14 paź 2025·7 min
Czym jest GraphQL? Jasny przewodnik po API i pobieraniu danych
Dowiedz się, czym jest GraphQL, jak działają zapytania, mutacje i schematy, oraz kiedy warto wybrać go zamiast REST — plus praktyczne zalety, wady i przykłady.
Dowiedz się, czym jest GraphQL, jak działają zapytania, mutacje i schematy, oraz kiedy warto wybrać go zamiast REST — plus praktyczne zalety, wady i przykłady.
GraphQL to język zapytań i runtime dla API. Mówiąc prościej: to sposób, w jaki aplikacja (web, mobilna lub inna usługa) może poprosić API o dane używając jasnego, ustrukturyzowanego zapytania — a serwer zwraca odpowiedź zgodną z tym zapytaniem.
Wiele API zmusza klientów do akceptowania tego, co zwraca dany, stały endpoint. To często prowadzi do dwóch problemów:
Dzięki GraphQL klient może poprosić dokładnie o te pola, których potrzebuje, ani więcej, ani mniej. To szczególnie przydatne, gdy różne ekrany (lub różne aplikacje) potrzebują różnych „wycinków” tych samych danych.
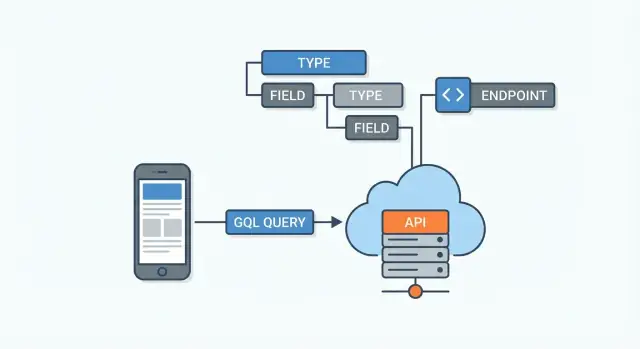
GraphQL zwykle znajduje się pomiędzy aplikacjami klienckimi a źródłami danych. Źródła te mogą być:
Serwer GraphQL otrzymuje zapytanie, ustala, skąd pobrać każde żądane pole, a potem składa finalną odpowiedź JSON.
Pomyśl o GraphQL jak o zamawianiu odpowiedzi o określonym kształcie:
GraphQL bywa mylony, więc kilka wyjaśnień:
Jeśli zapamiętasz rdzeń definicji — język zapytań + runtime dla API — będziesz mieć dobrą podstawę do dalszej pracy.
GraphQL powstał, by rozwiązać praktyczny problem produktowy: zespoły traciły zbyt dużo czasu na dostosowywanie API do rzeczywistych potrzeb UI.
Tradycyjne API oparte na endpointach często zmuszały do wyboru między przesyłaniem danych, których nie potrzeba, a wykonywaniem dodatkowych wywołań, by uzyskać to, czego potrzeba. W miarę rozwoju produktów taka frakcja objawiała się wolniejszymi stronami, bardziej skomplikowanym kodem po stronie klienta i trudną koordynacją frontend-backend.
Nadmierne pobieranie pojawia się, gdy endpoint zwraca „pełny” obiekt, nawet jeśli ekran potrzebuje tylko kilku pól. Widok profilu mobilnego może potrzebować tylko imienia i avatara, a API zwraca dodatkowo adresy, preferencje, pola audytowe i więcej. To marnuje pasmo i może pogorszyć UX.
Niedostateczne pobieranie to odwrotność: żaden pojedynczy endpoint nie ma wszystkiego, więc klient musi wykonać wiele żądań i złożyć wyniki. To dodaje opóźnień i zwiększa ryzyko częściowych awarii.
Wiele API w stylu REST reaguje na zmiany dodając nowe endpointy lub wersjonując (v1, v2, v3). Wersjonowanie bywa potrzebne, ale generuje długotrwałą pracę utrzymaniową: stare klientów nadal używają starych wersji, a nowe funkcje trafiają gdzie indziej.
Podejście GraphQL to rozwijanie schematu przez dodawanie pól i typów w czasie, przy zachowaniu stabilności istniejących pól. To często zmniejsza presję na tworzenie „nowych wersji” tylko po to, by wspierać nowe potrzeby UI.
Współczesne produkty rzadko mają tylko jednego konsumenta. Web, iOS, Android i integracje partnerskie potrzebują różnych kształtów danych.
