Budowa aplikacji webowej do zarządzania zgodnością i ścieżek audytu
Praktyczny plan budowy aplikacji webowej do zarządzania zgodnością z wiarygodną ścieżką audytu: wymagania, model danych, logowanie, kontrola dostępu, retencja i raportowanie.
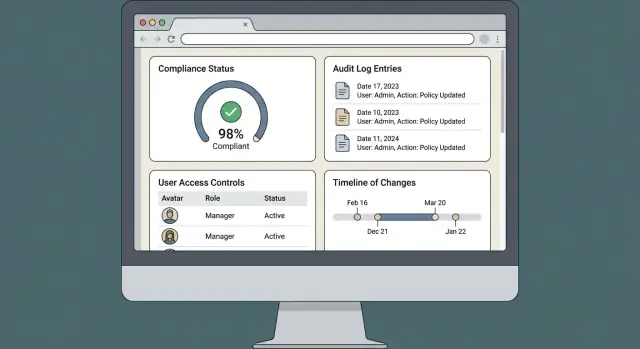
Budowanie aplikacji webowej do zarządzania zgodnością to mniej „ekrany i formularze”, a bardziej zapewnienie powtarzalności audytów. Produkt się sprawdza, gdy pomaga szybko i konsekwentnie udokumentować intencję, uprawnienia i śledzalność — bez ręcznego porównywania.
Zacznij od celów zgodności i user stories
Zanim wybierzesz bazę danych lub naszkicujesz ekrany, zapisz, co „zarządzanie zgodnością” naprawdę oznacza w twojej organizacji. Dla niektórych zespołów to ustrukturyzowany sposób śledzenia kontroli i dowodów; dla innych to przede wszystkim silnik workflow do zatwierdzeń, wyjątków i okresowych przeglądów. Definicja ma znaczenie, bo determinuje, co musisz udowodnić podczas audytu — i co aplikacja musi uprościć.
Zdefiniuj cel prostym językiem
Dobrym zdaniem startowym jest:
„Musimy pokazać, kto co zrobił, kiedy, dlaczego i na czyje uprawnienie — i szybko odnaleźć dowody.”
To utrzymuje projekt skoncentrowany na rezultatach, nie na funkcjach.
Zidentyfikuj role (i czego każda potrzebuje)
Wypisz osoby, które będą korzystać z systemu i decyzje, które podejmują:
- Administratorzy: konfigurują polityki, użytkowników, integracje, ustawienia retencji.
- Menadżerowie / właściciele kontroli: zatwierdzają zmiany, przeglądają dowody, podpisują wyjątki.
- Użytkownicy końcowi: przesyłają dowody, proszą o wyjątki, wykonują przypisane zadania.
- Audytorzy (wewnętrzni/zewnętrzni): dostęp tylko do odczytu, eksporty i jasna ścieżka śladowa.
Zarejestruj kluczowe przepływy pracy
Udokumentuj „happy path” i typowe odchylenia:
- Zatwierdzenia (aktualizacje polityk, zmiany kontroli, prośby o dostęp)
- Wyjątki (tymczasowe odstępstwa z datą wygaśnięcia i uzasadnieniem)
- Zbieranie dowodów (uploady, linki, oświadczenia, logi generowane przez system)
- Raportowanie (status kontroli, zaległe elementy, historia zmian)
Określ kryteria sukcesu dla v1
Dla aplikacji zgodności v1 sukces to zazwyczaj:
- Śledzalność: kompletna historia zmian i odpowiedzialni aktorzy
- Wyszukiwalność: odnalezienie decyzji lub dowodu w kilka sekund
- Odporność na manipulacje: wykrywanie nieautoryzowanych edycji i zachowanie oryginałów
Utrzymaj v1 wąskie: role, podstawowe workflowy, ścieżka audytu i raportowanie. Odłóż „miłe do mieć” (zaawansowana analityka, niestandardowe dashboardy, szerokie integracje) na późniejsze wydania, gdy audytorzy i właściciele kontroli potwierdzą, że fundamenty działają.
Dopasuj regulacje i standardy do konkretnych wymagań aplikacji
Praca nad zgodnością idzie w bok, gdy regulacje pozostają abstrakcyjne. Celem tego kroku jest zamienić „spełniać SOC 2 / ISO 27001 / SOX / HIPAA / GDPR” w jasny backlog funkcji, które aplikacja musi dostarczyć — i dowodów, które musi wygenerować.
Zacznij od zakresu: co ma zastosowanie (a co nie)
Wypisz ramy nadzorcze istotne dla twojej organizacji i dlaczego. SOC 2 może być wymuszany przez kwestionariusze klientów, ISO 27001 przez plan certyfikacji, SOX przez raportowanie finansowe, HIPAA przez przetwarzanie PHI, a GDPR przez użytkowników z UE.
Potem zdefiniuj granice: które produkty, środowiska, jednostki biznesowe i typy danych są w zakresie. To zapobiega budowaniu kontroli dla systemów, których audytorzy nawet nie sprawdzą.
Przetłumacz wymagania na funkcje systemu
Dla każdego wymagania z frameworka zapisz „wymóg aplikacji” prostym językiem. Typowe tłumaczenia to:
- Logowanie i ścieżka audytu: udowodnij, kto co zrobił, kiedy i skąd.
- Kontrola dostępu: dostęp oparty na rolach, zasada najmniejszych uprawnień, separacja obowiązków dla wrażliwych akcji.
- Retencja i cykl życia: przechowuj rekordy przez wymagany okres, potem archiwizuj lub usuwaj bezpiecznie.
- Zatwierdzenia i przeglądy: wspieraj podpisy, okresowe przeglądy dostępu i atestacje kontroli.
