28 sie 2025·8 min
Autouzupełnianie i tolerancja literówek w wyszukiwaniu indyjskiego e‑commerce
Dowiedz się, jak wdrożyć autouzupełnianie i tolerancję literówek w indyjskim e‑commerce — z planowaniem synonimów, terminami lokalnymi, transliteracjami i analizą danych, by poprawić wyniki wyszukiwania.
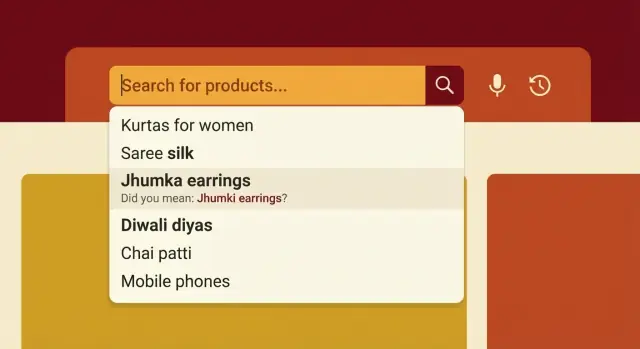
Dlaczego nazewnictwo produktów w Indiach psuje wyszukiwanie
Wyszukiwanie w indyjskim e‑commerce zawodzi z prostego powodu: ludzie nie nazywają tej samej rzeczy w ten sam sposób. Ten sam produkt można wpisać po angielsku, po hindi, po tamilsu, albo mieszając języki, a w każdej części kraju używa się innych codziennych słów.
Kupujący może szukać „atta”, „aata”, „gehu ka atta” albo tylko po nazwie marki. Inna osoba wpisze „jeera”, „zeera” albo po prostu „cumin”. Jeśli w katalogu jest tylko jedna z tych form, normalne zapytanie może nie dać wyników.
Niewielkie różnice w pisowni szkodzą bardziej, niż się wydaje, bo silniki wyszukiwania często traktują zapytanie jako dokładny tekst. Brakująca samogłoska, dodatkowa spacja albo inny szyk słów może wpychać właściwy produkt poza pierwsze wyniki albo do zera wyników.
Typowe powody, dla których nazwy produktów w Indiach dzielą się na wiele wersji:
- Wiele skryptów i transliteracji (hindi zapisywane literami angielskimi, lokalne pisownie)
- Regionalne określenia tej samej rzeczy (jedzenie, ubrania, artykuły gospodarstwa domowego)
- Nazwy zaczynające się od marki vs od nazwy ogólnej („Surf Excel 1kg” vs „detergent powder”)
- Skróty i formy mówione („kurti” vs „kurta top”, „1 ltr” vs „1L”)
- Błędy klawiaturowe i autokorekta („pista” → „pita”, „saree” vs „sarri”)
Autouzupełnianie i tolerancja literówek zmieniają doświadczenie kupującego. Autouzupełnianie zmniejsza wysiłek, podpowiadając słowa, które sklep rozumie, zanim użytkownik kliknie szukaj. Tolerancja literówek zapobiega porażce "prawie poprawnych" zapytań, dzięki czemu kupujący nadal widzą relewantne produkty nawet przy nieidealnej pisowni.
Praktyczny cel autouzupełniania i tolerancji literówek w indyjskim e‑commerce nie jest „idealne wsparcie językowe”. Jest mierzalny: mniej zapytań bez wyników i szybsze odnajdowanie produktów, tak aby więcej kupujących docierało do listy produktów zamiast do ślepego zaułka.
Kluczowe idee prostym językiem
Dobre wyszukiwanie w Indiach to mniej kwestia wyszukanych algorytmów, a bardziej zrozumienie, jak ludzie naprawdę wpisują nazwy produktów. Wielu kupujących miesza angielski ze słowami lokalnymi, pisze tę samą rzecz na trzy sposoby i oczekuje, że wyszukiwarka „i tak to zrozumie”.
