Czego potrzebuje wieloetapowy proces onboardingu
A wieloetapowy onboarding to prowadzona sekwencja ekranów, która pomaga nowemu użytkownikowi przejść od „zarejestrowany” do „gotowy do użycia produktu”. Zamiast prosić o wszystko naraz, dzielisz konfigurację na mniejsze kroki, które można ukończyć podczas jednej sesji lub w czasie.
Potrzebujesz wieloetapowego onboardingu, gdy konfiguracja to więcej niż jeden formularz — szczególnie jeśli obejmuje wybory, warunki wstępne lub kontrole zgodności. Jeśli produkt wymaga kontekstu (branża, rola, preferencje), weryfikacji (email/telefon/identyfikacja) lub początkowej konfiguracji (workspace, billing, integracje), przepływ oparty na krokach utrzymuje wszystko zrozumiałym i zmniejsza liczbę błędów.
Typowe przepływy onboardingu, które już widziałeś
Wieloetapowy onboarding jest wszechobecny, bo wspiera zadania, które naturalnie zachodzą etapami, takie jak:
- Konfiguracja konta: utwórz workspace, zaproś współpracowników, wybierz plan
- Uzupełnienie profilu: imię, rola, cele, preferencje
- Weryfikacja: potwierdzenie email/telefonu, KYC/ID, konfiguracja 2FA
- Samouczki i pierwsze użycie: oprowadzanie po produkcie, utworzenie przykładowego projektu, checklist „zrób to jako pierwsze”
Jak powinien wyglądać „sukces”
Dobry przepływ onboardingu to nie „ukończone ekrany”, lecz użytkownicy szybko osiągający wartość. Zdefiniuj sukces w terminach dopasowanych do Twojego produktu:
- Aktywacja: użytkownik wykonuje kluczową akcję przewidującą długoterminową retencję (np. tworzy pierwszy projekt, podłącza źródło danych)
- Współczynnik ukończenia: jaki % użytkowników kończy wymagane kroki (i kroki opcjonalne, jeśli to istotne)
- Czas-do-wartości: jak długo zajmuje nowemu użytkownikowi osiągnięcie pierwszego znaczącego rezultatu
Przepływ powinien także wspierać wznowienie i ciągłość: użytkownicy mogą odejść i wrócić bez utraty postępu, i powinni trafić na logiczny następny krok.
Typowe ryzyka projektowe
Wieloetapowy onboarding zwykle zawodząc w przewidywalny sposób:
- Odpływy: zbyt wiele kroków, niejasne korzyści lub prośba o wrażliwe dane zbyt wcześnie
- Zamieszanie: mgławicowe etykiety („Setup”), ukryte wymagania lub niespójna nawigacja
- Utrata danych: problemy przy odświeżeniu/wstecz, timeouty sesji, nieobsłużone zapisy częściowe
Twoim celem jest, aby onboarding wydawał się drogą prowadzoną, a nie testem: jasny cel dla każdego kroku, niezawodne śledzenie postępu i łatwy sposób wznowienia.
Zdefiniuj cele, użytkowników i kryteria „ukończenia”
Zanim narysujesz ekrany lub napiszesz kod, zdecyduj, co onboarding ma osiągnąć — i dla kogo. Wieloetapowy przepływ jest „dobry” tylko wtedy, gdy niezawodnie doprowadza właściwych użytkowników do właściwego stanu końcowego przy minimalnym zamieszaniu.
Zidentyfikuj kluczowe typy użytkowników
Różni użytkownicy przychodzą z różnym kontekstem, uprawnieniami i pilnością. Zacznij od nazwania głównych person wejściowych i tego, co już o nich wiesz:
- Nowy użytkownik (self-serve signup): zwykle potrzebuje utworzenia konta, potwierdzenia email, podstawowego profilu i wykonania pierwszych działań.
- Użytkownik zaproszony: często należy już do organizacji i powinien pominąć tworzenie org; może potrzebować akceptacji warunków, ustawienia hasła i potwierdzenia roli.
- Konto utworzone przez admina: może mieć pola wstępnie wypełnione i obowiązkowe kroki bezpieczeństwa (MFA, reset hasła przy pierwszym logowaniu).
