Dlaczego Kubernetes zmienił codzienne operacje
Kubernetes nie wprowadził tylko nowego narzędzia — zmienił to, jak wyglądają „codzienne opsy”, gdy uruchamiasz dziesiątki (albo setki) usług. Zanim pojawiła się orkiestracja, zespoły często sklejały skrypty, ręczne runbooki i wiedzę tribalną, żeby odpowiadać na te same powtarzające się pytania: Gdzie powinna działać ta usługa? Jak bezpiecznie wprowadzić zmianę? Co się dzieje, gdy węzeł pada o 2 w nocy?
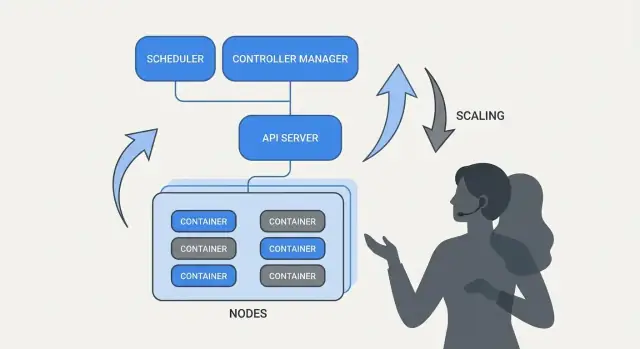
Co właściwie rozwiązuje „orkiestracja"
U podstaw orkiestracja to warstwa koordynacji między twoją intencją („uruchom tę usługę w ten sposób”) a chaosem maszyn, które zawodzą, ruchem, który się przesuwa, i ciągłymi wdrożeniami. Zamiast traktować każdy serwer jak wyjątkowy przypadek, orkiestracja traktuje zasoby obliczeniowe jako pulę, a obciążenia jako jednostki, które można harmonogramować i przenosić.
Kubernetes spopularyzował model, w którym zespoły opisują, co chcą, a system nieustannie pracuje, aby rzeczywistość odpowiadała temu opisowi. Ta zmiana ma znaczenie, ponieważ sprawia, że operacje przestają być opartą na bohaterskich akcjach pracą, a stają się powtarzalnymi procesami.
Trzy rezultaty, które zespoły odczuły od razu
Kubernetes ustandaryzował rezultaty operacyjne, których potrzebuje większość zespołów usługowych:
- Deployment: spójny sposób deklarowania, co powinno działać, jak to aktualizować i jak weryfikować zdrowie.
- Skalowanie: praktyczna ścieżka od jednej instancji do wielu, bez przebudowy usługi czy ręcznego dostarczania maszyn.
- Operacje usług: stabilne sposoby, by usługi się odnajdywały, kierowały ruchem i działały wraz ze zmianami instancji.
Uwaga o zakresie i źródłach
Ten artykuł koncentruje się na ideach i wzorcach związanych z Kubernetes (i liderami takimi jak Brendan Burns), a nie na biografii. Kiedy mówimy „jak to się zaczęło” lub „dlaczego zaprojektowano to w ten sposób”, warto opierać się na publicznych źródłach — konferencyjnych wystąpieniach, dokumentach projektowych i dokumentacji upstream — żeby opowieść była weryfikowalna, a nie mitu oparta.