Autouzupełnianie pomaga przed dokończeniem zapytania. Gdy ktoś wpisze „jeer…”, możesz zasugerować „jeera rice”, „jeera powder” albo „jeera whole”. Dobrze zrobione autouzupełnianie zmniejsza wysiłek i delikatnie kieruje kupujących do terminów, które są w katalogu.
Tolerancja literówek oznacza, że nadal dopasujesz, gdy użytkownik popełni typowy błąd, np. „zeera” vs „jeera” lub „shampo” vs „shampoo”. Celem jest naprawiać powszechne błędy bez zmiany znaczenia. Zbyt duża tolerancja prowadzi do dziwnych trafień (np. krótkie „ram” zaczyna pasować do niezwiązanych produktów).
Synonimy to prosta sprawa: różne słowa, ten sam zamiar. „Atta” i „wheat flour” powinny prowadzić do tego samego zestawu produktów. W indyjskim e‑commerce synonimy często obejmują terminy wyglądające jak marki („biscuit” vs „cookies”), regionalne słowa i przezwiska kategorii.
Transliteracja to sytuacja, gdy ludzie wpisują słowa w językach indyjskich używając liter łacińskich. Ktoś może wpisać „namkeen”, „nimeen” albo „namkin” w zależności od nawyku i klawiatury. Zasady transliteracji pomagają dopasować te warianty, nawet jeśli katalog używa tylko jednej pisowni.
Praktyczny sposób myślenia o autouzupełnianiu i tolerancji literówek w indyjskim e‑commerce:
- Autouzupełnianie prowadzi użytkownika do ważnego, popularnego zapytania.
- Tolerancja literówek ratuje użytkownika, gdy źle napisze prawidłowe zapytanie.
- Synonimy łączą różne słowa o tym samym zamiarze zakupowym.
- Transliteracja łączy różne pisownie tego samego lokalnego terminu.
Gdy to jest jasne, możesz zbudować mały, kontrolowany zestaw mapowań i rozszerzać go, używając rzeczywistej analityki wyszukiwań, zamiast zgadywać.
Zbuduj słownik nazw indyjskich produktów (wejścia do zebrania)
Dobry słownik wyszukiwania zaczyna się od twoich danych, nie od domysłów. Cel jest prosty: uchwycić, jak ludzie naprawdę nazywają produkty w Indiach — w tym terminy lokalne, pisownie i skróty — żeby autouzupełnianie i tolerancja literówek miały na czym pracować.
Najpierw przejrzyj katalog. Tytuły produktów, nazwy kategorii, atrybuty, etykiety wariantów, marki, rozmiary opakowań i jednostki często zawierają „oficjalne” sformułowania, do których użytkownicy powinni mieć dostęp. Dla artykułów spożywczych może to obejmować zarówno nazwy ogólne, jak i specyficzne, np. „toor dal”, „arhar dal” i „split pigeon peas”, jeśli je stosujesz.
Następnie zbierz rzeczywisty język klientów. Logi wyszukiwań pokazują, co ludzie wpisują, gdy się śpieszą, a czaty z obsługą klienta ujawniają, jak opisują produkty, gdy ich nie mogą znaleźć. Już kilka tygodni logów może odsłonić powtarzające się wzory jak „aata/atta”, „dahi/curd” czy „chilli/chili”.
Zbuduj wejścia z pięciu źródeł, potem je połącz i wyczyść:
- Teksty z katalogu (tytuły, atrybuty, warianty, marki, rozmiary)
- Zapytania wyszukiwawcze (w tym zapytania bez wyników)
- Czat z obsługą klienta i notatki z rozmów
- Regionalne i lokalne terminy, których już używa zespół
- Skróty jednostek i pakietów (ml, ltr, pcs, combo, 1+1)
Na koniec oddziel terminy ogólne od nazw marek. „Atta” powinno pasować do wielu produktów, podczas gdy nazwa marki nie powinna przypadkowo przyciągać wyników dla niepowiązanych przedmiotów. Trzymaj dwie oznaczone listy (ogólne vs marka), żeby późniejsze reguły nie zatarły intencji i nie pomieszały rankingów.
