪਸ਼ਟ ਨਹੀਂ ਛੱਡਣਾ ਚਾਹੀਦਾ:
ਇਸ ਤੋਂ ਇਲਾਵਾ analysis window, units counted (users, sessions, orders), ਅਤੇ metric definition version ਦਿਖਾਓ। ਇਹ “ਤਫਸੀਲਾਂ” consistent reporting ਅਤੇ ਬਹਿਸ ਵਿੱਚ ਫਰਕ ਲਿਆਉਂਦੀਆਂ ਹਨ।
ਜੇ ਟੀਮਾਂ ਕਈ variants, ਕਈ metrics ਟੈਸਟ ਕਰ ਰਹੀਆਂ ਹਨ, ਜਾਂ ਦੈਨਿਕ ਨਤੀਜੇ ਦੇਖ ਰਹੀਆਂ ਹਨ, false positives ਵੱਧਦੇ ਹਨ। ਤੁਹਾਡੀ ਐਪ ਨੂੰ policy encode ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ:
ਆਟੋਮੈਟਿਕ ਫਲੈਗ ਜੋ results ਦੇ ਨਜ਼ਦੀਕ ਦਿਖਾਏ ਜਾਣ:
ਅੰਕਾਂ ਦੇ ਨਾਲ ਇੱਕ ਛੋਟੀ ਵਿਆਖਿਆ ਜੋ non-technical ਪਾਠਕ ਭਰੋਸਾ ਕਰ ਸਕੇ, ਜਿਵੇਂ: “ਸਭ ਤੋਂ ਵਧੀਆ ਅੰਦਾਜ਼ਾ +2.1% lift ਹੈ, ਪਰ ਅਸਲੀ ਪ੍ਰਭਾਵ -0.4% ਅਤੇ +4.6% ਦੇ ਵਿਚਕਾਰ ਹੋ ਸਕਦਾ ਹੈ। ਸਾਡੇ ਕੋਲ ਜਿੱਤ ਕਹਿਣ ਲਈ ਕਾਫ਼ੀ ਪੱਕਾ ਸਬੂਤ ਨਹੀਂ ਹੈ।”
ਚੰਗਾ experiment tooling ਲੋਕਾਂ ਨੂੰ ਦੋ ਸਵਾਲ ਜਲਦ ਜਵਾਬ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ: ਅਗਲੇ ਕੀ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ? ਅਤੇ ਸਾਨੂੰ ਇਸ ਬਾਰੇ ਕੀ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ? UI context ਲਈ hunting ਘਟਾਉਂਦੀ ਅਤੇ “decision state” ਨੂੰ explicit ਬਣਾਉਂਦੀ ਹੈ।
ਤਿੰਨ ਪੰਨਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਜ਼ਿਆਦਾਤਰ ਵਰਤੋਂ ਨੂੰ cover ਕਰਦੇ ਹਨ:
List ਅਤੇ product pages 'ਤੇ filters ਤੇਜ਼ ਅਤੇ sticky ਬਣਾਓ: product, owner, date range, status, primary metric, ਅਤੇ segment। ਲੋਕਾਂ ਨੂੰ ਸਕਿੰਟਾਂ ਵਿੱਚ narrow ਕਰਨ ਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
Status ਨੂੰ controlled vocabulary ਵਜੋਂ treat ਕਰੋ, free text ਨਹੀਂ:
Draft → Running → Stopped → Shipped / Rolled back
Status ਹਰ ਜਗ੍ਹਾ ਦਿਖਾਓ (list rows, detail header, share links) ਅਤੇ ਦਰਜ ਕਰੋ ਕਿ ਕਿਸਨੇ ਕਦੋਂ ਤੇ ਕਿਉਂ badਲਿਆ। ਇਹ "quiet launches" ਅਤੇ unclear outcomes ਨੂੰ ਰੋਕਦਾ ਹੈ।
Experiment detail view ਵਿੱਚ, ਇੱਕ compact results table metric ਪ੍ਰਤੀ ਲੀਡ ਕਰੋ:
ਅਗਨੀ charts “More details” ਹਿੱਸੇ ਦੇ ਪਿੱਛੇ ਰੱਖੋ ਤਾਂ decision-makers overwhelm ਨਾ ਹੋਣ।
Analysts ਲਈ CSV export ਅਤੇ stakeholders ਲਈ shareable links ਜੋ permissions ਮੰਨਣ। ਇੱਕ simple “Copy link” ਬਟਨ ਅਤੇ “Export CSV” action ਜ਼ਿਆਦਾ collaboration ਲਈ ਕਾਫੀ ਹੁੰਦਾ ਹੈ।