Dla każdego typu wypisz ograniczenia (np. „nie może edytować nazwy firmy”), wymagane dane (np. „musi wybrać workspace”) i potencjalne skróty (np. „już zweryfikowany przez SSO”).
Zdefiniuj, co oznacza „done”
Stan końcowy onboardingu powinien być jawny i mierzalny. „Zrobione” to nie „ukończono wszystkie ekrany”; to stan gotowy dla biznesu, np.:
- profil spełnia minimalną kompletność
- organizacja/workspace jest skonfigurowana
- billing ustawiony (lub wyraźnie odroczony)
- użytkownik osiągnął pierwszą znaczącą akcję (np. utworzył projekt)
Spisz kryteria ukończenia jako checklistę, którą backend może ocenić, a nie jako ogólny cel.
Kroki wymagane vs opcjonalne, zależności i reguły pomijania
Zmapuj, które kroki są wymagane dla stanu końcowego, a które są opcjonalne. Potem udokumentuj zależności („nie można zaprosić współpracowników zanim workspace nie istnieje”).
Na koniec dokładnie określ reguły pomijania: które kroki można pominąć, przez który typ użytkownika i przy jakich warunkach (np. „pomiń weryfikację email, jeśli użytkownik jest uwierzytelniony przez SSO”), oraz czy pominięte kroki można później uzupełnić w ustawieniach.
Zaprojektuj mapę przepływu: kroki, gałęzie i punkty wejścia
Zanim zbudujesz ekrany czy API, narysuj onboarding jako mapę przepływu: mały diagram pokazujący każdy krok, dokąd użytkownik może przejść dalej i jak można wrócić później.
1) Zacznij od konkretnej listy kroków
Wypisz kroki w krótkich, zorientowanych na akcję nazwach (czasowniki pomagają): „Utwórz hasło”, „Potwierdź email”, „Dodaj dane firmy”, „Zaproś współpracowników”, „Podłącz billing”, „Zakończ”. Zachowaj prostotę na pierwszym etapie, potem dodaj szczegóły, takie jak wymagane pola i zależności (np. billing nie może wystąpić przed wyborem planu).
Przydatna kontrola: każdy krok powinien odpowiadać na jedno pytanie — albo „Kim jesteś?”, „Czego potrzebujesz?” albo „Jak skonfigurować produkt?”. Jeśli krok próbuje zrobić wszystkie trzy, rozdziel go.
2) Zdecyduj, liniowy czy z warunkowymi gałęziami
Większość produktów zyskuje na liniowym szkielecie z warunkowymi gałęziami tylko tam, gdzie doświadczenie naprawdę się różni. Typowe reguły rozgałęzień:
- Rola: admin vs. członek
- Plan: darmowy vs. płatny
- Region: wymagania VAT, zgody prywatności
- Przypadek użycia: osobiste vs. biznesowe
Dokumentuj je jako notatki „if/then” na mapie (np. „If region = EU → show VAT step”). To utrzymuje przepływ zrozumiałym i zapobiega tworzeniu labiryntu.
3) Zdefiniuj punkty wejścia (skąd zaczyna się onboarding)
Wypisz każde miejsce, z którego użytkownik może wejść w przepływ:
- Pierwsze logowanie po rejestracji
- Akceptacja linku zaproszeniowego
- Przypomnienie „Ukończ konfigurację” z ustawień (
/settings/onboarding)
Każde wejście powinno prowadzić użytkownika do właściwego następnego kroku, nie zawsze do kroku pierwszego.
4) Zaplanuj ponowne wejście (zachowanie resume)
Zakładaj, że użytkownicy opuszczą proces w połowie. Zdecyduj, co się dzieje, gdy wrócą:
- Wznów od ostatniego nieukończonego kroku
- Zachowuj pola częściowo wypełnione (draft) vs. czyść je przy wyjściu
- Obsłuż „przestarzałe” kroki, gdy przepływ zmieni się później
Twoja mapa powinna pokazywać jasną ścieżkę „resume”, aby doświadczenie było niezawodne, a nie kruche.
