Dlaczego Dijkstra wciąż ma znaczenie, gdy oprogramowanie rośnie
Oprogramowanie rzadko zawodzi dlatego, że nie da się go napisać. Zawodzi, ponieważ rok później nikt nie może bezpiecznie go zmienić.
Wraz z rozrostem bazy kodu każda „mała” zmiana zaczyna falować: poprawka błędu psuje odległą funkcjonalność, nowe wymaganie wymusza przepisywanie, a prosty refactor zamienia się w tydzień starannej koordynacji. Trudne nie jest dodawanie kodu — trudne jest utrzymanie przewidywalności zachowania, gdy wszystko wokół się zmienia.
Obietnica: poprawność i prostota obniżają długoterminowe koszty
Edsger Dijkstra twierdził, że poprawność i prostota powinny być celami pierwszorzędnymi, a nie dodatkami. Zysk nie jest akademicki. Gdy system jest łatwiejszy do rozumienia, zespoły spędzają mniej czasu na gaszeniu pożarów, a więcej na budowaniu.
- Poprawność zmniejsza koszt błędów: mniej incydentów, mniej regresji, mniej kodu „nie dotykać”.
- Prostota zmniejsza koszt zmian: mniej ukrytych założeń, mniej wyjątków, mniej niespodzianek podczas przeglądów.
Co tak naprawdę znaczy „skalować”?
Kiedy ludzie mówią, że oprogramowanie musi „skalować”, często mają na myśli wydajność. Punkt widzenia Dijkstry jest inny: rośnie też złożoność.
Skalowanie objawia się jako:
- Więcej funkcji: nowe ścieżki, przypadki brzegowe i oczekiwania użytkowników.
- Więcej osób: przekazy pracy, różne style i rozmaity kontekst.
- Więcej integracji: zewnętrzne API, źródła danych i tryby awarii.
- Więcej czasu: decyzje legacy, zmieniające się wymagania i częściowe przepisywanie.
Sedno: struktura ułatwia przewidywanie zachowania
Programowanie strukturalne nie polega na rygorze dla samego rygoru. Chodzi o wybór przepływu sterowania i dekompozycji, które ułatwiają odpowiedź na dwa pytania:
- „Co dzieje się dalej?”
- „W jakich warunkach?”
Gdy zachowanie jest przewidywalne, zmiana staje się rutyną, a nie ryzykiem. Dlatego Dijkstra ma znaczenie: jego dyscyplina uderza w prawdziwe wąskie gardło rosnącego oprogramowania — w możliwość jego zrozumienia na tyle dobrze, by je ulepszać.
Krótkie wprowadzenie do Edsgera Dijkstry i jego celu
Edsger W. Dijkstra (1930–2002) był holenderskim informatykiem, który ukształtował sposób myślenia programistów o budowaniu niezawodnego oprogramowania. Pracował nad wczesnymi systemami operacyjnymi, wniósł wkład w algorytmy (w tym algorytm najkrótszej ścieżki, który nosi jego nazwisko) i — co najważniejsze dla codziennych programistów — promował ideę, że programowanie powinno być czymś, co potrafimy uzasadnić, a nie tylko czymś, co próbujemy aż „wydaje się działać”.
Jego główny nacisk: rozumowanie zamiast „u mnie działa”
Dijkstra mniej interesował się tym, czy program da się tak skonfigurować, żeby dla kilku przykładów zwracał poprawne wyniki, a bardziej — czy potrafimy wyjaśnić, dlaczego jest poprawny dla istotnych przypadków.
Jeśli potrafisz określić, co fragment kodu ma robić, powinieneś umieć krok po kroku uzasadnić, że naprawdę to robi. Taki sposób myślenia prowadzi naturalnie do kodu łatwiejszego do śledzenia, prostszego do przeglądu i mniej zależnego od heroicznego debugowania.
Dlaczego jego ton może brzmieć surowo — i dlaczego to pomaga
Pisma Dijkstry bywają bezkompromisowe. Krytykował „sprytne” sztuczki, nieporządny przepływ sterowania i nawyki kodowania, które utrudniają rozumowanie. Surowość nie polegała na dbaniu o styl; chodziła o redukcję niejednoznaczności. Gdy znaczenie kodu jest jasne, tracisz mniej czasu na dyskusje o intencjach i więcej na weryfikację zachowania.
