14 cze 2025·7 min
Dlaczego istnieje boilerplate i jak frameworki go redukują
Dowiedz się, dlaczego powstaje kod szablonowy, jakie problemy rozwiązuje i jak frameworki zmniejszają powtarzalność przez konwencje, scaffolding i wielokrotnego użytku komponenty.
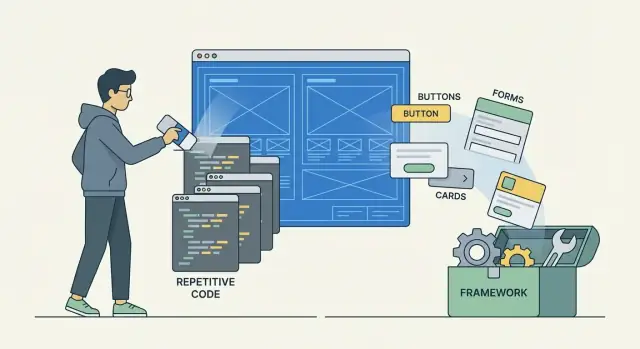
Co oznacza kod szablonowy (a czego nie oznacza)
Kod szablonowy to powtarzalny „kod startowy” i kod łączący, który zwykle piszesz w wielu projektach — nawet gdy sama koncepcja produktu się zmienia. To rusztowanie, które pomaga aplikacji wystartować, połączyć elementy i zachowywać się spójnie, ale zwykle nie zawiera unikatowej wartości twojej aplikacji.
Kod szablonowy, prosto mówiąc
Pomyśl o kodzie szablonowym jak o standardowej liście kontrolnej, którą wciąż używasz:
- utworzenie punktu wejścia aplikacji
- podłączenie tras lub ekranów
- ładowanie konfiguracji (zmienne środowiskowe, sekrety, feature flagi)
- połączenie z bazą danych lub zewnętrznym API
- dodanie uwierzytelniania, uprawnień i obsługi sesji
- zdefiniowanie obsługi błędów i logowania
Jeśli budowałeś więcej niż jedną aplikację, prawdopodobnie skopiowałeś część tego z wcześniejszego projektu lub powtarzałeś te same kroki.
Dlaczego pojawia się w większości aplikacji
Większość aplikacji ma te same podstawowe potrzeby: użytkownicy logują się, strony lub endpointy potrzebują routingu, żądania mogą się nie powieść, a dane trzeba walidować i przechowywać. Nawet proste projekty zyskują na zestawie zabezpieczeń — inaczej tracisz czas na ściganie niespójnego zachowania (np. różnych odpowiedzi błędów w różnych endpointach).
Kod szablonowy nie jest automatycznie „zły”
Powtarzalność może irytować, ale kod szablonowy często zapewnia strukturę i bezpieczeństwo. Spójny sposób obsługi błędów, uwierzytelniania użytkowników czy konfiguracji środowisk może zapobiegać błędom i ułatwiać zespołowi zrozumienie bazy kodu.
Problem pojawia się wtedy, gdy kod szablonowy nabiera takiej skali, że spowalnia zmiany, ukrywa logikę biznesową lub sprzyja błędom wynikającym z kopiuj‑wklej.
Prosty przykład nietechniczny
Wyobraź sobie budowę kilku stron internetowych. Każda potrzebuje tego samego nagłówka i stopki, formularza kontaktowego z walidacją i standardowego sposobu wysyłki zgłoszeń do e‑maila lub CRM.
Albo rozważ aplikację, która wywołuje zewnętrzną usługę: każdy projekt potrzebuje tego samego ustawienia klienta API — base URL, token uwierzytelniający, mechanizm retry i przyjazne komunikaty o błędach. To powtarzające się rusztowanie to boilerplate.
Dlaczego boilerplate istnieje
Boilerplate nie powstaje zwykle dlatego, że deweloperzy lubią powtarzalność. Istnieje, ponieważ wiele aplikacji ma te same niezbędne potrzeby: obsługę żądań, walidację wejścia, połączenia do magazynów danych, logowanie zdarzeń i bezpieczne awarie.
