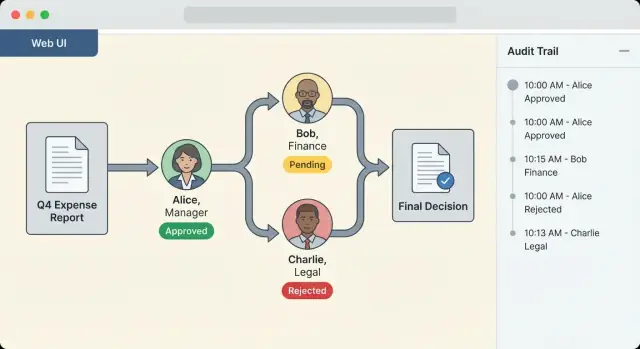
Co to są łańcuchy zatwierdzeń wieloetapowych (i dlaczego są ważne)
Łańcuch zatwierdzeń wieloetapowych to uporządkowana sekwencja decyzji, przez które musi przejść żądanie, zanim będzie mogło iść dalej. Zamiast polegać na doraźnych e-mailach i wiadomościach „wydaje się w porządku”, łańcuch zatwierdzeń zamienia decyzje w powtarzalny proces z jasną odpowiedzialnością, znacznikami czasu i wynikami.
Na podstawowym poziomie Twoja aplikacja odpowiada na trzy pytania dla każdego żądania:
- Kto musi zatwierdzić?
- W jakiej kolejności (albo na jakim etapie)?
- Co się dzieje po każdej decyzji?
Krok sekwencyjny vs. równoległy
Łańcuchy zatwierdzeń zwykle łączą dwa wzorce:
- Zatwierdzenia sekwencyjne: krok B nie może się rozpocząć, dopóki krok A nie zostanie zatwierdzony. Przykład: wniosek zakupowy może wymagać najpierw zgody lidera zespołu, potem finansów, potem działu zaopatrzenia.
- Zatwierdzenia równoległe: kilku zatwierdzających może oceniać jednocześnie. Przykład: zmiana polityki może wymagać równoległych zgód od działu prawnego i bezpieczeństwa, i dopiero potem można iść dalej.
Dobre systemy obsługują oba tryby, a także warianty takie jak „wystarczy jeden z tych zatwierdzających” vs. „wszyscy muszą zatwierdzić”.
Typowe zastosowania w przedsiębiorstwach (przykłady ogólne)
Łańcuchy zatwierdzeń pojawiają się wszędzie tam, gdzie organizacja chce kontrolowanej zmiany z możliwością jej śledzenia:
- Zakupy: wybór dostawcy, sprawdzenie budżetu, akceptacja działu zaopatrzenia
- Wydatki: zatwierdzenie przez przełożonego, walidacja finansowa, wyjątki przy wyższych kwotach
- Prośby o dostęp: zgoda menedżera, zatwierdzenie właściciela systemu, przegląd bezpieczeństwa
- Zmiany w politykach: tworzenie, akceptacja interesariuszy, przegląd zgodności, publikacja
Niezależnie od typu żądania potrzeba jest ta sama: konsekwentne podejmowanie decyzji, które nie zależy od tego, kto akurat jest online.
Czego oczekują przedsiębiorstwa od łańcuchów zatwierdzeń
Dobrze zaprojektowany przepływ zatwierdzeń to nie tylko „większa kontrola”. Powinien równoważyć cztery praktyczne cele:
- Szybkość: redukować zbędne korespondencje i usunąć niepotrzebne oczekiwanie
- Kontrola: zapewnić, że właściwe osoby zatwierdzają właściwe rzeczy
- Widoczność: każdy widzi status, kolejny krok i blokery
- Gotowość do audytu: pełna ścieżka audytu (kto, co, kiedy, decyzja i uzasadnienie)
Typowe pułapki do uniknięcia
Łańcuchy zatwierdzeń rzadziej zawodzą z powodu technologii, a częściej z powodu niejasnych procesów. Zwróć uwagę na te problemy:
- Niejasna odpowiedzialność: żądania stoją, bo nikt nie wie, kto ma zatwierdzić
- Brak historii audytu: decyzje zapadają w czacie lub e-mailu i nie da się ich udowodnić później
- Zbyt wiele etapów manualnych: przeglądy „do wiadomości” stają się obowiązkowymi zatwierdzeniami, co spowalnia proces
Reszta tego przewodnika skupia się na budowie aplikacji, tak aby zatwierdzenia pozostały elastyczne dla biznesu, przewidywalne dla systemu i audytowalne, gdy to ważne.
