Zdefiniuj zakres i metryki sukcesu
Zanim zaprojektujesz workflow moderacji treści, zdecyduj, co dokładnie moderujesz i jak wygląda „dobrze”. Jasny zakres zapobiega zapełnieniu kolejki moderacji przypadkami brzegowymi, duplikatami i zgłoszeniami, które tam nie należą.
Co liczy się jako „treść”
Wypisz każdy typ treści, który może stwarzać ryzyko lub szkodzić użytkownikom. Typowe przykłady to tekst tworzony przez użytkowników (komentarze, posty, recenzje), obrazy, wideo, transmisje na żywo, pola profilu (imię, opis, avatar), wiadomości prywatne, grupy społecznościowe oraz ogłoszenia na rynku (tytuły, opisy, zdjęcia, ceny).
Zanotuj też źródła: zgłoszenia użytkowników, automatyczne importy, edycje istniejących elementów oraz raporty od innych użytkowników. To zapobiega zbudowaniu systemu działającego tylko dla „nowych postów” i pomijającego edycje, ponowne przesłania czy nadużycia w DM.
Twoje cele (i kompromisy)
Większość zespołów równoważy cztery cele:
- Szybkość: krótki czas do decyzji, aby szkoda była szybko adresowana
- Spójność: podobne przypadki otrzymują podobne rozstrzygnięcia niezależnie od recenzenta
- Zgodność z polityką i bezpieczeństwo: decyzje zgodne z zasadami i zobowiązaniami prawnymi
- Kontrola kosztów: czas recenzentów jest ograniczony; automatyzacja i priorytetyzacja są ważne
Bądź jawny, który cel jest priorytetowy w danym obszarze. Na przykład w przypadkach wysokiej wagi nadużyć priorytet może być na prędkości ponad idealną spójnością.
Akcje, które musisz wspierać
Wypisz pełen zestaw wyników wymaganych przez produkt: zatwierdź, odrzuć/usunąć, edytuj/cenzuruj, oznacz/ogródkuj wiekowo, ogranicz widoczność, umieść pod przeglądem, eskaluj do lidera oraz działania na poziomie konta jak ostrzeżenia, tymczasowe blokady czy bany.
Metryki sukcesu do śledzenia
Zdefiniuj mierzalne cele: mediana i 95. percentyl czasu przeglądu, rozmiar backlogu, wskaźnik uchyleń po odwołaniu, dokładność polityki z próbkowania QA oraz odsetek przypadków wysokiej wagi obsłużonych w ramach SLA.
Interesariusze do włączenia wcześnie
Uwzględnij moderatorów, liderów zespołów, policy, support, inżynierię i dział prawny. Brak zgodności na tym etapie powoduje przeróbki później—szczególnie w kwestii tego, co znaczy „eskalacja” i kto ponosi odpowiedzialność za ostateczne decyzje.
Zmodeluj workflow moderacji end-to-end
Zanim zbudujesz ekrany i kolejki, naszkicuj pełny cykl życia pojedynczej treści. Jasny workflow zapobiega „tajemniczym stanom”, które mylą recenzentów, psują powiadomienia i utrudniają audyty.
Mapuj cykl życia jako jawne stany
Zacznij od prostego, end-to-end modelu stanów, który możesz umieścić w diagramie i w bazie danych:
Submitted → Queued → In review → Decided → Notified → Archived
Utrzymuj stany wzajemnie wykluczające i zdefiniuj, które przejścia są dozwolone (i przez kogo). Na przykład: „Queued” może przejść do „In review” tylko po przypisaniu, a „Decided” powinno być niemodyfikowalne poza przepływem odwołań.
Oddziel automatyczne sygnały od decyzji ludzkich
Klasyfikatory automatyczne, dopasowania słów kluczowych, limity częstotliwości i raporty użytkowników powinny być traktowane jako sygnały, a nie decyzje. Projekt z „człowiekiem w pętli” utrzymuje system w równowadze:
- Sygnały wpływają na priorytet i rekomendowane akcje.
- Decyzja recenzenta jest ostatecznym wynikiem.