- Zbieranie dowodów: przechowuj eksporty, zrzuty ekranu, załączniki i „proof of operation”.
Praktyczną techniką jest utworzenie tabeli mapującej w dokumencie wymagań:
Kontrola frameworka → funkcja aplikacji → dane uchwycone → raport/eksport, który to udowadnia
Zdefiniuj zdarzenia audytowalne i okres przechowywania
Audytorzy zwykle proszą o „kompletną historię zmian”, ale musisz to zdefiniować precyzyjnie. Zdecyduj, które zdarzenia są istotne dla audytu (np. logowanie, zmiany uprawnień, edycje kontroli, upload dowodów, zatwierdzenia, eksporty, akcje związane z retencją) i minimalne pola, które każde zdarzenie powinno zapisać.
Udokumentuj też oczekiwania retencyjne dla każdego typu zdarzenia. Na przykład zmiany dostępu mogą wymagać dłuższej retencji niż rutynowe zdarzenia przeglądu, podczas gdy zasady GDPR mogą ograniczać przechowywanie danych osobowych dłużej niż jest to konieczne.
Wczesne określenie potrzeb dowodowych
Traktuj dowody jako pierwszorzędny wymóg produktu, a nie jako cechę-dodatek. Określ, jakie dowody muszą wspierać każdą kontrolę: zrzuty ekranu, linki do ticketów, eksporty raportów, podpisane zatwierdzenia, pliki.
Zdefiniuj metadane potrzebne do audytowalności — kto to wgrał, co to wspiera, wersjonowanie, znaczniki czasu oraz czy zostało to przejrzane i zaakceptowane.
Uzgodnij się z audytorami przed budową
Umów krótką sesję roboczą z audytem wewnętrznym lub zewnętrznym, aby potwierdzić oczekiwania: jak wygląda „dobrze”, jak będzie stosowane próbkowanie i jakie raporty będą potrzebne.
Takie wczesne uzgodnienie może oszczędzić miesięcy pracy i pomoże budować tylko to, co rzeczywiście wspiera audyt.
Zaprojektuj model danych dla kontroli, dowodów i przeglądów
Aplikacja zgodności żyje lub umiera w zależności od modelu danych. Jeśli kontrole, dowody i przeglądy nie są jasno ustrukturyzowane, raportowanie stanie się uciążliwe, a audyt zamieni się w poszukiwanie zrzutów ekranu.
Podstawowe encje do zamodelowania
Zacznij od niewielkiego zestawu dobrze zdefiniowanych tabel/kolekcji:
- Users i roles (plus tabela złączeniowa dla relacji wiele-do-wielu)
- Policies (dokumenty wysokiego poziomu, np. „Polityka kontroli dostępu”)\n- Controls (operacyjne wymagania, które testujesz i dla których zbierasz dowody)
- Tasks (zadania, np. „Wgraj dowód kwartalnego przeglądu dostępu”)
- Evidence (pliki, linki, rekordy, zrzuty ekranu, tickety)
- Reviews/Tests (instancja oceny kontroli: kto sprawdził, kiedy, wynik)
Relacje, które ułatwiają audyty
Modeluj relacje jawnie, aby móc odpowiedzieć na „pokaż, jak udowadniamy, że ta kontrola działa” jednym zapytaniem:
- Control ↔ Evidence: zwykle relacja wiele-do-wielu (jeden dowód może wspierać wiele kontroli)
- Control ↔ Tests/Reviews: jeden-do-wielu (każdy okres generuje nowy rekord przeglądu)
- Owner ↔ Control: użytkownicy mogą być właścicielami wielu kontroli; kontrola może mieć właściciela głównego i zapasowego
- Policy ↔ Controls: jeden-do-wielu (kontrole pogrupowane pod polityką)
Identyfikatory i wersjonowanie
Używaj stabilnych, czytelnych identyfikatorów dla kluczowych rekordów (np. CTRL-AC-001) obok wewnętrznych UUID.
Wersjonuj wszystko, co audytorzy uznają za niemodyfikowalne w czasie:
- wersje polityk (data publikacji, data wejścia w życie)
- wersje definicji kontroli (treść, częstotliwość, zakres)
- zmiany metadanych dowodów (zachowaj wskaźnik historii zmian, nie nadpisuj)
Załączniki: przechowuj pliki, nie bloby
Przechowuj załączniki w object storage (np. zgodnym z S3) i trzymaj metadane w bazie: nazwa pliku, MIME type, hash, rozmiar, uploader, uploaded_at i tag retencyjny. Dowód może także być referencją URL (ticket, raport, strona wiki).
Pola wspierające raportowanie i filtrowanie
Projektuj pod filtry, których faktycznie będą używać audytorzy i menadżerowie: mapowanie do frameworka/standardu, system/aplikacja w zakresie, status kontroli, częstotliwość, właściciel, data ostatniego testu, data następnego terminu, wynik testu, wyjątki i wiek dowodów. Taka struktura upraszcza późniejsze /reports i eksporty.
Zdefiniuj ścieżkę audytu, która odpowiada na pytania audytora
Pierwsze pytania audytora są przewidywalne: Kto co zrobił, kiedy i na czyje uprawnienie — i czy potrafisz to udowodnić? Zanim wdrożysz logowanie, zdefiniuj, co znaczy „zdarzenie audytowe” w twoim produkcie, aby każdy zespół (inżynieria, compliance, support) rejestrował tę samą historię.