Lista wymagań dla zatwierdzeń w przedsiębiorstwie
Zanim zaprojektujesz ekrany lub wybierzesz silnik workflow, uzgodnij wymagania prostym językiem. Łańcuchy zatwierdzeń dotykają wielu zespołów, a małe luki (np. brak delegowania) szybko prowadzą do obejść operacyjnych.
Interesariusze do włączenia wcześnie
Zacznij od nazwiska osób, które będą korzystać z systemu — lub go inspekcjonować:
- Wnioskodawcy (pracownicy, kontraktorzy, dostawcy)
- Zatwierdzający (menedżerowie, dział finansów, prawnicy, IT, bezpieczeństwo)
- Administratorzy (operacje/wsparcie zarządzające szablonami, regułami routingu i dostępem)
- Audytorzy/zgodność (audyt wewnętrzny, regulatorzy zewnętrzni)
Praktyczna wskazówka: przeprowadź 45‑minutowy przegląd „typowego żądania” i „najgorszego przypadku” (escalacja, ponowne przypisanie, wyjątek polityki) z co najmniej jedną osobą z każdej grupy.
Niezbędne możliwości workflow
Formułuj to jako stwierdzenia testowalne (powinieneś móc udowodnić, że każde działa):
- Składanie żądań z załącznikami i polami strukturalnymi
- Zatwierdzanie/odrzucanie, komentowanie i rejestrowanie decyzji na każdym etapie
- Delegowanie tymczasowe (urlop) i trwałe przekazywanie (zmiany organizacyjne)
- Obsługa zatwierdzeń równoległych (np. Finans i Prawo) oraz kroków sekwencyjnych
- Wymuszanie, kto co widzi (widoczność wnioskodawcy vs. notatki tylko dla zatwierdzających)
Jeśli potrzebujesz inspiracji, możesz potem mapować te wymagania na potrzeby UX w tekście widocznym jako /blog/approver-inbox-patterns.
Wymagania niefunkcjonalne (co czyni system gotowym dla przedsiębiorstwa)
Zdefiniuj cele, nie życzenia:
- Dostępność i RTO/RPO (jak długo może być niedostępny i jaka utrata danych jest akceptowalna)
- Wydajność (np. widok skrzynki załaduje się w < 2 sekundy przy 10k oczekujących pozycji)
- Retencja danych (jak długo przechowywać żądania, komentarze i załączniki)
- Model wsparcia (kto jest na wezwanie, godziny pracy, SLA dla incydentów)
Ograniczenia i metryki sukcesu
Zidentyfikuj ograniczenia: typy danych regulowanych, zasady regionalnego przechowywania, zdalna siła robocza (zatwierdzanie mobilne, strefy czasowe).
Na koniec uzgodnij metryki sukcesu: czas-do-zatwierdzenia, % po terminie i współczynnik poprawek (jak często żądania wracają z powodu brakujących informacji). Te metryki kierują priorytetami i pomagają uzasadnić wdrożenie.
Model danych: żądania, kroki, decyzje i szablony
Jasny model danych zapobiega późniejszym „tajemniczym zatwierdzeniom” — możesz wyjaśnić, kto co zatwierdził, kiedy i na jakich zasadach. Zacznij od oddzielenia obiektu biznesowego zatwierdzanego (Request) od definicji procesu (Template).
Podstawowe byty
Request to rekord tworzony przez wnioskodawcę. Zawiera tożsamość wnioskodawcy, pola biznesowe (kwota, dział, dostawca, daty) oraz powiązania z materiałami wspierającymi.
Step reprezentuje jeden etap w łańcuchu. Kroki zwykle generowane są z Template w momencie złożenia, dzięki czemu każde Request ma własną niemodyfikowalną sekwencję.
Approver to zazwyczaj odwołanie do użytkownika (lub grupy) przypisane do Step. Jeśli obsługujesz routing dynamiczny, przechowuj zarówno rozstrzygniętego zatwierdzającego(-ych), jak i regułę, która ich wyprodukowała, dla celów śledzenia.
Decision to dziennik zdarzeń: zatwierdź/odrzuć/zwrot, aktor, znacznik czasu i opcjonalne metadata (np. delegated-by). Modeluj to jako dodawane tylko dopisaniem, aby można było przeprowadzić audyt zmian.
Attachment przechowuje pliki (w object storage) oraz metadane: nazwę pliku, rozmiar, typ treści, sumę kontrolną i osobę przesyłającą.