Wzorce UX dla klarownego i niskotarciowego onboardingu
Dobry onboarding przypomina prowadzenie za rękę, nie test. Celem jest zmniejszyć zmęczenie decyzjami, uczynić oczekiwania oczywistymi i pomagać szybko wrócić na właściwy tor, gdy coś pójdzie nie tak.
Wybierz wzorzec dopasowany do zadania
Kreator (wizard) sprawdza się, gdy kroki muszą być wykonane w kolejności (np. tożsamość → billing → uprawnienia). Checklist pasuje do onboardingu, który można wykonać w dowolnej kolejności (np. „Dodaj logo”, „Zaproś współpracowników”, „Podłącz kalendarz”). Zadania prowadzone (wskazówki osadzone w produkcie) są świetne, gdy nauka polega na działaniu, nie na wypełnianiu formularzy.
Jeśli nie jesteś pewien, zacznij od checklisty + deep linków do każdego zadania, a blokuj jedynie naprawdę wymagane kroki.
Pokaż postęp, nie naciskając
Informacja o postępie powinna odpowiadać na pytanie: „Ile zostało?”. Użyj jednego z:
- Liczba kroków (np. Krok 2 z 5) dla liniowych kreatorów
- Kamienie milowe (np. Konto → Zespół → Integracje) dla grupowanych zadań
- Procent tylko jeśli jest uczciwy i stabilny (unikaj skoków)
Dodaj też wskazówkę „Zapisz i dokończ później”, zwłaszcza przy dłuższych przepływach.
Etykiety, mikrocopy i przyjazne wartości domyślne
Używaj prostych etykiet („Nazwa firmy”, nie „Entity identifier”). Dodaj mikrocopy wyjaśniające dlaczego prosisz o dane („Używamy tego do personalizacji faktur”). W miarę możliwości wstępnie wypełniaj z istniejących danych i wybieraj bezpieczne wartości domyślne.
Stany błędów i odzyskiwanie
Projektuj błędy jako drogę naprzód: podświetl pole, wyjaśnij co zrobić, zachowaj wprowadzone dane i ustaw fokus na pierwsze niepoprawne pole. Przy awariach serwera pokaż opcję ponowienia i zachowaj postęp, żeby użytkownik nie musiał powtarzać ukończonych kroków.
Mobile i dostępność od pierwszego dnia
Zadbaj o duże cele dotyku, unikaj formularzy wielokolumnowych i trzymaj przyciski główne widoczne. Zapewnij pełną nawigację klawiaturą, widoczne stany focus, oznaczenia pól i czytelny tekst postępu dla czytników ekranu (nie tylko pasek wizualny).
Model danych: użytkownicy, kroki, postęp i wersje
Płynny wieloetapowy onboarding opiera się na modelu danych, który potrafi odpowiedzieć na trzy pytania: co użytkownik powinien zobaczyć następne, co już podał i jaką wersję przepływu realizuje.
Podstawowe byty (co przechowywać)
Zacznij od małego zestawu tabel/kolekcji i rozrastaj go tylko gdy potrzeba:
- User: istniejący rekord użytkownika.
- OnboardingFlow: nazwana definicja przepływu (np. „Default onboarding”, „Enterprise onboarding”).
- Step: pojedyncza definicja kroku (tytuł, typ, kolejność, wymagane pola, tekst pomocniczy). Kroki powinny należeć do konkretnej wersji flow.
- StepResponse: zapisane dane użytkownika dla kroku (odpowiedzi) oraz status walidacji.
- Completion (lub OnboardingProgress): rekord podsumowujący łączący użytkownika z wersją flow i śledzący ogólny status.
To rozdzielenie utrzymuje konfigurację (Flow/Step) oddzielnie od danych użytkownika (StepResponse/Progress).
Wersje: nie psuj użytkowników w trakcie
Zdecyduj wcześnie, czy przepływy będą wersjonowane. W większości produktów odpowiedź brzmi: tak.
Gdy edytujesz kroki (zmiana nazw, kolejności, dodanie wymaganych pól), nie chcesz, żeby użytkownicy w trakcie zostali nagle unieważnieni lub stracili miejsce. Prosty sposób to:
- Flow ma
id i version (lub niezmienny flow_version_id).
- Progress wskazuje na konkretny
flow_version_id na zawsze.
