Dlaczego Docker jest tak pomocny przy wdrożeniach w chmurze
Większość problemów z wdrożeniami w chmurze zaczyna się od dobrze znanej niespodzianki: aplikacja działa na laptopie, a potem zawodzi po uruchomieniu na serwerze w chmurze. Może na serwerze jest inna wersja Pythona lub Node, brakuje biblioteki systemowej, plik konfiguracyjny jest nieco inny albo jakiś proces w tle nie działa. Te drobne różnice się kumulują i zespoły kończą debugując środowisko zamiast poprawiać produkt.
Docker w prostych słowach
Docker pomaga, pakując aplikację razem z runtime i zależnościami potrzebnymi do uruchomienia. Zamiast wysyłać listę kroków typu „zainstaluj wersję X, potem dodaj bibliotekę Y, ustaw tę konfigurację”, wysyłasz obraz kontenera, który już zawiera te elementy.
Przydatny model mentalny to:
- Obraz = zapakowana aplikacja (snapshot ze wszystkim, czego potrzeba do uruchomienia)
- Kontener = uruchomiona instancja tego obrazu
Gdy uruchamiasz ten sam obraz w chmurze, który testowałeś lokalnie, dramatycznie zmniejszasz problemy typu „ale mój serwer jest inny”.
Kto na tym zyskuje (podpowiedź: to nie tylko deweloperzy)
Docker pomaga różnym rolom z różnych powodów:
- Deweloperzy otrzymują przewidywalne środowisko i szybsze wdrożenie do pracy („uruchom ten kontener” zamiast wielostronicowej instrukcji).
- Zespoły operacyjne i platformowe zyskują bardziej spójne wdrożenia i wyraźniejsze granice między aplikacjami a serwerami.
- Małe zespoły mają powtarzalną drogę do produkcji bez tworzenia niestandardowych skryptów wdrożeniowych dla każdego projektu.
- Enterprise’y zyskują standaryzację: ten sam format pakowania w wielu zespołach i usługach.
Realistyczne oczekiwania
Docker jest niezwykle pomocny, ale nie jest jedynym narzędziem, którego będziesz potrzebować. Nadal trzeba zarządzać konfiguracją, sekretami, przechowywaniem danych, siecią, monitoringiem i skalowaniem. Dla wielu zespołów Docker jest elementem budulcowym, który współpracuje z narzędziami takimi jak Docker Compose dla lokalnych przepływów pracy i platformami orkiestrującymi w produkcji.
Myśl o Dockerze jak o kontenerze transportowym dla Twojej aplikacji: sprawia, że dostawa jest przewidywalna. To, co dzieje się w porcie (konfiguracja chmury i runtime), nadal ma znaczenie — ale staje się dużo łatwiejsze, gdy każda wysyłka jest zapakowana w ten sam sposób.
Podstawy Dockera: kontenery, obrazy i rejestry
Docker może się wydawać zbiorem nowych terminów, ale główna idea jest prosta: zapakuj aplikację tak, aby działała tak samo wszędzie.
Kontener kontra maszyna wirtualna (VM)
Maszyna wirtualna pakuje pełny system gościa plus Twoją aplikację. To daje elastyczność, ale jest cięższe w uruchamianiu i wolniej się startuje.
Kontener pakuje aplikację i jej zależności, ale dzieli kernel systemu hosta zamiast dostarczać cały system operacyjny. Dzięki temu kontenery są zwykle lżejsze, startują w kilka sekund i możesz uruchomić ich więcej na tym samym serwerze.
Kluczowe terminy, które zobaczysz wszędzie
Obraz: szablon tylko do odczytu Twojej aplikacji. Wyobraź sobie go jako pakowany artefakt zawierający kod, runtime, biblioteki systemowe i domyślne ustawienia.
Kontener: uruchomiona instancja obrazu. Jeśli obraz jest planem, kontener to dom, w którym aktualnie mieszkasz.
Dockerfile: instrukcje krok po kroku, które Docker używa do zbudowania obrazu (instalacja zależności, kopiowanie plików, ustawienie komendy startowej).
Rejestr: usługa przechowywania i dystrybucji obrazów. „Pushujesz” obrazy do rejestru i „pullujesz” je później na serwery (rejestry publiczne lub prywatne w firmie).
