Zdefiniuj wpływ incydentu i decyzje, które ma wspierać
Zanim zbudujesz obliczenia lub pulpity, zdecyduj, co „wpływ” oznacza w Twojej organizacji. Jeśli pominiesz ten krok, otrzymasz wynik, który wygląda naukowo, ale nie pomaga nikomu działać.
Co liczy się jako „wpływ” (a co nie)
Wpływ to mierzalna konsekwencja incydentu dla czegoś, na czym zależy biznesowi. Powszechne wymiary obejmują:
- Użytkownicy: liczba użytkowników, którzy nie mogą się zalogować, skoki wskaźnika błędów w kluczowych ścieżkach, pogorszone opóźnienia w regionie.
- Przychody: nieudane finalizacje zakupów, blokowane odnowienia subskrypcji, spadek wyświetleń reklam.
- Ryzyko SLA/SLO: minuty przestoju względem celu dostępności, tempo zużycia budżetu błędów.
- Zespoły wewnętrzne: wolumen zgłoszeń do supportu, obciążenie on-call, zablokowane wdrożenia.
Wybierz 2–4 główne wymiary i zdefiniuj je wprost. Na przykład: „Wpływ = dotknięci płacący klienci + minuty ryzyka SLA”, a nie „Wpływ = wszystko, co źle wygląda na wykresach”.
Kto używa aplikacji i czego potrzebuje w pierwszych 10 minutach
Różne role podejmują różne decyzje:
- Dowódcy incydentu potrzebują szybkiego, obronnego podsumowania: co się zepsuło, kogo to dotyczy i jak się to zmienia.
- Support potrzebuje zakresu do komunikacji z klientem: które konta, regiony lub plany są dotknięte.
- Inżynieria potrzebuje hipotezy blast radius, która ukierunkuje debugowanie i mitigację.
- Kadra zarządzająca potrzebuje zwięzłego komunikatu biznesowego: ciężkość, wpływ na klientów i pewność ETA.
Zaprojektuj wyniki „wpływu”, aby każda grupa odpowiadała na swoje najważniejsze pytanie bez tłumaczenia metryk.
Real-time vs near-real-time: ustal oczekiwania wcześnie
Zdecyduj, jakie opóźnienie jest akceptowalne. „Czas rzeczywisty” jest kosztowny i często niepotrzebny; near-real-time (np. 1–5 minut) często wystarcza do podejmowania decyzji.
Zapisz to jako wymaganie produktowe, bo wpłynie na pobieranie danych, cache i UI.
Decyzje, które aplikacja powinna umożliwić podczas incydentu
Twoje MVP powinno bezpośrednio wspierać akcje, takie jak:
- ogłoszenie ważności i poziomu eskalacji
- uruchomienie komunikacji do klientów (status page, makra supportu)
- priorytetyzacja pracy naprawczej (która usługa/zespół najpierw)
- decyzje o rollbackach, flagach funkcji lub przesunięciu ruchu
- identyfikacja klientów wymagających proaktywnego kontaktu
Jeśli metryka nie zmienia decyzji, prawdopodobnie nie jest „wpływem” — to jedynie telemetria.
Lista wymagań: wejścia, wyjścia i ograniczenia
Zanim zaprojektujesz ekrany lub wybierzesz bazę danych, zapisz, na jakie pytania „analiza wpływu” musi odpowiadać podczas prawdziwego incydentu. Cel nie jest perfekcyjna precyzja od pierwszego dnia — to spójne, wyjaśnialne wyniki, którym respondenci mogą ufać.
Wymagane wejścia (minimum)
Rozpocznij od danych, które musisz pobierać lub odnosić, aby obliczyć wpływ:
- Incydenty: ID, czasy rozpoczęcia/zakończenia, status, zespół odpowiedzialny, streszczenie, linki do kanału incydentu/biletu.
- Usługi: kanoniczna lista usług (nazwa, właściciel, poziom/krytyczność, link do runbooka).
- Zależności: które usługi polegają na których innych (nawet jeśli pierwsza wersja jest przybliżona).
- Sygnały telemetryczne: alerty, zużycie SLO, współczynnik błędów/opóźnienia, zdarzenia deploy — wszystko, co wskazuje na degradację.