Takie oddzielenie ułatwia też poprawianie modeli później bez przepisywania logiki polityki.
Zaplanuj odwołania i ponowne przeglądy
Decyzje będą kwestionowane. Dodaj priorytetowe przepływy dla:
- Złożenia odwołania przez użytkownika (powiązanego z oryginalną sprawą)
- Ponownego przeglądu przez innego recenzenta lub zespół specjalistyczny
- Możliwych wyników: podtrzymanie, uchylenie, zmiana lub prośba o więcej informacji
Modeluj odwołania jako nowe zdarzenia przeglądowe zamiast edytowania historii. Dzięki temu możesz opowiedzieć pełną historię przebiegu sprawy.
Zdecyduj, co musi być śledzone
Dla audytów i sporów określ, które kroki trzeba rejestrować z timestampami i aktorami:
- Zmiany przypisań
- Obejrzane dowody (gdzie to stosowne)
- Decyzja, powód politykowy i akcja egzekucyjna
- Wysłane powiadomienia
Jeśli później nie będziesz w stanie wyjaśnić decyzji, załóż, że się nie wydarzyła.
Zaprojektuj role, uprawnienia i strukturę zespołu
Narzędzie moderacyjne żyje lub umiera na kontroli dostępu. Jeśli każdy może wszystko, otrzymasz niespójne decyzje, przypadkowe ujawnienia danych i brak odpowiedzialności. Zacznij od zdefiniowania ról odpowiadających rzeczywistej pracy zespołu Trust & Safety, a potem przełóż je na uprawnienia, które aplikacja potrafi egzekwować.
Podstawowe role do wsparcia
Większość zespołów potrzebuje niewielkiego zestawu jasnych ról:
- Moderator: przegląda elementy w kolejce, stosuje wyniki (zatwierdź/usunąć/oznacz) i zostawia notatki wewnętrzne.
- Senior reviewer: wszystko, co moderator może robić, plus nadpisania, obsługa eskalacji i coaching (np. rozwiązywanie sporów).
- Policy editor: aktualizuje tekst polityki, definicje reguł i wytyczne decyzyjne, ale nie moderuje bezpośrednio elementów.
- Admin: zarządza użytkownikami, rolami, ustawieniami zespołu, integracjami i akcjami wysokiego ryzyka.
- Read-only: może przeglądać dashboardy, sprawy i wpisy w dzienniku audytu, ale niczego nie zmieniać.
To rozdzielenie pomaga uniknąć „przypadkowych zmian polityki” i utrzymuje zarządzanie polityką oddzielnie od codziennego egzekwowania.
Uprawnienia według zasady najmniejszych przywilejów (RBAC)
Wdroż kontrolę dostępu opartą na rolach, by każda rola miała tylko to, czego potrzebuje:
- Ogranicz, kto może oglądać wrażliwe dane użytkownika (PII, raporty, sygnały urządzeń).
- Ogranicz działania o wysokim wpływie, takie jak zbiorcze decyzje, kary na poziomie konta i usuwanie spraw.
- Dziel uprawnienia według zdolności (np.
can_apply_outcome, can_override, can_export_data) zamiast według stron.
Jeśli później dodasz nowe funkcje (eksporty, automatyzacje, integracje zewnętrzne), przypniesz je do uprawnień bez przebudowy całej struktury organizacyjnej.
Struktura wielu zespołów (język, region, produkt)
Planuj na wiele zespołów już wcześniej: pody językowe, grupy regionalne lub oddzielne linie dla różnych produktów. Modeluj zespoły jawnie, a potem ograniczaj kolejki, widoczność treści i przypisania według zespołu. To zapobiega błędom międzynarodowych przeglądów i utrzymuje mierzalne obciążenie pracy na grupę.
Zabezpieczenia przy podszywaniu się i zatwierdzeniach
Administratorzy czasem muszą się podszyć pod użytkowników, by debugować dostęp lub odtworzyć problem recenzenta. Traktuj podszywanie jako wrażliwą akcję:
- Wymagaj konkretnego uprawnienia do podszywania się.