Dlaczego standaryzacja ma znaczenie
Gdy Twoja aplikacja jest zdefiniowana jako obraz zbudowany z Dockerfile, zyskujesz ujednoliconą jednostkę dostawy. Ta standaryzacja sprawia, że wydania są powtarzalne: ten sam obraz, który testowałeś, jest tym, który wdrażasz.
Uproszcza to też przekazy między zespołami. Zamiast „u mnie działa”, możesz wskazać konkretną wersję obrazu w rejestrze i powiedzieć: uruchom ten kontener z tymi zmiennymi środowiskowymi na tym porcie. To podstawa spójnych środowisk deweloperskich i produkcyjnych.
Spójność od laptopa do chmury: główna korzyść
Najważniejszy powód, dla którego Docker ma znaczenie w wdrożeniach chmurowych, to spójność. Zamiast polegać na tym, co jest zainstalowane na laptopie, runnerze CI czy VM w chmurze, definiujesz środowisko raz (w Dockerfile) i używasz go we wszystkich etapach.
Co „spójność” oznacza w praktyce
W praktyce spójność przejawia się jako:
- Te same wersje runtime w dev, test i produkcji (np. ta sama wersja Node/Python/JVM i pakiety OS)
- Mniej problemów z dryfem zależności (biblioteki, pakiety systemowe)
- Łatwiejsze przywracanie przez wdrożenie poprzedniego tagu obrazu
- Czytelniejsze debugowanie, bo środowiska się zgadzają
Ta spójność szybko się opłaca. Błąd, który pojawia się w produkcji, można odtworzyć lokalnie, uruchamiając ten sam tag obrazu. Wdrożenie, które zawiodło z powodu brakującej biblioteki, staje się mało prawdopodobne, bo biblioteka byłaby również brakująca w Twoim kontenerze testowym.
Dlaczego to różni się od „po prostu zainstaluj to samo”
Zespoły często próbują standaryzować przez dokumenty instalacyjne lub skrypty konfiguracyjne. Problem to dryf: maszyny zmieniają się z czasem w wyniku poprawek i aktualizacji pakietów, a różnice narastają.
Z Dockerem środowisko jest traktowane jak artefakt. Jeśli trzeba je zaktualizować, przebudowujesz nowy obraz i go wdrażasz — zmiany są jawne i poddane przeglądowi. Jeśli aktualizacja powoduje problemy, rollback jest często prosty: wdrożenie poprzedniego, znanego dobrego tagu.
Przenośność między chmurami i serwerami
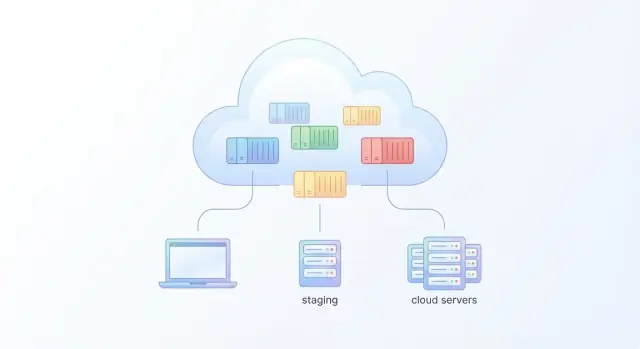
Drugie duże zwycięstwo Dockera to przenośność. Obraz kontenera zamienia Twoją aplikację w przenośny artefakt: zbuduj raz, uruchom wszędzie tam, gdzie działa kompatybilne środowisko kontenerowe.
Ten sam obraz, różne miejsca docelowe
Obraz Docker pakuje kod aplikacji oraz jej zależności runtime (np. Node.js, pakiety Pythona, biblioteki systemowe). Oznacza to, że obraz uruchomiony na laptopie może też działać na:
- VM w AWS, Azure lub Google Cloud
- Twoich własnych serwerach w centrum danych
- Zarządzanych platformach kontenerowych (np. usługi oparte na Kubernetes)
To zmniejsza vendor lock-in na poziomie runtime aplikacji. Nadal możesz korzystać z usług chmurowych (bazy danych, kolejki, storage), ale rdzeń aplikacji nie musi być przebudowywany tylko dlatego, że zmieniłeś dostawcę hostingu.
Gdzie pasują rejestry
Przenośność działa najlepiej, gdy obrazy są przechowywane i wersjonowane w rejestrze — publicznym lub prywatnym. Typowy przepływ wygląda tak:
- Zbuduj obraz raz (np.
myapp:1.4.2).
- Wypchnij go do rejestru.
