23 kwi 2025·8 min
Jak bazy wektorowe napędzają wyszukiwanie semantyczne w aplikacjach AI
Dowiedz się, jak bazy wektorowe przechowują osadzenia, wykonują szybkie wyszukiwanie podobieństwa i wspierają wyszukiwanie semantyczne, chatboty RAG, rekomendacje oraz inne aplikacje AI.
Co oznacza wyszukiwanie semantyczne (bez żargonu)
Wyszukiwanie semantyczne to sposób przeszukiwania, który skupia się na tym, co masz na myśli, a nie tylko na dokładnych słowach, które wpisujesz.
Jeśli kiedykolwiek wyszukałeś coś i pomyślałeś: „odpowiedź jest ewidentnie tutaj — dlaczego nie może tego znaleźć?”, to właśnie poczułeś ograniczenia wyszukiwania opartego na słowach-kluczach. Tradycyjne wyszukiwanie dopasowuje terminy. Działa to, gdy sformułowanie w zapytaniu i w treści się pokrywają.
Dlaczego wyszukiwanie po słowach często nie wystarcza
Wyszukiwanie po słowach ma problemy z:
- Synonimami i sformułowaniami: „cancel” vs „close” vs „terminate” konta.
- Intencją: „how do I stop being billed?” to tak naprawdę kwestia anulowania subskrypcji.
- Kontextem: „apple charger” (marka) vs „apple tree charger” (nonsens, ale o co chodzi).
Może też przeceniać powtarzające się słowa, zwracając wyniki, które na pierwszy rzut oka wyglądają na trafne, podczas gdy ignorują stronę, która naprawdę odpowiada na pytanie innymi słowami.
Prosty przykład
Wyobraź sobie centrum pomocy z artykułem zatytułowanym „Pause or cancel your subscription.” Użytkownik wyszukuje:
“stop my payments next month”
System oparty na słowach-kluczach może nie ustawić tego artykułu wysoko, jeśli nie zawiera „stop” lub „payments”. Wyszukiwanie semantyczne ma na celu zrozumieć, że „stop my payments” jest bliskie „cancel subscription” i podnieść ten artykuł na szczyt — bo znaczenie jest zgodne.
Gdzie pasują bazy wektorowe
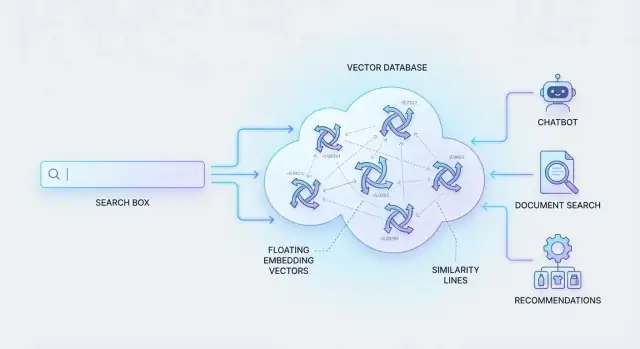
Aby to zadziałało, systemy reprezentują treści i zapytania jako „odciski znaczenia” (liczby, które uchwytują podobieństwo). Potem trzeba przeszukać miliony takich odcisków szybko.
Na tym właśnie polegają bazy wektorowe: przechowywaniu tych numerycznych reprezentacji i efektywnemu odnajdywaniu najbardziej podobnych dopasowań, aby wyszukiwanie semantyczne było natychmiastowe nawet przy dużej skali.
Osadzenia (embeddings): zamiana treści w użyteczne wektory
Embedding to numeryczna reprezentacja znaczenia. Zamiast opisywać dokument słowami-kluczami, reprezentujesz go jako listę liczb (wektor), które oddają, o czym jest zawartość. Dwa fragmenty treści o podobnym znaczeniu będą miały wektory blisko siebie w tej przestrzeni numerycznej.
Jak wygląda embedding w praktyce
Pomyśl o embeddingu jak o współrzędnej na bardzo wysokowymiarowej mapie. Zwykle nie czytasz tych liczb bezpośrednio — nie są przeznaczone dla ludzi. Ich wartość polega na tym, jak się zachowują: jeśli „cancel my subscription” i „how do I stop my plan?” dają podobne wektory, system może traktować je jako powiązane nawet przy małym (lub zerowym) nakładaniu się słów.
Tekst, obrazy i audio też mogą stać się wektorami
Osadzenia nie ograniczają się do tekstu.
- Osadzenia tekstowe reprezentują zdania, akapity, zgłoszenia wsparcia, opisy produktów i więcej.
- Osadzenia obrazów reprezentują podobieństwo wizualne i koncepcje (np. „czerwone buty do biegania”).
- Osadzenia audio mogą reprezentować mówcę, ton lub znaczenie wypowiedzi, gdy są połączone z modelami mowy.