Określ minimalny zestaw pól „kto/co/kiedy/gdzie/dlaczego”
Dla każdego zdarzenia audytowego zapisuj spójny zestaw pól:
- Kto: ID użytkownika, rola w czasie zdarzenia i (jeśli istotne) działanie w imieniu kogo / konto serwisowe
- Co: akcja i obiekt (np. „update Control #184”)
- Kiedy: znacznik czasu serwera (UTC) i, jeśli trzeba, czas lokalny użytkownika do wyświetleń
- Gdzie: tenant/org, środowisko i źródło żądania (IP)
- Dlaczego: pole z uzasadnieniem dla wrażliwych akcji (zmiany uprawnień, zatwierdzenia, usunięcia)
Ustandaryzuj typy zdarzeń, które będziesz raportować
Audytorzy oczekują czytelnych kategorii, nie swobodnych komunikatów. Minimum to typy zdarzeń dla:
- Tworzenie / aktualizacja / usunięcie kluczowych rekordów (kontrole, dowody, polityki, ustalenia)
- Uwierzytelnianie: logowanie sukces/porażka, wylogowanie, rejestracja/zmiana MFA
- Zmiany autoryzacji: zmiany ról, nadania/odbierania uprawnień, członkostwo w grupach
- Akcje workflow: zatwierdzenia, odrzucenia, podpisy przeglądów, zgłoszenia „gotowe do audytu”
Zapisuj wartości przed/po (z bezpiecznym redagowaniem)
Dla ważnych pól przechowuj przed i po wartości, aby zmiany były wytłumaczalne bez domysłów. Redaguj lub haszuj wrażliwe wartości (np. zapisz „zmieniono z X na [REDACTED]”) i skup się na polach wpływających na decyzje zgodności.
Dodaj kontekst żądania do śledztw
Dołącz metadane żądania, aby powiązać zdarzenia z rzeczywistymi sesjami:
- adres IP, user agent
- ID sesji (lub ID urządzenia)
- correlation ID / request ID (żeby support mógł odtworzyć transakcję)
Jasno określ, co nigdy nie jest logowane
Spisz tę zasadę wcześnie i egzekwuj ją w code review:
- Hasła, seedy MFA, klucze sekretne, access tokeny
- Pełne dane kart płatniczych, CVV lub podobnie regulowane dane
Prosty kształt zdarzenia do uzgodnienia:
{
"event_type": "permission.change",
"actor_user_id": "u_123",
"target_user_id": "u_456",
"resource": {"type": "user", "id": "u_456"},
"occurred_at": "2026-01-01T12:34:56Z",
"before": {"role": "viewer"},
"after": {"role": "admin"},
"context": {"ip": "203.0.113.10", "user_agent": "...", "session_id": "s_789", "correlation_id": "c_abc"},
"reason": "Granted admin for quarterly access review"
}
Wdróż append-only, wykrywalne manipulacje w logowaniu audytu
Log audytu jest przydatny tylko wtedy, gdy mu ufamy. To oznacza traktowanie go jak zapisu write-once: możesz dopisać wpisy, ale nigdy nie „poprawiasz” starych. Jeśli coś było nie tak, logujesz nowe zdarzenie wyjaśniające korektę.
Zacznij od append-only event store
Użyj tabeli logów append-only (lub strumienia zdarzeń), gdzie każdy rekord jest niemutowalny. Unikaj UPDATE/DELETE na wierszach audytu w kodzie aplikacji i egzekwuj niemienność na poziomie bazy, gdy to możliwe (uprawnienia, triggery lub osobny system przechowywania).
Każdy wpis powinien zawierać: kto/co zadziałało, co się stało, jaki obiekt został dotknięty, wskaźniki before/after (lub odnośnik do diffu), kiedy to nastąpiło i skąd pochodziło (request ID, IP/urządzenie jeśli istotne).
Dodaj integralność, by manipulacje były wykrywalne
Aby edycje były wykrywalne, dodaj środki integralności takie jak:
- Haszowanie i łańcuchowanie: przechowuj hasz wpisu plus hasz poprzedniego wpisu, tworząc łańcuch.
- Podpisywanie (gdzie stosowne): podpisuj partie/pojedyncze wpisy kluczem przechowywanym poza runtime aplikacji.
- Write-once storage dla eksportów/archiwów: okresowo zapieczętuj i przechowuj segmenty logów w niezmiennym magazynie.
Celem nie jest kryptografia dla samej kryptografii — chodzi o to, by móc przed audytorem pokazać, że brakujące lub zmienione zdarzenia byłoby łatwo wykryć.
Rozdziel akcje użytkownika od akcji systemowych
Loguj akcje systemowe (zadania w tle, importy, automatyczne zatwierdzenia, synchronizacje okresowe) wyraźnie oddzielone od akcji użytkownika. Użyj pola „actor type” (user/service), aby „kto to zrobił” nigdy nie było niejasne.
Uczyń czas i retry przewidywalnymi
Stosuj UTC wszędzie i polegaj na zaufanym źródle czasu (np. znaczniki czasu bazy lub zsynchronizowane serwery). Zaplanuj idempotency: przydzielaj unikalny klucz zdarzenia (request ID / idempotency key), aby retry nie tworzył mylących duplikatów, jednocześnie pozwalając rejestrować rzeczywiste powtórzenia akcji.
Zbuduj kontrolę dostępu i separację obowiązków
Kontrola dostępu to miejsce, gdzie oczekiwania zgodności stają się codziennym zachowaniem. Jeśli aplikacja ułatwia robienie błędów (lub utrudnia udowodnienie, kto co zrobił), audyty zamienią się w spory. Celuj w proste reguły odzwierciedlające rzeczywiste procesy w organizacji i egzekwuj je konsekwentnie.
Zacznij od RBAC i zasady najmniejszych uprawnień
Użyj RBAC, aby zarządzanie uprawnieniami było zrozumiałe: role takie jak Viewer, Contributor, Control Owner, Approver i Admin. Nadaj każdej roli tylko to, co jest potrzebne. Na przykład Viewer może tylko czytać kontrole i dowody, ale nie może nic uploadować ani edytować.