GraphQL został zaprojektowany tak, żeby każdy klient mógł zażądać dokładnie tych pól, których potrzebuje — bez tworzenia przez backend osobnego endpointu dla każdego ekranu czy urządzenia.
API GraphQL definiuje się przez schemat. Pomyśl o nim jako umowie między serwerem a klientami: wymienia, jakie dane istnieją, jak są połączone i co można żądać lub zmieniać. Klienci nie zgadują endpointów — czytają schemat i proszą o konkretne pola.
Schemat składa się z typów (np. User czy Post) i pól (np. name czy title). Pola mogą wskazywać na inne typy — w ten sposób GraphQL modeluje relacje.
Oto prosty przykład w Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Ponieważ schemat jest silnie typowany, GraphQL może zweryfikować zapytanie przed jego wykonaniem. Jeśli klient poprosi o pole, którego nie ma (np. Post.publishDate gdy schemat go nie zna), serwer może odrzucić lub częściowo spełnić zapytanie z jasnymi błędami — bez niejednoznacznego „może zadziała”.
Schematy są projektowane z myślą o rozwoju. Zazwyczaj można dodawać nowe pola (np. User.bio) bez łamania istniejących klientów, ponieważ klienci otrzymują tylko to, o co poprosili. Usuwanie lub zmiana pól jest bardziej wrażliwa, więc zespoły często najpierw oznaczają pola jako przestarzałe (deprecate) i migrują klientów stopniowo.
API GraphQL zazwyczaj udostępnia jeden endpoint (np. /graphql). Zamiast wielu URL-i dla różnych zasobów (jak /users, /users/123, /users/123/posts) wysyłasz zapytanie w jedno miejsce i opisujesz dokładnie dane, które chcesz otrzymać.
Zapytanie to w zasadzie „lista zakupów” pól. Możesz poprosić o proste pola (np. id i name) oraz zagnieżdżone dane (np. ostatnie posty użytkownika) w tym samym żądaniu — bez pobierania dodatkowych, niepotrzebnych pól.
Oto mały przykład:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Odpowiedzi GraphQL są przewidywalne: JSON, który otrzymujesz, odzwierciedla strukturę zapytania. Dzięki temu prostsze jest przetwarzanie po stronie frontendu, bo nie trzeba zgadywać, gdzie będą dane ani parsować różnych formatów odpowiedzi.
Uproszczony przykład odpowiedzi może wyglądać tak:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Jeśli nie poprosisz o pole, nie zostanie ono uwzględnione. Jeśli poprosisz, możesz spodziewać się go w odpowiednim miejscu — dzięki temu zapytania GraphQL to czysty sposób pobierania dokładnie tego, czego potrzebuje każdy ekran czy funkcja.
Zapytania służą do odczytu; mutacje to sposób na zmianę danych w API GraphQL — tworzenie, aktualizacja lub usuwanie rekordów.
Większość mutacji podąża za podobnym wzorcem:
input) z polami do zaktualizowania.Mutacje w GraphQL zwykle świadomie zwracają dane, zamiast tylko success: true. Zwrócenie zaktualizowanego obiektu (lub przynajmniej jego id i kluczowych pól) pomaga UI:
Częstym wzorcem jest typ „payload”, który zawiera zarówno zaktualizentą encję, jak i ewentualne błędy.
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Dla API sterowanego przez UI dobrą zasadą jest: zwracaj to, co potrzebne do wyrenderowania kolejnego stanu (np. zaktualizowany user oraz ewentualne errors). To upraszcza klienta, eliminuje domysły co się zmieniło i ułatwia obsługę błędów.
Schemat GraphQL opisuje, o co można zapytać. Resolverzy opisują, jak to faktycznie pobrać. Resolver to funkcja przypisana do konkretnego pola w schemacie. Gdy klient poprosi o to pole, GraphQL wywoła resolver, aby pobrać lub obliczyć wartość.
GraphQL wykonuje zapytanie, przemierzając żądany kształt. Dla każdego pola znajduje odpowiadający resolver i go uruchamia. Niektóre resolve'y po prostu zwracają właściwość z obiektu, który już jest w pamięci; inne wywołują bazę danych, inną usługę lub łączą kilka źródeł.
Na przykład, jeśli schemat ma User.posts, resolver posts może zapytać tabelę posts po userId, albo wywołać oddzielną usługę Posts.
Resolvery stanowią spoiwo między schematem a rzeczywistymi systemami:
To mapowanie jest elastyczne: możesz zmienić implementację backendu bez zmiany kształtu zapytania klienta — pod warunkiem, że schemat pozostanie spójny.
