Kafka w prostych słowach
Apache Kafka to rozproszona platforma do strumieniowania zdarzeń. Mówiąc prosto: to współdzielony, trwały „przewód”, który pozwala wielu systemom publikować fakty o tym, co się wydarzyło, i pozwala innym systemom czytać te fakty — szybko, na dużą skalę i w kolejności.
Zespoły używają Kafki, gdy dane muszą przepływać niezawodnie między systemami bez silnego powiązania. Zamiast jednej aplikacji wywołującej drugą bezpośrednio (i zawodzącej, gdy jest niedostępna lub wolna), producenci zapisują zdarzenia do Kafki. Konsumenci czytają je, gdy są gotowi. Kafka przechowuje zdarzenia przez konfigurowalny okres, więc systemy mogą odzyskać się po awariach, a nawet przetworzyć historię ponownie.
Kilka terminów, które spotkasz
- Zdarzenie / Wiadomość: zapis czegoś, co się wydarzyło (np. „OrderPlaced” lub „PaymentFailed”). Użytkownicy Kafki często mówią „wiadomość”, ale „zdarzenie” podkreśla, że reprezentuje zmianę w świecie rzeczywistym.
- Strumień: ciągły przepływ zdarzeń w czasie.
- Log: Kafka organizuje zdarzenia jako log tylko-dopisujący — nowe zdarzenia dodawane są na końcu, a czytelnicy przesuwają się do przodu we własnym tempie.
Dla kogo jest ten przewodnik (i czego się nauczysz)
Przewodnik jest dla inżynierów myślących produktowo, specjalistów od danych i liderów technicznych, którzy chcą praktycznego modelu mentalnego Kafki.
Nauczysz się podstawowych elementów (producenci, konsumenci, tematy, brokerzy), jak Kafka skaluje się dzięki partycjom, jak przechowuje i odtwarza zdarzenia oraz gdzie pasuje w architekturze zdarzeniowej. Omówimy też typowe przypadki użycia, gwarancje dostarczenia, podstawy bezpieczeństwa, planowanie operacji i kiedy Kafka jest (lub nie jest) właściwym narzędziem.
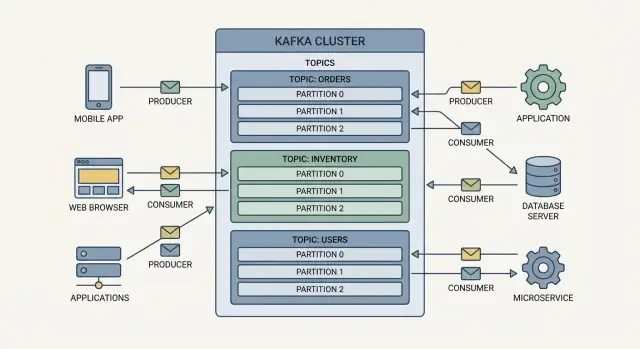
Podstawowe pojęcia: producenci, konsumenci, tematy, brokerzy
Kafkę najłatwiej zrozumieć jako współdzielony log zdarzeń: aplikacje zapisują do niego zdarzenia, a inne aplikacje czytają te zdarzenia później — często w czasie rzeczywistym, czasem godzinę czy dzień po zdarzeniu.
Producenci i konsumenci
Producenci to pisarze. Producent może opublikować zdarzenie typu „order placed”, „payment confirmed” lub „temperature reading”. Producenci nie wysyłają zdarzeń bezpośrednio do określonych aplikacji — wysyłają je do Kafki.
Konsumenci to czytelnicy. Konsument może zasilać pulpit nawigacyjny, uruchamiać workflow wysyłki lub ładować dane do analityki. Konsumenci decydują, co zrobić ze zdarzeniami, i mogą czytać we własnym tempie.
