06 maj 2025·8 min
Bazy klucz‑wartość do cache, sesji i szybkich wyszukiwań
Dowiedz się, jak bazy klucz‑wartość napędzają cache, sesje i szybkie wyszukiwania — plus TTL, wypieranie, opcje skalowania i praktyczne kompromisy.
Dowiedz się, jak bazy klucz‑wartość napędzają cache, sesje i szybkie wyszukiwania — plus TTL, wypieranie, opcje skalowania i praktyczne kompromisy.
Główny cel sklepu klucz‑wartość jest prosty: zmniejszyć opóźnienia dla użytkowników końcowych i zmniejszyć obciążenie głównej bazy danych. Zamiast wykonywać to samo kosztowne zapytanie lub ponownie obliczać wynik, aplikacja może pobrać wcześniej obliczoną wartość w pojedynczym, przewidywalnym kroku.
Sklep klucz‑wartość jest zoptymalizowany pod jedną operację: „dla podanego klucza zwróć wartość”. Taka wąska specjalizacja pozwala na bardzo krótką ścieżkę krytyczną.
W wielu systemach odczyt można obsłużyć dzięki:
W efekcie otrzymujesz niskie i spójne czasy odpowiedzi — dokładnie to, czego potrzebujesz do cache, przechowywania sesji i innych szybkich odczytów.
Nawet dobrze dostrojona baza musi analizować zapytania, planować je, odczytywać indeksy i koordynować współbieżność. Jeśli tysiące żądań proszą o tę samą listę „top products”, to powtarzająca się praca narasta.
Cache klucz‑wartość przesuwa ten powtarzalny ruch odczytów z bazy. Baza może poświęcić więcej zasobów na zapisy, złożone złączenia, raportowanie i odczyty wymagające spójności.
Szybkość nie jest darmowa. Sklepy klucz‑wartość zwykle rezygnują z bogatego możliwości filtrowania i łączeń, a także mogą mieć różne gwarancje trwałości i spójności zależnie od konfiguracji.
Sprawdzają się, gdy możesz nazwać dane jasnym kluczem (np. user:123, cart:abc) i chcesz szybkiego odczytu. Jeśli często potrzebujesz „znajdź wszystkie elementy, gdzie X”, to baza relacyjna lub dokumentowa zwykle będzie lepszym źródłem prawdy.
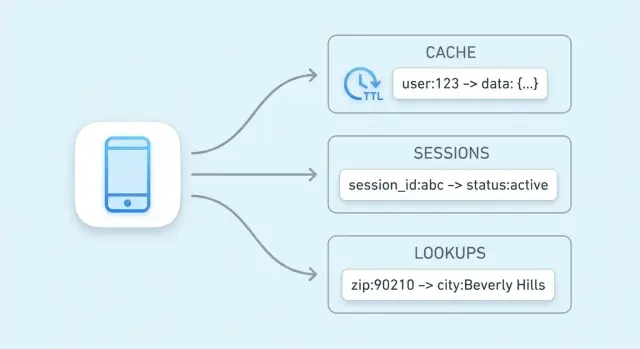
Sklep klucz‑wartość to najprostszy rodzaj bazy: przechowujesz wartość (jakieś dane) pod unikalnym kluczem (etykietą), a później pobierasz wartość, podając klucz.
Pomyśl o kluczu jako identyfikatorze, który łatwo odtworzyć dokładnie, a o wartości jako o tym, co chcesz otrzymać.
Klucze zwykle są krótkimi łańcuchami (np. user:1234 lub session:9f2a...). Wartości mogą być małe (licznik) lub większe (obiekt JSON).
Sklepy klucz‑wartość są budowane pod zapytania „daj wartość dla tego klucza”. Wewnątrz wiele z nich używa struktury podobnej do tablicy mieszającej (hash table): klucz jest transformowany do lokalizacji, gdzie szybko znajduje się wartość.
Dlatego często mówi się o odczytach w czasie stałym (O(1)): wydajność zależy bardziej od liczby zapytań niż od liczby rekordów. To nie magia — kolizje i ograniczenia pamięci mają znaczenie — ale dla typowego użycia jako cache/sesje jest bardzo szybkie.
