26 lis 2025·8 min
Dlaczego bazy grafowe są świetne do relacji — nie we wszystkim
Bazy grafowe błyszczą, gdy to powiązania napędzają pytania. Dowiedz się o najlepszych zastosowaniach, kompromisach i kiedy lepsze będą bazy relacyjne lub dokumentowe.
Bazy grafowe błyszczą, gdy to powiązania napędzają pytania. Dowiedz się o najlepszych zastosowaniach, kompromisach i kiedy lepsze będą bazy relacyjne lub dokumentowe.
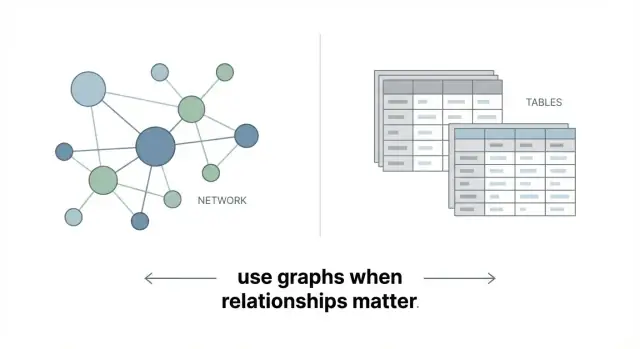
Baza grafowa przechowuje dane jako sieć zamiast zbioru tabel. Główna idea jest prosta:
I to wszystko: baza grafowa została stworzona, by bezpośrednio reprezentować dane połączone.
W bazie grafowej relacje nie są dodatkiem — są przechowywane jako rzeczywiste, zapytalne obiekty. Relacja może mieć własne właściwości (np. relacja KUPIONE może przechowywać datę, kanał i rabat) i możesz efektywnie przechodzić od jednego węzła do drugiego.
To ma znaczenie, ponieważ wiele biznesowych pytań naturalnie dotyczy ścieżek i połączeń: „Kto jest połączony z kim?”, „Ile kroków dzieli te byty?” lub „Jakie są wspólne ogniwa między tymi dwoma rzeczami?”.
Bazy relacyjne świetnie radzą sobie ze strukturami rekordów: klienci, zamówienia, faktury. Relacje też tam istnieją, ale zwykle są reprezentowane pośrednio przez klucze obce, a łączenie wielu kroków często oznacza pisanie JOINów po kilku tabelach.
Grafy trzymają połączenia tuż przy danych, więc eksplorowanie wieloetapowych relacji jest zazwyczaj prostsze do zamodelowania i zapytania.
Bazy grafowe są świetne, gdy relacje są głównym celem — rekomendacje, grupy oszustów, mapowanie zależności, grafy wiedzy. Nie są automatycznie lepsze do prostych raportów, sum czy bardzo tabelarycznych obciążeń. Cel nie polega na zastąpieniu każdej bazy, lecz na użyciu grafu tam, gdzie łączność generuje wartość.
Większość biznesowych pytań nie dotyczy pojedynczych rekordów — chodzi o to, jak rzeczy są połączone.
Klient to nie tylko wiersz; jest powiązany z zamówieniami, urządzeniami, adresami, zgłoszeniami wsparcia, poleceniami i czasem z innymi klientami. Transakcja to nie tylko zdarzenie; jest połączona z merchantem, metodą płatności, lokalizacją, oknem czasowym i łańcuchem powiązanych aktywności. Gdy pytanie brzmi „kto/co jest połączone z czym i jak?”, dane o relacjach stają się głównym bohaterem.
Bazy grafowe są zaprojektowane do traversali: zaczynasz w jednym węźle i „chodzisz” po sieci, podążając krawędziami.
Zamiast powtarzać JOINy, wyrażasz ścieżkę, na której Ci zależy: Klient → Urządzenie → Logowanie → Adres IP → Inni Klienci. To krokowe przedstawienie odpowiada temu, jak ludzie naturalnie badają oszustwa, śledzą zależności lub tłumaczą rekomendacje.
Różnica widać, gdy potrzebujesz wielu skoków (dwa, trzy, pięć kroków) i nie wiesz z góry, gdzie pojawią się interesujące połączenia.
