Co budujesz: aplikacja webowa IDP w prostych słowach
Aplikacja webowa IDP to wewnętrzne „drzwi wejściowe” do twojego systemu inżynierskiego. To miejsce, gdzie deweloperzy znajdują, co już istnieje (usługi, biblioteki, środowiska), podążają za preferowanym sposobem budowania i uruchamiania oprogramowania oraz zgłaszają zmiany bez przeszukiwania tuzina narzędzi.
Jednocześnie nie jest to kolejny zastępca dla Git, CI, konsol chmurowych czy systemu zgłoszeń. Celem jest zmniejszenie tarcia przez orkiestrację tego, czego już używasz — tak, aby właściwa ścieżka była najprostszą ścieżką.
Problemy, które powinna rozwiązać
Większość zespołów buduje aplikację webową IDP, ponieważ codzienna praca jest spowolniona przez:
- Rozsypkę narzędzi: wiedza o „gdzie kliknąć” żyje w pamięci plemiennej.
- Wolne wdrożenie: nowi inżynierowie spędzają tygodnie na poznaniu procesu zamiast dostarczać.
- Niespójne standardy: usługi tworzone i obsługiwane są różnie, co utrudnia niezawodność i bezpieczeństwo.
Aplikacja powinna zamienić to w powtarzalne workflowy i jasne, przeszukiwalne informacje.
Podstawowe bloki budowy
Praktyczna aplikacja IDP ma zwykle trzy części:
- Portal UI: katalog usług, punkty wejścia do dokumentacji i formularze samoobsługowe (np. „utwórz usługę”, „poproś o dostęp”, „przydziel bazę danych”).
- Backendowe API: logika biznesowa, która waliduje żądania, stosuje polityki i zapisuje działania.
- Integracje: konektory do twojego toolchaina (hosting Git, CI/CD, narzędzia infra, menedżery sekretów, zarządzanie incydentami), żeby działania odbywały się w systemach zapisu.
Kto za to odpowiada (a kto nie)
Zwykle zespół platformowy odpowiada za produkt portalu: doświadczenie użytkownika, API, szablony i zabezpieczenia.
Zespoły produktowe odpowiadają za swoje usługi: utrzymanie metadanych, dokumentacji/runbooków i przyjęcie dostarczonych szablonów. Zdrowy model to współdzielona odpowiedzialność: zespół platformowy buduje utwardzoną drogę; zespoły produktowe z niej korzystają i pomagają ją ulepszać.
Użytkownicy, przypadki użycia i metryki sukcesu
Aplikacja IDP odnosi sukces lub porażkę w zależności od tego, czy obsługuje właściwych ludzi z właściwymi „happy pathami”. Zanim wybierzesz narzędzia czy narysujesz diagramy architektury, wyjaśnij, kto będzie korzystał z portalu, co chce osiągnąć i jak będziesz mierzyć postęp.
Główni użytkownicy (i co ich interesuje)
Większość portali IDP ma cztery główne grupy odbiorców:
- Deweloperzy aplikacji: chcą szybkich, bezpiecznych domyślnych ustawień, aby tworzyć i uruchamiać usługi bez czekania na zgłoszenia.
- SRE / operacje: chcą standaryzacji, mniej niespodziewanych zmian i jasnej odpowiedzialności podczas incydentów.
- Bezpieczeństwo / zgodność: chcą spójnych kontroli (przeglądy dostępu, obsługa sekretów, ścieżki audytu) bez blokowania dostaw.
- Managerowie inżynieryjni / liderzy produktu: chcą widoczności — co istnieje, kto jest właścicielem i czy zespoły dostarczają niezawodnie.
Jeśli nie potrafisz w jednym zdaniu opisać, jak każda grupa zyskuje, prawdopodobnie budujesz portal, który będzie odczuwalny jako opcjonalny.
Zmapuj 5–10 kluczowych podróży
Wybierz podróże, które zdarzają się co tydzień (nie raz w roku) i zrób je naprawdę end-to-end:
- Utwórz nową usługę ze szablonu (repozytorium + CI + właściciel + tagi).
- Poproś o środowisko (dev/stage) z zabezpieczeniami.
- Zobacz stan usługi (status wdrożenia, alerty, zależności).
- Zrotuj klucze / sekrety z audytowalnym workflowem.
- Poproś o dostęp do systemu lub zbioru danych z zatwierdzeniami.
Opisz każdą podróż jako: wyzwalacz → kroki → systemy zaangażowane → oczekiwany wynik → tryby błędów. To staje się backlogiem produktu i kryteriami akceptacji.
