27 wrz 2025·8 min
Wdrożenia Blue/Green & Canary: Jasna strategia wydania
Dowiedz się, kiedy używać wdrożeń Blue/Green a kiedy Canary, jak działa przesuwanie ruchu, co monitorować oraz praktyczne kroki wdrożenia i wycofywania, by wydania były bezpieczniejsze.
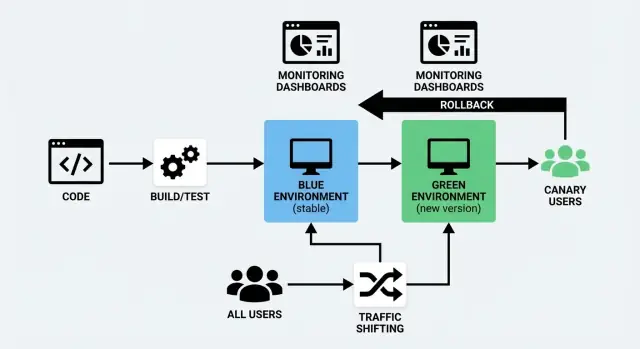
Co oznaczają wdrożenia Blue/Green i Canary
Wypuszczanie nowego kodu wiąże się z ryzykiem z prostego powodu: nie wiesz na pewno, jak zachowa się w kontakcie z prawdziwymi użytkownikami. Blue/Green i Canary to dwa powszechne sposoby zmniejszenia tego ryzyka przy jednoczesnym utrzymaniu niemal zerowych przestojów.
Blue/Green prosto mówiąc
W wdrożeniu blue/green używasz dwóch oddzielnych, ale podobnych środowisk:
- Blue: wersja aktualnie obsługująca użytkowników (środowisko „live”).
- Green: drugie, gotowe środowisko, gdzie wdrażasz nową wersję.
Przygotowujesz Green w tle — wdrażasz nowy build, uruchamiasz testy, rozgrzewasz cache — a potem przełączasz ruch z Blue na Green, gdy jesteś pewny. Jeśli coś pójdzie nie tak, możesz szybko wrócić.
Kluczową ideą nie są „dwa kolory”, lecz czyste, odwracalne przełączenie.
Canary prosto mówiąc
Wydanie canary to stopniowe wdrażanie. Zamiast przełączać wszystkich naraz, wysyłasz nową wersję najpierw do małego wycinka użytkowników (np. 1–5%). Jeśli wszystko wygląda dobrze, stopniowo rozszerzasz wdrożenie, aż 100% ruchu obsłuży nowa wersja.
Kluczem jest uczenie się na podstawie realnego ruchu przed pełnym zaangażowaniem.
Wspólny cel: bezpieczniejsze wydania i mniej przestojów
Obie metody to strategie wdrażania, które mają na celu:
- zmniejszyć wpływ awarii na użytkowników
- wspierać wdrożenie bez przestojów (lub jak najbliżej tego)\
- uczynić wycofania mniej stresującymi i przewidywalnymi
Robią to w różny sposób: Blue/Green skupia się na szybkim przełączeniu między środowiskami, Canary na kontrolowanej ekspozycji przez przesuwanie ruchu.
Nie ma jednej „najlepszej” opcji
Żadna z nich nie jest z automatu lepsza. Wybór zależy od tego, jak używany jest produkt, jak bardzo ufasz testom, jak szybko potrzebujesz informacji zwrotnej i jakiego rodzaju awarii chcesz unikać.
Wiele zespołów łączy obie metody — używając Blue/Green dla prostoty infrastruktury oraz technik Canary dla stopniowej ekspozycji użytkowników.
W kolejnych sekcjach porównamy je bezpośrednio i pokażemy, kiedy każda z nich sprawdza się najlepiej.
Blue/Green vs Canary: szybkie porównanie
Blue/Green i Canary to sposoby wypuszczania zmian bez przerywania pracy użytkowników — różnią się jednak sposobem, w jaki ruch przechodzi na nową wersję.
Jak zmienia się ruch
Blue/Green uruchamia dwa pełne środowiska: „Blue” (aktualne) i „Green” (nowe). Weryfikujesz Green, a następnie przełączasz cały ruch naraz — jakbyś przekręcał pojedynczy, kontrolowany przełącznik.
