03 paź 2025·6 min
Dane na zewnątrz vs wewnątrz — lekcje Pata Hellanda dla aplikacji
Poznaj koncepcję Pata Hellanda „dane na zewnątrz vs wewnątrz” — jak wyznaczać granice, projektować idempotentne żądania i rekoncyliować stan przy awariach sieci.
Poznaj koncepcję Pata Hellanda „dane na zewnątrz vs wewnątrz” — jak wyznaczać granice, projektować idempotentne żądania i rekoncyliować stan przy awariach sieci.
Kiedy budujesz aplikację, łatwo wyobrazić sobie żądania przychodzące ładnie, jedno po drugim, w odpowiedniej kolejności. Sieci w rzeczywistości tak nie działają. Użytkownik naciska „Pay” dwa razy, bo ekran się zawiesił. Połączenie mobilne znika zaraz po naciśnięciu przycisku. Webhook przychodzi późno albo dwa razy. Czasem w ogóle nie przyjdzie.
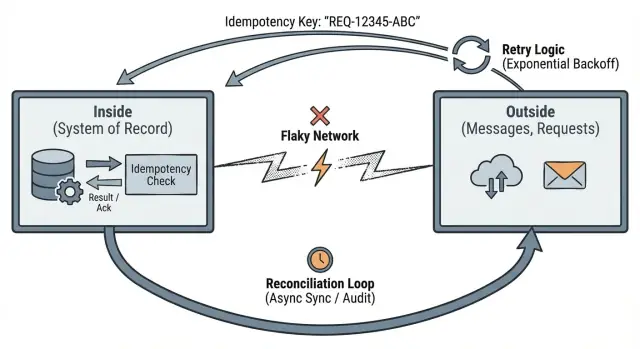
Pomysł Pata Hellanda o danych na zewnątrz vs wewnątrz to przejrzawy sposób myślenia o tym bałaganie.
„Na zewnątrz” to wszystko, czego twój system nie kontroluje. To miejsca, gdzie rozmawiasz z innymi ludźmi i systemami, i gdzie dostarczenie jest niepewne: żądania HTTP z przeglądarek i aplikacji mobilnych, komunikaty z kolejek, webhooki stron trzecich (płatności, e‑mail, wysyłka) oraz ponowienia wyzwalane przez klientów, proxy lub zadania w tle.
Na zewnątrz zakładaj, że komunikaty mogą być opóźnione, powielone lub przyjść poza kolejnością. Nawet jeśli coś jest „zwykle niezawodne”, projektuj pod kątem dnia, kiedy takie nie będzie.
„Wewnątrz” to to, co twój system potrafi uczynić zależnym. To trwały stan, który przechowujesz, reguły, które egzekwujesz, i fakty, które możesz później udowodnić:
Wewnątrz chronisz inwarianty. Jeśli obiecujesz „jedna płatność na zamówienie”, ta obietnica musi być wymuszana wewnątrz, bo na zewnątrz nie można ufać, że wszystko zachowa się poprawnie.
Zmiana sposobu myślenia jest prosta: nie zakładaj idealnego dostarczenia ani idealnego czasu. Traktuj każdą interakcję z zewnątrz jako zawodną sugestię, która może się powtórzyć, i spraw, by wnętrze reagowało bezpiecznie.
To ma znaczenie nawet dla małych zespołów i prostych aplikacji. Pierwsza awaria sieci, która stworzy podwójne obciążenie lub zablokowane zamówienie, przestaje być teorią i staje się zwrotem, ticketem do supportu i utratą zaufania.
Konkretny przykład: użytkownik klika „Place order”, aplikacja wysyła żądanie i połączenie przerywa. Użytkownik próbuje ponownie. Jeśli wewnątrz nie ma sposobu na rozpoznanie „to ta sama próba”, możesz utworzyć dwa zamówienia, zarezerwować towar dwukrotnie lub wysłać dwa potwierdzenia e‑mail.
Punkt Hellanda jest prosty: świat zewnętrzny jest niepewny, ale wnętrze systemu musi pozostać spójne. Sieci gubią pakiety, telefony tracą zasięg, zegary się rozjeżdżają, a użytkownicy naciskają odśwież. Twoja aplikacja nie może tego kontrolować. Może jednak kontrolować to, co przyjmuje za „prawdę”, gdy dane przekroczą jasną granicę.