Zdefiniuj metryki sukcesu, które możesz naprawdę śledzić
Dobre metryki wiążą się bezpośrednio z zaoszczędzonym czasem i usuniętym tarciem:
- Czas do pierwszego wdrożenia nowej usługi (mediana, p90).
- Wolumen ręcznych zgłoszeń dla typowych próśb (i czas do rozwiązania).
- Wskaźnik adopcji: % zarejestrowanych usług, % zespołów korzystających z szablonów.
- Wskaźnik awaryjności zmian i średni czas przywrócenia (jeśli portal ustandaryzuje dostawy).
Napisz oświadczenie zakresu „wersji 1”
Utrzymaj je krótkie i widoczne:
Zakres V1: „Portal, który pozwala deweloperom utworzyć usługę z zatwierdzonych szablonów, zarejestrować ją w katalogu usług z właścicielem i pokazać status wdrożenia + zdrowie. Zawiera podstawowe RBAC i logi audytu. Wyklucza niestandardowe dashboardy, pełne zastąpienie CMDB i niestandardowe workflowy.”
To oświadczenie jest twoim filtrem przed funkcjami i kotwicą roadmapy na kolejne kroki.
Zakres MVP i roadmapa dla portalu wewnętrznego
Portal udaje się, gdy rozwiązuje jedno bolesne zadanie end-to-end, a potem zyskuje prawo do rozbudowy. Najszybsza ścieżka to wąskie MVP wysłane do prawdziwego zespołu w ciągu tygodni — nie kwartałów.
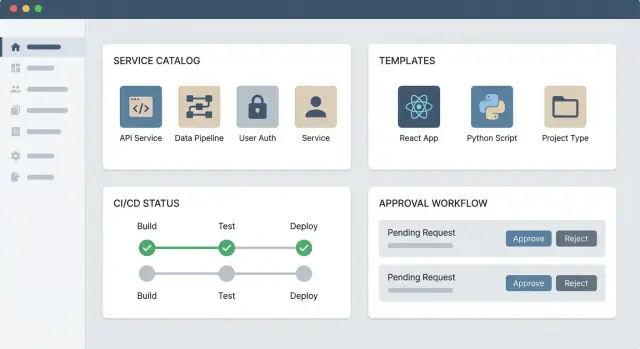
Wąskie MVP, które nadal wydaje się „kompletne”
Zacznij od trzech bloków:
- Katalog usług: jedno miejsce do odkrywania, co istnieje, kto jest właścicielem i gdzie znajdują się linki operacyjne.
- Jeden workflow samoobsługowy: wybierz często wykonywane żądanie (np. „utwórz nowe repozytorium usługi” lub „przydziel standardowe środowisko”) i zautomatyzuj je.
- Centrum dokumentacji/linków: nie migruj wszystkiego — linkuj do istniejących źródeł prawdy (CI/CD, narzędzia incydentów, runbooki), ucząc się, czego ludzie faktycznie używają.
To MVP jest małe, ale dostarcza jasny efekt: „Mogę znaleźć moją usługę i wykonać jedną ważną akcję bez pisania na Slacku”.
Jeśli chcesz szybko zweryfikować UX i happy path, platforma vibe-coding taka jak Koder.ai może pomóc w prototypowaniu UI portalu i ekranów orkiestracji na podstawie opisanego przepływu. Ponieważ Koder.ai może wygenerować aplikację React z backendem Go + PostgreSQL i wspiera eksport kodu, zespoły mogą szybko iterować i zachować długoterminowe prawo własności kodu.
Struktura backlogu: odkrywaj, twórz, operuj, zarządzaj
Aby uporządkować roadmapę, grupuj pracę w cztery kubełki:
- Odkrywaj: wyszukiwanie, tagi, własność, strony zespołów, widoki zależności.
- Twórz: szablony, scaffolding, provisioning środowisk, standardowe konfiguracje.
- Operuj: linki do dashboardów/runbooków, informacje on-call, podsumowania SLO, typowe akcje.
- Zarządzaj: RBAC, kroki zatwierdzające, logi audytu, kontrole polityk.
Ta struktura zapobiega portalowi, który jest „tylko katalogiem” lub „tylko automatyzacją” bez powiązania.
Automatyzować teraz vs. linkować na zewnątrz
Automatyzuj tylko to, co spełnia przynajmniej jedno z kryteriów: (1) powtarza się co tydzień, (2) jest podatne na błędy przy ręcznym wykonaniu, (3) wymaga koordynacji wielu zespołów. Wszystko inne może być dobrze skuratowanym linkiem do właściwego narzędzia, z jasnymi instrukcjami i właścicielstwem.