W modelu relacyjnym pytania wieloskokowe często zamieniają się w długie łańcuchy JOINów plus dodatkową logikę, by unikać duplikatów i kontrolować długość ścieżki. W grafie „znajdź wszystkie ścieżki do N skoków” to normalny, czytelny wzorzec — zwłaszcza w modelu property graph używanym przez wiele baz grafowych.
Krawędzie to nie tylko linie; mogą nosić dane:
Te właściwości pozwalają zadawać lepsze pytania: „połączone w ostatnich 30 dniach”, „najsilniejsze więzi” lub „ścieżki zawierające transakcje wysokiego ryzyka” — bez zmuszania wszystkiego do osobnych tabel wyszukiwania.
Bazy grafowe błyszczą, gdy twoje pytania zależą od powiązań: „kto jest połączony z kim, przez co i ile kroków dalej?” Jeśli wartość danych mieszka w relacjach (nie tylko w wierszach z atrybutami), model grafowy może uczynić modelowanie i zapytania bardziej naturalnymi.
Wszystko, co ma kształt sieci — znajomi, obserwujący, współpracownicy, zespoły, polecenia — dobrze odwzorowuje się jako węzły i relacje. Typowe pytania: „wspólne połączenia”, „najkrótsza ścieżka do osoby” lub „kto łączy te dwie grupy?”. Wymuszanie tego w wielu tabelach JOIN często bywa niewygodne lub wolne.
Silniki rekomendacji często zależą od wieloetapowych połączeń: użytkownik → produkt → kategoria → podobne produkty → inni użytkownicy. Bazy grafowe nadają się do „ludzie, którzy lubili X, również lubili Y”, „produkty często współoglądane” oraz „znajdź produkty połączone wspólnymi atrybutami lub zachowaniem”. To szczególnie przydatne, gdy sygnały są różnorodne i dodajesz nowe typy relacji.
Grafy wykrywania oszustw działają dobrze, ponieważ podejrzane zachowania rzadko są izolowane. Konta, urządzenia, transakcje, numery telefonów, e-maile i adresy tworzą sieć współdzielonych identyfikatorów. Graf ułatwia dostrzeganie pierścieni, powtarzających się wzorców i połączeń pośrednich (np. dwa „niepowiązane” konta używają tego samego urządzenia przez łańcuch aktywności).
Dla usług, hostów, API, wywołań i właścicieli podstawowe pytanie to zależność: „co się zepsuje, jeśli to zmienimy?” Grafy wspierają analizę wpływu, poszukiwanie przyczyn źródłowych i zapytania o „promień zniszczeń”, gdy systemy są połączone.
Grafy wiedzy łączą byty (osoby, firmy, produkty, dokumenty) z faktami i odniesieniami. Pomaga to w wyszukiwaniu, rozwiązywaniu bytów i śledzeniu „dlaczego” fakt jest znany (proweniencja) przez wiele powiązanych źródeł.
Bazy grafowe błyszczą, gdy pytanie dotyczy połączeń: kto jest połączony z kim, przez jaki łańcuch i jakie wzorce się powtarzają. Zamiast wielokrotnego łączenia tabel, pytasz bezpośrednio o relacje i utrzymujesz czytelność zapytania w miarę rozrostu sieci.
Typowe pytania:
Przydatne w obsłudze klienta („dlaczego to zasugerowaliśmy?”), zgodności („pokaż łańcuch własności”) i dochodzeniach („jak to się rozprzestrzeniło?”).
Grafy pomagają zauważyć naturalne grupowania:
Można to wykorzystać do segmentacji użytkowników, znalezienia załóg oszustw lub zrozumienia współkupowanych produktów. Kluczowe jest to, że „grupa” definiowana jest przez połączenia, a nie przez pojedynczą kolumnę.
Czasem pytanie to nie tylko „kto jest połączony”, lecz „kto ma największe znaczenie” w sieci:
Te centralne węzły często wskazują na influencerów, krytyczną infrastrukturę lub wąskie gardła warte monitorowania.