Canary wysyła nową wersję najpierw do małego wycinka użytkowników (np. 1–5%), a potem stopniowo przesuwa ruch, obserwując zachowanie w rzeczywistości.
Zalety i wady, które mają znaczenie
| Czynnik | Blue/Green | Canary |
|---|---|---|
| Szybkość | Bardzo szybkie przełączenie po weryfikacji | Wolniejsze przez design (stopniowe kroki) |
| Ryzyko | Średnie: po przełączeniu błędna wersja wpływa na wszystkich | Niższe: problemy często pojawiają się przed pełnym wdrożeniem |
| Złożoność | Umiarkowana (dwa środowiska, czyste przełączenie) | Wyższa (dzielenie ruchu, analiza, stopniowe kroki) |
| Koszt | Wyższy (podwójne zasoby podczas rolloutu) | Często niższy (można rampować używając istniejącej pojemności) |
| Najlepsze do | Dużych, skoordynowanych zmian | Częstych, małych usprawnień |
Prosta wskazówka decyzyjna
Wybierz Blue/Green, gdy chcesz mieć czysty, przewidywalny moment do przełączenia — szczególnie przy większych zmianach, migracjach lub wydaniach wymagających wyraźnego rozgraniczenia starej i nowej wersji.
Wybierz Canary, gdy często wypuszczasz, chcesz uczyć się z rzeczywistego ruchu bezpiecznie i zmniejszać promień rażenia, pozwalając metrykom kierować kolejnymi krokami.
Jeśli nie jesteś pewien, zacznij od Blue/Green dla prostoty operacyjnej, a potem dodaj techniki Canary dla usług o wyższym ryzyku, gdy monitoring i nawyki wycofywania będą stabilne.
Kiedy Blue/Green jest właściwe
Blue/Green sprawdza się, gdy chcesz, by wydania wyglądały jak „przekręcenie przełącznika”. Uruchamiasz dwa środowiska produkcyjne: Blue (aktualne) i Green (nowe). Gdy Green jest zweryfikowany, kierujesz do niego użytkowników.
Potrzebujesz niemal zerowego przestoju
Jeśli produkt nie może pozwolić sobie na widoczne okna konserwacji — np. procesy zakupowe, systemy rezerwacji, pulpity zalogowanych użytkowników — Blue/Green pomaga, bo nowa wersja jest uruchomiona, rozgrzana i sprawdzona zanim trafi do prawdziwych użytkowników. Większość czasu wdrożenia odbywa się w tle, a nie przed klientami.
Chcesz najprostszego możliwego rollbacku
Wycofanie to często po prostu ponowne skierowanie ruchu do Blue. To cenna opcja, gdy:
- wydanie musi być odwracalne w ciągu kilku minut
- chcesz uniknąć paniki i gorączkowych hotfixów
- potrzebujesz jasnego, powtarzalnego planu postępowania przy awarii
Kluczowa korzyść to to, że rollback nie wymaga przebudowy ani ponownego wdrożenia — to przełączenie ruchu.
Zmiany w bazie danych muszą być kompatybilne wstecz
Blue/Green jest najłatwiejszy, gdy migracje bazy danych są wstecznie kompatybilne, bo przez pewien czas Blue i Green mogą współistnieć (i potencjalnie oba zapisywać/odczytywać, w zależności od routingu i zadań). Dobrymi przypadkami są:
- dodatnie zmiany schematu (nowe kolumny nullable, nowe tabele)
- rozszerzanie formatów danych tak, by stary kod mógł je ignorować
Ryzykowne są usunięcia kolumn, zmiany nazw pól lub zmiany znaczeń w miejscu — mogą one złamać obietnicę „szybkiego powrotu”, chyba że zaplanujesz migracje w kilku krokach.
Możesz pozwolić sobie na duplikację środowisk i kontrolę routingu
Blue/Green wymaga dodatkowej pojemności (dwóch stosów) i sposobu kierowania ruchem (load balancer, ingress lub routing platformy). Jeśli masz automatyzację do provisioningu środowisk i czysty mechanizm routingu, Blue/Green staje się praktycznym domyślnym sposobem na wydania o wysokiej pewności i niskim stresie.
