10 ਦਸੰ 2025·7 ਮਿੰਟ
Claude Code ਨਾਲ ਵਿਹਾਰ ਤੋਂ OpenAPI ਬਣਾਓ — ਇਮਾਨਦਾਰੀ ਨਾਲ
Claude Code ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਵਿਹਾਰ ਤੋਂ OpenAPI ਬਣਾਉਣ ਦਾ ਤਰੀਕਾ ਸੋਝਾ ਕਰੋ, ਫਿਰ ਇਸਨੂੰ ਚਲਦੀ API ਨਾਲ ਤੁਲਨਾ ਕਰੋ ਅਤੇ ਸਧਾਰਣ ਕਲਾਇੰਟ-ਅਤੇ-ਸਰਵਰ ਵੈਧਤਾ ਉਦਾਹਰਣ ਬਣਾਓ।
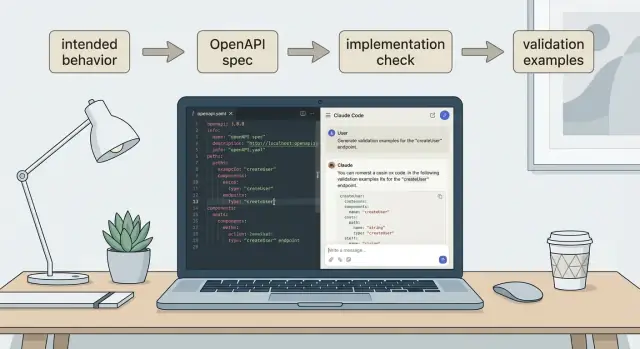
Claude Code ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਵਿਹਾਰ ਤੋਂ OpenAPI ਬਣਾਉਣ ਦਾ ਤਰੀਕਾ ਸੋਝਾ ਕਰੋ, ਫਿਰ ਇਸਨੂੰ ਚਲਦੀ API ਨਾਲ ਤੁਲਨਾ ਕਰੋ ਅਤੇ ਸਧਾਰਣ ਕਲਾਇੰਟ-ਅਤੇ-ਸਰਵਰ ਵੈਧਤਾ ਉਦਾਹਰਣ ਬਣਾਓ।
OpenAPI ਠੇਕਾ ਤੁਹਾਡੀ API ਦੀ ਇੱਕ ਸਾਂਝੀ ਵਿਆਖਿਆ ਹੈ: ਕਿਹੜੇ endpoints ਹਨ, ਤੁਸੀਂ ਕੀ ਭੇਜਦੇ ਹੋ, ਤੁਹਾਨੂੰ ਕੀ ਵਾਪਸ ਮਿਲਦਾ ਹੈ, ਅਤੇ errors ਕਿਵੇਂ ਦਿਖਦੇ ਹਨ। ਇਹ ਸਰਵਰ ਅਤੇ ਉਹ ਹਰ ਕੀਤਾ-ਕੌਲ ਕਰਨ ਵਾਲੀ ਚੀਜ਼ (web app, mobile app ਜਾਂ ਹੋਰ ਸੇਵਾ)ਦਰਮਿਆਂਨ ਇਕ ਸਮਝੌਤਾ ਹੈ।
ਮੁੱਦਾ ਇਹ ਹੈ ਕਿ ਵਿਛਲਨ (drift) ਹੁੰਦਾ ਹੈ। ਚੱਲਦੀ API ਬਦਲ ਜਾਂਦੀ ਹੈ, ਪਰ spec ਨਹੀਂ। ਜਾਂ spec ਨੂੰ "ਸੁੰਦਰ" ਬਣਾਉਣ ਲਈ ਸਾਫ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਪਰ ਅਮਲੀਅਤ ਅਜਿਹਾ ਕੁਝ ਵਾਪਸ ਕਰਦੀ ਰਹਿੰਦੀ ਹੈ ਜੋ spec ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦਾ—ਅਜੀਬ ਫੀਲਡ, ਗੁੰਮ ਸਟੇਟਸ ਕੋਡ ਜਾਂ inconsistent error shapes. ਸਮੇਂ ਦੇ ਨਾਲ-ਨਾਲ ਲੋਕ OpenAPI ਫਾਇਲ 'ਤੇ ਭਰੋਸਾ ਘਟਾ ਦਿੰਦੇ ਹਨ ਅਤੇ ਇਹ ਇੱਕ ਹੋਰ ਡੌਕ ਬਣ ਕੇ ਰਹਿ ਜਾਂਦੀ ਹੈ ਜਿਸ ਨੂੰ ਕੋਈ ਨਹੀਂ ਪੜ੍ਹਦਾ।
ਵਿੱਚਲਨ ਆਮ ਤੌਰ 'ਤੇ ਆਮ ਦਬਾਅਾਂ ਤੋਂ ਆਉਂਦਾ ਹੈ: ਇੱਕ ਛੋਟਾ ਫਿਕਸ spec ਅੱਪਡੇਟ ਕੀਤੇ ਬਿਨਾਂ ship ਹੋ ਜਾਂਦਾ ਹੈ, ਇੱਕ ਨਵਾਂ optional field "ਅਸਥਾਈ" ਤੌਰ 'ਤੇ ਜੋੜ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ, pagination ਵਿਕਸਤ ਹੁੰਦੀ ਹੈ, ਜਾਂ ਟੀਮਾਂ ਵੱਖ-ਵੱਖ "sources of truth" (backend ਕੋਡ, Postman collection, ਅਤੇ OpenAPI ਫਾਇਲ) ਅਪਡੇਟ ਕਰਦੀਆਂ ਹਨ।
ਇਸਨੂੰ ਇਮਾਨਦਾਰ ਰੱਖਣ ਦਾ ਮਤਲਬ ਹੈ ਕਿ spec ਹਕੀਕਤੀ ਵਿਹਾਰ ਨਾਲ ਮਿਲੇ। ਜੇ API ਕਈ ਵਾਰੀ 409 ਰਿਟਰਨ ਕਰਦੀ ਹੈ ਤਾਂ ਉਹ ਠੇਕੇ ਵਿੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਕੋਈ field nullable ਹੈ ਤਾਂ ਉਸਨੂੰ ਦੱਸੋ। ਜੇ auth ਲੋੜੀਂਦਾ ਹੈ ਤਾਂ ਉਸਨੂੰ ਅਣਨਿਰਧਾਰਿਤ ਨਾ ਛੱਡੋ।
ਇੱਕ ਚੰਗਾ workflow ਤੁਹਾਨੂੰ ਦਿੰਦਾ ਹੈ:
ਆਖਰੀ ਗੱਲ ਮਤਲਬੀ ਹੈ ਕਿਉਂਕਿ ਇਕ ਠੇਕਾ ਤਦ ਹੀ ਫ਼ਾਇਦੇਮੰਦ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਉਹ ਲਾਗੂ ਕੀਤਾ ਜਾਵੇ। ਇਕ ਇਮਾਨਦਾਰ spec ਅਤੇ ਦੁਹਰਾਅਯੋਗ ਚੈੱਕ "API ਡੌਕ" ਨੂੰ ਉਸ ਚੀਜ਼ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ ਜਿਸ 'ਤੇ ਟੀਮਾਂ ਭਰੋਸਾ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਜੇ ਤੁਸੀਂ ਕੋਡ ਪੜ੍ਹ ਕੇ ਜਾਂ routes ਕਾਪੀ ਕਰਕੇ ਸ਼ੁਰੂ ਕਰਦੇ ਹੋ ਤਾਂ ਤੁਹਾਡੇ OpenAPI ਵਿੱਚ ਅਜਿਹੇ ਸਾਰੇ ਅੰਗ ਸ਼ਾਮਿਲ ਹੋਣਗੇ ਜੋ ਅੱਜ ਮੌਜੂਦ ਹਨ, ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਉਹ quirks ਵੀ ਹਨ ਜੋ ਤੁਸੀਂ ਵਾਅਦਾ ਨਹੀਂ ਕਰਣਾ ਚਾਹੁੰਦੇ। ਇਸ ਦੀ ਬਜਾਏ, ਵਰਣਨ ਕਰੋ ਕਿ API ਇੱਕ caller ਲਈ ਕੀ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ, ਫਿਰ spec ਦੀ ਵਰਤੋਂ implementation ਨੂੰ ਜਾਂਚਣ ਲਈ ਕਰੋ।