Ponieważ resolvery mogą być wywoływane dla każdego pola i każdego elementu listy, łatwo przypadkowo wywołać wiele małych zapytań (np. pobieranie postów dla 100 użytkowników osobno). Ten wzorzec „N+1” może spowolnić odpowiedzi.
Typowe rozwiązania to grupowanie i cache’owanie (np. zbieranie ID i pobieranie jednym zapytaniem) oraz świadome zachęcanie klientów do wybierania tylko tych zagnieżdżonych pól, które są niezbędne.
Autoryzacja często jest egzekwowana w resolverach (lub wspólnym middleware), ponieważ resolvery wiedzą kto pyta (przez kontekst) i o jakie dane. Walidacja zwykle występuje na dwóch poziomach: GraphQL radzi sobie z walidacją typu/kształtu, a resolvery egzekwują reguły biznesowe (np. „tylko admin może ustawić to pole”).
Jedną z rzeczy, które zaskakują osoby nowe w GraphQL, jest fakt, że żądanie może „powieść się” i jednocześnie zawierać błędy. Dzieje się tak, ponieważ GraphQL jest zorientowany na pola: jeśli niektóre pola da się rozwiązać, a inne nie, możesz otrzymać częściowe dane.
Typowa odpowiedź GraphQL może zawierać zarówno data, jak i tablicę errors:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
To jest użyteczne: klient może wyrenderować to, co ma (np. profil użytkownika), jednocześnie obsługując brakujące pole.
data często jest null.Pisz komunikaty błędów dla użytkownika końcowego, nie dla debugowania. Unikaj ujawniania stack trace’ów, nazw baz danych lub wewnętrznych identyfikatorów. Dobry wzorzec to:
message,extensions.code,retryable: true).Szczegóły błędów loguj po stronie serwera z identyfikatorem żądania, żeby móc je badać bez ujawniania wewnętrznych informacji.
Zdefiniuj mały kontrakt błędów, którym będą się kierować aplikacje web i mobilne: wspólne wartości extensions.code (np. UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), reguły, kiedy pokazywać toast, a kiedy błędy inline, oraz jak obsługiwać częściowe dane. Spójność zapobiega temu, by każdy klient wymyślał własne zasady obsługi błędów.
Subscriptions to sposób GraphQL na pushowanie danych do klientów, gdy się zmieniają, zamiast ciągłego pytania przez klienta. Zwykle dostarczane są przez trwałe połączenie (najczęściej WebSockets), dzięki czemu serwer może wysyłać zdarzenia natychmiast po ich wystąpieniu.
Subscription przypomina zapytanie, ale wynik nie jest pojedynczą odpowiedzią. To strumień wyników — każdy element reprezentuje zdarzenie.
Pod spodem klient „subskrybuje” temat (np. messageAdded w aplikacji czatu). Gdy serwer opublikuje zdarzenie, wszyscy podłączeni subskrybenci otrzymają payload odpowiadający selekcji pól w subskrypcji.
Subscriptions sprawdzają się, gdy oczekuje się natychmiastowych zmian:
W pollingu klient pyta „Czy coś nowego?” co N sekund. To proste, ale może marnować żądania (szczególnie gdy nic się nie zmienia) i nadal daje opóźnienia.
W subscriptions serwer wysyła aktualizację natychmiast. To może zmniejszyć ruch sieciowy i poprawić odczucie szybkości — kosztem utrzymywania połączeń i obsługi infrastruktury realtime.
Subscriptions nie zawsze są warte wysiłku. Jeśli aktualizacje są rzadkie, niekrytyczne czasowo albo łatwe do batchowania, polling (lub odświeżanie po akcjach użytkownika) zwykle wystarczy.
Dodatkowo wprowadzają narzut operacyjny: skalowanie połączeń, autoryzacja na długich sesjach, retry i monitorowanie. Dobra zasada: używaj subscriptions tylko wtedy, gdy czas rzeczywisty jest wymaganiem produktowym, a nie tylko „fajnie mieć”.
GraphQL bywa opisywany jako „moc klienta”, ale ta moc ma swoje koszty. Znając kompromisy z wyprzedzeniem, łatwiej zdecydować, kiedy GraphQL to dobry wybór, a kiedy będzie przesadą.
Największym atutem jest elastyczne pobieranie danych: klienci proszą o dokładnie te pola, których potrzebują, co zmniejsza nadmierne pobieranie i przyspiesza wprowadzanie zmian w UI.
Kolejną zaletą jest silny kontrakt w postaci schematu. Schemat staje się pojedynczym źródłem prawdy dla typów i dostępnych operacji, co ułatwia współpracę i korzystanie z narzędzi.
