26 gru 2025·7 min
Narzędzia wewnętrzne z Claude Code: bezpieczne pulpity CLI
Buduj wewnętrzne narzędzia z Claude Code, rozwiązując wyszukiwanie logów, feature toggle i kontrole danych przy zachowaniu najmniejszych uprawnień i jasnych zabezpieczeń.
Jaki problem Twoje narzędzie wewnętrzne naprawdę powinno rozwiązać
Narzędzia wewnętrzne często zaczynają się jako skrót: jedna komenda lub jedna strona, która ratuje zespół o 20 minut podczas incydentu. Ryzyko polega na tym, że ten sam skrót może po cichu przemienić się w uprzywilejowany backdoor, jeśli nie zdefiniujesz problemu i granic z góry.
Zespoły zwykle sięgają po narzędzie, gdy ten sam ból powtarza się codziennie, na przykład:
- Wyszukiwanie w logach, które jest wolne, niejednolite lub rozproszone między systemami
- Przełączniki funkcji, które wymagają ryzykownej ręcznej edycji lub bezpośredniego zapisu do bazy
- Kontrole danych zależne od jednej osoby uruchamiającej skrypt z laptopa
- Zadania on-call, które są proste, ale łatwo je sknocić o 2 w nocy
Te problemy wydają się małe, dopóki narzędzie nie może czytać logów produkcyjnych, zapytywać danych klientów lub przełączać flag. Wtedy masz do czynienia z kontrolą dostępu, ścieżkami audytu i przypadkowymi zapisami. Narzędzie „tylko dla inżynierów” wciąż może spowodować awarię, jeśli wykona szerokie zapytanie, trafi w niewłaściwe środowisko lub zmieni stan bez jasnego kroku potwierdzającego.
Zdefiniuj sukces w wąskich, mierzalnych kategoriach: szybsze operacje bez rozszerzania uprawnień. Dobre narzędzie wewnętrzne usuwa kroki, nie zabezpieczenia. Zamiast dawać wszystkim szeroki dostęp do bazy, by sprawdzić podejrzany problem z rozliczeniami, zbuduj narzędzie, które odpowie na jedno pytanie: „Pokaż dzisiejsze nieudane zdarzenia rozliczeniowe dla konta X”, używając poświadczeń tylko do odczytu i zakresowych.
Zanim wybierzesz interfejs, zdecyduj, czego ludzie potrzebują w danym momencie. CLI świetnie sprawdza się przy powtarzalnych zadaniach podczas on-call. Pulpit webowy lepiej, gdy wyniki wymagają kontekstu i współdzielonej widoczności. Czasami wypuszczasz oba, ale tylko jeśli są cienkimi widokami nad tymi samymi strzeżonymi operacjami. Celem jest jedna dobrze zdefiniowana funkcjonalność, nie nowa powierzchnia administracyjna.
Wybierz jedną bolącą rzecz i trzymaj zakres mały
Najszybszy sposób, by narzędzie wewnętrzne było użyteczne (i bezpieczne), to wybrać jedno jasne zadanie i zrobić je dobrze. Jeśli od razu ma obsługiwać logi, feature flagi, naprawy danych i zarządzanie użytkownikami, zacznie rosnąć i kryć niespodziewane zachowania.
Zacznij od jednego pytania, które użytkownik zadaje podczas realnej pracy. Na przykład: „Dla danego request ID pokaż błąd i linie wokół niego w usługach.” To wąskie, testowalne i łatwe do wyjaśnienia.
Bądź precyzyjny, dla kogo jest to narzędzie. Programista debugujący lokalnie potrzebuje innych opcji niż osoba on-call, a obie różnią się od supportu czy analityka. Mieszając odbiorców, kończysz z „potężnymi” komendami, których większość użytkowników nigdy nie powinna używać.
Zapisz wejścia i wyjścia jak mały kontrakt.