Grafy świetnie nadają się do wyszukiwania powtarzalnych kształtów:
W Cypher (popularny język zapytań grafowych) trójkąt może wyglądać tak:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
Nawet jeśli nigdy nie napiszesz Cypher samodzielnie, pokazuje to, dlaczego grafy są przystępne: zapytanie odzwierciedla obraz w Twojej głowie.
Bazy relacyjne są świetne w tym, do czego zostały stworzone: transakcje i dobrze ustrukturyzowane rekordy. Jeśli dane ładnie mieszczą się w tabelach (klienci, zamówienia, faktury) i głównie pobierasz je po ID, filtrach i agregatach, system relacyjny często jest najprostszym i najbezpieczniejszym wyborem.
JOINy są w porządku, gdy są okazjonalne i płytkie. Tarcie zaczyna się, gdy twoje najważniejsze pytania wymagają wielu JOINów, cały czas, w wielu tabelach.
Przykłady:
W SQL mogą to być długie zapytania z powtarzającymi się self-JOINami i skomplikowaną logiką. Stają się też trudniejsze do strojenia, gdy rośnie głębokość relacji.
Bazy grafowe przechowują relacje explicite, więc wieloetapowe traversale po połączeniach są naturalną operacją. Zamiast zszywać tabele w czasie zapytania, przechodzisz po powiązanych węzłach i krawędziach.
To często oznacza:
Jeśli zespół często zadaje pytania wieloskokowe — „połączone z”, „przez”, „w tej samej sieci co”, „w N krokach” — warto rozważyć bazę grafową.
Jeśli główny workload to wysokowolumenowe transakcje, ścisłe schematy, raportowanie i proste JOINy, relacyjna baza jest zwykle lepszym domyślnym wyborem. Wiele systemów używa obu; zobacz /blog/practical-architecture-graph-alongside-other-databases.
Bazy grafowe błyszczą, gdy relacje są „głównym wydarzeniem”. Jeśli wartość aplikacji nie zależy od przeszukiwania połączeń (kto-znajomkogo, jak przedmioty się łączą, ścieżki, sąsiedztwa), graf może dodać złożoności bez większego zysku.
Jeśli większość zapytań to „pobierz użytkownika po ID”, „zaktualizuj profil”, „utwórz zamówienie”, a potrzebne dane mieszczą się w jednym rekordzie (lub przewidywalnym, małym zestawie tabel), baza grafowa zwykle nie jest potrzebna. Poświęcisz czas na modelowanie węzłów i krawędzi, strojenie traversali i naukę nowego stylu zapytań — podczas gdy relacyjna baza poradzi sobie wydajnie i przy użyciu znanych narzędzi.
Pulpity oparte na sumach, średnich i grupowanych metrykach (przychód według miesiąca, zamówienia według regionu, współczynnik konwersji według kanału) zwykle lepiej pasują do SQL i analityki kolumnowej niż do zapytań grafowych. Silniki grafowe mogą odpowiadać na niektóre agregaty, ale rzadko są najprostszą lub najszybszą ścieżką do ciężkich obciążeń OLAP.
Gdy polegasz na dojrzałych funkcjach SQL — złożonych JOINach ze ścisłymi ograniczeniami, zaawansowanych strategiach indeksowania, procedurach składowanych lub ustalonych wzorcach transakcyjnych ACID — systemy relacyjne często będą naturalnym wyborem. Wiele baz grafowych wspiera transakcje, ale ekosystem i wzorce operacyjne mogą nie pasować do tego, na czym już polega twój zespół.
Jeśli dane to w dużej mierze zestaw niezależnych bytów (zgłoszenia, faktury, odczyty sensorów) z minimalnym powiązaniem między nimi, model grafowy może wydawać się na siłę dopasowany. W takich przypadkach skup się na czystym schemacie relacyjnym (lub modelu dokumentowym) i rozważ graf tylko wtedy, gdy pytania o relacje staną się centralne.
Dobra zasada: jeśli możesz opisać swoje najważniejsze zapytania bez słów takich jak „połączony”, „ścieżka”, „sąsiedztwo” czy „poleć”, baza grafowa może nie być najlepszym pierwszym wyborem.
Grafy błyszczą, gdy trzeba szybko podążać po połączeniach — ale ta siła ma cenę. Zanim się zobowiążesz, warto zrozumieć, gdzie grafy zwykle są mniej efektywne, droższe lub po prostu inne w codziennym prowadzeniu.
