Zdefiniuj cele i sygnały adopcji
Zanim zbudujesz ocenę zdrowia adopcji klientów, ustal, co chcesz, aby wynik robił dla biznesu. Wynik przeznaczony do wywoływania alertów ryzyka churnu będzie inny niż ten służący do kierowania onboardingiem, edukacją klientów czy ulepszaniem produktu.
Określ, co oznacza „adopcja” w Twoim produkcie
Adopcja to nie tylko „ostatnie logowanie”. Wypisz kilka zachowań, które naprawdę wskazują, że klienci osiągają wartość:
- Aktywacja: pierwszy moment, gdy użytkownik osiąga znaczący rezultat (np. „zaprosił współpracownika”, „podłączył źródło danych”, „opublikował raport”).
- Kluczowe działania: powtarzalne, wysokosygnałowe zachowania skorelowane z sukcesem kont (np. cotygodniowe eksporty, uruchomienia automatyzacji, pulpity oglądane przez wielu użytkowników).
- Retencja: kontynuowane użycie w odpowiednim rytmie dla produktu (codziennie, co tydzień, co miesiąc), najlepiej przez więcej niż jednego użytkownika na koncie.
To staje się Twoimi początkowymi sygnałami adopcji do analizy użycia funkcji i późniejszej analizy kohort.
Wypisz decyzje, które ma wspierać aplikacja
Bądź konkretny, co się dzieje, gdy wynik się zmienia:
- Kto zostaje powiadomiony, gdy konto spadnie poniżej progu?
- Jakie playbooki należy uruchomić (kontakt, szkolenie, check-in wsparcia)?
- Które insighty powinny zasilać monitorowanie adopcji produktu (punkty tarcia, niedostatecznie używane funkcje, time-to-value)?
Jeśli nie potrafisz nazwać decyzji, nie śledź jeszcze tej metryki.
Zidentyfikuj użytkowników, role i okna czasowe
Wyjaśnij, kto korzysta z pulpitu customer success:
- Menedżerowie CS potrzebują priorytetyzacji i kontekstu konta.
- Produkt potrzebuje wzorców, kohort i ruchu na poziomie funkcji.
- Wsparcie potrzebuje niedawnej aktywności wokół zgłoszeń i incydentów.
- Zarząd potrzebuje zrozumiałego podsumowania i trendu.
Wybierz standardowe okna — ostatnie 7/30/90 dni — i rozważ etapy cyklu życia (trial, onboarding, steady-state, odnowienie). To zapobiega porównywaniu świeżo założonego konta z dojrzałym.
Ustal kryteria sukcesu
Zdefiniuj „gotowe” dla modelu oceny zdrowia:
- Dokładność: czy przewiduje ryzyko i sygnały ekspansji lepiej niż obecne podejście?
- Wyjaśnialność: czy CSM potrafi w minutę wytłumaczyć, dlaczego wynik jest wysoki/niski?
- Łatwość użycia: czy oszczędza czas i wymusza spójne akcje?
Te cele kształtują wszystko dalej: śledzenie zdarzeń, logikę punktowania i workflowy dookoła wyniku.
Wybierz metryki do oceny zdrowia
Wybór metryk decyduje, czy wynik będzie pomocnym sygnałem, czy hałaśliwą liczbą. Postaw na mały zestaw wskaźników, które odzwierciedlają rzeczywistą adopcję — a nie tylko aktywność.
Zacznij od sygnałów adopcji produktu
Wybierz metryki pokazujące, czy użytkownicy wielokrotnie osiągają wartość:
- Logowania / aktywni użytkownicy: np. tygodniowi aktywni użytkownicy (WAU) i trend za ostatnie 4–8 tygodni.
- Dni aktywności: ile unikalnych dni konto było aktywne w tygodniu/miesiącu (pomaga uniknąć fałszywych pozytywów „jednej wielkiej sesji”).
- Głębokość funkcji: użycie „funkcji wartościowych”, nie każdy klik przycisku.
- Podłączone integracje: szczególnie jeśli zwiększają koszt zmiany lub odblokowują kluczowe workflowy.
- Wykorzystanie miejsc: procent zakupionych miejsc, które zostały zaproszone, aktywowane i faktycznie używane.