Kiedy wydania Canary mają sens
Wydanie canary to strategia, gdzie zmianę wdrażasz najpierw do małego wycinka prawdziwych użytkowników, uczysz się z zachowania systemu, a potem rozszerzasz. To dobry wybór, gdy chcesz zmniejszyć ryzyko bez zatrzymywania całego świata dużym, jednorazowym wydaniem.
Masz dużo ruchu i jasne sygnały
Canary najlepiej działa w aplikacjach o dużym ruchu, ponieważ nawet 1–5% ruchu da szybko użyteczne dane. Jeśli już monitorujesz wyraźne metryki (wskaźniki błędów, opóźnienia, konwersje, ukończenie checkoutu, timeouty API), możesz weryfikować wydanie na podstawie rzeczywistych wzorców użycia, a nie tylko testów.
Obawiasz się wydajności i przypadków brzegowych
Niektóre problemy ujawniają się tylko pod prawdziwym obciążeniem: wolne zapytania do bazy, brak trafień w cache, opóźnienia regionalne, nietypowe urządzenia czy rzadkie ścieżki użytkowników. Dzięki canary możesz potwierdzić, że zmiana nie zwiększa błędów ani nie pogarsza wydajności, zanim dotrze do wszystkich.
Potrzebujesz etapowych wydań, nie jednorazowego przełączenia
Jeśli produkt jest często aktualizowany, pracuje nad nim wiele zespołów lub zmiany można wprowadzać stopniowo (np. poprawki UI, eksperymenty cenowe, logika rekomendacji), canary pasuje naturalnie. Możesz rozszerzać z 1% → 10% → 50% → 100% w oparciu o obserwowane metryki.
Flagi funkcji są częścią Twojego zestawu narzędzi
Canary świetnie współgra z flagami funkcji: wdrażasz kod bezpiecznie, a potem włączasz funkcjonalność dla podzbioru użytkowników, regionów lub kont. Wycofanie często polega na wyłączeniu flagi zamiast ponownego wdrażania.
Jeśli dążysz do stopniowego dostarczania (progressive delivery), wydania canary są elastycznym punktem startowym.
Zobacz też: flagi funkcji i stopniowe dostarczanie
Podstawy przesuwania ruchu (bez żargonu)
Przesuwanie ruchu oznacza po prostu kontrolowanie, kto i kiedy otrzymuje nową wersję aplikacji. Zamiast przełączać wszystkich naraz, przesuwasz żądania stopniowo (lub selektywnie) ze starej wersji na nową. To praktyczne sedno zarówno wdrożenia blue/green, jak i wydania canary — i to właśnie sprawia, że wdrożenie bez przestojów jest realistyczne.
„Kierownica”: gdzie kierowany jest ruch
Możesz przesuwać ruch na kilku poziomach stosu. Wybór zależy od tego, co już używasz i jak precyzyjnej kontroli potrzebujesz.
- Load balancer: dzieli przychodzące żądania między dwa środowiska lub grupy serwerów.
- Ingress controller (Kubernetes): kieruje ruch do różnych Service'ów na podstawie reguł.
- Service mesh: kontroluje ruch między usługami z precyzyjnymi regułami i lepszą widocznością.
- CDN / routing na krawędzi: przydatne, gdy chcesz podejmować decyzje o routingu blisko użytkowników, często dla ruchu webowego.
Nie potrzebujesz wszystkich warstw. Wybierz jedno miejsce jako „źródło prawdy” dla decyzji routingowych, żeby zarządzanie wydaniem nie zamieniło się w zgadywanie.
Popularne sposoby dzielenia ruchu
Większość zespołów korzysta z jednego (lub mieszanki) poniższych podejść do przesuwania ruchu:
- Procentowe: 1% → 5% → 25% → 50% → 100%. Klasyczny wzorzec canary.
- Na podstawie nagłówków: kieruj żądania z określonym nagłówkiem (np. od narzędzi QA lub wewnętrznych testerów) do nowej wersji.
- Kohorty użytkowników: najpierw konkretne grupy — pracownicy, beta testerzy, region lub poziom konta.
Procenty są najłatwiejsze do wyjaśnienia, ale kohorty bywają bezpieczniejsze, bo możesz kontrolować którym użytkownikom pokazujesz zmianę (i uniknąć zaskakiwania kluczowych klientów na samym początku).
