15 lis 2025·8 min
Stwórz aplikację webową do prognozowania zapasów i planowania popytu
Zaprojektuj i zbuduj aplikację webową do prognozowania zapasów i planowania popytu: konfiguracja danych, metody prognozowania, UX, integracje, testy i wdrożenie.
Zaprojektuj i zbuduj aplikację webową do prognozowania zapasów i planowania popytu: konfiguracja danych, metody prognozowania, UX, integracje, testy i wdrożenie.
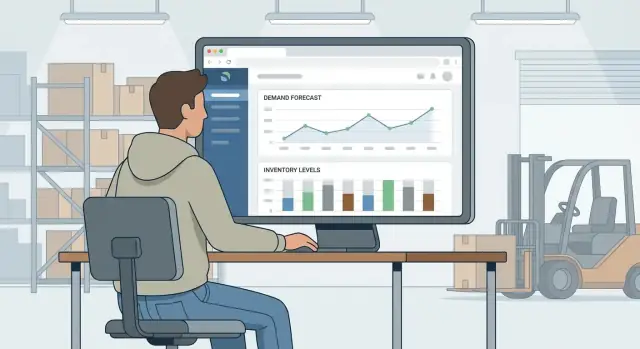
Aplikacja webowa do prognozowania zapasów i planowania popytu pomaga firmie zdecydować co kupić, kiedy kupić i ile kupić—na podstawie przewidywanego popytu i aktualnej pozycji zapasowej.
Prognozowanie zapasów przewiduje sprzedaż lub zużycie dla każdego SKU w czasie. Planowanie popytu zamienia te przewidywania w decyzje: punkty ponownego zamówienia, ilości zamówień i terminy, które odpowiadają celom serwisowym i ograniczeniom finansowym.
Bez wiarygodnego systemu zespoły często polegają na arkuszach i intuicji. To zwykle prowadzi do dwóch kosztownych rezultatów:
Dobrze zaprojektowana aplikacja do prognozowania zapasów tworzy wspólne źródło prawdy dla oczekiwań popytu i rekomendowanych działań—tak aby decyzje były spójne w lokalizacjach, kanałach i zespołach.
Dokładność i zaufanie buduje się w czasie. Twoje MVP może zacząć od:
Gdy użytkownicy przyjmą workflow, możesz stopniowo poprawiać dokładność dzięki lepszym danym, segmentacji, obsłudze promocji i inteligentniejszym modelom. Celem nie jest „perfekcyjna” prognoza—lecz powtarzalny proces decyzyjny, który z każdym cyklem staje się lepszy.
Typowi użytkownicy to:
Oceniaj aplikację przez pryzmat biznesowy: mniej braków, niższy nadmiar zapasów i jaśniejsze decyzje zakupowe—wszystko widoczne na dashboardzie planowania zapasów, który podpowiada następną akcję.
Aplikacja do prognozowania zapasów zwycięża lub przegrywa dzięki klarowności: jakie decyzje ma wspierać, dla kogo i na jakim poziomie szczegółu? Zanim zaczniesz modele i wykresy, zdefiniuj najmniejszy zestaw decyzji, które Twoje MVP musi poprawić.
Formułuj je jako działania, nie funkcje:
Jeśli nie możesz powiązać ekranu z jednym z tych pytań, prawdopodobnie należy to zostawić na później.
Wybierz horyzont dopasowany do czasów realizacji i rytmu zakupów:
Potem wybierz cadence aktualizacji: codziennie jeśli sprzedaż zmienia się szybko, co tydzień jeśli zakupy odbywają się cyklicznie. Cadence determinuje też jak często aplikacja uruchamia zadania i odświeża rekomendacje.
„Właściwy” poziom to poziom, który ludzie faktycznie mogą kupić i przesuwać zapasy:
Uczyń sukces mierzalnym: poziom serwisu / wskaźnik braków, obrót zapasów, i błąd prognozy (np. MAPE lub WMAPE). Powiąż metryki z wynikami biznesowymi, np. zapobieganie brakowi i redukcja nadmiaru.