Bazy grafowe często przechowują i indeksują relacje w sposób przyspieszający skoki (np. od klienta do jego urządzeń i transakcji). Kosztem może być większe zapotrzebowanie na pamięć i przestrzeń niż porównywalne rozwiązanie relacyjne, zwłaszcza po dodaniu indeksów dla typowych wyszukiwań.
Jeśli twoje obciążenie przypomina arkusz kalkulacyjny — duże skany tabelowe, zapytania raportowe na milionach wierszy lub ciężkie agregacje — baza grafowa może być wolniejsza lub droższa dla tego samego wyniku. Grafy są zoptymalizowane pod traversale („kto jest połączony z czym?”), nie pod przetwarzanie dużych partii niezależnych rekordów.
Złożoność operacyjna może być istotna. Kopie zapasowe, skalowanie i monitoring różnią się od tego, do czego wiele zespołów przywykło przy systemach relacyjnych. Niektóre platformy grafowe skalują najlepiej przez większe maszyny (scale up), inne wspierają skalowanie poziome, ale wymagają starannego planowania spójności, replikacji i wzorców zapytań.
Zespół może potrzebować czasu na naukę nowych wzorców modelowania i podejścia do zapytań (np. modelu property graph i języków jak Cypher). Krzywa uczenia się jest do opanowania, ale to ciąży — zwłaszcza gdy zastępujesz dojrzałe, oparte na SQL przepływy raportowania.
Praktyczne podejście: używaj grafu tam, gdzie relacje są produktem, a istniejące systemy pozostaw do raportowania, agregacji i analityki tabelarycznej.
Przydatny sposób myślenia o modelowaniu grafu jest prosty: węzły to rzeczy, a krawędzie to relacje między rzeczami. Ludzie, konta, urządzenia, zamówienia, produkty, lokalizacje — to węzły. „Kupił”, „zalogowano z”, „współpracuje z”, „jest rodzicem” — to krawędzie.
Większość komercyjnych baz grafowych używa modelu property graph: zarówno węzły, jak i krawędzie mogą mieć właściwości (pola klucz–wartość). Na przykład krawędź PURCHASED może przechowywać date, amount i channel. To naturalne do modelowania „relacji z detalami”.
RDF reprezentuje wiedzę jako trójki: subject – predicate – object. Dobrze sprawdza się przy interoperacyjnych słownikach i łączeniu danych między systemami, ale często przenosi „szczegóły relacji” do dodatkowych węzłów/trójek. Praktycznie RDF skłania ku standardowym ontologiom i wzorcom SPARQL, podczas gdy property graph jest bliższy modelowaniu danych aplikacyjnych.
Nie musisz od razu zapamiętywać składni — ważne, że zapytania grafowe zwykle wyrażane są jako ścieżki i wzorce, a nie łączenie tabel.
Grafy są często elastyczne pod względem schematu, co oznacza, że możesz dodać nową etykietę węzła lub właściwość bez ciężkiej migracji. Ale elastyczność wymaga dyscypliny: definiuj konwencje nazewnictwa, wymagane pola (np. id) i zasady dla typów relacji.
Wybierz typy relacji, które wyjaśniają znaczenie („FRIEND_OF” vs „CONNECTED”). Używaj kierunku, by klarować semantykę (np. FOLLOWS od obserwującego do twórcy), i dodawaj właściwości krawędzi, gdy relacja ma własne fakty (czas, pewność, rola, waga).
Problem jest „napędzany relacjami”, gdy trudność nie polega na przechowywaniu rekordów — lecz na rozumieniu, jak rzeczy się łączą i jak znaczenie zmienia się zależnie od ścieżki.
Zacznij od zapisania 5–10 najważniejszych pytań prostym językiem — tych, o które interesariusze najczęściej pytają, a które twój obecny system odpowiada wolno lub niespójnie. Dobre kandydaty grafowe często zawierają frazy typu „połączony z”, „przez”, „podobny do”, „w N krokach” lub „kto jeszcze”.