Sesje i cache: dwa „ziarna piasku”
Dwie rzeczy najczęściej psują inaczej solidne plany wdrożenia:
Trwałe sesje (sticky sessions). Jeśli system wiąże użytkownika z konkretnym serwerem/wersją, rozdzielenie 10% ruchu może nie zachowywać się jak 10%. Może też powodować błędy, gdy użytkownicy przełączają się między wersjami w trakcie sesji. Jeśli możesz, używaj wspólnego przechowywania sesji lub zapewnij, że routing trzyma użytkownika konsekwentnie na jednej wersji.
Rozgrzewanie cache. Nowe wersje często trafiają na zimne cache'e (CDN, cache aplikacji, cache zapytań do bazy). To może wyglądać jak regresja wydajności, nawet jeśli kod jest w porządku. Zaplanuj czas na rozgrzanie cache'ów przed zwiększaniem ruchu, szczególnie dla stron o dużym ruchu i drogich endpointów.
Traktuj zmiany ruchu jak operację produkcyjną
Traktuj zmiany routingu jak zmiany w produkcji, a nie przypadkowe kliknięcie przycisku.
Udokumentuj:
- kto może zmieniać proporcje ruchu
- jak to jest zatwierdzane (on-call? release manager? ticket zmianowy?)
- gdzie się to robi (konfiguracja load balancera, reguły ingress, polityka mesha)
- czym jest „stop” (warunek wstrzymania rolloutu i uruchomienia planu wycofania)
Trochę takiej gouvernance zapobiega sytuacjom, w których ktoś „po prostu popycha na 50%”, podczas gdy zespół wciąż sprawdza, czy canary jest zdrowy.
Co monitorować podczas rolloutu
Run A Release Drill
Zbuduj jeden workflow, wdroż go i poćwicz wycofanie, żeby dzień wydania był spokojniejszy.
Rollout to nie tylko pytanie „czy deploy się powiódł?”. To pytanie „czy prawdziwi użytkownicy mają gorsze doświadczenia?”. Najprościej zachować spokój podczas Blue/Green lub Canary, obserwując mały zestaw sygnałów, które odpowiedzą: czy system jest zdrowy i czy zmiana szkodzi klientom?
Cztery podstawowe sygnały: błędy, opóźnienia, nasycenie, wpływ na użytkownika
Wskaźnik błędów: monitoruj HTTP 5xx, nieudane żądania, timeouty i błędy zależności (baza, płatności, zewnętrzne API). Canary, który zwiększa „drobne” błędy, może i tak generować dużą liczbę zgłoszeń do supportu.
Opóźnienia: obserwuj p50 i p95 (oraz p99, jeśli masz). Zmiana, która nie zmienia średniej, może wciąż powodować długie ogony opóźnień, które użytkownicy odczuwają.
Nasycenie: patrz, jak „pełny” jest system — CPU, pamięć, IO dysku, połączenia do bazy, głębokość kolejek, pule wątków. Problemy z nasyceniem często pojawiają się przed całkowitymi awariami.
Sygnały wpływu na użytkownika: mierz to, co użytkownicy faktycznie doświadczają — nieudane zakupy, sukces logowania, zwracane wyniki wyszukiwania, crash rate aplikacji, czas ładowania kluczowych stron. To często ważniejsze niż same statystyki infrastruktury.
Zbuduj „dashboard wydania”, który każdy zrozumie
Stwórz mały dashboard mieszczący się na jednym ekranie i udostępnij go na kanale wydania. Zachowaj spójność między rolloutami, żeby nikt nie marnował czasu na szukanie wykresów.
Uwzględnij:
- wskaźnik błędów (ogólnie + kluczowe endpointy)
- opóźnienia (p50/p95 dla krytycznych ścieżek)
- nasycenie (top 3 ograniczenia w Twoim stacku, np. CPU aplikacji, połączenia DB, głębokość kolejek)
- KPI wpływające na biznes (1–3 najważniejsze ścieżki biznesowe)
Jeśli robisz canary, segmentuj metryki według wersji/grupy instancji, żeby bezpośrednio porównać canary z baseline. Dla blue/green porównaj nowe środowisko ze starym w oknie przełączenia.