Brendan Burns w historii powstania Kubernetes (ogólnie)
Brendan Burns jest powszechnie uznawany za jednego z trzech oryginalnych współtwórców Kubernetes, obok Joe Beda i Craiga McLuckie. We wczesnych pracach nad Kubernetes w Google Burns pomagał kształtować zarówno kierunek techniczny, jak i sposób, w jaki projekt był tłumaczony użytkownikom — szczególnie wokół tego, „jak obsługiwać oprogramowanie”, a nie tylko „jak uruchamiać kontenery”. (Źródła: Kubernetes: Up & Running, O’Reilly; listingi AUTHORS/maintainers w repozytorium Kubernetes)
Współpraca open source kształtowała projekt
Kubernetes nie został po prostu „wydany” jako skończony system wewnętrzny; był budowany publicznie z rosnącym zestawem współtwórców, przypadków użycia i ograniczeń. Ta otwartość pchnęła projekt w stronę interfejsów, które mogłyby przetrwać różne środowiska:
- czytelne, wersjonowane API zamiast ukrytych szczegółów implementacji
- przenośne zachowania w chmurach i środowiskach on-prem
- punkty rozszerzeń, aby rdzeń pozostał stosunkowo mały, jednocześnie wspierając wiele potrzeb
Ten nacisk współpracy miał znaczenie, bo wpływał na to, co Kubernetes optymalizował: współdzielone prymitywy i powtarzalne wzorce, z którymi mogło zgodzić się wiele zespołów, nawet jeśli różniły się narzędziami.
Co tu oznacza „ustandaryzował"
Gdy ludzie mówią, że Kubernetes "ustandaryzował" wdrażanie i operacje, zwykle nie mają na myśli, że wszystko stało się identyczne. Chodzi o to, że dostarczył wspólny słownik i zestaw workflowów, które można powtarzać w różnych zespołach:
- wspólne terminy: „Deployment”, „Service”, „Ingress”, „Job”, „namespace”
- spójny model deklarowania tego, czego się chce (i pozwalania systemowi dążyć do tego)
- przewidywalne sposoby wdrażania zmian, skalowania i odzyskiwania po awariach
Ten wspólny model ułatwił przenoszenie dokumentacji, narzędzi i praktyk między firmami.
Projekt Kubernetes vs. ekosystem
Warto rozdzielić Kubernetes (projekt open-source) od ekosystemu Kubernetes.
Projekt to rdzeń API i komponenty control plane implementujące platformę. Ekosystem to wszystko, co wokół niego powstało — dystrybucje, usługi zarządzane, dodatki i powiązane projekty CNCF. Wiele rzeczy, na których polegają zespoły w praktyce (stacki obserwowalności, silniki polityk, narzędzia GitOps), żyje w tym ekosystemie, a niekoniecznie w samym rdzeniu projektu.
Główna idea: deklaratywny stan pożądany
Konfiguracja deklaratywna to prosty zwrot w sposobie opisywania systemów: zamiast spisywać kroki, które trzeba wykonać, mówisz, jaki chcesz mieć efekt końcowy.
W terminologii Kubernetes nie mówisz „uruchom kontener, potem otwórz port, potem zrestartuj, jeśli padnie”. Deklarujesz: „ma być trzy kopie tej aplikacji, dostępne na tym porcie, używające tego obrazu kontenera”. Kubernetes bierze na siebie odpowiedzialność, aby rzeczywistość odpowiadała temu opisowi.
Stan pożądany vs. skrypty imperatywne
Operacje imperatywne przypominają runbook: sekwencję poleceń, które działały poprzednim razem i są powtarzane, gdy coś się zmienia.
Stan pożądany jest bliższy kontraktowi. Zapisujesz oczekiwany rezultat w pliku konfiguracyjnym, a system nieustannie dąży do tego rezultatu. Gdy coś się rozjedzie — proces padnie, węzeł zniknie, ktoś zrobi ręczną zmianę — platforma wykrywa rozbieżność i ją koryguje.
Przed/po: polecenia runbooka vs. YAML
Przed (myślenie runbookowe, imperatywne):
- SSH na serwer
- pobierz nowy obraz kontenera
- zatrzymaj stary proces
- uruchom nowy proces
- zaktualizuj regułę load balancera
- jeśli ruch rośnie, powtórz na kolejnych serwerach
To podejście działa, ale łatwo o „śnieżynkowe” serwery i długi checklist, któremu ufa tylko kilka osób.