Dzięki temu jedna baza wektorowa może obsługiwać „wyszukiwanie obrazem”, „znajdź podobne piosenki” lub „poleć produkty podobne do tego”.
Generowane przez modele — nie ręcznie
Wektory nie powstają przez ręczne tagowanie. Generują je modele uczenia maszynowego wytrenowane do kompresji znaczenia w liczby. Wysyłasz treść do modelu osadzeń (hostowanego przez ciebie lub dostawcę), on zwraca wektor. Twoja aplikacja przechowuje ten wektor wraz z oryginalną treścią i metadanymi.
Dlaczego wybór modelu osadzeń wpływa na jakość i koszt
Wybrany model osadzeń mocno wpływa na wyniki. Większe lub bardziej wyspecjalizowane modele często poprawiają trafność, ale kosztują więcej (i mogą być wolniejsze). Mniejsze modele mogą być tańsze i szybsze, ale mogą nie wychwycić niuansów — zwłaszcza w przypadku języka branżowego, wielojęzyczności lub krótkich zapytań. Wiele zespołów testuje kilka modeli na początku, aby znaleźć najlepszy kompromis przed skalowaniem.
Jak bazy wektorowe przechowują dane
Baza wektorowa opiera się na prostym pomyśle: przechowuj „znaczenie” (wektor) razem z informacjami potrzebnymi do identyfikacji, filtrowania i wyświetlania wyników.
Podstawowy model danych
Większość rekordów wygląda tak:
- ID: unikalny identyfikator, którym zarządzasz (np.
doc_18492lub UUID) - Wektor (embedding): tablica liczb reprezentujących znaczenie treści
- Metadane: pola klucz–wartość takie jak title, URL, tags, author, language, created_at lub tenant_id
Na przykład artykuł centrum pomocy może przechowywać:
- ID:
kb_123 - Wektor: 768 liczb zmiennoprzecinkowych (dla popularnego modelu osadzeń)
- Metadane:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
To wektor napędza podobieństwo semantyczne. ID i metadane sprawiają, że wynik jest użyteczny.
Dlaczego metadane mają większe znaczenie niż się wydaje
Metadane pełnią dwie role:
- Filtrowanie przed/po wyszukiwaniu wektorowym: „Pokaż tylko wyniki z produktu X”, „Tylko po angielsku”, „Tylko dokumenty, do których użytkownik ma dostęp” lub „Tylko elementy młodsze niż 90 dni.” To kluczowe dla trafności i kontroli dostępu.
- Prezentacja i akcje: Użytkownicy nie chcą widzieć wektora — chcą tytułu, fragmentu i linku (URL). Metadane dostarczają szczegóły potrzebne UI.
Bez dobrych metadanych możesz odnaleźć właściwe znaczenie, ale wciąż pokazać niewłaściwy kontekst.
Typowe rozmiary wektorów i implikacje przechowywania
Rozmiar osadzeń zależy od modelu: 384, 768, 1024 i 1536 wymiarów są powszechne. Więcej wymiarów może uchwycić niuanse, ale zwiększa też:
- Przestrzeń dyskową (każdy rekord przechowuje więcej liczb)
- Obciążenie pamięci dla szybkiego wyszukiwania
- Czas budowy indeksu (zwłaszcza przy indeksowaniu ANN)
Jako intuicja: podwojenie wymiarów zwykle podnosi koszty i opóźnienia, chyba że skompensujesz to wyborem indeksowania lub kompresją.
Wzorce aktualizacji: wstawienia, zmiany i usuwania
Zbiory danych się zmieniają, więc bazy wektorowe zwykle obsługują:
- Insert: dodaj nową treść z jej osadzeniem i metadanymi
- Update: zmień metadane (np. tagi) lub zastąp wektor, jeśli treść się zmieniła
- Delete: usuń nieaktualną lub cofniętą treść
- Re-embed: ponownie oblicz wektory, gdy zmieniasz model osadzeń, sposób dzielenia na fragmenty lub znacznie edytujesz tekst
Planowanie aktualizacji wcześnie zapobiega problemowi „starych wiedzy”, gdy wyszukiwanie zwraca treści, które już nie odpowiadają temu, co widzą użytkownicy.
Wyszukiwanie podobieństwa: szybkie znajdowanie „najbliższego znaczenia”
Gdy tekst, obrazy lub produkty zostaną zamienione na osadzenia (wektory), wyszukiwanie staje się problemem geometrycznym: „Które wektory są najbliższe wektorowi zapytania?” To nazywa się nearest-neighbor search. Zamiast dopasowywać słowa-klucze, system porównuje znaczenie, mierząc, jak blisko są dwa wektory.