Krok po kroku: stwórz plan synonimów i transliteracji
Zacznij od małego zakresu. Wybierz 20–50 kategorii, które generują większość wyszukiwań i przychodów, np. produkty podstawowe, kosmetyki i popularna elektronika. To utrzymuje pracę w fokusie i pomaga szybko zobaczyć wpływ na autouzupełnianie i tolerancję literówek.
Potem stwórz jedną wspólną „tabelę nazewnictwa”, którą każdy może edytować (merch, content, support). Najpierw trzymaj ją w arkuszu kalkulacyjnym, potem zsynchronizuj z indeksem wyszukiwania.
1) Stwórz listę kanoniczną
Dla każdej kategorii wybierz jedno określenie, które system będzie traktował jako „główną” nazwę (kanoniczną). Wybierz to, co rozpoznają klienci, niekoniecznie to, co nazywa to dostawca.
Utwórz wiersze takie jak poniżej:
| Term kanoniczny | Synonimy (ten sam produkt) | Częste literówki | Transliteracje | Notatki |
|---|---|---|---|---|
| cumin | jeera | jeera, jeeraa | zeera, zira | Trzymaj „caraway” osobno |
| face wash | cleanser | fash wash | fes wash | Nie mapuj do „face cream” |
Dodaj jednostki i wzorce opakowań jako osobne, wielokrotnego użytku tokeny: 1kg, 500 g, 2x, combo pack, family pack. To często powoduje zero-results, bo użytkownicy wpisują cały ciąg.
2) Ustal ścisłe reguły „ten sam produkt”
Synonim powinien oznaczać, że klient będzie zadowolony z tych samych wyników. Napisz krótką regułę, której zespół będzie przestrzegać:
- Dozwolone: warianty regionalne, skróty używane przez klientów, powszechne pisownie
- Dozwolone: transliteracja Hinglish tam, gdzie znaczenie się nie zmienia
- Niedozwolone: sąsiednie produkty (cleanser vs toner, cumin vs carom)
- Niedozwolone: różne rozmiary jako synonimy (rozmiar to filtr)
- Niedozwolone: „healthy” czy „premium” jako synonim podstawowego produktu
3) Utrzymuj to proste w obsłudze
Przypisz jednego właściciela dla każdej kategorii i wprowadź prosty rytuał przeglądu (najpierw co tydzień). Gdy support widzi skargi „nie znaleziono”, dodają terminy do tabeli tego samego dnia.
Jeśli budujesz to w własnym stacku wyszukiwania, narzędzie typu Koder.ai może pomóc szybko wystawić ekran administracyjny i workflow synchronizacji, pozostawiając listę synonimów edytowalną dla nietechnicznych zespołów.
Projektuj autouzupełnianie, które „brzmi” dobrze w Indiach
Autouzupełnianie powinno być szybkie, znajome i wyrozumiałe. Dla indyjskiego e‑commerce największy zysk to użyteczne sugestie przy pierwszych literach. Ludzie często piszą szybko, przełączają się między angielskim a lokalnymi terminami i nie pamiętają dokładnej pisowni.
Zacznij od strojenia pod kątem prefiksów. Pierwsze 2–4 znaki powinny już pokazywać mocne, intencyjne sugestie. Jeśli ktoś wpisze "sha", nie marnuj topowych pozycji na rzadkie produkty. Pokaż to, co większość kupujących ma na myśli i to, co naprawdę dobrze sprzedajesz.
Rób sugestie świadome kategorii, nie tylko słów. Jeśli użytkownik wpisuje lokalne słowo jak „shakkar”, sugestie powinny wyraźnie kierować do kategorii (cukier) i popularnych podtypów, które masz (cukier puder, organiczny itp.). To zmniejsza zamieszanie i obniża ryzyko wybrania niepowiązanego wyniku.
