21 wrz 2025·8 min
Jak C i C++ wciąż napędzają systemy operacyjne, bazy danych i silniki gier
Zobacz, jak C i C++ wciąż tworzą rdzeń systemów operacyjnych, baz danych i silników gier — poprzez kontrolę pamięci, szybkość i dostęp niskiego poziomu.
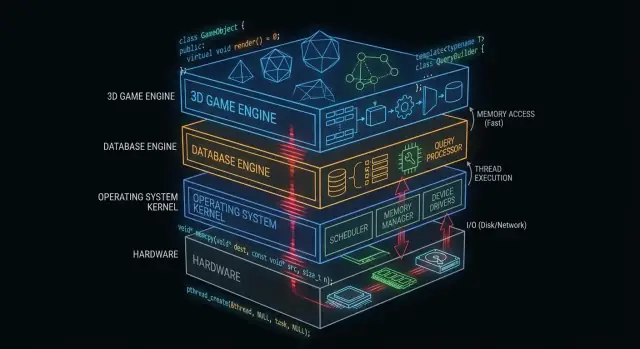
Dlaczego C i C++ wciąż mają znaczenie „za kulisami"
„Pod maską" kryje się wszystko, od czego zależy twoja aplikacja, ale czego rzadko dotykasz bezpośrednio: jądra systemów operacyjnych, sterowniki urządzeń, silniki magazynów danych, stosy sieciowe, runtime'y i biblioteki krytyczne pod względem wydajności.
Dla kontrastu, to co wielu deweloperów aplikacji widzi na co dzień to powierzchnia: frameworki, API, zarządzane środowiska wykonawcze, menedżery pakietów i usługi w chmurze. Te warstwy są projektowane pod kątem bezpieczeństwa i produktywności — nawet jeśli celowo ukrywają złożoność.
Dlaczego niektóre warstwy muszą być blisko sprzętu
Niektóre komponenty oprogramowania mają wymagania trudne do spełnienia bez bezpośredniej kontroli:
- Przewidywalna wydajność i opóźnienia (np. planowanie czasu CPU, obsługa przerwań, strumieniowanie zasobów)
- Precyzyjna kontrola pamięci (układ, wyrównanie, zachowanie cache, unikanie przerw)
- Bezpośredni dostęp do sprzętu (rejestry, DMA, sterowniki, systemy plików i urządzenia blokowe)
- Małe, przenośne binaria, które mogą działać wcześnie podczas rozruchu lub w środowiskach z ograniczeniami
C i C++ wciąż są tu powszechne, ponieważ kompilują się do kodu natywnego bez narzutu runtime i dają inżynierom drobiazgową kontrolę nad pamięcią i wywołaniami systemowymi.
Gdzie dziś najczęściej pojawiają się C i C++
Na wysokim poziomie znajdziesz C i C++ napędzające:
- Jądra systemów operacyjnych i niskopoziomowe biblioteki
- Sterowniki i oprogramowanie wbudowane
- Silniki baz danych (wykonywanie zapytań, magazynowanie, indeksowanie)
- Silniki gier i systemy czasu rzeczywistego (rendering, fizyka, dźwięk)
- Kompilatory, toolchainy i runtime'y języków, na których opierają się inne języki
Co obejmie (i czego nie obejmie) ten wpis
Artykuł skupia się na mechanice: co robią te komponenty „za kulisami", dlaczego zyskują na kodzie natywnym i jakie kompromisy wiążą się z tą mocą.
Nie będziemy twierdzić, że C/C++ to najlepszy wybór dla każdego projektu, ani prowokować wojny językowej. Celem jest praktyczne zrozumienie, gdzie te języki wciąż się sprawdzają — i dlaczego nowoczesne stosy programistyczne wciąż na nich bazują.
Co czyni C i C++ odpowiednimi dla oprogramowania systemowego
C i C++ są szeroko używane w oprogramowaniu systemowym, ponieważ pozwalają na programy „blisko metalu": małe, szybkie i ściśle zintegrowane z OS i sprzętem.
Kompilowane do kodu natywnego (prosto i po ludzku)
Gdy kod C/C++ jest kompilowany, staje się instrukcjami maszynowymi, które CPU może wykonywać bezpośrednio. Nie ma wymaganego runtime tłumaczącego instrukcje w czasie działania.
