ਸੈਮੈਂਟਿਕ ਖੋਜ ਦਾ ਮਤਲਬ (ਬਿਨਾਂ ਜ਼ਿਆਦਾ ਜਾਰਗਨ ਦੇ)
ਸੈਮੈਂਟਿਕ ਖੋਜ ਉਹ ਤਰੀਕਾ ਹੈ ਜੋ ਤੁਹਾਡੇ ਦੇ ਮਤਲਬ 'ਤੇ ਧਿਆਨ ਦਿੰਦਾ ਹੈ, ਸਿਰਫ਼ ਲਫ਼ਜ਼ਾਂ 'ਤੇ ਨਹੀਂ।
ਜੇ ਤੁਸੀਂ ਕਦੇ ਖੋਜ ਕੀਤੀ ਅਤੇ ਸੋਚਿਆ, “ਜਵਾਬ ਇੱਥੇ ਹੀ ਹੈ—ਫਿਰ ਇਹ ਕਿਵੇਂ ਨਹੀਂ ਲੱਭ ਰਿਹਾ?”, ਤਾਂ ਤੁਸੀਂ keyword search ਦੀਆਂ ਹੱਦਾਂ ਮਹਿਸੂਸ ਕੀਤੀਆਂ। ਰਵਾਇਤੀ ਖੋਜ ਸ਼ਬਦਾਂ ਨੂੰ ਮਿਲਦੀ ਹੈ। ਇਹ ਉਸ ਵੇਲੇ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਪ੍ਰਸ਼ਨ ਅਤੇ ਸਮਗਰੀ ਵਿਚ ਲਫ਼ਜ਼ ਮਿਲਦੇ ਹੋਣ।
ਕਿਉਂ keyword search ਅਕਸਰ ਗਲਤ ਨਿਕਲਦੀ ਹੈ
Keyword search ਵਿੱਚ ਮੁਸ਼ਕਿਲਾਂ ਹੁੰਦੀਆਂ ਹਨ:
- ਸਮਾਨ ਅਰਥ ਵਾਲੇ ਸ਼ਬਦ ਅਤੇ ਫਰੇਜ਼ਿੰਗ: “cancel” vs “close” vs “terminate” an account.
- ਇਰਾਦਾ: “how do I stop being billed?” ਦਰਅਸਲ subscription cancel ਕਰਨ ਦੀ ਗੱਲ ਹੈ.
- ਸੰਦਰਭ: “apple charger” (ਬ੍ਰਾਂਡ) vs “apple tree charger” (ਬੇਸਰ) — ਖ਼ਿਆਲ ਸਮਝ ਆ ਰਿਹਾ ਹੈ।
ਇਹ ਵਾਰ-ਵਾਰ ਆਏ ਸ਼ਬਦਾਂ ਨੂੰ ਬਹੁਤ ਉੱਚਾ ਵਜ਼ਨ ਦੇ ਸਕਦਾ ਹੈ, ਨਤੀਜੇ ਸਤਹ 'ਤੇ ਸਬੰਧਿਤ ਦਿੱਸ ਸਕਦੇ ਹਨ ਪਰ ਉਹ ਸਫ਼ਾ ਜੋ ਵੱਖਰੇ ਸ਼ਬਦਾਂ ਵਿੱਚ ਬੇਹਤਰੀਨ ਜਵਾਬ ਦਿੰਦਾ ਹੈ, ਗੁਆਚ ਸਕਦਾ ਹੈ।
ਇੱਕ ਸਧਾਰਣ ਉਦਾਹਰਣ
ਕਲਪਨਾ ਕਰੋ ਇੱਕ help center ਵਿੱਚ ਆਲੇਖ ਹੈ ਜਿਸਦਾ ਸਿਰਲੇਖ “Pause or cancel your subscription.” ਇੱਕ ਯੂਜ਼ਰ ਸರ್ಚ ਕਰਦਾ:
“stop my payments next month”
ਜੇ ਆਲੇਖ ਵਿੱਚ “stop” ਜਾਂ “payments” ਨਹੀਂ ਹੈ, ਤਾਂ keyword ਸਿਸਟਮ ਉਸਨੂੰ ਉੱਚ ਰੈਂਕ ਨਹੀਂ ਦੇ ਸਕਦਾ। ਸੈਮੈਂਟਿਕ ਖੋਜ ਸਮਝਣ ਲਈ ਬਣਾਈ ਗਈ ਹੈ ਕਿ “stop my payments” ਅਤੇ “cancel subscription” ਕਹਿਣ ਦਾ ਮਤਲਬ ਇੱਕੋ ਜਿਹਾ ਹੈ, ਅਤੇ ਉਹਹੇ ਆਲੇਖ ਸਿਖਰ ਤੇ ਲਿਆ ਸਕਦੀ ਹੈ—ਕਿਉਂਕਿ ਅਰਥ ਮੇਲ ਖਾਂਦਾ ਹੈ।
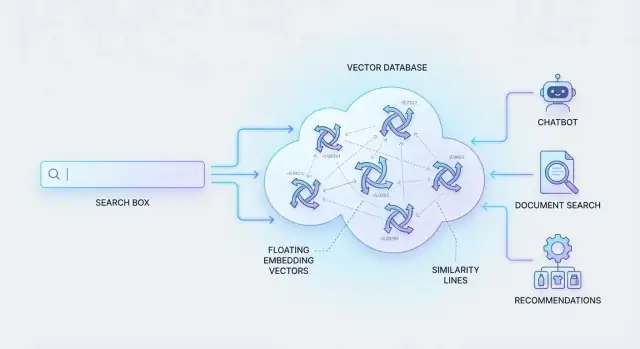
ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਇੱਥੇ ਕਿਉਂ ਲੋੜੀਂਦੇ ਹਨ
ਇਸ ਨੂੰ ਕੰਮ ਕਰਵਾਉਣ ਲਈ, ਸਿਸਟਮ ਸਮਗਰੀ ਅਤੇ ਕ੍ਵੈਰੀਆਂ ਨੂੰ “ਮਾਨਤਾ ਦੇ ਫਿੰਗਰਪ੍ਰਿੰਟ” (ਉਹ ਨੰਬਰ ਜੋ ਸਮਾਨਤਾ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ) ਵਜੋਂ ਦਰਸਾਉਂਦੇ ਹਨ। ਫਿਰ ਉਹਨਾਂ ਫਿੰਗਰਪ੍ਰਿੰਟਾਂ ਵਿੱਚੋਂ ਲੱਖਾਂ ਤੱਕ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਖੋਜਣ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਇਹੀ ਕੰਮ ਵੈਕਟਰ ਡੇਟਾਬੇਸ ਲਈ ਬਣਾਇਆ ਗਿਆ ਹੈ: ਇਹ ਨੰਬਰਾਤਮਕ ਪ੍ਰਤੀਨਿਧੀਆਂ ਨੂੰ ਸਟੋਰ ਕਰਦੇ ਹਨ ਅਤੇ ਸਭ ਤੋਂ ਸਮਾਨ ਮੈਚਾਂ ਨੂੰ ਕੁਸ਼ਲਤਾ ਨਾਲ ਰਿਟਰੀਵ ਕਰਦੇ ਹਨ, ਤਾਂ ਜੋ ਸੈਮੈਂਟਿਕ ਖੋਜ ਵੱਡੇ ਪੈਮਾਨੇ 'ਤੇ ਵੀ ਤੁਰੰਤ ਮਹਿਸੂਸ ਹੋਵੇ।
ਐਂਬੈਡਿੰਗ: ਸਮਗਰੀ ਨੂੰ ਮਾਇਨੇ ਵਾਲੇ ਵੇਕਟਰ ਵਿੱਚ ਬਦਲਣਾ
ਐਂਬੈਡਿੰਗ ਇੱਕ ਨੰਬਰਾਤਮਕ ਪ੍ਰਤੀਨਿਧੀ ਹੈ ਜੋ ਮਾਨਤਾ ਦਰਸਾਉਂਦੀ ਹੈ। ਇੱਕ ਦਸਤਾਵੇਜ਼ ਨੂੰ keywords ਨਾਲ ਵਰਣਨ ਕਰਨ ਦੀ ਬਜਾਏ, ਤੁਸੀਂ ਇਸਨੂੰ ਨੰਬਰਾਂ ਦੀ ਇੱਕ ਲੜੀ (ਇੱਕ “ਵੇਕਟਰ”) ਦੇ ਰੂਪ ਵਿੱਚ ਦਰਸਾਉਂਦੇ ਹੋ ਜੋ ਸਮੱਗਰੀ ਦਾ ਮੂਲ ਮਤਲਬ ਕੈਪਚਰ ਕਰਦੀ ਹੈ। ਦੋ ਸਮੱਗਰੀ ਦੇ ਟੁਕੜੇ ਜਿਨ੍ਹਾਂ ਦਾ ਅਰਥ ਮਿਲਦਾ ਹੈ, ਉਹਨਾਂ ਦੇ ਵੇਕਟਰ ਨਿਕਟ ਇੱਕ ਦੂਜੇ ਦੇ ਹੋਂਦੇ ਹਨ।
ਇੱਕ ਐਂਬੈਡਿੰਗ ਅਸਲ ਵਿੱਚ ਕੀ ਲੱਗਦੀ ਹੈ
ਇੱਕ ਐਂਬੈਡਿੰਗ ਨੂੰ ਇੱਕ ਬਹੁ-ਮਾਪੀ ਨਕਸ਼ੇ ਉੱਤੇ ਕੋਆਰਡੀਨੈਟ ਸਮਝੋ। ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਨੰਬਰ ਸਿੱਧੇ ਨਹੀਂ ਪੜ੍ਹਦੇ—ਉਹ ਮਨੁੱਖ-ਮਿਤ੍ਰ ਨਹੀਂ ਹਨ। ਉਹਨਾਂ ਦੀ ਕੀਮਤ ਇਸਦੇ ਵਿਹਾਰ ਵਿੱਚ ਹੈ: ਜੇ “cancel my subscription” ਅਤੇ “how do I stop my plan?” ਨੇ ਨੇੜਲੇ ਵੇਕਟਰ ਬਣਾਏ, ਤਾਂ ਸਿਸਟਮ ਉਹਨਾਂ ਨੂੰ ਸੰਬੰਧਤ ਮੰਨ ਸਕਦਾ ਹੈ ਭਾਵੇਂ ਸ਼ਬਦ ਮਿਲਦੇ-ਜੁਲਦੇ ਹੀ ਨਾ ਹੋਣ।
ਟੈਕਸਟ, ਚਿੱਤਰ, ਅਤੇ ਆਡੀਓ ਵੀ ਵੇਕਟਰ ਬਣ ਸਕਦੇ ਹਨ
ਐਂਬੈਡਿੰਗ ਸਿਰਫ਼ ਟੈਕਸਟ ਲਈ ਨਹੀਂ ਹਨ।
- Text embeddings ਸੈਂਟੈਂਸ, ਪੈਰਾ, ਸਹਾਇਤਾ ਟਿਕਟ, ਪ੍ਰੋਡਕਟ ਵੇਰਵੇ ਆਦਿ ਦਰਸਾਉਂਦੇ ਹਨ।
- Image embeddings ਵਿਜ਼ੁਅਲ ਸਮਾਨਤਾ ਅਤੇ ਧਾਰਣਾਵਾਂ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ (ਜਿਵੇਂ “ਲਾਲ ਰਨਿੰਗ ਸ਼ੂਜ਼”).