MVP: jedna prognoza na SKU(-lokalizacja), jedno obliczenie punktu ponownego zamówienia, prosty workflow zatwierdzania/eksportu.
Później: optymalizacja wieloechelonowa, ograniczenia dostawców, promocje i planowanie scenariuszy.
Prognozy są tak dobre, jak dane, które je zasilają. Zanim wybierzesz modele lub zbudujesz ekrany, wyjaśnij jakie dane masz, gdzie leżą i co oznacza „dostatecznie dobre” dla MVP.
Minimum to konsekwentny widok:
Zespoły łączą zazwyczaj wiele systemów:
Zdecyduj jak często aplikacja odświeża dane (godzinowo, codziennie) i co się stanie, gdy dane przyjdą późno lub zostaną edytowane. Praktyczny wzorzec to utrzymywanie niezmiennej historii transakcji i stosowanie rekordów korekcyjnych zamiast nadpisywania danych z poprzednich dni.
Przypisz właściciela dla każdego zbioru danych (np. inventory: operacje magazynowe; lead times: zaopatrzenie). Prowadź krótki słownik danych: znaczenie pola, jednostki, strefa czasowa i dozwolone wartości.
Spodziewaj się problemów typu brakujące czasy realizacji, konwersje jednostek (each vs case), zwroty i anulacje, duplikaty SKU i niespójne kody lokalizacji. Wczesne oznaczanie takich problemów pozwala MVP albo je naprawić, ustawić domyślną wartość, albo wykluczyć—jawnie i widocznie.
Aplikacja do prognozowania zyskuje zaufanie, jeśli wszyscy ufają liczbom. To zaufanie zaczyna się od modelu danych, który sprawia, że „co się stało” (sprzedaż, przyjęcia, transfery) jest jednoznaczne, a „co jest teraz prawdą” (on-hand, on-order) spójne.
Zdefiniuj mały zestaw encji i używaj ich konsekwentnie w całej aplikacji:
Wybierz dzienną lub tygodniową ziarnistość jako kanoniczną. Wymuś dopasowanie każdego inputu: zamówienia mogą mieć znaczniki czasu, liczenia zapasów to koniec dnia, a faktury mogą pojawiać się później. Ustal jasną regułę wyrównania (np. „sprzedaż przypisujemy do daty wysyłki, zgrupowane po dniu”).
Jeśli sprzedajesz w each/case/kg, przechowuj zarówno oryginalną jednostkę, jak i znormalizowaną jednostkę do prognozowania (np. „each”). Jeśli prognozujesz przychód, przechowuj oryginalną walutę plus znormalizowaną walutę raportową z odniesieniem kursu wymiany.
Śledź zapasy jako sekwencję zdarzeń dla SKU-lokalizacja-czas: snapshoty on-hand, on-order, przyjęcia, transfery i korekty. To ułatwia wyjaśnianie braków i audyt.
Dla każdej kluczowej miary (sprzedaż jednostkowa, on-hand, lead time) wybierz jedno autorytatywne źródło i udokumentuj to w schemacie. Kiedy systemy się nie zgadzają, model powinien pokazywać, które źródło wygrało—i dlaczego.
Interfejs prognozowania jest tyle wart, ile dane, które go zasilają. Jeśli liczby zmieniają się bez wyjaśnień, użytkownicy stracą zaufanie—nawet jeśli model działa poprawnie. Twój ETL powinien uczynić dane przewidywalnymi, debuggowalnymi i śledzalnymi.
Najpierw zapisz „źródło prawdy” dla każdego pola (zamówienia, wysyłki, on-hand, lead times). Następnie wdroż powtarzalny flow:
Utrzymuj dwie warstwy:
Gdy planner zapyta „dlaczego popyt z zeszłego tygodnia się zmienił?”, powinieneś móc wskazać rekord surowy i transformację, która go zmieniła.