- Konta klientów: ID kont, plan/SLA, region, kluczowe kontakty oraz mapa, jak konta powiązane są z usługami (bezpośrednio lub przez obciążenia).
Opcjonalne przy starcie (zaplanuj, ale nie wymagaj)
Większość zespołów nie ma na dzień pierwszy idealnego mapowania zależności czy klientów. Zdecyduj, co pozwolisz wprowadzać ręcznie, żeby aplikacja była użyteczna:
- ręczny wybór dotkniętych usług/klientów gdy brakuje danych
- szacowany czas rozpoczęcia lub zakres gdy telemetria jest opóźniona
- nadpisania z uzasadnieniem (np. „false positive alert”, „wpływ tylko wewnętrzny”)
Zaprojektuj te pola jako jawne pola (nie ad-hoc notatki), żeby można było je później przeszukiwać.
Kluczowe wyjścia (co aplikacja musi produkować)
Twoje pierwsze wydanie powinno niezawodnie generować:
- Dotknięte usługi i jasne „dlaczego” (sygnały + zależności)
- Listę klientów z podziałem na plany/regiony i widok „top accounts”
- Wynik/ciężkość wpływu możliwy do wytłumaczenia prostym językiem
- Oś czasu kiedy wpływ prawdopodobnie się zaczął, osiągnął szczyt i został przywrócony
- Opcjonalnie: szacunkowy koszt (kredyty SLA, obciążenie supportu, ryzyko przychodów) z zakresami pewności
Ograniczenia niefunkcjonalne (co czyni to wiarygodnym)
Analiza wpływu jest narzędziem decyzyjnym, więc ograniczenia mają znaczenie:
- Opóźnienie: pulpity powinny ładować się w ciągu sekund podczas incydentu
- Dostępność: traktuj to jak wewnętrzne narzędzie krytyczne; zdefiniuj cel dostępności
- Audytowalność: loguj, kto zmienił nadpisanie, kiedy i jaka była poprzednia wartość
- Kontrola dostępu: ogranicz dostęp do wrażliwych danych klientów; rozdziel uprawnienia do odczytu i zapisu
Formułuj te wymagania jako przetestowalne stwierdzenia. Jeśli nie możesz tego zweryfikować, nie możesz na tym polegać podczas awarii.
Model danych: Incydenty, Usługi, Zależności i Klienci
Model danych jest umową między warstwą pobierania, obliczeń i UI. Jeśli wykonasz to dobrze, będziesz mógł wymieniać źródła narzędzi, udoskonalać scoring i wciąż odpowiadać na te same pytania: „Co się zepsuło?”, „Kto jest dotknięty?” i „Jak długo?”.
Główne byty (utrzymuj je małe i łączalne)
Przynajmniej modeluj te rekordy jako obiekty pierwszej klasy:
- Incydent: kontener narracji (tytuł, ciężkość, status, właściciel) oraz wskaźniki do dowodów.
- Usługa: jednostka, dla której mapujesz zależności (API, baza, kolejka, dostawca zewnętrzny).
- Zależność: skierowana krawędź usługa A → usługa B z metadanymi (typ, krytyczność).
- Sygnał: obserwacja z znacznikiem czasu (alert, zużycie SLO, skok błędów, niepowodzenie kontroli syntetycznej).
- Klient: konto lub organizacja korzystająca z usług.
- Subskrypcja/SLA: czego klient ma prawo (plan, cele SLA/SLO, zasady raportowania).
Utrzymuj stabilne ID i spójność między źródłami. Jeśli masz już katalog usług, traktuj go jako źródło prawdy i mapuj zewnętrzne identyfikatory narzędzi do niego.
Modelowanie czasu (wpływ to problem okna czasowego)
Przechowuj wiele znaczników czasu w incydencie, żeby wspierać raportowanie i analizę:
- start_time / end_time: rzeczywiste okno wpływu (można później doprecyzować)
- detection_time: kiedy po raz pierwszy się dowiedzieliście
- mitigation_time: kiedy rozpoczęto naprawy zmniejszające wpływ
Przechowuj także obliczone okna czasowe do skoringu (np. wiadra 5-minutowe). Ułatwia to odtwarzanie i porównania.
Relacje napędzające „kto jest dotknięty?”
