Dlaczego TCP/IP jest ukrytą podstawą współczesnego oprogramowania
Większość aplikacji wydaje się „natychmiastowa”: stukasz przycisk, feed się odświeża, płatność kończy się powodzeniem, wideo startuje. Tego, co dzieje się pod spodem — przesyłania malutkich kawałków danych przez Wi‑Fi, sieci komórkowe, domowe routery i centra danych — zwykle nie widzisz. Często dane przemierzają kraje, a ty nie musisz myśleć o wszystkich bałaganie po drodze.
Ta niewidoczność to obietnica, jaką realizuje TCP/IP. To nie pojedynczy produkt ani funkcja chmurowa. To zbiór wspólnych zasad, które pozwalają urządzeniom i serwerom rozmawiać ze sobą w sposób, który zwykle wydaje się płynny i wiarygodny, nawet gdy sieć jest zaszumiona, przeciążona lub częściowo zawodzi.
Bob Kahn był jedną z kluczowych osób, które to umożliwiły. Wraz z współpracownikami, jak Vint Cerf, Kahn pomógł ukształtować podstawowe idee, które stały się TCP/IP: wspólny „język” dla sieci i sposób dostarczania danych, któremu aplikacje mogą ufać. Bez zbędnego hype’u — ta praca miała znaczenie, bo zamieniła zawodliwe połączenia w coś, na czym oprogramowanie mogło budować w sposób przewidywalny.
Sieci pakietowe w pigułce
Zamiast wysyłać całą wiadomość jako jeden ciągły strumień, sieci pakietowe dzielą ją na małe kawałki zwane pakietami. Każdy pakiet może iść swoją własną ścieżką do miejsca przeznaczenia, jak oddzielne koperty przechodzące przez różne urzędy pocztowe.
Czego dowiesz się z tego artykułu
Wyjaśnimy, jak TCP tworzy odczucie niezawodności, dlaczego IP świadomie nie obiecuje perfekcji i jak warstwowanie utrzymuje system zrozumiałym. Na koniec będziesz potrafił wyobrazić sobie, co się dzieje, gdy aplikacja wywołuje API — i dlaczego te idee sprzed dziesięcioleci dalej napędzają nowoczesne usługi w chmurze.
Problem, który musiał rozwiązać TCP/IP
Wczesne sieci komputerowe nie powstawały jako „Internet”. Budowano je dla określonych grup i celów: sieć uniwersytecka tu, wojskowa tam, laboratorium badawcze gdzie indziej. Każda działała dobrze lokalnie, ale często używała innego sprzętu, formatów wiadomości i zasad przesyłania danych.
To tworzyło frustrującą rzeczywistość: nawet jeśli dwa komputery były „podłączone do sieci”, mogły nie być w stanie wymienić informacji. To trochę jak wiele systemów kolejowych z różnymi szerokościami torów i innymi sygnałami. Można poruszać pociągi wewnątrz jednego systemu, ale przejście do innego jest trudne, kosztowne lub niemożliwe.
Internetworking: łączenie sieci, nie tylko komputerów
Kluczowe wyzwanie Boba Kahna nie brzmiało po prostu „połącz komputer A z komputerem B”. Brzmiało: jak połączyć sieci między sobą tak, aby ruch mógł przechodzić przez wiele niezależnych systemów, jakby były jednym większym systemem?
To właśnie znaczy „internetworking” — budować metodę, dzięki której dane mogą przeskakiwać z jednej sieci do następnej, nawet gdy te sieci są zaprojektowane inaczej i zarządzane przez różne organizacje.
Dlaczego wspólne zasady (protokoły) miały znaczenie
Aby internetworking działał w skali, wszyscy potrzebowali wspólnego zestawu zasad — protokołów — które nie zależały od wewnętrznej budowy żadnej pojedynczej sieci. Te zasady musiały też uwzględniać realne ograniczenia:
- Sieci będą zawodzić, gubić dane lub dostarczać je w złej kolejności.
- Żaden centralny operator nie mógł zarządzać wszystkimi połączeniami ręcznie.
- Nowe sieci będą dołączać z czasem.