Gorące dane to mały zestaw informacji, o które często się pyta (popularne strony produktów, aktywne sesje, liczniki limitów). Trzymanie gorących danych w sklepie klucz‑wartość — zwłaszcza w pamięci — unika wolniejszych zapytań do bazy i utrzymuje przewidywalne czasy odpowiedzi pod obciążeniem.
Cache oznacza trzymanie kopii często potrzebnych danych w miejscu szybszym niż źródło oryginalne. Sklep klucz‑wartość jest tu powszechnym wyborem, bo potrafi zwrócić wartość w jednym odczycie po kluczu, często w kilka milisekund.
Cache pomaga, gdy te same pytania powtarzają się wielokrotnie: popularne strony, powtarzane wyszukiwania, często wywoływane API lub kosztowne obliczenia. Przydaje się też, gdy źródło jest wolniejsze lub ograniczone (np. baza pod dużym obciążeniem albo zewnętrzne API płatne za wywołanie).
Dobrymi kandydatami są wyniki czytane często i które można odtworzyć:
Prosta zasada: cachuj wyniki, które możesz odtworzyć w razie potrzeby. Unikaj cachowania danych, które ciągle się zmieniają lub muszą być absolutnie spójne (np. saldo bankowe).
Bez cache każda wizyta strony mogłaby uruchomić wiele zapytań do bazy lub wywołań API. Z cache aplikacja może obsłużyć wiele żądań z warstwy klucz‑wartość i tylko przy missie sięgnąć do bazy lub API. To obniża ruch zapytań, zmniejsza konkurencję o połączenia i poprawia niezawodność przy skokach ruchu.
Cache to wymiana świeżości na szybkość. Jeśli wartości w cache nie są szybko aktualizowane, użytkownicy mogą widzieć przestarzałe informacje. W systemach rozproszonych dwa żądania mogą chwilowo odczytać różne wersje tych samych danych.
Zarządzasz tymi ryzykami przez odpowiednie TTL, wybór danych, które mogą być „trochę stare”, i projekt aplikacji tak, by tolerowała sporadyczne missy lub opóźnienia w odświeżaniu.
Wzorzec cache to powtarzalny sposób odczytu i zapisu danych w aplikacji z udziałem cache. Wybór zależy bardziej od częstotliwości zmian danych i tolerancji na nieświeżość niż od konkretnego narzędzia (Redis, Memcached itp.).
W cache‑aside aplikacja kontroluje cache bezpośrednio:
Najlepiej pasuje do danych często czytanych, rzadko zmieniających się. To też dobre domyślne podejście — awarie degradują się łagodnie: jeśli cache jest pusty, nadal możesz odczytać z bazy.
Read‑through: warstwa cache automatycznie pobiera z bazy przy missie (aplikacja czyta „z cache”, a cache wie jak załadować). Upraszcza kod aplikacji, ale dodaje złożoność po stronie cache (potrzeba integracji loadera).
Write‑through: każdy zapis trafia do cache i do bazy synchronicznie. Odczyty są zwykle szybkie i spójne, ale zapisy wolniejsze, bo trzeba wykonać dwie operacje.
Pasuje tam, gdzie zależy Ci na mniejszej liczbie missów i prostszej spójności odczytów, a opóźnienie zapisu jest akceptowalne.
W write‑back aplikacja zapisuje najpierw do cache, a cache spłukuje zmiany do bazy później (często partiami).
Zalety: bardzo szybkie zapisy i mniejsze obciążenie bazy.
Ryzyko: jeśli węzeł cache padnie przed spłukaniem, możesz stracić dane. Stosuj tylko tam, gdzie możesz tolerować utratę lub masz silne mechanizmy trwałości.
Jeśli dane zmieniają się rzadko, cache‑aside z rozsądnym TTL zwykle wystarcza. Jeśli dane zmieniają się często i przestarzałe odczyty są kosztowne, rozważ write‑through (lub bardzo krótkie TTL plus aktywne unieważnianie). Jeśli wolumen zapisów jest ekstremalny i dopuszczasz sporadyczne straty, write‑behind może się opłacać.