Niezawodność: sprawdzone wzorce zmniejszają błędy
Gdy zespół znajduje „sprawdzony” sposób na zrobienie czegoś — np. bezpieczne parsowanie wejścia użytkownika czy retry połączenia z bazą — jest on ponownie wykorzystywany. Powtarzalność to forma zarządzania ryzykiem: kod może być nudny, ale jest mniej podatny na awarie w produkcji.
Spójność: zespoły potrzebują przewidywalnej struktury
Nawet małe zespoły korzystają na tym, że foldery, konwencje nazewnicze i przepływ żądanie/odpowiedź są podobne między projektami. Spójność przyspiesza wdrożenie nowych osób, ułatwia code review i naprawę błędów, bo każdy wie, gdzie szukać.
Integracja: klej między narzędziami
Rzeczywiste aplikacje rzadko żyją w izolacji. Boilerplate pojawia się tam, gdzie systemy się łączą: serwer WWW + routing, baza danych + migracje, logowanie + monitoring, zadania tła + kolejki. Każda integracja wymaga kodu startowego, konfiguracji i „okablowania”, żeby elementy współpracowały.
Zgodność i bezpieczeństwo: podstawowe zabezpieczenia domyślnie
Wiele projektów wymaga minimalnych zabezpieczeń: walidacji, hooków autoryzacji, nagłówków bezpieczeństwa, limitów szybkości i sensownej obsługi błędów. Nie da się tego pominąć, więc zespoły powtarzają szablony, żeby nie pomijać krytycznych zabezpieczeń.
Presja czasu: szybkie wdrożenie sprzyja ponownemu użyciu
Terminy sprawiają, że deweloperzy kopiują działające wzorce zamiast ich odtwarzać od zera. Boilerplate staje się skrótem: nie najlepszą częścią kodu, ale praktycznym sposobem przejścia od pomysłu do wydania. Jeśli używasz szablonów projektów, widzisz to w praktyce.
Rzeczywiste koszty zbyt dużo boilerplate
Boilerplate może wydawać się „bezpieczny”, bo jest znany i już napisany. Ale gdy rozrasta się po bazie kodu, cicho obciąża każdą przyszłą zmianę. Koszt to nie tylko dodatkowe linie — to więcej decyzji, więcej miejsc do przeglądania i więcej szans na dryf.
Ciężar utrzymania i przeglądów
Każdy powtarzalny wzorzec zwiększa powierzchnię:
- więcej plików i linii do sprawdzenia
- więcej miejsc do aktualizacji przy zmianie wymagań
- mniej czasu na pracę produktową
Nawet drobne zmiany — dodanie nagłówka, aktualizacja komunikatu o błędzie czy zmiana wartości konfiguracji — mogą zamienić się w poszukiwanie po wielu niemal identycznych plikach.
Wdrożenie i „tajemniczy kod” dla nowych
Projekt z dużą ilością boilerplate jest trudniejszy do opanowania, bo nowicjusze nie potrafią łatwo odróżnić, co ma znaczenie:
- więcej kodu typu „dlaczego to tu jest?”
- artefakty frameworka lub szablonu, za które nikt nie czuje odpowiedzialności
Gdy projekt ma wiele sposobów na osiągnięcie tego samego, ludzie poświęcają energię na zapamiętywanie dziwactw, zamiast rozumieć produkt.
Rozbieżność po kopiuj-wklej i niespójne zachowanie
Zduplikowany kod rzadko pozostaje identyczny:
- jeden zespół poprawia fragment, inny nie
- zachowanie różni się między endpointami czy usługami
- organizacja zaczyna wspierać wiele „prawie takich samych” implementacji
Błędy ukryte na pierwszy rzut oka
Boilerplate starzeje się źle:
- przestarzałe fragmenty i niezgodne wersje zależności
- przestarzałe ustawienia, które „działają, dopóki nie przestaną”
Fragment skopiowany ze starego projektu może polegać na dawnych domyślnych wartościach. Może działać „wystarczająco dobrze”, aż zawiedzie pod obciążeniem, podczas aktualizacji lub w produkcji — gdy koszt debugowania jest największy.