Przynajmniej waliduj:
Zawieszaj run (lub kwarantannuj daną partycję) zamiast cicho publikować złe dane.
Jeśli zakupy robi się co tydzień, codzienny batch zwykle wystarczy. Near-real-time używaj tylko wtedy, gdy decyzje operacyjne tego wymagają (dostawy tego samego dnia, gwałtowne e-commerce), bo to zwiększa złożoność i hałas alertów.
Udokumentuj co się dzieje przy awarii: które kroki retryują automatycznie, ile razy i kto otrzymuje powiadomienia. Wysyłaj alerty gdy extracty padną, liczba wierszy spadnie gwałtownie lub walidacje nie przejdą—i prowadź run log, by audytować każde wejście do prognozy.
Metody prognozowania nie są „lepsze” same w sobie—są lepsze dla Twoich danych, SKU i rytmu planowania. Dobra aplikacja ułatwia zaczęcie od prostoty, mierzenie wyników, a potem przejście do zaawansowanych modeli tam, gdzie to ma sens.
Bazy są szybkie, wyjaśnialne i świetne jako sanity check. Uwzględnij co najmniej:
Zawsze raportuj dokładność prognoz względem tych baz—jeśli model złożony ich nie przebije, nie wdrażaj go.
Gdy MVP jest stabilne, dodaj kilka „kroków w górę”:
Możesz szybciej wdrożyć jeden domyślny model z kilkoma parametrami. Często jednak lepsze rezultaty daje wybór modelu per-SKU (dobór rodziny modelu na podstawie backtestów), zwłaszcza gdy katalog miesza stałe bestsellery, sezonowe produkty i długi ogon.
Jeśli wiele SKU ma dużo zer, traktuj to poważnie. Dodaj metody odpowiednie do przerywanego popytu (np. podejścia typu Croston) i oceniaj metrykami, które nie penalizują zer niesprawiedliwie.
Plannerzy będą potrzebować nadpisań dla launchów, promocji i znanych zakłóceń. Zbuduj workflow nadpisania z powodami, datami wygaśnięcia i śladem audytu, aby ręczne edycje poprawiały decyzje bez ukrywania historii.
Dokładność prognozy często zależy od cech: dodatkowego kontekstu poza "sprzedażą z ostatniego tygodnia". Celem nie jest dodanie setek sygnałów—lecz kilku, które odzwierciedlają zachowanie biznesu i które plannerzy rozumieją.
Popyt zwykle ma rytm. Dodaj kilka cech kalendarzowych, które chwytają ten rytm bez overfittingu:
Jeśli promocje są chaotyczne, zacznij od prostej flagi „na promocji” i dopracowuj później.
Prognozowanie zapasów to nie tylko popyt—to też dostępność. Użyteczne, wyjaśnialne sygnały to zmiany cen, aktualizacje lead time i ograniczenia dostawcy. Rozważ dodanie:
Dzień z zero sprzedaży z powodu braku nie oznacza zerowego popytu. Jeśli podasz takie zera bez korekty, model nauczy się, że popyt zniknął.
Typowe podejścia:
Nowe produkty nie mają historii. Zdefiniuj jasne reguły:
Utrzymuj mały zestaw cech i nazywaj je po biznesowemu w aplikacji (np. „Tydzień świąteczny” zamiast „x_reg_17”), aby plannerzy ufali—i mogli kwestionować—działanie modelu.
Prognoza jest użyteczna tylko wtedy, gdy mówi komuś, co zrobić dalej. Twoja aplikacja powinna konwertować przewidywany popyt na konkretne, możliwe do przejrzenia działania zakupowe: kiedy zamawiać, ile kupić i ile zapasu bezpieczeństwa trzymać.
Zacznij od trzech wyjść na SKU (lub SKU-lokalizacja):
Praktyczna struktura to:
Jeśli możesz zmierzyć, uwzględnij zmienność lead time (nie tylko średnią). Nawet prosta odchyłka standardowa na poziomie dostawcy może znacząco zmniejszyć braki.