YAML ਜਾਂ JSON ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ, ਹਰ endpoint ਲਈ ਕੁਝ ਛੋਟੀ-ਛੋਟੀ ਤਥਾਂ ਇਕੱਠਾ ਕਰੋ:
ਫਿਰ ਵਿਹਾਰ ਨੂੰ ਉਦਾਹਰਣਾਂ ਵਜੋਂ ਲਿਖੋ। ਉਦਾਹਰਣ ਤੁਹਾਨੂੰ ਵਿਸ਼ੇਸ਼ ਹੋਣ 'ਤੇ ਮਜ਼ਬੂਰ ਕਰਦੇ ਹਨ ਅਤੇ ਇੱਕ ਸਥਿਰ ਠੇਕਾ ਡਰਾਫਟ ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ।
Tasks API ਲਈ, ਇੱਕ ਖੁਸ਼-ਮਾਰਗ ਉਦਾਹਰਣ ਹੋ ਸਕਦੀ ਹੈ: “title ਨਾਲ ਇੱਕ task ਬਣਾਓ ਅਤੇ id, title, status, ਅਤੇ createdAt ਵਾਪਸ ਮਿਲਦਾ ਹੈ।” ਆਮ ਫੇਲਿਆਸ਼ਨ ਜੋੜੋ: “Missing title 400 ਰਿਟਰਨ ਕਰਦਾ ਹੈ { "error": "title is required" }” ਅਤੇ “No auth 401 ਰਿਟਰਨ ਕਰਦਾ ਹੈ।” ਜੇ ਤੁਹਾਨੂੰ edge cases ਪਤਾ ਹਨ ਤਾਂ ਉਹਾਂ ਨੂੰ ਭੀ ਸ਼ਾਮਿਲ ਕਰੋ: duplicate titles ਮਨਜ਼ੂਰ ਹਨ ਕਿ ਨਹੀਂ, ਅਤੇ ਜਦੋਂ task ID ਨਹੀਂ ਮਿਲਦੀ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ।
ਨਿਯਮ ਸਧਾਰਣ ਵਾਕਾਂ ਵਿਚ ਲਿਖੋ ਜੋ ਕੋਡ ਵਿਸਥਾਰਾਂ 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਕਰਦੀਆਂ:
title ਲਾਜ਼ਮੀ ਹੈ ਅਤੇ 1-120 ਅੱਖਰ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ।”limit ਨਾ ਹੋਣ 'ਤੇ 50 ਆਇਟਮ ਤੱਕ ਫਿਰਦਾ ਹੈ (ਅਧਿਕਤਮ 200)।”dueDate ISO 8601 date-time ਹੈ।”ਅੰਤ ਵਿੱਚ, ਆਪਣੇ v1 ਦਾ ਦਾਇਰਾ ਨਿਰਧਾਰਤ ਕਰੋ। ਜੇ ਤੁਹਾਨੂੰ ਸ਼ੱਕ ਹੈ, ਤਾਂ v1 ਨੂੰ ਛੋਟਾ ਅਤੇ ਸਪਸ਼ਟ ਰੱਖੋ (create, read, list, update status). search, bulk updates, ਅਤੇ complex filters ਬਾਅਦ ਲਈ ਛੱਡ ਦਿਓ ਤਾਂ ਜੋ ਠੇਕਾ ਵਿਸ਼ਵਾਸਯੋਗ ਰਹੇ।
Claude Code ਨੂੰ spec ਲਿਖਣ ਲਈ ਬੇਨਤੀ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਵਿਹਾਰ ਨੋਟਾਂ ਇੱਕ ਛੋਟੇ, ਦੁਹਰਾਅਯੋਗ ਫਾਰਮੈਟ ਵਿੱਚ ਲੇਖੋ। ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਗਲਤੀ ਨਾਲ gaps ਪੂਰੇ ਕਰਨ ਨੂੰ ਮੁਸ਼ਕਲ ਬਣਾਇਆ ਜਾਵੇ।
ਇਕ ਚੰਗਾ ਟੈਮਪਲੇਟ ਛੋਟਾ ਹੋਵੇ ਤਾਂ ਕਿ ਤੁਸੀਂ ਇਸਦਾ ਅਸਲ ਵਿੱਚ ਉਪਯੋਗ ਕਰੋ, ਪਰ ਇਹਨਾ ਵੱਡਾ ਹੋ ਕਿ ਦੋ ਲੋਕ ਇੱਕੋ endpoint ਨੂੰ ਇੱਕੋ ਤਰ੍ਹਾਂ ਵਰਣਨ ਕਰਨ। ਇਹਨਾਂ ਨੂੰ API ਕੀ ਕਰਦੀ ਹੈ ਤੇ ਕੇਂਦ੍ਰਿਤ ਰੱਖੋ, ਕਿ ਇਹ ਕਿਵੇਂ ਲਿਖੀ ਗਈ ਹੈ ਨਹੀਂ।
Use one block per endpoint:
METHOD + PATH:
Purpose (1 sentence):
Auth:
Request:
- Query:
- Headers:
- Body example (JSON):
Responses:
- 200 OK example (JSON):
- 4xx example (status + JSON):
Edge cases:
Data types (human terms):
ਹਰ endpoint ਲਈ ਘੱਟੋ-ਘੱਟ ਇੱਕ ਕਾਂਕ੍ਰੀਟ request ਅਤੇ ਦੋ responses ਲਿਖੋ। status codes ਅਤੇ ਹਕੀਕਤੀ JSON ਬਾਡੀਜ਼ ਦਿਓ। ਜੇ ਕੋਈ field optional ਹੈ ਤਾਂ ਇੱਕ ਉਦਾਹਰਣ ਦਿਖਾਓ ਜਿੱਥੇ ਉਹ ਮੌਜੂਦ ਨਹੀਂ।
Edge cases ਖੁੱਲ ਕੇ ਦਰਸਾਓ—ਇਹ ਉਹ ਥਾਵਾਂ ਹੁੰਦੀਆਂ ਹਨ ਜਿੱਥੇ spec ਆਮ ਤੌਰ 'ਤੇ ਬਾਅਦ ਵਿੱਚ ਗਲਤ ਹੋ ਜਾਂਦੀ ਹੈ ਕਿਉਂਕਿ ਲੋਕ ਵੱਖ-ਵੱਖ ਮੰਨ ਲੈਂਦੇ ਹਨ: empty results, invalid IDs (400 vs 404), duplicates (409 vs idempotent), validation failures, ਅਤੇ pagination limits.
ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਕਿ ਤੁਸੀਂ schemas ਬਾਰੇ ਸੋਚੋ, plain ਭਾਸ਼ਾ ਵਿੱਚ data types ਨੋਟ ਕਰੋ: string vs number, date-time formats, booleans, ਅਤੇ enums (ਲੱਭੇ ਹੋਏ ਮੁੱਲ). ਇਹ ਇਕ "ਸੁੰਦਰ" schema ਜੋ ਅਸਲ payload ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀ ਉਸ ਨੂੰ ਰੋਕਦਾ ਹੈ।
Claude Code ਨੂੰ ਇੱਕ ਧਿਆਨਪੂਰਵਕ ਸੈਕਰੇਟਰੀ ਵਾਂਗ ਵਰਤੋ। ਆਪਣੀਆਂ ਵਿਹਾਰ ਨੋਟਾਂ ਅਤੇ OpenAPI ਫਾਰਮੈਟ ਬਾਰੇ ਸਖਤ ਨਿਰਦੇਸ਼ ਦਿਓ। ਜੇ ਤੁਸੀਂ ਸਿਰਫ਼ ਕਹਿਓ "OpenAPI spec ਲਿਖੋ", ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ guesses, inconsistent naming, ਅਤੇ ਗੁੰਮ ਹੋਏ error cases ਆ ਸਕਦੇ ਹਨ।
ਆਪਣੀਆਂ ਵਿਹਾਰ ਨੋਟਾਂ ਪਹਿਲਾਂ ਪੇਸਟ ਕਰੋ, ਫਿਰ ਇੱਕ ਟਾਈਟ instruction block ਸ਼ਾਮਿਲ ਕਰੋ। ਇਕ ਪ੍ਰਯੋਗਿਕ prompt ਇਸ ਤਰ੍ਹਾਂ ਹੋ ਸਕਦਾ ਹੈ:
You are generating an OpenAPI 3.1 YAML spec.
Source of truth: the behavior notes below. Do not invent endpoints or fields.
If anything is unclear, list it under ASSUMPTIONS and leave TODO markers in the spec.
Requirements:
- Include: info, servers (placeholder), tags, paths, components/schemas, components/securitySchemes.
- For each operation: operationId, tags, summary, description, parameters, requestBody (when needed), responses.
- Model errors consistently with a reusable Error schema and reference it in 4xx/5xx responses.
- Keep naming consistent: PascalCase schema names, lowerCamelCase fields, stable operationId pattern.
Behavior notes:
[PASTE YOUR NOTES HERE]
Output only the OpenAPI YAML, then a short ASSUMPTIONS list.
ਡਰਾਫਟ ਮਿਲਣ ਤੋਂ ਬਾਅਦ, ਪਹਿਲਾਂ ASSUMPTIONS ਸਕੈਨ ਕਰੋ। ਇਹ ਉਹ ਖੇਤਰ ਹਨ ਜਿੱਥੇ ਇਮਾਨਦਾਰੀ ਜਿੱਤੀ ਜਾਂ ਹਾਰੀ ਹੁੰਦੀ ਹੈ। ਸਹੀ ਚੀਜ ਮਨਜ਼ੂਰ ਕਰੋ, ਗਲਤਾਂ ਠੀਕ ਕਰੋ, ਅਤੇ ਅਪਡੇਟ ਨੋਟਾਂ ਨਾਲ ਦੁਬਾਰਾ ਚਲਾਓ।
ਨਾਮਕਰਨ ਸਥਿਰ ਰੱਖਣ ਲਈ, ਸ਼ੁਰੂ ਵਿੱਚ conventions ਦੱਸੋ ਅਤੇ ਉਨ੍ਹਾਂ 'ਤੇ ਟਿਕੇ ਰਹੋ: ਉਦਾਹਰਣ ਲਈ operationId ਪੈਟਰਨ, noun-only tag names, singular schema names, ਇੱਕ shared Error schema, ਅਤੇ ਇੱਕ auth scheme name ਜੋ ਹਰ ਜਗ੍ਹਾ ਵਰਤੀ ਜਾਵੇ।
ਜੇ ਤੁਸੀਂ Koder.ai ਜਿਹੇ vibe-coding ਵਾਤਾਵਰਣ ਵਿੱਚ ਕੰਮ ਕਰਦੇ ਹੋ, ਤਾਂ YAML ਨੂੰ ਜਲਦੀ ਰੀਅਲ ਫਾਇਲ ਵਜੋਂ ਸੇਵ ਕਰੋ ਅਤੇ ਛੋਟੇ diffs ਵਿੱਚ iterate ਕਰੋ। ਇਸ ਤਰ੍ਹਾਂ ਤੁਸੀਂ ਵੇਖ ਸਕਦੇ ਹੋ ਕਿ ਕਿਹੜੇ ਬਦਲਾਅ ਮਨਜ਼ੂਰ ਕੀਤੇ ਵਿਹਾਰ ਫੈਸਲਿਆਂ ਕਰਕੇ ਆਏ ਤੇ ਕਿਹੜੇ guess ਕਰਕੇ।
ਤੁਲਨਾ ਤੋਂ ਪਹਿਲਾਂ OpenAPI ਫਾਇਲ ਨੂੰ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ consistent ਬਣਾਓ। ਇਹ wishful thinking ਅਤੇ vague wording ਨੂੰ ਫੜਨ ਦਾ ਤੇਜ਼ ترین ਜਗ੍ਹਾ ਹੈ।
ਹਰ endpoint ਨੂੰ ਇੱਕ ਕਲਾਇੰਟ ਡਿਵੈਲਪਰ ਵਾਂਗ ਪੜ੍ਹੋ। ਧਿਆਨ ਦਿਓ ਕਿ ਕਾਲ ਕਰਨ ਵਾਲੇ ਨੂੰ ਕੀ ਭੇਜਣਾ ਜਰੂਰੀ ਹੈ ਅਤੇ ਉਹ ਕੁਝ ਕੀ ਤੱਕ ਨਿਰਭਰ ਕਰ ਸਕਦੇ ਹਨ۔