ਜੇ ਤੁਹਾਡਾ tracker ਕਈ ਉਤਪਾਦਾਂ ਵਿੱਚ ਫੈੱਲਿਆ ਹੈ, access control ਅਤੇ auditability ਵਿਕਲਪ ਨਹੀਂ—ਉਹ ਇਹਨੂੰ ਵ੍ਹੀਕਾਰ ਬਣਾਉਂਦੇ ਹਨ। ਇਹ ਉਹੀ ਚੀਜ਼ਾਂ ਹਨ ਜੋ ਟੂਲ ਨੂੰ ਇੱਕਸਾਰ ਅਪਣਾਉਣਯੋਗ ਬਣਾਉਂਦੀਆਂ ਹਨ।
ਸਧਾਰਨ roles ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ app 'ਚ consistent ਰੱਖੋ:
RBAC decisions centralized ਰੱਖੋ (ਇਕ policy layer), ਤਾਂ ਕਿ UI ਅਤੇ API ਦੋਹਾਂ ਇੱਕੋ ਨਿਯਮ ਲਾਗੂ ਕਰਨ।
ਕਈ ਸੰਸਥਾਵਾਂ ਨੂੰ product-scoped access ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: Team A صرف Product A ਦੇ experiments ਵੇਖ ਸਕਦਾ है ਨਾ ਕਿ Product B। ਇਸਨੂੰ explicit ਮਾਡਲ ਕਰੋ (ਉਦਾਹਰਨ: user ↔ product memberships) ਅਤੇ ਹਰ query ਨੂੰ product ਵੱਲੋਂ filter ਕਰਨ ਯਕੀਨੀ ਬਣਾਓ।
ਸੰਵੇਦਨਸ਼ੀਲ ਕੇਸਾਂ ਲਈ (ਉਦਾਹਰਨ: partner data, regulated segments), row-level restrictions ਜੋੜੋ। ਪ੍ਰਯੋਗਾਂ ਨੂੰ sensitivity level ਨਾਲ tag ਕਰਨ ਅਤੇ ਵੇਖਣ ਲਈ ਵੱਖ permission ਚਾਹੀਦਾ ਹੋ ਸਕਦਾ ਹੈ।
ਦੋ ਚੀਜ਼ਾਂ ਅਲੱਗ-ਅਲੱਗ ਲੌਗ ਕਰੋ:
Change history UI ਵਿੱਚ ਦਿਖਾਓ ਅਤੇ deeper logs investigations ਲਈ ਰੱਖੋ।
Retention rules ਨਿਰਧਾਰਤ ਕਰੋ:
Retention product ਅਤੇ sensitivity ਦੇ ਅਨੁਸਾਰ configurabble ਰੱਖੋ। ਜਦੋਂ ਦਾਤਾ ਮਿਟਾਉਣੀ ਹੋਵੇ, minimal tombstone record (ID, deletion time, reason) ਰੱਖੋ ਤਾਂ reporting integrity ਸੁਰੱਖਿਅਤ ਰਹੇ ਬਿਨਾਂ ਸੰਵੇਦਨਸ਼ੀਲ ਸਮੱਗਰੀ ਰੱਖਣ ਦੇ।
ਇੱਕ tracker ਅਸਲ ਵਿੱਚ ਉਸ ਵੇਲੇ ਬਹੁਤ ਲਾਹੇ ਵਾਲਾ ਬਣਦਾ ਹੈ ਜਦੋਂ ਇਹ ਪੂਰੇ experiment lifecycle ਨੂੰ cover ਕਰੇ—ਸਿਰਫ਼ ਅੰਤਿਮ p-value ਨਹੀਂ। Workflow ਫੀਚਰ scattered docs, tickets, ਅਤੇ charts ਨੂੰ repeatable ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ ਜੋ ਗੁਣਵੱਤਾ ਸੁਧਾਰਦੇ ਹਨ ਅਤੇ ਸਿੱਖਿਆ ਦੁਬਾਰਾ ਵਰਤਣ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
Experiments ਨੂੰ state ਦੀ ਇੱਕ ਲੜੀ ਵਜੋਂ model ਕਰੋ (Draft, In Review, Approved, Running, Ended, Readout Published, Archived)। ਹਰ state ਦੇ "exit criteria" ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ ਕਿ experiments essentials (hypothesis, primary metric, guardrails) ਬਿਨਾਂ ਜ਼ਰੂਰੀ ਚੀਜ਼ਾਂ ਦੇ ਲਾਈਵ ਨਾ ਚੱਲ ਜਾਏਂ।