Zespoły często zauważają większą produktywność front-endu, bo deweloperzy mogą iterować bez czekania na nowe endpointy, a narzędzia jak Apollo Client potrafią generować typy i upraszczać pobieranie danych.
GraphQL może skomplikować cache’owanie. W REST cache często opiera się na URL. W GraphQL wiele zapytań trafia do tego samego endpointu, więc cache zależy od kształtu zapytania, znormalizowanych cache’y i starannej konfiguracji serwera/klienta.
Po stronie serwera pojawiają się pułapki wydajnościowe. Pozornie małe zapytanie może uruchomić wiele wywołań backendu, jeśli nie zaprojektujesz resolverów ostrożnie (batching, unikanie N+1, kontrola kosztownych pól).
Jest też krzywa uczenia się: schematy, resolvery i wzorce klientów mogą być nowe dla zespołów przyzwyczajonych do endpointów.
Ponieważ klienci mogą żądać dużo, API GraphQL powinno egzekwować limity głębokości zapytań i złożoności, by zapobiec nadużyciom lub przypadkowym „zbyt dużym” żądaniom.
Uwierzytelnianie i autoryzacja powinny być egzekwowane na poziomie pola, nie tylko na warstwie trasy, bo różne pola mogą mieć różne reguły dostępu.
Operacyjnie zainwestuj w logowanie, śledzenie i monitorowanie zrozumiałe dla GraphQL: śledź nazwy operacji, zmienne (ostrożnie), czasy resolverów i wskaźniki błędów, żeby szybko wykrywać wolne zapytania i regresje.
GraphQL i REST oba umożliwiają komunikację aplikacji z serwerami, ale organizują tę rozmowę w bardzo różny sposób.
REST jest oparty na zasobach. Pobierasz dane, wywołując wiele endpointów (URL) reprezentujących „rzeczy” jak /users/123 czy /orders?userId=123. Każdy endpoint zwraca stały kształt danych ustalony przez serwer.
REST też opiera się na semantyce HTTP: metody GET/POST/PUT/DELETE, kody statusu i reguły cache’owania. To sprawia, że REST jest naturalny przy prostym CRUD lub gdy zależy ci na cache’owaniu po stronie przeglądarki/proxy.
GraphQL jest oparty na schemacie. Zamiast wielu endpointów zwykle masz jeden endpoint, a klient wysyła zapytanie opisujące dokładne pola. Serwer waliduje zapytanie względem schematu GraphQL i zwraca odpowiedź dopasowaną do kształtu zapytania.
To „wybór po stronie klienta” jest powodem, dla którego GraphQL może zmniejszyć nadmierne i niedostateczne pobieranie danych, szczególnie w UI, gdzie potrzeba danych z kilku powiązanych modeli.
REST często lepiej pasuje, gdy:
Wiele zespołów miesza oba podejścia:
Pytanie praktyczne brzmi nie „Które jest lepsze?”, lecz „Co pasuje do tego przypadku użycia przy najmniejszej złożoności?”.
Projektowanie API GraphQL jest najprostsze, gdy traktujesz je jako produkt dla osób budujących ekrany, a nie jako odzwierciedlenie bazy danych. Zacznij od małego zakresu, zweryfikuj rzeczywiste przypadki użycia i rozszerzaj w miarę potrzeb.
Wypisz kluczowe ekrany (np. „Lista produktów”, „Szczegóły produktu”, „Checkout”). Dla każdego ekranu zapisz dokładne pola, których potrzebuje i interakcje, które obsługuje.
To pomaga uniknąć „bogatych zapytań” (god queries), zmniejsza nadmierne pobieranie i klaruje, gdzie potrzebne będą filtrowanie, sortowanie i paginacja.
Zdefiniuj najpierw podstawowe typy (np. User, Product, Order) i ich relacje. Potem dodaj:
Wybieraj nazwy w języku biznesowym zamiast nazw tabel bazodanowych. „placeOrder” lepiej komunikuje zamiar niż „createOrderRecord”.
Utrzymuj spójność nazewnictwa: liczba pojedyncza dla pojedynczych elementów (product), mnoga dla kolekcji (products). Dla paginacji zwykle wybierzesz jedno:
Decyzja kształtuje strukturę odpowiedzi, więc warto ustalić ją wcześnie.