Statusy ułatwiające raportowanie
Używaj małego, spójnego zestawu statusów Request:
- Draft: edytowalny, nie skierowany do routingu
- Submitted: zablokowany zgodnie z regułami routingu, wygenerowane kroki
- In Review: co najmniej jeden oczekujący krok
- Approved: wszystkie wymagane kroki spełnione
- Rejected: odrzucenie zakończyło żądanie
- Canceled: wnioskodawca/admin je wycofał
Typy kroków, których będziesz potrzebować na początku
Obsługuj typowe semantyki kroków:
- Pojedynczy zatwierdzający: jedna osoba musi podjąć decyzję
- Grupa: dowolny członek może zdecydować
- Kwarantum: N z M zatwierdzeń wymagane
- Warunkowy: uwzględniany tylko jeśli warunek jest prawdziwy (np. kwota > $10k)
Wersjonowanie szablonów bez niespodzianek
Traktuj Workflow Template jako wersjonowany. Gdy szablon się zmienia, nowe Requests używają najnowszej wersji, ale trwające Requests zachowują wersję, z którą zostały utworzone.
Przechowuj template_id i template_version na każdym Request i zrób snapshot krytycznych wejść routingu (np. dział lub centrum kosztów) w momencie złożenia.
Komentarze i pliki
Modeluj komentarze jako osobną tabelę powiązaną z Request (i opcjonalnie Step/Decision), aby móc kontrolować widoczność (tylko wnioskodawca, zatwierdzający, admini).
Dla plików: wymuś limity rozmiaru (np. 25–100 MB), skanuj przesyłane pliki pod kątem złośliwego oprogramowania (asynchroniczna kwarantanna + zwolnienie) i przechowuj w bazie tylko referencje. To utrzymuje dane workflow szybkie, a storage skalowalny.
Projektowanie elastycznych reguł routingu zatwierdzeń
Reguły routingu decydują kto musi zatwierdzić co, i w jakiej kolejności. W przepływie zatwierdzeń przedsiębiorstwa sztuka polega na zbalansowaniu rygorystycznej polityki z rzeczywistymi wyjątkami — bez zamieniania każdego żądania w niestandardowy proces.
Zacznij od klarownych „sygnałów”
Większość routingu można wyprowadzić z kilku pól w żądaniu. Typowe przykłady:
- Progi kwotowe (np. powyżej $10k dodaje Finans)
- Dział lub centrum kosztów (routuje do właściciela centrum kosztów)
- Lokalizacja (lokalna jednostka prawna lub zgodność regionalna)
- Poziom ryzyka (dodaje InfoSec/Prawo dla ryzykownych dostawców)
Traktuj je jako konfigurowalne reguły, nie jako logikę na stałe w kodzie, aby admini mogli aktualizować polityki bez wdrożenia.
Obsługuj dynamicznych zatwierdzających
Statyczne listy szybko się psują. Zamiast tego rozstrzygaj zatwierdzających w czasie rzeczywistym, korzystając z katalogu i danych organizacyjnych:
- Łańcuch managerski (bezpośredni menedżer, potem skip-level powyżej progu)
- Właściciel centrum kosztów z Finance/ERP
- Lider projektu z systemu projektowego
Uczyń resolver jawny: przechowuj jak zatwierdzający został wybrany (np. „manager_of: user_123”), a nie tylko końcowe imię i nazwisko.
Kroki równoległe i logika scalania
Często potrzebne są równoległe zatwierdzenia. Modeluj równoległe kroki z jasnym zachowaniem scalającym:
- Wszyscy muszą zatwierdzić (np. Finans i Prawo)
- Ktokolwiek może zatwierdzić (np. jeden z kilku osób odpowiedzialnych za budżet)
Zdecyduj też, co dzieje się przy odrzuceniu: zatrzymać natychmiast, czy pozwolić na „poprawkę i ponowne złożenie”.
Eskalacje i wyjątki
Zdefiniuj reguły eskalacji jako pierwszorzędne polityki:
- Przypomnienia po X godzinach/dniach
- Obsługa przeterminowań (eskalacja do menedżera, ponowne przypisanie do kolejki)
- Auto‑eskalacja po przekroczeniu SLA
Zaplanuj wyjątki z wyprzedzeniem: nieobecność, delegowanie i zastępcy, z audytowalnym powodem zapisaným dla każdej zmiany trasy.
Silnik workflow: niezawodne orkiestracje kroków
Aplikacja do zatwierdzeń wieloetapowych osiąga sukces lub porażkę dzięki jednej rzeczy: czy silnik workflow potrafi przesuwać żądania do przodu przewidywalnie — nawet gdy użytkownicy klikają dwa razy, integracje się opóźniają, albo zatwierdzający jest na urlopie.