ਇਕ ਕਾਰਗਰ review pass:
Error responses ਨੂੰ ਵਧੇਰੇ ਧਿਆਨ ਦੀ ਲੋੜ ਹੈ। ਇੱਕ shared shape ਚੁਣੋ ਅਤੇ ਸਾਰੇ 4xx/5xx ਵਿੱਚ reuse ਕਰੋ। ਕੁਝ ਟੀਮਾਂ ਬਹੁਤ ਸਾਦਾ ਰੱਖਦੀਆਂ ਹਨ ({ error: string }), ਹੋਰਾਂ ਨੇ ਇੱਕ ਢਾਂਚਾ ਵਰਤਣ ਲਈ ({ error: { code, message, details } }). ਦੋਹਾਂ ਚੰਗੇ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ endpoints 'ਚ mix ਨਾ ਕਰੋ। ਜੇ ਤੁਸੀਂ mix ਕਰੋਗੇ ਤਾਂ ਕਲਾਇੰਟ ਕੋਡ ਵਿੱਚ ਕਈ ਵਿਸ਼ੇਸ਼ ਕੇਸ ਇਕੱਤਰ ਹੋ ਜਾਣਗੇ।
ਇੱਕ ਛੋਟਾ sanity scenario ਫਾਇਦੈਮੰਦ ਹੈ। ਜੇ POST /tasks ਨੂੰ title ਲਾਜ਼ਮੀ ਹੈ ਤਾਂ schema ਨੂੰ required ਦਿਖਾਓ, failure response ਉਹੀ error body ਦਿਖਾਓ ਜੋ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਵਾਪਸ ਕਰਦੇ ਹੋ, ਅਤੇ operation ਵਿੱਚ ਸਪਸ਼ਟ ਕਰੋ ਕਿ auth ਲੋੜੀਦਾ ਹੈ ਜਾਂ ਨਹੀਂ।
ਜਦ spec ਅਰਾਮਦਾ ਢੰਗ ਨਾਲ ਤੁਹਾਡੇ ਮਨਜ਼ੂਰ ਕੀਤੇ ਵਿਹਾਰ ਵਰਗਾ ਲੱਗ ਜਾਵੇ, ਤਾਂ ਚੱਲਦੀ API ਨੂੰ ਕਲਾਇੰਟ ਦੀ nazar ਨਾਲ ਸਚ ਸਮਝੋ। ਮਕਸਦ ਟੀਚਾ ਜਿੱਤਣਾ ਨਹੀਂ—ਮਕਸਦ ਅੰਤਰਾਂ ਨੂੰ ਝਲਕਣਾ ਅਤੇ ਹਰ ਇੱਕ 'ਤੇ ਸਪਸ਼ਟ ਫੈਸਲਾ ਕਰਨਾ ਹੈ।
ਪਹਿਲੀ ਕਦਮ ਲਈ, ਅਸਲ request/response ਨਮੂਨੇ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਸਧਾਰਣ ਵਿਕਲਪ ਹੁੰਦੇ ਹਨ। ਲੋਗਸ ਅਤੇ automated tests ਵੀ ਕੰਮ ਕਰਦੇ ਹਨ ਜੇ ਉਹ ਭਰੋਸੇਯੋਗ ਹਨ।
ਆਮ mismatches 'ਤੇ ਧਿਆਨ ਦਿਓ: endpoints ਜੋ ਇਕ ਥਾਂ ਹਨ ਪਰ ਦੂਜੀ 'ਚ ਨਹੀਂ, field ਨਾਂ ਜਾਂ shape ਦਾ ਫਰਕ, status code ਦੇ ਫਰਕ (200 vs 201, 400 vs 422), ਅਣਦਸਤਾਵੇਜ਼ ਵਰਤਾਰੀਆਂ (pagination, sorting, filtering), ਅਤੇ auth ਫਰਕ (spec ਕਹਿੰਦੀ ਹੈ public, ਪਰ ਕੋਡ token ਲੋੜ...).
ਉਦਾਹਰਨ: ਤੁਹਾਡਾ OpenAPI ਕਹਿੰਦਾ ਹੈ POST /tasks 201 ਨਾਲ {id,title} ਦੇਵੇਗਾ। ਤੁਸੀਂ ਚਲਦੀ API ਨੂੰ ਕਾਲ ਕਰਦੇ ਹੋ ਅਤੇ 200 ਮਿਲਦਾ ਹੈ ਨਾਲ {id,title,createdAt}। ਜੇ ਤੁਸੀਂ SDKs spec ਤੋਂ ਜਨਰੇਟ ਕਰਦੇ ਹੋ ਤਾਂ ਇਹ "ਕਾਫੀ ਨੇੜੇ" ਨਹੀਂ ਹੈ।
ਕਿਉਂਕਿ ਟੁੱਟ-ਫੱਟ ਜਿਹੇ ਮਸਲੇ ਗਾਹਕੀ ਉਤੇ ਅਸਰ ਪਾ ਸਕਦੇ ਹਨ, ਸੋਧਣ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਨਿਰਧਾਰਿਤ ਕਰੋ:
ਹਰ ਸੋਧ ਛੋਟੀ ਅਤੇ reviewable ਰੱਖੋ: ਇੱਕ endpoint, ਇੱਕ response, ਇੱਕ schema tweak। ਇਹ review ਅਤੇ retest ਲਈ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
ਜਦ ਤੁਸੀਂ ਇੱਕ spec 'ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹੋ, ਉਸ ਨੂੰ ਛੋਟੇ validation ਉਦਾਹਰਣਾਂ ਵਿੱਚ ਬਦਲੋ। ਇਹੀ ਉਹ ਚੀਜ਼ ਹੈ ਜੋ ਡ੍ਰਿਫਟ ਨੂੰ ਮੁੜ ਵਾਪਸ ਆਉਣ ਤੋਂ ਰੋਕਦੀ ਹੈ।
ਸਰਵਰ ਤੇ validation ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਜੇ request contract ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀ ਤਾਂ ਫੇਲ-ਫਾਸਟ ਕਰੋ ਅਤੇ ਇੱਕ ਸਪਸ਼ਟ error ਵਾਪਸ ਕਰੋ। ਇਹ ਤੁਹਾਡੇ ਡੇਟਾ ਨੂੰ ਬਚਾਉਂਦਾ ਹੈ ਅਤੇ ਬੱਗਾਂ ਨੂੰ ਖੋਜਣਾ ਆਸਾਨ ਕਰਦਾ ਹੈ।
