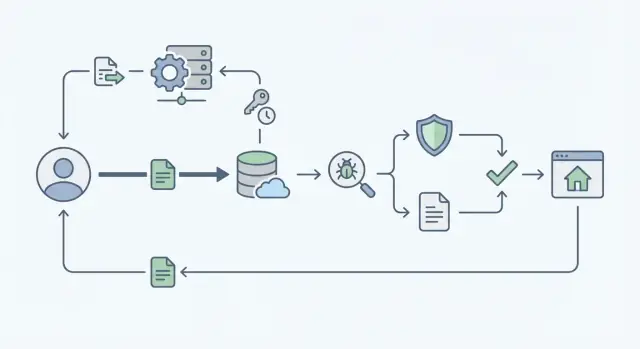
Co sprawia, że przesyłanie plików jest trudne w dużej skali
Przesyłanie plików wygląda prosto, dopóki nie pojawią się prawdziwi użytkownicy. Najpierw jedna osoba wysyła zdjęcie profilowe. Potem dziesięć tysięcy osób w tym samym czasie wrzuca PDF-y, filmy i arkusze. Nagle aplikacja zaczyna zwalniać, koszty przechowywania rosną, a zgłoszeń do supportu przybywa.
Typowe punkty awarii są przewidywalne. Strony uploadu zawieszają się lub kończą czasem, gdy serwer próbuje obsłużyć cały plik zamiast pozwolić, by object storage wykonał ciężką pracę. Uprawnienia mogą dryfować, więc ktoś zgaduje URL pliku i widzi coś, czego nie powinien. „Nieszkodliwe” pliki przychodzą z malware albo w formatach, które rozbijają narzędzia downstream. A logi są niekompletne, więc nie jesteś w stanie odpowiedzieć na podstawowe pytania: kto co i kiedy wrzucił.
Chcesz czegoś nudnego, ale niezawodnego: szybkich uploadów, jasnych reguł (dozwolone typy i rozmiary) oraz śladu audytu, który ułatwia dochodzenia.
Najtrudniejszy kompromis to prędkość vs. bezpieczeństwo. Jeśli przeprowadzisz wszystkie kontrole zanim użytkownik skończy, będzie czekać i powtarzać próby, co zwiększa obciążenie. Jeśli odłożysz sprawdzenia za długo, niebezpieczne lub nieautoryzowane pliki mogą się rozprzestrzenić, zanim je złapiesz. Praktyczne podejście to oddzielenie samego przesyłu od sprawdzeń i utrzymanie każdego kroku krótkiego i mierzalnego.
Bądź też konkretny co do „skali”. Zapisz liczby: pliki na dzień, szczytowe przesyły na minutę, maksymalny rozmiar pliku i gdzie są twoi użytkownicy. Regiony mają znaczenie dla opóźnień i zasad prywatności.
Jeśli budujesz aplikację na platformie takiej jak Koder.ai, warto zdecydować te limity wcześnie, bo wpływają na projekt uprawnień, storage i workflow skanowania w tle.
Prosty model zagrożeń dla uploadów
Zanim wybierzesz narzędzia, ustal, co może pójść źle. Model zagrożeń nie musi być dużym dokumentem. To krótkie, wspólne zrozumienie tego, czego musisz zapobiec, co możesz wykryć później i jakie kompromisy zaakceptujesz.
Atakujący zwykle próbują wkraść się w kilku przewidywalnych punktach: klient (zmiana metadanych lub podszywanie się pod MIME type), krawędź sieci (replay i nadużycia limitów), storage (zgadywanie nazw obiektów, nadpisywanie) oraz pobieranie/podgląd (wywoływanie ryzykownego renderowania albo kradzież plików przez współdzielony dostęp).
Następnie zmapuj zagrożenia na proste kontrole:
Nadmiernie duże pliki to najprostsze nadużycie. Mogą zwiększać koszty i spowalniać prawdziwych użytkowników. Zatrzymaj je wcześnie twardymi limitami bajtów i szybkim odrzuceniem.