Zbudować własny silnik vs. przyjąć bibliotekę
Jeśli Twoje łańcuchy zatwierdzeń są głównie liniowe (Krok 1 → Krok 2 → Krok 3) z kilkoma warunkami, prosty silnik wewnętrzny jest często najszybszą drogą. Kontrolujesz model danych, możesz dopasować zdarzenia audytu i unikasz zbędnych konceptów.
Jeśli spodziewasz się złożonego routingu (zatwierdzenia równoległe, dynamiczne wstawianie kroków, działania kompensacyjne, timery długotrwałe, wersjonowane definicje), przyjęcie biblioteki workflow lub usługi może zmniejszyć ryzyko. Kosztem jest złożoność operacyjna i mapowanie Twoich pojęć zatwierdzania do prymitywów biblioteki.
Jeśli jesteś w fazie „musimy szybko wysłać działające narzędzie wewnętrzne”, platforma vibe‑codingowa taka jak Koder.ai może być przydatna do prototypowania end‑to‑end (formularz żądania → skrzynka zatwierdzającego → oś czasu audytu) i iterowania reguł routingu w trybie planowania, jednocześnie generując rzeczywisty kod React + Go + PostgreSQL, który możesz eksportować i posiadać.
Zdefiniuj jasną maszynę stanów
Traktuj każde żądanie jako maszynę stanów z explicytnymi, walidowanymi przejściami. Na przykład: DRAFT → SUBMITTED → IN_REVIEW → APPROVED/REJECTED/CANCELED.
Każde przejście powinno mieć zasady: kto może je wykonać, wymagane pola i jakie skutki uboczne są dozwolone. Utrzymuj walidację po stronie serwera, aby UI nie mógł omijać kontroli.
Idempotencja: załóż, że przyciski będą klikane dwukrotnie
Akcje zatwierdzających muszą być idempotentne. Gdy zatwierdzający kliknie „Zatwierdź” dwa razy (albo odświeży podczas wolnej odpowiedzi), API powinno wykryć duplikat i zwrócić ten sam rezultat.
Typowe podejścia to klucze idempotencji na akcję lub wymuszanie unikalnych ograniczeń, np. „jedna decyzja na krok na aktora”.
Zadania w tle dla timerów i eskalacji
Timery (przypomnienia SLA, eskalacja po 48 godzinach, automatyczne anulowanie po wygaśnięciu) powinny działać w zadaniach backgroundowych, nie w kodzie request/response. To utrzymuje UI responsywnym i zapewnia, że timery zadziałają nawet przy dużym ruchu.
Oddziel logikę workflow od UI i integracji
Umieść routing, przejścia i zdarzenia audytu w dedykowanym module/usłudze workflow. UI powinno wywoływać „submit” lub „decide”, a integracje (SSO/HRIS/ERP) powinny dostarczać dane wejściowe — nie osadzać reguł workflow. To oddzielenie ułatwia bezpieczne zmiany i prostsze testy.
Bezpieczeństwo, kontrola dostępu i gotowość do audytu
Support Approvals on Mobile
Create a mobile-friendly approval experience, including Flutter apps when you need them.
Zatwierdzenia przedsiębiorstwa często blokują wydatki, dostęp lub wyjątki polityk — więc bezpieczeństwo nie może być traktowane po macoszemu. Dobra zasada: każda decyzja musi być przypisana do realnej osoby (lub tożsamości systemowej), uprawnionej do tej konkretnej akcji i udokumentowanej.
Uwierzytelnianie: udowodnij, kim jest użytkownik
Zacznij od single sign-on, aby tożsamości, dezaktywacje i polityki haseł były scentralizowane. Większość przedsiębiorstw oczekuje SAML lub OIDC, często z MFA.
Dodaj polityki sesji zgodne z oczekiwaniami korporacyjnymi: krótkotrwałe sesje dla działań wysokiego ryzyka (np. finalne zatwierdzenie), zapamiętywanie urządzeń tylko tam, gdzie dozwolone, oraz ponowne uwierzytelnianie przy zmianie ról.
Autoryzacja: udowodnij, że mogą działać
Użyj kontroli dostępu opartej na rolach (RBAC) dla szerokich uprawnień (Wnioskodawca, Zatwierdzający, Admin, Audytor), a następnie nałóż uprawnienia per‑żądanie.
Na przykład zatwierdzający może widzieć jedynie żądania dla swojego centrum kosztów, regionu lub bezpośrednich raportów. Wymuszaj uprawnienia po stronie serwera przy każdym odczycie i zapisie — szczególnie dla akcji „Zatwierdź”, „Deleguj” czy „Edytuj routing”.