Wyobraź sobie kogoś zamawiającego kawę na telefonie, przechodzącego przez budynek z kiepskim Wi‑Fi. Naciska „Pay”. Pojawia się spinner. Sieć się rozłącza. Kliknie ponownie.
Może pierwsze żądanie dotarło do serwera, ale odpowiedź nigdy do klienta nie wróciła. Albo może żadne żądanie nie dotarło. Z punktu widzenia użytkownika obie możliwości wyglądają tak samo.
To jest czas i niepewność: jeszcze nie wiesz, co się stało, i możesz dowiedzieć się później. Twój system musi zachowywać się rozsądnie, czekając na wyjaśnienie.
Gdy zaakceptujesz, że zewnętrze jest zawodliwe, kilka „dziwnych” zachowań staje się normalnych:
Dane z zewnątrz to roszczenie, nie fakt. „Zapłaciłem” to tylko stwierdzenie wysłane przez zawodny kanał. Staje się faktem dopiero, gdy zapiszesz je wewnątrz systemu w sposób trwały i spójny.
To skłania do trzech praktycznych nawyków: zdefiniuj jasne granice, zabezpiecz ponowienia poprzez idempotencję i zaplanuj rekoncyliację, gdy rzeczywistość się nie zgadza.
Pomysł „na zewnątrz vs wewnątrz” zaczyna się od praktycznego pytania: gdzie zaczyna się i kończy prawda twojego systemu?
Wewnątrz granicy możesz dawać silne gwarancje, bo kontrolujesz dane i reguły. Na zewnątrz robisz najlepsze próby i zakładasz, że wiadomości mogą zginąć, zostać powielone, opóźnione lub przyjść poza kolejnością.
W rzeczywistych aplikacjach granica często pojawia się w miejscach takich jak:
Gdy narysujesz tę linię, zdecyduj, które inwarianty są niepodważalne wewnątrz. Przykłady:
Granica potrzebuje też jasnego języka opisującego „gdzie jesteśmy”. Wiele błędów żyje w luki między „usłyszeliśmy” a „skończyliśmy”. Pomocny wzorzec to oddzielenie trzech znaczeń:
Gdy zespoły to pominą, dostają błędy, które pojawiają się tylko pod obciążeniem lub podczas częściowych awarii. Jeden system używa „paid” na oznaczenie pobrania pieniędzy; inny używa go jako rozpoczęcia próby płatności. Taka niezgodność tworzy duplikaty, zablokowane zamówienia i bilety, których nikt nie potrafi odtworzyć.
Idempotencja oznacza: jeśli to samo żądanie zostanie wysłane dwukrotnie, system potraktuje je jak jedno i zwróci ten sam wynik.
Ponowienia są normalne. Timeouty się zdarzają. Klienci się powtarzają. Jeśli zewnętrze może się powtarzać, twoje wnętrze musi zamienić to w stabilne zmiany stanu.
Prosty przykład: aplikacja mobilna wysyła „pay $20” i połączenie ginie. Aplikacja ponawia. Bez idempotencji klient może zostać obciążony dwa razy. Z idempotencją drugie żądanie zwraca wynik pierwszego obciążenia.
Większość zespołów używa jednego z tych wzorców (czasem mieszanych):
Idempotency-Key: ...). Serwer zapisuje klucz i ostateczną odpowiedź.Gdy przychodzi duplikat, najlepszym zachowaniem zwykle nie jest „409 conflict” ani ogólny błąd. To zwrócenie tego samego rezultatu, co za pierwszym razem, łącznie z tym samym ID zasobu i statusem. To sprawia, że ponowienia są bezpieczne dla klientów i zadań w tle.
Rekord idempotencji musi żyć wewnątrz twojej granicy w trwałym magazynie, nie w pamięci. Jeśli API się zrestartuje i zapomni, gwarancja bezpieczeństwa znika.
Przechowuj rekordy wystarczająco długo, by pokryć realistyczne ponowienia i opóźnione dostawy. Okno zależy od ryzyka biznesowego: minuty–godziny dla niskoryzykownych tworzeń, dni dla płatności/e‑maili/wysyłek gdzie duplikaty kosztują, i dłużej, jeśli partnerzy mogą ponawiać przez dłuższy czas.
Transakcje rozproszone brzmią kojąco: jeden duży commit przez usługi, kolejki i bazy. W praktyce często są nieosiągalne, wolne lub zbyt kruche, by na nich polegać. Gdy w grę wchodzi skok sieciowy, nie możesz zakładać, że wszystko zatwierdzi się razem.