ਸਰਵਰ validation ਉਦਾਹਰਣਾਂ ਨੂੰ ਤਿੰਨ ਹਿੱਸਿਆਂ ਵਜੋਂ ਦਰਸਾਇਆ ਜਾ ਸਕਦਾ ਹੈ: input, expected output, ਅਤੇ expected error (ਇੱਕ error code ਜਾਂ message ਪੈਟਰਨ, ਨਿੱਕੀ ਨਹੀਂ)।
Example (contract ਕਹਿੰਦਾ ਹੈ title required ਅਤੇ 1 ਤੋਂ 120 chars):
{
"name": "Create task without title returns 400",
"request": {"method": "POST", "path": "/tasks", "body": {"title": ""}},
"expect": {"status": 400, "body": {"error": {"code": "VALIDATION_ERROR"}}}
}
ਕਲਾਇੰਟ ਪਾਸੇ validation ਦਾ ਮਕਸਦ ਹੈ ਕਿ ਸਰਵਰ ਦੇ ਤਬਦੀਲ shape ਜਾਂ ਲਾਜ਼ਮੀ field ਦੀ ਗਾਇਬੀ ਤੋਂ ਪਹਿਲਾਂ ਹੀ ਟੈਸਟ ਫੇਲ ਹੋ ਜਾਣ। ਆਪਣੇ checks ਨੂੰ ਕੇਵਲ ਉਹਨਾਂ ਚੀਜ਼ਾਂ 'ਤੇ ਕੇਂਦ੍ਰਿਤ ਰੱਖੋ ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਨਿਰਭਰ ਹੋ, ਜਿਵੇਂ “a task has id, title, status.” ਹਰ optional field ਜਾਂ exact ordering ਦੀ assert ਨਾ ਕਰੋ। ਤੁਸੀਂ ਤਬਦੀਲੀ 'ਤੇ fail ਚਾਹੁੰਦੇ ਹੋ, ਨਾ ਕਿ harmless additions 'ਤੇ।
ਕੁਝ ਹਦਾਇਤਾਂ ਜੋ tests ਨੂੰ ਪੜ੍ਹਨਯੋਗ ਰੱਖਦੀਆਂ ਹਨ:
ਜੇ ਤੁਸੀਂ Koder.ai ਨਾਲ ਬਣਦੇ ਹੋ, ਤਾਂ ਇਹ example cases OpenAPI ਫਾਇਲ ਦੇ ਨਾਲ ਰੱਖੋ ਅਤੇ ਜਦੋਂ ਵਰਤਾਰਾ ਬਦਲੇ ਤਾਂ ਇੱਕੋ ਸਮੀਖਿਆ 'ਚ update ਕਰੋ।
ਕਲਪਨਾ ਕਰੋ ਇੱਕ ਛੋਟੀ API ਜਿਸ ਵਿੱਚ ਤਿੰਨ endpoints ਹਨ: POST /tasks task ਬਣਾਉਂਦਾ, GET /tasks tasks ਦੀ ਲਿਸਟ ਦਿੰਦਾ, ਅਤੇ GET /tasks/{id} ਇੱਕ task ਵਾਪਸ ਦਿੰਦਾ।
ਇੱਕ endpoint ਲਈ ਥੋੜੇ concrete examples ਲਿਖਣ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਜਿਵੇਂ ਤੁਸੀਂ ਇਹ ਕਿਸੇ ਟੈਸਟਰ ਨੂੰ ਸਮਝਾ ਰਹੇ ਹੋ।
POST /tasks ਲਈ ਇਰਾਦਾ ਕੀਤੀ ਵਿਹਾਰ ਹੋ ਸਕਦੀ ਹੈ:
{ "title": "Buy milk" } ਭੇਜੋ ਅਤੇ 201 ਨਾਲ ਇੱਕ ਨਵਾ task object ਮਿਲੇ, ਜਿਸ ਵਿੱਚ id, title, ਅਤੇ done:false ਸ਼ਾਮਿਲ ਹੋਣ।{} ਭੇਜੋ ਅਤੇ 400 ਮਿਲੇ { "error": "title is required" }।{ "title": "x" } (ਬਹੁਤ ਛੋਟਾ) ਭੇਜੋ ਅਤੇ 422 ਮਿਲੇ { "error": "title must be at least 3 characters" }।ਜਦੋਂ Claude Code OpenAPI ਡਰਾਫਟ ਕਰੇ, ਤਾਂ endpoint ਲਈ snippet schema, status codes, ਅਤੇ ਹਕੀਕਤੀ examples ਵਰਗੀਆਂ ਚੀਜ਼ਾਂ ਕੈਪਚਰ ਕਰਨੀ ਚਾਹੀਦੀਆਂ ਹਨ:
paths:
/tasks:
post:
summary: Create a task
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreateTaskRequest'
examples:
ok:
value: { "title": "Buy milk" }
responses:
'201':
description: Created
content:
application/json:
schema:
$ref: '#/components/schemas/Task'
examples:
created:
value: { "id": "t_123", "title": "Buy milk", "done": false }
'400':
description: Bad Request
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
missingTitle:
value: { "error": "title is required" }
'422':
description: Unprocessable Entity
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
tooShort:
value: { "error": "title must be at least 3 characters" }