Ochrona danych: chroń treść i sekrety
Szyfruj dane w tranzycie (TLS) i w spoczynku (zarządzane klucze, jeśli to możliwe). Przechowuj sekrety (certy SSO, klucze API) w menedżerze sekretów, nie w rozproszonych zmiennych środowiskowych.
Przemyśl, co logujesz; szczegóły żądań mogą zawierać wrażliwe dane HR lub finansowe.
Gotowość do audytu: spraw, by każda decyzja była wyjaśnialna
Audytorzy oczekują niezmiennej ścieżki: kto zrobił co, kiedy i skąd.
Rejestruj każdą zmianę stanu (submitted, viewed, approved/denied, delegated) ze znacznikiem czasu, tożsamością aktora i identyfikatorami request/step. Tam, gdzie dozwolone, przechowuj IP i kontekst urządzenia. Zapewnij, by logi były dopisywalne i wykazywały próby manipulacji.
Zapobieganie nadużyciom: blokuj typowe ataki
Ograniczaj częstość akcji zatwierdzania, chroń przed CSRF i wymagaj tokenów akcji generowanych przez serwer jednorazowego użytku, aby zapobiec podszywaniu się pod zatwierdzenia przez sfałszowane linki lub replay.
Dodaj alerty dla podejrzanych wzorców (masowe zatwierdzenia, szybkie decyzje, nietypowe lokalizacje).
Doświadczenie użytkownika: przepływ wnioskodawcy i skrzynka zatwierdzającego
Zatwierdzenia przedsiębiorstw odnoszą sukces lub porażkę dzięki jasności. Jeśli ludzie szybko nie rozumieją, co mają zatwierdzić (i dlaczego), będą opóźniać, delegować lub odrzucać.
Kluczowe ekrany do zaprojektowania
Formularz zgłoszeniowy powinien prowadzić wnioskodawcę, by podał właściwy kontekst od razu. Używaj inteligentnych domyślnych wartości (dział, centrum kosztów), walidacji inline i krótkiej informacji „co się stanie dalej”, aby wnioskodawca wiedział, że łańcuch zatwierdzeń nie będzie tajemnicą.
Skrzynka zatwierdzającego musi natychmiast odpowiadać na dwa pytania: co wymaga mojej uwagi teraz i jakie jest ryzyko zwłoki. Grupuj pozycje według priorytetu/SLA, dodaj szybkie filtry (zespół, wnioskodawca, kwota, system) i umożliwiaj operacje zbiorcze tylko tam, gdzie to bezpieczne (np. dla niskiego ryzyka).
Szczegóły żądania to miejsce decyzji. Trzymaj czytelne podsumowanie na górze (kto, co, koszt/ wpływ, data obowiązywania), następnie szczegóły wspierające: załączniki, powiązane rekordy i oś czasu aktywności.
Kreator admina (dla szablonów i routingu) powinien czytać się jak polityka, nie diagram. Użyj reguł w języku potocznym, podglądów („to żądanie trafi do Finans → Prawo”) oraz dziennika zmian.
Ułatwiaj podejmowanie decyzji (i rób to bezpiecznie)
Wyróżniaj, co się zmieniło od ostatniego etapu: różnice na poziomie pola, zaktualizowane załączniki i nowe komentarze. Zapewnij akcje jednym kliknięciem (Zatwierdź / Odrzuć / Poproś o zmiany) oraz wymagaj uzasadnienia przy odrzuceniach.
Przejrzystość bez przeciążenia
Pokaż bieżący krok, następną grupę zatwierdzającą (niekoniecznie osobę) i timery SLA. Prosty wskaźnik postępu zmniejsza pytania „gdzie jest moje żądanie?”.
Przyjazność mobilna i dostępność
Umożliwiaj szybkie zatwierdzenia na urządzeniach mobilnych przy zachowaniu kontekstu: sekcje zwijane, przyklejone podsumowanie i podgląd załączników.
Podstawy dostępności: pełna nawigacja klawiaturą, widoczne stany fokusu, czytelne kontrasty i etykiety zgodne z czytnikami ekranu dla statusów i przycisków.
Powiadomienia, przypomnienia i eskalacje
Set Up Template Versioning
Add admin-ready template versioning and change history so in-flight requests keep their rules.
Zatwierdzenia zawodzą, gdy ludzie ich nie zauważają. Dobry system powiadomień utrzymuje pracę w ruchu bez zamieniania jej w hałas oraz tworzy jasny zapis, kto i kiedy został powiadomiony i dlaczego.