- Pociągnij i uruchom ten dokładny obraz w każdym środowisku.
Rejestry ułatwiają też odtwarzalność i audyt wdrożeń: jeśli w produkcji działa 1.4.2, możesz później pobrać ten sam artefakt i otrzymać identyczne bity.
Scenariusze praktyczne
Migracja hostów: jeśli przenosisz się do innego dostawcy VM, nie reinstalujesz całego stosu. Wskazujesz nowy serwer na rejestr, pobierasz obraz i uruchamiasz kontener z tą samą konfiguracją.
Skalowanie: potrzebujesz więcej zasobów? Uruchom dodatkowe kontenery z tego samego obrazu na kolejnych serwerach. Ponieważ każda instancja jest identyczna, skalowanie staje się operacją powtarzalną, a nie ręczną konfiguracją.
Budowanie obrazów małych, powtarzalnych i łatwych w utrzymaniu
Dobry obraz Docker to nie tylko „coś, co działa”. To pakowany, wersjonowany artefakt, który możesz później odbudować i ufać mu. To właśnie sprawia, że wdrożenia w chmurze są przewidywalne.
Dockerfile: Twoja recepta budowania
Plik Dockerfile opisuje krok po kroku, jak złożyć obraz aplikacji — jak przepis z dokładnymi składnikami i instrukcjami. Każda linia tworzy warstwę i razem definiują:
- punkt wyjścia (base image)
- jakie zależności zainstalować
- jak skopiować kod
- jaka komenda uruchamia aplikację
Utrzymanie tego pliku w czytelnej i świadomej formie ułatwia debugowanie, przegląd i utrzymanie obrazu.
Najlepsze praktyki, które utrzymują obrazy lekkimi i powtarzalnymi
Małe obrazy szybciej się pobierają, szybciej startują i mają mniej „rzeczy”, które mogą się zepsuć lub zawierać luki.
- Wybierz mały base image (np.
alpine lub warianty slim), gdy pasuje do Twojej aplikacji.
- Przypinaj wersje dla obrazów bazowych i kluczowych pakietów. „Pływające” wersje mogą się zmieniać i dawać różne buildy.
- Minimalizuj warstwy i pliki: łącz powiązane komendy i sprzątaj cache instalatora, aby nie wysyłać tymczasowych artefaktów builda.
Multi-stage builds: buduj duże, wysyłaj małe
Wiele aplikacji potrzebuje kompilatorów i narzędzi do budowy, ale nie potrzebuje ich do uruchomienia. Multi-stage builds pozwalają użyć jednej fazy do budowy, a drugiej, minimalnej fazy do produkcji.
# build stage
FROM node:20 AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
# runtime stage
FROM nginx:1.27-alpine
COPY --from=build /app/dist /usr/share/nginx/html
W efekcie otrzymujesz mniejszy obraz produkcyjny z mniejszą liczbą zależności do łatania.
Strategia tagowania: spraw, by wdrożenia były śledzalne
Tagi identyfikują dokładnie to, co wdrożyłeś.
- Unikaj polegania na
latest w produkcji; jest niejednoznaczny.
- Używaj wersji semantycznych (np.
1.4.2) dla wydań.
- Dodaj tag z SHA commit (np.
1.4.2-<sha> lub po prostu <sha>), aby zawsze móc odtworzyć kod, który wygenerował obraz.
To wspiera czyste rollbacky i jasne audyty, gdy coś się zmieni w chmurze.
Uruchamianie rzeczywistych aplikacji: sieć, konfiguracja i dane
Przejdź od budowy do wdrożenia
Wdróż swoją aplikację z Koder.ai, gdy chcesz szybką ścieżkę do działającego środowiska.
„Prawdziwa” aplikacja chmurowa zwykle nie jest jednym procesem. To mały system: frontend webowy, API, może worker w tle i baza danych lub cache. Docker wspiera zarówno proste, jak i wielousługowe zestawy — trzeba tylko rozumieć, jak kontenery się komunikują, gdzie przechowywana jest konfiguracja i jak dane przetrwają restarty.
Aplikacje jedno-kontenerowe kontra wielousługowe
Aplikacja jedno-kontenerowa może być statyczną stroną lub prostym API, które nie zależy od niczego innego. Eksponujesz jeden port (np. 8080) i uruchamiasz ją.
Wielousługowe aplikacje są częstsze: web zależy od api, api od db, a worker konsumuje zadania z kolejki. Zamiast hardkodować adresy IP, kontenery zwykle komunikują się po nazwie usługi w wspólnej sieci (np. db:5432).
