Wyjaśnij cel: co powinna dostarczać pętla opinii
Aplikacja do zarządzania opiniami nie jest „miejsce do przechowywania wiadomości”. To system, który pomaga zespołowi niezawodnie przejść od wejścia do działania do odpowiedzi widocznej dla klienta, a potem uczyć się na podstawie uzyskanych wyników.
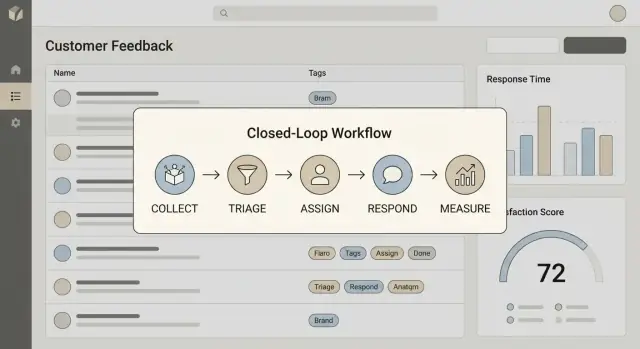
Zdefiniuj, co znaczy „zamknąć pętlę”
Napisz jednosekundowe określenie, które zespół będzie powtarzał. Dla większości zespołów zamknięcie pętli obejmuje cztery kroki:
- Zbieranie: przechwycenie opinii z wystarczającym kontekstem (kto, co, skąd pochodzi)
- Działanie: przekształcenie w pracę lub decyzję (naprawić, wypuścić, wyjaśnić lub odrzucić)
- Odpowiedź: poinformowanie klienta o wyniku i terminie (nawet jeśli to „jeszcze nie”)
- Nauka: włączenie wyników do priorytetyzacji, discovery produktu i playbooków wsparcia
Jeśli którykolwiek z tych kroków zaginie, Twoja aplikacja szybko stanie się mogiłą backlogu.
Zidentyfikuj kluczowych użytkowników i ich potrzeby
Pierwsza wersja powinna obsługiwać rzeczywiste role dnia codziennego:
- Wsparcie: szybki triage, jasność statusu, szablony odpowiedzi
- Product: trendy, wpływ, linki do roadmapy
- Customer success: widoczność kont, aktualizacje proaktywne
- Administratorzy: konfiguracja, higiena danych, kontrola dostępu
- Klienci końcowi (opcjonalnie): potwierdzenie otrzymania, aktualizacje, status samoobsługowy
Wypisz decyzje, które aplikacja musi wspierać
Bądź konkretny co do „decyzji na kliknięcie”:
- O czym jest ta opinia (tag/kategoria)?
- Kto ją właściwie posiada i jaki jest następny krok?
- Jaki jest bieżący status i co zmieniło się od zeszłego tygodnia?
- Jaką odpowiedź wysyłamy i kiedy?
Ustal mierzalne rezultaty (by wiedzieć, czy działa)
Wybierz niewielki zestaw metryk odzwierciedlających szybkość i jakość, takich jak czas do pierwszej odpowiedzi, wskaźnik rozwiązania oraz zmiana CSAT po follow‑upie. Staną się one twoją gwiazdą przewodnią przy późniejszych decyzjach projektowych.
Zmapuj podróż opinii i model danych
Zanim zaprojektujesz ekrany czy wybierzesz bazę danych, narysuj, co dzieje się z opinią od momentu jej utworzenia do momentu odpowiedzi. Prosta mapa podróży utrzymuje zespoły zgodne co do tego, co znaczy „zrobione” i zapobiega budowaniu funkcji, które nie pasują do rzeczywistej pracy.
Zacznij od źródeł, potem normalizuj
Wypisz źródła opinii i zanotuj, jakie dane każde z nich wiarygodnie dostarcza:
- Widget w aplikacji (często zawiera kontekst użytkownika/sesji)
- E‑mail (wątki, załączniki)
- Czat (znaczniki czasu, info o agencie)
- Formularz WWW (pola strukturalne)
- Opinie w sklepie z aplikacjami (tekst publiczny, ocena)
- Ankiety (wyniki plus komentarze wolnego formatu)
Nawet jeśli wejścia się różnią, twoja aplikacja powinna znormalizować je do spójnego „elementu opinii”, aby zespoły mogły wszystkie triage’ować w jednym miejscu.