Kanały: docieraj tam, gdzie pracują użytkownicy
Większość przedsiębiorstw potrzebuje przynajmniej e‑maili i powiadomień w aplikacji. Jeśli firma używa narzędzi czatowych (np. Slack lub Microsoft Teams), traktuj je jako opcjonalny kanał odzwierciedlający powiadomienia w aplikacji.
Utrzymuj spójne zachowanie: to samo zdarzenie powinno tworzyć ten sam „task” w systemie, niezależnie od tego, czy dostarczono go e‑mailem czy czatem.
Unikaj spamu dzięki inteligentnemu harmonogramowi
Zamiast wysyłać wiadomość przy każdej drobnej zmianie, grupuj aktywność:
- Grupowanie: łącz kilka aktualizacji dotyczących tego samego żądania w krótkim oknie (np. 5–10 minut)
- Digesty: codzienne/tygodniowe podsumowania dla obserwatorów lub odbiorców FYI
- Inteligentne przypomnienia: przypominaj tylko, jeśli pozycja nadal jest oczekująca i zatwierdzający nie podjął działania
Szanuj też godziny ciszy, strefy czasowe i preferencje użytkownika. Zatwierdzający, który rezygnuje z e‑maili, powinien nadal widzieć jasną kolejkę w aplikacji w /approvals.
Treść wiadomości: bądź konkretny i nakieruj na akcję
Każde powiadomienie powinno odpowiedzieć na trzy pytania:
- Co się zmieniło? (Złożono, etap przesunięty, odrzucono, dodano komentarz.)
- Jakie działanie jest potrzebne? (Zatwierdź/Odrzuć/Poproś o zmiany; do kiedy.)
- Gdzie mam iść? Dołącz głębokie łącze do dokładnego ekranu, np. /requests/123?tab=decision.
Dodaj kluczowy kontekst inline (tytuł żądania, wnioskodawca, kwota, tag polityki), aby zatwierdzający mogli szybko ocenić priorytet.
Kadenсja przypomnień i eskalacje
Zdefiniuj domyślną kadenсję (np. pierwsze przypomnienie po 24 godzinach, potem co 48 godzin), ale pozwól na nadpisanie per‑szablon.
Eskalacje muszą mieć jasnego właściciela: eskaluj do roli menedżera, zapasowego zatwierdzającego lub kolejki operacyjnej — nie do „wszystkich”. Gdy eskalacja nastąpi, zapisz powód i znacznik czasu w ścieżce audytu.
Szablony i lokalizacja
Zarządzaj szablonami powiadomień centralnie (temat/treść na kanał), wersjonuj je i pozwól na zmienne. Dla lokalizacji przechowuj tłumaczenia razem z szablonem i stosuj fallback do języka domyślnego, gdy tłumaczenie jest brakujące.
To zapobiega „półprzetłumaczonym” wiadomościom i utrzymuje spójność komunikatów zgodnych z wymaganiami compliance.
Integracje i API dla systemów przedsiębiorstwa
Zatwierdzenia rzadko żyją w jednej aplikacji. Aby zredukować ręczne przepisywanie (i problem „czy zaktualizowałeś drugi system?”), traktuj integracje jako element pierwszorzędny.
Systemy, z którymi prawdopodobnie trzeba się połączyć
Zacznij od źródeł prawdy, których organizacja już używa:
- Katalog HR / dostawca tożsamości (dla relacji menedżerskich, działów, statusu zatrudnienia)
- ERP / system finansowy (dla centrów kosztów, budżetów, rekordów dostawców, zamówień)
- System ticketowy (łączenie zatwierdzeń z incydentami/zmianami dla operacyjnego śladu)
- Przechowywanie dokumentów (umowy, oferty, polityki, pliki wspierające)
Nawet jeśli nie zintegrujesz wszystkiego od pierwszego dnia, zaplanuj to w modelu danych i uprawnieniach.
Projekt API i webhooków
Dostarcz stabilne REST API (lub GraphQL) dla podstawowych działań: tworzenie żądania, pobieranie statusu, listowanie decyzji i pobieranie pełnej ścieżki audytu.
Dla automatyzacji zewnętrznej daj webhooki, aby inne systemy mogły reagować w czasie rzeczywistym.
Zalecane typy zdarzeń:
request.submittedrequest.step_approvedrequest.step_rejectedrequest.completed
Uczyń webhooki niezawodnymi: dołącz identyfikatory zdarzeń, znaczniki czasu, retry z backoffem i weryfikację podpisu.