Tematy: organizacja zdarzeń
Zdarzenia w Kafce grupowane są w tematy, które są właściwie nazwanymi kategoriami. Na przykład:
orders dla zdarzeń związanych z zamówieniamipayments dla zdarzeń płatnościinventory dla zmian stanu magazynowego
Temat staje się „strumieniem prawdy” dla danego rodzaju zdarzeń, co ułatwia wielu zespołom ponowne użycie tych samych danych bez tworzenia jednorazowych integracji.
Brokerzy i klastry
Broker to serwer Kafka, który przechowuje zdarzenia i udostępnia je konsumentom. W praktyce Kafka działa jako klaster (wiele brokerów współpracujących), dzięki czemu może obsłużyć większy ruch i działać dalej nawet przy awarii maszyny.
Grupy konsumentów: skalowanie czytelników bez duplikowania pracy
Konsumenci często działają w grupie konsumentów. Kafka rozdziela pracę odczytu wśród grupy, więc możesz dodać więcej instancji konsumenta, aby skalować przetwarzanie — bez tego, by każda instancja robiła to samo.
Jak tematy i partycje pozwalają Kafka skalować
Kafka skaluje się, dzieląc pracę na tematy (strumienie powiązanych zdarzeń), a potem dzieląc każdy temat na partycje (mniejsze, niezależne kawałki strumienia).
Partycje = równoległość i przepustowość
Temat z jedną partycją może być odczytywany w danym czasie przez jednego konsumenta w grupie. Dodaj więcej partycji, a możesz dodać więcej konsumentów, żeby przetwarzać zdarzenia równolegle. W ten sposób Kafka wspiera wysokowydajne strumieniowanie zdarzeń i potoki danych w czasie rzeczywistym bez tworzenia wąskiego gardła.
Partycje pomagają też rozłożyć obciążenie na brokerach. Zamiast jednej maszyny obsługującej wszystkie zapisy i odczyty dla tematu, różne partycje mogą być hostowane na różnych brokerach i współdzielić ruch.
Kolejność: co Kafka gwarantuje (a czego nie)
Kafka gwarantuje kolejność w obrębie pojedynczej partycji. Jeśli zdarzenia A, B i C zostaną zapisane do tej samej partycji w tej kolejności, konsumenci odczytają je A → B → C.
Kolejność między partycjami nie jest gwarantowana. Jeśli potrzebujesz ścisłej kolejności dla konkretnego bytu (np. klienta lub zamówienia), zwykle dbasz, by wszystkie zdarzenia dla tego bytu trafiały do tej samej partycji.
Klucze decydują, gdzie trafiają zdarzenia
Przy wysyłaniu zdarzenia producenci mogą dołączyć klucz (np. order_id). Kafka używa klucza, by konsekwentnie kierować powiązane zdarzenia do tej samej partycji. To daje przewidywalną kolejność dla danego klucza, przy jednoczesnym skalowaniu tematu na wiele partycji.
Repliki utrzymują dostępność danych
Każda partycja może być replikowana na inne brokery. Gdy jeden broker padnie, inny z repliką może przejąć. Replikacja jest głównym powodem, dla którego Kafka jest zaufana w krytycznych systemach pub-sub messaging i systemach zdarzeniowych: poprawia dostępność i wspiera odporność na awarie bez konieczności budowania własnej logiki awaryjnego przełączania w każdej aplikacji.
Przechowywanie, retencja i odtwarzanie zdarzeń
Kluczową ideą w Apache Kafka jest to, że zdarzenia nie są tylko przekazywane i zapominane. Zapisuje się je na dysku w uporządkowanym logu, więc konsumenci mogą je czytać teraz — lub później. To sprawia, że Kafka jest użyteczna nie tylko do przesyłania danych, ale też do utrzymywania trwałej historii zdarzeń.
Zdarzenia są zapisywane, nie tylko „w tranzycie”
Gdy producent wysyła zdarzenie do tematu, Kafka dopisuje je do magazynu na brokerze. Konsumenci następnie czytają z tego zapisanego logu we własnym tempie. Jeśli konsument będzie nieaktywny godzinę, zdarzenia nadal istnieją i można je odczytać po jego przywróceniu.