Nearest neighbors prostymi słowami
Wyobraź sobie, że każdy fragment treści to punkt w ogromnej wielowymiarowej przestrzeni. Gdy użytkownik wyszukuje, jego zapytanie zamienia się na kolejny punkt. Wyszukiwanie podobieństwa zwraca elementy, których punkty są najbliżej — twoich „najbliższych sąsiadów”. Ci sąsiedzi prawdopodobnie dzielą intencję, temat lub kontekst, nawet jeśli nie dzielą dokładnych słów.
Typowe metryki podobieństwa
Bazy wektorowe zazwyczaj obsługują kilka standardowych sposobów oceniania „bliskości”:
- Cosine similarity: porównuje kąt między wektorami (dobre, gdy zależy ci od kierunku/znaczenia bardziej niż od długości)
- Dot product: powiązane z kosinusem, ale wpływa też długość wektora; często używane z normalizowanymi osadzeniami
- Euclidean distance: odległość w prostej linii między punktami (przydatna w niektórych modelach i domenach)
Różne modele osadzeń są trenowane z myślą o konkretnej metryce, więc warto stosować tę rekomendowaną przez dostawcę modelu.
Wyszukiwanie dokładne vs przybliżone (ANN)
Dokładne wyszukiwanie sprawdza każdy wektor, by znaleźć prawdziwych najbliższych sąsiadów. To może być dokładne, ale staje się wolne i kosztowne przy milionach elementów.
Większość systemów korzysta z approximate nearest neighbor (ANN). ANN używa sprytnych struktur indeksów, by zawęzić wyszukiwanie do najbardziej obiecujących kandydatów. Zwykle otrzymujesz wyniki „wystarczająco bliskie” prawdziwym najlepszym dopasowaniom — znacznie szybciej.
Kompromis opóźnienie vs recall
ANN jest popularne, bo pozwala stroić zachowanie:
- Niższe opóźnienie (szybsze odpowiedzi) przez przeszukiwanie mniejszej liczby kandydatów.
- Wyższy recall (znalezienie większej liczby prawdziwych najlepszych dopasowań) przez przeszukiwanie większej liczby kandydatów.
To strojenie sprawia, że wyszukiwanie wektorowe dobrze działa w realnych aplikacjach: możesz utrzymać responsywność, jednocześnie zwracając bardzo trafne wyniki.
Przepływ wyszukiwania semantycznego krok po kroku
Wyszukiwanie semantyczne najłatwiej rozumieć jako prosty pipeline: zamieniasz tekst w znaczenie, wyszukujesz podobne znaczenia, a potem prezentujesz najbardziej użyteczne dopasowania.
1) Osadź zapytanie
Użytkownik wpisuje pytanie (np. „How do I cancel my plan without losing data?”). System przesyła ten tekst do modelu osadzeń, który zwraca wektor — tablicę liczb reprezentującą znaczenie zapytania, zamiast jego dokładnych słów.
2) Przeszukaj bazę wektorową
Ten wektor zapytania trafia do bazy wektorowej, która wykonuje wyszukiwanie podobieństwa, aby znaleźć „najbliższe” wektory wśród przechowywanej zawartości.
Większość systemów zwraca top-K dopasowań: K najbardziej podobnych fragmentów/dokumentów.
- Dlaczego K jest konfigurowalne: mniejsze K jest szybsze i często wystarczające (np. K=5).
- Większe K zwiększa recall (mniejsze ryzyko przeoczenia właściwej odpowiedzi), ale może zawierać więcej „prawie trafnych” wyników (np. K=50).
3) (Opcjonalnie) Rerank dla precyzji
Wyszukiwanie podobieństwa jest zoptymalizowane pod szybkość, więc początkowe top-K może zawierać bliskie pudła. Reranker to drugi model, który bierze zapytanie i każdy kandydat razem i ponownie sortuje je według trafności.
Pomyśl o tym tak: wyszukiwanie wektorowe daje mocną krótką listę; reranking wybiera najlepszą kolejność.
4) Zwróć wyniki (lub przekaż dalej)
Na końcu zwracasz najlepsze dopasowania użytkownikowi (jako wyniki wyszukiwania) albo przekazujesz je do asystenta AI (np. system RAG) jako „grounding” kontekst.
Jeśli budujesz taki przepływ w aplikacji, platformy takie jak Koder.ai mogą pomóc szybko prototypować: opisujesz doświadczenie wyszukiwania semantycznego lub RAG w interfejsie czatu, potem iterujesz nad front-endem w React i backendem w Go/PostgreSQL, utrzymując pipeline (embedding → vector search → optional rerank → answer) jako element pierwszorzędny produktu.
Krótki przykład „słowa-klucz vs semantyka”
Jeśli artykuł centrum pomocy mówi „terminate subscription”, a użytkownik szuka „cancel my plan”, wyszukiwanie po słowach może to przegapić, bo „cancel” i „terminate” się nie pokrywają.