Unikaj „jednej roli super-użytkownika”, którą wszyscy dostają. Zamiast tego dodaj tymczasowe podniesienie uprawnień (time-boxed admin), a to podniesienie uczyn audytowalnym.
Definiuj uprawnienia według akcji i zakresu
Uprawnienia powinny być jawne dla każdej akcji — view / create / edit / export / delete / approve — i ograniczone zakresem. Zakres może być:
- jednostka biznesowa lub dział
- system/aplikacja
- konkretny framework (np. SOX vs. kontrole wewnętrzne)
- projekt lub okres audytu
To zapobiega typowemu błędowi: ktoś ma właściwą akcję, ale w zbyt szerokim obszarze.
Uczyń separację obowiązków wymuszalną
Separacja obowiązków nie powinna być dokumentem polityki — powinna być regułą w kodzie.
Przykłady:
- Osoba, która wnioskuje o zmianę kontroli, nie może jej zatwierdzić.
- Osoba, która uploaduje dowód, nie może go zaznaczyć jako sprawdzonego dla tej samej kontroli.
- Administratorzy mogą zarządzać dostępem, ale nie mogą edytować rekordów zgodności bez drugiego zatwierdzającego.
Gdy reguła blokuje akcję, pokaż jasny komunikat („Możesz zgłosić tę zmianę, ale konieczny jest podpis Approvera.”), aby użytkownicy nie szukali obejść.
Traktuj zmiany ról/uprawnień jako kluczowe zdarzenia audytowe
Każda zmiana ról, członkostwa w grupie, zakresu uprawnień lub łańcucha zatwierdzeń powinna wygenerować ważny wpis audytowy z informacją kto/co/kiedy/dlaczego. Dołącz poprzednie i nowe wartości oraz ticket lub powód, jeśli jest dostępny.
Dodaj step-up authentication dla wrażliwych akcji
Dla operacji wysokiego ryzyka (eksport kompletu dowodów, zmiana ustawień retencji, nadanie dostępu admina) wymagaj dodatkowego uwierzytelnienia — ponowne wpisanie hasła, MFA lub ponowne zalogowanie SSO. To redukuje przypadkowe nadużycia i wzmacnia historię audytu.
Obsługuj retencję, archiwizację i usuwanie bezpiecznie
Retencja to miejsce, w którym narzędzia zgodności często zawodzą w prawdziwych audytach: rekordy istnieją, ale nie potrafisz udowodnić, że były przechowywane przez właściwy okres, chronione przed przedwczesnym usunięciem i usuwane przewidywalnie.
Zdefiniuj retencję wg typu rekordu (nie „cała baza”)
Utwórz jawne okresy retencji dla kategorii rekordów i zapisz zastosowaną politykę z każdym rekordem (by polityka była audytowalna później). Typowe koszyki:
- Logi audytu (zwykle najdłużej): zdarzenia bezpieczeństwa, dostępu i administracji
- Dowody i załączniki: zrzuty ekranu, PDFy, eksporty, zatwierdzenia
- Przeglądy i podpisy: testy kontroli, wyjątki, atestacje zarządcze
- Konta użytkowników i role: daty dołączenia/odejścia, historia ról
Pokaż politykę w UI (np. „przechowywane przez 7 lat po zamknięciu”) i uczyn ją niemienną po finalizacji rekordu.
Dodaj legal hold jako funkcję pierwszej klasy
Legal hold powinien nadpisywać każde automatyczne usuwanie. Traktuj go jako stan z jasnym powodem, zakresem i znacznikami czasu:
- kto nałożył hold, kiedy i dlaczego
- czego dotyczy (tenant, projekt, zestaw kontroli, konkretne rekordy)
- kto może go zdjąć (zwykle ograniczona rola)
Jeśli aplikacja wspiera żądania usunięcia, legal hold musi wyraźnie wyjaśnić, dlaczego usuwanie jest wstrzymane.
Automatyzuj harmonogramy retencji (archiwuj, eksportuj, kasuj)
Retencja jest łatwiejsza do obrony, gdy jest konsekwentna:
- Auto-archiwizacja starszych rekordów do tańszego storage z zachowaniem możliwości wyszukiwania
- Eksport przed kasacją (jeśli wymagane): wygeneruj podpisany pakiet eksportu i zarejestruj przekazanie
- Zasady purge uruchamiane cyklicznie, generujące raport i zapisujące zdarzenie audytowe dla każdej partii
Kopie zapasowe i testy przywracania są częścią retencji
Udokumentuj, gdzie żyją kopie zapasowe, jak długo są przechowywane i jak są zabezpieczone. Planuj testy przywracania i zapisuj wyniki (data, zestaw danych, kryteria sukcesu). Audytorzy często pytają o dowód, że „potrafimy przywrócić” to więcej niż obietnica.
Usuwanie vs. redakcja dla prywatności
Dla zobowiązań prywatności zdefiniuj, kiedy usuwasz, kiedy redagujesz, i co musi pozostać dla integralności (np. zostaw audit event, ale zredaguj pola osobowe). Redakcje powinny być logowane jako zmiany, z zapisem „dlaczego” i podlegać przeglądowi.
Stwórz raportowanie, wyszukiwanie i eksporty, które oczekują audytorzy
Audytorzy rzadko chcą zwiedzania UI — oczekują szybkich odpowiedzi, które można zweryfikować. Twoje raporty i funkcje wyszukiwania powinny ograniczać wymianę maili: „Pokaż wszystkie zmiany tej kontroli”, „Kto zatwierdził ten wyjątek”, „Co jest zaległe” i „Skąd wiemy, że dowód został przejrzany?”.