Ustal progi do zatrzymania/wycofania
Zasady ustal przed przesunięciem ruchu. Przykładowe progi:
- wskaźnik błędów wzrasta o X% względem baseline przez Y minut
- p95 przekracza ustalony limit (lub rośnie o X% względem baseline)
- KPI użytkownika spada poniżej minimalnego dopuszczalnego poziomu
Dokładne liczby zależą od usługi, ale ważne jest porozumienie. Jeśli wszyscy znają plan wycofania i progi, unikniesz dyskusji w momencie, gdy klienci są dotknięci.
Alerty skoncentrowane na oknie rolloutu
Dodaj (lub tymczasowo zaostrz) alerty dla okien rolloutu:
- niespodziewane skoki 5xx/timeoutów
- nagłe regresje opóźnień na kluczowych ścieżkach
- szybki wzrost sygnałów nasycenia (pule połączeń, kolejki)
Utrzymuj alerty akcyjne: „co się zmieniło, gdzie i co robić dalej”. Jeśli alerty są zbyt hałaśliwe, ludzie przegapią ten jeden istotny sygnał podczas przesuwania ruchu.
Kontrole przed wydaniem, które łapią problemy wcześnie
Większość awarii rolloutu nie wynika z „wielkich błędów”. To małe niezgodności: brakujący parametr konfiguracyjny, zła migracja bazy, wygasły certyfikat czy integracja zachowująca się inaczej w nowym środowisku. Kontrole przed wydaniem to Twoja szansa, by wykryć te problemy, gdy promień rażenia jest jeszcze mały.
Zacznij od health checków i smoke testów
Zanim przesuniesz ruch (czy to blue/green, czy canary), upewnij się, że nowa wersja jest żywa i potrafi obsługiwać żądania.
- sprawdź, czy endpointy health zwracają OK (nie tylko że proces działa)
- zweryfikuj zależności: baza, cache, kolejki, storage obiektów, dostawcy email/SMS
- potwierdź obecność secretów i zmiennych środowiskowych oraz ich poprawne zakresy
Uruchom krótkie testy end-to-end przeciwko nowemu środowisku
Testy jednostkowe są ważne, ale nie udowadniają, że wdrożony system działa. Uruchom krótki, zautomatyzowany zestaw testów end-to-end przeciwko nowemu środowisku, który kończy się w minutach, a nie godzinach.
Skoncentruj się na przepływach, które przechodzą przez granice usług (web → API → baza → integracje) i wykonaj przynajmniej jedno „rzeczywiste” żądanie dla kluczowej integracji.
Zweryfikuj krytyczne ścieżki użytkownika
Automatyzacja czasem pomija oczywistości. Wykonaj krótką, ręczną weryfikację najważniejszych przepływów:
- logowanie i reset hasła
- proces zakupu lub płatności (łącznie ze ścieżkami błędów)
- podstawowe akcje „stwórz/edytuj/usun” wykonywane codziennie przez użytkowników
Jeśli obsługujesz wiele ról (admin vs klient), sprawdź przynajmniej jedną ścieżkę dla każdej roli.
Miej checklistę gotowości przed wydaniem
Checklista zamienia wiedzę plemienną w powtarzalną strategię wdrożenia. Niech będzie krótka i wykonalna:
- migracje bazy zastosowane i odwracalne (lub jasno bezpieczne)
- observability gotowe: logi, dashboardy, alerty dla kluczowych metryk
- plan wycofania przejrzany (kto, jak i co oznacza „stop”)
Gdy te kontrole stają się rutyną, przesuwanie ruchu to kontrolowany krok — nie skok wiary.
Blue/Green: praktyczny plan działania
Deploy With Confidence
Wdrażaj i hostuj aplikację z prostą możliwością snapshotów i wycofania zmian.
Wdrożenie blue/green jest najłatwiejsze, gdy traktujesz je jak checklistę: przygotuj, wdroż, zweryfikuj, przełącz, obserwuj, sprzątnij.
1) Wdróż do Green (bez dotykania użytkowników)
Wdróż nową wersję do Green, podczas gdy Blue nadal obsługuje ruch. Trzymaj konfiguracje i sekrety zsynchronizowane, aby Green był wiernym lustrzanym odbiciem.