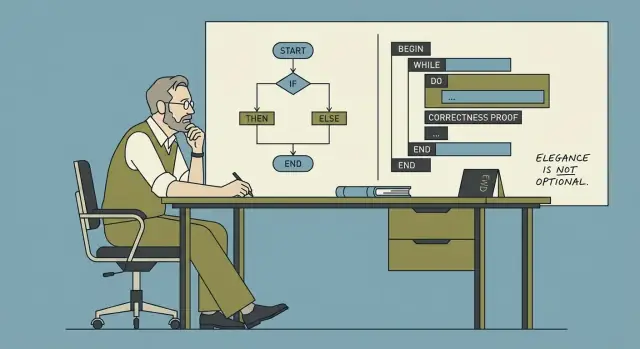
Co znaczy „programowanie strukturalne” (na wysokim poziomie)
Programowanie strukturalne to praktyka budowania programów z niewielkiego zestawu czytelnych struktur sterowania — sekwencja, selekcja (if/else) i iteracja (pętle) — zamiast poplątanych skoków w przepływie. Cel jest prosty: sprawić, by ścieżka przez program była zrozumiała, aby można było ją wyjaśnić, utrzymać i zmieniać z pewnością.
Poprawność: ukryta cecha, na której polegają użytkownicy
Ludzie często opisują jakość oprogramowania jako „szybkie”, „ładne” lub „bogate w funkcje”. Użytkownicy odczuwają poprawność inaczej: jako cichą pewność, że aplikacja ich nie zaskoczy. Gdy poprawność istnieje, nikt tego nie zauważa. Gdy jej brakuje, reszta przestaje się liczyć.
„Działa teraz” kontra „działa dalej”
„Działa teraz” zwykle oznacza, że przetestowano kilka ścieżek i otrzymano oczekiwany rezultat. „Działa dalej” oznacza, że zachowuje zamierzone właściwości w czasie, w przypadkach brzegowych i przy zmianach — po refaktoryzacji, nowych integracjach, większym obciążeniu i po tym, jak nowi członkowie zespołu dotkną kodu.
Funkcja może „działać teraz”, a mimo to być krucha:
- zakłada, że wejście zawsze jest czyste
- zakłada, że wywołanie sieciowe zawsze szybko odpowiada
- przechodzi testy, które pokrywają tylko ścieżkę szczęśliwą
Poprawność polega na usuwaniu tych ukrytych założeń — albo ich jawnej dokumentacji.
Jak małe błędy mnożą się w dużych systemach
Niewielki błąd rzadko pozostaje mały, gdy oprogramowanie rośnie. Jeden niepoprawny stan, jeden błąd o przesunięciu o jeden, czy jedna niejasna reguła obsługi błędów zostaje skopiowana do nowych modułów, opakowana przez inne usługi, cache'owana, powtarzana lub „obejściowana”. Z czasem zespoły przestają pytać „co jest prawdą?” i zaczynają pytać „co zazwyczaj się zdarza?”. Wtedy reagowanie na incydenty zamienia się w archeologię.
Mnożnikiem jest zależność: drobne niewłaściwe zachowanie zamienia się w wiele zachowań po stronie downstream, z własnymi częściowymi naprawami.
Jasność jako narzędzie poprawności (nie tylko wybór stylu)
Czytelny kod poprawia poprawność, bo poprawia komunikację:
- Przeglądy kodu wychwytują prawdziwe problemy, gdy intencja jest oczywista.
- Onboarding jest szybszy, gdy reguły są czytelne, a nie częścią plemiennej wiedzy.
- Incydenty rozwiązują się szybciej, gdy przepływ sterowania i tryby awarii są łatwe do śledzenia.
Praktyczna definicja poprawności dla zespołów produktowych
Poprawność oznacza: dla wejść i sytuacji, które deklarujemy wspierać, system konsekwentnie produkuje wyniki, które obiecujemy — a gdy nie może, zawodzi w przewidywalny, wytłumaczalny sposób.