Retencja: jak długo Kafka przechowuje dane
Kafka przechowuje zdarzenia zgodnie z politykami retencji:
- Retencja czasowa: przechowuj zdarzenia przez określony czas (np. 7 dni).
- Retencja rozmiarowa: przechowuj zdarzenia do osiągnięcia skonfigurowanego rozmiaru logu, potem usuwaj najstarsze dane.
Retencję konfiguruje się per temat, co pozwala traktować tematy „śledzące audyt” inaczej niż tematy telemetryczne o dużym wolumenie.
Kompaktacja: zachowanie najnowszej wartości na klucz
Niektóre tematy są bardziej jak dziennik zmian niż archiwum historyczne — np. „bieżące ustawienia klienta”. Kompaktacja logu zachowuje przynajmniej najświeższe zdarzenie dla każdego klucza, podczas gdy starsze, nadpisane rekordy mogą być usunięte. Nadal masz trwałe źródło prawdy dla najnowszego stanu, bez nieograniczonego wzrostu danych.
Odtwarzanie zdarzeń: odbudowa stanu i naprawa błędów
Ponieważ zdarzenia są przechowywane, możesz je odtworzyć, aby zrekonstruować stan:
- Odbudować indeks wyszukiwania lub zmaterializowany widok od zera
- Odzyskać usługę po błędnym wdrożeniu, przetwarzając ponownie od wcześniejszego punktu
- Przyjąć nowego konsumenta i pozwolić mu przeczytać dane historyczne
W praktyce odtwarzanie kontroluje punkt, od którego konsument „zaczyna czytać” (jego offset), dając zespołom potężne zabezpieczenie podczas ewolucji systemów.
Podstawy niezawodności i odporności na awarie
Kafka jest zbudowana tak, by dane płynęły nawet wtedy, gdy części systemu zawodzą. Osiąga to dzięki replikacji, jasnym regułom, kto jest „liderem” danej partycji, oraz konfigurowalnym potwierdzeniom zapisu.
Replikacja: lider i followerzy (ogólnie)
Każda partycja tematu ma jednego lidera i jednego lub więcej followerów (replik) na innych brokerach. Producenci i konsumenci rozmawiają z liderem tej partycji.
Followerzy ciągle kopiują dane lidera. Jeśli lider padnie, Kafka może wypromować aktualnego followera na lidera, by partycja pozostała dostępna.
Co się dzieje podczas awarii brokera (krótko)
Jeśli broker padnie, partycje, których był liderem, staną się chwilowo niedostępne. Kontroler Kafki wykrywa awarię i uruchamia wybór lidera dla tych partycji.
Jeśli przynajmniej jedna replika jest wystarczająco zaktualizowana, może przejąć rolę lidera i klienci wznowią produkcję/konsumpcję. Jeśli nie ma dostępnej repliki w sync, Kafka może wstrzymać zapisy (w zależności od ustawień), aby uniknąć utraty potwierdzonych danych.
Trwałość: replication factor i acknowledgments
Dwa główne ustawienia kształtują trwałość:
- Replication factor: ile kopii każdej partycji istnieje (np. 3 kopie na 3 brokerach).
- Acknowledgments (acks): kiedy producent uznaje zapis za udany.
Na poziomie koncepcyjnym:
- acks=0: producent nie czeka — szybkie, ale możesz utracić wiadomości.
- acks=1: lider potwierdza zapis — lepiej, ale jeśli lider padnie zanim followerzy przekopiują dane, możesz utracić niedawno zapisane wiadomości.
- acks=all (lub -1): lider czeka na potwierdzenia od replik „w sync” — bezpieczniej, zwykle trochę wolniej.
Aby zredukować duplikaty przy retry, zespoły często łączą bezpieczniejsze acks z idempotentnymi producentami i solidnym obsługiwaniem konsumentów.