2) Zweryfikuj Green przed jakimkolwiek przełączeniem ruchu
Wykonaj szybkie, wysokosygnałowe kontrole: aplikacja uruchamia się poprawnie, kluczowe strony ładują się, płatności/logowanie działają, a logi wyglądają normalnie. Jeśli masz zautomatyzowane smoke testy, uruchom je teraz. To także moment na sprawdzenie dashboardów i alertów dla Green.
3) Plan migracji bazy: rozszerzaj/zwężaj
Blue/Green komplikuje się przy zmianach w bazie. Stosuj podejście expand/contract:
- Expand: dodaj nowe kolumny/tabele w sposób wstecznie kompatybilny.
- Wdróż Green tak, by działał ze starym i nowym schematem.
- Contract: usuń stare pola dopiero po zakończeniu użycia Blue i upewnieniu się, że nowy kod jest stabilny.
To unika sytuacji „Green działa, Blue łamie się” podczas przełączenia.
4) Rozgrzej cache i obsłuż zadania tła
Przed przełączeniem ruchu rozgrzej krytyczne cache'e (strona główna, popularne zapytania), aby użytkownicy nie doświadczyli kosztu „zimnego startu”.
Dla zadań tła/cronów zdecyduj, kto je uruchamia:
- uruchamiaj zadania w jednym środowisku podczas cutoveru, aby uniknąć podwójnego przetwarzania
5) Przełącz ruch i obserwuj
Przełącz routing z Blue na Green (load balancer/DNS/ingress). Obserwuj wskaźnik błędów, opóźnienia i metryki biznesowe przez krótkie okno.
6) Weryfikacja po przełączeniu i sprzątanie
Sprawdź rzeczywiste zachowania użytkowników, trzymaj Blue dostępne krótko jako fallback. Gdy wszystko jest stabilne, wyłącz zadania w Blue, zarchiwizuj logi i zdeprowizjonuj Blue, by obniżyć koszty i uniknąć zamieszania.
Canary: praktyczny plan działania
Canary to uczenie się bezpieczne. Zamiast wysyłać wszystkich naraz, wystawiasz nową wersję na niewielki fragment ruchu, uważnie obserwujesz i dopiero potem rozszerzasz. Celem nie jest „wolno iść”, lecz „udowodnić bezpieczeństwo” krok po kroku.
Prosty plan rampowania (1–5% → 25% → 50% → 100%)
- Przygotuj canary
Wdróż nową wersję obok stabilnej. Upewnij się, że możesz kierować zdefiniowany procent ruchu do każdej wersji i że obie wersje są widoczne w monitoringu (osobne dashboardy lub tagi się przydają).
- Etap 1: 1–5%
Zacznij od małego ruchu. Tutaj wychwycisz oczywiste problemy: brakujące endpointy, złe konfiguracje, niespodzianki migracji DB, czy nagłe skoki latencji.
Zapisuj obserwacje dla etapu:
- co zmieniło się w wydaniu (nawet „małe” zmiany konfiguracji)
- czego się spodziewałeś
- co zaobserwowano (błędy, opóźnienia, problemy wpływające na użytkownika)
- Etap 2: 25%
Jeśli pierwszy etap jest czysty, zwiększ do około ćwierci ruchu. Zobaczysz teraz więcej różnorodności zachowań: różne urządzenia, przypadki brzegowe, większą współbieżność.
- Etap 3: 50%
Połowa ruchu ujawnia problemy z pojemnością i wydajnością. Jeśli masz limit skalowalności, często dostrzeżesz pierwsze sygnały ostrzegawcze tutaj.
- Etap 4: 100% (promocja)
Gdy metryki są stabilne i wpływ na użytkownika akceptowalny, przełącz cały ruch na nową wersję i uznaj ją za promowaną.
Jak długo czekać na każdym etapie
Czas zależy od ryzyka i wolumenu ruchu:
- Zmiana wysokiego ryzyka lub niski ruch: czekaj dłużej na każdym etapie, by uzyskać sygnał (np. 30–60 minut lub więcej). Usługi o małym ruchu mogą potrzebować godzin, by zebrać znaczące dane.
- Niskie ryzyko i wysoki ruch: krótsze etapy (np. 5–15 minut) mogą wystarczyć, bo dane zbierają się szybko.
Uwzględnij też cykle biznesowe. Jeśli produkt ma szczyty (np. przerwy obiadowe, weekendy, runy billingowe), uruchom canary wystarczająco długo, by objąć warunki, które zwykle powodują problemy.