Wejścia powinny być jawne: request ID, zakres czasu, środowisko. Wyjścia powinny być przewidywalne: dopasowane linie, nazwa usługi, znacznik czasu, liczba. Unikaj ukrytych efektów ubocznych typu „także czyści cache” czy „także ponawia zadanie”. To cechy, które powodują wypadki.
Domyślnie ustaw tryb tylko do odczytu. Narzędzie nadal może być wartościowe poprzez wyszukiwanie, diff, walidację i raportowanie. Dodawaj akcje zapisujące tylko wtedy, gdy potrafisz nazwać realny scenariusz, który tego potrzebuje i możesz go mocno ograniczyć.
Proste oświadczenie zakresu, które trzyma zespoły w ryzach:
- Jedno główne zadanie, jeden główny ekran lub polecenie
- Jedno źródło danych (lub jedna logiczna perspektywa), nie „wszystko”
- Jawne flagi dla środowiska i zakresu czasu
- Najpierw tylko odczyt, bez działań w tle
- Jeśli istnieją zapisy, wymagaj potwierdzenia i loguj każdą zmianę
Zmapuj źródła danych i wrażliwe operacje wcześnie
Zanim Claude Code cokolwiek zapisze, zapisz, czego narzędzie będzie dotykać. Większość problemów z bezpieczeństwem i niezawodnością pojawia się tutaj, nie w UI. Traktuj to mapowanie jak kontrakt: mówi recenzentom, co jest w zakresie, a co poza nim.
Zacznij od konkretnego inwentarza źródeł danych i właścicieli. Na przykład: logi (app, gateway, auth) i ich lokalizacje; dokładne tabele lub widoki bazy danych, które narzędzie może zapytywać; sklep feature flagów i reguły nazewnictwa; metryki i trace’y oraz które etykiety są bezpieczne do filtrowania; oraz czy planujesz zapisywać notatki do systemu ticketowego lub incydentowego.
Następnie nazwij operacje, które narzędzie może wykonać. Unikaj „admin” jako uprawnienia. Zamiast tego zdefiniuj audytowalne czasowniki. Typowe przykłady: wyszukiwanie tylko do odczytu i eksport (z limitami), adnotacja (dodanie notatki bez edycji historii), przełączanie konkretnych flag z TTL, ograniczone backfille (zakres dat i liczba rekordów) oraz tryby dry-run pokazujące wpływ bez zmiany danych.
Pola wrażliwe wymagają jawnego traktowania. Zdecyduj, co trzeba maskować (emaile, tokeny, identyfikatory sesji, klucze API, identyfikatory klientów) i co można pokazywać tylko w formie skróconej. Na przykład: pokaż ostatnie 4 znaki ID, albo hashuj je konsekwentnie, by można było łączyć zdarzenia bez widoku surowej wartości.
Na koniec uzgodnij zasady retencji i audytu. Jeśli użytkownik uruchomi zapytanie lub przełączy flagę, zapisz kto to zrobił, kiedy, jakie filtry użyto i ile wyników zwrócono. Przechowuj logi audytu dłużej niż logi aplikacji. Nawet prosta reguła „zapytania przechowywane 30 dni, rekordy audytu 1 rok” zapobiega bolesnym dyskusjom podczas incydentu.
Model dostępu najmniejszych uprawnień, który pozostaje prosty
Zasada najmniejszych uprawnień jest najłatwiejsza, gdy model jest nudny. Zacznij od listy tego, co narzędzie może robić, a potem oznacz każdą akcję jako tylko do odczytu lub zapis. Większość narzędzi wewnętrznych potrzebuje dostępu do odczytu dla większości osób.
Dla pulpitu webowego użyj istniejącego systemu tożsamości (SSO przez OAuth). Unikaj lokalnych haseł. Dla CLI preferuj krótkotrwałe tokeny, które szybko wygasają i mają zakres tylko do potrzebnych akcji. Długowieczne współdzielone tokeny mają tendencję do wklejania się w tickety, zapisywania w historii shell i kopiowania na prywatne maszyny.
