21 sie 2025·7 min
6 JOINów w SQL, które musisz znać (proste, jasne przykłady)
Poznaj 6 JOINów w SQL, które powinien znać każdy analityk — INNER, LEFT, RIGHT, FULL OUTER, CROSS i SELF — z praktycznymi przykładami i typowymi pułapkami.
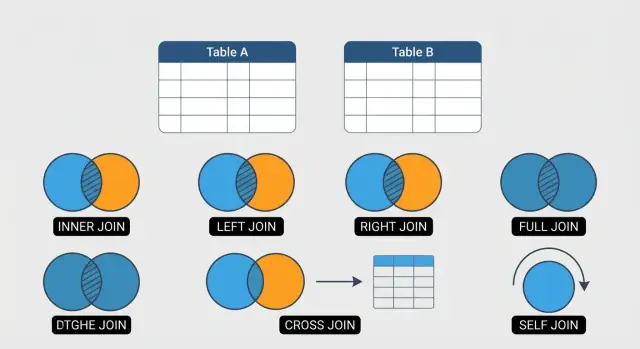
Poznaj 6 JOINów w SQL, które powinien znać każdy analityk — INNER, LEFT, RIGHT, FULL OUTER, CROSS i SELF — z praktycznymi przykładami i typowymi pułapkami.
SQL JOIN pozwala połączyć wiersze z dwóch (lub więcej) tabel w jeden wynik, dopasowując je po powiązanej kolumnie — zwykle po identyfikatorze (ID).
Większość rzeczywistych baz danych jest celowo podzielona na oddzielne tabele, żeby nie powielać tych samych informacji. Na przykład imię klienta znajduje się w tabeli customers, a jego zamówienia w tabeli orders. JOINy to sposób, by te części znowu połączyć, gdy potrzebujesz odpowiedzi.
Dlatego JOINy pojawiają się wszędzie w raportowaniu i analizie:
Bez JOINów musiałbyś uruchamiać osobne zapytania i łączyć wyniki ręcznie — wolne, podatne na błędy i trudne do powtórzenia.
Jeśli budujesz produkty na relacyjnej bazie danych (dashboardy, panele administracyjne, narzędzia wewnętrzne, portale klientów), JOINy też przekształcają „surowe tabele” w widoki dostępne dla użytkownika. Platformy takie jak Koder.ai (które generują aplikacje React + Go + PostgreSQL z rozmowy) wciąż polegają na solidnych podstawach JOINów, gdy potrzebujesz dokładnych list, raportów i ekranów do rekonsyliacji — logika bazodanowa nie znika, nawet gdy rozwój przyspiesza.
Ten przewodnik skupia się na sześciu JOINach, które pokrywają większość codziennej pracy z SQL:
Składnia JOINów jest bardzo podobna w większości baz SQL (PostgreSQL, MySQL, SQL Server, SQLite). Istnieją pewne różnice — zwłaszcza wsparcie FULL OUTER JOIN i zachowania w rzadkich przypadkach — ale koncepcje i podstawowe wzorce łatwo się przenoszą.
Aby uprościć przykłady JOINów, użyjemy trzech małych tabel odzwierciedlających typową rzeczywistą konfigurację: klienci składają zamówienia, a zamówienia mogą (lub nie) mieć płatności.
Mała uwaga: przykładowe tabele poniżej pokazują tylko kilka kolumn, ale w dalszych zapytaniach pojawią się dodatkowe pola (jak order_date, created_at, status, czy paid_at) — traktuj je jako typowe pola, które często występują w produkcyjnych schematach.
Primary key: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Zwróć uwagę, że order_id = 104 odnosi się do customer_id = 5, który nie istnieje w customers. Ten „brakujący dopasowanie” jest przydatny, by zobaczyć, jak działają LEFT JOIN, RIGHT JOIN i FULL OUTER JOIN.
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Dwie ważne "naukowe" wskazówki:
order_id = 102 ma dwa wiersze płatności (podzielona płatność). Gdy połączysz orders z payments, to zamówienie pojawi się dwukrotnie — tutaj duplikaty często zaskakują.payment_id = 9004 odnosi się do order_id = 999, który nie istnieje w orders. To tworzy kolejną sytuację „bez dopasowania”.orders z payments powtórzy zamówienie 102, ponieważ ma dwie powiązane płatności.INNER JOIN zwraca tylko wiersze, gdzie istnieje dopasowanie w obu tabelach. Jeśli klient nie ma zamówień, nie pojawi się w wyniku. Jeśli zamówienie wskazuje na nieistniejącego klienta (błędne dane), to zamówienie również nie pojawi się.
Wybierasz „lewą” tabelę, dołączasz „prawą” i łączysz je warunkiem w klauzuli ON.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
Kluczowy element to ON o.customer_id = c.customer_id: to mówi SQL, jak wiersze są powiązane.
Jeśli chcesz listę klientów, którzy faktycznie złożyli przynajmniej jedno zamówienie (i szczegóły zamówień), INNER JOIN jest naturalnym wyborem:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
To przydatne do rzeczy typu „wyślij przypomnienie o zamówieniu” lub „oblicz przychód na klienta” (gdy interesują Cię tylko klienci z zakupami).
Jeśli napiszesz join, ale zapomnisz ON (lub połączysz po złych kolumnach), możesz przypadkowo stworzyć iloczyn kartezjański (każdy klient połączony z każdym zamówieniem) albo uzyskać subtelnie błędne dopasowania.
Złe (nie rób tego):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Zawsze upewnij się, że masz jasny warunek łączenia w ON (lub USING w specyficznych przypadkach — omówione dalej).
LEFT JOIN zwraca wszystkie wiersze z lewej tabeli i dołącza dopasowane dane z prawej jeśli istnieją. Gdy dopasowania brak, kolumny z prawej będą NULL.
Użyj LEFT JOIN, gdy chcesz pełną listę z tabeli podstawowej oraz opcjonalne dane powiązane.
Przykład: „Pokaż mi wszystkich klientów i dołącz ich zamówienia jeśli je mają.”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id (i inne kolumny orders) będą NULL.Bardzo częstym powodem użycia LEFT JOIN jest znalezienie elementów, które nie mają powiązanych rekordów.
Przykład: „Którzy klienci nigdy nie złożyli zamówienia?”
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
To WHERE ... IS NULL zachowuje tylko wiersze lewej tabeli, dla których łączenie nie znalazło dopasowania.
LEFT JOIN może „powielić” wiersze lewej tabeli, gdy istnieje wiele pasujących wierszy po prawej.
Jeśli jeden klient ma 3 zamówienia, ten klient pojawi się 3 razy — po jednym dla każdego zamówienia. To jest oczekiwane, ale może zaskoczyć, jeśli próbujesz policzyć klientów.
Na przykład to liczy zamówienia (nie klientów):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Jeśli chcesz liczyć klientów, zwykle zliczasz klucz klienta (np. COUNT(DISTINCT c.customer_id)), w zależności od tego, co chcesz mierzyć.
RIGHT JOIN zachowuje wszystkie wiersze z prawej tabeli i tylko dopasowane wiersze z lewej. Gdy brak dopasowania, kolumny z lewej będą NULL. To w zasadzie lustrzana wersja LEFT JOIN.
Wyobraź sobie, że chcesz wypisać wszystkie płatności, nawet jeśli nie można ich powiązać z zamówieniem (może zamówienie zostało usunięte albo dane płatności są nieporządne).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Co otrzymujesz:
payments jest po prawej).o.order_id i o.customer_id będą NULL.W większości przypadków możesz przepisać RIGHT JOIN jako LEFT JOIN, zamieniając kolejność tabel:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Zwróci to ten sam wynik, ale wiele osób uważa to za czytelniejsze: zaczynasz od „głównej” tabeli, którą Ci zależy (tu: payments), a potem opcjonalnie dołączasz powiązane dane.
Wiele wytycznych stylu SQL odradza RIGHT JOIN, ponieważ zmusza czytelnika do odwrócenia wzorca myślenia:
Gdy opcjonalne relacje są konsekwentnie pisane jako LEFT JOIN, zapytania łatwiej się skanuje.
RIGHT JOIN może być przydatny, gdy edytujesz istniejące długie zapytanie i zdajesz sobie sprawę, że tabela "do zachowania" jest po prawej. Zamiast przepisywać całe zapytanie, zmiana jednego JOIN na RIGHT JOIN może być szybka i niskiego ryzyka.
FULL OUTER JOIN zwraca wszystkie wiersze z obu tabel.
INNER JOIN).NULL w kolumnach prawej tabeli.NULL w kolumnach lewej tabeli.Klasyczny biznesowy przypadek to rekonsyliacja zamówień vs płatności:
Przykład:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN jest obsługiwany w PostgreSQL, SQL Server i Oracle.
Nie jest dostępny w MySQL i SQLite (trzeba zastosować obejście).
Jeśli Twoja baza nie obsługuje FULL OUTER JOIN, możesz go zasymulować, łącząc:
orders (z dopasowanymi płatnościami, jeśli są), orazpayments, które nie dopasowały się do orders.Jednen powszechny wzorzec:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Wskazówka: gdy widzisz NULL po jednej stronie, to sygnał, że wiersz brakował w drugiej tabeli — dokładnie tego chcesz przy audytach i rekonsyliacji.
CROSS JOIN zwraca wszystkie możliwe pary wierszy z dwóch tabel. Jeśli tabela A ma 3 wiersze, a tabela B ma 4 wiersze, wynik będzie mieć 3 × 4 = 12 wierszy. To nazywa się też iloczyn kartezjański.
To brzmi groźnie — i może być — ale jest naprawdę przydatne, gdy CHCESZ wygenerować kombinacje.
Wyobraź sobie, że przechowujesz opcje produktów w oddzielnych tabelach:
sizes: S, M, Lcolors: Red, BlueCROSS JOIN może wygenerować wszystkie warianty (przydatne do tworzenia SKU, wstępnego budowania katalogu lub testowania):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Wynik (3 × 2 = 6 wierszy):
Ponieważ liczba wierszy się mnoży, CROSS JOIN może bardzo szybko eksplodować:
To może spowolnić zapytania, przeciążyć pamięć i wygenerować wynik, którym nikt nie będzie umiał sensownie operować. Jeśli potrzebujesz kombinacji, trzymaj wejściowe tabele małe i rozważ dodanie limitów lub filtrów w kontrolowany sposób.
SELF JOIN to dokładnie to, co sugeruje nazwa: łączysz tabelę z samą sobą. Przydaje się, gdy jeden wiersz w tabeli odnosi się do innego wiersza w tej samej tabeli — najczęściej w hierarchiach typu pracownicy i ich menedżerowie.
Ponieważ używasz tej samej tabeli dwukrotnie, musisz nadać każdej „kopii” inną nazwę aliasu. Alias sprawia, że zapytanie jest czytelne i mówi SQL, której strony używasz.
Typowy wzorzec:
e dla pracownikam dla menedżeraWyobraź sobie tabelę employees z polami:
idnamemanager_id (wskazuje na id innego pracownika)Aby wypisać każdego pracownika z imieniem jego menedżera:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Zauważ, że zapytanie używa LEFT JOIN, a nie INNER JOIN. To ważne, ponieważ niektórzy pracownicy mogą nie mieć menedżera (np. CEO). W takich przypadkach manager_id jest często NULL, a LEFT JOIN zachowuje wiersz pracownika, pokazując manager_name jako NULL.
Gdybyś użył INNER JOIN, pracownicy najwyższego szczebla zniknęliby z wyników, bo nie ma wiersza menedżera, do którego można się dołączyć.
JOIN nie „wie” automatycznie, jak dwie tabele się wiążą — musisz to powiedzieć. Relacja jest definiowana w warunku łączenia i powinna znaleźć się tuż przy JOIN, bo wyjaśnia, jak tabele się dopasowują, a nie jak chcesz filtrować ostateczny wynik.
ON: najbardziej elastyczne (i najczęściej stosowane)Używaj ON, gdy chcesz pełnej kontroli nad logiką dopasowania — różne nazwy kolumn, wiele warunków lub dodatkowe reguły.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON to też miejsce, gdzie możesz zdefiniować bardziej złożone dopasowania (np. dopasowanie po dwóch kolumnach) bez zamieniania zapytania w zgadywankę.
USING: krótsze, ale tylko dla kolumn o tej samej nazwieNiektóre bazy (np. PostgreSQL i MySQL) obsługują USING. To wygodne skrócenie, gdy obie tabele mają kolumnę o tej samej nazwie i chcesz ją użyć do łączenia.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Jedną z korzyści jest to, że USING zwykle zwraca tylko jedną kolumnę customer_id w wyniku (zamiast dwóch kopii).
Po dołączeniu tabel nazwy kolumn często się pokrywają (id, created_at, status). Jeśli napiszesz SELECT id, baza może zgłosić błąd „ambiguous column” — albo co gorsza, możesz przypadkowo odczytać złe id.
Wol preferuj prefiksy tabel (lub aliasy) dla jasności:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * w zapytaniach z JOINamiSELECT * szybko robi bałagan z joinami: pobierasz niepotrzebne kolumny, ryzykujesz duplikaty nazw i utrudniasz zrozumienie, co zapytanie ma zwrócić.
Zamiast tego wybieraj dokładne kolumny, których potrzebujesz. Wynik będzie czyściejszy, łatwiejszy do utrzymania i często bardziej wydajny — szczególnie gdy tabele są szerokie.
Gdy łączysz tabele, WHERE i ON oba „filtrują”, ale robią to w różnym momencie.
Ta różnica czasu wykonania to powód, dla którego ludzie przypadkowo zmieniają LEFT JOIN w INNER JOIN.
Powiedzmy, że chcesz wszystkich klientów, nawet tych bez niedawnych opłaconych zamówień.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Problem: dla klientów bez dopasowania o.status i o.order_date są NULL. Klauzula WHERE odrzuca te wiersze, więc nieudane dopasowania znikają — Twój LEFT JOIN zachowuje się jak INNER JOIN.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Teraz klienci bez kwalifikujących zamówień nadal się pojawiają (z NULL w kolumnach zamówień), co zwykle jest celem LEFT JOIN.
WHERE o.order_id IS NOT NULL jawnie).Joiny nie tylko „dodają kolumny” — mogą też pomnożyć wiersze. To zwykle poprawne zachowanie, ale często zaskakuje, gdy sumy nagle się podwajają (albo gorzej).
Join zwraca jeden wiersz wyjściowy dla każdej pary dopasowanych wierszy.
customers z orders, klient może pojawić się wielokrotnie — po jednym dla każdego zamówienia.orders z payments i każde zamówienie może mieć wiele płatności, możesz otrzymać wiele wierszy na zamówienie. Jeśli dodatkowo dołączysz inną tabelę "wiele" (np. order_items), możesz stworzyć efekt mnożenia: payments × items dla jednego zamówienia.Jeśli celem jest „jeden wiersz na klienta” lub „jeden wiersz na zamówienie”, podsumuj stronę "wiele" najpierw, a potem dołącz.
-- One row per order from payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
To utrzymuje przewidywalny kształt łączenia: jeden wiersz zamówienia pozostaje jednym wierszem.
SELECT DISTINCT może wyglądać jak szybkie rozwiązanie, ale może ukryć prawdziwy problem:
Używaj go dopiero, gdy jesteś pewien, że duplikaty są przypadkowe i rozumiesz, dlaczego wystąpiły.
Zanim zaufasz wynikom, porównaj liczby wierszy:
JOINy często obwinia się o „wolne zapytania”, ale prawdziwą przyczyną jest zwykle ile danych próbujesz połączyć i jak łatwo baza może znaleźć dopasowania.
Pomyśl o indeksie jak o spisie treści książki. Bez niego baza może musieć przeszukać wiele wierszy, żeby znaleźć dopasowania do warunku JOIN. Z indeksem na kluczu łączenia (np. customers.customer_id i orders.customer_id) baza może szybko przejść do odpowiednich wierszy.
Nie musisz znać wnętrza silnika, żeby używać tego dobrze: jeśli kolumna jest często używana do dopasowań (ON a.id = b.a_id), warto rozważyć indeks na tej kolumnie.
Gdy to możliwe, łącz po stabilnych, unikalnych identyfikatorach:
customers.customer_id = orders.customer_idcustomers.email = orders.email lub customers.name = orders.nameImiona się zmieniają i mogą się powtarzać. E-maile mogą się zmienić, brakować lub różnić wielkością liter. ID są zaprojektowane do spójnego dopasowywania i zwykle są indeksowane.
Dwa nawyki robią JOINy zauważalnie szybszymi:
SELECT * przy łączeniu wielu tabel — dodatkowe kolumny zwiększają pamięć i ruch sieciowy.Przykład: ogranicz zamówienia, a potem dołącz:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Jeśli iterujesz nad tymi zapytaniami w aplikacji (np. tworząc stronę raportową opartą na PostgreSQL), narzędzia takie jak Koder.ai mogą przyspieszyć tworzenie szkieletu — schematu, endpointów, UI — podczas gdy Ty zachowujesz kontrolę nad logiką JOIN, która decyduje o poprawności.
NULL gdy brak)NULL gdy brak)NULLSQL JOIN łączy wiersze z dwóch (lub więcej) tabel w jeden wynik, dopasowując powiązane kolumny — najczęściej klucz podstawowy do klucza obcego (np. customers.customer_id = orders.customer_id). Dzięki temu „ponownie łączysz” znormalizowane tabele, gdy potrzebujesz raportów, audytów lub analiz.
Użyj INNER JOIN, gdy chcesz tylko wiersze, dla których relacja istnieje w obu tabelach.
To dobry wybór do „potwierdzonych relacji”, np. listy klientów, którzy rzeczywiście złożyli zamówienia.
Użyj LEFT JOIN, gdy potrzebujesz wszystkich wierszy z głównej (lewej) tabeli i opcjonalnych dopasowań z prawej.
Aby znaleźć „brakujące dopasowania”, zrób join, a następnie przefiltruj prawą stronę do NULL:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
RIGHT JOIN zachowuje wszystkie wiersze z prawej tabeli i wstawia NULL w kolumny lewej tabeli, gdy brak dopasowania. Wiele zespołów unika go, bo czyta się „od tyłu”.
W większości przypadków możesz przepisać go jako LEFT JOIN przez zamianę kolejności tabel:
FROM payments p
LEFT orders o o.order_id p.order_id
Użyj FULL OUTER JOIN do rekonsyliacji: chcesz mieć w jednym wyniku dopasowania, wiersze występujące tylko po lewej oraz tylko po prawej stronie.
To świetne rozwiązanie do audytów typu „zamówienia bez płatności” i „płatności bez zamówień”, ponieważ brakujące strony pojawiają się jako kolumny NULL.
Niektóre bazy (szczególnie MySQL i SQLite) nie obsługują FULL OUTER JOIN bezpośrednio. Popularne obejście to połączenie dwóch zapytań:
orders LEFT JOIN paymentsZwykle robi się to z UNION (lub UNION ALL z ostrożnym filtrowaniem), aby zachować zarówno rekordy "tylko z lewej", jak i "tylko z prawej".
CROSS JOIN zwraca każdą kombinację wierszy między dwiema tabelami (produkt kartezjański). Przydaje się do generowania scenariuszy (np. rozmiary × kolory) lub budowania siatki kalendarza.
Uważaj: liczba wierszy szybko rośnie, więc jeśli wejścia nie są małe i kontrolowane, wynik może eksplodować i spowolnić zapytanie.
Self join to joinowanie tabeli z samą sobą, aby powiązać wiersze w tej samej tabeli (często dla hierarchii typu pracownik → menedżer).
Musisz użyć aliasów, by rozróżnić dwie „kopie” tabeli:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON definiuje, które wiersze dopasowują się podczas łączenia; WHERE filtruje wynik już po złączeniu. W przypadku LEFT JOIN warunek WHERE odnoszący się do kolumn prawej tabeli może usunąć wiersze z NULL i skutecznie zmienić LEFT JOIN w INNER JOIN.
Jeśli chcesz zachować wszystkie wiersze lewej tabeli, ale ograniczyć, które wiersze prawej tabeli mogą dopasować się, umieść filtr prawej tabeli w .
Joiny mnożą wiersze, gdy relacje są one-to-many lub many-to-many. Np. zamówienie z dwiema płatnościami pojawi się dwa razy przy joinie orders z payments.
Aby utrzymać „po jednym wierszu na zamówienie/klienta”, najpierw agreguj stronę "wiele" (np. SUM(amount) grupując po order_id), a potem dołącz wynik. DISTINCT używaj tylko jako ostateczności — może ukryć prawdziwy problem i zafałszować sumy oraz zliczenia.
ON