Trzymaj sugestie krótkie i czytelne. Dobry wzorzec to: marka + produkt (gdy jest naprawdę powszechna) albo produkt + kluczowy atrybut. Unikaj upychania rozmiarów, długich numerów modeli i wielu atrybutów w jednej linii.
Praktyczne zasady UI, które zwykle działają dobrze:
- Pokaż maksymalnie 5–8 sugestii, z top 3 zoptymalizowanymi pod wysoki konwers.
- Normalizuj spacje i interpunkcję, więc "t-shirt", "tshirt" i "t shirt" prowadzą do tych samych sugestii.
- Preferuj przedmioty i kategorie, które możesz zrealizować teraz (dostępne w magazynie i aktywne listingi).
- Mieszaj typy ostrożnie: 1–2 sugestie kategorii, potem produkty, potem marki.
- Nie pokazuj sugestii, których nie możesz sprzedać (brak martwych kategorii czy wycofanych marek).
Przykład: użytkownik wpisuje "dett". W Indiach wiele osób myśli „Dettol” (intencja marki), ale część chce „handwash” lub „sanitizer” (intencja produktu). Twoje autouzupełnianie może pokazać "Dettol Handwash", "Dettol Sanitizer" i kategorię "Handwash", żeby obie intencje były pokryte bez nadmiernego zgadywania.
Gdy robisz to konsekwentnie, autouzupełnianie i tolerancja literówek w indyjskim e‑commerce przestają być o sprytnych algorytmach, a stają się o dawaniu użytkownikom oczywistego następnego kroku.
Ustal tolerancję literówek bez chaotycznych trafień
Umieść prototyp w produkcji
Wdróż i hostuj narzędzia wyszukiwania, żeby zespoły mogły z nich korzystać od razu.
Tolerancja literówek pomaga znaleźć produkty, nawet gdy ktoś się pomyli. Ale jeśli ustawisz ją zbyt luźno, wyszukiwarka zacznie pokazywać „wystarczająco bliskie” przedmioty, które będą czuły się błędne. Cel jest prosty: łapać oczywiste błędy i być ostrożnym, gdy intencja może się zmienić.
Zacznij od bezpiecznych reguł odległości edycji (edit distance) opartych na długości słowa. Krótkie słowa łatwo się psują, więc trzymaj je ścisło. Dłuższe słowa mogą mieć większą elastyczność.
- 1–4 litery: pozwól na 0–1 edycję (np. „atta" -> „atta", „atta" -> „attta")
- 5–8 liter: pozwól na maksymalnie 2 edycje
- 9+ liter: pozwól na maksymalnie 3 edycje
- Jeśli zapytanie ma wiele słów, stosuj edycje na słowo, ale ogranicz łączną liczbę edycji dla całego zapytania
Traktuj liczby jako oddzielną klasę. "1kg" i "10kg" nigdy nie powinny być zamienne, a "500ml" nie powinno stać się "1500ml". Praktyczna reguła: nie stosuj tolerancji literówek wewnątrz tokenów numerycznych i nie zmieniaj jednostek. Pozwalaj tylko na poprawki formatu, jak spacje czy wielkość liter ("1 kg", "1KG", "1kg").
Chroń nazwy marek i terminy wysokiej intencji przed „poprawianiem” ich na słowa ogólne. Trzymaj małą listę chronioną (top marki, private labels i powszechne zapytania wyglądające jak marki). Jeśli zapytanie blisko pasuje do chronionego terminu, lepiej pokaż sugestię zamiast przepisywać je.
Błędy sąsiadów klawiszy są powszechne na urządzeniach mobilnych, zwłaszcza przy Hinglish. Dodaj dodatkową tolerancję dla sąsiednich klawiszy (a-s, i-o, n-m), ale tylko gdy reszta słowa jest silnym dopasowaniem.
Gdy poprawka jest niejednoznaczna, pokaż ją jako sugestię, nie jako cichą zmianę. Na przykład, jeśli „dove” może stać się „done” albo „dovee”, pokaż „Czy chodziło o dove?” i pozostaw oryginalne wyniki widoczne. To utrzymuje zaufanie i zmniejsza irytację użytkowników.