Wyszukiwalne widoki logów audytu (jak narzędzie śledcze)
Dostarcz widok logu audytu, łatwy do filtrowania po użytkowniku, zakresie dat, obiekcie (kontrola, polityka, dowód, konto użytkownika) i akcji (create/update/approve/export/login/permission change). Dodaj wyszukiwanie tekstowe po kluczowych polach (np. ID kontroli, nazwa dowodu, numer ticketu).
Uczyń filtry możliwymi do skopiowania (URL), aby audytor mógł odwołać się do dokładnego widoku. Rozważ funkcję „zapisane widoki” dla częstych zapytań jak „zmiany uprawnień w ostatnich 90 dniach”.
Raporty odpowiadające rzeczywistym pytaniom audytu
Stwórz mały zestaw wysokosygnałowych raportów zgodności:
- Status kontroli (wdrożona / w toku / nie dotyczy), z właścicielem i datą ostatniego przeglądu
- Zaległe przeglądy według zespołu i stopnia ważności
- Kompletność dowodów (wymagane dowody vs. dostarczone), z informacją o stanie przeglądu/zaakceptowania
Każdy raport powinien jawnie pokazywać definicje (co liczy się jako „kompletne” lub „zaległe”) i znacznik czasu zestawu danych (as-of).
Eksporty, którym audytor zaufa (i które potrafisz obronić)
Obsługuj eksporty do CSV i PDF, ale traktuj eksport jako operację regulowaną. Każdy eksport powinien generować zdarzenie audytowe zawierające: kto eksportował, kiedy, który raport/widok, użyte filtry, liczba rekordów i format pliku. Jeśli to możliwe, dołącz checksum dla wyeksportowanego pliku.
Aby zachować spójność i powtarzalność danych do eksportu:
- Użyj stabilnego sortowania (np. po ID + updated time)
- Zapisz „as-of” i parametry zapytania
- Unikaj mieszania danych żywych w jednym eksporcie bez deklaracji
Widoki „wyjaśnij ten rekord”
Dla każdej kontroli, elementu dowodu lub uprawnienia użytkownika dodaj panel „Wyjaśnij ten rekord”, który tłumaczy historię zmian prostym językiem: co się zmieniło, kto to zmienił, kiedy i dlaczego (z polami komentarza/uzasadnienia). To redukuje nieporozumienia i zapobiega temu, że audyt stanie się serią przypuszczeń.
Dodaj zabezpieczenia, które wspierają zgodność
Kontrole bezpieczeństwa to to, co sprawia, że funkcje zgodności są wiarygodne. Jeśli aplikacja może być edytowana bez właściwych kontroli — lub dane mogą być odczytane przez niewłaściwe osoby — ścieżka audytu nie zadowoli SOX, GxP ani recenzentów wewnętrznych.
Traktuj każde żądanie jako nieufne
Waliduj wejścia na każdym endpointzie, nie tylko w UI. Używaj walidacji po stronie serwera dla typów, zakresów i dozwolonych wartości i odrzucaj nieznane pola. Paruj walidację ze silnymi kontrolami autoryzacji dla każdej operacji (view, create, update, export). Prosta zasada: „Jeśli zmienia dane zgodności, wymaga eksplicytnego uprawnienia.”
Aby zredukować błędy kontroli dostępu, unikaj „bezpieczeństwa przez ukrywanie UI”. Egzekwuj reguły autoryzacji w backendzie, także dla pobierania plików i filtrów API (np. eksport dowodów dla jednej kontroli nie powinien ujawniać dowodów z innej).
Chroń przed typowymi zagrożeniami webowymi
Systematycznie zabezpieczaj podstawy:
- Injection: parametryzowane zapytania, bezpieczne użycie ORM i ścisła walidacja wejść.
- XSS: kodowanie wyjścia, sanitacja HTML dla pól rich text i Content Security Policy.
- CSRF: tokeny anti-CSRF dla sesji cookie oraz ustawienia same-site cookie.
- Bezpieczeństwo sesji: krótkie sesje dla adminów, ponowne uwierzytelnianie dla wrażliwych akcji.
Szyfruj, izoluj i zarządzaj sekretami
Używaj TLS wszędzie (w tym dla połączeń wewnętrznych między usługami). Szyfruj wrażliwe dane w spoczynku (baza i backupy) i rozważ szyfrowanie na poziomie pól dla elementów jak klucze API czy identyfikatory. Przechowuj sekrety w dedykowanym managerze sekretów (nie w repozytorium kodu ani logach CI). Rotuj poświadczenia i klucze cyklicznie i natychmiast po odejściu osób.
Monitoruj i alertuj o podejrzanej aktywności
Zespoły compliance cenią widoczność. Twórz alerty dla skoków nieudanych logowań, powtarzających się 403/404, zmian uprawnień, nowych tokenów API i nietypowej liczby eksportów. Upewnij się, że alerty są akcyjne: kto, co, kiedy i jakie obiekty dotyczyły.
Ograniczenia tempa i reguły blokowania
Stosuj rate limiting dla logowania, resetu hasła i endpointów eksportu. Dodaj blokadę konta lub step-up weryfikację opartą na ryzyku (np. zablokuj po powtarzających się niepowodzeniach, ale zapewnij bezpieczny sposób odzyskania konta dla legalnych użytkowników).
Testuj śledzalność, uprawnienia i gotowość do audytu
Testowanie aplikacji zgodności to nie tylko „czy działa?”, ale „czy potrafimy udowodnić, co się stało, kto to zrobił i czy miał do tego uprawnienia?” Traktuj gotowość do audytu jako kryterium akceptacji.
Weryfikuj logowanie audytu z precyzją przed/po
Pisz automatyczne testy, które sprawdzają:
- Powstanie właściwego zdarzenia (np.