Kompromis między opóźnieniem a bezpieczeństwem
Większe bezpieczeństwo zwykle oznacza czekanie na więcej potwierdzeń i utrzymywanie większej liczby replik w sync, co może zwiększać opóźnienie i zmniejszać maksymalną przepustowość.
Niższe opóźnienia mogą być akceptowalne dla telemetrii lub clickstreamu, gdzie sporadyczna utrata jest dopuszczalna, ale płatności, zarządzanie zapasami i logi audytu zwykle uzasadniają większe bezpieczeństwo.
Rola Kafki w architekturze zdarzeniowej
Zostań właścicielem kodu
Zachowaj pełną kontrolę, eksportując kod źródłowy, gdy będziesz gotów wyjść poza prototyp.
Architektura zdarzeniowa (EDA) to sposób budowania systemów, w którym zdarzenia biznesowe — zamówienie złożone, płatność potwierdzona, paczka wysłana — są reprezentowane jako zdarzenia, na które inne części systemu mogą reagować.
Publikuj zdarzenia, reaguj konsumentami
Kafka często stoi w centrum EDA jako współdzielony „strumień zdarzeń”. Zamiast usługa A wywoływać usługę B bezpośrednio, usługa A publikuje zdarzenie (np. OrderCreated) do tematu Kafka. Dowolna liczba usług może konsumować to zdarzenie i wykonać akcję — wysłać e-mail, zarezerwować zapas, uruchomić kontrolę fraudową — bez potrzeby, by usługa A wiedziała o ich istnieniu.
Luźne powiązanie (mniej bezpośrednich zależności)
Ponieważ usługi komunikują się przez zdarzenia, nie muszą koordynować API request/response dla każdej interakcji. To zmniejsza mocne powiązania między zespołami i ułatwia dodawanie nowych funkcji: możesz wprowadzić nowego konsumenta dla istniejącego zdarzenia bez zmiany producenta.
Workflow asynchroniczny i odporność na skoki ruchu
EDA jest naturalnie asynchroniczna: producenci szybko zapisują zdarzenia, a konsumenci przetwarzają je we własnym tempie. Podczas skoków ruchu Kafka pomaga zbuforować nadmiar, żeby systemy downstream nie padły natychmiast. Konsumenty mogą się skalować, by nadrobić zaległości, a jeśli jeden konsument padnie czasowo, wznowi od miejsca, w którym przerwał.
Praktyczny model mentalny
Pomyśl o Kafce jak o „feedzie aktywności” systemu. Producenci publikują fakty; konsumenci subskrybują fakty, które ich interesują. Ten wzorzec umożliwia potoki danych w czasie rzeczywistym i workflowy zdarzeniowe, jednocześnie utrzymując usługi prostsze i bardziej niezależne.
Typowe przypadki użycia Kafki we współczesnych systemach
Kafka pojawia się tam, gdzie zespoły muszą przesyłać dużą ilość małych „faktów, które się wydarzyły” — szybko, niezawodnie i tak, by wiele konsumentów mogło je ponownie wykorzystać.
Śledzenie aktywności i logi audytu
Aplikacje często potrzebują logu tylko-dopisującego: logowania logowań użytkowników, zmian uprawnień, aktualizacji rekordów czy działań administratorów. Kafka sprawdza się jako centralny strumień takich zdarzeń, dzięki czemu narzędzia bezpieczeństwa, raportowanie i eksporty zgodności czytają to samo źródło bez dodatkowego obciążania bazy produkcyjnej. Ponieważ zdarzenia są przechowywane przez pewien czas, można je też odtworzyć po błędzie lub zmianie schematu.
Komunikacja mikroserwisów przez zdarzenia
Zamiast usług wywołujących się bezpośrednio, mogą publikować zdarzenia typu „order created” lub „payment received”. Inne usługi subskrybują i reagują we własnym czasie. To zmniejsza powiązania, pomaga utrzymać działanie przy częściowych awariach i ułatwia dodawanie nowych możliwości (np. kontrole fraud) poprzez konsumpcję istniejącego strumienia zdarzeń.