Modeluj dwa kluczowe grafy:
- Zależności usługa→usługa (blast radius)
- Użytkowanie klient→usługa (zakres dotknięcia)
Prosty wzorzec to customer_service_usage(customer_id, service_id, weight, last_seen_at), aby móc rankować wpływ wg „jak bardzo klient na tym polega”.
Wersjonowanie i historia (zależności się zmieniają)
Zależności ewoluują, a obliczenia wpływu powinny odzwierciedlać to, co było prawdą w danym czasie. Dodaj datowanie efektywności do krawędzi:
dependency(valid_from, valid_to)
Zrób to samo dla subskrypcji klientów i snapshotów użycia. Dzięki wersjom historycznym możesz poprawnie odtworzyć przeszłe incydenty podczas analizy poincydentowej i generować spójne raporty SLA.
Zbieranie i normalizacja danych z narzędzi
Analiza wpływu jest tyle dobra, ile dobre są dane wejściowe. Cel jest prosty: pobierać sygnały z narzędzi, których już używasz, i konwertować je na spójny strumień zdarzeń, którym aplikacja może rozumieć.
Co pobierać (i dlaczego)
Zacznij od krótkiej listy źródeł, które wiarygodnie opisują „coś się zmieniło” podczas incydentu:
- Alerty monitoringu (PagerDuty, Opsgenie, CloudWatch alarms): szybkie wskaźniki symptomów i ciężkości
- Logi i ślady (ELK, Datadog, OpenTelemetry backends): dowody zakresu (które endpointy, którzy klienci)
- Aktualizacje status page (Statuspage, Cachet): oficjalna narracja i znaczniki czasu dla klientów
- Narzedzia do ticketów/incydentów (Jira, ServiceNow): właściciel, znaczniki czasu i dane po incydencie
Nie próbuj wszystkiego naraz. Wybierz źródła, które pokrywają wykrycie, eskalację i potwierdzenie.
Metody pobierania do wyboru
Różne narzędzia wspierają różne wzorce integracji:
- Webhooky dla near-real-time aktualizacji (najlepsze dla alertów i status page)
- Polling dla API bez webhooków (stosuj backoff i limity)
- Importy batchowe dla historycznego backfillu (użyteczne na początek)
- Wprowadzanie ręczne dla „ostatniej mili” korekt (analityk może poprawić brakujące tagi usługi)
Praktyczne podejście: webhooki dla krytycznych sygnałów plus importy batchowe do wypełniania luk.
Normalizacja do wspólnej schemy
Znormalizuj każdy przychodzący element do jednego kształtu „zdarzenia”, nawet jeśli źródło nazywa to alertem, incydentem lub adnotacją. Przynajmniej ustandaryzuj:
- Znaczniki czasu: occurred_at, detected_at, resolved_at (gdy dostępne)
- Identyfikatory usług: mapuj tagi/nazwy źródła do kanonicznych service ID
- Ważność/prioritet: konwertuj poziomy specyficzne dla narzędzia na Twoją skalę
- Źródło i surowy payload: zachowaj oryginalne JSON dla audytu i debugu
Higiena danych: duplikaty, kolejność, brakujące pola
Spodziewaj się bałaganu. Używaj kluczy idempotency (source + external_id) do deduplikacji, toleruj zdarzenia poza kolejnością sortując po occurred_at (nie czasie przybycia) i stosuj bezpieczne domyślne wartości, jednocześnie flagując brakujące pola do przeglądu.
Mała kolejka „niezmapowane usługi” w UI zapobiega cichym błędom i utrzymuje wyniki wpływu wiarygodne.
Mapowanie zależności usług dla dokładnego blast radius
Test impact scoring ideas
Prototypuj model danych incydentów i reguły oceny wpływu zanim zdecydujesz się na pełną budowę.
Jeśli Twoja mapa zależności jest błędna, blast radius też będzie błędny — nawet jeśli sygnały i scoring są perfekcyjne. Celem jest zbudowanie grafu zależności, któremu można ufać podczas incydentu i po nim.
Zacznij od katalogu usług (Twoje „źródło prawdy”)
Zanim zmapujesz krawędzie, zdefiniuj węzły. Stwórz wpis katalogu usług dla każdego systemu, który może pojawić się w incydencie: API, zadania background, bazy danych, dostawcy zewnętrzni i inne współdzielone krytyczne komponenty.