Fałszywe typy plików są kolejnym problemem. Plik o nazwie invoice.pdf może być czymś innym. Nie ufaj rozszerzeniom ani kontrolkom w UI. Zweryfikuj na podstawie rzeczywistych bajtów po przesłaniu.
Malware jest inny. Zwykle nie przeskanujesz wszystkiego przed zakończeniem uploadu bez pogorszenia doświadczenia. Zwykły wzorzec to wykrywanie asynchroniczne, kwarantanna podejrzanych elementów i blokada dostępu, aż skan zakończy się pozytywnie.
Nieautoryzowany dostęp bywa najbardziej szkodliwy. Traktuj każdy upload i każde pobranie jako decyzję dotyczącą uprawnień. Użytkownik powinien przesyłać tylko tam, gdzie ma prawo zapisu, i pobierać tylko to, co ma prawo zobaczyć.
Dla wielu aplikacji solidna polityka v1 to:
- Wymuszaj maksymalny rozmiar i dozwolone kategorie (obrazy, PDF itp.)
- Weryfikuj rzeczywisty typ pliku po stronie serwera po przesłaniu
- Skanuj asynchronicznie i trzymaj w kwarantannie, dopóki nie będzie czysty
- Wymagaj jawnej autoryzacji do uploadu i pobrania
- Loguj i alertuj powtarzające się błędy (rozmiar, typ, auth)
Praktyczna architektura uploadu, która pozostaje szybka
Najszybszy sposób obsługi uploadów to trzymanie serwera aplikacji z dala od „biznesu bajtów”. Zamiast przesyłać każdy plik przez backend, pozwól klientowi wysyłać bezpośrednio do object storage przy użyciu krótkotrwałego podpisanego adresu URL. Backend koncentruje się na decyzjach i zapisach, nie na przesyłaniu gigabajtów.
Podział jest prosty: backend odpowiada na pytanie „kto może wysłać co i gdzie”, a storage przyjmuje dane pliku. To eliminuje częsty wąski punkt: serwery aplikacji wykonujące podwójną pracę (auth i proxy pliku) i wyczerpujące CPU, pamięć lub sieć przy dużym obciążeniu.
Minimalne elementy
Przechowuj mały rekord uploadu w bazie danych (np. PostgreSQL), tak żeby każdy plik miał wyraźnego właściciela i cykl życia. Utwórz ten rekord przed rozpoczęciem uploadu, potem aktualizuj go w miarę pojawiania się zdarzeń.
Pola, które zwykle się przydają, to identyfikator właściciela i tenant/workspace, klucz obiektu w storage, status, zadeklarowany rozmiar i MIME type oraz checksum, którą możesz zweryfikować.
Zaplanuj stany uploadu z wyprzedzeniem
Traktuj uploady jak maszynę stanów, aby kontrole uprawnień pozostały poprawne nawet przy retryach.
Praktyczny zestaw stanów to:
- requested
- uploaded
- scanned
- approved
- rejected
Pozwalaj klientowi użyć podpisanego URL dopiero po tym, jak backend stworzy rekord requested. Po potwierdzeniu uploadu przez storage przejdź do uploaded, uruchom skanowanie w tle i udostępnij plik dopiero po approved.
Krok po kroku: podpisane URL bez wąskich gardeł
Zacznij, gdy użytkownik klika Upload. Twoja aplikacja wywołuje backend, aby rozpocząć upload z podstawowymi szczegółami jak nazwa pliku, rozmiar i przeznaczenie (avatar, faktura, załącznik). Backend sprawdza uprawnienia dla docelowego miejsca, tworzy rekord uploadu i zwraca krótkotrwały podpisany URL.
Podpisany URL powinien mieć wąski zakres. Najlepiej pozwalać tylko na jednokrotny upload do jednego, dokładnego klucza obiektu, z krótkim wygaśnięciem i jasnymi warunkami (limit rozmiaru, dozwolony typ, opcjonalny checksum).