Stopniowe ulepszenia bez przeprojektowania
Projektuj portal tak, aby nowe workflowy podłączały się jako dodatkowe „akcje” na stronie usługi lub środowiska. Jeśli każdy nowy workflow wymaga zmiany nawigacji, adopcja zahamuje. Traktuj workflowy jak moduły: spójne wejścia, spójny status, spójna historia — dzięki temu dodasz więcej bez zmiany modelu mentalnego.
Architektura referencyjna: UI, API i integracje
Praktyczna architektura portalu IDP utrzymuje prosty UX, podczas gdy „brudna” praca integracji odbywa się niezawodnie w tle. Celem jest dostarczyć deweloperom jedną aplikację webową, choć działania często przekraczają Git, CI/CD, konta chmurowe, systemy zgłoszeń i Kubernetes.
Wybierz model wdrożenia
Są trzy popularne wzorce, a właściwy wybór zależy od tego, jak szybko musisz wysłać MVP i ile zespołów będzie rozszerzać portal:
- Pojedyncza aplikacja (monolit): najszybsze MVP. UI, API i logika integracji dostarczane razem. Dobre, gdy zespół platformowy kontroluje większość funkcji.
- Modułowe serwisy: oddzielne UI, rdzeń API i kilka serwisów integracyjnych. Łatwiejsze skalowanie i jaśniejsze przypisanie właściciela w miarę rozwoju.
- Oparte na pluginach: stabilne „jądro” plus pluginy dla źródeł katalogu, scaffolding, dokumentacji i workflowów. Najlepsze, gdy wiele zespołów wnosi funkcje.
Główne komponenty (co działa gdzie)
Przynajmniej oczekuj następujących bloków:
- Web UI (portal deweloperski): przeglądanie katalogu, golden pathy, formularze, strony statusu.
- Backend API (często za API gateway): auth, sprawdzenia RBAC, walidacja, orkiestracja.
- Workerzy integracji: zadania długotrwałe (tworzenie repo, provisioning środowisk, konfiguracja CI) wykonywane asynchronicznie.
- Baza danych: konfiguracja portalu, zbuforowane widoki katalogu, historia workflowów, zdarzenia audytu.
Gdzie powinien przechowywać stan
Zdecyduj wcześnie, co portal „posiada”, a co tylko wyświetla:
- Trzymaj źródła prawdy w istniejących systemach (Git, cloud IAM, CI/CD, Kubernetes, system zgłoszeń).
- Przechowuj w bazie portalu: żądania workflowów, statusy, zatwierdzenia, logi audytu i zbuforowane indeksy przyspieszające UI.
Niezawodność integracji
Integracje zawodzą z normalnych powodów (limity zapytań, przejściowe awarie, częściowe sukcesy). Projektuj dla:
- Ponawiania z backoffem i jasnych komunikatów o błędach
- Idempotencji (ponowne uruchomienie żądania nie powinno tworzyć duplikatów)
- Timeoutów i anulowania
- Trwałej historii workflowów, aby użytkownicy widzieli, co się stało i mogli bezpiecznie odzyskać system
Model danych: katalog usług i własność
Twój katalog usług jest źródłem prawdy o tym, co istnieje, kto jest właścicielem i jak to pasuje do reszty systemu. Jasny model danych zapobiega „tajemniczym usługom”, duplikatom i zepsutym automatyzacjom.
Zdefiniuj podstawowy byt „Service”
Zacznij od zgody, co „usługa” oznacza w twojej organizacji. Dla większości zespołów to jednostka wdrażalna (API, worker, strona) z cyklem życia.
Przynajmniej zamodeluj te pola:
- Nazwa + opis (czytelne dla człowieka)
- Właściciele: główny zespół oraz opcjonalni kontaktowi (on-call, tech lead)
- Repozytoria źródłowe: jedno lub więcej linków/ID repo
- Środowiska runtime: dev/stage/prod lub warianty specyficzne dla regionów
- Zależności: usługi upstream/downstream i współdzielone biblioteki
Dodaj praktyczne metadane, które napędzają portal:
- Cykl życia (eksperymentalny, aktywny, wycofywany)
- Krytyczność/poziom (dla oczekiwań wsparcia i zarządzania)
- Linki (runbooki, dashboardy, SLO, kanał incydentów)
Modeluj relacje explicite
Traktuj relacje jako pierwszorzędne, nie tylko pola tekstowe:
- Services ↔ teams: wiele usług na zespół; czasem wspólne własnictwo (użyj
primary_owner_team_id plus additional_owner_team_ids).
- Services ↔ resources: powiąż z zasobami chmurowymi (namespace Kubernetes, kolejki, bazy danych), by można było odpowiedzieć „z czego korzysta ta usługa?”.