Każda usługa powinna zawierać przynajmniej: właściciela/zespołu, poziom/krytyczność (np. skierowane do klienta vs. wewnętrzne), cele SLA/SLO oraz linki do runbooków i dokumentów on-call (np. /runbooks/payments-timeouts).
Zbieraj zależności: statyczne vs odkrywane
Użyj dwóch uzupełniających się źródeł:
- Statyczne (zadeklarowane) zależności: na co zespoły mówią, że polegają (z IaC, konfiguracji, manifestów usług, ADR). Stabilne i łatwe do audytu.
- Odkrywane (zaobserwowane) zależności: co systemy faktycznie wywołują (ze śladów, telemetryki service mesh, logów bramy API, logów egress). Łapią „nieznane nieznane”, np. zapomniane wywołanie downstream.
Traktuj to jako różne typy krawędzi, aby ludzie rozumieli pewność: „zadeklarowane przez zespół” vs „zaobserwowane w ciągu ostatnich 7 dni”.
Kierunkowość i krytyczność mają znaczenie
Zależności powinny być kierunkowe: Checkout → Payments to nie to samo co Payments → Checkout. Kierunkowość napędza rozumowanie („jeśli Payments jest zdegradowane, które upstreamy mogą zawieść?”).
Modeluj też zależności twarde vs miękkie:
- Twarde: awaria blokuje podstawową funkcjonalność (serwis auth dla logowania).
- Miękkie: degradacja obniża jakość, ale istnieje fallback (rekomendacje, opcjonalne wzbogacenie).
To zapobiega przecenianiu wpływu i pomaga responderom priorytetyzować.
Snapshot grafu dla odtwarzania i analizy po incydencie
Twoja architektura zmienia się co tydzień. Jeśli nie przechowujesz snapshotów, nie możesz dokładnie analizować incydentu sprzed dwóch miesięcy.
Przechowuj wersje grafu zależności w czasie (codziennie, przy deployu lub przy zmianie). Przy obliczaniu blast radius rozwiąż znacznik czasu incydentu do najbliższego snapshotu grafu, aby „kto był dotknięty” odzwierciedlał rzeczywistość w tym momencie — nie dzisiejszą architekturę.
Obliczanie wpływu: od sygnałów do wyników i zakresu dotkniętych
Gdy zaczniesz pobierać sygnały (alerty, zużycie SLO, kontrole syntetyczne, zgłoszenia klientów), aplikacja potrzebuje spójnego sposobu na przekształcenie chaotycznych wejść w jasne stwierdzenie: co jest zepsute, jak źle i kto jest dotknięty?
Wybierz podejście scoringowe (zacznij prosto)
Możesz dojść do użytecznego MVP jednym z tych wzorców:
- Scoring oparty na regułach: „Jeśli error rate w checkout > 5% przez 10 minut, wpływ = Wysoki.” Łatwe do wyjaśnienia i debugowania.
- Formuła ważona: łącz normalizowane metryki w jedną liczbę (np. 0–100). Przydatne przy wielu sygnałach dla płynnej krzywej.
- Mapowanie wg tierów: przypisz systemy do tierów biznesowych (Tier 0–3) i ogranicz lub zwiększaj ciężkość na tej podstawie. To utrzymuje wyniki zgodne z priorytetami biznesu.
Niezależnie od wyboru, zapisuj wartości pośrednie (trafienia progów, wagi, tier), aby ludzie mogli zrozumieć dlaczego wynik powstał.
Zdefiniuj wymiary wpływu
Unikaj zbyt szybkiego łączenia wszystkiego w jedną liczbę. Najpierw śledź kilka wymiarów osobno, a potem wyprowadź ogólną ciężkość:
- Dostępność: przestoje, nieudane żądania, niedostępne endpointy
- Opóźnienie: pogorszenie p95/p99 względem baseline lub SLO
- Błędy: skoki wskaźnika błędów, nieudane zadania, time-outy
- Poprawność danych: brakujące/nieprawidłowe rekordy, opóźnione przetwarzanie
- Ryzyko bezpieczeństwa: podejrzane wzorce dostępu, wskaźniki wycieku danych
To pomaga responderom precyzyjnie komunikować („dostępne, ale wolne” vs „wyniki nieprawidłowe”).
Oblicz zakres dotkniętych (klienci/użytkownicy)
Wpływ to nie tylko zdrowie usługi — to kto go odczuł.