- Nowi użytkownicy dostają najnowszą wersję; istniejący kontynuują przypisaną wersję, chyba że migrujesz ich celowo.
Postęp częściowy i znaczniki czasu
Dla zapisu postępu wybierz między autosave (zapis przy wpisywaniu) a jawny przycisk „Dalej”. Wiele zespołów łączy oba podejścia: autosave dla draftów, a oznaczenie kroku jako „ukończony” dopiero po kliknięciu Next.
Śledź znaczniki czasu do raportów i debugowania: started_at, completed_at i last_seen_at (plus per-step saved_at). Te pola napędzają analitykę onboardingu i pomagają wsparciu zrozumieć, gdzie ktoś ugrzązł.
Logika workflow: stany i przejścia
Zaplanuj zanim zaczniesz kodować
Najpierw zdefiniuj kroki, gałęzie i kryteria ukończenia, a potem generuj implementację z mniejszą liczbą przeróbek.
Wieloetapowy onboarding łatwiej zrozumieć traktując go jak maszynę stanów: sesja onboardingu użytkownika zawsze znajduje się w jednym „stanie” (aktualny krok + status), i tylko wybrane przejścia między stanami są dozwolone.
Modeluj przepływ jako dozwolone przejścia
Zamiast pozwalać frontendowi skakać na dowolny URL, zdefiniuj mały zestaw statusów na krok (np. not_started → in_progress → completed) i jasny zestaw przejść (np. start_step, save_draft, submit_step, go_back, reset_step).
To daje przewidywalne zachowanie:
- Użytkownicy nie mogą pominąć wymaganych kroków, chyba że reguły przepływu na to pozwalają.
- „Wznów onboarding” to po prostu załadowanie ostatniego znanego stanu.
- Gałęzie są jawne: przejście może skierować do różnych następnych kroków w zależności od zapisanych odpowiedzi.
Zasady ukończenia kroku (walidacja + sprawdzenia serwera)
Krok jest „ukończony” tylko, gdy oba warunki są spełnione:
- Walidacja po stronie klienta przejdzie (pola wymagane, formaty itp.).
- Sprawdzenia po stronie serwera przejdą (reguły biznesowe i weryfikacje zewnętrzne), np. „ten email nie jest już używany”, „NIP pasuje do kraju” lub „nazwa firmy jest dozwolona”.
Zapisuj decyzję serwera razem z krokem, włącznie z kodami błędów. To unika sytuacji, w której UI myśli, że krok jest zrobiony, a backend ma inne zdanie.
Inwalidacja gdy wcześniejsze odpowiedzi się zmieniają
Łatwy do przeoczenia przypadek brzegowy: użytkownik edytuje wcześniejszy krok i powoduje, że późniejsze kroki stają się niepoprawne. Przykład: zmiana „Kraju” może unieważnić „Dane podatkowe” lub „dostępne plany”.
Obsłuż to śledząc zależności i ponownie oceniając kroki zależne po każdym submit. Typowe skutki:
- Oznacz kroki jako
needs_review (lub cofnij do in_progress).
- Wyczyść konkretne pola, które nie mają już zastosowania.
- Ponownie oblicz następny krok na podstawie nowych reguł gałęzi.
Nawigacja wstecz i ponowna walidacja
„Wstecz” powinien być wspierany, ale bezpiecznie:
- Pozwól na nawigację do wcześniejszych kroków bez utraty danych.
- Gdy użytkownik wraca do późniejszego kroku, uruchom ponownie walidację z aktualnymi odpowiedziami i aktualnymi regułami serwera.
To utrzymuje elastyczność doświadczenia, jednocześnie zapewniając spójność i egzekwowalność stanu sesji.
Projekt API backendu dla onboardingów opartych na krokach
Backend jest „źródłem prawdy” dotyczącej miejsca użytkownika w onboardingu, tego, co już wpisał i co może zrobić dalej. Dobre API upraszcza frontend: renderuje aktualny krok, bezpiecznie zapisuje dane i pozwala odzyskać stan po odświeżeniu lub problemach sieciowych.
Podstawowe endpointy, które zwykle potrzebujesz
Minimum do zaprojektowania:
- Get current step (and progress)
GET /api/onboarding → zwraca klucz aktualnego kroku, % postępu oraz zapisane wartości potrzebne do wyrenderowania kroku.