Po (deklaratywny stan pożądany):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Zmieniając plik (np. aktualizując image lub replicas) i aplikując go, kontrolery Kubernetes pracują nad uzgodnieniem tego, co jest uruchomione, z tym, co zadeklarowano.
Dlaczego to zmniejsza powtarzalną pracę i dryft
Deklaratywny stan pożądany obniża pracochłonność operacyjną, zamieniając „zrób te 17 kroków” w „utrzymaj to tak”. Redukuje też dryft konfiguracji, ponieważ źródło prawdy jest jawne i możliwe do przeglądu — często w kontroli wersji — więc niespodzianki łatwiej wykryć, audytować i spójnie cofnąć.
Kontrolery i uzgadnianie stanu: system, który pilnuje zgodności
Kubernetes wydaje się „samoobsługowy”, ponieważ zbudowano go wokół prostego wzorca: opisujesz, czego chcesz, a system nieustannie pracuje, by rzeczywistość odpowiadała temu opisowi. Silnikiem tego wzorca jest kontroler.
Co to jest kontroler (prosto)
Kontroler to pętla, która obserwuje aktualny stan klastra i porównuje go ze stanem pożądanym zadeklarowanym w YAML (lub przez wywołanie API). Gdy wykryje rozbieżność, podejmuje działania, aby ją zmniejszyć.
To nie jest jednorazowy skrypt ani oczekiwanie na kliknięcie przez człowieka. Działa cyklicznie — obserwuj, zdecyduj, działaj — więc może reagować na zmiany w dowolnym momencie.
Uzgadnianie stanu: jak Kubernetes „utrzymuje zgodność"
To powtarzające się porównywanie i korygowanie nazywa się uzgadnianiem stanu (reconciliation). To mechanizm stojący za obietnicą „samonaprawiania”. System nie zapobiega magicznie awariom; zauważa dryft i go koryguje.
Dryft może powstawać z banalnych powodów:
- proces się zawiesza
- węzeł znika
- ktoś ręcznie zmienia skalowanie
- wdrażana jest nowa wersja
Uzgadnianie oznacza, że Kubernetes traktuje te zdarzenia jako sygnały do ponownego sprawdzenia intencji i przywrócenia jej.
Wyniki, na których zależy ludziom
Kontrolery przekładają się na znajome rezultaty operacyjne:
- Zastępowanie padniętych Podów: jeśli Pod umiera, kontroler zauważa, że wciąż go chcesz i planuje nowy.
- Utrzymanie liczby replik: jeśli poprosiłeś o 5 replik, a działają 4, Kubernetes dąży do stworzenia brakującej.
- Postęp rolloutu: podczas aktualizacji kontrolery przesuwają system w stronę nowej wersji, zachowując pożądaną dostępność.
Kluczowe jest to, że nie gonisz manualnie za objawami. Deklarujesz cel, a pętle kontrolne robią ciągłą pracę „utrzymaj to tak”.
Dlaczego to skalowalne poza jednym zasobem
To podejście nie ogranicza się do jednego typu zasobu. Kubernetes stosuje tę samą ideę kontrolera i uzgadniania w wielu obiektach — Deployment, ReplicaSet, Job, Node, Endpoint i innych. Ta spójność to duży powód, dla którego Kubernetes stał się platformą: kiedy rozumiesz wzorzec, możesz przewidzieć zachowanie systemu przy dodawaniu nowych możliwości (w tym niestandardowych zasobów stosujących tę samą pętlę).
Harmonogramowanie jako funkcja produktu, nie zadanie ręczne
Rozszerz na mobile później
Dodaj aplikację Flutter, gdy będzie potrzebna, bez restartowania projektu.
Gdyby Kubernetes tylko „uruchamiał kontenery”, wciąż pozostawiłby zespołom najtrudniejszą część: zdecydowanie, gdzie każde obciążenie powinno działać. Scheduling to wbudowany system, który automatycznie umieszcza Pody na właściwych węzłach, bazując na wymaganiach zasobowych i regułach, które definiujesz.