Utrzymuj RBAC mały. Jeśli potrzebujesz więcej niż kilku ról, narzędzie prawdopodobnie robi za dużo. Wiele zespołów radzi sobie dobrze z trzema rolami:
- Viewer: tylko do odczytu, bezpieczne domyślnie
- Operator: odczyt plus mały zestaw niskiego ryzyka akcji
- Admin: akcje wysokiego ryzyka, używane rzadko
Rozdzielaj środowiska wcześnie, nawet jeśli UI wygląda tak samo. Utrudnij „przypadkowe zrobienie prod”. Używaj różnych poświadczeń na środowisko, różnych plików konfiguracyjnych i różnych endpointów API. Jeśli ktoś obsługuje tylko staging, nie powinien nawet móc się uwierzytelnić przeciwko produkcji.
Akcje wysokiego ryzyka zasługują na krok zatwierdzający. Myśl o usuwaniu danych, zmianie feature flag, restarcie usług czy uruchamianiu ciężkich zapytań. Dodaj weryfikację drugiej osoby, gdy promień rażenia jest duży. Praktyczne wzorce to potwierdzenia wpisywane ręcznie zawierające cel (nazwa usługi i środowisko), rejestrowanie kto prosił i kto zatwierdził, oraz krótka zwłoka albo zaplanowane okno dla najniebezpieczniejszych operacji.
Jeżeli generujesz narzędzie z Claude Code, wprowadź regułę, że każdy endpoint i komenda deklaruje wymaganą rolę z góry. Ten nawyk sprawia, że przegląd uprawnień pozostaje wykonalny w miarę rozwoju narzędzia.
Zabezpieczenia zapobiegające wpadkom i złym zapytaniom
Od deva do wdrożenia
Wdróż i hostuj swoje narzędzie wewnętrzne, gdy będziesz gotów podzielić się nim z zespołem.
Najczęstszy tryb awarii narzędzi wewnętrznych to nie atakujący. To zmęczony współpracownik, uruchamiający „właściwą” komendę z złymi wejściami. Traktuj zabezpieczenia jako cechy produktu, nie dopracowanie.
Bezpieczne domyślne ustawienia
Zacznij od bezpiecznej pozycji: domyślnie tylko do odczytu. Nawet jeśli użytkownik jest adminem, narzędzie powinno otwierać się w trybie, który może tylko pobierać dane. Akcje zapisujące niech będą opcją i dobrze widoczne.
Dla każdej operacji zmieniającej stan (przełączenie flagi, backfill, usunięcie rekordu) wymagaj jawnego wpisania potwierdzenia. „Na pewno? y/N” jest zbyt łatwe do wykonania w odruchu. Poproś o przepisanie czegoś konkretnego, np. nazwy środowiska plus ID celu.
Ścisła walidacja wejścia zapobiega większości katastrof. Przyjmuj tylko kształty, które naprawdę obsługujesz (ID, daty, środowiska) i odrzucaj resztę wcześnie. Dla wyszukiwań ogranicz siłę: ogranicz liczbę wyników, wymuszaj sensowne zakresy dat i stosuj podejście allow-list zamiast pozwalać na dowolne wzorce trafiające do Twojego magazynu logów.
Aby uniknąć zapętleń zapytań, dodaj timeouty i limity rate. Bezpieczne narzędzie szybko się kończy i wyjaśnia powód, zamiast zawieszać się i bombardować bazę.