Gdzie pojawia się boilerplate w typowych aplikacjach
Boilerplate to zwykle nie jeden gruby kawałek „dodatkowego kodu”. Pojawia się w małych, powtarzających się wzorcach rozproszonych po całym projekcie — zwłaszcza gdy aplikacja rośnie poza pojedynczą stronę lub skrypt.
Okablowanie żądanie/odpowiedź
Większość aplikacji webowych i API powtarza tę samą strukturę obsługi żądań:
- Routing (mapowanie URL do akcji)
- Kontrolery/handlery (czytanie wejścia, wywoływanie logiki biznesowej, kształtowanie odpowiedzi)
- Modele (struktury danych, reguły walidacji, mapowania do bazy)
- Widoki/szablony (renderowanie HTML lub formatowanie odpowiedzi)
- Konfiguracja (porty, URL baz danych, feature flagi)
Nawet gdy każdy plik jest krótki, wzorzec powtarza się w wielu endpointach.
Zadania uruchamiania i okablowania
Dużo boilerplate pojawia się zanim aplikacja zacznie robić cokolwiek użytecznego:
- konfiguracja dependency injection lub kontenerów usług
- rejestracja middleware (kompresja, parsowanie żądań, CORS)
- ładowanie zmiennych środowiskowych i ustawień per‑środowisko (dev/staging/prod)
- definiowanie kroków „bootstrap” aplikacji w odpowiedniej kolejności
Ten kod jest często podobny w projektach, ale nadal trzeba go napisać i utrzymywać.
Przekrojowe funkcje
Funkcje te dotykają wielu części kodu, co sprzyja powtarzalności:
- Logowanie (spójne pola, identyfikatory korelacji)
- Retry/timeouts przy wywołaniach zewnętrznych
- Cache i haki odświeżania cache
- Metryki i health checki
Podstawy bezpieczeństwa i testowania
Bezpieczeństwo i testy dodają niezbędnej ceremonii:
- Auth, sesje/tokeny, CSRF i limity szybkości
- runnery testowe, fixtures, mocki i wspólny setup testów
To nie jest „zmarnowane” — to właśnie tam frameworki starają się ustandaryzować i zmniejszyć powtórzenia.
Jak frameworki redukują boilerplate (główne mechanizmy)
Frameworki tną boilerplate, dając domyślną strukturę i jasny „happy path”. Zamiast składać wszystko samodzielnie — routing, konfiguracja, okablowanie zależności, obsługa błędów — zaczynasz od wzorców, które już do siebie pasują.
Domyślna struktura, która eliminuje kod startowy
Większość frameworków dostarcza szablon projektu: foldery, reguły nazewnictwa plików i podstawową konfigurację. Oznacza to, że nie musisz pisać (ani ponownie decydować o) tego samego bootstrappingu dla każdej aplikacji. Dodajesz funkcje wewnątrz znanego kształtu, zamiast najpierw wymyślać ten kształt.
Odwrócenie kontroli: framework wywołuje twój kod
Kluczowym mechanizmem jest inversion of control. Nie wywołujesz ręcznie wszystkiego w odpowiedniej kolejności; framework uruchamia aplikację i wywołuje twój kod w odpowiednim momencie — gdy przychodzi żądanie, gdy uruchamia się zadanie, gdy działa walidacja.
Zamiast pisać glue typu „jeśli ten route pasuje, to wywołaj ten handler, potem zserializuj odpowiedź”, implementujesz handler, a framework robi resztę.
Konwencje i domyślne ustawienia zmniejszają konfigurację
Frameworki często zakładają sensowne domyśły (lokacje plików, nazewnictwo, standardowe zachowania). Gdy trzymasz się tych konwencji, piszesz mniej konfiguracji i mniej powtarzalnych mapowań. Nadal możesz nadpisać domyślne ustawienia, ale nie musisz.
Wbudowane komponenty zastępują ręczny klej
Wiele frameworków zawiera powszechne bloki budulcowe — routing, helpery do autoryzacji, walidację formularzy, integracje z logowaniem i ORM — więc nie odtwarzasz tych samych adapterów i wrapperów w każdym projekcie.