Zdefiniuj podstawowe byty (i trzymaj je proste)
Praktyczny model początkowy zwykle obejmuje:
- Customer: osoba przekazująca opinię
- Account: firma lub organizacja (opcjonalnie w B2C)
- Feedback item: główny rekord (wiadomość, źródło, metadata)
- Tag: kategoryzacja (np. „Billing”, „Bug”, „Feature request”)
- Status: gdzie się znajduje w workflow
- Assignment: kto jest właścicielem następnego kroku (osoba/zespół)
- Reply: wiadomości wychodzące powiązane z elementem opinii (opcjonalnie z wątkiem)
Statusy na start: New → Triaged → Planned → In Progress → Shipped → Closed. Zapisz znaczenia statusów, aby „Planned” nie znaczyło „może” dla jednego zespołu i „zobowiązane” dla innego.
Zdecyduj, co znaczy „duplikat”
Duplikaty są nieuniknione. Zdefiniuj reguły wcześnie:
- Kiedy dwa elementy są duplikatami: ten sam podstawowy problem, ta sama prośba o funkcję lub podobne słowa kluczowe?
- Co robi łączenie: łączy tagi, zachowuje obie osoby zgłaszające, przenosi odpowiedzi?
Częsty sposób: utrzymać jeden kanoniczny element feedbacku i powiązać inne jako duplikaty, zachowując atrybucję (kto zapytał) bez fragmentacji pracy.
Zaprojektuj podstawowe przepływy użytkownika (Inbox → Triage → Action → Reply)
Aplikacja do obsługi pętli opinii odnosi sukces lub porażkę już w dniu uruchomienia w zależności od tego, czy ludzie potrafią szybko przetwarzać opinie. Celuj w przepływ, który daje wrażenie: „przeskanuj → zdecyduj → idź dalej”, przy jednoczesnym zachowaniu kontekstu do późniejszych decyzji.
1) Inbox: szybkie skanowanie z właściwymi filtrami
Inbox to wspólna kolejka zespołu. Powinien wspierać szybki triage przez mały zestaw mocnych filtrów:
- Źródło (in‑app, e‑mail, czat, app store, notatki sprzedaży)
- Tag (billing, bugs, feature request, onboarding)
- Status (new, triaged, in progress, shipped, replied)
- Priorytet (low → urgent)
- Poziom klienta (free, pro, enterprise)
Dodaj „Zapisane widoki” wcześnie (nawet podstawowe), ponieważ różne zespoły skanują inaczej: Support chce „pilne + płacący”, Product chce „prośby o funkcje + wysoki ARR”.
2) Widok szczegółowy: wszystko potrzebne do podjęcia decyzji
Gdy użytkownik otworzy element, powinien zobaczyć:
- Pełną historię opinii (oryginalny tekst plus edycje, łączenia i zmiany statusu)
- Kontekst klienta (plan, wartość konta, firma, ostatnia aktywność, NPS/CSAT jeśli dostępne)
- Wątek konwersacji oddzielający odpowiedzi zewnętrzne od notatek wewnętrznych
Celem jest unikanie przełączania zakładek, aby odpowiedzieć na pytania: „Kim jest ten użytkownik, co miał na myśli i czy już odpowiadaliśmy?”
3) Działania triage: lekkie, ale kompletne
Z widoku szczegółowego triage powinien wymagać jednej akcji na decyzję:
- Otaguj i ustaw priorytet
- Przypisz właściciela (lub kolejkę zespołową)
- Scal duplikaty (z jednym „kanonicznym” elementem)
- Powiąż z funkcją/issue, aby praca pozostała związana z rzeczywistością klienta
4) Odpowiedź: zadecyduj co jest zewnętrzne, a co wewnętrzne
Prawdopodobnie potrzebne będą dwa tryby:
- Tylko śledzenie wewnętrzne (większość zespołów B2B): statusy i notatki prywatne; klienci otrzymują bezpośrednie odpowiedzi przy aktualizacjach.