Utrzymanie cache „dostatecznie świeżego” polega głównie na dobraniu strategii wygaszeń dla każdego klucza. Celem nie jest perfekcyjna dokładność — to zapobieganie zaskoczeniom użytkowników przy jednoczesnym zachowaniu szybkich odpowiedzi.
TTL ustawia automatyczne wygaśnięcie klucza po czasie. Krótkie TTL zmniejszają nieświeżość, ale zwiększają missy i obciążenie backendu. Dłuższe TTL poprawiają współczynnik trafień, ale ryzykują serwowanie nieaktualnych wartości.
Praktyczne podejście:
TTL to pasywna metoda. Gdy wiesz, że dane się zmieniły, często lepiej aktywnie unieważnić: usuń stary klucz lub zapisz nową wartość natychmiast.
Przykład: po aktualizacji e‑maila użytkownika usuń user:123:profile lub odśwież go w cache. Aktywne unieważnianie zmniejsza okno nieświeżości, ale wymaga, by aplikacja niezawodnie wykonywała aktualizacje cache.
Zamiast usuwać klucze, dołącz wersję do nazwy klucza, np. product:987:v42. Po zmianie produktu inkrementujesz wersję i zaczynasz używać v43. Stare wersje wygasną naturalnie. To unika wyścigów, gdy jeden serwer usuwa klucz, a inny właśnie go zapisuje.
Stampede zdarza się, gdy gorący klucz wygasa i wiele żądań go odbudowuje.
Popularne naprawy:
Dane sesji to mały pakiet informacji potrzebnych do rozpoznania przeglądarki lub klienta mobilnego: token sesji mapowany na stan po stronie serwera. Minimalnie to token i powiązane z nim dane (ID użytkownika, flagi zalogowania), ale może też zawierać tymczasowe preferencje, zawartość koszyka lub krok w zakupie.
Dostęp do sesji to proste odczyty i zapisy: znajdź token, pobierz/zmień wartość, ustaw wygaszenie. Łatwo też stosować TTL, aby nieaktywne sesje znikały automatycznie, co porządkuje przechowywanie i zmniejsza ryzyko, gdy token zostanie ujawniony.
Typowy przepływ:
Używaj jasnych, zasięgowych kluczy i trzymaj wartości małe:
sess:<token> lub sess:v2:<token> (wersjonowanie pomaga przy zmianach w przyszłości).user_sess:<userId> -> <token> by wymusić „jedną aktywną sesję na użytkownika” lub odwoływać sesje po użytkowniku.Wylogowanie powinno usuwać klucz sesji i powiązane indeksy (np. user_sess:<userId>). Przy rotacji (zalecane po logowaniu, zmianie uprawnień lub okresowo) utwórz nowy token, zapisz nową sesję, a potem usuń stary klucz — zawęża to okno, w którym skradziony token jest użyteczny.
Cache to najczęstsze użycie sklepu klucz‑wartość, ale nie jedyne. Wiele aplikacji potrzebuje szybkich odczytów małych, często sprawdzanych stanów — rzeczy „sąsiednie” względem źródła prawdy, które trzeba sprawdzić przy niemal każdym żądaniu.
Sprawdzenia uprawnień często są na ścieżce krytycznej: każde wywołanie API może pytać „czy ten użytkownik może to zrobić?”. Pobieranie uprawnień z bazy przy każdym żądaniu dodaje opóźnienie i obciążenie.
Sklep klucz‑wartość może trzymać skondensowane dane autoryzacyjne do szybkich odczytów, np.:
perm:user:123 → lista kodów uprawnieńentitlement:org:45 → dostępne funkcje planuTo przydatne, gdy model uprawnień jest czytany dużo częściej niż się zmienia. Gdy uprawnienia się zmieniają, możesz zaktualizować lub unieważnić niewielki zestaw kluczy.
Flagi funkcji to małe wartości czytane często, które muszą być szybko dostępne i spójne w wielu usługach.
Popularny wzorzec:
flag:new-checkout → true/falseconfig:tax:region:EU → obiekt JSON lub wersjonowana konfiguracjaSklepy klucz‑wartość dobrze się tu sprawdzają: odczyty są proste, przewidywalne i szybkie. Możesz też wersjonować wartości (np. config:v27:...) dla bezpieczniejszych wydań i łatwego rollbacku.