Prostota jako strategia, nie preferencja stylu
Prostota nie polega na robieniu kodu „uroczym”, minimalnym czy sprytnym. Chodzi o uczynienie zachowania łatwym do przewidzenia, wyjaśnienia i modyfikacji bez obaw. Dijkstra cenił prostotę, ponieważ poprawia ona naszą zdolność do rozumowania o programach — szczególnie gdy baza kodu i zespół rosną.
Czym jest prostota (a czym nie jest)
Prosty kod utrzymuje niewielką liczbę konceptów jednocześnie: jasny przepływ danych, czytelny przepływ sterowania i wyraźne odpowiedzialności. Nie każe czytelnikowi symulować wielu alternatywnych ścieżek w głowie.
Prostota to nie:
- mniej linii za wszelką cenę
- „sprytne” sztuczki, gęste one-linery czy ciężkie abstrakcje
- unikanie struktury, by wyglądać na elastyczny
Przypadkowa złożoność: to, czego nie chciałeś dodać
Wiele systemów staje się trudnych do zmiany nie dlatego, że domena jest złożona, lecz dlatego, że dodajemy przypadkową złożoność: flagi wchodzące ze sobą w interakcje w nieoczekiwany sposób, łatki na specjalne przypadki, które nigdy nie zostają usunięte, warstwy istniejące głównie po to, by obejść wcześniejsze decyzje.
Każdy dodatkowy wyjątek to podatek na zrozumienie. Koszt pojawia się później, gdy ktoś próbuje naprawić błąd i odkrywa, że zmiana w jednym miejscu subtelnie psuje kilka innych.
Proste projekty zmniejszają potrzebę bohaterstwa
Gdy projekt jest prosty, postęp przychodzi dzięki stałej pracy: przeglądy możliwe do zrobienia, mniejsze dify i mniej awaryjnych poprawek. Zespoły nie potrzebują „bohaterskich” programistów, którzy pamiętają każdy historyczny wyjątek lub potrafią debugować pod presją o 2 w nocy. Zamiast tego system wspiera normalne ludzkie zakresy uwagi.
Zasada praktyczna: mniej wyjątków, mniej niespodzianek
Test praktyczny: jeśli ciągle dodajesz wyjątki („chyba że…”, „z wyjątkiem, gdy…”, „tylko dla tego klienta…”), prawdopodobnie kumulujesz przypadkową złożoność. Preferuj rozwiązania redukujące rozgałęzienia w zachowaniu — jedna spójna reguła bije pięć wyjątków, nawet jeśli ta reguła jest nieco bardziej ogólna, niż początkowo myślałeś.
Programowanie strukturalne: czytelny przepływ sterowania, któremu możesz zaufać
Programowanie strukturalne to prosta idea o dużych konsekwencjach: pisz kod tak, żeby ścieżka jego wykonania była łatwa do śledzenia. Mówiąc prosto, większość programów da się zbudować z trzech bloków konstrukcyjnych — sekwencja, selekcja i powtarzanie — bez polegania na poplątanych skokach.
Trzy bloki konstrukcyjne (po ludzku)
- Sekwencja: wykonaj krok A, potem B, potem C.
- Selekcja: wybierz ścieżkę na podstawie warunku (np.
if/else, switch).
- Powtarzanie: powtarzaj zbiór kroków, dopóki warunek jest spełniony (np.
for, while).
Gdy przepływ sterowania jest zbudowany z tych struktur, zwykle możesz wyjaśnić, co program robi, czytając od góry do dołu, bez „teleportowania się” po pliku.
Co to zastąpiło: ścieżki wykonania w stylu spaghetti
Zanim programowanie strukturalne stało się normą, wiele kodów opierało się na dowolnych skokach (klasyczny styl goto). Problem nie polega na tym, że skoki są zawsze złe; chodzi o to, że nieograniczone skoki tworzą ścieżki wykonania trudne do przewidzenia. Kończysz z pytaniami typu „Jak tu trafiliśmy?” i „Jaki jest stan tej zmiennej?” — a kod nie odpowiada jasno.