- Publiczna strona statusu: przydatna, gdy chcesz transparentności na dużą skalę (publiczne aktualizacje w stylu changelogu). Trzymaj to opcjonalnie i starannie kuratorowane.
Cokolwiek wybierzesz, zrób z „odpowiedzi z kontekstem” ostatni krok—tak aby zamykanie pętli było częścią workflow, a nie dodatkiem na końcu.
Zaplanuj role, uprawnienia i podstawy bezpieczeństwa
Aplikacja do opinii szybko staje się wspólnym systemem zapisu: product chce tematy, support szybkich odpowiedzi, a leadership eksportów. Jeśli nie zdefiniujesz, kto może co robić (i nie udowodnisz, co się stało), zaufanie się załamie.
Zacznij od granic multi‑tenant
Jeśli będziesz obsługiwać wiele firm, traktuj każde workspace/org jako twardą granicę od pierwszego dnia. Każdy główny rekord (feedback item, customer, conversation, tagi, raporty) powinien zawierać workspace_id, a każde zapytanie być do niego ograniczone.
To nie tylko szczegół bazy danych—wpływa na URL‑e, zaproszenia i analitykę. Bezpieczny domyślny wybór: użytkownicy należą do jednego lub więcej workspace’ów, a ich uprawnienia oceniane są per workspace.
Zdefiniuj role odpowiadające rzeczywistej pracy
Utrzymaj prostotę w pierwszej wersji:
- Admin: zarządza ustawieniami workspace, rozliczeniami, integracjami i rolami
- Manager: konfiguruje kategorie/routing, akcje masowe, widzi raporty, eksportuje dane
- Agent: triage’uje elementy, przypisuje, komentuje i odpowiada klientom
Mapuj uprawnienia do akcji, nie ekranów: view vs edit feedback, merge duplicates, change status, export data, send replies. Dzięki temu łatwiej dodać rolę „tylko do odczytu” później bez większych zmian.
Dodaj audit log wcześnie
Audit log zapobiega debatom „kto to zmienił?”. Loguj kluczowe zdarzenia z aktorem, timestampem i before/after tam, gdzie to pomocne:
- zmiany przypisań
- aktualizacje statusów i łączenia
- edycje tagów/kategorii
- wysłane odpowiedzi
Podstawowe bezpieczeństwo, które nie spowolni pracy
Wymuszaj rozsądną politykę haseł, zabezpieczaj endpointy ograniczaniem liczby zapytań (zwłaszcza logowanie i ingestię) oraz bezpieczne zarządzanie sesjami.
Projektuj z myślą o SSO (SAML/OIDC) nawet jeśli wdrożysz je później: przechowuj identyfikator dostawcy tożsamości i planuj łączenie kont. To uchroni cię przed bolesnym refaktorem na życzenie klientów enterprise.
Wybierz architekturę dopasowaną do pierwszej wersji
Na początku największym ryzykiem architektonicznym nie jest „czy się skalujemy?”, lecz „czy będziemy mogli szybko to zmieniać bez psucia wszystkiego?”. Aplikacja do opinii ewoluuje szybko, gdy uczysz się, jak zespoły faktycznie triage’ują, routują i odpowiadają.
Zacznij prosto: monolit modularny
Modularny monolit często jest najlepszym wyborem na start. Masz jedną deployowalną usługę, jedne logi i prostsze debugowanie—przy jednoczesnym porządkowaniu kodu.
Praktyczny podział modułów wygląda tak:
- Auth & orgs: użytkownicy, zespoły, SSO później
- Feedback: źródła, zgłoszenia, załączniki, tagi
- Workflow: status triage, reguły routingu, przypisania
- Messaging: odpowiedzi wychodzące, szablony, audit trail
- Analytics: raporty, eksporty, dashboardy
Pomyśl „oddzielne foldery i interfejsy” zanim pomyślisz o „oddzielnych usługach”. Jeśli granica stanie się uciążliwa później (np. duży wolumen ingestii), możesz ją wyekstrahować z mniejszym drama.