- Loguj kto się podszył pod kogo, kiedy i dlaczego.
- Wyświetlaj trwały baner „impersonating” i domyślnie wyłącz ryzykowne akcje.
Dla działań nieodwracalnych lub wysokiego ryzyka dodaj zatwierdzenie administracyjne (lub przegląd dwóch osób). Taka niewielka tarcie chroni przed pomyłkami i nadużyciami wewnętrznymi, a jednocześnie utrzymuje szybkość rutynowej moderacji.
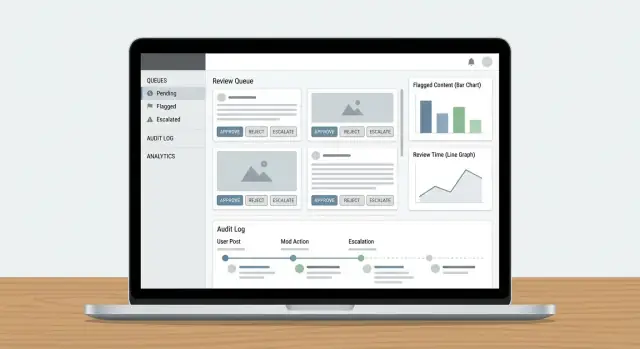
Buduj kolejki, priorytetyzację i przypisania
Kolejki to miejsce, gdzie praca moderacyjna staje się zarządzalna. Zamiast jednej niekończącej się listy, podziel pracę na kolejki odzwierciedlające ryzyko, pilność i intencję — i utrudnij wpadanie elementów między krzesła.
Zdefiniuj typy kolejek
Zacznij od małego zestawu kolejek odpowiadających rzeczywistej pracy zespołu:
- Nowe elementy: świeża treść czekająca na pierwszą recenzję.
- Wysokie ryzyko: elementy mogące wyrządzić szkodę (np. sygnały dotyczące nieletnich, samookaleczeń, znane wzorce oszustw).
- Eskalacje: wszystko, czego recenzent nie jest pewien lub co wymaga specjalisty.
- Odwołania: żądania użytkowników o ponowne rozpatrzenie decyzji.
- Backlog: starsze elementy, niższy priorytet lub przelanie podczas szczytów.
Utrzymuj kolejki możliwie wzajemnie wykluczające się (element powinien mieć jedno „miejsce”), a dla atrybutów drugorzędnych używaj tagów.
Wybierz reguły priorytetyzacji, których nie da się łatwo oszukać
W obrębie kolejki zdefiniuj reguły scoringowe decydujące, co trafia na górę:
- Ważność (kategoria polityki + pewność)
- Wirusowość/zasięg (wyświetlenia, udostępnienia, liczba obserwujących)
- Zgłoszenia użytkowników (liczba, reputacja zgłaszających, unikalni zgłaszający)
- Timery SLA (wiek, terminy eskalacji, czas od pierwszego zgłoszenia)
Spraw, by priorytety były wyjaśnialne w UI („Dlaczego to widzę?”), aby recenzenci ufali kolejności.
Zapobiegaj podwójnej pracy przez przyjmowanie + timeouty
Użyj claiming/locking: kiedy recenzent otwiera element, jest on przypisany do niego i ukryty przed innymi. Dodaj timeout (np. 10–20 minut), by porzucone elementy wracały do kolejki. Zawsze loguj zdarzenia claim, release i completion.
Zapewnij sprawiedliwość: unikaj faworyzowania „łatwych” przypadków
Jeśli system premiuje szybkość, recenzenci będą wybierać szybkie sprawy i omijać trudne. Zminimalizuj to przez:
- Automatyczne przypisywanie części pracy
- Mieszanie poziomów trudności (inteligentne grupowanie)
- Rotowanie kolejek wysokiego wpływu w zespole
Celem jest równe pokrycie, nie tylko wysoka wydajność.
Zamień polityki w wykonalne reguły
Powiąż decyzje z efektami
Modeluj zdarzenia decyzji tak, aby powiadomienia i działania egzekucyjne były spójne.