- Audio embeddings ਬੋਲਣ ਵਾਲੇ, ਟੋਨ, ਜਾਂ ਬੋਲੀ ਦੇ ਅਰਥ ਨੂੰ ਦਰਸਾ ਸਕਦੇ ਹਨ ਜਦੋਂ speech models ਨਾਲ ਜੋੜਿਆ ਜਾਵੇ।
ਇਸ ਤਰ੍ਹਾਂ ਇੱਕ ਹੀ ਵੇਕਟਰ ਡੇਟਾਬੇਸ “ਇਮੇਜ ਨਾਲ ਖੋਜ”, “ਸਮਾਨ ਗੀਤ ਲੱਭੋ”, ਜਾਂ “ਇਸ ਵਰਗੇ ਪ੍ਰੋਡਕਟ ਸੁਝਾਓ” ਵਰਗੀਆਂ ਜ਼ਰੂਰਤਾਂ ਨੂੰ ਸਪੋਰਟ ਕਰ ਸਕਦਾ ਹੈ।
ਇਹ ਮਾਡਲਾਂ ਦੁਆਰਾ ਬਣਦੇ ਹਨ—ਹੱਥੋਂ ਨਹੀਂ
ਵੇਕਟਰ ਹੱਥੋਂ ਟੈਗ ਕਰਨ ਨਾਲ ਨਹੀਂ ਆਉਂਦੇ। ਇਹ ਮਸ਼ੀਨ-ਲਰਨਿੰਗ ਮਾਡਲਾਂ ਦੁਆਰਾ ਤਿਆਰ ਕੀਤੇ ਜਾਂਦੇ ਹਨ ਜੋ ਅਰਥ ਨੂੰ ਨੰਬਰਾਂ ਵਿੱਚ ਕੰਪ੍ਰੈੱਸ ਕਰਦੇ ਹਨ। ਤੁਸੀਂ ਸਮੱਗਰੀ ਨੂੰ ਇਕ ਐਂਬੈਡਿੰਗ ਮਾਡਲ (ਆਪਣੇ-host ਕੀਤੇ ਜਾਂ ਪ੍ਰੋਵਾਇਡਰ ਵੱਲੋਂ) ਵਿੱਚ ਭੇਜਦੇ ਹੋ, ਅਤੇ ਉਹ ਇੱਕ ਵੇਕਟਰ ਵਾਪਸ ਕਰਦਾ ਹੈ। ਤੁਹਾਡੀ ਐਪ ਉਹ ਵੇਕਟਰ ਮੁਲਕ ਸਮਗਰੀ ਅਤੇ ਮੈਟਾ ਡੇਟਾ ਦੇ ਨਾਲ ਸਟੋਰ ਕਰਦੀ ਹੈ।
ਐਂਬੈਡਿੰਗ ਚੋਣ ਗੁਣਵੱਤਾ ਅਤੇ ਲਾਗਤ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਉਂਦੀ ਹੈ
ਜੋ ਐਂਬੈਡਿੰਗ ਮਾਡਲ ਤੁਸੀਂ ਚੁਣਦੇ ਹੋ, ਉਹ ਨਤੀਜਿਆਂ ਨੂੰ ਬਹੁਤ ਪ੍ਰਭਾਵਤ ਕਰਦਾ ਹੈ। ਵੱਡੇ ਜਾਂ ਵਿਰਿਸ਼ਟ ਮਾਡਲ ਆਮ ਤੌਰ ਤੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਪ੍ਰਸੰਗਿਕਤਾ ਦਿੰਦੇ ਹਨ ਪਰ ਮਹਿੰਗੇ (ਅਤੇ ਕਦੇ-ਕਦੇ ਧੀਮੇ) ਹੁੰਦੇ ਹਨ। ਛੋਟੇ ਮਾਡਲ ਸਸਤੇ ਅਤੇ ਤੇਜ਼ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਵਿਸ਼ੇਸ਼ ਡੋਮੇਨ ਭਾਸ਼ਾ, ਬਹੁਭਾਸ਼ੀ ਸਮੱਗਰੀ, ਜਾਂ ਛੋਟੇ ਕ੍ਵੈਰੀਆਂ ਦੀ ਸੁਭਾਵਕਤਾ ਨੂੰ ਛੱਡ ਸਕਦੇ ਹਨ। ਬਹੁਤੀਆਂ ਟੀਮਾਂ ਪਹਿਲਾਂ ਕੁੱਝ ਮਾਡਲਾਂ ਦੀ ਪਰੀਖਿਆ ਕਰਦੀਆਂ ਹਨ ਤਾਂ ਜੋ ਸਭ ਤੋਂ ਚੰਗਾ ਟਰੇਡ-ਆਫ਼ ਲਭ ਸਕਣ।
ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਡੇਟਾ ਕਿਵੇਂ ਸਟੋਰ ਕਰਦੇ ਹਨ
ਇੱਕ ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਸਾਦੇ ਵਿਚਾਰ 'ਤੇ ਬਣਿਆ ਹੈ: “ਮਾਨਤਾ” (ਇੱਕ ਵੇਕਟਰ) ਨੂੰ ਉਸ ਜਾਣਕਾਰੀ ਦੇ ਨਾਲ ਸਟੋਰ ਕਰੋ ਜੋ ਤੁਹਾਨੂੰ ਨਤੀਜੇ ਪਛਾਣਨ, ਫਿਲਟਰ ਕਰਨ ਅਤੇ ਦਿਖਾਉਣ ਲਈ ਚਾਹੀਦੀ ਹੈ।
ਮੂਲ ਡੇਟਾ ਮਾਡਲ
ਜਿਆਦਾਤਰ ਰਿਕਾਰਡ ਇਸ ਤਰ੍ਹਾਂ ਦੇਖਦੇ ਹਨ:
- ID: ਇੱਕ ਯੂਨੀਕ ਆਈਡੈਂਟੀਫਾਇਰ ਜੋ ਤੁਸੀਂ ਕੰਟਰੋਲ ਕਰਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ
doc_18492 ਜਾਂ UUID)
- Vector (embedding): ਸਮੱਗਰੀ ਦੇ ਮਤਲਬ ਨੂੰ ਦਰਸਾਉਂਣ ਵਾਲੀ ਨੰਬਰਾਂ ਦੀ ਲੜੀ
- Metadata: key–value ਫੀਲਡ ਜਿਵੇਂ title, URL, tags, author, language, created_at, ਜਾਂ tenant_id
ਉਦਾਹਰਣ ਲਈ, ਇੱਕ help-center ਆਲੇਖ ਸਟੋਰ ਕਰ ਸਕਦਾ ਹੈ:
- ID:
kb_123
- Vector: 768 floating-point numbers (for a common embedding model)
- Metadata:
{ \"title\": \"Reset your password\", \"url\": \"/help/reset-password\", \"tags\": [\"account\", \"security\"] }
ਵੇਕਟਰ ਉਹ ਚੀਜ਼ ਹੈ ਜੋ ਸੈਮੈਂਟਿਕ ਸਮਾਨਤਾ ਚਲਾਉਂਦੀ ਹੈ। ID ਅਤੇ metadata ਉਹ ਹਨ ਜੋ ਨਤੀਜਿਆਂ ਨੂੰ ਵਰਤਣਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
ਮੈਟਾ ਡੇਟਾ ਕਿਸ ਲਈ ਜ਼ਰੂਰੀ ਹੈ (ਲੋਕਾਂ ਤੋਂ ਵਧ ਕੇ)
Metadata ਦੋ ਕੰਮ ਕਰਦਾ ਹੈ:
- Vector search ਤੋਂ ਪਹਿਲਾਂ/ਬਾਅਦ ਫਿਲਟਰਿੰਗ: “ਸਿਰਫ਼ ਪ੍ਰੋਡਕਟ X ਤੋਂ ਨਤੀਜੇ ਦਿਖਾਓ”, “ਸਿਰਫ਼ English”, “ਸਿਰਫ਼ ਉਹ ਦਸਤਾਵੇਜ਼ ਜੋ ਯੂਜ਼ਰ ਦੇ ਕੋਲ ਐਕਸੈੱਸ ਹਨ”, ਜਾਂ “ਸਿਰਫ਼ 90 ਦਿਨਾਂ ਤੋਂ ਨਵੇਂ ਆਈਟਮ”. ਇਹ relevance ਅਤੇ access control ਲਈ ਜ਼ਰੂਰੀ ਹੈ।
- ਡਿਸਪਲੇਅ ਅਤੇ ਕਾਰਵਾਈਆਂ: ਯੂਜ਼ਰ ਨੂੰ ਇੱਕ ਵੇਕਟਰ ਨਹੀਂ ਚਾਹੀਦਾ—ਉਹ ਇੱਕ title, ਇੱਕ snippet, ਅਤੇ ਇੱਕ link (URL) ਚਾਹੁੰਦੇ ਹਨ। Metadata ਉਹ ਵੇਰਵਾ ਦਿੰਦੀ ਹੈ ਜੋ ਤੁਹਾਡੇ UI ਨੂੰ ਚਾਹੀਦਾ ਹੈ।
ਵਧੀਆ metadata ਬਿਨਾਂ, ਤੁਸੀਂ ਸਹੀ ਅਰਥ ਰਿਟਰੀਵ ਕਰ ਸਕਦੇ ਹੋ ਪਰ ਫਿਰ ਵੀ ਗਲਤ ਸੰਦਰਭ ਦਿਖਾ ਸਕਦੇ ਹੋ।
ਆਮ ਵੇਕਟਰ ਆਕਾਰ ਅਤੇ ਸਟੋਰੇਜ ਪ੍ਰਭਾਵ
ਐਂਬੈਡਿੰਗ ਦਾ ਆਕਾਰ ਮਾਡਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ: 384, 768, 1024, ਅਤੇ 1536 ਪਰਿਮਾਣ ਆਮ ਹਨ। ਜ਼ਿਆਦਾ ਮਾਪ ਨੂਕਸਾਨ ਨੂੰ ਕੈਪਚਰ ਕਰ ਸਕਦੇ ਹਨ, ਪਰ ਉਹ ਵੀ ਵਧਾਉਂਦੇ ਹਨ:
- ਸਟੋਰੇਜ (ਹਰ ਰਿਕਾਰਡ ਵਧੇਰੇ ਨੰਬਰ ਸਟੋਰ ਕਰਦਾ ਹੈ)
- ਮੈਮੋਰੀ ਪ੍ਰੈਸ਼ਰ ਤੇਜ਼ ਖੋਜ ਲਈ
- ਇੰਡੈਕਸ ਬਣਾਉਣ ਦਾ ਸਮਾਂ (ਖਾਸ ਕਰਕੇ ANN ਇੰਡੈਕਸਿੰਗ ਨਾਲ)
ਇੱਕ ਰough ਸੰਕੇਤ: ਡਾਇਮੇੰਸ਼ਨ ਦੋਹਰਾ ਹੋਣ ਨਾਲ ਲਾਗਤ ਅਤੇ ਲੇਟੈਂਸੀ ਆਮ ਤੌਰ 'ਤੇ ਵਧਦੀ ਹੈ ਜਦ ਤਕ ਤੁਸੀਂ ਇੰਡੈਕਸਿੰਗ ਵਿਕਲਪ ਜਾਂ ਕੰਪ੍ਰੈਸ਼ਨ ਨਾਲ ਸਮਤੁਲਨ ਨਾ ਕਰੋ।
ਅੱਪਡੇਟ ਪੈਟਰਨ: ਇੰਸਰਟ, ਬਦਲਾਅ, ਅਤੇ ਮਿਟਾਉਣਾ
ਅਸਲ ਡੈਟਾਸੈਟ ਬਦਲਦੇ ਹਨ, ਇਸ ਲਈ ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਸਹਿਯੋਗ ਦਿੰਦੇ ਹਨ:
- Insert: ਨਵੀਂ ਸਮੱਗਰੀ ਉਸ ਦੀ ਐਂਬੈਡਿੰਗ ਅਤੇ metadata ਦੇ ਨਾਲ ਜੋੜੋ
- Update: metadata ਬਦਲੋ (ਜੈਸੇ tags) ਜਾਂ ਵੇਕਟਰ ਨੂੰ ਬਦਲੋ ਜੇ ਸਮੱਗਰੀ ਬਦਲੀ ਹੋਈ ਹੋਵੇ
- Delete: ਪ੍ਰਚੀਨ ਜਾਂ ਰੱਦ ਕੀਤੀ ਸਮੱਗਰੀ ਹਟਾਓ
- Re-embed: ਜਦੋਂ ਤੁਸੀਂ ਐਂਬੈਡਿੰਗ ਮਾਡਲ ਬਦਲੋ, chunking ਬਦਲੋ, ਜਾਂ ਪਾਠ ਨੂੰ ਖਾਸ ਤੌਰ 'ਤੇ ਐਡਿਟ ਕਰੋ ਤਾਂ ਵੇਕਟਰ ਮੁੜ ਗਣਨਾ ਕਰੋ
ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਅੱਪਡੇਟਾਂ ਲਈ ਯੋਜਨਾ ਬਣਾਉਣ ਨਾਲ “stale knowledge” ਦੀ ਸਮੱਸਿਆ ਰੋਕੀ ਜਾ ਸਕਦੀ ਹੈ ਜਿੱਥੇ ਖੋਜ ਉੱਠਾਂ ਸਮੱਗਰੀ ਦੇ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀ ਜੋ ਯੂਜ਼ਰ ਵੇਖਦੇ ਹਨ।