To ma znaczenie dla komponentów infrastruktury — jąder, silników baz danych, silników gier — gdzie nawet niewielkie narzuty kumulują się pod obciążeniem.
Przewidywalna wydajność dla krytycznej infrastruktury
Oprogramowanie systemowe często potrzebuje spójnych czasów reakcji, nie tylko dobrego średniego czasu. Na przykład:
- Planista systemu operacyjnego musi reagować szybko pod obciążeniem.
- Baza danych musi utrzymywać stabilne opóźnienia przy wielu zapytaniach jednocześnie.
- Silnik gry musi trafić w budżet klatki (np. ~16 ms dla 60 FPS).
C/C++ dają kontrolę nad zużyciem CPU, układem pamięci i strukturami danych, co pomaga uzyskać przewidywalną wydajność.
Bezpośredni dostęp do pamięci i wskaźników
Wskaźniki pozwalają operować bezpośrednio na adresach pamięci. Ta moc może wydawać się przerażająca, ale otwiera możliwości, które wiele języków wyższego poziomu abstrahuje:
- Własne alokatory dopasowane do konkretnych obciążeń
- Kompaktowe formaty w pamięci (przydatne w bazach danych i cache'ach)
- Schematy zero-copy I/O, gdzie dane nie są wielokrotnie kopiowane
Użyte ostrożnie, takie sterowanie może dać dramatyczne zyski wydajności.
Kompromisy: bezpieczeństwo, złożoność i czas wytwarzania
Ta sama wolność to również ryzyko. Typowe kompromisy to:
- Bezpieczeństwo: błędy mogą powodować awarie, uszkodzenia danych lub luki bezpieczeństwa.
- Złożoność: ręczne zarządzanie pamięcią i niedefiniowane zachowania wymagają dyscypliny.
- Czas wytwarzania: testy, code review i narzędzia stają się niezbędne dla niezawodności.
Częstym podejściem jest trzymanie rdzenia krytycznego wydajnościowo w C/C++, a otaczanie go bezpieczniejszymi językami dla funkcji produktu i UX.
C/C++ w jądrach systemów operacyjnych
Jądro systemu operacyjnego leży najbliżej sprzętu. Gdy laptop się budzi, przeglądarka się otwiera, albo program żąda więcej RAM, to jądro koordynuje te żądania i decyduje, co dalej.
Co jądro robi w praktyce
W praktyce jądra zajmują się kilkoma podstawowymi zadaniami:
- Planowanie: decydowanie, który program (i który wątek) dostanie czas procesora i na jak długo.
- Zarządzanie pamięcią: przydzielanie pamięci procesom, izolacja i bezpieczne zwalnianie pamięci.
- Zarządzanie urządzeniami: komunikacja ze sprzętem przez sterowniki (dysk, sieć, klawiatura, GPU itp.).
- Granice bezpieczeństwa: egzekwowanie uprawnień, aby jeden program nie mógł odczytać lub uszkodzić danych innego.
Ponieważ te odpowiedzialności stoją w centrum systemu, kod jądra jest zarówno wrażliwy na wydajność, jak i na poprawność.
Dlaczego ścisła kontrola sprzyja C (czasem C++)
Deweloperzy jądra potrzebują precyzyjnej kontroli nad:
- Układem pamięci: struktury o stałym rozmiarze, wyrównanie i przewidywalne zachowanie alokacji.
- Instrukcjami CPU i konwencjami wywołań: interakcje z przerwaniami, przełączaniem kontekstu i niskopoziomową synchronizacją.
- Rejestrami sprzętowymi: odczyt/zapis konkretnych adresów i obsługa specjalnych trybów CPU.
C pozostaje powszechnym „językiem jądra", bo mapuje się czysto na pojęcia maszynowe, a jednocześnie jest czytelny i przenośny między architekturami. Wiele jąder korzysta też z assemblera dla najmniejszych, sprzętowo-specyficznych fragmentów, pozostawiając C jako większość kodu.
C++ może pojawiać się w jądrze, ale zwykle w ograniczonym stylu (ograniczone funkcje runtime, ostrożna polityka wyjątków i ścisłe zasady alokacji). Gdy jest używany, zwykle ma poprawić abstrakcję bez utraty kontroli.