- Poziomy usług: przechowuj poziom jako enum i powiąż go z polityką (np. tier-0 wymaga on-call i logów audytu).
Taka relacyjna struktura umożliwia strony typu „wszystko, co należy do Zespołu X” lub „wszystkie usługi korzystające z tej bazy danych”.
Identyfikatory i zasady nazewnictwa
Zdecyduj wcześnie o kanonicznym ID, by po imporcie nie pojawiały się duplikaty. Typowe wzorce:
- Stabilny slug (np.
payments-api) wymuszony jako unikalny
- Niezmienny UUID plus przyjazny dla ludzi slug
- Opcjonalnie: klucz pochodzący z repo (
github_org/repo) jeśli repo są 1:1 z usługami
Udokumentuj zasady nazewnictwa (dozwolone znaki, unikalność, zasady zmiany nazwy) i waliduj je przy tworzeniu.
Zaplanuj, jak dane pozostają świeże
Katalog usług przestaje działać, gdy się zestarzeje. Wybierz jedną z metod lub ich kombinację:
- Harmonogramowane importy (synchronizacja nocna z Git, CI/CD, inwentarzem chmury)
- Webhooki (aktualizacja przy zmianach w repo, wdrożeniach, zmianach właściciela)
- Strumienie zdarzeń (publikuj zdarzenia takie jak „service.created” lub „dependency.updated”)
Trzymaj pole last_seen_at i data_source dla każdego rekordu, by pokazywać świeżość i debugować konflikty.
Uwierzytelnianie, autoryzacja i audytowalność
Dodaj historię przepływów i audyt
Utwórz API w Go z PostgreSQL do przechowywania żądań, zatwierdzeń i zdarzeń audytowych.
Jeśli portal IDP ma być godny zaufania, potrzebuje trzech współdziałających elementów: uwierzytelniania (kim jesteś?), autoryzacji (co możesz zrobić?) i audytowalności (co się stało i kto to zrobił?). Uczyń to dobrze wcześnie, a unikniesz przeróbek, gdy portal zacznie wykonywać zmiany produkcyjne.
Domyślnie SSO z mapowaniem grup
Większość firm ma już infrastrukturę tożsamości. Wykorzystaj ją.
Uczyń SSO przez OIDC lub SAML domyślną ścieżką logowania i pobieraj członkostwo w grupach z IdP (Okta, Azure AD, Google Workspace itp.). Następnie mapuj grupy na role portalu i członkostwo zespołów.
To upraszcza onboarding („zaloguj się i jesteś w odpowiednim zespole”), unika przechowywania haseł i pozwala IT wymuszać globalne polityki jak MFA i timeouty sesji.
Zdefiniuj jasne role (i co mogą robić)
Unikaj niejasnego modelu „admin vs wszyscy”. Praktyczny zestaw ról dla wewnętrznego portalu to:
- Developer: przegląda portal, korzysta z szablonów i workflowów samoobsługowych w dozwolonych zakresach.
- Service Owner: zarządza wpisem katalogu usługi (metadane, on-call, linki, cykl życia), widzi historię specyficzną dla usługi.
- Approver: zatwierdza lub odrzuca wrażliwe żądania (dostęp do produkcji, nowe środowiska, zasoby wpływające na koszty).
- Platform Admin: zarządza szablonami, integracjami, ustawieniami globalnymi i domyślnymi politykami.
- Auditor: dostęp tylko do odczytu do logów audytu, zatwierdzeń i historii konfiguracji.
Utrzymuj role małe i zrozumiałe. Zawsze możesz je rozwinąć później, ale zbyt skomplikowany model zniechęca użytkowników.
RBAC plus uprawnienia na poziomie zasobu
RBAC jest potrzebny, ale niewystarczający. Portal musi też mieć uprawnienia na poziomie zasobu: dostęp powinien być ograniczony do zespołu, usługi lub środowiska.
Przykłady:
- Deweloper może uruchomić workflow „utwórz środowisko sandbox” dla usług swojego zespołu, ale nie innych.
- Właściciel usługi może edytować wpis katalogu dla usług, którymi zarządza.
- Zatwierdzający może zatwierdzać żądania tylko dla określonych cost centerów lub przestrzeni produkcyjnych.
Zaimplementuj to prostym wzorcem polityki: (podmiot) może (akcja) na (zasobie) jeśli (warunek). Zacznij od zakresowania do zespołu/usługi i rozwijaj dalej.