Dlaczego czytelność ma znaczenie dla rzeczywistych zespołów
Jasny przepływ sterowania pomaga ludziom zbudować poprawny model mentalny. Na tym modelu polegasz podczas debugowania, przeglądu pull requesta czy zmiany zachowania pod presją czasu.
Gdy struktura jest spójna, modyfikacja staje się bezpieczniejsza: możesz zmienić jedną gałąź bez przypadkowego wpływu na inną albo zrefaktoryzować pętlę bez pominięcia ukrytego punktu wyjścia. Czytelność to nie tylko estetyka — to fundament, żeby zmieniać zachowanie z pewnością, nie łamiąc istniejących funkcji.
Narzędzia do rozumowania: inwarianty, preconditions i postconditions
Uczyń strukturę domyślną
Zbuduj małą, uporządkowaną funkcję w Koder.ai i utrzymaj kontrolę nad przepływem wykonania.
Dijkstra proponował prostą ideę: jeśli potrafisz wytłumaczyć, dlaczego kod jest poprawny, możesz zmieniać go z mniejszym lękiem. Trzy małe narzędzia rozumowania czynią to praktyczne — bez zamieniania zespołu w matematyków.
Inwarianty: „fakty, które pozostają prawdziwe”
Inwariant to fakt, który pozostaje prawdziwy podczas działania fragmentu kodu, szczególnie wewnątrz pętli.
Przykład: sumujesz ceny w koszyku. Przydatny inwariant to: „total równa się sumie wszystkich przetworzonych do tej pory pozycji.” Jeśli to stwierdzenie pozostaje prawdziwe na każdym kroku, to po zakończeniu pętli wynik jest godny zaufania.
Inwarianty są silne, bo skupiają uwagę na tym, co nigdy nie może się złamać, a nie tylko na tym, co ma się wydarzyć dalej.
Preconditions i postconditions: codzienne kontrakty
Precondition to to, co musi być prawdą przed uruchomieniem funkcji. Postcondition to to, co funkcja gwarantuje po zakończeniu.
Przykłady z życia:
- Precondition: „Można wypłacić pieniądze tylko wtedy, gdy konto ma wystarczające środki.”
- Postcondition: „Po wypłacie saldo zmniejsza się dokładnie o tę kwotę i nigdy nie staje się ujemne.”
W kodzie precondition może brzmieć: „lista wejściowa jest posortowana”, a postcondition: „lista wyjściowa jest posortowana i zawiera te same elementy plus wstawiony element.”
Jak zapisanie ich zmienia kodowanie i przeglądy
Gdy je zapiszesz (nawet nieformalnie), projekt staje się ostrzejszy: decydujesz, czego funkcja oczekuje i co obiecuje, i naturalnie robisz ją mniejszą i bardziej skoncentrowaną.
W przeglądach przesuwa to dyskusję z stylu („napisałbym to inaczej”) na poprawność („Czy ten kod utrzymuje inwariant?” „Czy egzekwujemy precondition, czy tylko ją dokumentujemy?”).
Lekka praktyka: komentuj miejsca, gdzie kumulują się błędy
Nie potrzebujesz formalnych dowodów, żeby odnieść korzyść. Wybierz najbardziej błędogenną pętlę lub najbardziej zawiłą aktualizację stanu i dodaj jednowierszowy komentarz-inwariant nad nią. Kiedy ktoś później edytuje kod, ten komentarz działa jak bariera: jeśli zmiana łamie to założenie, kod przestaje być bezpieczny.
Testowanie kontra rozumowanie: co każde może (i czego nie może) zagwarantować
Testowanie i rozumowanie dążą do tego samego rezultatu — oprogramowania zachowującego się zgodnie z zamierzeniem — ale robią to inaczej. Testy odkrywają problemy przez próbowanie przykładów. Rozumowanie zapobiega całym kategoriom problemów, czyniąc logikę jawną i sprawdzalną.