Transliteracja i lokalne terminy (praktyczne zasady)
Indyjskie zapytania często mieszają skrypty i zwyczaje w jednym wierszu: „जीरा rice”, „jeera चावल”, „zeera rice” czy „poha nashta”. Twoje wyszukiwanie powinno traktować to jako tę samą intencję, a nie oddzielne światy. Dla autouzupełniania i tolerancji literówek celem jest prosty: mapować wiele sposobów zapisu nazwy produktu do jednego czystego znaczenia produktu.
Zacznij od małego, praktycznego zestawu reguł i rozwijaj go tylko wtedy, gdy działa.
Praktyczne reguły normalizacji
- Akceptuj mieszanie skryptów przez normalizowanie wszystkiego do wspólnej „formy wyszukiwawczej” (zachowaj oryginalne zapytanie dla analityki, ale dopasowuj względem znormalizowanej wersji).
- Dodawaj pary transliteracji tylko dla topowych pozycji najpierw (np. namkeen, bhujia, poha, jeera). Uwzględniaj powszechne pisownie, które użytkownicy faktycznie wpisują.
- Obsługuj warianty długich samogłosek jako jawne pary tam, gdzie mają znaczenie (poha vs pauha, jeera vs zeera), zamiast próbować zgadnąć każdą zmianę samogłosek.
- Używaj zamian dźwięków ostrożnie i wąsko: v-w, b-v, j-z. Stosuj je tylko na znanych tokenach produktowych, nie na całym zapytaniu, aby uniknąć dziwnych dopasowań.
- Trzymaj nazwy marek i SKU raczej „jak wpisane”, żeby ich nie przepisać przypadkowo w coś innego.
Które języki wspierać najpierw
Wybieraj w oparciu o ruch i zapytania bez wyników, nie ambicję. Zwykła kolejność to angielski + Hinglish najpierw, potem dodaj skrypt hindi gdy znacząca część zapytań go używa. Jeśli później zobaczysz popyt w jakimś regionie, rozszerz obsługę o następny język w logach, kategoriami po kategorii.
Pętla analityczna: poprawiaj wyszukiwanie na podstawie zachowań
Szybko twórz reguły wyszukiwania
Prototypuj autouzupełnianie, synonimy i reguły literówek jako prawdziwą usługę w dniach, nie miesiącach.
Jakość wyszukiwania to nie jednorazowe ustawienie. Traktuj ją jak cotygodniowy zwyczaj: obserwuj, co ludzie wpisują, co klikają i gdzie rezygnują. W ten sposób autouzupełnianie i tolerancja literówek w indyjskim e‑commerce poprawiają się bez zgadywania.
Zacznij od małego zestawu kluczowych metryk i trzymaj je spójnie tydzień do tygodnia:
- Wskaźnik zapytań bez wyników (ogólny i dla top zapytań)
- Wskaźnik poprawek (użytkownicy przepisują lub dodają filtry zaraz po wyszukaniu)
- Dodania do koszyka po wyszukiwaniu (lub kliknięcia produktów, jeśli koszyki są hałaśliwe)
- Użycie autouzupełniania (kliknięcia sugestii vs pełne manualne wpisywanie)
- Wpływ korekt (zapytania poprawione z literówek, które prowadzą do kliknięć vs odrzuceń)
Raz w tygodniu wyciągnij top zapytań bez wyników i sklasyfikuj każde. Trzymaj kategorie proste, żeby zespoły rzeczywiście z nich korzystały: brak synonimu (jeera vs zeera), wariant pisowni, niezgodność marki lub modelu, zły język lub skrypt albo luka w katalogu (produkt niedostępny). Celem jest oddzielić „wyszukiwanie potrzebuje synonimu” od „brakuje towaru w magazynie”.