Kod „przyjąderkowy" często w C/C++
Nawet jeśli jądro jest konserwatywne, wiele sąsiednich komponentów to C/C++:
- Sterowniki urządzeń (zwłaszcza te krytyczne wydajnościowo)
- Biblioteki standardowe i runtime'y (części libc, niskopoziomowe wątki)
- Bootloadery i kod uruchamiany na starcie
- Usługi systemowe wymagające natywnej szybkości (np. pomocniki sieciowe lub magazynujące)
Więcej o tym, jak sterowniki łączą oprogramowanie ze sprzętem, znajdziesz pod ścieżką /blog/device-drivers-and-hardware-access.
Sterowniki urządzeń i dostęp do sprzętu
Sterowniki tłumaczą komunikację między systemem operacyjnym a sprzętem — karty sieciowe, GPU, kontrolery SSD, urządzenia audio i inne. Gdy klikasz „odtwórz", kopiujesz plik lub łączysz się z Wi‑Fi, sterownik często jest pierwszym kodem, który musi zareagować.
Ponieważ sterowniki leżą na ścieżce gorącej dla I/O, są bardzo wrażliwe na wydajność. Kilka dodatkowych mikrosekund na pakiet lub żądanie dysku może się szybko zsumować w intensywnych systemach. C i C++ są tu powszechne, bo potrafią wywołać API jądra OS bez pośredników, precyzyjnie kontrolować układ pamięci i działać z minimalnym narzutem.
Przerwania, DMA i dlaczego niskopoziomowe API są ważne
Sprzęt nie czeka grzecznie na swoją kolej. Urządzenia sygnalizują CPU przez przerwania — pilne powiadomienia, że coś się stało (przyszedł pakiet, zakończył się transfer). Kod sterownika musi obsłużyć te zdarzenia szybko i poprawnie, często pod ścisłymi ograniczeniami czasowymi i wątkowymi.
Dla dużej przepustowości sterowniki polegają też na DMA (Direct Memory Access), gdzie urządzenia czytają/piszą pamięć systemową bez kopiowania każdego bajtu przez CPU. Konfiguracja DMA zwykle obejmuje:
- Przygotowanie buforów we właściwym formacie i wyrównaniu
- Przekazanie urządzeniu fizycznych adresów lub opisników mapowanych
- Synchronizację własności pamięci między urządzeniem a CPU
Te zadania wymagają niskopoziomowych interfejsów: mapowanych rejestrów pamięci, flag bitowych i starannego porządkowania odczytów/zapisów. C/C++ sprawiają, że wyrażenie takiej logiki „blisko metalu" jest praktyczne i nadal przenośne między kompilatorami i platformami.
Stabilność jest bezdyskusyjna
W przeciwieństwie do zwykłej aplikacji, błąd sterownika może zresetować cały system, uszkodzić dane lub otworzyć luki bezpieczeństwa. To kształtuje sposób pisania i przeglądania kodu sterowników.
Zespoły ograniczają ryzyko przez surowe standardy kodowania, defensywne kontrole i warstwowe przeglądy. Powszechne praktyki to ograniczanie niebezpiecznego użycia wskaźników, walidacja danych od sprzętu/firmware i uruchamianie analizy statycznej w CI.
Zarządzanie pamięcią: moc i pułapki
Zaplanuj architekturę
Użyj Trybu Planowania, by rozrysować komponenty, granice i kompromisy przed generowaniem kodu.
Zarządzanie pamięcią to jeden z głównych powodów, dla których C i C++ wciąż dominują w częściach systemów operacyjnych, baz danych i silników gier. To także jedno z najłatwiejszych miejsc do stworzenia subtelnych błędów.
Co oznacza „zarządzanie pamięcią"
W praktyce zarządzanie pamięcią obejmuje:
- Alokowanie pamięci (pozyskanie fragmentu na dane)
- Zwalnianie jej (oddanie, gdy nie jest już potrzebna)
- Radzenie sobie z fragmentacją (dziury, które utrudniają późniejsze alokacje)
W C jest to często jawne (malloc/free). W C++ może być jawne (new/delete) lub owinięte w bezpieczniejsze wzorce.
Dlaczego ręczna kontrola może być zaletą
W komponentach krytycznych wydajnościowo ręczna kontrola może być cechą:
- Możesz uniknąć nieprzewidywalnych pauz z garbage collectorów.
- Możesz wybrać gdzie i jak pamięć jest alokowana (np. puli, arena), poprawiając spójność.
- Możesz dopasować wzorce alokacji do rzeczywistych obciążeń (wiele małych obiektów vs. duże ciągłe bufory).