ਸਮਾਨਤਾ ਖੋਜ: "ਨਜ਼ਦੀਕੀ ਮਤਲਬ" ਤੇਜ਼ੀ ਨਾਲ ਲੱਭਣਾ
ਜਦੋਂ ਤੁਹਾਡਾ ਟੈਕਸਟ, ਚਿੱਤਰ, ਜਾਂ ਪ੍ਰੋਡਕਟ ਐਂਬੈਡਿੰਗਾਂ ਵਿੱਚ ਤਬਦੀਲ ਹੋ ਜਾਂਦਾ ਹੈ, ਖੋਜ ਇੱਕ ਜਿਓਮੈਟ੍ਰੀ ਸਮੱਸਿਆ ਬਣ ਜਾਂਦੀ ਹੈ: “ਇਸ ਕ੍ਵੈਰੀ ਵੇਕਟਰ ਦੇ ਸਭ ਤੋਂ ਨੇੜਲੇ ਵੇਕਟਰ ਕਿਹੜੇ ਹਨ?” ਇਸਨੂੰ nearest-neighbor search ਕਹਿੰਦੇ ਹਨ। ਸ਼ਬਦਾਂ ਨੂੰ ਮੇਲ ਕਰਨ ਦੀ ਬਜਾਏ, ਸਿਸਟਮ ਦੋ ਵੇਕਟਰਾਂ ਦੀ ਦੂਰੀ ਮਾਪ ਕੇ ਅਰਥ ਦੀ ਤੁਲਨਾ ਕਰਦਾ ਹੈ।
nearest neighbors ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ
ਹਰ ਸਮੱਗਰੀ ਦੇ ਟੁਕੜੇ ਨੂੰ ਇੱਕ ਬਹੁ-ਮਾਪੀ ਖੇਤਰ ਵਿੱਚ ਇੱਕ ਬਿੰਦੂ ਸੋਚੋ। ਜਦੋਂ ਯੂਜ਼ਰ ਖੋਜ ਕਰਦਾ ਹੈ, ਉਸ ਦੀ ਕ੍ਵੈਰੀ ਨੂੰ ਵੀ ਇੱਕ ਬਿੰਦੂ ਵਿੱਚ ਬਦਲਿਆ ਜਾਂਦਾ ਹੈ। ਸਮਾਨਤਾ ਖੋਜ ਉਹ ਆਈਟਮ ਵਾਪਸ ਕਰਦੀ ਹੈ ਜਿਨ੍ਹਾਂ ਦੇ ਬਿੰਦੂ ਸਭ ਤੋਂ ਨੇੜੇ ਹਨ—ਤੁਹਾਡੇ “nearest neighbors”। ਉਹ ਨੇਬਰ ਅਕਸਰ ਇਰਾਦਾ, ਵਿਸ਼ਾ, ਜਾਂ ਸੰਦਰਭ ਸਾਂਝੇ ਕਰਦੇ ਹਨ, ਭਾਵੇਂ ਉਹ ਸਹੀ-ਸਹੀ ਲਫ਼ਜ਼ ਨਾ ਸਾਂਝੇ ਕਰਦੇ ਹੋਣ।
ਆਮ similarity metrics
ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਕੁਝ ਮਿਆਰੀ ਤਰੀਕੇ ਸਪੋਰਟ ਕਰਦੇ ਹਨ:
- Cosine similarity: ਵੇਕਟਰਾਂ ਦੇ ਕੋਣ ਦੀ ਤੁਲਨਾ ਕਰਦੀ ਹੈ (ਜਦੋਂ ਤੁਸੀਂ ਦਿਸ਼ਾ/ਮਤਲਬ ਨੂੰ ਲੋੜੀਂਦਾ ਸਮਝਦੇ ਹੋ ਤਾਂ ਵਧੀਆ)
- Dot product: cosine ਨਾਲ ਜੁੜੀ ਹੈ, ਪਰ ਵੇਕਟਰ ਦੀ ਲੰਬਾਈ ਨਾਲ ਵੀ ਪ੍ਰਭਾਵਿਤ ਹੁੰਦਾ ਹੈ; ਆਮ ਤੌਰ 'ਤੇ ਨਾਰਮਲਾਈਜ਼ਡ embeddings ਨਾਲ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ।
- Euclidean distance: ਬਿੰਦੂਆਂ ਦਰਮਿਆਨ ਸਿੱਧੀ ਲਕੀਰ ਦੀ ਦੂਰੀ (ਕੁਝ ਮਾਡਲਾਂ ਅਤੇ ਡੋਮੇਨ ਲਈ ਉਪਯੋਗੀ)
ਵੱਖ-ਵੱਖ ਐਂਬੈਡਿੰਗ ਮਾਡਲ ਕਿਸੇ ਖਾਸ ਮੈਟ੍ਰਿਕ ਲਈ ਟ੍ਰੇਨ ਹੁੰਦੇ ਹਨ, ਇਸ ਲਈ ਮਾਡਲ ਪ੍ਰਦਾਤਾ ਦੀ ਸੁਝਾਈ ਮੈਟ੍ਰਿਕ ਵਰਤਣਾ ਮਹੱਤਵਪੂਰਣ ਹੈ।
ਸਹੀ ਖੋਜ vs ਤਕਰੀਬੀ (ANN)
ਇੱਕ exact search ਹਰ ਵੇਕਟਰ ਨੂੰ ਚੈੱਕ ਕਰਦੀ ਹੈ ਤਾਂ ਕਿ ਸੱਚੇ nearest neighbors ਲੱਭੇ ਜਾ ਸਕਣ। ਇਹ ਸਹੀ ਹੋ ਸਕਦੀ ਹੈ, ਪਰ ਲੱਖਾਂ ਆਈਟਮਾਂ ਤੇ ਸਕੇਲ ਹੋਣ 'ਤੇ ਇਹ ਧੀਮੀ ਅਤੇ ਮਹਿੰਗੀ ਹੋ ਜਾਂਦੀ ਹੈ।
ਜਿਆਦਾਤਰ ਸਿਸਟਮ approximate nearest neighbor (ANN) search ਵਰਤਦੇ ਹਨ। ANN ਸਮਾਰਟ ਇੰਡੈਕਸਿੰਗ ਸਟਰੱਕਚਰਾਂ ਦੀ ਵਰਤੋਂ ਕਰਦਾ ਹੈ ताकि ਖੋਜ ਦੀ ਰੇਂਜ ਸੰਕੁਚਿਤ ਕੀਤੀ ਜਾ ਸਕੇ। ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਨਤੀਜੇ ਪਾਉਂਦੇ ਹੋ ਜੋ “ਕਾਫੀ ਨੇੜਲੇ” ਹੁੰਦੇ ਹਨ—ਬਹੁਤ ਤੇਜ਼।
ਲੇਟੈਂਸੀ vs ਰੀਕਾਲ ਟਰੇਡ-ਆਫ਼
ANN ਲੋਕਪ੍ਰિય ਹੈ ਕਿਉਂਕਿ ਤੁਹਾਨੂੰ ਆਪਣੇ ਲੋੜਾਂ ਅਨੁਸਾਰ ਟਿਊਨ ਕਰਨ ਦਿੰਦਾ:
- ਘੱਟ ਲੇਟੈਂਸੀ (ਤੇਜ਼ ਜਵਾਬ) ਲਈ ਘੱਟ ਉਮੀਦਵਾਰ ਖੋਜੋ
- ਵਧੀਆ ਰੀਕਾਲ (ਅਸਲ ਚੋਟੀ ਦੇ ਮੈਚ ਹੋਰ ਲੱਭਣਾ) ਲਈ ਹੋਰ ਖੋਜੋ
ਇਹ ਟਿਊਨਿੰਗ ਹੀ ਹੈ ਜੋ ਵੇਕਟਰ ਸਰਚ ਨੂੰ ਅਸਲ ਐਪ ਵਿੱਚ ਚੰਗਾ ਬਨਾਉਂਦੀ ਹੈ: ਤੁਸੀਂ ਜਵਾਬ ਤੇਜ਼ ਰੱਖ ਸਕਦੇ ਹੋ ਪਰ ਫਿਰ ਵੀ ਬਹੁਤ ਪ੍ਰਸੰਗਿਕ ਨਤੀਜੇ ਮੁਹੱਈਆ ਕਰ ਸਕਦੇ ਹੋ।
ਸੈਮੈਂਟਿਕ ਖੋਜ ਵर्कਫਲੋ ਐਂਡ-ਟੂ-ਐਂਡ
ਸੈਮੈਂਟਿਕ ਖੋਜ ਨੂੰ ਇੱਕ ਸਧਾਰਣ ਪਾਈਪਲਾਈਨ ਵਜੋਂ ਸੋਚਣਾ ਆਸਾਨ ਹੈ: ਤੁਸੀਂ ਪਾਠ ਨੂੰ ਮਤਲਬ ਵਿੱਚ ਬਦਲਦੇ ਹੋ, ਮਿਲਦਾ-ਜੁਲਦਾ ਮਤਲਬ ਲੱਭਦੇ ਹੋ, ਫਿਰ ਸਭ ਤੋਂ ਉਪਯੋਗ ਨਤੀਜੇ ਪੇਸ਼ ਕਰਦੇ ਹੋ।
1) ਕ੍ਵੈਰੀ ਨੂੰ ਐਂਬੈਡ ਕਰੋ
ਇੱਕ ਯੂਜ਼ਰ ਸਵਾਲ ਲਿਖਦਾ ਹੈ (ਉਦਾਹਰਣ: “How do I cancel my plan without losing data?”). ਸਿਸਟਮ ਉਹ ਟੈਕਸਟ ਇੱਕ ਐਂਬੈਡਿੰਗ ਮਾਡਲ ਤੋਂ ਲੰਗਾਂਦਾ ਹੈ, ਜੋ ਇੱਕ ਵੇਕਟਰ ਤਿਆਰ ਕਰਦਾ ਹੈ—ਲਫ਼ਜ਼ਾਂ ਦੀ ਬਜਾਏ ਪ੍ਰਸ਼ਨ ਦੇ ਮਤਲਬ ਨੂੰ ਦਰਸਾਉਂਦੀ ਨੰਬਰਾਂ ਦੀ ਲੜੀ।
2) ਵੇਕਟਰ ਡੇਟਾਬੇਸ 'ਚ ਖੋਜ ਕਰੋ
ਉਹ ਕ੍ਵੈਰੀ ਵੇਕਟਰ ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਨੂੰ ਭੇਜਿਆ ਜਾਂਦਾ ਹੈ, ਜੋ ਤੁਹਾਡੇ ਸਟੋਰ ਕੀਤੇ ਸਮੱਗਰੀ ਵਿਚੋਂ “ਨੇੜਲੇ” ਵੇਕਟਰਾਂ ਦੀ similarity search ਕਰਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਸਿਸਟਮ top-K ਮੈਚ ਰਿਟਰਨ ਕਰਦੇ ਹਨ: K ਸਭ ਤੋਂ ਸਮਾਨ chunks/documents।
- K کیوں configureable ہے: ਛੋਟਾ K ਤੇਜ਼ ਹੁੰਦਾ ਅਤੇ ਅਕਸਰ ਕਾਫੀ ਹੁੰਦਾ (ਜਿਵੇਂ K=5)
- ਵੱਡਾ K ਰੀਕਾਲ ਵਧਾਉਂਦਾ ਹੈ (ਤੁਸੀਂ ਗਲਤ ਜਵਾਬ ਨੂੰ ਛੱਡਣਾ ਘੱਟ ਕਰ ਦਿੰਦੇ ਹੋ), ਪਰ ਇਹ “ਲਗਭਗ ਸਬੰਧਿਤ” ਨਤੀਜੇ ਵੀ ਸ਼ਾਮਿਲ ਕਰ ਸਕਦਾ ਹੈ (ਜਿਵੇਂ K=50)
3) (Optional) precision ਲਈ rerank ਕਰੋ
Similarity search ਤੇਜ਼ੀ ਲਈ optimise ਹੁੰਦੀ ਹੈ, ਇਸ ਲਈ ਸ਼ੁਰੂਆਤੀ top-K ਵਿੱਚ ਨੇੜਲੇ-ਮਿਸ ਹੋ ਸਕਦੇ ਹਨ। ਇੱਕ ਰੀਰੈਂਕਰ ਦੂਜਾ ਮਾਡਲ ਹੈ ਜੋ ਕ੍वੈਰੀ ਅਤੇ ਹਰ ਉਮੀਦਵਾਰ ਨਤੀਜੇ ਨੂੰ ਇੱਕਠੇ ਦੇਖਦਾ ਹੈ ਅਤੇ relevance ਅਨੁਸਾਰ ਦੁਬਾਰਾ ਕ੍ਰਮ ਕਰਦਾ ਹੈ।
ਇਸਨੂੰ ਸੋਚੋ: ਵੇਕਟਰ ਖੋਜ ਤੁਹਾਨੂੰ ਇੱਕ ਮਜ਼ਬੂਤ shortlist ਦਿੰਦੀ ਹੈ; ਰੀਰੈਂਕਿੰਗ ਸਭ ਤੋਂ ਚੰਗੀ ਤਰਤੀਬ ਚੁੰਨਦੀ ਹੈ।
4) ਨਤੀਜੇ ਵਾਪਸ ਕਰੋ (ਜਾਂ ਡਾਉਨਸਟਰੀਮ ਭੇਜੋ)
ਅਖੀਰਕਾਰ, ਤੁਸੀਂ ਸਭ ਤੋਂ ਚੰਗੇ ਮੈਚ ਯੂਜ਼ਰ ਨੂੰ ਵਾਪਸ ਕਰਦੇ ਹੋ (ਸਰਚ ਨਤੀਜੇ ਵਜੋਂ), ਜਾਂ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਇਕ AI ਸਹਾਇਕ (ਉਦਾਹਰਣ ਵਜੋਂ RAG ਸਿਸਟਮ) ਨੂੰ “grounding” context ਵਜੋਂ ਭੇਜਦੇ ਹੋ।