Zestaw zabezpieczeń, który dobrze działa w praktyce:
- Domyślnie tylko odczyt, z wyraźnym przełącznikiem "tryb zapisu"
- Potwierdzenie przez wpisanie dla zapisów (zawierające env + target)
- Ścisła walidacja ID, dat, limitów i dozwolonych wzorców
- Timeouty zapytań i limity na użytkownika
- Maskowanie sekretów w output i w logach narzędzia
Higiena wyników
Zakładaj, że output narzędzia będzie kopiowany do ticketów i czatów. Domyślnie maskuj sekrety (tokeny, ciasteczka, klucze API, a w razie potrzeby emaile). Odrób także to, co przechowujesz: logi audytu powinny zapisywać, co próbowano, nie surowe dane zwrócone.
Dla dashboardu wyszukiwania logów zwracaj krótki podgląd i liczbę, nie pełne payloady. Jeśli ktoś naprawdę potrzebuje pełnego zdarzenia, niech to będzie osobna, wyraźnie bramkowana akcja z własnym potwierdzeniem.
Jak pracować z Claude Code, nie tracąc kontroli
Traktuj Claude Code jak szybkiego młodszego współpracownika: pomocny, ale nieczytający w myślach. Twoim zadaniem jest utrzymać pracę w granicach, możliwą do przeglądu i łatwą do cofnięcia. To różnica między narzędziami, które wydają się bezpieczne, a tymi, które zaskakują o 2 w nocy.
Zacznij od specyfikacji, której model może przestrzegać
Zanim poprosisz o kod, napisz krótką specyfikację, która nazwie akcję użytkownika i oczekiwany rezultat. Trzymaj się zachowania, nie szczegółów frameworka. Dobra specyfikacja zwykle mieści się na pół stronie i obejmuje:
- Komendy lub ekrany (dokładne nazwy)
- Wejścia (flagi, pola, formaty, limity)
- Wyjścia (co się pokazuje, co jest zapisywane)
- Przypadki błędów (nieprawidłowe dane, timeouty, puste wyniki)
- Kontrole uprawnień (co się dzieje przy odmowie dostępu)
Na przykład, jeśli budujesz CLI do wyszukiwania logów, zdefiniuj jedną komendę end-to-end: logs search --service api --since 30m --text "timeout", z twardym limitem wyników i jasnym komunikatem "brak dostępu".
Proś o małe przyrosty, które możesz zweryfikować
Poproś najpierw o szkielet: wiring CLI, ładowanie konfiguracji i stubowane wywołanie danych. Potem poproś o dokładnie jedną funkcję ukończoną w całości (włącznie z walidacją i błędami). Małe diffy sprawiają, że przeglądy są realne.
Po każdej zmianie poproś o wyjaśnienie w prostym języku, co się zmieniło i dlaczego. Jeśli wyjaśnienie nie pasuje do diffu, zatrzymaj się i sformułuj ponownie zachowanie i ograniczenia bezpieczeństwa.
Generuj testy wcześnie, zanim dodasz więcej funkcji. Przynajmniej pokryj ścieżkę szczęścia, nieprawidłowe wejścia (złe daty, brak flag), odmowę dostępu, puste wyniki oraz limity rate lub timeouty backendu.
CLI kontra web dashboard: wybór odpowiedniego interfejsu
CLI i wewnętrzny pulpit webowy mogą rozwiązać ten sam problem, ale zawodzą na różne sposoby. Wybierz interfejs, który sprawia, że bezpieczna ścieżka jest najłatwiejsza.
CLI zwykle najlepiej sprawdza się, gdy liczy się szybkość i użytkownik wie, czego chce. Pasuje też do przepływów tylko do odczytu, bo można utrzymać wąskie uprawnienia i unikać przycisków przypadkowo wywołujących zapisy.
CLI to dobry wybór dla szybkich zapytań on-call, skryptów i automatyzacji, jawnych ścieżek audytu (każde polecenie jest wypisane) oraz niskiego nakładu wdrożenia (jeden binarny plik, jedna konfiguracja).