To ma znaczenie, gdy baza danych musi utrzymać stabilne opóźnienia, a silnik gry trafić w budżet klatki.
Typowe tryby awarii (i dlaczego są poważne)
Ta sama wolność rodzi klasyczne problemy:
- Wycieki pamięci: zapomnienie o zwolnieniu pamięci, powodujące narastające zużycie aż do degradacji wydajności lub awarii procesu.
- Przepływy bufora: zapis poza końcem tablicy, uszkadzający dane lub umożliwiający ataki.
- Use-after-free: użycie wskaźnika po zwolnieniu pamięci, prowadzące do awarii trudnych do odtworzenia.
Te błędy są subtelne, bo program może „działać" do momentu, gdy konkretne obciążenie je ujawni.
Jak współczesne praktyki pomagają
Współczesne C++ zmniejsza ryzyko bez rezygnacji z kontroli:
- RAII (Resource Acquisition Is Initialization) wiąże żywotność zasobu ze zasięgiem, więc sprzątanie dzieje się automatycznie.
- Smart pointers (np.
std::unique_ptristd::shared_ptr) czynią własność jawna i zapobiegają wielu wyciekom. - Sanitizery (AddressSanitizer, UndefinedBehaviorSanitizer) i analiza statyczna wykrywają problemy wcześnie, często w CI.
Użyte dobrze, te narzędzia utrzymują szybkość C/C++, jednocześnie zmniejszając prawdopodobieństwo wycieków pamięci w produkcji.
Współbieżność i wydajność wielordzeniowa
Współczesne CPU nie zyskują dramatycznie na szybkości pojedynczego rdzenia — zyskują więcej rdzeni. To przesuwa pytanie wydajności z „Jak szybki jest mój kod?” na „Jak dobrze mój kod działa równolegle, nie wchodząc sobie w drogę?”. C i C++ są tu popularne, bo pozwalają na niskopoziomową kontrolę wątków, synchronizacji i zachowania pamięci z minimalnym narzutem.
Wątki, rdzenie i planowanie
Wątek to jednostka pracy programu; rdzeń CPU to miejsce, gdzie ta praca się wykonuje. Planista systemu operacyjnego mapuje gotowe wątki na dostępne rdzenie, stale podejmując kompromisy.
Szczegóły planowania mają znaczenie w kodzie krytycznym: zatrzymanie wątku w złym momencie może zablokować pipeline, spowodować kolejki lub przerywane działania. Dla zadań CPU-bound utrzymanie liczby aktywnych wątków zbliżonej do liczby rdzeni często zmniejsza thrashing.
Podstawy blokad: mutexy, atomiki i kontencja
- Mutexy są łatwe do zrozumienia, ale duże współdzielenie powoduje kontencję — czas spędzony na czekaniu zamiast pracy.
- Atomiki mogą być szybsze dla drobnych aktualizacji wspólnego stanu, ale wymagają ostrożnego projektowania, by uniknąć subtelnych błędów poprawności.
Praktycznym celem nie jest „nigdy nie blokować”, lecz: blokować mniej, mądrzej — utrzymywać krótkie sekcje krytyczne, unikać locków globalnych i redukować współdzielony mutowalny stan.
Dlaczego skoki opóźnień mają znaczenie
Bazy danych i silniki gier nie dbają tylko o średnią szybkość — dbają o najgorsze przerwy. Kolejka blokująca, page fault lub zahamowany worker może powodować zauważalne przycięcia, opóźnienie wejścia lub wolne zapytanie łamiące SLA.
Typowe wzorce C/C++
Wiele systemów wysokiej wydajności polega na:
- Pulach wątków do ponownego użycia workerów i przewidywalnego planowania.
- Kolejkach work-stealing do wyrównywania obciążenia między rdzeniami.
- Kolejkach lock-free (w wybranych gorących ścieżkach) by zmniejszyć blokowanie — stosowane ostrożnie, bo poprawność trudniej udowodnić.
Te wzorce dążą do stabilnej przepustowości i spójnych opóźnień pod presją.
Silniki baz danych: gdzie C/C++ daje przewagę
Silnik bazy danych to nie tylko „przechowywanie wierszy”. To ciasna pętla CPU i I/O działająca miliony razy na sekundę, gdzie drobne nieefektywności szybko się sumują. Dlatego wiele silników i kluczowych komponentów nadal jest napisanych w C lub C++.