Wybierz stos, który zespół utrzyma
Wybierz frameworki i biblioteki, które twój zespół potrafi pewnie wdrożyć. Nudny, dobrze znany stack zwykle wygrywa, bo:
- rekrutacja i onboarding są łatwiejsze
- aktualizacje bardziej przewidywalne
- debugowanie produkcji szybsze
Nowe narzędzia mogą poczekać, aż pojawią się realne ograniczenia. Do tego czasu optymalizuj pod jasność i stałe dostarczanie.
Przechowywanie danych: relacyjna baza najpierw, search później
Większość podstawowych bytów—feedback, customers, accounts, tags, assignments—pasuje naturalnie do bazy relacyjnej. Potrzebujesz dobrych zapytań, ograniczeń i transakcji dla zmian workflow.
Jeśli pełnotekstowe wyszukiwanie i filtrowanie staną się ważne, dodaj dedykowany indeks wyszukiwania później (lub użyj najpierw wbudowanych możliwości). Unikaj dwóch źródeł prawdy zbyt wcześnie.
Używaj zadań w tle tam, gdzie użytkownicy nie powinni czekać
System opinii szybko zapełnia się pracą „zrób to później”: wysyłanie e‑maili, synchronizacja integracji, przetwarzanie załączników, generowanie digestów, wywołania webhook. Umieść to w kolejce/pracowniku w tle od początku.
To utrzymuje UI responsywnym, zmniejsza timeouty i pozwala na ponawianie prób—bez zmuszania do mikrousług od pierwszego dnia.
Szybka ścieżka do działającego MVP (gdy chcesz być szybszy)
Jeśli celem jest szybko zwalidować workflow i UI (inbox → triage → replies), rozważ użycie platformy vibe‑coding takiej jak Koder.ai do wygenerowania pierwszej wersji z ustrukturyzowanej specyfikacji chatowej. Może pomóc postawić front‑end w React z backendem Go + PostgreSQL, iterować w „trybie planowania” i nadal wyeksportować kod źródłowy, gdy będziesz gotów przejąć klasyczny workflow inżynieryjny.
Zaimplementuj warstwę przechowywania: schemat, indeksy i reguły retencji
Zarabiaj kredyty podczas budowy
Zyskaj kredyty za treści lub polecenia, budując aplikację z Koder.ai.
Warstwa przechowywania decyduje, czy twoja pętla opinii będzie szybka i godna zaufania—czy też powolna i myląca. Celuj w schemat łatwy do zapytań dla codziennej pracy (triage, przypisanie, status), a jednocześnie zachowuj wystarczająco dużo surowych danych do audytu.
Praktyczny początkowy model danych
Dla MVP pokryjesz większość potrzeb kilkoma tabelami/kolekcjami:
- workspaces: kontener na poziomie konta (plan, ustawienia, polityka retencji)
- users: członkowie zespołu (rola, workspace_id)
- customers: końcowi użytkownicy/organizacje (email, external_id, workspace_id)
- feedback: główny rekord (tytuł, body/summary, status, priority, source, customer_id, assigned_to, created_at)
- tags: znormalizowane definicje tagów (nazwa, kolor, workspace_id)
- feedback_tags (join): feedback_id ↔ tag_id
- events: append‑only timeline (zmiany statusów, przypisań, łączenia, notatki)
- replies: odpowiedzi wychodzące (kanał, wiadomość, sent_at, feedback_id, customer_id)
Przydatna zasada: utrzymuj feedback slim (to, po czym często zapytujesz) i przenieś „resztę” do events i specyficznych metadanych kanału.
Przechowuj surowe payloady dla rozliczalności
Gdy ticket przychodzi przez e‑mail, czat lub webhook, zachowaj surowy payload dokładnie tak, jak został otrzymany (np. oryginalne nagłówki + body e‑maila albo JSON webhooka). To pomaga:
- debugować problemy z parsowaniem („dlaczego temat się obciął?”)
- udowodnić, co faktycznie przyszło w sporze
- ponownie przetworzyć stare dane po poprawie parsera
Wzorzec: tabela ingestions z source, received_at, raw_payload (JSON/text/blob) i linkiem do utworzonego/aktualizowanego feedback_id.