Co testy robią dobrze
Testy to praktyczna siatka bezpieczeństwa. Wyłapują regresje, weryfikują scenariusze zbliżone do rzeczywistych i dokumentują oczekiwane zachowanie tak, żeby cały zespół mógł je uruchomić.
Ale testy mogą wykazać jedynie obecność błędów, nie ich brak. Żaden zestaw testów nie pokryje każdego wejścia, każdej wariancji czasowej ani każdej interakcji między funkcjami. Wiele błędów „u mnie działa” bierze się z nieprzetestowanych kombinacji: rzadkie wejście, specyficzna kolejność operacji lub subtelny stan pojawiający się po kilku krokach.
Co rozumowanie może zagwarantować (i czego nie)
Rozumowanie polega na dowodzeniu własności kodu: „ta pętla zawsze się kończy”, „ta zmienna nigdy nie jest ujemna”, „ta funkcja nigdy nie zwraca nieprawidłowego obiektu”. Przy dobrym zastosowaniu eliminuje całe klasy defektów — szczególnie dotyczące granic i przypadków brzegowych.
Ograniczeniem jest wysiłek i zakres. Pełne, formalne dowody dla całego produktu rzadko są opłacalne. Rozumowanie działa najlepiej selektywnie: nad kluczowymi algorytmami, przepływami wrażliwymi na bezpieczeństwo, logiką finansową i współbieżnością.
Zrównoważone podejście, które skaluje
Używaj testów szeroko i stosuj głębsze rozumowanie tam, gdzie awaria jest kosztowna.
Praktycznym mostem między nimi jest uczynienie intencji wykonalną:
- Asercje dla wewnętrznych założeń (np. „indeks mieści się w zakresie”).
- Preconditions i postconditions (kontrakty) dla wejść/wyjść funkcji.
- Inwarianty dla trwałych prawd (np. „suma koszyka równa się sumie pozycji”).
Te techniki nie zastępują testów — wzmacniają siatkę. Zamieniają niejasne oczekiwania w sprawdzalne reguły, co utrudnia pisanie błędów i ułatwia ich diagnozę.
Dyscyplina: jak zespoły unikają „długu sprytu”
„Sprytny” kod często wydaje się zwycięski w danej chwili: mniej linii, sprytna sztuczka, one-liner, który sprawia, że czujesz się mądrze. Problem w tym, że spryt nie skaluje w czasie ani między ludźmi. Po sześciu miesiącach autor zapomina sztuczkę. Nowy członek zespołu czyta kod dosłownie, nie dostrzega ukrytego założenia i zmienia go tak, że psuje zachowanie. To „dług sprytu”: krótkoterminowa szybkość kupiona kosztem długoterminowego zamieszania.
Dyscyplina przyspiesza zespół
Punkt Dijkstry nie brzmiał „pisz nudny kod” jako preferencja stylu — chodziło o to, że zdyscyplinowane ograniczenia ułatwiają rozumowanie o programach. W zespole ograniczenia też zmniejszają zmęczenie decyzyjne. Jeśli wszyscy znają domyśły (jak nazywać rzeczy, jak strukturyzować funkcje, co oznacza „done”), przestajecie w każdej prośbie o pull request ponownie rozstrzygać podstawy. Ten czas wraca do pracy produktowej.
Dyscyplina przejawia się w rutynowych praktykach:
- Przeglądy kodu nagradzające czytelność ponad nowość („Czy ktoś inny może to bezpiecznie zmienić?”).
- Wspólne standardy (formatowanie, nazewnictwo, obsługa błędów), aby baza kodu czytała się jednym głosem.
- Refaktoryzacja jako utrzymanie, nie misja ratunkowa — małe poprawki robione regularnie.
Jak wygląda „zdyscyplinowany” kod
Kilka konkretnych nawyków zapobiega kumulowaniu długu sprytu:
- Małe funkcje robiące jedną rzecz, z oczywistymi wejściami i wyjściami.
- Jasne nazwy tłumaczące intencję (wolę
calculate_total() niż do_it()).
- Brak ukrytego stanu: minimalizuj globalne zmienne i zaskakujące efekty uboczne; przekazuj zależności jawnie.