Przeglądarka wysyła plik bezpośrednio do storage używając tego URL. Po zakończeniu przeglądarka wywołuje backend, aby sfinalizować. Przy finalizacji sprawdź ponownie uprawnienia (użytkownik mógł stracić dostęp) i zweryfikuj, co faktycznie trafiło do storage: rozmiar, wykryty typ treści i checksum, jeśli go używasz. Uczyń finalizację idempotentną, aby retry nie tworzyły duplikatów.
Następnie oznacz rekord jako uploaded i wyzwól skanowanie w tle (kolejka/zadanie). UI może pokazywać „Przetwarzanie” podczas skanowania.
Walidacja typu i rozmiaru, której można ufać
Ship multi-tenant permissions
Generate clear upload and download authorization rules per workspace or tenant.
Co sprawdzać i gdzie
Ufanie rozszerzeniu to sposób, w jaki invoice.pdf.exe trafia do twojego bucketu. Traktuj walidację jako powtarzalny zestaw kontroli, wykonywany w więcej niż jednym miejscu.
Zacznij od limitów rozmiaru. Umieść maksymalny rozmiar w polityce podpisanego URL (lub w warunkach pre-signed POST), aby storage mógł odrzucić zbyt duże uploady wcześnie. Wymuś ten sam limit ponownie, gdy backend zapisuje metadane, ponieważ klienci nadal mogą próbować obejść UI.
Kontrole typu powinny opierać się na zawartości, a nie na nazwie pliku. Zbadaj pierwsze bajty pliku (magic bytes), aby potwierdzić, że odpowiada oczekiwanemu formatowi. Prawdziwy PDF zaczyna się od %PDF, a PNG ma stały podpis. Jeśli zawartość nie pasuje do allowlisty, odrzuć plik nawet jeśli rozszerzenie wygląda poprawnie.
Utrzymuj allowlisty specyficzne dla każdej funkcji. Upload avatara może pozwalać tylko JPEG i PNG. Funkcja dokumentów może dopuszczać PDF i DOCX. To zmniejsza ryzyko i upraszcza reguły.
Sumy kontrolne i nazwy plików
Nigdy nie używaj oryginalnej nazwy pliku jako klucza w storage. Normalizuj ją do wyświetlania (usuń dziwne znaki, przytnij długość), ale przechowuj własny bezpieczny klucz obiektu, np. UUID plus rozszerzenie przypisane po wykryciu typu.
Przechowuj checksum (np. SHA-256) w bazie i porównuj ją później podczas przetwarzania lub skanowania. Pomaga to wykryć uszkodzenia, częściowe uploady lub manipulacje, szczególnie gdy uploady są ponawiane pod obciążeniem.
Skanowanie antywirusowe, które nie zmusza użytkowników do czekania
Skanowanie malware jest ważne, ale nie powinno siedzieć w ścieżce krytycznej. Przyjmij upload szybko, a następnie traktuj plik jako zablokowany, dopóki nie przejdzie skanowania.
Wzorzec asynchroniczny
Utwórz rekord uploadu ze statusem typu pending_scan. UI może pokazywać plik, ale nie powinien być on jeszcze użyteczny.
Skanowanie zwykle uruchamia zdarzenie storage po utworzeniu obiektu, publikowanie zadania do kolejki tuż po zakończeniu uploadu albo obie metody (kolejka plus zdarzenie storage jako zabezpieczenie).
Worker skanujący pobiera lub streamuje obiekt, uruchamia skanery, a następnie zapisuje wynik w bazie. Zachowuj niezbędne dane: status skanowania, wersję skanera, znaczniki czasu i kto zainicjował upload. Taki ślad audytu znacznie ułatwia supportowi wyjaśnianie „Dlaczego mój plik został zablokowany?”.