Docker Compose dla dev i stagingu
Docker Compose to praktyczny wybór do lokalnego developmentu i stagingu, bo pozwala uruchomić cały stack jednym poleceniem. Dokumentuje też „kształt” aplikacji (usługi, porty, zależności) w pliku, którym cały zespół może się dzielić.
Typowy przebieg to:
- Compose lokalnie (szybki feedback)
- Compose na VM stagingowym (bliżej produkcji)
- Runtime chmurowy/orkiestrator w produkcji
Konfiguracja: co powinno zostać poza obrazem
Obrazy powinny być wielokrotnego użytku i bezpieczne do dzielenia się. Trzymaj poza obrazem ustawienia zależne od środowiska:
- Sekrety (klucze API, hasła do DB)
- URL-e różne między staging a produkcją
- Flagi funkcji
Przekazuj je przez zmienne środowiskowe, plik .env (uwaga: nie commituj go) lub menedżera sekretów chmury.
Trwałe dane z wolumenami
Kontenery są wymienialne; Twoje dane nie powinny być. Używaj wolumenów dla tego, co musi przetrwać restart:
- Bazy danych (Postgres, MySQL)
- Przesłane pliki użytkowników
- Wygenerowane pliki, których nie da się łatwo odtworzyć
W wdrożeniach chmurowych odpowiednikiem są zarządzane magazyny (managed DB, dyski sieciowe, object storage). Kluczowa idea: kontenery uruchamiają aplikację; trwałe przechowywanie przechowuje stan.
Przepływy wdrożeniowe: od builda do uruchomienia w chmurze
Zdrowy workflow z Dockerem jest celowo prosty: zbuduj obraz raz, a następnie uruchom ten sam obraz wszędzie. Zamiast kopiować pliki na serwery czy ponownie uruchamiać instalatory, zamieniasz wdrożenie na powtarzalną rutynę: pull image, run container.
Podstawowy przepływ: build → push → run
Większość zespołów stosuje pipeline podobny do tego:
- Zbuduj wersjonowany obraz (np.
myapp:1.8.3).
- Wypchnij go do rejestru (Docker Hub, rejestr chmury lub prywatny).
- Wdróż, pobierając ten obraz w środowisku chmurowym i uruchamiając kontenery.
To ostatnie sprawia, że Docker staje się „nudny” w dobrym sensie:
docker build -t registry.example.com/myapp:1.8.3 .
docker push registry.example.com/myapp:1.8.3
docker pull registry.example.com/myapp:1.8.3
docker run -d --name myapp -p 80:8080 registry.example.com/myapp:1.8.3
Typowe wzorce w chmurze
Dwa popularne sposoby uruchamiania aplikacji Docker w chmurze:
- VM + Docker: zarządzasz maszyną wirtualną, instalujesz Dockera i uruchamiasz kontenery samodzielnie. Proste i dobre dla mniejszych setupów.
- Zarządzane usługi kontenerowe: dostawca chmury zarządza hostami kontenerowymi za Ciebie. Nadal wdrażasz ten sam obraz, ale skalowanie, restarty i sieć są bardziej zautomatyzowane.
Podstawy zerowej przerwy podczas wdrożeń
Aby zredukować przestoje podczas wydań, produkcyjne wdrożenia zwykle dodają trzy elementy:
- Health checki, które potwierdzają, że kontener jest faktycznie gotowy (nie tylko „uruchomiony”).
- Rolling updates, które zastępują kontenery stopniowo, a nie wszystkie naraz.
- Load balancery, które kierują ruch tylko do zdrowych kontenerów i rozkładają obciążenie.
Rejestr to coś więcej niż magazyn — to sposób utrzymania spójności środowisk. Częstą praktyką jest promowanie tego samego obrazu z dev → staging → prod (często przez re-tag), zamiast przebudowywać go za każdym razem. Dzięki temu produkcja uruchamia dokładnie ten artefakt, który już testowałeś, co ogranicza niespodzianki "działało na stagingu".
CI/CD z Dockerem: szybsze, czyściejsze wydania
Ucz się przez budowanie
Iteruj nad usługami, konfiguracjami i ustawieniami Dockera za pomocą prowadzonego przepływu czatu.
CI/CD to taśma montażowa do wypuszczania oprogramowania. Docker sprawia, że ta taśma jest bardziej przewidywalna, bo każdy etap działa w znanym środowisku.