Nie każdy produkt zasługuje na taki sam poziom ochrony. Pozwól użytkownikom wybierać cele serwisowe według klasy ABC, marży lub krytyczności:
Rekomendacje muszą być wykonalne. Dodaj obsługę ograniczeń typu:
Każdy zasugerowany zakup powinien zawierać krótkie wyjaśnienie: prognozowany popyt w czasie realizacji, aktualna pozycja zapasowa, wybrany poziom serwisu i zastosowane korekty ograniczeń. To buduje zaufanie i ułatwia zatwierdzanie wyjątków.
Aplikacja do prognozowania jest łatwiejsza w utrzymaniu, gdy traktujesz ją jak dwa produkty: doświadczenie webowe dla ludzi i silnik prognozujący działający w tle. To rozdzielenie utrzymuje UI szybkie, zapobiega timeoutom i sprawia, że wyniki są odtwarzalne.
Zacznij od czterech bloków:
Kluczowa decyzja: runy prognoz nie powinny wykonywać się w trakcie żądania UI. Umieść je w kolejce (lub jako zaplanowane zadania), zwróć run ID i strumieniuj postęp w UI.
Jeśli chcesz przyspieszyć budowę MVP, platforma vibe-codingowa taka jak Koder.ai może być praktycznym wyborem dla tej architektury: możesz prototypować React UI, API w Go z PostgreSQL i workflowy zadań w tle z jednego chat-driven build loop—a następnie eksportować kod źródłowy, gdy będziesz gotów go wzmocnić lub self-hostować.
Trzymaj tabele „systemu zapisu” (tenancy, SKU, lokalizacje, konfiguracje runów, statusy, zatwierdzenia) w głównej bazie danych. Przechowuj duże wyjścia—prognozy per-dzień, diagnostyki i eksporty—w tabelach zoptymalizowanych pod analitykę lub w object storage, a w aplikacji odwołuj się do nich przez run ID.
Jeśli obsługujesz wiele jednostek biznesowych lub klientów, egzekwuj granice tenantów w warstwie API i schemacie bazy. Proste podejście to tenant_id w każdej tabeli oraz RBAC w UI. Nawet single-tenant MVP zyska na tym, bo zapobiegnie przypadkowemu mieszaniu danych w przyszłości.
Mierz się małą, jasną powierzchnią:
POST /data/upload (lub konektory), GET /data/validationPOST /forecast-runs (start), GET /forecast-runs/:id (status)GET /forecasts?run_id=... i GET /recommendations?run_id=...POST /approvals (akceptuj/override), GET /audit-logsPrognozowanie może być kosztowne. Ogranicz ciężkie retrainy przez cache’owanie cech, ponowne używanie modeli gdy konfiguracje się nie zmieniają, i planowanie pełnych retrainów (np. tygodniowo) podczas gdy codzienne aktualizacje są lekkie. To utrzyma UI responsywnym i koszty stabilne.
Model prognozowy jest wartościowy tylko wtedy, gdy plannerzy mogą szybko i pewnie na niego zareagować. Dobry UX zamienia „liczby w tabeli” w jasne decyzje: co kupić, kiedy i co wymaga natychmiastowej uwagi.
Zacznij z małym zbiorem ekranów odpowiadających codziennym zadaniom planowania:
Utrzymuj spójną nawigację, aby użytkownicy mogli przejść z wyjątku do szczegółów SKU i z powrotem bez utraty kontekstu.
Plannerzy ciągle tną dane. Uczyń filtrowanie natychmiastowym i przewidywalnym według zakresu dat, lokalizacji, dostawcy i kategorii. Używaj sensownych domyślnych (np. ostatnie 13 tygodni, główny magazyn) i zapamiętuj ostatnie wybory użytkownika.
Buduj zaufanie pokazując dlaczego prognoza się zmieniła:
Unikaj ciężkiej matematyki w UI; skup się na języku prostym i tooltipach.