Wyszukiwanie semantyczne zwykle to znajdzie, ponieważ embedding uchwyci, że obie frazy wyrażają tę samą intencję. Dodaj reranking, a najlepsze wyniki zwykle staną się nie tylko „podobne”, ale bezpośrednio użyteczne dla pytania użytkownika.
Wyszukiwanie hybrydowe i filtry metadanych dla lepszych wyników
Deploy your AI app
Przejdź od lokalnego pomysłu do hostowanej aplikacji, którą możesz udostępnić zespołowi.
Czyste wyszukiwanie wektorowe świetnie odnajduje „znaczenie”, ale użytkownicy nie zawsze szukają po znaczeniu. Czasem potrzebne jest dokładne dopasowanie: pełne imię i nazwisko, SKU, numer faktury lub kod błędu skopiowany z logu. Wyszukiwanie hybrydowe łączy sygnały semantyczne (wektory) z leksykalnymi (tradycyjne wyszukiwanie słów-klucz, np. BM25).
Co robi „wyszukiwanie hybrydowe” w praktyce
Zapytanie hybrydowe zwykle uruchamia dwa równoległe ścieżki:
- Wyszukiwanie wektorowe: znajduje treści konceptualnie podobne, nawet jeśli sformułowanie się różni.
- Wyszukiwanie słów/ BM25: znajduje treści dzielące te same tokeny, premiując dokładne terminy i rzadkie słowa.
System potem scala te kandydatury w jedną posortowaną listę.
Kiedy hybrydowe jest lepszym wyborem domyślnym
Wyszukiwanie hybrydowe błyszczy, gdy w danych występują ciągi „must-match”:
- Nazwy produktów z precyzyjnymi modyfikatorami (np. „Pro Max”, „Gen 2”)
- ID (numery zamówień, zgłoszeń, numerów części)
- Kody błędów („E0421”, „ORA-00933”) i flagi poleceń
- Rzadkie terminy branżowe, gdzie synonimy byłyby ryzykowne
Wyszukiwanie semantyczne samo może zwrócić strony powiązane ogólnie; wyszukiwanie słów-klucz może przegapić odpowiedzi sformułowane inaczej. Hybryda pokrywa oba tryby błędów.
Używanie filtrów metadanych do zawężenia przestrzeni wyszukiwania
Filtry metadanych ograniczają pobór przed sortowaniem (lub obok niego), poprawiając trafność i szybkość. Typowe filtry to:
- Język (zwróć tylko dokumenty po angielsku)
- Zakres dat (najnowsza polityka, ostatnie release notes)
- Kategoria lub źródło (docs vs tickets; „billing” vs „security”)
- Tagi kontroli dostępu (tylko to, co użytkownik może zobaczyć)
Jak działa scoring (wysoki poziom)
Większość systemów używa praktycznego podejścia: uruchamia oba wyszukiwania, normalizuje wyniki, aby były porównywalne, a następnie aplikuje wagi (np. „bardziej polegaj na słowach-klucz przy ID”). Niektóre produkty rerankują scentralizowaną shortlistę lekkim modelem lub regułami, podczas gdy filtry zapewniają, że rankujesz właściwy podzbiór od początku.
RAG: używanie baz wektorowych do ugruntowania odpowiedzi LLM
Retrieval-Augmented Generation (RAG) to praktyczny wzorzec, by uzyskać bardziej wiarygodne odpowiedzi od LLM: najpierw pobierz relewantne informacje, potem wygeneruj odpowiedź powiązaną z pobranym kontekstem.
Idea RAG w jednym zdaniu
Zamiast polegać na tym, że model „zapamięta” dokumenty twojej firmy, przechowujesz te dokumenty (jako osadzenia) w bazie wektorowej, pobierasz najbardziej relewantne fragmenty w czasie zapytania i przekazujesz je do LLM jako wspierający kontekst.
Dlaczego baza wektorowa pomaga zmniejszyć halucynacje
LLMy są świetne w generowaniu tekstu, ale potrafią pewnie wypełniać luki, gdy brakuje faktów. Baza wektorowa ułatwia pobranie najbliższych znaczeniem fragmentów z bazy wiedzy i dostarczenie ich w prompt. To przesuwa model z „wymyśl odpowiedź” na „podsumuj i wyjaśnij te źródła”.
To także ułatwia audytowanie odpowiedzi, bo możesz śledzić, które fragmenty zostały pobrane i opcjonalnie pokazywać cytowania.
Podstawy chunkowania (żeby retrieval działał)
Jakość RAG często zależy bardziej od chunkowania niż od modelu.
- Rozmiar chunku: Celuj w fragmenty zawierające kompletną myśl (często krótki rozdział/sekcja). Zbyt małe tracą sens; zbyt duże wprowadzają szum.
- Overlap: Dodaj niewielkie nakładanie, żeby ważne szczegóły na granicach nie zostały odcięte od kontekstu.