Gdzie Docker pasuje w pipeline
Przyjazny Dockerowi pipeline zwykle ma trzy etapy:
- Build: utwórz wersjonowany obraz Docker z kodu (np.
myapp:1.8.3).
- Test: uruchom automatyczne testy w kontenerach, aby narzędzia i zależności odpowiadały temu, co uruchomisz później.
- Publish: wypchnij obraz do rejestru (prywatnego lub publicznego), aby inne środowiska mogły pobrać identyczny artefakt.
Ten przepływ jest też łatwy do wytłumaczenia osobom nietechnicznym: „Budujemy jedne zapieczętowane pudełko, testujemy pudełko, a potem wysyłamy to samo pudełko do każdego środowiska.”
Testowanie w kontenerach (aby produkcja nie była niespodzianką)
Testy często przechodzą lokalnie, a zawodzą w produkcji z powodu niespójnych runtime’ów, brakujących bibliotek systemowych lub różnych zmiennych środowiskowych. Uruchamianie testów w kontenerze zmniejsza te luki. Twój runner CI nie potrzebuje specjalnie dopasowanej maszyny — wystarczy Docker.
Docker wspiera zasadę „promuj, nie przebudowuj”. Zamiast przebudowy dla każdego środowiska:
- Zbuduj i przetestuj
myapp:1.8.3 raz.
- Wdróż ten sam obraz na dev.
- Jeśli wszystko jest OK, wdroż go na staging.
- Na koniec wdroż go na produkcję.
Tylko konfiguracja zmienia się między środowiskami (URL-e, credentials), nie artefakt aplikacji. To zmniejsza niepewność dnia wydania i upraszcza rollbacky: wdrażasz poprzedni tag obrazu.
Gdzie Koder.ai może pomóc
Jeśli działasz szybko i chcesz korzyści Dockera bez spędzania dni na przygotowaniu szkieletu, Koder.ai może pomóc wygenerować aplikację przygotowaną na produkcję z przepływu czatowego i konteneryzować ją w czytelny sposób.
Na przykład zespoły często używają Koder.ai, aby:
- stworzyć frontend w React i backend w Go z PostgreSQL,
- dodać Dockerfile i
docker-compose.yml wcześnie (aby zachować zgodność dev i prod),
- wyeksportować pełne źródło i podłączyć je do standardowego pipeline build → push → run,
- używać snapshotów i rollbacków podczas iteracji, żeby zmiany wdrożeniowe były kontrolowane.
Kluczowa korzyść jest taka, że Docker pozostaje prymitywem wdrożeniowym, a Koder.ai przyspiesza drogę od pomysłu do kodu gotowego do konteneryzacji.
Skalowanie poza jeden serwer: Docker i orkiestracja
Docker ułatwia pakowanie i uruchamianie usługi na jednej maszynie. Ale gdy masz wiele usług, wiele kopii każdej usługi i wiele serwerów, potrzebujesz systemu do koordynacji. To jest orkiestracja: oprogramowanie, które decyduje, gdzie uruchamiać kontenery, dba o ich zdrowie i dostosowuje pojemność w zależności od obciążenia.
Dlaczego orkiestracja ma znaczenie przy wielu kontenerach
Przy kilku kontenerach można je ręcznie uruchamiać i restartować. Przy większej skali to się nie sprawdza szybko:
- Serwer może paść, zabierając ze sobą kilka kontenerów.
- Potrzebujesz 2, 10 lub 100 kopii usługi web w zależności od ruchu.
- Aktualizacje muszą być wdrażane bez przerywania działania aplikacji.
- Usługi potrzebują spójnego sposobu odnajdowania się (service discovery) i współdzielenia konfiguracji.
Kubernetes, wytłumaczony bez ciężkiego żargonu
Kubernetes (często „K8s”) to najpopularniejszy orkiestrator. Prosty model mentalny:
- Nodes: maszyny (VM lub serwery), które uruchamiają kontenery.
- Pods: najmniejsza jednostka, którą Kubernetes uruchamia (zwykle jeden kontener, czasem kilka, które muszą być razem).
- Deployments: „uruchom N kopii tego poda i utrzymaj to”, w tym rolling updates.
- Services: stabilna sieć, aby inne części aplikacji mogły pewnie trafić do tych podów.