Pulpit webowy lepiej, gdy potrzebujesz współdzielonej widoczności lub prowadzonych kroków. Może zmniejszać błędy, kierując ludzi do bezpiecznych domyślnych ustawień jak zakres czasu, środowisko i predefiniowane akcje. Dashboardy sprawdzają się też przy widokach statusu dla zespołu, zabezpieczonych akcjach wymagających potwierdzenia i wbudowanych wyjaśnieniach, co robi przycisk.
Gdy to możliwe, używaj tego samego backendowego API dla obu klientów. Umieść auth, limity rate, limity zapytań i logowanie audytu w API, nie w UI. Wtedy CLI i dashboard będą różnymi klientami o różnych ergonomiach.
Zdecyduj także, gdzie to działa, bo zmienia to ryzyko. CLI na laptopie może wyciekć tokeny. Uruchamianie go na bastionie lub w wewnętrznym klastrze może zmniejszyć ekspozycję i ułatwić logowanie oraz egzekucję polityk.
Przykład: dla wyszukiwania logów CLI jest świetne dla inżyniera on-call wyciągającego ostatnie 10 minut dla jednej usługi. Dashboard lepiej działa w pokoju incydentowym, gdzie każdy potrzebuje tego samego filtrowanego widoku oraz prowadzonej akcji „eksport do postmortem”, która jest sprawdzona pod kątem uprawnień.
Realistyczny przykład: narzędzie do wyszukiwania logów dla on-call
Wybierz dashboard zamiast skryptów
Stwórz dashboard w React z backendem w Go, gdy UI webowy to bezpieczniejszy wybór.
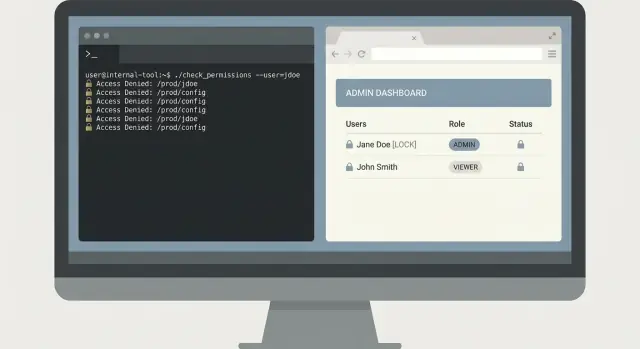
Jest 02:10, a on-call dostaje zgłoszenie: „Kliknięcie Płatności czasem się nie udaje dla jednego klienta.” Support ma screenshot z request ID, ale nikt nie chce wklejać przypadkowych zapytań do systemu logów z uprawnieniami admina.
Mały CLI może to rozwiązać bezpiecznie. Klucz to trzymać się wąsko: szybko znaleźć błąd, pokazać tylko to, co potrzebne i nie zmieniać danych produkcyjnych.
Minimalny przepływ CLI
Zacznij od jednej komendy, która wymusza ograniczenia czasowe i konkretny identyfikator. Wymagaj request ID i okna czasowego, domyślnie ustaw krótkie okno.
oncall-logs search --request-id req_123 --since 30m --until now
Zwróć najpierw podsumowanie: nazwa usługi, klasa błędu, liczba i trzy najważniejsze dopasowane komunikaty. Potem pozwól na wyraźny krok „rozwiń”, który drukuje pełne linie logów tylko wtedy, gdy użytkownik o to poprosi.
oncall-logs show --request-id req_123 --limit 20
Ten dwustopniowy projekt zapobiega przypadkowym zrzutom danych. Ułatwia też przeglądy, bo narzędzie ma wyraźną bezpieczną ścieżkę domyślną.
Opcjonalna akcja uzupełniająca (bez zapisów)
On-call często musi zostawić ślad dla następnej osoby. Zamiast zapisywać do bazy, dodaj opcjonalną akcję tworzącą treść notatki do ticketu lub dodającą tag w systemie incydentowym, ale nigdy nie dotykając rekordów klientów.