Utrzymaj listę wąską. Jeśli nie potrafisz wyjaśnić, dlaczego metryka ma znaczenie w jednym zdaniu, prawdopodobnie nie jest podstawowym wskaźnikiem.
Dodaj kontekst biznesowy (by wyniki były sprawiedliwe)
Adopcja powinna być interpretowana w kontekście. Zespół z 3 miejscami zachowa się inaczej niż wdrożenie na 500 miejsc.
Typowe sygnały kontekstowe:
- Poziom planu i uprawnienia do funkcji
- Wielkość kontraktu / przedział ARR
- Etap cyklu życia: trial vs świeżo płatne vs okno odnowienia
Nie muszą „dodawać punktów”, ale pomagają ustawić realistyczne progi według segmentu.
Zdecyduj o wskaźnikach prowadzących vs opóźnionych
Użyteczny wynik miesza:
- Wskaźniki prowadzące (predykcja przyszłego sukcesu): rosnące dni aktywności, ukończenie onboardingu, pierwsza podłączona integracja.
- Wskaźniki opóźnione (potwierdzają rezultaty): odnowienie, ekspansja, długoletnia retencja.
Unikaj nadmiernego ważenia metryk opóźnionych; mówią one, co już się wydarzyło.
Opcjonalnie: wkłady jakościowe (używaj ostrożnie)
Jeśli je masz, NPS/CSAT, wolumen zgłoszeń i notatki CSM mogą dodać niuans. Używaj ich jako modyfikatorów lub flag — nie jako fundamentu — ponieważ dane jakościowe bywają rzadkie i subiektywne.
Stwórz prosty słownik danych
Zanim zbudujesz wykresy, uzgodnij nazwy i definicje. Lekki słownik danych powinien zawierać:
- Nazwę metryki (np.
active_days_28d)
- Jasną definicję (co liczy się, a co nie)
- Okno czasowe i częstotliwość odświeżania
- System źródłowy (zdarzenia produktu, CRM, wsparcie)
To zapobiega późniejszemu zamieszaniu „ta sama metryka, inne znaczenie” przy wdrażaniu pulpitów i alertów.
Zaprojektuj wyjaśnialny model oceny zdrowia
Ocena adopcji działa tylko wtedy, gdy zespół jej ufa. Cel: model, który wyjaśnisz w minutę CSM-owi i w pięć minut klientowi.
Zacznij prosto: punktacja ważona (przed ML)
Rozpocznij od przejrzystego, regułowego modelu. Wybierz kilka sygnałów adopcji (np. aktywni użytkownicy, użycie kluczowych funkcji, włączone integracje) i przypisz wagi odzwierciedlające „aha” moments Twojego produktu.
Przykład wag:
- Tygodniowi aktywni użytkownicy na miejsce: 0–40 punktów
- Częstotliwość użycia kluczowych funkcji: 0–35 punktów
- Szerokość używanych funkcji: 0–15 punktów
- Czas od ostatniej znaczącej aktywności: 0–10 punktów
Trzymaj wagi łatwe do obrony. Możesz je później zweryfikować — nie czekaj na perfekcyjny model.
Normalizuj, by zmniejszyć uprzedzenia
Surowe zliczenia karzą małe konta i spłaszczają duże. Normalizuj tam, gdzie to ma znaczenie:
- Na miejsce (użycie / licencjonowane miejsca)
- Według wieku konta (nowe vs dojrzałe konta)
- Według poziomu planu (dostępność funkcji)
To pomaga, żeby ocena zdrowia odzwierciedlała zachowanie, a nie tylko rozmiar.
Zdefiniuj zielone/żółte/czerwone progi z uzasadnieniem
Ustal progi (np. Zielony ≥ 75, Żółty 50–74, Czerwony < 50) i udokumentuj, dlaczego każdy cutoff istnieje. Połącz progi z oczekiwanymi wynikami (ryzyko odnowienia, ukończenie onboardingu, gotowość do ekspansji) i trzymaj notatki w wewnętrznych dokumentach lub w tekście widocznym jako /blog/health-score-playbook.