Dane z autouzupełniania często dają najszybszy efekt. Jeśli użytkownicy często ignorują sugestie i kończą wpisywanie, twoje sugestie mogą być zbyt ogólne, w złej kolejności lub brakować lokalnych terminów. Jeśli klikają sugestie, ale dalej poprawiają lub odchodzą, sugestia może wyglądać dobrze, ale prowadzić do słabych wyników.
Literówki wymagają audytu, a nie tylko większej tolerancji. Wyciągnij losowo 20–50 poprawionych zapytań tygodniowo i oznacz je jako:
- Pomocne (naprawiło do zamierzonego produktu)
- Niekrytyczne (wystarczająco bliskie, użytkownik nadal znalazł produkty)
- Szkodliwe (naprawiło do innego produktu lub kategorii)
Włóż to do prostego widoku pulpitu, który produkt i marketing przeczytają w 2 minuty: top zapytań bez wyników z przypisaną przyczyną, top sugestii autouzupełniania i wskaźnik kliknięć oraz krótka lista działań na następne wydanie. Jeśli szybko budujesz narzędzia wewnętrzne (np. w Koder.ai), ten pulpit i tygodniowy pipeline eksportu to dobre pierwsze projekty.
Typowe błędy i pułapki do unikania
Większość problemów z wyszukiwaniem w Indiach nie polega na „więcej synonimów”. Wynikają z kilku przewidywalnych błędów, które powoli prowadzą ludzi do złych wyników i niszczą zaufanie.
Jedną z największych pułapek jest stosowanie zbyt szerokich synonimów, które łączą różne produkty. Jeśli „cream” i „lotion” staną się zamienne, użytkownicy szukający gęstego kremu do twarzy mogą trafić na lekki balsam do ciała i odejść. Trzymaj synonimy ciasno: mapuj warianty tej samej intencji, nie sąsiednie kategorie.
Innym częstym błędem jest ignorowanie rozmiaru opakowań i intencji jednostek. „Oil 1L” i „oil 5L” to inne misje zakupowe, podobnie jak „atta 5 kg” i „atta 10 kg”. Jeśli twoje reguły ignorują jednostki, użytkownik próbujący uzupełnić zapasy hurtowo może dostać małe opakowania, a ranking będzie wyglądać losowo.
Oto wysokodochodowe błędy, na które warto uważać:
- Traktowanie bliskich produktów jako synonimów (cream vs lotion, shampoo vs conditioner)
- Ignorowanie słów rozmiaru, liczby i jednostek (1L, 5L, 500 ml, 10 pcs)
- Pozwalanie tolerancji literówek „poprawiać” nazwy marek na inne marki
- Pokazywanie sugestii autouzupełniania, których nie da się dostarczyć do danego kodu PIN
- Ustawianie reguł i zapominanie o nich, szczególnie po promocjach i sezonowych skokach
Nazwy marek wymagają szczególnej ostrożności. Jeśli ktoś wpisze „Himalya face wash” i twoje ustawienia literówek „poprawią” to na inną markę, która akurat jest popularna, wygląda to jak bait. Bezpieczniejsza zasada: być wyrozumiałym wobec słów ogólnych („shampu”), ale surowszym wobec marek i tokenów przypominających modele.
Autouzupełnianie może też zaszkodzić, gdy sugeruje niedostępne produkty. Na przykład sugerowanie „ghee 2L” ponieważ to częste zapytanie, choć dostępne jest tylko 1L, powoduje rozczarowanie. Wybieraj sugestie, które faktycznie możesz zrealizować dziś.
Jeśli budujesz autouzupełnianie i tolerancję literówek w indyjskim e‑commerce, wprowadź rytuał przeglądu: po tygodniu sprzedaży sprawdź nowe top zapytania, rosnące literówki i terminy bez wyników. Nawet małe sezonowe zmiany (sezon ślubny, monsuny, egzaminy) mogą zmienić to, co ludzie wpisują.
Jeśli chcesz szybko przetestować zmiany, Koder.ai może pomóc prototypować serwis reguł wyszukiwania i stronę admina do zarządzania synonimami, jednostkami i ochroną marek, a potem eksportować kod, gdy będziesz gotowy.