Potoki danych do analityki i magazynów
Kafka jest częstym kręgosłupem do przesyłania danych z systemów operacyjnych do platform analitycznych. Zespoły mogą strumieniować zmiany z baz aplikacji i przekazywać je do magazynu danych lub jeziora z niskim opóźnieniem, trzymając aplikację produkcyjną oddzieloną od ciężkich zapytań analitycznych.
IoT i telemetria przy skokach ruchu
Czujniki, urządzenia i telemetria aplikacji często przychodzą w piku. Kafka może wchłonąć skoki, zbuforować je bezpiecznie i pozwolić downstreamowi nadrobić zaległości — przydatne do monitoringu, alertów i analiz długoterminowych.
Ekosystem Kafki: Connect, Streams i narzędzia
Kafka to więcej niż brokerzy i tematy. Większość zespołów polega na narzędziach towarzyszących, które ułatwiają codzienne przesyłanie danych, przetwarzanie strumieni i operacje.
Kafka Connect: przenoszenie danych bez customowego kodu
Kafka Connect to framework integracyjny Kafki do pobierania danych do Kafki (źródła) i wysyłania z Kafki (sinki). Zamiast budować i utrzymywać jednorazowe potoki, uruchamiasz Connect i konfigurujesz konektory.
Typowe przykłady: pobieranie zmian z baz danych, ingestowanie zdarzeń SaaS, dostarczanie danych z Kafki do hurtowni danych lub obiektu storage. Connect standaryzuje też kwestie operacyjne jak retry, offsety i równoległość.
Kafka Streams: przetwarzanie w czasie rzeczywistym w aplikacjach
Jeśli Connect to integracja, to Kafka Streams to obliczenia. To biblioteka, którą dodajesz do aplikacji, aby transformować strumienie w czasie rzeczywistym — filtrować zdarzenia, wzbogacać je, łączyć strumienie i budować agregaty (np. „zamówienia na minutę”).
Aplikacje Streams czytają z tematów i zapisują z powrotem do tematów, więc dobrze wpisują się w systemy zdarzeniowe i można je skalować, dodając instancje.
Zarządzanie schematami: spójność zdarzeń
Gdy wiele zespołów publikuje zdarzenia, spójność ma znaczenie. Zarządzanie schematami (często za pomocą schema registry) definiuje, jakie pola powinno mieć zdarzenie i jak ewoluują w czasie. Pomaga to zapobiegać awariom, np. gdy producent zmieni nazwę pola, od którego zależy konsument.
Narzędzia: monitorowanie tego, co ważne
Kafka jest wrażliwa operacyjnie, więc podstawowy monitoring jest niezbędny:
- Consumer lag: czy konsumenci zostają w tyle?
- Przepustowość: ile zdarzeń na sekundę płynie?
- Błędy: nieudane fetchy, błędy produkcji, awarie zadań konektorów
Wiele zespołów używa też UI do zarządzania i automatyzacji wdrożeń, konfiguracji tematów i polityk dostępu (zobacz /blog/kafka-security-governance).
Gwarancje dostarczania i wzorce przetwarzania
Zaprojektuj usługę EDA
Zaprototypuj usługę opartą na EDA z interfejsem React, backendem w Go i PostgreSQL w Koder.ai.
Często zespoły pytają: czy przetworzę każde zdarzenie raz i co się stanie, gdy coś zawiedzie? Kafka daje bloki konstrukcyjne — to od Ciebie zależy, jakie kompromisy wybierzesz.
Gwarancje dostarczenia (ogólnie)
At-most-once oznacza, że możesz utracić zdarzenia, ale nie przetworzysz duplikatów. Może się tak zdarzyć, jeśli konsument zatwierdzi offset przed zakończeniem pracy i potem padnie.
At-least-once oznacza, że nie stracisz zdarzeń, ale duplikaty są możliwe (np. konsument przetwarza zdarzenie, pada, a potem przetwarza je ponownie po restarcie). To najczęstszy domyślny wzorzec.