ਅਕਸਰ ਇੱਕ subtle mismatch ਹੁੰਦੀ ਹੈ: ਚਲਦੀ API 200 ਵਾਪਸ ਕਰਦੀ ਹੈ 201 ਦੀ ਬਜਾਏ, ਜਾਂ { "taskId": 123 } ਵਾਪਸ ਕਰਦੀ ਹੈ ਜਗ੍ਹੇ { "id": "t_123" } spec ਕਹਿੰਦੀ ਹੈ। ਇਹ "ਲਗਭਗ ਇੱਕੋ" ਫਰਕ generated clients ਨੂੰ ਤੋੜ ਸਕਦਾ ਹੈ।
ਇਸਨੂੰ ਠੀਕ ਕਰਨ ਲਈ ਇੱਕ ਸੱਚਾਈ ਸਰੋਤ ਚੁਣੋ। ਜੇ intended behavior ਸਹੀ ਹੈ ਤਾਂ implementation ਨੂੰ 201 ਅਤੇ ਮਨਜ਼ੂਰਸ਼ੁਦਾ Task shape ਦੇਣ ਲਈ ਬਦਲੋ। ਜੇ production behavior ਹੀ ਨਿਰਭਰ ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੈ, spec ਨੂੰ ਅਪਡੇਟ ਕਰੋ (ਅਤੇ behavior notes) ਤਾਂ ਜੋ ਰਣ-ਟਾਈਮ clients ਹੈਰਾਨ ਨਾ ਹੋਣ।
ਇੱਕ ਠੇਕਾ ਇਮਾਨਦਾਰ ਨਹੀਂ ਰਹਿੰਦਾ ਜਦੋਂ ਉਹ ਨਿਯਮਾਂ ਨੂੰ ਵਰਣਨ ਕਰਨਾ ਬੰਦ ਕਰਦਾ ਹੈ ਅਤੇ ਜਿਸ ਨੂੰ ਤੁਹਾਡੀ API ਨੇ ਇਕ ਚੰਗੇ ਦਿਨ 'ਤੇ ਵਾਪਸ ਕੀਤਾ ਉਹੀ ਕਾਨੂੰਨ ਬਣ ਜਾਂਦਾ ਹੈ। ਇਕ ਆਮ ਟੈਸਟ: ਕੀ ਕੋਈ ਨਵਾਂ ਇਮਪਲੀਮੇਂਟੇਸ਼ਨ ਇਸ spec ਨੂੰ ਪਾਸ ਕਰ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਅੱਜ ਦੇ quirks ਕਾਪੀ ਕੀਤੇ? ਜੇ ਹਾਂ ਤਾਂ spec overfitted ਹੋ ਸਕਦੀ ਹੈ।
ਇੱਕ ਜਾਲ ਹੈ overfitting। ਤੁਸੀਂ ਇੱਕ ਰਿਸਪਾਂਸ ਨੂੰ ਲੈ ਕੇ ਉਸਨੂੰ ਕਾਨੂੰਨ ਬਣਾ ਦਿੰਦੇ ਹੋ। ਉਦਾਹਰਣ: ਤੁਹਾਡੀ API ਇਸ ਸਮੇਂ ਹਰ task ਲਈ dueDate: null ਰਿਟਰਨ ਕਰ ਰਹੀ ਹੈ, ਤਾਂ spec ਕਹਿੰਦੀ ਹੈ ਫੀਲਡ ਹਮੇਸ਼ਾ nullable ਹੈ। ਪਰ ਅਸਲ ਨਿਯਮ ਹੋ ਸਕਦਾ ਹੈ "ਜਦੋਂ status scheduled ਹੋਵੇ ਤਾਂ required"। ਠੇਕਾ ਨਿਯਮ ਨੂੰ ਦਰਸਾਏ, ਸਿਰਫ਼ current dataset ਨੂੰ ਨਹੀਂ।
Errors ਉਹ ਥਾਣੀ ਹਨ ਜਿੱਥੇ ਇਮਾਨਦਾਰੀ ਅਕਸਰ ਟੁੱਟਦੀ ਹੈ। ਸਿਰਫ਼ success responses spec ਕਰਨਾ ਆਸਾਨ ਹੈ ਕਿਉਂਕਿ ਉਹ ਸਾਫ਼ ਲੱਗਦੇ ਹਨ, ਪਰ ਕਲਾਇੰਟਾਂ ਨੂੰ ਮੂਲ ਬੁਨਿਆਦੀਆਂ ਚੀਜ਼ਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: 401 ਜਦ token ਗੈਰਹਾਜ਼ਰ ਹੋਵੇ, 403 forbidden, 404 unknown IDs, ਅਤੇ ਇੱਕ ਲਗਾਤਾਰ validation error (400 ਜਾਂ 422).
ਹੋਰ ਪੈਟਰਨ ਜੋ ਸਮੱਸਿਆ ਬਣਾਉਂਦੇ ਹਨ:
taskId ਇਕ ਰੂਟ 'ਚ, id ਦੂਜੇ 'ਚ)string ਜਾਂ ਸਾਰੇ optional)ਇੱਕ ਚੰਗਾ ਠੇਕਾ testable ਹੁੰਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ spec ਤੋਂ ਇੱਕ failing test ਨਹੀਂ ਲਿਖ ਸਕਦੇ ਤਾਂ ਇਹ ਅਜੇ ਤਿਆਰ ਨਹੀਂ ਹੈ।
OpenAPI ਫਾਇਲ ਹੱਥ ਵਿੱਚ ਦੇਣ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਛੋਟੀ ਸਰੋਤ-ਪਾਸ ਚੈੱਕ ਕਰੋ: "ਕੀ ਕੋਈ ਵਿਅਕਤੀ ਇਸ ਨੂੰ ਬਿਨਾਂ ਤੁਹਾਡੇ ਮਨ ਨੂੰ ਪੜ੍ਹੇ ਵਰਤ ਸਕਦਾ ਹੈ?"
ਉਦਾਹਰਨਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਇੱਕ spec ਸਹੀ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਫਿਰ ਵੀ ਨਿਰਥਕ ਜੇ ਹਰ request ਅਤੇ response ਬਹੁਤ Abstract ਹੋਣ। ਹਰ operation ਲਈ ਘੱਟੋ-ਘੱਟ ਇੱਕ ਹਕੀਕਤੀ request example ਅਤੇ ਇੱਕ success response example ਸ਼ਾਮਿਲ ਕਰੋ। Errors ਲਈ ਵੀ ਪੂਰੇ ਸਮਾਨਤਾ ਨਾਲ ਇੱਕ example (auth, validation) ਦਾ ਹੀafi ਕਾਫੀ ਹੈ।