- Save step data (draft or final)
PUT /api/onboarding/steps/{stepKey} z { "data": {…}, "mode": "draft" | "submit" }
- Move next / previous (opcjonalne, jeśli wyliczasz następny krok po zapisaniu)
POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previous
- Complete onboarding
POST /api/onboarding/complete (serwer weryfikuje, że wszystkie wymagane kroki są spełnione)
Utrzymuj spójne odpowiedzi. Na przykład po zapisie zwróć zaktualizowany postęp oraz serwerowo wyznaczony następny krok:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
Idempotencja: chroń postęp przed podwójnymi submitami
Użytkownicy klikną dwukrotnie, będą retry przy słabym łączu, lub frontend może ponownie wysłać żądanie po timeout. Uczyń „save” bezpiecznym przez:
- Akceptowanie nagłówka
Idempotency-Key dla PUT/POST i deduplikację według (userId, endpoint, key).
- Traktowanie
PUT /steps/{stepKey} jako pełnego nadpisania ładunku tego kroku (lub jasne udokumentowanie reguł scalenia częściowego).
- Opcjonalnie dodanie
version (lub etag) by zapobiec nadpisaniu nowszych danych starszymi retry.
Jasne błędy i walidacja na poziomie pól
Zwracaj komunikaty możliwe do pokazania przy odpowiednich polach:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
Rozróżniaj też 403 (nieautoryzowane) od 409 (konflikt / zły krok) i 422 (walidacja), aby frontend mógł zareagować poprawnie.
Autentykacja i autoryzacja
Oddziel uprawnienia użytkownika i admina:
- Endpointy użytkownika wymagają zalogowanej sesji i mogą dostępować tylko do stanu onboardingu wywołującego.
- Endpointy admina (np.
GET /api/admin/onboarding/users/{userId} lub nadpisania) muszą być chronione rolami i audytowane.
Ta granica zapobiega przypadkowym przeciekom uprawnień, a jednocześnie pozwala wsparciu i operacjom pomagać użytkownikom, którzy utknęli.
Implementacja frontendu: routing, wznowienie i niezawodność
Zadaniem frontendu jest sprawić, by onboarding wydawał się płynny nawet przy niestabilnej sieci. To oznacza przewidywalny routing, niezawodne wznowienie i czytelną informację, gdy dane są zapisywane.
Routing: jeden URL na krok vs. jedna strona
Jeden URL na krok (np. /onboarding/profile, /onboarding/billing) jest zwykle najprostszy do zrozumienia. Wspiera back/forward przeglądarki, deep linking z maili i ułatwia odświeżanie bez utraty kontekstu.
Jedna strona z wewnętrznym stanem może być OK dla bardzo krótkich przepływów, ale zwiększa ryzyko przy odświeżeniach, crashach i scenariuszach „skopiuj link, aby kontynuować”. Jeśli używasz tej metody, potrzebujesz silnej persystencji i ostrożnego zarządzania historią.
Persistencja postępu: serwer jako źródło prawdy
Przechowuj ukończenie kroków i najnowsze zapisane dane na serwerze, nie tylko w localStorage. Przy ładowaniu strony pobierz stan onboardingu (aktualny krok, ukończone kroki i drafty) i renderuj z tego.
To umożliwia:
- bezpieczeństwo przy odświeżeniu
- kontynuację na różnych urządzeniach
- spójny widok po zmianach administracyjnych w przepływie
Optymistyczny UI bez dezorientowania użytkowników
Optymistyczny UI może zmniejszyć tarcie, ale potrzebuje zabezpieczeń:
- Pokaż wyraźny status Zapisuję… / Zapisano / Błąd przy głównym przycisku.
- Wyłącz przycisk submit, gdy żądanie jest w toku, by zapobiec podwójnym wysłaniom.
- Jeśli autosave, debouncuj zmiany i pokazuj błędy („Nie udało się zapisać. Spróbuj ponownie”).