- Zachowaj kontekst: Przechowuj tytuły, nagłówki i identyfikatory (nazwa dokumentu, sekcja, data) jako metadane, by wyniki były zrozumiałe i filtrowalne.
Prosty diagram pipeline RAG (opis)
Wyobraź sobie przepływ:
Pytanie użytkownika → Osadź pytanie → Vector DB pobiera top-k chunków (+ opcjonalne filtry metadanych) → Zbuduj prompt z pobranymi chunkami → LLM generuje odpowiedź → Zwróć odpowiedź (i źródła).
Baza wektorowa stoi w środku jako „szybka pamięć”, która dostarcza najbardziej relewantne dowody dla każdego zapytania.
Typowe zastosowania AI napędzane przez bazy wektorowe
Test a RAG prototype
Uruchom prosty prototyp RAG i iteruj nad osadzeniami, podziałem na fragmenty i retrieval.
Bazy wektorowe nie tylko sprawiają, że wyszukiwanie jest „mądrzejsze” — umożliwiają doświadczenia produktowe, gdzie użytkownicy opisują, czego chcą, językiem naturalnym i nadal otrzymują trafne wyniki. Poniżej kilka praktycznych przypadków użycia.
Obsługa klienta: znajdź odpowiedzi poza słowami-kluczami
Zespoły wsparcia często mają bazę wiedzy, stare zgłoszenia, transkrypty czatów i release notes — ale wyszukiwanie po słowach miewa problemy z synonimami, parafrazami i niejasnymi opisami problemów.
Dzięki wyszukiwaniu semantycznemu agent (lub chatbot) może odnaleźć przeszłe zgłoszenia, które mają takie samo znaczenie, nawet jeśli sformułowanie jest inne. To przyspiesza rozwiązywanie problemów, redukuje powielenie pracy i pomaga nowym agentom szybciej się wdrożyć. Połączenie wyszukiwania wektorowego z filtrami metadanych (linia produktu, język, typ problemu, zakres dat) utrzymuje wyniki w ryzach.
Odkrywanie produktów: katalogi tak, jak mówią ludzie
Kupujący rzadko znają dokładne nazwy produktów. Szukają intencji typu „mały plecak, który zmieści laptopa i wygląda profesjonalnie.” Osadzenia uchwycą te preferencje — styl, funkcję, ograniczenia — więc wyniki będą bliższe temu, co doradziłby sprzedawca.
To działa dla katalogów retail, ofert travel, nieruchomości, portali pracy i marketplace’ów. Możesz też łączyć semantyczną trafność z ograniczeniami strukturalnymi jak cena, rozmiar, dostępność czy lokalizacja.
Rekomendacje: „podobne przedmioty” i odkrywanie treści
Klasyczną funkcją bazy wektorowej jest „znajdź rzeczy podobne do tej”. Jeśli użytkownik ogląda produkt, czyta artykuł lub ogląda wideo, możesz pobrać inne treści o podobnym znaczeniu lub atrybutach — nawet gdy kategorie się nie pokrywają.
To przydatne dla:
- modułów „Więcej podobnych”
- powiązanych artykułów i sugestii w bazie wiedzy
- wykrywania duplikatów lub niemal-duplikatów (moderacja treści lub porządki)
Wewnętrzne wyszukiwanie z kontrolą dostępu: polityki, dokumenty, notatki z spotkań
W firmach informacje są porozrzucane po dokumentach, wiki, PDF-ach i notatkach. Wyszukiwanie semantyczne pomaga pracownikom zadawać naturalne pytania („Jaka jest nasza polityka zwrotów kosztów za konferencje?”) i znaleźć właściwy dokument.
Nienegocjowalna część to kontrola dostępu. Wyniki muszą respektować uprawnienia — często przez filtrowanie po zespole, właścicielu dokumentu, poziomie poufności lub liście ACL — aby użytkownicy widzieli tylko to, do czego mają dostęp.
Jeśli chcesz pójść dalej, ta sama warstwa retrieval napędza systemy Q&A oparte na groundingu (opisane w sekcji RAG).
Pipelines danych: ingest, chunking i aktualizacje
System wyszukiwania semantycznego jest tak dobry, jak pipeline, który go zasilają. Jeśli dokumenty napływają niespójnie, są źle podzielone na fragmenty lub nigdy nie są ponownie osadzone po edycjach, wyniki oddalają się od oczekiwań użytkowników.
Prosty flow ingestowy (który działa)
Większość zespołów stosuje powtarzalną sekwencję:
- Zbierz dane (dokumenty, PDF-y, zgłoszenia, logi czatu, strony wiki, dane produktowe).
- Oczyść je (usuń boilerplate, napraw kodowanie, znormalizuj białe znaki, wyekstrahuj główny tekst).
- Podziel na fragmenty (split na zjadliwe kawałki, które użytkownicy chcieliby pobierać).