Ślady audytu dla wrażliwych działań
Traktuj logi audytu jako funkcję pierwszej klasy, nie szczegół backendu. Portal powinien zapisywać:
- Kto zainicjował workflow (i skąd)
- Wartości parametrów przesłanych (zredaguj sekrety)
- Kto zatwierdził/odrzucił i komentarze
- Wynikające zmiany (linki do uruchomień CI/CD, zgłoszeń lub zmian infra)
- Zmiany w szablonach, uprawnieniach i integracjach
Ułatw dostęp do ścieżek audytu z miejsc pracy: strona usługi, zakładka „Historia” workflowu i widok administracyjny dla zgodności. To też przyspiesza przeglądy incydentów.
UX dla deweloperów: uczyń właściwą ścieżkę łatwą
Dobry UX portalu IDP to nie wygląd, lecz zmniejszenie tarcia, gdy ktoś próbuje dostarczyć. Deweloperzy powinni szybko odpowiedzieć na trzy pytania: Co istnieje? Co mogę utworzyć? Co wymaga uwagi teraz?
Projektuj nawigację wokół rzeczywistych zadań
Zamiast organizować menu według systemów backendowych („Kubernetes”, „Jira”, „Terraform”), strukturyzuj portal wokół pracy, którą deweloperzy faktycznie wykonują:
- Odkrywaj: znajdź usługi, API, dokumentację, właścicieli, runbooki
- Twórz: rozpocznij nową usługę, dodaj endpoint, poproś o bazę danych
- Operuj: zobacz zdrowie, incydenty, status wdrożeń, ostatnie zmiany
- Zarządzaj: uprawnienia, kontrole zgodności, wyjątki polityk
Ta nawigacja oparta na zadaniach ułatwia także onboarding: nowi członkowie nie muszą znać twojego toolchainu, by zacząć.
Spraw, by własność była nie do przeoczenia
Każda strona usługi powinna wyraźnie pokazywać:
- Zespół właścicielski i kanał zespołu
- Rotację on-call i ścieżkę eskalacji
- Główne repo i cel wdrożenia
Umieść panel „Kto jest właścicielem?” wysoko, nie ukrywaj go w zakładce. Przy incydentach każda sekunda się liczy.
Wyszukiwanie, filtry i statusy zgodne z myśleniem ludzi
Szybkie wyszukiwanie to siła portalu. Wspieraj filtry, których deweloperzy naturalnie używają: zespół, cykl życia (eksperymentalne/produkcyjne), poziom, język, platforma i „należy do mnie”. Dodaj czytelne wskaźniki statusu (zdrowe/obniżona wydajność, SLO zagrożony, zablokowane przez zatwierdzenie), by użytkownicy mogli przeskanować listę i podjąć decyzję.
Przy tworzeniu zasobów pytaj tylko o to, co naprawdę potrzebne teraz. Używaj szablonów („golden path”) i domyślnych ustawień, by zapobiegać błędom — konwencje nazewnicze, haki do logowania/metryk i standardowe ustawienia CI powinny być wstępnie wypełnione. Jeśli pole jest opcjonalne, ukryj je pod „Opcje zaawansowane”, by happy path pozostał szybki.
Workflowy samoobsługowe: szablony, zatwierdzenia i historia
Wypuść pilota do prawdziwych zespołów
Hostuj prototyp wewnętrznego portalu i szybko udostępnij go zespołowi pilotażowemu.
Samoobsługa to miejsce, w którym portal IDP zdobywa zaufanie: deweloperzy powinni wykonywać typowe zadania end-to-end bez otwierania zgłoszeń, a zespół platformowy nadal zachowuje kontrolę nad bezpieczeństwem, zgodnością i kosztami.
Wybierz typy workflowów, które najpierw mają znaczenie
Zacznij od małego zestawu workflowów odpowiadających częstym, frustrującym żądaniom. Typowe „pierwsze cztery”:
- Utwórz usługę: wygeneruj repo, zarejestruj w katalogu, ustaw właściciela i skonfiguruj CI/CD.
- Przydziel środowisko: uruchom środowisko dev/stage ze standardową siecią, logowaniem i budżetami.
- Poproś o dostęp: przydziel zasadę najmniejszych uprawnień do systemu z opcją wygaśnięcia.
- Rotacja sekretów: uruchom rotację, zaktualizuj konfiguracje i zweryfikuj, że aplikacje działają poprawnie po zmianie.
Te workflowy powinny być stanowcze i odzwierciedlać twój golden path, a jednocześnie pozwalać na kontrolowane wybory (język/runtime, region, poziom, klasyfikacja danych).
Zdefiniuj kontrakt workflowu (by szablony były przewidywalne)
Traktuj każdy workflow jak API produktu. Jasny kontrakt sprawia, że workflowy są wielokrotnego użytku, testowalne i łatwiejsze do integracji z toolchainem.