Approvals ਭਾਰੀ ਨਹੀਂ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ। ਸਧਾਰਨ reviewer step (ਉਦਾਹਰਨ: product + data) ਅਤੇ approval ਦਾ audit trail ਕਾਫੀ ਹੈ। ਮੁਕੰਮਲ ਹੋਣ 'ਤੇ, experiment ਨੂੰ "Published" ਮਾਰਕ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਛੋਟੀ post‑mortem ਲਾਜ਼ਮੀ ਕਰੋ ਤਾਂ ਕਿ results ਅਤੇ context capture ਹੋ ਸਕੇ।
Templates ਸ਼ਾਮਲ ਕਰੋ:
Templates "blank page" friction ਘਟਾਉਂਦੀਆਂ ਹਨ ਅਤੇ reviews ਤੇਜ਼ ਕਰਦੀਆਂ ਹਨ। ਉਨ੍ਹਾਂ ਨੂੰ product-ਵੇਖੇ editable ਰੱਖੋ ਪਰ ਇੱਕ common core preserve ਕਰੋ।
Experiments ਅਕਸਰ ਇਕੱਲੇ ਨਹੀਂ ਰਹਿੰਦੇ—ਲੋਕ surrounding context ਚਾਹੀਦਾ ਹੈ। ਯੂਜ਼ਰਾਂ ਨੂੰ tickets/specs ਅਤੇ related writeups attach ਕਰਨ ਦਿਓ (ਉਦਾਹਰਨ: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist)। Structured “Learning” fields ਰੱਖੋ ਜਿਵੇਂ:
Guardrails regress (ਉਦਾਹਰਨ: error rate, cancellations) ਜਾਂ late data/metric recalculation ਤੋਂ ਬਾਅਦ results materially change ਹੋਣ 'ਤੇ notifications support ਕਰੋ। Alerts actionable ਬਣਾਓ: metric, threshold, timeframe, ਅਤੇ ਇੱਕ owner ਦਿਖਾਓ ਜੋ acknowledge ਜਾਂ escalate ਕਰੇ।
ਇੱਕ library ਦਿਓ ਜੋ product, feature area, audience, metric, outcome, ਅਤੇ tags ਦੁਆਰਾ filter ਕਰ ਸਕੇ (ਉਦਾਹਰਨ: “pricing,” “onboarding,” “mobile”)। “Similar experiments” ਸੁਝਾਅ ਸ਼ਾਮਲ ਕਰੋ shared tags/metrics ਦੇ ਆਧਾਰ 'ਤੇ ਤਾਂ ਕਿ ਟੀਮਾਂ ਉਹੀ ਟੈਸਟ ਦੁਬਾਰਾ ਨਾ ਚਲਾਉਣ ਅਤੇ ਪਹਿਲਾਂ ਦੀਆਂ ਸਿੱਖਿਆਵਾਂ 'ਤੇ ਬਣਾਉਣ।
ਤੁਹਾਨੂੰ perfect stack ਦੀ ਲੋੜ ਨਹੀਂ ਕਿ experiment tracking web app ਬਣਾਉਣ ਲਈ—ਪਰ ਤੁਹਾਨੂੰ ਸਪਸ਼ਟ ਸਿਮਾਵਾਂ ਲੋੜੀਆਂ ਹਨ: ডਾਟਾ ਕਿੱਥੇ ਰਹੇਗਾ, ਲੱਕੜੀ ਕਿੱਥੇ ਚਲੇਗੀ, ਅਤੇ ਟੀਮਾਂ ਨਤੀਜਿਆਂ ਤੱਕ ਕਿਵੇਂ ਪਹੁੰਚਣਗੀਆਂ।
ਕਈ ਟੀਮਾਂ ਲਈ ਇੱਕ ਸਾਦਾ ਅਤੇ ਸਕੇਲ ਕਰਨ ਯੋਗ setup ਇਸ ਤਰ੍ਹਾਂ ਲੱਗਦਾ ਹੈ:
ਇਹ ਵੰਡ transactional workflows ਨੂੰ ਤੇਜ਼ ਰੱਖਦੀ ਹੈ ਜਦਕਿ warehouse heavy computation ਨੂੰ ਕੈਂਦਰਿਤ ਕਰਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ workflow UI (experiments list → detail → readout) ਨੂੰ prototype ਕਰਨ ਚਾਹੁੰਦੇ ਹੋ, ਇੱਕ vibe-coding platform ਵਰਗਾ Koder.ai ਤੁਹਾਨੂੰ React + backend foundation chat spec ਤੋਂ ਜਨਰੇਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ entities, forms, RBAC scaffolding, ਅਤੇ audit-friendly CRUD ਲਿਆਉਂਦਾ ਹੈ, ਫਿਰ analytics ਟੀਮ ਨਾਲ data contracts iterate ਕਰਨ ਲਈ ਸੌਖਾ ਬਣਾਉਂਦਾ ਹੈ।