Indeksuj pod kątem faktycznych zapytań
Większość ekranów sprowadza się do kilku przewidywalnych filtrów. Dodaj indeksy wcześnie dla:
(workspace_id, status) dla widoków inbox/kanban(workspace_id, assigned_to) dla „moich elementów”(workspace_id, created_at) dla sortowania i filtrów datowych- tagi: albo
(tag_id, feedback_id) w tabeli łączącej, albo dedykowany indeks wyszukiwania tagów
Jeśli wspierasz pełnotekstowe wyszukiwanie, rozważ oddzielny indeks wyszukiwania (lub wbudowaną funkcję DB) zamiast skomplikowanych LIKE w produkcji.
Retencja, usuwanie i „prawo do bycia zapomnianym”
Opinie często zawierają dane osobowe. Zdecyduj z góry:
- jak długo przechowywać surowe payloady (często krócej niż znormalizowany feedback)
- jak obsługiwać żądania usunięcia zgodnie z GDPR (usuń lub zanonimizuj identyfikatory klientów i zredaguj surowe payloady)
- co się dzieje, gdy klient kończy współpracę (eksport + zaplanowane usunięcie)
Wdróż retencję jako politykę per workspace (np. 90/180/365 dni) i egzekwuj ją zaplanowanym zadaniem, które wygasza najpierw surowe ingestie, potem starsze zdarzenia/odpowiedzi jeśli to konieczne.
Zbuduj ingestję: zbieraj opinie z wielu kanałów
Ingestia to moment, w którym twoja pętla opinii zostanie albo czysta i użyteczna, albo pogrzebana pod bałaganem. Celuj w „łatwe do wysłania, spójne do przetworzenia”. Zacznij od kilku kanałów, których klienci już używają, potem rozszerzaj.
Opcje przechwytywania do wysłania wcześnie
Praktyczny zestaw na start zwykle obejmuje:
- Widget w aplikacji: mały formularz na pomysły i problemy (opcjonalnie zrzut ekranu). Trzymaj minimalnie: wiadomość, kategoria, e‑mail.
- Endpoint API: pozwól wewnętrznym narzędziom lub partnerom wysyłać opinie programowo. Preferuj prosty JSON schema i klucz API per workspace.
- Ingestia e‑mail: unikalny adres per workspace (np. feedback+acme@…). Parsuj temat/treść, zachowaj surowy e‑mail do audytu.
- Import CSV: przydatny do migracji i partii badawczych. Waliduj kolumny i pokaż podgląd przed importem.
Kontrole spamu i jakości
Nie potrzebujesz ciężkiego filtrowania od pierwszego dnia, ale podstawowe zabezpieczenia są niezbędne:
- CAPTCHA dla publicznych wysyłek z widgetu
- Limity długości tekstu (np. 5–5 000 znaków) i limity rozmiaru załączników
- Wskaźniki duplikatów: hash znormalizowanej wiadomości + obszaru produktu albo wykrywanie „prawie duplikatów” przez podobne tematy. Nie usuwaj automatycznie; oznacz jako „możliwy duplikat”.
Normalizuj wejścia, żeby downstream było spójne
Normalizuj każde zdarzenie do wewnętrznego formatu z polami:
- Source (widget, API, e‑mail, CSV)
- Identyfikatory klienta (workspace, account ID, e‑mail kontaktu, plan)
- Obszar produktu (billing, onboarding, mobile itp.)
Przechowuj zarówno surowy payload, jak i znormalizowany rekord, aby móc poprawiać parsowanie bez utraty danych.
Auto‑potwierdzenie, które ustawia oczekiwania
Wyślij natychmiastowe potwierdzenie (dla e‑mail/API/widget gdzie możliwe): podziękuj, opisz, co dalej i unikaj obietnic. Przykład: „Przeglądamy każdą wiadomość. Jeśli potrzebujemy więcej szczegółów, odpowiemy. Nie możemy odpowiedzieć na każde zgłoszenie indywidualnie, ale Twoja opinia jest śledzona.”
Stwórz system triage i routingu, który skaluje
Zachowaj własność i przenośność
Eksportuj źródła w dowolnym momencie i przejdź do klasycznego workflow inżynieryjnego, gdy będziesz gotowy.