- Osadź (wygeneruj wektory wybranym modelem osadzeń).
- Upsert (zapisz wektory + metadane do bazy wektorowej, zastępując gdy potrzeba).
Krok „chunk” to miejsce, gdzie wiele pipeline’ów wygrywa lub przegrywa. Zbyt duże fragmenty rozwadniają znaczenie; zbyt małe tracą kontekst. Praktyczne podejście to dzielenie według naturalnej struktury (nagłówki, akapity, pary Q&A) i dodanie małego overlapu dla ciągłości.
Utrzymywanie osadzeń aktualnych
Treść zmienia się non-stop — polityki są aktualizowane, ceny się zmieniają, artykuły są przepisywane. Traktuj osadzenia jako dane pochodne, które trzeba regenerować.
Popularne taktyki:
- Przechowuj ID dokumentu źródłowego, ID chunku i hash treści. Jeśli hash się zmieni, ponownie osadź ten chunk.
- Używaj soft delete (oznacz stare chunk jako nieaktywne), aby unikać „duchowych” wyników.
- Odbudowuj selektywnie zamiast ponownie osadzać wszystkiego.
Batch vs streaming updates
- Batch pasuje do dużych backfilli, nocnych synchronizacji i przewidywalnych treści (dokumentacja, bazy wiedzy).
- Streaming lepiej dla szybko zmieniających się źródeł (zgłoszenia wsparcia, treści generowane przez użytkowników, inwentaryzacja). Zmniejsza przestarzałość, ale wymaga mocniejszego monitoringu i kontroli kosztów.
Wiele języków i wiele modeli
Jeśli obsługujesz wiele języków, możesz użyć modelu wielojęzycznego (prostsze) albo modeli per-język (często wyższa jakość). Jeśli eksperymentujesz z modelami, wersjonuj osadzenia (np. embedding_model=v3), aby móc prowadzić A/B testy i wycofać zmiany bez łamania wyszukiwania.
Jak oceniać jakość i wydajność
Wyszukiwanie semantyczne może „dobrze wyglądać” na demo i nadal zawodzić w produkcji. Różnica to pomiar: potrzebujesz jasnych metryk trafności i celów wydajnościowych, ocenianych na zapytaniach, które przypominają prawdziwe zachowania użytkowników.
Metryki trafności odzwierciedlające satysfakcję użytkownika
Zacznij od małego zestawu metryk i trzymaj się ich w czasie:
- Precision / Recall: Precision mówi, ile zwróconych wyników jest faktycznie trafnych; recall — ile trafnych elementów udało się pobrać.
- MRR (Mean Reciprocal Rank): Dobry, gdy użytkownik oczekuje jednej „najlepszej” odpowiedzi. Nagradza umieszczanie właściwego dokumentu blisko góry.
- nDCG: Przydatne, gdy wiele wyników może być relewantnych na różnych poziomach.
- Latency (p50/p95): Śledź zarówno medianę, jak i ogon. Szybkie p50 przy wolnym p95 nadal będzie odczuwalne jako powolne.
Zbuduj zestaw testowy, któremu możesz ufać
Stwórz zbiór ewaluacyjny z:
- Rzeczywistych zapytań z logów (anonymizowanych)
- Oczekiwanych dokumentów (gold labels) uzgodnionych przez ekspertów domenowych
- Przypadków brzegowych: krótkie zapytania („refund”), długie pytania, niejednoznaczne terminy, rzadkie nazwy produktów oraz zapytania „bez wyniku”, gdzie poprawne zachowanie to „nic nie znaleziono”
Wersjonuj test set, aby móc porównywać wyniki między wydaniami.
A/B testy i pętle feedbacku
Metryki offline nie pokazują wszystkiego. Uruchamiaj A/B testy i zbieraj lekkie sygnały:
- Kciuk w górę/w dół dla wyników
- Click-through i czas spędzony na stronie (dwell time)
- Zdarzenia „refine search”
Wykorzystaj ten feedback do aktualizacji ocen trafności i wykrywania wzorców błędów.
Monitorowanie dryfu w czasie
Wydajność może się zmienić, gdy:
- Zmienisz model osadzeń lub sposób chunkowania
- Korpus się przesunie (nowe produkty, zmiany polityk, sezonowe terminy)
Uruchamiaj ponownie swój test suite po każdej zmianie, monitoruj trendy metryk co tydzień i ustaw alerty na nagłe spadki w MRR/nDCG lub skoki w p95 latency.
Bezpieczeństwo, prywatność i kontrola dostępu
Launch better support search
Przekształć zawartość centrum pomocy w doświadczenie wyszukiwania z filtrami i opcjami rerankingu.