Automatyzuj promocję i wycofanie
Ręczne rollouts wprowadzają wahanie i niespójność. Gdzie to możliwe, zautomatyzuj:
- promocję, gdy kluczowe metryki pozostają w granicach przez określone okno
- wycofanie, gdy progi zostaną przekroczone (np. wskaźnik błędów lub latencja)
Automatyzacja nie odbiera ludzkiego osądu — usuwa opóźnienia.
Traktuj każdy etap jak eksperyment
Dla każdego kroku zapisz:
- podsumowanie zmiany (co dokładnie się zmieniło)
- kryteria sukcesu (które metryki muszą być stabilne)
- zaobserwowane wyniki (co zobaczono, łącznie z „brakiem anomalii”)
- decyzja (promuj, wstrzymaj lub wycofaj) i dlaczego
Te notatki zamieniają historię rolloutów w użyteczny playbook i ułatwiają diagnozę przyszłych incydentów.
Plany wycofania i postępowanie przy awarii
Wycofania są najprostsze, gdy wcześniej zdecydujesz, co oznacza „źle” i kto ma prawo nacisnąć guzik. Plan wycofania to nie pesymizm — to sposób na zatrzymanie małych problemów, zanim staną się poważnymi awariami.
Zdefiniuj jasne progi wycofania
Wybierz krótki zestaw sygnałów i ustaw konkretne progi, by nie debatować podczas incydentu. Typowe progi:
- wskaźnik błędów: skoki 5xx, nieudane checkouty, błędy logowania, timeouty API
- opóźnienia: p95/p99 ponad uzgodniony limit przez trwałe okno (np. 5–10 minut)
- KPI biznesowe: nagłe spadki konwersji, sukcesu płatności, rejestracji lub wzrosty anulowań
Ustal mierzalny trigger (np. „p95 > 800ms przez 10 minut”) i przypisz właściciela (on-call, release manager) z prawem do natychmiastowego działania.
Trzymaj wycofanie szybkie (i nudne)
Szybkość ma większe znaczenie niż elegancja. Wycofanie powinno być jednym z poniższych:
- odwrócenie przesunięcia ruchu (typowe dla blue/green i canary): skieruj ruch z powrotem na poprzednią, znaną dobrą wersję
- ponowne wdrożenie poprzedniej wersji: jeśli zmieniła się infrastruktura, wypchnij ostatni stabilny build i ponownie uruchom checki zdrowia
Unikaj „naprawy na gorąco i kontynuuj rollout” jako pierwszego kroku. Najpierw ustabilizuj, potem diagnozuj.
Planuj częściowe wycofania
W canary niektórzy użytkownicy mogli już wygenerować dane w nowym formacie. Zdecyduj wcześniej:
- czy użytkownicy canary mają być natychmiast skierowani z powrotem, czy zostawić ich na canary podczas analizy?
- jeśli zmienił się format danych, czy baza jest wstecznie kompatybilna? Jeśli nie — rollback może wymagać osobnej łaty.
Przegląd powdrożeniowy, który poprawia następne wydanie
Gdy sytuacja się uspokoi, napisz krótką notatkę po-akcji: co spowodowało rollback, jakie sygnały były brakujące i co zmienicie w checklistach. Traktuj to jako cykl ulepszania procesu wydania, a nie ćwiczenie obwiniania.
Flagi funkcji i stopniowe dostarczanie
Own Your Release Path
Zachowaj kontrolę, eksportując kod źródłowy zawsze, gdy tego potrzebujesz.
Flagi funkcji pozwalają rozdzielić „deploy” (wypuszczenie kodu do produkcji) od „release” (udostępnienie go użytkownikom). To ważne, bo możesz używać tego samego pipeline'u — blue/green lub canary — a kontrolować ekspozycję prostym przełącznikiem.
Wdróż bez presji, udostępniaj z intencją
Dzięki flagom możesz mergować i wdrażać nawet wtedy, gdy funkcja nie jest gotowa dla wszystkich. Kod jest w produkcji, ale uśpiony. Gdy będziesz pewny, włączysz flagę stopniowo — często szybciej niż wypychanie nowego builda — i jeśli coś pójdzie nie tak, wyłączysz ją równie szybko.