CONTROL_UPDATED,EVIDENCE_ATTACHED,APPROVAL_REVOKED). - Obecność aktora, znacznika czasu, tenant/org i ID obiektu.
- Zapis wartości przed/po dla zmian (w tym czyszczonych pól).
- Poprawne traktowanie pól wrażliwych (maskowanie lub wykluczenie zgodnie z polityką).
Testuj też przypadki negatywne: nieudane próby (brak uprawnień, błędy walidacji) powinny albo tworzyć oddzielne zdarzenie „odmowa”, albo być wyraźnie wyłączone — cokolwiek mówi twoja polityka.
Testuj uprawnienia jako „nie może”, a nie tylko „może"
Testy uprawnień powinny skupiać się na zapobieganiu dostępowi poza zakresem:
- Użytkownik nie może widzieć/eksportować/wyszukiwać danych poza swoją organizacją, programem lub przydzielonym systemem.
- Workflowy zatwierdzające egzekwują separację obowiązków (brak samo-zatwierdzania, jeśli reguły to zabraniają).
- Zmiany ról wchodzą w życie natychmiast i są odzwierciedlane w zdarzeniach audytu.
Uwzględniaj testy na poziomie API (nie tylko UI), bo audytorzy często patrzą na punkt, gdzie naprawdę jest egzekwowane sprawdzenie.
Ćwiczenia śledzalności: odtwórz historię zdarzenia
Przeprowadzaj sprawdzenia śledzalności, zaczynając od wyniku (np. kontrola oznaczona jako „Efektywna”) i potwierdź, że jesteś w stanie odtworzyć:
- jakie dowody to wspierały,
- kto to przeglądał,
- która wersja polityki miała zastosowanie,
- i co się zmieniało w czasie.
Testy wydajności dla rosnących logów
Logi audytu i raporty rosną szybko. Testuj obciążeniowo:
- przyjmowanie zdarzeń w szczycie aktywności,
- zapytania wyszukiwania/raporty po dużych zakresach czasowych,
- oraz eksporty (CSV/PDF) dla realistycznych wolumenów danych.
Zbuduj checklistę „gotowości do audytu” i pakiet dowodów
Utrzymuj powtarzalną checklistę (powiązaną z wewnętrznym runbookiem, np. /docs/audit-readiness) i wygeneruj przykładowy pakiet dowodów zawierający: kluczowe raporty, listy dostępu, próbki historii zmian i kroki weryfikacji integralności logów. To zamienia audyty z paniki w rutynę.
Wdróż, monitoruj i eksploatuj aplikację pod kontrolą
Wypuszczenie aplikacji zgodności to nie „wydaj i zapomnij”. Operacje to miejsce, w którym dobre intencje stają się powtarzalnymi kontrolami — albo przemieniają się w luki, których nie da się wytłumaczyć podczas audytu.
Chroń historię zmian za pomocą bezpiecznego zarządzania zmianami
Migracje schematu i zmiany API mogą cicho zniszczyć śledzalność, jeśli nadpisują lub reinterpretują stare rekordy.
Używaj migracji bazy jako kontrolowanych, przeglądanych jednostek zmian i preferuj zmiany addytywne (nowe kolumny, nowe tabele, nowe typy zdarzeń) zamiast destrukcyjnych. Gdy musisz zmienić zachowanie, utrzymuj kompatybilność wsteczną API wystarczająco długo, by wspierać starszych klientów i zadania odtwarzające/raportujące. Cel jest prosty: historyczne zdarzenia audytu i dowody muszą pozostać czytelne i spójne między wersjami.
Separuj środowiska i kontroluj wdrożenia
Utrzymuj wyraźne oddzielenie środowisk (dev/stage/prod) z odrębnymi bazami, kluczami i politykami dostępu. Staging powinien odzwierciedlać produkcję na tyle, by weryfikować reguły uprawnień, logowanie i eksporty — bez kopiowania danych produkcyjnych, chyba że masz zatwierdzone i sprawdzone sanetyzacje.
Utrzymuj kontrolowane i powtarzalne wdrożenia (CI/CD z zatwierdzeniami). Traktuj wdrożenie jako zdarzenie audytowe: zapisuj, kto zatwierdził, jaka wersja została wypuszczona i kiedy.
Loguj wdrożenia i zmiany konfiguracji
Audytorzy często pytają: „Co się zmieniło i kto to autoryzował?” Śledź wdrożenia, przełączniki feature-flag, zmiany modelu uprawnień i aktualizacje konfiguracji integracji jako pierwszorzędne wpisy audytowe.
Dobrym wzorcem jest wewnętrzny typ zdarzenia „system change":
SYSTEM_CHANGE: {
actor, timestamp, environment, change_type,
version, config_key, old_value_hash, new_value_hash, ticket_id
}
Monitoruj, co zagraża zgodności
Skonfiguruj monitoring związany z ryzykiem: wskaźniki błędów (szczególnie błędy zapisu), opóźnienia, zaległości w kolejkach (przetwarzanie dowodów, powiadomienia) i wzrost użycia storage (tabele logów audytu, buckety plików). Alertuj o brakujących logach, niespodziewanych spadkach wolumenu zdarzeń i skokach odmów dostępu, które mogą wskazywać na błąd konfiguracji lub nadużycie.
Przygotuj reakcję na incydenty dla integralności i dostępu
Udokumentuj kroki "pierwszej godziny" na wypadek podejrzenia naruszenia integralności danych lub nieautoryzowanego dostępu: zatrzymaj ryzykowne zapisy, zachowaj logi, rotuj poświadczenia, sprawdź ciągłość logów audytu i zbierz oś czasu. Utrzymuj krótkie, działańne runbooki i linkuj je z dokumentacją operacyjną (np. /docs/incident-response).