Inbox pozostaje użyteczny tylko wtedy, gdy zespoły szybko odpowiedzą na trzy pytania: O czym to jest? Kto za to odpowiada? Jak pilne to jest? Triage to część aplikacji, która zmienia surowe wiadomości w uporządkowaną pracę.
Zacznij od kontrolowanego systemu tagów
Tagi swobodne wydają się elastyczne, ale szybko fragmentują („login”, „log-in”, „signin”). Zacznij od małej, kontrolowanej taksonomii, która odzwierciedla sposób myślenia zespołów produktowych:
- Obszar produktu (Billing, Mobile, Admin)
- Temat (Bug, Feature request, UX issue)
- Wpływ (Blocker, High, Normal)
Pozwól użytkownikom sugerować nowe tagi, ale wymagaj właściciela (np. PM/lead wsparcia) do ich zatwierdzenia. Dzięki temu raportowanie pozostanie później sensowne.
Używaj reguł auto‑triage, by zmniejszyć ręczne sortowanie
Zbuduj prosty silnik reguł, który może automatycznie kierować opiniami na podstawie przewidywalnych sygnałów:
- Słowo klucz/intencja: „refund”, „cancel”, „invoice” → kolejka Billing
- Plan/poziom konta: Enterprise → kolejka wsparcia priorytetowego
- Obszar produktu: wyprowadzony z ścieżki URL, modułu aplikacji lub wybranej kategorii
Utrzymuj reguły przejrzyste: pokaż „Przekierowano, ponieważ: Enterprise + słowo 'SSO'”. Zespół ufa automatyzacji, gdy może ją audytować.
Widoczne SLA, nie ukryte
Dodaj timery SLA do każdego elementu i każdej kolejki:
- Czas do pierwszej odpowiedzi (jak szybko potwierdzasz)
- Czas do zamknięcia (jak szybko rozwiązujesz lub zamykasz)
Pokaż status SLA w widoku listy („pozostało 2h”) i na stronie szczegółów, aby pilność była współdzielona w zespole—nie tkwiła w czyjejś głowie.
Zbuduj eskalacje i przypomnienia w workflow
Stwórz jasną ścieżkę, gdy elementy utkną: kolejka przeterminowanych, codzienne digesty do właścicieli i lekki schemat eskalacji (Support → Team lead → On‑call/Manager). Celem nie jest naciskanie—tylko zapobieganie cichemu wygasaniu ważnych opinii.
Zamknij pętlę: powiąż pracę z odpowiedziami dla klientów
Zamykanie pętli to moment, kiedy system opinii przestaje być „skrzynką na zgłoszenia” i zaczyna budować zaufanie. Cel jest prosty: każdy element opinii może być powiązany z rzeczywistą pracą, a klienci, którzy o coś prosili, mogą zostać poinformowani o rezultacie—bez ręcznych arkuszy kalkulacyjnych.
Powiąż feedback z wewnętrzną pracą
Zacznij od pozwolenia, by pojedynczy element opinii wskazywał na jeden lub więcej wewnętrznych obiektów pracy (bug, zadanie, prośba o funkcję). Nie próbuj mirrorować całego issue trackera—przechowuj lekkie referencje:
work_type (np. issue/task/feature)external_system (np. jira, linear, github)external_id i opcjonalnie external_url
To utrzymuje model danych stabilny nawet przy zmianie narzędzi. Pozwala też na widoki „pokaż wszystkie opinie powiązane z tym wydaniem” bez skrobania innego systemu.
Zdefiniuj workflow „Shipped”, który powiadamia wszystkich
Gdy powiązana praca przejdzie do Shipped (lub Done/Released), aplikacja powinna móc powiadomić wszystkich klientów przypisanych do powiązanych elementów feedbacku.
Użyj szablonowanej wiadomości z bezpiecznymi placeholderami (imię, obszar produktu, podsumowanie, link do notatek wydania). Pozwól edytować wiadomość przed wysyłką, by uniknąć niezręcznego brzmienia. Jeśli masz publiczne notatki, odnoś je względnie, np. /releases.