Przykłady:
Gdy masz pytania, mapuj rzeczowniki i czasowniki:
Następnie zdecyduj, co musi być relacją, a co węzłem. Praktyczna zasada: jeśli coś potrzebuje własnych atrybutów i połączysz z tym wiele stron, zrób z tego węzeł (np. Order lub Login event).
Dodaj właściwości, które pozwolą zawężać wyniki i ustalać ranking bez dodatkowych JOINów lub przetwarzania po stronie aplikacji. Typowe wartości: czas, kwota, status, kanał, wynik ufności.
Jeśli większość ważnych pytań wymaga wieloskokowych połączeń plus filtrowania według tych właściwości, prawdopodobnie masz problem napędzany relacjami.
Większość zespołów nie zastępuje wszystkiego grafem. Bardziej praktyczne podejście to pozostawienie „systemu prawdy” tam, gdzie działa (zwykle SQL) i użycie bazy grafowej jako wyspecjalizowanego silnika do pytań ciężkich od relacji.
Używaj bazy relacyjnej do transakcji, ograniczeń i kanonicznych bytów (klienci, zamówienia, konta). Następnie projekcja widoku relacji do bazy grafowej — tylko tych węzłów i krawędzi, które są potrzebne do zapytań o powiązania.
To utrzymuje audytowalność i gobernancję danych prostą, a jednocześnie odblokowuje szybkie traversale.
Baza grafowa błyszczy, gdy przypniesz ją do wyraźnie ograniczonego feature’u, np.:
Zacznij od jednej funkcji, jednego zespołu i jednego mierzalnego rezultatu. Możesz rozszerzać zakres, jeśli wartość zostanie udowodniona.
Jeśli wąskim gardłem jest wysłanie prototypu (a nie dyskusja o modelu), platforma vibe-coding taka jak Koder.ai może pomóc szybko postawić prostą aplikację zasilaną grafem: opisujesz funkcję w czacie, generuje się interfejs React i backend Go/PostgreSQL, a ty iterujesz, podczas gdy zespół danych weryfikuje schemat grafu i zapytania.
Jak świeży musi być graf?
Wzorzec: zapis transakcji do SQL → publikacja zdarzeń zmian → aktualizacja grafu.
Grafy robią się chaotyczne, gdy ID się rozjeżdżają.
Zdefiniuj stabilne identyfikatory (np. customer_id, account_id) zgodne między systemami i dokumentuj, kto „własnościuje” każde pole i relację. Jeśli dwa systemy mogą tworzyć tę samą krawędź (np. „znajomy”), ustal, który ma pierwszeństwo.
Jeśli planujesz pilotaż, zobacz: /blog/getting-started-a-low-risk-pilot-plan dla podejścia etapowego.
Pilot grafowy powinien być eksperymentem, a nie przepisywaniem wszystkiego. Celem jest udowodnienie (albo obalenie), że zapytania ciężkie od relacji stają się prostsze i szybsze — bez stawiania wszystkiego na jedną kartę.
Zacznij od ograniczonego zbioru danych, który już powoduje ból: za dużo JOINów, kruche SQL lub wolne pytania „kto jest połączony z czym?”. Ogranicz do jednego workflow (np. klient ↔ konto ↔ urządzenie albo użytkownik ↔ produkt ↔ interakcja) i zdefiniuj kilka zapytań, które chcesz obsłużyć end-to-end.
Mierz więcej niż prędkość:
Jeśli nie znasz liczb „przed”, nie zaufasz „po”.
Łatwo modelować wszystko jako węzły i krawędzie. Powstrzymaj się. Obserwuj „graph sprawl”: zbyt wiele typów węzłów/krawędzi bez jasnego zapytania, które ich potrzebuje. Każda nowa etykieta lub relacja powinna zasłużyć na miejsce, umożliwiając realne pytanie.
Zaplanuj prywatność, kontrolę dostępu i retencję danych wcześnie. Dane relacyjne mogą ujawniać więcej niż pojedyncze rekordy (np. połączenia sugerujące zachowania). Zdefiniuj, kto może wykonywać zapytania, jak audytować wyniki i jak usuwać dane na żądanie.