Polityka moderacji, która istnieje tylko jako PDF, będzie interpretowana inaczej przez każdego recenzenta. Aby decyzje były spójne (i audytowalne), przetłumacz tekst polityki na ustrukturyzowane dane i wybory w UI, które workflow może egzekwować.
Stwórz taksonomię polityk
Zacznij od rozbicia polityki na wspólny słownik, który recenzenci będą wybierać. Przydatna taksonomia zwykle zawiera:
- Kategoria (np. Nękanie, Treści dla dorosłych, Dezinformacja)
- Typ naruszenia (np. mowa nienawiści vs ogólna obelga)
- Poziom ważności (np. Niski/Średni/Wysoki/Krytyczny)
- Wymagane dowody (co musi być obecne, by zastosować politykę — konkretne frazy, kontekst, raporty, linki, znaczniki czasu)
Ta taksonomia staje się podstawą dla kolejek, eskalacji i analityki.
Używaj szablonów decyzji, by zmniejszyć niespójność
Zamiast każdorazowo prosić recenzentów o napisanie decyzji od zera, zapewnij szablony decyzji powiązane z elementami taksonomii. Szablon może wstępnie wypełniać:
- Zalecaną akcję (usuń, oznacz, ogranicz, upomnij, brak akcji)
- Komunikat dla użytkownika (edytowalny, ale z wytycznymi)
- Wewnętrzną checklistę (jakie dowody trzeba potwierdzić)
Szablony przyspieszają „happy path”, pozwalając jednocześnie na wyjątki.
Wspieraj wersjonowanie polityk i daty wejścia w życie
Polityki się zmieniają. Przechowuj polityki jako wersjonowane rekordy z datami wejścia w życie i zapisuj, która wersja była zastosowana dla każdej decyzji. To zapobiega zamieszaniu przy odwołaniach i pozwala wyjaśnić rezultaty sprzed miesięcy.
Zbieraj ustrukturyzowane powody (nie tylko wolny tekst)
Wolny tekst jest trudny do analizy i łatwy do zapomnienia. Wymagaj, by recenzenci wybierali jeden lub więcej ustrukturyzowanych powodów (z taksonomii) i opcjonalnie dodawali notatki. Ustrukturyzowane powody poprawiają obsługę odwołań, próbkowanie QA i raportowanie trendów — bez zmuszania recenzentów do pisania esejów.
Zaprojektuj pulpit recenzenta i UX
Pulpit recenzenta odnosi sukces, gdy minimalizuje „szukanie” informacji i maksymalizuje pewne, powtarzalne decyzje. Recenzenci powinni móc zrozumieć, co się stało, dlaczego to ważne i co zrobić dalej — bez otwierania pięciu zakładek.
Pokaż treść z odpowiednim kontekstem
Nie pokazuj izolowanego posta i oczekuj spójnych wyników. Zaprezentuj kompaktowy panel kontekstu odpowiadający na typowe pytania na pierwszy rzut oka:
- Widok konwersacji/wątku: kilka wiadomości przed i po zgłoszonym elemencie, z wyraźnym wyróżnieniem zgłoszonej treści.
- Historia użytkownika: ostatnie ostrzeżenia, zawieszenia, wcześniejsze usunięcia i wyniki odwołań (ograniczone czasowo, by pozostać istotne).
- Poprzednie działania: kto wcześniej ingerował w element, jaka decyzja zapadła i notatki.
Domyślny widok powinien być zwięzły, z opcjami rozwinięcia do głębszego wglądu. Recenzenci rzadko powinni opuszczać pulpit, by podjąć decyzję.
Szybkie akcje odpowiadające realnym decyzjom
Belka akcji powinna odpowiadać wynikom polityki, nie ogólnym przyciskom CRUD. Typowe wzorce:
- Zatwierdź / Odrzuć jednym kliknięciem
- Oznaczanie (np. spam, nękanie, samookaleczenia, dezinformacja) do raportowania i treningu
- Edytuj lub zredaguj (gdy polityka pozwala na częściowe usunięcie)
- Eskaluj do specjalistów lub drugiego poziomu recenzji
- Poproś o więcej informacji (w przypadku niejednoznaczności) z gotowymi szablonami
Uczyń akcje widocznymi, a kroki nieodwracalne jasno oznaczonymi (potwierdzenie tylko tam, gdzie potrzebne). Rejestruj krótki kod powodu oraz opcjonalne notatki do późniejszych audytów.