Praktyczny kontrakt zawiera:
- Wejścia: typowane pola z domyślnymi wartościami (np. nazwa usługi, zespół właścicielski, środowisko, wrażliwość danych).
- Walidacja: reguły nazewnictwa, dozwolone regiony, sprawdzenia limitów, sprawdzenie „czy to już istnieje?”.
- Kroki: sekwencja akcji (uruchom szablon, wywołaj CI/CD, utwórz zasoby w chmurze, zaktualizuj katalog usług).
- Wyjścia: artefakty i linki potrzebne deweloperom (URL repo, URL wdrożenia, link do runbooka, utworzone zasoby).
Trzymaj UX skupiony: pokazuj tylko wejścia, które deweloper faktycznie może wybrać, a resztę wnioskowuj z katalogu usług i polityk.
Zatwierdzenia — szybkie, jasne i wykonalne
Zatwierdzenia są nieuniknione dla pewnych akcji (dostęp do produkcji, wrażliwe dane, wzrost kosztów). Portal powinien czynić zatwierdzenia przewidywalnymi:
- Kto zatwierdza: definiuj reguły automatycznych zatwierdzających (właściciel zespołu, właściciel systemu, bezpieczeństwo) zamiast ad-hoc pingów.
- Limity czasowe: ustaw SLA na zatwierdzenie i automatycznie wygaszaj przeterminowane żądania.
- Eskalacja: jeśli główny zatwierdzający nie jest dostępny, przekieruj do grupy zapasowej lub rotacji on-call.
Zatwierdzenia muszą być częścią silnika workflowów, nie ręcznym kanałem. Deweloper powinien widzieć status, kolejne kroki i dlaczego zatwierdzenie jest wymagane.
Przechowuj historię i wyniki, by zespoły mogły samodzielnie debugować
Każdy przebieg workflowu powinien generować trwały zapis:
- Użyte wejścia, wyniki walidacji i decyzje zatwierdzających
- Logi krok po kroku (z zredagowanymi sekretami)
- Końcowe wyjścia, utworzone zasoby i ewentualne akcje rollback
Ta historia staje się „papierowym śladem” i systemem wsparcia: gdy coś zawiedzie, deweloperzy widzą dokładnie gdzie i dlaczego — często rozwiązując problem bez zgłoszenia. Daje to też zespołowi platformowemu dane do poprawy szablonów i wykrywania powtarzających się błędów.
Portal IDP staje się „prawdziwy”, gdy potrafi czytać i działać na systemach, których deweloperzy już używają. Integracje zamieniają wpis katalogu w coś, co można wdrożyć, obserwować i wspierać.
Zacznij od jas checklisty integracji
Większość portali potrzebuje zestawu bazowych połączeń:
- Git (repozytoria, gałęzie domyślne, CODEOWNERS, pull requesty)
- CI/CD (pipeline’y, statusy buildów, artefakty, promocje)
- Kubernetes (klastry, namespace’y, workloady, rollouty)
- Chmura (konta/projekty, sieć, usługi zarządzane)
- IAM (zespoły, grupy, SSO, mapowania ról)
- Sekrety (vaulty, referencje sekretów, status rotacji)
Bądź jasny, jakie dane są tylko do odczytu (np. status pipeline) a jakie do zapisu (np. wyzwalanie wdrożenia).
Preferuj podejście API-first; używaj webhooków lub syncu, gdy trzeba
Integracje API-first są łatwiejsze do przetestowania i zrozumienia: możesz walidować auth, schematy i obsługę błędów.
Używaj webhooków dla zdarzeń niemal w czasie rzeczywistym (PR scalony, pipeline zakończony). Używaj harmonogramowanego syncu dla systemów, które nie potrafią wysyłać zdarzeń lub tam, gdzie akceptowalna jest spójność w czasie (np. nocny import kont chmurowych).
Zbuduj warstwę konektorów (nie integruj dostawców bezpośrednio w rdzeniu)
Stwórz cienki „connector” lub serwis integracyjny, który normalizuje szczegóły specyficzne dla dostawcy do stabilnego wewnętrznego kontraktu (np. Repository, PipelineRun, Cluster). To izoluje zmiany przy migracji narzędzi i utrzymuje czyste API/UI portalu.
Praktyczny wzorzec:
- Portal wywołuje konektor
- Konektor obsługuje auth, limity, retries, mapowanie
- Konektor zwraca znormalizowane dane + linki akcjonowalne (np.