Użyj mapowania użycia (tenant → service, plan klienta → funkcje, ruch użytkowników → endpoint) i oblicz dotkniętych klientów w oknie czasowym powiązanym z incydentem (start, mitigation, okres backfill).
Bądź jawny co do założeń: próbkowane logi, szacowany ruch lub częściowa telemetria.
Ręczne korekty — z odpowiedzialnością
Operatorzy będą musieli nadpisywać: false-positive, częściowy rollout, znany podzbiór tenantów.
Pozwól na ręczne edycje ciężkości, wymiarów i listy dotkniętych klientów, ale wymagaj:
- Kto zmienił
- Kiedy
- Dlaczego (krótkie uzasadnienie + opcjonalny link do biletu/runbooka)
Ten ślad audytowy chroni zaufanie do pulpitu i przyspiesza analizę po incydencie.
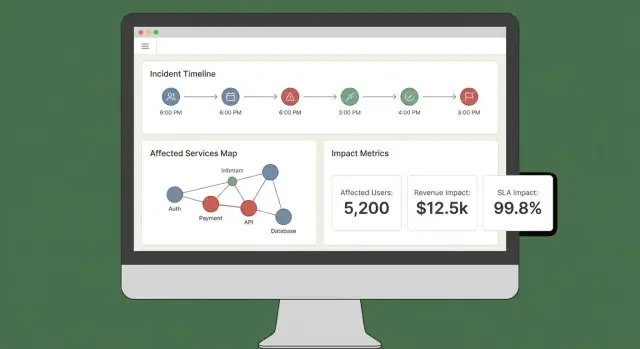
UX i pulpity: spraw, by wpływ był zrozumiały w kilka minut
Dobry pulpit wpływu odpowiada szybko na trzy pytania: Co jest dotknięte? Kto jest dotknięty? Jak bardzo jesteśmy pewni? Jeśli użytkownicy muszą otwierać pięć zakładek, aby to złożyć, nie będą ufać wynikom — ani działać na ich podstawie.
Kluczowe widoki do wysłania w MVP
Zacznij od małego zestawu widoków „zawsze obecnych”, które pasują do realnych workflow incydentowych:
- Przegląd incydentu: status, czas rozpoczęcia, aktualny wynik wpływu, top dotknięte usługi/klienci i najnowsze dowody.
- Dotknięte usługi: lista rankowana pokazująca ciężkość, region i ścieżkę zależności (żeby inżynierowie mogli zaplanować interwencję).
- Dotknięci klienci: liczby i nazwy kont wg tieru/planu oraz szacowany wpływ na użytkowników, jeśli to śledzisz.
- Oś czasu: pojedynczy strumień chronologiczny łączący wykrycia, deploye, alerty, mitigacje i zmiany wpływu.
- Akcje: sugerowane następne kroki, właściciele i linki do playbooków lub ticketów.
Uczyń „dlaczego” widocznym
Wyniki bez wyjaśnienia wydają się arbitralne. Każdy wynik powinien być śledzalny do wejść i reguł:
- Pokaż które sygnały przyczyniły się (błędy, opóźnienia, checki, wolumen supportu) i ich aktualne wartości.
- Wyświetl reguły i progi użyte (np. „p95 opóźnienia > 2s przez 10 min = degradacja”).
- Dodaj lekki wskaźnik pewności (np. „Wysoka pewność: potwierdzone przez 3 źródła”).
Prosty panel „Wyjaśnij wpływ” może to zrobić bez zaśmiecania głównego widoku.
Filtry i drilldowny odpowiadające prawdziwym pytaniom
Ułatw krojenie wpływu według usługi, regionu, tieru klienta i zakresu czasu. Pozwól kliknąć dowolny punkt wykresu lub wiersz, aby przejść do surowych dowodów (dokładne monitory, logi lub zdarzenia, które spowodowały zmianę).
Udostępnianie i eksporty
Podczas aktywnego incydentu ludzie potrzebują przenośnych aktualizacji. Dodaj:
- Udostępniane linki do widoku incydentu (z zachowaniem uprawnień)
- Eksport CSV list usług/klientów
- Eksport PDF do aktualizacji statusowych i podsumowań poincydentowych
Jeśli masz już status page, odnieś się do niego przez względną ścieżkę taką jak /status, by zespoły komunikacji mogły szybko porównać.
Bezpieczeństwo, uprawnienia i logowanie audytu
Build the MVP faster
Przekształć tę listę kontrolną w działający pulpit analizujący wpływ incydentów za pomocą Koder.ai w przepływie sterowanym czatem.
Analiza wpływu jest przydatna tylko wtedy, gdy ludzie jej ufają — to oznacza kontrolę, kto może co zobaczyć i jasny zapis zmian.
Role i uprawnienia (zacznij prosto)
Zdefiniuj mały zestaw ról dopasowanych do rzeczywistych działań incydentowych:
- Viewer: dostęp tylko do odczytu do podsumowań incydentów i ogólnych wyników wpływu.
- Responder: może dodawać notatki, potwierdzać dotknięte usługi i aktualizować pola operacyjne.
- Incident commander: może zatwierdzać nadpisania wpływu, ustawiać status dla klientów i zamykać incydenty.
- Admin: zarządza integracjami, przypisaniami ról i retencją danych.
Trzymaj uprawnienia powiązane z akcjami, a nie stanowiskami. Np. „może eksportować raport wpływu klienta” to uprawnienie, które możesz przyznać dowódcom i wybranym adminom.
Chroń wrażliwe dane klientów
Analiza wpływu często dotyka identyfikatorów klientów, poziomów umów i czasem danych kontaktowych. Stosuj zasadę najmniejszych uprawnień domyślnie:
- Maskuj pola wrażliwe (np. pokaż ostatnie 4 znaki ID konta), chyba że użytkownik ma eksplicytne uprawnienia.
- Oddziel „kto jest dotknięty” od „co jest zepsute”. Wielu użytkowników potrzebuje jedynie poziomu usługi, nie listy klientów.
- Zabezpiecz eksporty: dodawaj znaki wodne do PDF/CSV, umieszczaj żądającego użytkownika i ograniczaj eksporty do zatwierdzonych ról. Preferuj krótkotrwałe, podpisane linki do pobrania.
Logowanie audytu odpowiadające na „kto co zmienił?”
Loguj kluczowe akcje z wystarczającym kontekstem do przeglądów:
- ręczne edycje wejść wpływu (dotknięte usługi/klienci)
- nadpisania wyniku wpływu (stara wartość, nowa wartość, powód)
- potwierdzenia i przejścia statusu
- generowanie raportów i eksporty
Przechowuj logi audytu jako append-only z znacznikami czasu i tożsamością aktora. Uczyń je przeszukiwalnymi per incydent, aby były użyteczne podczas analizy po incydencie.
Planowanie zgodności (bez obiecywania za dużo)
Udokumentuj, co możesz wspierać teraz — okres retencji, kontrola dostępu, szyfrowanie i pokrycie audytu — i co jest na roadmapzie.
Krótka strona „Security & Audit” w aplikacji (np. /security) pomaga ustawić oczekiwania i zmniejsza ad-hoc pytania podczas krytycznych incydentów.
Workflow i powiadomienia podczas aktywnego incydentu
Analiza wpływu ma sens tylko wtedy, gdy napędza następne kroki. Twoja aplikacja powinna zachowywać się jak „współpilot” kanału incydentowego: przekształca nadchodzące sygnały w jasne aktualizacje i popycha ludzi, gdy wpływ znacząco się zmienia.
Podłącz do czatu i kanałów incydentowych
Zacznij od integracji z miejscem, gdzie respondenci już pracują (często Slack, Microsoft Teams lub dedykowane narzędzie incydentowe). Celem nie jest zastąpienie kanału — to publikowanie kontekstowych aktualizacji i utrzymanie wspólnego zapisu.
Praktyczny wzorzec traktuje kanał incydentowy jako wejście i wyjście:
- Wejście: respondenci tagują aplikację (np. „/impact summarize”, „/impact add affected customer Acme”) aby poprawić lub wzbogacić zakres.
- Wyjście: aplikacja publikuje zwięzłe, spójne aktualizacje (aktualny wynik wpływu, dotknięte usługi/klienci, trend względem ostatniej aktualizacji).