Exactly-once ma na celu uniknięcie zarówno strat, jak i duplikatów end-to-end. W Kafce zwykle używa się transakcyjnych producentów i kompatybilnego przetwarzania (często przez Kafka Streams). To potężne, ale bardziej ograniczone i wymaga starannej konfiguracji.
Idempotencja i deduplikacja
W praktyce wiele systemów akceptuje at-least-once i dodaje zabezpieczenia:
- Idempotentne zapisy: spraw, by krok „zastosuj zdarzenie” był bezpieczny przy powtórnym wykonaniu (np. upserty, warunkowe aktualizacje, unikalne klucze).
- Deduplikacja: przechowuj id zdarzenia (lub klucz biznesowy) i ignoruj powtórzenia w określonym oknie.
Offsety konsumenta: twoja „zakładka”
Offset konsumenta to pozycja ostatnio przetworzonego rekordu w partycji. Gdy zatwierdzasz offsety, mówisz: „skończyłem do tutaj”. Zatwierdź za wcześnie — ryzykujesz utratę; za późno — zwiększasz duplikaty po awarii.
Retry i wiadomości trujące
Retry powinny być ograniczone i widoczne. Typowy wzorzec:
- retry z backoffem dla błędów przejściowych,
- potem wyślij nieudany rekord do dead-letter topic do inspekcji i ponownego przetworzenia.
To zapobiega blokowaniu całej grupy konsumentów przez jedną „trującą” wiadomość, jednocześnie zachowując dane do późniejszego naprawienia.
Bezpieczeństwo i governance
Kafka często przenosi krytyczne zdarzenia biznesowe (zamówienia, płatności, aktywność użytkowników). Dlatego bezpieczeństwo i governance są częścią projektu, nie dodatkiem.
Uwierzytelnianie i autoryzacja
Uwierzytelnianie odpowiada na pytanie „kim jesteś?”, autoryzacja na „co możesz robić?”. W Kafce uwierzytelnianie często realizuje się przez SASL (np. SCRAM lub Kerberos), a autoryzacja przez ACL na poziomie tematów, grup konsumentów i klastra.
Praktyczny wzorzec to zasada najmniejszych uprawnień: producenci mogą pisać tylko do swoich tematów, a konsumenci czytać tylko te tematy, których potrzebują. Zmniejsza to ryzyko niezamierzonego wycieku danych i ogranicza zasięg szkód przy wycieku poświadczeń.
Szyfrowanie w tranzycie (TLS)
TLS szyfruje dane podczas przesyłu między aplikacjami, brokerami i narzędziami. Bez TLS zdarzenia można przechwycić w sieciach wewnętrznych, nie tylko w Internecie. TLS pomaga też zapobiegać atakom typu „man-in-the-middle”, weryfikując tożsamość brokerów.
Kafka wielodostępna i konwencje nazewnicze
Gdy wiele zespołów dzieli klaster, warto mieć zasadnicze reguły. Jasne konwencje nazewnicze tematów (np. <team>.<domain>.<event>.<version>) ułatwiają wskazanie właściciela i pomagają narzędziom stosować polityki.
Połącz nazewnictwo z limitami i szablonami ACL, by jedna głośna aplikacja nie zagłodziła innych oraz by nowe usługi startowały z bezpiecznymi ustawieniami domyślnymi.
Governance danych: PII, retencja i zgodność
Traktuj Kafkę jak system zapisu historii zdarzeń tylko wtedy, gdy to zamierzasz. Jeśli zdarzenia zawierają PII, stosuj minimalizację danych (wysyłaj identyfikatory zamiast pełnych profili), rozważ szyfrowanie na poziomie pól i dokumentuj, które tematy są wrażliwe.
Ustawienia retencji powinny odpowiadać wymaganiom prawnym i biznesowym. Jeśli polityka mówi „usuń po 30 dniach”, nie przechowuj 6 miesięcy „na wszelki wypadek”. Regularne przeglądy i audyty pomagają utrzymać konfiguracje zgodne z wymaganiami.