Co się dzieje, gdy plik nie przejdzie skanowania
Nie zostawiaj podejrzanych plików pomieszanych z czystymi. Wybierz jedną politykę i stosuj ją konsekwentnie: kwarantanna i usunięcie dostępu albo usunięcie, jeśli nie potrzebujesz pliku do dochodzenia.
Cokolwiek wybierzesz, komunikuj się z użytkownikiem spokojnie i konkretnie. Powiedz, co się stało i co dalej (prześlij ponownie, skontaktuj się z supportem). Alertuj zespół, jeśli wiele plików nie przechodzi skanów w krótkim czasie.
Najważniejsze: ustal twardą zasadę dla pobrań i podglądów — tylko pliki z oznaczeniem approved mogą być serwowane. Wszystko inne powinno zwracać bezpieczną odpowiedź, np. „Plik jest nadal sprawdzany.”
Kontrole uprawnień, które pozostają poprawne przy dużym obciążeniu
Szybkie uploady są świetne, ale jeśli niewłaściwa osoba może dołączyć plik do niewłaściwego workspace, masz poważniejszy problem niż wolne zapytania. Najprostsza zasada jest też najsilniejsza: każdy rekord pliku należy do dokładnie jednego tenanta (workspace/org/projekt) i ma wyraźnego właściciela lub twórcę.
Sprawdzaj uprawnienia dwukrotnie: gdy wydajesz podpisany URL do uploadu i ponownie gdy ktoś próbuje pobrać lub zobaczyć plik. Pierwsza kontrola powstrzymuje nieautoryzowane uploady. Druga chroni, jeśli dostęp zostanie odebrany, URL wycieknie lub rola użytkownika zmieni się po uploadzie.
Zasada najmniejszych uprawnień utrzymuje zarówno bezpieczeństwo, jak i przewidywalność wydajności. Zamiast jednej szerokiej roli „files”, rozdziel uprawnienia na „może wysyłać”, „może oglądać” i „może zarządzać (usuwać/udostępniać)”. Wiele żądań stanie się szybkimi sprawdzeniami (user, tenant, akcja) zamiast drogiej, niestandardowej logiki.
Aby zapobiec zgadywaniu ID, unikaj sekwencyjnych identyfikatorów plików w URL i API. Używaj nieprzezroczystych identyfikatorów i trzymaj klucze storage niezgadywalne. Podpisane URL są transportem, nie systemem uprawnień.
Współdzielenie plików to miejsce, gdzie systemy często zwalniają i robi się bałagan. Traktuj sharing jako jawne dane, nie domyślny dostęp. Proste podejście to oddzielny rekord udostępnienia, który przyznaje użytkownikowi lub grupie dostęp do jednego pliku, opcjonalnie z datą wygaśnięcia.
Utrzymanie szybkości uploadów w miarę wzrostu ruchu i rozmiarów plików
Deploy closer to users
Launch in AWS regions that match latency needs and data residency requirements.
Gdy mówi się o skalowaniu bezpiecznych uploadów, często skupia się na kontrolach bezpieczeństwa i zapomina o podstawach: przesuwanie bajtów jest powolne. Cel to trzymanie dużego ruchu plików z dala od serwerów aplikacji, kontrolowanie retry i unikanie przekształcania kontroli bezpieczeństwa w nieograniczoną kolejkę.
Uczyń duże pliki przewidywalnymi
Dla dużych plików używaj multipart lub chunked uploads, aby niestabilne połączenie nie zmuszało użytkownika do zaczynania od zera. Chunki pomagają też egzekwować jasne limity: maksymalny rozmiar całkowity, maksymalny rozmiar chunku i maksymalny czas uploadu.
Ustal timeouty i retry po stronie klienta świadomie. Kilka retry może uratować prawdziwych użytkowników; nieograniczone retry potrafią skokowo zwiększyć koszty, zwłaszcza w sieciach mobilnych. Celuj w krótkie timeouty na chunk, mały limit retry i twardy deadline dla całego uploadu.