Celowane włączanie (nie wszystko albo nic)
Stopniowe udostępnianie to zwiększanie dostępu w przemyślanych krokach. Flagę możesz włączyć dla:
- konkretnej grupy użytkowników (pracownicy, beta testerzy, płatny tier)
- regionu (zacznij od jednego kraju lub centrum danych)
- procentu użytkowników (1% → 10% → 50% → 100%)
To przydatne, gdy canary mówi, że nowa wersja jest zdrowa, ale wciąż chcesz zarządzać ryzykiem konkretnej funkcji.
Zabezpieczenia, które zapobiegają „długu flag”
Flagi funkcji są potężne, ale tylko jeśli są zarządzane. Kilka zasad pomaga utrzymać porządek:
- własność: każda flaga ma przypisaną odpowiedzialną osobę lub zespół
- termin ważności: ustaw datę usunięcia lub przeglądu, żeby stare flagi się nie kumulowały
- dokumentacja: opis, co flaga robi, kogo dotyczy i jak ją wycofać
Praktyczna zasada: jeśli ktoś nie potrafi odpowiedzieć „co się stanie, gdy wyłączymy to?”, flaga nie jest jeszcze gotowa.
Szczegółowe wskazówki dotyczące użycia flag funkcji w strategii wydania można znaleźć w materiałach opisujących tę tematykę.
Jak wybrać strategię i zacząć
Wybór między blue/green a canary to nie pytanie „co jest lepsze”. To decyzja, jakie ryzyko chcesz kontrolować i co realistycznie potrafisz obsłużyć z obecnym zespołem i narzędziami.
Szybki sposób na decyzję
Jeśli priorytetem jest czyste, przewidywalne przełączenie i łatwy przycisk „wróć do starej wersji”, blue/green zwykle jest prostszym wyborem.
Jeśli priorytetem jest zmniejszenie blast radius i uczenie się z rzeczywistego ruchu przed szerokim udostępnieniem, canary jest bezpieczniejszym wyborem — szczególnie gdy zmiany są częste lub trudne do pełnego przetestowania wcześniej.
Praktyczna reguła: wybierz podejście, które Twój zespół potrafi wykonać konsekwentnie o 2 w nocy, gdy coś pójdzie nie tak.
Zacznij od małego pilota
Wybierz jedną usługę (lub jeden widoczny dla użytkownika przepływ) i przeprowadź pilota podczas kilku wydań. Wybierz coś ważnego, ale nie krytycznego, żeby zespół mógł zdobyć doświadczenie w przesuwaniu ruchu, monitoringu i wycofywaniu.
Napisz prosty runbook (i przypisz właściciela)
Zwięźle — jedna strona wystarczy:
- co oznacza „dobrze” (kluczowe metryki i progi)
- kto jest odpowiedzialny podczas rolloutu
- jak wstrzymać, wycofać i komunikować
Upewnij się, że własność jest jasna. Strategia bez właściciela staje się jedynie sugestią.
Najpierw użyj tego, co już masz
Zanim dodasz nowe platformy, sprawdź narzędzia, na których już polegasz: ustawienia load balancera, skrypty deployu, istniejący monitoring i proces incydentowy. Dodawaj nowe narzędzia tylko wtedy, gdy usuwają realne tarcie, które poczułeś w pilocie.
Jeśli szybko tworzysz i wypuszczasz nowe usługi, platformy łączące generowanie aplikacji z kontrolą wdrożeń mogą zmniejszyć obciążenie operacyjne. Na przykład, Koder.ai to platforma vibe-coding, która pozwala zespołom tworzyć aplikacje webowe, backendy i mobilne z interfejsu chat — a potem wdrażać i hostować je z praktycznymi funkcjami bezpieczeństwa, takimi jak snapshoty i rollback, wsparcie dla własnych domen i eksportu kodu źródłowego. Te możliwości dobrze wpisują się w główny cel tego artykułu: uczynić wydania powtarzalnymi, obserwowalnymi i odwracalnymi.
Sugerowane kolejne kroki
Jeśli chcesz zobaczyć opcje wdrożenia i wspierane workflowy, przejrzyj cennik i dokumentację wdrożeń. Potem zaplanuj pierwszy pilot, zapisz, co zadziałało, i ulepszaj runbook po każdym rolloutu.