Wspieraj stałe zarządzanie i ciągłe usprawnianie
Aplikacja zgodności nie jest „skończona” po wdrożeniu. Audytorzy będą pytać, jak utrzymujesz kontrole aktualne, jak zatwierdzasz zmiany i jak użytkownicy pozostają zgodni z procesem. Wbuduj funkcje governance w produkt, aby ciągłe usprawnianie stało się normalną pracą — nie paniką przed audytem.
Trzymaj zarządzanie zmianami widoczne i audytowalne
Traktuj zmiany w aplikacji i kontrolach jako obiekty pierwszej klasy. Dla każdej zmiany zapisuj ticket lub prośbę, zatwierdzającego(ych), release notes i plan rollbacku. Powiąż to bezpośrednio z dotkniętymi kontrolami, aby audytor mógł prześledzić:
dlaczego to zmieniono → kto zatwierdził → co zmieniono → kiedy to wdrożono
Jeśli używasz systemu ticketowego, przechowuj referencje (ID/URL) i kopiuj kluczowe metadane do aplikacji, by dowody pozostały spójne, nawet jeśli narzędzia zewnętrzne się zmienią.
Wersjonuj polityki i kontrole (nie nadpisuj historii)
Unikaj edycji kontroli „w miejscu”. Twórz wersje z datami wejścia w życie i czytelnymi diffami (co zmieniło się i dlaczego). Gdy użytkownicy dostarczają dowody lub kończą przegląd, powiąż je z konkretną wersją kontroli, na którą odpowiadali.
To zapobiega częstemu problemowi audytowemu: dowody zebrane pod starszym wymaganiem wyglądają, jakby nie pasowały do obecnego brzmienia.
Ułatwiaj szkolenie i składanie dowodów
Większość luk zgodności to problemy procesowe. Dodaj zwięzłe wskazówki w aplikacji tam, gdzie użytkownik działa:
- Jak wyglądają dobre dowody (przykłady, akceptowalne formaty)
- Konwencje nazewnictwa i wymagane pola
- Typowe powody odrzucenia zgłoszeń
Śledź potwierdzenia szkoleń (kto, jaki moduł, kiedy) i wyświetlaj przypomnienia „just-in-time”, gdy użytkownik dostaje przydział kontroli lub przeglądu.
Dokumentuj system jak produkt, nie jak segregator
Utrzymuj żywą dokumentację w aplikacji (lub przez /help) obejmującą:
- Przepływy danych (skąd pochodzą dowody, gdzie są przechowywane, kto może je zobaczyć/eksportować)
- Model uprawnień i opisy ról
- Katalog zdarzeń audytu (jakie zdarzenia logujesz i jakie pola są zapisywane)
To redukuje wymianę z audytorami i przyspiesza onboarding nowych administratorów.
Zaplanuj okresowe przeglądy we workflowie
Wbuduj governance w powtarzalne zadania:
- Przeglądy dostępu: okresowa certyfikacja użytkowników/rol, z zatwierdzeniami i zapisanymi wyjątkami.
- Przeglądy kontroli: potwierdź właścicieli, częstotliwość i oczekiwania dowodowe; wycofaj kontrolę z udokumentowanym uzasadnieniem.
Gdy te przeglądy są zarządzane w aplikacji, "ciągłe usprawnianie" staje się mierzalne i łatwe do udokumentowania.
Prototypuj szybciej (bez kompromisów dla historii audytu)
Narzędzia zgodności często zaczynają jako wewnętrzny workflow — najszybsza droga do wartości to cienkie, audytowalne v1, z którego zespoły będą rzeczywiście korzystać. Jeśli chcesz przyspieszyć pierwszą budowę (UI + backend + baza), podejście generowania kodu może być praktyczne.
Na przykład Koder.ai pozwala zespołom tworzyć aplikacje webowe przez chat-driven workflow, jednocześnie produkując rzeczywisty kod (React na frontendzie, Go + PostgreSQL na backendzie). To może pasować do aplikacji zgodności, gdy potrzebujesz:
- jasnego modelu RBAC i separacji obowiązków wdrożonego w backendzie,
- struktury encji dla kontroli, dowodów i przeglądów,
- wzorców append-only audytowania od pierwszego dnia,
- możliwości eksportu kodu źródłowego lub wdrożenia/hostingu w kontrolowanych środowiskach.
Kluczowe jest traktowanie wymagań zgodności (katalog zdarzeń, zasady retencji, zatwierdzenia i eksporty) jako eksplicytne kryteria akceptacji — niezależnie od tego, jak szybko wygenerujesz pierwszą implementację.
Często zadawane pytania
Jaki jest najlepszy sposób, aby zdefiniować „zarządzanie zgodnością” przed budową aplikacji?
Zacznij od stwierdzenia w prostych słowach, np.: „Musimy pokazać, kto co zrobił, kiedy, dlaczego i na czyje uprawnienie — i szybko odnaleźć dowody.”
Następnie przekształć to w user stories dla każdej roli (administratorzy, właściciele kontroli, użytkownicy końcowi, audytorzy) oraz krótki zakres v1: role + podstawowe przepływy + ścieżka audytu + podstawowe raportowanie.
Co powinno znaleźć się w v1 aplikacji do zarządzania zgodnością?
Praktyczne v1 zwykle zawiera:
- Kontrole + właścicielstwo (kto jest za co odpowiedzialny)
- Zbieranie dowodów (pliki/linki + wymagane metadane)
- Przeglądy/atestacje (kto sprawdził, kiedy, wynik)
- Zatwierdzenia/ wyjątki (z uzasadnieniem i datą wygaśnięcia)
- Ścieżka audytu (kto/co/kiedy/gdzie/dlaczego)
- Wyszukiwanie + kilka kluczowych raportów (status, zaległości, kompletność dowodów)
Odsuń zaawansowane pulpity i szerokie integracje, dopóki audytorzy i właściciele kontroli nie potwierdzą, że fundamenty działają.