Jeśli prototypujesz szybko, rozważ zbudowanie pełnego przepływu end-to-end najpierw (widok incydentu → podsumuj → powiadom), zanim dopracujesz scoring. Platformy takie jak Koder.ai mogą przyspieszyć: pozwalają iterować nad React dashboardem i backendem Go/PostgreSQL przez workflow sterowany czatem, a potem eksportować kod, gdy UX odpowiada reality.
Powiadomienia progowe (nie spam)
Unikaj spamowania alertami, wysyłając powiadomienia tylko, gdy wpływ przekracza jawne progi. Typowe wyzwalacze:
- Zakres: skok liczby dotkniętych klientów (np. 10 → 100)
- Tier: dotknięcie usługi Tier 1
- Przychody / ryzyko SLA: prognozowane naruszenie SLA lub wysoka wartość kontraktu
- Rozszerzenie blast radius: nowe zależności dołączają do dotkniętego zbioru
Gdy próg jest przekroczony, wyślij wiadomość wyjaśniającą dlaczego (co się zmieniło), kto powinien działać i co należy zrobić dalej.
Linkuj do runbooków i workflowów
Każde powiadomienie powinno zawierać linki „następny krok”, aby respondenci mogli szybko działać:
- Runbooki: /blog/incident-runbook-template
- Polityka eskalacji: /pricing
- Strona własności usługi: /services/payments
Utrzymuj te odnośniki stabilne i względne, aby działały w różnych środowiskach.
Aktualizacje dla interesariuszy: wewnętrzne i dla klientów
Generuj dwa formaty podsumowań z tych samych danych:
- Aktualizacja wewnętrzna: szczegóły techniczne, podejrzana przyczyna, postęp mitigacji, pewność ETA.
- Aktualizacja dla klienta: prosty język, aktualny wpływ na użytkowników, obejścia, czas kolejnej aktualizacji.
Wspieraj zaplanowane podsumowania (np. co 15–30 minut) i ad-hoc „generuj aktualizację” z krokiem zatwierdzenia przed wysyłką zewnętrzną.
Walidacja: testy, odtwarzanie i sprawdzanie dokładności
Experiment without risk
Eksperymentuj bez ryzyka — iteruj reguły z migawkami i rollbackiem, gdy zmiana zachowuje się źle.
Analiza wpływu jest użyteczna tylko wtedy, gdy ludzie jej ufają podczas incydentu i po nim. Walidacja powinna udowodnić dwie rzeczy: (1) system produkuje stabilne, wyjaśnialne wyniki oraz (2) te wyniki zgadzają się z ustaleniami organizacji po incydencie.
Strategia testowa: reguły i pipeline'y
Zacznij od automatycznych testów obejmujących dwa najbardziej podatne obszary: logikę scoringu i pobieranie danych.
- Testy jednostkowe reguł: traktuj każdą regułę jako kontrakt. Dla określonych sygnałów (error rate, opóźnienie, checki syntetyczne, wolumen ticketów) test powinien asercją sprawdzić oczekiwany wynik wpływu i zakres dotkniętych. Uwzględnij testy brzegowe (tuż poniżej/powyżej progów), aby fluktuacje metryk nie odwracały wyników nieoczekiwanie.
- Testy integracyjne pobierania: zweryfikuj pełną ścieżkę od webhooka/zdarzenia do znormalizowanych rekordów i obliczonego wpływu. Użyj zarejestrowanych payloadów z narzędzi obserwowalności i incydentowych, aby wcześnie złapać dryft schematu.
Utrzymuj fixture testowe czytelne: gdy ktoś zmienia regułę, powinien rozumieć, dlaczego wynik się zmienił.
Odtwarzaj przeszłe incydenty, aby walidować wyniki
Tryb odtwarzania to szybka ścieżka do zaufania. Uruchom historyczne incydenty przez aplikację i porównaj, co system pokazałby „w danym momencie” z tym, do czego respondenci doszli później.
Praktyczne wskazówki:
- Rekonstruuj osi czasu używając timestampów zdarzeń (nie czasu przybycia), aby odzwierciedlić rzeczywistość.
- Zamrażaj graf zależności na datę incydentu, jeśli katalog usług się zmienił.
- Przechowuj wyniki replay, aby móc porównywać wersje po zmianach reguł.