/deployments/123)
Dokumentuj tryby awarii i co powinni zrobić użytkownicy
Każda integracja powinna mieć krótki runbook: jak wygląda „degradacja”, jak to pokazuje UI i co robić.
Przykłady:
- Git API ograniczone: portal pokazuje zbuforowane dane repo; użytkownik może przeglądać katalog, ale „Utwórz ze szablonu” jest wyłączone.
- CI/CD niedostępne: portal oferuje fallback manualny (link do UI pipeline) i informuje o czasie ponowienia.
- Menedżer sekretów niedostępny: blokuj zmiany wymagające nowych sekretów; pozwól na odczyt metadanych usługi.
Trzymaj dokumenty blisko produktu (np. /docs/integrations), żeby deweloperzy nie musieli zgadywać.
Observability: monitorowanie portalu i jego automatyzacji
Portal IDP to nie tylko UI — to warstwa orkiestracji, która wywołuje joby CI/CD, tworzy zasoby chmurowe, aktualizuje katalog usług i wymusza zatwierdzenia. Observability pozwala szybko i pewnie odpowiedzieć: „Co się stało?”, „Gdzie nastąpiła awaria?” i „Kto musi podjąć działanie?”.
Śledź każde żądanie przez kroki
Instrumentuj każdy przebieg workflowu identyfikatorem korelacji, który podąża od UI portalu przez backendowe API, sprawdzenia zatwierdzeń i narzędzia zewnętrzne (Git, CI, chmura, ticketing). Dodaj śledzenie żądań, by pojedynczy widok pokazywał pełną ścieżkę i czasy poszczególnych kroków.
Uzupełnij ślady strukturalnymi logami (JSON) zawierającymi: nazwę workflowu, run ID, nazwę kroku, docelową usługę, środowisko, aktora i wynik. To ułatwia filtrowanie (np. „wszystkie nieudane uruchomienia deploy-template” lub „wszystko dot. Usługi X”).
Metryki odzwierciedlające ból dewelopera
Podstawowe metryki infra to za mało. Dodaj metryki workflowów powiązane z rzeczywistymi rezultatami:
- Liczba uruchomień, wskaźnik sukcesu i czas trwania per workflow i krok
- Czas oczekiwania na zatwierdzenie vs. czas wykonania (identyfikuje wąskie gardła)
- Retries, timeouts i rate limits z konektorów
Widoki operacyjne wewnątrz portalu
Daj zespołom platformowym strony „na pierwszy rzut oka”:
- Kolejka workflowów: uruchomione, w kolejce, nieudane, oczekujące zatwierdzenia
- Zdrowie konektorów: ważność tokenów, ostatnie udane wywołanie, wskaźnik błędów
- Status synchronizacji: ostatni sync katalogu, wykryty drift, rozmiar backlogu
Połącz każdy status z możliwością zejścia do szczegółów i dokładnych logów/śladów dla tego przebiegu.
Alerty, retencja i audyt
Ustaw alerty dla zepsutych integracji (np. powtarzające się 401/403), zablokowanych zatwierdzeń (brak akcji przez N godzin) i nieudanych synchronizacji. Zaplanuj retencję danych: przechowuj krócej duże wolumeny logów, ale dłużej zdarzenia audytowe dla zgodności i śledztw, z jasnym zarządzaniem dostępem i opcjami eksportu.
Bezpieczeństwo i zarządzanie bez spowalniania zespołów
Wystaw katalog usług
Wygeneruj interfejs katalogu usług z polami właściciela, tagami i listami z możliwością wyszukiwania.
Bezpieczeństwo w portalu IDP działa najlepiej, gdy jest „barierą ochronną”, a nie przepustką. Celem jest zredukować ryzykowne wybory, czyniąc bezpieczną ścieżkę najprostszą — równocześnie dając zespołom autonomię do dostarczania.
Waliduj wejścia i wymuszaj standardy automatycznie
Większość zarządzania można wykonać w momencie, gdy deweloper żąda czegoś (nowa usługa, repo, środowisko, zasób chmurowy). Traktuj każdy formularz i wywołanie API jako nieufne wejście.
Wymuszaj standardy w kodzie, nie w dokumentach:
- Wymagaj własności (zespół, on-call, kontakt eskalacyjny) i blokuj tworzenie, gdy brakuje tych danych.
- Waliduj konwencje nazewnicze (nazwy usług, repo, środowisk), by unikać kolizji i zamieszania.
- Wymagaj tagów/metadanych używanych do alokacji kosztów, zgodności i odkrywania.
- Odrzucaj żądania niezgodne z polityką minimalną (np. „publiczne wystawienie” wymaga dodatkowego przeglądu).
To utrzymuje katalog czysty i znacznie ułatwia audyty.