Zdecydowane wybory redukują zmęczenie decyzjami
Wybierając standardowe podejście (układ projektu, styl dependency injection, wzorce testowe), framework zmniejsza liczbę decyzji „w którą stronę iść?” — oszczędzając czas i utrzymując spójność baz kodu.
Konwencje zamiast konfiguracji: mniej setupu, więcej postępu
Pomiń boilerplate od pierwszego dnia
Rozpocznij od spójnej bazy dla aplikacji webowych, serwerowych lub mobilnych bez kopiuj-wklej.
Konwencje over configuration oznacza, że framework podejmuje rozsądne decyzje domyślne, żebyś nie musiał pisać tyle „okablowania”. Zamiast mówić systemowi, jak wszystko jest zorganizowane, trzymasz się uzgodnionych wzorców — i to działa.
Jak wyglądają konwencje w praktyce
Większość konwencji dotyczy gdzie rzeczy się znajdują i jak są nazwane:
- Umiejscowienie plików: umieść strony UI w
pages/, wielokrotnego użytku komponenty wcomponents/, migracje wmigrations/. - Nazewnictwo: plik o nazwie
usersodpowiada funkcjom „users”, klasaUsermapuje na tabelęusers. - Routing: utwórz
products/, a framework automatycznie obsłuży/products; dodajproducts/[id]i obsłuży/products/123.
Dzięki tym domyślnym zasadom unikasz pisania powtarzalnej konfiguracji typu „zarejestruj tę trasę”, „mapuj tego kontrolera” czy „zadeklaruj, gdzie są szablony”.
Kiedy explicite konfiguracja nadal się przydaje
Konwencje nie zastępują konfiguracji — zmniejszają jej potrzebę. Zazwyczaj sięgasz po explicite ustawienia, gdy:
- potrzebujesz niestandardowych URL (legacy routes, marketingowe slugi)
- integrujesz z usługami zewnętrznymi (providerzy auth, bramki płatności)
- masz nietypowe wymagania deploymentu lub bezpieczeństwa
Dlaczego zespoły na tym zyskują
Wspólne konwencje ułatwiają nawigację w projektach. Nowy współpracownik może zgadnąć, gdzie znaleźć stronę logowania, handler API czy zmianę schematu bazy bez pytania. Code review stają się szybsze, bo struktura jest przewidywalna.
Wymiana: trzeba nauczyć się zasad
Głównym kosztem jest onboarding: uczysz się „stylu domu” frameworka. Aby uniknąć późniejszych nieporozumień, dokumentuj wyjątki od domyślnych ustawień w krótkim README (np. „Wyjątki routingu” lub „Notatki o strukturze folderów”).
Scaffolding i generatory: szybki start
Scaffolding to praktyka generowania kodu startowego komendą, żeby nie zaczynać każdego projektu od ręcznego pisania tych samych plików, folderów i okablowania. Zamiast kopiować stare projekty lub szukać idealnego szablonu, prosisz framework, by stworzył bazę zgodną z jego preferowanymi wzorcami.
Co zwykle generuje scaffolding
W zależności od stosu, scaffolding może wygenerować od całego szkieletu projektu po konkretne funkcje:
- Szablony projektów: foldery, konfiguracja builda, routing, podstawowe strony, pliki środowiskowe
- Generowanie CRUD: model, kontroler/handlery, trasy, widoki lub endpointy API do Create/Read/Update/Delete
- Startery auth: flow logowania/rejestracji, obsługa sesji, reset haseł
- Migracje: pliki zmian bazy generowane z modeli lub definicji schematu
Dlaczego to zmniejsza boilerplate
Generatory kodują konwencje. Oznacza to, że twoje endpointy, foldery, nazewnictwo i konfiguracja są spójne w całej aplikacji (i między zespołami). Unikasz też typowych pominięć — brakujących tras, niezarejestrowanych modułów, zapomnianych haków walidacji — bo generator wie, które elementy muszą istnieć razem.
Wymiana: „wygenerowane” nie znaczy „zrozumiane”
Największe ryzyko to traktowanie wygenerowanego kodu jak magii. Zespoły mogą wdrażać funkcje z kodem, którego nie rozumieją, lub zostawiać nieużywane pliki „na wszelki wypadek”, co zwiększa koszty utrzymania i zamieszanie.