Funkcje przyspieszające: skróty klawiaturowe i akcje zbiorcze
Praca o dużej objętości wymaga niskiego tarcia. Dodaj skróty klawiaturowe dla głównych akcji (zatwierdź, odrzuć, następny element, dodaj oznaczenie). Pokaż cheat-sheet skrótów w UI.
Dla kolejek z powtarzalną pracą (np. oczywisty spam) wspieraj zbiorczą selekcję z zabezpieczeniami: pokaż podgląd liczby elementów, wymagaj kodu powodu i loguj akcję grupową.
Projektuj z myślą o bezpieczeństwie recenzentów
Moderacja może wystawiać ludzi na szkodliwe materiały. Dodaj domyślne zabezpieczenia:
- Rozmywaj wrażliwe media domyślnie z opcją kliknięcia, by odsłonić
- Banery ostrzegawcze dla prawdopodobnego samookaleczenia, treści seksualnych lub drastycznej przemocy
- Szybki przełącznik ukrywania treści, który pozwala decydować bez długiej ekspozycji
Te rozwiązania chronią recenzentów, utrzymując decyzje trafne i spójne.
Dodaj dzienniki audytu i śledzenie
Stwórz workflow odwołań
Dodaj przypadki odwołań, routing do ponownej recenzji i niemodyfikowalną historię decyzji.
Dzienniki audytu są twoim „źródłem prawdy”, gdy ktoś pyta: Dlaczego ten post został usunięty? Kto zatwierdził odwołanie? Czy model czy człowiek podjął ostateczną decyzję? Bez śledzenia dochodzenia zamieniają się w domysły, a zaufanie recenzentów szybko maleje.
Zapisuj każdą decyzję (i dowody)
Dla każdej akcji moderacyjnej loguj kto ją wykonał, co się zmieniło, kiedy to nastąpiło i dlaczego (kod polityki + notatki). Równie ważne: przechowuj snapshoty before/after obiektów — tekst treści, hashe mediów, wykryte sygnały, etykiety i ostateczny wynik. Jeśli element może się zmienić (edycje, usunięcia), snapshoty zapobiegają dryfowaniu rekordu.
Praktyczny wzorzec to append-only rekord zdarzeń:
{
"event": "DECISION_APPLIED",
"actor_id": "u_4821",
"subject_id": "post_99102",
"queue": "hate_speech",
"decision": "remove",
"policy_code": "HS.2",
"reason": "slur used as insult",
"before": {"status": "pending"},
"after": {"status": "removed"},
"created_at": "2025-12-26T10:14:22Z"
}
Loguj zdarzenia kolejki dla jasności operacyjnej
Poza decyzjami, loguj mechanikę workflow: claimed, released, timed out, reassigned, escalated i auto-routed. Te zdarzenia wyjaśniają „dlaczego to zajęło 6 godzin” lub „dlaczego element był przekazywany między zespołami” i są niezbędne do wykrywania nadużyć (np. wybierania tylko łatwych spraw przez recenzentów).
Uczyń ślady audytu przeszukiwalnymi do dochodzeń
Daj śledczym filtry po użytkowniku, ID treści, kodzie polityki, przedziale czasu, kolejce i typie akcji. Uwzględnij eksport do pliku sprawy, z niemodyfikowalnymi timestampami i odniesieniami do powiązanych elementów (duplikaty, ponowne przesłania, odwołania).
Zdefiniuj reguły retencji zgodne z compliance
Ustal jasne okna retencji dla zdarzeń audytu, snapshotów i notatek recenzentów. Miej politykę jawną (np. 90 dni dla rutynowych logów kolejki, dłużej dla legal holds) i udokumentuj, jak żądania usunięcia/redakcji wpływają na przechowywane dowody.