Uczyń to wyjaśnialnym: wkładniki i trend
Każdy wynik powinien pokazywać:
- 3 główne wkładniki (co pomogło/zaszkodziło)
- Zmianę w czasie (ostatnie 7/30 dni)
- Krótkie podsumowanie w języku naturalnym („Użycie funkcji X spadło o 35% tydzień do tygodnia”)
Planuj iteracje: wersjonuj model
Traktuj scoring jak produkt. Wersjonuj go (v1, v2) i śledź wpływ: Czy alerty ryzyka churnu stały się dokładniejsze? Czy CSM-y reagują szybciej? Przechowuj wersję modelu z każdym obliczeniem, żeby móc porównywać wyniki w czasie.
Instrumentuj zdarzenia produktu i źródła danych
Ocena zdrowia jest tyle wiarygodna, ile dane aktywności, na których ją oparto. Zanim zbudujesz logikę punktowania, potwierdź, że właściwe sygnały są konsekwentnie rejestrowane we wszystkich systemach.
Wybierz źródła zdarzeń
Większość programów adopcji korzysta z mieszaniny:
- Zdarzenia frontendowe (widoki stron, kliknięcia, interakcje z funkcjami)
- Akcje backendowe (wywołania API, ukończone zadania, tworzone rekordy)
- Billing (plan, odnowienia, status płatności, liczba miejsc)
- Narzędzia wsparcia i sukcesu (zgłoszenia, CSAT, kamienie milowe onboardingu)
Praktyczna zasada: krytyczne akcje śledź po stronie serwera (trudniej je sfałszować, mniej podatne na blokery reklam), a frontend wykorzystuj do zaangażowania UI i odkrywania.
Zdefiniuj jasne schema zdarzeń
Utrzymuj spójny kontrakt, aby zdarzenia było łatwo łączyć, queryować i tłumaczyć interesariuszom. Wspólna baza to:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id itp.)
Używaj kontrolowanego słownika dla event_name (np. project_created, report_exported) i dokumentuj go w prostym planie śledzenia.
SDK vs. server-side (albo oba)
- Śledzenie przez SDK szybko się wdraża i świetnie nadaje się do zdarzeń UI.
- Śledzenie po stronie serwera lepiej nadaje się do akcji będących źródłem prawdy.
Wiele zespołów robi oba, ale upewnij się, że nie zliczasz tej samej rzeczy dwukrotnie.
Obsłuż prawidłowo tożsamość
Oceny zwykle agreguje się do poziomu konta, więc potrzebujesz niezawodnego mapowania użytkownik→konto. Zaplanuj:
- Użytkowników w wielu kontach
- Scalanie kont (przejęcia, konsolidacja workspace)
- Zanonimizowane ID dla zachowań przed logowaniem (z bezpiecznym scaleniem po rejestracji)
Wbuduj kontrole jakości danych
Przynajmniej monitoruj brakujące zdarzenia, duplikaty i spójność stref czasowych (przechowuj UTC; konwertuj do wyświetlania). Oznacz anomalie wcześnie, żeby alerty o ryzyku churnu nie włączały się, bo tracking przestał działać.
Zmodeluj dane i magazyn
Aplikacja oceny adopcji klientów żyje lub umiera na tym, jak dobrze modelujesz „kto co zrobił i kiedy”. Celem jest szybkie odpowiadanie na powszechne pytania: Jak radzi sobie to konto w tym tygodniu? Które funkcje idą w górę, a które w dół? Dobry model danych upraszcza scoring, pulpity i alerty.
Podstawowe encje do wymodelowania
Zacznij od małego zestawu tabel „źródła prawdy”:
- Accounts: account_id, plan, segment, lifecycle_stage, owner CSM
- Users: user_id, account_id, rola/persona, created_at, status
- Subscriptions (kontrakty): account_id, start/end, seats, MRR, data odnowienia
- Features: feature_id, nazwa, kategoria (activation, collaboration, admin itp.)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (lub computed_at), overall_score, component_scores, pola wyjaśnień
Utrzymuj spójność tych encji, używając stabilnych ID (account_id, user_id) wszędzie.
Rozdzielenie przechowywania: relacyjna + analityczna
Użyj bazy relacyjnej (np. Postgres) dla accounts/users/subscriptions/scores — rzeczy, które często aktualizujesz i łączysz.