Ma to znaczenie, bo decyzje o umiejscowieniu wpływają bezpośrednio na dostępność i koszty. API webowy na przeciążonym węźle może zwolnić lub paść. Job batchowy umieszczony obok usług wrażliwych na opóźnienia może stworzyć problem „hałaśliwego sąsiada”. Kubernetes przekształca to w powtarzalną funkcję produktu zamiast w arkusz kalkulacyjny i SSH.
Co optymalizuje scheduler
Na podstawowym poziomie scheduler szuka węzłów, które mogą spełnić żądania twojego Poda.
- Żądania CPU/pamięci: requests rezerwują pojemność przy podejmowaniu decyzji o umieszczeniu. Jeśli żądasz 500m CPU i 1Gi pamięci, Kubernetes rozważy tylko węzły z wystarczającą dostępną pojemnością.
Ten nawyk — ustawianie realistycznych żądań — często redukuje „losową” niestabilność, bo krytyczne usługi przestają konkurować ze wszystkim innym.
Typowe ograniczenia, których używają zespoły
Poza zasobami większość klastrów produkcyjnych korzysta z kilku praktycznych reguł:
- Affinity / anti-affinity: „umieść razem” (dla lokalności cache) lub „trzymaj osobno” (żeby awaria jednego węzła nie zabiła wszystkich replik).
- Taints i tolerations: oznaczaj węzły jako specjalnego przeznaczenia (GPU, węzły systemowe, wymagania zgodności) i pozwalaj tylko zatwierdzonym obciążeniom tam lądować.
Jak to zmniejsza przestoje
Funkcje harmonogramowania pozwalają zapisać intencję operacyjną:
- rozrzucić repliki po węzłach, aby przetrwać awarię węzła
- izolować „skokowe” zadania od usług klienckich
- chronić drogie węzły (GPU) przed nieuprawnionym użyciem
Praktyczne przesłanie: traktuj reguły harmonogramowania jak wymagania produktu — zapisz je, przeglądaj i stosuj konsekwentnie — żeby niezawodność nie zależała od tego, kto pamięta „właściwy węzeł” o 2 w nocy.
Skalowanie: od jednej instancji do tysięcy bez przepisywania aplikacji
Jednym z najbardziej praktycznych pomysłów Kubernetes jest to, że skalowanie nie powinno wymagać zmiany kodu aplikacji ani wynajdywania nowej metody wdrożenia. Jeśli aplikacja może działać jako jeden kontener, ta sama definicja obciążenia zwykle może rosnąć do setek czy tysięcy kopii.
Skalowanie ma dwie warstwy
Kubernetes oddziela skalowanie na dwa powiązane wybory:
- Ile podów uruchomić (więcej kopii aplikacji dla większej przepustowości lub redundancji).
- Ile masz pojemności w klastrze (wystarczająco węzłów i odpowiednie rozmiary, żeby ulokować te Pody).
To rozdzielenie ma znaczenie: możesz zażądać 200 Podów, ale jeśli klaster ma miejsce tylko na 50, „skalowanie” staje się kolejką oczekujących.
Autoskalowanie, koncepcyjnie (HPA, VPA, Cluster Autoscaler)
Kubernetes zwykle używa trzech autoskalerów, z których każdy operuje innym dźwignią:
- Horizontal Pod Autoscaler (HPA): zmienia liczbę Podów na podstawie sygnałów jak użycie CPU, pamięci lub niestandardowe metryki aplikacji.
- Vertical Pod Autoscaler (VPA): dopasowuje żądania/limity zasobów Podu, żeby każdy Pod dostał więcej (lub mniej) CPU/pamięci.
- Cluster Autoscaler: dodaje lub usuwa węzły, żeby scheduler miał miejsce na postawienie żądanych Podów.
Używane razem, to zmienia skalowanie w politykę: „utrzymaj opóźnienie stabilne” lub „utrzymuj CPU na około X%”, zamiast ręcznego wywoływania alarmów.