Jak obrazy Docker wpisują się w Kubernetes
Kubernetes nie buduje kontenerów; on je uruchamia. Nadal budujesz obraz Docker, pushujesz go do rejestru, potem Kubernetes pobiera ten obraz na node’y i uruchamia kontenery z niego. Twój obraz pozostaje przenośnym, wersjonowanym artefaktem używanym wszędzie.
Kiedy wystarczy prostsza opcja
Jeśli jesteś na jednym serwerze z kilkoma usługami, Docker Compose może wystarczyć. Orkiestracja zaczyna się opłacać, gdy potrzebujesz wysokiej dostępności, częstych wdrożeń, autoskalowania lub wielu serwerów dla pojemności i odporności.
Podstawy bezpieczeństwa i zgodności dla kontenerów
Kontenery same w sobie nie czynią aplikacji bezpieczną — przede wszystkim ułatwiają standaryzację i automatyzację działań bezpieczeństwa, które i tak powinieneś wykonywać. Plus jest taki, że Docker daje jasne, powtarzalne punkty, gdzie można dodać kontrole, których oczekują zespoły audytowe i bezpieczeństwa.
Skanowanie obrazów (i dlaczego to ważne)
Obraz kontenera to paczka aplikacji plus zależności, więc luki często pochodzą z obrazów bazowych lub pakietów systemowych, których sam nie pisałeś. Skanowanie obrazów sprawdza znane CVE przed wdrożeniem.
Zrób skanowanie bramą w pipeline: jeśli wykryto krytyczną lukę, build nie powinien przejść i przebuduj z poprawionym base image. Przechowuj wyniki skanów jako artefakty, aby móc pokazać, co zostało wysłane na potrzeby zgodności.
Zasada najmniejszych uprawnień domyślnie
Uruchamiaj procesy jako użytkownik nie-root, kiedy tylko to możliwe. Wiele ataków wykorzystuje dostęp root w kontenerze, aby wydostać się lub manipulować systemem plików.
Rozważ też filesystem tylko do odczytu dla kontenera i montuj tylko konkretne, zapisywalne ścieżki (dla logów lub uploadów). To ogranicza, co atakujący może zmienić po przełamaniu zabezpieczeń.
Obsługa sekretów: nie pakuj ich w obrazy
Nigdy nie kopiuj kluczy API, haseł ani prywatnych certyfikatów do obrazu Docker ani nie commituj ich do Gita. Obrazy są cache’owane, dzielone i wypychane do rejestrów — sekrety mogą się łatwo wyciec.
Zamiast tego wstrzykuj sekrety w czasie uruchamiania, używając magazynu sekretów platformy (np. Kubernetes Secrets lub menedżera sekretów chmury) i ogranicz dostęp tylko do usług, które tego potrzebują.
Aktualizacje i poprawki: przebudowuj regularnie
W przeciwieństwie do tradycyjnych serwerów, kontenery nie łatają się same podczas działania. Standardowe podejście: przebuduj obraz z zaktualizowanymi zależnościami, a potem ponownie wdroż.
Ustal rytm (co tydzień lub co miesiąc) na przebudowę nawet wtedy, gdy kod aplikacji się nie zmienia, i odbuduj natychmiast, gdy wysokiej klasy CVE dotyczy Twojego base image. To ułatwia audyty i zmniejsza ryzyko z czasem.
Najczęstsze błędy i jak ich unikać
Zachowaj pełną własność kodu
Eksportuj pełne źródło i uruchom swoje standardowe build → push → run pipeline.
Nawet zespoły, które „używają Dockera”, mogą wciąż wysyłać zawodzące wdrożenia do chmury, jeśli wpadnie kilka złych nawyków. Oto błędy, które sprawiają najwięcej bólu — i praktyczne sposoby ich unikania.
1) Traktowanie kontenerów jak "zwierząt domowych" (ręczne zmiany w prod)
Antywzorzec to „ssh na serwer i coś poprawię” albo wchodzenie do działającego kontenera, żeby zrobić hot-fix. Działa raz, potem się psuje, bo nikt nie odtworzy dokładnego stanu.
Zamiast tego traktuj kontenery jak bydło: wymienne i zastępowalne. Każdą zmianę dokonuj przez proces budowy obrazu i pipeline wdrożeniowy. Jeśli trzeba debugować, rób to w tymczasowym środowisku, a potem sformalizuj poprawkę w Dockerfile, konfiguracji lub ustawieniach infrastruktury.