Przechowuj zdarzenia o dużym wolumenie w hurtowni/analitice (np. BigQuery/Snowflake/ClickHouse). To utrzymuje responsywność pulpitów i analiz kohort bez przeciążania DB transakcyjnej.
Przechowuj agregaty dla szybkości
Zamiast przeliczać wszystko z surowych zdarzeń, utrzymuj:
- Dzienne podsumowania kont (po jednym wierszu na konto na dzień): aktywni użytkownicy, kluczowe liczniki zdarzeń, ostatnia aktywność, milestony adopcji
- Liczniki funkcji: użycie per account/day/feature, unikalni użytkownicy, czas spędzony (jeśli dostępny)
Te tabele napędzają wykresy trendów, insighty „co się zmieniło” i składowe oceny zdrowia.
Retencja, partycjonowanie i wydajność zapytań
Dla dużych tabel zdarzeń zaplanuj retencję (np. 13 miesięcy surowych danych, dłużej dla agregatów) i partycjonuj po dacie. Klasteruj/indexuj po account_id i timestamp/date, aby przyspieszyć zapytania „konto w czasie”.
W tabelach relacyjnych indeksuj pola używane przy filtrowaniu i joinach: account_id, (account_id, date) w podsumowaniach i klucze obce, by utrzymać integralność danych.
Zaplanuj architekturę web app
Uruchom swój pulpit
Wdróż i hostuj aplikację do monitorowania adopcji bez ręcznej konfiguracji infrastruktury.
Twoja architektura powinna umożliwić szybkie wypuszczenie wiarygodnego v1, a potem rozwój bez przepisywania wszystkiego. Zacznij od decyzji, ile elementów naprawdę potrzebujesz.
Monolit vs mikrousługi (dla v1 prościej)
Dla większości zespołów modularny monolit to najszybsza droga: jedna baza kodu z wyraźnymi granicami (ingestion, scoring, API, UI), jedno wdrożenie i mniej niespodzianek operacyjnych.
Przejdź do usług tylko wtedy, gdy masz jasny powód — potrzeby niezależnego skalowania, silna izolacja danych lub oddzielne zespoły. W przeciwnym razie przedwczesne rozbijanie na usługi zwiększa punkty awarii i spowalnia iterację.
Zdefiniuj rdzeniowe komponenty
Przynajmniej zaplanuj te odpowiedzialności (nawet jeśli na początku mieszczą się w jednej aplikacji):
- Ingestion: odbiera zdarzenia produktu (SDK, Segment, webhook, batch imports).
- Agregacja: zamienia surowe zdarzenia w dzienne/tygodniowe fakty użycia per account/user.
- Scoring: oblicza ocenę zdrowia adopcji i wspierające wyjaśnienia.
- API: udostępnia wyniki, trendy i „dlaczego” do UI i integracji.
- UI: pulpit customer success z widokami kont, kohortami i drill-down.
Jeśli chcesz szybko prototypować, podejście vibe-coding może pomóc wystawić działający dashboard bez nadmiernego inwestowania w szkielet. Na przykład Koder.ai może wygenerować Reactowy UI i backend w Go na podstawie prostego opisu encji (accounts, events, scores), endpointów i ekranów — użyteczne do postawienia v1, na który zespół CS może szybko zareagować.
Zadania zaplanowane vs streaming
Batchowe scoringi (np. godzinowe/nocne) zwykle wystarczają do monitorowania adopcji i są znacznie prostsze w obsłudze. Streaming ma sens, gdy potrzebujesz niemal w czasie rzeczywistym alertów (np. nagły spadek użycia) lub bardzo dużego wolumenu zdarzeń.
Praktyczny hybryd: ingestuj zdarzenia ciągle, agreguj/scoruj według harmonogramu, a streaming rezerwuj dla niewielkiego zestawu pilnych sygnałów.
Środowiska, sekrety i potrzeby niefunkcjonalne
Ustaw dev/stage/prod wcześnie, z przykładowymi kontami w stage do weryfikacji pulpitów. Użyj zarządzanego sklepu sekretów i rotuj poświadczenia.