Jak przetłumaczyć SOC 2 / ISO 27001 / SOX / HIPAA / GDPR na wymagania aplikacji?
Stwórz tabelę mapującą abstrakcyjne wymagania na konkretne funkcje:
- Kontrola z frameworka → funkcja w aplikacji → dane do uchwycenia → raport/eksport, który to potwierdza
Rób to dla każdego produktu, środowiska i typu danych objętych zakresem, żeby nie budować kontroli dla systemów, których audytorzy nie będą sprawdzać.
Jaki model danych dobrze sprawdza się dla kontroli, dowodów i okresowych przeglądów?
Zaprojektuj niewielki zestaw podstawowych encji i jawnie zdefiniuj relacje:
- Użytkownicy, Role (często wiele-do-wielu)
- Polityki → Kontrole (jeden-do-wielu)
- Kontrole ↔ Dowody (często wiele-do-wielu)
- Kontrole → Przeglądy/Testy (jeden-do-wielu, okresowo)
- Zadania do powtarzalnej pracy (np. kwartalne przeglądy)
Używaj stabilnych, czytelnych ID (np. CTRL-AC-001) i wersjonuj definicje polityk/kontrol, aby stare dowody były powiązane z wymaganiem obowiązującym w czasie ich zebrania.
Co powinna zawierać ścieżka audytu, aby zadowolić audytorów?
Zdefiniuj schemat „zdarzenia audytu” i trzymaj się go konsekwentnie:
- Kto: ID aktora + rola w czasie zdarzenia (i tożsamość usługi, jeśli automatyczne)
- Co: akcja + typ/ID zasobu
- Kiedy: znacznik czasu serwera (UTC)
- Gdzie: tenant/org + źródło żądania (IP) + correlation/request ID
- Dlaczego: uzasadnienie dla wrażliwych operacji
Standaryzuj typy zdarzeń (auth, zmiany uprawnień, zatwierdzenia workflow, CRUD kluczowych rekordów) i zapisuj wartości przed/po z bezpiecznym redakcjonowaniem.
Jak zaimplementować append-only, wykrywające manipulacje logowanie audytu?
Traktuj logi jako niezmienne:
- Użyj append-only event store (brak UPDATE/DELETE w kodzie aplikacji)
- Dodaj wykrywanie manipulacji (np. hash + hash poprzednika)
- Opcjonalnie podpisuj/zabezpieczaj partie i przechowuj archiwa w niezmiennym/WORM storage
- Rejestruj akcje systemowe oddzielnie od akcji użytkowników (actor type: user/service)
Jeśli trzeba „poprawić” błąd, zapisz nowe zdarzenie wyjaśniające korektę zamiast zmieniać historię.
Jak egzekwować kontrolę dostępu i separację obowiązków?
Zacznij od RBAC i zasady najmniejszych uprawnień (np. Viewer, Contributor, Control Owner, Approver, Admin). Potem egzekwuj zakres:
- jednostka biznesowa / system / framework / okres audytu
Upewnij się, że separacja obowiązków jest wymuszana w kodzie:
- Wnioskodawca ≠ zatwierdzający
- Osoba dodająca dowód ≠ osoba go weryfikująca (dla tej samej kontroli)
Traktuj zmiany ról/zakresu i eksporty jako wysokopriorytetowe zdarzenia audytowe i stosuj step-up authentication dla wrażliwych operacji.
Jak bezpiecznie obsługiwać retencję, archiwizację, legal hold i usuwanie?
Zdefiniuj retencję wg typu rekordu i zapisz zastosowaną politykę razem z rekordem, aby była audytowalna później.
Typowe potrzeby:
- Długa retencja: logi audytu, zmiany dostępu/admina
- Średnia: przeglądy/podpisy, wyjątki
- Zmienna: dowody/załączniki (zależnie od frameworka i umów)
Dodaj legal hold, który nadpisuje automatyczne czyszczenie, i rejestruj działania retencyjne (archiwizacja/eksport/purge) z raportami batch. Dla prywatności zdecyduj, kiedy usuwać a kiedy redagować, zachowując integralność (np. zostawić zdarzenie audytu, ale zredagować pola osobowe).
Jakie raporty, wyszukiwanie i funkcje eksportu audytorzy zwykle oczekują?
Zbuduj wyszukiwarkę typu „narzędzie śledcze” i niewielki zestaw raportów odpowiadających typowym pytaniom audytu:
- Filtrowalny widok logów audytu: użytkownik, zakres dat, obiekt, akcja + wyszukiwanie tekstowe
- Raporty: status kontroli, zaległe przeglądy, kompletność dowodów
Dla eksportów loguj: kto eksportował, kiedy, który widok/filtr, liczba rekordów i format; dodaj znacznik „as-of” i stabilne sortowanie dla powtarzalnych wyników.
Jak testować i obsługiwać aplikację, aby była na bieżąco gotowa do audytu?
Testuj gotowość audytową jako kryterium akceptacji:
- Automatyczne testy, że właściwe typy zdarzeń powstają z wymaganymi polami
- Logowanie przed/po zmianie (w tym czyszczeń pól)
- Testy negatywne dla zabronionych działań (i czy odmowy są logowane zgodnie z polityką)
- Testy autoryzacji na poziomie API, aby zapobiec dostępowi poza zakresem
Operacyjnie: traktuj wdrożenia/zmiany konfiguracji jako zdarzenia audytowe, separuj środowiska i utrzymuj runbooki (np. /docs/incident-response, /docs/audit-readiness).