ਜੇ ਤੁਸੀਂ ਇਸ ਤਰ੍ਹਾਂ ਦਾ ਵర్కਫਲੋ ਆਪਣੀ ਐਪ ਵਿੱਚ ਬਣਾਉਣੀ ਸੋਚ ਰਹੇ ਹੋ, ਤਾਂ ਪਲੇਟਫਾਰਮਾਂ ਜਿਵੇਂ Koder.ai ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰੋਟੋ타ਇਪ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ: ਤੁਸੀਂ ਸੈਮੈਂਟਿਕ ਸਰਚ ਜਾਂ RAG ਅਨੁਭਵ ਨੂੰ ਚੈਟ ਇੰਟਰਫੇਸ ਵਿੱਚ ਵਰਣਨ ਕਰਦੇ ਹੋ, ਫਿਰ React ਫਰੰਟਐਂਡ ਅਤੇ Go/PostgreSQL ਬੈਕਐਂਡ 'ਤੇ ਦੁਹਰਾਉਂਦੇ ਹੋ, ਜਦੋਂ retrieval pipeline (embedding → vector search → optional rerank → answer) ਉਤਪਾਦ ਦਾ ਇੱਕ ਮੁੱਖ ਹਿੱਸਾ ਰਹਿੰਦਾ ਹੈ।
ਇੱਕ ਛੋਟਾ “keywords vs semantic” ਉਦਾਹਰਣ
ਜੇ ਤੁਹਾਡਾ help center ਆਲੇਖ ਕਹਿੰਦਾ “terminate subscription” ਅਤੇ ਯੂਜ਼ਰ ਖੋਜਦਾ “cancel my plan,” keyword search ਇਸਨੂੰ ਮਿਸ ਕਰ ਸਕਦੀ ਹੈ ਕਿਉਂਕਿ “cancel” ਅਤੇ “terminate” ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ।
ਸੈਮੈਂਟਿਕ ਖੋਜ ਆਮ ਤੌਰ 'ਤੇ ਇਸਨੂੰ ਰਿਟਰੀਵ ਕਰੇਗੀ ਕਿਉਂਕਿ ਐਂਬੈਡਿੰਗ ਦੋਹਾਂ ਫਰੇਜ਼ਾਂ ਦੇ ਇੱਕੋ ਹੀ ਇਰਾਦੇ ਨੂੰ ਕੈਪਚਰ ਕਰਦੇ ਹਨ। ਰੀਰੈਂਕਿੰਗ ਜੋੜੋ, ਅਤੇ ਸਿਖਰ ਨਤੀਜੇ ਬਹੁਤ ਵਾਰ ਕੇਵਲ “ਸਮਾਨ” ਨਹੀਂ ਬਲਕਿ ਯੂਜ਼ਰ ਦੇ ਸਵਾਲ ਲਈ ਸਿੱਧੇ ਕਾਰਜਯੋਗ ਬਣ ਜਾਂਦੇ ਹਨ।
ਹਾਈਬ੍ਰਿਡ ਸਰਚ ਅਤੇ ਮੈਟਾ ਡੇਟਾ ਫਿਲਟਰ ਵਧੀਆ ਨਤੀਜੇ ਲਈ
Experiment safely
Use snapshots and rollback while you tune top-K, filters, and hybrid search behavior.
ਖਾਲੀ ਵੇਕਟਰ ਸਰਚ “ਅਰਥ” ਵਿੱਚ ਬਿਹਤਰ ਹੁੰਦੀ ਹੈ, ਪਰ ਯੂਜ਼ਰ ਹਰ ਵਾਰੀ ਅਰਥ ਨਾਲ ਨਹੀਂ ਖੋਜਦੇ। ਕਈ ਵਾਰੀ ਉਨ੍ਹਾਂ ਨੂੰ ਇੱਕ ਸਹੀ-ਮਿਲਾਪ ਚਾਹੀਦਾ ਹੋ ਸਕਦਾ ਹੈ: ਕਿਸੇ ਵਿਅਕਤੀ ਦਾ ਪੂਰਾ ਨਾਮ, SKU, ਇਨਵੌਇਸ ID, ਜਾਂ ਲੌਗ ਵਿੱਚੋਂ ਨਕਲ ਕੀਤਾ error ਕੋਡ। ਹਾਈਬ੍ਰਿਡ ਸਰਚ ਸੈਮੈਂਟਿਕ ਸਿਗਨਲਾਂ (ਵੇਕਟਰ) ਨੂੰ ਲੈਕਸੀਕਲ ਸਿਗਨਲਾਂ (ਰਵਾਇਤੀ keyword search ਜਿਵੇਂ BM25) ਨਾਲ ਜੋੜਦੀ ਹੈ।
“ਹਾਈਬ੍ਰਿਡ ਸਰਚ” ਅਸਲ ਵਿੱਚ ਕੀ ਕਰਦਾ ਹੈ
ਇੱਕ ਹਾਈਬ੍ਰਿਡ ਕ੍वੈਰੀ ਆਮ ਤੌਰ 'ਤੇ ਦੋ ਰੀਟਰੀਵ ਪਾਥਾਂ ਨੂੰ ਪੈਰਲੇਲ ਚਲਾਉਂਦੀ ਹੈ:
- Vector search: ਸਮਗਰੀ ਲੱਭਦੀ ਹੈ ਜੋ ਧਾਰਣਾਤਮਕ ਤੌਰ 'ਤੇ ਸਮਾਨ ਹੈ, ਭਾਵੇਂ ਸ਼ਬਦ ਵੱਖਰੇ ਹੋਣ
- Keyword/BM25 search: ਸਮਗਰੀ ਲੱਭਦੀ ਹੈ ਜੋ ਇਕੋ ਟੋਕਨ ਸਾਂਝੀ ਕਰਦੀ ਹੈ, ਅਸਲੀ ਸ਼ਬਦ ਅਤੇ ਦੁਲਭ ਸ਼ਬਦਾਂ ਨੂੰ ਇਨਾਮ ਦਿੰਦੀ ਹੈ
ਸਿਸਟਮ ਫਿਰ ਉਹ ਉਮੀਦਵਾਰ ਨਤੀਜੇ ਇੱਕ ਹੀ ਰੈਂਕ ਕੀਤੀ ਸੂਚੀ ਵਿੱਚ ਮਿਲਾ ਦਿੰਦਾ ਹੈ।
ਕਦੋਂ ਹਾਈਬ੍ਰਿਡ ਬਿਹਤਰ ਡੀਫੌਲਟ ਹੁੰਦਾ ਹੈ
ਹਾਈਬ੍ਰਿਡ ਸਰਚ ਟਾਈਮ 'ਤੇ ਚਮਕਦੀ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਡੇਟਾ ਵਿੱਚ “must-match” strings ਹੋਣ:
- ਵਾਧੂ ਨਾਮਾਂ ਵਾਲੇ ਪ੍ਰੋਡਕਟ (ਜਿਵੇਂ “Pro Max”, “Gen 2”)
- IDs (order numbers, ticket IDs, part numbers)
- Error codes (“E0421”, “ORA-00933”) ਅਤੇ command flags
- ਕਦੇ-ਕਦੇ ਖਾਸ ਡੋਮੇਨ ਸ਼ਬਦ ਜਿੱਥੇ synonyms ਖਤਰਨਾਕ ਹੋ ਸਕਦੇ ਹਨ
ਸੈਮੈਂਟਿਕ ਸਰਚ अकेला ਵੱਧ-ਖ਼ੁਲ੍ਹੇ ਪੰਨੇ ਵਾਪਸ ਕਰ ਸਕਦਾ ਹੈ; keyword search अकेਲਾ ਵੱਖਰੇ ਫਰੇਜ਼ ਵਾਲੀਆਂ ਜਵਾਬਾਂ ਨੂੰ ਮਿਸ ਕਰ ਸਕਦਾ ਹੈ। ਹਾਈਬ੍ਰਿਡ ਦੋਹਾਂ ਅਤੇ ਦੋਹਾਂ ਦੀਆਂ ਖਾਮੀਆਂ ਕਵਰ ਕਰਦਾ ਹੈ।
Metadata filters retrieval ਨੂੰ ਰੈਂਕਿੰਗ ਤੋਂ ਪਹਿਲਾਂ (ਜਾਂ ਉਸ ਦੇ ਨਾਲ) ਸੀਮਿਤ ਕਰਦੇ ਹਨ, relevance ਅਤੇ ਗਤੀ ਵਿੱਚ ਸੁਧਾਰ ਕਰਦੇ ਹਨ। ਆਮ ਫਿਲਟਰਾਂ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹਨ:
- Language (ਸਿਰਫ਼ English ਦਸਤਾਵੇਜ਼ ਵਾਪਸ)
- Date range (ਸਭ ਤੋਂ ਨਵੀਨੀਤ ਨੀਤੀ, ਆਖਰੀ ਰਿਲੀਜ਼ ਨੋਟ)
- Category or source (docs vs. tickets; “billing” vs. “security”)
- Access control tags (ਸਿਰਫ਼ ਉਹ ਜੋ ਇਹ ਯੂਜ਼ਰ ਵੇਖ ਸਕਦਾ ਹੈ)
ਸਕੋਰਿੰਗ ਕਿਵੇਂ ਕੰਮ ਕਰਦੀ ਹੈ (ਉੱਚ-ਸਤਹ)
ਜਿਆਦਾਤਰ ਸਿਸਟਮ ਇੱਕ ਵਿਕਾਰੀ ਸਮਿਸ਼੍ਰਣ ਵਰਤਦੇ ਹਨ: ਦੋਹਾਂ search ਚਲਾਉ, ਸਕੋਰ ਨਾਰਮਲਾਈਜ਼ ਕਰਕੇ ਤੁਲਨਯੋਗ ਬਣਾਓ, ਫਿਰ ਵਜ਼ਨ ਲਗਾਓ (ਉਦਾਹਰਨ: “IDs ਲਈ keywords ਤੇ ਜ਼ਿਆਦਾ ਭਰੋਸਾ ਕਰੋ”). ਕੁਝ ਪ੍ਰੋਡਕਟ ਦੋਹਰੀ shortlist ਨੂੰ ਇੱਕ ਹਲਕੀ ਰੀਰੈਂਕਿੰਗ ਮਾਡਲ ਜਾਂ ਨਿਯਮ ਨਾਲ ਦੁਬਾਰਾ ਕ੍ਰਮ ਵੀ ਕਰਦੇ ਹਨ, ਜਦੋਂ ਕਿ ਫਿਲਟਰ ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦੇ ਹਨ ਕਿ ਤੁਸੀਂ ਸਹੀ ਉਪਸੈੱਟ ਰੈਂਕ ਕਰ ਰਹੇ ਹੋ।
RAG: LLM ਦੇ ਜਵਾਬਾਂ ਨੂੰ ਗਰਾਉਂਡ ਕਰਨ ਲਈ ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਵਰਤਣਾ
Retrieval-Augmented Generation (RAG) LLM ਤੋਂ ਹੋਰ ਭਰੋਸੇਯੋਗ ਜਵਾਬ ਲੈਣ ਦਾ ਇੱਕ ਪ੍ਰੈਕਟਿਕਲ ਪੈਟਰਨ ਹੈ: ਪਹਿਲਾਂ ਪ੍ਰਸੰਗਿਕ ਜਾਣਕਾਰੀ ਰਿਟਰੀਵ ਕਰੋ, ਫਿਰ ਉਹਨਾਂ ਨੂੰ ਵਰਤ ਕੇ ਜਵਾਬ ਜਨਰੇਟ ਕਰੋ।
RAG ਦਾ ਖਿਆਲ ਇੱਕ ਵਾਕ ਵਿੱਚ
ਮਾਡਲ ਨੂੰ ਤੁਹਾਡੇ ਕੰਪਨੀ ਦਸਤਾਵੇਜ਼ ਯਾਦ ਰੱਖਣ ਦੀ ਬਜਾਏ, ਤੁਸੀਂ ਉਹ ਦਸਤਾਵੇਜ਼ (ਐਂਬੈਡਿੰਗ ਵਜੋਂ) ਇੱਕ ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਵਿੱਚ ਸਟੋਰ ਕਰਦੇ ਹੋ, spørgsmål ਸਮੇਂ ਸਭ ਤੋਂ ਪ੍ਰਸੰਗਿਕ chunks ਰਿਟਰੀਵ ਕਰਦੇ ਹੋ, ਅਤੇ ਉਹਨਾਂ ਨੂੰ LLM ਨੂੰ ਸਹਾਇਕ ਸੰਦਰਭ ਵਜੋਂ ਪਾਸ ਕਰਦੇ ਹੋ।
ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਹੱਲੂਸੀਨੇਸ਼ਨ ਘਟਾਉਣ ਵਿੱਚ ਕਿਵੇਂ ਮਦਦ ਕਰਦਾ ਹੈ