Dodaj lekkie funkcje współpracy: notatki inline, krok zatwierdzania dla zamówień o dużym wpływie i historię zmian (kto zmienił nadpisanie prognozy, kiedy i dlaczego). To wspiera audytowalność bez spowalniania rutynowych decyzji.
Nawet nowoczesne zespoły wciąż dzielą się plikami. Dostarcz czyste eksporty CSV i widok zamówienia przyjazny do druku (pozycje, ilości, dostawca, sumy, żądana data dostawy), aby dział zakupów mógł wykonać zamówienia bez konieczności formatowania.
Prognozy są użyteczne tylko wtedy, gdy systemy, które mają je aktualizować, mogą się z nimi zintegrować—i gdy ludzie im ufają. Zaplanuj integracje, kontrolę dostępu i ślad audytu wcześnie, aby aplikacja przeszła z etapu „interesujące” do „operacyjnego”.
Zacznij od obiektów kluczowych dla decyzji zapasowych:
Bądź jawny co do systemu źródłowego dla każdego pola. Na przykład status SKU i UOM z ERP, ale nadpisania prognozy z Twojej aplikacji.
Większość zespołów potrzebuje drogi, która działa teraz i skaluje się później:
Niezależnie od wybranej ścieżki, przechowuj logi importu (liczby wierszy, błędy, znaczniki czasu), aby użytkownicy mogli diagnozować brakujące dane bez pomocy inżynierii.
Zdefiniuj uprawnienia zgodnie z operacjami biznesu—zwykle według lokalizacji i/lub działu. Typowe role: Viewer, Planner, Approver i Admin. Upewnij się, że akcje wrażliwe (edycja parametrów, zatwierdzanie PO) wymagają odpowiedniej roli.
Zapisuj kto co zmienił, kiedy i dlaczego: nadpisania prognoz, edycje punktów ROP, korekty lead time i decyzje zatwierdzające. Przechowuj diffy, komentarze i linki do wpływających rekomendacji.
Jeśli publikujesz KPI prognoz, odnoś definicje w aplikacji (lub referencje /blog/forecast-accuracy-metrics). Dla planowania wdrożenia, prosty model dostępu warstwowego może być powiązany z /pricing.
Aplikacja prognozująca jest użyteczna jedynie wtedy, gdy możesz udowodnić, że działa dobrze—i gdy potrafisz wykryć, kiedy przestaje. Testowanie to nie tylko „czy kod działa”, ale „czy prognozy i rekomendacje poprawiają wyniki?”.
Zacznij od małego zestawu metryk, które wszyscy rozumieją:
Raportuj te metryki według SKU, kategorii, lokalizacji i horyzontu prognozy (następny tydzień vs następny miesiąc może zachowywać się zupełnie inaczej).
Backtesting powinien odzwierciedlać sposób działania w produkcji:
Dodaj alerty, gdy dokładność nagle spada lub gdy wejścia wyglądają podejrzanie (brak sprzedaży, zduplikowane zamówienia, nietypowe skoki). Mały panel monitoringu w /admin może zapobiec tygodniom złych decyzji zakupowych.
Zanim rozwiniesz rollout, przeprowadź pilotaż z małą grupą plannerów/zakupów. Śledź, czy rekomendacje zostały zaakceptowane lub odrzucone i z jakiego powodu. Ten feedback to dane treningowe do dopracowania reguł, wyjątków i lepszych domyślnych ustawień.
Aplikacje prognozujące często dotykają najwrażliwszych obszarów biznesu: historii sprzedaży, cen dostawców, pozycji zapasowych i planów zakupowych. Traktuj bezpieczeństwo i operacje jako cechy produktu—bo jeden wyciek eksportu lub zepsuty nocny job może zniszczyć miesiące zaufania.
Chroń wrażliwe dane zasadą najmniejszych uprawnień. Zacznij od ról: Viewer, Planner, Approver i Admin, a następnie grupuj działania (nie tylko strony): oglądanie kosztów, edycja parametrów, zatwierdzanie rekomendacji i eksportowanie danych.