Kanały odpowiedzi i śledzenie
Wspieraj odpowiedzi przez kanały, z których możesz niezawodnie wysyłać:
- E‑mail
- Powiadomienie w aplikacji
- Webhook do twojego systemu komunikacji
Cokolwiek wybierzesz, śledź odpowiedzi per element feedbacku z audytowalnym timeline: sent_at, channel, author, template_id i status dostarczenia. Jeśli klient odpowie, przechowaj wiadomości przychodzące z timestampami, aby zespół mógł udowodnić, że pętla faktycznie została zamknięta—nie tylko „oznaczona jako wysłane”.
Dodaj raportowanie, które pomaga zespołom podejmować decyzje
Raportowanie jest użyteczne tylko wtedy, gdy zmienia zachowania zespołów. Celuj w kilka widoków, które ludzie będą sprawdzać codziennie, potem rozszerzaj, gdy będziesz pewny, że dane workflow (status, tagi, właściciele, znaczniki czasu) są spójne.
Dashboardy, które odpowiadają na pytanie „co wymaga uwagi?”
Zacznij od operacyjnych dashboardów wspierających routowanie i follow‑up:
- Wolumen według źródła (e‑mail, in‑app, social, calls): wykrywanie zmian kanałów i potrzeb obsadowych
- Top tagów/kategorii: jakie tematy rosną w tym tygodniu
- Backlog według statusu (new, triaged, in progress, waiting on customer, closed): gdzie praca stoi
- Zgodność z SLA: czas do pierwszej odpowiedzi i czas do zamknięcia względem celów
Utrzymuj wykresy proste i klikalne, żeby menedżer mógł wejść w dokładne elementy stojące za skokiem.
Widok na poziomie klienta dla lepszych rozmów
Dodaj stronę „customer 360”, która pomaga supportowi i success odpowiadać z kontekstem:
- Wszystkie opinie od tego klienta przez kanały
- Ostatni kontakt i kto odpowiadał
- Otwarta praca i bieżący status/właściciel
- Miejsce na lekkie notatki o sentymencie (np. „zirytowany fakturami; woli e‑mail”)—nie jako czarny‑skrzynkowy wynik
Ten widok zmniejsza powtarzane pytania i sprawia, że follow‑upy są celowe.
Eksportuj bez naruszania zaufania
Zespoły poproszą o eksporty wcześnie. Zapewnij:
- Eksport CSV respektujący te same filtry co UI
- Endpointy API tylko do odczytu dla raportów/BI
Upewnij się, że filtrowanie jest spójne wszędzie (te same nazwy tagów, zakresy dat, definicje statusów). Spójność zapobiega „dwóm wersjom prawdy”.
Unikaj mierników próżności
Pomiń dashboardy mierzące tylko aktywność (utworzone tickety, dodane tagi). Faworyzuj metryki wynikowe powiązane z działaniem i odpowiedzią: czas do pierwszej odpowiedzi, % elementów, które osiągnęły decyzję, i powtarzające się problemy, które faktycznie zostały zaadresowane.
Integruj z narzędziami, których zespół już używa
Prototypuj integracje bezpiecznie
Użyj Koder.ai do konfiguracji webhooków i stubów dla Slack, Jira lub synchronizacji CRM.
Pętla opinii działa tylko wtedy, gdy żyje tam, gdzie ludzie już spędzają czas. Integracje zmniejszają kopiowanie wklejanie, utrzymują kontekst przy pracy i sprawiają, że „zamknięcie pętli” staje się nawykiem, a nie specjalnym projektem.
Zacznij od integracji odblokowujących codzienną pracę
Priorytetyzuj systemy, których zespół używa do komunikacji, budowy i zarządzania klientami:
- Slack / Microsoft Teams: powiadamiaj odpowiedni kanał o wysokopoziomowych opiniach, przypisaniach lub odpowiedziach klienta
- Jira / Linear: powiąż feedback z ticketem (lub utwórz nowy), aby praca inżynieryjna była śledzalna względem wejść klientów
- Sync CRM (Salesforce/HubSpot): dołączaj opinie do kont/kontaktów, aby support i success mieli pełen kontekst
Utrzymaj pierwszą wersję prostą: powiadomienia jednokierunkowe + głębokie linki z powrotem do twojej aplikacji, potem dodaj akcje zapisujące zmiany (np. „Przypisz właściciela” z Slacka).