Uprzejme wznowienie
Gdy użytkownik wraca, nie zrzucaj go od razu na krok pierwszy. Zaproponuj coś w stylu: „Jesteś w 60% — kontynuować skąd przerwałeś?” z dwiema akcjami:
- Kontynuuj (link do następnego wymaganego kroku)
- Dokończę później (przenosi do aplikacji, z trwałym bannerem linkującym z powrotem do
/onboarding)
Ten drobny gest zmniejsza porzucenia, szanując użytkowników, którzy nie są gotowi dokończyć wszystkiego od razu.
Strategia walidacji i obsługa danych częściowych
Zaprototypuj swój kreator onboardingu
Opisz swój proces onboardingu, a otrzymasz działający szkielet aplikacji React + Go + Postgres szybko.
Walidacja decyduje, czy onboarding będzie płynny czy frustrujący. Celem jest wychwycić błędy wcześnie, utrzymać ruch użytkowników i nadal chronić system, gdy dane są niekompletne lub podejrzane.
Waliduj w przeglądarce (szybka odpowiedź)
Użyj walidacji po stronie klienta, by zapobiec oczywistym błędom przed wysłaniem żądania. To zmniejsza churn i sprawia, że każdy krok wydaje się responsywny.
Typowe sprawdzenia: pola obowiązkowe, limity długości, podstawowe formaty (email/telefon) i proste reguły między polami (potwierdzenie hasła). Komunikaty trzymaj konkretne („Wprowadź prawidłowy adres służbowy”) i umieszczaj obok pola.
Waliduj po stronie serwera (poprawność i bezpieczeństwo)
Traktuj walidację serwera jako źródło prawdy. Nawet jeśli UI waliduje idealnie, użytkownicy mogą to obejść.
Walidacja serwera powinna wymusić:
- autoryzację (użytkownik może edytować tylko swój onboarding)
- dozwolone wartości (enumy, kody krajów, typy dokumentów)
- integralność danych (unikatowość, klucze obce)
- zabezpieczenia (limity, sanitacja wejścia)
Zwracaj strukturalne błędy na poziomie pól, aby frontend mógł dokładnie wskazać, co poprawić.
Obsługa walidacji asynchronicznej
Niektóre sprawdzenia zależą od zewnętrznych lub opóźnionych sygnałów: unikatowość emaila, kody zaproszeń, sygnały fraudowe lub weryfikacja dokumentów.
Obsłuż to jawnie ze statusami (np. pending, verified, rejected) i czytelnym stanem UI. Gdy check jest pending, pozwól użytkownikowi kontynuować tam, gdzie to możliwe, i pokaż, kiedy go powiadomisz albo jaki krok odblokuje się później.
Jak traktować częściowe niepowodzenia
Wieloetapowy onboarding często oznacza, że częściowe dane są normą. Zdecyduj per krok czy:
- Zapisujesz draft: przechowuj częściowe dane i pozwól na opuszczenie; oznacz krok jako „in progress”.
- Blokujesz postęp: wymagaj minimalnego zestawu pól przed przejściem dalej.
Praktyczne podejście: „zapisuj draft zawsze, blokuj tylko przy finalnym ukończeniu kroku.” To wspiera wznowienie sesji bez obniżania jakości danych.
Analityka: mierz ukończenie i znajduj miejsca odpływu
Analityka onboardingu powinna odpowiadać na dwa pytania: „Gdzie ludzie utknęli?” i „Jaka zmiana poprawi ukończenie?”. Kluczem jest śledzenie niewielkiego, spójnego zestawu zdarzeń dla każdego kroku i utrzymanie porównywalności nawet przy zmianach przepływu.
Zdarzenia, którym można ufać
Śledź te same podstawowe zdarzenia dla każdego kroku:
step_viewed (użytkownik zobaczył krok)step_completed (użytkownik wysłał i przeszedł walidację)step_failed (użytkownik próbował wysłać, ale walidacja lub check serwera się nie powiódł)flow_completed (użytkownik osiągnął finalny stan sukcesu)
Dołącz minimalny, stabilny kontekst do każdego zdarzenia: user_id, flow_id, flow_version, step_id, step_index i session_id (żeby odróżnić „jedna sesja” od „wiele dni”). Jeśli wspierasz wznowienie, dodaj też resume=true/false na step_viewed.