Główne zadanie silnika: parsowanie, planowanie, wykonanie
Gdy wysyłasz SQL, silnik:
- Parsuje go (zamienia tekst na strukturę)
- Planuje (wybiera efektywny sposób odpowiedzi na zapytanie)
- Wykonuje (skanuje, wyszukuje indeksy, łączy, sortuje, agreguje i zwraca wiersze)
Każdy etap korzysta z ostrej kontroli nad pamięcią i czasem CPU. C/C++ umożliwiają szybkie parsery, mniejszą liczbę alokacji podczas planowania i szczupłą, gorącą ścieżkę wykonania — często z własnymi strukturami danych dopasowanymi do obciążenia.
Silnik magazynowania: strony, indeksy, buforowanie
Pod warstwą SQL silnik magazynowania zajmuje się nieefektownymi, lecz kluczowymi szczegółami:
- Strony: dane czyta się i zapisuje w blokach o stałym rozmiarze, a nie wiersz po wierszu.
- Indeksy: B-drzewa, LSM-trees i podobne struktury muszą być efektywnie aktualizowane.
- Buforowanie: pool buforów decyduje, co trzymać w pamięci, co usuwać i jak grupować odczyty/zapisy.
C/C++ dobrze pasują do tych zadań, bo polegają na przewidywalnym układzie pamięci i bezpośredniej kontroli granic I/O.
Struktury przyjazne cache'owi (dlaczego to ważne)
Wydajność często zależy bardziej od cache'ów CPU niż od surowej prędkości CPU. W C/C++ deweloperzy mogą upakować często używane pola razem, przechowywać kolumny w ciągłych tablicach i minimalizować skoki wskaźnikowe — wzorce, które trzymają dane blisko CPU i zmniejszają przestoje.
Gdzie widać języki wyższego poziomu
Nawet w bazach opartych głównie na C/C++ języki wyższego poziomu często napędzają narzędzia administracyjne, backupy, monitoring, migracje i orkiestrację. Krytyczne fragmenty pozostają natywne; otoczenie stawia na szybkość iteracji i użyteczność.
Magazyn, cache i I/O w bazach danych
Wypuść pierwszą wersję szybko
Przekształć pomysł w działającą aplikację webową bez wcześniejszego konfigurowania całego toolchaina.
Bazy danych wydają się natychmiastowe, bo robią wszystko, by unikać dysku. Nawet na szybkich SSD odczyt ze storage jest o rzędy wielkości wolniejszy niż odczyt z RAM. Silnik bazy napisany w C/C++ może kontrolować każdy krok tego oczekiwania — i często go unikać.
Pool buforów i page cache prostym językiem
Pomyśl o danych na dysku jak o pudełkach w magazynie. Pobranie pudełka (odczyt z dysku) zajmuje czas, więc trzymasz najczęściej używane rzeczy na biurku (RAM).
- Buffer pool: własne „biurko” bazy, trzymające ostatnio używane strony (stałe kawałki tabel i indeksów).
- Page cache: „biurko” systemu operacyjnego, cache plików.
Wiele baz zarządza własnym buffer poolem, by przewidzieć, co powinno pozostać gorące i uniknąć walki z OS o pamięć.
Dlaczego dysk jest wolny — i jak cache to ukrywa
Storage jest nie tylko wolny; jest też nieprzewidywalny. Skoki opóźnień, kolejkowanie i losowy dostęp dodają opóźnień. Cache to maskuje poprzez:
- Serwowanie odczytów z RAM najczęściej
- Grupowanie zapisów w mniejsze liczby, większe operacje I/O
- Prefetching stron prawdopodobnych do użycia (np. podczas skanów indeksów)
Wybory projektowe, które korzystają z kontroli niskopoziomowej
C/C++ pozwalają silnikom baz danych dostroić detale istotne przy dużym przepływie: wyrównane odczyty, direct I/O vs buffered I/O, własne polityki wyrzucania i starannie zbudowane układy pamięci dla indeksów i logów. Te decyzje mogą zmniejszyć kopiowanie, uniknąć kontencji i utrzymać cache CPU napełnione użytecznymi danymi.
Kompresja i sumy kontrolne mogą obciążać CPU
Cache zmniejsza I/O, ale zwiększa pracę CPU. Dekompresja stron, obliczanie sum kontrolnych, szyfrowanie logów i walidacja rekordów mogą stać się wąskimi gardłami. Ponieważ C i C++ dają kontrolę nad wzorcami dostępu do pamięci i pętlami przyjaznymi SIMD, często używa się ich, by wycisnąć więcej z każdego rdzenia.