Połącz zgłoszenia, powiadomienia i działania użytkowników
Narzędzie moderacyjne jest użyteczne tylko wtedy, gdy zamyka pętlę: zgłoszenia stają się zadaniami do recenzji, decyzje trafiają do właściwych osób, a działania na poziomie użytkownika są wykonywane spójnie. W tym miejscu wiele systemów zawodzi—ktoś rozwiązuje kolejkę, ale nic poza tym się nie dzieje.
Intake: ujednolić każdy rodzaj zgłoszenia
Traktuj zgłoszenia użytkowników, automatyczne flagi (spam/CSAM/hash matches/sygnały toksyczności) i wewnętrzne eskalacje (support, community managers, legal) jako ten sam obiekt: report, który może wygenerować jedno lub więcej zadań przeglądowych.
Użyj jednego routera zgłoszeń, który:
- Deduplikuje (ta sama treść zgłaszana wiele razy)
- Łączy powiązane elementy (ten sam autor, ten sam wątek)
- Stosuje podstawową triage (ważność, kategoria, jurysdykcja)
- Tworzy/aktualizuje elementy w kolejce moderacji
Jeśli eskalacje supportu są częścią przepływu, powiąż je bezpośrednio (np. /support/tickets/1234) żeby recenzenci nie musieli zmieniać kontekstu.
Wyniki: powiadamiaj użytkowników bez tworzenia nowych ryzyk
Decyzje moderacyjne powinny generować szablonowe powiadomienia: treść usunięta, wystawiono ostrzeżenie, brak akcji lub działanie na koncie. Utrzymuj komunikację spójną i zwięzłą—wyjaśnij wynik, odnieś się do odpowiedniej polityki i podaj instrukcje odwoławcze.
Operacyjnie wysyłaj powiadomienia przez zdarzenie takie jak moderation.decision.finalized, aby e-mail/in-app/push mogły subskrybować bez spowalniania recenzenta.
Działania użytkownika: powiąż z kontrolami konta
Decyzje często wymagają działań wykraczających poza pojedynczą treść:
- Zawieszenia (czasowe/stałe)
- Ograniczenia (limity publikowania, limity DM, shadow bans tam, gdzie dozwolone)
- Aktualizacje score'ów zaufania/poziomów ryzyka
Uczyń te akcje jawne i odwracalne, z jasnymi czasami trwania i powodami. Powiąż każde działanie ze źródłową decyzją i raportem dla śledzenia oraz zapewnij szybki dostęp do odwołań, by decyzje mogły być ponownie rozpatrzone bez żmudnego śledztwa.
Wybierz modele danych i strategię przechowywania
Dodaj RBAC z jasnymi rolami
Skonfiguruj role i uprawnienia z zasadą najmniejszych uprawnień dla moderatorów, redaktorów polityki i administratorów.
Twój model danych jest „źródłem prawdy” o tym, co się wydarzyło z każdym elementem: co było recenzowane, przez kogo, według jakiej polityki i jaki był wynik. Jeśli dobrze zrobisz tę warstwę, reszta—kolejki, dashboardy, audyty i analityka—będzie prostsza.
Oddziel treść, decyzje i kody polityk
Unikaj trzymania wszystkiego w jednym rekordzie. Praktyczny wzorzec to:
- Referencje treści (co jest przeglądane): stabilne ID, typ treści (post/komentarz/obraz/wideo), ID autora, czas utworzenia i wskaźnik do lokalizacji surowej treści.
- Decyzje moderacyjne (co recenzenci zrobili): ID decyzji, ID recenzenta, wynik decyzji, znaczniki czasowe, notatki oraz pola ustrukturyzowane (np. pewność, ważność).
- Kody polityk (dlaczego podjęto decyzję): kanoniczne identyfikatory polityk jak
HARASSMENT.H1 czy NUDITY.N3, przechowywane jako referencje, by polityki mogły ewoluować bez przepisywania historii.
To utrzymuje spójne egzekwowanie polityk i ułatwia raportowanie (np. „najczęściej łamane kody polityk w tym tygodniu”).