Udokumentuj wymagania z wyprzedzeniem: oczekiwany wolumen zdarzeń, freshness wyniku (SLA), cele latencji API, dostępność, retencja danych i ograniczenia prywatności (obsługa PII i kontrola dostępu). To zapobiega podejmowaniu kluczowych decyzji architektonicznych pod presją czasu.
Zbuduj pipeline danych i zadania scoringowe
Ocena zdrowia jest tak wiarygodna, jak pipeline ją produkujący. Traktuj scoring jak system produkcyjny: odtwarzalny, obserwowalny i łatwy do wyjaśnienia, gdy ktoś zapyta „Dlaczego to konto spadło dzisiaj?”.
Prosty pipeline: raw → validated → aggregates
Zacznij od przepływu etapowego, który zawęża dane do formy gotowej do scoringu:
- Raw events: append-only ingest z aplikacji, mobile, integracji i eksportów z billing/CRM.
- Validated events: zdarzenia, które przeszły checki schematu (wymagane pola, poprawne typy), checki tożsamości (user→account mapowanie) i deduplikację.
- Daily aggregates: rollupy po koncie (opcjonalnie workspace/team) jak aktywni użytkownicy, kluczowe liczniki zdarzeń, ostatnia aktywność, milestone’y adopcji i delty trendu.
Taka struktura utrzymuje zadania scoringowe szybkie i stabilne, bo operują na czystych, kompaktowych tabelach zamiast miliardów surowych wierszy.
Harmonogramy przeliczeń i backfille
Zdecyduj, jak „świeża” musi być ocena:
- Godzinne scoringi dla działań high-touch, gdzie CSM reagują szybko.
- Dziennie zwykle wystarcza dla SMB/self-serve i obniża koszty.
Zaprojektuj scheduler tak, by wspierał backfille (np. reprocessing ostatnich 30/90 dni) przy poprawkach trackingu lub zmianach wag. Backfille powinny być funkcją pierwszej klasy, nie awaryjnym skryptem.
Idempotentność: unikaj podwójnego zliczania
Zadania będą ponawiane. Importy będą uruchamiane ponownie. Webhooki będą dostarczane dwukrotnie. Projektuj z myślą o tym.
Użyj klucza idempotency dla zdarzeń (event_id lub stabilny hash timestamp + user_id + event_name + properties) i wymuś unikalność na warstwie validated. Dla agregatów używaj upsertów po (account_id, date), aby przeliczenie zastępowało poprzedni wynik, zamiast go dodawać.
Monitorowanie i checki anomalii
Dodaj monitoring operacyjny dla:
- Sukces/porażka zadań i liczby ponowień
- Opóźnień danych (jak bardzo za „teraz” są najnowsze agregaty)
- Anomalii wolumenów (nagłe spadki/skoki zdarzeń, aktywnych użytkowników, kluczowych akcji)
Nawet lekkie progi (np. „zdarzeń o 40% mniej vs 7-dniowa średnia”) zapobiegają cichym awariom, które wprowadziłyby w błąd pulpit customer success.
Ślady audytu dla każdej oceny
Przechowuj rekord audytu na konto na każdy przebieg scoringu: metryki wejściowe, pochodne, wersja modelu i końcowy wynik. Gdy CSM kliknie „Dlaczego?”, pokaż dokładnie, co się zmieniło i kiedy — bez rekonstruowania tego z logów.
Stwórz bezpieczne API dla zdrowia i insightów
Wersjonuj bezpiecznie
Wdrażaj nowe wersje oceny z pewnością dzięki snapshotom i szybkiej możliwości przywrócenia.
Twoja aplikacja żyje lub umiera przez API. To kontrakt między zadaniami scoringowymi, UI i narzędziami downstream (platformy CS, BI, eksporty). Cel: API szybkie, przewidywalne i bezpieczne domyślnie.
Rdzeniowe endpointy wspierające workflowy
Projektuj endpointy wokół tego, jak Customer Success eksploruje adopcję:
- Account health:
GET /api/accounts/{id}/health zwraca najnowszy wynik, pasmo statusu (np. Green/Yellow/Red) i czas ostatniego obliczenia.
- Trendy:
GET /api/accounts/{id}/health/trends?from=&to= dla wyniku w czasie i kluczowych deltas.