Najlepsze praktyki
Odrzucaj agresywnie: usuwaj to, czego nie potrzebujesz i upraszczaj wcześnie, gdy zmiany są tanie.
Trzymaj generatory wersjonowane i powtarzalne (w repo albo przypięte przez narzędzia), aby przyszłe scaffoldingi pasowały do dzisiejszych konwencji — a nie do outputu narzędzia z przyszłości.
Wielokrotnego użytku komponenty i ekosystemy, które zastępują powtarzalność
Przerwij powtarzalne ustawienia
Stwórz czysty szkielet projektu w czacie i poświęć czas na prawdziwą logikę biznesową.
Frameworki nie tylko upraszczają start, ale redukują boilerplate w czasie, pozwalając na ponowne użycie tych samych elementów między projektami. Zamiast przepisywać kod łączący (i od nowa go debugować), składasz sprawdzone części.
Wbudowane moduły: mniej ręcznych wzorców
Większość popularnych frameworków dostarcza już zintegrowane potrzeby:
- Routing + middleware pozwalają definiować endpointy i przekrojowe obawy (logowanie, rate limiting, parsowanie żądań) bez powtarzania tego samego okablowania w każdej usłudze.
- Walidacja upraszcza „jeśli brakuje pola, zwróć 400” do spójnego wzorca zamiast kilkudziesięciu customowych sprawdzeń.
Warstwy danych, które eliminują powtarzalne ustawienia SQL
ORMy i narzędzia migracyjne usuwają duży kawał powtarzalności: konfigurację połączenia, wzorce CRUD, zmiany schematu i skrypty rollback. Nadal musisz zaprojektować model danych, ale przestajesz pisać ten sam bootstrap SQL i „create table if not exists” dla każdego środowiska.
Bloki bezpieczeństwa
Moduły autoryzacji i uwierzytelniania zmniejszają ryzykowne, bespoke rozwiązania. Warstwa auth frameworka standardyzuje sesje/tokeny, hashowanie haseł, sprawdzenia ról i ochronę tras — dzięki czemu nie implementujesz tych detali w każdym projekcie.
Ekosystem UI i systemy szablonów
Na froncie systemy szablonów i biblioteki komponentów usuwają powtarzalną strukturę UI — nawigację, formularze, modalne okna i stany błędów. Spójne komponenty ułatwiają utrzymanie aplikacji w miarę jej rozwoju.
Pluginy: dodaj funkcje bez budowania fundamentów od nowa
Dobry ekosystem pluginów pozwala dodać możliwości (uploady, płatności, panele admina) przez konfigurację i niewielki kod integracyjny, zamiast budować tę samą architekturę za każdym razem.
Kiedy frameworki dodają własny boilerplate (i jakie są tego koszty)
Frameworki zmniejszają powtórzenia, ale mogą też wprowadzić inny rodzaj boilerplate: kod zgodny z wymaganiami frameworka, lifecycle hookami i wymaganymi plikami.
Ukryte zachowanie i dodatkowa złożoność
Framework może robić wiele rzeczy implicitnie (auto‑okablowanie, magiczne domyśły, refleksja, łańcuchy middleware). To wygodne — dopóki debugujesz. Kod, którego nie napisałeś, może być najtrudniejszy do zrozumienia, zwłaszcza kiedy zachowanie zależy od konfiguracji rozproszonej po wielu miejscach.
Nadmierna abstrakcja: gdy zaczynasz z nią walczyć
Frameworki są optymalizowane pod typowe przypadki użycia. Jeśli twoje wymagania są nietypowe — niestandardowe flow auth, nietypowy routing, niecodzienne modele danych — możesz potrzebować adapterów, wrapperów i obejść. Ten klej może przypominać boilerplate i często starzeje się źle, bo jest silnie związany z wewnętrznymi założeniami frameworka.
Wydajność i zależności
Frameworki mogą ładować funkcje, których nie potrzebujesz. Dodatkowe middleware, moduły czy domyślne abstrakcje zwiększają czas startu, użycie pamięci lub rozmiar bundle’a. Za to produktywność często rekompensuje koszt, ale warto to zauważyć przy małych aplikacjach.