Odpływ i czas na krok
Aby zmierzyć odpływ, porównuj liczbę step_viewed vs. step_completed dla tej samej flow_version. Aby mierzyć czas, rejestruj znaczniki czasu i oblicz:
- czas od
step_viewed → step_completed
- czas od
step_viewed → następne step_viewed (przydatne, gdy użytkownicy pomijają)
Trzymaj metryki pogrupowane po wersji; mieszanie starych i nowych wersji może ukryć poprawy.
Hooki do eksperymentów bez psucia metryk
Jeśli robisz A/B testy copy lub zmiany kolejności kroków, traktuj to jako część tożsamości analitycznej:
- dodaj
experiment_id i variant_id do każdego zdarzenia
- utrzymuj
step_id stabilne nawet gdy tekst się zmienia
- przy zmianie kolejności zachowaj ten sam
step_id i użyj step_index dla pozycji
Kokpity i eksporty dla interesariuszy
Zbuduj prosty dashboard pokazujący współczynnik ukończenia, odpływ po krokach, medianowy czas na krok i „najczęściej błędne pola” (z metadanych step_failed). Dodaj eksport CSV, aby zespoły mogły analizować dane w arkuszach i dzielić się wynikami bez dostępu do narzędzia analitycznego.
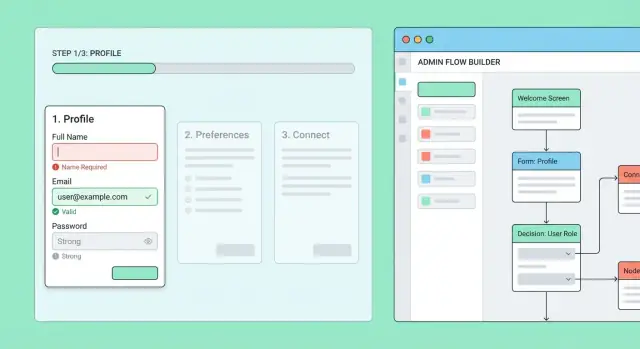
Narzędzia administracyjne: edytor przepływów, rollouty i nadpisania
Zbuduj kroki z mapy przepływu
Przekształć mapę kroków w trasy, API i zapisaną progresję za pomocą czatu napędzającego budowę.
System wieloetapowego onboardingu będzie w końcu potrzebował codziennej kontroli operacyjnej: zmiany produktowe, wyjątki wsparcia i bezpieczne eksperymenty. Prosty wewnętrzny panel zapobiega temu, by inżynieria stała się wąskim gardłem.
Edytor przepływów: twórz i edytuj kroki bez deployów
Zacznij od prostego „flow buildera”, który pozwala uprawnionym osobom tworzyć i edytować przepływy oraz ich kroki.
Każdy krok powinien być edytowalny z:
- tytułem i krótkim tekstem pomocniczym
- typem kroku (formularz, checklist, upload dokumentu, planowanie itp.)
- wymaganymi polami i regułami walidacji
- opcjonalnymi regułami rozgałęzień (np. „If user selects Company, show VAT step”)
Dodaj tryb podglądu, który renderuje krok tak, jak zobaczy go użytkownik. To wychwyci mylące treści, brakujące pola i błędne gałęzie zanim trafią do realnych użytkowników.
Wersjonowanie i bezpieczne wdrożenia
Unikaj edycji aktywnego przepływu w miejscu. Zamiast tego publikuj wersje:
- Draft: edytowalny, możliwy do podglądu
- Published: niezmienna definicja używana przez użytkowników
- Archived: zachowana do wsparcia i audytu
Rollouty konfiguruj per wersję:
- Tylko nowi użytkownicy: istniejący użytkownicy pozostają na swojej wersji
- Stopniowy procent: zaczynaj od 5–10%, potem zwiększaj jeśli metryki są OK
- Targetowanie (opcjonalne): po planie, regionie, partnerze lub kampanii zaproszeń
To zmniejsza ryzyko i daje czyste porównania przy mierzeniu ukończenia i odpływu.