Wyszukiwanie wektorowe zmienia jak dane są odzyskiwane, ale nie powinno zmieniać kto ma do nich dostęp. Jeśli system semantyczny lub RAG może „znaleźć” właściwy chunk, może też przez pomyłkę zwrócić chunk, do którego użytkownik nie miał uprawnień — chyba że zaprojektujesz uprawnienia i prywatność na etapie retrieval.
Kontrola dostępu: egzekwuj ją przy pobieraniu
Najbezpieczniejsza zasada jest prosta: użytkownik powinien pobierać tylko to, co ma prawo czytać. Nie polegaj na aplikacji, że „ukryje” wyniki po tym, jak baza wektorowa je zwróci — bo wtedy treść już opuściła twój obszar przechowywania.
Praktyczne podejścia:
- ACL na dokument/fragment: przechowuj pola uprawnień obok każdego wektora, żeby każde zapytanie mogło je egzekwować.
- Izolacja tenantów: w aplikacjach multi-tenant oddziel dane według tenantów (partycyje logiczne, namespace’y lub oddzielne indeksy), by uniknąć przecieków między tenantami.
Filtry metadanych dla uprawnień
Wiele baz wektorowych wspiera filtry metadanych (np. tenant_id, department, project_id, visibility) które uruchamia się razem z wyszukiwaniem podobieństwa. Użyte poprawnie, to czysty sposób stosowania uprawnień przy retrieval.
Szczegół: upewnij się, że filtr jest obowiązkowy i po stronie serwera, a nie opcjonalną logiką klienta. Przy skomplikowanym modelu uprawnień rozważ prekomputowanie „efektywnych grup dostępu” lub użycie dedykowanej usługi autoryzacji do wygenerowania tokenu filtru w czasie zapytania.
PII i dane wrażliwe: zdecyduj, co nigdy nie osadzać
Osadzenia mogą kodować znaczenie z oryginalnego tekstu. To nie oznacza automatycznie ujawnienia surowego PII, ale zwiększa ryzyko (np. łatwiejsze odnalezienie poufnych faktów).
Dobre praktyki:
- Unikaj osadzania bardzo wrażliwych pól (PESEL, dane płatnicze, identyfikatory medyczne), gdy to możliwe.
- Redaguj przed osadzeniem jeśli tekst musi być przeszukiwalny (zamień dokładne wartości na placeholdery).
- Przechowuj oryginały osobno i pobieraj je dopiero po sprawdzeniu uprawnień.
Potrzeby operacyjne: backupy, retencja i audyt
Traktuj indeks wektorowy jak dane produkcyjne:
- Backupy i odzyskiwanie: indeksy bywają kosztowne do odbudowania; zaplanuj snapshoty lub ścieżkę odbudowy z danych źródłowych.
- Polityki retencji: usuwaj wektory, gdy dokument źródłowy wygasa lub użytkownik wnioskuje o usunięcie.
- Audytowalność: loguj kto pytał o co (przynajmniej kontekst zapytania i ID dokumentów zwróconych), by wspierać dochodzenia i zgodność.
Dobrze wykonane praktyki sprawiają, że wyszukiwanie semantyczne działa jak magia dla użytkowników — bez niespodzianek bezpieczeństwa.
Pułapki, koszty i praktyczna lista kontrolna wyboru
Bazy wektorowe mogą wydawać się „plug-and-play”, ale większość rozczarowań wynika z decyzji otoczenia: jak dzielisz dane, jaki model osadzeń wybierasz i jak rzetelnie utrzymujesz wszystko świeże.
Typowe tryby awarii (i jak je wykryć)
Złe chunkowanie to przyczyna nr 1 nieistotnych wyników. Zbyt duże fragmenty rozwadniają znaczenie; zbyt małe tracą kontekst. Jeśli użytkownicy często mówią „znalazł właściwy dokument, ale złą część”, prawdopodobnie trzeba poprawić strategię chunkowania.
Zły model osadzeń objawia się stałym niedopasowaniem semantycznym — wyniki są płynne, ale nie na temat. Dzieje się to, gdy model nie pasuje do twojej domeny (prawo, medycyna, zgłoszenia wsparcia) lub typu treści (tabele, kod, tekst wielojęzyczny).
Stare dane szybko niszczą zaufanie: użytkownik szuka najnowszej polityki, a dostaje wersję z poprzedniego kwartału. Jeśli źródło się zmienia, twoje osadzenia i metadane muszą być aktualizowane (a usuwania rzeczywiście usuwać).
Start od zimnego konta i obsługa braków wyników
Na początku możesz mieć za mało treści, za mało zapytań lub za mało feedbacku, by dobrze stroić retrieval. Zaplanuj:
- Fallbacky: wyszukiwanie słów-klucz lub kuratorowane „najlepsze odpowiedzi”, gdy semantyczne wyniki są słabe.
- UX dla pustych wyników: pokaż powiązane kategorie, zapytaj doprecyzowująco lub poszerz filtry.