TCP/IP stał się praktyczną odpowiedzią: wspólnym „porozumieniem”, które pozwoliło niezależnym sieciom współpracować i nadal przesyłać dane wystarczająco niezawodnie dla realnych aplikacji.
Wkład Boba Kahna prostym językiem
Bob Kahn jest najlepiej znany jako jeden z architektów zasad poruszania się po Internecie. W latach 70., pracując dla DARPA, pomógł przesunąć sieci od eksperymentów badawczych do czegoś, co mogło łączyć różne rodzaje sieci — bez narzucania wszystkim tych samych rozwiązań sprzętowych, okablowania czy projektów wewnętrznych.
Główna idea: pozwolić sieciom rozmawiać ze sobą
ARPANET udowodnił, że komputery mogą komunikować się przez łącza pakietowe. Pojawiały się jednak inne sieci: radiowe, satelitarne i kolejne eksperymentalne systemy — każda ze swoimi dziwactwami. Kahn skupił się na interoperacyjności: umożliwić wiadomości podróżowanie przez wiele sieci tak, jakby była to jedna sieć.
Zamiast budować jedną „idealną” sieć, forsował podejście, w którym:
- Każda lokalna sieć zachowuje własny projekt.
- Wspólny protokół leży powyżej i przesyła dane przez granice sieci.
- „Klej” jest na tyle ogólny, że zadziała z przyszłymi sieciami, które jeszcze nie powstały.
Wspólnie z Vintem Cerfem Kahn współprojektował to, co stało się TCP/IP. Trwały efekt to czyste rozdzielenie odpowiedzialności: IP zajmuje się adresowaniem i przesyłaniem między sieciami, a TCP — niezawodnym dostarczaniem dla aplikacji, które tego potrzebują.
Dlaczego programiści wciąż na tym korzystają
Jeśli kiedykolwiek wywoływałeś API, wczytywałeś stronę WWW albo wysyłałeś logi z kontenera do usługi monitorującej, polegasz na modelu internetworkingu, który promował Kahn. Nie musisz się przejmować, czy pakiety lecą przez Wi‑Fi, światłowód, LTE czy szkielet chmury. TCP/IP sprawia, że wszystko wygląda jak jeden ciągły system — dzięki czemu oprogramowanie może skupić się na funkcjach, a nie na okablowaniu.
Pomysł warstw TCP/IP: prosty, ale potężny
Jednym z najlepszych pomysłów stojących za TCP/IP jest warstwowanie: zamiast budować jeden olbrzymi system „robiący wszystko”, układasz warstwy, z których każda robi jedną rzecz dobrze.
To ma znaczenie, bo sieci nie są takie same. Różne kable, radio, routery i dostawcy mogą współpracować, jeśli zgodzą się na kilka czystych odpowiedzialności.
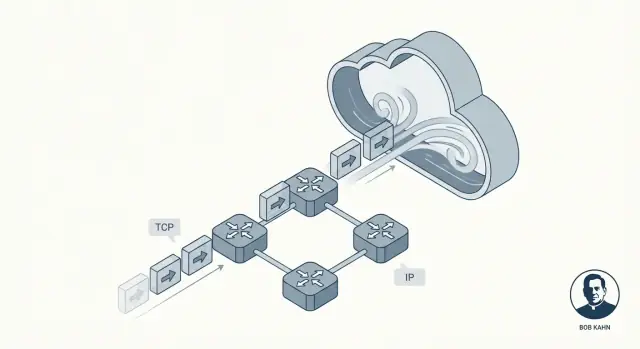
IP: adresowanie i trasowanie między sieciami
Pomyśl o IP (Internet Protocol) jako części odpowiadającej na pytanie: Dokąd idą te dane i jak zbliżamy je do tego miejsca?
IP zapewnia adresy (identyfikujące maszyny) i podstawowe trasowanie (żeby pakiety mogły skakać między sieciami). Co ważne, IP nie próbuje być perfekcyjne. Skupia się na przesuwaniu pakietów do przodu, krok po kroku, nawet jeśli ścieżka się zmienia.
TCP: niezawodne dostarczanie na IP
Następnie TCP (Transmission Control Protocol) leży nad IP i odpowiada: Jak sprawić, by to wyglądało jak niezawodne połączenie?