Ograniczanie często sprowadza się do liczników na użytkownika, klucz API lub IP. Sklepy klucz‑wartość zwykle oferują operacje atomowe, które pozwalają bezpiecznie inkrementować licznik przy dużej współbieżności.
Możesz śledzić:
rl:user:123:minute → inkrementuj każde żądanie, wygasa po 60srl:ip:203.0.113.10:second → kontrola krótkich wybuchów ruchuDzięki TTL liczniki resetują się automatycznie bez dodatkowych zadań.
Operacje płatnicze i inne „wykonaj dokładnie raz” wymagają ochrony przed ponownymi próbami. Sklep klucz‑wartość może przechować klucze idempotentności:
idem:pay:order_789:clientKey_abc → zapisany wynik lub statusPrzy pierwszym żądaniu przetwarzasz i zapisujesz wynik z TTL. Przy ponownych próbach zwracasz zapisany wynik zamiast powtarzać operację. TTL zapobiega nieograniczonemu wzrostowi stanu.
Te użycia nie zawsze są „cache’owaniem” w klasycznym sensie — chodzi o utrzymanie niskich opóźnień dla częstych odczytów i mechanizmów koordynacji, które wymagają szybkości i atomowości.
„Sklep klucz‑wartość” nie zawsze oznacza „string in, string out”. Wiele systemów oferuje bogatsze struktury danych, które pozwalają modelować powszechne potrzeby bez przenoszenia wszystkiego do logiki aplikacji — często szybciej i z mniejszą liczbą elementów do zarządzania.
Hash (mapa) jest idealny, gdy masz jeden „obiekt” z kilkoma powiązanymi atrybutami. Zamiast wielu kluczy user:123:name, user:123:plan, user:123:last_seen, możesz trzymać je razem pod user:123 z polami.
To redukuje namnażanie kluczy i pozwala pobrać lub zmienić tylko potrzebne pole — przydatne dla profili, flag czy małych konfiguracji.
Zbiory nadają się do pytań „czy X jest w grupie?”:
Zbiory z sortowaniem (sorted sets) dodają porządek przez score — pasują do rankingów, list top N i sortowania po czasie lub popularności.
Problemy współbieżności pojawiają się przy licznikach, limitach i akcjach jednorazowych. Gdy dwa żądania robią „odczyt → +1 → zapis”, można stracić aktualizacje.
Operacje atomowe wykonują zmianę jako jedną, niepodzielną operację:
Dzięki inkrementom atomowym nie potrzebujesz blokad ani dodatkowej koordynacji między serwerami. To mniej wyścigów, prostsze ścieżki kodu i przewidywalniejsze zachowanie pod obciążeniem — szczególnie tam, gdzie „prawie poprawne” szybko staje się problemem widocznym dla klientów.
Gdy sklep klucz‑wartość zaczyna obsługiwać poważny ruch, „przyspieszanie” zwykle oznacza „poszerzanie”: rozkładanie odczytów i zapisów na wiele węzłów przy zachowaniu przewidywalności podczas awarii.
Replikacja utrzymuje wiele kopii tych samych danych.
Sharding dzieli przestrzeń kluczy między węzły.
Wiele wdrożeń łączy oba podejścia: shardy dla przepustowości i repliki na shard dla dostępności.
„Wysoka dostępność” oznacza, że warstwa cache/sesji dalej obsługuje żądania, nawet gdy węzeł padnie.
Przy routing klienta aplikacja (lub biblioteka) oblicza, który węzeł trzyma dany klucz (częste przy consistent hashing). To szybkie, ale klienci muszą znać zmiany topologii.
Przy routing serwera wysyłasz żądania do proxy lub punktu końcowego klastra, który przekierowuje do odpowiedniego węzła. Upraszcza to klientów, ale dodaje dodatkowy hop.
Planuj pamięć od ogółu do szczegółu:
Sklepy klucz‑wartość wydają się „natychmiastowe”, bo trzymają gorące dane w pamięci i optymalizują pod szybkie odczyty/zapisy. Ta szybkość ma koszt: często trzeba wybierać między wydajnością, trwałością i spójnością. Zrozumienie kompromisów wcześniej zapobiega przykrym niespodziankom.