Aby utrzymać najmniejsze uprawnienia, CLI powinien używać tokena tylko do odczytu logów i osobnego, zakresowego tokena dla akcji ticket/tag.
Przechowuj rekord audytu dla każdego uruchomienia: kto to wykonał, które request ID, jakie zakresy czasu użyto i czy rozwinął szczegóły. Ten log audytu jest Twoją siatką bezpieczeństwa, gdy coś pójdzie nie tak lub gdy trzeba przeprowadzić przegląd dostępu.
Najczęstsze błędy powodujące problemy z bezpieczeństwem i niezawodnością
Małe narzędzia wewnętrzne często zaczynają się jako „szybka pomoc”. To dokładnie powód, dla którego kończą z ryzykownymi domyślnymi ustawieniami. Najszybszy sposób, by stracić zaufanie, to jeden zły incydent, jak narzędzie które usuwa dane zamiast tylko je czytać.
Najczęściej pojawiające się błędy:
- Przyznanie narzędziu zapisu do bazy produkcyjnej, gdy potrzebuje tylko odczytów, a potem założenie „będziemy ostrożni”
- Pomijanie ścieżki audytu, przez co później nie da się odpowiedzieć, kto uruchomił komendę, jakich użył parametrów i co się zmieniło
- Pozwalanie na dowolne SQL, regexy lub ad hoc filtry, które przypadkowo skanują ogromne tabele lub logi i doprowadzają systemy do awarii
- Mieszanie środowisk tak, że staging może sięgnąć produkcji z powodu współdzielonych konfiguracji, tokenów lub bazowych URL
- Wypisywanie sekretów do terminala, konsoli przeglądarki lub logów, a potem zapominanie, że te dane trafiają do ticketów i czatów
Realistyczna awaria wygląda tak: inżynier on-call używa CLI do wyszukiwania logów podczas incydentu. Narzędzie akceptuje dowolny regex i wysyła go do backendu logów. Jeden kosztowny wzorzec biega po godzinach wysokiego ruchu, generuje koszty i spowalnia wyszukiwania dla wszystkich. W tej samej sesji CLI wypisuje token API w debugu, który trafia do publicznego dokumentu incydentu.
Bezpieczniejsze domyślne ustawienia, które zapobiegają większości incydentów
Traktuj tylko-odczyt jako prawdziwą granicę bezpieczeństwa, nie jako zwyczaj. Używaj oddzielnych poświadczeń per środowisko i oddzielnych kont serwisowych per narzędzie.
Parę zabezpieczeń, które robią większość pracy:
- Używaj zapytań z allow-listy (lub szablonów) zamiast surowego SQL i ogranicz zakresy czasowe oraz liczbę wierszy
- Loguj każdą akcję z request ID, tożsamością użytkownika, środowiskiem docelowym i dokładnymi parametrami
- Wymagaj jawnego wyboru środowiska, z głośnym potwierdzeniem dla produkcji
- Redaguj sekrety domyślnie i wyłącz debug output chyba, że użyty zostanie uprzywilejowany flag
Jeśli narzędzie nie może zrobić czegoś niebezpiecznego z założenia, Twój zespół nie będzie musiał polegać na perfekcyjnej uwadze o 3 nad ranem.
Szybka lista kontrolna przed wypuszczeniem narzędzia
Utrzymaj narzędzie możliwe do przeglądu
Uzyskaj pełne źródło, aby zespół mógł przeglądać i przejmować każdą zmianę.
Zanim narzędzie trafi do realnych użytkowników (szczególnie on-call), traktuj je jak system produkcyjny. Potwierdź, że dostęp, uprawnienia i limity bezpieczeństwa są realne, a nie domniemane.
Zacznij od dostępu i uprawnień. Wiele wypadków zdarza się, bo „tymczasowy” dostęp staje się trwały, albo narzędzie z czasem zyskuje moce zapisu.