ਤੁਹਾਡੇ ਕੋਲ ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਵਿਕਲਪ ਹੁੰਦੇ ਹਨ:
ਜੇ ਤੁਹਾਡੀ ਡਾਟਾ ਟੀਮ ਪਹਿਲਾਂ ਹੀ trusted SQL ਰੱਖਦੀ ਹੈ ਤਾਂ warehouse-first ਆਮ ਤੌਰ ਤੇ ਸਭ ਤੋਂ ਸਧਾਰਨ ਹੈ। backend-heavy low-latency updates ਲਈ ਚੰਗਾ ਹੈ ਪਰ application complexity ਵਧਾਂਦਾ ਹੈ।
Experiment dashboards ਅਕਸਰ ਇੱਕੋ queries ਦੁਹਰਾਉਂਦੇ ਹਨ (top-line KPIs, time series, segment cuts)। ਯੋਜਨਾ ਬਣਾਓ:
ਜੇ ਤੁਸੀਂ ਬਹੁਤ ਸਾਰੇ products ਜਾਂ business units support ਕਰਦੇ ਹੋ, ਪਹਿਲਾਂ ਨਿਰਧਾਰਤ ਕਰੋ:
ਆਮ ਸਹਿਮਤੀ shared infrastructure ਹੈ ਜਿਸ ਵਿੱਚ ਇੱਕ ਮਜ਼ਬੂਤ tenant_id ਮਾਡਲ ਅਤੇ ਲਾਗੂ ਰੋ-ਲੇਵਲ access ਹੁੰਦੀ ਹੈ।
API surface ਛੋਟਾ ਅਤੇ explicit ਰੱਖੋ। ਜ਼ਿਆਦਾਤਰ ਸਿਸਟਮਾਂ ਨੂੰ endpoints ਚਾਹੀਦੀਆਂ ਹੁੰਦੀਆਂ ਹਨ: experiments, metrics, results, segments, ਅਤੇ permissions ( ਨਾਲ ਹੀ audit-friendly reads)। ਇਸ ਨਾਲ ਨਵੇਂ products add ਕਰਨ ਆਸਾਨੀ ਰਹਿੰਦੀ ਹੈ।
ਇੱਕ experiment tracker ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਲਾਭਕਾਰੀ ਹੈ ਜਦੋਂ ਲੋਕ ਉਸ 'ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹਨ। ਇਹ ਭਰੋਸਾ disciplined testing, ਸਪੱਸ਼ਟ monitoring, ਅਤੇ predictable operations ਤੋਂ ਆਉਂਦਾ ਹੈ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਕਈ ਉਤਪਾਦ ਅਤੇ pipelines ਇਕੱਠੇ ਦਾਤਾ ਦੇ ਰਹੇ ਹੁੰਦੇ ਹਨ।
ਹਰ critical step ਲਈ structured logging ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: event ingestion, assignment, metric rollups, result computation। identifiers ਸ਼ਾਮਲ ਕਰੋ ਜਿਵੇਂ product, experiment_id, metric_id, ਅਤੇ pipeline run_id ਤਾਂ ਕਿ support ਇੱਕ ਨਤੀਜੇ ਨੂੰ ਉਸਦੇ inputs ਤੱਕ ਤੱਕ ਪਾ ਸਕੇ।
System metrics (API latency, job runtimes, queue depth) ਅਤੇ data metrics (events processed, % late events, % dropped by validation) ਸ਼ਾਮਲ ਕਰੋ। tracing across services ਨਾਲ ਪੁੱਛ ਸਕੋ, “ਇਹ experiment ਕਿਉਂ ਕੱਲ੍ਹ ਦਾ data missing ਹੈ?”
Data freshness checks silent failures ਨੂੰ ਰੋਕਣ ਲਈ ਸਭ ਤੋਂ ਤੇਜ਼ ਹਨ। ਜੇ SLA "daily by 9am" ਹੈ, freshness per product ਅਤੇ per source monitor ਕਰੋ ਅਤੇ alert ਕਰੋ ਜਦੋਂ:
ਤਿੰਨ ਪੱਧਰਾਂ ਤੇ tests ਬਣਾਓ:
ਇੱਕ ਛੋਟੀ “golden dataset” ਰੱਖੋ ਜਿਸਦੇ ਜਾਣੇ-ਪਛਾਣੇ outputs ਹਨ ਤਾਂ ਕਿ regressions production ਵਿੱਚ ਜਾ ਕੇ ਫਸਣ ਤੋਂ ਪਹਿਲਾਂ ਫੜੇ ਜਾ ਸਕਨ।
Migrations ਨੂੰ operations ਦਾ ਹਿੱਸਾ ਸਮਝੋ: metric definitions ਅਤੇ result computation logic ਨੂੰ version ਕਰੋ, ਅਤੇ historical experiments rewrite ਕਰਨ ਤੋਂ ਬਚੋ ਜਦ ਤੱਕ ਖਾਸ ਤੌਰ 'ਤੇ ਮੰਗਿਆ ਨਾ ਜਾਵੇ। ਜਦੋਂ ਬਦਲਾਅ ਲਾਜ਼ਮੀ ਹੋਵੇ, controlled backfill path ਦਿਓ ਅਤੇ audit trail ਵਿੱਚ ਕੀ ਬਦਲਿਆ ਦਸਤਾਵੇਜ਼ ਕਰੋ।
ਇੱਕ admin view ਦਿਓ ਜੋ specific experiment/date range ਲਈ pipeline re-run ਕਰੇ, validation errors inspect ਕਰਨ ਦਿਓ, ਅਤੇ incidents ਨੂੰ status updates ਨਾਲ mark ਕਰਨ ਦੀ ਸਹੂਲਤ ਦਿਓ। incident notes ਨੂੰ प्रभावित experiments ਤੋਂ link ਕਰੋ ਤਾਂ ਕਿ ਯੂਜ਼ਰਾਂ ਨੂੰ delays ਦੇ ਕਾਰਨ ਪਤਾ ਲੱਗੇ ਅਤੇ ਉਹ ਅਧੂਰੇ data 'ਤੇ ਫੈਸਲੇ ਨਾ ਕਰਨ।
Experiment tracking web app ਦਾ rollout "launch day" ਤੋਂ ਘੱਟ ਅਤੇ ambiguity ਘਟਾਉਣ ਦੀ ਲਗਾਤਾਰ ਪ੍ਰਕਿਰਿਆ 'ਤੇ ਜ਼ਿਆਦਾ ਨਿਰਭਰ ਹੈ: ਕੀ track ਕੀਤਾ ਜਾ ਰਿਹਾ, ਕਿਸਦਾ ਮਾਲਕ ਹੈ, ਅਤੇ ਅੰਕਾਂ ਹਕੀਕਤ ਨਾਲ ਮਿਲਦੇ ਹਨ ਕਿ ਨਹੀਂ।
ਇੱਕ ਉਤਪਾਦ ਅਤੇ ਇੱਕ ਛੋਟੀ, high-confidence metric set (ਉਦਾਹਰਨ: conversion, activation, revenue) ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਉਦੇਸ਼ end-to-end workflow validate ਕਰਨਾ ਹੈ—experiment ਬਣਾਉਣ, exposure ਅਤੇ outcomes capture, results calculate, ਅਤੇ decision record—ਫਿਰ ਜটਿਲਤਾ ਵਧਾਓ।
ਪਹਿਲਾ ਉਤਪਾਦ stable ਹੋਣ ਤੇ, product-by-product expand ਕਰੋ predictable onboarding cadence ਨਾਲ। ਹਰ ਨਵਾਂ ਉਤਪਾਦ repeatable setup ਵਾਂਗ ਮਹਿਸੂਸ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਨਾ ਕਿ ਇੱਕ custom project।
ਜੇ ਤੁਸੀਂ ਲੰਬੇ "platform build" ਚੱਕਰਾਂ ਵਿੱਚ ਫਸਦੇ ਹੋ, ਦੋ-ਟਰੈਕ ਦ੍ਰਿਸ਼ਟੀਯੋਗ ਰੱਖੋ: durable data contracts (events, IDs, metric definitions) ਇੱਕ ਪਾਸੇ ਤੇ ਅਤੇ ਇੱਕ ਪਤਲਾ application layer ਦੂਜੇ ਪਾਸੇ। ਕਈ ਸਮੇਂ Koder.ai ਵਰਗੀਆਂ ਸੇਵਾਵਾਂ ਨਾਲ ਪਤਲਾ layer ਤੇਜ਼ੀ ਨਾਲ ਖੜਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ—forms, dashboards, permissions, export—ਫਿਰ adoption ਵਧਣ 'ਤੇ ਇਸਨੂੰ harden ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਇੱਕ ਹਲਕੀ ਚੈੱਕਲਿਸਟ ਵਰਤੋ:
ਜਿੱਥੇ ਮਦਦ ਮਿਲਦੀ ਹੈ adoption, experiment results ਤੋਂ relevant product areas ਲਈ "next steps" link ਕਰੋ (ਉਦਾਹਰਨ: pricing-related experiments ਨੂੰ /pricing)। Links ਜਾਣਕਾਰੀ ਅਤੇ neutral ਰਹਿਣ—ਕੋਈ implied outcomes ਨਹੀਂ।
ਟੂਲ default decision ਸਥਾਨ ਬਣ ਰਿਹਾ ਹੈ ਜਾਂ ਨਹੀਂ, ਮਾਪੋ:
ਅਮਲ ਵਿੱਚ, ਜ਼ਿਆਦਾਤਰ rollouts ਕੁਝ ਮੁੱਖ ਗਲਤੀਆਂ 'ਤੇ ਫਸਦੇ ਹਨ:
Start by centralizing the final, agreed record of each experiment:
You can link out to feature-flag tools and analytics systems, but the tracker should own the structured history so results stay searchable and comparable over time.
No—keep the scope focused on tracking and reporting results.
A practical MVP:
This avoids rebuilding your entire experimentation platform while still fixing “scattered results.”
A minimum model that works across teams is:
Use stable IDs and treat display names as editable labels:
product_id: never changes, even if the product name doesexperiment_id: immutable internal IDexperiment_key: readable slug (can be enforced unique per product)Make “success criteria” explicit at setup time:
This structure reduces debates later because readers can see what “winning” meant before the test ran.
Create a canonical metric catalog with:
When the logic changes, publish a new metric version instead of editing history—then store which version each experiment used.
At minimum, you need reliable joins between exposure and outcomes:
Then automate checks like:
Pick one “dialect” and standardize UI terms and thresholds:
Whichever you choose, always show:
Treat access control as foundational, not a later add-on:
Also keep two audit trails:
Roll out in a repeatable sequence:
Avoid common pitfalls:
product_id)experiment_id + human-friendly experiment_key)control, treatment_a, etc.)Add Segment and Time window early if you expect consistent slicing (e.g., new vs returning, 7-day vs 30-day).
variant_key: stable strings like control, treatment_aThis prevents collisions and makes cross-product reporting reliable when naming conventions drift.
Surface these as warnings on the experiment page so they’re hard to ignore.
Consistency matters more than sophistication for org-wide trust.
This is what makes the tracker safe to adopt across products and teams.