- Drivers („dlaczego”):
GET /api/accounts/{id}/health/drivers pokazuje top pozytywów/negatywów (np. „tygodniowi aktywni na miejscu -35%”).
- Kohorty:
GET /api/cohorts/health?definition= dla analizy kohortowej i benchmarków rówieśniczych.
- Eksporty:
POST /api/exports/health do generowania CSV/Parquet ze spójnymi schematami.
Filtrowanie, paginacja i cache
Ułatw fragmentowanie list:
- Filtry:
plan, segment, csm_owner, lifecycle_stage, date_range to podstawa.
- Paginacja: użyj paginacji kursorowej (
cursor, limit) dla stabilności przy zmieniających się danych.
- Cache: cachuj ciężkie zapytania (kohorty, szeregi trendów) i zwracaj
ETag / If-None-Match, by redukować powtórne ładowania. Klucze cache bądź świadome filtrów i uprawnień.
Bezpieczeństwo z RBAC
Chroń dane na poziomie kont. Wdróż RBAC (np. Admin, CSM, Read-only) i egzekwuj je po stronie serwera dla każdego endpointu. CSM powinien widzieć tylko przypisane konta; role finansowe mogą widzieć agregaty planowe, ale nie szczegóły użytkowników.
Zawsze zwracaj wyjaśnienia
Obok liczbowej oceny zdrowia adopcji zwracaj pola „dlaczego”: top driverów, dotknięte metryki i bazę porównawczą (poprzedni okres, mediana kohorty). To zamienia monitorowanie adopcji produktu w działanie, a nie tylko raportowanie, i sprawia, że twój pulpit customer success jest wiarygodny.
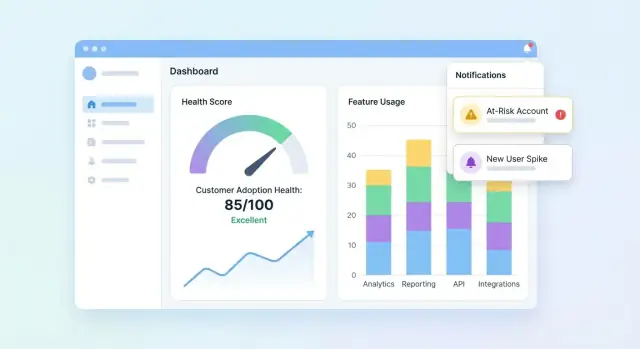
Zaprojektuj pulpity i widoki kont
UI powinno szybko odpowiadać na trzy pytania: Kto jest zdrowy? Kto słabnie? Dlaczego? Zacznij od pulpitowego podsumowania portfela, a potem pozwól drillować w konto, by poznać historię stojącą za wynikiem.
Najważniejsze elementy pulpitu portfela
Zawieraj kompaktowy zestaw kafelków i wykresów, które zespół CS przeskanuje w kilka sekund:
- Rozkład wyników (histogram lub kubełki: Healthy / Watch / At-risk)
- Lista zagrożonych z polami potrzebnymi do działania (konto, właściciel, wynik, ostatnia aktywność, główny driver)
- Trend wyników w czasie (wykres liniowy) z opcją filtrowania po segmencie
Uczyń listę zagrożonych klikalną, aby użytkownik mógł otworzyć konto i od razu zobaczyć, co się zmieniło.
Widok konta: wytłumacz wynik
Strona konta powinna czytać się jak oś czasu adopcji:
- Oś czasu kluczowych zdarzeń (ukończone kroki onboardingu, podłączone integracje, zmiany adminów, pierwsze użycie ważnych funkcji)
- Kluczowe metryki (aktywni użytkownicy, kluczowe akcje, czas od ostatniej znaczącej aktywności)
- Breakdown adopcji funkcji pokazujący, które funkcje są adoptowane, ignorowane lub cofające się
Dodaj panel „Dlaczego ten wynik?”: kliknięcie wyniku ujawnia sygnały przyczynowe (pozytywne i negatywne) z prostymi wyjaśnieniami w języku naturalnym.