Silniki gier: ograniczenia czasu rzeczywistego
Silniki gier działają pod ścisłymi wymaganiami czasu rzeczywistego: gracz porusza kamerą, naciska przycisk i świat musi odpowiedzieć natychmiast. To mierzy się czasem na klatkę, a nie średnią przepustowością.
Budżety klatek: dlaczego liczą się milisekundy
Przy 60 FPS masz około 16,7 ms na wygenerowanie klatki: symulacja, animacja, fizyka, miksowanie dźwięku, culling, przygotowanie renderu i często strumieniowanie zasobów. Przy 120 FPS budżet spada do 8,3 ms. Przekroczenie budżetu gracz odbiera jako przycięcie, opóźnienie wejścia lub nieregularność.
Dlatego programowanie w C i programowanie w C++ pozostają powszechne w rdzeniach silników: przewidywalna wydajność, niski narzut i precyzyjna kontrola pamięci oraz zużycia CPU.
Podsystemy rdzeniowe zwykle w C/C++
Większość silników korzysta z natywnego kodu do ciężkiej pracy:
- Rendering (przejście sceny, budowa draw-calli, zarządzanie zasobami GPU)
- Fizyka (detekcja kolizji, ograniczenia, ciała sztywne)
- Animacja (blendowanie szkieletów, IK, ewaluacja póz)
- Audio (miksowanie w czasie rzeczywistym, spatializacja)
Te systemy działają co klatkę, więc drobne nieefektywności szybko się mnożą.
Ścisłe pętle i układ danych
Wiele wydajności w grach zależy od ciasnych pętli: iteracja po encjach, aktualizacja transformów, testy kolizji, skininowanie wierzchołków. C/C++ ułatwiają układanie pamięci pod kątem efektywności cache (ciągłe tablice, mniej alokacji, mniej wskazań wirtualnych). Układ danych może mieć równie duże znaczenie jak wybór algorytmu.
Gdzie pasuje skryptowanie (a gdzie nie)
Wiele studiów używa języków skryptowych do logiki rozgrywki — questy, reguły UI, wyzwalacze — bo liczy się szybkość iteracji. Rdzeń silnika zwykle pozostaje natywny, a skrypty wywołują systemy C/C++ przez bindingi. Typowy wzorzec: skrypty orkiestrują; C/C++ wykonują drogie operacje.
Kompilatory, toolchainy i interoperacyjność
Uruchom backend
Stwórz backend w Go + PostgreSQL i iteruj nad API w minutach, nie dniach.
C i C++ nie tylko „działają” — są budowane do natywnych binariów dopasowanych do konkretnego CPU i systemu operacyjnego. Ten pipeline buildów to jeden z głównych powodów, dla których te języki pozostają centralne w OS, bazach danych i silnikach gier.
Co się dzieje podczas budowy
Typowy build ma kilka etapów:
- Kompilator: zamienia źródło C/C++ w pliki obiektowe specyficzne dla maszyny.
- Linker: łączy obiekty z bibliotekami, tworząc wykonywalny plik lub bibliotekę współdzieloną.
- Wynik binarny: finalny artefakt, który OS może załadować bezpośrednio (często z oddzielnymi symbolami debugowania).
To etap linkowania ujawnia wiele realnych problemów: brakujące symbole, niezgodne wersje bibliotek czy niekompatybilne ustawienia builda.
Dlaczego toolchainy i wsparcie platformy mają znaczenie
Toolchain to pełny zestaw: kompilator, linker, biblioteka standardowa i narzędzia buildowe. Dla oprogramowania systemowego pokrycie platformowe często przesądza o wyborze:
- SDK konsol i mobilnych może wymagać konkretnych kompilatorów i linkerów.
- Bazy i backendy potrzebują stabilnych buildów na różnych dystrybucjach Linuksa i typach CPU.
- Prace nad OS i sterownikami mogą wymagać cross-kompilatorów, surowych flag i dyscypliny ABI.
Zespoły często wybierają C/C++ częściowo dlatego, że toolchainy są dojrzałe i dostępne w wielu środowiskach — od urządzeń wbudowanych po serwery.