- Prosty przepływ sterowania: unikaj logiki zależnej od subtelnego porządku, magicznych wartości czy „działa, jeśli znasz trik”.
Dyscyplina to nie perfekcja — to sprawianie, że następna zmiana jest przewidywalna.
Modułowość i granice: utrzymywanie zmian lokalnymi
Zbuduj zdyscyplinowaną wersję startową
Wybierz web, serwer lub Flutter mobile i zbuduj pierwszą zdyscyplinowaną wersję przez chat.
Modułowość to nie tylko „dzielenie kodu na pliki”. To izolowanie decyzji za czytelnymi granicami, tak aby reszta systemu nie musiała znać (ani przejmować się) szczegółami wewnętrznymi. Moduł ukrywa zawiłości — struktury danych, przypadki brzegowe, tricki wydajnościowe — i udostępnia małą, stabilną powierzchnię.
Jak moduły zmniejszają promień rażenia zmian
Gdy przychodzi żądanie zmiany, idealnym rezultatem jest: zmienia się jeden moduł, a reszta pozostaje nienaruszona. To praktyczne znaczenie „utrzymywania zmiany lokalnej”. Granice zapobiegają przypadkowemu sprzężeniu — kiedy aktualizacja jednej funkcji cicho psuje trzy inne, bo latami korzystały z tych samych założeń.
Dobra granica ułatwia też rozumowanie. Jeśli potrafisz powiedzieć, co moduł gwarantuje, możesz rozumować o większym programie bez czytania całej jego implementacji za każdym razem.
Interfejsy jako obietnice (i jak umożliwiają równoległą pracę)
Interfejs to obietnica: „Dając takie wejścia, zwrócę takie wyjścia i utrzymam te reguły.” Gdy ta obietnica jest klarowna, zespoły mogą pracować równolegle:
- jedna osoba implementuje moduł
- inna buduje wywołujący go kod według interfejsu
- QA projektuje testy wokół obiecanego zachowania
To nie biurokracja — to tworzenie bezpiecznych punktów koordynacji w rosnącej bazie kodu.
Proste kontrole modułów, które zapobiegają dryfowi
Nie potrzebujesz wielkiej rewizji architektury, żeby poprawić modułowość. Wypróbuj te lekkie kontrole:
- Wejścia/wyjścia: Czy potrafisz wypisać wejścia, wyjścia i skutki uboczne modułu w kilku linijkach? Jeśli nie, prawdopodobnie robi za dużo.
- Własność: Kto odpowiada za jego zachowanie i zmiany? Moduły bez właściciela stają się składowiskiem.
- Zależności: Czy zależy od „wszystkiego”, czy tylko od tego, czego naprawdę potrzebuje? Mniej zależności to mniej niespodzianek.
Dobre granice zamieniają „zmianę” z wydarzenia obejmującego cały system w lokalną edycję.
Dlaczego te idee wygrywają w skali (zespoły, bazy kodu i czas)
Gdy oprogramowanie jest małe, możesz „mieć wszystko w głowie”. W skali to przestaje być prawdą — i pojawiają się znane tryby awarii.
Typowe objawy wyglądają tak:
- awarie sięgające jednego zaskakującego przypadku brzegowego
- wydania zwalniają, bo każda zmiana wydaje się ryzykowna
- kruche integracje, gdzie drobna aktualizacja psuje trzy systemy downstream
Struktura zmniejsza obciążenie poznawcze
Główne założenie Dijkstry było takie, że ludzie są wąskim gardłem. Jasny przepływ sterowania, małe zdefiniowane jednostki i kod, który można rozumieć, to nie wybory estetyczne — to mnożniki zdolności.
W dużej bazie kodu struktura działa jak kompresja dla zrozumienia. Jeśli funkcje mają jawne wejścia/wyjścia, moduły mają nazwane granice, a „scenariusz szczęśliwy” nie jest splątany ze wszystkimi przypadkami brzegowymi, deweloperzy spędzają mniej czasu na rekonstruowaniu intencji i więcej na świadomych zmianach.