Chroń sekrety z założenia
Portal często operuje poświadczeniami (tokeny CI, dostęp do chmury, klucze API). Traktuj sekrety jak radioaktywny materiał:
- Nigdy nie loguj sekretów ani nie umieszczaj ich w komunikatach o błędach.
- Preferuj krótkotrwałe tokeny (OIDC, dostęp federacyjny, poświadczenia czasowe) zamiast długowiecznych kluczy.
- Przechowuj sekrety wyłącznie w dedykowanym menedżerze sekretów; portal powinien się do nich odwoływać, a nie kopiować.
Upewnij się też, że logi audytu rejestrują kto co i kiedy zrobił — bez zapisywania wartości sekretów.
Modeluj zagrożenia dla „normalnych” awarii
Skup się na realistycznych ryzykach:
- Eskalacja przywilejów przez źle skonfigurowane RBAC i zbyt szerokie uprawnienia.
- Fałszywe webhooki lub callbacki wyzwalające akcje bez weryfikacji.
- Wycieki danych przez debugowe endpointy, nadmiernie szczegółowe logi lub zbyt szerokie wyszukiwanie.
Zminimalizuj to za pomocą podpisanych webhooków, zasady najmniejszych przywilejów i ścisłego rozdzielenia operacji „odczyt” i „zmiana”.
Przesuń kontrole w lewo z CI i przeglądami uprawnień
Uruchamiaj kontrole bezpieczeństwa w CI dla kodu portalu i dla generowanych szablonów (linting, polityki, skanowanie zależności). Następnie zaplanuj regularne przeglądy:
- Ról RBAC i mapowań grup
- Uprawnień szablonów (kto może co tworzyć)
- Procedur dostępu awaryjnego i ich rotacji
Zarządzanie jest trwałe, gdy jest rutynowe, zautomatyzowane i widoczne — nie jednorazowe.
Wdrożenie, adopcja i długoterminowe utrzymanie
Portal deweloperski dostarcza wartość tylko wtedy, gdy zespoły go rzeczywiście używają. Traktuj wdrożenie jak launch produktu: zacznij od małego, ucz się szybko, a potem skaluj na podstawie dowodów.
Zacznij od skoncentrowanego pilotażu
Pilotaż z 1–3 zespołami, które są zmotywowane i reprezentatywne (jeden „greenfield”, jeden z legacy, jeden z wyższymi wymaganiami zgodności). Obserwuj, jak wykonują rzeczywiste zadania — rejestrację usługi, żądanie infra, uruchomienie deploya — i natychmiast usuwaj tarcie. Celem nie jest kompletność funkcji, lecz udowodnienie, że portal oszczędza czas i zmniejsza błędy.
Uczyń migrację nudną i przewidywalną
Dostarcz kroki migracji mieszczące się w normalnym sprincie. Na przykład:
- zarejestruj istniejącą usługę w katalogu,
- dołącz własność i on-call,
- podłącz CI/CD,
- zastosuj jeden szablon (repo, pipeline lub infra) dla następnego komponentu.
Utrzymuj „day 2” aktualizacje proste: pozwól zespołom stopniowo dodawać metadane i zastępować niestandardowe skrypty workflowami portalu.
Dokumentacja i pomoc w produkcie, które ludzie przeczytają
Pisz zwięzłą dokumentację dla najważniejszych workflowów: „Zarejestruj usługę”, „Poproś o bazę danych”, „Cofnij wdrożenie”. Dodaj pomoc w produkcie obok pól formularzy i linkuj do /docs/portal oraz /support dla głębszego kontekstu. Traktuj dokumentację jak kod: wersjonuj ją, przeglądaj i przycinaj.
Własność to zobowiązanie długoterminowe
Zaplanuj stałe utrzymanie od początku: ktoś musi triagować backlog, utrzymywać konektory do narzędzi zewnętrznych i wspierać użytkowników, gdy automatyzacje zawiodą. Zdefiniuj SLA na incydenty portalu, ustal rytm aktualizacji konektorów i regularnie przeglądaj logi audytu, by wykrywać powtarzające się problemy i luki w politykach.
W miarę dojrzewania portalu będziesz chciał funkcje takie jak snapshoty/rollback konfiguracji portalu, przewidywalne wdrożenia i łatwe promowanie środowisk między regionami. Jeśli budujesz lub eksperymentujesz szybko, Koder.ai może pomóc zespołom wystawić wewnętrzne aplikacje z trybem planowania, hostingiem wdrożeń i eksportem kodu — przydatne do pilotażu funkcji portalu, zanim je utrwalisz jako elementy platformy.