Nadpisania dla wsparcia i operacji
Zespoły wsparcia potrzebują narzędzi do odblokowywania użytkowników bez ręcznych poprawek w bazie:
- Oznacz krok jako ukończony (z powodem)
- Zresetuj przepływ użytkownika do początku lub do konkretnego kroku
- Cofnij użytkownika o krok po pomyłce
- Wyślij ponownie invite / magic link / email weryfikacyjny powiązany z onboardingiem
Logi audytu i uprawnienia
Każda akcja administracyjna powinna być logowana: kto co zmienił, kiedy i wartości przed/po. Ogranicz dostęp rolami (tylko do odczytu, edytor, publisher, override wsparcia), żeby wrażliwe działania—np. reset postępu—były kontrolowane i możliwe do zaudytowania.
Testy, bezpieczeństwo i monitoring przed uruchomieniem
Przed wypuszczeniem załóż dwie rzeczy: użytkownicy pójdą nietypowymi ścieżkami, i coś przerwie się w połowie (sieć, walidacja, uprawnienia). Dobra lista kontrolna przed startem udowadnia, że przepływ działa poprawnie, chroni dane i daje wczesne sygnały, gdy rzeczy odbiegają od planu.
Testuj mapę przepływu, nie tylko UI
Zacznij od testów jednostkowych logiki workflow (stany i przejścia). Testy powinny weryfikować, że każdy krok:
- można wejść tylko z dozwolonych poprzednich kroków
- daje oczekiwany następny krok przy konkretnej odpowiedzi/roli/planu
- obsługuje edge case’y (pomięcia, nawigacja wstecz, wygasłe sesje)
Następnie dodaj testy integracyjne, które ćwiczą API: zapisywanie payloadów kroków, wznawianie postępu i odrzucanie niepoprawnych przejść. Testy integracyjne wychwycą „działa lokalnie” problemy jak brak indeksów, błędy serializacji czy niezgodność wersji między frontendem a backendem.
Testy end-to-end dla krytycznych ścieżek
E2E powinny pokrywać przynajmniej:
- ścieżkę szczęśliwą od startu do ukończenia
- typowe awarie: błędy walidacji, 500 serwera, timeout/retry oraz wznowienie po zamknięciu przeglądarki
Trzymaj scenariusze E2E krótkie, ale znaczące — skup się na tych ścieżkach, które reprezentują większość użytkowników i największy wpływ na aktywację/przychody.
Domyślna ochrona danych wrażliwych
Stosuj zasadę najmniejszych uprawnień: admini onboardingu nie powinni automatycznie mieć pełnego dostępu do rekordów użytkowników, a konta serwisowe powinny mieć dostęp tylko do potrzebnych tabel i endpointów.
Szyfruj tam, gdzie trzeba (tokeny, identyfikatory regulowane, pola wrażliwe) i traktuj logi jako ryzyko wycieku. Unikaj logowania surowych payloadów formularzy; loguj ID kroków, kody błędów i timing. Jeśli musisz logować fragmenty payloadu do debugowania, redaguj pola konsekwentnie.
Monitoring, który wykryje problemy wcześnie
Zainstrumentuj onboarding zarówno jako lejek produktowy, jak i API.
Śledź błędy po kroku, opóźnienia zapisów (p95/p99) i awarie wznowienia. Ustaw alerty na nagłe spadki współczynnika ukończenia, skoki błędów walidacji dla jednego kroku lub wzrosty błędów API po wydaniu. To pozwoli naprawić uszkodzony krok, zanim pojawi się masa zgłoszeń do supportu.
Gdzie pasuje Koder.ai (jeśli chcesz to zbudować szybciej)
Jeśli implementujesz system onboardingu opartego na krokach od zera, najwięcej czasu pójdzie na te same fundamenty: routing kroków, persystencję, walidacje, logikę stanu i panel admina do wersjonowania i rolloutów. Koder.ai może pomóc szybciej zaprototypować i wypuścić te elementy, generując aplikacje full-stack z czatu — typowo z frontendem React, backendem Go i modelem danych Postgres, który mapuje się czysto na flows, steps i step_responses.
Ponieważ Koder.ai wspiera eksport kodu źródłowego, hosting/deploy i snapshoty z rollbackiem, jest też przydatny, gdy chcesz iterować nad wersjami onboardingu bezpiecznie (i szybko wrócić, jeśli rollout obniży konwersję).