LLMs ਲਿਖਣ ਵਿੱਚ ਉਤਮ ਹਨ, ਪਰ ਜਦੋਂ ਉਹਨਾਂ ਕੋਲ ਲੋੜੀਂਦੇ ਤੱਥ ਨਹੀਂ ਹੁੰਦੇ ਤਾਂ ਉਹ ਆਤਮ-ਭਰੋਸੇ ਨਾਲ ਫ਼ਿਲ ਕਰ ਲੈਂਦੇ ਹਨ। ਇੱਕ ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਨਜ਼ਦੀਕੀ-ਅਰਥ वाले passages ਨੂੰ ਤੁਹਾਡੇ ਨੋलेज ਬੇਸ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਲਿਆਉਣਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਉਹਨਾਂ ਨੂੰ prompt ਵਿੱਚ ਦਿੰਦਾ ਹੈ।
ਇਹ grounding ਮਾਡਲ ਨੂੰ “ਜਵਾਬ ਬਣਾਉ” ਤੋਂ “ਇਨ੍ਹਾਂ ਸ੍ਰੋਤਾਂ ਨੂੰ ਸਾਰ ਅਤੇ ਸਮਝਾਓ” ਵੱਲ ਭੇਜਦਾ ਹੈ। ਇਹ ਉੱਤਰਾਂ ਨੂੰ ਆਡੀਟ ਕਰਨਯੋਗ ਵੀ ਬਣਾ ਦਿੰਦਾ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਟ੍ਰੈਕ ਕਰ ਸਕਦੇ ਹੋ ਕਿ ਕਿਹੜੇ chunks ਰਿਟਰੀਵ ਕੀਤੇ ਗਏ ਤੇ ਚਾਹੇ ਤਾਂ citation ਵੀ ਦਿਖਾ ਸਕਦੇ ਹੋ।
chunking ਬੁਨਿਆਦੀ ਗੱਲਾਂ (ਤਾਕਿ retrieval ਅਸਲ ਵਿੱਚ ਕੰਮ ਕਰੇ)
RAG ਦੀ ਗੁਣਵੱਤਾ ਕਈ ਵਾਰ ਮਾਡਲ ਤੋਂ ਵੱਧ chunking 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੀ ਹੈ।
- Chunk size: ਉਸੇ ਹਦ ਤੱਕ chunk ਰੱਖੋ ਜੋ ਇੱਕ ਪੂਰਾ ਵਿਚਾਰ ਰੱਖਦਾ ਹੋਵੇ (ਅਕਸਰ ਇੱਕ ਛੋਟੀ ਸੈਕਸ਼ਨ). ਬਹੁਤ ਛੋਟਾ ਹੋਣ ਨਾਲ ਮਤਲਬ ਘੱਟ ਜਾਂਦਾ ਹੈ; ਬਹੁਤ ਵੱਡਾ ਹੋਣ ਨਾਲ ਸ਼ੋਰ ਜਿਆਦਾ ਆ ਜਾਂਦਾ ਹੈ।
- Overlap: ਇੱਕ ਛੋਟਾ overlap ਰੱਖੋ ਤਾਂ ਜੋ ਬਰਡਰ 'ਤੇ ਮਹੱਤਵਪੂਰਨ ਵੇਰਵੇ ਕਟ ਕੇ ਨਾ ਜਾਉਂ।
- Keep context: ਸਿਰਲੇਖ, ਹੈਡਿੰਗ, ਅਤੇ ਪਹਚਾਣ (doc name, section, date) metadata ਵਜੋਂ ਰੱਖੋ ਤਾਂ ਕਿ ਨਤੀਜੇ ਸਮਝਣਯੋਗ ਅਤੇ filterable ਰਹਿਣ।
ਸਧਾਰਣ RAG ਪਾਈਪਲਾਈਨ ਆਲੇ-ਦੁਆਲੇ (ਵਰਣਨ)
ਇਸ flow ਨੂੰ ਸੋਚੋ:
User question → Embed question → Vector DB retrieve top-k chunks (+ optional metadata filters) → Build prompt with retrieved chunks → LLM generates answer → Return answer (and sources).
ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਦਰمیਅਨ ਵਿੱਚ “ਤੇਜ਼ ਮੈਮੋਰੀ” ਵਜੋਂ ਖੜਾ ਹੈ ਜੋ ਹਰ ਬੇਨਤੀ ਲਈ ਸਭ ਤੋਂ ਪ੍ਰਸੰਗਿਕ ਸਬੂਤ ਮੁਹੱਈਆ ਕਰਦਾ ਹੈ।
ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਦੁਆਰਾ ਸਮਰਥਤ ਆਮ AI ਯੂਜ਼ ਕੇਸ
Get the source code
Keep full ownership with source code export when you’re ready to go beyond prototypes.
ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਸਿਰਫ਼ ਸਰਚ ਨੂੰ “ਸਮਾਰਟ” ਨਹੀਂ ਬਣਾਉਂਦੇ—ਉਹ ਉਤਪਾਦ ਅਨੁਭਵਾਂ ਨੂੰ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ ਜਿੱਥੇ ਯੂਜ਼ਰ ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਵਿੱਚ ਆਪਣੀ ਲੋੜ ਵਰਨਣ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਫਿਰ ਵੀ ਪ੍ਰਸੰਗਿਕ ਨਤੀਜੇ ਮਿਲਦੇ ਹਨ। ਹੇਠਾਂ ਕੁਝ ਪ੍ਰਯੋਗਿਕ ਯੂਜ਼ ਕੇਸ ਹਨ ਜੋ ਵਾਰ-ਵਾਰ ਆਉਂਦੇ ਹਨ।
ਗਾਹਕ ਸਹਾਇਤਾ: keywords ਤੋਂ ਪਰਾਂਤੂ ਜਵਾਬ ਲੱਭੋ
ਸਪੋਰਟ ਟੀਮਾਂ ਕੋਲ ਅਕਸਰ ਇੱਕ knowledge base, ਪੁਰਾਣੇ ਟਿਕਟ, ਚੈਟ ਟ੍ਰਾਂਸਕ੍ਰਿਪਟ, ਅਤੇ ਰਿਲੀਜ਼ ਨੋਟ ਹੁੰਦੇ ਹਨ—ਪਰ keyword search synonyms, paraphrasing, ਅਤੇ ਅਸਪਸ਼ਟ ਸਮੱਸਿਆ ਵਰਣਨਾਂ ਨਾਲ ਜੂਝਦਾ ਹੈ।
ਸੈਮੈਂਟਿਕ ਖੋਜ ਨਾਲ, ਇੱਕ ਏਜੰਟ (ਜਾਂ chatbot) ਪਿਛਲੇ ਟਿਕਟ ਰਿਟਰੀਵ ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਉਹੀ ਮਤਲਬ ਰੱਖਦੇ ਹਨ ਭਾਵੇਂ ਲਫ਼ਜ਼ ਵੱਖਰੇ ਹੋਣ। ਇਹ ਰਿਜ਼ੋਲੂਸ਼ਨ ਨੂੰ ਤੇਜ਼ ਕਰਦਾ, ਦੁਹਰਾਏ ਕੰਮ ਨੂੰ ਘਟਾਉਂਦਾ, ਅਤੇ ਨਵੀਆਂ ਟੀਮ ਮੈਂਬਰਾਂ ਨੂੰ ਰੈਂਪ ਅੱਪ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ। ਵੇਕਟਰ ਖੋਜ ਨੂੰ metadata filters (product line, language, issue type, date range) ਨਾਲ ਜੋੜਨਾ ਨਤੀਜੇ ਧਿਆਨ ਕੇਂਦ੍ਰਿਤ ਰੱਖਦਾ ਹੈ।
ਉਤਪਾਦ ਖੋਜ: ਲੋਕ ਗੱਲ ਕਰਨ ਦੇ ਤਰੀਕੇ ਨਾਲਸਰਚ
ਖਰੀਦਦਾਰ ਅਕਸਰ ਸਹੀ ਉਤਪਾਦ ਨਾਂ ਨਹੀਂ ਜਾਣਦੇ। ਉਹ “small backpack that fits a laptop and looks professional” ਵਰਗੀਆਂ ਇਰਾਦਿਆਂ ਲਈ ਖੋਜ ਕਰਦੇ ਹਨ। ਐਂਬੈਡਿੰਗ ਉਹ ਪਸੰਦ, ਸ਼ੈਲੀ, ਕਾਰਜ, ਅਤੇ ਸੀਮਾਵਾਂ ਕੈਪਚਰ ਕਰ ਲੈਂਦੇ ਹਨ, ਤਾਂ ਨਤੀਜੇ ਇਕ ਮਨੁੱਖੀ ਸੇਲਜ਼ ਅਸਿਸਟੈਂਟ ਵਰਗੇ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ।
ਇਹ ਰੀਟੇਲ ਕੈਟਲੌਗ, ਟਰੈਵਲ ਲਿਸਟਿੰਗ, ਰੀਅਲ ਐਸਟੇਟ, ਜੌਬ ਬੋਰਡ, ਅਤੇ ਮਾਰਕੀਟਪਲੇਸ ਲਈ ਵੀ ਵਰਕ ਕਰਦਾ ਹੈ। ਤੁਸੀਂ semantic relevance ਨੂੰ structured constraints ਜਿਵੇਂ ਕੀਮਤ, ਆਕਾਰ, ਉਪਲਬਧਤਾ, ਜਾਂ ਟਿਕਾਣਾ ਨਾਲ ਵੀ ਮਿਲਾ ਸਕਦੇ ਹੋ।
ਸੁਝਾਅ: “ਇਸ ਵਰਗੇ ਆਈਟਮ” ਅਤੇ ਸਮੱਗਰੀ ਖੋਜ
“Find items like this” ਇੱਕ ਪਰੰਪਰਾਗਤ ਵੇਕਟਰ-ਡੇਟਾਬੇਸ ਫੀਚਰ ਹੈ। ਜੇ ਯੂਜ਼ਰ ਇਕ ਆਈਟਮ ਵੇਖਦਾ, ਇੱਕ ਲੇਖ ਪੜ੍ਹਦਾ, ਜਾਂ ਇੱਕ ਵੀਡੀਓ ਵੇਖਦਾ, ਤੁਸੀਂ ਹੋਰ ਸਮੱਗਰੀ ਰਿਟਰੀਵ ਕਰ ਸਕਦੇ ਹੋ ਜੋ ਸਮਾਨ ਮਤਲਬ ਜਾਂ ਲੱਛਣ ਰੱਖਦੀ ਹੈ—ਭਾਵੇਂ ਵਰਗ-ਅਨੁਸਾਰ ਨਹੀਂ।
ਇਹ ਵਰਤੋਂ ਵਿੱਚ ਆਉਂਦਾ ਹੈ:
- “More like this” ਮੋਡੀਊਲ
- ਸੰਬੰਧਤ ਲੇਖ ਅਤੇ knowledge base ਸੁਝਾਅ
- ਡੁਪਲੀਕੇਟ ਜਾਂ ਨਜ਼ਦੀਕੀ-ਡੁਪਲੀਕੇਟ ਪਤਾ ਲਗਾਉਣਾ (content moderation ਜਾਂ cleanup ਲਈ)
ਅੰਤਰਕਤ ਸਰਚ ਤੇ ਪਰਮੀਸ਼ਨ: ਨੀਤੀਆਂ, ਦਸਤਾਵੇਜ਼, ਮੀਟਿੰਗ ਨੋਟ