Wiele sklepów oferuje różne tryby trwałości:
Wybierz tryb zgodny z przeznaczeniem danych: cache toleruje utratę; przechowywanie sesji wymaga większej ostrożności.
W rozproszonych konfiguracjach możesz mieć spójność ostateczną — odczyty chwilowo mogą zwracać starszą wartość po zapisie, zwłaszcza przy failoverze lub lagu replikacji. Silniejsza spójność (np. wymaganie potwierdzeń od wielu węzłów) zmniejsza anomalia, ale zwiększa opóźnienie i może obniżyć dostępność przy problemach sieciowych.
Cache się zapełnia. Polityka wypierania decyduje, co usunąć: least‑recently‑used, least‑frequently‑used, losowe lub „nie wypieraj” (co zamiast tego kończy się błędami zapisu). Zdecyduj, czy wolisz brak wpisów w cache, czy błędy przy zapisie pod presją.
Zakładaj, że awarie się zdarzają. Typowe działania:
Świadome zaprojektowanie tych zachowań sprawia, że system wydaje się użytkownikom bardziej niezawodny.
Sklepy klucz‑wartość często leżą na ścieżce krytycznej aplikacji. To czyni je zarówno wrażliwymi (możliwe przechowywanie tokenów sesji i identyfikatorów), jak i kosztownymi (zwykle dużo pamięci). Dobrze zrobione podstawy zapobiegają poważnym incydentom.
Zadbaj o granice sieciowe: umieść sklep w prywatnej podsieci/VPC i zezwól tylko serwisom, które naprawdę go potrzebują.
Używaj uwierzytelniania, jeśli produkt to wspiera, i stosuj zasadę najmniejszych uprawnień: oddzielne poświadczenia dla aplikacji, adminów i automatyzacji; rotuj sekrety; unikaj współdzielonych tokenów root.
Szyfruj ruch w tranzycie (TLS), zwłaszcza gdy przekracza hosty lub strefy. Szyfrowanie w spoczynku zależy od produktu i wdrożenia — jeśli jest dostępne, włącz je dla usług zarządzanych i sprawdź szyfrowanie kopii zapasowych.
Kilka metryk mówi, czy cache pomaga, czy szkodzi:
Dodaj alerty dla nagłych zmian, nie tylko progów absolutnych, i loguj operacje na kluczach ostrożnie (unikaj logowania wrażliwych wartości).
Najważniejsze czynniki kosztowe:
Praktyczny lewar kosztowy to zmniejszanie rozmiaru wartości i realistyczne TTL, tak by sklep trzymał tylko to, co rzeczywiście przydatne.
Zacznij od ustandaryzowania nazewnictwa kluczy, aby cache i klucze sesji były przewidywalne, wyszukiwalne i bezpieczne do operacji masowych. Prosta konwencja jak app:env:feature:id (np. shop:prod:cart:USER123) pomaga unikać konfliktów i przyspiesza debugowanie.
Zdefiniuj strategię TTL przed wdrożeniem. Zdecyduj, które dane można wygaszać szybko (sekundy/minuty), które potrzebują dłuższego czasu (godziny) i czego w ogóle nie powinno się cachować. Jeśli cachujesz wiersze bazy danych, dopasuj TTL do częstotliwości zmian danych.
Spisz plan unieważniania dla każdego rodzaju cachowanych elementów:
product:v3:123) gdy chcesz proste „unieważnij wszystko” zachowanieWybierz kilka metryk i śledź je od początku:
Monitoruj też liczbę wypieranych kluczy i użycie pamięci, aby potwierdzić właściwe rozmiarowanie cache.
Zbyt duże wartości zwiększają czas sieci i presję pamięci — preferuj cachowanie mniejszych, przygotowanych fragmentów. Unikaj brakujących TTL (stare dane i wycieki pamięci) oraz nieograniczonego wzrostu kluczy (np. cachowanie każdego zapytania wyszukiwania na zawsze). Uważaj na cachowanie danych specyficznych dla użytkownika pod współdzielonymi kluczami.
Jeśli oceniasz opcje, porównaj lokalny cache w procesie vs rozproszony cache i zdecyduj, gdzie spójność jest najważniejsza. Dla szczegółów implementacyjnych i wskazówek operacyjnych przejrzyj /docs. Jeśli planujesz pojemność lub potrzebujesz założeń kosztowych, zobacz /pricing.