2) Przeładowane obrazy i wolne buildy z chaotycznego Dockerfile
Olbrzymie obrazy spowalniają CI/CD, zwiększają koszty przechowywania i powiększają powierzchnię ataku.
Unikniesz tego, poprawiając strukturę Dockerfile:
- Używaj mniejszego base image tam, gdzie to sensowne.
- Kopiuj pliki zależności najpierw (aby cache budowy mógł przyspieszać instalacje), potem kod aplikacji.
- Używaj multi-stage builds dla aplikacji kompilowanych, aby finalny obraz zawierał tylko to, co potrzebne do uruchomienia.
- Dodaj
.dockerignore, aby nie wysyłać node_modules, artefaktów builda czy lokalnych sekretów.
Celem jest build powtarzalny i szybki — nawet na czystej maszynie.
3) Ignorowanie logów i metryk (obserwowalność nadal ma znaczenie)
Kontenery nie eliminują potrzeby rozumienia, co robi aplikacja. Bez logów, metryk i trace’ów zauważysz problemy, gdy użytkownicy zaczną narzekać.
Przynajmniej upewnij się, że aplikacja pisze logi do stdout/stderr (nie lokalnych plików), ma podstawowe endpointy health i emituje kilka kluczowych metryk (rate błędów, latencja, długość kolejki). Potem podłącz te sygnały do narzędzi monitorujących Twojej chmury.
4) Nieplanowanie usług stanowych od początku (bazy, kolejki, pliki)
Bezustatkowe (stateless) kontenery są proste do zastąpienia; dane stanowe nie. Zespoły często odkrywają zbyt późno, że baza uruchomiona w kontenerze „działała”, aż restart ją skasował.
Zdecyduj wcześnie, gdzie będzie przechowywany stan:
- Korzystaj z zarządzanych baz i kolejek, jeśli to możliwe.
- Jeśli musisz prowadzić usługi stanowe samodzielnie, zaplanuj storage, backupy i procedury upgrade od pierwszego dnia.
Docker świetnie nadaje się do pakowania aplikacji — ale niezawodność pochodzi z przemyślenia, jak te kontenery są budowane, obserwowane i połączone z trwałym magazynem.
Praktyczna lista kontrolna na start
Jeśli zaczynasz z Dockerem, najszybszy sposób na wartość to konteneryzacja jednej realnej usługi end-to-end: zbuduj, uruchom lokalnie, wypchnij do rejestru i wdroż w chmurze. Użyj tej listy, aby utrzymać zakres mały i wyniki użyteczne.
1) Zacznij od jednej usługi (end-to-end)
Wybierz jedną, bezstanową usługę (API, worker lub prostą aplikację web). Zdefiniuj, co potrzebne do startu: port, na którym nasłuchuje, wymagane zmienne środowiskowe i zależności zewnętrzne (np. baza, którą możesz uruchomić osobno).
Cel: „Mogę uruchomić tę samą aplikację lokalnie i w chmurze z tego samego obrazu.”
2) Stwórz minimalny Dockerfile + Compose do lokalnego użytku
Napisz najmniejszy Dockerfile, który buduje i uruchamia Twoją aplikację niezawodnie. Preferuj:
- mały base image
- kopiowanie tylko tego, co potrzebne
- czytelną komendę startową
Dodaj docker-compose.yml do pracy lokalnej, który podłącza zmienne środowiskowe i zależności (np. DB) bez instalowania czegokolwiek na laptopie poza Dockerem.
Możesz później rozszerzyć ten setup — zaczynaj prosto.
3) Wybierz rejestr i konwencję tagów
Zdecyduj, gdzie będą przechowywane obrazy (Docker Hub, GHCR, ECR, GCR itp.). Przyjmij tagi, które czynią wdrożenia przewidywalnymi:
:dev dla testów lokalnych (opcjonalnie):git-sha (niemutowalny, najlepszy do wdrożeń):v1.2.3 dla wydań
Unikaj polegania na :latest w produkcji.
4) Dodaj CI, aby automatycznie budować i publikować
Skonfiguruj CI tak, aby każdy merge do głównej gałęzi budował obraz i wypychał go do rejestru. Pipeline powinien:
- Zbudować obraz
- Uruchomić podstawowe testy (lub smoke run)
- Wypchnąć z ustalonymi tagami
Gdy to zadziała, możesz podłączyć opublikowany obraz do kroku wdrożeniowego w chmurze i iterować dalej.