TCP zajmuje się pracą nad „niezawodnością”, której zwykle oczekują aplikacje: poprawia kolejność danych, wykrywa brakujące kawałki, ponawia wysyłkę w razie potrzeby i reguluje tempo, by nadawca nie zalał odbiorcy ani sieci.
Prosta analogia pocztowa
Przydatny obrazek rozdzielenia ról:
- IP to adresowanie i sieć trasowania, która przesuwa koperty między miastami i urzędami pocztowymi.
- TCP to śledzenie i potwierdzenie, które upewnia się, że wieloczęściowa przesyłka dotarła kompletna i we właściwej kolejności.
Nie prosisz systemu adresowego, żeby zagwarantował dostarczenie paczki; budujesz tę pewność na wierzchu.
Dlaczego ten „prosty stos” pozostał potężny
Dzięki rozdzieleniu odpowiedzialności można ulepszać jedną warstwę bez przebudowy wszystkiego. Nowe sieci fizyczne mogą przenosić IP, a aplikacje mogą polegać na zachowaniu TCP, nie musząc rozumieć, jak działa trasowanie. To właśnie ten czysty podział sprawił, że TCP/IP stał się niewidzialną, wspólną podstawą pod prawie każdą aplikacją i API, z którego korzystasz.
Przełączanie pakietów: szybkość, elastyczność i chaos
Przełączanie pakietów to idea, która uczyniła duże sieci praktycznymi: zamiast rezerwować dedykowaną linię dla całej wiadomości, dzielisz ją na małe kawałki i wysyłasz każdy niezależnie.
Co to jest „pakiet” (i dlaczego kawałki wygrywają)
Pakiet to mały zbiór danych z nagłówkiem (kto wysyła, dokąd, inne informacje trasowania) oraz fragmentem treści.
Dzielenie danych na kawałki pomaga, bo sieć może:
- Dzielić łącza między wielu użytkowników (nikt nie „zajmuje” kabla)
- Omijać wolne lub uszkodzone fragmenty sieci
- Odzyskiwać dane przez ponowne wysłanie tylko brakujących części, a nie całego pliku
Różne trasy, mieszana kolejność
I tu zaczyna się „chaos”. Pakiety z tego samego pobierania czy wywołania API mogą iść różnymi trasami przez sieć, w zależności od tego, co jest akurat zajęte lub dostępne. To oznacza, że mogą dotrzeć w złej kolejności — pakiet nr 12 może przyjść przed pakietem nr 5.
Przełączanie pakietów nie stara się tego zapobiegać. Priorytetem jest jak najszybsze przepuszczenie pakietów, nawet jeśli porządek dotarcia jest bałaganiarski.
Dlaczego pakiety znikają
Utrata pakietów nie jest rzadka i nie zawsze jest czyjąś winą. Typowe przyczyny:
- Przeciążenie: routery kończą bufor i usuwają pakiety.
- Zakłócenia: szczególnie na łączach bezprzewodowych.
- Awarie i zmiany tras: łącze pada w trakcie transmisji i część pakietów nie dociera.
Niedoskonałość jako cecha, nie błąd
Kluczową decyzją projektową było zaakceptowanie, że sieć może być niedoskonała. IP koncentruje się na przesyłaniu pakietów najlepiej jak potrafi, bez obiecywania dostarczenia czy kolejności. Ta swoboda pozwala sieciom rosnąć — i dlatego warstwy wyższe (jak TCP) sprzątają ten bałagan.
Jak TCP sprawia, że zawodne sieci wydają się niezawodne
Zaplanuj ustawienia sieciowe
Zmapuj endpointy, limity czasu i idempotencję zanim zaczniesz pisać kod, używając Planning Mode.
IP dostarcza pakiety w modelu „best effort”: niektóre mogą przyjść z opóźnieniem, w złej kolejności, zduplikowane lub wcale. TCP siedzi nad tym i tworzy coś, czemu aplikacje mogą ufać: pojedynczy, uporządkowany, kompletny strumień bajtów — taki, jakiego oczekujesz podczas wysyłania pliku, ładowania strony czy wywołania API.