Od czego zależy „dobre skalowanie"
Skalowanie działa tylko tak dobrze, jak dane wejściowe:
- Metryki: CPU jest proste, ale nie zawsze trafne; często lepiej pasują liczba zapytań, głębokość kolejki czy opóźnienie.
- Żądania/limity zasobów: mówią schedulerowi, czego pod potrzebuje. Bez nich decyzje o umieszczeniu i autoskalowaniu stają się zgadywanką.
- Wzorce obciążenia: skokowy ruch, wolne rozgrzewanie i ciężkie zadania tła zmieniają, jak szybko skalowanie powinno reagować.
Typowe pułapki
Dwa błędy pojawiają się często: skalowanie na niewłaściwej metryce (CPU niskie, a żądania timeoutują) oraz brak żądań zasobów (autoskalery nie przewidują pojemności, Pody są upychane zbyt ciasno i wydajność staje się nieprzewidywalna).
Bezpieczne wdrożenia: rollouty, sondy zdrowia i rollbacki
Duża zmiana, którą spopularyzował Kubernetes, to traktowanie „wdrożenia” jako ciągłego problemu kontrolnego, a nie jednorazowego skryptu uruchamianego w piątek o 17:00. Rollouty i rollbacki są zachowaniami natywnymi: deklarujesz wersję, którą chcesz, a Kubernetes przesuwa system w jej stronę, jednocześnie sprawdzając, czy zmiana jest bezpieczna.
Rollout jako kontrolowana zmiana
W Deployment rollout to stopniowa wymiana starych Podów na nowe. Zamiast zatrzymywać wszystko i uruchamiać od nowa, Kubernetes może aktualizować etapami — zachowując pojemność, gdy nowa wersja udowadnia, że poradzi sobie z ruchem produkcyjnym.
Jeśli nowa wersja zaczyna zawodzić, rollback nie jest procedurą awaryjną. To normalna operacja: możesz przywrócić poprzedni ReplicaSet (ostatnią znaną dobrą wersję) i pozwolić kontrolerowi odtworzyć stary stan.
Proby (probes): zapobieganie „dobrym, ale wadliwym” wydaniom
Sondy zdrowia zamieniają rollouty z opartych na nadziei na mierzalne:
- Readiness probes decydują, czy Pod powinien otrzymywać ruch. Kontener może być uruchomiony, ale jeszcze nie gotowy (rozgrzewanie cache, oczekiwanie na zależności). Readiness zapobiega wysyłaniu ruchu do instancji, która nie odpowie poprawnie.
- Liveness probes wykrywają, czy kontener utknął lub jest niesprawny i wymaga restartu. To unika trybu, w którym proces jest „żywy”, ale uszkodzony.
Dobre użycie sond zmniejsza fałszywe sukcesy — wdrożenia, które wyglądają poprawnie, bo Pody wystartowały, ale w rzeczywistości nie obsługują żądań.
Strategie wdrożeń: rolling, blue/green, canary
Kubernetes wspiera rolling update natywnie, ale zespoły często nakładają dodatkowe wzorce:
- Blue/green: trzymaj dwa pełne środowiska i przesuń ruch z blue na green, gdy green zostanie zweryfikowany.
- Canary: kieruj mały procent ruchu do nowej wersji, obserwuj metryki, potem rozszerzaj stopniowo.
Bezpieczeństwo, które da się mierzyć (i zautomatyzować)
Bezpieczne wdrożenia zależą od sygnałów: wskaźników błędów, opóźnień, nasycenia i wpływu na użytkownika. Wiele zespołów podłącza decyzje rolloutów do SLO i budżetów błędów — jeśli canary zużyje zbyt dużo budżetu, promocja zostaje zatrzymana.