Eksploatacja Kafki: co zespoły muszą zaplanować
Dodaj workflow DLQ
Stwórz małą aplikację obsługującą wiadomości DLQ i przeglądanie błędów bez blokowania konsumentów.
Uruchamianie Apache Kafka to nie „zainstaluj i zapomnij”. Zachowuje się raczej jak usługa współdzielona: wiele zespołów od niej zależy i drobne błędy mogą rozlać się na systemy downstream.
Podstawy planowania pojemności
Pojemność Kafki to głównie zadanie matematyczne, które warto regularnie przeglądać. Najważniejsze dźwignie to partycje (równoległość), przepustowość (MB/s in/out) i wzrost magazynu (jak długo przechowujesz dane).
Jeśli ruch się podwoi, może być potrzebnych więcej partycji, by rozłożyć obciążenie na brokerach, więcej dysku na retencję i więcej przepustowości sieci na replikację. Praktyczny nawyk to prognozowanie szczytowej szybkości zapisu i przemnożenie przez retencję, by oszacować wzrost dysku, a potem dodanie bufora na replikację i „nieoczekiwany sukces”.
Codzienne zadania operacyjne
Oczekuj rutynowej pracy poza utrzymaniem serwerów:
- Aktualizacje: planuj rolling upgrades, testuj kompatybilność klientów i wprowadzaj zmiany przy najmniejszym ruchu.
- Rebalansowanie: rebalans grup konsumentów może powodować krótkie przerwy; potrzebujesz bezpiecznych wzorców wdrożeń i jasnych właścicieli.
- Reakcja na incydenty: miej playbooki na awarie brokerów, zapełnienie dysku i źle skonfigurowanych producentów zalewających temat.
Główne koszty i wybory wdrożeniowe
Koszty generują dyski, transfer sieciowy i liczba/rozmiar brokerów. Zarządzana Kafka może zmniejszyć nakład pracy i uprościć aktualizacje, podczas gdy samodzielne hostowanie może być tańsze przy skali, jeśli masz doświadczonych operatorów. Kompromisem jest czas przywracania i obciążenie on-call.
Co mierzyć (żeby nie zgadywać)
Zespoły zwykle monitorują:
- End-to-end latency (od zapisu do odczytu)
- Consumer lag (jak bardzo konsumenci są w tyle)
- Stan brokerów (użycie dysku, under-replicated partitions, wskaźniki błędów żądań)
Dobre dashboardy i alerty zamieniają Kafkę z „czarnej skrzynki” w zrozumiałą usługę.
Kiedy używać Kafki (a kiedy nie)
Kafka sprawdza się, gdy potrzebujesz przesyłać dużo zdarzeń niezawodnie, przechowywać je przez pewien czas i pozwolić wielu systemom reagować na te same dane we własnym tempie. Jest szczególnie użyteczna, gdy dane powinny być odtwarzalne (do backfilli, audytów lub odbudowy nowych usług) i gdy spodziewasz się rosnącej liczby producentów/konsumentów.
Gdy warto wybrać Kafkę
Kafka błyszczy, gdy masz:
- Strumienie o wysokiej przepustowości (clicki, zamówienia, dane czujników)
- Wielu konsumentów potrzebujących tych samych zdarzeń (analityka, monitoring, fraud, powiadomienia)
- Potrzebę odtwarzania i długotrwałej historii, nie tylko „dostarcz i zapomnij”
- Prace integracyjne, gdzie odłączenie zespołów i usług ma znaczenie
Kiedy Kafka może być zbyt ciężka
Kafka może być przerostem formy, jeśli potrzeby są proste:
- Jeden niskoszeregowy queue między dwiema usługami
- Zadania krótkotrwałe (background jobs), gdzie odtworzenie nie ma wartości
- Zespoły bez czasu na operowanie i monitorowanie systemu rozproszonego
W takich przypadkach koszty operacyjne (rozmiar klastra, aktualizacje, monitoring, on-call) mogą przewyższyć korzyści.