Nie trzymaj dużych obrazów/wideo bezpośrednio w bazie danych. Użyj object storage i zapisuj jedynie klucze obiektów + metadane w tabeli treści.
Dla recenzentów generuj krótkotrwałe podpisane URL-e, aby media były dostępne bez upubliczniania. Podpisane URL-e pozwalają kontrolować wygaśnięcie i odwoływać dostęp w razie potrzeby.
Indeksuj tam, gdzie szybkość ma znaczenie
Kolejki i dochodzenia zależą od szybkich wyszukiwań. Dodaj indeksy dla:
- Filtrów kolejek (status, priorytet, przypisany recenzent, czas utworzenia)
- Wyszukiwania tekstowego (powód zgłoszenia, tekst treści tam, gdzie dozwolone)
- Zapytania do dzienników audytu (aktor, typ akcji, przedział czasu, ID treści)
Śledź przejścia stanów, by zapobiegać „zablokowanym” elementom
Modeluj moderację jako jawne stany (np. NEW → TRIAGED → IN_REVIEW → DECIDED → APPEALED). Przechowuj zdarzenia zmiany stanu (z timestampami i aktorem), by móc wykryć elementy, które nie posuwają się do przodu.
Proste zabezpieczenie: pole last_state_change_at plus alerty dla elementów przekraczających SLA i zadanie naprawcze, które requeueuje elementy pozostające w IN_REVIEW po timeoutcie.
Bezpieczeństwo, prywatność i odporność na nadużycia
Narzędzia Trust & Safety często przetwarzają najbardziej wrażliwe dane w produkcie: treści użytkowników, raporty, identyfikatory kont i czasem żądania prawne. Traktuj aplikację moderacyjną jako system wysokiego ryzyka i wbuduj bezpieczeństwo i prywatność od początku.
Bezpieczny dostęp dla recenzentów i administratorów
Zacznij od silnej autentykacji i kontroli sesji. Dla większości zespołów oznacza to:
- SSO (SAML/OIDC), aby dostęp był zgodny z firmową polityką tożsamości
- MFA dla ról uprzywilejowanych (admini, policy editorzy, eksporty)
- Krótkie timeouty sesji i ponowna autoryzacja dla ryzykownych akcji (akcje zbiorcze, eksporty, zmiany ról)
- Whitelisty IP dla narzędzi wewnętrznych, tam gdzie ma to sens (np. stanowiska kontraktorów lub zakresy biurowe)
Połącz to z RBAC, by recenzenci widzieli tylko to, czego potrzebują (np. jedna kolejka, jeden region lub jeden typ treści).
Chroń wrażliwe treści i dane użytkowników
Szyfruj dane w tranzycie (HTTPS wszędzie) i w spoczynku (szyfrowanie zarządzane przez bazę/storage). Następnie skup się na minimalizacji ekspozycji:
- Pokaż zredagowane podglądy domyślnie (rozmyte media, zamaskowane telefon/email) z akcją reveal, która jest logowana
- Oddziel uprawnienia do przeglądania od uprawnień do eksportu
- Ogranicz dostęp do pól wysokiego ryzyka (dokładne adresy, dane płatnicze) do niewielkiej grupy ról
Jeśli obsługujesz zgody lub specjalne kategorie danych, zaznacz te flagi recenzentom i egzekwuj je w UI (np. ograniczony podgląd lub reguły retencji).
Odporność na nadużycia dla zgłoszeń i odwołań
Punkty końcowe zgłoszeń i odwołań są często celem spamu i nadużyć. Dodaj:
- Ograniczenia szybkości na użytkownika/IP/urządzenie
- Ochronę przed botami (wyzwania przy nagłych skokach, wykrywanie anomalii)
- Kontrole kosztów (limity dzienne, rosnące tarcie przy powtarzającym się nadużyciu)
Na koniec uczynij każdą wrażliwą akcję śledzalną w dzienniku audytu, by móc badać błędy recenzentów, skompromitowane konta lub skoordynowane nadużycia.