GraphQL pozwala dodawać opisy bezpośrednio do schematu — korzystaj z nich dla pól, argumentów i przypadków brzegowych. Dodaj też kilka przykładów copy-paste w dokumentacji (w tym paginację i typowe scenariusze błędów). Dobrze opisany schemat sprawia, że introspekcja i eksploratory API są znacznie użyteczniejsze.
Rozpoczęcie pracy z GraphQL to głównie wybór kilku dobrze wspieranych narzędzi i ustawienie zaufanego workflow. Nie musisz adoptować wszystkiego naraz — uruchom jedno zapytanie end-to-end, a potem rozszerzaj.
Wybierz serwer zgodny z twoim stackiem i tym, ile „baterii w pudełku” chcesz mieć:
Praktyczny pierwszy krok: zdefiniuj mały schemat (kilka typów + jedno zapytanie), zaimplementuj resolvery i podłącz rzeczywiste źródło danych (nawet jeśli to zastępcza lista w pamięci).
Jeśli chcesz szybciej przejść od „pomysłu” do działającego API, platforma vibe-codingowa jak Koder.ai może pomóc zainscenizować małą aplikację full-stack (React frontend, Go + PostgreSQL backend) i iterować nad schematem/resolverami przez chat — następnie wyeksportować kod, gdy będziesz gotowy przejąć implementację.
Na froncie wybór zależy od tego, czy chcesz opiniotwórcze konwencje, czy elastyczność:
Jeśli migrujesz z REST, zacznij od jednej strony/cechy używającej GraphQL i zachowaj REST dla reszty, dopóki podejście się nie sprawdzi.
Traktuj schemat jak kontrakt API. Przydatne warstwy testów to:
Aby pogłębić wiedzę, kontynuuj lekturę:
GraphQL to język zapytań i runtime dla API. Klienci wysyłają zapytanie opisujące dokładne pola, których potrzebują, a serwer zwraca odpowiedź JSON odzwierciedlającą tę strukturę.
Najwygodniej myśleć o nim jako o warstwie między klientami a jednym lub kilkoma źródłami danych (bazy danych, usługi REST, API zewnętrzne, mikrousługi).
GraphQL pomaga głównie w:
Dzięki możliwości żądania tylko konkretnych pól (w tym zagnieżdżonych), GraphQL zmniejsza nadmiarowy transfer i upraszcza kod po stronie klienta.
GraphQL nie jest:
Traktuj go jako kontrakt API i silnik wykonawczy, a nie magiczne rozwiązanie wydajnościowe czy magazyn danych.
Większość API GraphQL udostępnia pojedynczy endpoint (często /graphql). Zamiast kilku URL-i wysyłasz różne operacje (zapytania/mutacje) na ten sam punkt końcowy.
W praktyce cache’owanie i obserwowalność opierają się zwykle na nazwie operacji + zmiennych, a nie tylko na URL-u.
Schemat to kontrakt API. Definiuje:
User, Post)User.name)User.posts)Dzięki silnemu typowaniu serwer może zweryfikować zapytania przed ich wykonaniem i zwrócić jasne błędy, gdy pola nie istnieją.
Zapytania GraphQL to operacje odczytu. Określasz pola, których potrzebujesz, a odpowiedź JSON odzwierciedla strukturę zapytania.
Wskazówki:
query GetUserWithPosts) dla lepszego debugowania i monitoringu.posts(limit: 2)).Mutacje to operacje zapisu (create/update/delete). Typowy wzorzec:
input,Zwracanie danych (nie tylko success: true) pozwala interfejsowi zaktualizować stan natychmiast i utrzymać spójność cache’a.
Resolvery to funkcje na poziomie pola, które mówią GraphQL, jak pobrać lub obliczyć wartość pola.
W praktyce resolvery mogą:
Uprawnienia i reguły biznesowe często egzekwuje się w resolverach (lub w middleware), ponieważ to one wiedzą, kto żąda dostępu i do jakich danych.
Łatwo wygenerować wzorzec N+1 (np. ładowanie postów osobno dla każdego z 100 użytkowników).
Typowe sposoby naprawy:
Mierz czasy wykonania resolverów i obserwuj powtarzające się zewnętrzne wywołania w ramach jednego żądania.
GraphQL może zwrócić częściowe dane wraz z tablicą errors. Dzieje się tak, gdy niektóre pola udało się rozwiązać, a inne zakończyły błędem (np. brak uprawnień, timeout zewnętrznej usługi).
Dobre praktyki:
message,extensions.code (np. FORBIDDEN, BAD_USER_INPUT),Klient powinien zdecydować, kiedy renderować częściowe dane, a kiedy traktować operację jako nieudaną.