Widoki kohort i segmentów
Udostępnij filtry kohortowe zgodne z zarządzaniem kontami: kohorty onboardingowe, poziomy planu, branże. Pokaż dla każdej kohorty linie trendów i małą tabelę top moverów, aby zespoły mogły porównywać wyniki i wychwytywać wzorce.
Dostępne i wiarygodne wizualizacje
Używaj jasnych etykiet i jednostek, unikaj niejednoznacznych ikon i oferuj kolorowo-bezpieczne wskaźniki statusu (np. etykiety tekstowe + kształty). Traktuj wykresy jako narzędzia decyzyjne: adnotuj skoki, pokaż zakresy dat i zachowaj spójność drill-down na stronach.
Dodaj alerty, zadania i workflowy
Ocena zdrowia jest użyteczna tylko wtedy, gdy powoduje działanie. Alerty i workflowy zamieniają „interesujące dane” w szybki kontakt, poprawki onboardingu lub product nudges — bez zmuszania zespołu do ciągłego pilnowania pulpitów.
Zdefiniuj reguły alertów odpowiadające realnemu ryzyku
Zacznij od małego zestawu wysokosygnałowych triggerów:
- Spadki wyniku (np. -15 punktów tydzień do tygodnia)
- Status Czerwony (przekroczenie krytycznego progu)
- Nagły spadek użycia (kluczowa funkcja spada poniżej progu)
- Nieudany krok onboardingu (zatrzymany item w checkliście, integracja nieukończona)
Uczyń każdą regułę explicit i wyjaśnialną. Zamiast „Zły stan”, alertuj „Brak aktywności w Funkcji X przez 7 dni + onboarding nieukończony”.
Wybierz kanały i pozwól na konfigurację
Różne zespoły pracują inaczej, więc zbuduj obsługę kanałów i preferencji:
- Email dla właścicieli kont i menedżerów
- Slack dla widoczności zespołowej i szybkiej reakcji
- Zadania w aplikacji w Twoim pulpicie CS, żeby praca się nie gubiła
Niech każdy zespół konfiguruje: kto otrzymuje powiadomienia, które reguły są włączone i jakie progi oznaczają „pilne”.
Ogranicz hałas przez strażnice
Zmęczenie alertami zabija monitoring. Dodaj kontrolki takie jak:
- Okna cooldown (nie powiadamiaj ponownie dla tego samego konta przez N godzin/dni)
- Minimalne progi danych (pomiń alerty, jeśli konto ma zbyt mało danych)
- Grupowanie/digesty dla sygnałów niepilnych (podsumowania dzienne/tygodniowe)
Dodaj kontekst i sugerowane kolejne kroki
Każdy alert powinien odpowiadać: co się zmieniło, dlaczego to ma znaczenie i co dalej zrobić. Dołącz ostatnie drivery wyniku, krótką oś czasu (np. ostatnie 14 dni) i sugerowane zadania typu „Umów call onboardingowy” lub „Wyślij przewodnik integracji”. Linkuj do widoku konta (np. /accounts/{id}).
Śledź rezultaty, by zamknąć pętlę
Traktuj alerty jako pracę z statusami: zaakceptowane, skontaktowane, odzyskane, churned. Raportowanie wyników pomaga dopracować reguły, ulepszyć playbooki i udowodnić, że ocena zdrowia faktycznie wpływa na retencję.
Zapewnij jakość danych, prywatność i governance
Buduj razem
Współpracuj z produktem i zespołem CS w tej samej aplikacji podczas dopracowywania driverów i progów.
Jeśli ocena zdrowia opiera się na zawodnych danych, zespoły przestaną jej ufać — i przestaną na nią reagować. Traktuj jakość, prywatność i governance jako funkcje produktu, nie dodatek.
Wprowadź zautomatyzowane checki danych
Zacznij od lekkiej walidacji na każdym etapie (ingest → warehouse → scoring output). Kilka wysokosygnałowych testów wychwytuje większość problemów wcześnie:
- Checki schematu: oczekiwane kolumny są obecne, typy nie zmieniły się, enumy są ważne.
- Checki zakresu: niemożliwe wartości (ujemne sesje, przyszłe timestampy) odrzucaj szybko.
- Checki nulli: wymagane pola (account_id, event_name, occurred_at) nie mogą być puste.