Niezawodność prostymi słowami
Gdy mówimy, że TCP jest „niezawodny”, zwykle mamy na myśli:
- Uporządkowanie: dane trafiają do aplikacji w tej samej kolejności, w jakiej zostały wysłane.
- Kompletność: brakujące kawałki są wykrywane i ponownie wysyłane.
- Brak luk: aplikacja czyta ciągły strumień, nie rozsypane pakiety.
Kluczowe mechanizmy (i dlaczego działają)
TCP dzieli dane na fragmenty i oznacza je numerami sekwencji. Odbiorca odsyła potwierdzenia (ACK), by poinformować, co dotarło.
Jeśli nadawca nie zobaczy ACK w określonym czasie, zakłada, że coś zaginęło i wykonuje ponowną transmisję. To podstawowa „iluzja”: mimo że sieć może gubić pakiety, TCP próbuje tyle razy, aż odbiorca potwierdzi odbiór.
Sterowanie przepływem kontra sterowanie przeciążeniem
Brzmi podobnie, ale rozwiązują różne problemy:
- Sterowanie przepływem chroni odbiorcę. Mówi: „Jestem zajęty — wysyłaj wolniej, bo mój bufor się zapełni”.
- Sterowanie przeciążeniem chroni sieć. Mówi: „Ścieżka między nami jest przeciążona — cofnij tempo, by nie pogorszyć korka”.
Razem pomagają TCP być szybkim, ale rozważnym.
Timeouty, które się dostosowują
Stały timeout zawiódłby na sieciach powolnych i szybkich. TCP ciągle dostosowuje timeout na podstawie mierzonego czasu podróży tam i z powrotem. Jeśli warunki się pogorszą, czeka dłużej przed ponowną transmisją; jeśli przyspieszą, reaguje szybciej. Ta adaptacja sprawia, że TCP działa w Wi‑Fi, sieciach mobilnych i łączach dalekodystansowych.
Projekt, który się skalował: myślenie end-to-end
Jedna z najważniejszych idei stojących za TCP/IP to zasada end-to-end: umieść „inteligencję” na krawędziach sieci (endpoints), a środek sieci zostaw stosunkowo prosty.
Inteligencja na krawędziach
W praktyce endpoints to urządzenia i programy, którym naprawdę zależy na danych: twój telefon, laptop, serwer oraz systemy operacyjne i aplikacje na nich działające. Rdzeń sieci — routery i łącza między nimi — skupia się głównie na przesyłaniu pakietów.
Zamiast próbować uczynić każdy router „perfekcyjnym”, TCP/IP akceptuje niedoskonałość środka i pozwala endpointom zajmować się tym, co wymaga kontekstu.
Dlaczego prostszy rdzeń ułatwił rozrost
Utrzymanie prostoty rdzenia ułatwiło rozbudowę Internetu. Nowe sieci mogły dołączać bez potrzeby, by każde pośrednie urządzenie rozumiało potrzeby każdej aplikacji. Routery nie muszą wiedzieć, czy pakiet należy do rozmowy wideo, pobierania pliku czy żądania API — po prostu go przekazują.
Co gdzie się odbywa (z przykładami)
Na krawędziach zwykle obsługujesz:
- Niezawodność: ponowne transmisje, kolejność, deduplikacja (TCP).
- Bezpieczeństwo: szyfrowanie i tożsamość (często TLS na poziomie aplikacji/OS).
- Zachowanie aplikacji: timeouty, ponowienia, cache, limity.
W sieci głównie:
- Adresowanie i przekazywanie (IP).
- Podstawowa obsługa pakietów i sygnały o przeciążeniu.
Kompromis
Myślenie end-to-end dobrze się skaluje, ale przesuwa złożoność na zewnątrz. Systemy operacyjne, biblioteki i aplikacje muszą „dopilnować”, by działało to pośród nieporządnej sieci. To świetne dla elastyczności, ale też oznacza, że błędy, źle skonfigurowane timeouty czy zbyt agresywne ponowienia mogą powodować realne problemy dla użytkowników.
Dlaczego „best effort” IP był funkcją, nie wadą
Wypróbuj połączenia w czasie rzeczywistym
Uruchom funkcję w stylu websocket i zobacz, gdzie blokowanie head-of-line w TCP może dać się we znaki.