To skaluje się z zespołami, nie tylko z kodem
Wraz ze wzrostem liczby osób koszty komunikacji rosną szybciej niż liczba linii. Zdyscyplinowany, czytelny kod zmniejsza ilość plemiennej wiedzy potrzebnej do bezpiecznego uczestnictwa.
W praktyce widać to od razu w onboardingu: nowi inżynierowie mogą podążać za przewidywalnymi wzorcami, nauczyć się niewielkiego zestawu konwencji i wprowadzać zmiany bez długiego przeglądu „pułapek”. Kod sam uczy systemu.
Incydenty są prostsze do debugowania — i bezpieczniejsze do wycofania
Podczas incydentu czasu jest mało, a pewność krucha. Kod napisany z jawnymi założeniami (preconditions), sensownymi sprawdzeniami i prostym przepływem sterowania łatwiej prześledzić pod presją.
Co równie ważne, zdyscyplinowane zmiany łatwiej cofnąć. Mniejsze, lokalne edycje z klarownymi granicami zmniejszają szansę, że rollback wywoła nowe awarie. Efekt nie jest perfekcją — to mniej niespodzianek, szybsze odzyskiwanie i system, który pozostaje utrzymywalny w miarę upływu lat i przyrostu współautorów.
Zastosowanie idei Dijkstry bez dogmatyzmu
Dodaj invariants jako zabezpieczenia
Poproś Koder.ai o invariants i preconditions wokół najtrudniejszej pętli lub aktualizacji stanu.
Punkt Dijkstry nie brzmiał „pisz kod po staremu”. Brzmiał: „pisz kod, który potrafisz wyjaśnić.” Możesz przyjąć to podejście bez zamieniania każdej funkcji w formalny dowód.
Zmień zasady w codzienne nawyki
Zacznij od wyborów, które czynią rozumowanie tanim:
- preferuj prosty przepływ sterowania: kilka małych funkcji zamiast jednej wielogałęziowej rutyny
- ogranicz efekty uboczne: mutacje trzymaj blisko miejsca ich potrzeby i nie pozwalaj funkcjom cicho zmieniać stanu globalnego
- stosuj jasne kontrakty: określ wejścia, wyjścia i zachowanie błędów (w typach, nazwach i komentarzach)
Dobry heurystyk: jeśli nie potrafisz streścić, co funkcja gwarantuje, w jednym zdaniu, prawdopodobnie robi za dużo.
Małe „ulepszenia struktury” (bez przepełnych rewrites)
Nie potrzebujesz wielkiego sprintu refaktoryzacyjnego. Wprowadzaj strukturę na styku komponentów:
- wydziel złożoną pętlę do nazwanej funkcji i określ, co pozostaje prawdą przy każdej iteracji
- zamień „magiczne” warunki na dobrze nazwane predykaty (np.
isEligibleForRefund)
- enkapsuluj trudną zmianę stanu za jedną funkcją, żeby reszta kodu nie mogła jej błędnie używać
Te ulepszenia są inkrementalne: zmniejszają obciążenie poznawcze dla następnej zmiany.
Pytania do przeglądu kodu, które trzymają cię w ryzach
Przy przeglądzie (lub pisząc zmianę) zapytaj:
- „Co tu musi być prawdą?” (inwarianty, założenia, wymagany stan)
- „Co może się bezpiecznie zmieniać?” (które części mogą się różnić bez łamania wywołujących)
Jeśli recenzenci nie potrafią szybko odpowiedzieć, kod sygnalizuje ukryte zależności.
Dokumentuj rozumowanie, nie tylko kroki
Komentarze, które powtarzają kod, szybko się starzeją. Zamiast tego zapisz dlaczego kod jest poprawny: kluczowe założenia, przypadki brzegowe, które chronisz, i co się złamie, gdy owe założenia przestaną być prawdziwe. Krótka notatka typu „Inwariant: total zawsze równa się sumie przetworzonych elementów” może być cenniejsza niż akapit narracji.
Jeśli chcesz lekkiego miejsca na zbieranie takich nawyków, zgromadź je w wspólnym checkliście (zobacz /blog/practical-checklist-for-disciplined-code).