Kontroluj krok „utwórz upload”
Podpisane URL utrzymują ciężką ścieżkę danych szybką, ale żądanie tworzące je nadal jest newralgiczne. Chroń je, żeby pozostało responsywne:
- Rate-limituj „create upload” na użytkownika i na IP
- Egzekwuj limity rozmiaru przed wydaniem podpisanego URL
- Trzymaj krótki TTL, aby nieużyte URL wygasały szybko
- Śledź uploady w toku, żeby jeden użytkownik nie uruchomił setek jednocześnie
- Używaj kluczy idempotencyjnych, aby odświeżenia nie tworzyły duplikatów
Opóźnienia zależą też od geografii. Trzymaj aplikację, storage i workerów skanujących w tym samym regionie, gdy to możliwe. Jeśli potrzebujesz hostingu specyficznego dla kraju ze względu na zgodność, zaplanuj routing wcześnie, aby uploady nie przelatywały przez kontynenty. Platformy działające globalnie (jak Koder.ai) mogą umieszczać zasoby bliżej użytkowników, gdy kwestia rezydencji danych ma znaczenie.
Na koniec planuj też pobieranie, nie tylko upload. Serwuj pliki z podpisanymi URL do pobrania i ustaw zasady cache zależnie od typu pliku i poziomu prywatności. Zasoby publiczne można cache’ować dłużej; prywatne potwierdzenia powinny mieć krótkotrwałe i sprawdzane URL.
Przykładowy scenariusz: faktury i paragony w aplikacji wieloużytkownikowej
Wyobraź sobie małą aplikację biznesową, gdzie pracownicy uploadują faktury i zdjęcia paragonów, a menedżer zatwierdza je do zwrotu kosztów. Tutaj projekt uploadu przestaje być akademicki: masz wielu użytkowników, duże obrazy i realne pieniądze na szali.
Dobry przepływ używa jasnych statusów, aby każdy wiedział, co się dzieje, i aby można było zautomatyzować nudne rzeczy: plik ląduje w object storage i zapisujesz rekord powiązany z użytkownikiem/workspace/expense; zadanie w tle skanuje plik i ekstrahuje podstawowe metadane (np. rzeczywisty MIME type); potem element jest albo zatwierdzony i staje się użyteczny w raportach, albo odrzucony i zablokowany.
Użytkownicy potrzebują szybkiego, konkretnego feedbacku. Jeśli plik jest za duży, pokaż limit i aktualny rozmiar (np. „Plik ma 18 MB. Maksymalnie 10 MB.”). Jeśli typ jest nieprawidłowy, powiedz, co jest dozwolone („Wgraj PDF, JPG lub PNG”). Jeśli skanowanie nie powiedzie się, komunikat powinien być spokojny i użyteczny („Ten plik może być niebezpieczny. Proszę wrzuć nową kopię.”).
Zespoły wsparcia potrzebują śladu, który pozwala debugować bez otwierania pliku: upload ID, user ID, workspace ID, timestamphy dla created/uploaded/scan started/scan finished, kody wyników (too large, type mismatch, scan failed, permission denied), plus klucz storage i checksum.
Ponowne przesyłanie i zamiana plików są częste. Traktuj je jako nowe uploady, dołącz je do tej samej expense jako nową wersję, przechowuj historię (kto i kiedy zamienił) i oznaczaj najnowszą wersję jako aktywną. Jeśli budujesz tę aplikację na Koder.ai, mapuje się to czysto na tabelę uploads plus tabelę expense_attachments z polem wersji.
Częste błędy i proste poprawki
Keep bytes off your servers
Implement direct-to-storage uploads while your app handles auth and audit logs.
Większość błędów związanych z uploadem to nie wymyślne ataki, a małe skróty, które cicho stają się ryzykiem przy wzroście ruchu.
Pięć najczęstszych błędów
- Zaufanie tylko checkom po stronie klienta. Naprawa: waliduj ponownie po stronie serwera na podstawie rzeczywistych bajtów (magic bytes) i egzekwuj limity rozmiaru używając metadanych storage, nie tylko raportu przeglądarki.