Typowa pułapka to budowanie workflowu, który działa tylko wtedy, gdy każdy krok powiedzie się od razu: zapisz zamówienie, obciąż kartę, zarezerwuj magazyn, wyślij potwierdzenie. Jeśli krok 3 timeoutuje, czy się powiódł czy nie? Jeśli ponowisz, czy podwójnie obciążysz lub podwójnie zarezerwujesz?
Dwa praktyczne podejścia to:
Wybierz jeden styl dla danego workflowu i trzymaj się go. Mieszanie „czasem outbox” z „czasem zakładamy sukces synchroniczny” tworzy trudne do przetestowania przypadki brzegowe.
Prosta zasada: jeśli nie możesz atomowo commitować przez granice, projektuj pod kątem ponowień, duplikatów i opóźnień.
Rekoncyliacja to przyznanie podstawowej prawdy: gdy twoja aplikacja rozmawia z innymi systemami przez sieć, czasem będziecie się nie zgadzać co do tego, co się stało. Żądania timeoutują, callbacki przychodzą późno, a ludzie powtarzają akcje. Rekoncyliacja to sposób wykrywania rozbieżności i naprawiania ich w czasie.
Traktuj zewnętrzne systemy jako niezależne źródła prawdy. Twoja aplikacja prowadzi własny wewnętrzny rejestr, ale potrzebuje sposobu porównania tego rejestru z tym, co dostawcy, partnerzy i użytkownicy faktycznie zrobili.
Większość zespołów używa kilku prostych narzędzi (prostota jest zaletą): worker, który ponawia zaległe akcje i ponownie sprawdza zewnętrzny status, harmonogram skanu wyszukujący niespójności oraz prosta akcja naprawcza dla supportu, by spróbować ponownie, anulować lub oznaczyć jako sprawdzone.
Rekoncyliacja działa tylko wtedy, gdy wiesz, co porównywać: wewnętrzny ledger vs ledger dostawcy (płatności), stan zamówienia vs stan wysyłki (fulfillment), stan subskrypcji vs stan billingowy.
Uczyń stany naprawialnymi. Zamiast przeskakiwać od „created” do „completed”, używaj stanów pośrednich typu pending, on hold lub needs review. Dzięki temu można bezpiecznie powiedzieć „nie jesteśmy pewni” i dać rekoncyliacji miejsce do lądowania.
Zachowuj mały ślad audytu przy ważnych zmianach:
Przykład: jeśli twoja aplikacja poprosiła o etykietę wysyłkową i sieć padła, możesz mieć „brak etykiety” wewnętrznie, podczas gdy przewoźnik faktycznie ją stworzył. Worker rekonsyliacyjny może wyszukać po ID korelacji, odkryć, że etykieta istnieje i posunąć zamówienie dalej (albo oznaczyć do przeglądu, jeśli dane się nie zgadzają).
Gdy założysz, że sieć zawiedzie, cel się zmienia. Nie chodzi o to, by każdy krok za każdym razem się powiódł. Chodzi o to, żeby każdy krok był bezpieczny do powtórzenia i łatwy do naprawienia.
Napisz jednozdaniowe stwierdzenie granicy. Bądź konkretny, co twój system posiada (źródło prawdy), co tylko odwzorowuje, a co tylko żąda od innych.
Wypisz tryby awarii przed happy path. Przynajmniej: timeouty (nie wiesz, czy zadziałało), duplikaty żądań, częściowy sukces (jeden krok się powiódł, kolejny nie), i zdarzenia poza kolejnością.
Wybierz strategię idempotencji dla każdego wejścia. Dla synchronicznych API to często klucz idempotencji + zapisany wynik. Dla komunikatów/zdarzeń zwykle unikalne ID wiadomości i rekord „czy przetworzyłem to?”.
Zapisz intencję, potem działaj. Najpierw przechowaj coś trwałego, np. PaymentAttempt: pending lub ShipmentRequest: queued, potem wykonaj wywołanie zewnętrzne, potem zapisz wynik. Zwróć stabilne ID referencyjne, żeby ponowienia wskazywały na tę samą intencję, zamiast tworzyć nową.
Zbuduj rekoncyliację i ścieżkę naprawczą, i udostępnij je. Rekoncyliacja może być zadaniem, które skanuje „pending za długo” i ponownie sprawdza status. Ścieżka naprawcza to bezpieczna akcja administracyjna: „retry”, „cancel” lub „mark resolved”, z notatką audytu. Dodaj podstawową obserwowalność: ID korelacji, jasne pola statusu i kilka liczników (pending, retries, failures).
Przykład: jeśli checkout timeoutuje zaraz po wywołaniu dostawcy płatności, nie zgaduj. Zapisz próbę, zwróć ID próby i pozwól użytkownikowi ponowić z tym samym kluczem idempotencji. Później rekoncyliacja potwierdzi, czy dostawca obciążył, i zaktualizuje próbę bez podwójnego obciążenia.
Klient naciska „Place order”. Twoja usługa wysyła żądanie płatności do dostawcy, ale sieć jest niestabilna. Dostawca ma własną prawdę, a twoja baza ma swoją. Będą dryfować, jeśli ich nie zaprojektujesz do tego.
Z twojej perspektywy zewnętrze to strumień komunikatów, które mogą być późne, powtarzane lub brakujące:
Żaden z tych kroków nie gwarantuje „exactly once”. Gwarantują raczej „może”.
Wewnątrz granicy przechowuj trwałe fakty i minimum potrzebne do powiązania zewnętrznych zdarzeń z tymi faktami.
Gdy klient pierwszy raz składa zamówienie, utwórz rekord order w jasnym stanie, np. pending_payment. Stwórz też rekord payment_attempt z unikalnym referencem dostawcy oraz idempotency_key powiązanym z akcją klienta.
Jeśli klient timeoutuje i ponawia, twoje API nie powinno tworzyć drugiego zamówienia. Powinno wyszukać idempotency_key i zwrócić ten sam order_id i aktualny stan. Ten prosty wybór zapobiega duplikatom przy awariach sieci.
Teraz webhook przychodzi dwukrotnie. Pierwszy callback aktualizuje payment_attempt do authorized i przechodzi zamówienie do paid. Drugi callback trafia do tego samego handlera, ale wykrywasz, że już przetworzyłeś to zdarzenie dostawcy (przez zapisanie ID zdarzenia dostawcy albo kontrolę bieżącego stanu) i nic nie robisz. Nadal możesz odpowiedzieć 200 OK, bo rezultat jest już prawdziwy.
Na końcu rekoncyliacja zajmuje się trudnymi przypadkami. Jeśli zamówienie jest nadal pending_payment po upływie czasu, zadanie w tle pyta dostawcę po zapisanym referencu. Jeśli dostawca mówi „authorized”, ale przegapiłeś webhook, aktualizujesz swoje rekordy. Jeśli dostawca mówi „failed”, a ty oznaczyłeś jako opłacone, flagujesz to do przeglądu lub wyzwalasz kompensacyjną akcję, np. zwrot.
Większość duplikatów i „zawieszonych” workflowów wynika z mieszania tego, co stało się na zewnątrz (żądanie dotarło, wiadomość została odebrana) z tym, co bezpiecznie zatwierdziłeś wewnątrz.
Klasyczna awaria: klient wysyła „place order”, serwer zaczyna pracę, sieć pada, klient ponawia. Jeśli traktujesz każde ponowienie jak nową prawdę, dostaniesz podwójne obciążenia, zdublowane zamówienia lub wiele maili.
Zwykłe przyczyny:
Jedno zagadnienie pogarsza wszystko: brak śladu audytu. Jeśli nadpisujesz pola i zostawiasz tylko ostatni stan, tracisz dowody potrzebne do późniejszej rekoncyliacji.
Dobry test zdrowego rozsądku to: „Jeśli uruchomię ten handler dwa razy, czy dostanę ten sam rezultat?” Jeśli odpowiedź brzmi nie, duplikaty nie są rzadkim przypadkiem. Są gwarantowane.
Jeśli zapamiętasz jedną rzecz: twoja aplikacja musi być poprawna nawet wtedy, gdy wiadomości przyjdą późno, przyjdą dwa razy lub wcale nie przyjdą.
Użyj tej listy, by znaleźć słabe punkty zanim zamienią się w zdublowane rekordy, brakujące aktualizacje lub zablokowane workflowy:
Jeśli nie potrafisz szybko odpowiedzieć na jedno z tych pytań, to użyteczna wskazówka. Zazwyczaj oznacza to, że granica jest nieostra lub brakuje przejścia stanu.
Praktyczne następne kroki:
Najpierw naszkicuj granice i stany. Zdefiniuj mały zestaw stanów dla workflowu (np.: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
Dodaj idempotencję tam, gdzie najbardziej się liczy. Zacznij od najbardziej ryzykownych zapisów: create order, capture payment, issue refund. Przechowuj klucze idempotencji w PostgreSQL z unikalnym ograniczeniem, żeby duplikaty były odrzucane bezpiecznie.
Traktuj rekoncyliację jak normalną funkcję. Zaplanuj zadanie, które wyszukuje rekordy „pending za długo”, sprawdza zewnętrzne systemy i naprawia lokalny stan.
Iteruj bezpiecznie. Dostosuj przejścia i reguły ponawiania, a potem testuj, celowo ponawiając to samo żądanie i ponownie przetwarzając to samo zdarzenie.
Jeśli budujesz szybko na platformie sterowanej czatem jak Koder.ai (koder.ai), nadal warto wdrożyć te reguły w wygenerowanych serwisach od początku: szybkość pochodzi z automatyzacji, ale niezawodność pochodzi z jasnych granic, idempotentnych handlerów i rekoncyliacji.
"Na zewnątrz" to wszystko, czego nie kontrolujesz: przeglądarki, sieci mobilne, kolejki, webhooki stron trzecich, ponowienia i timeouty. Zakładaj, że wiadomości mogą być opóźnione, powielone, utracone lub przyjść poza kolejnością.
"Wewnątrz" to to, co kontrolujesz: stan, który przechowujesz, zasady biznesowe i fakty, które możesz później udowodnić (zwykle w bazie danych).
Bo sieć „kłamie”.
Timeout po stronie klienta nie znaczy, że serwer nie przetworzył żądania. Webhook przychodzący dwukrotnie nie oznacza, że dostawca wykonał akcję dwukrotnie. Jeśli potraktujesz każdą wiadomość jako nową, stworzy to duplikaty zamówień, podwójne obciążenia i zablokowane przepływy pracy.
Jasna granica to punkt, w którym zawodna wiadomość staje się trwałym faktem.
Typowe granice to:
Gdy dane przekroczą tę granicę, wymuszaj reguły wewnątrz (np. "zamówienie można opłacić tylko raz").
Użyj idempotencji. Zasada: ta sama intencja powinna dawać ten sam rezultat, nawet jeśli zostanie wysłana wielokrotnie.
Praktyczne wzorce:
Nie przechowuj tego tylko w pamięci. Zapisuj wewnątrz granicy (np. w PostgreSQL), żeby restart nie skasował ochrony.
Zasada retencji:
Przechowuj wystarczająco długo, aby pokryć realistyczne ponowienia i opóźnione callbacki.
Używaj stanów, które przyznają niepewność.
Prosty, praktyczny zestaw:
pending_* (zaakceptowaliśmy intencję, ale nie znamy jeszcze wyniku)succeeded / failed (zapisano ostateczny wynik)needs_review (wykryto rozbieżność wymagającą człowieka lub specjalnej pracy)Bo nie da się atomowo zatwierdzić zmian w wielu systemach przez sieć.
Jeśli robisz synchronne kroki: zapisz zamówienie → obciąż kartę → zarezerwuj magazyn, a krok 2 timeoutuje, nie wiesz, czy powtarzać. Powtórzenie może spowodować duplikaty; brak powtórzenia może pozostawić pracę niedokończoną.
Projektuj na częściowy sukces: najpierw zapisz intencję, potem wykonaj zewnętrzne akcje, potem zapisz wynik.
Wzorzec outbox/inbox umożliwia niezawodną komunikację między systemami, bez udawania, że sieć jest doskonała.
Rekoncyliacja to sposób odzyskiwania, gdy twoje rekordy i zewnętrzny system się nie zgadzają.
Dobre domyślne rozwiązania:
needs_reviewTo nie jest opcjonalne dla płatności, fulfillmentu, subskrypcji ani czegokolwiek z webhookami.
Tak. Szybkie budowanie nie usuwa awarii sieci — po prostu szybciej je napotkasz.
Jeśli generujesz serwisy za pomocą Koder.ai (koder.ai), wdroż te domyślne reguły wcześnie:
Dzięki temu ponowienia i duplikaty staną się nudne, zamiast kosztownych.
To zapobiega zgadywaniu podczas timeoutów i ułatwia rekoncyliację.