IP (Internet Protocol) składa prostą obietnicę: spróbuje przesunąć twoje pakiety w kierunku celu. Tylko tyle. Bez gwarancji, że pakiet dotrze, dotrze raz, w kolejności czy w określonym czasie.
Może to brzmieć jak wada — dopóki nie spojrzysz, czego Internet potrzebował, by powstać: globalnej sieci złożonej z wielu mniejszych sieci, należących do różnych organizacji i ciągle się zmieniających.
Co robią (a czego nie robią) routery
Routery to „kierowcy ruchu” w IP. Ich główne zadanie to przekazywanie: gdy pakiet przychodzi, router patrzy na adres docelowy i wybiera kolejny skok, który teraz wydaje się najlepszy.
Routery nie śledzą rozmowy jak centralny operator telefoniczny. Zazwyczaj nie rezerwują dla ciebie przepustowości i nie czekają na potwierdzenie dostarczenia. Utrzymując routery skupione na przekazywaniu, rdzeń sieci pozostaje prosty — i może skalować do ogromnej liczby urządzeń i połączeń.
Dlaczego „best effort” skaluje globalnie
Gwarancje są drogie. Gdyby IP próbował zagwarantować dostarczenie, kolejność i czasy dla każdego pakietu, każda sieć na Ziemi musiałaby ściśle współpracować, przechowywać dużo stanu i odzyskiwać awarie w ten sam sposób. Ten ciężar koordynacji spowolniłby wzrost i uczynił awarie bardziej dotkliwymi.
Zamiast tego IP toleruje bałagan. Gdy łącze zawiedzie, router może wysłać pakiety inną trasą. Gdy ścieżka się zakorkuje, pakiety mogą być opóźnione lub odrzucone, ale ruch często może trwać alternatywnymi ścieżkami.
Efekt to odporność: Internet może działać mimo awarii lub zmian — bo sieć nie musi być perfekcyjna, by być użyteczną.
Od aplikacji i API do pakietów: co się naprawdę dzieje
Gdy wywołujesz fetch() do API, klikasz „Zapisz” lub otwierasz websocket, nie „rozmawiasz z serwerem” jednym gładkim strumieniem. Twoja aplikacja przekazuje dane systemowi operacyjnemu, który dzieli je na pakiety i wysyła przez wiele odrębnych sieci — każdy skok podejmuje własne decyzje.
Proste mapowanie: działania dewelopera → zachowanie TCP/IP
- Żądanie HTTP / wywołanie API: aplikacja zapisuje bajty (żądanie HTTP). TCP zamienia ten strumień w segmenty, numeruje je i oczekuje potwierdzeń. IP pakuje segmenty w pakiety i trasuje je.
- Otwarcie połączenia: handshake TCP ustala wspólny stan (numery sekwencji, rozmiary okien). To nie jest darmowe — dodaje opóźnienie przed pierwszym użytecznym bajtem.
- Wysyłanie pliku: TCP może mieć dużą przepustowość, ale wydajność może wydawać się niska, jeśli opóźnienia są duże.
Opóźnienie kontra przepustowość (dlaczego aplikacja „wydaje się” wolna)
- Opóźnienie (latency) to czas jednej podróży w obie strony. Duże opóźnienia szkodzą wzorcom rozmownym: wielu małych żądań, przekierowaniom, powtarzanym wywołaniom.
- Przepustowość (throughput) to ile danych na sekundę można dostarczyć. Ma znaczenie przy dużych transferach: obrazy, kopie zapasowe, wideo.
Częste zaskoczenie: możesz mieć świetną przepustowość, a mimo to interfejs działać wolno, bo każde żądanie czeka na rundę w obydwie strony.
Ponowienia i timeouty: dlaczego aplikacje powtarzają coś, co TCP już próbuje
TCP powtarza zgubione pakiety, ale nie wie, co oznacza „zbyt długo” dla twojego UX. Dlatego aplikacje dodają:
- Timeouty: „Jeśli brak odpowiedzi w 2 sekundy, pokaż błąd.”