Celem są automatyczne wyzwalacze rollbacku na podstawie realnych wskaźników (nieudane readiness, wzrost 5xx, skoki opóźnień), aby „rollback” stał się przewidywalną reakcją systemu — a nie nocną akcją bohatera.
Operacje usług: odkrywanie, trasowanie i stabilna sieć
Wystartuj na swojej domenie
Opublikuj projekt na własnej domenie, gdy będziesz gotowy, by go udostępnić.
Platforma kontenerowa wydaje się „automatyczna” tylko wtedy, gdy pozostałe części systemu dalej znajdą twoją aplikację po jej przemieszczeniu. W produkcyjnych klastrach Pody są tworzone, usuwane, przesuwane i skalowane cały czas. Gdyby każda zmiana wymagała aktualizacji adresów IP w konfiguracjach, operacje zamieniłyby się w ciągłą bieganinę — i awarie byłyby rutyną.
Dlaczego odkrywanie usług jest ważne
Odkrywanie usług to praktyka zapewniania klientom niezawodnego sposobu dotarcia do zmiennego zestawu backendów. W Kubernetes kluczowa zmiana polega na tym, że przestajesz celować w pojedyncze instancje („dzwoń na 10.2.3.4”) i zamiast tego kierujesz ruch do nazwanego serwisu („dzwoń do checkout”). Platforma obsługuje, które Pody aktualnie obsługują tę nazwę.
Services, selectors i endpoints (prosto)
Service to stabilne wejście do grupy Podów. Ma stałą nazwę i wirtualny adres w klastrze, nawet gdy podlegające mu Pody się zmieniają.
Selector to sposób, w jaki Kubernetes decyduje, które Pody są „za” tym wejściem. Najczęściej dopasowuje etykiety, np. app=checkout.
Endpoints (lub EndpointSlices) to żywa lista aktualnych adresów IP Podów, które pasują do selektora. Gdy Pody się skalują, rolloutują lub są przemieszczane, ta lista aktualizuje się automatycznie — klienci dalej używają tej samej nazwy Service.
Stabilne adresy, load balancing i trasowanie ruchu
Operacyjnie daje to:
- Stabilne adresowanie: aplikacje odwołują się do nazwy DNS Service, zamiast ścigać IP Podów.
- Load balancing: ruch rozkłada się po zdrowych Podach za Service.
- Przewidywalne trasowanie: możesz oddzielić „kto powinien otrzymywać ruch” (labels/selectors) od „gdzie Pody akurat działają”.
Dla ruchu północ–południe (spoza klastra) Kubernetes zwykle używa Ingress lub nowszego podejścia Gateway. Oba dają kontrolowane wejście, gdzie możesz kierować żądania po hostname lub ścieżce i centralizować kwestie jak TLS. Ważna idea jest taka sama: utrzymaj stabilny dostęp zewnętrzny, podczas gdy backendy zmieniają się pod spodem.
Samonaprawianie: co to naprawdę znaczy w produkcji
„Samonaprawianie” w Kubernetes nie jest magią. To zestaw zautomatyzowanych reakcji na awarie: restart, reschedule i replace. Platforma obserwuje to, co zadeklarowałeś (stan pożądany) i stale popycha rzeczywistość z powrotem w jego stronę.
Restart: gdy kontener pada
Jeśli proces zakończy się lub kontener stanie się niezdrowy, Kubernetes może go zrestartować na tym samym węźle. Zwykle sterują tym:
- Liveness probes: „Czy ten kontener dalej działa prawidłowo?” Jeśli nie, wykonaj restart.
- Polityki restartu: reguły określające, kiedy restartować.
Typowy wzorzec produkcyjny: pojedynczy kontener pada → Kubernetes go restartuje → Service nadal kieruje ruch tylko do zdrowych Podów.