Realistyczny przykład: naprawa zapytań „jeera rice” i „zeera rice”
Kupujący wpisuje „zeera rice” i otrzymuje zero wyników. Nie szuka innego produktu — miał na myśli „jeera rice” (cumin rice), ale napisał tak, jak mówi.
Naprawisz to dwiema małymi, bezpiecznymi zmianami: synonimami dla powszechnych wariantów pisowni i konserwatywną regułą tolerancji literówek. Dla tego zapytania traktuj „zeera” jako wariant transliteracyjny „jeera”, a nie osobne znaczenie.
Praktyczne mapowanie, które zwykle działa dobrze:
- Synonim zapytania: zeera -> jeera
- Synonim zapytania: zira -> jeera
- Trzymaj nazwy produktów w katalogu bez zmian (nie zmieniaj SKU)
Dodaj też regułę tolerancji literówek, która jest ścisła dla krótkich słów. Na przykład pozwól na 1 edycję (jeden błędny, brakujący lub zamieniony znak) tylko gdy długość tokenu to 5+ znaków. To pomaga złapać „jeera” vs „jeeraa”, ale unika kłopotliwych trafień dla bardzo krótkich tokenów.
Po zmianie autouzupełnianie powinno kierować kupującego zamiast nadmiernie zgadywać. Gdy wpisze „zee…”, sugeruj:
- „jeera rice”
- „jeera basmati rice”
- „jeera (cumin)”
A po wysłaniu „zeera rice” wyniki powinny pokazać twoje produkty „jeera rice” na pierwszym miejscu, plus powiązane pozycje jak cumin i basmati, w zależności od reguł rankingu.
Tydzień później sprawdź analitykę zorientowaną na zachowanie, nie tylko kliknięcia:
- Wskaźnik zapytań bez wyników dla „zeera”, „zira” i „jeera"
- Wskaźnik poprawek wyszukiwania (czy użytkownicy przepisywali zapytanie?)
- Wskaźnik dodania do koszyka po wyszukaniu dla tych zapytań
- Top kliknięć, żeby potwierdzić, że synonim nie przyciąga niepowiązanych produktów
Jeśli wyniki się pogorszą (np. „zira” zaczyna pasować do nazwy marki lub innej kategorii), szybko wycofaj tylko tę grupę synonimów, a nie cały system autouzupełniania i tolerancji. Trzymaj wersjonowaną konfigurację, żeby móc cofnąć zmiany w minutach. Taki ścisły feedback loop to sedno udanego autouzupełniania i tolerancji literówek w indyjskim e‑commerce.
Krótka lista przed wdrożeniem zmian
Testuj wyszukiwanie na urządzeniach mobilnych
Stwórz lekką aplikację Flutter do QA wyszukiwania i szybkiego przeglądu reguł w terenie.
Zanim wypchniesz nowe synonimy, autouzupełnianie czy ustawienia tolerancji literówek, zrób krótkie połączenie rzeczywistych danych z ręcznym testem. To zapobiega temu, by „pomocne” zmiany stworzyły hałas i złe dopasowania.
Użyj tej krótkiej checklisty przed wdrożeniem zmian w autouzupełnianiu i tolerancji literówek dla indyjskiego e‑commerce:
- Wyciągnij top 50 zapytań z ostatnich 7–14 dni i pogrupuj je według intencji (marka, produkt ogólny, wariant jak rozmiar lub kolor, problem do rozwiązania jak „hair fall oil”). Jeśli zapytanie może znaczyć dwie rzeczy, zanotuj obie.
- Wyciągnij top 50 zapytań bez wyników i zdecyduj naprawę dla każdego: zmapuj do istniejącej kategorii, dodaj synonim (lokalny termin lub pisownia), dodaj brakujący produkt lub zablokuj je, jeśli jest nieistotne. Nie zostawiaj „naprawimy później”.