Dodaj system webhooków dla rozszerzalności
Nawet jeśli udostępnisz tylko kilka natywnych integracji, webhooki pozwolą klientom i zespołom wewnętrznym łączyć cokolwiek innego.
Oferuj mały, stabilny zestaw zdarzeń:
feedback.createdfeedback.updatedfeedback.closed
Dołącz klucz idempotencyjny, znaczniki czasu, tenant/workspace id oraz minimalny payload i URL do pobrania pełnych szczegółów. To zapobiega łamaniu konsumentów przy ewolucji modelu danych.
Uczyń błędy widocznymi i możliwymi do naprawienia
Integracje zawodzą z normalnych powodów: cofnięte tokeny, limity przepustowości, problemy sieciowe, niezgodności schematu. Projektuj to od początku:
- Retry z backoffem dla błędów przejściowych
- Dead‑letter queue dla powtarzających się porażek
- Prosty status zdrowia integracji (ostatni sukces, ostatni błąd, następna próba)
- Akcyjne stany błędów w UI (np. „Połącz ponownie Slack” lub „Brak uprawnień w Jira”)
Jeśli sprzedajesz to jako produkt, integracje są też czynnikiem decydującym o zakupie. Dodaj jasne następne kroki w aplikacji (i materiałach), np. /pricing i /contact, dla zespołów, które chcą demo lub pomocy przy podłączeniu stosu.
Wydaj MVP, potem ulepszaj na podstawie rzeczywistych danych użycia
Skuteczna aplikacja do opinii nie jest „gotowa” po premierze—kształtuje się na podstawie tego, jak zespoły naprawdę triage’ują, działają i odpowiadają. Cel pierwszego wydania jest prosty: udowodnić workflow, zmniejszyć ręczną pracę i zebrać czyste dane, którym można ufać.
Zdefiniuj MVP małe, ale kompletne
Utrzymaj wąski zakres, żeby szybko wysłać i uczyć się. Praktyczne MVP zwykle obejmuje:
- Jeden workspace (bez złożoności multi‑org)
- Główny inbox z wyszukiwaniem i podstawowymi filtrami
- Tagowanie/kategoryzację i proste przypisanie
- Podstawowy flow odpowiedzi (nawet jeśli to najpierw zwykłe szablony e‑mail)
Jeśli funkcja nie pomaga zespołowi przeprocesować feedback end‑to‑end, może poczekać.
Testuj, co łamie zaufanie
Wczesni użytkownicy wybaczą brak funkcji, ale nie zgubionych opinii czy błędnego routingu. Testuj tam, gdzie pomyłka jest kosztowna:
- Testy jednostkowe dla reguł routingu, logiki tagowania i sprawdzeń uprawnień
- Testy integracyjne dla źródeł ingestii i webhooków (w tym retry i zdublowane zdarzenia)
Celuj w pewność workflow, nie w idealne pokrycie testami.
Zaplanuj rzeczywistość operacyjną
Nawet MVP potrzebuje kilku „nudnych” fundamentów:
- Monitoring dla błędów ingestii i backlogów kolejek
- Kopie zapasowe i proces przywracania, który rzeczywiście testowałeś
- Śledzenie błędów z wystarczającym kontekstem do reprodukcji problemów
- Proste narzędzia administracyjne (odtwórz zdarzenie, przypisz ponownie, popraw złe tagi)
Wdróż jak eksperyment produktowy
Zacznij od pilota: jeden zespół, ograniczony zestaw kanałów i jasna metryka sukcesu (np. „odpowiedz na 90% wysokopriorytetowych opinii w ciągu 2 dni”). Zbieraj punkty tarcia co tydzień i iteruj workflow zanim zaprosisz więcej zespołów.
Traktuj dane użycia jako roadmapę: gdzie ludzie klikają, gdzie porzucają, które tagi są nieużywane i które „obejścia” odsłaniają rzeczywiste wymagania.