Użyj prostej synchronizacji (batch lub streaming), by zasilić graf, podczas gdy istniejący system pozostaje źródłem prawdy. Gdy pilot udowodni wartość, rozszerz zakres — ostrożnie, przypadek po przypadku.
Jeśli wybierasz bazę, nie zaczynaj od technologii — zacznij od pytań. Bazy grafowe błyszczą, gdy twoje najtrudniejsze problemy dotyczą połączeń i ścieżek, a nie tylko przechowywania rekordów.
Użyj tej listy, by sprawdzić dopasowanie przed inwestycją:
Jeśli odpowiedziałeś „tak” na większość, graf może być trafnym wyborem — zwłaszcza gdy potrzebujesz wieloskokowego dopasowywania wzorców, np.:
Jeśli pracujesz głównie z prostymi odczytami (po ID/email) lub agregatami („suma sprzedaży według miesiąca”), baza relacyjna lub key-value/document store jest zwykle prostsza i tańsza w utrzymaniu.
Zapisz 10 najważniejszych pytań biznesowych prostymi zdaniami, a potem przetestuj je na rzeczywistych danych w małym pilocie. Zmierz czasy zapytań, zanotuj, co trudne do wyrażenia, i prowadź krótki dziennik zmian modelu. Jeśli pilot sprowadza się głównie do „więcej JOINów” lub „więcej cache’owania”, to sygnał, że graf może się opłacić. Jeśli to głównie liczniki i filtry, prawdopodobnie nie.
Baza grafowa przechowuje dane jako węzły (byty) i relacje (połączenia) z właściwościami na obu. Jest zoptymalizowana do pytań typu „jak A jest połączone z B?” oraz „kto jest w odległości N skoków?”, a nie przede wszystkim do raportów tabelarycznych.
Oznacza to, że relacje są przechowywane jako prawdziwe, zapytalne obiekty (a nie tylko wartości klucza obcego). Możesz efektywnie przemieszczać się po wielu skokach i przypisywać właściwości do samej relacji (np. date, amount, risk_score), co ułatwia modelowanie i zapytania zależne od powiązań.
Bazy relacyjne reprezentują relacje pośrednio (klucze obce) i często wymagają wielu JOINów przy pytaniach wieloskokowych. Bazy grafowe trzymają połączenia bezpośrednio przy danych, więc zapytania o zmienną głębokość przeszukiwania (np. 2–6 skoków) są zwykle łatwiejsze do wyrażenia i utrzymania.
Używaj baz grafowych, gdy twoje kluczowe pytania dotyczą ścieżek, sąsiedztw i wzorców:
Typowe zapytania przyjazne grafom to:
Zazwyczaj gdy Twoje obciążenie to:
W takich przypadkach system relacyjny lub analityczny zwykle będzie prostszy i tańszy.
Modeluj to jako krawędź, gdy relacja głównie łączy dwa byty i może mieć własne właściwości (czas, rola, waga). Modeluj to jako węzeł, gdy to zdarzenie lub byt z wieloma atrybutami, łączący wielu uczestników (np. Order lub zdarzenie Login powiązane z użytkownikiem, urządzeniem, IP i czasem).
Typowe kompromisy to:
Grafy z właściwościami pozwalają węzłom i relacjom mieć właściwości (pola klucz–wartość) i są powszechne w modelowaniu aplikacji. RDF reprezentuje wiedzę jako trójki (subject–predicate–object) i lepiej pasuje do interoperacyjnych słowników i SPARQL. Wybierz na podstawie tego, czy potrzebujesz właściwości relacji w modelu aplikacyjnym (property graph), czy interoperacyjnego modelowania semantycznego (RDF).
Zachowaj istniejący system jako źródło prawdy (często SQL), a następnie odwzoruj widok relacji do grafu dla jednego, ograniczonego feature’u (rekomendacje, wykrywanie oszustw, rozwiązywanie tożsamości). Synchronizuj batchowo lub strumieniowo, używaj stabilnych identyfikatorów między systemami i mierz sukces (opóźnienie, złożoność zapytań, czas dewelopera) zanim rozszerzysz zakres.
Zobacz: /blog/practical-architecture-graph-alongside-other-databases i /blog/getting-started-a-low-risk-pilot-plan.