Aktualizacje nie są darmowe
Główne wersje mogą zmieniać konwencje, formaty konfiguracji lub API rozszerzeń. Prace migracyjne stają się własną formą boilerplate: powtarzalne edycje wielu plików, aby dopasować się do nowych oczekiwań.
Zasada praktyczna
Trzymaj niestandardowy kod blisko oficjalnych punktów rozszerzeń (pluginy, hooki, middleware, adaptery). Jeśli przepisujesz kluczowe części lub kopiujesz wewnętrzny kod, framework może kosztować więcej boilerplate’u niż oszczędza.
Framework vs biblioteka: jak przepływ kontroli wpływa na boilerplate
Użyteczny sposób rozróżnienia biblioteki od frameworka to przepływ kontroli: bibliotekę wywołujesz ty; framework wywołuje ciebie.
Ta różnica „kto rządzi?” często decyduje o ilości pisanego boilerplate’u. Gdy framework przejmuje lifecycle aplikacji, może scentralizować setup i automatycznie uruchamiać powtarzalne kroki, które inaczej musiałbyś ręcznie okablować.
Biblioteka: łączysz elementy samodzielnie
Biblioteki to klocki. Decydujesz, kiedy je inicjalizować, jak przekazywać dane, jak obsługiwać błędy i jak strukturujesz pliki.
To świetne dla małych lub bardzo wyspecjalizowanych aplikacji, ale może zwiększyć boilerplate, bo odpowiadasz za kod łączący:
- tworzenie wspólnej konfiguracji
- łączenie modułów (routing → kontrolery → serwisy → DB)
- ujednolicenie logowania, walidacji i odpowiedzi błędów
Framework: dostarcza szkielet
Frameworki definiują happy path dla powszechnych zadań (obsługa żądań, routing, dependency injection, migracje, zadania tła). Podłączasz swój kod w przewidzianych miejscach, a framework orkiestruje resztę.
To odwrócenie kontroli redukuje boilerplate, czyniąc domyślne zachowania standardem. Zamiast powtarzać ten sam setup w każdej funkcji, trzymasz się konwencji i nadpisujesz tylko to, co różne.
Kiedy pasuje co
Biblioteka wystarczy, gdy:
- aplikacja jest mała, krótkotrwała lub bardzo niestandardowa
- potrzebujesz tylko jednej funkcjonalności (np. klient HTTP, templating, uwierzytelnianie)
Framework lepiej pasuje, gdy:
- zespół potrzebuje wspólnych wzorców i przewidywalnej struktury
- produkt będzie ewoluował przez lata (nowe funkcje, onboarding, utrzymanie)
Bezpieczne mieszanie podejść
Często najlepsze rozwiązanie to rdzeń frameworka + wyspecjalizowane biblioteki. Pozwól frameworkowi obsługiwać lifecycle i strukturę, a bibliotekom dodawaj wyspecjalizowane możliwości.
Czynniki decyzyjne: umiejętności zespołu, terminy, ograniczenia deploymentu i ile spójności chcesz w bazie kodu.
Jak wybrać framework, żeby zminimalizować powtórzenia
Zachowaj własność kodu
Generuj szybko, a potem eksportuj źródła, zachowując pełną kontrolę nad kodem.
Wybór frameworka to nie pogoń za „najmniejszą ilością kodu”, ale wybór zestawu domyślnych ustawień, które usuwają twoje najczęstsze powtarzalności — bez ukrywania zbyt wiele.
Zacznij od ograniczeń (nie listy funkcji)
Zanim porównasz opcje, zapisz wymagania projektu:
- Rozmiar i długość życia projektu: narzędzie jednorazowe może tolerować więcej „magii” niż produkt utrzymywany lata.
- Wielkość i doświadczenie zespołu: silne konwencje pomagają zespołom o zróżnicowanym doświadczeniu; bardzo małe zespoły wolą elastyczność.
- Wymogi zgodności: audyt, przechowywanie danych i kontrola dostępu często wymuszają explicite wzorce, które wpływają na ilość nieuniknionego boilerplate.