Interfejs z innymi językami (FFI)
C jest często traktowany jako „uniwersalny adapter”. Wiele języków potrafi wywoływać funkcje C przez FFI, więc zespoły umieszczają logikę krytyczną wydajnościowo w bibliotece C/C++ i wystawiają prostą API do kodu wyższego poziomu. Dlatego Python, Rust, Java i inne często opakowują istniejące komponenty C/C++ zamiast ich przepisywać.
Debugowanie i profilowanie: co zespoły mierzą
Zespoły C/C++ zwykle mierzą:
- Czas CPU (gorące funkcje, stosy wywołań)
- Zużycie pamięci (alokacje, wycieki, fragmentacja)
- Opóźnienia (czas klatki w grach, czas zapytania w bazach)
- Zachowanie I/O (missy w cache, odczyty z dysku, wywołania systemowe)
Workflow jest spójny: znajdź wąskie gardło, potwierdź danymi, zoptymalizuj najmniejszy fragment, który ma znaczenie.
Wybór C/C++ dziś: praktyczny przewodnik decyzji
C i C++ wciąż są świetnymi narzędziami — gdy budujesz oprogramowanie, gdzie liczą się milisekundy, bajty lub konkretna instrukcja CPU. Nie są jednak domyślnym wyborem dla każdej funkcji czy zespołu.
Kiedy C/C++ to właściwy wybór
Wybierz C/C++, gdy komponent jest krytyczny wydajnościowo, potrzebuje ściślejszej kontroli pamięci lub musi się ściśle integrować z OS lub sprzętem.
Typowe przypadki:
- Gorące ścieżki, gdzie opóźnienie jest zauważalne (parsowanie, kompresja, rendering, wykonywanie zapytań)
- Moduły niskiego poziomu, które muszą być przewidywalne (alokatorki, planisty, prymitywy sieciowe)
- Biblioteki wieloplatformowe, gdzie kod natywny jest produktem (SDK, silniki, embedded)
- Sytuacje, gdzie przenośność między kompilatorami/toolchainami jest wymaganiem
Kiedy lepiej wybrać inne języki
Wybierz język wyższego poziomu, gdy priorytetem jest bezpieczeństwo, szybkość iteracji lub skalowalność utrzymania.
Często lepiej użyć Rust, Go, Java, C#, Python lub TypeScript, gdy:
- Zespół jest duży i przewidywany jest rotacja (mniej „pułapek” w języku ma znaczenie)
- Funkcja często się zmienia i poprawność przewyższa wyciskanie cykli CPU
- Potrzebne są silne gwarancje bezpieczeństwa pamięci
- Produktywność deweloperów i dostępność kandydatów są ważniejsze niż surowa szybkość
W praktyce większość produktów to miks: natywne biblioteki dla ścieżki krytycznej i języki wyższego poziomu dla reszty.
Praktyczna uwaga dla zespołów aplikacyjnych (gdzie pasuje Koder.ai)
Jeśli głównie budujesz web, backend lub funkcje mobilne, zwykle nie musisz pisać C/C++, aby z niego korzystać — konsumujesz go przez OS, bazę danych, runtime i zależności. Platformy takie jak Koder.ai wykorzystują ten podział: możesz szybko tworzyć aplikacje React, backendy Go + PostgreSQL lub aplikacje Flutter za pomocą workflow opartego na czacie, jednocześnie integrując komponenty natywne tam, gdzie to potrzebne (np. wywołanie istniejącej biblioteki C/C++ przez FFI). Dzięki temu większość powierzchni produktu pozostaje w kodzie szybkim do iteracji, nie ignorując miejsc, gdzie kod natywny jest właściwym narzędziem.
Lista kontrolna praktycznych pytań (komponent po komponencie)
Zadaj sobie te pytania przed podjęciem decyzji:
- Czy to jest ścieżka krytyczna? Najpierw zmierz; nie zgaduj.
- Jakie są tryby awarii? Uszkodzenie pamięci w C/C++ może być katastrofalne.
- Jaka jest granica interfejsu? Czy możesz odizolować kod natywny za małym API?
- Czy macie kompetencje? Przegląd, testy i profilowanie są niezbędne.
- Jaki jest cel wdrożenia? Konsole, embedded, jądra i sterowniki często preferują C/C++.
- Jak to przetestujesz i zprofilujesz? Zaplanuj narzędzia i CI od pierwszego dnia.
Proponowane dalsze lektury
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing