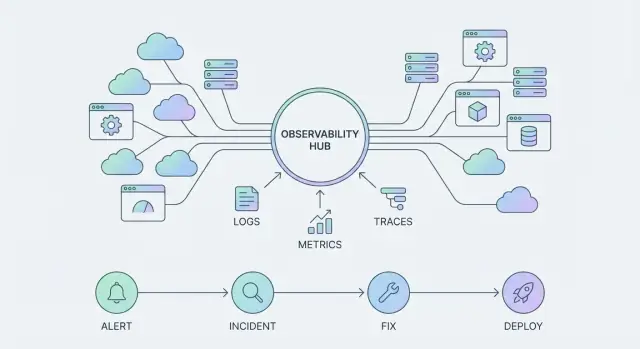
Narzędzie do obserwowalności pomaga odpowiedzieć na konkretne pytania o system — zwykle pokazując wykresy, logi lub wynik zapytania. To coś, czego „używasz”, gdy pojawia się problem.
Platforma obserwowalności jest szersza: standaryzuje sposób zbierania telemetrii, sposób, w jaki zespoły ją eksplorują, oraz jak incydenty są obsługiwane end-to-end. Staje się tym, czym twoja organizacja „zarządza” codziennie, w wielu usługach i zespołach.
Od wykresów do rezultatów
Większość zespołów zaczyna od dashboardów: wykresy CPU, grafy współczynnika błędów, może kilka wyszukiwań logów. To użyteczne, ale prawdziwy cel to nie ładniejsze wykresy — to szybsze wykrywanie i szybsze rozwiązywanie.
Zmiana w kierunku platformy następuje, gdy przestajesz pytać „Czy możemy to zwizualizować?” i zaczynasz pytać:
- Czy inżynier na dyżurze znajdzie przyczynę w minutach, a nie godzinach?
- Czy możemy automatycznie skierować właściwy alert do właściwego zespołu?
- Czy powtarzające się wzorce incydentów da się zamienić w powtarzalne playbooki?
To pytania skoncentrowane na rezultatach, i wymagają one więcej niż wizualizacji. Potrzebne są wspólne standardy danych, spójne integracje i przepływy pracy łączące telemetrię z działaniem.
Trzy filary, które naprawdę kupujesz
W miarę rozwoju platform takich jak Datadog observability platform, „powierzchnia produktu” to nie tylko dashboardy. To trzy współpowiązane filary:
- Telemetria: logi, metryki i śledzenia zbierane konsekwentnie i na tyle dobrze opisywane, by można im ufać.
- Integracje: gotowe połączenia ułatwiające adopcję i rozszerzające pokrycie bez własnych klejących rozwiązań.
- Przepływy pracy: reagowanie na incydenty, routing alertów, przypisanie odpowiedzialności i follow-up — żeby nauka kumulowała się.
Pojedynczy dashboard pomaga jednemu zespołowi. Platforma staje się silniejsza z każdą usługą dołączoną, każdą integracją dodaną i każdym ustandaryzowanym przepływem. Z czasem kumuluje się to w mniejszej liczbie niewidocznych obszarów, mniej zduplikowanych narzędzi i krótszych incydentach — bo każda poprawa staje się wielokrotnego użytku, a nie jednorazowa.
Telemetria staje się powierzchnią produktu
Gdy obserwowalność przestaje być „narzędziem, które zapytujemy”, a staje się „platformą, na której budujemy”, telemetria przestaje być surowym wydechem i zaczyna działać jak powierzchnia produktu. To, co zdecydujesz emitować — i jak konsekwentnie to robisz — determinuje, co twoje zespoły mogą zobaczyć, zautomatyzować i komukolwiek zaufać.
Podstawowe typy telemetrii (i do czego służą)
Większość zespołów standaryzuje kilka sygnałów:
- Metryki: wartości liczbowe w czasie (opóźnienie, współczynnik błędów, nasycenie).
- Logi: szczegółowe, czytelne dla człowieka zapisy do dochodzenia i audytu.
- Śledzenia (traces): ścieżki żądań przez usługi, żeby znaleźć miejsca, gdzie tracony jest czas i występują błędy.
- Zdarzenia: dyskretne wpisy „coś się zmieniło” (deployy, feature flagi, incydenty).
- Profile: zachowanie CPU/pamięci, by wskazać kosztowne ścieżki w kodzie.
Osobno każdy sygnał jest użyteczny. Razem stają się jednolitym interfejsem do systemów — tym, co widzisz na dashboardach, w alertach, na osi czasu incydentu i w postmortem.
Konsekwencja ważniejsza niż wolumen
Częsty błąd to zbieranie „wszystkiego”, ale nazywanie tego niespójnie. Jeśli jedna usługa używa userId, inna uid, a trzecia nie loguje nic, nie da się wiarygodnie kroić danych, łączyć sygnałów ani budować wielokrotnego użytku monitorów.
Zespoły otrzymują więcej wartości, zgadzając się na kilka konwencji — nazwy usług, tagi środowiska, identyfikatory żądań i standardowy zestaw atrybutów — niż przez podwajanie wolumenu ingestu.
Co naprawdę oznacza wysoka kardynalność (i dlaczego ma znaczenie)
Pola o wysokiej kardynalności to atrybuty z wieloma możliwymi wartościami (jak user_id, order_id, session_id). Są potężne przy debugowaniu problemów „tylko jednym klientowi”, ale mogą też zwiększać koszty i spowalniać zapytania, jeśli używane są wszędzie.
Podejście platformowe jest celowe: trzymaj wysoką kardynalność tam, gdzie daje jasną wartość dochodzeniową, i unikaj jej tam, gdzie liczy się globalna agregacja.
Ujednolicony kontekst redukuje robotę przy korelacji
Zysk to prędkość. Gdy metryki, logi, śledzenia, zdarzenia i profile dzielą ten sam kontekst (service, version, region, request ID), inżynierowie spędzają mniej czasu na zszywaniu dowodów, a więcej na naprawie właściwego problemu. Zamiast skakać między narzędziami i zgadywać, podążasz jedną nitką od objawu do przyczyny źródłowej.
Od zbierania danych do strategii telemetrii
Większość zespołów zaczyna od „wprowadzenia danych”. To konieczne, ale to nie strategia. Strategia telemetrii utrzymuje szybkie onboardingi i sprawia, że dane są na tyle spójne, by zasilać wspólne dashboardy, wiarygodne alerty i sensowne SLO.
Typowe ścieżki ingestu (i co robią najlepiej)
Datadog zazwyczaj otrzymuje telemetrię przez kilka praktycznych dróg:
- Agenci na hostach/VM: najszybszy sposób zbierania metryk infrastruktury, logów i APM bez dużych zmian w kodzie.
- Kolektory i bramki (np. OpenTelemetry Collector): przydatne, gdy chcesz centralnej kontroli, routingu do wielu miejsc, redakcji lub standardowego przetwarzania.
- API i bezpośrednie SDK: pomocne dla niestandardowych zdarzeń, metryk biznesowych lub gdy agent nie wchodzi w grę.
- Integracje serverless: wygodne w zarządzanych runtime’ach, gdzie nie kontrolujesz hosta — warto jednak przemyśleć, co emitujesz.
Szybkość kontra standaryzacja: zdecyduj, co optymalizujesz
Na początku wygrywa szybkość: zespoły instalują agenta, włączają kilka integracji i od razu widzą wartość. Ryzyko jest takie, że każdy zespół wymyśli własne tagi, nazwy usług i formaty logów — co utrudnia widoki międzyserwisowe i sprawia, że alerty są trudne do zaufania.
Prosta zasada: pozwól na „quick start”, ale wymagaj „standaryzacji w ciągu 30 dni”. Daje to zespołom impet bez trwałego bałaganu.
Lekka konwencja nazewnictwa i tagowania
Nie potrzebujesz olbrzymiej taksonomii. Zacznij od niewielkiego zestawu, który każdy sygnał (logi, metryki, śledzenia) musi nieść:
service: krótka, stabilna, małymi literami (np. checkout-api)\n- env: prod, staging, dev\n- team: identyfikator zespołu odpowiedzialnego (np. payments)\n- version: wersja wdrożenia lub git SHA
Jeśli chcesz jeszcze jeden, który szybko się zwraca, dodaj tier (frontend, backend, data) by uprościć filtrowanie.
Sampling, retencja i domyślne ustawienia świadome kosztu
Problemy z kosztami zwykle wynikają z zbyt hośnych ustawień domyślnych:\n\n- Śledzenia: zacznij od samplingowania head-based dla punktów o dużym wolumenie; trzymaj 100% dla krytycznych przepływów.\n- Logi: domyślnie „błędy + ważne zdarzenia biznesowe”, potem selektywnie dodawaj info/debug z ograniczoną retencją.\n- Retencja: przechowuj dane o wysokiej rozdzielczości krócej (dni), agregaty lub kluczowe metryki dłużej (tygodnie/miesiące).\n\nCelem nie jest zbieranie mniej — to zbieranie właściwych danych konsekwentnie, aby skalowanie użycia nie przyniosło niespodzianek.
Integracje jako prawdziwy kanał dystrybucji
Większość myśli o narzędziach obserwowalności jak o „czymś, co instalujesz”. W praktyce rozprzestrzeniają się one w organizacji tak, jak dobre konektory: jedna integracja na raz.
Co właściwie oznacza „integracja”?
Integracja to nie tylko rura danych. Zazwyczaj składa się z trzech części:
- Źródła danych: pobieranie metryk, logów, śledzeń, zdarzeń i topologii z systemów, które już uruchamiasz (usługi chmurowe, Kubernetes, bazy danych, CI/CD, narzędzia SaaS).\n- Wzbogacanie: dodawanie kontekstu, aby telemetria była od razu użyteczna — nazwy usług, środowiska, tagi właścicieli, wersje wdrożeń i metadane chmury.\n- Akcje: robienie czegoś z tym, co odkryjesz — tworzenie ticketów, wezwanie on-call, adnotowanie deployów, skalowanie zasobów lub uruchamianie runbooków.
Ta ostatnia część zamienia integracje w dystrybucję. Jeśli narzędzie tylko czyta, jest miejscem docelowym dashboardu. Jeśli także pisze, staje się częścią codziennej pracy.
Dlaczego integracje przyspieszają adopcję
Dobre integracje skracają czas konfiguracji, bo dostarczają sensowne ustawienia domyślne: gotowe dashboardy, rekomendowane monitory, reguły parsowania i typowe tagi. Zamiast każdego zespołu tworzącego własny „dashboard CPU” czy „alerty Postgres”, dostajesz punkt wyjścia zgodny z najlepszymi praktykami.
Zespoły nadal dostosowują — ale zaczynają od wspólnej bazy. Ta standaryzacja ma znaczenie podczas konsolidacji narzędzi: integracje tworzą powtarzalne wzorce, które nowe usługi mogą kopiować, co utrzymuje wzrost w ryzach.
Priorytetyzuj integracje dwukierunkowe
Przy ocenie zapytaj: czy potrafi przyjmować sygnały i wykonywać akcje? Przykłady to tworzenie incydentów w systemie ticketowym, aktualizacja kanałów incydentowych lub dodawanie linku do śledzenia w PR albo widoku deployu. Dwukierunkowe ustawienia to miejsce, gdzie przepływy pracy zaczynają być „natywne”.
Prosta metoda shortlisty
Zacznij mało i przewidywalnie:
- Krytyczna infrastruktura najpierw (dostawca chmury, Kubernetes, load balancery, kluczowe bazy danych).\n2. Potem pipeline wdrożeniowy (CI/CD, feature flagi, śledzenie wydań), żeby telemetria korelowała ze zmianami.\n3. Dodaj SaaS per zespół (kolejki, cache, auth, płatności), gdy reguły tagowania i właścicielstwa są stabilne.
Zasada kciuka: priorytetyzuj integracje, które od razu poprawiają reakcję na incydenty, a nie te, które tylko dodają kolejne wykresy.
Standardowe widoki: usługi, dashboardy i monitory
Standardowe widoki to miejsce, gdzie platforma obserwowalności staje się użyteczna na co dzień. Gdy zespoły dzielą ten sam model mentalny — czym jest „usługa”, jak wygląda „zdrowie” i gdzie kliknąć najpierw — debugowanie przyspiesza, a przekazanie pracy jest czystsze.
Zacznij od golden signals (i udostępnij je)
Wybierz mały zestaw „golden signals” i przypisz każdemu konkretny, wielokrotnego użytku dashboard. Dla większości usług to:
- Opóźnienie (p95/p99 dla kluczowych endpointów)\n- Ruch (requests per second, przetworzone zadania)\n- Błędy (współczynnik i najczęstsze typy błędów)\n- Nasycenie (CPU, pamięć, długość kolejek, połączenia do DB)
Kluczem jest spójność: jeden układ dashboardu działający we wszystkich usługach bije dziesięć wyszukanych, jednorazowych widoków.
Katalog usług tworzy wspólną własność
Katalog usług (nawet lekki) zamienia „ktoś powinien to oglądać” w „ten zespół za to odpowiada”. Gdy usługi są otagowane właścicielami, środowiskami i zależnościami, platforma może od razu odpowiedzieć na pytania: Które monitory dotyczą tej usługi? Jakie dashboardy otworzyć? Kogo powiadomić?
Ta przejrzystość redukuje ping-ponga na Slacku podczas incydentów i pomaga nowym inżynierom samodzielnie działać.
Bloki budulcowe, które skalują
Traktuj te elementy jako standardowe artefakty, nie opcjonalne dodatki:
- Dashboardy dla golden signals i kluczowych zależności\n- Monitory powiązane z SLO lub symptomami wpływającymi na użytkownika\n- Notatniki do dochodzeń i osi czasu post-incident\n- Runbooki (linkowane z monitorów) na pierwsze 5–10 minut reakcji
Antywzorce do uniknięcia
Dashboardy dla galanterii (ładne wykresy bez decyzji), jednorazowe alerty (stworzono w pośpiechu, nigdy wyregulowane) i niezudokumentowane zapytania (tylko jedna osoba rozumie magię filtra) tworzą hałas platformy. Jeśli zapytanie ma znaczenie, zapisz je, nazwij i dołącz do widoku usługi, aby inni mogli je znaleźć.
Przepływy pracy: gdzie obserwowalność daje wartość biznesową
Prototypuj spoiwo platformy
Zbuduj szybki prototyp React + Go dla zespołu platformowego w jedno popołudnie.
Obserwowalność staje się „realna” dla biznesu, gdy skraca czas między problemem a pewną naprawą. Dzieje się to przez przepływy pracy — powtarzalne ścieżki zabierające cię od sygnału do działania, i od działania do nauki.
Podróż incydentu: alert → triage → komunikacja → złagodzenie → nauka
Skalowalny przepływ to więcej niż wezwanie kogoś na dyżur.
Alert powinien otwierać skoncentrowaną pętlę triage: potwierdź wpływ, zidentyfikuj dotkniętą usługę i pobierz najbardziej istotny kontekst (ostatnie deployy, zdrowie zależności, skoki błędów, sygnały nasycenia). Potem komunikacja zamienia zdarzenie techniczne w skoordynowaną odpowiedź — kto prowadzi incydent, co widzą użytkownicy i kiedy będzie następna aktualizacja.
Złagodzenie to miejsce, gdzie chcesz mieć „bezpieczne ruchy” pod ręką: feature flagi, przesunięcie ruchu, rollback, ograniczenia szybkości lub znane obejścia. Na końcu nauka zamyka pętlę lekkim przeglądem, który zapisuje, co się zmieniło, co zadziałało i co warto zautomatyzować następnym razem.
Narzędzia incidentowe + ChatOps = współpraca, nie bohaterskie akcje
Platformy takie jak Datadog observability platform dodają wartość, gdy wspierają wspólną pracę: kanały incydentów, aktualizacje statusu, przekazania i spójne osie czasu. Integracje ChatOps mogą zamienić alerty w ustrukturyzowane rozmowy — tworząc incydent, przypisując role i wklejając kluczowe wykresy i zapytania bezpośrednio w wątek, by wszyscy widzieli te same dowody.
Co naprawdę powinien zawierać dobry runbook
Przydatny runbook jest krótki, stanowczy i bezpieczny. Powinien zawierać: cel (przywrócić usługę), jasnych właścicieli/rotacje on-call, kroki kontrolne, linki do odpowiednich dashboardów/monitorów oraz „bezpieczne akcje” redukujące ryzyko (z krokami rollback). Jeśli nie da się tego wykonać o 3:00 rano, to runbook nie jest gotowy.
Powiąż incydenty z deployami i zmianami
Root cause jest szybsze, gdy incydenty są automatycznie powiązane z deployami, zmianami konfiguracji i flipami feature flagów. Uczyń „co się zmieniło?” widokiem pierwszej klasy, żeby triage zaczynał się od dowodów, a nie domysłów.
SLO i budżety błędów jako system operacyjny zespołu
Czym jest SLO (i dlaczego bije „zielone dashboardy”)
SLO (Service Level Objective) to prosta obietnica dotycząca doświadczenia użytkownika w określonym oknie czasowym — na przykład „99,9% żądań zakończy się sukcesem w ciągu 30 dni” lub „p95 ładowania strony poniżej 2 sekund”.
To bije „zielone dashboardy”, bo dashboardy często pokazują zdrowie systemu (CPU, pamięć, kolejki), a nie wpływ na klienta. Usługa może wyglądać na zieloną, a użytkownicy i tak cierpią (np. zależność timeoutuje lub błędy są skoncentrowane w jednym regionie). SLO zmusza zespół do mierzenia tego, co faktycznie odczuwa użytkownik.
Budżety błędów: wspólny sposób rozmowy o ryzyku
Budżet błędów to dopuszczalna ilość niestabilności wynikająca z SLO. Jeśli obiecujesz 99,9% sukcesu w 30 dniach, „dozwolone” jest ok. 43 minut błędów w tym oknie.
To tworzy praktyczny system decyzyjny:\n\n- Budżet zdrowy: wprowadzaj funkcje, eksperymentuj, podejmuj rozsądne ryzyko.\n- Budżet się topi: spowolnij wydania, skup się na pracach poprawiających niezawodność, ogranicz zmiany.\n- Budżet wyczerpany: wstrzymaj ryzykowne deployy i zajmij się głównymi źródłami błędów.
Zamiast debat w spotkaniu wydawniczym, dyskutujesz liczbę, którą każdy może zobaczyć.
Alertuj na burn rate, nie na każdą pikę
Alertowanie SLO działa najlepiej, gdy alarmujesz na burn rate (jak szybko zużywasz budżet błędów), a nie na surową liczbę błędów. To redukuje szum:\n\n- Krótkotrwała, samonaprawiająca się pika może nie wywołać page'u.\n- Trwały problem, który wkrótce wyczerpie budżet, wywołuje jasny, wykonalny alert.
Wiele zespołów używa dwóch okien: szybki burn (szybkie pagowanie) i wolny burn (ticket/powiadomienie).
Lekki zestaw SLO na start dla typowej usługi webowej
Zacznij mało — 2–4 SLO, z których naprawdę będziesz korzystać:\n\n- Dostępność: % żądań zakończonych sukcesem (np. HTTP 2xx/3xx) w 30 dni.\n- Opóźnienie: p95 czasu odpowiedzi poniżej progu (oddzielnie dla odczytu i zapisu w razie potrzeby).\n- Ścieżka krytyczna: współczynnik sukcesu dla jednego kluczowego endpointu biznesowego (np. checkout).\n- Świeżość (jeśli dotyczy): zadania batchowe kończą się w ciągu X minut.
Gdy to jest stabilne, możesz rozszerzać — inaczej zbudujesz następne ściany dashboardów. Dla więcej, zobacz /blog/slo-monitoring-basics.
Alertowanie, które skaluje bez wypalania ludzi
Utrzymaj przewidywalność kosztów telemetrii
Zaprojektuj małą aplikację do przeglądu ustawień logów, śladów i retencji per zespół, żeby kontrolować koszty.
Alertowanie to miejsce, w którym wiele programów obserwowalności utknie: dane są, dashboardy ładne, ale doświadczenie on-call staje się hałaśliwe i niegodne zaufania. Jeśli ludzie uczą się ignorować alerty, twoja platforma traci zdolność ochrony biznesu.
Dlaczego występuje zmęczenie alertami (i skąd biorą się zdublowane sygnały)
Najczęstsze przyczyny są zaskakująco powtarzalne:\n\n- Zbyt dużo alertów „FYI”, które nie wymagają działania.\n- Progi kopiowane między usługami bez kontekstu (ten sam próg CPU dla różnych obciążeń).\n- Wiele narzędzi lub zespołów alertujących na ten sam symptom — np. monitor APM i monitor logów pagingujące z powodu tego samego incydentu.\n- Hałaśliwe metryki (pikujące percentyle opóźnień, efekty autoskalowania), które wyzwalają fluktuacje zamiast prawdziwych problemów.
W terminologii Datadog, zduplikowane sygnały często pojawiają się, gdy monitory tworzone są z różnych „powierzchni” (metryki, logi, śledzenia) bez ustalenia, która z nich jest kanonicznym źródłem pagingu.
Routing: właścicielstwo, poziom ważności i godziny ciszy
Skalowanie alertowania zaczyna się od reguł routingu, które mają sens dla ludzi:\n\n- Właścicielstwo: każdy monitor powinien mieć jasnego właściciela (usługa/zespół) i ścieżkę eskalacji.\n- Ważność: paging zarezerwuj dla pilnych, wpływających na użytkownika problemów; niższe ważności do ticketów lub powiadomień w czacie.\n- Okna konserwacji: planowane deployy, migracje i testy obciążeniowe nie powinny generować pagów.
Proste reguły utrzymujące alerty wykonalnymi
Użyteczny domyślny sposób: alertuj na symptomy, nie na każdą zmianę metryki. Page’uj na rzeczy, które odczuwają użytkownicy (współczynnik błędów, nieudane checkouty, utrzymujące się opóźnienia, burn SLO), a nie na „wejścia” (CPU, liczba podów), chyba że one przewidują wpływ.
Kadr recenzji, który rzeczywiście działa
Zrób higienę alertów elementem operacji: miesięczne przeglądy i oczyszczanie monitorów. Usuń monitory, które nigdy nie strzelają, dostosuj progi, które strzelają za często, i scal duplikaty, tak by każdy incydent miał jeden główny page plus kontekst wspierający.
Dobrze zrobione, alertowanie staje się przepływem pracy, któremu ludzie ufają — nie generatorem tła hałasu.
Nazywanie obserwowalności „platformą” to nie tylko posiadanie logów, metryk, śledzeń i wielu integracji w jednym miejscu. To też governance: spójność i zabezpieczenia, które utrzymują system użytecznym, gdy mnożą się zespoły, usługi, dashboardy i alerty.
Bez governance, Datadog (albo każda platforma) może zmienić się w hałaśliwy album — setki nieco różnych dashboardów, niespójne tagi, niejasne właścicielstwo i alerty, którym nikt nie ufa.
Governance to problem ludzi i procesów
Dobre zarządzanie wyjaśnia, kto decyduje o czym i kto jest odpowiedzialny, gdy platforma się rozrasta:\n\n- Zespół platformowy: definiuje standardy (tagowanie, nazewnictwo, wzory dashboardów), dostarcza współdzielone komponenty i utrzymuje integracje.\n- Właściciele usług: odpowiadają za jakość telemetrii swoich usług i utrzymanie sensowności monitorów.\n- Bezpieczeństwo i zgodność: ustala reguły przetwarzania danych (PII, retencja, granice dostępu) i przegląda integracje wysokiego ryzyka.\n- Liderstwo: dopasowuje governance do priorytetów biznesowych (cele niezawodności, oczekiwania w reagowaniu na incydenty) i finansuje prace.
Praktyczne zabezpieczenia zapobiegające „rozrostowi obserwowalności”
Kilka lekkich kontroli daje więcej niż długie polityki:\n\n- Szablony domyślnie: starter dashboardy i paczki monitorów na typ usługi (API, worker, baza danych), żeby zespoły zaczynały spójnie.\n- Polityka tagowania: mały wymagany zestaw (np. service, env, team, tier) i jasne reguły dla tagów opcjonalnych. Egzekwuj w CI, gdzie się da.\n- Dostęp i właścicielstwo: używaj RBAC dla wrażliwych danych i wymagaj właściciela dla dashboardów i monitorów.\n- Procesy zatwierdzania dla zmian wysokiego wpływu: monitory, które page’ują ludzi, pipeline’y logów wpływające na koszty i integracje pobierające wrażliwe dane powinny mieć kroki przeglądu.
Ponowne użycie bije wynalazki na nowo
Najszybszy sposób skalowania jakości to dzielenie się tym, co działa:\n\n- Wspólne biblioteki: wewnętrzne pakiety lub snippet’y standaryzujące pola logów, atrybuty śledzeń i wspólne metryki.\n- Wielokrotnego użytku dashboardy i monitory: centralny katalog „golden” dashboardów i szablonów monitorów, które zespoły mogą klonować i adaptować.\n- Wersjonowane standardy: traktuj kluczowe zasoby jak kod — dokumentuj zmiany, deprecjonuj stare wzorce i ogłaszaj aktualizacje w jednym miejscu.
Jeśli chcesz, żeby to zostało, spraw by ścieżka zarządzana była najprostszą ścieżką — mniej kliknięć, szybsze uruchomienie, jaśniejsze właścicielstwo.
Gdy obserwowalność zaczyna działać jak platforma, zaczyna podlegać ekonomii platform: im więcej zespołów ją adoptuje, tym więcej telemetrii powstaje i tym bardziej użyteczna się staje.
To tworzy flywheel:\n\n- Więcej usług na pokładzie → lepsza widoczność cross-service i korelacja\n- Lepsza widoczność → szybsza diagnoza, mniej powtarzających się incydentów, większe zaufanie do narzędzia\n- Więcej zaufania → więcej zespołów instrumentuje i integruje → jeszcze więcej danych
Złapaniem jest to, że ta sama pętla zwiększa koszty. Więcej hostów, kontenerów, logów, śledzeń, syntetyków i niestandardowych metryk może rosnąć szybciej niż budżet, jeśli nie zarządzasz tym świadomie.
Praktyczne dźwignie kosztowe (bez zabijania sygnału)
Nie musisz wszystkiego wyłączać. Zacznij od kształtowania danych:\n\n- Sampling: trzymaj wysoką wierność śledzeń dla krytycznych endpointów, agresywniej sample’uj wszędzie indziej.\n- Poziomy retencji: krótka retencja dla surowych, wysokowolumenowych logów; dłuższa retencja dla wyselekcjonowanych strumieni bezpieczeństwa/audytu.\n- Filtrowanie i parsowanie logów: odrzucaj oczywisty szum wcześnie (health checki, żądania zasobów statycznych) i standaryzuj parsowanie, żeby móc routować po atrybutach.\n- Agregacja metryk: preferuj percentyle, wskaźniki i rollupy zamiast nieograniczonej kardynalności (np. per-user IDs).
KPI łączące koszty z rezultatami
Śledź mały zestaw miar pokazujących, czy platforma się zwraca:\n\n- MTTD (mean time to detect)\n- MTTR (mean time to resolve)\n- Liczba incydentów i powtarzające się incydenty (ta sama przyczyna źródłowa)\n- Częstotliwość wdrożeń (i wskaźnik nieudanych zmian, jeśli go monitorujesz)
Kwartalny przegląd „wartość kontra koszt” (bez obwiniania)
Zrób to przegląd produktu, nie audyt. Zaproś właścicieli platformy, kilku właścicieli usług i finansów. Przejrzyj:\n\n- Główne czynniki kosztów wg typu danych (logi/metryki/śledzenia) i wg zespołu\n- Największe zwycięstwa: skrócone incydenty, uniknięte outage’y, usunięty toil\n- 2–3 uzgodnione działania (np. dostosować reguły samplingowe, dodać tierowanie retencji, naprawić hałaśliwą integrację)
Cel to współwłasność: koszt staje się danymi wejściowymi do lepszych decyzji instrumentalizacyjnych, a nie powodem, by przestać obserwować.
Co to oznacza dla twojego stosu narzędzi obserwowalności
Uczyń postmortemy powtarzalnymi
Stwórz formularz przeglądu po incydencie, który zapisze, co się zmieniło i co zautomatyzować dalej.
Jeśli obserwowalność zmienia się w platformę, twój „stos narzędzi” przestaje być zbiorem punktowych rozwiązań i zaczyna działać jak wspólna infrastruktura. Ta zmiana sprawia, że rozrost narzędzi to więcej niż irytacja: tworzy zduplikowaną instrumentację, niespójne definicje (co liczy się jako błąd?) i większe obciążenie on-call, bo sygnały nie pokrywają się między logami, metrykami, śledzeniami i incydentami.
Konsolidacja nie oznacza domyślnie „jeden dostawca na wszystko”. To mniej systemów źródłowych telemetrii i reakcji, jaśniejsze właścicielstwo i mniejsza liczba miejsc, które trzeba przeglądać podczas outage’u.
Co konsolidacja może rozwiązać
Rozrost narzędzi zwykle ukrywa koszty w trzech miejscach: czasie spędzonym na przeskakiwaniu między UI, kruchych integracjach, które trzeba utrzymywać, i fragmentarycznym governance (nazewnictwo, tagi, retencja, dostęp).\n\nBardziej skonsolidowane podejście platformowe może zmniejszyć przełączanie kontekstu, ustandaryzować widoki usług i uczynić przepływy incydentowe powtarzalnymi.
Lista kontrolna decyzji (szybka, ale praktyczna)
Przy ocenie stosu (Datadog lub alternatywy) przetestuj:\n\n- Krytyczne integracje: dostawca chmury, Kubernetes, CI/CD, zarządzanie incydentami, paging i kluczowe magazyny danych — plus każde systemy biznesowe „bez których nie wyślemy”.\n- Przepływy: czy przejdziesz od alert → właściciel → runbook → oś czasu → postmortem bez manualnego kopiowania?\n- Governance: standardy tagowania, kontrola dostępu, retencja i zabezpieczenia przed rozrostem dashboardów/monitorów.\n- Model cenowy: co napędza koszty (hosty, kontenery, ingestiowane logi, indeksowane śledzenia)? Czy możesz prognozować wzrost bez niespodzianek?
Przeprowadź pilotaż z jasnym celem sukcesu
Wybierz jedną lub dwie usługi z realnym ruchem. Zdefiniuj jedną miarę sukcesu typu „czas do identyfikacji przyczyny skraca się z 30 minut do 10” lub „zmniejszyć hałaśliwe alerty o 40%”. Instrumentuj tylko to, co potrzebne, i oceniaj wyniki po dwóch tygodniach.
Centralizuj dokumentację wewnętrzną, żeby nauka kumulowała się — dołącz runbook pilota, reguły tagowania i dashboardy w jednym miejscu (na przykład /blog/observability-basics jako wewnętrzny punkt startowy).
Praktyczny plan adopcji, który możesz skopiować
Nie „wdrażasz Datadog” raz i koniec. Zaczynasz mało, ustalasz standardy wcześnie, a potem skaluje to, co działa.
Plan 30/60/90 dni
Dni 0–30: Onboard (udowodnij wartość szybko)
Wybierz 1–2 krytyczne usługi i jedną ścieżkę kliencką. Zainstrumentuj logi, metryki i śledzenia konsekwentnie, i podłącz integracje, na których już polegasz (chmura, Kubernetes, CI/CD, on-call).
Dni 31–60: Standaryzuj (zrób to powtarzalnym)
Przekształć nauki w ustawienia domyślne: nazewnictwo usług, tagowanie, szablony dashboardów, nazwy monitorów i właścicielstwo. Stwórz widoki golden signals (opóźnienie, ruch, błędy, nasycenie) i minimalny zestaw SLO dla najważniejszych endpointów.
Dni 61–90: Skaluj (rozszerzaj bez chaosu)
Onboarduj kolejne zespoły korzystając z tych samych szablonów. Wprowadź governance (reguły tagowania, wymagane metadane, proces przeglądu nowych monitorów) i zacznij śledzić koszt vs użycie, żeby platforma pozostała zdrowa.
Gdzie pasuje Koder.ai (praktycznie)
Gdy traktujesz obserwowalność jako platformę, zwykle będziesz chciał małych „klejących” aplikacji wokół niej: UI katalogu usług, hub runbooków, strona osi czasu incydentów lub wewnętrzne portal łączący właścicieli → dashboardy → SLO → playbooki.
To rodzaj lekkiego narzędzia wewnętrznego, które możesz szybko zbudować na Koder.ai — platformie vibe-coding, która pozwala generować aplikacje webowe przez chat (często React na frontendzie, Go + PostgreSQL na backendzie), z eksportem kodu źródłowego i wsparciem deploymentu/hostingu. W praktyce zespoły używają jej do prototypowania i wdrażania powierzchni operacyjnych, które upraszczają governance i przepływy pracy bez odciągania całego zespołu produktowego z roadmapy.
Szybkie zwycięstwa do wypuszczenia w tygodniu pierwszym
- Top 10 monitorów dla dostępności, współczynnika błędów, opóźnienia, nasycenia i kluczowych zależności\n- Markery wdrożeń (z CI/CD) na dashboardach i śledzeniach dla natychmiastowej korelacji zmian\n- Szablon incydentu: co się stało, wpływ, oś czasu, właściciele, linki do dashboardów/zapytań, następne kroki
Szkolenie, które naprawdę działa
Przeprowadź dwie 45-minutowe sesje: (1) „Jak tu zapytać” z wspólnymi wzorcami zapytań (wg service, env, region, version), oraz (2) „Playbook rozwiązywania problemów” z prostym flow: potwierdź wpływ → sprawdź markery deployu → zawęź do usługi → przeanalizuj śledzenia → potwierdź zdrowie zależności → zdecyduj rollback/mitigację.
Checklist do kopiowania