Alternatywy i uzupełnienia
- RabbitMQ: świetny do klasycznych kolejek zadań i wzorców routingu.
- NATS: lekka komunikacja z niskim opóźnieniem.
- Cloud pub/sub: dobre, gdy chcesz zarządzaną infrastrukturę i prostsze operacje.
Kafka też uzupełnia — nie zastępuje — baz danych (system zapisu), cache (szybkie odczyty) i narzędzia ETL batch (duże okresowe transformacje).
Szybka checklista decyzyjna
Zadaj pytania:
- Czy potrzebujemy wielu konsumentów i możliwości odtworzenia?
- Czy przepustowość będzie znacząco rosła?
- Czy retencja/historia zdarzeń jest funkcją, której potrzebujemy?
- Czy możemy przejąć odpowiedzialność operacyjną (albo użyć zarządzanej Kafki)?
- Czy strumienujemy zdarzenia, a nie tylko wysyłamy polecenia/zadania?
Jeśli na większość odpowiedź brzmi „tak”, Kafka zwykle jest sensownym wyborem.
Pierwsze kroki: prosty path adopcji
Kafka najlepiej pasuje, gdy potrzebujesz współdzielonego „źródła prawdy” dla strumieni zdarzeń w czasie rzeczywistym: wiele systemów produkujących fakty (zamówienia utworzone, płatności autoryzowane, zmiany zapasów) i wiele systemów konsumujących te fakty, by zasilać potoki, analitykę i funkcje reaktywne.
Krok 1: wybierz jeden konkretny przypadek użycia
Zacznij od wąskiego, wysokowartościowego przepływu — np. publikowania zdarzeń „OrderPlaced” dla downstreamu (email, fraud, fulfilment). Unikaj traktowania Kafki jako catch-all już na dzień pierwszy.
Krok 2: zdefiniuj zdarzenia i tematy
Zapisz:
- Zdarzenia: co się stało, w prostych, biznesowych słowach
- Tematy: gdzie te zdarzenia będą żyć (często jeden temat na typ zdarzenia lub domenę)
- Konsumenci: które zespoły/usługi potrzebują zdarzeń i dlaczego
Utrzymuj wczesne schematy proste i spójne (znacznik czasu, identyfikatory, jasna nazwa zdarzenia). Zdecyduj, czy będziesz egzekwować schematy od początku, czy ewoluować ostrożnie.
Krok 3: ustal odpowiedzialność i podstawy operacji
Kafka działa najlepiej, gdy ktoś jest odpowiedzialny za:
- Tworzenie tematów i konwencje nazewnicze
- Polityki retencji i dostęp
- Obowiązki on-call i runbooki
Dodaj monitoring od razu (consumer lag, stan brokerów, przepustowość, błędy). Jeśli nie masz platformy, zacznij od oferty zarządzanej i jasnych limitów.
Krok 4: zbuduj „cienki” pierwszy pipeline
Produkuj zdarzenia z jednego systemu, konsumuj je w jednym miejscu i sprawdź pętlę end-to-end. Dopiero potem rozszerzaj do większej liczby konsumentów, partycji i integracji.
Jeśli chcesz szybko przejść od „pomysłu” do działającej usługi zdarzeniowej, narzędzia takie jak Koder.ai mogą pomóc w prototypowaniu otaczającej aplikacji (React UI, backend w Go, PostgreSQL) i stopniowym dodawaniu producentów/konsumentów Kafka przez prowadzone czaty. Przydaje się to szczególnie do budowy wewnętrznych dashboardów i lekkich usług konsumujących tematy, oferując tryb planowania, eksport kodu źródłowego, wdrożenie/hosting oraz snapshoty z możliwością rollbacku.
Jeśli mapujesz to na podejście zdarzeniowe, zobacz /blog/event-driven-architecture. Aby zaplanować koszty i środowiska, sprawdź /pricing.