Jeśli integrujesz SSO, mapuj grupy na role, by offboarding był automatyczny.
Szyfruj dane w tranzycie i tam, gdzie to możliwe, w spoczynku. Używaj HTTPS wszędzie, rotuj klucze API i przechowuj sekrety w zarządzanym vault zamiast plików środowiskowych na serwerach. W bazach włącz szyfrowanie at-rest i ogranicz dostęp sieciowy tylko do aplikacji i runnerów zadań.
Loguj dostęp i krytyczne akcje (eksporty, edycje, zatwierdzenia). Trzymaj strukturalne logi dla:
To nie jest biurokracja—tylko sposób na debugowanie niespodzianek w dashboardzie planowania zapasów.
Zdefiniuj polityki retencji dla uploadów i historycznych runów. Wiele zespołów trzyma surowe uploady krótko (np. 30–90 dni) i przytrzymuje wyniki agregowane dłużej dla analizy trendów.
Przygotuj plan reagowania: kto jest na dyżurze, jak odwołać dostęp i jak przywrócić bazę. Testuj restore'y regularnie i udokumentuj RTO dla API, jobów i storage, aby Twoje narzędzie do planowania popytu pozostało niezawodne pod obciążeniem.
Zacznij od zdefiniowania decyzji, które aplikacja ma poprawić: ile zamówić, kiedy zamówić i dla jakiego miejsca/kanalu (SKU, lokalizacja, kanał). Następnie wybierz praktyczny horyzont planowania (np. 4–12 tygodni) i jedną ziarnistość czasu (dzienna lub tygodniowa), która pasuje do rytmu zakupu i uzupełniania magazynu.
Solidne MVP zwykle zawiera:
Wszystko inne (promocje, planowanie scenariuszy, optymalizacja wieloechelonowa) zostaw na później.
Minimum to:
Stwórz słownik danych i wymuś spójność w:
W potoku dodaj automatyczne walidacje na brakujące klucze, ujemne stany, duplikaty i outliery—kwarantannuj wadliwe partycje zamiast je publikować.
Traktuj zapasy jako zbiór zdarzeń i snapshotów:
To ułatwia audyt, wyjaśnianie braków i gwarantuje, że „co jest teraz prawdą” jest spójne. Pomaga też w rekonsyliacji rozbieżności między ERP, WMS i POS/eCommerce.
Zacznij od prostych, wyjaśnialnych baz:
Zawsze porównuj dokładność modeli z tymi bazami—jeśli model złożony ich nie pokonuje, nie powinien trafiać do produkcji. Dodawaj bardziej zaawansowane metody tylko wtedy, gdy backtest pokaże poprawę i gdy masz wystarczająco dużo czystej historii oraz przyczynowych zmiennych.
Nie podawaj do treningu zer z okresów braku stanu. Typowe podejścia:
Chodzi o to, by model nie miał wniosku, że popyt zniknął, gdy w rzeczywistości brakowało dostępności.
Ustal jasne zasady cold-start:
Pokaż te reguły w UI, aby plannerzy wiedzieli, kiedy prognoza jest proxy, a kiedy oparta na danych.
Przekonwertuj prognozy na trzy konkretne wyjścia:
Następnie zastosuj ograniczenia realnego świata: MOQ i pakiety (zaokrąglanie), limity budżetowe (priorytetyzacja) i ograniczenia pojemności (miejsce/palety). Zawsze pokazuj „dlaczego” stojące za rekomendacją.
Oddziel UI od silnika prognoz:
Nigdy nie uruchamiaj prognozy w żądaniu UI—użyj kolejki lub scheduler’a, zwracaj run ID i pokazuj status/postęp w aplikacji. Przechowuj duże wyjścia (prognozy, diagnostyki) w storage przyjaznym analityce i odwołuj się do nich po run ID.
Jeśli któreś z tych danych jest zawodnie, wyeksponuj brak (domyślne wartości, flagi, wyłączenia) zamiast milcząco zgadywać.