Reschedule i replace: gdy węzeł zawiedzie
Jeśli cały węzeł padnie (awaria sprzętu, kernel panic, utrata sieci), Kubernetes oznacza węzeł jako niedostępny i zaczyna przenosić pracę gdzie indziej. Na wysokim poziomie:
- węzeł jest oznaczany jako unhealthy/not ready
- Pody, które tam działały, traktuje się jako utracone
- kontrolery tworzą repliki zastępcze na innych zdrowych węzłach, aby przywrócić pożądaną liczbę replik
To jest „samonaprawianie” na poziomie klastra: system przywraca pojemność, zamiast czekać na człowieka z SSH.
Obserwowalność: jak wiesz, że się naprawia
Samonaprawianie ma znaczenie tylko wtedy, gdy możesz to zweryfikować. Zespoły zwykle monitorują:
- Logi (logi aplikacji i zdarzenia platformy), by zobaczyć, co się zrestartowało i dlaczego
- Metryki jak liczba restartów, nieudane sondy, gotowość węzłów
- Alerty gdy naprawa nie działa (np. powtarzający się CrashLoopBackOff, niedobór replik, zbyt wiele evictions)
Błędne konfiguracje, które łamią samonaprawianie
Nawet z Kubernetes, „naprawianie” może zawodzić, jeśli zabezpieczenia są źle ustawione:
- złe lub brakujące liveness/readiness probes (fałszywe pozytywy lub Pody nigdy niegotowe)
- brak żądań/limitów zasobów, co prowadzi do nieprzewidywalnego harmonogramowania lub OOM killów
- zbyt mała liczba replik (pojedynczy Pod nie zapewnia ciągłości)
- zbyt agresywne parametry sond powodujące „burze restartów”
- obciążenia polegające na stanie lokalnym węzła bez trwałej strategii przechowywania
Gdy samonaprawianie jest dobrze skonfigurowane, przestoje stają się krótsze i mniejsze — i co ważniejsze, mierzalne.
Zamień naukę na kredyty
Zdobądź kredyty, tworząc treści o Koder.ai lub polecając innych użytkowników.
Kubernetes nie wygrał tylko dlatego, że potrafił uruchamiać kontenery. Wygrał, bo zaoferował standardowe API dla najczęstszych potrzeb operacyjnych — wdrażania, skalowania, sieciowania i obserwowalności. Gdy zespoły zgadzają się co do „kształtu” obiektów (jak Deployment, Service, Job), narzędzia można dzielić między organizacjami, szkolenia stają się prostsze, a przekazy między dev i ops przestają opierać się na wiedzy tribalnej.
Dlaczego standardowe API zmieniają pracę zespołów
Spójne API oznacza, że pipeline wdrożeniowy nie musi znać dziwactw każdej aplikacji. Może wykonać te same akcje — create, update, rollback, check health — używając tych samych pojęć Kubernetes.
To też poprawia zgodność: zespoły bezpieczeństwa mogą wyrażać polityki jako reguły; SRE mogą standaryzować runbooki wokół wspólnych sygnałów zdrowia; deweloperzy mogą myśleć o wydaniach wspólnym językiem.
Rozszerzanie Kubernetes: CRD i Operatorzy
„Przemiana w platformę” staje się oczywista dzięki Custom Resource Definitions (CRD). CRD pozwalają dodać nowy typ obiektu do klastra (np. Database, Cache, Queue) i zarządzać nim tym samym API, co zasobami wbudowanymi.
Operator łączy te niestandardowe obiekty z kontrolerem, który stale uzgadnia stan pożądany z rzeczywistością — automatyzując zadania, które kiedyś były ręczne, jak backupy, failovery czy aktualizacje wersji. Kluczową korzyścią nie jest magiczna automatyka, lecz ponowne użycie tej samej pętli kontrolnej, którą Kubernetes stosuje wszędzie.
Dopasowanie do GitOps, CI/CD i kontroli polityk
Ponieważ Kubernetes jest sterowany przez API, dobrze integruje się z nowoczesnymi workflowami:
- GitOps: stan pożądany żyje w Git; zmiany podlegają przeglądom jak kod.