- Długotrwałe podpisane URL. Naprawa: trzymaj je krótkie (minuty), jednorazowe i ograniczone do jednego klucza obiektu. Rotuj dane dostępowe i loguj każde wystawienie.
- Pozwalanie na pobieranie plików przed zakończeniem skanowania. Naprawa: uploaduj do lokalizacji kwarantanny, skanuj asynchronicznie, a potem promuj/serwuj po czystym wyniku.
- Używanie nazw lub ścieżek dostarczonych przez użytkownika jako kluczy storage. Naprawa: generuj własne klucze obiektów (UUID) i przechowuj oryginalną nazwę jako metadane wyświetlane.
- Pomijanie kontroli uprawnień przy pobieraniu. Naprawa: traktuj pobranie jako osobną decyzję i każdorazowo sprawdzaj własność, członkostwo w workspace i reguły udostępniania przed wygenerowaniem podpisanego URL.
Proste poprawki zapobiegające wąskim gardłom
Więcej kontroli nie musi znaczyć wolniejszych uploadów. Oddziel szybką ścieżkę od ciężkiej.
Wykonuj szybkie kontrole synchronicznie (auth, rozmiar, dozwolony typ, rate limit), a skanowanie i głębszą inspekcję deleguj do workerów w tle. Użytkownicy mogą kontynuować pracę, gdy plik przejdzie z uploaded do ready. Jeśli budujesz z narzędziem typu Koder.ai, zachowaj to samo podejście: endpoint uploadu ma być mały i ścisły, a skanowanie i post-processing idą do zadań.
Szybka lista kontrolna i dalsze kroki
Zanim wypuścisz uploady, określ, co znaczy „bezpiecznie wystarczające” dla v1. Zespoły zazwyczaj wpadają w kłopoty przez mieszanie zbyt ostrych reguł (które blokują prawdziwych użytkowników) z brakującymi regułami (które zapraszają nadużycia). Zacznij skromnie, ale upewnij się, że każdy upload ma jasną ścieżkę od „odebrane” do „dozwolone do pobrania”.
Zwarta lista pre-launch:
- Wymuszaj twardy limit rozmiaru wcześnie (zanim koszty storage urosną)
- Używaj allowlisty typów plików, walidowanej po zawartości (magic bytes), nie tylko po nazwie pliku
- Zatrzymuj dostęp do plików do momentu zakończenia skanowania
- Wymagaj kontroli autoryzacji przy każdym pobraniu
- Prowadź logi audytowe dla uploadu, wyniku skanowania i prób pobrania
Jeśli potrzebujesz minimalnej polityki, trzymaj ją prostą: limit rozmiaru, wąska allowlista typów, upload przez podpisany URL i „kwarantanna do czasu przejścia skanu”. Dodawaj lepsze funkcje później (podglądy, więcej typów, przebudowy w tle), gdy ścieżka podstawowa jest stabilna.
Monitoring to to, co zapobiega temu, by „szybko” zamieniło się w „tajemniczo wolno” w miarę wzrostu. Śledź współczynnik błędów uploadu (klient vs serwer/storage), wskaźnik niepowodzeń skanów i latencję skanowania, średni czas uploadu wg przedziałów rozmiarów, odmowy autoryzacji przy pobieraniu i wzorce egressu storage.
Przeprowadź mały test obciążeniowy z realistycznymi rozmiarami plików i rzeczywistymi sieciami (dane mobilne zachowują się inaczej niż Wi‑Fi biurowe). Napraw timeouty i retry przed premierą.
Jeśli implementujesz to w Koder.ai (koder.ai), Planning Mode to praktyczne miejsce, by najpierw zaprojektować stany uploadu i endpointy, a potem wygenerować backend i UI wokół tego przepływu. Snapshots i rollback pomagają przy dopracowywaniu limitów i reguł skanowania.