Integracje przychodzące: tworzenie żądań z innych narzędzi
Wiele zespołów chce, żeby zatwierdzenia startowały tam, gdzie pracują — ekrany ERP, formularze ticketowe lub portal wewnętrzny. Wspieraj uwierzytelnianie serwis‑do‑serwisu i pozwól systemom zewnętrznym na:
- tworzenie żądania ze szablonu
- dołączanie metadanych (kwota, centrum kosztów, dostawca)
- dołączanie łączy do rekordu źródłowego
Mapowanie danych i dopasowanie tożsamości
Tożsamość to częsty punkt awarii. Zdecyduj o kanonicznym identyfikatorze (często ID pracownika) i mapuj e‑maile jako aliasy.
Obsługuj przypadki brzegowe: zmiany nazw, kontrahenci bez ID oraz duplikaty e‑maili. Loguj decyzje mapujące, aby admini mogli szybko rozwiązywać niezgodności i pokazuj stan w raportach administracyjnych (więcej w /pricing dla typowych różnic planów, jeśli segmentujesz integracje).
Konsola admina i raportowanie dla operacji
Aplikacja zatwierdzająca w przedsiębiorstwie odnosi sukces lub porażkę na dzień drugi: jak szybko zespoły mogą dostosowywać szablony, utrzymywać kolejki w ruchu i udowadniać, co się stało podczas audytu.
Konsola admina powinna przypominać centrum kontroli — potężne, ale bezpieczne.
Zarządzaj szablonami, grupami, politykami i SLA
Zacznij od przejrzystej architektury informacji:
- Szablony workflow (np. „Zatwierdzenie wydatków”, „Zakładanie dostawcy”) z właścicielami i opisem kiedy używać
- Grupy zatwierdzających (Finance Ops, Legal Reviewers) mapujące role i lokalizacje, a nie pojedyncze osoby
- Polityki i SLA (np. „krok CFO wymagany powyżej $50k”, „Krok 2: 2 dni robocze")
Admini powinni móc wyszukiwać i filtrować po jednostce biznesowej, regionie i wersji szablonu, aby uniknąć przypadkowych edycji.
Bezpieczne edycje: szkic/opublikuj, wersjonowanie, rollback
Traktuj szablony jak konfig, który można wypuścić:
- Szkic vs opublikowany stan, z podglądem pokazującym, jakie żądania będą wpływać
- Historia wersji i jednoklikowy rollback, jeśli reguła routingu powoduje opóźnienia
- Jasna zasada: żądania w toku zachowują swoją oryginalną wersję, nowe żądania używają najnowszego opublikowanego szablonu
To zmniejsza ryzyko operacyjne bez spowalniania niezbędnych zmian polityki.
Uprawnienia: admini, superadmini, audytorzy
Rozdziel odpowiedzialności:
- Admini zarządzają szablonami i grupami w przypisanym zakresie
- Superadmini zmieniają globalne polityki, retencję i integracje
- Audytorzy mają dostęp tylko do odczytu do logów, eksportów i raportów
Połącz to z niezmiennym dziennikiem aktywności: kto co zmienił, kiedy i dlaczego.
Raportowanie, eksporty i retencja
Praktyczny dashboard pokazuje:
- Wąskie gardła (kroki z najdłuższym medianowym czasem)
- Kolejki przeterminowane (po zespole, szablonie, regionie)
- Najważniejsze typy żądań i powody odrzuceń
Eksporty powinny obejmować CSV dla operacji oraz pakiet audytowy (żądania, decyzje, znaczniki czasu, komentarze, referencje do załączników) z konfigurowalnymi oknami retencji.
Linkuj z raportów do /admin/templates i /admin/audit-log dla szybkiego follow‑up.
Testowanie, monitorowanie i obsługa błędów
Design the Workflow Engine
Model sequential and parallel approvals with clear states, transitions, and idempotent actions.
Zatwierdzenia zawiodą w nieczystych, realnych warunkach: ludzie zmieniają role, systemy timeoutują, a żądania przychodzą falami. Traktuj niezawodność jako cechę produktu, nie dodatek.
Strategia testów dopasowana do ryzyka
Zacznij od szybkich testów jednostkowych dla reguł routingu: mając wnioskodawcę, kwotę, dział i politykę — czy workflow zawsze wybiera właściwy łańcuch? Trzymaj te testy w postaci tabelarycznej, aby reguły biznesowe można było łatwo rozszerzać.
Następnie dodaj testy integracyjne, które ćwiczą cały silnik workflow: utwórz żądanie, przejdź krok po kroku, zapisz decyzje i zweryfikuj stan końcowy (zatwierdzone/odrzucone/anulowane) oraz ścieżkę audytu.