ਕੰਪਨੀਆਂ ਦੇ ਅੰਦਰ, ਜਾਣਕਾਰੀ ਦਸਤਾਵੇਜ਼ਾਂ, ਵਿਕੀਜ਼, PDF, ਅਤੇ ਮੀਟਿੰਗ ਨੋਟਾਂ ਵਿੱਚ ਫੈਲੀ ਹੁੰਦੀ ਹੈ। ਸੈਮੈਂਟਿਕ ਖੋਜ ਕਰਮਚਾਰੀਆਂ ਨੂੰ ਕੁਦਰਤੀ ਤਰੀਕੇ ਨਾਲ ਸਵਾਲ ਪੁੱਛਣ ਤੇ ਸਹੀ ਸਰੋਤ ਲੱਭਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ (“What’s our reimbursement policy for conferences?”) ਅਤੇ ਸਹੀ ਸਰੋਤ ਦਿਖਾਉਂਦੀ।
ਅਣ-ਮੁੜ ਸਕਣ ਵਾਲੀ ਗੱਲ ਪਰਮੀਸ਼ਨ ਹੈ। ਨਤੀਜੇ ਨੂੰ ਪਰਮੀਸ਼ਨਾਂ ਦਾ ਸਤਿਕਾਰ ਕਰਨਾ ਲਾਜਮੀ ਹੈ—ਅਕਸਰ ਫਿਲਟਰ tenant, document owner, confidentiality level, ਜਾਂ ACL list 'ਤੇ ਕੀਤਾ ਜਾਂਦਾ ਹੈ—ਤਾਂ ਜੋ ਯੂਜ਼ਰ ਸਿਰਫ਼ ਉਹੀ ਆਈਟਮ ਰਿਟਰੀਵ ਕਰ ਸਕੇ ਜੋ ਉਹ ਦੇਖਣ ਲਈ ਅਨੁਮਤ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਹੋਰ ਅੱਗੇ ਲੈ ਜਾਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਇਹੀ retrieval ਲੇਅਰ grounded Q&A ਸਿਸਟਮਾਂ ਨੂੰ ਪੌਂਚਾਉਂਦੀ ਹੈ (RAG ਸੈਕਸ਼ਨ ਵਿੱਚ ਕਵਰ ਕੀਤਾ ਗਿਆ)।
ਡੇਟਾ ਪਾਈਪਲਾਈਨ: ingest, chunking, ਅਤੇ ਅੱਪਡੇਟ
ਇੱਕ ਸੈਮੈਂਟਿਕ ਖੋਜ ਸਿਸਟਮ ਉਸ pipeline ਦੇ ਬਰਾਬਰ ਚੰਗਾ ਹੈ ਜੋ ਉਸਨੂੰ ਫੀਡ ਕਰਦਾ ਹੈ। ਜੇ ਦਸਤਾਵੇਜ਼ ਅਸਮਾਂਤਰੀਤ ਆਉਂਦੇ ਹਨ, ਖਰਾਬ chunking ਹੁੰਦੀ ਹੈ, ਜਾਂ ਐਡਿਟਾਂ ਦੇ ਬਾਅਦ ਕਦੇ re-embed ਨਹੀਂ ਹੁੰਦੇ, ਤਾਂ ਨਤੀਜੇ ਉਹ ਨਹੀਂ ਹੋਂਦੇ ਜੋ ਯੂਜ਼ਰ ਉਮੀਦ ਕਰਦੇ ਹਨ।
ਇੱਕ ਸਧਾਰਣ ingestion flow (ਜੋ ਕੰਮ ਕਰਦਾ ਹੈ)
ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਇੱਕ ਦੋਹਰਾਏ ਯੋਗ ਕ੍ਰਮ ਫਾਲੋ ਕਰਦੀਆਂ ਹਨ:
- Collect data (docs, PDFs, tickets, chat logs, wiki pages, product data).
- Clean it (remove boilerplate, fix encoding, normalize whitespace, extract main text).
- Chunk it (split into bite-sized passages users would actually want to retrieve).
- Embed it (generate vectors with your chosen embedding model).
- Upsert it (write vectors + metadata into the vector database, replacing when needed).
“Chunk” ਕਦਮ ਉਹੀ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਬਹੁਤ ਸਾਰੀਆਂ pipelines ਜਿੱਤ ਜਾਂ ਹਾਰਦੀਆਂ ਹਨ। ਬਹੁਤ ਵੱਡੇ chunks ਮਤਲਬ dilute ਕਰ ਦਿੰਦੇ ਹਨ; ਬਹੁਤ ਛੋਟੇ context ਖੋ ਦਿੰਦੇ ਹਨ। ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਤਰੀਕਾ ਹੈ ਕੁਦਰਤੀ ਸਟਰੱਕਚਰ (ਹੈਡਿੰਗ, ਪੈਰੇ, Q&A ਜੋੜੀਆਂ) ਦੇ ਅਧਾਰ 'ਤੇ chunk ਕਰਨਾ ਅਤੇ continuity ਲਈ ਛੋਟਾ overlap ਰੱਖਣਾ।
ਐਂਬੈਡਿੰਗ ਨੂੰ ਅਪ-ਟੁ-ਡੇਟ ਰੱਖਣਾ
ਸਮੱਗਰੀ ਲਗਾਤਾਰ ਬਦਲਦੀ ਹੈ—ਕਈ ਨੀਤੀਆਂ ਅੱਪਡੇਟ ਹੁੰਦੀਆਂ ਹਨ, ਕੀਮਤਾਂ ਬਦਲਦੀਆਂ ਹਨ, ਲੇਖ ਮੁੜ ਲਿਖੇ ਜਾਂਦੇ ਹਨ। ਐਂਬੈਡਿੰਗ ਨੂੰ ਇੱਕ derived data ਵਜੋਂ ਸਮਝੋ ਜੋ ਮੁੜ ਬਣਾਈ ਜਾਣੀ ਚਾਹੀਦੀ ਹੈ।
ਆਮ ਤਰੀਕੇ:
- Source document ID, chunk ID, ਅਤੇ content hash ਸਟੋਰ ਕਰੋ। ਜੇ hash ਬਦਲਦਾ ਹੈ, ਉਸ chunk ਨੂੰ ਮੁੜ-ਐਂਬੈਡ ਕਰੋ।
- Soft deletes ਵਰਤੋ (ਪੁਰਾਨੇ chunks ਨੂੰ inactive ਮਾਰਕ ਕਰੋ) ਤਾਂ ਜੋ ghost results ਤੋਂ ਬਚਿਆ ਜਾ ਸਕੇ।
- ਸਾਰੇ ਚੀਜ਼ਾਂ ਨੂੰ ਮੁੜ ਬਣਾਉਣ ਦੀ ਬਜਾਏ selective rebuild ਕਰੋ।
ਬੈਚ vs. ਸਟ੍ਰੀਮਿੰਗ ਅੱਪਡੇਟ
- Batch ਵੱਡੇ backfills, nightly syncs, ਅਤੇ predictable content (documentation, knowledge bases) ਲਈ ਢੰਗ-ਪੂਰਨ ਹੈ।
- Streaming ਤੇਜ਼-ਬਦਲਣ ਵਾਲੇ ਸਰੋਤ (support tickets, user-generated content, inventory) ਲਈ ਬਿਹਤਰ ਹੈ। ਇਹ stale-ness ਘਟਾਉਂਦਾ ਹੈ ਪਰ ਇਸ ਲਈ ਵਧੇਰੇ ਮਾਨੀਟਰਿੰਗ ਅਤੇ ਲਾਗਤ-ਨਿਯੰਤਰਣ ਦੀ ਜ਼ਰੂਰਤ ਹੁੰਦੀ ਹੈ।
ਬਹੁ-ਭਾਸ਼ੀ ਅਤੇ ਬਹੁ-ਮਾਡਲ
ਜੇ ਤੁਸੀਂ ਇੱਕ ਤੋਂ ਵਧ ਕੇ ਭਾਸ਼ਾਵਾਂ ਨੂੰ ਸਰਵ ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਇੱਕ multilingual embedding model (ਸਧਾਰਨ) ਜਾਂ per-language models (ਕਈ ਵਾਰੀ ਉੱਚ ਗੁਣਵੱਤਾ) ਵਰਤ ਸਕਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ ਮਾਡਲਾਂ ਨਾਲ ਪ੍ਰਯੋਗ ਕਰਦੇ ਹੋ, ਤਾਂ ਆਪਣੀਆਂ embeddings ਨੂੰ ਵਰਜਨ ਕਰੋ (ਉਦਾਹਰਨ: embedding_model=v3) ਤਾਂ ਜੋ ਤੁਸੀਂ A/B ਟੈਸਟ ਅਤੇ ਰੋਲਬੈਕ ਕਰ ਸਕੋ ਬਿਨਾਂ ਖੋਜ ਨੂੰ ਤੋੜੇ।
ਗੁਣਵੱਤਾ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਕਿਵੇਂ ਮੁਲਾਂਕਣ ਕਰੀਏ
ਸੈਮੈਂਟਿਕ ਖੋਜ ਡੈਮੋ ਵਿੱਚ “ਚੰਗੀ” ਲੱਗ ਸਕਦੀ ਹੈ ਪਰ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਫੇਲ ਹੋ ਸਕਦੀ ਹੈ। ਫ਼ਰਕ ਮਾਪ ਹੈ: ਤੁਹਾਨੂੰ ਸਪਸ਼ਟ relevance metrics ਅਤੇ speed targets ਦੀ ਲੋੜ ਹੈ, ਜੋ ਅਸਲ ਯੂਜ਼ਰ ਵਹਿਵਾਰ ਵਰਗੇ ਕ੍ਵੈਰੀਆਂ ਤੇ ਅੰਕਿਤ ਹੋਣ।
ਯੂਜ਼ਰ ਸੰਤੋਸ਼ ਨੂੰ ਦਰਸਾਉਣ ਵਾਲੇ relevance metrics
ਸ਼ੁਰੂਆਤ ਇੱਕ ਛੋਟੀ metrics ਸੈਟ ਨਾਲ ਕਰੋ ਅਤੇ ਸਮੇਂ ਨਾਲ ਇਹਨਾਂ ਉੱਤੇ ਟਿਕੇ ਰਹੋ:
- Precision / Recall: Precision ਦੱਸਦਾ ਹੈ ਕਿ ਵਾਪਸ ਕੀਤੇ ਨਤੀਜੇ ਵਿੱਚੋਂ ਕਿੰਨੇ ਸਰਹੱਦੀ ਤੌਰ 'ਤੇ ਪ੍ਰਸੰਗਿਕ ਸਨ; recall ਦੱਸਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕੁੱਲ ਪ੍ਰਸੰਗਿਕ ਆਈਟਮਾਂ ਵਿੱਚੋਂ ਕਿੰਨੇ ਰਿਟਰੀਵ ਕੀਤੇ। ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ “ਪ੍ਰਸੰਗਿਕ” ਦੀ ਸਾਫ਼ ਪਰਿਭਾਸ਼ਾ ਹੋਵੇ ਤਾਂ ਇਹ ਵਰਤੋ।