Oceń „historię boilerplate” frameworka
Spójrz poza przykłady "hello world" i sprawdź:
- Domyślne funkcje: auth, routing, walidacja, migracje i konfiguracja — czy oszczędzasz czas na ich okablowaniu, czy musisz je spiąć ręcznie?
- Jakość dokumentacji: jasne złote ścieżki zmniejszają DIY glue code.
- Społeczność i ekosystem: utrzymane pluginy i integracje zastępują powtarzalne customowe wrappery.
- Ścieżka aktualizacji: częste breaking changes mogą ponownie wprowadzać powtarzalne poprawki.
Nie pomijaj testów, obserwowalności i bezpieczeństwa
Framework, który oszczędza 200 linii w kontrolerach, ale wymusza niestandardowy setup do testów, logowania, metryk i tracingu, często zwiększa ogólną powtarzalność. Sprawdź, czy oferuje wbudowane haki do testów, strukturalnego logowania, reportowania błędów i sensowną postawę bezpieczeństwa.
Zrób prototyp end-to-end, zanim zdecydujesz
Zbuduj jedną małą funkcję z rzeczywistymi wymaganiami: formularz/input, walidacja, persystencja, auth i odpowiedź API. Zmierz, ile kodu‑kleju napisałeś i jak czytelne jest to rozwiązanie.
Popularność to sygnał, ale nie wybieraj tylko na jej podstawie — wybierz framework, którego domyślne ustawienia pasują do twojej najczęściej powtarzanej pracy.
Praktyczne sposoby na redukcję boilerplate bez utraty jasności
Redukcja boilerplate to nie tylko pisanie mniej — to ułatwienie dostrzegania tego, co istotne. Celem jest utrzymanie rutynowego setupu przewidywalnego, a jednocześnie jawne eksponowanie decyzji aplikacji.
1) Zacznij od domyślnych ustawień frameworka (i uzasadniaj każde nadpisanie)
Większość frameworków ma sensowne domyślne ustawienia dla routingu, logowania, formatowania i struktury folderów. Traktuj je jako bazę. Gdy dostosujesz coś, dokumentuj powód w konfiguracji lub README, aby przyszłe zmiany nie zamieniały się w archeologię.
Zasada pomocna: jeśli nie potrafisz wyjaśnić korzyści w jednym zdaniu, zostań przy domyśle.
2) Twórz wewnętrzne szablony dla często powtarzanych typów projektów
Jeśli zespół często buduje podobne aplikacje (panele admina, API, strony marketingowe), złap konfigurację raz jako szablon. To obejmuje strukturę folderów, linting, testy i wiring deploymentu.
Trzymaj szablony małe i stanowcze; unikaj wkładania do nich specyficznego kodu produktowego. Hostuj je w repo i odnoś do nich w dokumentacji wdrożeniowej.
Często zadawane pytania
What is boilerplate code in simple terms?
Kod szablonowy to powtarzalne elementy „ustawieniowe” i „klejowe”, które piszesz w wielu projektach — kod startowy, routing, ładowanie konfiguracji, obsługa uwierzytelniania/sesji, logowanie i standardowa obsługa błędów.
Zwykle nie jest to unikatowa logika biznesowa aplikacji; to spójne rusztowanie, które sprawia, że wszystko działa bezpiecznie i przewidywalnie.
Is boilerplate code always a bad thing?
Nie. Boilerplate często pomaga, bo wymusza spójność i zmniejsza ryzyko.
Staje się problemem, gdy urośnie tak bardzo, że spowalnia zmiany, ukrywa logikę biznesową lub sprzyja kopiuj-wklej i rozbieżnościom.
Why does boilerplate exist in most applications?
Pojawia się, ponieważ większość aplikacji ma wspólne, nieuniknione potrzeby:
- obsługa żądań i routing
- walidacja danych i parsowanie wejścia
- zarządzanie konfiguracją i środowiskami
- integracje z bazami danych/API
- uwierzytelnianie/autoryzacja
- logowanie, metryki i bezpieczne ścieżki awaryjne
Nawet „proste” aplikacje potrzebują tych zabezpieczeń, żeby uniknąć niespójnego zachowania i niespodzianek w produkcji.