ਫਿਰ consistency ਚੈੱਕ ਕਰੋ। ਜੇ ਇਕ endpoint { "error": "..." } ਰਿਟਰਨ ਕਰਦਾ ਹੈ ਅਤੇ ਦੂਜਾ { "message": "..." } ਤਾਂ ਕਲਾਇੰਟਾਂ ਕੋਲ ਹਰ ਜਗ੍ਹਾ branching logic ਬਣੇਗਾ। ਇੱਕ single error shape ਚੁਣੋ ਅਤੇ ਸਾਰੇ ਕੁਝ ਵਿੱਚ reuse ਕਰੋ, ਨਾਲ ਨਾਲ predictable status codes।
ਛੋਟਾ ਚੈੱਕਲਿਸਟ:
ਇੱਕ ਕਾਰਗਰ ਟ੍ਰਿਕ: ਇੱਕ endpoint ਚੁਣੋ, ਧਰੋ ਤੁਸੀਂ ਕਦੇ API ਨਹੀਂ ਵੇਖੀ, ਅਤੇ ਜਵਾਬ ਦਿਓ "ਮੈਂ ਕੀ ਭੇਜਾਂ, ਮੈਂ ਕੀ ਵਾਪਸ ਪਾਵਾਂਗਾ, ਅਤੇ ਕੀ ਟੁੱਟ ਸਕਦਾ ਹੈ?" ਜੇ OpenAPI ਇਹ ਸਪਸ਼ਟ ਨਹੀਂ ਕਰ ਸਕਦਾ ਤਾਂ ਉਹ ਤਿਆਰ ਨਹੀਂ ਹੈ।
ਇਹ workflow ਉਸ ਸਮੇਂ ਲਾਭਕਾਰੀ ਬਣਦੀ ਹੈ ਜਦੋਂ ਇਹ ਨਿਯਮਤ ਤੌਰ 'ਤੇ ਚੱਲੇ, ਨਾ ਕਿ ਸਿਰਫ਼ ਰਿਲੀਜ਼ ਸਕ੍ਰੈਮਬਲ ਦੌਰਾਨ। ਇੱਕ ਸਧਾਰਣ ਨਿਯਮ ਚੁਣੋ ਅਤੇ ਉਸ 'ਤੇ ਟਿਕੇ ਰਹੋ: ਜਦੋਂ ਕੋਈ endpoint ਬਦਲੇ, ਇਹ ਚਲਾਓ, ਅਤੇ ਰਿਲੀਜ਼ ਤੋਂ ਪਹਿਲਾਂ ਫਿਰ ਚਲਾਓ।
ਮਾਲਕੀ ਸਧਾਰਨ ਰੱਖੋ। ਜੋ ਵਿਅਕਤੀ endpoint ਬਦਲਦਾ ਹੈ, ਉਹ behavior notes ਅਤੇ spec draft ਅਪਡੇਟ ਕਰੇ। ਦੂਜਾ ਵਿਅਕਤੀ "spec vs implementation" diff ਨੂੰ ਕੋਡ ਰਿਵਿਊ ਵਾਂਗ ਰਿਵਿਊ ਕਰੇ। QA ਜਾਂ support ਟੀਮ ਦੇ ਮੈਂਬਰ ਅਚਛੇ reviewer ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ unclear responses ਅਤੇ edge cases ਨੂੰ ਜ਼ਲਦੀ ਪਛਾਣ ਲੈਂਦੇ ਹਨ।
Contract edits ਨੂੰ ਕੋਡ edits ਵਾਂਗ ਵਰਤੋਂ। ਜੇ ਤੁਸੀਂ chat-driven builder (ਜਿਵੇਂ Koder.ai) ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ risky edits ਤੋਂ ਪਹਿਲਾਂ snapshot ਲੈਣਾ ਅਤੇ rollback ਵਰਤਣਾ iteration ਨੂੰ ਸੁਰੱਖਿਅਤ ਰੱਖਦਾ ਹੈ। Koder.ai ਸੋਰਸ ਕੋਡ export ਕਰਨ ਦੀ ਵੀ ਸਹੂਲਤ ਦਿੰਦਾ ਹੈ, ਜੋ spec ਅਤੇ implementation ਨੂੰ ਇਕੱਠੇ ਰੱਖਣਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਇੱਕ ਰੁਟੀਨ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਟੀਮਾਂ ਨੂੰ ਧੀਮਾ ਨਹੀਂ ਕਰਦੀ:
ਅਗਲਾ ਐਕਸ਼ਨ: ਇੱਕ ਮੌਜੂਦ endpoint ਚੁਣੋ। 5-10 ਲਾਈਨਾਂ ਦੇ ਵਿਹਾਰ ਨੋਟ (inputs, outputs, error cases) ਲਿਖੋ, ਉਸ ਨੋਟ ਤੋਂ OpenAPI ਡਰਾਫਟ ਜਨਰੇਟ ਕਰੋ, ਉਸਨੂੰ validate ਕਰੋ, ਫਿਰ running implementation ਨਾਲ ਤੁਲਨਾ ਕਰੋ। ਇੱਕ mismatch ਠੀਕ ਕਰੋ, ਰੀਟੈਸਟ ਕਰੋ, ਅਤੇ ਦੁਹਰਾਓ। ਇਕ endpoint ਤੋਂ ਬਾਅਦ ਇਹ ਆਦਤ ਅਕਸਰ ਟਿਕ ਜਾਂਦੀ ਹੈ।
OpenAPI ਦਾ ਵਿਛੋੜਾ (drift) ਉਸ ਸਮੇਂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਸੱਚੀ ਚਲ ਰਹੀ API ਅਤੇ ਲੋਕਾਂ ਨਾਲ ਸਾਂਝੀ ਕੀਤੀ ਗਈ OpenAPI ਫਾਈਲ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀਆਂ। Spec ਵਿੱਚ ਨਵੇਂ ਫੀਲਡ, ਸਟੈਟਸ ਕੋਡ ਜਾਂ auth ਨਿਯਮ ਗਾਇਬ ਹੋ ਸਕਦੇ ਹਨ, ਜਾਂ spec "ਆਦਰਸ਼" ਵਰਤੋਂ ਦਿਖਾਉਂਦੀ ਹੈ ਜੋ ਸਰਵਰ ਮਾਣ ਨਹੀਂ ਰਿਹਾ।
ਇਹ ਅਹਿਮ ਹੈ ਕਿਉਂਕਿ ਕਲਾਇੰਟ (ਐਪਸ, ਹੋਰ ਸੇਵਾਵਾਂ, ਜਨਰੇਟ ਕੀਤੇ SDKs, ਟੈਸਟ) ਤੁਹਾਡੇ ਠੇਕੇ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ, ਨ ਕਿ ਸਰਵਰ ਦੀ "ਆਮ" ਰਵਾਇਤ 'ਤੇ।
ਡ੍ਰਿਫਟ ਬਹੁਤ ਸਾਰੀਆਂ ਰਸਤਿਆਂ ਨਾਲ ਕਲਾਇੰਟ-ਪਾਸੇ ਬਗ ਬਣਾਉਂਦਾ: ਮੋਬਾਈਲ ਐਪ 201 ਦੀ ਉਮੀਦ ਕਰਦਾ ਹੈ ਪਰ 200 ਆ ਰਿਹਾ ਹੈ, SDK ਕੋਈ ਫੀਲਡ ਡੀਸੇਰੀਅਲਾਈਜ਼ ਨਹੀਂ ਕਰ ਸਕਦਾ ਕਿਉਂਕਿ ਨਾਮ ਬਦਲ ਗਿਆ, ਜਾਂ ਐਰਰ ਹੈਂਡਲਿੰਗ ਫੇਲ ਹੋ ਜਾਂਦੀ ਹੈ।
ਜਦੋਂ ਕੁਝ ਕਰੈਸ਼ ਨਹੀਂ ਵੀ ਹੁੰਦਾ, ਟੀਮਾਂ ਸਪੈਕ 'ਤੇ ਭਰੋਸਾ ਘਟਾ ਦਿੰਦੀਆਂ ਹਨ ਅਤੇ spec ਦੀ ਵਰਤੋਂ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ — ਇਸ ਨਾਲ ਤੁਹਾਡਾ ਪਹਿਲਾ ਚੇਤਾਵਨੀ ਤੰਤਰ ਖਤਮ ਹੋ ਜਾਂਦਾ ਹੈ।
ਕ्योंਕਿ ਕੋਡ ਮੌਜੂਦਾ ਵਰਤੋਂ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ, ਉਹ ਅਕਸਰ ਐਸੀਆਂ ਅਦਤਾਂ ਵਿਕਸਿਤ ਕਰ ਲੈਂਦਾ ਹੈ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ ਲੰਮੀ ਮਿਆਦ ਲਈ ਵਚਨ ਨਹੀਂ ਦੇਣਾ ਚਾਹੁੰਦੇ।
ਇੱਕ ਚੰਗਾ ਡੈਫਾਲਟ ਇਹ ਹੈ: ਪਹਿਲਾਂ ਇਰਾਦਾ ਕੀਤੀ ਵਿਹਾਰ ਲਿਖੋ (inputs, outputs, errors), ਫਿਰ implementation ਨੂੰ ਇਸਦੇ ਨਾਲ ਜਾਂਚੋ। ਇਸ ਤਰ੍ਹਾਂ ਤੁਹਾਡੇ ਕੋਲ ਇਕ ਐਸਾ ਠੇਕਾ ਹੁੰਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਲਾਗੂ ਕਰਵਾ ਸਕਦੇ ਹੋ, ਨਾ ਕਿ ਸਿਰਫ਼ ਅੱਜ ਦੀਆਂ ਰੂਟਾਂ ਦਾ ਸ્નੈਪਸ਼ਾਟ।
ਹਰ endpoint ਲਈ ਘੱਟੋ-ਘੱਟ ਲਿਖੋ:
ਜੇ ਤੁਸੀਂ ਇਕ ਕਾਂਕ੍ਰੀਟ ਰਿਕਵੈਸਟ ਅਤੇ ਦੋ ਰਿਸਪਾਂਸ ਲਿਖ ਸਕਦੇ ਹੋ, ਤਾਂ ਅਕਸਰ ਤੁਸੀਂ ਇੱਕ ਸੱਚਾ spec ਡਰਾਫਟ ਕਰਨ ਲਈ ਕਾਫੀ ਹੋ।
ਇਕ ਹੀ ਏਰਰ ਬਾਡੀ ਆਕਾਰ ਚੁਣੋ ਅਤੇ ਸਾਰੇ ਠੇਕੇ 'ਚ ਵਰਤੋਂ. ਇੱਕ ਸਧਾਰਨ ਡਿਫੌਲਟ:
{ "error": "message" }, ਜਾਂ{ "error": { "code": "...", "message": "...", "details": ... } }ਫਿਰ ਇਹ ਸਾਰੇ endpoints ਅਤੇ ਉਦਾਹਰਣਾਂ ਵਿੱਚ ਲਗਾਤਾਰ ਰੱਖੋ। ਲਗਾਤਾਰਤਾ ਵਿਸ਼ੇਸ਼ਤੋਂ ਵੱਧ ਮਾਇਨੇ ਰੱਖਦੀ ਹੈ ਕਿਉਂਕਿ ਕਲਾਇੰਟ ਇਸ ਆਕਾਰ ਨੂੰ hard-code ਕਰਨਗੇ।
Claude Code ਨੂੰ ਆਪਣੀਆਂ ਵਿਹਾਰ ਨੋਟਾਂ ਦੇਵੋ ਅਤੇ ਸਖਤ ਨਿਰਦੇਸ਼ ਦਿਓ ਤਾਂ ਜੋ ਉਹ ਕੁਝ ਨਵਾਂ ਨਾ ਬਣਾਏ। ਇੱਕ ਕਾਰਗਰ ਹਦਾਇਤ ਸੈੱਟ:
Error) ਸ਼ਾਮਿਲ ਕਰੋ ਅਤੇ reference ਕਰੋ.”ਜਨਰੇਸ਼ਨ ਤੋਂ ਬਾਅਦ, ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਨੂੰ ਚੈੱਕ ਕਰੋ — ਇੱਥੇ ਹੀ ਇਮਾਨਦਾਰੀ ਟੁੱਟ ਸਕਦੀ ਹੈ ਜੇ ਤੁਸੀਂ guesses ਮਨਜ਼ੂਰ ਕਰ ਲੈਂਦੇ ਹੋ।
Spec ਨੂੰ production ਨਾਲ ਤੁਲਨਾ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਇਸਦੀ ਜਾਂਚ ਕਰੋ:
ਇਹ wishful thinking ਅਤੇ vague wording ਨੂੰ production ਨਾਲ ਤੁਲਨਾ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਰੋਕਦਾ ਹੈ।
ਇਕ-ਇਕ ਤਕਲਫ਼ ਦੇ ਨਿਰਣੇ ਲਈ ਨੀਤੀ ਬਣਾਓ:
ਹਰ ਸੋਧ ਛੋਟੀ ਰੱਖੋ (ਇੱਕ endpoint ਜਾਂ ਇੱਕ schema ਤਬਦੀਲੀ) ਤਾਂ ਜੋ review ਅਤੇ retest ਆਸਾਨ ਹੋਵੇ।
ਸਰਵਰ ਪਾਸੇ validation ਦਾ ਮਤਲਬ ਹੈ: ਜੇ request contract ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੀ ਤਾਂ ਫਾਸਟ reject ਕਰ ਦਿਓ ਅਤੇ ਇੱਕ ਸਪਸ਼ਟ error ਵਾਪਸ ਕਰੋ। ਇਹ ਤੁਹਾਡੇ ਡੇਟਾ ਦੀ ਰੱਖਿਆ ਕਰਦਾ ਹੈ ਅਤੇ ਬੱਗਾਂ ਨੂੰ ਖोजना ਆਸਾਨ ਕਰਦਾ ਹੈ।
ਕਲਾਇੰਟ ਪਾਸੇ validation ਦਾ ਮਤਲਬ ਹੈ: ਜੇ ਸਰਵਰ ਨਵਾਂ shape ਲੈਕੇ ਆਵੇ ਤਾਂ ਉਬਾਲ ਆਉਣ ਤੋਂ ਪਹਿਲਾਂ ਉਸਨੂੰ ਦਿਖਾ ਦਿਓ। ਟੈਸਟਾਂ ਨੂੰ ਉਨਾਂ ਚੀਜ਼ਾਂ 'ਤੇ ਕੇਂਦ੍ਰਿਤ ਰੱਖੋ ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਸੀਂ ਸਚਮੁਚ ਨਿਰਭਰ ਹੋ।
ਸਧਾਰਨ ਰੁਟੀਨ ਜੋ ਫ੍ਰਿਕਸ ਨਹੀਂ ਲਿਆਉਂਦੀ:
Koder.ai ਵਰਤਦੇ ਹੋਏ, ਤੁਸੀਂ OpenAPI ਫਾਇਲ ਨੂੰ ਕੋਡ ਨਾਲ ਇਕੱਠੇ ਰੱਖ ਸਕਦੇ ਹੋ ਅਤੇ risky edits ਤੋਂ ਪਹਿਲਾਂ snapshots ਲੈ ਸਕਦੇ ਹੋ।