Uwzględnij kontrole uprawnień (kto może zatwierdzać, delegować lub widzieć), aby zapobiec przypadkowemu ujawnieniu danych.
Przypadki brzegowe, które trzeba zasymulować
Kilka scenariuszy powinno być „must pass”:
- Zatwierdzający odchodzi z firmy w trakcie żądania (ponowne przypisanie kroku przez rolę, menedżera lub nadpisanie admina)
- Konfliktujące decyzje (podwójne kliknięcia, kroki równoległe, późne odpowiedzi po eskalacji)
- Zmiany szablonu w czasie (upewnij się, że żądania w toku nadal używają swojego oryginalnego
template_version)
Testy obciążeniowe i widoczność operacyjna
Przetestuj obciążenie widoku skrzynki i powiadomień przy gwałtownych zgłoszeniach, zwłaszcza jeśli żądania mogą zawierać duże załączniki. Mierz głębokość kolejki, czas przetwarzania na krok i najgorsze opóźnienie zatwierdzenia.
Dla obserwowalności loguj każde przejście stanu z correlation ID, emituj metryki dla „zablokowanych” workflow (bez postępu poza SLA) i dodaj śledzenie przez async workers.
Alertuj przy: rosnących retry, wzroście dead‑letter queue i żądaniach przekraczających oczekiwany czas kroku.
Bramy jakości przed wydaniem
Zanim wdrożysz zmiany do produkcji, wymagaj przeglądu bezpieczeństwa, przeprowadź ćwiczenie backup/restore i zweryfikuj, że odtwarzanie zdarzeń potrafi odbudować poprawny stan workflow.
To sprawia, że audyty są nudne — w dobrym sensie.
Wdrożenie, rollout i zarządzanie zmianą
Dobra aplikacja zatwierdzająca może wciąż zawieść, jeśli zostanie wdrożona nagle dla wszystkich. Traktuj rollout jak produkt: etapowy, mierzony i wspierany.
Wprowadzaj stopniowo (i trzymaj zakres wąski)
Zacznij od zespołu pilota reprezentującego rzeczywistą złożoność (menedżer, finansy, prawo i jeden zatwierdzający wykonawczy). Ogranicz pierwsze wydanie do niewielkiego zestawu szablonów i jednej‑dwóch reguł routingu.
Gdy pilot będzie stabilny, rozszerz na kilka departamentów, a potem na całą firmę.
Podczas każdego etapu zdefiniuj kryteria sukcesu: odsetek zakończonych żądań, medianę czasu‑do‑decyzji, liczbę eskalacji i główne powody odrzuceń.
Opublikuj prostą notkę „co się zmienia” i jedno miejsce na aktualizacje (na przykład /blog/approvals-rollout).
Zaplanuj migrację danych (jeśli zastępujesz starszy proces)
Jeśli zatwierdzenia żyją w wątkach e‑mailowych lub arkuszach, migracja polega mniej na przenoszeniu wszystkiego, a bardziej na uniknięciu zamieszania:
- Importuj aktywne/rozpoczęte żądania tam, gdzie to możliwe, lub zamroź stare żądania i uruchom je ponownie w nowym systemie z wyraźnymi etykietami
- Migracja szablonów, grup zatwierdzających i polityk najpierw — to elementy kształtujące codzienną pracę
- Trzymaj archiwum starego systemu w trybie read‑only (lub eksport), dla potrzeb audytu i odniesienia
Uczyń zarządzanie zmianą deliverable
Dostarcz krótkie szkolenia i szybkie przewodniki dopasowane do ról: wnioskodawca, zatwierdzający, admin.
Dołącz „etykietę zatwierdzania”: kiedy dodawać kontekst, jak używać komentarzy i spodziewany czas reakcji.
Zaoferuj wsparcie w pierwszych tygodniach (office hours + dedykowany kanał). Jeśli masz konsolę admina, uwzględnij panel „znane problemy i obejścia”.
Ustanów governance dla szablonów i zmian reguł
Zdefiniuj właścicieli: kto może tworzyć szablony, kto modyfikuje reguły routingu i kto zatwierdza te zmiany.
Traktuj szablony jak dokumenty polityk — wersjonuj je, wymagaj powodu zmiany i planuj aktualizacje, aby unikać niespodziewanych zmian w środku kwartału.
Zbuduj pętlę ciągłego ulepszania
Po każdym etapie rolloutu analizuj metryki i feedback. Organizuj kwartalne przeglądy, aby dostroić szablony, przypomnienia/eskalacje i wycofywać nieużywane workflow.
Małe, regularne poprawki utrzymują system w zgodzie z rzeczywistą pracą zespołów.