Gdy testy padają, zablokuj zadanie scoringowe (lub oznacz wyniki jako „stare”), aby zepsuty pipeline nie generował cichych, mylących alertów.
Obsłuż typowe edge case’y explicite
Scoring łamie się w „dziwnych, ale normalnych” scenariuszach. Zdefiniuj reguły dla:
- Nowych kont z małą ilością danych: pokaż „niewystarczające dane” lub użyj ramp-up baseline zamiast niskiego wyniku.
- Sezonowego użycia: porównuj do poprzedniego okresu konta lub benchmarku kohortowego zamiast uniwersalnego progu.
- Awarii i braków trackingu: oznacz dotknięte okna i nie karaj klientów za przestoje Twojego systemu.
Dodaj prawa i kontrolę prywatności
Ogranicz PII domyślnie: przechowuj tylko to, co potrzebne do monitorowania adopcji produktu. Wdróż RBAC w aplikacji webowej, loguj kto wyświetlał/eksportował dane i redaguj eksporty, gdy pola nie są wymagane (np. ukryj emaile w CSV).
Stwórz runbooki i praktyki governance
Napisz krótkie runbooki dla incident response: jak wstrzymać scoring, backfillować dane i ponownie uruchomić historyczne zadania. Przeglądaj metryki sukcesu klienta i wagi score regularnie — co miesiąc lub kwartalnie — aby zapobiec dryftowi wraz z ewolucją produktu. Dla spójności procesów odnoś się do wewnętrznej listy kontrolnej widocznej jako /blog/health-score-governance.
Waliduj, iteruj i skaluj ocenę zdrowia
Walidacja to moment, gdy ocena zdrowia przestaje być „ładnym wykresem”, a zaczyna być zaufanym narzędziem do działania. Traktuj pierwszą wersję jako hipotezę, nie ostateczność.
Przeprowadź pilota i skalibruj z oceną ludzką
Zacznij od grupy pilota (np. 20–50 kont w różnych segmentach). Dla każdego konta porównaj wynik i powody ryzyka z oceną CSM.
Szukaj wzorców:
- Wyniki systematycznie wyższe/niższe od oceny CSM (kalibracja)
- „Fałszywe alarmy” (wysokie ryzyko, a konto OK) vs „pudła” (zdrowy wynik, ale konto churnuje)
- Powody, które nie pasują do rzeczywistości (luki w wyjaśnialności)
Mierz, czy to naprawdę użyteczne
Dokładność jest ważna, ale użyteczność to to, co przynosi zwrot. Śledź outcome’y operacyjne takie jak:
- Czas wykrywania ryzyka (jak wcześnie flagujesz problem)
- Skuteczność outreachu (odsetek kont ryzykownych, które się poprawiły po interwencji)
- Proksy redukcji churnu (ruch w kierunku odnowienia, sygnały ekspansji, zmiany obciążenia wsparcia)
Testuj zmiany bezpiecznie przez wersjonowanie
Gdy dostosowujesz progi, wagi lub dodajesz sygnały, traktuj to jako nową wersję modelu. A/B testuj wersje na porównywalnych kohortach i przechowuj historyczne wersje, by wyjaśnić, dlaczego wyniki się zmieniły.
Zbieraj feedback w UI
Dodaj lekką kontrolkę typu „Wynik jest nieprawidłowy” wraz z powodem (np. „ukończenie onboardingu nie uwzględnione”, „użycie sezonowe”, „błędne mapowanie konta”). Kieruj feedback do backlogu i taguj go powiązaniem z kontem i wersją modelu, by szybciej debugować.
Skaluj z roadmapą
Gdy pilot jest stabilny, zaplanuj prace skalujące: głębsze integracje (CRM, billing, wsparcie), segmentację (wg planu, branży, lifecycle), automatyzację (zadania i playbooki) oraz samoobsługowe ustawienia, by zespoły mogły konfigurować widoki bez angażowania inżynierii.
W miarę skalowania utrzymuj krótki cykl build/iterate. Zespoły często korzystają z Koder.ai, by wystawiać nowe strony dashboardu, poprawiać kształt API lub dodawać funkcje workflow (zadania, eksporty, release’y gotowe do rollbacku) bez spowalniania cyklu opinii CS.