- Retry: „Spróbuj jeszcze raz raz.” To pomaga przy przejściowych utratach, ale może być ryzykowne przy operacjach nie-idempotentnych, jak płatności.
Kiedy „błędy” to w rzeczywistości właściwości sieci
Pakiety mogą być opóźnione, przemieszane, zduplikowane lub zgubione. Przeciążenie może nagle zwiększyć opóźnienie. Serwer może odpowiedzieć, ale odpowiedź nigdy do ciebie nie dotrze. Objawia się to jako niestabilne testy, losowe 504 lub „u mnie działa”. Często kod jest w porządku — to ścieżka między maszynami jest problematyczna.
TCP/IP w chmurze: te same zasady, większa skala
Platformy chmurowe mogą wydawać się nowym rodzajem obliczeń — zarządzane bazy, funkcje serverless, „nieskończone” skalowanie. Pod spodem jednak twoje żądania dalej jadą po tych samych fundamentach TCP/IP, które uruchomił Bob Kahn: IP przesuwa pakiety między sieciami, a TCP (albo czasem UDP) kształtuje sposób, w jaki aplikacje doświadczają sieci.
Co się zmienia w chmurze (głównie opakowanie)
Wirtualizacja i kontenery zmieniają gdzie oprogramowanie działa i jak jest pakowane:
- „Server” może być maszyną wirtualną, kontenerem lub krótkotrwałą funkcją.
- Sieci często są definiowane programowo i łączone przez dostawcę.
To są jednak detale wdrożeniowe. Pakiety nadal używają adresowania IP i trasowania, a wiele połączeń dalej polega na TCP dla uporządkowanego, niezawodnego dostarczania.
Co pozostaje takie samo (wzorce, które rozpoznasz)
Typowe architektury chmurowe budują się z dobrze znanych elementów:
- Load balancery akceptują połączenia TCP (często HTTPS) i rozdzielają ruch do backendów.
- Wywołania serwis‑to‑serwis w klastrze to dalej połączenia sieciowe — HTTP/gRPC nad TCP jest powszechne — tylko między prywatnymi adresami IP.
- Bazy danych i cache (zarządzane lub samodzielne) są osiągane przez standardowe protokoły na TCP (np. sterownik bazy utrzymuje sesję TCP).
Nawet jeśli nigdy „nie widzisz” adresu IP, platforma go przydziela, trasuje pakiety i śledzi połączenia za kulisami.
Niezawodność to wciąż wspólna odpowiedzialność
TCP może odzyskać zgubione pakiety, uporządkować dostawy i dopasować się do przeciążenia — ale nie może obiecać rzeczy niemożliwych. W systemach chmurowych niezawodność to wysiłek zespołowy:
- Sieć: trasowanie, przepustowość, utrata pakietów, przejściowe błędy.
- OS/runtime: bufory gniazd, timeouty, cache DNS, ponowne użycie połączeń.
- Aplikacja: retry z backoffem, idempotencja, sensowne timeouty i degradacja funkcji.
Dlatego nawet platformy generujące i wdrażające full-stack (np. Koder.ai) opierają się na tych samych fundamentach: gdy aplikacja rozmawia z API, bazą czy klientem mobilnym, wracasz do tematu TCP/IP — połączeń, timeoutów i ponowień.
TCP vs UDP i co wybierają dziś programiści
Wypuść demo full-stack
Przekształć pomysł w aplikację React z backendem w Go bez lokalnej konfiguracji pełnego stosu.
Kiedy mówimy „sieć”, często wybieramy między dwoma transportami: TCP i UDP. Oba leżą na IP, ale robią różne kompromisy.
TCP: niezawodny strumień (i jego ukryte koszty)
TCP jest świetny, gdy dane muszą przyjść w kolejności, bez braków, i wolisz poczekać niż zgadywać. Myśl: strony WWW, wywołania API, transfery plików, połączenia z bazą.
Dlatego większość codziennego Internetu jeździ na TCP — HTTPS działa na TCP (przez TLS), a większość oprogramowania request/response zakłada zachowanie TCP.
Wadą jest to, że niezawodność TCP może dodać opóźnień. Jeśli jeden pakiet zaginie, późniejsze pakiety mogą być trzymane, aż luka zostanie wypełniona (tzw. head-of-line blocking). Dla interaktywnych doświadczeń to czekanie może być gorsze niż od czasu do czasu drobne zakłócenie.