Obsłuż przypadki brzegowe, które łamią naiwny scoring
Prawdziwe incydenty rzadko wyglądają jak czyste awarie. Twoja suite walidacyjna powinna obejmować scenariusze takie jak:
- Częściowe awarie (niektóre endpointy lub segmenty klientów zawodzą)
- Degradacja wydajności (wolno, ale nie upadek) gdzie biznesowy wpływ może być wysoki
- Awaria multi-regionowa gdzie ta sama usługa ma różne zdrowie w regionach
Dla każdego asercji testuj nie tylko wynik, ale i wyjaśnienie: które sygnały i które zależności/klienci pociągnęły rezultat.
Mierzenie dokładności względem ustaleń po incydencie
Zdefiniuj dokładność w operacyjnych terminach i śledź ją.
Porównuj obliczony wpływ z wynikami analizy po incydencie: dotknięte usługi, czas trwania, liczba klientów, naruszenie SLA i klasyfikacja ciężkości. Loguj rozbieżności jako problemy walidacyjne z kategorią (brak danych, błędna zależność, zły próg, opóźniony sygnał).
Z czasem cel nie jest perfekcja — to mniej niespodzianek i szybsze porozumienie podczas incydentów.
Wdrożenie, skalowanie i iteracja po MVP
Wypuszczenie MVP analizy wpływu to głównie niezawodność i pętle sprzężenia zwrotnego. Pierwszy wybór wdrożeniowy powinien optymalizować szybkość zmian, nie teoretyczną skalę przyszłości.
Wybierz styl wdrożenia, który możesz ewoluować
Zacznij od modularnego monolitu, chyba że masz już silny zespół platformowy i jasne granice usług. Jeden unit do wdrożenia upraszcza migracje, debugowanie i testy end-to-end.
Dziel na serwisy dopiero, gdy pojawi się realny ból:
- pipeline pobierania musi niezależnie skalować
- wiele zespołów musi wdrażać niezależnie
- domeny błędów są trudne do rozumienia w jednym appie
Pragmatyczny kompromis to jedna aplikacja + background workers (kolejki) + oddzielne „ingestion edge” jeśli potrzeba.
Jeśli chcesz szybko i bez wielkiego nakładu, Koder.ai może przyspieszyć MVP: ich workflow czatowy jest dopasowany do budowy React UI, Go API i modelu danych PostgreSQL, z migawkami/rollbackami przy iterowaniu reguł i workflowów.
Wybierz storage wg wzorców dostępu
Użyj relacyjnego storage (Postgres/MySQL) dla bytów core: incydenty, usługi, klienci, właściciele i obliczone snapshoty wpływu. Łatwo zapytujesz, audytujesz i ewoluujesz.
Dla wysokowoltowych sygnałów (metryki, zdarzenia pochodzące z logów) dodaj time-series store lub magazyn kolumnowy, gdy surowe przechowywanie i rollupy robią się drogie w SQL.
Rozważ bazę grafową tylko, gdy zapytania zależności staną się wąskim gardłem albo model zależności bardzo dynamiczny. Wiele zespołów poradzi sobie z tabelami sąsiedztwa i cache’em.
Dodaj obserwowalność samej aplikacji
Twoja aplikacja analizy wpływu staje się elementem łańcucha incydentowego, więc instrumentuj ją jak produkcję:
- tempo błędów i wolne endpointy (szczególnie „recalculate impact”)
- głębokość/lag kolejek workerów i wskaźniki retry
- przepustowość pobierania i liczby błędów na źródło
- świeżość danych (czas od ostatniego udanego pull/push)
- czas trwania obliczeń i hit rate cache
Wystaw widok „health + freshness” w UI, aby respondenci mogli ufać (lub kwestionować) liczby.
Planuj iteracje i refaktory świadomie
Zdefiniuj zakres MVP wąsko: mały zestaw narzędzi do pobierania, jasny wynik wpływu i pulpit odpowiadający „kto jest dotknięty i jak bardzo”. Potem iteruj:
- Następne funkcje: lepsza dokładność zależności, ważenie specyficzne dla klientów, eksporty raportów SLA, tryb odtwarzania przeszłych incydentów
- Wyzwalacze refaktoru: dodajesz przypadki specjalne co tydzień, przeliczenie jest zbyt wolne albo model danych nie potrafi wyrazić rzeczywistości bez obejść
Traktuj model jako produkt: wersjonuj go, migracje wykonuj bezpiecznie i dokumentuj zmiany dla analizy po incydencie.