- CI/CD: pipeline'y mogą aplikować manifesty, czekać na gotowość i promować wersje.
- Kontrole polityk: admission controllers mogą blokować ryzykowne konfiguracje przed trafieniem do produkcji.
Jeśli chcesz więcej praktycznych porad wdrożeniowych i operacyjnych opartych na tych ideach, zajrzyj do /blog.
Co zespoły mogą zastosować dziś (nawet poza Kubernetes)
Najważniejsze idee z Kubernetes — wiele z nich kojarzonych z wczesnym ramowaniem przez Brendana Burnsa — dobrze przekładają się, nawet jeśli działasz na VM-ach, serverless lub mniejszym środowisku kontenerowym.
Wzorce, które poprawiają codzienne operacje
Zapisz „stan pożądany” i pozwól automatyzacji go egzekwować. Niezależnie czy to Terraform, Ansible czy pipeline CI, traktuj konfigurację jako źródło prawdy. Efekt to mniej ręcznych kroków wdrożeniowych i o wiele mniej niespodzianek „działa na mojej maszynie”.
Używaj uzgadniania, nie jednorazowych skryptów. Zamiast skryptów, które uruchamiają się raz i liczą na szczęście, buduj pętle, które nieustannie weryfikują kluczowe właściwości (wersja, konfiguracja, liczba instancji, zdrowie). To sposób na powtarzalne opsy i przewidywalne odzyskiwanie.
Traktuj harmonogramowanie i skalowanie jako funkcje produktu. Zdefiniuj, kiedy i dlaczego dodajesz pojemność (CPU, głębokość kolejki, SLO opóźnienia). Nawet bez Kubernetesa zespoły mogą standaryzować reguły skalowania, żeby wzrost nie wymagał przepisywania aplikacji lub budzenia kogoś w środku nocy.
Ustandaryzuj rollouty. Rolling updates, health checks i szybkie rollbacki zmniejszają ryzyko zmian. Możesz to wdrożyć z load balancerami, flagami funkcji i pipeline'ami, które blokują wydania na podstawie realnych sygnałów.
Lista kontrolna bezpiecznego wdrożenia
- Zdefiniuj stan pożądany usługi: wersja, konfiguracja, zależności i minimalna liczba instancji
- Dodaj endpointy zdrowia (odpowiedniki liveness i readiness) i podłącz je do load balancera lub pipeline'u wdrożeniowego
- Zautomatyzuj kroki rollout: deploy, weryfikacja, przesunięcie ruchu i rollback przy błędach
- Stwórz mały „reconciler”: okresowe sprawdzenia, które korygują dryft (zła konfiguracja, brakujące instancje)
- Dodaj wyzwalacze skalowania z jasnymi limitami (max instancji, okna schładzania, reguły zatwierdzania)
Czego to samo w sobie nie rozwiąże
Te wzorce nie naprawią słabego projektu aplikacji, niebezpiecznych migracji danych ani kontroli kosztów. Nadal potrzebujesz wersjonowanych API, planów migracji, budżetowania/limitów i obserwowalności, która wiąże wdrożenia z wpływem na klientów.
Kolejne kroki
Wybierz jedną usługę skierowaną do klienta i zaimplementuj listę kontrolną end-to-end, potem rozszerzaj.
Jeśli budujesz nowe usługi i chcesz szybciej dojść do „czegoś wdrożalnego”, Koder.ai może pomóc wygenerować pełną aplikację web/backend/mobile na podstawie specyfikacji prowadzonej w czacie — zazwyczaj React na frontendzie, Go z PostgreSQL na backendzie i Flutter na mobile — a następnie wyeksportować kod źródłowy, żebyś mógł zastosować tu opisane wzorce Kubernetes (deklaratywne konfiguracje, powtarzalne rollouty i przyjazne rollbacki). Dla zespołów oceniających koszty i zarządzanie, możesz też sprawdzić /pricing.