- Auth i offboarding: potwierdź, kto może się logować, jak przydziela się dostęp i jak go cofać tego samego dnia, gdy ktoś zmienia zespół
- Ról nie za dużo: trzymaj maksymalnie 2-3 role (viewer, operator, admin) i zapisz, co każda rola może robić
- Domyślnie tylko odczyt: oglądanie jako domyślna ścieżka, wyraźna rola dla wszystkiego, co zmienia dane
- Obsługa sekretów: przechowuj tokeny i klucze poza repozytorium i sprawdź, że narzędzie ich nie wypisuje w logach ani komunikatach błędów
- Break-glass: jeśli potrzebujesz dostępu awaryjnego, niech będzie ograniczony czasowo i logowany
Potem zweryfikuj zabezpieczenia zapobiegające powszechnym błędom:
- Potwierdzenia przy akcjach ryzykownych: wymagaj wpisywanego potwierdzenia dla kasowań, backfilli lub zmian konfiguracji
- Limity i timeouty: ogranicz rozmiar wyników, wymuszaj okna czasowe i timeouty, aby złe zapytanie nie trwało wiecznie
- Walidacja wejścia: waliduj ID, daty i nazwy środowisk; odrzucaj wszystko, co wygląda jak "run everywhere"
- Logi audytu: zapisuj kto co zrobił, kiedy i skąd; ułatw przeszukiwanie logów w incydentach
- Podstawowe metryki i błędy: monitoruj wskaźnik sukcesu, opóźnienia i najczęstsze typy błędów, by zauważyć awarie wcześnie
Wprowadzaj zmiany z kontrolą: przegląd koleżeński, kilka skoncentrowanych testów dla ścieżek niebezpiecznych i plan rollbacku (włącznie ze sposobem szybkiego wyłączenia narzędzia, jeśli źle działa).
Kolejne kroki: wdrażaj bezpiecznie i ciągle poprawiaj
Traktuj pierwsze wydanie jak kontrolowany eksperyment. Zacznij z jednym zespołem, jednym przepływem i małym zestawem realnych zadań. Narzędzie do wyszukiwania logów dla on-call to dobry pilotaż, bo łatwo zmierzyć zaoszczędzony czas i szybko wykryć ryzykowne zapytania.
Utrzymuj przewidywalny rollout: pilotaż z 3–10 użytkownikami, start w staging, kontroluj dostęp rolami o najmniejszych uprawnieniach (nie współdzielone tokeny), ustaw jasne limity użycia i zapisuj logi audytu dla każdej komendy lub kliknięcia. Upewnij się, że możesz szybko cofnąć konfigurację i zmiany uprawnień.
Zapisz kontrakt narzędzia prostym językiem. Wymień każdą komendę (lub akcję dashboardu), dozwolone parametry, co oznacza sukces i co oznaczają błędy. Ludzie przestają ufać narzędziom wewnętrznym, gdy wyniki są niejednoznaczne, nawet jeśli kod jest poprawny.
Dodaj pętlę informacji zwrotnej, którą faktycznie przeglądasz. Śledź, które zapytania są wolne, które filtry są powszechne i które opcje mylą użytkowników. Kiedy widzisz powtarzające się obejścia, zwykle znaczy to, że interfejs brakuje bezpiecznego domyślnego.
Konserwacja potrzebuje właściciela i harmonogramu. Ustal, kto aktualizuje zależności, kto rotuje poświadczenia i kto jest pagerowany, jeśli narzędzie padnie podczas incydentu. Przeglądaj zmiany generowane przez AI jak serwis produkcyjny: sprawdzaj różnice uprawnień, bezpieczeństwo zapytań i logowanie.
Jeśli Twój zespół woli iterować przez czat, Koder.ai (koder.ai) może być praktycznym sposobem na wygenerowanie małego CLI lub dashboardu z rozmowy, zachowanie snapshotów znanych-dobrych stanów i szybkie rollbacki, gdy zmiana wprowadza ryzyko.