Jeśli tworzysz nowy produkt (lub modernizujesz istniejący), warto od początku traktować cache i przechowywanie sesji jako elementy pierwszorzędne. Na Koder.ai zespoły często prototypują aplikację end-to-end (React na web, usługi w Go z PostgreSQL i opcjonalnie Flutter na mobile) i iterują nad wydajnością, stosując wzorce takie jak cache‑aside, TTL i liczniki do ograniczania ruchu. Funkcje takie jak tryb planowania, snapshoty i rollback ułatwiają eksperymentowanie z projektowaniem kluczy i strategiami unieważniania, a kod źródłowy można eksportować, gdy chcesz uruchomić go we własnym pipeline.
Sklepy klucz‑wartość są zoptymalizowane pod jedną operację: dla tego klucza zwróć wartość. Taka wąska specjalizacja pozwala na szybkie ścieżki wykonywania, np. indeksy w pamięci i haszowanie, bez narzutu planowania zapytań charakterystycznego dla baz ogólnego przeznaczenia.
Dodatkowo odciążają system: przenoszą powtarzalne odczyty (popularne strony, często żądane API) z głównej bazy, dzięki czemu ta może skupić się na zapisach i złożonych zapytaniach.
Klucz to unikalny identyfikator, który możesz powtórzyć dokładnie (często ciąg jak user:123 lub sess:<token>). Wartość to dowolne dane, które chcesz otrzymać — od małego licznika po obiekt JSON.
Dobre klucze są stabilne, zasięgowe i przewidywalne, co ułatwia operacje cache, sesji i szybkich odczytów.
Cachuj wyniki, które są często czytane i można je odtworzyć w razie potrzeby.
Typowe przykłady:
Unikaj cachowania danych, które muszą być absolutnie aktualne (np. stan konta), chyba że masz solidną strategię unieważniania.
Cache‑aside (leniwe ładowanie) działa zwykle tak:
key z cache.To dobre domyślne podejście: jeśli cache jest pusty lub niedostępny, nadal możesz obsłużyć żądanie z bazy (z odpowiednimi zabezpieczeniami).
Użyj read-through, gdy chcesz, żeby warstwa cache samodzielnie ładowała dane przy missie (prostszy kod aplikacji, więcej integracji po stronie cache).
Użyj write-through, gdy chcesz, żeby każdy zapis aktualizował jednocześnie cache i bazę (czyli odczyty są zwykle ciepłe i spójne, ale zapisy wolniejsze).
Wybór zależy od tego, czy akceptujesz dodatkową złożoność operacyjną (read‑through) lub wyższy koszt zapisu (write‑through).
TTL (time to live) automatycznie wygasza klucz po zadanym czasie. Krótkie TTL zmniejszają nieświeżość, ale zwiększają liczbę missów i obciążenie zaplecza; długie TTL poprawiają trafienia, ale niosą ryzyko serwowania przestarzałych danych.
Praktyczne wskazówki:
Cache stampede pojawia się, gdy popularny klucz wygasa i wiele żądań jednocześnie próbuje go odbudować.
Typowe rozwiązania:
Sesje to mały zestaw danych potrzebny do rozpoznania powracającego klienta: token sesji mapowany na stan po stronie serwera. Najprostsze operacje to odczyt, zapis i ustawienie wygaszenia.
Dobre praktyki:
sess:<token> (wersjonowanie jak sess:v2:<token> pomaga przy migracjach).Wiele sklepów klucz‑wartość obsługuje atomowe inkrementy, co czyni liczniki bezpiecznymi przy współbieżnych żądaniach.
Typowy wzorzec:
rl:user:123:minute → inkrementuj przy każdym żądaniuGdy licznik przekroczy próg, throttluj lub odrzuć żądanie. TTL automatycznie resetuje limity bez dodatkowych zadań tła.
Najważniejsze kompromisy:
Przygotuj tryby degradacji: pomijanie cache, serwowanie lekko nieświeżych danych, lub twarde odmowy dla krytycznych operacji — zależnie od wymagań.