Gdzie mieści się budowanie wspomagane AI (bez utraty dyscypliny)
Współczesne zespoły coraz częściej używają AI, by przyspieszyć dostarczanie. Ryzyko jest znane: szybkość dziś może zamienić się w zamęt jutro, jeśli wygenerowany kod będzie trudny do wyjaśnienia.
Dijkstra-przyjazny sposób używania AI to traktować je jako akcelerator strukturalnego myślenia, a nie jego zastępstwo. Na przykład, budując w Koder.ai — platformie vibe-coding, gdzie tworzysz aplikacje web, backend i mobilne przez chat — możesz utrzymać nawyki „rozumowania najpierw” przez jawne zapytania i kroki przeglądu:
- proś o jasne kontrakty: „Zdefiniuj preconditions, postconditions i zachowanie błędów dla tego endpointu.”
- proś o inwarianty w przepływach stanowych: „Co musi być prawdą po każdym kroku maszyny stanów checkout?”
- używaj trybu planowania, by rozbić zadanie na małe, możliwe do przeglądu kawałki (moduły, interfejsy, odpowiedzialności) zanim wygenerujesz implementację
- polegaj na snapshotach i rollbackach, by utrzymać zmiany małymi i odwracalnymi — to odzwierciedlenie zasad lokalnych zmian i bezpiecznego cofania
Nawet jeśli ostatecznie eksportujesz kod i uruchamiasz go gdzie indziej, ta sama zasada obowiązuje: wygenerowany kod powinien być kodem, który potrafisz wyjaśnić.
Lekki checklist dla poprawnego, prostego i zdyscyplinowanego kodu
To lekki „Dijkstra-przyjazny” checklist, którego możesz używać podczas przeglądów, refaktorów lub przed mergem. Nie chodzi o codzienne pisanie dowodów — chodzi o uczynienie poprawności i jasności wartością domyślną.
Szybki self-check (nowy kod i refaktory)
- Czy potrafię wyjaśnić kod koledze w 60 sekund? Jeśli wyjaśnienie wymaga „zaufaj mi”, uprość.
- Czy przepływ sterowania jest oczywisty? Preferuj kod liniowy; trzymaj pętle i warunki małe; unikaj ukrytych punktów wyjścia i głębokich zagnieżdżeń.
- Jakie są preconditions i postconditions? Zapisz je w komentarzu, docstringu lub nazwie funkcji. Jeśli nie potrafisz ich podać, funkcja prawdopodobnie robi za dużo.
- Czy każda funkcja robi jedną rzecz i ma jasne granice? Wejścia do środka, wyjścia na zewnątrz — minimalne poleganie na stanie globalnym.
- Jaki inwariant utrzymuje tę pętlę w ryzach? Nawet jednowierszowy komentarz typu „
total zawsze równa się sumie przetworzonych elementów” zapobiega subtelnym błędom.
- Czy jest mniej „sprytnych” sztuczek niż potrzeba? Jeśli kod potrzebuje przewodnika, akumuluje dług sprytu.
Co mierzyć jakościowo
- Łatwość wyjaśnienia: Czy ktoś nieznający modułu potrafi powiedzieć, co robi i dlaczego jest poprawny?
- Łatwość testowania: Czy przypadki brzegowe są naturalnie testowalne, czy wymagają skomplikowanego setupu i mocków?
- Ryzyko zmiany: Gdy wymagania się zmieniają, czy potrafisz przewidzieć, co się zepsuje? Jeśli każda zmiana budzi strach, granice przeciekają.
Praktyczny następny krok
Wybierz jeden zagracony moduł i najpierw uporządkuj przepływ sterowania:
- wydziel małe funkcje z jasnymi nazwami;
- zamień poplątane gałęzie prostszymi, jawnie opisanymi przypadkami;
- przenieś wyjątki na krawędzie (walidacja wejścia, wczesne zwroty).
Następnie dodaj kilka skoncentrowanych testów wokół nowych granic. Jeśli chcesz więcej wzorców jak ten, zobacz powiązane wpisy na /blog.