- MRR (Mean Reciprocal Rank): ਉਦੋਂ ਵਧੀਆ ਜਦੋਂ ਯੂਜ਼ਰ ਇੱਕ “ਸਭ ਤੋਂ ਵਧੀਆ” ਜਵਾਬ ਦੀ ਉਮੀਦ ਕਰਦਾ ਹੈ। ਇਹ ਸਹੀ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਉੱਚੇ ਸਥਾਨ ਤੇ ਰੱਖਣ ਨੂੰ ਇਨਾਮ ਦਿੰਦਾ ਹੈ।
- nDCG: ਉਪਯੋਗੀ ਜਦੋਂ ਕਈ ਨਤੀਜੇ ਵੱਖ-ਵੱਖ ਪੱਧਰਾਂ 'ਤੇ ਪ੍ਰਸੰਗਿਕ ਹੋ ਸਕਦੇ ਹਨ (ਬਹੁਤ ਪ੍ਰਸੰਗਿਕ vs ਥੋੜ੍ਹਾ-ਕਿਸੇ-ਲਿਆਂ)।
- Latency (p50/p95): ਦੋਹਾਂ average ਅਤੇ tail latency ਟ੍ਰੈਕ ਕਰੋ। ਤੇਜ਼ p50 ਪਰ ਸੁਸਤ p95 ਵੀ ਯੂਜ਼ਰ ਨੂੰ ਅਜੇਹਾ ਮਹਿਸੂਸ ਕਰਾ ਸਕਦਾ ਹੈ।
ਇੱਕ ਭਰੋਸੇਯੋਗ ਟੈਸਟ ਸੈੱਟ ਤਿਆਰ ਕਰੋ
ਮੁਲਾਂਕਣ ਲਈ ਸੈੱਟ ਇਹਨਾਂ ਤਰੀਕਿਆਂ ਤੋਂ ਬਣਾਉ:
- ਅਸਲ ਕ੍वੈਰੀਆਂ search logs ਜਾਂ support tickets ਤੋਂ (anonymized)
- ਉਮੀਦ ਵਾਲੇ ਦਸਤਾਵੇਜ਼ (gold labels) ਜੋ ਡੋਮੇਨ ਵਿਸ਼ੇਸ਼ਜ्ञਾਂ ਦੁਆਰਾ ਸਹਿਮਤ ਹੋਣ
- Edge cases: ਛੋਟੇ ਕ੍वੈਰੀ ("refund"), ਲੰਬੇ ਪ੍ਰਸ਼ਨ, ਅੰਬਿਗيوس ਟਰਮ, ਦੁਲਭ ਉਤਪਾਦ ਨਾਮ, ਅਤੇ “no-result” ਕ੍वੈਰੀਆਂ ਜਿੱਥੇ ਸਹੀ ਬਿਹੈਵਿਓਰ “ਕੁਝ ਨਹੀਂ ਮਿਲਿਆ” ਹੋਣਾ ਹੈ
ਟੈਸਟ ਸੈੱਟ ਨੂੰ version ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਰਿਲੀਜ਼ਾਂ ਦੇ ਪਾਰ ਨਤੀਜਿਆਂ ਦੀ ਤੁਲਨਾ ਕਰ ਸਕੋ।
A/B ਟੇਸਟਿੰਗ ਅਤੇ ਫੀਡਬੈਕ ਲੂਪ
ਆਫਲਾਈਨ metrics ਹਮੇਸ਼ਾ ਸਭ ਕੁਝ ਨਹੀਂ ਕੈਪਚਰ ਕਰਦੀਆਂ। A/B ਟੈਸਟ ਚਲਾਓ ਅਤੇ ਹਲਕੀ ਸੰਕੇਤ ਇਕੱਠੇ ਕਰੋ:
- ਥੰਬਸ ਅੱਪ/ਡਾਊਨ ਨਤੀਜਿਆਂ 'ਤੇ
- Click-through ਅਤੇ dwell time
- “Refine search” ਇਕਸ਼ਨ
ਇਸ ਫੀਡਬੈਕ ਨੂੰ relevance judgments ਅਪਡੇਟ ਕਰਨ ਅਤੇ failure patterns ਦੀ ਪਛਾਣ ਕਰਨ ਲਈ ਵਰਤੋ।
ਸਮੇਂ ਦੇ ਨਾਲ ਡ੍ਰਿਫਟ ਦੀ ਨਿਗਰਾਨੀ
ਪਰਦਰਸ਼ਨ ਤਦ ਬਦਲ ਸਕਦਾ ਹੈ ਜਦੋਂ:
- ਤੁਸੀਂ ਐਂਬੈਡਿੰਗ ਮਾਡਲ ਬਦਲਦੇ ਹੋ ਜਾਂ chunking ਤਰੀਕਾ ਬਦਲਦੇ ਹੋ
- ਤੁਹਾਡੀ ਕੋਰਪਸ ਵਿਖੇਕ (ਨਵੇਂ ਪ੍ਰੋਡਕਟ, ਨੀਤੀ ਅੱਪਡੇਟ, ਸੀਜ਼ਨਲ ਸ਼ਬਦ)
ਕਿਸੇ ਵੀ ਬਦਲਾਅ ਤੋਂ ਬਾਅਦ ਆਪਣੀ ਟੈਸਟ ਸੂਟ ਦੁਬਾਰਾ ਚਲਾਓ, metric trends ਹਫਤਾਵਾਰ ਮਾਨੀਟਰ ਕਰੋ, ਅਤੇ MRR/nDCG ਵਿੱਚ ਅਚਾਨਕ ਘਟੋਤਰੀਆਂ ਜਾਂ p95 latency ਵਿੱਚ spike ਲਈ alerts ਸੈੱਟ ਕਰੋ।
ਸੁਰੱਖਿਆ, ਗੋਪਨਯਤਾ, ਅਤੇ ਐਕਸੈੱਸ ਕੰਟਰੋਲ ਵਿਚਾਰ
Plan the pipeline first
Map out ingestion, chunking, and updates before you generate a single line of code.
ਵੇਕਟਰ ਖੋਜ ਇਹ ਬਦਲ ਦਿੰਦਾ ਹੈ ਕਿ ਡੇਟਾ ਕਿਵੇਂ ਰਿਟਰੀਵ ਹੁੰਦਾ ਹੈ, ਪਰ ਇਹ ਨਹੀਂ ਬਦਲਣਾ ਚਾਹੀਦਾ ਕਿ ਕੌਣ ਇਸ ਨੂੰ ਦੇਖ ਸਕਦਾ ਹੈ। ਜੇ ਤੁਹਾਡੀ ਸੈਮੈਂਟਿਕ ਖੋਜ ਜਾਂ RAG ਸਿਸਟਮ ਸਹੀ chunk ਲੱਭ ਸਕਦੀ ਹੈ, ਤਾਂ ਇਹ ਗਲਤੀ ਨਾਲ ਉਹ chunk ਯੂਜ਼ਰ ਨੂੰ ਦਿੱਤਾ ਵੀ ਕਰ ਸਕਦੀ ਹੈ ਜੇ ਤੁਸੀਂ retrieval ਕਦਮ 'ਤੇ permissions ਅਤੇ privacy ਨੂੰ ਡਿਜ਼ਾਈਨ ਨਹੀਂ ਕਰਦੇ।
ਐਕਸੈੱਸ ਕੰਟਰੋਲ: retrieval ਸਮੇਂ ਇਹ ਲਾਗੂ ਕਰੋ
ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਨਿਯਮ ਸਧਾਰਨ ਹੈ: ਯੂਜ਼ਰ ਸਿਰਫ਼ ਉਹੀ ਸਮੱਗਰੀ ਰਿਟਰੀਵ ਕਰੇ ਜੋ ਉਹ ਪੜ੍ਹ ਸਕਦਾ ਹੈ। ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਵਾਪਸ ਕਰਨ ਤੋਂ ਬਾਅਦ ਐਪ 'ਤੇ ਨਤੀਜੇ ਲੁਕਾਉਣ 'ਤੇ ਭਰੋਸਾ ਨਾ ਕਰੋ—ਕਿਉਂਕਿ ਉਸ ਵੇਲੇ ਸਮੱਗਰੀ ਪਹਿਲਾਂ ਹੀ ਸਟੋਰੇਜ ਬਾਊਂਡਰੀ ਨੂੰ ਛੱਡ ਚੁੱਕੀ ਹੁੰਦੀ ਹੈ।
ਪ੍ਰਯੋਗਿਕ ਤਰੀਕੇ ਸ਼ਾਮਿਲ ਹਨ:
- Per-document (ਜਾਂ per-chunk) ACLs: ਹਰ ਵੇਕਟਰ ਦੇ ਨਾਲ permission fields ਸਟੋਰ ਕਰੋ ਤਾਂ ਕਿ ਹਰ ਕ੍वੈਰੀ 'ਤੇ ਇਹ ਲਾਗੂ ਹੋ ਸਕੇ।
- Tenant isolation: multi-tenant ਐਪ ਲਈ, ਡੇਟਾ ਨੂੰ tenant ਵੱਲੋਂ ਵੱਖਰਾ ਰੱਖੋ (ਲੌਜਿਕਲ partitions, namespaces, ਜਾਂ ਵੱਖਰੇ indexes) ਤਾਂ ਜੋ cross-tenant leakage ਨਾ ਹੋਵੇ।
ਕਈ ਵੇਕਟਰ ਡੇਟਾਬੇਸ metadata-based filters (ਜਿਵੇਂ tenant_id, department, project_id, visibility) ਸਪੋਰਟ ਕਰਦੇ ਹਨ ਜੋ similarity search ਦੇ ਨਾਲ ਚੱਲਦੇ ਹਨ। ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਵਰਤੇ ਜਾਣ ਤੇ, ਇਹ retrieval ਦੌਰਾਨ permissions ਲਗਾਉਣ ਦਾ ਸਹੀ ਤਰੀਕਾ ਹੈ।
ਇੱਕ ਮੁੱਖ ਨੁਕਤਾ: ਇਹ ਫਿਲਟਰ ਲਾਜ਼ਮੀ ਅਤੇ ਸਰਵਰ-ਸਾਈਡ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, client logic 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ। ਅਤੇ “role explosion” (ਬਹੁਤ ਸਾਰੀਆਂ ਕੰਬੀਨੇਸ਼ਨ) ਨਾਲ ਸਾਵਧਾਨ ਰਹੋ। ਜੇ ਤੁਹਾਡਾ permission ਮਾਡਲ ਜਟਿਲ ਹੈ, ਤਾਂ “effective access groups” ਪਹਿਲਾਂੋਂ ਕੈਂਪਿਊਟ ਕਰੋ ਜਾਂ ਇੱਕ ਅਲੱਗ authorization ਸੇਵਾ ਵਰਤੋ ਜੋ ਕ੍वੈਰੀ ਸਮੇਂ ਫਿਲਟਰ ਟੋਕਨ ਜਾਰੀ ਕਰੇ।
PII ਅਤੇ ਸੰਵੇਦਨਸ਼ੀਲ ਡੇਟਾ: ਕਿਹੜੀ ਚੀਜ਼ ਕਦੇ ਵੀ ਐਂਬੈਡ ਨਾ ਕਰੋ
ਐਂਬੈਡਿੰਗ ਮੂਲ ਪਾਠ ਤੋਂ ਅਰਥ encode ਕਰ ਸਕਦੀ ਹੈ। ਇਹ ਸਿੱਧਾ raw PII ਖੁਲਾਸਾ ਨਹੀਂ ਕਰਦੀ, ਪਰ ਜੋਖਮ ਵੱਧ ਸਕਦਾ ਹੈ (ਜਿਵੇਂ ਸੰਵੇਦਨਸ਼ੀਲ ਤੱਥ ਲੱਭਣਾ ਆਸਾਨ ਹੋ ਜਾਵੇ)।
ਚੰਗੀਆਂ ਹਦਾਇਤਾਂ:
- ਬਹੁਤ ਸੰਵੇਦਨਸ਼ੀਲ ਫੀਲਡ (SSNs, payment details, medical identifiers) ਨੂੰ ਐਂਬੈਡ ਕਰਨ ਤੋਂ ਬਚੋ ਜੇ ਸੰਭਵ ਹੋਵੇ।
- Embedding ਤੋਂ ਪਹਿਲਾਂ redact ਕਰੋ ਜੇ ਟੈਕਸਟ ਨੂੰ searchable ਬਣਾਉਣਾ ਜ਼ਰੂਰੀ ਹੈ (ਠੀਕ ਮੁੱਲਾਂ ਨੂੰ placeholders ਨਾਲ ਬਦਲੋ)।