Where does boilerplate usually show up in a typical app?
Typowe miejsca to:
- uruchamianie aplikacji/bootstrapping (ładowanie zmiennych środowiskowych, inicjalizacja usług)
- przepływ żądanie/odpowiedź (kontrolery/handlery, serializacja)
- przekrojowe obawy (logowanie, identyfikatory korelacji, retry/timeouts)
- podstawy bezpieczeństwa (auth, CSRF, ograniczenia szybkości)
- konfiguracja testów (fixtures, mocki, wspólne helpery)
Jeśli widzisz te same wzorce w wielu plikach lub repozytoriach, prawdopodobnie to boilerplate.
What are the real costs of having too much boilerplate?
Zbyt dużo boilerplate zwiększa koszty w długim terminie:
- zmiany wymagają edycji w wielu miejscach
- przeglądy kodu trwają dłużej (większa powierzchnia)
- onboarding jest trudniejszy ("co tu naprawdę się liczy?")
- zduplikowane fragmenty zaczynają się różnić i zachowywać niespójnie
- przestarzały skopiowany kod może ukrywać błędy do czasu aktualizacji lub awarii
Dobry sygnał problemu to sytuacja, gdy drobna zmiana (np. format błędu) zamienia się w polowanie po wielu plikach.
How do frameworks reduce boilerplate code?
Frameworki zmniejszają boilerplate, oferując „happy path”:
- domyślną strukturę projektu i przepływ startowy
- wbudowane komponenty (routing, walidacja, pomocniki auth, integracje ORM)
- konwencje i domyślne ustawienia, dzięki którym konfigurujesz mniej
- odwrócenie kontroli (framework orkiestruje cykl życia i wywołuje twój kod)
Piszesz tylko części specyficzne dla funkcji; framework zajmuje się powtarzalnym klejem.
What does “inversion of control” have to do with boilerplate?
Odwrócenie kontroli oznacza, że nie ręcznie łączysz każdy krok we właściwej kolejności. Zamiast tego implementujesz handlery/hooki, a framework wywołuje je we właściwym momencie (przy żądaniu, podczas walidacji, przy wykonaniu zadania).
W praktyce eliminuje to wiele kodu typu „jeśli ścieżka pasuje, to wywołaj handler, potem zserializuj odpowiedź”, bo framework przejmuje cykl życia.
What is “conventions over configuration,” and when do I still need config?
Konwencje zamiast konfiguracji oznaczają, że framework przyjmuje sensowne domyślne ustawienia (lokacje folderów, nazwy, wzorce routingu), dzięki czemu nie musisz pisać powtarzalnych mapowań.
Zwykle dodajesz explicite konfigurację, gdy potrzebujesz czegoś niestandardowego — np. legacy URLs, specjalne polityki bezpieczeństwa lub integracje z podmiotami trzecimi, których domyślne ustawienia nie obsłużą.
How does scaffolding reduce boilerplate without creating “mystery code”?
Scaffolding/generatory tworzą strukturę startową (szkielet projektu, CRUD, flow auth, migracje), żebyś nie pisał ręcznie tych samych plików.
Dobre praktyki:
- usuń nieużywane wygenerowane pliki szybko
- traktuj wygenerowany kod jako czytelny kod (upewnij się, że zespół go rozumie)
- wersjonuj/pinuj generatory, aby przyszłe wygenerowane wyniki pasowały do obecnych konwencji
How should I choose a framework if my goal is to minimize repetition?
Zadaj sobie dwa pytania:
- Czy framework usuwa twoje najczęstsze powtarzalności (auth, walidacja, migracje, logowanie), czy tylko przenosi je w ceremoniał specyficzny dla frameworka?
- Czy możesz zbudować jedną prawdziwą funkcję end-to-end (input → walidacja → persystencja → odpowiedź) z minimalnym klejem i dalej rozumieć, co się dzieje?
Oceń też jakość dokumentacji, dojrzałość ekosystemu wtyczek i stabilność ścieżki aktualizacji — częste breaking changes mogą przywrócić boilerplate przez konieczność przepisywania adapterów.