UDP: prosty, szybki i sterowany przez aplikację
UDP to „wyślij wiadomość i miej nadzieję, że dotrze”. Nie ma porządkowania, retransmisji ani kontroli przeciążenia na poziomie UDP.
Deweloperzy wybierają UDP, gdy czas ma większe znaczenie niż perfekcja, np. dźwięk/wideo na żywo, gry czy telemetryka w czasie rzeczywistym. Wiele aplikacji buduje własną lekką niezawodność (albo wcale) na podstawie tego, co użytkownicy rzeczywiście zauważają.
Współczesny przykład: QUIC działa na UDP, pozwalając aplikacjom uzyskać szybsze zestawienie połączeń i ominąć niektóre ograniczenia TCP — bez zmiany podstawowej sieci IP.
Praktyczne wskazówki przy wyborze
Wybieraj według:
- Potrzeby niezawodności: Czy każdy bajt musi dotrzeć w kolejności? Wybierz TCP.
- Wrażliwość na opóźnienia: Czy „teraz” ważniejsze niż „perfekcyjnie”? Rozważ UDP.
- Kontrola: Czy chcesz, aby aplikacja decydowała, co ponawiać i jak odzyskiwać? UDP (lub QUIC) daje więcej swobody projektowej.
Czego „nie zapewni” nawet niezawodność: pułapki z życia
TCP często nazywany jest „niezawodnym”, ale to nie znaczy, że aplikacja zawsze będzie działać płynnie. TCP może odzyskać wiele problemów sieciowych, ale nie zapewni niskich opóźnień, stabilnej przepustowości ani dobrego UX, gdy ścieżka między systemami jest niestabilna.
Typowe problemy sieciowe, z którymi się spotkasz
Utrata pakietów zmusza TCP do retransmisji. Niezawodność jest zachowana, ale wydajność może spaść.
Duże opóźnienie (długi RTT) spowalnia każdy cykl request/response, nawet jeśli pakiety nie są tracone.
Bufferbloat ma miejsce, gdy routery lub kolejki OS trzymają za dużo danych. TCP widzi mniej strat, ale użytkownicy doświadczają dużych opóźnień i „lagów”.
Nieprawidłowe MTU może powodować fragmentację lub „czarne dziury” (pakiety znikają, bo są „za duże”), co daje trudne do zdiagnozowania time-outy.
Jak to wygląda w aplikacjach
Zamiast czystego „błędu sieci” często zobaczysz:
- Timeouty na API, które zwykle działają.
- Wolne uploady/pobierania: zaczynają szybko, a potem pełzną.
- Niestabilne połączenia: powtarzające się reconnecty, zamarłe strumienie lub częściowe ładowania strony.
Te symptomy są prawdziwe, ale nie zawsze wywołane przez twój kod. Często to TCP wykonuje swoje zadanie: retransmituje, cofa tempo i czeka, podczas gdy zegar aplikacji nadal tyka.
Gdzie zacząć debugowanie
Klasyfikacja problemu: czy to głównie utrata, opóźnienie czy zmiany trasy?
- Proste sprawdzenia w stylu ping pomagają ocenić opóźnienie i utratę (choć ICMP bywa czasem blokowane).
- Myślenie w stylu traceroute pomaga znaleźć, gdzie zaczyna się opóźnienie lub gubienie.
- Dodaj logi i metryki: czas żądania, liczba timeoutów, retry, sygnały kolejek/backpressure.
Jeśli szybko prototypujesz (np. w Koder.ai i wdrażasz z hostingiem i własnymi domenami), warto od początku włączyć podstawy obserwowalności — bo awarie sieci pojawiają się najpierw jako timeouty i ponowienia, nie jako czyste wyjątki.
Projektuj z myślą o awarii
Zakładaj, że sieci będą się źle zachowywać. Używaj timeoutów, retry z eksponencjalnym backoffem i projektuj operacje jako idempotentne, by ponowienia nie powodowały podwójnych obciążeń, dublowania tworzeń czy uszkodzeń stanu.