- Zaktualizuj listę synonimów i transliteracji z przypisanym właścicielem, datą ostatniej aktualizacji i krótkim powodem. To zapobiega chaotycznym edycjom jak dodawanie „atta = aata = aataa” w trzech różnych miejscach.
- Przetestuj autouzupełnianie w topowych kategoriach realnymi sformułowaniami użytkowników: angielski, Hinglish i powszechne skróty. Sprawdź, czy sugestie nie wskakują w niszowe pozycje zbyt wcześnie i czy zawierają popularne warianty (jak „1kg”, „500g”, „pack of 2").
- Przetestuj tolerancję literówek 20 trudnymi zapytaniami: literówki marek (zwłaszcza podwójne litery), mieszane liczby („iPhone 15 pro 256”), i podobnie wyglądające słowa produktowe („jeera/zeera”, „besan/besan flour”). Potwierdź, że top wyniki nadal są poprawne, nie tylko „bliskie”.
Jeśli coś zawiedzie, wypuść mniejszą zmianę najpierw. Wąskie wdrożenie lepsze niż duża aktualizacja, która sprawi, że wyszukiwanie będzie wydawało się losowe.
Kolejne kroki: prosty plan wdrożenia (i jak to zrobić szybciej)
Zacznij od jednej kategorii, gdzie ból wyszukiwania jest oczywisty, np. grocery, personal care lub akcesoria do telefonów. Trzymaj zakres mały przez tydzień, żeby zobaczyć przyczynę i skutek. Wybierz 2–3 metryki sukcesu, które możesz realnie poprawić, np. wskaźnik zapytań bez wyników, współczynnik kliknięć po wyszukaniu i dodania do koszyka po wyszukaniu.
Prosty plan wdrożenia, który zwykle działa dla autouzupełniania i tolerancji literówek w indyjskim e‑commerce:
- Day 1: Baseline — zarejestruj obecne metryki, top zapytania i top zapytania bez wyników dla kategorii.
- Days 2–3: Wdróż mały słownik — dodaj ograniczony zestaw synonimów i transliteracji Hinglish dla top 50 zapytań oraz top 20 wzorców marek i rozmiarów opakowań.
- Day 4: Zabezpieczenia — dodaj wykluczenia tam, gdzie znaczenie się zmienia (np. „atta” nie powinno pasować do „ATA” jeśli to marka lub kod w katalogu).
- Days 5–6: Monitoruj — śledź wygrane (mniej zero results, więcej kliknięć) i straty (więcej nieistotnych kliknięć, wyższy back-to-search).
- Day 7: Decyzja — zachowaj, popraw lub wycofaj, potem zaplanuj następny pakiet na podstawie poprawy.
Rób zmiany odwracalne. Traktuj reguły synonimów i literówek jak kod: wersjonuj je, rób snapshoty i miej jasną ścieżkę rollbacku. Jeśli nowa reguła nagle sprawi, że „face wash” pokazuje „dishwash liquid”, musisz móc cofnąć to w minutach, nie dniach.
Własność ma większe znaczenie niż sprytne reguły. Wyznacz jedną osobę do 30‑minutowego cotygodniowego przeglądu: top nowe zapytania bez wyników, top „dobrych napraw” (poprawione literówki) i wszelkie skoki niskiej jakości kliknięć.
Jeśli chcesz szybciej iterować, Koder.ai może pomóc zaimplementować warstwę wyszukiwania przez rozmowę, użyć trybu planowania, by zmapować reguły i metryki przed wdrożeniem, i utrzymać eksportowalny kod źródłowy, żeby zespół mógł przejąć go na własność. Obsługuje też snapshoty i rollback, co jest idealne, gdy trzeba szybko cofnąć zmianę.
Planuj kolejną iterację na podstawie zmierzonych wyników. Na przykład, jeśli „zeera rice” zaczęło konwertować, ale „jeera” teraz pasuje do niepowiązanych produktów „zera”, masz jasne następne zadanie: zaostrzyć tę regułę, nie przepisywać wszystkiego.