- ਆਰਜੀਨਲ ਨੂੰ ਅਲੱਗ ਸਟੋਰ ਕਰੋ ਅਤੇ ਸਿਰਫ਼ ਪਰਮੀਸ਼ਨ ਚੈੱਕ ਹੋਣ ਤੋਂ ਬਾਅਦ ਹੀ ਰਿਕਵਰ ਕਰੋ।
ਓਪਰੇਸ਼ਨਲ ਲੋੜਾਂ: ਬੈਕਅਪ, retention, ਅਤੇ audit
ਤੁਹਾਡੇ ਵੇਕਟਰ ਇੰਡੇਕਸ ਨੂੰ ਪ੍ਰੋਡਕਸ਼ਨ ਡੇਟਾ ਵਾਂਗ ਸਮਝੋ:
- Backups and recovery: ਇੰਡੈਕਸ rebuild ਮਹਿੰਗਾ ਹੋ ਸਕਦਾ ਹੈ; snapshots ਜਾਂ source data ਤੋਂ rebuild ਰਾਹ ਦੀ ਯੋਜਨਾ ਬਣਾਓ।
- Retention policies: vectors ਹਟਾਓ ਜਦੋਂ source documents expire ਜਾਂ user deletion requests ਆਉਂਦੀਆਂ ਹਨ।
- Auditability: ਕਿਸ ਨੇ ਕਿਹੜੀ ਕ੍वੈਰੀ ਕੀਤੀ ਅਤੇ ਕਿਹੜੇ document IDs ਵਾਪਸ ਹੋਏ—ਇਸ ਤਰ੍ਹਾਂ ਦੇ ਲੋਗਾਂ ਨਾਲ ਜਾਂਚ ਅਤੇ compliance ਲਈ ਸਹਿਯੋਗ ਕਰੋ।
ਚੰਗੀ ਤਰ੍ਹਾਂ ਕੀਤਾ ਗਿਆ, ਇਹ ਅਭਿਆਸ ਸੈਮੈਂਟਿਕ ਖੋਜ ਨੂੰ ਯੂਜ਼ਰਾਂ ਲਈ ਜਾਦੂਈ ਮਹਿਸੂਸ ਕਰਾਉਂਦੇ ਹਨ—ਬਿਨਾਂ ਭਵਿੱਖ ਵਿੱਚ ਸੁਰੱਖਿਆ-ਸਬੰਧੀ ਚੌਕਸੀ ਦੇ।
ਫ਼ਲੋ, ਲਾਗਤ, ਅਤੇ ਇਕ ਪ੍ਰੈਕਟਿਕਲ ਚੋਣ ਚੈਕਲਿਸਟ
ਵੇਕਟਰ ਡੇਟਾਬੇਸ “plug-and-play” ਲੱਗ ਸਕਦੇ ਹਨ, ਪਰ ਜ਼ਿਆਦਾਤਰ ਨਿਰਾਸ਼ਾਵਾਂ ਆਂਦਰੇ ਚੋਣਾਂ ਤੋਂ ਆਉਂਦੀਆਂ ਹਨ: ਤੁਹਾਡਾ chunking, ਜਿਹੜਾ ਐਂਬੈਡਿੰਗ ਮਾਡਲ ਤੁਸੀਂ ਚੁਣਦੇ ਹੋ, ਅਤੇ ਤੁਸੀਂ ਕਿਵੇਂ ਨਿਰਤਕ ਰੱਖਦੇ ਹੋ—ਇਹ ਸਭ ਫਰਕ ਪੈਂਦਾ ਹੈ।
ਆਮ failure modes (ਅਤੇ ਇਨ੍ਹਾਂ ਦੀ ਪਛਾਣ ਕਿਵੇਂ ਕਰੋ)
ਖ਼ਰਾਬ chunking #1 ਕਾਰਨ ਹੈ ਅਣਉਚਿਤ ਨਤੀਜਿਆਂ ਦਾ। ਜੇ chunks ਬਹੁਤ ਵੱਡੇ ਹਨ ਤਾਂ ਮਤਲਬ dilute ਹੋ ਜਾਂਦਾ ਹੈ; ਜੇ ਬਹੁਤ ਛੋਟੇ ਹਨ ਤਾਂ context ਖੋ ਜਾਂਦਾ ਹੈ। ਜੇ ਯੂਜ਼ਰ ਅਕਸਰ ਕਹਿੰਦੇ ਹਨ “ਇਹ ਸਹੀ ਦਸਤਾਵੇਜ਼ ਲੱਭਿਆ ਪਰ ਗਲਤ ਪੈਸੇਜ,” ਤਾਂ ਤੁਹਾਡੀ chunking ਰਣਨੀਤੀ ਮੁੜ ਵੇਖੋ।
ਗਲਤ ਐਂਬੈਡਿੰਗ ਮਾਡਲ ਨਿਰੰਤਰ semantic mismatch ਵਜੋਂ ਦਿੱਸਦਾ ਹੈ—ਨਤੀਜੇ fluent ਹਨ ਪਰ off-topic। ਇਹ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਮਾਡਲ ਤੁਹਾਡੇ ਡੋਮੇਨ (ਕਾਨੂੰਨੀ, ਮੈਡੀਕਲ, ਸਪੋਰਟ ਟਿਕਟ) ਲਈ ਉਚਿਤ ਨਹੀਂ ਹੁੰਦਾ ਜਾਂ ਤੁਹਾਡੀ ਸਮੱਗਰੀ ਕਿਸਮ (ਟੇਬਲਾਂ, ਕੋਡ, ਬਹੁਭਾਸ਼ੀ ਟੈਕਸਟ) ਲਈ ਨਹੀਂ ਬਣਾਇਆ।
ਸਕੇਲਡ ਡੇਟਾ stale ਹੋਣਾ ਤੇਜ਼ੀ ਨਾਲ ਭਰੋਸਾ ਗਾਇਬ ਕਰ ਦਿੰਦਾ: ਯੂਜ਼ਰ ਨਵੀਨਤਮ ਨੀਤੀ ਖੋਜਦਾ ਹੈ ਪਰ ਪਿਛਲੇ ਕਵਾਰਟਰ ਦਾ ਵਰਜਨ ਮਿਲਦਾ ਹੈ। ਜੇ ਤੁਹਾਡਾ ਸੋਸ ਡੇਟਾ ਬਦਲਦਾ ਹੈ, ਤੁਹਾਡੇ ਐਂਬੈਡਿੰਗ ਅਤੇ metadata ਨੂੰ ਵੀ ਅਪਡੇਟ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ (ਅਤੇ deletions ਅਸਲ ਵਿੱਚ delete ਕਰਨੇ ਚਾਹੀਦੇ ਹਨ)।
Cold-start ਅਤੇ empty-results ਸੰਭਾਲ
ਸ਼ੁਰੂ ਵਿੱਚ, ਤੁਹਾਡੇ ਕੋਲ ਘੱਟ ਸਮੱਗਰੀ, ਘੱਟ ਕ੍वੈਰੀਆਂ, ਜਾਂ ਫੀਡਬੈਕ ਨਾ ਹੋਣ ਦੇ ਕਾਰਨ retrieval ਟਿਊਨ ਕਰਨ ਲਈ ਸਮੱਗਰੀ ਘੱਟ ਹੋ ਸਕਦੀ ਹੈ। ਤਿਆਰ ਰਹੋ:
- Fallbacks: ਜਦੋਂ semantic ਨਤੀਜੇ ਕਮਜ਼ੋਰ ਹੋਣ ਤਾਂ keyword search ਜਾਂ curated “top answers” ਦਿਖਾਓ।
- Empty-result UX: ਸੰਬੰਧਤ ਸ਼੍ਰੇਣੀਆਂ ਦਿਖਾਓ, ਸਪਸ਼ਟੀਕਰਨ ਪੁੱਛੋ, ਜਾਂ ਫਿਲਟਰ ਖੋਲ੍ਹ ਦਿਓ।
- Warm-up queries: ਸਰਵੇਖਣ ਲਈ ਕੁਝ ਨਮੂਨਾ ਪ੍ਰਸ਼ਨ ਨਾਲ ਟੈਸਟ ਕਰੋ ਪਹਿਲਾਂ ਲਾਂਚ।
ਲਾਗਤ ਵਾਲੇ ਸਰੋਤ ਜਿਨ੍ਹਾਂ ਦੀ ਬਜਟ ਰੱਖੋ
ਲਾਗਤ ਆਮ ਤੌਰ 'ਤੇ ਚਾਰ ਥਾਵਾਂ ਤੋਂ ਆਉਂਦੀ ਹੈ:
- Embedding compute (ਇੱਕ ਵਾਰੀ backfill + ongoing updates)
- Storage (vectors, metadata, ਅਤੇ indexes)
- Query volume (reads, network egress, ਅਤੇ concurrency)
- Reranking (ਵਿਕਲਪੀਕ ਪਰ ਬਲਵੇਦਾਰ; ਪ੍ਰਤੀ-ਕ੍वੈਰੀ ਮਾਡਲ ਲਾਗਤ ਜੋੜ ਸਕਦਾ ਹੈ)
ਜੇ ਤੁਸੀਂ vendors ਦੀ ਤੁਲਨਾ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਆਪਣੇ ਉਮੀਦ ਕੀਤੇ document count, average chunk size, ਅਤੇ peak QPS ਦੇ ਆਧਾਰ 'ਤੇ ਇੱਕ ਸਾਰਲ ਮਾਸਿਕ ਅੰਦਾਜ਼ਾ ਮੰਗੋ। ਕਈ ਸਰਪ੍ਰਾਈਜ਼ indexing ਅਤੇ ਟ੍ਰੈਫਿਕ spike ਦੌਰਾਨ ਹੁੰਦੇ ਹਨ।
ਇਕ ਪ੍ਰੈਕਟਿਕਲ ਚੋਣ ਚੈਕਲਿਸਟ
ਇਹ ਛੋਟੀ ਚੈਕਲਿਸਟ ਨਾਲ ਉਹ ਵੇਕਟਰ ਡੇਟਾਬੇਸ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਲਈ ਫਿਟ ਬੈਠਦਾ ਹੈ:
- Search quality: ਕੀ ਇਹ hybrid search (keyword + vectors) ਅਤੇ metadata filters ਸਪੋਰਟ ਕਰਦਾ ਹੈ? ਕੀ ਤੁਸੀਂ reranking ਜੋੜ ਸਕਦੇ ਹੋ?
- Performance: ANN ਇੰਡੈਕਸਿੰਗ ਵਿਕਲਪ, ਤੁਹਾਡੇ ਪੀਕ ਟ੍ਰੈਫਿਕ 'ਤੇ ਪੇਸ਼ਗੋਈ ਲੇਟੈਂਸੀ, ਅਤੇ ਆਸਾਨ ਸਕੇਲਿੰਗ।
- Data operations: Upserts, deletes, re-indexing, versioning, ਅਤੇ backfills ਬਿਨਾਂ ਡਾਊਨਟਾਈਮ ਦੇ।
- Observability: Query logs, recall/latency metrics, ਅਤੇ “ਇਸ ਨਤੀਜੇ ਦੀyon ਕਿਉਂ?” ਡਿਬੱਗ ਕਰਨ ਦੇ ਟੂਲ।
- Security: Encryption, tenant isolation, role-based access, ਅਤੇ filter-by-permission ਪੈਟਰਨ।
- Integration: SDKs, supported languages, ਅਤੇ ਤੁਹਾਡੇ storage (S3, databases, docs) ਲਈ connectors।
- Total cost: Storage, writes, reads, ਅਤੇ ਕਿਸੇ managed compute ਲਈ ਪਾਰਦਰਸ਼ੀ ਕੀਮਤ।
ਸਹੀ ਚੋਣ ਨਵੀਂ ਇੰਡੈਕਸ ਕਿਸਮ ਦੇ ਪਿੱਛੇ ਦੌੜਣ ਨਾਲ ਘੱਟ ਸਬੰਧਤ ਹੈ ਅਤੇ ਇਸ ਗੱਲ 'ਤੇ ਵੱਧ ਕਿ: ਕੀ ਤੁਸੀਂ ਡੇਟਾ ਤਾਜ਼ਾ ਰੱਖ ਸਕਦੇ ਹੋ, ਪਰਮੀਸ਼ਨ ਕੰਟਰੋਲ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਜਿਵੇਂ ਤੁਹਾਡੀ ਸਮੱਗਰੀ ਅਤੇ ਟ੍ਰੈਫਿਕ ਵਧੇਗੀ ਤਿਵੇਂ ਗੁਣਵੱਤਾ ਬਣਾਈ ਰੱਖ ਸਕਦੇ ਹੋ?