- Zapytania rozruchowe: przetestuj z małym zestawem reprezentatywnych pytań przed uruchomieniem.
Główne koszty do zaplanowania
Koszty zwykle pochodzą z czterech źródeł:
- Obliczenia osadzeń (jednorazowy backfill + bieżące aktualizacje)
- Przechowywanie (wektory, metadane, indeksy)
- Ruch zapytań (odczyty, egress sieciowy, konkurencja)
- Reranking (opcjonalne, ale potężne; może dodać koszt modelu na zapytanie)
Porównując dostawców, poproś o prosty miesięczny szacunek na podstawie oczekiwanej liczby dokumentów, średniego rozmiaru chunku i szczytowego QPS. Wiele niespodzianek pojawia się po zindeksowaniu i przy skokach ruchu.
Praktyczna lista kontrolna wyboru
Użyj tej krótkiej checklisty przy wyborze bazy wektorowej:
- Jakość wyszukiwania: Czy obsługuje search hybrydowy (słowa + wektory) i filtry metadanych? Czy można dodać reranking?
- Wydajność: Opcje indeksowania ANN, przewidywalne opóźnienia przy szczytowym ruchu i łatwe skalowanie.
- Operacje na danych: Upserty, usuwania, reindeksacja, wersjonowanie i backfille bez downtime.
- Obserwowalność: Logi zapytań, metryki recall/latency i narzędzia debugujące „dlaczego ten wynik?”.
- Bezpieczeństwo: Szyfrowanie, izolacja tenantów, role-based access i wzorce filtrowania po uprawnieniach.
- Integracja: SDKi, obsługiwane języki i konektory do magazynów (S3, bazy danych, docs).
- Całkowity koszt: Przejrzyste ceny za storage, zapisy, odczyty i ewentualny zarządzany compute.
Dobry wybór to mniej gonitwa za najnowszym typem indeksu, a bardziej pytanie: czy potrafisz utrzymać dane świeże, kontrolować dostęp i zachować jakość w miarę wzrostu treści i ruchu?
Często zadawane pytania
What is semantic search, in simple terms?
Keyword search matches exact tokens. Semantic search matches meaning by comparing embeddings (vectors), so it can return relevant results even when the query uses different phrasing (e.g., “stop payments” → “cancel subscription”).
What does a vector database actually do in a semantic search system?
A vector database stores embeddings (arrays of numbers) plus IDs and metadata, then performs fast nearest-neighbor lookups to find items with the closest meaning to a query. It’s optimized for similarity search at large scale (often millions of vectors).
What is an embedding, and why is it important?
An embedding is a model-generated numeric “fingerprint” of content. You don’t interpret the numbers directly; you use them to measure similarity.
In practice:
- Convert documents (or chunks) into embeddings
- Convert the user’s query into an embedding
- Retrieve the most similar embeddings as results
What data should I store for each item in a vector database?
Most records include:
- (you control it)
Why is metadata so important for relevance and security?
Metadata enables two critical capabilities:
- Filtering: limit results to the right subset (language, product, date range, permissions)
- Presentation: show a title/snippet/link instead of just returning an internal ID
Without metadata, you can retrieve the right meaning but still show the wrong context or leak restricted content.
Which similarity metric should I use (cosine, dot product, Euclidean)?
Common options are:
- Cosine similarity (compares direction; often used for text)
- Dot product (related to cosine; can depend on normalization)
- Euclidean distance (straight-line distance)
You should use the metric the embedding model was trained for; the “wrong” metric can noticeably degrade ranking quality.
What’s the difference between exact search and ANN (approximate) search?
Exact search compares a query to every vector, which becomes slow and expensive at scale. ANN (approximate nearest neighbor) uses indexes to search a smaller candidate set.
Trade-off you can tune:
- Faster responses (lower latency)
- Better coverage of true best matches (higher recall)
When should I use hybrid search instead of pure vector search?
Hybrid search combines:
- Vector search for meaning and paraphrases
- Keyword/BM25 search for exact tokens (IDs, error codes, SKUs, names)
It’s often the best default when your corpus includes “must-match” strings and natural-language queries.
How does a vector database support RAG for LLM apps?
RAG (Retrieval-Augmented Generation) retrieves relevant chunks from your data store and supplies them as context to an LLM.
A typical flow:
- Embed user question
- Retrieve top-K chunks from the vector DB (with metadata filters)
- Insert chunks into the prompt
- LLM generates an answer grounded in those sources
What are the most common pitfalls when building semantic search with vector databases?
Three high-impact pitfalls:
- Poor chunking: too large adds noise; too small loses context
- Stale embeddings: content updates without re-embedding leads to outdated results
- No permission filtering at retrieval: can return restricted chunks before your app can hide them
Mitigations include chunking by structure, versioning embeddings, and enforcing mandatory server-side metadata filters (e.g., , ACL fields).